Training Robots without Robots: Deep Imitation Learning for Master-to-Robot Policy Transfer
Abstract
Deep imitation learning is promising for robot manipulation because it only requires demonstration samples. In this study, deep imitation learning is applied to tasks that require force feedback. However, existing demonstration methods have deficiencies; bilateral teleoperation requires a complex control scheme and is expensive, and kinesthetic teaching suffers from visual distractions from human intervention. This research proposes a new master-to-robot (M2R) policy transfer system that does not require robots for teaching force feedback-based manipulation tasks. The human directly demonstrates a task using a controller. This controller resembles the kinematic parameters of the robot arm and uses the same end-effector with force/torque (F/T) sensors to measure the force feedback. Using this controller, the operator can feel force feedback without a bilateral system. The proposed method can overcome domain gaps between the master and robot using gaze-based imitation learning and a simple calibration method. Furthermore, a Transformer is applied to infer policy from F/T sensory input. The proposed system was evaluated on a bottle-cap-opening task that requires force feedback.
Index Terms:
Imitation Learning, Deep Learning in Grasping and Manipulation, Dual Arm Manipulation, Force and Tactile SensingI Introduction
Deep imitation learning is a model-free method for policy optimization that imitates expert (typically, human)-demonstrated behaviors using a deep neural network. This method has been applied to dexterous robot manipulation tasks for which the manual definition of the optimal solution is infeasible (e.g., [1, 2, 3]).
| \hlineB2 Method | Safety | No visual distraction | Force feedback | No robot required during training |
|---|---|---|---|---|
| Master-to-robot (proposed) | ✓ | ✓ | ✓ | ✓ |
| Teleoperation | ✓ | ✓ | ✗ | ✗ |
| Bilateral teleoperation | ✗ | ✓ | ✓ | ✗ |
| Kinesthetic teaching | ✓ | ✗ | ✓ | ✗ |
| Learning from watching | ✓ | ✓ | ✗ | ✓ |
| \hlineB2 |
The aim of this study is the imitation learning of a manipulation task that requires force feedback for successful manipulation. Previous demonstration methods (i.e., teleoperation, bilateral teleoperation, kinesthetic teaching, and learning from watching) suffer when they consider force feedback during deep imitation learning (Table I). In teleoperation-based methods in which the human operator teleoperates the robot using a controller (e.g., [3, 4]), force feedback is not provided to the human operator. Bilateral teleoperation enables accurate force control by reproducing the force feedback of the robot at the master’s actuators (e.g., [5]) . However, in this method, the safety of the human operator who physically interacts with the moving actuators must be considered [5]. A complex control scheme is required to compensate for the time delay caused by communication between the master and robot [6] or to ensure stability, and the system is expensive because both the master and robot require a motor. Previous approach to bilateral teleoperation with force feedback using a relatively low-cost and safe haptic device (Geomagic touch) was presented [7], however, it lacks the power required for practical manipulation tasks. Kinesthetic teaching is another robot teaching method in which a human grasps the robot arm and teaches the task by moving it (e.g., [8, 9]). However, when adapting the method to the end-to-end learning of visuomotor control, this method suffers from severe visual distractions, such as the human body. Additionally, this method requires a torque sensor on each joint for gravity and friction compensation; therefore, a high-cost force-controllable robot is required. A few researchers have studied a robot that learns from watching humans demonstrate tasks [10, 11, 12]. However, these methods cannot transfer force feedback because it cannot be acquired from video demonstrations. To summarize, current demonstration generation methods lack force feedback or require expensive robots in the demonstration system. This problem raises the demand for a simple demonstration method that can be applied to force feedback-based tasks.
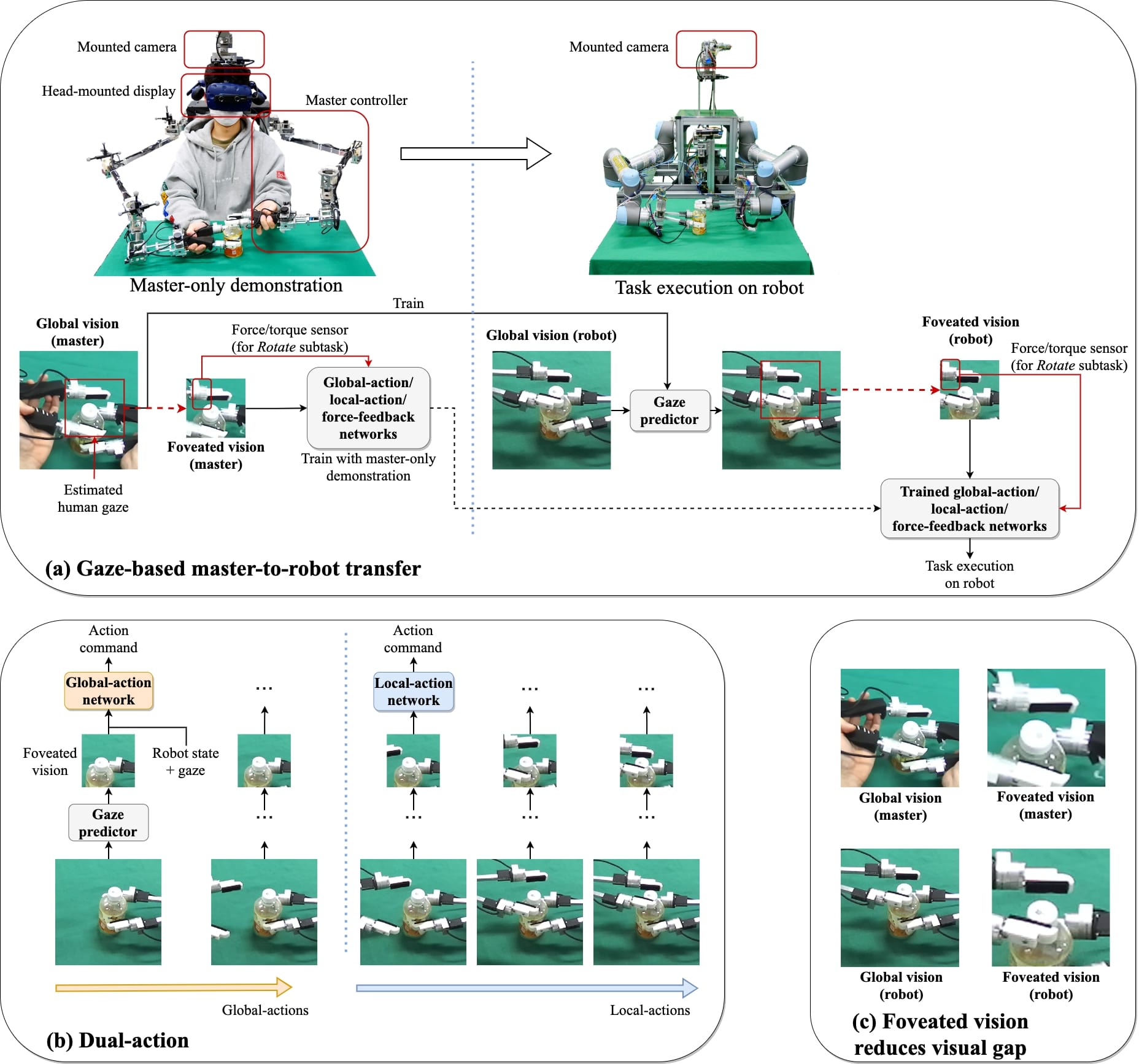
In this study, a simple master-only demonstration system that can imitate tasks that require force feedback (Fig. 1) is proposed. The proposed method includes the hardware structure for the demonstration, methods to reduce the domain gap between the demonstration and the real-robot environment, and dual-action-based deep imitation learning with Transformer-based force/torque (F/T) sensory attention.
