Training and challenging models for text-guided fashion image retrieval
Abstract
Retrieving relevant images from a catalog based on a query image together with a modifying caption is a challenging multimodal task that can particularly benefit domains like apparel shopping, where fine details and subtle variations may be best expressed through natural language. We introduce a new evaluation dataset, Challenging Fashion Queries (CFQ), as well as a modeling approach that achieves state-of-the-art performance on the existing Fashion IQ (FIQ) dataset. CFQ complements existing benchmarks by including relative captions with positive and negative labels of caption accuracy and conditional image similarity, where others provided only positive labels with a combined meaning. We demonstrate the importance of multimodal pretraining for the task and show that domain-specific weak supervision based on attribute labels can augment generic large-scale pretraining. While previous modality fusion mechanisms lose the benefits of multimodal pretraining, we introduce a residual attention fusion mechanism that improves performance. We release CFQ and our code111https://github.com/yahoo/maaf to the research community.
1 Introduction

Fine-grained image retrieval with natural language modification offers the possibility of a flexible, intuitive user experience for search and discovery. Flexible natural language inputs are especially valuable in domains like fashion where items may differ in subtle ways that are not easily captured by categories and lists of attributes alone. The challenge of building a machine learning system to fulfill this promise has recently attracted attention, instigating efforts to collect appropriate data [66, 15, 69].
Fashion IQ [69] contains pairs of product images together with human-written relative captions that can be used to train and evaluate models, but this approach is limited in two ways. First, the lack of negative labels and the noisiness of the positive labels make the evaluation less meaningful. Second, it is impractical to collect enough labels for the model to learn a rich vocabulary of variations from this data alone.
In this paper, we address the first limitation explicitly by collecting an evaluation dataset with positive and negative labels over a catalog of possible responses, with judgments made by multiple annotators to decrease noise. Since a fashion assistant system should provide value above and beyond existing systems that search by keywords and filter by attributes, we choose a set of image-text queries that mostly depend on subtle changes from the reference image. We name this dataset Challenging Fashion Queries (CFQ).
We address the scale limitation by studying how to leverage large, readily available datasets. In particular, we generate relative captions from the attribute labels of the iMaterialist-Fashion dataset [14] to show how such labels can support a text-guided image retrieval model.
We use CLIP [53], a recent model trained on an image-text pair corpus with 400M examples, as a baseline and find that this generalist multimodal pretraining provides an excellent starting point for text-guided fashion image retrieval, even before fine-tuning with images from the apparel domain. Utilizing this model also allows us to take advantage of a language model that has been pretrained on diverse text with a large vocabulary.
While sophisticated mechanisms to fuse text and image features have been shown to improve text-guided image retrieval performance[66, 23, 5, 9], we show that such mechanisms can actually harm performance when used with CLIP as they disrupt the existing alignment between text and image features. We introduce a fusion approach that does not disrupt this alignment and improves performance beyond the strong CLIP baseline. We also show by explicit ablation that the precise alignment between text and image features drives the strong results we observe.
Our CFQ annotations break down the text-guided image retrieval task in two parts: caption understanding (accuracy) and image similarity conditioned on the captioned change (reasonableness). These labels allow us to see how different approaches provide different benefits and may trade off between these two parts, and we show that Fashion IQ primarily evaluates models on the accuracy part.
To summarize our contributions:
-
1.
Our new Challenging Fashion Queries (CFQ) dataset provides a complementary evaluation to existing text-guided fashion image retrieval data, with both positive and negative labels on the accuracy of a relative caption with respect to an image pair and the reasonableness of the second image as a suggestion.
-
2.
We show that a model with multimodal pretraining significantly outperforms the state of the art on the Fashion IQ (FIQ) dataset. Weakly supervised domain-specific pretraining and a modality fusion mechanism tailored to preserve the benefit of multimodal pretraining further improve performance on FIQ.
-
3.
Several ablation studies and the dual labels of CFQ show the importance of direct alignment of single-modality features and provide insight into the nature of the text-guided image retrieval task and the contribution of each input.
2 Related Work
The work of Vo et al. [66] established benchmarks and inspired progress on the text-guided image retrieval task by proposing an attention mechanism to fuse image and text information, superseding several prior methods [65, 48, 54, 51]. Subsequent improvements were made by incorporating dot-product attention into the text-image fusion mechanism [23, 5, 9], learning image-text compositional embeddings [4], incorporating a correction module along with fusion [30], explicitly modeling local versus global image changes [68], and selecting from and applying corrective comments to a retrieval list, rather than a single retrieved item [73]. Many of these methods are applied to the Fashion IQ dataset and the related Shoes dataset [15], which were introduced to study text-guided image retrieval in the context of a dialog recommendation system for apparel. The dataset we introduce in this paper is complementary to Fashion IQ, as we discuss in Section 3.
Other relevant fashion datasets include Fashion200k [18] and UT-Zap50k [71, 72], which has been used for a comparison task based on attribute differences. Datasets that have been adapted for text-guided image retrieval include the ‘States and transformations’ dataset [27], ‘Birds to words’ [10], and ‘Spot-the-diff’ [28]. Vo et al. synthesized CSS3D, a dataset of simple shapes of various colors, shapes, and sizes [66].
While our work focuses on a single interaction, others have also studied the setting of a multi-turn back-and-forth with a user [15, 69, 75].
2.1 Vision and language pretraining
Pretraining of visual-linguistic representations has attracted attention in the context of tasks such as visual commonsense reasoning, visual question answering (VQA), referring expressions, and image retrieval from captions. Several works [60, 63, 39, 46, 79, 1, 6, 40, 61, 37, 19, 42] train multimodal Transformer-based [64] models in a similar manner to the masked language modeling popularized by BERT [8] using visuo-linguistic datasets [57, 3, 49, 70, 26, 13, 52]. This family of Transformer-based models relies on getting visual region proposals from an object detector [2, 77] and is trained on object annotated datasets [34, 41, 35, 56].
