Ultra-fast model emulation with PRISM; analyzing the Meraxes galaxy formation model
Abstract
We demonstrate the potential of an emulator-based approach to analyzing galaxy formation models in the domain where constraining data is limited. We have applied the open-source Python package Prism to the galaxy formation model Meraxes. Meraxes is a semi-analytic model, purposefully built to study the growth of galaxies during the Epoch of Reionization (EoR). Constraining such models is however complicated by the scarcity of observational data in the EoR. Prism’s ability to rapidly construct accurate approximations of complex scientific models using minimal data is therefore key to performing this analysis well.
This paper provides an overview of our analysis of Meraxes using measurements of galaxy stellar mass densities; luminosity functions; and color-magnitude relations. We demonstrate the power of using Prism instead of a full Bayesian analysis when dealing with highly correlated model parameters and a scarce set of observational data. Our results show that the various observational data sets constrain Meraxes differently and do not necessarily agree with each other, signifying the importance of using multiple observational data types when constraining such models. Furthermore, we show that Prism can detect when model parameters are too correlated or cannot be constrained effectively. We conclude that a mixture of different observational data types, even when they are scarce or inaccurate, is a priority for understanding galaxy formation and that emulation frameworks like Prism can guide the selection of such data.
1 Introduction
Recent years have seen the establishment of a concordance cosmological model, called CDM, based on decades of increasingly sophisticated observations, with the universe being made up of dark energy and mass (dark matter, DM; and baryonic matter) (Planck Collaboration et al., 2016). Within the CDM paradigm, a key transition occurs in the early universe, when sufficient ionizing photons have been produced to reionize the majority of the volume, called the Epoch of Reionization (EoR; Loeb & Barkana 2001). Studying the EoR is quite challenging, as a limited number of observations is available due to the very high redshifts at which this event occurs, plus the opaque wall of neutral hydrogen along the line-of-sight. Also, the formation of large-scale structures during the EoR is influenced by small-scale physics, such as star formation, making modelling the EoR rather complex. In order to attempt to explain the EoR with galaxy formation, three different main types of approaches are used: N-body simulations; hydrodynamic simulations; and semi-analytic models.
Following the descriptions given in Lacey (2001); Benson (2010) and Kuhlen et al. (2012), an N-body simulation models the physics of large-scale galaxy structure, by directly evolving a large number of particles solely based on the fundamental equations of gravitation. Such simulations are very successful (like the Millennium simulation; Springel et al. 2005), as DM particles are known to only interact gravitationally and make up the majority of the total mass, leaving baryonic matter with only a small contribution.
Hydrodynamic simulations (e.g., Schaye et al. 2010; Genel et al. 2014; Schaye et al. 2015) involve, as the name already suggests, explicit calculations of the hydrodynamic forces together with gravity. The inclusion of hydrodynamics means that baryons play a more explicit role in structure formation, especially at small scales, because baryons can radiatively lose energy and thereby collapse to higher densities. Hence, to follow their evolution, the required resolution timescales are much smaller as well as being more complex to simulate in general. Therefore, hydrodynamic simulations tend to be much more computationally expensive than N-body simulations.
Finally, semi-analytic models (SAMs; e.g., Cole et al. 2000; Croton et al. 2006; Henriques et al. 2013; Somerville et al. 2015; Croton et al. 2016; Mutch et al. 2016; Qin et al. 2017; Lagos et al. 2018) use approximations of the involved physics to model galaxy formation. SAMs are commonly applied to a static halo merger tree that is obtained from an N-body simulation, and the galaxy formation physics is treated in a phenomenological way. In practice, this means that there are typically far more parameters in the model that can be tuned than in hydrodynamic simulations, but SAMs are also far less computationally expensive. This allows SAMs to explore different evolution tracks much quicker, providing broader insight into the underlying physics. The disadvantage, however, is that a higher degree of approximation is used, which can give rise to unforeseen artifacts and unknown variances. In order to find out to what extent this has an effect on the accuracy and reliability of a SAM, the model needs to be thoroughly analyzed. While this paper explores a means to efficiently and thoroughly explore SAMs, we note that the technique could be similarly valuable in hydrodynamic simulations and their parametrizations.
Commonly, a combination of Markov chain Monte Carlo (MCMC) methods and Bayesian statistics (e.g., Sivia & Skilling 2012; Gelman et al. 2014) is employed when performing model parameter estimations, as performed by Henriques et al. (2013); Martindale et al. (2017); Henriques et al. (2019) for galaxy formation SAMs. This is used to obtain an accurate approximation of the posterior probability distribution function (PDF), which allows for regions in parameter space that compare well to the available data to be identified. As a consequence, MCMC and Bayesian statistics tend to be used for analyzing (exploring the behavior of) a model as well, even though obtaining the posterior PDF is an inherently slow process. However, van der Velden et al. (2019), hereafter V19, argued that an accurate approximation of the posterior PDF is not required for analyzing a model, but the converging process towards the PDF is required instead. V19 therefore proposed the combination of the Bayes linear approach (Goldstein, 1999; Goldstein & Wilkinson, 2000; Goldstein & Wooff, 2007) and the emulation technique (Sacks et al., 1989; Currin et al., 1991; Oakley & O’Hagan, 2002; O’Hagan, 2006) with history matching (Raftery et al., 1995; Craig et al., 1996, 1997; Kennedy & O’Hagan, 2001; Goldstein & Rougier, 2006) as an alternative. A combination of these techniques has been applied to galaxy formation SAMs before (Bower et al., 2010; Vernon et al., 2010, 2014; Rodrigues et al., 2017), showing their value.
In this work, we use an open-source Python implementation of these techniques, called Prism (van der Velden et al., 2019; van der Velden, 2019), to explore one such semi-analytic model; Meraxes (Mutch et al., 2016). Unlike other SAMs, like SAGE (Croton et al., 2016) and Shark (Lagos et al., 2018), Meraxes walks through the aforementioned static halo trees of an N-body simulation horizontally instead of vertically. This means that for each snapshot (time instance), all halos at that snapshot within all trees are processed simultaneously, such that interactions between the different trees can be taken into account. For Meraxes, this is necessary, as it was purposefully built to self-consistently couple the galaxy formation to the reionization history at high redshifts (). This makes the model suitable to obtain more insight into reionization, but it also makes it much slower to explore due to the coupling mechanism requiring many additional calculations for each snapshot. It is therefore crucial that we use a framework like Prism to efficiently explore and analyze Meraxes.
This work is structured in the following way: In 2, we give a short overview of how the Bayes linear approach, emulation technique and history matching can be used to analyze models. Then, using the Prism framework, we analyze the Meraxes model and discuss our findings in 3. After that, we explore a modified version of Meraxes by Qiu et al. (2019) in 4, and compare our results with theirs. Finally, in 5, we give a summary of the results in this work and discuss the potential implications they may have.
2 Model analysis & emulation
In this section, we give a short overview of how emulation in Prism works and how it can be used to analyze scientific models efficiently. Note that this section is meant for those seeking a basic understanding of the methodology and terminology used throughout this work. We refer to Goldstein & Wooff (2007) and Vernon et al. (2010) for further details on the Bayes linear approach, emulation technique and history matching; or to V19 for their specific use in Prism.
