Trading under the Proof-of-Stake Protocol
– a Continuous-Time Control Approach
Abstract.
We develop a continuous-time control approach to optimal trading in a Proof-of-Stake (PoS) blockchain, formulated as a consumption-investment problem that aims to strike the optimal balance between a participant’s (or agent’s) utility from holding/trading stakes and utility from consumption. We present solutions via dynamic programming and the Hamilton-Jacobi-Bellman (HJB) equations. When the utility functions are linear or convex, we derive close-form solutions and show that the bang-bang strategy is optimal (i.e., always buy or sell at full capacity). Furthermore, we bring out the explicit connection between the rate of return in trading/holding stakes and the participant’s risk-adjusted valuation of the stakes. In particular, we show when a participant is risk-neutral or risk-seeking, corresponding to the risk-adjusted valuation being a martingale or a sub-martingale, the optimal strategy must be to either buy all the time, sell all the time, or first buy then sell, and with both buying and selling executed at full capacity. We also propose a risk-control version of the consumption-investment problem; and for a special case, the “stake-parity” problem, we show a mean-reverting strategy is optimal.
Key words: Consumption-investment, Proof of Stake (PoS) protocol, cryptocurrency, dynamic programming, HJB equations, continuous-time control, risk control.
1. Introduction
As a digital exchange vehicle, blockchain technology has been successfully deployed in many applications including cryptocurrency [18], healthcare [9], supply chain [8], electoral voting [27], and non-fungible tokens [26]. A blockchain is a growing chain of accounting records, called blocks, which are jointly maintained by participants of the system using cryptography. Consider for instance Bitcoin – a peer to peer decentralized payment system. In contrast to traditional payment processing networks, Bitcoin provides a permissionless environment in which everyone is free to participate. At the core of Bitcoin is the consensus protocol known as Proof of Work (PoW), in which “miners” compete with each other by solving a hashing puzzle so as to validate an ever-growing log of transactions (the “longest chain”) to update a distributed ledger; and the miner who solves the puzzle first receives a reward (a number of coins). Thus, while the competition is open to all participants, the chance of winning is proportional to a miner’s computing power.
Despite its popularity, the PoW protocol has some obvious drawbacks. Competition among miners has led to exploding levels of energy consumption in Bitcoin mining, [17, 20]. [1, 3, 7] pointed out that PoW mining will lead to centralization, violating the core tenet of decentralization. To solve the problem of energy efficiency, [14, 28] introduced another consensus protocol – Proof of Stake (PoS), which is a bidding mechanism to select a miner to validate the new block. Participants who choose to join the bidding process are required to commit certain stakes (coins they own), and the winning probability is proportional to the stakes committed. Hence, a participant in a PoS blockchain is a “bidder”, and only the winning bidder becomes the miner who does the validation. As yet the PoS protocol has not been as popular as PoW. However, it is catching up quickly, and blockchain developers have strong incentives to switch from a PoW to a PoS ecosystem. A prominent case in this direction is Ethereum 2.0, where two parallel chains – Mainnet (PoW) and Beacon Chain (PoS) are expected soon to merge into one unified PoS blockchain [10].
There has been an active stream of recent studies on PoS in the research literature; and here we briefly mention several that relate closely to our study. In [22] it is shown that the PoS protocol is “without waste” from an economic standpoint. Issues of stability and decentralization of the PoS protocol are examined in [21, 24]. Specifically, it is shown in [21] that for large owners of initial wealth in a PoS system their shares of the total wealth will remain stable in the long run (i.e., proportions to the total wealth will remain constant), and hence the rich-get-richer phenomenon will not happen. [24] further extends this to medium and small participants, and reveals a phase transition in share stability among those different types of participants. In [21, 25], various aspects of the consumption-investment problem in PoS are examined, and certain conditions are identified under which a participant may have no incentive to trade with others. This leads to the complementing question, given a participant does prefer to trade, what is the optimal trading strategy?
Motivated by the above question, the objective of our study here is to develop a continuous-time control approach to optimal trading in a PoS blockchain. While the control (or game) approach has been proposed in previous studies [4, 5, 15], they are all for the PoW protocol. To the best of our knowledge, ours is the first control model developed for optimal trading under the PoS protocol.
Here is an overview of our main results. We first formulate the consumption-investment problem, which aims to strike a balance between a participant’s utility from holding/trading stakes and utility from consumption. It takes the form of a deterministic control problem with the real-time trading strategy being the control variable. We start with a detailed analysis on a special case that we call the “stake-hoarding” problem (Proposition 3.1), where we bring out the possible scenario of monopoly. We then solve the general consumption-investment problem via dynamic programming and the Hamilton-Jacobi-Bellman (HJB) equations (Theorem 3.4).
