UAV-enabled Collaborative Beamforming via Multi-Agent Deep Reinforcement Learning
Abstract
In this paper, we investigate an unmanned aerial vehicle (UAV)-assistant air-to-ground communication system, where multiple UAVs form a UAV-enabled virtual antenna array (UVAA) to communicate with remote base stations by utilizing collaborative beamforming. To improve the work efficiency of the UVAA, we formulate a UAV-enabled collaborative beamforming multi-objective optimization problem (UCBMOP) to simultaneously maximize the transmission rate of the UVAA and minimize the energy consumption of all UAVs by optimizing the positions and excitation current weights of all UAVs. This problem is challenging because these two optimization objectives conflict with each other, and they are non-concave to the optimization variables. Moreover, the system is dynamic, and the cooperation among UAVs is complex, making traditional methods take much time to compute the optimization solution for a single task. In addition, as the task changes, the previously obtained solution will become obsolete and invalid. To handle these issues, we leverage the multi-agent deep reinforcement learning (MADRL) to address the UCBMOP. Specifically, we use the heterogeneous-agent trust region policy optimization (HATRPO) as the basic framework, and then propose an improved HATRPO algorithm, namely HATRPO-UCB, where three techniques are introduced to enhance the performance. Simulation results demonstrate that the proposed algorithm can learn a better strategy compared with other methods. Moreover, extensive experiments also demonstrate the effectiveness of the proposed techniques.
Index Terms:
Unmanned aerial vehicle, collaborative beamforming, energy efficiency, trust region learning, multi-agent deep reinforcement learning.1 Introduction
Unmanned aerial vehicles (UAVs) are aircraft without pilots, which are flying by remote or autonomous control [1]. With the advantages of high mobility, low cost and line-of-sight (LoS) communications, UAVs can be applied in many wireless communication scenarios. For instance, a UAV can act as an aerial base station (BS) to provide emergency communication service for ground users when the ground BSs are unavailable[2, 3]. Moreover, a UAV can serve as a relay to improve the coverage and connectivity of wireless networks [4]. In addition, the UAVs can be regarded as the new aerial users which is able to deliver packages [5].
Despite the application prospect of UAVs being promising, many challenges still exist. Specifically, the limited battery capacity will affect the work efficiency of a UAV [6] [7], thus some relevant optimizations (e.g., flight trajectory [8] and mission execution time [9]) are necessary to prolong the working time of UAVs. Besides, a UAV is difficult to communicate with remote BSs due to its limited transmission power [10], and it cannot fly close to the BSs because of the finite energy capacity. Therefore, it is significant to improve the transmission ability of a UAV.
Collaborative beamforming (CB) has been justified to efficiently improve the transmission performance of distributed systems with limited resources [11]. Specifically, the UAVs can form a virtual antenna array (VAA), where each UAV is regarded as a single antenna element, then the UAV-assisted VAA (UVAA) can produce a high-gain mainlobe toward the remote BS by utilizing CB, such that achieving the long distance air-to-ground (A2G) communication between the UAVs and remote BS. To obtain an optimal beam pattern so that achieving a higher receiving rate of the BS, all UAVs need to fly to more appropriate positions and adjust their excitation current weights [12]. However, for communicating with different BSs, all UAVs need to adjust their positions constantly, which will consume extra energy. Hence, in addition to improving the transmission rate, the optimization to the motion energy consumption of UVAA is also required so as to prolong the lifespan of UVAA.
Previous studies usually optimize the communication performance or energy efficiency separately by using the traditional methods (e.g., convex optimization, or evolutionary computation). However, it is difficult to achieve optimal performance of these two optimization objectives simultaneously because they conflict with each other. Furthermore, since the cooperation among UAVs is very complex and the number of UAVs is usually large in the UVAA system, traditional methods will take much time to compute the optimization results. Besides, the system is dynamic, causing the currently obtained optimization results will become invalid when the system status changes. Therefore, it is inappropriate to apply traditional methods to simultaneously optimize the two objectives of the UVAA system.
Deep reinforcement learning (DRL) is an effective approach to solve complex and dynamic optimization problems without prior knowledge, and it has been proven to be an effective method to deal with complex optimization problems with high-dimensional continuous spaces [13]. Several studies have applied DRL to solve single-UAV communication optimization problems [14] [15]. However, DRL methods usually consider only single-agent learning frameworks, which are inappropriate for dealing with the UAV-enabled CB optimization problem. Thus, multi-agent deep reinforcement learning (MADRL) can be regarded as a potential approach to obtain the optimal policies since the learned policy of each agent involves the cooperation with other agents in MADRL. Specifically, all agents use the deep neural network (DNN) for policy learning. Benefiting from the powerful learning ability of DNN, all agents can learn excellent strategies. Meanwhile, compared with traditional methods, all agents can make corresponding decision directly without consuming much computing resource when the environment changes.
In this work, we utilize MADRL to deal with the UAV-enabled CB optimization problem. Consider that the cooperation is very complex among UAVs, we use the heterogeneous-agent trust region policy optimization (HATRPO) [16] as the main MADRL framework. Besides, the number of UAVs is usually large in the UVAA, which may cause the curse of dimensionality for MADRL algorithm. Furthermore, the policy gradient estimation problem may exists. Therefore, we propose an improved algorithm for solving our constructed problem well. The main contributions are summarized as follows:
-
•
UAV-enabled CB Multi-objective Optimization Formulation: We study a UAV-assistant A2G communication system, where a swarm of UAVs form a UVAA to perform CB for communicating with remote BSs. Then, we formulate a UAV-enabled CB multi-objective optimization problem (UCBMOP), aiming at simultaneously maximizing the transmission rate of UVAA and minimizing the energy consumption of the UAV elements by optimizing the positions and the excitation current weights of all UAVs. The problem is difficult to address because the two optimization objectives conflict with each other, and they are non-concave with respect to the optimization variables, such as the coordinates and the excitation current weights of UAVs.
-
•
New MADRL Approach: We model a multi-agent Markov decision process, called Markov game, for characterizing the formulated UCBMOP. Then, we propose an improved HATRPO algorithm, namely HATRPO-UCB, to solve the UCBMOP. Specifically, three techniques are proposed to enhance the performance of conventional HATRPO, which are observation enhancement, agent-specific global state and Beta distribution for policy, respectively. The first technique is to combine the algorithm with the problem well, so as to learn the better strategy for UCBMOP. The other two techniques are used to enhance the learning performance of critic and actor network, respectively.
-
•
Simulation and Performance Analysis: Simulation results show that the proposed HATRPO-UCB learns the best strategy compared with two classic antenna array solutions, three baseline MADRL algorithms and the conventional HATRPO. Besides, ablation experiments also demonstrate the effectiveness of our proposed techniques.
2 Related Work
Several previous works have studied the energy optimization in UAV-based communication scenarios. For example, Zeng et al. [8] considered a scenario where a UAV needs to communicate with multiple ground nodes, then proposed an efficient algorithm to achieve the energy minimization by jointly optimizing the hovering locations and durations, as well as the flying trajectory connecting these hovering locations. Cai et al. [17] studied the energy-efficient secure downlink UAV communication problem, with the purpose of maximizing the system energy efficiency. The authors divided the optimization problem into two subproblems, and proposed an alternating optimization-based algorithm to jointly optimize the resource allocation strategy, the trajectory of information UAV, and the jamming policy of jammer UAV. Wang et al. [18] investigated a multiple UAVs-assisted mobile edge computing (MEC) system, where a natural disaster has damaged the edge server. The authors proposed two game theory-based algorithms, where the first algorithm is used to minimize the total energy consumption of multiple UAVs, and the second one is designed to achieve the utility trade-off between the UAV-MEC server and mobile users.
Except for adopting traditional methods, some works also use DRL to optimize the energy consumption of UAV. For optimizing the energy consumption of cellular-connected UAV, Zhan et al. [9] developed a DRL algorithm based on dueling deep Q network (DQN) with multi-step double Q-learning to jointly optimize the mission completion time, trajectory of UAV and associations to BSs. Abedin et al. [19] propose an agile deep reinforcement learning algorithm to achieve an energy-efficient trajectory optimization for multiple UAVs so as to improve the data freshness and connectivity to the Internet of Things (IoT) devices. Liu et al. [20] proposed a decentralized DRL-based framework to control multiple UAVs for achieving the long-term communication coverage in an area. The goal is to simultaneously maximize the temporal average coverage score achieved by all UAVs in a task, maximize the geographical fairness of all considered point-of-interests (PoIs), and minimize the total energy consumption.
UAV communications enabled by CB are also investigated in previous works. For example, Garza et al. [12] proposed the differential evolution method for a UAV-based 3D antenna array, aiming at achieving a maximum performance with respect to directivity and sidelobe level (SLL). Mozaffari et al. [21] considered a UAV-based linear antenna array (LAA) communication system and proposed two optimization algorithms, where the first algorithm is used to minimize the transmission time for ground users, and the second one is designed to optimize the control time of UAV-based LAA. Sun et al. [22] developed a multi-objective optimization algorithm to simultaneously minimize the total transmission time, total performing time of UVAA, and total motion and hovering energy consumption of UAVs. Moreover, the authors in [23] studied a secure and energy-efficient relay communication problem, where the UVAA serves as an aerial relay for providing communications to the blocked or low-quality terrestrial networks. The authors designed an improved evolutionary computation method to jointly circumvent the effects of the known and unknown eavesdroppers and minimize the propulsion energy consumption of UAVs.
Likewise, Sun et al. [24] considered a UAV-enabled secure communication scenario, where multiple UAVs form a UVAA to perform CB for communicating with the remote BSs, and multiple known and unknown eavesdroppers exist to wiretap the information. Li et al. [25] studied the UAV-assisted IoT and introduced CB into IoTs and UAVs simultaneously to achieve energy and time-efficient data harvesting and dissemination from multiple IoT clusters to remote BSs. Huang et al. [26] studied a dual-UAVs jamming-aided system to implement physical layer encryption in maritime wireless communication. Li et al. [27] considered a UAV-enabled data collection scenario, where CB is adopted to mitigate the interference of the LoS channel of UAV to the terrestrial network devices. Moorthy et al. [28] aimed at achieving the high data rate of CB of UAV swarm, and then designed a distributed solution algorithm based on a combination of echo state network learning and online reinforcement learning to maximize the throughput of UAV swarm. However, all of these abovementioned methods will take much time to compute the solution for a task. More seriously, when the task changes, the previous optimization solution is invalid, causing a longer latency for recalculation.
