Triangle Graph Interest Network for Click-through
Rate Prediction
Abstract.
Click-through rate prediction is a critical task in online advertising. Currently, many existing methods attempt to extract user potential interests from historical click behavior sequences. However, it is difficult to handle sparse user behaviors or broaden interest exploration. Recently, some researchers incorporate the item-item co-occurrence graph as an auxiliary. Due to the elusiveness of user interests, those works still fail to determine the real motivation of user click behaviors. Besides, those works are more biased towards popular or similar commodities. They lack an effective mechanism to break the diversity restrictions.
In this paper, we point out two special properties of triangles in the item-item graphs for recommendation systems: Intra-triangle homophily and Inter-triangle heterophiy. Based on this, we propose a novel and effective framework named Triangle Graph Interest Network (TGIN). For each clicked item in user behavior sequences, we introduce the triangles in its neighborhood of the item-item graphs as a supplement. TGIN regards these triangles as the basic units of user interests, which provide the clues to capture the real motivation for a user clicking an item. We characterize every click behavior by aggregating the information of several interest units to alleviate the elusive motivation problem. The attention mechanism determines users’ preference for different interest units. By selecting diverse and relative triangles, TGIN brings in novel and serendipitous items to expand exploration opportunities of user interests. Then, we aggregate the multi-level interests of historical behavior sequences to improve CTR prediction. Extensive experiments on both of public and industrial datasets clearly verify the effectiveness of our framework.
✉ denotes corresponding author.
1. Introduction
Click-Through Rate (CTR) prediction is an essential task for recommendation systems in industrial applications, such as online advertising and sponsored search, etc (Covington et al., 2016). Currently, existing works (Song et al., 2016; Covington et al., 2016; Yu et al., 2016; Zhou et al., 2018b, 2019, a; Feng et al., 2019; Li et al., 2019; Xiao et al., 2020) extract user interests just from historical click behavior sequences to improve the performance of this task. However, it is difficult to handle sparser user behaviors or jump out of their specific behaviors for possible interest exploration (Li et al., 2019).
Recently, a few graph embedding methods are suggested to alleviate these problems (Wang et al., 2018a; Li et al., 2019; Feng et al., 2020b). They introduce item-item co-occurrence graphs as an auxiliary to reveal the hidden patterns of user historical behaviors. However, the existing works emphasize discovering user interest from historical clicked item sequences, which causes the problem of elusive motivation. In general, user interests are implicit and elusive while each item has multiple attributes. It is difficult to determine the real motivation for a user clicking an item. For example, users may click on a skirt because of its color, material, or style. Yet, related works lack an effective mechanism to capture implicit user interests. In addition, graph embedding based methods attempt to aggregate neighborhoods in the item-item graph to enrich item representations and broaden the exploration. Nevertheless, they still suffer from the problem of diversity restriction. For a specific item, most of its neighbors in the item-item graph are similar (such as the case shown in Figure 1). Although some works adopt the weight-based strategy to sample the neighbors with higher weights, it is biased towards the popular commodities. Hence, it is a challenge to make diverse recommendations beyond user existing interests.
To alleviate these problems, we introduce the triangles in the item co-occurrence graph as the basic units of user interests. Triangle is an important structure in complex graph analysis in different fields, such as social networks (Watts and Strogatz, 1998; Newman et al., 2002; Leskovec et al., 2010) and protein networks (Leskovec et al., 2010). Many existing works in graph theory have mentioned the properties of triangles (Wasserman et al., 1994; Wimmer and Lewis, 2010). For instance, the homophily of triangles indicates the nodes in a triangle are often relatively similar (Kolountzakis et al., 2012). Statistics and analysis reveal two special properties of triangles in item co-occurrence graphs for recommendation systems. 1) Intra-triangle homophily. The three items in a triangle usually share some common attributes. It can reflect user’s real motivations to click these items. Therefore, triangles can be regarded as the most basic user interest unit. Compared with modeling single items, modeling triangles is more helpful to capture users’ elusive and implicit interests. Moreover, item-item co-occurrence graphs in real-world scenarios are usually large-scale and inevitably noisy. By modeling triangles, we can filter out isolated items and reduce noises to improve the quality of user interest extraction. 2) Inter-triangle heterophily. The shared attributes of different triangles are distinct. They can reflect different aspects of user interests. A variety of triangles can introduce novel and diverse commodities to users. Consequently, users can obtain more exploration opportunities and expanding their interests. For example, we can recommend to users not only clothes of the similar material or color, but also other products of the same store or brand.

Triangle structures widely exist in graph structures. To better capture and broaden user interests, the essential concern is how to choose the triangles for the recommendation system. The following three principles need to be considered. 1) Relevance. To make better use of the user’s historical click behavior, the sampled triangle structure should have a strong correlation with the item being clicked. 2) Diversity. To further expand user interests, it is required that the sampled triangles are as different and diverse as possible. 3) Efficiency. The CTR prediction task has a high requirement for timeliness. Thus, we need to consider efficient extraction and selection strategies. In addition, limiting the number of triangles makes it more feasible.
