Training High-Performance Low-Latency Spiking Neural Networks by Differentiation on Spike Representation
Abstract
Spiking Neural Network (SNN) is a promising energy-efficient AI model when implemented on neuromorphic hardware. However, it is a challenge to efficiently train SNNs due to their non-differentiability. Most existing methods either suffer from high latency (i.e. missing, long simulation time steps), or cannot achieve as high performance as Artificial Neural Networks (ANNs). In this paper, we propose the Differentiation on Spike Representation (DSR) method, which could achieve high performance that is competitive to ANNs yet with low latency. First, we encode the spike trains into spike representation using (weighted) firing rate coding. Based on the spike representation, we systematically derive that the spiking dynamics with common neural models can be represented as some sub-differentiable mapping. With this viewpoint, our proposed DSR method trains SNNs through gradients of the mapping and avoids the common non-differentiability problem in SNN training. Then we analyze the error when representing the specific mapping with the forward computation of the SNN. To reduce such error, we propose to train the spike threshold in each layer, and to introduce a new hyperparameter for the neural models. With these components, the DSR method can achieve state-of-the-art SNN performance with low latency on both static and neuromorphic datasets, including CIFAR-10, CIFAR-100, ImageNet, and DVS-CIFAR10.
1 Introduction
Inspired by biological neurons that communicate using spikes, Spiking Neural Networks (SNNs) have recently received surging attention. This promise depends on their energy efficiency on neuromorphic hardware [35, 7, 39], while deep Artificial Neural Networks (ANNs) require substantial power consumption.
However, the training of SNNs is a major challenge [49] since information in SNNs is transmitted through non-differentiable spike trains. Specifically, the non-differentiability in SNN computation hampers the effective usage of gradient-based backpropagation methods. To tackle this problem, the surrogate gradient (SG) method [37, 52, 45, 16, 59] and the ANN-to-SNN conversion method [4, 10, 44, 42, 56] have been proposed and yielded the best performance. In the SG method, an SNN is regarded as a recurrent neural network (RNN) and trained by the backpropagation through time (BPTT) framework. And during backpropagation, gradients of non-differentiable spike functions are approximated by some surrogate gradients. Although the SG method can train SNNs with low latency (i.e., short simulation time steps), it cannot achieve high performance comparable to leading ANNs. Besides, the adopted BPTT framework needs to backpropagate gradients through both the layer-by-layer spatial domain and the temporal domain, leading to a long training time and high memory cost of the SG method. The high training costs further limit the usage of large-scale network architectures. On the other hand, the ANN-to-SNN conversion method directly determines the network weights of an SNN from a corresponding ANN, relying on the connection between firing rates of the SNN and activations of the ANN. The conversion method enables the obtained SNN to perform as competent as its ANN counterpart. However, intolerably high latency is typically required, since only a large number of time steps can make the firing rates closely approach the high-precision activation values of ANNs [42, 22]. Overall, SNNs obtained by the two widely-used methods either cannot compete their ANN counterparts, or suffer from high latency.
| Conversion | SG | DSR | |
|---|---|---|---|
| Latency | High | Low | Low |
| Performace w/ | Low | Medium | High |
| Low Latency | |||
| Neuromorphic | Non-appli- | Appli- | Appli- |
| Data | cable | cable | cable |
In this paper, we overcome both the low performance and high latency issues by introducing the Differentiation on Spike Representation (DSR) method to train SNNs. First, we treat the (weighted) firing rate of the spiking neurons as spike representation. Based on the representation, we show that the forward computation of an SNN with common spiking neurons can be represented as some sub-differentiable mapping. We then derive the backpropagation algorithm while treating the spike representation as the information carrier. In this way, our method encodes the temporal information into spike representation and backpropagates through sub-differentiable mappings of it, avoiding calculating gradients at each time step. To effectively train SNNs with low latency, we further study the representation error due to the SNN-to-mapping approximation, and propose to train the spike thresholds and introduce a new hyperparameter for the spiking neural models to reduce the error. With these methods, we can train high-performance low-latency SNNs. And the comparison of the properties between the DSR method and other methods is illustrated in Tab. 1. Formally, our main contributions are summarized as follows:
-
1.
We systematically study the spike representation for common spiking neural models, and propose the DSR method that uses the representation to train SNNs by backpropagation. The proposed method avoids the non-differentiability problem in SNN training and does not require the costly error backpropagation through the temporal domain.
-
2.
We propose to train the spike thresholds and introduce a new hyperparameter for the spiking neural models to reduce the representation error. The two techniques greatly help the DSR method to train SNNs with high performance and low latency.
- 3.
2 Related Work
Many works seek biological plausibility in training SNNs [5, 26, 31] using derivations of the Hebbian learning rule [21]. However, this method cannot achieve competitive performance and cannot be applicable on complicated datasets. Besides the brain-inspired method, SNN learning methods can be mainly categorized into two classes: ANN-to-SNN conversion [10, 56, 44, 42, 24, 11, 27, 19, 18, 12] and direct training[2, 23, 58, 59, 36, 53, 52, 1, 37, 57, 55, 45, 16, 13, 14]. We discuss both the conversion and direct training method, then analyze the information representation used in them.
ANN-to-SNN Conversion
The feasibility of this conversion method relies on the fact that the firing rates of an SNN can be estimated by activations of an ANN with corresponding architecture and weights[42]. With this method, the parameters of a target SNN are directly determined from a source ANN. And the performance of the target SNN is supposed to be not much worse than the source ANN. Many effective techniques have been proposed to reduce the performance gap, such as weight normalization[44], temporal switch coding[18], rate norm layer[12], and bias shift[10]. Recently, the conversion method has achieved high-performance ANN-to-SNN conversion [33, 56, 10], even on ImageNet. However, the good performance is at the expense of high latency, since only high latency can make the firing rates closely approach the high-precision activation. This fact hurts the energy efficiency of SNNs when using the conversion method. Furthermore, the conversion method is not suitable for neuromorphic data. In this paper, we borrow the idea of ANN-SNN mapping to design the backpropagation algorithm for training SNNs. However, unlike usual ANN-to-SNN conversion methods, the proposed DSR method can obtain high performance with low latency on both static and neuromorphic data.