A master controller is proposed that imitates the same Denavit-Hartenberg (DH) parameters as the UR5 (Universal Robots) robot, and the robot and controller have the same end-effector design and F/T sensors (Fig. 2(a) and 2(b)). The human demonstrator uses this controller to directly manipulate the object and receive force feedback during manipulation. The shared DH parameters between the master and robot facilitate the transfer of motor skills from humans to robots by constraining the human operators’ physicality through the use of the master controller. This master controller for the M2R policy transfer system has a few advantages. First, a demonstration with force feedback is possible without an expensive bilateral system; this controller does not require any motor or gear, only a simple encoder. Second, no complex control scheme is required to ensure safety and stability because the human controls the end-effector while performing the demonstration. Third, this controller can teach tasks that require force feedback with the Transformer-based F/T sensory attention.
This system must overcome two types of domain gaps between the master and robot: visual gap and kinematic gap. The visual gap is a domain gap in vision caused by different visual components, such as the human arm. Gaze-based deep imitation learning [4] has been proposed, which can suppress the visual gap using the human gaze that is naturally estimated during the demonstration. Because the human naturally gazes at the target object [13], foveated vision cropped from global vision using the predicted gaze position effectively suppresses the visual gap.
The kinematic gap is a domain gap between the master controller and robot caused by their kinematic difference. This study uses a master controller with the same DH parameters as the robot to minimize the kinematic gap. Additionally, a simple calibration method is used to minimize the kinematic difference between the master and robot caused by deflection.
In this study, the Transformer architecture [14] is used to process force/torque (F/T) sensory information to make the robot attend to important channels from the relatively high-dimensional dual-arm F/T sensory inputs. Additionally, dual-action separation[1] is used to ensure precise object manipulation.
The proposed imitation learning method, accompanied by a master-only demonstration system, was validated in the real-world robot experiment of a bottle-cap-opening task, which requires both a precise grasping-cap policy, and the policy considers force feedback.
To summarize, the contributions of this study are as follows:
-
•
Master-to-robot policy transfer system is proposed that can learn the task requires force feedback with the master-only demonstration data.
-
•
Gaze-based visual attention is proposed that can minimize the visual gap.
-
•
Transformer-based F/T sensory input attention is proposed that can train a robot on tasks that require force feedback.
II Method
The proposed M2R policy transfer system consists of a hardware for master-only demonstrations, gaze-based visual attention and a kinematic calibration method to minimize the domain gap between the master and robot, and dual-action deep imitation learning with the Transformer-based F/T sensory attention. In this section, each component is described.
II-A Hardware for master-only demonstrations
This framework uses a dual-arm robot system with two UR5 robots. In the authors’ previous study (e.g., [4]), this system was operated in teleoperation mode. By contrast, in the present study, demonstration data are generated in master-only mode. In this mode, the human demonstrator uses the fingertip of the master controller (Fig. 2(a)) to execute tasks. The controller collects joint angles from its encoders mounted on a structure that has DH parameters identical to those of the UR5 robot. The shared DH parameters between the master and robot facilitate the transfer of motor skills from humans to robots. The idea behind this is that the physicality of the robot has a significant influence on motor skills, and constraining the physicality of the human operators through the use of the master controller allows them to develop motor skills suitable for the robot. This helps to ensure that the kinematics of the system can be solved. Therefore, the robot can easily reproduce human behavior by following the recorded encoder values. The end effectors on the robot and master are identical: one degree-of-freedom grippers (Fig. 2(b)). Additionally, an F/T sensor (Leptrino, PFS 030YA301) is placed between the fingertip and rod so that the F/T of the fingertip can be measured.



The human operator observes a stereo image from a stereo camera (ZED-Mini, StereoLabs) using a head-mounted display (HMD). The stereo cameras are mounted in identical relational positions on both the robot and master sides (Fig. 2(c)). For the master, this location is just above the operator’s head. This shared camera mount position minimizes the visual gap between the master and robot caused by different viewpoints. The developed pan-tilt camera system can control its direction, which can be used in future studies.
II-B Calibration
The proposed controller and UR5 robot have identical DH parameters. However, the authors found that there is still an error because of deflection caused by gravity. Therefore, calibration is required to reduce the error.