In this paper, by integrating above main ideas together, we propose a novel, effective and scalable CTR prediction model, Triangle Graph Interest Network (TGIN) 111Source code: https://github.com/alibaba/tgin. Considering the homophily of triangles in the item-item co-occurrence graph, our method takes advantage of triangle structures as the basic units of user interests to model complex user behaviors and alleviates the elusive motivation problem. Instead of relying on single clicked items, our method can reduce the noise caused by complicated user behaviors, and capture implicit user interests effectively. We design an efficient triangle extraction and selection mechanism. In the item-item graph, a set of relevant triangles is extracted from the neighborhood of the clicked items, which provides clues to potential user interests. We adopt the selection mechanism to choose a few triangles with diversity to bring in serendipitous items for users and expand exploration opportunities. We represent every user click behavior by aggregating the information of several interest units. The attention mechanism determines the user’s preference for different interest units. As the result, our proposed method can break diversity restrictions. Based on this, we model the historical behavior sequences including user clicks at different times to learn the user’s profile, which can better capture the trend of user interests over time.
The main contributions of this paper are summarized as follows.
-
•
We propose a novel and effective model, Triangle Graph Interest Network, which introduces triangle structures in item-item co-occurrence graphs as the basic unit of user interests. Compared with modeling single clicked items, our method can capture the implicit user interests effectively.
-
•
We design an efficient triangle extraction and selection mechanism to produce relevant and diverse interest units. It can provide exploration opportunities to discover serendipitous items. Besides, the attention mechanism can determine users’ preferences and broaden their interests.
-
•
In the experiments, our method significantly outperforms the state-of-the-art baselines on both public and industrial datasets.
2. Preliminary
In recommender systems, there are a series of historical clicks between users and items typically. Let denote a set of users and denote a set of items. We denote user clicks as . Here, represents historical behaviors ( i.e., item list) for user . is the implicit feedback when recommending item to user , where when user clicking item is observed, and 0 otherwise.
Definition 0.
(Item-Item Co-Occurrence Graph): In this paper, the item-item co-occurrence graph is defined as an undirected graph , where is the node set and is the edge set. Each node in denotes an item. For user , if two items and co-occur in his historical behavior sequence , then the triplet . denotes the co-occurrence times.
In practice, to construct an item-item co-occurrence graph, we set a sliding window and slide it on behavior sequences of all users. Each pair of items within the window are connected by an undirected edge. The weight of each edge is assigned as the total number of occurrences of the two connected items in all users’ behaviors.
Definition 0.
(Triangle): In an item-item co-occurrence graph , for node , we denote the set of its K-order (K>0) neighbor nodes as . For three nodes and , we define the triplet as a triangle only if and .
The number of triangles can increase exponentially with the number of nodes. Thus, to effectively incorporate triangle structure information, we set as a relative small number. Moreover, for a target node, since the influence of triangles of different distances is also distinct, we further introduce the definition of k-order triangles.
Definition 0.
(k-Order Triangle): For node , given a triangle , if the shortest distance from these three nodes to is , then we define this triplet as a k-order triangle of .
Generally speaking, the triangle order is a natural number, which is smaller than the order of the neighborhood .
3. Observation


In this section, we observe the triangles in item-item co-occurrence graphs and summarize their properties by statistics and analysis. Specifically, we use the Alibaba dataset (more details about the dataset are in Table 1) to construct the graph and randomly select 100,000 items. For each item, a group of triangles in its neighborhood is extracted. We compare multiple attributes of three items involved in each triangle. The attributes include brand, seller, store, category, and keyword, price, review, star, and sale. We counted how many triangles share attributes and which attributes are shared. The results are showed in Figure 2. Consequently, we summarize two properties of triangles in the item co-occurrence graph.
(1) Intra-triangle homophily As showed in the left of Figure 2, we find that 92.30% triangles have the three items that share at least one attribute. Conversely, only 7.7% of the triangles have the items that are not related clearly. Hence, we can summarize that three items in a triangle usually share some common attribute.
(2) Inter-triangle heterophily In the right of Figure 2, we counted the proportion of the triangles sharing each attribute. More than 49% of the triangle belong to the same category, and only 6% of the items in the triangles are of the similar sales. Therefor, although these triangles come from the neighborhoods of the same batch of items, the shared attributes of different triangles differs greatly.
| Occurrence Probability | Homophily | |
|---|---|---|
| 2-Clique | 3.92% | 0.817 |
| 3-Clique | 1.77% | 0.909 |
| 4-Clique | 0.8% | 0.228 |
| 5-Clique | 0.21% | 0.005 |
So far in this paper, we have only focused on triangles, which are a particular kind of motifs (3-clique). Hence, we also study 2/4/5-cliques in a similar way. We extract a subgraph, randomly sample 2/3/4/5 nodes from it, and check if they can form a 2/4/5-clique. This process is repeated 1,000,000 times to calculate the occurrence probability of each clique. The probability can reflect the number of these cliques in the graph. In addition, we compare all the attributes of the items in each clique and measure the average homophily of cliques. The results are shown in Table 1. We infer that, there are too few 4-cliques and 5-cliques to provide sufficient information while the homophily of 2-cliques is relatively lower due to the contingency. Therefore, the proposed method targets on triangle structures. It is worth mentioning our method can be easily extended to other kinds of motifs.