Direct Training
Inspired by the immense success of gradient descent-based algorithms for training ANN, some works regard an SNN as an RNN and directly train it with the BPTT method. This scheme typically leverages surrogate gradient to deal with the discontinuous spike functions [2, 52, 59, 37], or calculate the gradients of loss with respect to spike times[36, 54, 60]. Between them, the surrogate gradient method achieves better performance with lower latency[16, 59]. However, those approaches need to backpropagate error signals through time steps and thus suffer from high computational costs during training [9]. Furthermore, the inaccurate approximations for computing the gradients or the “dead neuron” problem[45] limit the training effect and the use of large-scale network architectures. The proposed method uses spike representation to calculate the gradients of loss and need not backpropagate error through time steps. Therefore, the proposed method avoids the common problems for direct training. A few works [50, 51] also use the similar idea of decoupling the forward and backward passes to train feedforward SNNs; however, they neither systematically analyze the representation schemes nor the representation error, and they cannot achieve comparable accuracy as ours, even with high latency.
Information Representation in SNNs
In SNNs, information is carried by some representation of spike trains [38]. There are mainly two representation schemes: temporal coding and rate coding. These two schemes treat exact firing times and firing rates, respectively, as the information carrier. Temporal coding is adopted by some direct training methods that calculate gradients with respect to spike times [36, 54, 60], or few ANN-to-SNN methods [18, 48]. With temporal coding, those methods typically enjoy low energy consumption on neuromorphic chips due to sparse spikes. However, those methods either require chip-unfriendly neuron settings [18, 48, 60], or only perform well on simple datasets. Rate coding is adopted by most ANN-to-SNN methods [10, 56, 44, 42, 11, 27, 19, 12] and many direct training methods [55, 51]. The rate coding-based methods typically achieve better performances than those with temporal coding. Furthermore, recent progress shows the potential of rate-coding based methods on low latency or sparse firing [55], making it possible to reach the same or even better level of energy efficiency as temporal coding scheme. In this paper, we adopt the rate coding scheme to train SNNs.
3 Proposed Differentiation on Spike Representation (DSR) Method
3.1 Spiking Neural Models
Spiking neurons imitate the biological neurons that communicate with each other by spike trains. In this paper, we adopt the widely used integrate-and-fire (IF) model and leaky-integrate-and-fire (LIF) model [3], both of which are simplified models to characterize the process of spike generation. Each IF neuron or LIF neuron ‘integrates’ the received spike as its membrane potential , and the dynamics of membrane potential can be formally depicted as
| (1) | |||
| (2) |
where is the resting potential, is the time constant, is the spike threshold, and is the input current which is related to received spikes. Once the membrane potential exceeds the predefined threshold at time , the neuron will fire a spike and reset its membrane potential to the resting potential . The output spike train can be expressed using the Dirac delta function .
In practice, discretization for the dynamics is required. The discretized model is described as:
| (3a) | |||||
| (3b) | |||||
| (3c) |
where is the membrane potential before resetting, is the output spike, is the time step index and is the latency, is the Heaviside step function, and is the membrane potential update function. In the discretization, both and are set to be for simplicity, and therefore . The function for IF and LIF models can be described as:
| (4) | |||
| (5) |
where is the discrete step for LIF model. In practice, we set to be much less that . Different from other literature [52, 17, 10], we explicitly introduce the hyperparameter to ensure a large feasible region for , since the discretization for LIF model is only valid when the discrete step [17]. For example, is allowed in our setting, while some other works prohibit it since they set . We use the “reduce by subtraction” method [55, 51] for resetting the membrane potential in Eq. (3c). Combing Eqs. (3a) and (3c), we get a more concise update rule for the membrane potential:
| (6) |
Eq. 6 is used to define the forward pass of SNNs.
3.2 Forward Pass
In this paper, we consider -layer feedforward SNNs with the IF or LIF models. According to Eqs. 6 and 4, the spiking dynamics for an SNN with the IF model can be described as:
| (7) |
where is the layer index, are the input data to the network, are the output spike trains of the layer for , and are trainable synaptic weights from the layer to the layer. Spikes are generated according to Eq. (3b), and are treated as input currents to the layer. Furthermore, the spike thresholds are the same for all IF neurons in one particular layer. Similarly, according to Eqs. 6 and 5, the spiking dynamics for an SNN with the LIF model can be shown as:
| (8) | ||||
where is set to be a positive number much less than , and it appears to simplify the analysis on spike representation schemes in Sec. 3.3. In Eqs. 7 and 8, we only consider fully connected layers. However, other neural network components like convolution, skip connection, and average pooling can also be adopted.
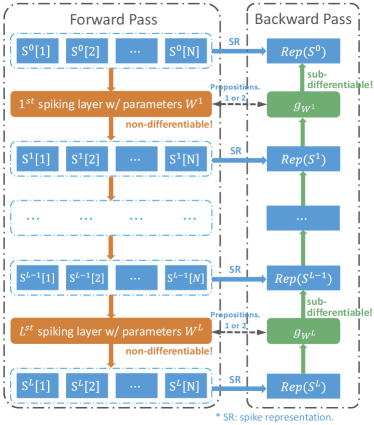
The input to the SNN can be both neuromorphic data or static data (e.g., images). While neuromorphic data are naturally adapted to SNNs, for static data, we repeatedly apply them to the first layer at each time step [55, 59, 42]. With this method, the first layer can be treated as the spike-train data generator. We use the spike trains as the output data of the SNN, whose setting is more biologically plausible than prohibiting firing for the last layer and using the membrane potentials as the network output [50, 30].