Motion capture is used for calibration. The accurate end effector position and rotation are measured using the Optitrack motion capture device. The master controller is moved randomly by the human operator while it records the joint angle, and the motion capture device measures the exact position simultaneously, which is then played back in the robot. A transformation from the motion-captured master position/rotation to the robot position/rotation transforms the position/rotation calculated from the joint angle into the calibrated robot state .
The position and orientation are separated, and the homogeneous transformation matrix and rotation matrix are calculated by learning the least-squares solution:
| (1) |
| (2) |
Therefore, the calibration of robot state is calculated using the following equations:
| (3) |
| (4) |
and the calibrated robot state is used for neural network model training.
II-C Gaze-based visual attention
Gaze-based visual attention was proposed in [4]. This method reproduces the human’s gaze, which can be acquired naturally during demonstration using an eye tracker on the HMD (Fig. 1). The gaze-based visual attention is used to minimize the visual gap between the demonstration data from the master and the test on the robot. Because the human gaze is correlated with the target object position [13, 15], this method can eliminate distractions from the human hand. Therefore, the visual appearance of both the robot and master are similar in foveated vision (Fig. 1 (c)).
This method first collects the two-dimensional gaze coordinates using the eye tracker during the demonstration. Then, mixture density network (MDN)-based [16] gaze prediction architecture [17, 4] is trained to reproduce the probability of the gaze position based on the global vision. The trained MDN predicts the gaze position in the test environment using robots. Foveated vision is an area around the gaze position cropped from the global vision. This visual attention process can suppress visual distractions from task-unrelated objects or background while fully providing information about the task-related object or area.
The details of MDN architecture are as follows: First, a series of five convolutional neural networks (CNNs) and rectified linear units (ReLUs) followed by SpatialSoftmax [18] extract visual features, which are then processed by the MDN, which is composed of a Gaussian mixture model (GMM) with eight Gaussians. Finally, this GMM is fit to the coordinates of the gaze using [2]
| (5) |
where and represent the weight, mean, and covariance matrix of the th Gaussian, respectively, and denotes a target gaze coordinate. The gaze position is used to crop foveated vision from global vision.
It is important to note that kinesthetic teaching is unable to utilize the advantage of gaze-based attention as the human operator must control the dual-arm robot from the opposite side of the table, which creates confusion when attempting to observe the view from the robot’s camera through the HMD.
II-D Dual-action

Because cap-reaching behavior requires precise manipulation, the dual-action architecture proposed in [1] is used. Based on a physiological study [19] in which the human’s reaching movement was divided into two distinctive systems, the dual-action architecture divides the entire robot trajectory into the global action and local action. This architecture first detects whether the end effector is in foveated vision [20]: if not, the global action, which is the fast action that delivers the hand to the vicinity of the target, is used; and if so, the local action, which is a precise and slow action when the hand is near the target, is activated (Fig. 1b). This enables high-precision manipulation, such as needle threading [1] or banana peeling [20].
In the dual-action architecture, each step is labeled as global-action, local-action from the demonstration data and used to train the global-action network or local-action network, respectively. A human manually annotated some demonstrations to train a CNN-based classifier to classify the remaining demonstrations. The classifier’s output was verified by a human (The details can be found at III-C1). The global and local-action networks are distinctively trained using the annotated data. During the test, a binary classifier, which inputs foveated vision to classify the global and local actions, is used to choose which action network to use.
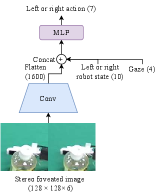
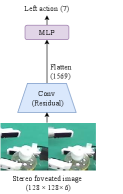
The global-action network inputs stereo foveated images, the robot state, and the stereo gaze position to output the action (Fig. 4(a)). The local-action network inputs foveated vision to output the precise local action. Because the robot’s kinematic state is not used for input, this network can accurately predict the action regardless of the kinematic gap between the demonstration data from the master and the test environment of the robot (Fig. 4(b)).
The action is defined as the difference between the seven-dimensional robot state (three-dimensional position, three-dimensional orientation, and a gripper angle) at the next step and the current robot state. The orientations of the robot state input into the neural network models are decomposed using cosine and sine to prevent the drastic change of the angle representation; therefore, it is ten-dimensional. The global-action network uses a series of CNN, ReLU, and max-pooling layers with the stride equal to 2. The local-action network uses one CNN layer with an ReLU followed by nine residual blocks [21], and a max-pooling layer is inserted in every two residual blocks with the stride equal to 2. The CNN layer uses a filter with 32 channels. The multilayer perceptron (MLP) module is a series of fully connected layers (FCs) with a node size of 200 and an ReLU between the FCs. The action is optimized using loss.
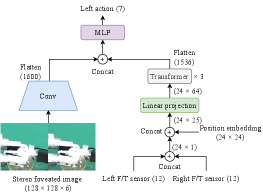
II-E Transformer-based force-feedback network
The force feedback network uses the dual-arm F/T sensory data and foveated image to compute the action command (Fig. 4). This architecture processes F/T sensory data with the Transformer-based self-attention architecture [14], inspired by a study [2] in which researchers implemented the self-attention architecture to reduce distractions in dual-arm somatosensory inputs. In the present study, the Transformer is used to attend to useful F/T sensory information from both arms and reduce distractions from other F/T sensory information. The feed-forward network also processes the foveated image using the same CNN architecture as the global-action network. The output of the CNN and Transformer is concatenated and then processed with the MLP to predict the action command.
