UET-Headpose: A sensor-based top-view head pose dataset
Abstract
Head pose estimation is a challenging task that aims to solve problems related to predicting three dimensions vector, that serves for many applications in human-robot interaction or customer behavior. Previous researches have proposed some precise methods for collecting head pose data. But those methods require either expensive devices like depth cameras or complex laboratory environment setup. In this research, we introduce a new approach with efficient cost and easy setup to collecting head pose images, namely UET-Headpose dataset, with top-view head pose data. This method uses an absolute orientation sensor instead of Depth cameras to be set up quickly and small cost but still ensure good results. Through experiments, our dataset has been shown the difference between its distribution and available dataset like CMU Panoptic Dataset [7]. Besides using the UET-Headpose dataset and other head pose datasets, we also introduce the full-range model called FSANet-Wide, which significantly outperforms head pose estimation results by the UET-Headpose dataset, especially on top-view images. Also, this model is very lightweight and takes small size images.
Index Terms:
head pose estimation, sensor based, deep learningI Introduction
Today with the strong development of technology infrastructure, security cameras are widely used to observe and monitor behavior. From this massive amount of data obtained, it is beneficial to extract the necessary information. Many research addresses the head pose estimation problem, which has numerous applications, such as identifying customer behavior and driver behavior monitoring. Most head pose estimation methods use the 300W-LP dataset or the BIWI dataset, which just has estimated head pose in small range yaw angles . So some methods use another dataset - CMU Panoptic Dataset [7] to have full-range yaw [-179, 179]. However, the CMU Panoptic Dataset dataset has the disadvantage that the background of the images is similar because it was recorded in the same setup. Moreover, this laboratory environment is hard to set up, requiring multiple cameras with high resolution to attach around the room. We have tons of public cameras; our proposed methods will not be convenient and adaptive for using available cameras. This paper also developed FSANet-Wide, which extends head-pose estimation to the full range of yaws (hence wide) by improving FSANet [8] architecture. In doing so, we make the following contributions:
-
•
We introduce a new data-driven approach to collecting head pose images based on an IMU sensor, various devices and a top-view camera.
-
•
We also publish the new dataset, namely UET-Headpose collected by new method.
II Related works
Head pose estimation. In 2018, the FAN model [14] was announced, that work by detected facial landmarks, the MAE evaluation results reached on the BIWI [6] dataset and on the AFLW2000 [5] dataset.
The method based on landmark points also has a considerable disadvantage: When the face orientation is completely greater than , it will be complicated to find these landmarks. Therefore, direct head direction estimation models from the image without detecting the landmarks were carried from this fatal drawback.
In 2018, Ruiz and colleagues proposed the HopeNet model [16], a convolutional neural network using multiple loss functions trained to predict Euler angles directly from the image. The classification loss also is used to guides the networks to learn the neighborhood of poses robustly. The evaluation results with the HopeNet [16] model on the BIWI [6] dataset reached and were state-of-the-art when published.
In 2019, Yang and colleagues published the FSA-Net [8] model and became the best model at the time of publication when evaluated on the BIWI [6] dataset with an MAE of , and the model was very lightweight at only MB. The FSA-Net [8] model also only needs to use a single RGB image without depth information or video. The vital improvement of the FSA-Net [8] plot in two parts is feature extraction, using a phased regression model (SSR) to predict face orientation with a light size and attention mechanism.
The Rankpose [18] and QuatNet [17] models both use the ResNet50 [19] backbone to estimate head poses. The improvements of these models are mainly in the loss function. QuatNet model [17] estimates predict the quaternion of head pose instead of Euler angles. QuatNet [17] uses two regression functions, L2 regression loss, and ordinal regression loss, to address the non-stationarity property in head pose estimation by ranking different intervals of angles with the classification loss. The resulting model also gives good results with an MAE of with the BIWI [6] dataset.
Head pose dataset. Currently, there are two primary datasets for training: 300W-LP [5] and BIWI [6], corresponding two main dataset for testing: AFLW2000 [5] and a part of BIWI [6].