3.3 Spike Representation
In this subsection, we show that the forward computation for each layer of an SNN with the IF or LIF neurons can be represented as a sub-differentiable mapping using spike representation as the information carrier. And the spike representation is obtained by (weighted) firing rate coding. Specifically, denoting by the output spike trains of the layer, the relationship between the SNN and the mapping can be expressed as
| (9) |
where is the spike representation of , are the SNN parameters for the layer, and is the sub-differentiable mapping also parameterized by . Then the SNN parameters can be learned through gradients of . The illustration of the SNN-to-mapping representation is shown in Fig. 1.
We first use weighted firing rate coding to derive the formulae of spike representation and the sub-differentiable mapping for the LIF model. Then we briefly introduce the formulae for the IF model, which are simple extensions of those for the LIF model. Training SNNs based on the spike representation schemes is described in Sec. 3.4.
3.3.1 Spike Representation for the LIF Model
We first consider the LIF model defined by Eqs. (3a) to (3c) and (5). To simplify the notation, define . We further define as the weighted average input current until the time step , and define as the scaled weighted firing rate. Here we treat as the spike representation of the spike train for the LIF model. The key idea is to directly determine the relationship between and using a (sub-)differentiable mapping.
In detail, combining Eqs. 6 and 5, and multiplying the combined equation by , we have
| (10) | ||||
Summing Eq. 10 over to , we can get
| (11) |
Dividing Eq. 11 by and then rearrange the terms, we have
| (12) |
Note that we can further approximate in Eq. 12 by , since and we set . Then we have
| (13) |
Eq. 13 is the basic formula to determine the mapping from to . Note that in Eq. 13, the term cannot be directly determined only given . However, taking into consideration and assuming is small, we can ignore the term in Eq. 13, and further approximate as
| (14) |
where . Detailed derivation and mild assumptions for Eq. 14 are shown in the Supplementary Materials. Applying Eq. 14 to feedforward SNNs with multiple LIF neurons, we have Proposition 1, which is used to train SNNs.
Proposition 1.
Consider an SNN with LIF neurons defined by Eq. 8. Define and , where . Further define sub-differentiable mappings
If for , then approximates when .
3.3.2 Spike Representation for the IF Model
We then consider the IF model defined by Eqs. (3a) to (3c) and (4). Define as the average input current until the time step , and define as the scaled firing rate. We treat as the spike representation of the spike train for the IF model. We can use similar arguments shown in Sec. 3.3.1 to determine the relationship between and as
| (15) |
Detailed assumptions and derivation for Eq. 15 are shown in the Supplementary Materials. With Eq. 15, we can have Proposition 2 to train feedforward SNNs with the IF model.
Proposition 2.
Consider an SNN with IF neurons defined by Eq. 7. Define and . Further define sub-differentiable mappings:
If , then .
3.4 Differentiation on Spike Representation
In this subsection, we use the spike representation for the IF and the LIF models to drive the backpropagation training algorithm for SNNs, based on Propositions 2 and 1. And the illustration can be found in Fig. 1.
Define the spike representation operator with spike train as input, such that for the IF model, and for the LIF model, where . With the spike representation, we define the final output of the SNN as , where is the output spike trains from the last layer and is defined element-wise. We use cross-entropy as the loss function .
The proposed DSR method backpropagates the gradient of error signals based on the representation of spike trains in each layer, , where is the layer index. By applying chain rule, the required gradient can be computed as
| (16) |
where and can be computed with Propositions 2 and 1. Specifically, from Sec. 3.3, we have
| (17) |
where for the IF model, and for the LIF model. Therefore, we can calculate and based on Eq. 17. The pseudocode of the proposed DSR method can be found in the Supplementary Materials.
With the proposed DSR method, we avoid two common problems in SNN training. First, this method does not require backpropagation through the temporal domain, improving the training efficiency when compared with the BPTT type methods, especially when the number of time steps is not ultra-small. Second, this method does not need to handle the non-differentiability of spike functions, since the signals are backpropagated through sub-differentiable mapping. Although there exists representation error due to finite time steps, we can reduce it, as described in Sec. 4.
4 Reducing Representation Error
Propositions 2 and 1 show that the (weighted) firing rate can gradually estimate or converge to the output of a sub-differentiable mapping. And Sec. 3.4 shows that we can train SNNs by backpropagation using spike representation. However, in practice we want to simulate SNNs with only a small number of time steps, for the sake of low energy consumption. The low latency will further introduce representation error that hinders effective training. In this subsection, we study the representation error and propose to train the spike threshold and introduce a new hyperparameter for the neural models to reduce the error.
The representation error can be decomposed as , where is the “quantization error” and is the “deviation error”. The quantization error exists due to the imperfect precision of the firing rate, when assuming the same input currents at all time steps. For example, it can only take value in the form for the IF neuron, where and is the number of time steps. And the deviation error exists due to the inconsistency of input currents at different time steps. For example, when the average input current is , the output firing rate is supposed to be 0; however, it can be significantly larger than if the input currents are positive during the first few time steps.

From the statistical perspective, the expectation for is 0, assuming i.i.d. input currents at different time steps. Therefore, the “deviation error” will not affect training too much when using stochastic optimization algorithms. Next, we dig into with the IF model and then propose methods to reduce it. Similar arguments can be derived for the LIF model. When given unchanged input currents at all time steps to the IF neuron, the scaled average firing rate can be determined as
| (18) |
shown as the red curve in Fig. 2, where is the floor rounding operator. Inspired by Eq. 18, we propose two methods to reduce the quantization error.