The basics of the emulation technique is as follows. Suppose that we have a model that takes a vector of input parameters , and whose output is given by the hypothetical function . As is both continuous and defined over a closed input interval, we can apply the Stone-Weierstrass theorem (Stone, 1948), which states that such a function can be uniformly approximated by a polynomial function as closely as desired. Using this, we can say that the output of , , is given by
| (1) |
with unknown scalars; deterministic functions of ; a weakly stochastic process with constant variance; and all remaining variance. The vector represents the vector of active input arguments for output ; those values that are considered to have a non-negligible impact on the output.
The goal of an emulator is to find out what the form of this function is for a given model. However, as model evaluations tend to be complex and very time-consuming, we would like to avoid evaluating the model millions of times. To solve this problem, we use the Bayes linear approach, which can be seen as an approximation of a full Bayesian analysis that uses expectations instead of probabilities as its main output. By using the Bayes linear approach, for a given vector of known model realizations , we can calculate what the adjusted expectation and adjusted variance values are for a given output :
| (2) | ||||
| (3) | ||||
with the prior expectation of ; the vector of covariances between the unknown output and all known outputs ; and the matrix of covariances between all known outputs with elements .
2 and 3 can be used to update our beliefs about the function given a vector of known outputs . With our updated beliefs, we can determine the collection , which contains those input parameters that give an ‘acceptable’ match to the observations 111Not to be confused with redshift when evaluated in , including the unknown ‘best’ vector of input parameters . The process of obtaining this collection is called history matching, which can be seen as the equivalent to model calibration when performing a full Bayesian analysis. History matching is achieved through evaluating functions called implausibility measures (Craig et al., 1996, 1997), which have the following form:
| (4) |
with the adjusted emulator expectation (2); the adjusted emulator variance (3); the model discrepancy variance; and the observational variance. Here, the model discrepancy variance (Kennedy & O’Hagan, 2001; Vernon et al., 2010) is a measure of the (un)certainty that the output of the model is correct, given its intrinsic implementation and functionality (e.g., approximations; stochasticity; missing features; etc.) As this variance can be rather challenging to properly calculate, it is usually estimated using a justified assumption.
For a given input parameter set , the corresponding implausibility value tells us how (un)likely it is that we would view the match between the model output and the observational data as acceptable or plausible, in terms of the standard deviation . The higher the implausibility value, the more unlikely it is that we would consider to be part of the collection . Because the implausibility measure is both unimodal and continuous, we can use the -rule given by Pukelsheim (1994) to show that of its probability must lie within (). Values higher than would usually mean that the proposed input parameter set should be discarded, but we show later in this work that this is not always necessary in order to heavily reduce parameter space.


To show how the theory above can be applied to a model, we have created an emulator of a simple Gaussian function, given in 1a. On the left in the figure, we show the model output function as the dashed line, which is usually not known but shown here for convenience. This model has been evaluated a total of five times, represented by the black dots. Using these evaluations, we have created an emulator using 2 and 3, given by the solid line and the shaded area. This shaded area shows the -confidence interval, with . Finally, we added a single comparison data point, given as the horizontal line with its confidence interval.
Using all of this information, we can calculate what the implausibility values are for all values of using 4, which is shown on the right in 1a. If we state that we consider values of to be acceptable, as indicated by the dashed line, then we can see that there are only a few regions in parameter space that satisfy this condition and thus require further analysis. After evaluating the model six more times in these regions and updating our beliefs, we obtain the plots in 1b. We can now see that the emulator solely focused on the important parts of parameter space, where it has been greatly improved, and that the implausibility values are only acceptable for and , which is as expected.
When making emulators of models that are more complex than the one shown in Fig. 1, it is very likely that the model has more than a single output (and thus multiple comparison data points). In this scenario, every model output has its own defined implausibility measure, which are evaluated and combined together. In order for an input parameter set to be considered plausible, all implausibility measures must meet a specific criterion. This criterion, called the implausibility cut-off, is given by
| (5) |
with being the maximum value that the th highest implausibility value is allowed to have, for a given . In cases where there are many model outputs, it can sometimes be desirable to ignore the first few highest implausibility measures regardless of their values. In this scenario, we apply so-called implausibility wildcards to the emulator, which allows us to analyze a model in a slower fashion by ignoring as many implausibility measures as there are wildcards. As a higher implausibility value implies a more constraining data point, this effectively removes the heavier constraints from the analysis.
By performing history matching iteratively, a process called refocusing, we can remove parts of parameter space based on the implausibility values of evaluated input parameter sets. This in turn leads to a smaller parameter space to evaluate the model in, and thus a higher density of parameter sets to update our beliefs with. As this leads to a more accurate emulator, we can progressively make a better approximation of the model with each iteration.
The concepts discussed in this section allow the Prism framework to quickly make accurate approximations of models in those parts of parameter space that are important, and provide us with insights into the behavior of the model. In the remainder of this work, we use its unique features to analyze the Meraxes model in various different ways, as shown in 3 and 4 using Prism version 1.3.0. For more detailed information on Prism, see V19.
3 Analyzing the Meraxes model
In this section, we discuss the results of our analysis of the Meraxes galaxy formation model by Mutch et al. (2016), hereafter M16. These results are based on two emulators made with Prism. The emulators only differ in the constraining observational data that was used, and are described below.
The emulator uses a ModelLink subclass (a Python class that wraps a model such that Prism can interface with it) that maps the stellar mass function (SMF) number density values from its logarithmic scale to an function, while also mapping the associated SMF data errors accordingly as well. This results in all SMF data values to be in the range , which was used for all subsequent emulators in this work as well. The reason we use an function here is to limit the range of orders of magnitude for the data values, decreasing the possibility of artifacts due to floating point errors in the emulation process. The ModelLink subclass uses the SMF parameter values as described in Table 1 in M16 with appropriate ranges, which are given in Tab. 1. We used the SMFs presented in Song et al. (2016) at redshifts to constrain the parameters for a combined total of data points. Note that because of this, in the following, whenever we refer to the SMF, we specifically mean the SMF at these redshifts. As the Meraxes model is expected to be reasonably well constrained in this redshift range, we assumed a static model discrepancy variance of for all data points in this section.
| Name | Min | Max | Estimate |
|---|---|---|---|
| MergerBurstFactor | |||
| SfCriticalSDNorm | |||
| SfEfficiency | |||
| SnEjectionEff | |||
| SnEjectionNorm | |||
| SnEjectionScaling | |||
| SnReheatEff | |||
| SnReheatNorm | |||
| SnReheatScaling |
The nine parameters shown in Tab. 1 can be subdivided into two different groups; namely those related to the star formation (MergerBurstFactor; SfCriticalSDNorm; and SfEfficiency) and the supernova feedback (SnEjection… and SnReheat…). The star formation parameters determine the star formation burst that happens after a galaxy/halo merger (MergerBurstFactor); the critical surface density required for star formation (SfCriticalSDNorm); and the efficiency with which available cold gas is converted into stars (SfEfficiency). Therefore, all three of these parameters directly influence the stellar mass of a galaxy/halo. On the other hand, the SnEjection… and SnReheat… parameters are each a group of three free parameters that determine a single physical quantity in Meraxes; the supernova energy coupling efficiency and the mass loading factor, respectively. Since the supernova feedback heavily influences the amount of (cold) gas that is available for star formation, they are very important for the model predictions.