Two datasets 300W-LP [5] and AFLW2000 [6], are created by 3DDFA [5]. This method passes RGB images through morphable 3D and outputs another RGB image with head pose changed. The 300W-LP [5] dataset includes images, and AFLW-2000 [5] includes images. In two datasets, yaw angles in the range of , pitch and roll angles in the range .
BIWI [6] dataset includes videos recorded by Kinect. People in this dataset are sitting in front of the camera and turning their heads in different directions. Head poses are estimated by in-depth information from Kinect. BIWI [6] dataset includes over images; the head pose range covers about degrees of yaw angle and degrees of pitch angle.
All three datasets 300W-LP [5], AFLW-2000 [5], and BIWI [6], have been used by many models for training and evaluation of the FSA-Net [8], Rankpose [18], and achieved good results when the mean error (MAE) was only about .
However, a major drawback of the 300W-LP [5], AFLW-2000 [5], and BIWI [6] datasets is that the head pose angles (including yaw, pitch, roll) are all in the range of degrees and these data are collected from depth camera to create 3D head orientation, so the prediction model is less effective with large-angle data such as from security cameras.
From that disadvantage, WHENet [15] used additional head pose datasets extracted from the CMU Panoptic dataset [7]. Head pose dataset from CMU Panoptic dataset [7] providing comprehensive yaw angle face orientation from improved a lot when evaluated with camera data compared to models trained only with 300W-LP [5] dataset.