Training the Spike Threshold
From Fig. 2 and Eq. 18, we observe that using small spike thresholds can reduce the quantization error. However, it also weakens the approximation capacity of the SNNs, since the scaled (weighted) firing rate will be in a small range then. Inspired by activation clipping methods for training quantized neural networks [6], in this paper, we treat the spike threshold of each layer as parameters to be trained, and include an L2-regularizer for the thresholds in the loss function to balance the tradeoff between quantization error and approximation capacity. To train the spike thresholds using backpropagation, we calculate the gradients with respect to them based on the spike representation introduced in Sec. 3.3. For example, using Eq. 15, for one IF neuron with average input current and steady scaled firing rate , we have
| (19) |
Then we can calculate the gradient of the loss function with respect to the threshold by the chain rule. A similar calculation applies to LIF neurons. In practice, since we use mini-batch optimization methods to train SNNs, the gradient for each threshold is proportional to the batch size by the chain rule. Thus, we scale the gradient regarding different batch sizes and spiking neural models.
Introducing a new hyperparameter for the neural models
We can introduce a new hyperparameter for spiking neurons to control the neuron firing to reduce the quantization error. Formally, we change Eq. (3b) to
| (20) |
to get a new firing mechanism, where is a hyperparameter. For the IF model with the new firing mechanism and , using the same notation as in Eq. 18, the scaled firing rate becomes
| (21) |
shown as the green curve in Fig. 2, where is the rounding operator. From Fig. 2, we can see that the maximum absolute quantization error is halved when using this mechanism. Furthermore, since makes the average absolute quantization error minimized, is the best choice for the IF model. On the other hand, for the LIF model, the best choice for changes when setting different latency , so we choose different in our experiments to minimize the average absolute quantization error.
| Method | Network | Neural Model | Time Steps | Accuracy | |
| CIFAR-10 | ANN 1 | PreAct-ResNet-18 | / | / | |
| ANN-to-SNN[10] | ResNet-20 | IF | 128 | ||
| ANN-to-SNN[19] | VGG-16 | IF | 2048 | ||
| ANN-to-SNN[56] | VGG-like | IF | 600 | ||
| Tandem Learning[51] | CIFARNet | IF | 8 | ||
| ASF-BP[50] | VGG-7 | IF | 400 | ||
| STBP[52] | CIFARNet | LIF | 12 | ||
| IDE[55] | CIFARNet-F | LIF | 100 | ||
| STBP-tdBN[59] | ResNet-19 | LIF | 6 | ||
| TSSL-BP[58] | CIFARNet | LIF w/ synaptic model | 5 | ||
| DSR (ours) | PreAct-ResNet-18 | IF | 20 | ||
| PreAct-ResNet-18 | LIF | 20 | |||
| CIFAR-100 | ANN 1 | PreAct-ResNet-18 | / | / | |
| ANN-to-SNN[10] | ResNet-20 | IF | 400-600 | ||
| ANN-to-SNN[19] | VGG-16 | IF | 768 | ||
| ANN-to-SNN[56] | VGG-like | IF | 300 | ||
| Hybrid Training[41] | VGG-11 | LIF | 125 | ||
| DIET-SNN[40] | VGG-16 | LIF | 5 | ||
| IDE[55] | CIFARNet-F | LIF | 100 | ||
| DSR (ours) | PreAct-ResNet-18 | IF | 20 | ||
| PreAct-ResNet-18 | LIF | 20 | |||
| ImageNet | ANN 1 | PreAct-ResNet-18 | / | / | |
| ANN-to-SNN[44] | ResNet-34 | IF | 2000 | ||
| ANN-to-SNN[19] | ResNet-34 | IF | 4096 | ||
| Hybrid training[41] | ResNet-34 | LIF | 250 | ||
| STBP-tdBN[59] | ResNet-34 | LIF | 6 | ||
| SEW ResNet[16] | SEW ResNet-34 | LIF | 4 | ||
| SEW ResNet[16] | SEW ResNet-18 | LIF | 4 | ||
| DSR (ours) | PreAct-ResNet-18 | IF | 50 | ||
| DVS-CIFAR10 | ASF-BP[50] | VGG-7 | IF | 50 | |
| Tandem Learning[51] | 7-layer CNN | IF | 20 | ||
| STBP[53] | 7-layer CNN | LIF | 40 | ||
| STBP-tdBN[59] | ResNet-19 | LIF | 10 | ||
| Fang et al. [17] | 7-layer CNN | LIF | 20 | ||
| DSR (ours) | VGG-11 | IF | 20 | ||
| VGG-11 | LIF | 20 |
-
1
Self-implemented results for ANN.
5 Experiments
We first evaluate the proposed DSR method and compare it with other works on visual object recognition benchmarks, including CIFAR-10, CIFAR-100, ImageNet, and DVS-CIFAR10. We then demonstrate the effectiveness of our method when the number of time steps becomes smaller and smaller, or the network becomes deeper and deeper. We also test the effectiveness of the methods for reducing representation error. Please refer to the Supplementary Materials for experiment details. Our code is available at https://github.com/qymeng94/DSR.
5.1 Comparison to the State-of-the-Art
The comparison on CIFAR-10, CIFAR-100, ImageNet, and DVS-CIFAR10 is shown in Tab. 2.
For the CIFAR-10 and the CIFAR-100 datasets, we use pre-activation ResNet-18 [20] as the network architecture. Tab. 2 shows that the proposed DSR method outperforms all other methods on CIFAR-10 and the CIFAR-100 with 20 time steps for both the IF and the LIF models, based on 3 runs of experiments. Especially, our method achieves accuracies that are 5%-10% higher on CIFAR-100 when compared to others. Furthermore, the obtained SNNs have similar or even better performance compared to ANNs with the same network architectures. Although some direct training methods use smaller time steps than ours, our method can also achieve better performances than others when the number of time steps and , as shown in Fig. 3(a).