4. Method
4.1. Efficient Triangle Extraction
Extracting triangles is a time-consuming process, especially for large-scale graph data. However, as a real-time task, CTR prediction has a high demand for efficiency. Empirically, for a specific item, the triangles near to it have a stronger influence. Hence, in our paper, triangles are extracted only from small-scale neighborhood of each item. Take the 0-order triangle as an example, for each node in the co-occurrence graph, we sample all its 1-order neighbors. Then we check if each pair of neighbor nodes can form a triangle with the specific item. That is, it is necessary to judge whether there is an edge between each pair. We solve it by constructing a Hashmap for edges, which can limit the time complexity to (1). But it requires high storage capacity and encounters an obstacle when handling billions of edges. Thus, we use Bloom Filters (Broder and Mitzenmacher, 2004) to alleviate this problem. We can produce all the 1-order triangles after deduplication. Based on this, triangles of any order can be obtained in a similar way.
4.2. Diverse Triangle Selection
Inspired by (Chen et al., 2018), we adopt Determinantal Point Processes (DPP) to model the selection probability of a relevant yet diverse set of triangles. Specifically, a DPP on the triangle set is a probability distribution on the powerset of . If it assigns non-zero probability to the empty set , there exists a positive semi-definite kernel matrix , such that for each subset of , the probability of is defined as follows:
| (1) |
where is restricted to those rows and columns which are indexed by , and is the identity matrix.
As revealed in (Chen et al., 2018), the kernel matrix can be written as a Gram matrix . The rows of are vectors representing the feature of triangles. Each row vector are empirically constructed as the product of the triangle relevance score and the triangle feature vector , i.e., . Hence, an element of is written as . Moreover, if the feature vector is normalized, the cosine similarity between two triangles can be calculated as . Hence, can be re-written as follows:
| (2) |
where is the triangle similarity matrix, and is a diagonal matrix with the element being . Following (Chen et al., 2018), we modify the DPP kernel matrix as follows:
| (3) |
where and . is a hyper-parameter used to trade-off between relevance and diversity.
In practice, we calculate the triangle feature vector by averaging the features of three nodes within it. As to the triangle relevance score, we introduce the inner weight and the outer weight of the triangle. The inner weight is the average weight of its three edges. For the outer weight, we set the denominator as the sum of the distances from three inner nodes to the central node, and set the numerator as the sum of the edge weights connecting three inner nodes and the central node. Based on this, the triangle relevance score is the arithmetic square root of the product of the inner and outer weights. After the DPP kernel is determined, the inference algorithm (Chen et al., 2018) is applied to find the optimal diverse while relevant triangle set for the recommendation.
4.3. Model Architecture
4.3.1. Embedding Layer

In the real-world recommendation scenario, both users and items have extensive features. In this paper, we use four categories of feature: User Profile, User Historical Behavior, Context and Target Item. They are represented as and , respectively. Especially, there are several items in User Historical Behavior. Thus, it can be represented by , where is the length of user behavior sequences and is the dimension of item embeddings. Besides, to model the dynamic changes of user interests, we also consider the position of each item in user behavior sequences. User Behavior Position is represented by , where is the position encoding for the -th item. After triangle extraction and selection, we produce a set of triangles for all items in the user behavior sequence. We stack the node representations in all triangles. Consequently, User Behavior Triangle is represented as where is the number of triangles. Particularly, we also extract triangles for target items. Target Item Triangle is represented as . Notably, for the convenience of description, we ignore the order of the triangle here. In practice, we also consider triangles of different orders. We will discuss it later.
4.3.2. Intra-triangle Aggregation Layer
Given a set of relevant and diverse triangles for user behaviors and target item, we use these triangles to represent the potential interest units behind items. Here, we use a simple pooling operation to aggregate intra-triangle information and produce the representations of user behavior sequences.
| (4) |
where and Average indicates the average pooling operation. is the number of triangles for each item. In particular, we also enrich the features of the candidate items by introducing triangles in a similar way. The representation of the target item is calculated as:
| (5) |
where . Instead of modeling each behavior simply, incorporating triangles can provide opportunities to discover serendipitous items.
4.3.3. Inter-triangle Aggregation Layer
In this part, we describe how to aggregate multiple triangles with multi-head self-attention (Vaswani et al., 2017; Devlin et al., 2018) for each item a user clicks. We employ multi-head self-attention to realize the aggregation among multiple triangles. The input of the self-attention module consists of query, key, and value and these three components are the same. Multi-head self-attention is a combination of multiple self-attention structures, which can learn the relationship in different representation subspaces (Devlin et al., 2018). To be specific, the output of the is calculated as follows:
| (6) |
where are projection matrices of the -th head for query, key and value respectively. is the dimension of each head. Thus, each head represents a latent item representation in a subspace.
Then vectors of different heads are concatenated to produce the item representations, which can be defined as follows:
| (7) |
where is the number of heads, is a linear matrix.
For the target item, we also need to aggregate multiple triangles to get its representation. Similarly, we use multi-head self-attention to get the target item representation:
| (8) |
Unlike previous works that used single item features, we aggregate multiple triangles to represent each item’s potential interests. As a result, the model can determine whether the user behaviors closely match the target item.
