Tweet Sentiment Extraction using Viterbi Algorithm with Transfer Learning
Abstract
Tweet sentiment extraction extracts the most significant portion of the sentence, determining whether the sentiment is positive or negative. This research aims to identify the part of tweet sentences that strikes any emotion. To reach this objective, we continue improving the Viterbi algorithm previously modified by the author to make it able to receive pre-trained model parameters. We introduce the confidence score and vector as two indicators responsible for evaluating the model internally before assessing the final results. We then present a method to fine-tune this nonparametric model. We found that the model gets highly explainable as the confidence score vector reveals precisely where the least confidence predicted states are and if the modifications approved ameliorate the confidence score or if the tuning is going in the wrong direction.
1 Introduction
Determining the sentiment of a tweet can be a laborious task for NLP specialists, as they need to identify the specific segment of the sentence that accurately reflects the sentiment and its boundaries. It can be challenging to accomplish this task when the sentences are lengthy and the intended emotion is conveyed using multiple words or placed at the start or end.
Information extraction and sentiment analysis are indispensable for processing news feeds and posts from public profiles of celebrities and ordinary persons to determine the sentiment of a tweet. When automated, these activities allow the categorization of tweets into several predefined classes and perhaps avoid the diffusion of fake news or toxic posts. Emotional writing can engage users and encourage them to spend more time browsing a website or getting more information about a product. However, it can also negatively impact the reader’s mood, especially when they come across a toxic text with a high frequency of negative emotions, such as insulting comments or discriminatory remarks from followers on social media. Detecting such infractions early can increase the audience number on a web page and avoid unsubscribing clicks.
When it comes to opinion mining, analyzing public opinion can be highly beneficial in assessing satisfaction and agreement with political decisions and programs. This type of analysis can offer valuable insights into a candidate’s popularity and even aid in predicting their likelihood of winning an election compared to their competitors. Xia \BOthers. (\APACyear2021)Das \BOthers. (\APACyear2021).
In machine translation systems, Identifying a sentence appearing sentiment can also help traduction systems evaluate the correct meaning generated by a token, develop a traduced text with high accuracy, and keep the original text sentiments and nuances Xu \BOthers. (\APACyear2018)Mohammad \BOthers. (\APACyear2016).
By gathering data through keywords, marketing agencies can determine whether their product advertisements effectively reach the intended audience and whether that audience is engaging with the postsRambocas \BBA Pacheco (\APACyear2018). Additionally, analyzing comments and posts on public profiles can provide insight into the interests of a particular group, allowing targeted advertising to reach individuals with similar hobbies or areas of focusFan \BBA Chang (\APACyear2010)Qiu \BOthers. (\APACyear2010).
Twitter is an excellent platform for extracting sentiment since various users from diverse fields express their opinions or announce upcoming events through tweets or textual posts. Since tweets could be considered a sequence of words, we can use an approved NLP model to perform this task. Still, this article aims to develop a new model using the transfer learning capabilities of transferring pre-trained model parameters. We used a portion of the tweet sentiment extraction datasetMaggie (\APACyear2020). The dataset and the Matlab scripts used are available from this GitHub link: - .
2 Related Work
The Viterbi algorithm is a dynamic programming algorithm used in various scientific models to predict the most probable sequence of hidden states in a Hidden Markov Model (HMM). In NLP, HMM models are primarily used to determine sequences of part-of-speech (POS) taggingToutanvoa \BBA Manning (\APACyear2000)Toutanova \BOthers. (\APACyear2003), named entity recognition (NER)Ratinov \BBA Roth (\APACyear2009), or speech recognition Rabiner (\APACyear1989).
Contextualizing information is an important aspect of information extraction. The words and POS that follow a predicted state can give insight into the status of the current token in an HMM model. Ratinov \BBA Roth (\APACyear2009).
