Two-phase analysis and study design for survival models with error-prone exposures
Abstract
Increasingly, medical research is dependent on data collected for non-research purposes, such as electronic health records data (EHR). EHR data and other large databases can be prone to measurement error in key exposures, and unadjusted analyses of error-prone data can bias study results. Validating a subset of records is a cost-effective way of gaining information on the error structure, which in turn can be used to adjust analyses for this error and improve inference. We extend the mean score method for the two-phase analysis of discrete-time survival models, which uses the unvalidated covariates as auxiliary variables that act as surrogates for the unobserved true exposures. This method relies on a two-phase sampling design and an estimation approach that preserves the consistency of complete case regression parameter estimates in the validated subset, with increased precision leveraged from the auxiliary data. Furthermore, we develop optimal sampling strategies which minimize the variance of the mean score estimator for a target exposure under a fixed cost constraint. We consider the setting where an internal pilot is necessary for the optimal design so that the phase two sample is split into a pilot and an adaptive optimal sample. Through simulations and data example, we evaluate efficiency gains of the mean score estimator using the derived optimal validation design compared to balanced and simple random sampling for the phase two sample. We also empirically explore efficiency gains that the proposed discrete optimal design can provide for the Cox proportional hazards model in the setting of a continuous-time survival outcome.
Keywords: Mean score method, Neyman allocation, pilot study, adaptive design, measurement error, surrogate variable, auxiliary variable
1 Introduction
Error-prone exposures are common in many epidemiological settings, such as clinical studies relying on electronic health records, medical claims data, or large observational cohort studies where a gold standard measure was not collected on all subjects. In some cases, a validation subset is available, in which observations without error can be obtained on a subset of subjects and used to inform measurement error correction methods. Two-phase sampling has been widely used for a number of settings in clinical and epidemiological studies with budgetary constraints. The first sampling phase includes readily available data (e.g., electronic health records data) on all study subjects, and the second phase includes additional information on a subsample of records (e.g., extensive chart validation of a key exposure variable).
The efficiency of two-phase sampling can vary substantially based on the selection of the second phase sample. For logistic regression, Breslow and Chatterjee (1999) showed stratification of the phase two sample on the outcome and covariates with equal numbers per stratum performed well and better than stratifying on the outcome or covariates alone. When the outcome and error-prone exposure are discrete, the mean score method (Reilly and Pepe, 1995; Reilly, 1996) can be used to derive regression parameter estimates that have been corrected for measurement error and can improve efficiency over the complete case analysis by incorporating information from auxiliary data. Further, these authors developed an optimal sampling strategy for the mean score estimator to find the proportion allocated into each outcome-exposure stratum of the validation sample that can minimize cost for a fixed variance or minimize the variance of a target regression parameter for a fixed validation subset size, studying the performance of this method for a binary outcome and covariate. McIsaac and Cook (2014) compared response-dependent two-phase sampling designs for the setting of a binary outcome when both the true and auxiliary covariate were also binary. They found that the mean score estimator was an efficient approach, even when the model used to derive the optimal design was misspecified. They also found that the mean score optimal design improved the efficiency of other estimation approaches, such as maximum likelihood.
For survival outcomes, however, the focus of most of the previous work on two phase sampling has been on estimation and hypothesis testing and not design. Lawless (2018) reviews two-phase estimators for outcome dependent sampling and failure time data, and mentions that efficiency can be gained by sampling extremes of the outcome those with early events and late censoring. Tao et al. (2019) develop an optimal two-phase sampling designs for a general regression model framework, but these designs are only optimal under the null assumption that the regression coefficient for the expensive/mis-measured exposure of interest is zero. While this framework in principle applies to the Cox proportional hazards regression model, these designs require estimation of several nuisance parameters related to the conditional distribution of expensive covariate given the surrogate, as well as a potentially infinite dimensional nuisance parameter related to the log-partial likelihood; and their performance have not yet been studied for survival outcomes.
In this study, we consider an extension of the mean score method to handle survival outcomes, in which error prone exposures are treated as auxiliary variables. The mean score approach is appealing because it is intuitive and offers a straightforward method to implement an optimal design (Whittemore and Halpern, 1997). In order to take advantage of the mean score approach, we will first consider a discrete-time survival model, but will also consider how the derived optimal design can be advantageous for a continuous time analysis. Discrete survival data are natural for settings where the occurrence of an event is monitored periodically and occur frequently in clinical studies where there is routine follow-up at fixed intervals. We develop an application of the mean score method to the discrete proportional hazards model. We will also extend the work of Reilly (1996) to derive an optimal sampling design for the validation subset, which minimizes the variance of the regression parameter estimation for a given size of the validation subset. This approach requires an estimate of several nuisance parameters in the absence of external estimates, which can be estimated with internal pilot data. We consider a multi-wave sampling strategy that in the first wave obtains a pilot phase two sample to estimate the parameters necessary to derive the optimal design and then for the second wave adopts an adaptive sampling strategy for the remaining phase two subjects to achieve the optimal allocation. McIsaac and Cook (2015) considered a similar approach for binary outcomes.
We compare the relative efficiency of our mean score estimator under simple random sampling, balanced sampling and the proposed optimal design. We also examine the efficiency gains of the mean score approach over the complete case estimator of the validated data. The proposed method is further illustrated with data from the National Wilms Tumor Study (NWTS). In the NWTS, the true validated exposure was measured on everyone, allowing the evaluation of different two-phase sampling strategies on the precision of the final study estimates in this applied setting. In the context of this example, which had a continuous survival outcome, we study the efficiency gains of using the proposed optimal design of the discretized outcome for the usual continuous-time analysis. We also investigate how different allocations of the pilot sample affect the efficiency gains of the mean score estimator, depending on how individuals with censored versus observed outcomes are sampled. Finally, we provide some concluding remarks on the advantages of the mean score estimator in this setting and discuss directions for future work.
2 The mean score method for discrete-time survival models
2.1 Setup and notation for the discrete-time model
Let be a discrete random variable. Denote the -th discrete value of by and write , where is the baseline hazard function for defined by for , where is the index set for the discrete times with positive mass. We assume the time to event response is associated with a -dimensional covariate vector such that the conditional hazard function is given by
| (2.1) |
for some coefficient vector , where is a monotone transformation and . For example, the odds transformation yields the logit hazard model, where for and . It follows that the likelihood function under the logit hazard model has the same representation with the logistic regression model such that the number of events at a time represents binomial outcomes with probability for each (Meier et al., 2003). The complementary log transformation gives a proportional log-survival model , where and for the baseline survival function for . Kalbfleisch and Prentice (2011) provide further details.
We consider that may be subject to random censoring prior to the finite maximum follow-up time of . For a random censoring time , independent of , let be the observed censored survival time and be the event indicator. We assume that are independent and identically distributed and will not be completely observed on all subjects as -random copies of . Instead, are the data available for all subjects in the first phase of a study, where are discrete surrogates or auxiliary variables associated with . Complete data for the likelihood are observed on the phase two sample, denoted by , where is a subset of having the cardinality of . For example, the auxiliary variables might be error-prone discrete measures of while may or may not be discrete. We also allow for settings where some components of are available on all subjects, such as sex or other demographic information ascertained in the first phase of the study. For this setting, we may introduce a slight abuse of notation writing and , where are the components of observed on everyone, are the incomplete components of not observed at the phase one, and indicates a generic notation for auxiliary variables in the first phase of the study. In this case, denotes the set of subject indices for which the true covariates are fully observed, with sampled in the second phase of the study, and the auxiliary phase one variables are limited to (Reilly and Pepe, 1995; McIsaac and Cook, 2015).
Unlike previous literature (Lawless et al., 1999; Chatterjee et al., 2003; Chatterjee and Chen, 2007; Tao et al., 2017), we note that the model (2.1) does not include auxiliary variables as predictors, but rather is a surrogate by the Prentice criterion (Prentice, 1989). That means the likelihood function equals , where is the collection of parameters involved in (2.1). Thus, the complete information for is carried by , while may represent extra information of compared to likelihood-based inference using only complete case data for . In this paper, we consider the mean score method, which is valid when the validation subset for the phase two sample is randomly chosen from the full cohort given information obtained from the first phase of a study. Therefore, we use the log-likelihood from all available observations written by
| (2.2) |
where denotes the conditional density function of given and indicates a set of indices for individuals whose complete covariates are not available. For an individual and time , we define the observed event indicator and denote subject ’s censored survival time index by for . Thus, for all . Then, it follows that the log-likelihood function given can be written by
| (2.3) |
for each . In the above equation, we used the fact that and the conditional survival function was calculated by for , together with by definition.
2.2 The mean score method
We apply the mean score method (Reilly and Pepe, 1995; Reilly, 1996) to the conditional hazard model (2.1) when auxiliary variables are discrete. Employing the Expectation-Maximization (EM) technique (Dempster et al., 1977) with (2.2) and (2.3), we may find the maximum likelihood estimator of . However, is generally unknown and a parametric approach for the estimation of may result in inconsistent inference of in likelihood-based methods. Lawless et al. (1999) introduced a semi-parametric method, estimating the conditional density function nonparametrically, such that the integration in (2.2) is replaced with a single-step approximation (McIsaac and Cook, 2014). Following the mean score approach, for those not in the phase two subset, we can replace the unobserved score contribution based on with its expected value based on the observed phase one data. By replacing the expected value to an empirical mean, the semi-parametric estimation of can then be achieved by maximizing an inverse probability weighted log-likelihood
| (2.4) |
where is an empirical estimate of , the sampling probability of the -th individual selected into the validation subset, which can be consistently estimated by as and increase. Here, is the number of subjects in who have the same observations with in the first phase study; is defined similarly to with replacement of the index set with of the full sample.
