∎
Chengdu, Sichuan 611756, China
2. National Engineering Laboratory of Integrated Transportation Big Data Application Technology
Chengdu, Sichuan 611756, China
3. School of Mathematical Sciences, University of Electronic Science and Technology of China
Chengdu, Sichuan, 611731, China
[email protected] 33institutetext: Zhen-yin Lei 44institutetext: 1. Department of Mathematics, Southwest Jiaotong University
Chengdu, Sichuan 611756, China
2. National Engineering Laboratory of Integrated Transportation Big Data Application Technology
Chengdu, Sichuan 611756, China
[email protected] 55institutetext: Xin Long 66institutetext: 1. Department of Mathematics, Southwest Jiaotong University
Chengdu, Sichuan 611756, China
2. National Engineering Laboratory of Integrated Transportation Big Data Application Technology
Chengdu, Sichuan 611756, China
[email protected] 77institutetext: Zhang-you Chen 88institutetext: 1. Department of Mathematics, Southwest Jiaotong University
Chengdu, Sichuan 611756, China
2. National Engineering Laboratory of Integrated Transportation Big Data Application Technology
Chengdu, Sichuan 611756, China
[email protected]
Tseng Splitting Method with Double Inertial Steps for Solving Monotone Inclusion Problems
Abstract
In this paper, based on double inertial extrapolation steps strategy and relaxed techniques, we introduce a new Tseng splitting method with double inertial extrapolation steps and self-adaptive step sizes for solving monotone inclusion problems in real Hilbert spaces. Under mild and standard assumptions, we establish successively the weak convergence, nonasymptotic convergence rate, strong convergence and linear convergence rate of the proposed algorithm. Finally, several numerical experiments are provided to illustrate the performance and theoretical outcomes of our algorithm.
Keywords Monotone inclusion problem; Tseng splitting method; Double inertial extrapolation steps; Strong and weak convergence; Linear convergence rate
1 Introduction
Let be a real Hilbert space with the inner product and the induced norm . The monotone inclusion problem (MIP) is as follows
| (1.1) |
where is a single mapping and is a multivalued mapping. The solution set is denoted by .
The monotone inclusion problem has drawn much attention because it provides a broad unifying frame for variational inequalities, convex minimization problems, split feasibility problems and equilibrium problems, and has been applied to solve several real-world problems from machine learning, signal processing and image restoration, see AB ; BH ; CD ; CW ; DS ; RF ; TYCR .
One of famous methods for solving MIP (1.1) is forward-backward splitting method, which was introduced by Passty PG and Lions et al. LP . This method generates an iterative sequence in following way
| (1.2) |
where the mapping is -co-coercive, is maximal monotone, is an identity mapping on and . The operator is called an forward operator and is said to be a backward operator.
Tseng TP proposed a modified forward-backward splitting method (also known as Tseng splitting algorithm), whose iterative formula is as follows
| (1.3) |
where is -lipschitz continuous and . However, the Lipschitz constant of an operator is often unknown or difficult to estimate in nonlinear problems. To overcome this drawback, Cholamjiak et al. CV introduce a relaxed forward-backward splitting method, which uses a simple step-size rule without the prior knowledge of Lipschitz constant of the operator, for solving MIP (1.1) and prove the linear convergence rate of the proposed algorithm.
In recent year, the inertial method was introduced in AF , which can be regarded as a procedure of speeding up the convergence rate of algorithms. Many researchers utilize inertial methods to design algorithm for solving monotone inclusion problems and variational inequalities, see, for example, AB ; CD ; CV ; CH ; CHG ; DQ ; LN ; PTK ; SY ; TD ; YI . To enhance the numerical efficiency, Çopur et al. CHG introduce firstly the double inertial extrapolation steps for solving quasi-variational inequalities in real Hilbert spaces. Combining relaxation techniques with the inertial methods, Cholamjiak et al. CV modify Tseng splitting method to solve MIP (1.1) in real Hilbert spaces. Very recently, incorporating double inertial extrapolation steps and relaxation techniques, Yao et al. YI present a novel subgradients extragradient method to solve variational inequalities, and prove its strong convergence, weak convergence and linear convergence, respectively. However, the linear convergence of YI is obtained under a single inertia rather than double inertias.
