\ul
Training Entire-Space Models for Target-oriented Opinion Words Extraction
Abstract.
Target-oriented opinion words extraction (TOWE) is a subtask of aspect-based sentiment analysis (ABSA). Given a sentence and an aspect term occurring in the sentence, TOWE extracts the corresponding opinion words for the aspect term. TOWE has two types of instance. In the first type, aspect terms are associated with at least one opinion word, while in the second type, aspect terms do not have corresponding opinion words. However, previous researches trained and evaluated their models with only the first type of instance, resulting in a sample selection bias problem. Specifically, TOWE models were trained with only the first type of instance, while these models would be utilized to make inference on the entire space with both the first type of instance and the second type of instance. Thus, the generalization performance will be hurt. Moreover, the performance of these models on the first type of instance cannot reflect their performance on entire space. To validate the sample selection bias problem, four popular TOWE datasets containing only aspect terms associated with at least one opinion word are extended and additionally include aspect terms without corresponding opinion words. Experimental results on these datasets show that training TOWE models on entire space will significantly improve model performance and evaluating TOWE models only on the first type of instance will overestimate model performance111Data and code are available at https://github.com/l294265421/SIGIR22-TOWE.
1. Introduction
Aspect-based sentiment analysis (ABSA) (Hu and Liu, 2004; Pontiki et al., 2014, 2015, 2016) is a branch of sentiment analysis (Nasukawa and Yi, 2003; Liu, 2012). Target-oriented opinion words extraction (TOWE) (Fan et al., 2019) is a subtask of ABSA. Given a sentence and an aspect term occurring in the sentence, TOWE extracts the corresponding opinion words for the aspect term. For example, as shown in Figure 1, given the sentence “Try the rose roll (not on menu). ” and an aspect term “rose roll” appearing in the sentence, TOWE extracts the opinion word “Try”.

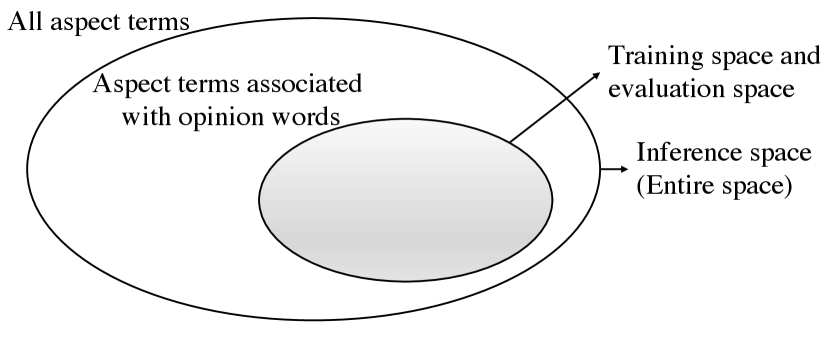
TOWE has two types of instance. In the first type of instance, called Type I instance, aspect terms are associated with at least one opinion word. An example of Type I instance is shown in Figure 1 (a). In the second type of instance, called Type II instance, aspect terms don’t have corresponding opinion words. An example of Type II instance is shown in Figure 1 (b). However, previous studies (Fan et al., 2019; Wu et al., 2020; Pouran Ben Veyseh et al., 2020; Feng et al., 2021; Mensah et al., 2021; Jiang et al., 2021; Kang et al., 2021) trained and evaluated their models only on Type I instances and ignored Type II instances. The percentages of Type II instance in the four SemEval challenge datasets (Pontiki et al., 2014, 2015, 2016), which the four popular TOWE datasets only including Type I instances were built by Fan et al. (2019) based on, range from 9.05% to 32.33%. This indicates that there is a considerable amount of Type II instances and Type II instances should not be ignored.
Furthermore, as illustrated in Figure 2, ignoring Type II instances leads to a sample selection bias problem (Zadrozny, 2004; Ma et al., 2018). Specifically, TOWE models are trained with only Type I instances, while these models will be utilized to make inference on the entire space with both Type I and Type II instances. Thus, the generalization performance of trained models will be hurt. Moreover, the performance of these models on Type I instances cannot reflect their performance on entire space, i.e. real-world scenarios.
To validate the sample selection bias problem, four popular TOWE datasets containing only Type I instances are extended and additionally include Type II instances. Experimental results on these datasets show that training TOWE models on entire space will significantly improve model performance and evaluating TOWE models only on Type I instances will overestimate model performance.