To address the issue of interpretability in new NLP models and the challenges educators and learners face in comprehending the workings of large language models, experts in NLP are placing significant emphasis on creating explainable modelsBarredo Arrieta \BOthers. (\APACyear2020). They aim to achieve a level of intelligence comparable to humans using limited memorized observations.
When designing a suitable model for NLP tasks, algorithm concepts rely on interdisciplinarity as an essential criterion. To develop more robust models, it is necessary to understand the theory behind the decision-making procedure of information extractionBaklouti (\APACyear2019)Baklouti (\APACyear2021). Using punctuation when writing textual data, especially for long sentences, is crucial. It serves as an excellent indicator of how the human brain needs to restructure long structures into smaller ones to assimilate information better. This helps to avoid losing attention to the words’ meaning and combinations.
Transfer learning is a technique that enhances the capability of NLP models to carry out information extraction tasks. It achieves this by improving the model’s interpretability and combining contextual information in categorical or quantified form with the predefined model. This is achieved by transferring knowledge from another related modelBaklouti (\APACyear2021).
Getting the best performance out of deep neural network models demands a lot of computation power because these models have intricate architectures comprising various layers and parameters. It’s not straightforward to grasp how this specific model operates. To ensure explainable AI, it is essential to have transparency and avoid relying solely on black-box modelsGuidotti \BOthers. (\APACyear2018)Rudin (\APACyear2019).
Labeling the inputs is also an essential procedure for AI-based systems, and for more interpretable mechanisms, observing a strong dependence between the model structure sizes and the labeling criteria is an excellent step toward an explainable AI. For DNN models, the choice of nodes and layer number doesn’t variate during the model implementation leading to static interpretation of the model performances, and the improvements are based on more hyperparameters fine-tuning Lipton (\APACyear2018).
3 Methodology
We used the last advances in the Viterbi algorithm developed by the author to incorporate external knowledge into this algorithm logicBaklouti (\APACyear2021). There are three agents used in our model to extract the sentiment in a tweet:
-
•
Word-level tokens: We utilized the ’tokenizedDocument’ function from the Text Analytics Toolbox of Matlab to extract tokens from the processed text. The phrase-level tokens in the output were formed solely with words from the Word-level tokens generated.
-
•
POS tags: We attributed to each token a POS tag generated by the function ’addPartOfSpeechDetails’ of the Text Analytics Toolbox of Matlab. This agent represents an external transferred knowledge to the HMM model.
-
•
coeff: This is an estimation of the coefficient for a generalized linear model that predicts the sentiment category of a sentence as either negative, neutral, or positive. The input data for this model is generated using the ’bagOfWords’ function from the Text Analytics Toolbox of Matlab. This agent represents an external transferred knowledge to the HMM model.
We used the Viterbi algorithm with transfer learning to extract tweet sentiment. This involved a modified version of the double-agent Viterbi algorithm. The parameters of the HMM model used were as follows:
-
•
, the states of the model, if the token is not selected then else if the token is selected . For selected tokens for the first token and the other states depend on the POS tag of the token, if the then automatically and else the state is incremented by one
-
•
, the state transition probability distribution. The probability is the probability that the system will move in one transition from state to state given at state POS and coeff agents are known.
-
•
, the observation symbol probability distribution. The probability is the probability that the observation is emitted in position when the model moves from state in position to state in position given at state POS is known.
-
•
, the initial state distribution. The probability is the probability that the system will start in state given that the initial coeff is known.
-
•
, the initial observation symbol probability distribution. The probability is the probability that the observation will be emitted at the beginning of the sentence when the model has the initial state given at the initial state POS is known.
-
•
, the initial observation symbol probability distribution with initial states transition. The probability is the probability that the token will be emitted at the beginning of the sentence when the model moves from the initial state to the second state given at state POS is known.
To evaluate the model, two scores are used: the Jaccard score and the confidence score. The confidence score is utilized to determine the model’s level of certainty in estimating the output’s state. If the confidence score is one, the model is highly confident in its estimation, and there’s a high likelihood of obtaining an accurate estimation. However, if the confidence score decreases, there’s a lower level of confidence, which leads to hesitation regarding the estimation. The confidence score is calculated using the following formulas:
| (1) |
| (2) |
Where is a set of confidence matrices obtained using the formulas :
| (3) |
| (4) |
Where , and .