DRL has been an effective way to solve the online computation problems about UAV communications. For example, Wang et al. [14] investigated a UAV-assisted IoT system, and they proposed a twin-delayed deep deterministic policy gradient (TD3)-based method that optimizes the trajectory of UAV to efficiently collect data from IoT ground nodes. Xie et al. [15] proposed a multi-step dueling double DQN (multi-step D3QN)-based method to optimize the trajectory of cellular-connected UAV while guaranteeing the stable connectivity of UAV to the cellular network during its flight. Besides, MADRL can be also applied to solve the communication problems involving multiple UAVs. For instance, Zhang et al. [29] proposed a continuous action attention multi-agent deep deterministic policy gradient (CAA-MADDPG) algorithm to operate a UAV transmitter to communicate with ground users and multiple UAV jammers. Dai et al. [30] studied the joint decoupled uplink-downlink association and trajectory design problem for full-duplex UAV network, with the purpose of maximizing the sum-rate of user equipments in both uplink and downlink. The authors proposed a MADRL-based approach and developed an improved clip and count-based proximal policy optimization (PPO) algorithm. However, in the above works, the cooperation pattern among UAVs is only the coordination, which is less complex than CB, and the completion of CB involves more UAVs. Hence, these abovementioned MADRL algorithms are not suitable for solving our formulated optimization problem.
In summary, different from the above works, we investigate a joint problem about communication performance and energy consumption under a scenario where multiple UAVs perform CB. Then, the MADRL is adopted to efficiently solve our formulated optimization problem.
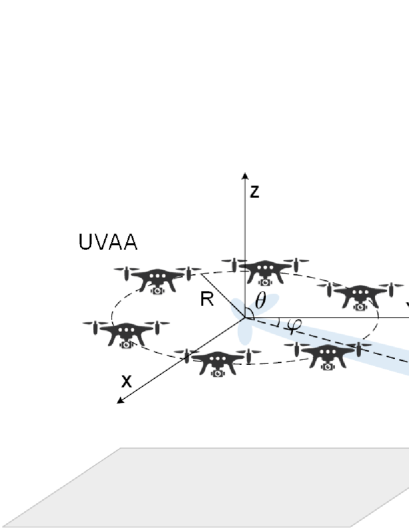
3 System Model and Problem Formulation
As shown in Fig. 1, a UAV-assisted A2G wireless communication system is considered. Specifically, there are UAVs flying in a square area with length , where the set of UAVs is denoted as . Some BSs are distributed in the far-field region, and their positions are assumed to be known by all UAVs. Each UAV is equipped with a single omni-directional antenna, and they will perform the communication tasks with these BSs. For example, their stored data or some generated emergency data needs to be uploaded to BSs. However, each UAV is not able to support such the long-distance communication due to the limited transmission ability, and they also can not fly to these BSs because of their own limited battery energy capacity. Note that for all UAVs, the distances among them are much shorter than those to BSs, which means that they are close to each other. Thus, all UAVs can fly closer to form an UVAA for performing CB to complete communication tasks. Moreover, the UVAA only communicates with one BS at each time as performing CB.
In the considered system, the 3D Cartesian coordinate system is utilized. Specifically, the positions of the -th UAV and the target BS are denoted as and , respectively. Furthermore, the elevation and azimuth angles from each UAV to the target BS can be computed by and , respectively.
| Notation | Definition |
| Notation used in system model | |
| Array factor | |
| Transmission bandwidth | |
| Distance from origin of UVAA to target BS | |
| Minimal distance between two UAVs | |
| Total energy consumption of UAV | |
| Energy consumed by gravity during UAV flight | |
| Energy consumption from kinetic energy during UAV flight | |
| Carrier frequency | |
| Array gain of UVAA | |
| Channel power gain | |
| Minimum flight altitude of UAV | |
| Maximum flight altitude of UAV | |
| Excitation current weight of the -th UAV | |
| Length of monitor area | |
| Mass of UAV | |
| Number of UAVs | |
| LoS probability | |
| NLoS probability | |
| Total transmit power of UVAA | |
| Transmission rate | |
| Magnitude of far-field beam pattern of UVA element | |
| Path loss exponent | |
| Antenna array efficiency | |
| Elevation angle between UVAA and target BS | |
| Wavelength | |
| Attenuation factor for LoS link | |
| Attenuation factor for NLoS link | |
| Noise power | |
| Azimuth angle between UVAA and target BS | |
| Initial phase of the -th UAV | |
| Notation used in reinforcement learning | |
| Action of the -th agent | |
| Joint action of all agents | |
| action space of the -th agent | |
| Advantage function for joint policy | |
| Maximal KL-divergence between two policies | |
| Gradient of maximization objective of the -th agent | |
| Hessian of expected KL-divergence of the -th agent | |
| Expected total reward for all agents | |
| Surrogate equation of the -th agent | |
| Local observation of the -th agent | |
| Observation space of the -th agent | |
| State-action value function for joint policy | |
| Reward of the -th agent | |
| Global state | |
| Global state space | |
| State value function for joint policy | |
| A coefficient is found by backtracking line search | |
| Discount factor | |
| KL constraint threshold | |
| Marginal state distribution for joint policy | |
3.1 UVAA Communication Model
The goal of UVAA is to enable multiple UAVs to simulate the classical beamforming for achieving the far-field communication with remote BSs. The gain towards the target BS will be enhanced by the superposition of electromagnetic waves emitted from all UAVs through CB. Before the CB-enabled communication, all UAVs can be synchronized in terms of the carrier frequency, time and initial phase [31], and then send the same data to the target BS.
Benefiting from the high altitude of UAV, a higher LoS probability between the UVAA and BS can be achieved. Additionally, the LoS probability depends also on the propagation environment and the statistic modeling of the building density. Hence, the LoS probability can be modeled as [32]
| (1) |
where and are the parameters that depend on the propagation environment. is the elevation angle from the UVAA to the target BS. Then, the non-LoS (NLoS) probability is given by .
According to the probability of LoS and NLoS, the channel power gain can be expressed as
| (2) |
where , is the distance from the origin of UVAA to the target BS, and are different attenuation factors for the LoS and NLoS links, respectively, is a constant representing the path loss exponent, is the carrier frequency, and is the speed of light.
Combining the above channel model, the UVAA will perform CB to generate a beam pattern with a sharp mainlobe for the target BS. Then, the transmission rate can be expressed as [21]
| (3) |
where represent the 3D coordinates and excitation current weights of all UAVs while communicating with the BS, is the transmission bandwidth, is the total transmit power of UVAA, and is the noise power. In addition, is the array gain of UVAA toward the location of BS, which is given by [21]
| (4) |
where is the antenna array efficiency, represents the direction toward the target BS, and is the magnitude of the far-field beam pattern of each UAV element. Note that the array gain is equal to the array directivity multiplied by . The array directivity , where is the maximum radiation intensity produced by the array factor (AF) to the BS, and is the average radiation intensity. Besides, is always equal to 0 dB in this work because the omni-directional antenna equipped on the UAV has the identical power constraints.
As for the AF, it is an important index to describe the status of beam pattern, which is written as [12] [33]
| (5) |
where and are the elevation and azimuth angles, respectively. is the wavelength and denotes the wave number. Additionally, and are the excitation current weight and initial phase of the -th UAV, where the phase synchronization is completed by compensating the distance between an UAV and the origin of UVAA [34]. Hence, is expressed as
| (6) | ||||
As can be seen, the locations and excitation current weights of UAVs are directly related to the AF.
3.2 UAV Energy Consumption Model
In this work, we adopt a typical rotary-wing UAV. This is due to the fact that rotary-wing UAVs have the inherent benefit of hovering capabilities, which simplifies the difficulty of beam alignment and handling Doppler effects during transmission. In this work, the considered communication system is required to provide a stable and high-rate communication service for the far-field BSs. In this case, rotary-wing UAVs are more suitable for the considered scenario since they can hover for collecting and forwarding data. In general, the total energy consumption of a UAV includes two main components that are the propulsion and communication [8]. Specifically, the propulsion energy consumption is related to the hovering and movement of the UAVs, and communication-related energy consumption is used for signal processing, circuits, transmitting and receiving, respectively. Typically, the propulsion energy consumption is much more than communication-related energy consumption (e.g., hundreds of watts (w) versus a few w) [8] [35]. Thus, the communication-related energy consumption is neglected in this work. Then, the propulsion power consumption of UAV with speed during the straight and horizontal flight is calculated as [8]
| (7) | ||||
where and are blade profile power and induced power under the hovering condition, respectively. is the tip speed of rotor blade, and is mean rotor induced velocity in hovering. , , , and denote the fuselage drag ratio, air density, rotor solidity and rotor disc area, respectively. Besides, the additional/less energy consumption caused by the acceleration/deceleration of horizontal flight is ignored because it only takes a small proportion of the total operation time of UAV manoeuvring duration [8].
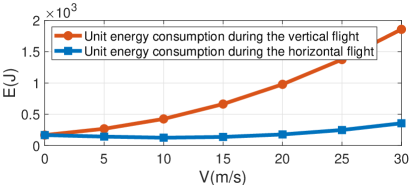
For arbitrary 3D UAV trajectory with UAV climbing and descending over time, the heuristic closed-form approximation of energy consumption is derived as [1]
| (8) | ||||
where is the total flight time. is the instantaneous UAV speed at time . The second and third parts represent the kinetic energy consumption and potential energy consumption, respectively. is the mass of UAV, and is the gravitational acceleration. As can be seen, Eq. (8) has more terms than Eq. (7), meaning that more energy will be consumed in the vertical direction. Moreover, Fig. 2 shows that the motion energy consumption of UAV per second in the vertical directioon is more than that in the horizontal direction under different speeds.
In this work, the UAV follows the flight rule that it first flies along the horizontal direction, then in the vertical direction, which is a common adopted flight strategy [36][37][38]. Therefore, when a UAV reaches the target position, the corresponding energy consumption can be expressed as
| (9) |
where , and . are the horizontal, climbing and descending flight powers, respectively, and are the corresponding flying distance during the horizontal, climbing and descending flights. Furthermore, represent the maximum-endurance (ME) speed of the horizontal, climbing and descending flights, respectively, which are the optimal UAV speed that maximizes the UAV endurance with any given onboard energy [1].
Remark 1.