For the ImageNet dataset, we also use the pre-activation ResNet-18 network architecture. To accelerate training, we adopt the hybrid training technique [41, 40]. And considering the data complexity and the 1000 classes, we use a moderate number of time steps to achieve satisfactory results. Our proposed method can outperform the direct training methods even if they use larger network architectures. Although some ANN-to-SNN methods have better accuracy, they use much more time steps than ours.
5.2 Model Validation and Ablation Study


Effectiveness of the Proposed Method with Low Latency
We validate that the proposed method can achieve competitive performances even with ultra-low latency, as shown in Fig. 3(a). Each model is trained from scratch. From 20 to 5 time steps, our models only suffer from less than accuracy drop. The results for 5 time steps also outperform other SOTA shown in Tab. 2. More training details can be found in the Supplementary Materials.
Effectiveness of the Proposed Method with Deep Network Structure
Many SNN learning methods cannot adapt to deep network architectures, limiting the potential of SNNs. The reason is that the error for gradient approximation or ANN-to-SNN conversion will accumulate through layers, or the methods are computationally expensive for large-scale network structures. In this part, we test the proposed method on CIFAR-10 using pre-activation ResNet with different depths, namely 20, 32, 44, 56, 110 layers. Note that the channel size is smaller than the PreAct-ResNet-18, since the deep networks with large channel size as in PreAct-ResNet-18 perform not much better and are harder to train even for ANNs. More details about network architectures can be found in the Supplementary Materials. Results are shown in Fig. 3(b). The figure shows that our method is effective on deep networks (>100 layers), and performs better with deeper network structures. This indicates the great potential of our method to achieve more advanced performance when using very deep networks.
Ablation Study on Methods to Reduce Representation Error
We conduct the ablation study on the representation error reduction methods, namely training the threshold and introducing a new hyperparameter for the neural models. The models are trained on CIFAR-10 with PreAct-ResNet-18 structure and 20 time steps, and the results are shown in Tab. 3. The experiments imply that the representation error significantly hinders training and also demonstrate the superiority of the two methods to reduce the representation error. Note that the threshold training method also helps stabilize training, since the results become unstable for large thresholds without this method (e.g., the standard deviation is when ). Furthermore, the average accuracy of not using both methods is better than the one of only using the firing mechanism modification, maybe due to the instability of the results when is large.
| Setting | Accuracy |
|---|---|
| DSR, init. | |
| DSR w/o F, init. | |
| DSR w/o T, | |
| DSR w/o T, | |
| DSR w/o F&T, |
6 Conclusion and Discussions
In this work, we show that the forward computation of SNNs can be represented as some sub-differentiable mapping. Based on the SNN-to-mapping representation, we propose the DSR method to train SNNs that avoids the non-differentiability problem in SNN training and does not require backpropagation through the temporal domain. We also analyze the representation error due to the small number of time steps, and propose to train the thresholds and introduce a new hyperparameter for the IF and LIF models to reduce the representation error. With the error reduction methods, we can train SNNs with low latency by the DSR method. Experiments show that the proposed method could achieve SOTA performance on mainstream vision tasks, and show the effectiveness of the method when dealing with ultra-low latency or very deep network structures.
Societal impact and limitations. As for societal impact, there is no direct negative societal impact since this work only focuses on training SNNs. In fact, the development of high-performance low-latency SNNs allows SNNs to replace ANNs in some real-world tasks. This replacement will alleviate the huge energy consumption by ANNs and reduce carbon dioxide emissions. As for limitations, the DSR method may suffer from a certain degree of performance drop when the latency is extremely low (e.g., with only 2 or 3 time steps), since the method requires relatively accurate spike representation to conduct backpropagation.
Acknowledgment
We thank Jiancong Xiao and Zeyu Qin for useful discussion. We thank Jin Wang for pointing out typos. The work of Z.-Q. Luo was supported by the National Natural Science Foundation of China under Grant 61731018, and the Guangdong Provincial Key Laboratory of Big Data Computation Theories and Methods. Z. Lin was supported by the NSF China (No. 61731018), NSFC Tianyuan Fund for Mathematics (No. 12026606), Project 2020BD006 supported by PKU-Baidu Fund, and Qualcomm. The work of Yisen Wang was partially supported by the National Natural Science Foundation of China under Grant 62006153, and Project 2020BD006 supported by PKU-Baidu Fund.
References
- [1] Guillaume Bellec, Darjan Salaj, Anand Subramoney, Robert Legenstein, and Wolfgang Maass. Long short-term memory and learning-to-learn in networks of spiking neurons. In NIPS, 2018.
- [2] Sander M Bohte, Joost N Kok, and Johannes A La Poutré. Spikeprop: backpropagation for networks of spiking neurons. In ESANN, 2000.
- [3] Anthony N Burkitt. A review of the integrate-and-fire neuron model: I. homogeneous synaptic input. Biological cybernetics, 95(1):1–19, 2006.
- [4] Yongqiang Cao, Yang Chen, and Deepak Khosla. Spiking deep convolutional neural networks for energy-efficient object recognition. IJCV, 113(1):54–66, 2015.
- [5] Natalia Caporale and Yang Dan. Spike timing–dependent plasticity: a hebbian learning rule. Annu. Rev. Neurosci., 31:25–46, 2008.
- [6] Jungwook Choi, Zhuo Wang, Swagath Venkataramani, Pierce I-Jen Chuang, Vijayalakshmi Srinivasan, and Kailash Gopalakrishnan. Pact: Parameterized clipping activation for quantized neural networks. arXiv preprint arXiv:1805.06085, 2018.
- [7] Mike Davies, Narayan Srinivasa, Tsung-Han Lin, Gautham Chinya, Yongqiang Cao, Sri Harsha Choday, Georgios Dimou, Prasad Joshi, Nabil Imam, Shweta Jain, et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro, 38(1):82–99, 2018.
- [8] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. IEEE, 2009.