In contrast, the fashion domain requires understanding fine-grained information in a single clothing items, which some models address by using image regions [32, 11, 80] instead of object proposals. Another line of work takes image pixels as input directly, instead of high level region proposals [24, 25]. Zhuge et al. pretrain vision-language models for fine-grained features in the fashion domain [80]. However, none of these methods have been applied to text-guided image retrieval.
2.2 Vision-language contrastive pre-training and combining different modalities
Radford et al. collected billions of image/alt-text pairs, trained models to match the pairs within large minibatches, and showed that the resulting image models have strong and robust performance on many vision tasks [53]. Jia et al. used similar methods with less-filtered data and showed strong results fine-tuning on image classification and vision-language tasks. Of particular relevance to our work, they also showed that their models could be used for text-guided image retrieval [29]. We have used Contrastive Language-Image Pre-training (CLIP) [53] models as our baseline, with vector addition to combine modalities as suggested in [29]. Other mechanisms for image-text fusion include MAAF [9], and the utilization of a contrastive loss to align image and text representations before fusing them [38]. In our work, we experiment with variations on a MAAF-style fusion mechanism.
2.3 Fine-grained image retrieval
Several datasets and methods have addressed the challenge of fine-grained image retrieval without language. Examples in the fashion domain include Street-to-Shop [17], DeepFashion [44], and DeepFashion-v2 [12]. The methods that have been applied include the triplet loss [22] with sampling techniques [55, 21] and several variations on cross-entropy [7, 67, 47, 62, 43, 20], particularly in the domain of face recognition.
2.4 Retrieval by attribute changes
3 Data
Test data for text-guided fashion image retrieval should serve two purposes: it should allow robust comparisons of different approaches, and it should permit calibration of a model’s real-world performance. Existing datasets partly address the first purpose, but the lack of negative labels makes it unclear how metrics will relate to real-world performance. We address this gap and provide additional metrics for comparing approaches by collecting a new dataset we call Challenging Fashion Queries (CFQ)222CFQ is available for academic research use. For more info see https://webscope.sandbox.yahoo.com/catalog.php?datatype=a&did=92 . Since the collection of both positive and negative labels limits the feasible size of the dataset, we turn to larger existing datasets for training by weak supervision to augment training on Fashion IQ, the only dataset with direct supervision for this task.
3.1 Challenging Fashion Queries (CFQ)
The CFQ dataset satisfies several desiderata:
-
1.
CFQ has explicit positive and negative labels for all images in the same category as responses for each query. This allows us to compute precision/recall and other metrics with direct practical significance. Other datasets have only one label per query and assume any other response is negative, which leads to many false negatives as shown in [45].
-
2.
CFQ has independent labels for accuracy of the caption and for reasonableness of the image pair. These allow us to disentangle these aspects of the task and improve our overall approach as discussed in Section 5.
-
3.
CFQ focuses on challenging captions such as relative shape attributes (e.g., “tighter at the waist”), negations (“not floral”), and subtle holistic changes (“a little less fancy”).
-
4.
CFQ has minimal noise as each judgment is made by three human annotators and strong disagreements are checked for misunderstanding by two more annotators.
The difference between CFQ labels and Fashion IQ labels is illustrated Fig. 2. Note in particular that the lack of complete labels for Fashion IQ means that many assumed negatives are effectively false negatives. The tradeoff for the desiderata above is that CFQ is relatively small (see Table 1). Nevertheless, we found that results are robust and usually repeatable to within a percentage point. See Section 5 for results with uncertainties.

| Category | Images | Queries | Judgments |
|---|---|---|---|
| Dress | 134 | 20 | 26603 |
| Gown | 100 | 10 | 9903 |
| Sundress | 100 | 10 | 9903 |
| Total | 334 | 40 | 46403 |
3.2 Image collection
We collected a set of images from online advertisements333Images are not current advertisements and are used for information purposes only. No endorsement is intended. from various fashion brands and retailers that feature one dress, usually worn by a model. Dresses were chosen as a large category with many subtle variations, where a user may express preferences not easily captured by attribute labels. Since judges found only a few pairs of dresses to be similar enough to make the target a reasonable suggestion given the query item plus a caption, we selected images from finer subcategories for the second half of the queries and the catalogs of response images. Pairs of images from within these subcategories were more likely to be similar than pairs from the broader “dress” category. The total number of images in each (sub)category is listed in Table 1.
While categories at the level of “dress” were available with the advertisements, the images in the finer subcategories “gown” and “sundress” were chosen by first filtering for the subcategory name in the ad title and then considering examples by hand and including appropriate ones until 100 images were obtained.
For each query-response pair, three annotators were asked two questions as shown in Fig. 3. Although for some examples the answers to these questions are clear without further guidance, our focus on challenging queries led to ambiguities of at least two types.

First, natural language generally admits multiple interpretations, particularly with limited context. For example, the caption “less pink” clearly demands a “Yes” for question 1 if the response item has some pink coloration but less than the query item, but it is unclear whether a user would be satisfied with an item with no pink at all. To resolve these ambiguities of linguistic intent, our annotation team agreed on one consistent interpretation for each caption. For example, annotators were instructed to answer “No” to question 1 for the caption “less pink” if the response item had no pink. Our evaluation protocol includes averaging over four phrasings of each relative caption, some more explicit than others.
Second, reasonable people may disagree on what is “reasonable” for question 2. To mitigate this, the annotation team established criteria for question 2 and reviewed several examples to ensure conceptual agreement.
Counts of each judgment within each of category are shown in Table 2 along with the fraction of judgments on which all annotators agreed.
| Question | Judgment | Dress | Gown | Sun | Total |
|---|---|---|---|---|---|
| Accurate | Yes | 3959 | 1449 | 1461 | 6869 |
| Not sure | 110 | 23 | 47 | 180 | |
| No | 3911 | 1498 | 1462 | 6871 | |
| unanim % | 75.7 | 78.6 | 89.3 | 79.8 | |
| Reasonable | Yes | 174 | 41 | 89 | 304 |
| Somewhat | 1559 | 532 | 451 | 2542 | |
| No | 6247 | 2397 | 2430 | 11074 | |
| unanim % | 62.5 | 63.6 | 75.4 | 66.0 |
3.3 Evaluation metrics and protocol
We use three metrics to summarize a model’s performance on CFQ. For each question, we translate the judgments to -1, 0, and +1 and average over annotators to get a collective judgment between -1 and 1 for “accuracy” (question 1) and another for “reasonableness” (question 2).