Another problem is evaluating models, in older datasets like BIWI [6], AFLW-2000 [5], there are not enough angle to evaluate full range, yaw model. From that disadvantage, the paper further developed a dataset UET-Headpose with images captured directly from a system that combines a camera and an angle sensor mounted directly on the face. It is very adaptive; the device and set up everywhere quickly can collect for the actual situation.
III Proposed Method
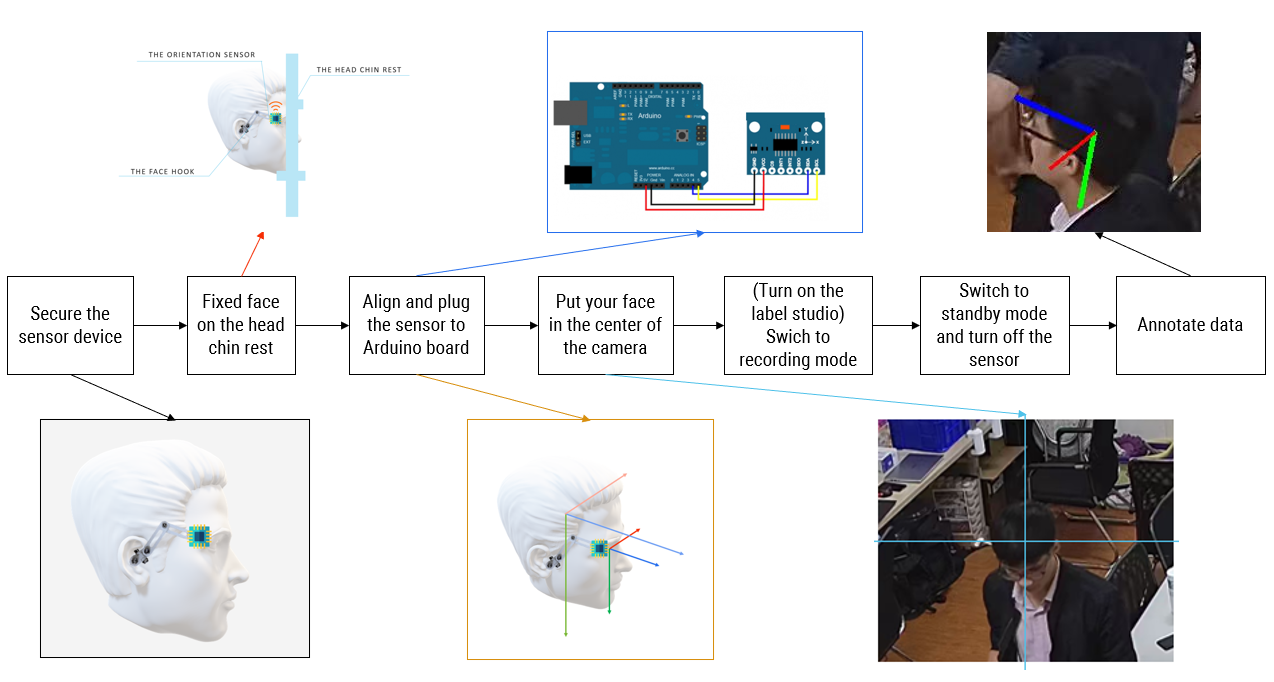
In this chapter, we will present in detail the approach to solving the above problem. First, in section 3.1, we will introduce the new approach for the face orientation data acquisition, the overall architecture of the new approach in Fig. 1, we have seven main phases, with the beginning is the process of wearing sensor for humans, and we have annotated data in the final phase. Then, section 3.2 will analyze the new dataset and present a baseline model for head pose estimation for security cameras. A new model is called FSANet-Wide, and using this model with a new dataset UET-Headpose-train and two other datasets.
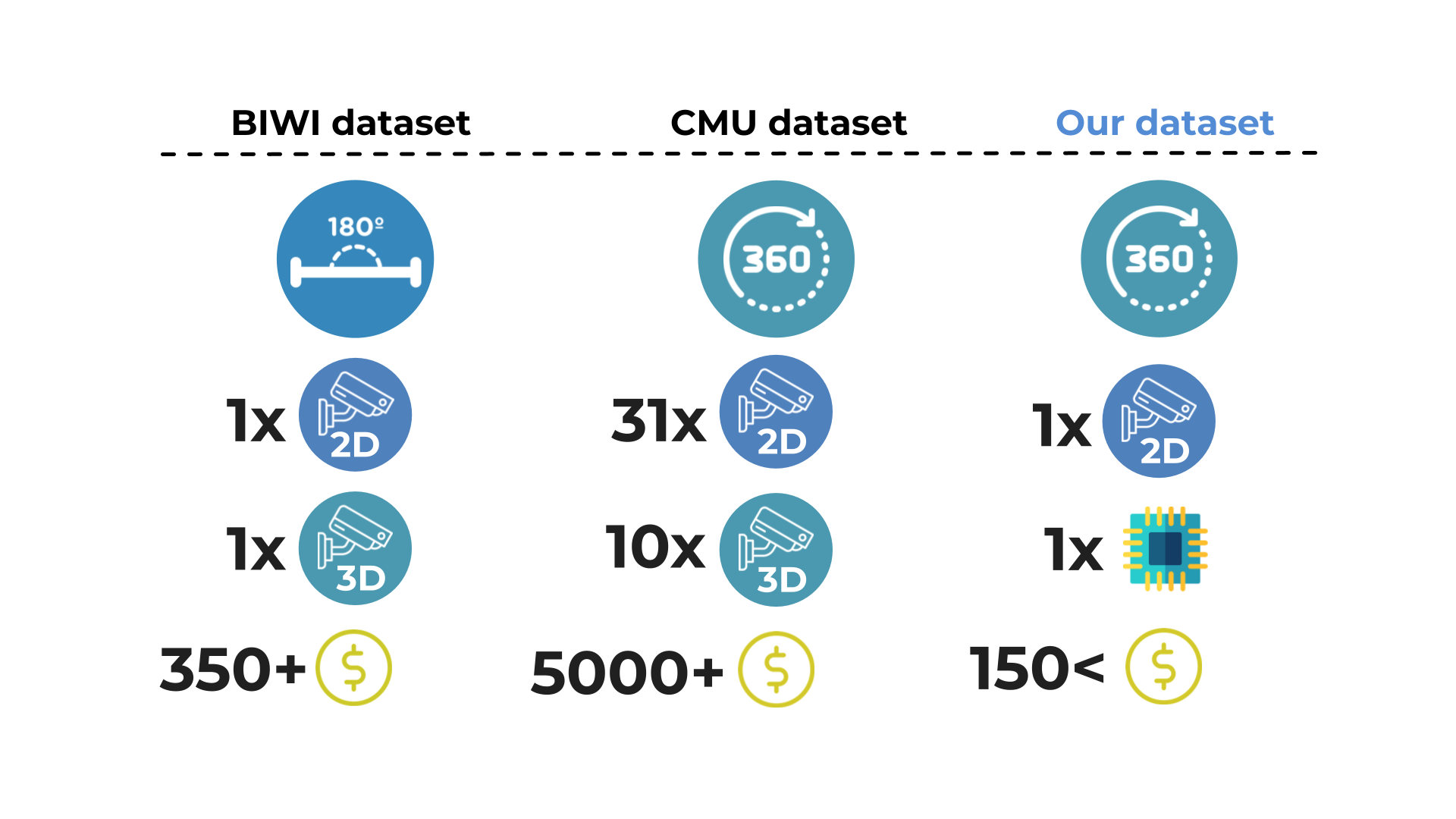
Structure Design We propose a new dataset called UET-Headpose with the advantages of background richness, overcoming the disadvantages of the head pose dataset extracted from the CMU Panoptic dataset [7] while ensuring the distribution of yaw angle is uniform in the range degrees. Moreover, our proposed setup is very efficient for carrying in real life.
The UET-Headpose dataset was created to capture the head pose of annotated people in many conditions with a wide yaw range and top view security cameras. The system includes a head-mounted sensor module, an arduino aboard, a surveillance camera, a chin rest for fixing the head, and a server to control, store and process data. In this paper, the surveillance camera used is HIK Vision 4 MP ColorVu Fixed Bullet Network Camera (DS-2CD2T47G1-L).
The surveillance camera is placed high with an inclination angle as zero-point compared to the fixed face , and for roll, pitch, yaw angle, respectively. This result is found by experimentally measuring the deflection angle between the plane parallel to a chin rest and the surveillance camera through the sensor. Firstly, the sensor is fixed to a plane of the rectangular box and is guaranteed to be perpendicular to the four surrounding planes. Then, the rectangular box is placed on a plane parallel to the support in the yaw, pitch, roll direction.
The chin rest is attached directly to the edge of the table. The design of the chin rest [21] includes 02 table legs, 02 fixed pivot bars, 01 adjustable height forehead support bar, 01 adjustable height chin rest bar, 01 adjustable depth chin rest, and 02 fixed bars sensor. Notably, the two fixed axles use 3030 aluminum profiles. The rest of the parts are 3D printed in 105 hours. The phase “Fixed face on the head” in Fig. 1 shows the chin rest and the way to locating the head of people on that.
The head-mounted sensor module equipment for recording the head’s angle value includes the 9-axis smart sensor MCU-055, the Arduino board WeMos D1 R2, a 10000 mAh battery, an ear hook, and wires. The device is designed to ensure optimal speed and increase certainty to limit sensor slippage and signal loss.
The system also includes one management computer for storage and processing data.
