Two-way Spectrum Pursuit for Decomposition and Its Application in Joint Column/Row Subset Selection
Abstract
The problem of simultaneous column and row subset selection is addressed in this paper. The column space and row space of a matrix are spanned by its left and right singular vectors, respectively. However, the singular vectors are not within actual columns/rows of the matrix. In this paper, an iterative approach is proposed to capture the most structural information of columns/rows via selecting a subset of actual columns/rows. This algorithm is referred to as two-way spectrum pursuit (TWSP) which provides us with an accurate solution for the CUR matrix decomposition. TWSP is applicable in a wide range of applications since it enjoys a linear complexity w.r.t. number of original columns/rows. We demonstrated the application of TWSP for joint channel and sensor selection in cognitive radio networks, informative users and contents detection, and efficient supervised data reduction.
Index Terms:
Column and rows subset selection, CUR matrix decomposition, spectrum pursuit1 Introduction
Matrix factorization provides a concise representation of data. Despite desirable uniqueness conditions and computational simplicity of the well-known singular value decomposition (SVD), it comes with some fundamental shortcomings. The intrinsic structure of data is not inherited to the singular components. Moreover, SVD implies orthogonality on the components which is irrelevant to the underlying structure of the original data. This enforced structure makes the bases, a.k.a. singular vectors, hard to interpret [9]. On the other hand, it is shown that borrowing bases from the actual samples of a dataset provides a robust representation, which can be employed in interesting applications where sampling is their key factor [20]. This problem is studied under the literature of column subset selection problem (CSSP) [5, 2] and CUR decomposition [16, 3]. A general problem for CSSP and CUR can be written in the following form:
| (1) |
where, is the data matrix containing data points in an -dimensional space. Here, and indicate column space projection and row space projection, respectively. These operators project all columns (rows) to a low-dimensional subspace spanned by selected columns (rows) of matrix indexed by the set (). The chronological order in applying and does not affect the problem since these operators are linear. Moreover, substituting with the identity projection simplifies the problem to CSSP. Fig. 1 illustrates the structure of CUR matrix decomposition as a self-representative approach.
A versatile metric for evaluating the performance of a data subset selection algorithm can be defined by the approximation error resulted from the projection of the entire data to the span of selected rows/columns. How close to the optimal selection an algorithm can reach, is determined by comparing its approximation error to the best low-rank approximation error specified by the spectral decomposition. Recently, we proposed a fast and accurate algorithm for solving CSSP which is called spectrum pursuit (SP) [12].
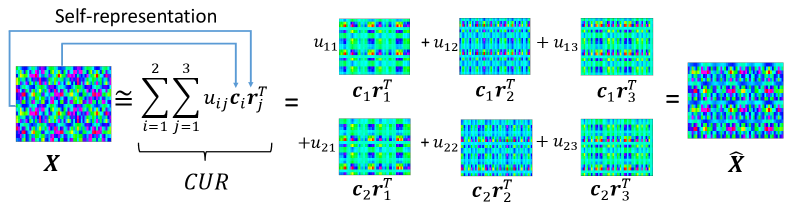
Inspired by SP, we propose a new algorithm to address the more general case of the CUR matrix decomposition. The main contributions of our paper are summarized as follows:
-
•
A novel algorithm for CUR decomposition, referred to as two-way spectrum pursuit (TWSP), is proposed. TWSP provides an accurate solution for CUR decomposition.
-
•
TWSP enjoys a linear complexity w.r.t. the number of columns and the number of rows of a matrix.
-
•
TWSP is a parameter-free algorithm that only requires the number of desired columns and rows for selection. Thus, TWSP does not require any parameter fine-tuning.
-
•
The TWSP algorithm is put to the test and investigated in a set of synthetic and real experiments.
-
•
The role of the core matrix in decomposition is illustrated which shows the connection between selected columns and rows. Based on analysis of , an interesting application for joint sensor/channel selection is presented.