4.3.4. Behavior Refiner Layer
In practice, the downstream task benefits from high-quality item representations. Hence, after obtaining the item representations, we describe how to further refine it. Inspired by (Xiao et al., 2020), we use another multi-head self-attention same as the previous part to realize the interaction among multiple interests:
| (9) |
Similarly, are projection matrices of the -th head for query, key and value respectively. We pack all output head vectors as a matrix .
An auxiliary loss (Xiao et al., 2020) is used to supervise better item representation learning. It uses the -th user behavior original item embedding, , to supervise the -th learnt item representation, . The positive example represents the actual next behavior, while the negative example is drawn from the entire item set, excluding the clicked items. Mathematically, the auxiliary loss is formulated as:
| (10) |
where is the sigmoid activation function and denotes the inner product. is the original embedding of negative example, represents the number of training examples.
4.3.5. User Behavior Modeling Layer
In this paper, to capture the drifting trend of user interests over time, we extract position features from user behavior sequences. A position-aware attention mechanism is proposed to calculate the importance of user behaviors at different positions for user modeling. Specifically, the attention coefficient for every user behavior of user representations is calculated as follows:
| (11) |
where are projection matrices for query, key and value respectively. Thus, represents a vector of the attention coefficients. Note that the position of each item in the user behavior is the reverse sequential order sorted by timestamp when it has occurred.
Considering the different importance of each behavior, we can obtain users representations for a target item. Mathematically, the adaptive representation of the user behavior w.r.t. the target item is calculated as follows:
| (12) |
where is the -th row of . It represents the representation vector of the -th item in the user behavior sequences. denotes how relevant of the behavior to the target item.
4.3.6. Multi-Level Interest Fusion Layer
Triangles of different orders reflect different levels of interest. Therefore, as mentioned earlier, for user historical behaviors and target items, we extracted the multi-order triangles. For each order , the representation of user behaviors can be obtained in a similar way, which is denoted as . Considering their different importance to users, we fuse multi-level interests with the attention mechanism. We stack all the user behavior representations of different orders as . The attention coefficient of the behavior representation to the user can be calculated as:
| (13) |
where is a linear transformation matrix. Based on this, we can finally fuse multi-level interests for the learned representations. Mathematically, the adaptive representation of the user behavior sequences w.r.t. the user is calculated as follows:
| (14) |
where represents the representations learned from -order triangles. denotes how important the representation is to the user.
4.3.7. Optimization
All the features vectors, and , are concatenated and fed into the MLP layer for final prediction. Since the click-through rate prediction task is a binary classification task, the loss function is chosen as cross-entropy loss, which is usually defined as:
| (15) |
where is the training set with size is the click label, is the prediction output of our network. As we use the auxiliary loss to supervise item representation refining, the final loss can be defined as,
| (16) |
where is a hyper-parameter in order to balance the two sub-tasks.
5. Experiment
In this section, extensive experiments are conducted on two public datasets and an industrial dataset to verify the effectiveness of TGIN.
5.1. Dataset
| Dataset | #User | #Item | #Categoriy | #Sample |
|---|---|---|---|---|
| Books | 603,668 | 367,982 | 1,600 | 603,668 |
| Electronics | 192,403 | 63,001 | 801 | 192,403 |
| Industrial | 9 million | 62 million | 7,131 | 1 billion |
We adopt both public and industrial datasets. The statistics of all datasets are shown in Table 2:
-
•
Public dataset: Following the setting of (Zhou et al., 2019), we use two subsets of Amazon dataset (McAuley et al., 2015): Books and Electronics. For these two datasets, we regard the reviews as the user behaviors and sort the reviews from each user by the time order. Based on user historical behaviors, our purpose is to predict whether a user will write a review.
-
•
Industrial dataset: We collect the click logs for 30 days from Alibaba online display advertising system. A sample instance consists of the candidate item, user, context and its historical behaviors. The items that user clicked in the previous 29 days contribute to user sequential behaviors. Our goal is to predict whether the user clicks at the candidate item on the last day.
| Model | Books | Electronics |
|---|---|---|
| Wide&Deep | 0.7735 0.00051 | 0.7456 0.00127 |
| PNN | 0.7799 0.00181 | 0.7543 0.00101 |
| DIN | 0.7880 0.00216 | 0.7603 0.00028 |
| GIN | 0.7967 0.00039 | 0.7684 0.00174 |
| MIMN | 0.8262 0.00109 | 0.7563 0.00083 |
| DIEN w/o AuxLoss | 0.7911 0.00150 | 0.7640 0.00073 |
| DIEN | 0.8453 0.00476 | 0.7792 0.00243 |
| DMIN w/o AuxLoss | 0.8319 0.00150 | 0.7553 0.00108 |
| DMIN | 0.8550 0.00137 | 0.7778 0.00110 |
| TGIN w/o AuxLoss | 0.8808 0.00112 | 0.7908 0.00016 |
| TGIN | 0.8934 0.00103 | 0.7944 0.00202 |
5.2. Baselines
We compare TGIN with the following state-of-the-art approaches:
-
•
Wide&Deep (Cheng et al., 2016) consists of two parts: its deep model is the same as Base Model, and its wide model is a linear model.