This paper devotes to further modifying Tseng splitting method for solving MIP (1.1) in real Hilbert spaces. We obtain successively the weak convergence, nonasymptotic convergence rate, strong convergence and linear convergence rate of the proposed algorithm. Our results obtained in this paper improve the corresponding results in AB ; CV ; CH ; VA ; YI as follows:
Combining double inertial extrapolation steps strategy and relaxed techniques, we propose a new Tseng splitting method, which include the corresponding methods considered in AB ; CV ; YI as special cases. The two inertial factors in our algorithm are variable sequences, different from the constant inertial factor in AB ; CV ; CH ; YI . Especially, when our algorithm is applied to solving variational inequalities, its some parameters have larger choosing interval than the ones of YI . In addition, one of our inertial factors can be equal to 1, which is not allowed in the single inertial methods CV ; CH , which require that the inertial factor must be strictly less than 1.
We prove the strong convergence, nonasymptotic convergence rate and linear convergence rate of the proposed algorithm. Note that that the strong convergence does not require to know the modulus of strong monotonicity and the Lipschitz constant in advance. As far as we know, there is no convergence rate results in the literature for methods with double inertial extrapolation steps for solving MIP (1.1) in infinite-dimensional Hilbert spaces.
Our algorithm use double inertial extrapolation steps to accelerate the speed of the algorithm. The step sizes of our algorithm are updated by a simple calculation without knowing the Lipschitz constant of the underlying operator. Some numerical experiments show that our algorithm has better efficiency than the corresponding algorithms in AB ; CV ; CH ; VA ; YI .
The structure of this article is as follows. In section 2, we recall some essential definitions and results which is relate to this paper. In section 3, we present our algorithm and analyze its weak convergence. In section 4, we establish the strong convergence and the linear convergence rate of our method. In section 5, we present some numerical experiments to demonstrate the performance of our algorithm. We give some concluding remarks in section 6.
2 Preliminaries
In this section, we first give some definitions and results that will be used in this paper. The weak convergence and strong convergence of sequences are denoted by and , respectively.
Definition 1
The mapping is called
-
(i)
pseudomonotone on if implies that ;
-
(ii)
monotone on if
-
(iii)
-strongly monotone on if there exists a positive constant
-
(iv)
-lipschitz continuous on if there exists a scalar satisfying
-
(v)
-strongly pseudomonotone on if there exists a positive constant such that
implies that
Definition 2
The graph of is the set in defined by
Let be a nonempty, closed and convex set. The normal cone of at is represented by
The projection of onto , denoted by , is defined as
and is has
The sequence is -linear convergence if there is such that for all large enough.
Definition 3
The set-valued mapping is called
-
(i)
monotone on if for all , and implies that
-
(ii)
maximal monotone on if it is monotone and for any for every implies that ;
-
(iii)
-strongly monotone on if for all , and implies that
Lemma 1
(MP )Let and be sequences in such that
and there exists a real number with for all .Then the following hold :
-
(i)
where ;
-
(ii)
there exists such that .
Lemma 2
(OZ )Let be a nonempty set of and be a sequence in such that the following two conditions hold:
-
(i)
for every exists;
-
(ii)
every sequential weak cluster point of is in .
Then converges weakly to a point in .
Lemma 3
TX Let be a maximal monotone mapping and be a Lipschitz continuous and monotone mapping. Then the mapping is a maximal monotone mapping.
Lemma 4
Lemma 5
XH Let , , and be nonnegative real numbers sequences and there exists such that
where , and satisfy the following conditions
-
(i)
and
-
(ii)
-
(iii)
.
Then .
Lemma 6
GT Let be a set-valued maximal monotone mapping and is a mapping. Define . Then .
Lemma 7
(BH ,Corollaty 2.14) For all and , the following equality holds:
3 Weak convergence
In this section, we introduce the Tseng splitting method with double inertial steps to solve MIP (1.1) and discuss convergence and convergence rate of the new algorithm. We firstly give the following conditions.
-
()
The solution set of the inclusion problem (1.1) is nonempty, that is, .
-
()
The mappings is -Lipschitz continuous and monotone and the set-valued mapping is maximal monotone.
-
()
The real sequences , , , , and satisfy the following conditions
-
(i)
;
-
(ii)
;
-
(iii)
;
-
(iv)
is a non-decreasing sequence;
-
(v)
and .
Remark 1
Note that if is a non-decreasing sequence, and , then the condition ()(iv) holds naturally. In addition, if we choose , and , then the condition ()(iv) is also true.