Notations: Throughout this paper, vectors, and matrices are denoted by bold lowercase, and bold uppercase letters, respectively. Moreover sets are indicated by blackboard bold characters. The column of matrix is denoted by and the row of matrix is denoted by .
2 Column Subset Selection Problem
Selecting the most diverse subset of data in an optimal sense is studied vastly [5, 14, 13]. However, these methods do not guarantee that the unselected columns are well represented by the selected ones. Further, outliers are selected with a high probability using such algorithms due to their diversity [12]. A more effective approach is selecting some representatives which are able to approximate the rest of data accurately [7] as defined as a special case of (1). This is an NP-hard problem [18] and there are several efforts for solving this problem [1, 5, 17, 21]. There are computationally expensive approaches based on convex relaxation [7, 6] that are not computationally feasible for large datasets since their complexity is of order , where is the number of original columns. Recently, we proposed a new algorithm for solving CSSP with a linear complexity which is called Spectrum pursuit (SP) [12]. The SP algorithm finds columns of such that their span is close to that of the best rank- approximation of . SP is an iterative approach where at each iteration one sample selection is optimized such that the ensemble of selected samples describes the whole dataset more accurately. SP finds representatives such that the column space is spanned accurately via consecutive rank- approximations as theoretically analyzed in [11]. In the present paper, we extend the SP algorithm for selecting columns and rows jointly such that their outer product can represent the whole matrix accurately. A naive approach is applying SP algorithm on the matrix of interest to select a subset of columns and applying SP on its transpose in order to find a subset of rows. However, this approach is not efficient and we will compare it with our proposed approach which is optimized through a joint representation of selected columns and rows.
3 Two-way Spectrum Pursuit
The introduced joint column/row subset selection in (1) can be written as a CUR decomposition in the following form in which factor matrices must be drawn from actual columns/rows of the original matrix as
| (2) | |||
In this problem, , and indicate the set of normalized columns and rows of matrix , respectively. Here, and denote the column and the row of and , respectively. In other words, for all columns and for all rows. Please note that replacing constraints in (2) with orthogonality constraint on ’s and on ’s results in the truncated singular value decomposition (SVD) with most significant components. In this case, and contain the first left singular vectors and the first right singular vectors of , respectively. Moreover, the core matrix will be diagonal and the entries will be singular values with diagonal entries as singular values. However, the underlying constraints in (2) turn the problem into a joint subset of row and column selection problem instead of matrix low-rank approximation problem.
To solve this complicated problem, we split it into two consecutive problems for optimization on the selected column/row. Our optimization approach is alternative, i.e., a random subset of columns and rows are picked. Then, one column or row is considered to be replaced with a more efficient one at each iteration. Since scaling a vector does not change its span, without loss of generality we assume that the column or the row subject of the optimization lie on the unit sphere. At each iteration, a rank- component is optimized characterized by or given by
| (3a) | |||
| (3b) |
Matrix is the set of selected columns except the one and is the set of selected rows except the row. The first subproblem can be solved easily w.r.t. using singular value decomposition. In other words, and are the best rank- approximations of the residual and , respectively. The obtained / is the best column/row that can be added to the pool of selected columns/rows. However, the obtained vector is not available in the given dataset as a column or row since it is a singular vector which is a function of all columns/rows. The following step re-imposes the underlying constraints at each iteration,
| (4a) | |||
| (4b) |
Here, indicates a singleton that contains selected column and corresponds to the selected row. In each iteration, one column or one row is the subject of optimization. The impact of the latest estimation for that column/row on the representation is neglected. Then, an optimized replacement is found. At each iteration of TWSP, sub-problems in (3) are solved and their solutions are matched to the accessible column samples and row samples through matching equations in (4). The new selected column or row is stored in or , respectively. At each iteration we need to compute only the first singular vector and there are fast methods to do so [4]. The pair of (3a) and (4a) optimizes and matches a column. Similarly, performing (3b) and (4b) provides us with an optimized row. However, we do not update both of them per each iteration. In fact, we need to perform a column update or a row update in each iteration. It should be determined that which update (column or row) is more efficient in each iteration of the algorithm. To this aim, first, we choose a random previously selected column and a random previously selected row. Then, we find the best possible replacement column and the best possible replacement row. Accordingly, we choose whichever that minimizes the cost function more. The best modified column-wise subset is denoted by and denotes the best row-wise modified subset. Alg. 1 indicates the steps of TWSP algorithm. Here, refers to the Moore–Penrose pseudo-inverse operator. Iterations can be terminated either once CUR decomposition error is saturated or when a maximum number of iterations is reached.