-
•
PNN (Qu et al., 2016) uses a product layer to capture interactive patterns between interfield categories.
-
•
DIN (Zhou et al., 2018b) uses the embedding product attention mechanism to learn the adaptive representation of user behaviors w.r.t. the target item.
-
•
GIN (Li et al., 2019) is the first to mine and aggregate the user’s latent intention on the co-occurrence item graph with graph attention technique.
-
•
DIEN (Zhou et al., 2019) designs an auxiliary network to capture user’s temporal interests and proposes AUGRU to model the interest evolution.
-
•
MIMN (Pi et al., 2019) is a multi-channel memory network to capture user interests from long sequential behaviors.
-
•
DMIN (Xiao et al., 2020) models latent multiple user interests from user behavior sequences to improve the CTR task.
5.3. Experiment Setting
As introduced in Section 2, the item-item co-occurrence graph is constructed with a sliding window. To prevent information leakage, graph construction is only based on the train set for each dataset. The window size is set as 3 to avoid too extensive connections in the graphs. In our experiment, the dimension of the item and user embedding is set as 18, and the size of position embedding is set as 2. The learning rate is 0.001 and the batch size is 128. The maximum order of triangles is 2. The lengths of user behavior sequences vary in different datasets. Therefore, we set the maximum length to 10, 20, 15 for the Books dataset, the Electronics dataset, and the industrial dataset respectively. The evaluation metrics is Area Under the Curve (AUC). To ensure the fairness of comparison experiments, we reuse the metrics already reported in original papers or choose optimal hyper-parameters carefully after reproducing the code for different baselines.
5.4. Results on Public Datasets.
The results on the public datasets are shown in Table 3. Compared with the benchmark algorithm, our proposed model achieves the highest AUC scores on both two datasets. Among all baselines, compared with traditional methods, Wide & Deep and PNN, DIN and other models can achieve higher AUC scores obviously by capturing user interests. GIN outperforms DIN, demonstrating that introducing the item-item co-occurrence graph can alleviate the behavior sparsity problem. Due to longer user behavior sequences in the Books dataset, MIMN performs better on this dataset than on the Electronic dataset. DIEN uses a specially designed AUGRU, thus, it is better at modeling the interest evolving process. As to DMIN, its advantages benefit from capturing multiple interests. Markedly, the auxiliary loss can bring a large improvement to all of DIEN, DMIN and our method. It is worth mentioning that our method can outperform all baselines even without the auxiliary loss. We own it to resolving the problems of elusive motivation and diversity restriction effectively.
| Model | AUC |
|---|---|
| Wide&Deep | 0.6575 |
| PNN | 0.6583 |
| DIN | 0.6613 |
| GIN | 0.6626 |
| DIEN | 0.6658 |
| DMIN | 0.6691 |
| TGIN | 0.6732 |
5.5. Results on Industrial Dataset
We further conduct the experiments on the industrial dataset of display advertisement. The results are shown in Table 4. Different from only one category of goods in the public Amazon dataset, our industrial dataset contains various types of items. Thus, it is much more challenging and complex. DIN and DIEN use the attention mechanism to capture the relevance of items, significantly improving performance. Furthermore, when compared to GIN, DIEN, and MIMN, our proposed model outperformed them all. Even when compared to DMIN, which performs the best on this dataset, TGIN achieves a 0.004 absolute AUC gain. It is notable that in commercial advertising systems with hundreds of millions of traffics, 0.004 absolute AUC gain is significant and worthy of model deployment empirically. TGIN shows great superiority to better understand and make use of the characteristics of user behavior data.
5.6. Ablation Study


We test several variations of our full model, including BaseModel (MeanAgg), BaseModel (WeightAgg), BaseModel (AttentionAgg), BaseModel + AuxLoss. BaseModel is the base model to uses a set of triangles in the item-item co-occurrence graph to model every user behavior. There are three strategies to aggregate triangle information and click behaviors for each user, including MeanAgg, WeightAgg and AttentionAgg. They represent the average pooling, the weighted pooling and the attention pooling, respectively. BaseModel + AuxLoss denotes the base model with the best pooling operation and the auxiliary loss. All of these variations adopt the weight-based strategy to sample triangles. And TGIN is our full model, which samples relevant and diverse triangles as introduced in Section 4.2.
Figure 4 shows the results of different variations of our full model on the public datasets. When compared to DIN in Table 3, all triangle-based models achieve a clear advantage on the Books and Electronics datasets. We own it to the effectiveness of modeling triangles as the basic units of user interests. It makes a great contribution to capturing implicit user interests. Considering different aggregation strategies, we find that the best choices for these two datasets are different: the attention pooling is better for Books while the weighted pooling is suitable for Electronics. We speculate that the reason is that the user behavior of the Electronic is sparser than that of Books, and complex aggregation mechanisms may cause overfitting. For all the experiments in this paper, we always choose the best aggregation strategies for each dataset. As to the auxiliary loss, it brings great improvements for both datasets. It reflects the importance of supervision information for the learning of sequential interests. However, the improvement on Electronics is not as obvious as that on Books. The difference may derive from the longer user behavior sequences in the Books dataset.