- [9] Lei Deng, Yujie Wu, Xing Hu, Ling Liang, Yufei Ding, Guoqi Li, Guangshe Zhao, Peng Li, and Yuan Xie. Rethinking the performance comparison between snns and anns. Neural Networks, 121:294–307, 2020.
- [10] Shikuang Deng and Shi Gu. Optimal conversion of conventional artificial neural networks to spiking neural networks. In ICLR, 2021.
- [11] Peter U Diehl, Daniel Neil, Jonathan Binas, Matthew Cook, Shih-Chii Liu, and Michael Pfeiffer. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In IJCNN, 2015.
- [12] Jianhao Ding, Zhaofei Yu, Yonghong Tian, and Tiejun Huang. Optimal ann-snn conversion for fast and accurate inference in deep spiking neural networks. In IJCAI, 2021.
- [13] Steve K Esser, Rathinakumar Appuswamy, Paul Merolla, John V Arthur, and Dharmendra S Modha. Backpropagation for energy-efficient neuromorphic computing. In NeurIPS, 2015.
- [14] Steven K. Esser, Paul A. Merolla, John V. Arthur, Andrew S. Cassidy, Rathinakumar Appuswamy, Alexander Andreopoulos, David J. Berg, Jeffrey L. McKinstry, Timothy Melano, Davis R. Barch, Carmelo di Nolfo, Pallab Datta, Arnon Amir, Brian Taba, Myron D. Flickner, and Dharmendra S. Modha. Convolutional networks for fast, energy-efficient neuromorphic computing. PNAS, 113(41):11441–11446, 2016.
- [15] Wei Fang, Yanqi Chen, Jianhao Ding, Ding Chen, Zhaofei Yu, Huihui Zhou, Yonghong Tian, and other contributors. Spikingjelly. https://github.com/fangwei123456/spikingjelly, 2020.
- [16] Wei Fang, Zhaofei Yu, Yanqi Chen, Tiejun Huang, Timothée Masquelier, and Yonghong Tian. Deep residual learning in spiking neural networks. In NIPS, 2021.
- [17] Wei Fang, Zhaofei Yu, Yanqi Chen, Timothée Masquelier, Tiejun Huang, and Yonghong Tian. Incorporating learnable membrane time constant to enhance learning of spiking neural networks. In ICCV, 2021.
- [18] Bing Han and Kaushik Roy. Deep spiking neural network: Energy efficiency through time based coding. In ECCV, 2020.
- [19] Bing Han, Gopalakrishnan Srinivasan, and Kaushik Roy. RMP-SNN: residual membrane potential neuron for enabling deeper high-accuracy and low-latency spiking neural network. In CVPR, 2020.
- [20] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In ECCV, 2016.
- [21] Donald Olding Hebb. The organisation of behaviour: a neuropsychological theory. Science Editions New York, 1949.
- [22] Yangfan Hu, Huajin Tang, Yueming Wang, and Gang Pan. Spiking deep residual network. arXiv preprint arXiv:1805.01352, 2018.
- [23] Dongsung Huh and Terrence J. Sejnowski. Gradient descent for spiking neural networks. In NIPS, 2018.
- [24] Eric Hunsberger and Chris Eliasmith. Spiking deep networks with lif neurons. arXiv preprint arXiv:1510.08829, 2015.
- [25] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
- [26] Saeed Reza Kheradpisheh, Mohammad Ganjtabesh, Simon J Thorpe, and Timothée Masquelier. Stdp-based spiking deep convolutional neural networks for object recognition. Neural Networks, 99:56–67, 2018.
- [27] Sei Joon Kim, Seongsik Park, Byunggook Na, and Sungroh Yoon. Spiking-yolo: Spiking neural network for energy-efficient object detection. In AAAI, 2020.
- [28] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
- [29] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [30] Chankyu Lee, Syed Shakib Sarwar, Priyadarshini Panda, Gopalakrishnan Srinivasan, and Kaushik Roy. Enabling spike-based backpropagation for training deep neural network architectures. Frontiers in Neuroscience, 14:119, 2020.
- [31] Robert Legenstein, Dejan Pecevski, and Wolfgang Maass. A learning theory for reward-modulated spike-timing-dependent plasticity with application to biofeedback. PLoS computational biology, 4(10):e1000180, 2008.
- [32] Hongmin Li, Hanchao Liu, Xiangyang Ji, Guoqi Li, and Luping Shi. Cifar10-dvs: an event-stream dataset for object classification. Frontiers in neuroscience, 11:309, 2017.
- [33] Yuhang Li, Shikuang Deng, Xin Dong, Ruihao Gong, and Shi Gu. A free lunch from ann: Towards efficient, accurate spiking neural networks calibration. In ICML, 2021.
- [34] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. In ICLR, 2017.
- [35] Paul A Merolla, John V Arthur, Rodrigo Alvarez-Icaza, Andrew S Cassidy, Jun Sawada, Filipp Akopyan, Bryan L Jackson, Nabil Imam, Chen Guo, Yutaka Nakamura, et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science, 345(6197):668–673, 2014.
- [36] Hesham Mostafa. Supervised learning based on temporal coding in spiking neural networks. TNNLS, 29(7):3227–3235, 2017.
- [37] Emre O Neftci, Hesham Mostafa, and Friedemann Zenke. Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Processing Magazine, 36(6):51–63, 2019.
- [38] Stefano Panzeri and Simon R Schultz. A unified approach to the study of temporal, correlational, and rate coding. Neural Computation, 13(6):1311–1349, 2001.
- [39] Jing Pei, Lei Deng, Sen Song, Mingguo Zhao, Youhui Zhang, Shuang Wu, Guanrui Wang, Zhe Zou, Zhenzhi Wu, Wei He, et al. Towards artificial general intelligence with hybrid tianjic chip architecture. Nature, 572(7767):106–111, 2019.
- [40] Nitin Rathi and Kaushik Roy. Diet-snn: Direct input encoding with leakage and threshold optimization in deep spiking neural networks. arXiv preprint arXiv:2008.03658, 2020.