We note that Flanders and Greenland (1991) also proposed a similar estimating equation to (2.4) based on the pseudo-likelihood method, which coincides to the filling in method introduced by Vach and Blettner (1991) when is categorical. However, depending on the choice of transformation in (2.1), different forms of score equations follow from the above weighted log-likelihood (2.4). In Supplementary Material Section A.2, we provide the detailed forms of the mean score equations and the associated Hessian matrices when the logit transformation and the complementary log transformation are used.
2.3 Connection to the Cox model for a continuous-time outcome
Our expectation that the optimal design for our discrete time proportional hazards model will also be advantageous for the continuous time Cox model is based on the connection between the parameters in these two models. For this, we briefly review this connection. For further discussion, see Kalbfleisch and Prentice (2011).
From the log-likelihood (2.3), we note that the logit hazard model is the canonical form of the discrete-time survival model (2.1) under the odds transformation , such that , where is the logit transformation of the baseline hazard. However, we also note that any model with an arbitrary monotone transformation in (2.1) leads to a reparameterization of the logit hazard model. For example, suppose the complementary log transformation defines the true survival model. Then it can be easily seen that , where is the complementary log-log transformation of the baseline hazard, and the application of chain rules to (2.3) is followed by likelihood-based estimation of , which is also equivalent to reparameterization of the logit hazard model.
In particular, if usual continuous-time Cox proportional hazards are grouped into discrete disjoint intervals, this will lead to the conditional hazard model (2.1) for discrete-time outcomes with the complementary log transformation. To be specific, let be the conditional hazard function in the Cox model for the continuous-time survival outcome such that , where is the associated baseline hazard function. Suppose we are only able to observe survival outcomes censored by disjoint intervals with , so that statistical inference on conditional hazards by each interval is a goal of the study. Then, we may denote the conditional hazards on the -th interval by
| (2.5) |
for each . Since the conditional survival function is equivalent to in the Cox model, we note that represents the cumulative conditional hazard on the interval and, under the proportional hazards assumption, it can be shown that
| (2.6) |
where is the associated cumulative baseline hazard on . Thus, the cumulative hazard model (2.6) is directly connected with the discrete-time survival model (2.1) under the complementary log transformation, and the two models have the same regression coefficient .
3 Adaptive sampling design for optimal estimation
As introduced by Reilly and Pepe (1995) and Reilly (1996), we consider a sampling design that asymptotically minimizes the variance of parameter estimates of interest under constraints that the validation sample size is fixed. In Theorem 1, we establish that the asymptotic variance of the mean score estimator depends on the sampling probability for the phase two validation subset.
Theorem 1.
For each , let be transformation of baseline hazards in (2.1). Suppose that the censoring time is bounded, that is for some fixed constant , and that the conditional hazard functions are bounded away from 0 and 1 for all . Under the regularity conditions in Supplementary Material Section A.1, the mean score estimator of solving the score equation of (2.4) is asymptotically normal such that as , where with and for the score function .
Suppose that we fix the sample probability for the validation subset by , or empirically . Then, the mean score estimator of , the -th component of , is asymptotically efficient when the validation sampling probability is proportional to , so that we empirically assign the optimal sampling size for each -stratum
| (3.1) |
satisfying , where denotes the -element of a matrix . We note that (3.1) can be viewed as Neyman allocation (Neyman, 1934) maximizing the survey precision in the stratified sampling based on the phase one information. Such an optimal design can be also obtained by the Lagrangian multiplier method to minimize in Theorem 1, which equivalently minimizes the variance of the target parameter with respect to under the constraint of a fixed-validation rate , or empirically .
Note that the optimal sampling design depends on external information about population structure, namely and , which are usually unknown. McIsaac and Cook (2015) introduced an adaptive procedure for multi-phase analyses such that one first draws a pilot sample for validation and then adaptively draws an additional validation set, write and , respectively. That is, the overall validation corresponds to the optimal design, where . Similarly, we consider an adaptive constraint on the final validation size, , where and are sampling sizes on each -stratum for the pilot and adaptive validation, respectively. We apply the Lagrangian multiplier method to minimize in Theorem 1 with respect to under the adaptive constraint. Then, the adaptive sampling design is given by
| (3.2) |
where is the estimated optimal sampling size of (3.1). Here, the information matrix and the conditional variance of the score function can be consistently estimated using the individuals in the phase two pilot sample. We employ inverse probability weighting to estimate by
| (3.3) |
Also, is estimated by the sample covariance matrix of the score function within each -stratum such that
| (3.4) |
where , for . Then, we evaluate (3.3) and (3.4) with the inverse probability weighted estimator of based on the first phase sample and the pilot validation set . The expressions for the score function and Hessian matrix of (2.3) for two discussed choices of the survival models can be found in Supplementary Material Section A.2. Due to sparse observations or oversampled pilot data on some strata, we may not achieve practically the optimal design with (3.2) when or . In either case, we set for the saturated strata and distribute the remaining validation allocation to the other strata proportional to the estimated optimal sampling sizes. This approach for handling saturated strata is similar to that of McIsaac and Cook (2015), originally introduced by Reilly and Pepe (1995).
4 Numerical illustrations
In this section, we examine the performance of our proposed mean score estimator and adaptive phase two sampling procedure first by a computer simulation study. We then further illustrate the method with an analysis of data from the National Wilms Tumor Study (NWTS). For this example, the original survival outcome was continuous and so in addition to presenting the discrete time analysis, we consider whether the proposed phase two sampling procedure provided efficiency gains for the analysis of the continuous time outcome. We also provide further discussion on phase two sampling in the setting of intermittently censored outcomes. Data and source code in R (version 3.6.1) for our numerical studies are provided at https://github.com/kyungheehan/mean-score.
4.1 Simulation Study
Here, we evaluate the empirical performance of the proposed mean score estimator for the discrete survival time setting via a simulation study. We also evaluate the degree to which the proposed adaptive validation design improves estimation performance compared to simple random sampling and a balanced design for several scenarios.
We consider the conditional hazard model (2.1) with the complementary log transformation , where . We assume survival status is observed at discrete times . As previously mentioned in Section 2.3, this model will estimate the same as in the underlying continuous-time Cox proportional hazards model. We first generate a four dimensional covariate vector , which consists of both continuous and binary variables.
We simulate correlated covariates with a unit scale between and , by first considering a multivariate normal random vector with zero mean and , so that we put for and for , where is the cumulative standard normal distribution function, and and are quantile functions of the beta distribution with pairs of the shape and rate parameters and , respectively. By doing this, all ’s are correlated with each other, and particularly and are marginally beta random variables with . Since continuous covariates are generally bounded in practice, the simulated continuous covariates represent standardized covariates over the range of observations into unit intervals.
For discrete survival outcomes, we note that enables us to generate the discrete survival outcomes as multinomial random variables associated with covariates. To simplify the censoring mechanism in our simulation, we set a fixed censoring time as the maximum follow-up for all subjects, so that we observe a truncated survival time and , It is worth mentioning that the proposed method also allows a random censoring time . An application of the method with a more complex censoring mechanism will be considered in Section 4.2.
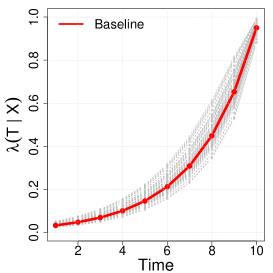
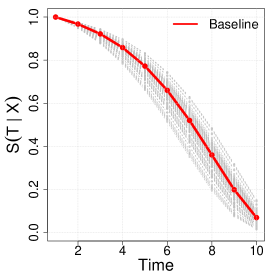
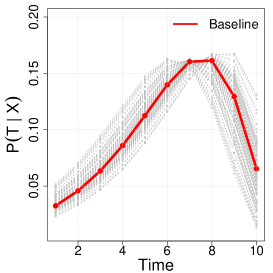
Next, we generate -random copies of , which will inform the benchmark full cohort analysis. We consider full cohort sizes in the simulation. By choosing different baseline hazards, we considered three scenarios of overall censoring rates with , and . Here, we mainly refer to simulation results when the censoring rate is , since we found that this setting fundamentally provides similar lessons with the other scenarios which can be found in the Supplementary Material Tables B.1 and B.2. Figure 1 illustrates the conditional hazard, survival and probability functions in our simulation settings.
We assume that direct observations of are not available in the phase one sample of the cohort, but instead one observes a discretized and error-prone exposure such that
| (4.1) |
where is perturbation of with an independent measurement error . Let be the true discretization of defined similarly to by replacing with . For the assumed parameter values, the discordance or misclassified rate between and was and this shows that is not only a discrete but also an error-prone surrogate of , and potentially associated with . Finally, we set to be the phase one sample available on all subjects.
Efficient estimation of the regression coefficient of is of interest and the optimal sampling allocations are designed to minimize the variance of the estimate in our simulation study. Since the optimal sampling design (3.1) depends on nuisance parameters defined by the population structure, namely and in Theorem 1, we approximate their true values with empirical estimates obtained from an externally generated large sample of size that was independent from the full cohort . We define the optimal sampling strategy based on these values as the oracle procedure and refer to Supplementary Material Section A.2 for some technical details for the derived optimal allocation. In practice, however, the oracle procedure is infeasible and so we are interested in evaluating the adaptive sampling design as described in Section 3. For this, we first sample a pilot validation subset and estimate the optimal sampling design together with the phase one sample . To accommodate all possible strata information in the first phase sample, we employ balanced sampling for the pilot study, with equal for all . We then estimate and , as outlined at the end of the previous section. Next, we draw an additional validation subset for each stratum following (3.2), and the mean score method is finally applied to the two-stage analysis for the phase one sample and the adaptive phase two sample . We considered validation subset sizes of and took equal proportions for the pilot and adaptive samples.