5.7. Hyperparameter Analysis


Now we examine the influence of two key parameters in our framework: the number of triangles and the parameter in triangle selection. The results on two public datasets are shown in Figure 5. We can find that when the number of triangles increases from 1 to 10, our model can achieve better results on two datasets simultaneously. Because more triangles can provide more clues about user interests. However, in practice, we set as 10 to balance efficiency and effectiveness. We set the parameter for a trade-off between relevance and diversity when choosing triangles. As shown in the right of Figure 5, it has a little effect on the Electronics dataset while the Books dataset benefits from a higher . We assume that the item features in these two datasets are very sparse, which may have a negative impact on triangle selection.
5.8. Diversity Analysis
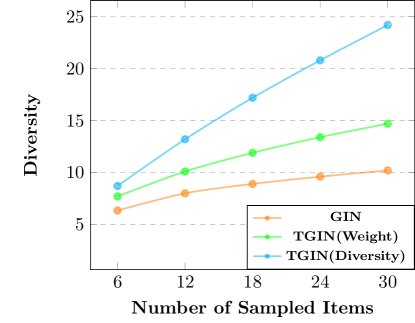
To verify whether a variety of triangles can bring more novel items, we analyzed different item sampling methods, including weight-based node sampling in GIN, weight-based triangle sampling in TGIN, and diversity-based triangle sampling in TGIN (in Section 4.2). For the fairness of comparison, we use different methods to sample the same number of items on the industrial dataset, and then, count the number of keywords involved in these items. The more different keywords, the more diverse items. The experimental results are shown in Figure 6. We can find that the items sampled by GIN are relatively homologous. Because GIN is bias to popular or similar items. In contrast, by introducing triangle structures, weight-based sampling in GIN can improve diversity to a certain extent. In our full model, we try to select diverse and relevant triangles. In this way, higher diversity can be achieved with fewer items. Inspired by this, we improve the model efficiency by reducing the number of sampled triangles.
5.9. Model Efficiency
The calculation time of TGIN is compared with other popular sequential models, including DIN, GIN, MIMN, DIEN, DMIN. We recorded the training time of these models per epoch on the Books dataset with 1 NVIDIA Tesla P100 GPU. For TGIN, we extracted and selected triangles through preprocessing. The order of triangles is fixed to 2. The number of triangles is set as 5. For other methods, we directly run their released codes or reproduce their results. The experimental results show that the efficiency of TGIN is comparable to, if not better than, that of these baselines. Specifically, DIN costs 367 seconds, TGIN 430s, GIN 457s, DMIN 1,309s, DIEN 1,354s, and MIMN 7,954s per epoch. GIN and TGIN are slower than DIN because they introduce item-item co-occurrence graphs as an auxiliary for broader exploration. When compared with other baselines, TGIN shows a distinct advantage by modeling a few and diverse triangles. For online deployment, we optimized every component for our algorithm and finally obtain quick responses to user clicks for online advertising. More details are described in the next section.
5.10. Result from online A/B testing.

From April 10 to April 17 in 2021, careful online A/B testing was conducted in the merchant advertising system of AliExpress (one of the biggest global e-commerce platform). During almost a week’s testing, TGIN has improved UV L-P by 3.62% and L-GMV by 3.16% compared to the base model. Besides, TGIN has improved commission earn per user (EPU) by 3.20%. This is a significant improvement and demonstrates the effectiveness of TGIN. Now, as showed in Figure 7, TGIN has been deployed online and serves the merchant traffic, which contributes a significant business revenue growth.
In practice, we employ the TPP platform to handle real-time user requests. ABFS (Ali Basic Feature Service) is used to obtain real-time behaviors and user portraits. Then we obtain the recall candidates via BE (Basic Engine). In the following step, item attribute information and the corresponding triangle index is requested via iGraph (GRAPH ENGINE). Finally, we calculate the CTR score through the TGIN model service deployed by RTP (REAL-TIME PREDICTION) and recommend items to users for online display. The average response time is about 30 milliseconds, which is sufficient to meet the timeliness requirement of the CTR prediction task. Meantime, the user behavior log is returned to ABFS through FLINK real-time data. In particular, all the triangle indexes are established offline. Firstly, a large-scale item-item co-occurrence graph is built for AliExpress. The triangle extraction and selection algorithm is implemented using Alibaba MaxCompute and MapReduce. To improve the efficiency, we restrict the number of triangles strictly.
6. Related Work
In recent years, click-through rate prediction for online advertising has become one of the hot research topics. Inspired by the success of deep learning in computer vision (Chen et al., 2020) and natural language processing (Devlin et al., 2018), deep learning-based methods have been proposed to improve the performance of the click-through rate prediction task (Song et al., 2016; Covington et al., 2016; Yu et al., 2016; Zhou et al., 2018b, 2019, a; Feng et al., 2019; Li et al., 2019; Xiao et al., 2020; Zhang et al., 2021; Li et al., 2020; Deng et al., 2021; Huang et al., 2021; Fei et al., 2021; Cheng and Xue, 2021). As the pioneer works, YoutubeNet (Covington et al., 2016) and DeepFM (Guo et al., 2017) present their potential of modeling complex interaction between users and items. Later, DIN (Zhou et al., 2018b) learns adaptive representations of historical behavior sequences to infer user preference. Inspired by DIN, the majority of subsequent works adopt this type of paradigm, such as DIEN (Zhou et al., 2019), SDM (Lv et al., 2019), DSIN (Feng et al., 2019), MIMN (Pi et al., 2019), and DMIN (Xiao et al., 2020). Though these methods bring great improvements, they summarize user interests only based on historical behaviors. It suffers greatly from the sparsity of user behaviors. Besides, they cannot jump out of user specific historical behaviors so that users lose their opportunities for possible interest exploration.