3.1 Testing the waters with mock data
Before exploring the Meraxes model, we first had to determine whether Prism was capable of handling such a complex non-linear model effectively. In order to do this, we created mock comparison data for which we knew the model realization . For convenience, we set the values of to be the estimates given in Tab. 1. Using this parameter set , we evaluated Meraxes and retrieved the output values at the same points as are given by Song et al. (2016), creating the mock data set. As mock data does not have an observational error associated with it, we used the square root of the model discrepancy variance as the error. Finally, as it is impossible for a model to make ‘perfect’ predictions, we also perturbed the mock data values by their own errors using a normal distribution.
Using this mock data, we created an emulator of Meraxes, whose statistics are shown in Tab. 2. Since we are simply testing if Prism works properly, we purposefully chose high implausibility cut-offs and several implausibility wildcards for this emulator, such that it would converge slower. As described earlier, every implausibility wildcard causes the next highest implausibility measure to be ignored when evaluating the emulator. Despite this however, the emulator converged quickly, demonstrating that small variances have a much bigger impact than the conservative choices for the algorithm. Because the observational variance and model discrepancy variance are the same, this may have a negative effect on the accuracy of the emulator (cf., V19), so we kept in mind that this might be an issue in the case that the emulator is incorrect.





In order to study the behavior of an emulator, Prism creates a series of 2D and 3D projection figures, which for this emulator are shown in Fig. 2. As described by V19, a 3D projection figure consists of two subplots for every combination of two active model parameters. Each subplot is created by analyzing a grid of points for the plotted parameters, where a Latin-Hypercube design (McKay et al., 1979) of samples is used for the remaining parameter values in every grid point. All results are then processed to yield a single result per grid point that is independent of the non-plotted parameters. In every projection figure, the top subplot shows the minimum implausibility value (i.e., with the first non-wildcard cut-off) that can be reached, whereas the bottom subplot shows the fraction of samples (“line-of-sight depth”) that is plausible. An easy way to distinguish these plots is that the former shows where the best plausible samples can be found, while the latter shows where the most plausible samples are. A 2D projection is similar to a 3D projection, but only a single model parameter is plotted, and is more comparable to a marginalized likelihood/density plot often used in Bayesian statistics.
A combination of 2D and 3D projections can be used to study many properties of the Meraxes model. On the left in Fig. 2, we show the 2D projections of the three star formation parameters. These three projections show us quite clearly where the best parameter values can be found, especially for the star formation efficiency SfEfficiency, which all agree very well with their parameter estimates (the dashed lines). Although we know that the Meraxes model is capable of generating a model realization that corresponds to the data, as mock data was used instead of observational data, this result is still somewhat surprising. After all, almost the entire parameter range is still considered to be plausible for the MergerBurstFactor and SfCriticalSDNorm parameters, while the favored parameter values are very obvious. This shows that while Prism is quite conservative with removing plausible space despite low variances, it can still reach a result quickly, only requiring model evaluations to reduce plausible parameter space by almost a factor of .
On the right of Fig. 2, we show the 3D projections of the free parameters related to the supernova feedback. As each of these supernova feedback parameters are comprised of three free parameters, we expect the free parameters to be heavily correlated with each other. As demonstrated by these figures, this is indeed the case. While Prism can come to a good estimate of where the best parameter values are, it cannot pinpoint them nearly as easily as the star formation parameters. This would either require more model evaluations or more data points, where the latter would hopefully provide more constraining information for these free parameters.
3.2 Investigating the Meraxes model calibration
Now that we have established that Prism is indeed capable of retrieving the proper parameters with reasonable accuracy and a low number of model evaluations, we now use the observational data from Song et al. (2016). Apart from the different comparison data values, we kept all other variables, like the implausibility cut-offs and model discrepancy variance, as similar as possible. This allows us to compare the results of this emulator with the mock data one we studied previously. The statistics of this emulator are shown in Tab. 3.
When comparing the emulator statistics given in Tab. 3 with those in Tab. 2, we can see that both emulators behaved very similarly in iterations and . However, because we noted that the mock data emulator barely changed when we did not decrease the number of implausibility wildcards, we decided to use the same implausibility parameters for iteration as we did for iteration in Tab. 2. However, unlike the mock data emulator, this emulator vastly reduced its plausible parameter space, doing so by more than a factor . This can be an indication that either there are a select few data points that are heavily constraining the model (as they would be ignored when using more implausibility wildcards), or that the model cannot produce any realizations that can explain the data reasonably well. Given that the former trend was not observed in the mock data emulator, even though it would apply there as well, we expect that the latter is playing a role here.






In Fig. 3, we show the projection figures of this emulator for iteration . We show the iteration projections here instead of the iteration ones, as the latter show much less structure than the former. This is another indication that the Meraxes model might be incapable of producing realizations that fit the data, as a lack of structure is usually caused by no areas of parameter space being favored over others, thus creating a tiny hypercube shell of plausible samples.
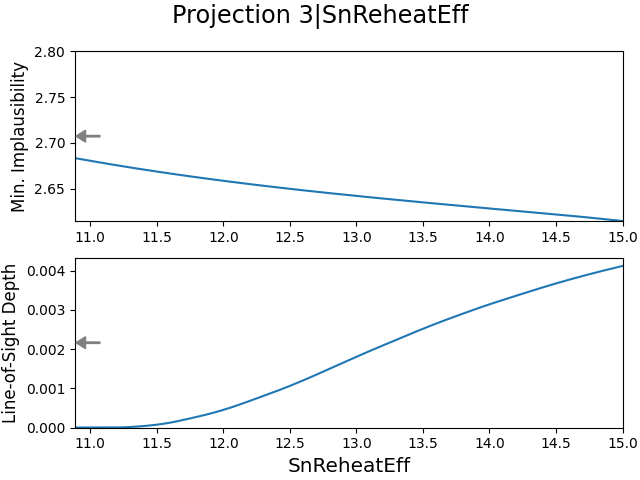
From the iteration projections, we can see that the star formation parameters, specifically the MergerBurstFactor and SfCriticalSDNorm, are not agreeing with their own estimates. Instead, it appears that they ‘prefer’ much lower values than their estimates indicate. The star formation efficiency SfEfficiency does agree with its estimate, but not nearly with the same confidence as it did in Fig. 2. We kept in mind here that this specific emulator iteration has a plausible space that is five times larger than the aforementioned emulator’s plausible space, but the plausible samples are still much more spread out. This is especially evident when comparing the 2D projection for SfEfficiency in both figures with each other.
However, when we examine the 3D projections in Fig. 3, we can clearly see that the range of plausible values is very large. The minimum implausibility plots show barely any structure (as this gets even worse for iteration , we do not show these figures here), unlike the corresponding projections in Fig. 2. Furthermore, the parameters are not consistent with their estimates at all. Because we noted earlier that the supernova feedback parameters used here are in fact groups of three free parameters that combined determine a single physical process, this might be an indication that the estimates are significantly perturbed due to correlation errors.