The challenge of adopting this type of rotary-wing UAVs lies in their weak transmission abilities and limited service time. To solve this issue, we correspondingly introduce the CB and give the problem formulation as follows.
3.3 Problem Formulation
In the system, the UVAA is required to communicate with more than one BS before the battery runs out. To achieve the maximum transmission performance, all UAVs need to fly to better locations and adjust their excitation current weights. However, the motion energy consumption of UAVs will be increased during their movements, which will reduce the lifespan of UVAA. Therefore, the optimization problems about transmission rate and energy consumption should be considered simultaneously.
In this work, we aim to maximize the transmission rate of UVAA for communicating with the BS and minimize the motion energy consumption of all UAVs simultaneously, through optimizing the hovering positions and excitation current weights of all UAVs. Then, the UCBMOP can be formulated as
| (10a) | ||||
| s.t. | (10b) | |||
| (10c) | ||||
| (10d) | ||||
| (10e) | ||||
| (10f) | ||||
where is the transmission rate of UVAA to a specific BS defined by Eq. (3). The motion energy consumption of all UAVs is , where is the motion energy consumption of UAV that can be obtained according to the Eq. (9). Constraints C1, C2 and C3 together specify the flight area of UAV, where is the length of monitor area, and and are altitude constraints of the UAVs. Constraint C4 specifies the adjustment range of excitation current weight. Moreover, Constraint C5 requires any two adjacent UAVs to keep a certain distance to avoid the collision, where is set as the minimum distance.
4 MADRL-Based UAV-enabled Collaborative Beamforming
The formulated UCBMOP is challenging and cannot be solved by traditional optimization methods, and the reasons are as follows:
-
•
UCBMOP is a non-convex and long-term optimization problem. Specifically, due to the complex non-linear relationship between UAV coordinates and excitation current weights with antenna gain, the optimization of the virtual antenna array transmission performance is a non-convex optimization problem. Meanwhile, UCBMOP involves long-term optimization objectives and needs an effective algorithm that can achieve long-term optimal solutions. As such, UCBMOP is challenging and cannot be solved by traditional convex optimization.
-
•
UCBMOP is an NP-hard problem. Specifically, UCBMOP can be simplified as a typical nonlinear multidimensional 0-1 knapsack problem that has been demonstrated to be NP-hard [39]. Therefore, the proposed UCBMOP is also NP-hard. Such NP-hard problems are challenging for traditional optimization methods to solve in polynomial time.
-
•
UCBMOP is a complex large-scale optimization problem. Specifically, the considered scenarios often involve a large number of UAVs, while each UAV also has multiple variables to be optimized (i.e., 3D coordinates and excitation current weights). In addition, the completion of CB also needs the complex cooperation of all UAVs. Hence, the complexity and massive dimension of decision variables make the traditional optimization method unable to solve it efficiently.
-
•
UCBMOP operates within a dynamic environment. In particular, UAVs in these scenarios must make decisions to adapt to highly dynamic channel conditions and the unpredictability of natural surroundings. Additionally, real-time response is crucial for UAVs, as prolonged hovering in the air results in significant energy consumption. Consequently, conventional offline algorithms or approaches reliant on temporary calculations cannot solve this problem.
Different from the traditional optimization methods, deep reinforcement learning can have real-time responses and handle the complexity and large-scale decision variables of UCBMOP. However, in the considered system, UAVs need to collaborate to achieve transmission gain while simultaneously competing to minimize their individual energy consumption. Such tasks are distributed and require multiple UAVs to work together to achieve common objectives. Standard reinforcement learning assumes individual agents to be isolated, making it less suitable for the scenario involving multiple decision-makers.
Remark 2.
In this case, MADRL has the capability to decentralize decision-making and adaptability for the changing environments, and enabling effective responses to complex interactions among multiple agents [40]. Moreover, MADRL allows agents to access the global state of the UAV collaborative beamforming system, providing them with information about the entire system and reducing non-stationarity. In addition, the scalability and robustness of MADRL to partial observability also enhance its applicability in the considered dynamic and distributed scenarios. Thus, we propose an MADRL-based method that is able to solve the formulated UCBMOP by learning the strategy in the considered dynamic scenario.
4.1 Markov Game for UCBMOP
In this section, the formulated UCBMOP is transformed into a Markov game [41] that is defined as . At time slot , all agents are with state , each agent uses its policy to take an action according to its local observation , and it will receive a reward from the environment, where denotes the joint action. Then, all agents move to the next state with probability and each of them receives its local observation correlated with the state. All agents aim to maximize their own expected total reward . The details about the state and observation space, the action space and the reward function are introduced as follows.
4.1.1 State and Observation Space
At each time slot, every agent observes its own local state information to make the decision. In the system, the local observation of any agents (i.e., UAVs) includes three parts that are its own related information, the relevant information of other UAVs and the related information of BS. Specifically, the local observation of the -th agent can be expressed as
| (11) |
where is the spherical coordinate of the target BS relative to the -th UAV. However, when the UVAA will communicate with more than one BS, then the gap among different BSs regarding is very large. Furthermore, all UAVs only fly in the fixed area. To eliminate the gap and let the UAV make decisions more efficiently, we compute a reference point in the monitor area that is closest to the target BS, where the coordinate of reference point is denoted as . Then, the distance between the -th UAV and the reference point is regarded as . Moreover, is the distance between the -th UAV and the origin of UVAA, and is the excitation current weight of the -th UAV. The information of other UAVs contains their own excitation current weights and the distances to the -th UAV. As for the information about the target BS, its coordinate is replaced by the reference point, which will be beneficial for the agent to learn the better strategy.
As for the global state of the -th agent , instead of using the concatenation of local observations or the environment-provided global state, we propose an agent-specific global state that combines some agent-related features (e.g., , , ) and the global information provided from the environment which includes the coordinates and excitation current weights of all UAVs, as well as the coordinate of reference point, which is inspired from [42].
4.1.2 Action Space
According to the local observation of UAVs, each UAV will take an action to fly to a certain location with the optimized excitation current weight for performing CB. Then, the action of each agent can be defined by
| (12) |
where is the location to which the -th UAV is going to fly, and is the excitation current weight of the -th UAV in the next time slot.
4.1.3 Reward Function
The reward function is used to evaluate how well an agent executes the actions. Specifically, a suitable reward function can make the agent learn the best strategy. UCBMOP involves two optimization objectives, which are maximizing the transmission rate of UVAA for communicating with the BS, i.e., , and minimizing the motion energy consumption of all UAVs, i.e., . To this end, we design a reward function by considering the following aspects:
-
1.
Reward Function for Optimizing . We find that there are three key components that affect the transmission rate , which are the transmit power and gain of UVAA, transmission distance, and A2G communication angle. Specifically, the transmit power and gain of UVAA determine the transmission performance of UVAA, the transmission distance indicates the signal fading degree, and the air-to-ground communication angle affects the A2G channel condition. Note that we do not directly set the transmission rate as a reward since it changes significantly with the transmission distance, making the DRL method unstable and decreasing the applicability of the model.
According to the analysis above, first, we regard the multiplication of the array gain and the total transmit powers as a reward, i.e., . Note that this reward is shared by all agents. Then, we set the distance between the UAV and BS as a penalty for each agent. However, the UAV only flies within a fixed area, and then the aforementioned distance is replaced by the one between the UAV and the reference point of target BS, which is denoted as . Finally, as shown in Eq. (1), the LoS probability is determined mainly by the height of the UAVs. Therefore, we set a reward to optimize the flight altitude of each UAV, denoted as . As such, the designed reward function considers all controllable components of the transmission rate, thereby achieving the optimization of the first objective.
-
2.
Reward Function for Optimizing . To achieve this goal, we regard the energy consumption of each UAV as a penalty, which is denoted as . As such, the optimization of the second objective can be achieved by the reward function.
-
3.
Reward Function for Coordinating and . To this end, we aim to enhance the connectivity among UAVs. Compared with , the optimization of is more directly tied to the action space (i.e., reducing the movement of the UAVs), which may lead the algorithm to prioritize the optimization of and under-optimize . To overcome this issue, we try to concentrate the array elements (i.e., the UAVs in UVAA) on an applicable distance to achieve a higher CB performance [43] [23], thereby facilitating the optimization of . Specifically, we design a reward to coordinate the UAVs by minimizing the cumulative distances between the current UAV and other UAVs, as well as between the current UAV and the origin of the UVAA, i.e.,
(13) where is a large constant for scaling. Since this reward decreases the difficulty of optimizing , the designed reward function can well coordinate the optimization processes of the two optimization objectives.
In summary, the whole reward function of each agent is
| (14) |
where , , , , and represent weight coefficients of different parts. Moreover, it is also worth noting that when any two UAVs violate the minimum separation constraint, they will receive a negative reward. These weighting coefficient values can be determined by considering their value ranges, importance, and characteristics. Specifically, larger weights are assigned to rewards with wider ranges to appropriately reflect their significance in optimization. Moreover, higher weights are allocated to rewards that play a more critical role in achieving the optimization objectives. In addition, the weights can also be adjusted based on the unique characteristics of each reward, ensuring that the optimization process addresses their specific complexities.
4.2 HATRPO-UCB Algorithm
In this section, we propose a HATRPO-UCB, which extends from conventional HATRPO to find the solution strategy for UCBMOP. Specifically, each UAV acts as an agent that has an actor network and a critic network consisting of DNNs. The algorithm uses the sequential policy update scheme to train all agents. The scheme can make the update of the current agent includes the updates of previous agents, and thus our algorithm can make the actor networks of all agents learn the joint policy. Moreover, each agent has not only the individual rewards (i.e., , , etc.) but also the shared rewards (i.e., ). Meanwhile, we design an agent-specific global state that contains global information provided by the environment and some features from the local observation. As such, each UAV is guided by the shared rewards, and considers the global information and local observation, thereby obtaining a policy associated to the global state. We begin with introducing the conventional HATRPO.
4.2.1 Conventional HATRPO
HATRPO was proposed by Kuba et al. [16], which has the better performance than other baseline MADRL algorithms in many multi-agent tasks (e.g., Multi-Agent MuJoCo [44], StarCraftII Multi-Agent Challenge (SMAC) [45]). HATRPO applies the trust region learning [46] to MADRL successfully, achieving the monotonic improvement guarantee for joint policy of multiple agents such as the trust region policy optimization (TRPO) algorithm [47]. The detailed theory of HATRPO is introduced in the following.