Due to saturated strata, there might be some remaining validation size to be allocated, for example in the pilot study. In this case, we randomly select unvalidated subjects for the remaining allocation, which is also similarly applied to the adaptive sample. We note that the proportion of the pilot sample size to the adaptive entails a trade-off between precision of the nuisance parameters needed for optimal sampling design and efficiency gains from the adaptive validation when the final phase two sample size is fixed. Some preliminary simulations showed that the adaptive sampling design with nearly equal sizes of the pilot and adaptive samples usually produced robust and efficient estimates (data not shown), which is similar to observations made by McIsaac and Cook (2015) for the two-stage analysis with binary outcomes.
We compare our proposed adaptive sampling method, which we refer to here as mean score adaptive (MS-A), to the mean score method using the oracle design (MS-O) and to some other standard estimation methods for two-phase designs. The complete case analysis of fully randomly selected -validation sample (CC-SRS) will give unbiased results in likelihood-based inference. Since CC-SRS does not use auxiliary information of the first stage sample, we examine if the optimal design for the mean score method improves estimation performance of CC-SRS and evaluate efficiency gains from the two-stage analysis (MS-SRS). We also conduct design-based estimation with balanced sampling such that validation size is equally allocated to each -stratum of the first stage sample. Similarly to the proposed adaptive procedure, if there are some remaining individuals to be allocated after balanced sampling, due to saturated strata, we randomly sample the remaining from the unvalidated subjects to yield a final total phase two sample of individuals. The design-based estimation with balanced sampling is given by a Horvitz-Thompson type estimator (MS-BAL), where sampling proportions of validation within strata are used for inverse probability weights as in (2.4). For our setting, we note that the inverse probability weighted (IPW) estimator is technically the same with the design-based mean score estimator which incorporates the balanced sampling weights pre-specified in the two-phase analysis (McIsaac and Cook, 2014). We implement the proposed mean score estimator with adaptive sampling described above, estimating the necessary nuisance parameters from the validation subset (MS-A) and the when using the oracle design (MS-O). Finally, we consider the full cohort analysis (Full-CC) based on fully observed data, as the benchmark performance, which empirically gives the upper bound of efficiency for the two-phase analysis, since the Full-CC uses the complete covariate information on all subjects.
| Sampling | Estimation | Criterion | Estimation performance by sample sizes | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Full cohort | CC | 0.094 | 0.094 | 0.094 | 0.129 | 0.094 | 0.067 | ||
| Bias | 0.003 | 0.003 | 0.003 | 0.004 | 0.003 | 0.000 | |||
| 0.094 | 0.094 | 0.094 | 0.129 | 0.094 | 0.067 | ||||
| SRS | CC | 0.470 | 0.330 | 0.228 | 0.324 | 0.330 | 0.321 | ||
| Bias | 0.017 | 0.014 | 0.005 | 0.011 | 0.014 | -0.010 | |||
| 0.470 | 0.329 | 0.228 | 0.324 | 0.329 | 0.321 | ||||
| MS | 0.332 | 0.220 | 0.155 | 0.237 | 0.220 | 0.200 | |||
| Bias | 0.053 | 0.035 | 0.004 | 0.020 | 0.035 | 0.027 | |||
| 0.330 | 0.217 | 0.155 | 0.236 | 0.217 | 0.198 | ||||
| Balanced | MS | 0.400 | 0.278 | 0.194 | 0.276 | 0.278 | 0.265 | ||
| Bias | 0.042 | 0.024 | 0.010 | 0.026 | 0.024 | 0.021 | |||
| 0.398 | 0.277 | 0.194 | 0.275 | 0.277 | 0.264 | ||||
| Adaptive | MS | 0.374 | 0.197 | 0.147 | 0.214 | 0.197 | 0.190 | ||
| Bias | 0.049 | 0.007 | 0.006 | 0.004 | 0.007 | 0.002 | |||
| 0.371 | 0.197 | 0.147 | 0.214 | 0.197 | 0.189 | ||||
| Oracle | MS | 0.253 | 0.182 | 0.133 | 0.202 | 0.182 | 0.174 | ||
| Bias | 0.009 | 0.003 | 0.005 | 0.012 | 0.003 | -0.005 | |||
| 0.252 | 0.182 | 0.133 | 0.202 | 0.182 | 0.174 | ||||
We investigated two different aspects of varying sample sizes and conducted six simulation scenarios; (i) increasing the phase two sample size from with a fixed full cohort size , (ii) increasing the full cohort size from when the phase two sample size is fixed by . Table 1 summarizes the relative performance for estimation of . Compared to CC-SRS, MS-SRS had a reduction of the variance, which demonstrates efficiency gains of the mean score method from employing auxiliary information of the phase one sample. For and 800, MS-A was more efficient than MS-SRS, whereas for , MS-SRS was more efficient. This suggests that is too small in this setting to gain efficiency using adaptive sampling; this is reasonable as the optimal sampling allocation is based on estimates derived from a pilot sample half that size. MS-BAL had relatively inferior performance compared to MS-SRS and MS-A, and this was true across all scenarios studied. The MS-O had the smallest mean squared error (MSE) in all scenarios, as expected, and it turned out that the superior performance of MS-O mostly came from variance reduction. As the cohort sample size increased, the associated adaptive sampling design (MS-A) behaved closely to MS-O, which indicates that the proposed adaptive approach consistently approximates the oracle procedure. In the scenarios studied, increasing the phase two sample size was much more beneficial for efficiency gains for MS-A and MS-O, compared to the sample size increment of the phase one study. For example, MS-A achieved variance reduction while the validation rate increased four-fold from to given in the left three columns of Table 1. On the contrary, increasing the phase one sample size from to only produced improvement in the right three columns when is fixed. This suggests that the performance of the proposed MS-A procedure is sensitive to the size of the phase two study, more so than the total cohort size for a fixed .
Simulation results for all regression parameters and various combinations of and can be found in Supplementary Material Tables B.3–B.7. Comparing the relative performance of the methods for the other regression parameters, including those for the discrete baseline hazards, we found that the MS-O outperformed the other estimators for all model parameters. The oracle sampling design is infeasible in most practical situations; however, the two mean score estimators consistently showed the best performance for the target parameter among all other practical competitors. MS-A generally achieved the minimum mean squared errors for all parameters when the phase two sample size exceeded 200, compared to the other practical estimators, for the scenarios studied (Supplementary Material Tables B.3–B.7). For the setting where , the MS-SRS performed the best amongst the practical estimators. These results suggest for that MS-A will perform well with respect to MSE for all model parameters, particularly the target and discrete proportional hazard parameters, for robust phase two sample size. For small phase two samples and similar censoring rates, the MS-SRS may be preferred.
4.2 Data example: The National Wilms Tumor Study
Wilms tumor is a rare renal cancer occurring in children, where tumor histology and the disease stage at diagnosis are two important risk factors for relapse and death. We consider data, reported by Kulich and Lin (2004), on 3915 subjects from two randomized clinical trials from the National Wilms Tumor Study (NWTS) (D’angio et al., 1989; Green et al., 1998). There are two measures of tumor histology, which is classified as either favorable (FH) or unfavorable (UH), one by a local pathologist and the other by an expert pathologist from a central facility. Because of the rarity of disease, local pathologists may be less familiar with Wilms Tumor and their assessment is subject to misclassification. The central assessment is considered to be the gold standard, or true histology in our analysis, and the local evaluations are considered surrogate observations for the central evaluation. Since histology for all subjects was validated by the central laboratory, NWTS data has been widely used to evaluate two-phase sampling methodology, such as by Breslow and Chatterjee (1999), Kulich and Lin (2004) and Lumley (2011).
We demonstrate our proposed mean score method for discrete-time survival in an analysis of relapse in this NWTS cohort. We assume that the local histology is available for all subjects in a first phase sample and that only a sub-cohort was sampled for evaluation by the central pathologist in a second phase sample. Specifically, we are interested in the proportional hazards discrete-time survival model (2.1) for time to relapse, under the complementary log transformation , in order to evaluate the risk associated with unfavorable central histology, late (III/IV) disease stage versus the early (I/II) stage, age at diagnosis (year), and tumor diameter (cm). For this model, we also include an interaction between histology and stage of disease.
In this cohort, of the events occurred within the first three years of diagnosis, while less than of non-relapsed subjects were censored in the same period. Based on this observation, we first define a modified, or reduced, cohort to include only patients who had an event or were fully followed up in the first 3 years, so that censoring only occurs at the third year (), the assumed end of the study. This modified cohort included subjects and is used in our NWTS data analysis. We consider the regression coefficients from the discrete-time survival analysis of the modified full cohort as the reference values. We took this approach first out of concern that the large number of nuisance parameters introduced by the small number of individuals with intermittent censored outcomes, due to the added strata for a binary outcome at each failure time interval, might adversely affect the mean score method. We will evaluate efficiency gains of the optimal mean score design, based on the discretized survival outcomes, for the continuous-time analysis in Section 4.3. Finally, we also conducted an analysis of all individuals, regardless of the time of censoring, and discuss design issues regarding how to handle intermittent censoring in our framework in Section 4.4.
We first discretize the continuous event time into six 6-month intervals, so that we model the hazard of relapse during the first three years after diagnosis. As in Section 4.1, we consider four different sampling scenarios for the phase two subsample: simple random sampling, balanced allocation across strata, the adaptive and optimal (oracle) mean score designs, where the last three employ stratified sampling based on the phase one sample. To evaluate the efficiency gains of the proposed mean score approach, we performed the two-stage analysis, with a phase two sample of , 1000 times. For implementation of the optimal design, we estimate parameters in (3.1) using the oracle procedure by using the central histology records of the full cohort. We refer to Section 4.1 for further details of implementation. Bias and efficiency are calculated using the estimates of the full cohort analysis with the central histology as the reference.