We measure how well a model’s scores for each (query , catalog image ) pair predict the answers to the two questions posed to the annotators. In order to compute binary decision metrics we fix a threshold for each question and compute mean (over queries) average precision (mAP). For caption accuracy, we set the threshold at 0. For similarity / reasonableness, we set the threshold as low as possible, i.e., we consider the response image “reasonable” if at least one annotator judged “Reasonable” or “Somewhat reasonable”. This low threshold mitigates the problem of class imbalance caused by the annotators’ high bar for reasonableness. We also compute an overall mAP metric for overall relevance, where a positive label requires positive answers to both questions.
An example query, the most relevant catalog images, and the top-ranked catalog images according to two models are shown in Fig. 1.
We also evaluate models on what we call FIQ score on the Fashion IQ validation set: the mean of R50 and R10.
3.4 Weak supervision from attributes
Since it would be very costly to scale the collection of supervised labels for text-guided image retrieval to cover a much larger vocabulary of visual concepts than the 10k-100k image datasets that currently exist, we studied a weakly supervised approach using attribute labels, a type of data that already exists in large quantities. To demonstrate the effectiveness of this approach, we used the iMaterialist Fashion Attribute dataset[14]. This dataset contains about 1M images with 228 fine-grained fashion attributes labeled, including groups of attributes for category, gender, color, material, etc. We sampled online from the 152 million pairs of images that differ in their attributes by exactly one label and generated simple relative captions from these differences (e.g., “black not red”). An example is shown in Fig. 4. We refer to the dataset together with these pseudo-labels as iMateralist Fashion Queries (iMFQ for short).

While the Fashion IQ dataset [69] provides tens of thousands of captions with associated image pairs, it has only 2192 distinct words and 448 words that occur at least 5 times in the training set. Without prior knowledge, it is unlikely that a model will learn what a “wrinkled” garment looks like from the single occurrence of that word in the training set. Our iMFQ labels provide many examples for each attribute as well as important words like “not”.
Furthermore, paired items in iMFQ share most of their attributes and so are likely to be relatively similar. As we show in Section 5, these pairings provide effective training for the image similarity aspect of the task.
4 Modeling
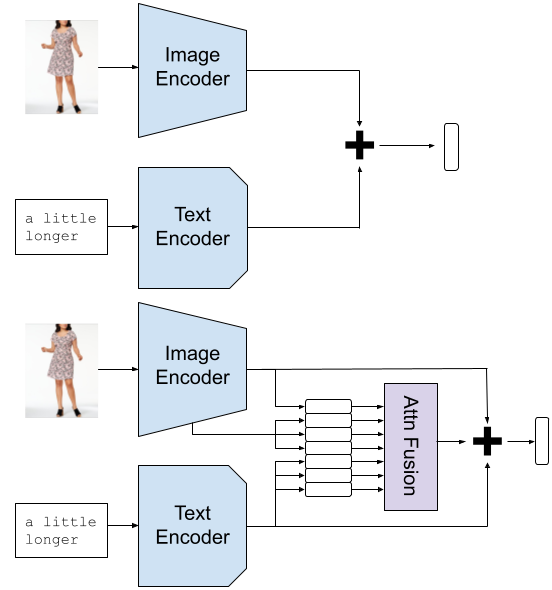
Much prior work on improving the performance of text-guided image retrieval models has focused on the model architecture, especially the mechanism for fusing text and image features [66, 5, 9, 23, 30]. For an (image, text) input (, ), these models compute a joint image-text embedding
| (1) |
where the image backbone model is pretrained on a visual task such as ImageNet classification and the text backbone model is pretrained separately on a text task such as masked language modeling. The simplest fusion function is to add embeddings from each modality:
| (2) |
We take as a baseline model the smallest available CLIP model [53] together with this vector addition (VA) mechanism. Thus and are respectively an image model and a text model that have been trained to coordinate. As we show in Section 5.3, this pretrained cooperation between and leads to strong performance. It is therefore important that any fusion mechanism not disrupt the alignment of the single-modality models. To this end, we introduce residual attention fusion (RAF)
| (3) |
where is a Transformer attention[64] block acting on the concatenation of image and text sequences and , and ensures that the model starts close to the powerful baseline. Several previous works showed state-of-the-art results with a similar mechanism to [5, 23, 9] alone; here the key is to allow the flexibility of attention fusion while preserving the pretrained alignment of the single-modality embeddings. Thus the model can benefit from CLIP being trained on a huge dataset while also gaining flexibility for the specific task and domain. The VA and RAF approaches are illustrated in Figure 5. The text sequence for the attention fusion inputs consists of the features corresponding to each token after CLIP’s Transformer text model. The image sequence includes the top-level feature map flattened to 49 vectors, to which we append the “attention pool” output of CLIP’s modified ResNet50 architecture for an image sequence of length 50.
Since we are interested in systems that can retrieve from a sizeable catalog based on a novel query, we evaluate models in a framework where an embedding is computed once for each catalog image and we retrieve from the catalog based on the dot products between an embedding for a query and each catalog item . The catalog embeddings are obtained using the same method as the query embeddings but with no text input. All embeddings are normalized, so ranking by dot product is equivalent to using cosine similarity.
5 Experiments
We train models on iMFQ and Fashion IQ and report results on Fashion IQ and CFQ. Each experiment is run 5 times and we report the mean and standard deviation of each metric, except for the CLIP model without fine-tuning.