Algorithm 3.1
Choose , and
- Step 1.
-
Step 2.
Compute
Let and return to Step 1.
Remark 2
- (i)
-
(ii)
In order to get the larger step sizes, being similar to the sequence in Algorithm 3.1 of W , the sequence is used to relax the parameter . The sequence can be called a relaxed parameter sequence, which can often improve numerical efficiency of algorithms, see CV . If , then the step size is the same as the one of Algorithm 4.1 in CH . If and , then the step size is the same as the one of Algorithm 3.1 of VA .
- (iii)
Lemma 8
The sequences from Algorithm 3.1 is bounded and . Furthermore there exists such that , where .
Proof
By the definition of , if , we get
| (3.1) |
Since , we have
| (3.2) |
It implies that .
We have
| (3.3) |
Thus
| (3.4) |
Since is bounded and , we get is convergent. Therefore, there exists such that . This proof is completed.
Remark 3
If , then . By Lemma 6, we know .
Lemma 9
Suppose that the sequence is generated by Algorithm 3.1. Thus the following assertions hold:
-
(i)
if the conditions () and () hold, then
-
(ii)
if the conditions () and () hold and or is -strongly monotone, then
Proof
(i) According to the definition of , we have that
| (3.5) |
Since and is maximal monotone, we obtain
| (3.6) |
Thus
Since is monotone and is a maximal monotone operator, Lemma 3 implies that is maximal monotone. Since , and so
Hence
| (3.7) |
Combing (3.5) with (3.7), we get
| (3.8) |
The proof of the part (i) is completed.
(ii) Case I is -strongly monotone.
Lemma 10
Assume that the conditions () and () hold, and and are sequences generated by Algorithm 3.1. If and converges weakly to some , then .
Proof
Theorem 3.1
Assume that the conditions ()-() hold. Then the sequence from Algorithm 3.1 converges weakly to some element .
Proof
By the definition of and Lemma 7, we have
| (3.18) |
The definition of implies that . Thus
| (3.19) |
By Lemma 9, we have
| (3.20) |
Substituting (3.19) and (3.20) into (3.18), we get
| (3.21) |
Lemma 8 and the fact imply that . Thus there exists a positive integer such that
Thanks to (3.21), we have
| (3.22) |
By the definition of and Lemma 7, we obtain
| (3.23) |
From the definition of and Lemma 7, it follows that
| (3.24) |
The definition of means that
| (3.25) |
Owing to (3.23), (3.24), (3.25) and (3.22), we know
| (3.26) |
where , and .
Define
Since is non-decreasing, by (3.26), we deduce that
| (3.27) |
The condition () means that
| (3.28) |
Combining (3.27) and (3.28), we infer that
| (3.29) |
where . Since , we conclude that . From (3.29), it follows that
Thus the sequence is nonincreasing. The condition () implies that . Thus
| (3.30) |
This implies that
| (3.31) |
where .
By definition of , we have
| (3.32) |
According to (3.31) and (3.32), we infer that
| (3.33) |
| (3.34) |
This implies
| (3.35) |
Thus
| (3.36) |
The definition of implies that
| (3.37) |
Since is bounded, by (3.37), we obtain
| (3.38) |
On the other hand
| (3.39) |
From (3.36) and (3.38), it follows that
| (3.40) |
By (3.26), we have
| (3.41) |
Since and is bounded, by Lemma 1 and (3.35), we know there exists such that
| (3.42) |
Then from (3.24), we have
| (3.43) |
Since is bounded, by (3.36) and (3.42), we obtain
| (3.44) |
Utilizing the similar discussion as in obtaining (3.44), we can get
| (3.45) |
Owing to (3.21), we have
| (3.46) |
Let is a nonempty, closed and convex subset of . If , then MIP (1.1) reduce to the following variational inequality, denoted by VI: find a point such that
Denote the solution set of VI by .
Assumption 3.1
-
(i)
The solution set of the problem (VI) is nonempty, that is, .
-
(ii)
The mapping is pseudomonotone, Lipschitz continuous and satisfies the condition: for any with , one has
Proposition 1
Proof
Proposition 2
Proof
This proof is the same as in Lemma 3.7 of TYCR , and we omit it.
Corollary 1
Proof
Remark 4
Compared with Theorem 4.2 of YI , the advantages of Corollary 1 have (i) the sequence may not be non-decreasing; (ii) the sequence may not be a constant; (iii) we require other than , which extend the taking value interval of . From the numerical experiment in Section 5, it can be seen that the larger the values of , the better the algorithm performs.