Table 2 demonstrates the performance of the different methods, where efficient estimation of the interaction between unfavorable histology and late stage of the disease is of main interest. MS-A outperformed the other practical competitors: CC-SRS, MS-SRS and MS-BAL. For example, MS-A had a variance reduction compared to CC-SRS for estimating the interaction term. We also note that performance of MS-A was pretty close to the oracle procedure, MS-O; MS-A was only less efficient than MS-O for estimating the regression coefficient of interest. Furthermore, across all parameters, MS-A achieved the smallest mean squared error among the practical competitors, not only for baseline hazards estimation but also regression coefficients. Overall, the proposed method performed better than the other two-phase estimators, with both an efficient design and by incorporating auxiliary information from the phase one sample.
| Sampling | Estimation | Criterion | Baseline hazard in complementary log-log scale | Regression coefficient | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.5yr | 1yr | 1.5yr | 2yr | 2.5yr | 3yr | UH1 | Stage2 | Age3 | dTmr4 | US5 | ||||
| Full cohort | CC | Estimate | -4.028 | -3.876 | -4.336 | -5.005 | -5.353 | -5.719 | 1.058 | 0.280 | 0.063 | 0.032 | 0.636 | |
| SRS | CC | 0.452 | 0.456 | 0.458 | 0.666 | 1.459 | 2.468 | 0.555 | 0.317 | 0.046 | 0.031 | 0.693 | ||
| Bias | -0.071 | -0.065 | -0.077 | -0.096 | -0.278 | -0.649 | -0.015 | 0.018 | -0.002 | 0.001 | 0.032 | |||
| 0.446 | 0.451 | 0.452 | 0.659 | 1.432 | 2.381 | 0.555 | 0.317 | 0.046 | 0.031 | 0.692 | ||||
| MS | 0.420 | 0.414 | 0.411 | 0.558 | 1.375 | 2.441 | 0.548 | 0.337 | 0.047 | 0.034 | 0.732 | |||
| Bias | -0.041 | -0.034 | -0.042 | -0.101 | -0.291 | -0.757 | -0.091 | 0.017 | -0.001 | 0.002 | 0.094 | |||
| 0.418 | 0.412 | 0.409 | 0.549 | 1.344 | 2.320 | 0.541 | 0.337 | 0.047 | 0.034 | 0.726 | ||||
| Balanced | MS | 0.410 | 0.404 | 0.396 | 0.391 | 0.389 | 0.388 | 0.370 | 0.353 | 0.056 | 0.035 | 0.554 | ||
| Bias | -0.109 | -0.096 | -0.084 | -0.076 | -0.072 | -0.070 | 0.043 | 0.007 | 0.013 | 0.005 | 0.004 | |||
| 0.396 | 0.393 | 0.387 | 0.383 | 0.382 | 0.382 | 0.368 | 0.353 | 0.054 | 0.035 | 0.554 | ||||
| Adaptive | MS | 0.315 | 0.309 | 0.303 | 0.299 | 0.297 | 0.296 | 0.284 | 0.254 | 0.042 | 0.025 | 0.425 | ||
| Bias | -0.065 | -0.058 | -0.052 | -0.048 | -0.046 | -0.045 | 0.003 | -0.007 | 0.008 | 0.003 | 0.034 | |||
| 0.308 | 0.304 | 0.298 | 0.295 | 0.294 | 0.293 | 0.284 | 0.254 | 0.041 | 0.025 | 0.424 | ||||
| Oracle | MS | 0.311 | 0.306 | 0.301 | 0.296 | 0.299 | 0.295 | 0.250 | 0.256 | 0.038 | 0.025 | 0.396 | ||
| Bias | -0.048 | -0.043 | -0.038 | -0.035 | -0.042 | -0.036 | 0.010 | 0.003 | 0.004 | 0.001 | 0.013 | |||
| 0.307 | 0.303 | 0.298 | 0.294 | 0.296 | 0.293 | 0.250 | 0.256 | 0.037 | 0.025 | 0.396 | ||||
1 Unfavorable histology versus favorable; 2 disease stage III/IV versus I/II;
3 year at diagnosis; 4 tumor diameter (cm); 5 interaction effect between UH and Stage.
In Figure 2, we examine the relative performance of the different estimators for each of the regression parameters and phase two sample sizes . In the top-left panel (a), we show the estimation results for the regression coefficient for unfavorable histology (UH) over 1000 repetitions of subsampling, when the adaptive and optimal mean score allocations were designed for the efficient estimation of UH. The rest of the panels are similar, showing results for the other regression coefficients they were set as targets, namely when the MS-A and MS-O designs were for efficient estimation of (b) late stage of the disease, (c) age of diagnosis (year), (d) tumor diameter (cm) and (e) the interaction between UH and stage of the disease, respectively. MS-O consistently showed superior performance for all phase two ample sizes; however, MS-A again had the smallest mean squared error among the practical methods. Further, the performance of MS-A tended to be close to MS-O as the validation size increased.
| (a) Unfavorable histology (UH) | (b) Late stage of disease |
 |
 |
| (c) Age | (d) Tumor diameter |
 |
 |
| (e) UH(Late stage of disease) | |
 |
|
4.3 Continuous-time survival analysis with the mean score design
In many practical settings, the continuous-time Cox model will be the analysis of primary interest. We further investigate benefits of the proposed mean score sampling design, when the phase two estimating equation employs the continuous-time Cox proportional hazards model. In Section 2.3, we discussed the direct connection between the the continuous-time Cox model (2.1) and the analogous grouped discrete-time model with the complementary log transformation, in the sense that the two models have the same regression coefficient . We can conduct the two-phase analysis of the Cox model with the proposed optimal mean score sampling method derived for the parameter of interest in the discretized model.
| Sampling | Criterion | Estimation performance by regressor | ||||
|---|---|---|---|---|---|---|
| UH1 | Stage2 | Age3 | dTmr4 | US5 | ||
| Full cohort analysis | Ref. | 1.027 | 0.292 | 0.064 | 0.022 | 0.620 |
| SRS | 0.388 | 0.313 | 0.046 | 0.033 | 0.600 | |
| Bias | -0.018 | 0.014 | -0.002 | 0.001 | 0.028 | |
| 0.387 | 0.312 | 0.046 | 0.033 | 0.599 | ||
| Balanced | 0.413 | 0.421 | 0.061 | 0.043 | 0.622 | |
| Bias | 0.057 | 0.020 | 0.010 | 0.006 | -0.008 | |
| 0.409 | 0.420 | 0.060 | 0.042 | 0.622 | ||
| Adaptive | 0.308 | 0.297 | 0.048 | 0.030 | 0.461 | |
| Bias | -0.000 | -0.006 | 0.007 | 0.003 | 0.039 | |
| 0.308 | 0.296 | 0.048 | 0.029 | 0.459 | ||
| Oracle | 0.313 | 0.332 | 0.046 | 0.031 | 0.477 | |
| Bias | -0.001 | 0.001 | 0.000 | 0.000 | 0.035 | |
| 0.313 | 0.332 | 0.046 | 0.031 | 0.476 | ||
1 Unfavorable histology versus favorable; 2 disease stage III/IV versus I/II;
3 year at diagnosis; 4 tumor diameter (cm); 5 interaction effect between UH and Stage.
Table 3 demonstrates performance comparison of different sampling methods when they were applied to the two-phase analysis of the usual Cox model based on 1000 repeated phase two samples in the NWTS data. Unlike the previous analysis in Table 2 or Figure 2, we assumed that the continuous relapse times were observed for the full cohort in the phase one study and employed the previously developed optimal and adaptive mean score design for the discrete-time survival model (2.1) only to design the allocation of the phase two sample. That is, we first calculated the sampling probabilities and associated inverse probability weights for the phase two sample, and then the design-based estimates of the continuous-time Cox model were reported in Table 3. We assumed efficient estimation of the interaction effect between unfavorable histology and disease stage was of primary interest in the adaptive and oracle sampling designs. We used the survival package in R (Therneau and Lumley, 2019) and applied the inverse probability weights of the phase two sample with the weights option of the coxph function. As shown in Table 3, the adaptive sampling design for the discrete-time analysis also provided efficiency gains for the continuous-time analysis. For example, the variance reduction was about compared to both the simple random sampling and the balanced design. In this example, the adaptive design happened to slightly outperform the oracle one, but we note that these two allocations were for the optimal design for the discrete-time and not the continuous survival model (2.1). We found that the proposed adaptive sampling design provided – of efficiency gains in each case varying the target parameter to be (a) unfavorable histology (UH), (b) late stage of the disease, (c) age of diagnosis (year) or (d) tumor diameter (cm) (data not shown).
4.4 Design considerations for general censoring patterns
The proposed method in Section 3 can be applied without modification for the setting where there is random intermittent censoring, as well as censoring at the end of the study; the only difference being that there will be more strata at the intermittent event times. The mean score estimation depends on nonparametric estimation of the probability distribution for the phase two variables conditional on each discrete value of the phase one surrogate. We note that in Section 2.2 is the empirical estimate of the sampling probability of the -th individual selected into the validation subset, which may suffer from the curse of dimensionality as the number of phase one strata increases. One could consider an increasing number of discretized intervals to approximate the continuous-time points, but the number of unique continuous-time survival outcomes observed will increase as the sample size increases. For this reason, in our data example we first studied the two-phase analyses of the discrete-time survival models in the previous sections where individuals were right-censored only at the sixth time point, an induced end of follow-up, which is equivalent to a fixed Type I censoring when individuals who were intermittently censored were excluded from analysis. Even in this simple setting in Section 4.1, there were -strata for the phase two sampling, resulting from a discrete surrogate having four categories. If we further considered random right-censoring for this setting, we would have to estimate sampling probabilities for -strata. The larger number of associated nuisance parameters in this case for MS-A estimator may require larger phase two samples to achieve the expected efficiency gains due to unstable nuisance parameter estimation in small strata. Indeed, in our simulation study with Type I censoring only, we saw that when , the MS-A did not outperform MS-SRS.