Using the results that we have collected thus far, mainly that the parameters do not converge, we conclude that the manually calibrated parameter values, as given by M16 and shown in Tab. 1, are likely to be biased and thus non-optimal. This conclusion is indeed implied by M16, whose caption of the parameter estimates in their Table 1 states that the “values were constrained to visually reproduce the observed evolution in the galaxy stellar mass function between and ”. Furthermore, even though we have shown that Prism is very capable of constraining Meraxes quickly, the free parameters for the energy coupling efficiency SnEjection… and the mass loading factor SnReheat… are very hard to constrain properly using the SMF at , as shown by the 3D projections in Fig. 2. Qiu et al. (2019) came to a similar conclusion, and decided to make some modifications to the Meraxes model and use luminosity data in order to attempt to constrain the star formation and supernova feedback parameters. In the next section, we use their modified Meraxes model with Prism to see whether this resolves the problem, and discover what else we can learn from its analysis.
4 Studying a modified Meraxes
In this section, we discuss the results of the emulators that were made using the methodology and parameter values for Meraxes as reported in Qiu et al. (2019), hereafter Q19. In the following, to avoid confusion, we refer to the two different versions of Meraxes using the corresponding work in which they are described (e.g., ‘M16 Meraxes’ and ‘Q19 Meraxes’), or simply refer to it as ‘Meraxes’ when we describe the model in general.
The Q19 Meraxes model is substantially modified from the M16 Meraxes model we explored in 3. The most significant difference between the two Meraxes models, is that the original (M16) uses three free parameters for calculating the mass loading factor and energy coupling efficiency (given by Eqs. (14) and (13) in M16, respectively), whereas the modified version (Q19) only uses a single free parameter for both quantities (Eqs. (9) and (10) in Q19, respectively). Not only does this reduce the number of parameters that need to be constrained by four (five if one also counts the MergerBurstFactor) compared to the previous emulators, but it also removes many correlation patterns between all the parameters.
Furthermore, the Q19 Meraxes model uses UV luminosity function (LF) and color-magnitude relation (CMR) data from Bouwens et al. (2014, 2015) as observational constraints, not the SMF data. To be able to handle this, Q19 implemented three different parametrizations of the dust model proposed by Charlot & Fall (2000) in Meraxes. We chose to use their dust-to-gas ratio (DTG) parametrization in this work as it seemed to be the least constrained, giving the emulation process more freedom. Despite this, the priors for all parameters as reported in Q19 are still much more heavily constrained than the priors we used earlier (as given in Tab. 1).
Finally, the initial mass function (IMF) used in Q19 Meraxes (Kroupa; Kroupa 2002) is different from the one used in M16 Meraxes (Salpeter; Salpeter 1955). Due to this change in the used IMF, the SMF data from Song et al. (2016) needs to be adjusted. According to Eq. (2) in Speagle et al. (2014), the SMF masses can be shifted from a Salpeter IMF to a Kroupa IMF, by applying the following offset:
| (6) |
with the and subscripts referring to the Kroupa and Salpeter IMFs, respectively. This translates into an offset of for logarithmic masses. For the emulators reported in this section, we have applied this offset to the SMF data from Song et al. (2016).
Since the Q19 Meraxes model uses different parameters than the original M16 Meraxes, the parameter ranges and estimates given in Tab. 1 are no longer correct. Therefore, we opted for using the same ranges and estimates for both the SMF and dust optical depth parameters, as described in Table 2 in Q19, which are given in Tab. 4. For the data, we used the same data as used in M16 and Q19, which is the observational data given by Song et al. (2016) (SMF), adjusted for a Kroupa IMF (Kroupa, 2002); and Bouwens et al. (2014, 2015) (LF/CMR), respectively. The parameter ranges and estimates in Q19 were calibrated manually by repeatedly using an MCMC estimator,222Y. Qiu, 2020, private communication, April 1st which we kept in mind during the analysis.
| Name | Min | Max | Estimate |
|---|---|---|---|
| SfCriticalSDNorm | |||
| SfEfficiency | |||
| SnEjectionEff | |||
| SnReheatEff | |||
| a | |||
| n | |||
| s1 | |||
| tauBC | |||
| tauISM |
4.1 Comparing the two Meraxes models
As the number of free parameters used for the mass loading factor and energy coupling efficiency in Q19 Meraxes was reduced to one and the used IMF was changed, we first decided to make an emulator using solely SMF data. We had concluded earlier that M16 Meraxes was very difficult to constrain properly using only SMF data at and we wished to determine whether the parameter reduction and/or change in the IMF has any positive effects on the convergence behavior of the parameter space. For this emulator, we assumed a model discrepancy variance set to , with being the value of the corresponding observational data point. This results in values that are very similar to the static we used earlier (as the SMF data values are mapped to an function and thus of the order of unity), but makes them dependent on the data value. We did this in order to prepare for the LF/CMR data points we will use later, as their values are of the order of and thus such a model discrepancy variance would not work well for them. The statistics of this emulator are shown in Tab. 5.
Looking at Tab. 5, we can see that the parameters in this emulator are constrained much more heavily than in previous emulators. As a reminder, every implausibility wildcard causes the next highest implausibility measure to be ignored when evaluating the emulator. Despite using no wildcards at all, this emulator still had of parameter space remaining in iteration . This may seem like much compared to the statistics of previous emulators (that do use wildcards), but this can be easily explained by noting that the parameter ranges are far smaller than those used before. Therefore only a potentially more interesting/plausible space was available to begin with.
We also note that there is a large reduction in plausible space between iterations and , corresponding to a factor of about . Given that the implausibility cut-offs were not reduced by a large amount when going to iteration and neither had any implausibility wildcards involved, this implies that many comparison data points were just barely plausible in iteration . This would mean that a majority of the data points have a high constraining power in Q19 Meraxes and similar implausibility values. The projection figures will allow us to see whether this is the case.