In the beginning, a cooperative Markov game with agents exists. A joint policy to all agents exists. At time slot , the agents are at state . Each agent utilizes its own policy to take an action , and then the actions of all agents form the joint action . Afterwards, all agents receive a joint reward , and move to a new state with probability . The goal of all agents is to maximize the expected total reward:
| (15) |
where is the discount factor and is the marginal state distribution [16]. Besides, the state value function and the state-action value function are defined as and . The advantage function is written as .
To extend the key idea of TRPO to MADRL, a sequential policy update scheme [16] is introduced. Then, the following inequality can be derived to achieve the monotonic improvement guarantee for joint policy.
| (16) |
where is the next candidate joint policy. is the maximal KL-divergence to measure the gap between two policies. is the penalty coefficient. Moreover, is a surrogate equation of the -th agent, which is expressed as
| (17) | ||||
where is the local advantage function of each agent. Based on the above theory, all agents can update their policies sequentially, and the updating procedure is given as
| (18) |
Furthermore, the sequential updating scheme does not require that the updating order of all agents is fixed, meaning that the updating order can be flexibly adjusted at each iteration. As such, the algorithm can adapt to dynamic changes in the environment and progressively assimilate new information in non-static conditions.
To implement the above procedure for parameterized joint policy in practice, in HATRPO, the amendment similar to TRPO is performed. As the maximal KL-divergence penalty is hard to compute, it is replaced by the expected KL-divergence constraint , where is a threshold hyperparameter. Then, at the +-th iteration, given a permutation, all agents can optimize their policy parameters sequentially according to the method as follows:
| (19) | ||||
For the computation of the above equation, similar to TRPO, the linear approximation to the objective function and the quadratic approximation to KL constraint are applied, derivating a closed-form updating scheme that is shown as
| (20) |
is a coefficient that is found via backtracking line search. is the Hessian of the expected KL-divergence. is the gradient of the objective in Eq. (19), whose computation requires the estimation about . According to the derivation in [16], given a batch of trajectories with length , can be computed as
| (21) |
where
| (22) |
is the compound policy ratio about the previous agents , which can be computed easily after these agents complete their updates.
Although HATRPO has the excellent performance, it still faces many challenges in solving the UCBMOP. First, the formulated problem involves the complex cooperation among UAVs. Furthermore, only one time slot exists for each episode in the problem, which is different from other traditional MADRL tasks. Thus, it is necessary to take measures to connect the algorithm with the problem closely. Second, there are many UAVs in the problem, which may increase the input dimension of critic network substantially, influencing the critic learning. Finally, the conventional HATRPO uses the Gaussian distribution to sample actions. However, all actions have the finite range in the problem. Thus, using the Gaussian distribution may induce the bias to the policy gradient estimation. Accordingly, these reasons motivate us to propose the HATRPO-UCB, and the details are described in the following sections.
4.2.2 Algorithm Design of HATRPO-UCB
In the proposed HATRPO-UCB, we take conventional HATRPO as the foundation algorithm framework, and propose three techniques that are observation enhancement, agent-specific global state and Beta distribution for policy, to enhance the performance of the algorithm.
Observation enhancement: In MADRL, the environmental information is usually the state that guides the agents to take action. However, in UCBMOP, each episode only has one time slot, and the UVAA may communicate with different remote BSs at various episodes. In this case, the state consisting of the simple Cartesian coordinates of the UAVs and BSs may not precisely characterize their positional relationship. This is because the distance between the UVAA and BSs is significantly larger than the relative distance between the UAVs, and even the same set of UAV coordinates may represent different environmental states when serving various BSs (e.g., transmission angle and distance). To overcome this issue, we propose two observation enhancement strategies as follows. First, we design a spherical coordinate enhancement strategy with dynamically changing origins to represent the UAV positions. Instead of the Cartesian coordinate of each UAV, we set the state to the spherical coordinates with the BS in the current episode as the origin. In this way, the state can adequately express the information about the orientation and distance between the BS and the UVAA. Second, we propose a position representation based on reference points to characterize the BS locations. Specifically, we regard the closest point to the target BS in the monitor area as the reference point and then adopt this reference point to replace the target BS as the state. This adjustment retains the BS information but amplifies the position differences between the UAVs, which better expresses the relative positions of the UAVs. The enhanced state and observation contain representative and adaptive information about the environment, which ensures the proposed method remains effective when the location of the served BS at different episodes changes significantly.
Agent-specific global state: In general, the global state employed by MADRL algorithms has two forms, which are the concatenation of all local observations and environment-provided global state. However, in the considered scenarios, the number of agents (i.e., UAVs) is often large, which means that the input dimension of the critic network grows a lot when using the concatenation of all local observations. This condition will increase the learning burden, thereby making the performance of critic learning degrade. Additionally, the environment-provided global state is also not an appropriate choice because its contained information is not sufficient, which only contains the coordinates and excitation current weights of all UAVs, as well as the coordinates of the reference point. Inspired by [42], we design an agent-specific global state that combines the global information provided by the environment and some features from local observation, such as the spherical coordinate of the target BS that is relative to the UAV and the distance between two UAVs , as the input of the critic network. This agent-specific global state can improve the fitting performance of critic learning and thus achieve better MADRL performance.
Beta distribution for policy: In the conventional HATRPO, the actor uses the Gaussian distribution to sample actions. However, the Gaussian distribution has been demonstrated to have the negative impact on reinforcement learning [48]. Specifically, for an action with the finite interval, the Gaussian distribution with infinite support will define the action range out of its boundary. Furthermore, the probability density of all actions is greater than 0, but the probability of actions beyond boundary should equal to 0. Hence, in our scenario where all actions of UAV have the finite interval, it is inevitable that some actions sampled from the Gaussian distribution will be truncated, leading to the boundary effect. Then, the boundary effect may cause bias about policy gradient estimation.
To handle the above issue, the authors of [48] conducted the research on Beta distribution for reinforcement learning. The study indicates that the Beta distribution does not have a bias because the Beta distribution has a finite range (i.e., [0, 1]), and thus the probability density of actions beyond the boundary is guaranteed to be 0. Furthermore, experimental results show that the Beta distribution can make reinforcement learning algorithms converge faster and obtain higher rewards. Thus, in this paper, we choose the Beta distribution instead of the original Gaussian distribution, and then the Beta distribution is defined as
| (23) |
where and are the shape parameters, and is the Gamma function that extends factorial to real numbers. In addition, and are set to be not less than 1 (i.e., ) in the work, which are modeled by softplus and then add a constant 1 [48].
4.2.3 Algorithm Workflow
Fig. 4 displays the framework of the proposed HATRPO-UCB algorithm, which has two phases that are the training phase and the implementation phase. Each UAV as an agent has a replay buffer and two networks (i.e., the actor network and critic network). The replay buffer is used to collect the data about the interaction between the UAV and the environment. Then, a central server is deployed with the replay buffers and networks of all agents for training.
Input: Number of episodes , number of agents ,
batch size , stepsize ,
possible steps in line search , line
search acceptance threshold .
Initialize: Actor networks , Critic networks
, Replay buffers .
Output: Trained models of all agents.
In the beginning, the central server will initialize the parameters of networks. Then, at each time slot, the central server will exchange the information with UAVs and then control them, where the amount of the information is very small because it only includes the observation information of UAVs and actions required to be done by UAVs, and the communication distance is very short compared with that between the UAVs and the BS. Hence, for performing the communication tasks, the above communication overhead is very small and acceptable. Then, for illustrating the specific process at each time slot, taking the -th agent as an example, after the central server receives the information, the actor network utilizes the observation to generate a Beta distribution about action, and then an action is sampled from the Beta distribution and sent to the UAV. The critic network is used to predict the Q-value of current global state . After executing the sampled action, the -th agent receives a reward from the environment and observes the next local state and global state . After that, the above information tuple will be stored in the replay buffer .
All agents will execute more time slots until their replay buffers accumulate enough data, and then the replay buffers will randomly select a mini-batch of tuples for training networks. The sequential updating scheme is adopted to update policies of all agents. In each training, all agents are updated sequentially in a randomly generated order. For the -th agent, the first step is to estimate the gradient , before that, the advantage function of -th agent and the compound policy ratio of the previous agents are required to compute. Then, the Hessian of the expected KL-divergence is computed to approximate the KL constraint. After completing the computation of and , the parameter of actor network can be updated via backtracking line search. As for the critic network , the update of network parameter can be achieved by optimizing the following loss function: . Therefore, the above updating procedure will be repeated until HATRPO-UCB converges. The whole training process can be seen in Algorithm 1.
During the implementation stage, only the trained actor network is deployed to the UAV. In each communication mission, all UAVs receive the local observations from the environment, and then select actions through the actor networks. Afterwards, according to the selected actions, all UAVs move to the target locations and adjust the excitation current weights for performing CB. Compared with the training stage, the implementation stage is completed online and does not need much computational resource. In contrast, the training stage costs much computational resource, which is conducted offline in a central server.
4.2.4 Analysis of HATRPO-UCB
In this section, the computational complexity of the training and implementation stage of the proposed HATRPO-UCB is discussed.
Complexity of training. For agents, each agent is equipped with an actor network and a critic network that are formed by DNNs. A DNN consists of an input layer, fully connected layers and an output layer, where , and denote the number of neurons of input layer, -th fully connected layer and output layer, respectively. Then, the computational complexity of DNN at each time slot is .
At each training process, a mini-batch of data with episodes is sampled from the replay buffer, but each episode only contains one time slot. Additionally, the critic network is updated by the stochastic gradient methods, thus the total computational complexity of critic network is . However, the actor network is updated using the backtracking line search. In Eq. (20), the gradient is first computed, whose computational complexity is . Then the Hessian of expected KL-divergence is computed to approximate the KL constraint. The computational complexity of expected KL-divergence is , and the computational one of Hessian matrix is . Hence, the computational complexity of is . For computing , the conjugate gradient algorithm is adopted, which obtains result by searching iteratively until convergence. The computational complexity of each iteration is . Then the total computational complexity of is , where is the number of iterations. During the backtracking line search, the computational complexity is , where is the search number and is the computational complexity in each search. Hence, the total computational complexity of actor network is . Assume that HATRPO-UCB needs to be trained times for convergence, the overall computational complexity in the training phase is .
Complexity of inference. In the implementation phase, all UAVs only use the trained actor networks to make decisions. Therefore, the computational complexity of HATRPO-UCB in the implementation stage is .