We suggest a simple strategy for the proposed adaptive mean score design aimed at under-sampling less informative strata in the pilot study, which may preserve efficiency gains by providing more precise nuisance parameters for the more informative strata. For example, under the random right-censoring assumption, individuals censored before the end of the follow-up period should generally be be less informative than a non-censored individuals with similar covariates for that same period. For a fixed phase two sample size, such under-sampling may enable us to re-allocate the pilot sample for the MS-A so that relatively more informative groups can be up-weighted. In fact, we anticipate that the optimal adaptive design would allocate very few individuals in these strata, so we seek to avoid putting too many individuals into these strata in the pilot. Supplementary Material Tables B.8 and B.9 provide analogous results for the discrete-time analysis in Table 2 and continuous time analysis of Table 3 for the NWTS, but we analyzed the full cohort () and under-sampled the censored individuals not relapsing before the end of the follow-up period in the balanced and the pilot samples. Specifically, we allocated a small number of the pilot sample size for individuals censored before the end of the follow-up period (i.e., and ) at each level of histology, and the remaining allocation was equally distributed to the other strata in the pilot sample. In this particular example, we set the under-sampling size to 4, which was approximately half of the balanced sampling size for each stratum in the pilot study with . Indeed, we found that the naive balanced sampling of all strata in the pilot often over-sampled censored-groups compared to the oracle design (data not shown), and consequently this simple remedy made the modified adaptive sampling design be closer to the oracle design than did the balanced pilot sample with the proposed adaptive design. As seen in Supplemental Table B.8, the modified approach produced a variance reduction compared to both the fully balanced and the MS-A with a balanced pilot sample. Additionally, the precision for all estimates, relative to the analogous estimates in Tables 2 and 3, benefited from including the intermittently censored () individuals who had been excluded in Section 4.2, with more gains seen for the MS-BAL and MS-A estimators. We hypothesize that this modification will allow for more robust efficiency gains for the proposed adaptive design in other settings with intermittent censoring. Supportive simulation studies that examine the performance of MS-A given the anticipated phase two sample size and other study parameters may provide useful insights to guide refinements of this strategy for a given setting.
5 Discussion
The mean score method is a practical approach for two-phase studies that allows for a relatively straightforward derivation of an optimal design for a phase two study, one that can minimize the variance of a target parameter given a fixed phase two sample size (Reilly and Pepe, 1995). In this study, we extended the mean score estimation method for the two-phase analysis of discrete-time survival outcomes. We also derived an adaptive sampling design approach that first draws a pilot phase two sample in order to estimate the nuisance parameters necessary to derive the optimal sampling proportions, similar to the approach of McIsaac and Cook (2015) for binary outcomes.
Through numerical studies with simulated data and the National Wilms Tumor Study data, we found that the proposed mean score estimator with an adaptive sampling design provided efficiency gains over the complete case estimator, as well as the mean score estimator with simple random or balanced stratified sampling, for selection of the phase two sample. For the studied settings, as the phase two sample size increased, the proposed adaptive sampling design not only outperformed the simple random sampling and balanced designs consistently but also behaved very close to the oracle design, which depends on the true (generally unknown) population parameters.
The mean score adaptive optimal design also provided efficiency gains for the two-phase analysis of the continuous-time outcome using the usual Cox proportional hazards model. This design offers a practical and straightforward approach two improve the efficiency of the two-phase estimator for the continuous survival time setting and can be applied for settings with both type I and random right censoring.
There are some limitations of our proposed method. The adaptive design requires estimating nuisance parameters to estimate the strata-specific sampling probabilities that minimize the variance of the target parameter, whose number increases with the number of strata. Many small strata could lead to instability in the necessary estimated nuisance parameters, which in turn could threaten the efficiency of the design. For continuous surrogates, a kernel smoothing approach proposed by Chatterjee and Chen (2007) may be useful. In the case of the Wilms Tumor data, undersampling the early censored individuals in the pilot was an advantageous approach that was compatible with the subsequent derived optimal sample, in that it avoided oversampling uninformative strata, and improved the performance of the adaptive design. Formalization of this strategy needs further study and is a subject for future work. Incorporation of prior information regarding the sampling priorities for certain strata may be an additional way to improve the performance of the adaptive design, particularly in the case of a small phase two sample. Chen et al. (2019) considers a method for incorporation of prior information into multi-wave sampling in a regression framework.
Two-phase studies are used in a variety of settings. In the era where the analysis of error-prone electronic health records data are of increasing interest, a phase two sample in which data can be validated to understand the error structure is a critical step towards valid inference. The proposed method and two-phase study design offer a practical and easy to implement framework for the common setting of survival outcomes, in which both the validated and error-prone exposures can be efficiently combined so that analyses are adjusted for errors in the surrogate data. Future work is needed to expand this method to also handle settings where there is error in both the exposure and survival outcome.
References
- Breslow and Chatterjee (1999) Breslow, N. E. and Chatterjee, N. (1999). Design and analysis of two-phase studies with binary outcome applied to wilms tumour prognosis. Journal of the Royal Statistical Society: Series C (Applied Statistics), 48 457–468.
- Chatterjee and Chen (2007) Chatterjee, N. and Chen, Y.-H. (2007). A semiparametric pseudo-score method for analysis of two-phase studies with continuous phase-I covariates. Lifetime Data Analysis, 13 607–622.
- Chatterjee et al. (2003) Chatterjee, N., Chen, Y.-H. and Breslow, N. E. (2003). A pseudoscore estimator for regression problems with two-phase sampling. Journal of the American Statistical Association, 98 158–168.
- Chen et al. (2019) Chen, T., Lumley, T. and Rivera-Rodriguez, C. (2019). Optimal multi-wave sampling for regression modelling. https://www.otago.ac.nz/nzsa/programme-and-speakers/otago720017.pdf.
- D’angio et al. (1989) D’angio, G. J., Breslow, N., Beckwith, J. B., Evans, A., Baum, E., Delorimier, A., Fernbach, D., Hrabovsky, E., Jones, B., Kelalis, P. et al. (1989). Treatment of wilms’ tumor. results of the third national wilms’ tumor study. Cancer, 64 349–360.
- Dempster et al. (1977) Dempster, A. P., Laird, N. M. and Rubin, D. B. (1977). Maximum likelihood from incomplete data via the em algorithm. Journal of the Royal Statistical Society. Series B (Methodological) 1–38.
- Flanders and Greenland (1991) Flanders, W. D. and Greenland, S. (1991). Analytic methods for two-stage case-control studies and other stratified designs. Statistics in Medicine, 10 739–747.
- Green et al. (1998) Green, D. M., Breslow, N. E., Beckwith, J. B., Finklestein, J. Z., Grundy, P. E., Thomas, P., Kim, T., Shochat, S. J., Haase, G. M., Ritchey, M. L. et al. (1998). Comparison between single-dose and divided-dose administration of dactinomycin and doxorubicin for patients with wilms’ tumor: a report from the national wilms’ tumor study group. Journal of Clinical Oncology, 16 237–245.
- Kalbfleisch and Prentice (2011) Kalbfleisch, J. D. and Prentice, R. L. (2011). The statistical analysis of failure time data, vol. 360. John Wiley & Sons.
- Kulich and Lin (2004) Kulich, M. and Lin, D. (2004). Improving the efficiency of relative-risk estimation in case-cohort studies. Journal of the American Statistical Association, 99 832–844.
- Lawless (2018) Lawless, J. (2018). Two-phase outcome-dependent studies for failure times and testing for effects of expensive covariates. Lifetime Data Analysis, 24 28–44.
- Lawless et al. (1999) Lawless, J., Kalbfleisch, J. and Wild, C. (1999). Semiparametric methods for response-selective and missing data problems in regression. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 61 413–438.
- Lumley (2011) Lumley, T. (2011). Complex surveys: a guide to analysis using R, vol. 565. John Wiley & Sons.
- McIsaac and Cook (2014) McIsaac, M. A. and Cook, R. J. (2014). Response-dependent two-phase sampling designs for biomarker studies. Canadian Journal of Statistics, 42 268–284.
- McIsaac and Cook (2015) McIsaac, M. A. and Cook, R. J. (2015). Adaptive sampling in two-phase designs: a biomarker study for progression in arthritis. Statistics in Medicine, 34 2899–2912.
- Meier et al. (2003) Meier, A. S., Richardson, B. A. and Hughes, J. P. (2003). Discrete proportional hazards models for mismeasured outcomes. Biometrics, 59 947–954.
- Neyman (1934) Neyman, J. (1934). On the two different aspects of the representative method: The method of stratified sampling and the method of purposive selection. Journal of the Royal Statistical Society, 97 558–625.
- Prentice (1989) Prentice, R. L. (1989). Surrogate endpoints in clinical trials: definition and operational criteria. Statistics in Medicine, 8 431–440.
- Reilly (1996) Reilly, M. (1996). Optimal sampling strategies for two-stage studies. American Journal of Epidemiology, 143 92–100.
- Reilly and Pepe (1995) Reilly, M. and Pepe, M. S. (1995). A mean score method for missing and auxiliary covariate data in regression models. Biometrika, 82 299–314.
- Tao et al. (2017) Tao, R., Zeng, D. and Lin, D.-Y. (2017). Efficient semiparametric inference under two-phase sampling, with applications to genetic association studies. Journal of the American Statistical Association, 112 1468–1476.
- Tao et al. (2019) Tao, R., Zeng, D. and Lin, D.-Y. (2019). Optimal designs of two-phase studies. Journal of the American Statistical Association 1–14.