Motivated by the Theorem 5.1 of SILD , which may be the first nonasymptotic convergence rate results of inertial projection-type algorithm for solving variational inequalities with monotone mappings, we give the nonasymptotic convergence rate with for Algorithm 3.1.
Theorem 3.2
Assume that the conditions ()-() hold, the sequence be generated by Algorithm 3.1 and . Then for any , there exist constants M such that the following estimate holds
Proof
From (3.55), it follows that
| (3.59) |
This implies that
| (3.60) |
and thus
| (3.61) |
Since , we get
| (3.62) |
This completes the proof.
4 Strong convergence
In this section, we analyse strong convergence and linear convergence of Algorithm 3.1. Firstly, we give the following assumption.
Assumption 4.1
The mapping is -Lipschitz continuous, -strongly monotone and the set-valued mapping is maximal monotone or the mapping is -Lipschitz continuous, monotone and the set-valued mapping is -strongly monotone.
Theorem 4.1
Proof
By (3.18) (3.19) and Lemma 9 (ii), we have
| (4.1) |
Lemma 8 and the fact imply that . Thus there exists a positive integer such that
It follows that from (4.1)
| (4.2) |
From Lemma 8, it follows that
| (4.3) |
where .
The definition of implies that
| (4.4) |
By utilizing the definition of , we have
| (4.5) |
Combining (4.3) (4.4) and (4.5), we obtain
| (4.6) |
In addition,
which implies that
| (4.7) |
In view of (4.6) and (4.7), we have
| (4.8) |
Since and , we obtain .
Remark 6
To the best of our knowledge, Theorem 4.1 is one of the few available strong convergence results for algorithms with the double inertial extrapolation steps to solve MIP (1.1). In addition, we emphasize that Theorem 4.1 does not need to know the modulus of strong monotonicity and the Lipschitz constant in advance.
Corollary 2
Let and is -strong pseudomonotone and -Lipschitz continuous. If the conditions () hold, then the sequence from Algorithm 3.1 converges strongly to a point .
Remark 7
In order to discuss the linear convergence rate of our algorithm, we need the following assumption.
Assumption 4.2
-
(i)
The solution set of the inclusion problem (1.1) is nonempty, that is, .
-
(ii)
The mapping is -Lipschitz continuous, -strongly monotone and the set-valued mapping is maximal monotone or the mapping is -Lipschitz continuous, monotone and the set-valued mapping is -strongly monotone.
-
(iii)
Let , and the following conditions hold:
-
()
-
()
-
()
Remark 8
The parameters set satisfying the condition is non-empty. For example, we can choose , , , , and .
Next, we establish the linear convergence rate of our algorithm under Assumption 4.2.
Theorem 4.2
Proof
By Lemma 8 we know . Since , . Thus it follows that from (4.1) there exists a positive integer such that
| (4.11) |
Substituting (3.23), (3.24) and (3.25) into (4.11), we have
| (4.12) |
This implies that
| (4.13) |
where and .
Now, we will show that :
| (4.14) |
Since , we get . From , it follows that . By (4.13), we have
| (4.15) |
where the last inequality follows from and .
Since , we have . Therefore we get
| (4.16) |
This implies that
| (4.17) |
Hence, the proof is completed.
Remark 9
Theorem 6.2 of YI gives a linear convergence rate result of the subgradient extragradient method with double inertial steps for solving variational inequalities. However, it only discuss the single inertial case in YI . As far as we know, algorithms with the double inertial extrapolation steps for solving variational inequalities and monotone inclusions have no linear convergent result. Hence Theorem 4.2 is a new result.
5 Numerical experiments
In this section, we provide some numerical examples to show the performance of our Algorithm 3.1 (shortly Alg1), and compare it with others, including Abubakar et al’s Algorithm 3.1 (shortly AKHAlg1) AB , Chlolamjiak et al’s Algorithm 3.2(CHCAlg2) CV , Cholamjiak et al’s Algorithm 3.1 (CHMAlg1) CH , Hieu et al’s Algorithm 3.1 (HAMAlg1) VA and Yao et al’s Algorithm 1 (YISAlg1) YI .
All the programs were implemented in MATLAB R2021b on Intel(R) Core(TM) i7-7700HQ CPU@
2.80GHZ computer with RAM 8.00GB. We denote the number of iterations by ”Iter.” and the CPU time seconds by ”CPU(s)”.