The proposed TWSP provides the selected columns and selected rows in order to form matrix and in CUR decomposition. It is straightforward to estimate the core matrix . Mathematically,
| (5) |
This matrix is a two-way compressed replica of the whole dataset and it contains valuable information in practice as will be discussed in Sec. 4.2. In general, the number of selected columns may differ from the desired number of rows. Here, refers to the number of columns and points to the number of rows. It is worthwhile to mention that the complexity order of TWSP is bottle-necked by computational burden for two pseudo-inverses and two singular vectors computation. Thus, the complexity can be expressed as per iteration and the algorithm needs iterations. Moreover, operator rnd() refers to an integer random number less than or equal to . In the next section, we evaluate the performance of our proposed algorithm.
The CSSP and CUR decomposition problems are NP-hard, i.e., a combinatorial search is required to find the best columns and rows. The proposed TWSP algorithm minimizes the main cost function (1) in practice. However, there is no theoretical guarantee for convergence of the proposed TWSP algorithm Alg. 1. In order to improve the convergence behavior of TWSP, we evade updating both columns and rows in each iteration. Rather, we prioritize updating a row or a column depending on which exhibits a smaller projection error, i.e., which is a better minimizer for the cost function per each iteration. The implementation steps of TWSP are summarized in Alg. 1. As seen in Alg. 1, the method adds up a revision feature to remedy the greediness associated with consecutive selection by removing samples and optimizing to select a sample for replacement and reiterating this procedure.
4 Experimental Results
In order to evaluate TWSP on machine-learning tasks in terms of CUR decomposition accuracy, we apply the proposed TWSP on synthetic data as well as three real applications.
4.1 CUR Decomposition on Synthetic Data
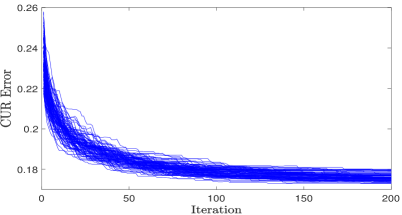
In order to evaluate the general performance of TWSP, we compared it with the state-of-the-art methods for selecting columns and rows. In this regards, we created a synthetic dataset. The dataset is generated by a rank- matrix contaminated with random noise. In Fig. 2, we have illustrated the CUR decomposition error for selecting a subset of rows and columns in the range of to . The reconstruction error of CUR is normalized by . We employ SP as the state-of-the-art algorithm for column subset selection [12]. We perform SP on the data matrix and its transpose in order to, respectively, select a subset of columns and rows independently. Then, employing (5) results in a CUR decomposition. We refer to the algorithm in [16] as adaptive CUR. A more accurate algorithm for solving CUR decomposition results in a bigger blue region in Fig. 2. TWSP exhibits the best performance in this experiment. The convergence behavior of TWSP for this experiment is shown in Fig. 3 for selecting 20 columns and 20 rows. The final solution of the TWSP algorithm depends on the initial selected columns and selected rows. However, regardless of the initial condition, the TWSP algorithm minimizes the cost function of CUR decomposition. TWSP prioritizes in selection of columns or rows such that the largest decrease in the projection error is obtained. It is the main feature to obtain convergence in practice.