The confidence score equation is represented by Equation (1). The vector has the same length as the output vector, which contains the states (where ). Additionally, Equation (2) represents the confidence vector equation, which contains the confidence score of each token. Equation (3) represents confidence matrix used to backtrack confidencce scores. Equation (4) represents the model parameter .
4 Results and Interpretation
The table[1] shows a clear connection between the confidence and Jaccardi scores. As the confidence score goes up, so does the Jaccardi score. This is because the confidence score reveals whether a sentiment exists in a specific position within a sentence and indicates how sure the system is about extracting that particular token as a part of the words that make up the sentiment. This metric improves the Jaccardi score by addressing the extracted emotion’s boundaries and preventing unwanted tokens’ extraction.
| Viterbi Form number | Jaccard training score | Confidence training score |
|---|---|---|
| viterbi Form One | 0.9485 | 0.9825 |
| viterbi Form Two | 0.9681 | 0.991 |
| viterbi Form Three | 0.9746 | 0.996 |
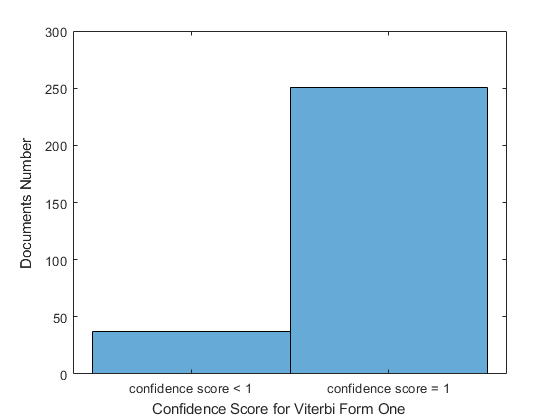
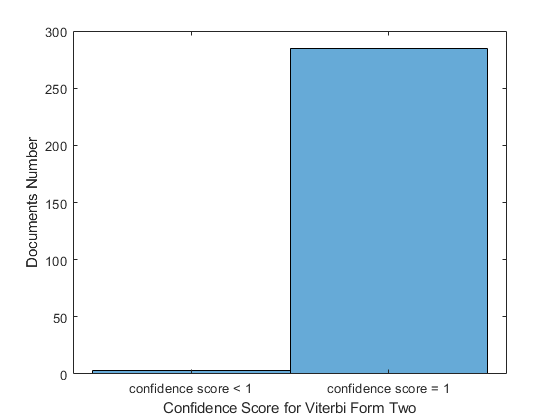
Additionally, the confidence score can identify areas where the model needs improvement by incorporating additional parameters. In Figure [1], we compare the confidence score values for the last tokens in sentences between Viterbi Form One presented by equation (5) and Viterbi Form Two presented by equation (6), which includes an extra parameter. This parameter, , is the probability distribution of the delayed observation symbol. The probability refers to the probability that observation will be emitted at position . When the model moves from state in position to state in position , given that the POS is known at state . By including this new model parameter, the number of documents with a maximum confidence score of one for the last token increased by 34 (251 for Viterbi Form One and 285 for Viterbi Form Two) for 288 total document numbers.
-
•
Viterbi Form One :
(5) -
•
Viterbi Form Two :
(6) -
•
Viterbi Form Three :
(7) where , , , is the set of state matrix , is the current state matrix, is state of the output at position ,
By adjusting the size of the state matrix in each iteration based on the Pos tags behind the predicted token and the previous state matrix, the interpretability of sentiment extraction models has improved. This adjustment reduces the area of the state matrix around the most likely estimated states, resulting in a more precise estimation and a smaller denominator in the confidence matrix equations (3). This leads to a more confident model.