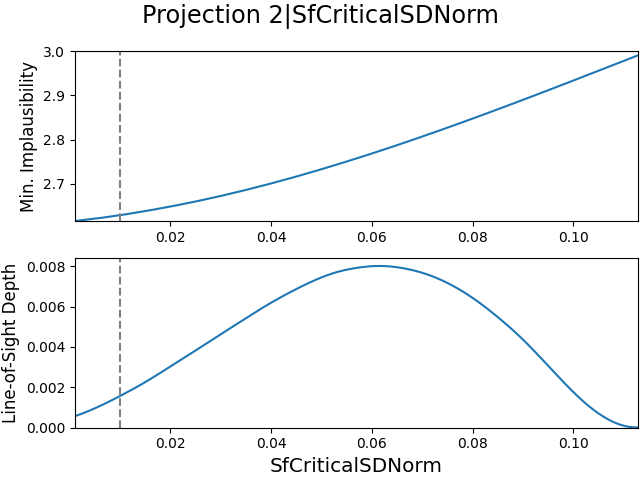










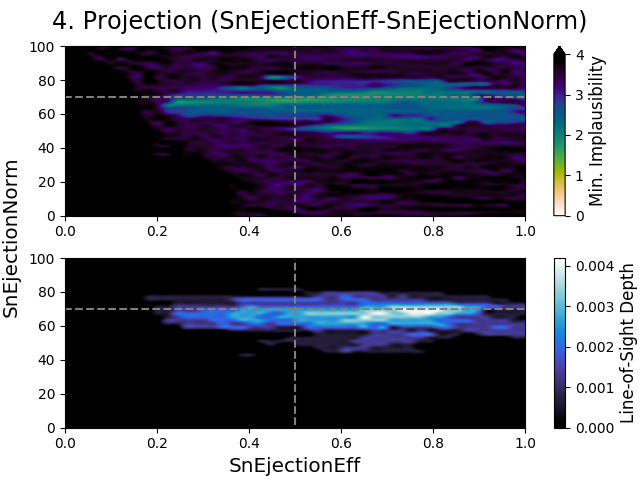
The 2D projections of the parameters related to the star formation and supernova feedback processes in Meraxes, are shown in Fig. 4 for all three emulator iterations. The dashed lines in the figures show the estimated value of the corresponding parameter as given in Tab. 4. Note that the parameter ranges in the projection figures differ between emulator iterations, as the emulator was only defined over that specific range. For comparison, we show the full parameter range for the parameters in emulator iteration in the final row.
Using this information, we can see some interesting trends in the projection figures. For example, all parameters except for the energy coupling efficiency, SnEjectionEff, seem to be moving away from their estimate. This could either mean that the parameter estimates are potentially biased, as we encountered earlier with the estimates given in Tab. 1, or that the LF/CMR data constrains these parameters differently. Despite this however, the parameters are much more well-behaved compared to the projections in Fig. 2 and Fig. 3, confirming that the parameter reduction has a positive effect on the convergence behavior.
Furthermore, we can see that our observation from earlier is indeed correct, that most data points have similar implausibility values. This is particularly evident in the projection figure of the energy coupling efficiency, SnEjectionEff, at iterations and (and to a lesser extent, the mass loading factor, SnReheatEff, shows this as well). As the y-axis in the top subplot ranges from the lowest (reachable) implausibility value to the highest (plausible) implausibility value, it shows that there is little variation in the values it can take. Taking into account the implausibility cut-offs reported in Tab. 5, this behavior can only be obtained when most data points have similar implausibility values and thus similar constraining power as well.
















In Fig. 5, we show the 3D projections for the parameters related to the star formation and supernova feedback processes, for all three emulator iterations. Because the star formation efficiency SfEfficiency is commonly the most well constrained and most correlated with the other parameters, the first three projections show the correlations between SfEfficiency and the other parameters. As the energy coupling efficiency SnEjectionEff and the mass loading factor SnReheatEff should be heavily correlated with each other, in addition to being modified in Q19 Meraxes, we show their 3D projections as well.
Looking at these projections, we can see that the star formation efficiency is indeed heavily correlated with the other parameters, revealing strong relations in all projection figures. Despite this however, it appears that the energy coupling efficiency, SnEjectionEff, cannot be effectively constrained. This is evident in both projection figures that show this parameter, which can be found in the second and fourth columns of Fig. 5. In fact, it appears that nearly all values for this parameter except its estimate are equally plausible, which is particularly visible in the iteration figure in the fourth column. This strongly implies that the SMF data cannot constrain this parameter, which might become important later.
Finally, we note that all parameters, with maybe the exception of the energy coupling efficiency SnEjectionEff, seem to be limited by their own priors, implying that their best values lie outside of their parameter ranges. This is particularly clear in their 3D projection figures in the third column of Fig. 5. This is another indication that the parameter priors might be too constrained, or that the LF/CMR data constrains these parameters differently. To test this hypothesis, we checked what the SMF looks like when the best plausible samples found in the emulator are used.

In Fig. 6, we show a comparison between the SMFs created by plausible samples in the emulator and the SMF given by the parameter estimates from Tab. 4. Because an emulator consists of approximations, it is unable to provide a true best parameter fit, and therefore we evaluated the emulator times within plausible space at iteration , and selected the best plausible samples. These samples were then evaluated in Q19 Meraxes to produce the solid lines shown in the figure.
From this figure, we can see that the emulator samples (solid lines) apparently fit the data much better than the parameter estimates from Tab. 4 (dashed line). However, even though the fits are better, the emulator still appears to be overestimating the number density of galaxies at low masses, for all redshifts. If we take a look at Fig. 4, we can see that the lowest implausibility values are reached at either boundary for all parameters. This means that these plausible samples all have values that are at the minimum/maximum value they can take. Therefore, this figure confirms the hypothesis we made earlier, that the parameter priors are too constrained, and/or that the LF/CMR data constrains these parameters differently. In order to test which of the two statements is true, we explore whether the trend is still apparent when using the LF/CMR data in the next section.
4.2 Exploring Meraxes using both SMF and luminosity data
Now that we have analyzed the Q19 Meraxes model and studied how it affects the behavior of the SMF parameters, it is time to analyze the model using all nine parameters. As mentioned before, we use the same data as used in M16 and Q19 (i.e., Bouwens et al. 2014, 2015; Song et al. 2016), and the same parameter ranges as given in Tab. 4. To allow for a better comparison with the previous emulator, this emulator also uses a model discrepancy variance of . The statistics of this emulator are shown in Tab. 6.
As this emulator uses over three times the number of data points as the previous one ( vs. ) and because we expect the LF/CMR data to constrain the model differently, we intentionally converged the emulator in a slower, more conservative fashion. We therefore have three implausibility wildcards for the first iteration. This can potentially also provide us with more information on the value of using the LF/CMR data as additional constraints for Meraxes.
Looking at Tab. 6, we can see that the emulator converged rather smoothly throughout all iterations. However, we do note that there is a reduction of roughly a factor in plausible space between iterations and . Given that the difference in the implausibility parameters between these two iterations is not very large, this is implies that all data points have similar implausibility values and thus similar constraining power. As we found a similar trend for the SMF-only emulator (see Tab. 5), we will investigate later using projection figures and emulator evaluations whether this is the case.








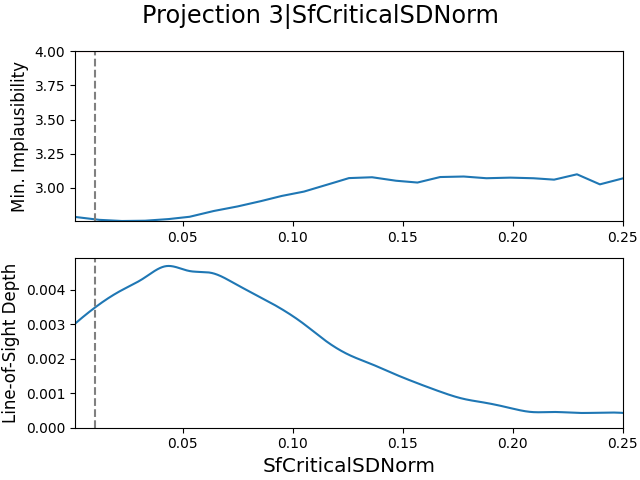











The 2D projections of the parameters related to the star formation and supernova feedback processes in Meraxes are shown in Fig. 7 for all four emulator iterations. The dashed lines in the figures show the estimated value of the corresponding parameter as given in Tab. 4. As with the previous emulator, the parameter ranges differ between emulator iterations.