4.2 Joint Sensor Selection and Channel Assignment
The output products of CUR decomposition are not limited to a subset of columns and rows. In some applications, interestingly, matrix is the most important output of a CUR decomposition. Entry () in indicates how important the contribution of the column and the row is to reconstruct the whole matrix . This interesting property is utilized for the problem of joint sensor selection and channel assignment in a cognitive radio network. To this aim the exact setup in [22] is considered with grid points and frequency channels. The received power magnitudes are organized in a matrix.
The only difference here, is that the uniform sampling pattern of sensing is replaced by the selection based on the CUR decomposition. Our proposed TWSP algorithm provides a fast and accurate solution for CUR decomposition. We select between and locations for spectrum sensing and all channels. Each row of matrix corresponds to a selected location and it has entries. We are to assign channels for each selected sensor. In other words, each location does not sense the whole spectrum and only frequency channels are assigned to each sensor. The top- entries in each row with the highest absolute value show the most important channels for the corresponding locations to be sensed.
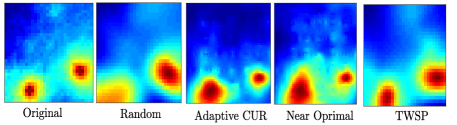
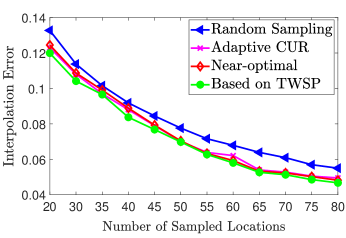
Fig. 4 shows the cartography error of spectrum sensing for the conventional random selection as introduced in [22] and our proposed optimized joint sensors and channels. For each sampled locations channels out of channels are sensed. The sampled spectrum map is interpolated using thin plane splines method [19] for both sampling methods. In addition to visual superiority in reconstruction of the spectrum map, channel assignment based on TWSP provides a better quantitative error as observed in Fig. 4
4.3 Supervised Sampling
The proposed TWSP algorithm is an unsupervised data selection algorithm. In supervised settings, labels can infuse information to perform a more viable joint selection [8]. A naive approach is to select representatives from each class independently. However, considering classes jointly is more effective for data reduction. Assume we are given two data classes as and . The goal is to select samples from class 1 and samples from class 2. To this aim, we propose to construct the cross correlation of two classes as a kernel representation for both classes jointly. Matrix which has columns and rows is fed to TWSP algorithm in order to select columns and rows jointly.
As an initial experiment, supervised sampling is performed on Kaggle cats and dogs dataset. The features are obtained by a trained Resnet-18 deep learning model as explained in [10]. Three mutually exclusive data subsets for training, validation, and testing are partitioned randomly from images of each class. The classification accuracy of % is achieved from a fine-tuned Resnet-18 using the whole training set containing samples for each class. Afterwards, samples are selected by applying TWSP on the kernel feature matrix and the Resnet-18 is fine-tuned by using the sampled data. The model’s accuracy is compared on the testing set with other sampling methods. Fig. 5 shows the performance of selection algorithms for different numbers of representatives per class. Using only two samples from each class, a classification accuracy of can be achieved which is more than improvement compared to random selection and more than improvement compared to other competitors.