- Therneau and Lumley (2019) Therneau, T. M. and Lumley, T. (2019). survival: Survival Analysis. R package version 3.1-8, URL https://CRAN.R-project.org/package=survival.
- Vach and Blettner (1991) Vach, W. and Blettner, M. (1991). Biased estimation of the odds ratio in case-control studies due to the use of ad hoc methods of correcting for missing values for confounding variables. American Journal of Epidemiology, 134 895–907.
- Whittemore and Halpern (1997) Whittemore, A. S. and Halpern, J. (1997). Multi-stage sampling in genetic epidemiology. Statistics in Medicine, 16 153–167.
Supplementary Material for “Two-phase analysis and study design for survival models with error-prone exposures”
Kyunghee Han1, Thomas Lumley2, Bryan E. Shepherd3 and Pamela A. Shaw1
1University of Pennsylvania, USA
2University of Auckland, New Zealand
3Vanderbilt University, USA
A Technical details
A.1 Regularity conditions for Theorem 1
We assume there exists such that with probability one. Let be the true parameter for some open and further assume the following conditions:
-
A1.
at .
-
A2.
is three-times continuously differentiable and bounded away from 0 near (a.s.).
-
A3.
is positive definite at .
-
A4.
for all .
Since we have formulated discrete-time survival models where the censoring time is bounded away from infinity, the right-censored survival time has an upper-bound almost surely so that finite numbers of baseline hazards suffice to specify likelihood for the discrete-time survival model (2.1). Without loss of generality, we write by the transformation of baseline hazards. Then, the above assumptions A1–A4 are the regularity conditions for the maximum likelihood estimation of finite-dimensional parameters , and therefore, the proof follows Theorem 1 in Reilly and Pepe (1995) which we refer the reader to for details.
A.2 Some derivations for numerical implementation
For the implementation of the optimal design in our numerical simulations, we empirically estimated certain parameters by generating a large independent sample of individuals. Let be an external random sample of independent on or . We estimate unknown quantities in the optimal sampling design (3.1) by
| (A.1) |
where and
| (A.2) |
for .
We now introduce some derivations for Newton-Raphson algorithm. Recall that the discrete-time survival model (2.1) under the odds transformation is given by , where is the logit transformation of the baseline hazard. The maximum likelihood estimates of and are obtained by solving score equations of (2.4) with
| (A.3) |
We numerically solve the system of equations (A.3) with the Newton-Raphson algorithm using the associated Hessian matrix whose components consist of
| (A.4) |
Similarly, suppose the complementary log transformation defines the true survival model (2.1). Then it can be easily seen that , where is the complementary log-log transformation of the baseline hazard. The maximum likelihood estimates of are obtained by solving score equations of (2.4) with
| (A.5) |
We numerically solve the system of equations (A.5) with the Newton-Raphson algorithm using the associated Hessian matrix whose components consist of
| (A.6) |
B Additional numerical results
B.1 Supplemental tables for the simulation study
| Sampling | Estimation | Criterion | Estimation performance by sample sizes | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Full cohort | CC | 0.079 | 0.079 | 0.079 | 0.112 | 0.079 | 0.056 | ||
| Bias | 0.004 | 0.004 | 0.004 | 0.000 | 0.004 | 0.001 | |||
| 0.079 | 0.079 | 0.079 | 0.112 | 0.079 | 0.056 | ||||
| SRS | CC | 0.408 | 0.284 | 0.198 | 0.281 | 0.284 | 0.282 | ||
| Bias | 0.013 | 0.012 | 0.011 | 0.013 | 0.012 | 0.015 | |||
| 0.408 | 0.284 | 0.197 | 0.281 | 0.284 | 0.282 | ||||
| MS | 0.268 | 0.177 | 0.132 | 0.191 | 0.177 | 0.170 | |||
| Bias | 0.067 | 0.016 | 0.012 | 0.014 | 0.016 | 0.017 | |||
| 0.259 | 0.176 | 0.131 | 0.190 | 0.176 | 0.169 | ||||
| Balanced | MS | 0.302 | 0.216 | 0.153 | 0.219 | 0.216 | 0.202 | ||
| Bias | 0.023 | 0.017 | 0.015 | 0.010 | 0.017 | 0.018 | |||
| 0.301 | 0.215 | 0.152 | 0.219 | 0.215 | 0.201 | ||||
| Adaptive | MS | 0.279 | 0.168 | 0.114 | 0.181 | 0.168 | 0.159 | ||
| Bias | 0.038 | 0.024 | 0.011 | 0.012 | 0.024 | 0.017 | |||
| 0.276 | 0.166 | 0.113 | 0.181 | 0.166 | 0.158 | ||||
| Oracle | MS | 0.213 | 0.155 | 0.112 | 0.166 | 0.155 | 0.137 | ||
| Bias | 0.025 | 0.001 | 0.001 | 0.005 | 0.001 | 0.002 | |||
| 0.212 | 0.155 | 0.112 | 0.166 | 0.155 | 0.137 | ||||
| Sampling | Estimation | Criterion | Estimation performance by sample sizes | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Full cohort | CC | 0.119 | 0.119 | 0.119 | 0.175 | 0.119 | 0.086 | ||
| Bias | 0.000 | 0.000 | 0.000 | 0.004 | 0.000 | 0.003 | |||
| 0.119 | 0.119 | 0.119 | 0.175 | 0.119 | 0.086 | ||||
| SRS | CC | 0.630 | 0.420 | 0.299 | 0.442 | 0.420 | 0.419 | ||
| Bias | 0.025 | 0.016 | 0.002 | -0.005 | 0.016 | 0.018 | |||
| 0.630 | 0.420 | 0.299 | 0.442 | 0.420 | 0.418 | ||||
| MS | 0.477 | 0.304 | 0.208 | 0.328 | 0.304 | 0.287 | |||
| Bias | 0.177 | 0.078 | 0.018 | 0.065 | 0.078 | 0.081 | |||
| 0.443 | 0.294 | 0.207 | 0.322 | 0.294 | 0.273 | ||||
| Balanced | MS | 0.535 | 0.330 | 0.225 | 0.347 | 0.330 | 0.327 | ||
| Bias | 0.092 | 0.026 | 0.005 | 0.033 | 0.026 | 0.029 | |||
| 0.527 | 0.329 | 0.224 | 0.346 | 0.329 | 0.326 | ||||
| Adaptive | MS | 0.411 | 0.250 | 0.178 | 0.259 | 0.250 | 0.225 | ||
| Bias | 0.018 | 0.007 | 0.001 | 0.003 | 0.007 | 0.003 | |||
| 0.410 | 0.250 | 0.178 | 0.259 | 0.250 | 0.225 | ||||
| Oracle | MS | 0.315 | 0.215 | 0.174 | 0.250 | 0.215 | 0.224 | ||
| Bias | 0.023 | 0.010 | 0.000 | 0.017 | 0.010 | 0.008 | |||
| 0.314 | 0.214 | 0.174 | 0.249 | 0.214 | 0.224 | ||||
| Sample size | Sampling | Estimation | Criterion | Estimation performance by regression coefficient | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SRS | CC | 0.547 | 0.520 | 0.447 | 0.429 | 0.409 | 0.396 | 0.470 | 0.555 | 0.214 | 0.203 | ||
| Bias | -0.086 | -0.076 | -0.064 | -0.034 | -0.033 | -0.008 | 0.017 | -0.017 | 0.013 | -0.009 | |||
| 0.540 | 0.514 | 0.443 | 0.428 | 0.408 | 0.396 | 0.470 | 0.555 | 0.214 | 0.202 | ||||
| MS | 0.479 | 0.381 | 0.330 | 0.316 | 0.306 | 0.301 | 0.332 | 0.602 | 0.236 | 0.219 | |||
| Bias | -0.267 | -0.166 | -0.112 | -0.086 | -0.074 | -0.056 | 0.053 | -0.021 | 0.020 | -0.017 | |||
| 0.398 | 0.343 | 0.310 | 0.304 | 0.297 | 0.295 | 0.330 | 0.601 | 0.235 | 0.218 | ||||
| Balanced | MS | 0.405 | 0.401 | 0.399 | 0.398 | 0.398 | 0.405 | 0.400 | 0.859 | 0.317 | 0.299 | ||
| Bias | -0.023 | -0.011 | -0.009 | -0.002 | 0.009 | 0.034 | 0.042 | -0.034 | 0.025 | -0.017 | |||
| 0.404 | 0.400 | 0.399 | 0.398 | 0.398 | 0.403 | 0.398 | 0.858 | 0.317 | 0.298 | ||||
| Adaptive | MS | 0.332 | 0.324 | 0.323 | 0.323 | 0.325 | 0.326 | 0.374 | 0.720 | 0.255 | 0.251 | ||
| Bias | -0.018 | -0.007 | -0.006 | -0.001 | 0.006 | 0.024 | 0.049 | -0.065 | 0.025 | -0.028 | |||
| 0.331 | 0.324 | 0.323 | 0.323 | 0.325 | 0.325 | 0.371 | 0.717 | 0.254 | 0.249 | ||||
| Oracle | MS | 0.258 | 0.253 | 0.255 | 0.252 | 0.251 | 0.254 | 0.253 | 0.519 | 0.198 | 0.189 | ||
| Bias | -0.013 | 0.003 | 0.002 | 0.005 | 0.007 | 0.018 | 0.009 | -0.027 | 0.001 | -0.017 | |||
| 0.257 | 0.253 | 0.255 | 0.252 | 0.251 | 0.253 | 0.252 | 0.518 | 0.198 | 0.188 | ||||
| Full cohort analysis | 0.107 | 0.096 | 0.091 | 0.085 | 0.080 | 0.079 | 0.094 | 0.116 | 0.044 | 0.042 | |||
| Bias | -0.010 | 0.000 | -0.003 | -0.002 | -0.005 | -0.002 | 0.003 | -0.001 | -0.000 | 0.000 | |||
| 0.107 | 0.096 | 0.091 | 0.085 | 0.080 | 0.079 | 0.094 | 0.116 | 0.044 | 0.042 | ||||
;
.