| \hlineB2 Subtask | Init | Goal | Network type | Description |
|---|---|---|---|---|
| GraspCap |
|
|
Global | Grasp the body of the bottle using the right hand |
| GraspBottle |
|
|
Global Local | Reach and grasp the bottle cap with the left hand |
| Rotate |
|
|
Force feedback | Open the bottle cap by rotating the left hand |
| \hlineB2 |
III Experiments
III-A Calibration results
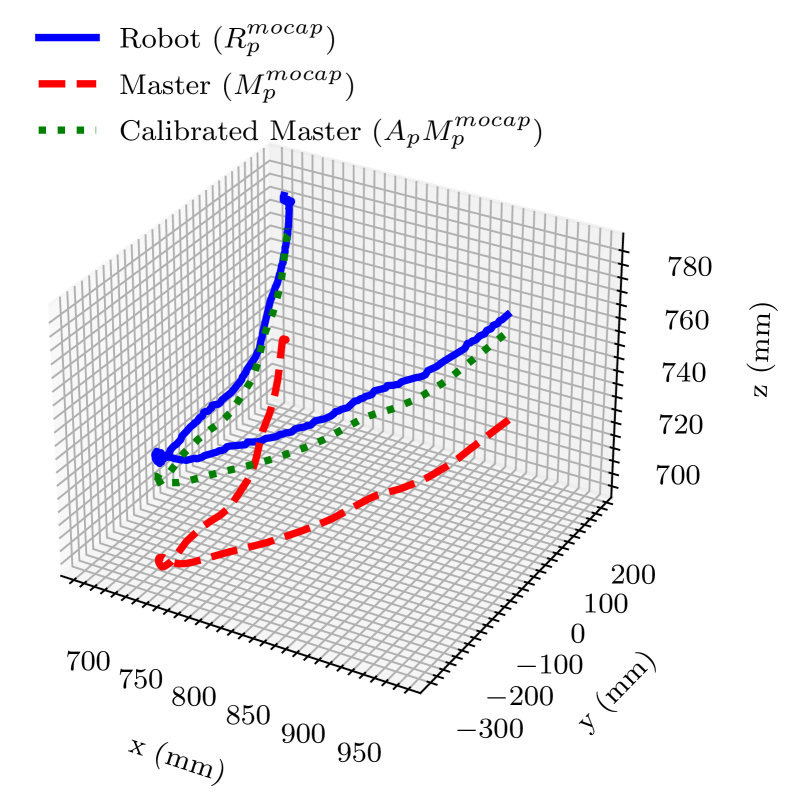
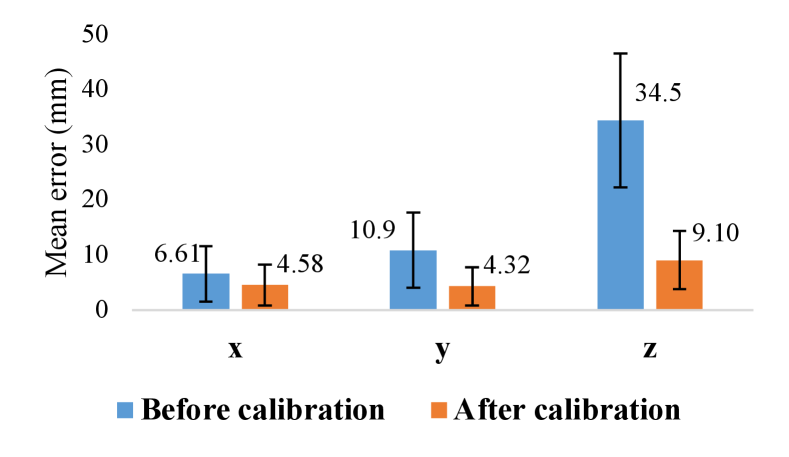
Fig. 5(a) illustrates part of the calibrated trajectory of the left arm. After calibration, the master controller’s position is translated into , which is much closer to the actual robot position . Fig. 5(b) compares the mean Euclidean distance between the master and robot, (blue), and after calibration, (orange). The result indicates that the overall error decreased after calibration. Particularly, the error on the -axis, which was mainly caused by the deflection of the upper arm because of gravity, occupied the most significant error between the master and robot, but decreased after calibration. This calibration was robust because the main error on the -axis was caused by gravity, which is almost constant on the surface of the earth.
III-B Bottle-cap-opening task
Our previous robot system successfully solved various dexterous manipulation tasks (e.g., [1, 2, 20]) by demonstration with teleoperation. However, we encountered limitations in achieving contact-rich tasks with strict geometrical constraints, which even human teleoperators could not accomplish. The proposed M2R framework targets bottle-opening, a representative example of such tasks that requires precise gripper rotation with exact (, ) translation to compensate for the offset between the cap and gripper. The M2R framework enables the demonstrator to directly feel force-feedback from the exerted action, facilitating the discovery of motor skills suitable for the robot in contact-rich tasks.
III-C Training setup
We trained and tested our model with three different plastic bottles (bottle-A,B, and C, Fig. 6) We used bottle-A for ablation studies and other analysis. Relatively small number of demonstration sets of bottle-B and C (Table III ) are added to and re-trained to evaluate the adaptation ability of the proposed model on new bottle with less dataset. Bottle-B has the same size and shape but different texture with the bottle-A. Bottle-C has the different size, shape and texture, thus require more adaptation ability than bottle-B.
The bottle-cap-opening task was segmented into the three subtasks GraspBottle, GraspCap, and Rotate described in Table II. GraspBottle GraspCap was segmented because the robot changes its manipulating arm from right to left, and then GraspCap Rotate because rotation requires force feedback, whereas GraspCap does not. Each subtask used a different neural-network architecture. First, GraspBottle is a simple grasping movement that the global-action network can accomplish. GraspCap is high-precision grasping, which requires a dual-action network that combines global and local-action networks. Finally, Rotate requires force feedback; therefore, a force feedback network was used.
III-C1 Demonstration data generation
During the demonstration, the human operator grasped the bottle with the right gripper (GraspBottle), reached the bottle cap with the left gripper (GraspCap), and repeatedly rotated the cap until it opened (Rotate). Each subtask was segmented during training using a foot keyboard. GraspCap was more complicated than the other subtasks because the exact grasping of the cap requires reaching to the cap with small clearance (i.e., small mistake in grasping results in failure to open the cap during Rotate).Therefore, demonstrations that repeated GraspCap were added. The entire demonstration set was divided into training and validation sets. The training dataset statistics are presented in Table III.
| \hlineB2 Dataset | Bottle index | # of demos | Total demo time (min) |
|---|---|---|---|
| GraspBottle | A | 312 | 9.475 |
| B | 297 | 8.192 | |
| C | 442 | 10.49 | |
| GraspCap | A | 5798 | 156.0 |
| B | 1029 | 25.81 | |
| C | 1063 | 29.30 | |
| Rotate | A | 1111 | 23.75 |
| B | 329 | 5.547 | |
| C | 329 | 5.025 | |
| \hlineB2 |
From a raw RGB stereo camera image, a region of pixels was cropped to form the global vision around the center position of for left vision and for right vision to reduce the visual gap.