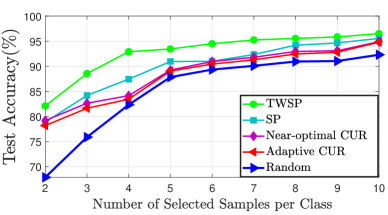
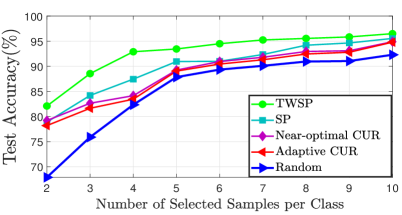
We have conducted further experiments to study the effectiveness of the proposed algorithm in the multi-class image classification problem. For this study, we use the Resnet-34 deep learning model pre-trained on CIFAR10 and trained on a subset of ImageNet Dataset comprising of classes. The classes used for this experiment are Tench, Goldfish, Great white shark, Tiger shark, Hammerhead, Electric ray, Stingray, Cock, Hen and Ostrich. The original training data consists of images of each class, and the idea is to use TWSP to select the data samples such that samples of each class are used for training. After training Resnet-34 for 10 classes of CIFAR10, the feature vectors of all the training images are extracted such that a 1300X512 matrix is obtained for each class. Since, TWPS is applicable for the two-class problem, we employ the one-versus-all approach. In other words, a separate cross correlation matrix is generated for each class such that has the dimensions 512X1300 and has the dimensions 512X11700 where represents the feature vector of the class for which samples will be selected while represents the feature vectors of the remaining classes. Hence, the number of cross correlation matrices is equal to the number of the classes. Then, rows and columns are selected separately by applying TWSP on each cross correlation matrix. This step of generating correlation matrices is different from binary classification where only one correlation matrix was formed. Pre-trained Resnet-34 on CIFAR10 has been refined again by using the sampled data from Imagenet dataset. The model’s accuracy is subsequently compared on the test set with other sampling methods in Fig. 6. As it can be seen, Our proposed TWSP algorithm shows a superior performance comparison to the state of the art methods in sampling.
4.4 Informative Users/Contents Detection
Another problem gaining a lot of interest by streaming service providers is choosing a set of users to decisively reflect their feedbacks about different products. Therefore, it is crucial for such companies to find a subset of users and media products, reviews of which contains information about other users’ unknown behavior. Each user has a limited scope of interest. For example, a user who only loves romance and action genres corresponds to a specific personality that is able to represent a cluster of users accurately. Moreover, such reviews for their areas of interest are more valuable, not reviews for all genres. Moreover, there exist movies well representing their genres.
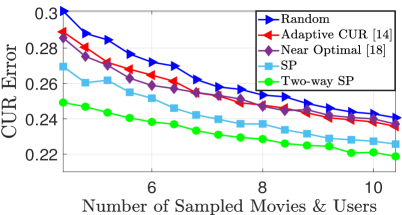
As a result, there exists a demand for a reliable algorithm to simultaneously choose the most informative subset of users and movies. Such a subset is desirable for streaming companies to the extent that they are willing to give the users incentives to leave comprehensive reviews for certain products. In this regards, we have evaluated our algorithm on Netflix Prize dataset containing movies and users. We have reduced the dataset to movies and users by considering only movies and users with most reviews. Then, we completed the dataset by Lin et al. method to have a ground truth [15]. We select a subset of rows and columns (users and media) from the completed dataset. Fig. 7 reveals that TWSP shows the best performance in terms of predicting scores for all users/movies based on a few selected users/movies.
5 Conclusion
Two-way spectrum pursuit is proposed as an accurate and efficient algorithm for solving CUR decomposition. TWSP can be employed for joint selection of columns and rows such that their outer products is able to reconstruct the whole matrix as accurate as possible. Some applications of the proposed algorithm are presented to show the efficacy of the proposed method. However, they are not limited to the mentioned applications. Moreover, the proposed algorithm can be extended to -way spectrum pursuit for efficient tensor subset selection.
References
- [1] Christos Boutsidis, Petros Drineas, and Malik Magdon-Ismail. Near-optimal column-based matrix reconstruction. SIAM Journal on Computing, 43(2):687–717, 2014.
- [2] Christos Boutsidis, Michael W Mahoney, and Petros Drineas. An improved approximation algorithm for the column subset selection problem. In Proceedings of the twentieth annual ACM-SIAM symposium on Discrete algorithms, pages 968–977. SIAM, 2009.