Remark 3.
Note that determining the theoretical bounds and convergence of the proposed MADRL-based algorithm confronts significant challenges [49]. Specifically, MADRL involves tuning numerous hyperparameters, such as learning rates, network architectures, and exploration strategies, resulting in an explosion of potential combinations. Thus, analyzing theoretical bounds and convergence becomes nearly infeasible given the vast parameter space. Moreover, DNNs introduce approximation errors when modeling complex functions, particularly in high-dimensional state spaces of the formulated optimization problem. These errors can lead to suboptimal performance in certain states, complicating the analysis of theoretical bounds and convergence. In addition, MADRL models interact with environments that introduce uncertainty factors, including noise and randomness. These uncertainties can yield different outcomes in various interaction trajectories, further complicating the analysis of the theoretical bounds and convergence [50]. Thus, we evaluate the performance of the proposed HATRPO-UCB by conducting extensive simulations like the works in [51, 40] in the following.
5 Simulation Results
In this section, we evaluate the performance of the proposed HATRPO-UCB algorithm for UCBMOP.
5.1 Simulation Configuration
We implement simulations in an environment with Python 3.8 and Pytorch 1.10, and perform all experiments on a server with AMD EPYC 7642 48-Core CPU, NVIDIA GeForce RTX 3090 GPU and 128GB RAM.
In the simulation, a 100 m 100 m square area is considered, where 16 UAVs are flying in the area. The mass (), the minimum and maximum flying heights ( and ) of each UAV are set as 2 kg, 100 m and 120 m [22], respectively. The minimum distance between any UAVs () is 0.5 m. Moreover, the transmit power of each UAV, the carrier frequency () and the total noisy power spectral density are 0.1 W, 2.4 GHz and -157 dBm/Hz, respectively [21] [52]. The path loss exponent (), as well as the attenuation factors of LoS and NLoS links (, ) are 2, 3 dB and 23 dB, respectively [53]. Other parameter configurations about system model are summarized in Table II. Based on these settings and the mathematical models shown in Section 3, we build a simulation environment for the DRL model to interact and collect data.
In the MADRL stage, an environment is built according to the UCBMOP. The MADRL algorithm learns by interacting with the environment. During the training stage, the environment will run episodes, where each episode only has one time slot. For the settings of reward weight coefficients, we first set the weight coefficients by normalizing each reward to make the rewards on the same order of magnitude. Then, we fine-tune the reward weights by considering their importance and characteristics (the tuning process and results are shown in Appendix A of the supplemental material). As such, the reward weight coefficients , , , , and are set to 100, 4, 30, 12 and 5, respectively.
In HATRPO-UCB, all actor and critic networks are three-layer fully connected neural networks (i.e., two hidden layers and one output layer). Each hidden layer contains 64 neurons, which is initialized by orthogonal initialization, and it is equipped with ReLU activation function. The actor network is updated by the backtracking line search, meanwhile, the KL-divergence between the new actor network and the old one must meet the KL-threshold which is set as 0.001. The Adam optimizer [54] is employed to update the critic network, where the learning rate is 0.005. The value setting of other related parameters is also presented in Table II.
| Parameter | Value |
|---|---|
| Fuselage drag ratio () | 0.6 |
| Air density () | 1.225 |
| Rotor solidity () | 0.05 |
| Rotor disc area () | 0.503 |
| Tip speed of the rotor blade () | 120 |
| Mean rotor induced velocity in hover () | 4.03 |
| Blade profile power () | 79.76 |
| Induced power () | 88.66 |
| Discount factor () | 0.99 |
| Number of line searches | 10 |
| Clip parameter for loss value | 0.2 |
| Max norm of gradients | 10 |
| Accept ratio of loss improve | 0.5 |
| Weight initialization gain for actor network | 0.01 |
| Weight initialization for neural network | Orthogonal |
In addition, to verify the effectiveness and performance of HATRPO-UCB, except for conventional HATRPO, the following baseline methods are also introduced for comparison.
-
•
LAA: All UAVs form a linear antenna array (LAA), and they are symmetrically excited and located about the origin of the array [21].
-
•
RAA: A rectangular antenna array (RAA) is formed by all UAVs, where all UAVs are also symmetrically excited and located about the origin of the array.
-
•
MADDPG: Multi-Agent Deep Deterministic Policy Gradient (MADDPG) is based on the centralized training with decentralized execution (CTDE) paradigm, extending Deep Deterministic Policy Gradient (DDPG) to MADRL [55].
-
•
IPPO: Independent Proximal Policy Optimization (IPPO) is that the single-agent PPO algorithm is adopted directly to solve multi-agent tasks [56]. The IPPO has been justified that it can achieve excellent performance on SMAC.
-
•
MAPPO: Multi-Agent Proximal Policy Optimization (MAPPO) is an extension of PPO [42]. MAPPO utilizes parameter-sharing trick, then all agents jointly use a policy network and a value network. The global state is the input of the value network.
Note that the proposed observation enhancement technique are added to these abovementioned MADRL algorithms, so that making sure that they can solve the UCBMOP properly. Furthermore, they are also tuned continuously and achieve the convergence.
5.2 Convergence Analysis
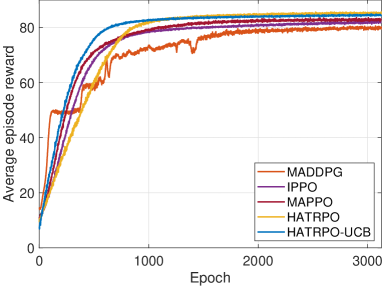
In practice, DRL-based models are usually deployed only after achieving convergence through training. Even if the practical environment changes dynamic, we also need to re-train and fine-tune the model before deploying it. Thus, the convergence performance of HATRPO-UCB is vital. As such, in the section, we compare the convergence performance of HATRPO-UCB with other algorithms. Fig. 5 shows the convergence performance of all algorithms. It can be observed that all algorithms converge successfully. HATRPO-UCB achieves the fastest convergence at approximately 750 epoch, then the second algorithm is HATRPO. MAPPO, IPPO and MADDPG are slowest, which all begin to converge at about 1400 epoch. However, in the performance, the reward obtained by HATRPO is higher than that of the HATRPO-UCB, reaching about 85. IPPO and MAPPO are both worse than HATRPO-UCB. MADDPG has the poorest performance, which only converges to around 80. The reasons are that the introduced observation enhancement provides representative and adaptive information for the agents to take action, the agent-specific global state is able to improve the fitting performance of critic learning, and the Beta distribution overcomes the boundary effect issue. Such improvements could effectively address the major issues in the training process, thus facilitating the algorithm in achieving reliable and high-performance outcomes and converging rapidly.
| First BS | Second BS | |||
|---|---|---|---|---|
| Method | Transmission rate (bps) | Energy consumption (J) | Transmission rate (bps) | Energy consumption (J) |
| LAA | 15208 | / | ||
| RAA | 14217 | / | ||
| MADDPG | 22319 | 17913 | ||
| IPPO | 15790 | 21110 | ||
| MAPPO | 15025 | 23252 | ||
| HATRPO | 13765 | 11779 | ||
| HATRPO-UCB | ||||
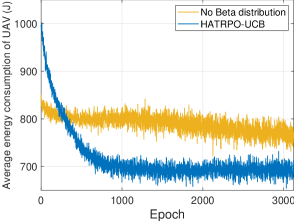
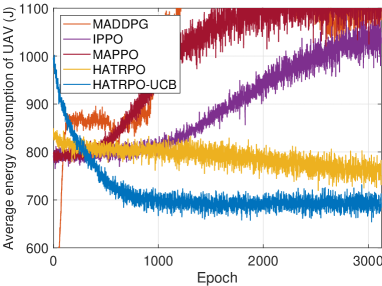
To further analyze these algorithms, we also depict the optimization process of all alogrithms to the UAV energy consumption in Fig. 6. It can be observed that HATRPO-UCB obtains the best optimization performance, making the energy consumption of UAV reduce to about 700 J and achieving the convergence at approximately 1000 epochs. Then, HATRPO has the certain optimization performance, but it does not have the obvious optimization effect like HATRPO-UCB and the ultimate optimization result is not better than that of HATRPO-UCB. In addition, MAPPO, IPPO and MADDPG have no optimization effect, whose optimization performance becomes worse continously with the training process. The more details about performance of all algorithms will be introduced in the following sections.
5.3 Performance Comparison
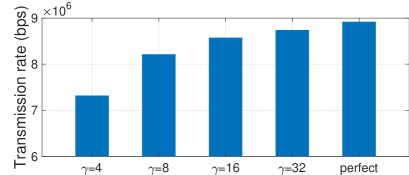
The practical performance of all approaches is compared in the section. In our system, all UAVs have other kinds of tasks after completing CB, but they may continue to perform CB for communicating with another BS. Thus, we will analyze the actual performance of UVAA communicating continuously with two BSs. Table III shows the numerical optimization results of various methods. It can be observed that HATRPO-UCB achieves the best performance on the optimization of energy consumption of UVAA, and obtains the outstanding results on the transmission rate optimization. The highest transmission rates to the two BSs are achieved by MAPPO and MADDPG, respectively, but they consume more energy. Furthermore, remaining MADRL approaches also outperform HATRPO-UCB in terms of the optimization of transmission rate. The reason may be that all UAVs optimized by these algorithms fly higher and closer to BS, thus the UVAA can get the lower path loss and shorter distance with BS. However, the more energy consumption will be induced.
We also show the flight paths of UAVs in the Appendix B of supplemental material. Benefiting from the DNN, the UVAA optimized by MADRL methods can directly perform CB for the second BS without consuming the much computation resource. Besides, we can also observe that all UAVs optimized by other MADRL approaches can achieve the higher altitude and the shorter distance with BS compared with HATRPO-UCB, and thus, they can obtain the higher transmission rate but will consume more energy as shown in Table III. In summary, HATRPO-UCB learns the best strategy, making UVAA obtain the great transmission rate and save the energy at the same time.