Improving the model tuning has become easier with a straightforward method for adding new parameters and identifying areas of low confidence to make adjustments. For instance, Viterbi Form One was weak in estimating the last token using equation (5). Still, by introducing a new model parameter while estimating the state for the last token in equation (6), we enhanced the model’s performance in Viterbi Form Two. This model-tuning approach can also be applied to all tokens in the sentence, as demonstrated in Viterbi Form Three equation (7). This modification has further increased the model’s performance compared to Viterbi Form Two.
5 Conclusion
Our paper presents improvements to the Viterbi algorithm, resulting in better performance. We accomplished this by developing a more easily understandable model and incorporating recent advancements through transfer learning techniques. Additionally, we created a state matrix that adapts its dimensions based on contextual information, resulting in a more effective NLP algorithm. We added a conditional probability distribution and calculated the confidence score vector to fine-tune the model. We compared the performances of various Viterbi forms. Our algorithm selected a set of POS tags where the state matrix’s second dimension is reset to 2. However, we acknowledge that more research is needed to effectively choose this list of POS tags using a more elaborate method.
References
- Baklouti (\APACyear2019) \APACinsertmetastarBaklouti2019HiddenMB{APACrefauthors}Baklouti, Z. \APACrefYearMonthDay2019. \BBOQ\APACrefatitleHidden Markov Based Mathematical Model dedicated to Extract Ingredients from Recipe Text Hidden markov based mathematical model dedicated to extract ingredients from recipe text.\BBCQ \APACjournalVolNumPagesArXivabs/2110.15707. {APACrefURL} \urlhttps://api.semanticscholar.org/CorpusID:240288474 \PrintBackRefs\CurrentBib
- Baklouti (\APACyear2021) \APACinsertmetastarBaklouti2021ExternalKT{APACrefauthors}Baklouti, Z. \APACrefYearMonthDay2021. \BBOQ\APACrefatitleExternal knowledge transfer deployment inside a simple double agent Viterbi algorithm External knowledge transfer deployment inside a simple double agent viterbi algorithm.\BBCQ \APACjournalVolNumPagesArXivabs/2110.00433. {APACrefURL} \urlhttps://api.semanticscholar.org/CorpusID:238253018 \PrintBackRefs\CurrentBib
- Barredo Arrieta \BOthers. (\APACyear2020) \APACinsertmetastar10.1016/j.inffus.2019.12.012{APACrefauthors}Barredo Arrieta, A., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A.\BDBLHerrera, F. \APACrefYearMonthDay2020jun. \BBOQ\APACrefatitleExplainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai.\BBCQ \APACjournalVolNumPagesInf. Fusion58C82–115. {APACrefURL} \urlhttps://doi.org/10.1016/j.inffus.2019.12.012 {APACrefDOI} \doi10.1016/j.inffus.2019.12.012 \PrintBackRefs\CurrentBib
- Das \BOthers. (\APACyear2021) \APACinsertmetastar9679946{APACrefauthors}Das, A., Gunturi, K\BPBIS., Chandrasekhar, A., Padhi, A.\BCBL \BBA Liu, Q. \APACrefYearMonthDay2021. \BBOQ\APACrefatitleAutomated Pipeline for Sentiment Analysis of Political Tweets Automated pipeline for sentiment analysis of political tweets.\BBCQ \BIn \APACrefbtitle2021 International Conference on Data Mining Workshops (ICDMW) 2021 international conference on data mining workshops (icdmw) (\BPG 128-135). {APACrefDOI} \doi10.1109/ICDMW53433.2021.00022 \PrintBackRefs\CurrentBib