Transmit angle data from board to server
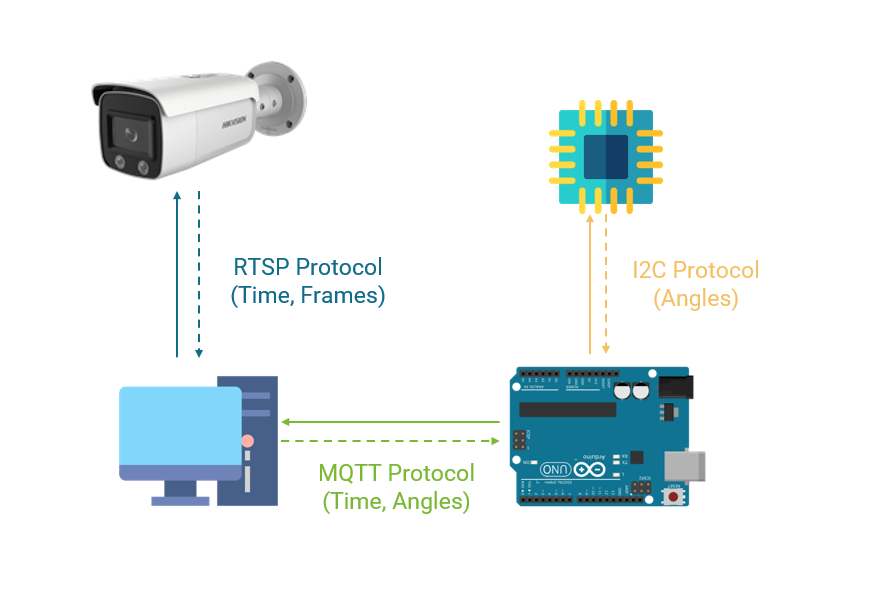
The sensor is connected to the Arduino board Wemos D1 R2 with the I2C protocol. The advantages of the I2C protocol simplicity and high reliability. The I2C protocol uses a clock line (SCL) transmitted at 100kHz and 400kHz, two wires GND and VCC, are responsible for stabilizing and supplying current to the sensor. The Arduino board Wemos D1 R2 is used due to the built-in 2.4 GHz Wifi router. The data from the sensor will be transmitted to the Arduino board continuously with a maximum frequency of 100 Mhz. The Arduino board captures data and transmits it to the computer via the MQTT [24] protocol.
The Arduino circuit has been directly integrated with the wifi router so that sensor information will be transmitted to the management computer via wifi to the MQTT [24] broker built on the management computer.
The Arduino circuit receives the signal from the sensor through 4 wires SCL, SDA, GND, and VCC. This information has been completely processed at the sensor, so the Arduino board will only receive and read yaw angles, pitch angles, and roll angles from the sensor and send it to the MQTT [24] broker.
Every s, the Arduino board will send data to the computer once in a JSON file, including information fields: time, x, y, z, where time is the time to record data from the sensor, obtained directly through the server pool.ntp.org. Three values x, y, z correspond to 3 information yaw, pitch, roll returned by the sensor.
The computer that stores and processes the data will continuously receive information from the sensor but selectively record it when the manager chooses. Based on the uploaded JSON file timer, the computer will request the camera the corresponding frame. We use this camera to provide images with a resolution of × , 60Hz: fps, 4mm focal length.
These frames will be manually labeled before being fed into the final training model. The labeling tool that we use is called “Eva.” [20] The advantage of this tool is that it is light, simple to deploy, and use because it is packaged into a complete docker.
Sensors
We use an angle sensor to record poses. Many types of sensors are used on the market that can be combined with an Arduino board, such as GY-50, MPU-6050, MPU-9250, MCU-055, … Sensor MCU-055 is a sensor developed by Bosch. In addition to integrating nine axes like the MPU-9250 sensor, sensor MCU-055 integrates a microprocessor responsible for combining parameters from the sensor, gyro, accelerometer, and magnetic field direction sensor. It returns absolute angular direction (Eulerian vector, 100Hz sampling frequency) as triaxial data based on the 360-degree sphere through a 32-bit microcontroller running BSX3.0 FusionLib software developed by Bosch. The raw data has been wholly preprocessed with algorithms and gives the final stable angular direction result.
Design board for wearing on head
The extended board consists of main parts: a sensor, an ear hook, an Arduino board, a battery, and all kinds of wires.