2. Related Work
Target-oriented opinion words extraction (TOWE) extracts the corresponding opinion words from sentences for a given aspect term and is proposed by Fan et al. (2019). Moreover, Fan et al. (2019) built four TOWE datasets (i.e., Rest14, Lapt14, Rest15, and Rest16) based on four SemEval challenge datasets. The four SemEval challenge datasets include three restaurant datasets (i.e. Rest14, Rest15, and Rest16) from the SemEval Challenge 2014 Task 4 (Pontiki et al., 2014), SemEval Challenge 2015 task 12 (Pontiki et al., 2015), and SemEval Challenge 2016 task 5 (Pontiki et al., 2016), and a laptop dataset (i.e. Lapt14) from the SemEval Challenge 2014 Task 4. In the original SemEval challenge datasets, the aspect terms are annotated, but the opinion words and the correspondence with aspect terms are not provided. Thus Fan et al. (2019) annotated the corresponding opinion words for the annotated aspect terms. Note that, in the four TOWE datasets that Fan et al. (2019) built, only the sentences that contain pairs of aspect terms and opinion words are kept and only the aspect terms associated with at least one opinion term are used as instances. Fan et al. (2019) also proposed an Inward-Outward LSTM with Global context (IOG) for TOWE.
Later, several other models were proposed for TOWE. Pouran Ben Veyseh et al. (2020) proposed ONG including Ordered-Neuron Long Short-Term Memory Networks as well as GCN, and Jiang et al. (2021) proposed a novel attention-based relational graph convolutional neural network (ARGCN), both of which exploited syntactic information over dependency graphs to improve model performance. Feng et al. (2021) proposed Target-Specified sequence labeling with Multi-head Self-Attention for TOWE. Wu et al. (2020) leveraged latent opinions knowledge from resource-rich review sentiment classification datasets to improve TOWE task. Kang et al. (2021) concentrated on incorporating aspect term information into BERT. Mensah et al. (2021) conducted an empirical study to examine the actual contribution of position embeddings. These models obtained better performance. However, all these studies, following Fan et al. (2019), only used Type I instances to train and evaluate their models.
| Datasets |
|
Ratio (%) | ||||
|---|---|---|---|---|---|---|
| Rest14-e | training | Type I instance | 2138 | 28.35 | ||
| Type II instance | 846 | |||||
| validation | Type I instance | 500 | 29.58 | |||
| Type II instance | 210 | |||||
| test | Type I instance | 865 | 23.72 | |||
| Type II instance | 269 | |||||
| Lapt14-e | training | Type I instance | 1304 | 32.33 | ||
| Type II instance | 623 | |||||
| validation | Type I instance | 305 | 30.21 | |||
| Type II instance | 132 | |||||
| test | Type I instance | 480 | 26.72 | |||
| Type II instance | 175 | |||||
| Rest15-e | training | Type I instance | 864 | 9.05 | ||
| Type II instance | 86 | |||||
| validation | Type I instance | 212 | 14.86 | |||
| Type II instance | 37 | |||||
| test | Type I instance | 436 | 19.56 | |||
| Type II instance | 106 | |||||
| Rest16-e | training | Type I instance | 1218 | 12.94 | ||
| Type II instance | 181 | |||||
| validation | Type I instance | 289 | 15.99 | |||
| Type II instance | 55 | |||||
| test | Type I instance | 456 | 25.49 | |||
| Type II instance | 156 | |||||
| Method | Test instance type | Rest14-e | Lapt14-e | Rest15-e | Rest16-e | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | ||