- Fan \BBA Chang (\APACyear2010) \APACinsertmetastarfan2010sentiment{APACrefauthors}Fan, T\BHBIK.\BCBT \BBA Chang, C\BHBIH. \APACrefYearMonthDay2010. \BBOQ\APACrefatitleSentiment-oriented contextual advertising Sentiment-oriented contextual advertising.\BBCQ \APACjournalVolNumPagesKnowledge and information systems23321–344. \PrintBackRefs\CurrentBib
- Guidotti \BOthers. (\APACyear2018) \APACinsertmetastar10.1145/3236009{APACrefauthors}Guidotti, R., Monreale, A., Ruggieri, S., Turini, F., Giannotti, F.\BCBL \BBA Pedreschi, D. \APACrefYearMonthDay2018aug. \BBOQ\APACrefatitleA Survey of Methods for Explaining Black Box Models A survey of methods for explaining black box models.\BBCQ \APACjournalVolNumPagesACM Comput. Surv.515. {APACrefURL} \urlhttps://doi.org/10.1145/3236009 {APACrefDOI} \doi10.1145/3236009 \PrintBackRefs\CurrentBib
- Lipton (\APACyear2018) \APACinsertmetastar10.1145/3236386.3241340{APACrefauthors}Lipton, Z\BPBIC. \APACrefYearMonthDay2018jun. \BBOQ\APACrefatitleThe Mythos of Model Interpretability: In Machine Learning, the Concept of Interpretability is Both Important and Slippery. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery.\BBCQ \APACjournalVolNumPagesQueue16331–57. {APACrefURL} \urlhttps://doi.org/10.1145/3236386.3241340 {APACrefDOI} \doi10.1145/3236386.3241340 \PrintBackRefs\CurrentBib
- Maggie (\APACyear2020) \APACinsertmetastartweet-sentiment-extraction{APACrefauthors}Maggie, W\BPBIC., Phil Culliton. \APACrefYearMonthDay2020. \APACrefbtitleTweet Sentiment Extraction. Tweet sentiment extraction. \APACaddressPublisherKaggle. {APACrefURL} \urlhttps://kaggle.com/competitions/tweet-sentiment-extraction \PrintBackRefs\CurrentBib
- Mohammad \BOthers. (\APACyear2016) \APACinsertmetastarmohammad2016translation{APACrefauthors}Mohammad, S\BPBIM., Salameh, M.\BCBL \BBA Kiritchenko, S. \APACrefYearMonthDay2016. \BBOQ\APACrefatitleHow translation alters sentiment How translation alters sentiment.\BBCQ \APACjournalVolNumPagesJournal of Artificial Intelligence Research5595–130. \PrintBackRefs\CurrentBib
- Qiu \BOthers. (\APACyear2010) \APACinsertmetastarqiu2010dasa{APACrefauthors}Qiu, G., He, X., Zhang, F., Shi, Y., Bu, J.\BCBL \BBA Chen, C. \APACrefYearMonthDay2010. \BBOQ\APACrefatitleDASA: dissatisfaction-oriented advertising based on sentiment analysis Dasa: dissatisfaction-oriented advertising based on sentiment analysis.\BBCQ \APACjournalVolNumPagesExpert Systems with Applications3796182–6191. \PrintBackRefs\CurrentBib
- Rabiner (\APACyear1989) \APACinsertmetastar18626{APACrefauthors}Rabiner, L. \APACrefYearMonthDay1989. \BBOQ\APACrefatitleA tutorial on hidden Markov models and selected applications in speech recognition A tutorial on hidden markov models and selected applications in speech recognition.\BBCQ \APACjournalVolNumPagesProceedings of the IEEE772257-286. {APACrefDOI} \doi10.1109/5.18626 \PrintBackRefs\CurrentBib
- Rambocas \BBA Pacheco (\APACyear2018) \APACinsertmetastarrambocas2018online{APACrefauthors}Rambocas, M.\BCBT \BBA Pacheco, B\BPBIG. \APACrefYearMonthDay2018. \BBOQ\APACrefatitleOnline sentiment analysis in marketing research: a review Online sentiment analysis in marketing research: a review.\BBCQ \APACjournalVolNumPagesJournal of Research in Interactive Marketing122146–163. \PrintBackRefs\CurrentBib