Example 1
We consider the signal recovery in compress sensing. This problem can be modeled as
| (5.1) |
where is observed or measured data, is bounded linear operator, is a vector with nonzero components and is the noise. It is know that the problem (5.1) can be viewed as the LASSO problem CV
| (5.2) |
The minimization problem 5.2 is equivalent to the following monotone inclusion problem
| (5.3) |
where and . In this experiment, the vector is from uniform distribution in the interval .
The matrix is produced by a normal distribution with mean zero and one variance. The vector is generated by Gaussian noise with variance . The initial points and are both zero. We use to measure the restoration accuracy. And the stopping criterion is .
In the first experiment we consider the influence of different and on the performance of our algorithm. We take , , , and .
| 0.2 | 0.4 | 0.6 | 0.8 | 0.9 | 1 | |
| 0 | 966 | 872 | 777 | 681 | 632 | 584 |
| 0.02 | 954 | 859 | 764 | 668 | 620 | 572 |
| 0.04 | 942 | 848 | 752 | 656 | 608 | 559 |
| 0.06 | 930 | 836 | 740 | 644 | 596 | 547 |
| 0.08 | 918 | 823 | 728 | 632 | 583 | 535 |
| 0.1 | 906 | 811 | 716 | 620 | 571 | 522 |
It can be seen from Table 1 that Algorithm 3.1 with double inertial extrapolation steps, that is, outperform the one with single inertia, moreover, the increase of and significantly improves the convergence speed of the algorithm. This implies that it is important to investigate double inertial methods from both theoretical and numerical viewpoint.
In second experiment we compared the performance of our algorithm with other algorithms. The following two cases are considered
Case 1: ;
Case 2: .
The parameters for algorithms are chosen as
Alg1: ,, , , , and
CHCAlg2: , , and
CHMAlg1: , , and ;
HAMAlg1: , ;
AKHAlg1: , , and .
Fig.1 and Table.2 show the numerical results of our algorithm and other algorithms in two cases respectively. We give the graphs of original signal and recovered signal in Fig. 2.
| Algorithms | Case 1 | Case 2 | ||
| Iter. | CPU(s) | Iter. | CPU(s) | |
| Alg1 | 525 | 0.2447 | 809 | 1.2297 |
| CHCAlg2 | 1347 | 0.5340 | 2595 | 3.0049 |
| CHMAlg1 | 887 | 0.3496 | 1554 | 1.9651 |
| HAMAlg1 | 971 | 0.3904 | 1577 | 1.5138 |
| AKHAlg1 | 3427 | 1.3142 | 6723 | 6.4723 |




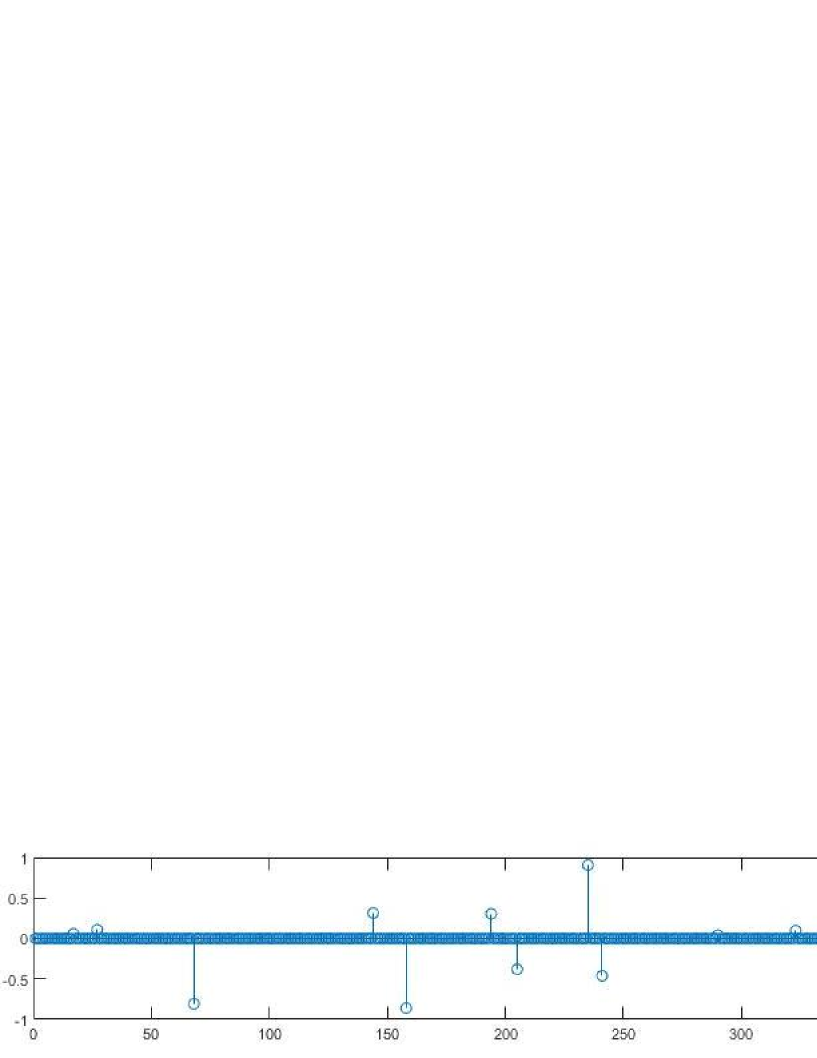




Remark 10
It can be seen from Fig.1 and Table 2 that the number of iterations and CPU time of our algorithm are better than other algorithms, indicating that our algorithm has better performance.