5.4 Ablation Analysis
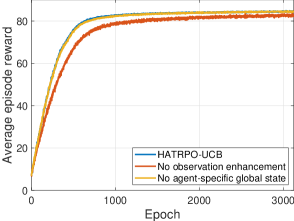
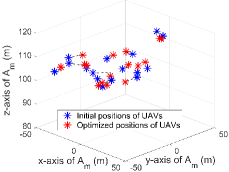
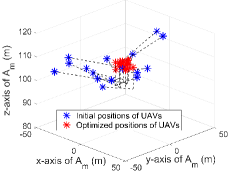
For verifying the effectiveness of proposed techniques, we conduct some ablation experiments. Fig. 7a displays some convergence performance as HATRPO-UCB is not implemented with some techniques. When HATRPO-UCB is not equipped with observation enhancement, we can observe that the performance is decreased. For further analysis, we present the practical performance of UVAA whether adopting observation enhancement or not in Fig. 8. As can be seen, when using observation enhancement, all UAVs can cooperate better, and they can also fly toward the BS to shorten the communication distance. On the contrary, without observation enhancement, all UAVs are scattered and have no clear flight targets. Furthermore, the CB performance is also influenced. The UVAA gets 24.85 reward about the transmission rate that is smaller than 25.05 obtained by the algorithm with observation enhancement. Therefore, the observation enhancement technique can significantly enable UVAA to learn the better strategy.
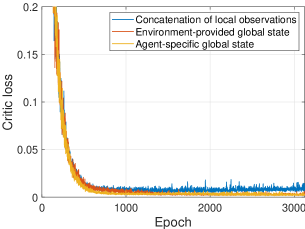
For testing the effectiveness of agent-specific global state, we replace the agent-specific global state, then use the environment-provided global state to evaluate the algorithm performance. As shown in Fig. 7a, HATRPO-UCB suffers from the performance degradation, which is because the information contained in the environment-provided global state is insufficient. Likewise, the critic learning is also influenced. Fig. 7b shows the learning curves of the critic network based on different global states, where the concatenation of all local observations is also added for comparison. It can be observed that the loss based on the agent-specific global state is lower than those under the other two global states. The reason is that the concatenation of local observations contains much redundant information, increasing the training burden, thus the learning process becomes very unstable and performance degrades. Then, the environment-provided global state also influences the training efficiency due to the insufficient information. However, according to the two figures, the influence produced by the two global states looks small. The reason could be that each episode only has one time slot in the UCBMOP, which distinctly differs from the regular MADRL tasks that require sequential decision-making. Hence, the role of critic network is not as significant as that in the regular tasks.
As for Beta distribution for policy, an action sampled from the Beta distribution is not beyond its setting range, which is beneficial for the policy gradient estimation so that no bias occurs. We show the impact of Beta distribution for policy to the optimization about the energy consumption of UAV in Fig. 7c. It can be seen that Beta distribution for policy can make HATRPO-UCB optimize the UAV energy consumption well, reducing the energy consumption to around 700 J. However, without Beta distribution for policy, the optimization effect is substantially weakened, and the ultimate performance is not better than the algorithm with Beta distribution for policy. Therefore, according to [48], adopting the Beta distribution can help the agent learn the better strategy compared with the Gaussian distribution.
5.5 Impact of Hyperparameter Setting
The appropriate hyperparameter setting is critical to the algorithm. In HATRPO-UCB, the following hyperparameters are closely related to the algorithm performance that are the Optimizer, Learning rate, KL-threshold and Number of neurons. Hence, we analyze the impact of different values of each hyperparameter to HATRPO-UCB and simultaneously verify the reasonableness of our setting.
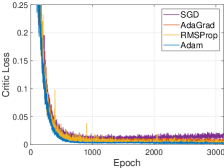
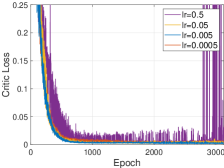
Algorithm performance under different optimizers. We first analyze the influence of various optimizers. Four optimizers are adopted to optimize the critic network, which are SGD[57], AdaGrad[58], RMSProp[59] and Adam[54], respectively. Their optimization results about the critic loss are shown in Fig. 9a. We can observe that, following the above order of optimizers, the optimized result becomes better. The performance of SGD is the worst, and the performance degradation appears in the following training. In the other optimizers, the training process also becomes unstable, resulting in an oscillating training curve. Then, when using Adam, the optimization performance is best and the training curve is smoothest. Therefore, Adam is choosen as the optimizer of HATRPO-UCB.
Algorithm performance under different learning rates. Except for determining the optimizer, the critic network is also optimized based on a certain learning rate. Hence, Fig. 9b shows the learning process of critic network based on Adam under four learning rates. It can be observed that the optimization performance is best and the critic loss curve is smoothest as the learning rate is 0.005. When equaling to 0.05 or 0.0005, the curve oscillates slightly, which demonstrates that they are not appropriate under the current hyperparameter configuration. However, as the learning rate is 0.5, the training process gets very unstable and the performance degrades seriously at the end of training. The probable reason is that the learning rate is too large to produce the fluctuation.
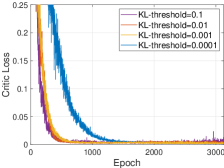
Algorithm performance under different KL-thresholds. As for the KL-threshold, it is related to the update of actor network, but the KL-threshold also influences the learning speed of the critic network. Fig. 9c describes the critic loss curve under various KL-thresholds. We can observe that critic network begins to converge at approximately 1000 epoch as the KL-threshold is 0.001. Then, when the KL-threshold equals 0.1 and 0.01, the convergence speed of critic network becomes faster. However, these large KL-thresholds also cause the instability to the critic learning in the second half of the whole process, and then also make the actor learning unstable. At last, 0.0001 KL-threshold makes the critic network learn so slowly that it converges at about 2000 epoch. Therefore, 0.001 KL-threshold is the best choice, which can make the critic network converge properly.
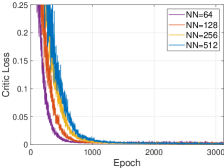
Algorithm performance under different neuron numbers. The number of neurons of hidden layer has the important effect to the DNN. Hence, Fig. 9d displays the performance of HATRPO-UCB under various numbers of neurons. We can observe that the convergence of critic network becomes slower as the number of neurons increases. The reason is that the large number of neurons makes the DNN big and complex, increasing the training burden. Hence, the number of neurons should be set to 64. In conclusion, according to all the above analysis, the hyperparameter setting with Adam, 0.005 learning rate, 0.001 KL-threshold and 64 neurons can make HATRPO-UCB achieve the best performance.
5.6 Impact of Imperfect Synchronization
The imperfect synchronization exists in CB, where the phase errors may be generated to influence the CB performance. Thus, we evaluate the impact of phase errors to the transmission performance of UVAA in the section.
The phase error at -th UAV antenna is denoted as , and then the AF of UVAA can be rewritten as [60]
| (24) | ||||
which is assumed to follow a Tikhonov (or von Mises) distribution [60] [61]. The Tikhonov distribution is described as
| (25) |
where , is the zero-th order modified Bessel function of the first kind, and is the inverse of the variance of the phase error. Then, the impact of phase errors to the transmission rate of UVAA under different values of is shown in Fig. 10. It can be seen that the phase errors make the UVAA transmission performance decline. However, the generated phase errors become smaller as gets large, weakening the influence. For tackling the imperfect synchronization, there has been many works proposing various closed-loop or open-loop methods [31]. Furthermore, as the better synchronization algorithms are being proposed continuously, the impact of the imperfect synchronization will become less and less.
6 Discussion
In this section, we discuss possible issues and solutions when deploying the proposed method in actual scenarios.
6.1 The Impact of UAV Collision
In this part, we discuss the impact of UAV collisions. As shown in Eq. (10f), we set the minimum separation between two UAVs in UCBMOP. Following this, we set a penalty in the reward. Specifically, when any two UAVs violate the minimum separation constraint, they will get a tiny negative reward. As such, the proposed algorithm is able to make UAVs keep the minimum separation.
Moreover, many mature methods of UAV collision avoidance can also help the UAVs avoid violating the minimum separation in reality. For example, cameras, infrared, radar, LiDAR, sonar, etc, can be utilized by UAVs for obstacle detection. Based on this, the existing methods such as sense & avoid [62] can be appropriately embedded in the proposed optimization framework. This type of method focuses on reducing the computational cost with a short response time, deviating the UAVs from their original paths when needed, and then turning the UAVs to the previous flight state quickly. Since this method only consumes very little computational resources, energy, and time, it does not have a significant effect on the results of our work. As such, UAV collisions do not affect the effectiveness of the proposed method.
6.2 Additional Energy Consumption in Synchronization
In the considered system, there is additional energy consumption in the synchronization process for beacon signal reception (for closed loop) and location estimation (for open loop). However, this additional energy consumption is minor and can be ignored, and the reasons are as follows.
First, the closed-loop synchronization methods are based on feedback, whose energy consumption is quite small compared to the transmission or motion energy consumption of the UAVs. Specifically, the closed-loop synchronization approaches mainly include two types that are the iterative bit feedback and rich feedback methods. In the considered UAV-enabled CB scenarios, both of these closed-loop methods result in negligible energy consumption. This is because the recently proposed methods, such as iterative bit feedback approaches and rich feedback methods, can achieve rapid convergence with minimal energy consumption (less than 1 Joule in most cases). As such, this additional energy consumption is much smaller than the motion energy of UAVs (often several hundred Joules each second).
To demonstrate, we select a representative method, i.e., D1BF [63], to implement and evaluate. Following this, we introduce the energy consumption of point-to-point sending and broadcast receiving models from [64]. As shown in Fig. 11(a), the energy consumption of the closed-loop synchronization is not larger than even 1 Joule. Thus, we can demonstrate that the additional energy consumption of closed-loop synchronization in the considered system is quite small and can be ignored.
Second, compared to the closed-loop synchronization methods, the open-loop synchronization methods are not based on iterative feedback and have less energy consumption. Specifically, the open-loop synchronization approaches can be divided into two categories that are the intra-node communication and blind method. On the one hand, the intra-node methods are mostly based on the master-slave architecture [65]. We also use the energy model above and assume that the master node sends a reference beacon to all slave nodes and then the slaves synchronize their own phases. In this case, the energy consumption of synchronization of the UAVs can be shown in Fig. 11(b). As can be seen, it is also not larger than 1 Joule and can be omitted. On the other hand, blind methods allow the nodes to synchronize among themselves and do not require feedback from the receiver or the reference nodes. Hence, the overhead of the blind method can be smaller. Thus, the additional energy consumption of open-loop synchronization in the considered system is also small and can be ignored.
Overall, the additional energy consumption for synchronization does not have an evident impact on the availability of the proposed method.