| ARGCN | Entire space | 71.70 | 81.30 | 76.17 | 60.99 | 69.48 | 64.90 | 68.10 | 75.90 | 71.72 | 69.85 | 81.91 | 75.37 |
| Type I instance | 85.25 | 82.29 | 83.73 | 74.00 | 70.41 | 72.14 | 76.56 | 75.66 | 76.05 | 86.00 | 82.33 | 84.10 | |
| (Gains (%)) | 18.89 | 1.22 | 9.93 | 21.32 | 1.33 | 11.15 | 12.43 | -0.32 | 6.05 | 23.11 | 0.51 | 11.58 | |
| ARGCNbert | Entire space | 73.19 | 83.46 | 77.98 | 63.19 | 73.22 | 67.80 | 73.88 | 74.73 | 74.27 | 74.26 | 83.78 | 78.72 |
| Type I instance | 86.00 | 83.01 | 84.46 | 75.79 | 76.02 | 75.88 | 78.21 | 75.74 | 76.92 | 86.91 | 84.05 | 85.45 | |
| (Gains (%)) | 17.50 | -0.54 | 8.31 | 19.95 | 3.83 | 11.92 | 5.87 | 1.35 | 3.58 | 17.03 | 0.32 | 8.54 | |
| IOG | Entire space | 73.02 | 76.62 | 74.77 | 61.60 | 67.25 | 64.19 | 70.78 | 69.98 | 70.32 | 68.37 | 81.41 | 74.29 |
| Type I instance | 82.80 | 78.66 | 80.64 | 72.43 | 69.63 | 70.96 | 77.19 | 69.86 | 73.29 | 85.67 | 79.81 | 82.58 | |
| (Gains (%)) | 13.39 | 2.66 | 7.85 | 17.57 | 3.54 | 10.55 | 9.05 | -0.17 | 4.23 | 25.30 | -1.97 | 11.15 | |
| IOGbert | Entire space | 73.38 | 85.92 | 79.14 | 60.41 | 80.32 | 68.92 | 71.03 | 81.70 | 75.96 | 69.69 | 90.31 | 78.62 |
| Type I instance | 86.50 | 85.81 | \ul86.13 | 77.62 | 80.92 | \ul79.22 | 78.88 | 81.70 | \ul80.24 | 88.68 | 89.66 | \ul89.16 | |
| (Gains (%)) | 17.88 | -0.14 | 8.84 | 28.50 | 0.75 | 14.95 | 11.05 | 0.00 | 5.64 | 27.25 | -0.72 | 13.40 | |
| Method | Training-validation instance type | Rest14-e | Lapt14-e | Rest15-e | Rest16-e | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | ||
| ARGCN | Type I instance | 71.70 | 81.30 | 76.17 | 60.99 | 69.48 | 64.90 | 68.10 | 75.90 | 71.72 | 69.85 | 81.91 | 75.37 |
| Entire space | 81.02 | 78.29 | 79.58 | 73.29 | 64.94 | 68.82 | 75.12 | 73.14 | 74.11 | 75.61 | 81.91 | 78.61 | |
| (Gains (%)) | 13.00 | -3.70 | 4.48 | 20.16 | -6.54 | 6.04 | 10.31 | -3.63 | 3.33 | 8.23 | 0.00 | 4.29 | |
| ARGCNbert | Type I instance | 73.19 | 83.46 | 77.98 | 63.19 | 73.22 | 67.80 | 73.88 | 74.73 | 74.27 | 74.26 | 83.78 | 78.72 |
| Entire space | 81.37 | 78.39 | 79.84 | 72.46 | 66.43 | 69.27 | 76.63 | 72.50 | 74.48 | 78.68 | 81.03 | 79.82 | |
| (Gains (%)) | 11.17 | -6.08 | 2.39 | 14.68 | -9.27 | 2.17 | 3.73 | -2.98 | 0.29 | 5.96 | -3.28 | 1.39 | |
| IOG | Type I instance | 73.02 | 76.62 | 74.77 | 61.60 | 67.25 | 64.19 | 70.78 | 69.98 | 70.32 | 68.37 | 81.41 | 74.29 |
| Entire space | 75.78 | 74.68 | 75.19 | 71.08 | 62.91 | 66.71 | 75.81 | 67.38 | 71.29 | 75.66 | 77.75 | 76.68 | |
| (Gains (%)) | 3.78 | -2.53 | 0.56 | 15.39 | -6.44 | 3.93 | 7.10 | -3.71 | 1.38 | 10.66 | -4.50 | 3.21 | |
| IOGbert | Type I instance | 73.38 | 85.92 | 79.14 | 60.41 | 80.32 | 68.92 | 71.03 | 81.70 | 75.96 | 69.69 | 90.31 | 78.62 |
| Entire space | 81.64 | 80.87 | 81.24 | 71.64 | 75.24 | 73.35 | 77.82 | 76.35 | 76.99 | 75.19 | 87.75 | 80.97 | |
| (Gains (%)) | 11.26 | -5.88 | 2.66 | 18.60 | -6.32 | 6.43 | 9.56 | -6.55 | 1.37 | 7.89 | -2.83 | 3.00 | |
3. Experimental Setup
3.1. Datasets and Metrics