| Sample size | Sampling | Estimation | Criterion | Estimation performance by regression coefficient | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SRS | CC | 0.377 | 0.347 | 0.319 | 0.295 | 0.288 | 0.280 | 0.330 | 0.404 | 0.146 | 0.143 | ||
| Bias | -0.050 | -0.045 | -0.037 | -0.014 | -0.025 | -0.008 | 0.014 | 0.000 | 0.006 | -0.004 | |||
| 0.374 | 0.344 | 0.316 | 0.295 | 0.287 | 0.280 | 0.329 | 0.404 | 0.146 | 0.143 | ||||
| MS | 0.253 | 0.226 | 0.216 | 0.209 | 0.204 | 0.203 | 0.220 | 0.423 | 0.154 | 0.147 | |||
| Bias | -0.081 | -0.046 | -0.039 | -0.032 | -0.030 | -0.022 | 0.035 | 0.005 | 0.007 | -0.005 | |||
| 0.240 | 0.222 | 0.213 | 0.207 | 0.202 | 0.202 | 0.217 | 0.423 | 0.154 | 0.147 | ||||
| Balanced | MS | 0.284 | 0.279 | 0.276 | 0.276 | 0.277 | 0.277 | 0.278 | 0.582 | 0.200 | 0.204 | ||
| Bias | -0.014 | -0.003 | -0.004 | -0.000 | 0.003 | 0.016 | 0.024 | -0.007 | 0.006 | -0.015 | |||
| 0.284 | 0.279 | 0.276 | 0.276 | 0.277 | 0.277 | 0.277 | 0.582 | 0.200 | 0.204 | ||||
| Adaptive | MS | 0.210 | 0.200 | 0.201 | 0.201 | 0.198 | 0.201 | 0.197 | 0.426 | 0.147 | 0.147 | ||
| Bias | -0.013 | -0.003 | -0.005 | -0.003 | -0.002 | 0.005 | 0.007 | -0.014 | 0.006 | -0.009 | |||
| 0.210 | 0.200 | 0.200 | 0.201 | 0.198 | 0.200 | 0.197 | 0.426 | 0.147 | 0.147 | ||||
| Oracle | MS | 0.189 | 0.184 | 0.182 | 0.177 | 0.178 | 0.178 | 0.182 | 0.354 | 0.134 | 0.132 | ||
| Bias | -0.003 | 0.007 | 0.005 | 0.006 | 0.005 | 0.011 | 0.003 | -0.014 | -0.005 | -0.008 | |||
| 0.189 | 0.184 | 0.182 | 0.177 | 0.178 | 0.177 | 0.182 | 0.354 | 0.133 | 0.132 | ||||
| Full cohort analysis | 0.107 | 0.096 | 0.091 | 0.085 | 0.080 | 0.079 | 0.094 | 0.116 | 0.044 | 0.042 | |||
| Bias | -0.010 | 0.000 | -0.003 | -0.002 | -0.005 | -0.002 | 0.003 | -0.001 | -0.000 | 0.000 | |||
| 0.107 | 0.096 | 0.091 | 0.085 | 0.080 | 0.079 | 0.094 | 0.116 | 0.044 | 0.042 | ||||
;
.
| Sample size | Sampling | Estimation | Criterion | Estimation performance by regression coefficient | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SRS | CC | 0.262 | 0.239 | 0.220 | 0.206 | 0.199 | 0.191 | 0.228 | 0.286 | 0.101 | 0.101 | ||
| Bias | -0.030 | -0.018 | -0.016 | -0.007 | -0.016 | -0.005 | 0.005 | 0.002 | 0.005 | -0.004 | |||
| 0.260 | 0.238 | 0.220 | 0.206 | 0.198 | 0.191 | 0.228 | 0.286 | 0.101 | 0.101 | ||||
| MS | 0.169 | 0.156 | 0.151 | 0.149 | 0.146 | 0.144 | 0.155 | 0.292 | 0.104 | 0.102 | |||
| Bias | -0.022 | -0.008 | -0.009 | -0.008 | -0.009 | -0.004 | 0.004 | 0.001 | 0.007 | -0.004 | |||
| 0.167 | 0.156 | 0.151 | 0.148 | 0.145 | 0.144 | 0.155 | 0.292 | 0.103 | 0.102 | ||||
| Balanced | MS | 0.202 | 0.196 | 0.193 | 0.191 | 0.189 | 0.190 | 0.194 | 0.396 | 0.145 | 0.141 | ||
| Bias | -0.017 | -0.006 | -0.009 | -0.007 | -0.007 | 0.000 | 0.010 | 0.008 | -0.002 | 0.002 | |||
| 0.201 | 0.195 | 0.193 | 0.190 | 0.189 | 0.190 | 0.194 | 0.396 | 0.145 | 0.141 | ||||
| Adaptive | MS | 0.154 | 0.149 | 0.145 | 0.142 | 0.139 | 0.140 | 0.147 | 0.280 | 0.099 | 0.102 | ||
| Bias | -0.010 | -0.001 | -0.003 | -0.003 | -0.003 | 0.001 | 0.006 | -0.010 | 0.005 | -0.003 | |||
| 0.154 | 0.149 | 0.145 | 0.142 | 0.139 | 0.140 | 0.147 | 0.280 | 0.099 | 0.102 | ||||
| Oracle | MS | 0.147 | 0.139 | 0.137 | 0.135 | 0.131 | 0.131 | 0.133 | 0.261 | 0.096 | 0.095 | ||
| Bias | -0.004 | 0.006 | 0.003 | 0.004 | 0.003 | 0.007 | 0.005 | -0.018 | 0.002 | -0.005 | |||
| 0.147 | 0.139 | 0.137 | 0.135 | 0.131 | 0.131 | 0.133 | 0.260 | 0.096 | 0.095 | ||||
| Full cohort analysis | 0.107 | 0.096 | 0.091 | 0.085 | 0.080 | 0.079 | 0.094 | 0.116 | 0.044 | 0.042 | |||
| Bias | -0.010 | 0.000 | -0.003 | -0.002 | -0.005 | -0.002 | 0.003 | -0.001 | -0.000 | 0.000 | |||
| 0.107 | 0.096 | 0.091 | 0.085 | 0.080 | 0.079 | 0.094 | 0.116 | 0.044 | 0.042 | ||||
;
.
| Sample size | Sampling | Estimation | Criterion | Estimation performance by regression coefficient | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SRS | CC | 0.381 | 0.342 | 0.323 | 0.288 | 0.281 | 0.284 | 0.324 | 0.419 | 0.145 | 0.147 | ||
| Bias | -0.049 | -0.044 | -0.039 | -0.025 | -0.020 | -0.019 | -0.011 | 0.029 | 0.006 | -0.005 | |||
| 0.378 | 0.340 | 0.321 | 0.287 | 0.280 | 0.283 | 0.324 | 0.418 | 0.145 | 0.147 | ||||
| MS | 0.267 | 0.245 | 0.232 | 0.224 | 0.217 | 0.223 | 0.237 | 0.434 | 0.150 | 0.156 | |||
| Bias | -0.072 | -0.050 | -0.044 | -0.036 | -0.028 | -0.031 | 0.020 | 0.027 | 0.005 | -0.004 | |||
| 0.258 | 0.240 | 0.228 | 0.221 | 0.215 | 0.221 | 0.236 | 0.433 | 0.150 | 0.156 | ||||
| Balanced | MS | 0.278 | 0.275 | 0.267 | 0.266 | 0.263 | 0.266 | 0.276 | 0.550 | 0.200 | 0.198 | ||
| Bias | -0.024 | -0.018 | -0.019 | -0.014 | -0.006 | -0.003 | 0.026 | -0.005 | 0.013 | -0.005 | |||
| 0.277 | 0.274 | 0.266 | 0.265 | 0.263 | 0.266 | 0.275 | 0.550 | 0.199 | 0.198 | ||||
| Adaptive | MS | 0.233 | 0.220 | 0.211 | 0.210 | 0.207 | 0.210 | 0.214 | 0.421 | 0.152 | 0.148 | ||
| Bias | -0.019 | -0.014 | -0.016 | -0.012 | -0.005 | -0.007 | 0.004 | 0.006 | 0.010 | -0.016 | |||
| 0.232 | 0.219 | 0.210 | 0.209 | 0.207 | 0.210 | 0.214 | 0.421 | 0.152 | 0.147 | ||||
| Oracle | MS | 0.215 | 0.204 | 0.195 | 0.195 | 0.186 | 0.195 | 0.202 | 0.383 | 0.134 | 0.136 | ||
| Bias | -0.021 | -0.012 | -0.014 | -0.010 | -0.004 | -0.008 | -0.012 | 0.021 | 0.001 | -0.004 | |||
| 0.214 | 0.203 | 0.194 | 0.194 | 0.186 | 0.195 | 0.202 | 0.382 | 0.134 | 0.136 | ||||
| Full cohort analysis | 0.152 | 0.136 | 0.124 | 0.121 | 0.112 | 0.118 | 0.129 | 0.172 | 0.062 | 0.061 | |||
| Bias | -0.009 | -0.005 | -0.008 | -0.006 | -0.002 | -0.008 | -0.004 | 0.010 | 0.001 | -0.001 | |||
| 0.152 | 0.136 | 0.124 | 0.121 | 0.112 | 0.118 | 0.129 | 0.171 | 0.062 | 0.061 | ||||
;
.