- [3] Christos Boutsidis and David P Woodruff. Optimal cur matrix decompositions. SIAM Journal on Computing, 46(2):543–589, 2017.
- [4] Pierre Comon and Gene H Golub. Tracking a few extreme singular values and vectors in signal processing. Proceedings of the IEEE, 78(8):1327–1343, 1990.
- [5] Amit Deshpande and Luis Rademacher. Efficient volume sampling for row/column subset selection. In 2010 ieee 51st annual symposium on foundations of computer science, pages 329–338. IEEE, 2010.
- [6] Ehsan Elhamifar, Guillermo Sapiro, and S Shankar Sastry. Dissimilarity-based sparse subset selection. IEEE transactions on pattern analysis and machine intelligence, 38(11):2182–2197, 2015.
- [7] Ehsan Elhamifar, Guillermo Sapiro, and Rene Vidal. See all by looking at a few: Sparse modeling for finding representative objects. In 2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012.
- [8] Ashkan Esmaeili, Kayhan Behdin, Mohammad Amin Fakharian, and Farokh Marvasti. Transduction with matrix completion using smoothed rank function. arXiv preprint arXiv:1805.07561, 2018.
- [9] Keaton Hamm and Longxiu Huang. Perspectives on cur decompositions. Applied and Computational Harmonic Analysis, 48(3):1088–1099, 2020.
- [10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [11] Mohsen Joneidi, Saeed Vahidian, Ashkan Esmaeili, and Siavash Khodadadeh. Optimality of spectrum pursuit for column subset selection problem: Theoretical guarantees and applications in deep learning. 2020.
- [12] Mohsen Joneidi, Saeed Vahidian, Ashkan Esmaeili, Weijia Wang, Nazanin Rahnavard, Bill Lin, and Mubarak Shah. Select to better learn: Fast and accurate deep learning using data selection from nonlinear manifolds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7819–7829, 2020.
- [13] Mohsen Joneidi, Alireza Zaeemzadeh, Behzad Shahrasbi, Guojun Qi, and Nazanin Rahnavard. E-optimal sensor selection for compressive sensing-based purposes. IEEE Transactions on Big Data, 2018.
- [14] Chengtao Li, Stefanie Jegelka, and Suvrit Sra. Polynomial time algorithms for dual volume sampling. In Advances in Neural Information Processing Systems, pages 5038–5047, 2017.
- [15] Zhouchen Lin, Minming Chen, and Yi Ma. The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices. arXiv preprint arXiv:1009.5055, 2010.
- [16] Michael W Mahoney and Petros Drineas. Cur matrix decompositions for improved data analysis. Proceedings of the National Academy of Sciences, 106(3):697–702, 2009.
- [17] Saurabh Paul, Malik Magdon-Ismail, and Petros Drineas. Column selection via adaptive sampling. In Advances in neural information processing systems, pages 406–414, 2015.
- [18] Yaroslav Shitov. Column subset selection is np-complete. Linear Algebra and its Applications, 2020.
- [19] Suzan Üreten, Abbas Yongaçoğlu, and Emil Petriu. A comparison of interference cartography generation techniques in cognitive radio networks. In 2012 IEEE International Conference on Communications (ICC), pages 1879–1883. IEEE, 2012.
- [20] Shusen Wang and Zhihua Zhang. Improving cur matrix decomposition and the nyström approximation via adaptive sampling. The Journal of Machine Learning Research, 14(1):2729–2769, 2013.
- [21] Alireza Zaeemzadeh, Mohsen Joneidi, Nazanin Rahnavard, and Mubarak Shah. Iterative projection and matching: Finding structure-preserving representatives and its application to computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5414–5423, 2019.
- [22] Guoyong Zhang, Xiao Fu, Jun Wang, Xi-Le Zhao, and Mingyi Hong. Spectrum cartography via coupled block-term tensor decomposition. IEEE Transactions on Signal Processing, 2020.