The global/local-action labels were annotated in GraspCap. First, a human manually annotated demonstrations from dataset of bottle-A. The result labels were used to train a simple CNN-based binary classifier , where denotes the foveated image. The trained classifier then automatically classified the remaining 5596 demonstrations. If the classification result of one demonstration episode provided more than one transition (i.e., there was any of which and for any time step ), the human reannotated the demonstration episode. Datasets of bottle-B and bottle-C were annotated with same process.
III-C2 Model training
The gaze predictor and policy network were trained on each subtask. These models were trained for 300 epochs with a learning rate of using rectified Adam [22] and a weight decay of 0.01. For training, eight NVIDIA v100 GPUs with Intel Xeon CPU E5-2698 v4 or four NVIDIA a100 GPUs with two AMD EPYC 7402 CPUs were used, and for the robot tests, one NVIDIA GTX 1080 and one Intel i7-8700K CPU were used.
III-D Test setup
The objective of the test was to evaluate whether the robot could grasp the bottle with its right hand, grasp the bottle cap with its left hand, and rotate the cap once without the cap slipping or bottle tilting. The test was repeated 18 times for different initial bottle positions, which were reproduced from the initial positions recorded in the randomly sampled validation set. The bottle cap was manually rotated approximately 90 degrees from the completed closed state because opening the completely locked cap required too much torque for the robot.
This study proposed the gaze-based dual-action approach with force feedback. Four types of neural network architecture were compared to evaluate the validity of each component:
-
•
DA-force: DA-force uses both F/T sensory feedback and gaze-based dual-action (DA) architecture.
-
•
No-force: to validate the necessity of an F/T sensor, No-force does not input F/T sensor information while rotating the cap.
-
•
No-DA: this architecture validates whether dual action is effective in the M2R framework. In this architecture, global and local actions are not distinguished. Therefore, the policy in each subtask is trained and inferred only from the global-action network.
-
•
No-gaze: DA-force inputs foveated images to minimize the visual gap. No-gaze inputs global vision to investigate whether the visual gap is indeed reduced by the gaze. As proposed in [3], the global image was processed using SpatialSoftmax after five layers of CNNs and ReLU.
III-E Experimental results

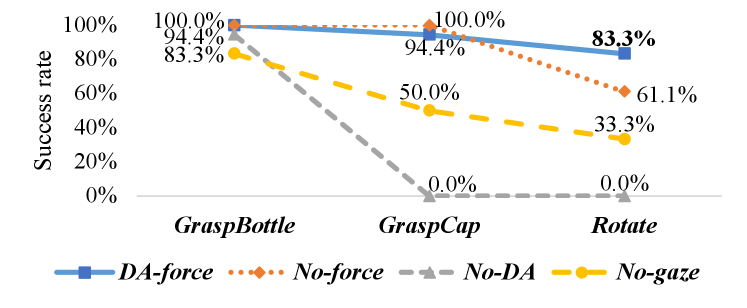
).
| \hlineB2 Bottle index | GraspBottle | GraspCap | Rotate |
|---|---|---|---|
| A | 100% | 94.4% | 83.3% |
| B | 100% | 94.4% | 77.8% |
| C | 88.9% | 77.8% | 77.8% |
| \hlineB2 |



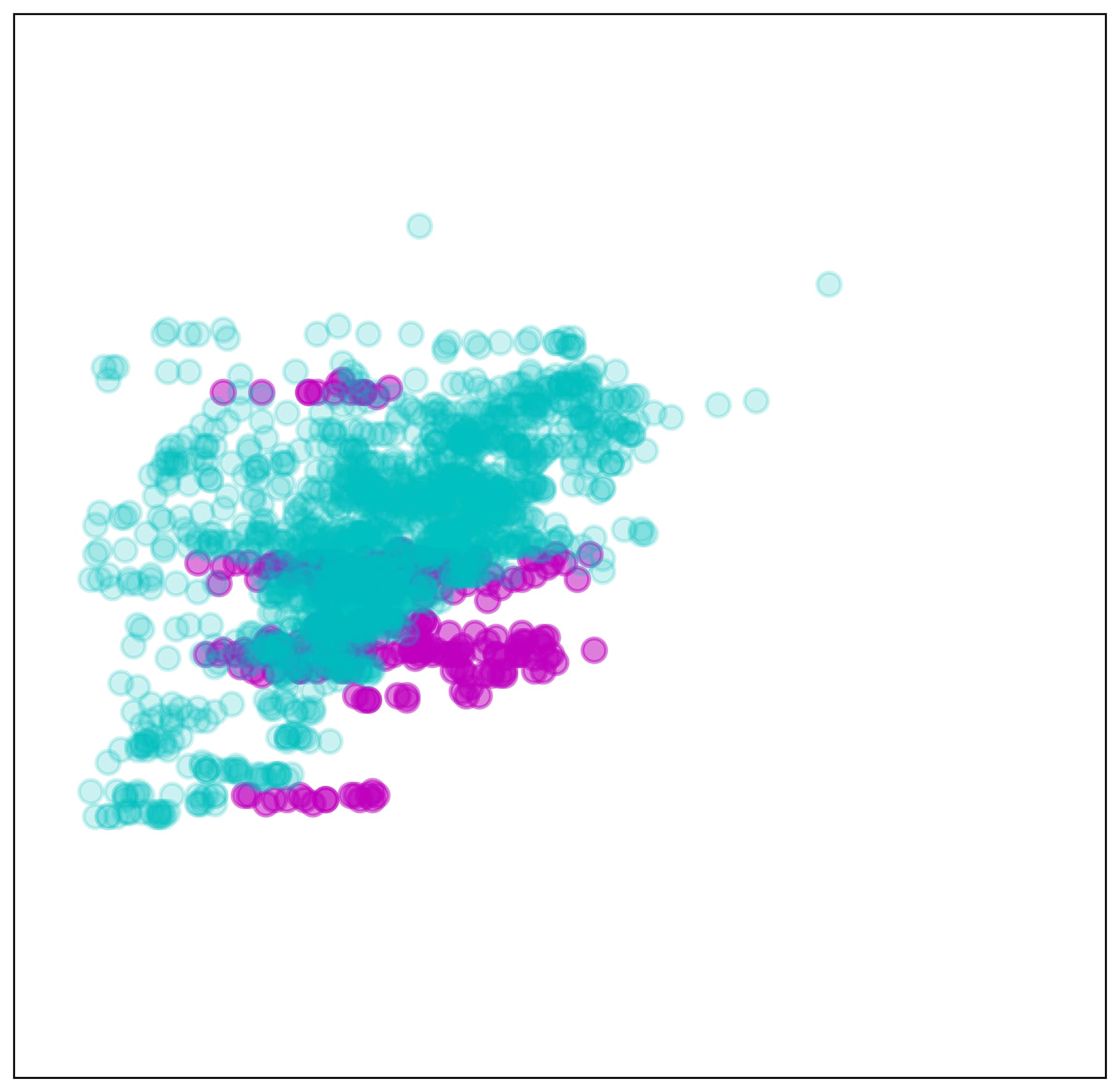
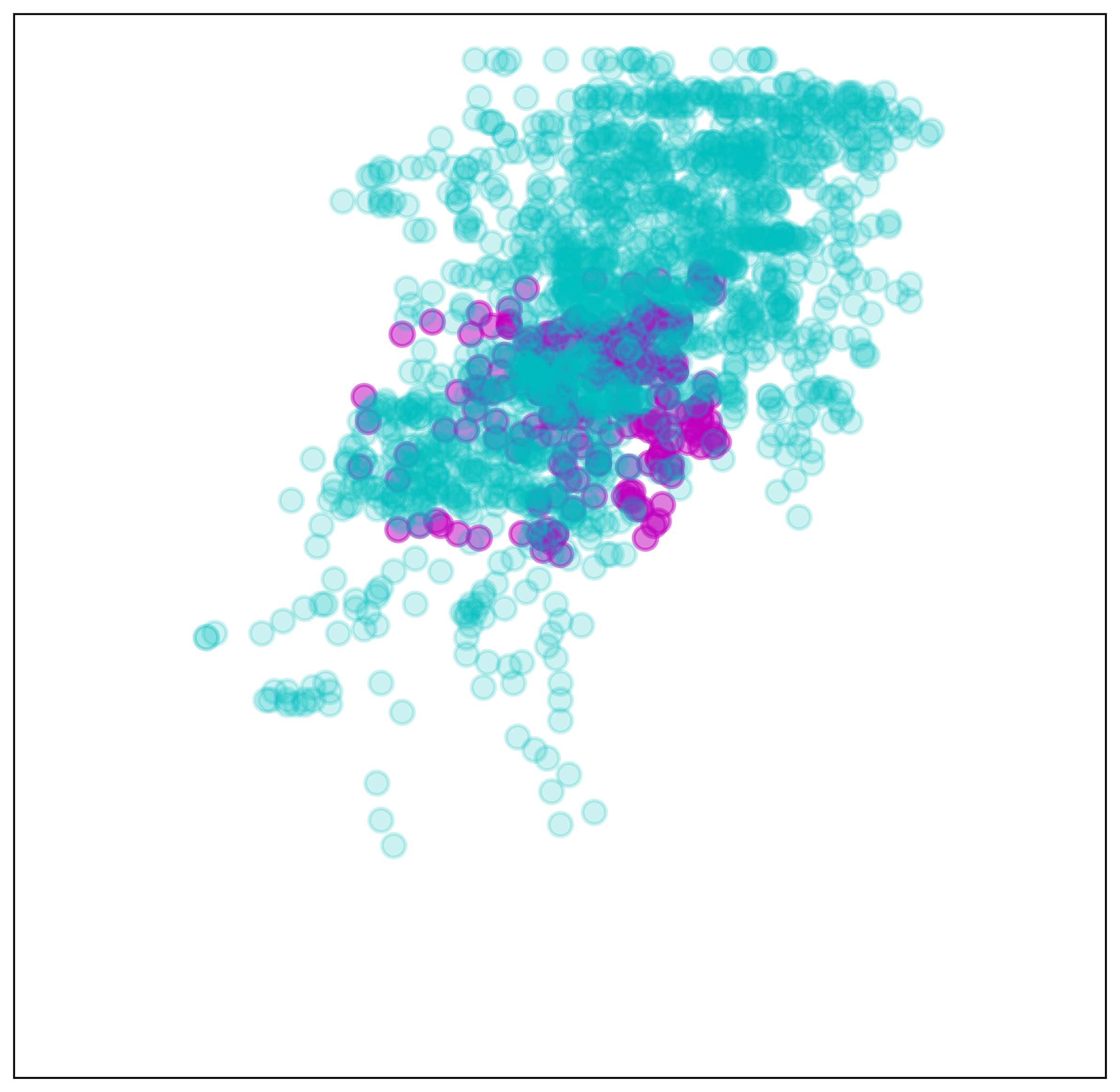


Fig. 3 illustrates that the proposed DA-force successfully executed the bottle-cap-opening task on bottle-A. Among all the tested model architectures, DA-force had the best final cumulative success rate of by combining DA, F/T sensor input, and gaze (Fig. 7).
Second, No-force, which did not use F/T sensory information, executed accurate reaching and grasping; however, poor manipulation during Rotate caused a slip during cap opening (Fig. 8(a)), which resulted in a lower final success rate than DA-force.