5.1 Pretraining and fusion
Multimodal pretraining is highly effective for the text-guided image retrieval task. Table 3 compares scores for single models on the Fashion IQ validation set as reported in several papers. Multimodal pretraining as provided by CLIP already outperforms the previous state of the art. Our approach enhances this strong result and approaches the score of 52 achieved using ensembles of models for the CVPR 2020 Fashion IQ challenge444https://sites.google.com/view/cvcreative2020/fashion-iq with a single model of similar size to the cited methods.
| Method | FIQ score |
|---|---|
| JVSM [4] | 19.26 |
| FiLM* [51] | 25.28 |
| Relationship* [54] | 29.39 |
| CIRPLANT[45] | 30.20 |
| TIRG** [66] | 31.20 |
| VAL w/ GloVE [5] | 35.38 |
| MAAF [9] | 36.6±0.4 |
| CurlingNet*** [74] | 38.45 |
| RTIC-GCN [58] | 39.00 |
| CoSMo [36] | 39.45 |
| DCNet [30] | 40.83 |
| CLVC-Net [68] | 44.56 |
| CLIP[53] VA | 28.4 |
| CLIP VA fine-tuned | 48.1±0.3 |
| CLIP + iMFQ RAF (Ours) | 50.2±0.3 |
There are two elements to our approach that improve the model’s performance on Fashion IQ, as shown in Table 4. First, weak supervision adapted from attribute labels on a domain-specific dataset (i.e., iMFQ) serves as an effective secondary pretraining before final fine-tuning on Fashion IQ, although training on iMFQ alone actually lowers Fashion IQ performance. Results on our CFQ dataset show why this happens. Training on iMFQ effectively improves a model’s ability to tell when an image pair is “reasonable” but does not similarly improve the model’s understanding of relative captions. So optimizing for iMFQ alone is not enough to improve both aspects of the task, and iMFQ-trained models tend to trade some caption understanding for image similarity performance. This tradeoff for iMFQ-trained models persists after fine-tuning on Fashion IQ.
We find that using a more complex fusion mechanism than vector addition (VA) can improve performance somewhat, but naively applying an existing mechanism tends to hurt performance relative to VA. Table 4 shows two examples of this, TIRG[66] and attention fusion (AF). These mechanisms and others have been shown in prior work to improve the performance of models built on single-modality modules that were pretrained (if at all) separately on single-modality data. Since CLIP trains the single-modality modules to directly align, the image and text embeddings “live in the same space” and can already be added meaningfully before any training with a fusion mechanism. We study this modality alignment by ablation in Section 5.3. Here we note that a fusion mechanism (AF) goes from harmful to helpful when we treat it as an initially small correction to VA. Note also that the residual connection to the final embedding is not enough: setting the residual multiplier in the RAF method leads to worse FIQ scores than leaving out the RAF mechanism entirely.
| training | FIQ | CFQ mAP scores | |||
|---|---|---|---|---|---|
| data | fusion | score | accurate | reasonable | relevant |
| CLIP | VA | 28.4 | 59.2 | 46.7 | 28.4 |
| FIQ | TIRG | ||||
| AF | |||||
| RAF | |||||
| VA | |||||
| RAF | |||||
| iMFQ | VA | ||||
| RAF | |||||
| iMFQ & FIQ | VA | ||||
| RAF | |||||
5.2 Caption understanding and image similarity
The text-guided image retrieval task has usually been framed in terms of a modifying caption, where the target image is like the query image except for a change. While the captions in CFQ were chosen to ensure the query image is relevant (“with less pink”), many FIQ captions make no reference to the query image (“is blue”) and the image pairs are not always similar. In fact we find that a CLIP-based model that ignores the query image entirely can achieve performance competitive with the state of the art on FIQ. Table 5 shows this result (“text trained”) and also that a model that instead ignores the caption (“img trained”) achieves comparably poor performance. As one might expect, the image-only model achieves decent performance on the CFQ reasonableness mAP and the text-only model does well on accuracy mAP, but each performs poorly on the other metric and therefore on the overall mAP.
| FIQ | CFQ mAP scores | |||
|---|---|---|---|---|
| model | score | acc | rea | relevant |
| random | ||||
| CLIP VA | 28.4 | 59.2 | 46.7 | 28.4 |
| CLIP img | 08.9 | 53.4 | 53.1 | 29.6 |
| CLIP text | 22.7 | 59.8 | 40.5 | 24.1 |
| img trained | ||||
| text trained | ||||
While a good text-guided image retrieval system should do well at both caption understanding and conditional image similarity, these subtasks may be in tension for actual systems. Table 6 shows using the CFQ reasonableness mAP that the models we study do better at predicting reasonableness judgments if the text input is hidden, although the gap is mitigated by training on both iMFQ and FIQ. At the level of performance currently achieved, accounting for the relative caption appears unimportant for conditional image similarity compared to the already challenging problem of matching images of similar products.
| training | CFQ reasonableness mAP | ||
|---|---|---|---|
| fusion | data | fused | image only |
| VA | CLIP | 46.7 | 53.1 |
| VA | FIQ | ||
| RAF | FIQ | ||
| VA | iMFQ | ||
| RAF | iMFQ | ||
| VA | iMFQ & FIQ | ||
| RAF | iMFQ & FIQ | ||
5.3 Modality alignment
To better understand the strong performance of CLIP applied directly to the text-guided image retrieval task, we conducted an ablation on the alignment between the CLIP modules. Specifically, we intentionally disrupted this alignment either by scrambling the channels of the text embedding or by replacing the text module with another CLIP-trained text module that was not trained in cooperation with the image module. The CLIP authors reported that few-shot training on ImageNet could recover the zero-shot performance using the text model to embed the category labels with only 4 images per category[53]. In the text-guided image retrieval setting, however, we find that it takes training on the entire Fashion IQ training set to surpass the baseline (see Tab. 7). Furthermore, fine-tuning from ordinary pretrained CLIP provides an enormous benefit (50% relative improvement in FIQ score) over fine-tuning from a model with disrupted modality alignment. We conclude that it is the direct alignment between the embeddings of the image and text modules of CLIP that is essential to CLIP’s performance on this task.
| FIQ | CFQ mAP scores | |||
| model | score | accurate | reasonable | relevant |
| random | ||||
| CLIP VA | 28.4 | 59.2 | 46.7 | 28.4 |
| scramble | ||||
| trained | ||||
| mismatch | 2.6 | 51.3 | 40.9 | 22.2 |
| trained | ||||
5.4 Average precision variation across queries
There is significant variability in the number of response images considered relevant overall for each query (see Sec. 3.3). The fraction of relevant responses per query ranges from 0.01 to 0.56, and is the expected AP for a random model. Figure 6 shows how two models perform on individual queries, revealing that gains come disproportionately from queries with few relevant catalog images.