To validate the sample selection bias problem in TOWE modeling, we built four new TOWE datasets (i.e. Rest14-e, Lapt14-e, Rest15-e, and Rest16-e) containing both Type I and Type II instances based on four popular TOWE datasets (i.e. Rest14, Lapt14, Rest15, and Rest16) (Fan et al., 2019) only including Type I instances. In our dataset names, the letter e stands for entire space. Specifically, Fan et al. (2019) built the four TOWE datasets by annotating the corresponding opinion words for the annotated aspect terms in four SemEval challenge datasets (Pontiki et al., 2014, 2015, 2016). However, only the aspect terms associated with at least one opinion word were kept and used as TOWE instances by Fan et al. (2019). To build our new TOWE datasets, first, our new TOWE datasets include all instances in the TOWE datasets built by Fan et al. (2019). Then, the aspect terms in the original SemEval challenge datasets, which don’t have corresponding opinion words and hence were excluded from the TOWE datasets built by Fan et al. (2019), are added as a part of our new TOWE datasets. The statistics of our new TOWE datasets are shown in Table 1.
Following previous works (Fan et al., 2019), we adopt evaluation metrics: precision (P), recall (R), and F1-score (F1). An extraction is considered as correct only when the opinion words from the beginning to the end are all predicted exactly as the ground truth.
| Method | Training-validation instance type | Rest14-e | Lapt14-e | Rest15-e | Rest16-e | ||||||||
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | ||
| IOGbert | Type I instance | 86.50 | 85.81 | 86.13 | 77.62 | 80.92 | 79.22 | 78.88 | 81.70 | 80.24 | 88.68 | 89.66 | 89.16 |
| Entire space | 88.37 | 80.79 | 84.40 | 80.23 | 75.73 | 77.90 | 82.295 | 76.06 | 79.01 | 89.84 | 88.32 | 89.06 | |
| Id | Sentence | Aspect term |
|
Prediction | Ground truth | ||
|---|---|---|---|---|---|---|---|
| chef | Type I instance | [”not”] | [] | ||||
| 1 | Even when the chef is not in the house, the food and service are right on target . | chef | Entire space | [] | [] | ||
| orange donut | Type I instance | [”never”] | [] | ||||
| 2 | I never had an orange donut before so I gave it a shot . | orange donut | Entire space | [] | [] | ||
| Entrees | Type I instance | [”classics”] | [] | ||||
| 3 | Entrees include classics like lasagna, fettuccine Alfredo and chicken parmigiana. | Entrees | Entire space | [] | [] | ||
| rose roll | [”Try”] | [”Try”] | |||||
| menu | Type I instance | [”Try”] | [] | ||||
| rose roll | [] | [”Try”] | |||||
| 4 | Try the rose roll (not on menu). | menu | Entire space | [] | [] |
3.2. TOWE Models
We run experiments based on four TOWE models:
-
•
ARGCN (Jiang et al., 2021) first incorporates aspect term information by combining word representations with corresponding category embeddings with respect to the target tag of words. Then an attention-based relational graph convolutional network is used to learn semantic and syntactic relevance between words simultaneously. Finally, BiLSTM is utilized to capture the sequential information. Then obtained word representations are used to predict word tags .
- •
-
•
IOG (Fan et al., 2019) uses an Inward-Outward LSTM to pass aspect term information to the left context and the right context of the aspect term, and obtains the aspect term-specific word representations. Then, a Bi-LSTM takes the aspect term-specific word representations as input and outputs the global contextualized word representations. Finally, the combination of the aspect term-specific word representations and the global contextualized word representations is used to predict word tags .
-
•
IOGbert is the BERT version of IOG. Specifically, the word embedding layer and Inward-Outward LSTM in IOG are replaced with BERT. Moreover, BERT takes “[CLS] sentence [SEP] aspect term [SEP]” as input.
We run all models for 5 times and report the average results on the test datasets.