First of all, we look at the top row in Fig. 7, which shows the 2D projection figures for emulator iteration . Given that this iteration still had of parameter space remaining (according to Tab. 6), we do not expect to see much structure here. However, we can see that there is a reasonable amount of structure in them, which shows us that the parameters agree relatively well with their estimates.
In iteration however, we note that this trend is starting to change for the star formation efficiency, SfEfficiency, and mass loading factor, SnReheatEff, which move away from their estimates. This becomes increasingly apparent over the next two iterations. When we compare the iteration projections in Fig. 7 to the iteration projections in Fig. 4, we can see that the parameters behave very similarly in both emulators.
Despite this however, the parameter ranges are not nearly as well constrained as they are in Fig. 4. Furthermore, whereas the minimum implausibility subplots showed strong correlations before, they do not do this in Fig. 7. This is interesting, as this suggests that the SMF data and the LF/CMR data constrain different regions of parameter space. It however also implies that it would be rather challenging to perform a global parameter estimation on these parameters, as no region of parameter space is removed quickly. Instead, there is a tiny hypercube shell of plausible samples that stretches over parameter space.















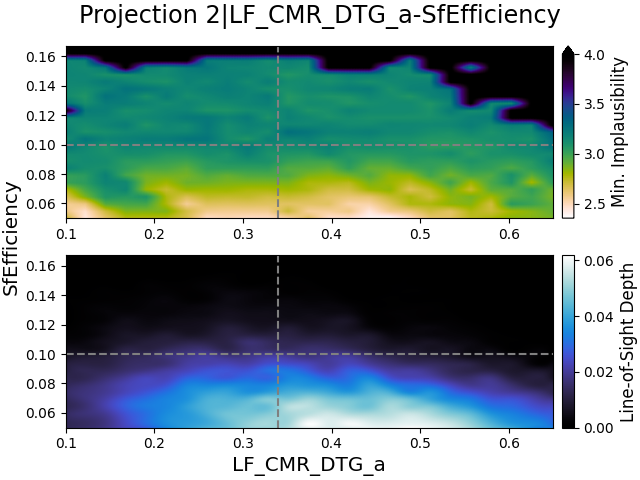
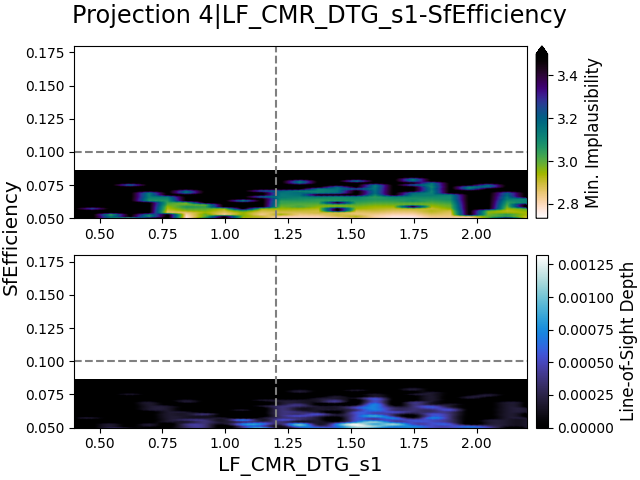
In Fig. 8, we show the 2D projection figures of the three free parameters used for calculating the dust optical depth. Note that the names of these parameters, as reported in the title of a projection figure, have an added LF_CMR_DTG_ prefix. As these parameters are free parameters in a single equation, we do not expect them to show interesting details.
Looking at these projection figures, all the free parameters appear to agree with their estimates in all iterations, although n is slightly questionable. However, with the exception of a small fraction for n, their plausible ranges are not reduced at all throughout the iterations. As these parameters are free parameters, they are expected to be heavily correlated with each other and thus the behavior in the projection figures is logical. It would however indicate a difficulty in finding their optimal values though.












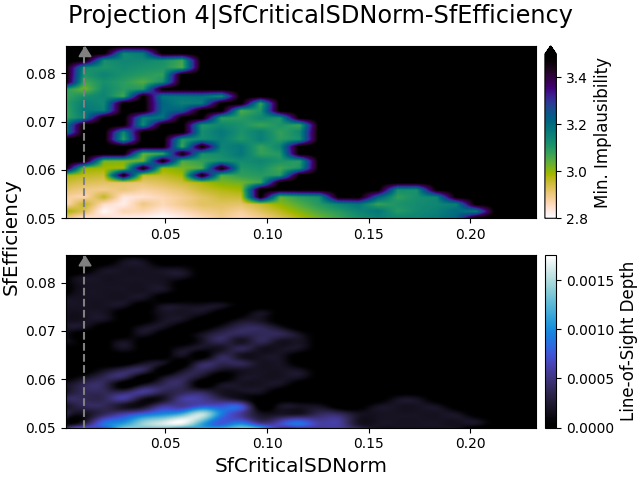







Similarly to the previous emulator, in Fig. 9, we show the 3D projections for the parameters related to the star formation and supernova feedback processes, for all four emulator iterations. As expected for the first emulator iteration, given its value of , the first row of projections shows nothing of great interest. There are a few small indications of correlations between the parameters, but nothing significant.













The second row of projection figures on the other hand, begins to exhibit some interesting behavior. Here, we can see that there are regions in parameter space where better (i.e., lower minimum implausibility) samples can be found, but the plausible samples are still very spread out over parameter space. The same can be observed for the third iteration. In the last iteration however, there are actually significant parts of parameter space that are no longer considered to be plausible. We also note that, unlike the projections in Fig. 5, the star formation efficiency SfEfficiency no longer dominates the other parameters as strongly. This further suggests that the SMF and LF/CMR data constrain different parts of parameter space, making it much harder to perform global parameter estimations.
And, finally, in Fig. 10, we show the 3D projection figures of the dust optical depth parameters. Similarly to the 3D projections shown in Fig. 9, it takes until iteration before parameter space finally begins to be restricted, despite only of it being plausible. Even then however, basically all values in the parameter ranges of the dust optical depth parameters are plausible, with no indication of converging. Here, it appears that the observational data is not enough to constrain these free parameters.



In Fig. 11, we show a comparison between the SMFs/LFs/CMRs created by plausible samples in the emulator and the SMF/LF/CMR given by the parameter estimates from Tab. 4. Similarly to Fig. 6, we evaluated the emulator times within plausible space at iteration , and selected the best plausible samples. These samples were then evaluated in Q19 Meraxes to produce the solid lines shown in the figure.