Third, No-DA failed at accurately reaching the cap because it lacked the dual-action system (Fig. 8(c)). Some may argue that the gripper touched the bottle cap; therefore, simply closing it may have led to successful grasping. However, the bottle collapsed when the gripper was closed manually.
Finally, No-gaze demonstrated low accuracy for both GraspBottle and GraspCap (Fig. 8(b)). This low accuracy was because the global vision-based policy was weak against distractions caused by the visual gap. The visualized example of two-dimensional visual features extracted by SpatialSoftmax on the global vision processing network demonstrated the difference in the feature coordinates between the demonstration data collected by the master (validation set) and the robot data collected by DA-force during the test (Fig. 9). Some features focused on similar areas (Fig. 9(a), 9(b)), whereas others focused on different areas (Fig. 9(c), 9(d)). This difference resulted in errors in the action output computed from the MLP layer. Therefore the architecture using global vision failed to predict the accurate action.

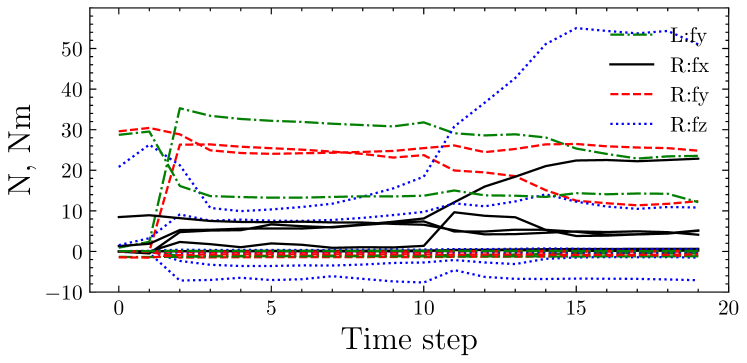
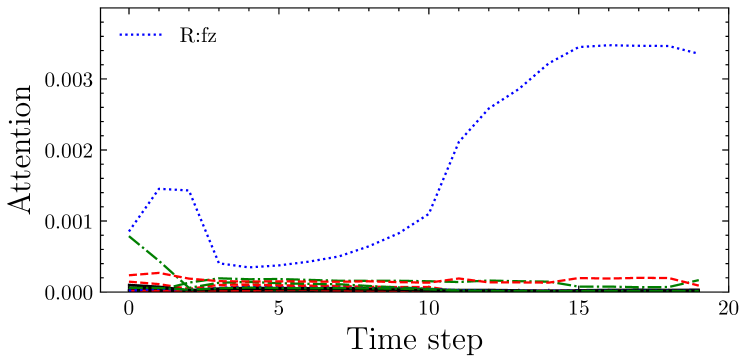
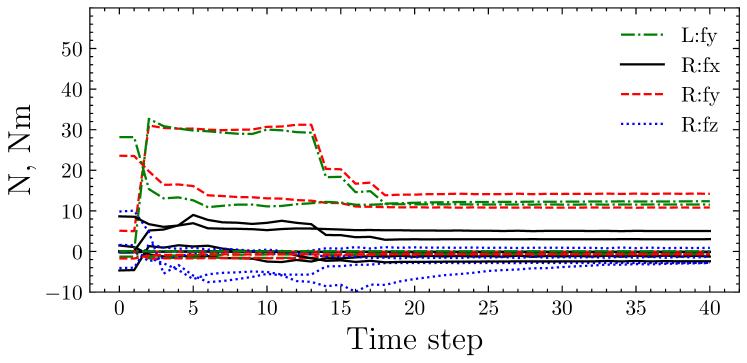
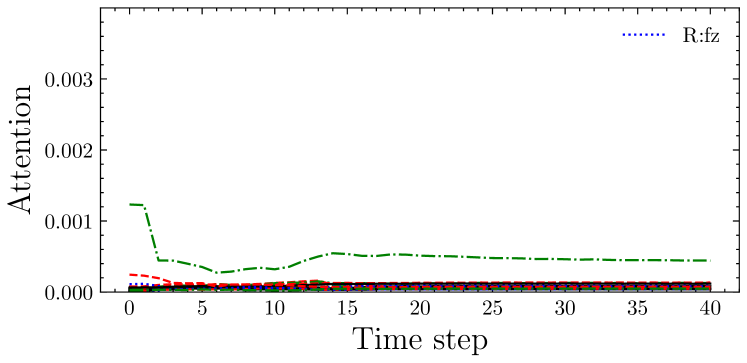
Fig. 10 shows examples of F/T sensory values and the attention. First, sensory values of successful and failure trial were separately gathered from trials of DA-force and No-force. Then, the attention rollout [23] of the Transformer from the force feedback network was computed. Then, the two-dimensional attention-rollout was averaged on each channel. The result demonstrates that if the robot failed to Rotate (Fig. 10(a)), the force of the -axis on the right arm (R:fz) increased during rotation (Fig. 10(b), time step ), and the Transformer captured such an abnormality (Fig. 10(c)). By contrast, in the successful trial, the force of R:fz did not increase (Fig. 10(d)); therefore, the Transformer did not give any alert (Fig. 10(e)). Therefore, the F/T sensor provides prediction whether the robot would fail, and the proposed Transformer-based method can capture such alert.
Table IV represents the results comparison of all bottles. Even though the bottle-B and C are trained with smaller number of dataset, the neural network well adapted to those new bottles.
IV Discussion
In this study, a master-to-robot policy transfer learning system using gaze-based dual-action deep imitation learning was demonstrated. This system is composed of hardware for the master-only demonstration, methods to reduce domain gaps, and gaze-based dual-action deep imitation learning with F/T sensory attention. The proposed system was tested on the bottle-cap-opening task for a real robot. In this task, the demonstration dataset was generated only from the master. The proposed method successfully learned bottle-cap opening with an success rate.