4. Results
4.1. Evaluation on Entire Space
To observe the difference of TOWE model performance on Type I instances and entire space, the four models are trained on Type I instances (Both the training set and validation set only include Type I instances) like previous studies (Fan et al., 2019), then are evaluated on both Type I instances and entire space. Experimental results are shown in Table 2. We can see that all models across all four datasets obtain much better performance on Type I instances than on entire space in terms of F1 score. For example, The performance gains of the best model on Rest14-e, Lapt14-e, Rest15-e and Rest16-e are 8.84%, 14.75%, 5.64% and 13.40%, respectively. The increase on Rest15-e is smallest, since the ratio of Type II instances in Rest15-e is smallest (Table 1). Whatever, evaluating TOWE models on Type I instances will overestimate model performance.
4.2. Training on Entire Space
In this section, the four models are trained in two settings: (1) both the training set and validation set only include Type I instances, and (2) both the training set and validation set include both Type I and Type II Instances (i.e. entire space). Then the trained models are evaluated on entire space. Experimental results are shown in Table 3. From Table 3 we draw the following two conclusions. First, all models trained on entire space outperform them trained on Type I instances in terms of F1 score across all four datasets, indicating that training models on entire space can improve the generalization performance of trained models. Second, while models trained on entire space obtain better precision, models trained on Type I instances obtain better recall. The reason is that the additional instances in entire space, i.e. Type II instances, only contain aspect terms without corresponding opinion words and hence help TOWE models to exclude incorrect opinion words for aspect terms, but also exclude some correct opinion words.
trained on Type I instances and entire space is also evaluated on Type I instances. The results are shown in Table 4. We can see in Table 4 that trained on Type I instances obtains better performance than trained on entire space. This indicates that it is necessary to design models which work well on entire space and we leave this for future research.
4.3. Case Study
To further understand the impact of Type II instances on TOWE models, we show the predictions of IOGbert (the best TOWE model in our experiments) trained on Type I instance and entire space on four sentences. The four sentences are from the test set of the Rest14-e dataset. All the first three sentences contain only one aspect term and all the three aspect terms are Type II instances. While IOGbert trained on entire space makes correct inferences on the three instances, IOGbert trained on Type I instances erroneously extracts opinion words for the three aspect terms. In fact, the words that IOGbert trained on Type I instances extracts are not opinion words. The reason is that the entire-space training set of Rest14-e additionally includes Type II instances, some of which are even similar to the instances appearing in the first three sentences. For example, the sentence “food was delivered by a busboy, not waiter” and the aspect term “waiter” in the sentence is a Type II instance in the training set of the Rest14-e. This instance may suggest that IOGbert extract nothing for the aspect term “chef” from the first sentence. Thus, it is essential to train TOWE models on entire space. From the predictions of the fourth sentence, we can see that IOGbert trained on Type I instances prefers to extract more opinion words, while IOGbert trained on entire space prefers to extract less opinion words. This is a case that show why the TOWE models trained on entire space obtain lower Recall than them trained on Type I instances.
5. CONCLUSION
In this paper, we explore the sample selection bias problem in target-oriented opinion words extraction (TOWE) modeling. Specifically, we divide TOWE instances into two types: Type I instances where the aspect terms are associated with at least one opinion word and Type II instances where the aspect terms don’t have opinion words. Previous studies only use Type I instances to train and evaluate their models, resulting in a sample selection bias problem. Training TOWE models only on Type I instances may hurt the generalization performance of TOWE models. Evaluating TOWE models only on Type I instances can’t reflect the performance of TOWE models on real-world scenarios. To validate our hypotheses, we add Type II instances to previous TOWE datasets only including Type I instances. Experimental results on these datasets demonstrate that training TOWE models on entire space including both Type I instances and Type II instances will significantly improve model performance and evaluating TOWE models only on Type I instances will overestimate model performance.
References
- (1)
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Fan et al. (2019) Zhifang Fan, Zhen Wu, Xinyu Dai, Shujian Huang, and Jiajun Chen. 2019. Target-oriented opinion words extraction with target-fused neural sequence labeling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2509–2518.
- Feng et al. (2021) Yuhao Feng, Yanghui Rao, Yuyao Tang, Ninghua Wang, and He Liu. 2021. Target-specified Sequence Labeling with Multi-head Self-attention for Target-oriented Opinion Words Extraction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 1805–1815.