5.5 Types of caption
Natural language can describe diverse changes, and we grouped the captions in CFQ based on whether they addressed certain attributes (elements, pattern, shape, color), whether they included a conjunction or a negation, and whether they requested a discrete attribute change (c.f. [78] or a change in degree (“relative” changes as in [50]). Fig. 7 uses CFQ accuracy mAP within these (not mutually exclusive) groups to show how several model properties improve performance across the caption types. While pretrained modality alignment, FIQ fine-tuning, and use of RAF increase accuracy mAP broadly, we see some variation including a larger improvement for relative changes compared to modifications.

5.6 Generality
While we focused on fashion, our modeling approach is appropriate for any domain that emphasizes fine-grained understanding of single objects. To show this generality we report results (with no hyperparameter tuning) on two other datasets that have been used for text-guided image retrieval in Table 8.
| Birds-to-Words | MIT-States | ||||
| method | R@10 | R@50 | R@1 | R@5 | R@10 |
| MAAF[9] | 34.8 | 66.3 | 12.7 | 32.6 | 44.8 |
| LB[23] | - | - | 14.7 | 35.3 | 46.6 |
| [76] | - | - | 14.27 | 33.21 | 45.34 |
| RTIC[58] | 37.56 | 67.72 | - | - | - |
| VA∗ | 22.8 | 55.9 | 8.7 | 29.0 | 40.8 |
| VA | 33.1 | 57.0 | 12.2 | 35.2 | 48.0 |
| TIRG | 39.8 | 76.6 | 18.2 | 42.1 | 53.6 |
| AF | 46.5 | 79.0 | 16.9 | 40.3 | 51.8 |
| RAF | 51.1 | 82.0 | 15.7 | 43.7 | 56.6 |
6 Conclusion
The problem of developing a system that understands and can retrieve high-quality results for a wide variety of subtle visual changes as expressed in natural language poses many challenges. Since a purely supervised approach would be impractical to scale to a large vocabulary of relevant visual concepts, we studied approaches based on using large pretrained models and pretraining with multimodal data readily obtainable from existing fashion catalogs. Our new evaluation dataset Challenging Fashion Queries (CFQ) provides a difficult benchmark showing that our approach is effective but leaves much room for improvement.
By disrupting the alignment between the single-modality modules of a multimodal-pretrained model, we showed that multimodal pretraining per se – as opposed to strong pretraining within each modality alone – is highly beneficial for this task. Indeed, all the other effects we observe and the differences between the various modality fusion mechanisms proposed in the literature (e.g.[9, 30]), while significant and interesting, are small by comparison. Future work should build on this observation. Our experiments also show that a properly trained fusion mechanism can improve performance, but it is crucial that the fusion mechanism be compatible with the learned cooperation between modalities from pretraining. Incorporating modality fusion in a large-scale pretraining effort may yield further improvements on text-guided image retrieval and other tasks.
7 Limitations and Assets
Although the methods discussed here offer benefits, they cannot fully overcome the limits of real datasets. In particular, even very large and/or carefully constructed pretraining datasets will omit or neglect some visual concepts and will have biases towards or against some styles, groups of people, etc. Addressing these biases directly will be important for a real-world system but is outside the scope of this paper.
The top score we achieve on our CFQ overall relevance mAP is 38.0, suggesting a great deal of room for improvement. While the exhaustive labels of CFQ provide a closer approximation to a test of real-world performance and permit the calculation of useful metrics such as recall at a fixed precision, the absolute values of such metrics would depend on application specifics such as the users, the user interface, and the catalog. CFQ is also limited to a category of items, so any method that singles out that category may achieve deceptively high scores.
Acknowledgments
The authors thank the members of the Content Analysis and Knowledge Engineering team at Yahoo for their assistance defining and collecting the Challenging Fashion Queries judgments. We also thank the other members of the Visual Intelligence team at Yahoo for feedback and support throughout our work.
References
- [1] Chris Alberti, Jeffrey Ling, Michael Collins, and David Reitter. Fusion of detected objects in text for visual question answering. arXiv preprint arXiv:1908.05054, 2019.
- [2] Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6077–6086, 2018.
- [3] Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015.
- [4] Yanbei Chen and Loris Bazzani. Learning joint visual semantic matching embeddings for language-guided retrieval. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16, pages 136–152. Springer, 2020.
- [5] Yanbei Chen, Shaogang Gong, and Loris Bazzani. Image search with text feedback by visiolinguistic attention learning. In The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [6] Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. Uniter: Learning universal image-text representations. arXiv preprint arXiv:1909.11740, 2019.
- [7] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4690–4699, 2019.
- [8] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [9] Eric Dodds, Jack Culpepper, Simao Herdade, Yang Zhang, and Kofi Boakye. Modality-agnostic attention fusion for visual search with text feedback. CoRR, abs/2007.00145, 2020.
- [10] Maxwell Forbes, Christine Kaeser-Chen, Piyush Sharma, and Serge Belongie. Neural naturalist: Generating fine-grained image comparisons. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 708–717, 2019.
- [11] Dehong Gao, Linbo Jin, Ben Chen, Minghui Qiu, Yi Wei, Yi Hu, and Hao Wang. Fashionbert: Text and image matching with adaptive loss for cross-modal retrieval. arXiv preprint arXiv:2005.09801, 2020.