From this figure, we can see that the SMF fits are very similar (if not the same) as those we showed in Fig. 6. This is in agreement with the projection figures in Fig. 4 and Fig. 7, which also showed similar parameter trends. However, whereas the emulator samples provide better fits for the SMF, it appears to provide roughly equal or slightly worse fits for the LF (the center row in Fig. 11), while the CMR fits seem to be equal (bottom row). This implies that the SMF data constrains the LF much more heavily than the LF data itself does, but also that Q19 Meraxes might be unable to fit both the SMF data and the LF/CMR data simultaneously.
When we take into account the information shown in all projection figures and the two realization figures, we come to the conclusion that the prior parameter ranges as given in Tab. 4 are too restrictive; and that the SMF and LF/CMR data constrain the Meraxes model differently. The former is clearly shown in the star formation and supernova feedback parameter projections in Fig. 4 and Fig. 7. In addition to the energy coupling efficiency, SnEjectionEff, all parameters have their best values at or very near the boundaries of their priors for both emulators. The projection figures in Fig. 7 and Fig. 8 on the other hand, show that the parameters are much harder to constrain when the LF/CMR data is used as well.
These findings demonstrate two significant results: The importance of having the correct data points when performing parameter estimations; and the value of using Prism for exploring models. Since only the LF/CMR data from Bouwens et al. (2014, 2015) was used by Q19 to constrain all nine parameters, the differing, stronger constraining power of the SMF data was not noted. As we can see in the 2D projections in Fig. 7, the best values for the star formation and supernova feedback parameters are similar to those in Fig. 4, implying that the SMF data constrains these parameters more heavily than the LF/CMR data. The two emulators discussed in this section required roughly evaluations of the Meraxes model, multiple orders of magnitude less than the average amount used by an MCMC approach. Despite this however, the emulators still show us all this crucial information.
In addition to the importance of using the correct data points, the projections in Fig. 9 highlight the potential dangers of having too many degrees-of-freedom in a model (or, alternatively, the dangers of not having enough constraining data points). Even though the SMF and the LF/CMR data constrain the Meraxes model differently, causing a wide range of parameter values to be plausible, we can see much more structure in these projections than in those we showed in Fig. 3. We therefore also note the importance of choosing the degrees-of-freedom for a scientific model wisely.
5 Conclusions
We have analyzed the galaxy formation model Meraxes using the emulation-based framework Prism. Two different versions of Meraxes have been studied: the original created by M16 and a modified one by Q19. Both versions have provided us with different, interesting results.
The M16 Meraxes model has shown to be difficult to constrain properly using the SMF observational data at alone. As described in 3, there are several indications that imply that the M16 Meraxes model has too many free parameters, mainly for the supernova feedback parameters SnEjection… (supernova energy coupling efficiency) and SnReheat… (mass loading factor) to be able to explain these SMF observations. We also come to the conclusion that the manually calibrated parameter values for M16 Meraxes are likely to be biased as the parameters do not converge, which is probably caused by the large correlations between the free parameters. Prism has demonstrated that it can quickly perform a rough parameter estimation using only a few thousand model evaluations, which provided us with the mentioned results.
In 4, we analyzed the Q19 Meraxes model, which has a reduced parameter space for the star formation parameters, and uses only a single degree-of-freedom for both supernova feedback parameters. Our analysis has shown that this greatly improves the convergence rate of the Meraxes model and that it greatly facilitates constraining Meraxes, as shown in Tab. 5 and Fig. 5. This figure also showed us the value of using the performance of acceptable parameter values (e.g., minimum implausibility) in addition to their density when performing parameter estimations.
Afterward, in 4.2, we constrained the Q19 Meraxes model using both SMF and LF/CMR data. This gave us two important results: The SMF and the LF/CMR data constrain the Meraxes model differently; and using heavily constrained parameter priors can bias the best parameter fits. The latter was shown in Fig. 4 and Fig. 7, where the best parameter values can be found very near or at the boundary of their priors. Alternatively, when looking at this from a physics standpoint, this can imply that aspects of the Meraxes model itself are incomplete or incorrect if the used priors are determined by their physical meaning, which is a rather important detail to know.
The results in 3 and 4 show us the importance of using more than one observational data type when constraining models, especially when appropriate observational data is scarce. Additionally, the choice of the degrees-of-freedom in a model should be made wisely as well. With our results, we have demonstrated the potential of using an emulation-based framework like Prism for analyzing scientific models, which is a task that a full Bayesian analysis cannot perform quickly. The use of Prism allows us to discover important details such as those mentioned above at an early stage and we therefore recommend it as a core component in the development of scientific models.
Acknowledgements
E.v.d.V. would like to thank Michael Goldstein, Manodeep Sinha and Ian Vernon for fruitful discussions and valuable suggestions. Parts of the results in this work make use of the rainforest and freeze colormaps in the CMasher package (van der Velden, 2020). We are thankful for the open-source software packages used extensively in this work, including e13tools333https://github.com/1313e/e13Tools; h5py (Collette, 2013); hickle (Price et al., 2018); matplotlib (Hunter, 2007); mlxtend (Raschka, 2018); mpi4py (Dalcín et al., 2005); mpi4pyd444https://github.com/1313e/mpi4pyd; numpy (van der Walt et al., 2011); scikit-learn (Pedregosa et al., 2011); scipy (Virtanen et al., 2020); sortedcontainers (Jenks, 2019); and tqdm555https://github.com/tqdm/tqdm. Parts of this research were supported by the Australian Research Council Centre of Excellence for All Sky Astrophysics in 3 Dimensions (ASTRO 3D), through project number CE170100013. Parts of this work were performed on the OzSTAR national facility at Swinburne University of Technology. OzSTAR is funded by Swinburne University of Technology and the National Collaborative Research Infrastructure Strategy (NCRIS).