- [41] Nitin Rathi, Gopalakrishnan Srinivasan, Priyadarshini Panda, and Kaushik Roy. Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation. In ICLR, 2019.
- [42] Bodo Rueckauer, Iulia-Alexandra Lungu, Yuhuang Hu, Michael Pfeiffer, and Shih-Chii Liu. Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Frontiers in neuroscience, 11:682, 2017.
- [43] David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors. nature, 323(6088):533–536, 1986.
- [44] Abhronil Sengupta, Yuting Ye, Robert Wang, Chiao Liu, and Kaushik Roy. Going deeper in spiking neural networks: Vgg and residual architectures. Frontiers in neuroscience, 13:95, 2019.
- [45] Sumit Bam Shrestha and Garrick Orchard. SLAYER: spike layer error reassignment in time. In NIPS, 2018.
- [46] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2014.
- [47] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1):1929–1958, 2014.
- [48] Christoph Stöckl and Wolfgang Maass. Optimized spiking neurons can classify images with high accuracy through temporal coding with two spikes. Nature Machine Intelligence, pages 1–9, 2021.
- [49] Amirhossein Tavanaei, Masoud Ghodrati, Saeed Reza Kheradpisheh, Timothée Masquelier, and Anthony Maida. Deep learning in spiking neural networks. Neural Networks, 111:47–63, 2019.
- [50] Hao Wu, Yueyi Zhang, Wenming Weng, Yongting Zhang, Zhiwei Xiong, Zheng-Jun Zha, Xiaoyan Sun, and Feng Wu. Training spiking neural networks with accumulated spiking flow. In AAAI, 2021.
- [51] Jibin Wu, Yansong Chua, Malu Zhang, Guoqi Li, Haizhou Li, and Kay Chen Tan. A tandem learning rule for effective training and rapid inference of deep spiking neural networks. TNNLS, 2021.
- [52] Yujie Wu, Lei Deng, Guoqi Li, Jun Zhu, and Luping Shi. Spatio-temporal backpropagation for training high-performance spiking neural networks. Frontiers in neuroscience, 12:331, 2018.
- [53] Yujie Wu, Lei Deng, Guoqi Li, Jun Zhu, Yuan Xie, and Luping Shi. Direct training for spiking neural networks: Faster, larger, better. In AAAI, 2019.
- [54] Timo C Wunderlich and Christian Pehle. Event-based backpropagation can compute exact gradients for spiking neural networks. Scientific Reports, 11(1):1–17, 2021.
- [55] Mingqing Xiao, Qingyan Meng, Zongpeng Zhang, Yisen Wang, and Zhouchen Lin. Training feedback spiking neural networks by implicit differentiation on the equilibrium state. In NIPS, 2021.
- [56] Zhanglu Yan, Jun Zhou, and Weng-Fai Wong. Near lossless transfer learning for spiking neural networks. In AAAI, 2021.
- [57] Yukun Yang, Wenrui Zhang, and Peng Li. Backpropagated neighborhood aggregation for accurate training of spiking neural networks. In ICML, 2021.
- [58] Wenrui Zhang and Peng Li. Temporal spike sequence learning via backpropagation for deep spiking neural networks. In NIPS, 2020.
- [59] Hanle Zheng, Yujie Wu, Lei Deng, Yifan Hu, and Guoqi Li. Going deeper with directly-trained larger spiking neural networks. In AAAI, 2021.
- [60] Shibo Zhou, Xiaohua Li, Ying Chen, Sanjeev T Chandrasekaran, and Arindam Sanyal. Temporal-coded deep spiking neural network with easy training and robust performance. In AAAI, 2021.
Appendix A Details about Spike Representation
A.1 Derivation for Eq. 14
In this subsection, we consider the LIF model defined by Eqs. (3a) to (3c) and (5), and derive Eq. 14 from Eq. 13 in the main content under mild assumptions.
From the main content, we have derived that
| (22) |
as shown in Eq. 13. Since the LIF neuron is supposed to fire no or very few spikes when and fire almost always when , we can separate the accumulated membrane potential into two parts: one part represents the “exceeded” membrane potential that does not contribute to spike firing, and the other part represents the “remaining” membrane potential. In detail, the “exceeded” membrane potential can be calculated as
| (23) |
And the “remaining” membrane potential can be calculated as . With the decomposition of membrane potential and the fact that when and , we can further approximate from Eq. 22 as
| (24) |
if the limit of right hand side exists.
Now we want to find the condition to ignore the term in Eq. 24. In the case , the magnitude of membrane potential would gradually increase with time. After introducing , the “remaining” membrane potential typically does not diverge over time. In fact, is typically bounded in when , except in the extreme case when the input current at different time steps distributes extremely unevenly. So we can just assume that . Furthermore, if we set a significantly smaller threshold compared to the magnitude of , the term can be ignored. Then from Eq. 24, we have
| (25) |
That is ,we can approximate by , with an approximation error bounded by when .
A.2 Derivation for Eq. 15
In this subsection, we consider the IF model defined by Eqs. (3a) to (3c) and (4) and derive Eq. 15 in the main content under mild assumptions.
Combining Eqs. (4) and (3c), and taking the summation over to , we can get
| (26) |
Define the scaled firing rate until the time step as , and the average input current as . Dividing Eq. 26 by , we have
| (27) |
Using similar arguments appeared in Section A.1, we can get
| (28) |
if the limit of right hand side exists. Here and
| (29) |
Similar to the LIF model, the “remaining” membrane potential for the IF model is typically bounded in when , except in the extreme case. For example, consider and the input current is non-zero only at the last time steps, then will be inconsistently large and will be unbounded when . However, this extreme case will not happen in SNN computation for normal input data. Therefore, we assume , and can get
| (30) |
if the limit of exists.