The sensor will be fixed through the face hook through a soft steel wire to align the sensor to each face, but still, make sure to keep the sensor fixed after alignment without tilting or deviating. After experimenting with many different types of wire, the soft steel wire used to fix the face hook is 1mm non-steel wire. Larger steel wires will be, but adjusting the sensor angle will be difficult, and conversely with smaller wires will not guarantee to hold the sensor firmly. However, the face hook version no. 1 using steel wire has the disadvantage of fine-tuning the sensor due to the elastic force of the steel wire. So the second version is made by 3D printing method was developed with the advantages: possible to adjust the directions through 3 rotating axes, no elastic phenomenon like steel wire. The face hook version no. 1 includes a soft steel wire responsible for fixing the sensor and ear hook. The sensor will be fixed to align the sensor to each face, but still, keep the sensor fixed after alignment without tilting or deviating. The image in block “Secure the sensor device” of Fig.1 shows the way the sensor is attached on the head of a person.
The ear hook is responsible for attaching tightly to the ear and keeping it fixed to the sensor. The first version of the hook is made entirely of soft silicone imported from abroad, it has the advantage of being soft and light. However, the ear attachment is not fixed because it has not yet adhered to the ear. Therefore, a 2mm steel thread was used by parallelizing the ear hooks through the soft black adhesive tape to overcome this shortcoming. With this additional steel wire, each time the sensor is attached, it can be easily adjusted to suit each person’s ears. When adding a steel wire, the ear hook was firmly attached around the ear, but it was still slightly shaken when tested.
This vibration error is identified because the upper end of the ear hook is not firmly attached to the fulcrum in the ear. So a foam cotton pad using PE Foam material was used. This sponge will tightly cushion the inside of the ear combined with the previously existing thin rim to form a solid structure, minimizing the vibration of the sensor.
Server
The management computer is used for annotating data will have the following tasks: Create an MQTT [24] broker to act as an intermediary between the sensor and the Arduino board, a system for receiving and storing, and processing data, an Eva labeling tool. The pipeline head pose and image data synchronization for the server is illustrated in Fig.2
The data receiving and processing system is responsible for storing the packets that the MQTT [24] broker requires the manager. The frames corresponding to the timestamps in the packet returned by the server and storing the data included raw images, head pose labels, and face position labels.
The data acquisition system is coded using python language, including two separate processing threads for collecting data from sensors and managing received data. The receiver stream will run continuously as soon as the system is turned on. The received data management flow will be displayed as a terminal, switching between two data recording modes and non-data recording.
When the system receives information from the MQTT [24] broker as a sensor result (JSON file containing time, yaw, pitch, roll fields) by default, the information will not be stored. However, when the data storage computer administrator switches to information storage mode, the system records information from the sensor to a log file. Each line corresponds to the information from the JSON file.
After having a log file containing information about the face orientation of the labeled person, the system will automatically retrieve the corresponding frames through the camera’s API. Since the surveillance camera only provides an API to playback saved video, view live video, and get the live snapshot, the method used to retrieve frames is to get a datum of the video start frame ( corresponding to the first frame in the log file), get the video from that point. Then, the time of the following frames will be calculated based on the FPS and the sequence number of that frame. The camera used has an FPS frequency of frames per second, so the number of packets sent by the sensor per second is chosen to be , so there will be a difference between the frame time and the packet time. Therefore, the message is a maximum interval of seconds.
Cost advantage
The method of collecting BIWI dataset and CMU panoptic dataset requires investment in at least one 3D camera [6], or ten 3D cameras, 480 VGA videos, 31 HD videos [7], so the cost of implementing this data acquisition system can be very expensive. It can be up to US$5000 accompanied by a complicated installation and deployment process.
Our face-to-face receivers are designed for simplicity and ease of deployment, including components: one sensor, one small 3d-printed system, the ear hook, and a 2D camera. These are very available components and easily obtainable for less than US$150. Easy to deploy and install anywhere with a variety of environments. In Fig.4, we describe differences between our proposed dataset and available dataset.