- Ratinov \BBA Roth (\APACyear2009) \APACinsertmetastarratinov-roth-2009-design{APACrefauthors}Ratinov, L.\BCBT \BBA Roth, D. \APACrefYearMonthDay2009\APACmonth06. \BBOQ\APACrefatitleDesign Challenges and Misconceptions in Named Entity Recognition Design challenges and misconceptions in named entity recognition.\BBCQ \BIn \APACrefbtitleProceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL-2009) Proceedings of the thirteenth conference on computational natural language learning (CoNLL-2009) (\BPGS 147–155). \APACaddressPublisherBoulder, ColoradoAssociation for Computational Linguistics. {APACrefURL} \urlhttps://aclanthology.org/W09-1119 \PrintBackRefs\CurrentBib
- Rudin (\APACyear2019) \APACinsertmetastarrudin2019stop{APACrefauthors}Rudin, C. \APACrefYearMonthDay2019. \APACrefbtitleStop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. \PrintBackRefs\CurrentBib
- Toutanova \BOthers. (\APACyear2003) \APACinsertmetastartoutanova-etal-2003-feature{APACrefauthors}Toutanova, K., Klein, D., Manning, C\BPBID.\BCBL \BBA Singer, Y. \APACrefYearMonthDay2003. \BBOQ\APACrefatitleFeature-Rich Part-of-Speech Tagging with a Cyclic Dependency Network Feature-rich part-of-speech tagging with a cyclic dependency network.\BBCQ \BIn \APACrefbtitleProceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics Proceedings of the 2003 human language technology conference of the north American chapter of the association for computational linguistics (\BPGS 252–259). {APACrefURL} \urlhttps://aclanthology.org/N03-1033 \PrintBackRefs\CurrentBib
- Toutanvoa \BBA Manning (\APACyear2000) \APACinsertmetastartoutanvoa-manning-2000-enriching{APACrefauthors}Toutanvoa, K.\BCBT \BBA Manning, C\BPBID. \APACrefYearMonthDay2000\APACmonth10. \BBOQ\APACrefatitleEnriching the Knowledge Sources Used in a Maximum Entropy Part-of-Speech Tagger Enriching the knowledge sources used in a maximum entropy part-of-speech tagger.\BBCQ \BIn \APACrefbtitle2000 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora 2000 joint SIGDAT conference on empirical methods in natural language processing and very large corpora (\BPGS 63–70). \APACaddressPublisherHong Kong, ChinaAssociation for Computational Linguistics. {APACrefURL} \urlhttps://aclanthology.org/W00-1308 {APACrefDOI} \doi10.3115/1117794.1117802 \PrintBackRefs\CurrentBib
- Xia \BOthers. (\APACyear2021) \APACinsertmetastar10.1145/3442442.3452322{APACrefauthors}Xia, E., Yue, H.\BCBL \BBA Liu, H. \APACrefYearMonthDay2021. \BBOQ\APACrefatitleTweet Sentiment Analysis of the 2020 U.S. Presidential Election Tweet sentiment analysis of the 2020 u.s. presidential election.\BBCQ \BIn \APACrefbtitleCompanion Proceedings of the Web Conference 2021 Companion proceedings of the web conference 2021 (\BPG 367–371). \APACaddressPublisherNew York, NY, USAAssociation for Computing Machinery. {APACrefURL} \urlhttps://doi.org/10.1145/3442442.3452322 {APACrefDOI} \doi10.1145/3442442.3452322 \PrintBackRefs\CurrentBib
- Xu \BOthers. (\APACyear2018) \APACinsertmetastarxu2018unpaired{APACrefauthors}Xu, J., Sun, X., Zeng, Q., Ren, X., Zhang, X., Wang, H.\BCBL \BBA Li, W. \APACrefYearMonthDay2018. \APACrefbtitleUnpaired Sentiment-to-Sentiment Translation: A Cycled Reinforcement Learning Approach. Unpaired sentiment-to-sentiment translation: A cycled reinforcement learning approach. \PrintBackRefs\CurrentBib