- Hu and Liu (2004) Minqing Hu and Bing Liu. 2004. Mining and Summarizing Customer Reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Seattle, WA, USA) (KDD ’04). Association for Computing Machinery, New York, NY, USA, 168–177. https://doi.org/10.1145/1014052.1014073
- Jiang et al. (2021) Junfeng Jiang, An Wang, and Akiko Aizawa. 2021. Attention-based Relational Graph Convolutional Network for Target-Oriented Opinion Words Extraction. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Association for Computational Linguistics, Online, 1986–1997. https://www.aclweb.org/anthology/2021.eacl-main.170
- Kang et al. (2021) Taegwan Kang, Minwoo Lee, Nakyeong Yang, and Kyomin Jung. 2021. RABERT: Relation-Aware BERT for Target-Oriented Opinion Words Extraction. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 3127–3131.
- Liu (2012) Bing Liu. 2012. Sentiment analysis and opinion mining. Synthesis lectures on human language technologies 5, 1 (2012), 1–167.
- Ma et al. (2018) Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire space multi-task model: An effective approach for estimating post-click conversion rate. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 1137–1140.
- Mensah et al. (2021) Samuel Mensah, Kai Sun, and Nikolaos Aletras. 2021. An Empirical Study on Leveraging Position Embeddings for Target-oriented Opinion Words Extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 9174–9179. https://doi.org/10.18653/v1/2021.emnlp-main.722
- Nasukawa and Yi (2003) Tetsuya Nasukawa and Jeonghee Yi. 2003. Sentiment Analysis: Capturing Favorability Using Natural Language Processing. In Proceedings of the 2nd International Conference on Knowledge Capture (Sanibel Island, FL, USA) (K-CAP ’03). Association for Computing Machinery, New York, NY, USA, 70–77. https://doi.org/10.1145/945645.945658
- Peng et al. (2020) Haiyun Peng, Lu Xu, Lidong Bing, Fei Huang, Wei Lu, and Luo Si. 2020. Knowing what, how and why: A near complete solution for aspect-based sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 8600–8607.
- Pontiki et al. (2016) Maria Pontiki, Dimitris Galanis, Haris Papageorgiou, Ion Androutsopoulos, Suresh Manandhar, Mohammad AL-Smadi, Mahmoud Al-Ayyoub, Yanyan Zhao, Bing Qin, Orphée De Clercq, Véronique Hoste, Marianna Apidianaki, Xavier Tannier, Natalia Loukachevitch, Evgeniy Kotelnikov, Nuria Bel, Salud María Jiménez-Zafra, and Gülşen Eryiğit. 2016. SemEval-2016 Task 5: Aspect Based Sentiment Analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016). Association for Computational Linguistics, San Diego, California, 19–30. https://doi.org/10.18653/v1/S16-1002
- Pontiki et al. (2015) Maria Pontiki, Dimitris Galanis, Haris Papageorgiou, Suresh Manandhar, and Ion Androutsopoulos. 2015. SemEval-2015 Task 12: Aspect Based Sentiment Analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015). Association for Computational Linguistics, Denver, Colorado, 486–495. https://doi.org/10.18653/v1/S15-2082
- Pontiki et al. (2014) Maria Pontiki, Dimitris Galanis, John Pavlopoulos, Harris Papageorgiou, Ion Androutsopoulos, and Suresh Manandhar. 2014. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014). Association for Computational Linguistics, Dublin, Ireland, 27–35. https://doi.org/10.3115/v1/S14-2004
- Pouran Ben Veyseh et al. (2020) Amir Pouran Ben Veyseh, Nasim Nouri, Franck Dernoncourt, Dejing Dou, and Thien Huu Nguyen. 2020. Introducing Syntactic Structures into Target Opinion Word Extraction with Deep Learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Online, 8947–8956. https://doi.org/10.18653/v1/2020.emnlp-main.719
- Wu et al. (2020) Zhen Wu, Fei Zhao, Xin-Yu Dai, Shujian Huang, and Jiajun Chen. 2020. Latent Opinions Transfer Network for Target-Oriented Opinion Words Extraction. arXiv preprint arXiv:2001.01989 (2020).
- Zadrozny (2004) Bianca Zadrozny. 2004. Learning and evaluating classifiers under sample selection bias. In Proceedings of the twenty-first international conference on Machine learning. 114.