III-A Analyze UET-Headpose dataset and baseline model
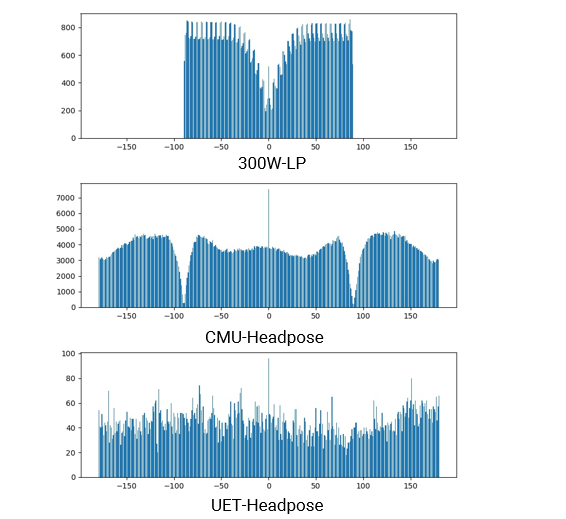
After collection, the UET-Headpose dataset includes images obtained from people with the distribution of yaw angles as shown in Fig. 3. So, the UET-Headpose dataset will be divided into seven people for training with images and two people for evaluation with images. These images will be cropped to the face on a scale increased by vertically and horizontally compared to the face. Label files also have additional coordinate information (x-min, y-min, x-max, y-max) so that the face can be accurately cut from the cropped image.
The UET-Headpose dataset had a uniform yaw angle distribution for all directions from . The dataset is obtained by having the annotated people rotated all yaw directions when collecting the dataset. So the dataset will make it possible for the model to learn all yaw angles within a range. Fig.3 illustrates a more extensive coverage of the yaw angle of our proposed dataset, the yaw angle of our proposed dataset covers a wider range than 300W-LP and also fixes the drawbacks of the CMU-Headpose dataset.
Model FSANet-Wide
FSA-Net [8] model was introduced by Yang et al. at the 2019 CVPR conference. This model has the advantage of being a very lightweight model with only million parameters for combining three sub-models, which gives good results when the average error with each angle is only . Therefore, the baseline will be based on the FSA-Net [8] model, doing experiments and improving it.
Original FSANet [8] model achieves good results in 300W-LP [5], as described above, the 300W-LP [5] dataset has yaw pose in a range . So this model results in the yaw pose range in . We will improve the SSR module in FSANet [8] and fusion mechanism by expand range of output model in a full-range yaw pose .
IV Experiments
In this section, the experiments will show the results and the evaluation of the proposed models. Before going into the detailed evaluation of the models, we will outline how to conduct the experiment and the evaluation methods. Specifically, Section 4.1 describes the data. Section 4.2 details the evaluation method. Section 4.3 shows result of the models mentioned in section 3.
4.1 Dataset
1. 300W-LP [5] dataset
The 300W-LP [5] dataset includes images, with a yaw angle in the range . All images are saved in .jpg image format; the head pose labels are saved in the .mat file format.
2. Head pose dataset extracted from CMU Panoptic dataset [7]
The original CMU Panoptic dataset [7] consists of sequences. Each sequence includes a JSON file of camera parameters and videos corresponding to each camera, a file of face coordinates in 3D space, a file of coordinate points of 3D human parts, VGA quality videos, and HD quality videos.
After processing the CMU Panoptic dataset [7] for the head pose problem, a dataset contains images. The yaw angle distribution of the dataset is almost the same as the uniform distribution, at angles near and will be less due to the effect of gimbal lock. Two angles pitch and roll, the magnitudes are in the range . Details of the processing steps are presented in [15].
3. Our new dataset UET-Headpose
The results are obtained from a new dataset consisting of images. Then, images were randomly divided into the UET-Headpose-val dataset and images into the UET-Headpose-train dataset. The data will be processed and converted to HDF5 format to optimize training time.
All datasets will be converted to HDF5 format with the help of the h5py library. Our experiment showed it expertly necessary. A model trained with data in jpg format needs more than 8x times longer HDF5 data.