References
- Benson (2010) Benson, A. J. 2010, PhR, 495, 33
- Bouwens et al. (2014) Bouwens, R. J., Illingworth, G. D., Oesch, P. A., et al. 2014, ApJ, 793, 115
- Bouwens et al. (2015) —. 2015, ApJ, 803, 34
- Bower et al. (2010) Bower, R. G., Vernon, I., Goldstein, M., et al. 2010, MNRAS, 407, 2017
- Charlot & Fall (2000) Charlot, S., & Fall, S. M. 2000, ApJ, 539, 718
- Cole et al. (2000) Cole, S., Lacey, C. G., Baugh, C. M., & Frenk, C. S. I. 2000, MNRAS, 319, 168
- Collette (2013) Collette, A. 2013, Python and HDF5: Unlocking scientific data, 1st edn. (O’Reilly Media)
- Craig et al. (1996) Craig, P. S., Goldstein, M., Seheult, A. H., & Smith, J. A. 1996, in Bayesian Statistics 5, ed. J. M. Bernardo, A. P. Berger, A. P. Dawid, & A. F. M. Smith (Oxford, UK: Clarendon Press), 69–95
- Craig et al. (1997) Craig, P. S., Goldstein, M., Seheult, A. H., & Smith, J. A. 1997, in Case Studies in Bayesian Statistics, ed. C. Gatsonis, J. S. Hodges, R. E. Kass, R. McCulloch, P. Rossi, & N. D. Singpurwalla (New York, NY: Springer New York), 37–93
- Croton et al. (2006) Croton, D. J., Springel, V., White, S. D. M., et al. 2006, MNRAS, 365, 11
- Croton et al. (2016) Croton, D. J., Stevens, A. R. H., Tonini, C., et al. 2016, ApJS, 222, 22
- Currin et al. (1991) Currin, C., Mitchell, T., Morris, M., & Ylvisaker, D. 1991, Journal of the American Statistical Association, 86, 953
- Dalcín et al. (2005) Dalcín, L., Paz, R., & Storti, M. 2005, Journal of Parallel and Distributed Computing, 65, 1108
- Gelman et al. (2014) Gelman, A., Carlin, J. B., Stern, H. S., et al. 2014, Bayesian data analysis, 3rd edn. (Taylor & Francis Group, LLC)
- Genel et al. (2014) Genel, S., Vogelsberger, M., Springel, V., et al. 2014, MNRAS, 445, 175
- Goldstein (1999) Goldstein, M. 1999, in Encyclopedia of Statistical Sciences (Wiley), 29–34
- Goldstein & Rougier (2006) Goldstein, M., & Rougier, J. 2006, Journal of the American Statistical Association, 101, 1132
- Goldstein & Wilkinson (2000) Goldstein, M., & Wilkinson, D. J. 2000, Statistics and Computing, 10, 311
- Goldstein & Wooff (2007) Goldstein, M., & Wooff, D. 2007, Bayes Linear Statistics: Theory and Methods, 1st edn. (John Wiley & Sons Ltd.)
- Henriques et al. (2019) Henriques, B. M. B., White, S. D. M., Lilly, S. J., et al. 2019, MNRAS, 485, 3446
- Henriques et al. (2013) Henriques, B. M. B., White, S. D. M., Thomas, P. A., et al. 2013, MNRAS, 431, 3373
- Hunter (2007) Hunter, J. D. 2007, Computing in Science and Engineering, 9, 90
- Jenks (2019) Jenks, G. 2019, The Journal of Open Source Software, 4, 1330
- Kennedy & O’Hagan (2001) Kennedy, M. C., & O’Hagan, A. 2001, Journal of the Royal Statistical Society: Series B (Statistical Methodology), 63, 425
- Kroupa (2002) Kroupa, P. 2002, Science, 295, 82
- Kuhlen et al. (2012) Kuhlen, M., Vogelsberger, M., & Angulo, R. 2012, Physics of the Dark Universe, 1, 50
- Lacey (2001) Lacey, C. 2001, in Astronomical Society of the Pacific Conference Series, Vol. 222, The Physics of Galaxy Formation, ed. M. Umemura & H. Susa, 273
- Lagos et al. (2018) Lagos, C. d. P., Tobar, R. J., Robotham, A. S. G., et al. 2018, MNRAS, 481, 3573
- Loeb & Barkana (2001) Loeb, A., & Barkana, R. 2001, ARA&A, 39, 19
- Martindale et al. (2017) Martindale, H., Thomas, P. A., Henriques, B. M., & Loveday, J. 2017, MNRAS, 472, 1981
- McKay et al. (1979) McKay, M. D., Beckman, R. J., & Conover, W. J. 1979, Technometrics, 21, 239
- Mutch et al. (2016) Mutch, S. J., Geil, P. M., Poole, G. B., et al. 2016, MNRAS, 462, 250
- Oakley & O’Hagan (2002) Oakley, J., & O’Hagan, A. 2002, Biometrika, 89, 769
- O’Hagan (2006) O’Hagan, A. 2006, Reliability Engineering & System Safety, 91, 1290
- Pedregosa et al. (2011) Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, Journal of Machine Learning Research, 12, 2825. http://jmlr.org/papers/v12/pedregosa11a.html
- Planck Collaboration et al. (2016) Planck Collaboration, Ade, P. A. R., Aghanim, N., et al. 2016, A&A, 594, A13
- Price et al. (2018) Price, D., van der Velden, E., Celles, S., et al. 2018, The Journal of Open Source Software, 3, 1115
- Pukelsheim (1994) Pukelsheim, F. 1994, The American Statistician, 48, 88
- Qin et al. (2017) Qin, Y., Mutch, S. J., Poole, G. B., et al. 2017, MNRAS, 472, 2009
- Qiu et al. (2019) Qiu, Y., Mutch, S. J., da Cunha, E., Poole, G. B., & Wyithe, J. S. B. 2019, MNRAS, 489, 1357
- Raftery et al. (1995) Raftery, A. E., Givens, G. H., & Zeh, J. E. 1995, Journal of the American Statistical Association, 90, 402
- Raschka (2018) Raschka, S. 2018, The Journal of Open Source Software, 3, 638
- Rodrigues et al. (2017) Rodrigues, L. F. S., Vernon, I., & Bower, R. G. 2017, MNRAS, 466, 2418
- Sacks et al. (1989) Sacks, J., Welch, W. J., Mitchell, T. J., & Wynn, H. P. 1989, Statistical Science, 4, 409
- Salpeter (1955) Salpeter, E. E. 1955, ApJ, 121, 161
- Schaye et al. (2010) Schaye, J., Dalla Vecchia, C., Booth, C. M., et al. 2010, MNRAS, 402, 1536
- Schaye et al. (2015) Schaye, J., Crain, R. A., Bower, R. G., et al. 2015, MNRAS, 446, 521
- Sivia & Skilling (2012) Sivia, D. S., & Skilling, J. 2012, Data Analysis: A Bayesian Tutorial, 2nd edn. (Oxford Science Publications)
- Somerville et al. (2015) Somerville, R. S., Popping, G., & Trager, S. C. 2015, MNRAS, 453, 4337
- Song et al. (2016) Song, M., Finkelstein, S. L., Ashby, M. L. N., et al. 2016, ApJ, 825, 5
- Speagle et al. (2014) Speagle, J. S., Steinhardt, C. L., Capak, P. L., & Silverman, J. D. 2014, ApJS, 214, 15
- Springel et al. (2005) Springel, V., White, S. D. M., Jenkins, A., et al. 2005, Nature, 435, 629
- Stone (1948) Stone, M. H. 1948, Mathematics Magazine, 21, 167. http://www.jstor.org/stable/3029750
- van der Velden (2019) van der Velden, E. 2019, The Journal of Open Source Software, 4, 1229
- van der Velden (2020) —. 2020, The Journal of Open Source Software, 5, 2004
- van der Velden et al. (2019) van der Velden, E., Duffy, A. R., Croton, D., Mutch, S. J., & Sinha, M. 2019, ApJS, 242, 22
- Vernon et al. (2010) Vernon, I., Goldstein, M., & Bower, R. G. 2010, Bayesian Anal., 5, 619
- Vernon et al. (2014) —. 2014, Statist. Sci., 29, 81. https://doi.org/10.1214/12-STS412
- Virtanen et al. (2020) Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nature Methods, 17, 261
- van der Walt et al. (2011) van der Walt, S., Colbert, S. C., & Varoquaux, G. 2011, Computing in Science and Engineering, 13, 22