Example 2
We consider our algorithm to solve the variational inequality problem . The operator is defined by with and , where is an matrix, is an skew-symmetric matrix and is an diagonal matrix. All entries of and are uniformly generated from and all diagonal entries of are uniformly generated from . It is easy to see that is positive definite. Define the feasible set and use to measure the accuracy, and the stoping criterion is .
In the first experiment we consider the effect of relaxation coefficients on the performance of Algorithm 3.1. We choose , , , , and .
| 0.05 | 0.1 | 0.15 | 0.2 | 0.25 | 0.3 | 0.35 | 0.4 | 0.45 | |
| 16988 | 8521 | 5562 | 4035 | 3095 | 2454 | 1987 | 1360 | 1346 | |
| 1.8752 | 0.9888 | 0.6785 | 0.4804 | 0.3879 | 0.2910 | 0.2436 | 0.2246 | 0.1674 |
Table 3 shows that the performance comparison of Algorithm 3.1 for different values of . It can be seen that the performance of the algorithm becomes better with the increase of the relaxed parameter . This indicates that the increase of the relaxation coefficient value range is of great significance to improve the performance of the algorithm.
In second experiment we compared the performance of our algorithm with other algorithms. The following cases are considered
Case 1: ; Case 2: ; Case 3: ; Case 4:
The parameters for algorithms are chosen as
Alg1: , , , , and
HAMAlg1: ,
CHCAlg2: , , and
YISAlg1: , , , and
AKHAlg1: , , and ;
CHMAlg1: , , and .
Fig.3 and Table.4 show the performance comparison of our algorithm with other algorithms in four cases respectively.
| Algorithms | ||||||||
| Iter. | CPU(s) | Iter. | CPU(s) | Iter. | CPU(s) | Iter. | CPU(s) | |
| Alg1 | 448 | 0.0191 | 642 | 0.0380 | 759 | 0.0968 | 1012 | 0.1681 |
| CHCAlg2 | 723 | 0.0224 | 1048 | 0.0499 | 1234 | 0.1105 | 1644 | 0.2128 |
| YISAlg1 | 600 | 0.0917 | 963 | 0.0635 | 1214 | 0.1374 | 1595 | 0.2125 |
| HAMAlg1 | 779 | 0.0203 | 1142 | 0.0475 | 1355 | 0.1410 | 1751 | 0.1940 |
| AKHAlg1 | 1049 | 0.0267 | 1425 | 0.0659 | 1691 | 0.1625 | 2371 | 0.2839 |
| CHMAlg1 | 871 | 0.0331 | 1182 | 0.0637 | 1408 | 0.1366 | 1879 | 0.2158 |




Remark 11
It can be seen that our algorithm performs better than other algorithms for such problems as Example 5.2 from Fig.3 and Table 4.
Example 3
Let with the norm
and the inner product
Let and define by
It is clear that is monotone and Lipschitz with . The orthogonal projection onto have the following explicit formula
The example is taken from YI . Use to measure the accuracy. The stoping criterion is .