- [12] Yuying Ge, Ruimao Zhang, Xiaogang Wang, Xiaoou Tang, and Ping Luo. Deepfashion2: A versatile benchmark for detection, pose estimation, segmentation and re-identification of clothing images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5337–5345, 2019.
- [13] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6904–6913, 2017.
- [14] Sheng Guo, Weilin Huang, Xiao Zhang, Prasanna Srikhanta, Yin Cui, Yuan Li, Matthew R.Scott, Hartwig Adam, and Serge Belongie. The imaterialist fashion attribute dataset. arXiv preprint arXiv:1906.05750, 2019.
- [15] Xiaoxiao Guo, Hui Wu, Yu Cheng, Steven Rennie, Gerald Tesauro, and Rogerio Feris. Dialog-based interactive image retrieval. In Advances in Neural Information Processing Systems, pages 678–688, 2018.
- [16] Xiaoxiao Guo, Hui Wu, Yupeng Gao, Steven Rennie, and Rogerio Feris. The fashion iq dataset: Retrieving images by combining side information and relative natural language feedback. arXiv preprint arXiv:1905.12794, 2019.
- [17] M Hadi Kiapour, Xufeng Han, Svetlana Lazebnik, Alexander C Berg, and Tamara L Berg. Where to buy it: Matching street clothing photos in online shops. In Proceedings of the IEEE international conference on computer vision, pages 3343–3351, 2015.
- [18] Xintong Han, Zuxuan Wu, Phoenix X Huang, Xiao Zhang, Menglong Zhu, Yuan Li, Yang Zhao, and Larry S Davis. Automatic spatially-aware fashion concept discovery. In Proceedings of the IEEE international conference on computer vision, pages 1463–1471, 2017.
- [19] Weituo Hao, Chunyuan Li, Xiujun Li, Lawrence Carin, and Jianfeng Gao. Towards learning a generic agent for vision-and-language navigation via pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13137–13146, 2020.
- [20] Lanqing He, Zhongdao Wang, Yali Li, and Shengjin Wang. Softmax dissection: Towards understanding intra-and inter-class objective for embedding learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 10957–10964, 2020.
- [21] Alexander Hermans, Lucas Beyer, and Bastian Leibe. In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737, 2017.
- [22] Elad Hoffer and Nir Ailon. Deep metric learning using triplet network. In International Workshop on Similarity-Based Pattern Recognition, pages 84–92. Springer, 2015.
- [23] Mehrdad Hosseinzadeh and Yang Wang. Composed query image retrieval using locally bounded features. In The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [24] Zhicheng Huang, Zhaoyang Zeng, Yupan Huang, Bei Liu, Dongmei Fu, and Jianlong Fu. Seeing out of the box: End-to-end pre-training for vision-language representation learning. CoRR, abs/2104.03135, 2021.
- [25] Zhicheng Huang, Zhaoyang Zeng, Bei Liu, Dongmei Fu, and Jianlong Fu. Pixel-bert: Aligning image pixels with text by deep multi-modal transformers. arXiv preprint arXiv:2004.00849, 2020.
- [26] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019.
- [27] Phillip Isola, Joseph J Lim, and Edward H Adelson. Discovering states and transformations in image collections. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1383–1391, 2015.
- [28] Harsh Jhamtani and Taylor Berg-Kirkpatrick. Learning to describe differences between pairs of similar images. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4024–4034, 2018.
- [29] Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. CoRR, abs/2102.05918, 2021.
- [30] Jongseok Kim, Youngjae Yu, Hoeseong Kim, and Gunhee Kim. Dual compositional learning in interactive image retrieval. Proceedings of the AAAI Conference on Artificial Intelligence, 35(2):1771–1779, May 2021.
- [31] Jin-Hwa Kim, Sang-Woo Lee, Dong-Hyun Kwak, Min-Oh Heo, Jeonghee Kim, Jung-Woo Ha, and Byoung-Tak Zhang. Multimodal residual learning for visual qa, 2016.
- [32] Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision-and-language transformer without convolution or region supervision. arXiv preprint arXiv:2102.03334, 2021.
- [33] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [34] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision, 123(1):32–73, 2017.
- [35] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4. International Journal of Computer Vision, 128(7):1956–1981, 2020.
- [36] Seungmin Lee, Dongwan Kim, and Bohyung Han. Cosmo: Content-style modulation for image retrieval with text feedback. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 802–812, June 2021.
- [37] Gen Li, Nan Duan, Yuejian Fang, Ming Gong, and Daxin Jiang. Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11336–11344, 2020.
- [38] Junnan Li, Ramprasaath R Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi. Align before fuse: Vision and language representation learning with momentum distillation. arXiv preprint arXiv:2107.07651, 2021.
- [39] Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557, 2019.
- [40] Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, Yejin Choi, and Jianfeng Gao. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors, Computer Vision – ECCV 2020, pages 121–137, Cham, 2020. Springer International Publishing.
- [41] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
- [42] Fenglin Liu, Yuanxin Liu, Xuancheng Ren, Xiaodong He, and Xu Sun. Aligning visual regions and textual concepts for semantic-grounded image representations. In Advances in Neural Information Processing Systems, pages 6847–6857, 2019.
- [43] Hao Liu, Xiangyu Zhu, Zhen Lei, and Stan Z Li. Adaptiveface: Adaptive margin and sampling for face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11947–11956, 2019.
- [44] Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1096–1104, 2016.
- [45] Zheyuan Liu, Cristian Rodriguez-Opazo, Damien Teney, and Stephen Gould. Image retrieval on real-life images with pre-trained vision-and-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2125–2134, 2021.
- [46] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. arXiv preprint arXiv:1908.02265, 2019.
- [47] Yair Movshovitz-Attias, Alexander Toshev, Thomas K Leung, Sergey Ioffe, and Saurabh Singh. No fuss distance metric learning using proxies. In Proceedings of the IEEE International Conference on Computer Vision, pages 360–368, 2017.