| Sample size | Sampling | Estimation | Criterion | Estimation performance by regression coefficient | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SRS | CC | 0.381 | 0.334 | 0.316 | 0.289 | 0.281 | 0.280 | 0.321 | 0.419 | 0.155 | 0.149 | ||
| Bias | -0.042 | -0.037 | -0.034 | -0.020 | -0.014 | -0.004 | -0.001 | 0.001 | 0.012 | -0.007 | |||
| 0.379 | 0.332 | 0.314 | 0.288 | 0.280 | 0.280 | 0.321 | 0.419 | 0.154 | 0.149 | ||||
| MS | 0.236 | 0.211 | 0.208 | 0.201 | 0.199 | 0.200 | 0.200 | 0.435 | 0.162 | 0.157 | |||
| Bias | -0.071 | -0.043 | -0.034 | -0.028 | -0.022 | -0.017 | 0.027 | -0.000 | 0.015 | -0.009 | |||
| 0.225 | 0.206 | 0.205 | 0.199 | 0.198 | 0.200 | 0.198 | 0.435 | 0.161 | 0.157 | ||||
| Balanced | MS | 0.272 | 0.271 | 0.271 | 0.268 | 0.269 | 0.270 | 0.265 | 0.572 | 0.211 | 0.207 | ||
| Bias | -0.012 | -0.009 | -0.007 | -0.004 | 0.004 | 0.014 | 0.021 | -0.002 | 0.007 | -0.017 | |||
| 0.272 | 0.271 | 0.271 | 0.268 | 0.269 | 0.270 | 0.264 | 0.572 | 0.211 | 0.207 | ||||
| Adaptive | MS | 0.196 | 0.194 | 0.195 | 0.193 | 0.194 | 0.195 | 0.190 | 0.417 | 0.153 | 0.148 | ||
| Bias | -0.009 | -0.008 | -0.007 | -0.005 | -0.001 | 0.004 | 0.002 | -0.014 | 0.008 | 0.001 | |||
| 0.196 | 0.193 | 0.195 | 0.193 | 0.194 | 0.195 | 0.189 | 0.417 | 0.153 | 0.148 | ||||
| Oracle | MS | 0.178 | 0.174 | 0.170 | 0.170 | 0.171 | 0.172 | 0.174 | 0.362 | 0.134 | 0.133 | ||
| Bias | -0.006 | -0.004 | -0.002 | -0.002 | 0.002 | 0.005 | -0.005 | -0.010 | -0.001 | 0.008 | |||
| 0.178 | 0.174 | 0.170 | 0.170 | 0.171 | 0.172 | 0.174 | 0.362 | 0.134 | 0.133 | ||||
| Full cohort analysis | 0.076 | 0.071 | 0.063 | 0.060 | 0.057 | 0.055 | 0.067 | 0.085 | 0.030 | 0.031 | |||
| Bias | -0.002 | -0.001 | -0.001 | -0.001 | 0.001 | 0.001 | 0.000 | -0.003 | 0.001 | 0.000 | |||
| 0.076 | 0.071 | 0.063 | 0.060 | 0.057 | 0.055 | 0.067 | 0.085 | 0.030 | 0.031 | ||||
;
.
B.2 Two-phase analysis with modified sampling design in the NWTS data example
| Sampling | Estimation | Criterion | Baseline hazard in complementary log-log scale | Regression coefficient | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.5yr | 1yr | 1.5yr | 2yr | 2.5yr | 3yr | UH1 | Stage2 | Age3 | dTmr4 | US5 | ||||
| Full cohort analysis | Ref. | -4.074 | -3.916 | -4.373 | -5.037 | -5.378 | -5.737 | 1.087 | 0.287 | 0.064 | 0.031 | 0.632 | ||
| SRS | CC | 0.469 | 0.460 | 0.479 | 0.706 | 1.537 | 2.601 | 0.640 | 0.340 | 0.050 | 0.034 | 0.763 | ||
| Bias | -0.074 | -0.067 | -0.074 | -0.136 | -0.283 | -0.694 | -0.025 | -0.011 | -0.001 | 0.001 | 0.070 | |||
| 0.463 | 0.455 | 0.473 | 0.693 | 1.511 | 2.507 | 0.640 | 0.340 | 0.050 | 0.034 | 0.759 | ||||
| MS | 0.433 | 0.428 | 0.429 | 0.580 | 1.464 | 2.587 | 0.635 | 0.355 | 0.051 | 0.037 | 0.815 | |||
| Bias | -0.028 | -0.023 | -0.035 | -0.109 | -0.330 | -0.829 | -0.102 | -0.005 | 0.001 | 0.001 | 0.131 | |||
| 0.432 | 0.428 | 0.428 | 0.570 | 1.426 | 2.450 | 0.627 | 0.355 | 0.051 | 0.037 | 0.804 | ||||
| Balanced | MS | 0.512 | 0.504 | 0.493 | 0.485 | 0.482 | 0.481 | 0.460 | 0.437 | 0.068 | 0.043 | 0.712 | ||
| Bias | -0.123 | -0.105 | -0.088 | -0.077 | -0.071 | -0.067 | 0.048 | 0.046 | 0.018 | 0.004 | -0.051 | |||
| 0.497 | 0.492 | 0.485 | 0.479 | 0.477 | 0.476 | 0.457 | 0.435 | 0.066 | 0.042 | 0.710 | ||||
| Balanced | MS | 0.436 | 0.428 | 0.419 | 0.412 | 0.410 | 0.409 | 0.403 | 0.371 | 0.061 | 0.036 | 0.614 | ||
| (†modified) | Bias | -0.090 | -0.075 | -0.062 | -0.054 | -0.049 | -0.046 | 0.038 | 0.009 | 0.016 | 0.003 | 0.002 | ||
| 0.426 | 0.421 | 0.415 | 0.409 | 0.407 | 0.406 | 0.401 | 0.371 | 0.059 | 0.036 | 0.614 | ||||
| Adaptive | MS | 0.350 | 0.343 | 0.336 | 0.331 | 0.329 | 0.327 | 0.326 | 0.313 | 0.045 | 0.028 | 0.519 | ||
| Bias | -0.071 | -0.060 | -0.052 | -0.047 | -0.044 | -0.042 | -0.010 | 0.002 | 0.009 | 0.003 | 0.056 | |||
| 0.342 | 0.337 | 0.332 | 0.327 | 0.326 | 0.325 | 0.326 | 0.313 | 0.044 | 0.027 | 0.516 | ||||
| Adaptive | MS | 0.342 | 0.336 | 0.329 | 0.324 | 0.323 | 0.322 | 0.290 | 0.266 | 0.042 | 0.027 | 0.448 | ||
| (‡modified) | Bias | -0.060 | -0.052 | -0.045 | -0.040 | -0.038 | -0.036 | -0.003 | -0.014 | 0.009 | 0.002 | 0.057 | ||
| 0.337 | 0.332 | 0.326 | 0.322 | 0.320 | 0.320 | 0.290 | 0.265 | 0.041 | 0.027 | 0.445 | ||||
| Oracle | MS | 0.269 | 0.267 | 0.264 | 0.261 | 0.261 | 0.260 | 0.234 | 0.232 | 0.035 | 0.022 | 0.379 | ||
| Bias | -0.007 | -0.009 | -0.008 | -0.006 | -0.006 | -0.005 | 0.006 | 0.008 | 0.002 | -0.000 | 0.030 | |||
| 0.269 | 0.267 | 0.264 | 0.261 | 0.261 | 0.260 | 0.234 | 0.232 | 0.034 | 0.022 | 0.377 | ||||
1 Unfavorable histology versus favorable; 2 disease stage III/IV versus I/II;
3 year at diagnosis; 4 tumor diameter (cm); 5 interaction effect between UH and Stage.
| Sampling | Criterion | Estimation performance by regressor | ||||
|---|---|---|---|---|---|---|
| UH1 | Stage2 | Age3 | dTmr4 | US5 | ||
| Full cohort analysis | Ref. | 1.050 | 0.297 | 0.065 | 0.021 | 0.620 |
| SRS | 0.444 | 0.322 | 0.049 | 0.033 | 0.648 | |
| Bias | -0.092 | 0.009 | -0.000 | 0.000 | 0.115 | |
| 0.434 | 0.322 | 0.049 | 0.033 | 0.638 | ||
| Balanced | 0.478 | 0.519 | 0.074 | 0.049 | 0.752 | |
| Bias | 0.061 | 0.032 | 0.016 | 0.006 | -0.037 | |
| 0.474 | 0.518 | 0.072 | 0.048 | 0.751 | ||
| Balanced | 0.440 | 0.434 | 0.065 | 0.043 | 0.643 | |
| (†modified) | Bias | 0.039 | 0.012 | 0.011 | 0.008 | 0.025 |
| 0.438 | 0.434 | 0.065 | 0.043 | 0.643 | ||
| Adaptive | 0.338 | 0.373 | 0.052 | 0.034 | 0.541 | |
| Bias | -0.001 | 0.005 | 0.005 | 0.002 | 0.035 | |
| 0.338 | 0.373 | 0.052 | 0.034 | 0.540 | ||
| Adaptive | 0.328 | 0.325 | 0.050 | 0.031 | 0.493 | |
| (†modified) | Bias | -0.023 | 0.000 | 0.008 | 0.002 | 0.053 |
| 0.327 | 0.325 | 0.049 | 0.031 | 0.491 | ||
| Oracle | 0.255 | 0.250 | 0.041 | 0.025 | 0.396 | |
| Bias | -0.001 | -0.006 | 0.004 | 0.001 | 0.043 | |
| 0.255 | 0.250 | 0.041 | 0.025 | 0.393 | ||
1 Unfavorable histology versus favorable; 2 disease stage III/IV versus I/II;
3 year at diagnosis; 4 tumor diameter (cm); 5 interaction effect between UH and Stage.