The following cases are considered
Case 1:
Case 2:
Case 3:
Case 4:
The parameters for algorithms are chosen as
Alg1: , , , and
CHCAlg2: , , and
HAMAlg1: ,
YISAlg1: , , , and
AKHAlg1: ,, and
CHMAlg1: , , and .
| Algorithms | Case1 | Case2 | Case3 | Case4 | ||||
| Iter. | CPU(s) | Iter. | CPU(s) | Iter. | CPU(s) | Iter. | CPU(s) | |
| Alg1 | 32 | 0.0554 | 32 | 0.0499 | 18 | 0.0296 | 36 | 0.0416 |
| CHCAlg2 | 40 | 0.0601 | 40 | 0.0616 | 24 | 0.0361 | 52 | 0.0664 |
| VAMAlg1 | 47 | 0.0616 | 46 | 0.0558 | 22 | 0.0311 | 70 | 0.0974 |
| YISAlg1 | 45 | 0.0894 | 45 | 0.0629 | 26 | 0.0457 | 53 | 0.0912 |
| AKHAlg1 | 38 | 0.0746 | 39 | 0.0506 | 20 | 0.0277 | 46 | 0.0697 |
| HAMAlg1 | 34 | 0.0651 | 37 | 0.0498 | 24 | 0.0343 | 70 | 0.0802 |




Remark 12
From Table 5 and Fig.4, we observe that our Algorithm 3.1 performs better and converges faster.
6 Conclusions
In this paper, we propose a new Tseng splitting method with double inertial extrapolation steps for solving monotone inclusion problems in real Hilbert spaces and establish the weak convergence, nonasymptotic convergence rate, strong convergence and linear convergence rate of the proposed algorithm, respectively. Our method has the following advantages:
(i) Our method uses adaptive step sizes, which can be updated by a simple calculation without knowing the Lipschitz constant of the underlying operator.
(ii) Our method own double inertial extrapolation steps, in which inertial factor can equal . This is not allowed in the corresponding algorithms of CV ; CH , where the only single inertial extrapolation step is considered and the inertial factor is bounded away from . From Table 1 in section 5, it can be seen Algorithm 3.1 with double inertial extrapolation steps outperforms the one with the single inertia.
(iii) Our method includes the corresponding methods considered in AB ; CV ; YI as special cases. Especially, when our algorithm is used to solve variational inequalities, the relaxed parameter sequence have larger choosing interval than the ones of YI . Via Table 3 in section 5, we observe that the performance of the algorithm becomes better with the increase of the relaxed parameter .
(iv) To the best of our knowledge, there are few available convergence rate results for algorithms with the double inertial extrapolation steps for solving variational inequalities and monotone inclusions. From numerical experiments in section 5, we can see that our algorithm has better efficiency than the corresponding algorithms in AB ; CV ; CH ; VA ; YI .
Acknowledgements.
This work was supported by the National Natural Science Foundation of China (11701479, 11701478), the Chinese Postdoctoral Science Foundation (2018M643434) and the Fundamental Research Funds for the Central Universities (2682021ZTPY040).References
- (1) Abubakar, J., Kumam, P., Hassan Ibrahim, A., Padcharoen, A.: Relaxed inertial Tsengs type method for solving the inclusion problem with application to image restoration. Mathematics. 8, 818 (2020)
- (2) Alvarez, F., Attouch, H.: An inertial proximal method for maximal monotone operators via discretization of a nonlinear oscillator with damping. Set-Valued Analysis. 9, 3-11 (2001)
- (3) Bauschke, H.H., Combettes, P.L.: Convex analysis and monotone operator theory in Hilbert spaces. Springer, New York (2011)
- (4) Cai, G., Dong, Q.L., Peng, Y.: Strong convergence theorems for inertial Tseng’s extragradient method for solving variational inequality problems and fixed point problems. Optim. Lett. 15, 1457-1474 (2021)
- (5) Cholamjiak, P., Hieu, D.V., Cho, Y.J.: Relaxed forward-backward splitting methods for solving variational inclusions and applications. J. Sci. Comput.88, 85 (2021)
- (6) Cholamjiak, P., Hieu, D.V., Muu, L.D.: Inertial splitting methods without prior constants for solving variational inclusions of two operators. Bull. Iran. Math. Soc. (2022).https://doi.org/10.1007/s41980-022-00682-3