- [48] Hyeonwoo Noh, Paul Hongsuck Seo, and Bohyung Han. Image question answering using convolutional neural network with dynamic parameter prediction. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 30–38, 2016.
- [49] Vicente Ordonez, Girish Kulkarni, and Tamara Berg. Im2text: Describing images using 1 million captioned photographs. Advances in neural information processing systems, 24:1143–1151, 2011.
- [50] Devi Parikh and Kristen Grauman. Relative attributes. In 2011 International Conference on Computer Vision, pages 503–510. IEEE, 2011.
- [51] Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- [52] Di Qi, Lin Su, Jia Song, Edward Cui, Taroon Bharti, and Arun Sacheti. Imagebert: Cross-modal pre-training with large-scale weak-supervised image-text data. arXiv preprint arXiv:2001.07966, 2020.
- [53] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. CoRR, abs/2103.00020, 2021.
- [54] Adam Santoro, David Raposo, David G Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap. A simple neural network module for relational reasoning. In Advances in neural information processing systems, pages 4967–4976, 2017.
- [55] Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 815–823, 2015.
- [56] Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8430–8439, 2019.
- [57] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, Melbourne, Australia, July 2018. Association for Computational Linguistics.
- [58] Minchul Shin, Yoonjae Cho, Byungsoo Ko, and Geonmo Gu. Rtic: Residual learning for text and image composition using graph convolutional network, 2021.
- [59] Kihyuk Sohn. Improved deep metric learning with multi-class n-pair loss objective. In Advances in neural information processing systems, pages 1857–1865, 2016.
- [60] Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, and Jifeng Dai. Vl-bert: Pre-training of generic visual-linguistic representations. arXiv preprint arXiv:1908.08530, 2019.
- [61] Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. Videobert: A joint model for video and language representation learning. In Proceedings of the IEEE International Conference on Computer Vision, pages 7464–7473, 2019.
- [62] Yifan Sun, Changmao Cheng, Yuhan Zhang, Chi Zhang, Liang Zheng, Zhongdao Wang, and Yichen Wei. Circle loss: A unified perspective of pair similarity optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6398–6407, 2020.
- [63] Hao Tan and Mohit Bansal. Lxmert: Learning cross-modality encoder representations from transformers. arXiv preprint arXiv:1908.07490, 2019.
- [64] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- [65] Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. Show and tell: A neural image caption generator. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3156–3164, 2015.
- [66] Nam Vo, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, and James Hays. Composing text and image for image retrieval-an empirical odyssey. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6439–6448, 2019.
- [67] Hao Wang, Yitong Wang, Zheng Zhou, Xing Ji, Dihong Gong, Jingchao Zhou, Zhifeng Li, and Wei Liu. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5265–5274, 2018.
- [68] Haokun Wen, Xuemeng Song, Xin Yang, Yibing Zhan, and Liqiang Nie. Comprehensive linguistic-visual composition network for image retrieval. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1369–1378, 2021.
- [69] Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogerio Feris. Fashion iq: A new dataset towards retrieving images by natural language feedback. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11307–11317, June 2021.
- [70] Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2:67–78, 2014.
- [71] Aron Yu and Kristen Grauman. Fine-grained visual comparisons with local learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 192–199, 2014.
- [72] Aron Yu and Kristen Grauman. Semantic jitter: Dense supervision for visual comparisons via synthetic images. In Proceedings of the IEEE International Conference on Computer Vision, pages 5570–5579, 2017.
- [73] Tong Yu, Yilin Shen, and Hongxia Jin. Towards hands-free visual dialog interactive recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 1137–1144, 2020.
- [74] Youngjae Yu, Seunghwan Lee, Yuncheol Choi, and Gunhee Kim. Curlingnet: Compositional learning between images and text for fashion iq data, 2020.
- [75] Yifei Yuan and Wai Lam. Conversational fashion image retrieval via multiturn natural language feedback, 2021.
- [76] Feifei Zhang, Mingliang Xu, Qirong Mao, and Changsheng Xu. Joint attribute manipulation and modality alignment learning for composing text and image to image retrieval. In Proceedings of the 28th ACM International Conference on Multimedia, pages 3367–3376, 2020.
- [77] Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. Vinvl: Making visual representations matter in vision-language models. CoRR, abs/2101.00529, 2021.
- [78] Bo Zhao, Jiashi Feng, Xiao Wu, and Shuicheng Yan. Memory-augmented attribute manipulation networks for interactive fashion search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1520–1528, 2017.
- [79] Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Jason J Corso, and Jianfeng Gao. Unified vision-language pre-training for image captioning and vqa. arXiv preprint arXiv:1909.11059, 2019.
- [80] Mingchen Zhuge, Dehong Gao, Deng-Ping Fan, Linbo Jin, Ben Chen, Haoming Zhou, Minghui Qiu, and Ling Shao. Kaleido-bert: Vision-language pre-training on fashion domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12647–12657, June 2021.
Appendix A Limitations and Assets
Although the methods discussed here offer benefits, they cannot fully overcome the limits of real datasets. In particular, even very large and/or carefully constructed pretraining datasets will omit or neglect some visual concepts and will have biases towards or against some styles, groups of people, etc. Addressing these biases directly will be important for a real-world system but is outside the scope of this paper.
The top score we achieve on our CFQ overall relevance mAP is 38.0, suggesting a great deal of room for improvement. While the exhaustive labels of CFQ provide a closer approximation to a test of real-world performance and permit the calculation of useful metrics such as recall at a fixed precision, the absolute values of such metrics would depend on application specifics such as the users, the user interface, and the catalog. CFQ is also limited to a category of items, so any method that singles out that category may achieve deceptively high scores.
We accessed the following existing datasets:
-
1.
iMaterialist-Fashion Attributes555https://github.com/visipedia/imat_fashion_comp[14] lists no license but was provided for non-commerical use for a Kaggle competition666https://www.kaggle.com/c/imaterialist-challenge-fashion-2018/rules.
-
2.
Fashion IQ777https://github.com/XiaoxiaoGuo/fashion-iq[16] was released under the CDLA888https://cdla.dev/.