Some researchers attempt to integrate graph structures for enriching relationships among user behaviors and items (Wang et al., 2018a; Li et al., 2019; Feng et al., 2020b). GIN (Li et al., 2019) is the first work of end-to-end joint training of graph learning and CTR prediction tasks. It introduces item-item co-occurrence graphs to enrich user historical behaviors. Typically, they sample neighbors with higher weights of clicked items in the graph. Then they model user behaviors by aggregating information from these neighbors. Also, some works introduce knowledge graphs to explores their potential interests, such as RippleNet (Wang et al., 2018b), KGAT (Wang et al., 2019), ATBRG (Feng et al., 2020a) and MTBRN (Feng et al., 2020b). However, most of these existing works still lack an effective mechanism to capture implicit user interests. In addition, due to the weakness of their sampling strategy from graphs, they are more biased towards the popular or similar commodities. Therefore, it is difficult to make diverse recommendations beyond user existing behaviors.
7. CONCLUSION
In this paper, we propose a novel and effective framework named Triangle Graph Interest Network (TGIN) for the click-through rate prediction task. For each clicked item in user behavior sequences, we introduce triangles in its neighborhood of the item-item graph as a supplement. TGIN regards these triangles as basic units of user interests, which provide the clues to capture the real motivation for a user clicking an item. We characterize user behaviors by aggregating information of several interest units to alleviate the elusive motivation problem. By selecting diverse and relative triangles, TGIN brings in novel and serendipitous items for users to break diversity restrictions and expand exploration opportunities.
8. Acknowledgement
This work is funded in part by the Natural Science Foundation of China Projects No.U1936213, No.U1636207.
References
- (1)
- Broder and Mitzenmacher (2004) Andrei Broder and Michael Mitzenmacher. 2004. Network applications of bloom filters: A survey. Internet mathematics 1, 4 (2004), 485–509.
- Chen et al. (2018) Laming Chen, Guoxin Zhang, and Hanning Zhou. 2018. Fast greedy map inference for determinantal point process to improve recommendation diversity. In Proceedings of the 32nd International Conference on Neural Information Processing Systems. 5627–5638.
- Chen et al. (2020) Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. In International conference on machine learning. PMLR, 1597–1607.
- Cheng et al. (2016) Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems. 7–10.
- Cheng and Xue (2021) Yuan Cheng and Yanbo Xue. 2021. Looking at CTR Prediction Again: Is Attention All You Need?. In SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Castells, Rosie Jones, and Tetsuya Sakai (Eds.). ACM, 1279–1287. https://doi.org/10.1145/3404835.3462936
- Covington et al. (2016) Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems. 191–198.
- Deng et al. (2021) Wei Deng, Junwei Pan, Tian Zhou, Deguang Kong, Aaron Flores, and Guang Lin. 2021. DeepLight: Deep Lightweight Feature Interactions for Accelerating CTR Predictions in Ad Serving. In WSDM ’21, The Fourteenth ACM International Conference on Web Search and Data Mining, Virtual Event, Israel, March 8-12, 2021, Liane Lewin-Eytan, David Carmel, Elad Yom-Tov, Eugene Agichtein, and Evgeniy Gabrilovich (Eds.). ACM, 922–930. https://doi.org/10.1145/3437963.3441727
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Fei et al. (2021) Hongliang Fei, Jingyuan Zhang, Xingxuan Zhou, Junhao Zhao, Xinyang Qi, and Ping Li. 2021. GemNN: Gating-enhanced Multi-task Neural Networks with Feature Interaction Learning for CTR Prediction. In SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Castells, Rosie Jones, and Tetsuya Sakai (Eds.). ACM, 2166–2171. https://doi.org/10.1145/3404835.3463116
- Feng et al. (2020a) Yufei Feng, Binbin Hu, Fuyu Lv, Qingwen Liu, Zhiqiang Zhang, and Wenwu Ou. 2020a. ATBRG: Adaptive Target-Behavior Relational Graph Network for Effective Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2231–2240.
- Feng et al. (2020b) Yufei Feng, Fuyu Lv, Binbin Hu, Fei Sun, Kun Kuang, Yang Liu, Qingwen Liu, and Wenwu Ou. 2020b. MTBRN: Multiplex Target-Behavior Relation Enhanced Network for Click-Through Rate Prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2421–2428.
- Feng et al. (2019) Yufei Feng, Fuyu Lv, Weichen Shen, Menghan Wang, Fei Sun, Yu Zhu, and Keping Yang. 2019. Deep session interest network for click-through rate prediction. arXiv preprint arXiv:1905.06482 (2019).
- Guo et al. (2017) Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence. 1725–1731.