7 Conclusion
In this paper, a UAV-assistant A2G communication system is investigated, where multiple UAVs form a UVAA to perform CB for communicating with remote BSs. Then, we formulate a UCBMOP, aiming at simultaneously maximizing the transmission rate of UVAA and minimizing the energy consumption of all UAVs. Consider that the system is dynamic and the cooperation among UAVs is complex, we propose the HATRPO-UCB, which is an MADRL algorithm to address the problem. Except for combining conventional HATRPO, three techniques are proposed to enhance the performance of the proposed algorithm. Simulation results demonstrate that the proposed HATRPO-UCB learns the better strategy than other baseline methods including LAA, RAA, MADDPG, IPPO, MAPPO and conventional HATRPO, making UVAA achieve the best transmission performance and save the energy consumption simultaneously. Furthermore, the effectiveness of three techniques is also verified by the ablation experiments.
References
- [1] Y. Zeng, Q. Wu, and R. Zhang, “Accessing from the sky: A tutorial on UAV communications for 5G and beyond,” Proc. IEEE, vol. 107, no. 12, pp. 2327–2375, 2019.
- [2] N. Zhao, W. Lu, M. Sheng, Y. Chen, J. Tang, F. R. Yu, and K.-K. Wong, “UAV-assisted emergency networks in disasters,” IEEE Wirel. Commun., vol. 26, no. 1, pp. 45–51, 2019.
- [3] S. Chen, J. Zhang, E. Bjornson, J. Zhang, and B. Ai, “Structured massive access for scalable cell-free massive MIMO systems,” IEEE J. Sel. Areas Commun., vol. 39, pp. 1086–1100, Apr. 2021.
- [4] S. Ahmed, M. Z. Chowdhury, and Y. M. Jang, “Energy-efficient uav relaying communications to serve ground nodes,” IEEE Commun. Lett., vol. 24, no. 4, pp. 849–852, 2020.
- [5] M. Khosravi and H. Pishro-Nik, “Unmanned aerial vehicles for package delivery and network coverage,” in Proc. VTC2020-Spring, pp. 1–5, IEEE, 2020.
- [6] Y. Zeng, R. Zhang, and T. J. Lim, “Wireless communications with unmanned aerial vehicles: Opportunities and challenges,” IEEE Commun. Mag., vol. 54, no. 5, pp. 36–42, 2016.
- [7] M. Li, L. Liu, Y. Gu, Y. Ding, and L. Wang, “Minimizing energy consumption in wireless rechargeable UAV networks,” IEEE Internet Things J., vol. 9, no. 5, pp. 3522–3532, 2021.
- [8] Y. Zeng, J. Xu, and R. Zhang, “Energy minimization for wireless communication with rotary-wing UAV,” IEEE Trans. Wireless Commun., vol. 18, no. 4, pp. 2329–2345, 2019.
- [9] C. Zhan and Y. Zeng, “Energy minimization for cellular-connected uav: From optimization to deep reinforcement learning,” IEEE Trans. Wireless Commun., 2022.
- [10] M. Mozaffari, W. Saad, M. Bennis, Y.-H. Nam, and M. Debbah, “A tutorial on UAVs for wireless networks: Applications, challenges, and open problems,” IEEE Commun. Surv. Tutorials, vol. 21, no. 3, pp. 2334–2360, 2019.
- [11] S. Liang, Z. Fang, G. Sun, Y. Liu, G. Qu, S. Jayaprakasam, and Y. Zhang, “A joint optimization approach for distributed collaborative beamforming in mobile wireless sensor networks,” Ad Hoc Netw., vol. 106, p. 102216, 2020.
- [12] J. Garza, M. A. Panduro, A. Reyna, G. Romero, and C. d. Rio, “Design of UAVs-based 3D antenna arrays for a maximum performance in terms of directivity and SLL,” Int. J. Antenn. Propag., vol. 2016, 2016.
- [13] S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,” in Proc. ICML, pp. 1587–1596, PMLR, 2018.
- [14] Y. Wang, Z. Gao, J. Zhang, X. Cao, D. Zheng, Y. Gao, D. W. K. Ng, and M. Di Renzo, “Trajectory design for UAV-based internet of things data collection: A deep reinforcement learning approach,” IEEE Internet Things J., vol. 9, no. 5, pp. 3899–3912, 2021.
- [15] H. Xie, D. Yang, L. Xiao, and J. Lyu, “Connectivity-aware 3D UAV path design with deep reinforcement learning,” IEEE Trans. Veh. Technol., vol. 70, no. 12, pp. 13022–13034, 2021.
- [16] J. G. Kuba, R. Chen, M. Wen, Y. Wen, F. Sun, J. Wang, and Y. Yang, “Trust region policy optimisation in multi-agent reinforcement learning,” arXiv preprint arXiv:2109.11251, 2021.
- [17] Y. Cai, Z. Wei, R. Li, D. W. K. Ng, and J. Yuan, “Joint trajectory and resource allocation design for energy-efficient secure uav communication systems,” IEEE Trans. Commun., vol. 68, no. 7, pp. 4536–4553, 2020.
- [18] M. Wang, L. Zhang, P. Gao, X. Yang, K. Wang, and K. Yang, “Stackelberg game-based intelligent offloading incentive mechanism for a multi-UAV-assisted mobile edge computing system,” IEEE Internet Things J., 2023.
- [19] S. F. Abedin, M. S. Munir, N. H. Tran, Z. Han, and C. S. Hong, “Data freshness and energy-efficient UAV navigation optimization: A deep reinforcement learning approach,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 9, pp. 5994–6006, 2020.
- [20] C. H. Liu, X. Ma, X. Gao, and J. Tang, “Distributed energy-efficient multi-uav navigation for long-term communication coverage by deep reinforcement learning,” IEEE Trans. Mob. Comput., vol. 19, no. 6, pp. 1274–1285, 2019.
- [21] M. Mozaffari, W. Saad, M. Bennis, and M. Debbah, “Communications and control for wireless drone-based antenna array,” IEEE Trans. Commun., vol. 67, no. 1, pp. 820–834, 2018.
- [22] G. Sun, J. Li, Y. Liu, S. Liang, and H. Kang, “Time and energy minimization communications based on collaborative beamforming for UAV networks: A multi-objective optimization method,” IEEE J. Sel. Areas Commun., vol. 39, no. 11, pp. 3555–3572, 2021.
- [23] G. Sun, J. Li, A. Wang, Q. Wu, Z. Sun, and Y. Liu, “Secure and energy-efficient UAV relay communications exploiting collaborative beamforming,” IEEE Trans. Commun., vol. 70, no. 8, pp. 5401–5416, 2022.
- [24] G. Sun, X. Zheng, Z. Sun, Q. Wu, J. Li, Y. Liu, and V. C. Leung, “UAV-enabled secure communications via collaborative beamforming with imperfect eavesdropper information,” IEEE Trans. Mob. Comput., vol. 23, no. 4, pp. 3291–3308, 2024.
- [25] J. Li, G. Sun, L. Duan, and Q. Wu, “Multi-objective optimization for UAV swarm-assisted iot with virtual antenna arrays,” IEEE Trans. Mob. Comput., pp. 1–18, 2024.
- [26] J. Huang, A. Wang, G. Sun, and J. Li, “Jamming-aided maritime physical layer encrypted dual-UAVs communications exploiting collaborative beamforming,” in Proc. CSCWD, IEEE, 2023.
- [27] H. Li, D. Wei, G. Sun, J. Wang, J. Li, and H. Kang, “Interference mitigation via collaborative beamforming in UAV-enabled data collections: A multi-objective optimization method,” 2022.
- [28] S. Krishna Moorthy, N. Mastronarde, S. Pudlewski, E. S. Bentley, and Z. Guan, “Swarm UAV networking with collaborative beamforming and automated ESN learning in the presence of unknown blockages,” Comput. Netw., vol. 231, p. 109804, 2023.
- [29] Y. Zhang, Z. Mou, F. Gao, J. Jiang, R. Ding, and Z. Han, “UAV-enabled secure communications by multi-agent deep reinforcement learning,” IEEE Trans. Veh. Technol., vol. 69, no. 10, pp. 11599–11611, 2020.
- [30] C. Dai, K. Zhu, and E. Hossain, “Multi-agent deep reinforcement learning for joint decoupled user association and trajectory design in full-duplex multi-UAV networks,” IEEE Trans. Mob. Comput., 2022.
- [31] S. Jayaprakasam, S. K. A. Rahim, and C. Y. Leow, “Distributed and collaborative beamforming in wireless sensor networks: Classifications, trends, and research directions,” IEEE Commun. Surv. Tutorials, vol. 19, no. 4, pp. 2092–2116, 2017.
- [32] A. Al-Hourani, S. Kandeepan, and S. Lardner, “Optimal lap altitude for maximum coverage,” IEEE Wireless Commun. Lett., vol. 3, no. 6, pp. 569–572, 2014.
- [33] G. Sun, Y. Liu, Z. Chen, A. Wang, Y. Zhang, D. Tian, and V. C. M. Leung, “Energy efficient collaborative beamforming for reducing sidelobe in wireless sensor networks,” IEEE Trans. Mob. Comput., vol. 20, no. 3, pp. 965–982, 2021.
- [34] S. Jayaprakasam, S. K. Abdul Rahim, C. Y. Leow, and T. O. Ting, “Sidelobe reduction and capacity improvement of open-loop collaborative beamforming in wireless sensor networks,” PloS one, vol. 12, no. 5, p. e0175510, 2017.
- [35] Y. Zeng, X. Xu, and R. Zhang, “Trajectory design for completion time minimization in UAV-enabled multicasting,” IEEE Trans. Wireless Commun., vol. 17, no. 4, pp. 2233–2246, 2018.
- [36] S.-F. Chou, A.-C. Pang, and Y.-J. Yu, “Energy-aware 3D unmanned aerial vehicle deployment for network throughput optimization,” IEEE Trans. Wireless Commun., vol. 19, no. 1, pp. 563–578, 2019.
- [37] Z. Yang, W. Xu, and M. Shikh-Bahaei, “Energy efficient UAV communication with energy harvesting,” IEEE Trans. Veh. Technol., vol. 69, no. 2, pp. 1913–1927, 2019.
- [38] C. You and R. Zhang, “Hybrid offline-online design for UAV-enabled data harvesting in probabilistic LoS channels,” IEEE Trans. Wireless Commun., vol. 19, no. 6, pp. 3753–3768, 2020.