Our code extended the MAAF codebase999https://github.com/yahoo/maaf, Apache License 2.0, which used the TIRG codebase101010https://github.com/google/tirg, Apache License 2.0[66] as a starting point. We also adapted code from CLIP111111https://github.com/openai/CLIP, MIT License[53].
Human judgments for the CFQ dataset were obtained with consent, and no personally identifiable information is included.
Appendix B CFQ examples




Appendix C Full results
Table 9 collects all the experiments presented in section 5 with all the metrics used there plus two additional metrics:
-
•
We compute mAP for held-out iMFQ data. A response image is considered correct if its attributes match the target attributes, which are the query image’s attributes modified according to the caption.
-
•
The normalized discounted cumulative gain (nDCG) for CFQ is a ranking metric that uses the graded judgment scores without thresholding. For relevance scores for the catalog images and a ranking , DCG is
(4) and this is divided by its optimal value to compute nDCG. Here the relevance scores are the sum of the “accuracy” and “reasonableness” scores described in section 3.3, plus a constant 2 to make all non-negative.
| training | FIQ | CFQ mAP sores | CFQ | iMFQ | ||||
|---|---|---|---|---|---|---|---|---|
| data | fusion | score | accurate | reasonable | relevant | img reas | nDCG | mAP |
| N/A | random | |||||||
| CLIP | VA | |||||||
| CLIP | image only | |||||||
| CLIP | text only | - | ||||||
| + FIQ | image only | |||||||
| + FIQ | text only | - | ||||||
| + FIQ | TIRG | |||||||
| + FIQ | AF | |||||||
| + FIQ | VA | |||||||
| + FIQ | RAF | |||||||
| + FIQ | RAF | |||||||
| + iMFQ | VA | |||||||
| + iMFQ | RAF | |||||||
| + iMFQ + FIQ | VA | |||||||
| + iMFQ + FIQ | RAF | |||||||
| + scramble | VA | |||||||
| + mismatch | VA | |||||||
| + scramble + FIQ | VA | |||||||
| + mismatch + FIQ | VA | |||||||
C.1 Fashion IQ score breakdown
Prior work usually reports R@10 and R@50 for each of the three categories in Fashion IQ as was done in the paper introducing the dataset[16]. The different scores are highly correlated with each other across models, so for space and simplicity we reported only the single summary score in the main text. In Table 10 we report the finer metrics for direct comparison with other work.
| Dress | Top&Tee | Shirt | Average | |||||
| Method | R@10 | R@50 | R@10 | R@50 | R@10 | R@50 | R@10 | R@50 |
| JVSM[4] | 10.7 | 25.9 | 13.0 | 26.9 | 12.0 | 27.1 | 11.9 | 26.6 |
| Relationship[54] | 15.44 | 38.08 | 21.10 | 44.77 | 18.33 | 38.63 | 18.29 | 40.49 |
| MRN[31] | 12.32 | 32.18 | 18.11 | 36.33 | 15.88 | 34.33 | 15.44 | 34.28 |
| FiLM[51] | 14.23 | 33.34 | 17.30 | 37.68 | 15.04 | 34.09 | 15.52 | 35.04 |
| TIRG[66] | 14.87 | 34.66 | 18.26 | 37.89 | 19.08 | 39.62 | 17.40 | 37.39 |
| CIRPLANT[45] | 17.45 | 40.41 | 21.64 | 45.38 | 17.53 | 38.81 | 18.87 | 41.53 |
| VAL[5] | 21.12 | 42.19 | 25.64 | 49.49 | 21.03 | 43.44 | 22.60 | 45.04 |
| CoSMo[36] | 25.64±0.21 | 50.30±0.10 | 29.21±0.12 | 57.46±0.16 | 24.90±0.25 | 49.18±0.27 | 26.58 | 52.31 |
| RTIC-GCN[58] | 29.15 | 54.04 | 31.61 | 57.98 | 23.79 | 47.25 | 21.18 | 53.09 |
| DCNet[30] | 28.95 | 56.07 | 30.44 | 58.29 | 23.95 | 47.30 | 27.78 | 53.89 |
| CLVC-Net | 29.85 | 56.47 | 33.50 | 64.00 | 28.75 | 54.76 | 30.70 | 58.41 |
| CLIP [53] VA | 19.2 | 37.6 | ||||||
| CLIP VA + FIQ | 35.0 | 61.3 | ||||||
| + RAF (Ours) | 37.4 | 63.1 | ||||||
Appendix D Training details
Models were trained with batch-wise softmax cross-entropy[59] with a learned inverse-temperature parameter, using Adam [33] for 14 FIQ epochs and/or 3 iMFQ epochs on one NVIDIA V100 GPU. This procedure clearly left the “scrambled” or “mismatched” models undertrained, so we trained these models for 42 epochs. The learning rate was set to for VA models and dropped by a factor of 10 after half the training epochs for FIQ and after each epoch for iMFQ. For models with fusion modules, the associated weights were randomly initialized and given 10x the learning rate of the pretrained parameters.
For FIQ only, we used simple image augmentations: horizontal flips, resize and crop with scales 0.8-1.0 and ratios 0.75-1.3, and Gaussian pixel noise with standard deviation 0.1.
Appendix E CFQ metrics
Our mAP metrics for CFQ depend on a choice of threshold for what counts as a positive judgment for each question considering the three annotators’ responses. Figure 12 shows results for several models on these metrics as we vary the threshold. When not otherwise specified, our accuracy mAP results use threshold 0 and our reasonableness mAP results use threshold -2/3 (meaning “not reasonable” must be a unanimous judgment or we count it as reasonable). Recall that the overall relevance judgment is the logical AND of the accuracy and reasonableness judgments.
We observed that while the base rate of the mAP metrics depends strongly on the thresholds (since chance performance is the fraction of positives), varying the threshold does not usually change the order in which models score. The unthresholded judgments still inform the nDCG metric, which we report in appendix C.