Experiment setup
In order to conduct training and evaluation of the model, we use the 300W-LP [5] dataset and Head pose data extracted from the CMU Panoptic dataset [7] and the UET-Headpose-train dataset for training. The AFLW2000 [5] and UET-Headpose-val are used for testing.
We used Pytorch for implementing the proposed FSA-Net [8]. For data augmentation in training, we applied numerous filters in the albumentation library to training images. We choose the MSE function as the loss function for the training; MAE and MAWE for evaluation. To train the models, we used the ADAM optimizer. Batch size is selected as , and the learning rate is initialized as . The learning rate was reduced by a factor of every epochs.
4.2 Metric evaluation
Normally, pose estimation methods are trained with the 300W-LP [5] dataset. The mean absolute error (MAE) is used as the evaluation metric. However, in this scenario, the head pose is estimated in the wide-range pose (yaw angles). This evaluation method will not be reasonable for the problem of evaluating wide-angle direction up to . For example, when the actual angle is , the predicted angle is ; then, the two angles are only apart, but the MAE value calculated is . So, in the evaluation with UET-Headpose-val, we use MAWE [15] instead:
| Model | Yaw | Pitch | Roll | MAWE |
|---|---|---|---|---|
| FSA-Net [8] (Fusion) | 4.5 | 6.08 | 4.64 | 5.07 |
| WHENet [15] | 5.11 | 6.24 | 4.92 | 5.42 |
| FSA-Net-Wide (1x1) | 5.75 | 5.98 | 3.07 | 4.93 |
| FSA-Net-Wide (var) | 4.36 | 5.95 | 3.27 | 4.52 |
| FSA-Net-Wide (w/o) | 5.01 | 6.32 | 3.28 | 4.87 |
| FSA-Net-Wide (Fusion) | 4.59 | 5.69 | 2.85 | 4.37 |
4.3 Results
| Models |
|
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FSA-Net [8] (Fusion) | No | 2.91 Mb | 54.03 | 5.07 | ||||||||
| WHENet [15] | Yes | 17.1 Mb | 53.65 | 5.42 | ||||||||
|
No | 2.91 Mb | 52.76 | 4.37 | ||||||||
|
Yes | 2.91 Mb | 56.72 | 10.77 | ||||||||
|
Yes | 2.91 Mb | 9.3 | 35.89 | ||||||||
|
Yes | 2.91 Mb | 7.29 | 7.55 |
In this section, we will show our baseline when training with different combinations of dataset.
Table II summarizes key results from FSANet-Wide-fusion in four type data training. We compare with model size, mean average wrapped errors on AFLW-2000 [5], UET-Headpose-Val, and report full-range MAE. From this table, we can see that because our proposed dataset has different distribution with other datasets, the available state-of-the-art model will not achieve high accuracy in our dataset.
Full-range results and comparisons
From Table II, FSA-Net with fusion mechanism, WHENet[15] achieve and FSA-Net-Wide after training with 300W-LP very bad performance in our dataset, with , and in MAWE, respectively. But our baseline model, FSA-Net-Wide trained with 300W-LP achieves the highest performance at MAWE of AFLW2000, with . After using our proposed dataset, we obtained the baseline trained with all dataset to get the lowest MAWE on our validation dataset, the figure is .
Narrow range results and comparisons
The experimental result in Table IV shows the performance of WHENet and FSA-net in different mechanisms, including our proposed baseline on AFLW2000. FSA-Net-Wide with fusion mechanism shows best performance in this dataset with MAWE overall, it is noticeable that the MAWE on Roll angle of this model is significantly small, the figure is .
V CONCLUSION
We have proposed the new approach for collecting a head pose dataset with easy to setup on any cameras and low-cost, so this approach can keep data distribution near real problems. And we also provide our dataset acquired through the proposed approach and baseline model for this dataset. In the future, we wish to extend our current dataset to many situations and apply it to handle the real-life problem.
Acknowledgment
This work has been supported by VNU University of Engineering and Technology.
References
- [1]