In summary, we derive Eq. 15 in the main content under following mild conditions:
-
1.
The IF neuron fires no or finite spikes as when . And the IF neuron does not fire only at a finite number of time steps as when .
-
2.
.
Appendix B Pseudocode of the Proposed DSR Method
We present the pseudocode of one iteration of SNN training with the DSR method in Algorithm 1 for better illustration.
Appendix C Implementation Details
C.1 Dataset Description and Preprocessing
CIFAR-10 and CIFAR-100
The CIFAR-10 dataset [29] contains 60,000 3232 color images in 10 different classes, which can be separated into 50,000 training samples and 10,000 testing samples. We apply data normalization to ensure that input images have zero mean and unit variance. We apply random cropping and horizontal flipping for data augmentation. The CIFAR-100 dataset [29] is similar to CIFAR-10 except that there are 100 classes of objects. We use the same data preprocessing as CIFAR-10. These two datasets are licensed under MIT.
ImageNet
The ImageNet-1K dataset [8] spans 1000 object classes and contains 1,281,167 training images, 50,000 validation images and 100,000 test images. This dataset is licensed under Custom (non-commercial). We apply data normalization to ensure zero mean and unit variance for input images. Moreover, we apply random resized cropping and horizontal flipping for data augmentation.
| 20-layers | 32-layers | 44-layers | 56-layers | 110-layers |
| conv (33,16) | ||||
| average pool, 10-d fc | ||||
DVS-CIFAR10
The DVS-CIFAR10 dataset [32] is a neuromophic dataset converted from CIFAR-10 using an event-based sensor. It contains 10,000 event-based images with resolution 128128 pixels. The images are in 10 classes, with 1000 examples in each class. The dataset is licensed under CC BY 4.0. Since each spike train contains more than one million events, we split the events into 20 slices and integrate the events in each slice into one frame. More details about the transformation could be found in [17]. To conduct training and testing, we separate the whole data into 9000 training images and 1000 test images. Both the event-to-frame integrating and data separation are handled with the SpikingJelly [15] framework. We also reduce the spatial resolution from 128128 to 4848 and apply random cropping for data augmentation.
C.2 Batch Normalization
Batch Normalization (BN) [25] is a widely used technique in the deep learning community to stabilize signal propagation and accelerate training. In this paper, BN is adopted in the network architectures. However, since the input data for SNNs have an additional time dimension when compared to input image data for ANNs, we need to make the BN components suitable for SNNs.
In this paper, we combine the time dimension and the batch dimension into one and then conduct BN. In detail, consider a batch of temporal data with batch size and temporal dimension such that , and for . Then define and to be the mean and variance of the reshaped data . With the defined and , BN transforms the original data to as
| (31) |
where and are learnable parameters, and is a small positive number to guarantee valid division.
C.3 Network Architectures
We use the pre-activation ResNet-18 [20] network architecture to conduct experiments on CIFAR-10, CIFAR-100, and ImageNet. To make the network architecture implementable on neuromorphic chips, we add spiking neurons after pooling operations and the last fully connected classifier. Furthermore, we replace all max pooling with average pooling. To stabilize the (weighted) firing rates of the output layer, we also introduce an additional BN operation between the last fully connected classifier and the last spiking neuron layer. The network contains four groups of basic block [20] structures, with channel sizes 64, 128, 256, and 512, respectively.
To test the effectiveness of the proposed DSR method with deeper networks structures, we conduct experiments with the pre-activation ResNet with 20, 32, 44, 56, 110 layers, whose architectures are shown in Tab. 4. We also add additional spiking neuron layers and BN layers like what we do for the PreAct-ResNet-18 structure.
We use the VGG-11 [46] network architecture to conduct experiments on DVS-CIFAR10. To enhance generalization capacity of the network, we further add dropout [47] layers after the spiking neurons, and we set the probability of zeroing elements to be . We only keep one fully connected layer to reduce the number of neurons.
C.4 Training Hyperparameters
First, we consider hyperparameters about the IF model. We set the initial threshold for each layer and restrict it to be no less than during training. We set in Eq. 20 to be .
Then we consider hyperparameters about the LIF model. We fix the time constant for the layer to be for each . The setting for initial , lower bound for , , and change with the number of time steps, as shown in Tab. 5.
| Time Steps | initial | LB for | ||
|---|---|---|---|---|
| 20 | 0.3 | 0.0005 | 0.05 | 0.3 |
| 15 | 0.3 | 0.0005 | 0.05 | 0.4 |
| 10 | 0.3 | 0.0005 | 0.05 | 0.4 |
| 5 | 0.6 | 0.001 | 0.1 | 0.5 |
Appendix D Firing Sparsity
To achieve low energy consumption on neuromorphic hardware, the number of spikes generated by an SNN should be small. Then the firing rate is an important quantity to measure the energy efficiency of SNNs. We calculate the average firing rates of the trained SNNs on CIFAR-10, as shown in Fig. 4. The results show that the firing rates of all layers are below 20%, and many layers have firing rates of no more than 5%. Regardless of the layer of neurons, the total firing rates are between 7.5% and 9.5% for different number of time steps and both neuron models. Since the firing rate does not increase as the number of time steps decreases, the proposed method can achieve satisfactory performance with both low latency and high firing sparsity.


Appendix E Weight Quantization
In our experiments, the network weights are 32-bit. However, we can also adopt low-bit weights when implementing our method on neuromorphic hardware, by combining existing quantization algorithms. The weights in neuromorphic hardware are generally 8-bit. So we simply quantize the weights of our trained SNNs to 8 bits and even 4 bits using the straight-through estimation method, and the results on CIFAR-10 are shown in Tab. 7.
| Neural Model | 32 bits | 8 bits | 4 bits |
|---|---|---|---|
| IF | 95.38% | 95.45% | 95.31% |
| LIF | 95.63% | 95.65% | 95.39% |