- [39] P. Goos, U. Syafitri, B. Sartono, and A. Vazquez, “A nonlinear multidimensional knapsack problem in the optimal design of mixture experiments,” Eur. J. Oper. Res., vol. 281, no. 1, pp. 201–221, 2020.
- [40] A. Feriani and E. Hossain, “Single and multi-agent deep reinforcement learning for ai-enabled wireless networks: A tutorial,” IEEE Commun. Surv. Tutorials, vol. 23, no. 2, pp. 1226–1252, 2021.
- [41] M. L. Littman, “Markov games as a framework for multi-agent reinforcement learning,” in Machine learning proceedings 1994, pp. 157–163, Elsevier, 1994.
- [42] C. Yu, A. Velu, E. Vinitsky, Y. Wang, A. Bayen, and Y. Wu, “The surprising effectiveness of ppo in cooperative, multi-agent games,” arXiv preprint arXiv:2103.01955, 2021.
- [43] D. Salama, T. K. Sarkar, M. N. Abdallah, X. Yang, and M. Salazar-Palma, “Adaptive processing at multiple frequencies using the same antenna array consisting of dissimilar nonuniformly spaced elements over an imperfectly conducting ground,” IEEE Trans. Antennas Propag., vol. 67, pp. 622–625, Jan. 2019.
- [44] C. S. de Witt, B. Peng, P.-A. Kamienny, P. Torr, W. Böhmer, and S. Whiteson, “Deep multi-agent reinforcement learning for decentralized continuous cooperative control,” arXiv preprint arXiv:2003.06709, 2020.
- [45] M. Samvelyan, T. Rashid, C. S. De Witt, G. Farquhar, N. Nardelli, T. G. Rudner, C.-M. Hung, P. H. Torr, J. Foerster, and S. Whiteson, “The starcraft multi-agent challenge,” arXiv preprint arXiv:1902.04043, 2019.
- [46] S. Kakade and J. Langford, “Approximately optimal approximate reinforcement learning,” in Proc. of ICML, p. 267–274, 2002.
- [47] J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz, “Trust region policy optimization,” in Proc. ICML, pp. 1889–1897, 2015.
- [48] P.-W. Chou, D. Maturana, and S. Scherer, “Improving stochastic policy gradients in continuous control with deep reinforcement learning using the beta distribution,” in Proc. ICML, pp. 834–843, 2017.
- [49] W. Zhou, Z. Cao, N. Deng, K. Jiang, and D. Yang, “Identify, estimate and bound the uncertainty of reinforcement learning for autonomous driving,” IEEE Trans. Intell. Transp. Syst., vol. 24, no. 8, pp. 7932–7942, 2023.
- [50] K. Zhang, Z. Yang, and T. Başar, Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms, pp. 321–384. Springer International Publishing, 2021.
- [51] T. Li, K. Zhu, N. C. Luong, D. Niyato, Q. Wu, Y. Zhang, and B. Chen, “Applications of multi-agent reinforcement learning in future internet: A comprehensive survey,” IEEE Commun. Surv. Tutorials, vol. 24, no. 2, pp. 1240–1279, 2022.
- [52] J. Li, H. Kang, G. Sun, S. Liang, Y. Liu, and Y. Zhang, “Physical layer secure communications based on collaborative beamforming for UAV networks: A multi-objective optimization approach,” in Proc. IEEE INFOCOM 2021, pp. 1–10, IEEE, 2021.
- [53] M. Mozaffari, W. Saad, M. Bennis, and M. Debbah, “Wireless communication using unmanned aerial vehicles (UAVs): Optimal transport theory for hover time optimization,” IEEE Trans. Wireless Commun., vol. 16, no. 12, pp. 8052–8066, 2017.
- [54] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [55] R. Lowe, Y. I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environments,” Advances in neural information processing systems, vol. 30, 2017.
- [56] C. S. de Witt, T. Gupta, D. Makoviichuk, V. Makoviychuk, P. H. Torr, M. Sun, and S. Whiteson, “Is independent learning all you need in the starcraft multi-agent challenge?,” arXiv preprint arXiv:2011.09533, 2020.
- [57] L. Bottou et al., “Stochastic gradient learning in neural networks,” Proceedings of Neuro-Nımes, vol. 91, no. 8, p. 12, 1991.
- [58] J. Duchi, E. Hazan, and Y. Singer, “Adaptive subgradient methods for online learning and stochastic optimization.,” Journal of machine learning research, vol. 12, no. 7, 2011.
- [59] T. Tieleman, G. Hinton, et al., “Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude,” COURSERA: Neural networks for machine learning, vol. 4, no. 2, pp. 26–31, 2012.
- [60] A. Minturn, D. Vernekar, Y. L. Yang, and H. Sharif, “Distributed beamforming with imperfect phase synchronization for cognitive radio networks,” in Proc. ICC, pp. 4936–4940, IEEE, 2013.
- [61] Y. S. Shmaliy, “Von mises/tikhonov-based distributions for systems with differential phase measurement,” Signal Process., vol. 85, no. 4, pp. 693–703, 2005.
- [62] Y. Zeng, Y. Hu, S. Liu, J. Ye, Y. Han, X. Li, and N. Sun, “Rt3d: Real-time 3-d vehicle detection in lidar point cloud for autonomous driving,” IEEE Robot. Autom. Lett., vol. 3, no. 4, pp. 3434–3440, 2018.
- [63] I. Thibault, G. E. Corazza, and L. Deambrogio, “Random, deterministic, and hybrid algorithms for distributed beamforming,” in 2010 5th Advanced Satellite Multimedia Systems Conference and the 11th Signal Processing for Space Communications Workshop, IEEE, 2010.
- [64] J. Feng, Y.-H. Lu, B. Jung, and D. Peroulis, “Energy efficient collaborative beamforming in wireless sensor networks,” in 2009 IEEE International Symposium on Circuits and Systems, IEEE, May 2009.
- [65] F. Quitin, M. M. Ur Rahman, R. Mudumbai, and U. Madhow, “Distributed beamforming with software-defined radios: Frequency synchronization and digital feedback,” in Proc. IEEE GLOBECOM, 2012.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9beacb27-64a7-4137-bb07-e80c523cf36a/SaichaoLiu.jpg) |
Saichao Liu received a BS degree and an MS degree in Software Engineering from Henan University, China, in 2019 and 2022, respectively. He is currently pursuing the Ph.D. degree with the College of Computer Science and Technology, Jilin University, Changchun, China. His research interests include wireless communications, UAV networks, antenna arrays and reinforcement learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9beacb27-64a7-4137-bb07-e80c523cf36a/GengSun.jpg) |
Geng Sun (S’17-M’19) received the B.S. degree in communication engineering from Dalian Polytechnic University, and the Ph.D. degree in computer science and technology from Jilin University, in 2011 and 2018, respectively. He was a Visiting Researcher with the School of Electrical and Computer Engineering, Georgia Institute of Technology, USA. He is an Associate Professor in College of Computer Science and Technology at Jilin University, and His research interests include wireless networks, UAV communications, collaborative beamforming and optimizations. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9beacb27-64a7-4137-bb07-e80c523cf36a/JiahuiLi.jpg) |
Jiahui Li (S’21) received a BS degree in Software Engineering, and an MS degree in Computer Science and Technology from Jilin University, Changchun, China, in 2018 and 2021, respectively. He is currently studying Computer Science at Jilin University to get a Ph.D. degree, and also a visiting Ph. D. at Singapore University of Technology and Design (SUTD), Singapore. His current research focuses on UAV networks, antenna arrays, and optimization. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9beacb27-64a7-4137-bb07-e80c523cf36a/Shuang-Liang.jpg) |
Shuang Liang received the B.S. degree in Communication Engineering from Dalian Polytechnic University, China in 2011, the M.S. degree in Software Engineering from Jilin University, China in 2017, and the Ph.D. degree in Computer Science from Jilin University, China in 2022. She is a post-doctoral in the School of Information Science and Technology, Northeast Normal University, and her research interests focus on wireless communication and UAV networks. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9beacb27-64a7-4137-bb07-e80c523cf36a/QingqingWu.jpg) |
Qingqing Wu (S’13-M’16-SM’21) received the B.Eng. and the Ph.D. degrees in Electronic Engineering from South China University of Technology and Shanghai Jiao Tong University (SJTU) in 2012 and 2016, respectively. From 2016 to 2020, he was a Research Fellow in the Department of Electrical and Computer Engineering at National University of Singapore. He is currently an Associate Professor with Shanghai Jiao Tong University. His current research interest includes intelligent reflecting surface (IRS), unmanned aerial vehicle (UAV) communications, and MIMO transceiver design. He has coauthored more than 100 IEEE journal papers with 26 ESI highly cited papers and 8 ESI hot papers, which have received more than 18,000 Google citations. He was listed as the Clarivate ESI Highly Cited Researcher in 2022 and 2021, the Most Influential Scholar Award in AI-2000 by Aminer in 2021 and World’s Top 2% Scientist by Stanford University in 2020 and 2021. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9beacb27-64a7-4137-bb07-e80c523cf36a/Pengfei-Wang.jpg) |
Pengfei Wang (Member, IEEE) received the B.S., M.S., and Ph.D. degrees in software engineering from Northeastern University (NEU), China, in 2013, 2015, and 2020, respectively. From 2016 to 2018, he was a Visiting Ph.D. Student with the Department of Electrical Engineering and Computer Science, Northwestern University, IL, USA. He is currently an Associate Professor with the School of Computer Science and Technology, Dalian University of Technology (DUT), China. He has authored more than 30 papers on high-quality journals and conferences, such as IEEE/ACM TRANSACTIONS ON NETWORKING, IEEE INFOCOM, IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS, DAC, IEEE ICNP, IEEE ICDCS, IEEE INTERNET OF THINGS JOURNAL, and JSA. He also holds a series of patents in U.S. and China. His research interests are ubiquitous computing, big data, and AIoT. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9beacb27-64a7-4137-bb07-e80c523cf36a/Dusit-Niyato.jpg) |
Dusit Niyato (Fellow, IEEE) received the B.Eng. degree from the King Mongkuts Institute of Technology Ladkrabang (KMITL), Thailand, in 1999, and the Ph.D. degree in electrical and computer engineering from the University of Manitoba, Canada, in 2008. He is currently a Professor with the School of Computer Science and Engineering, Nanyang Technological University, Singapore. His research interests include the Internet of Things (IoT), machine learning, and incentive mechanism design. |