- Huang et al. (2021) Jianqiang Huang, Ke Hu, Qingtao Tang, Mingjian Chen, Yi Qi, Jia Cheng, and Jun Lei. 2021. Deep Position-wise Interaction Network for CTR Prediction. In SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Castells, Rosie Jones, and Tetsuya Sakai (Eds.). ACM, 1885–1889. https://doi.org/10.1145/3404835.3463117
- Kolountzakis et al. (2012) Mihail N Kolountzakis, Gary L Miller, Richard Peng, and Charalampos E Tsourakakis. 2012. Efficient triangle counting in large graphs via degree-based vertex partitioning. Internet Mathematics 8, 1-2 (2012), 161–185.
- Leskovec et al. (2010) Jure Leskovec, Daniel Huttenlocher, and Jon Kleinberg. 2010. Predicting positive and negative links in online social networks. In Proceedings of the 19th international conference on World wide web. 641–650.
- Li et al. (2019) Feng Li, Zhenrui Chen, Pengjie Wang, Yi Ren, Di Zhang, and Xiaoyu Zhu. 2019. Graph Intention Network for Click-through Rate Prediction in Sponsored Search. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. 961–964.
- Li et al. (2020) Hao Li, Huichuan Duan, Yuanjie Zheng, Qianqian Wang, and Yu Wang. 2020. A CTR prediction model based on user interest via attention mechanism. Appl. Intell. 50, 4 (2020), 1192–1203. https://doi.org/10.1007/s10489-019-01571-9
- Lv et al. (2019) Fuyu Lv, Taiwei Jin, Changlong Yu, Fei Sun, Quan Lin, Keping Yang, and Wilfred Ng. 2019. SDM: Sequential deep matching model for online large-scale recommender system. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2635–2643.
- McAuley et al. (2015) Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel. 2015. Image-based recommendations on styles and substitutes. In Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52.
- Newman et al. (2002) Mark EJ Newman, Duncan J Watts, and Steven H Strogatz. 2002. Random graph models of social networks. Proceedings of the national academy of sciences 99, suppl 1 (2002), 2566–2572.
- Pi et al. (2019) Qi Pi, Weijie Bian, Guorui Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Practice on long sequential user behavior modeling for click-through rate prediction. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2671–2679.
- Qu et al. (2016) Yanru Qu, Han Cai, Kan Ren, Weinan Zhang, Yong Yu, Ying Wen, and Jun Wang. 2016. Product-based neural networks for user response prediction. In 2016 IEEE 16th International Conference on Data Mining (ICDM). IEEE, 1149–1154.
- Song et al. (2016) Yang Song, Ali Mamdouh Elkahky, and Xiaodong He. 2016. Multi-rate deep learning for temporal recommendation. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. 909–912.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems. 6000–6010.
- Wang et al. (2018b) Hongwei Wang, Fuzheng Zhang, Jialin Wang, Miao Zhao, Wenjie Li, Xing Xie, and Minyi Guo. 2018b. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management. 417–426.
- Wang et al. (2018a) Jizhe Wang, Pipei Huang, Huan Zhao, Zhibo Zhang, Binqiang Zhao, and Dik Lun Lee. 2018a. Billion-scale commodity embedding for e-commerce recommendation in alibaba. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 839–848.
- Wang et al. (2019) Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu, and Tat-Seng Chua. 2019. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 950–958.
- Wasserman et al. (1994) Stanley Wasserman, Katherine Faust, et al. 1994. Social network analysis: Methods and applications. (1994).
- Watts and Strogatz (1998) Duncan J Watts and Steven H Strogatz. 1998. Collective dynamics of ‘small-world’networks. nature 393, 6684 (1998), 440–442.
- Wimmer and Lewis (2010) Andreas Wimmer and Kevin Lewis. 2010. Beyond and below racial homophily: ERG models of a friendship network documented on Facebook. American journal of sociology 116, 2 (2010), 583–642.
- Xiao et al. (2020) Zhibo Xiao, Luwei Yang, Wen Jiang, Yi Wei, Yi Hu, and Hao Wang. 2020. Deep Multi-Interest Network for Click-through Rate Prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2265–2268.
- Yu et al. (2016) Feng Yu, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. 2016. A dynamic recurrent model for next basket recommendation. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. 729–732.
- Zhang et al. (2021) Kai Zhang, Hao Qian, Qing Cui, Qi Liu, Longfei Li, Jun Zhou, Jianhui Ma, and Enhong Chen. 2021. Multi-Interactive Attention Network for Fine-grained Feature Learning in CTR Prediction. In WSDM ’21, The Fourteenth ACM International Conference on Web Search and Data Mining, Virtual Event, Israel, March 8-12, 2021, Liane Lewin-Eytan, David Carmel, Elad Yom-Tov, Eugene Agichtein, and Evgeniy Gabrilovich (Eds.). ACM, 984–992. https://doi.org/10.1145/3437963.3441761
- Zhou et al. (2018a) Chang Zhou, Jinze Bai, Junshuai Song, Xiaofei Liu, Zhengchao Zhao, Xiusi Chen, and Jun Gao. 2018a. Atrank: An attention-based user behavior modeling framework for recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 32.
- Zhou et al. (2019) Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948.
- Zhou et al. (2018b) Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018b. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1059–1068.