The proposed method demonstrated that the visual and kinematics gap can be suppressed using the gaze-based visual attention and the simple calibration. The proposed system has a few advantages over other robot teaching methods. First, this system does not require a robot during the demonstration. Second, because demonstration data collection and training are possible from a simple controller that consists of encoders and F/T sensors, this demonstration system is comparatively low-cost compared with a bilateral teleoperation system. Third, a complex control scheme is not needed during the demonstration because the master controller is controlled directly by the human operator. Therefore, the proposed system is naturally safe, unlike a bilateral system that requires complex control schemes to achieve safety and stability. Finally, this M2R system can be scaled up efficiently. For example, a large-scale M2R system can consist of only one robot, and multiple masters can create large-scale demonstration data.
The method allows any gripper design provided it satisfies two conditions: (1) minimize human hand interference in the foveated vision, and (2) provide force feedback to the operator. For multi-DOF grippers, the design idea proposed in [24] may be beneficial.
One problem with the proposed system is that it requires cameras mounted in a fixed position on both the master and robot sides. This fixed camera mount restricts the robot’s design to prevent intervention with the human’s body. If the robot can learn from images acquired from different viewpoints, images from in front of the HMD will be available. This will be considered in future work.
References
- [1] H. Kim, Y. Ohmura, and Y. Kuniyoshi, “Gaze-based dual resolution deep imitation learning for high-precision dexterous robot manipulation,” Robotics and Automation Letters, pp. 1–1, 2021.
- [2] H. Kim, Y. Ohmura, and Y. Kuniyoshi, “Transformer-based deep imitation learning for dual-arm robot manipulation,” in International Conference on Intelligent Robots and Systems, 2021.
- [3] T. Zhang, Z. McCarthy, O. Jow, D. Lee, X. Chen, K. Goldberg, and P. Abbeel, “Deep imitation learning for complex manipulation tasks from virtual reality teleoperation,” in International Conference on Robotics and Automation, 2018, pp. 1–8.
- [4] H. Kim, Y. Ohmura, and Y. Kuniyoshi, “Using human gaze to improve robustness against irrelevant objects in robot manipulation tasks,” Robotics and Automation Letters, vol. 5, no. 3, pp. 4415–4422, 2020.
- [5] T. Hulin, K. Hertkorn, P. Kremer, S. Schätzle, J. Artigas, M. Sagardia, F. Zacharias, and C. Preusche, “The dlr bimanual haptic device with optimized workspace,” in International Conference on Robotics and Automation, 2011, pp. 3441–3442.
- [6] J. Guo, C. Liu, and P. Poignet, “A scaled bilateral teleoperation system for robotic-assisted surgery with time delay,” Journal of Intelligent & Robotic Systems, vol. 95, no. 1, pp. 165–192, 2019.
- [7] T. Adachi, K. Fujimoto, S. Sakaino, and T. Tsuji, “Imitation learning for object manipulation based on position/force information using bilateral control,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 3648–3653.
- [8] C. Schou, J. S. Damgaard, S. Bøgh, and O. Madsen, “Human-robot interface for instructing industrial tasks using kinesthetic teaching,” in IEEE ISR 2013. IEEE, 2013, pp. 1–6.
- [9] B. Akgun, M. Cakmak, J. W. Yoo, and A. L. Thomaz, “Trajectories and keyframes for kinesthetic teaching: A human-robot interaction perspective,” in International Conference on Human-Robot Interaction, 2012, pp. 391–398.
- [10] Y. Kuniyoshi, M. Inaba, and H. Inoue, “Learning by Watching: Extracting reusable task knowledge from visual observation of human performance,” Transactions on Robotics and Automation, vol. 10, no. 6, pp. 799–822, 1994.
- [11] T. Yu, C. Finn, A. Xie, S. Dasari, T. Zhang, P. Abbeel, and S. Levine, “One-shot imitation from observing humans via domain-adaptive meta-learning,” arXiv preprint arXiv:1802.01557, 2018.
- [12] Y. Liu, A. Gupta, P. Abbeel, and S. Levine, “Imitation from observation: Learning to imitate behaviors from raw video via context translation,” in International Conference on Robotics and Automation, 2018, pp. 1118–1125.
- [13] M. Hayhoe and D. Ballard, “Eye movements in natural behavior,” Trends in Cognitive Sciences, vol. 9, pp. 188–94, 2005.
- [14] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Neural Information Processing Systems, 2017, pp. 5998–6008.
- [15] J. Pelz, M. Hayhoe, and R. Loeber, “The coordination of eye, head, and hand movements in a natural task,” Experimental Brain Research, vol. 139, pp. 266–77, 2001.
- [16] C. M. Bishop, “Mixture density networks,” Neural Computing Research Group, Aston University, Tech. Rep., 1994.
- [17] L. Bazzani, H. Larochelle, and L. Torresani, “Recurrent mixture density network for spatiotemporal visual attention,” in International Conference on Learning Representations, 2016.
- [18] C. Finn, X. Y. Tan, Y. Duan, T. Darrell, S. Levine, and P. Abbeel, “Deep spatial autoencoders for visuomotor learning,” in International Conference on Robotics and Automation, 2016, pp. 512–519.
- [19] J. Paillard, “Fast and slow feedback loops for the visual correction of spatial errors in a pointing task: a reappraisal,” Canadian Journal of Physiology and Pharmacology, vol. 74, no. 4, pp. 401–417, 1996.
- [20] H. Kim, Y. Ohmura, and Y. Kuniyoshi, “Robot peels banana with goal-conditioned dual-action deep imitation learning,” arXiv preprint arXiv:2203.09749, 2022.
- [21] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [22] L. Liu, H. Jiang, P. He, W. Chen, X. Liu, J. Gao, and J. Han, “On the variance of the adaptive learning rate and beyond,” in International Conference on Learning Representations, 2020, pp. 1–14.
- [23] S. Abnar and W. Zuidema, “Quantifying attention flow in transformers,” in Annual Meeting of the Association for Computational Linguistics, 2020, pp. 4190–4197.
- [24] T. Kanai, Y. Ohmura, A. Nagakubo, and Y. Kuniyoshi, “Third-party evaluation of robotic hand designs using a mechanical glove,” arXiv preprint arXiv:2109.10501, 2021.