- (7) Combettes, P.L., Wajs, V.: Signal recovery by proximal forward-backward splitting. SIAM Multiscale Model Simul. 4, 1168-1200 (2005)
- (8) Çopur AK, Haciolu E, Grsoy F, et al.: An efficient inertial type iterative algorithm to approximate the solutions of quasi variational inequalities in real Hilbert spaces. J. Sci. Comput. 89:50(2022)
- (9) Dong, Q., Jiang, D., Cholamjiak, P.: A strong convergence result involving an inertial forward-backward algorithm for monotone inclusions. J. Fixed Point Theory Appl. 19, 3097-3118 (2017)
- (10) Duchi, J., Singer, Y.: Efficient online and batch learning using forward-backward splitting. J. Mach. Learn Res. 10, 2899-2934 (2009)
- (11) Gibali, A., Thong, D.V.: Tseng type methods for solving inclusion problems and its applications. Calcolo 55, 55:49 (2018)
- (12) Linh, N.X., Thong, D.V., Cholamjiak, P.: Strong convergence of an inertial extragradient method with an adaptive nondecreasing step size for solving variational inequalities. Acta Math. Sci. 42, 795-812 (2022)
- (13) Lions, P.L., Mercier, B.: Splitting algorithms for the sum of two nonlinear operators. SIAM J. Numer. Anal. 16, 964-979 (1979)
- (14) Liu, Q.: A convergence theorem of the sequence of Ishikawa iterates for quasi-contractive mappings. J. Math. Anal. Appl. 146, 301-305 (1990)
- (15) Maing, P. E.: Convergence theorems for inertial KM-type algorithms. J. Comput. Appl. Math. 219, 223-236 (2008)
- (16) Opial, Z.: Weak convergence of the sequence of successive approximations for nonexpansive mappings. Bull. Am. Math. Soc. 73, 591-597 (1967)
- (17) Padcharoen, A., Kitkuan, D., Kumam, W., Kumam, P.: Tseng methods with inertial for solving inclusion problems and application to image deblurring and image recovery problems. Comput. Math. Methods (2020). https://doi.org/10.1002/cmm4.1088
- (18) Passty, G.B.: Ergodic convergence to a zero of the sum of monotone operators in Hilbert space. J. Math. Anal. Appl. 72, 383-390 (1979)
- (19) Raguet, H., Fadili, J., Peyr, G.: A generalized forward-backward splitting. SIAM J. Imaging Sci. 6, 1199-1226 (2013)
- (20) Shehu, Y., Iyiola, O.S., Li, X.H., et al.: Convergence analysis of projection method for variational inequalities. Comput. Appl. Math. 38, 161 (2019)
- (21) Shehu, Y., Iyiola, O.S., Reich, S.: A modified inertial subgradient extragradient method for solving variational inequalities. Optimization and Engineering, 23, 421-449.(2021)
- (22) Tan, K.K., Xu, H.K.: Approximating fixed points of nonexpansive mappings by the Ishikawa iteration process. J. Math. Anal. Appl. 178, 301-308 (1993)
- (23) Thong, D.V., Vinh, N.T. Cho, Y.J.: A strong convergence theorem for Tseng’s extragradient method for solving variational inequality problems. Optim. Lett. 14, 1157-1175 (2020)
- (24) Thong, D.V., Yang, J., Cho, Y.J., Rassias, T.M.: Explicit extragradient-like method with adaptive stepsizes for pseudomonotone variational inequalities. Optim. Lett. 15, 2181-2199 (2021)
- (25) Tseng, P.: A modified forward-backward splitting method for maximal monotone mapping. SIAM J. Control Optim. 38, 431-446 (2000)
- (26) Van Hieu, D., Anh, P.K. Muu, L.D.: Modified forward-backward splitting method for variational inclusions. 4OR-Q J. Oper. Res. 19, 127-151 (2021)
- (27) Wang, Z.B., Chen, X., Jiang, Y,, et al.: Inertial projection and contraction algorithms with larger step sizes for solving quasimonotone variational inequalities. J. Glob. Optim. 82:499-522 (2022)
- (28) Xu, H.K.: Iterative algorithms for nonlinear operators. J. Lond. Math. Soc. 66, 240-256 (2002)
- (29) Yao, Y., Iyiola, O.S. Shehu, Y.: Subgradient extragradient method with double inertial steps for variational inequalities. J. Sci. Comput. 90, 71 (2022)