When the utility functions are linear or convex, more explicit solutions can be obtained, and we show that the bang-bang control is optimal, i.e., always buy or sell at full capacity (Propositions 4.1 and 4.3). Along with the optimal trading strategy, we are also able to bring out the explicit connection between the rate of return in trading/holding stakes and the participant’s risk-adjusted valuation of the stakes. In other words, the participant’s risk sensitivity is explicitly accounted for in the trading strategy. In particular, when a participant is risk-neutral or risk-seeking, corresponding to the risk-adjusted valuation being a martingale or a sub-martingale, the optimal strategy must be either buy all the time, sell all the time, or first buy then sell (with both buying and selling executed at full capacity).
Finally, we propose a risk control version of the consumption-investment problem, by adding a penalty term to control the level of stake holding so as to reduce the level of concentration risk (Theorem 5.1). A special case is a “stake-parity” problem, where the participant’s holding is controlled at a level that tries to track the system-wide average. We show that the “mean-reverting” strategy is the optimal solution to the stake-parity problem (Proposition 5.2).
The rest of the paper is organized as follows. Section 2 details the formulation of the consumption-investment problem under the PoS protocol. Section 3 presents the optimal solution to the problem, and Section 4 focuses on the special case of linear and convex utility functions. Section 5 presents extensions to risk-control objectives. Concluding remarks are summarized in Section 6.
2. Model Formulation
This section introduces the problem of trading under the PoS protocol in continuous time, and formulate a control model to solve the problem. First, collected below are some conventions that will be used throughout this paper.
-
–
denotes the set of real numbers, and denotes the set of nonnegative real numbers.
-
–
For , denotes the smaller number of and ; denotes the larger number of and .
-
–
The symbol means decays towards zero as .
-
–
For a random variable , denotes the expectation of .
-
–
Let be a subset of . A function if it is -time continuously differentiable in .
-
–
For , denotes the derivative of . For , (resp. ) denotes the partial derivative of with respect to (resp. ).
Time is continuous, indexed by , for a fixed representing the length of a finite horizon. Let (with ) denote the process of the total volume of stakes, which are issued over time by the PoS protocol, and can either be deterministic or stochastic. For ease of presentation, we consider a deterministic process , which is increasing in time and sufficiently smooth, with the derivative representing the instantaneous rate of “reward” — additional stakes (or “coins”) injected into the system specified (exogenously) by the PoS protocol. For instance, we will consider below, as a special case, the process of a polynomial form:
| (2.1) |
Then, , and , so the parametric family (2.1) covers different rewarding schemes according to the values of .
-
•
For , we have so the process corresponds to a decreasing reward (e.g. Bitcoin);
-
•
For , the process gives a rate one constant reward (e.g. Blackcoin);
-
•
For , we get and hence, the process amounts to an increasing reward (e.g. EOS).
Let denote the total number of participants in the system, who are indexed by . For each participant , let (with ) denote the process of the number of stakes that participant holds, with and for all . In the (discrete-time) PoS protocol, in each round of the bidding process, individual participants commit stakes so as to be selected to validate the block and receive a reward; and the winning probability is for participant , i.e., proportional to the number of stakes committed. (For instance, each round in Ethereum takes about seconds, corresponding to the block-generation time [6].) For our continuous-time PoS model here, in which the time required for each round of voting is “infinitesimal,” imagine there are rounds of bidding during any given time interval . In each round participant gets either some stake(s) or nothing; so the average total number of stakes will get over the rounds is (by law of large numbers when is large),
Hence, replacing by the infinitesimal , we know participant will receive (on average) stakes, where is ’s winning probability, and is the reward issued by the blockchain in .
Participants are allowed to trade (buy or sell) their stakes. Participant will buy stakes in if , and sell stakes if . This leads to the following dynamics of participant ’s stakes under trading:
| (2.2) |
where is the first time at which the process reaches zero. It is reasonable to stop the trading process if a participant runs out of stakes, or gets all available stakes:
-
•
If , then participant liquidates all his stakes by time , and ;
-
•
If , then participant gets all issued stakes by time , and hence .
We set for .
The problem is for each participant to decide how to trade stakes with others under the PoS protocol. Let be the price process of each (unit of) stake, which is a stochastic process assumed to be independent of the dynamics in (2.2). (This assumption has appeared in recent studies (e.g., [21]), and is somehow a reflection of the reality that the crypto price tends to be affected by market shocks such as macroeconomics, geopolitics, breaking news, etc much more than by trading activities.) Here, the price of each stake is measured in terms of an underlying risk-free asset (referred to as “cash” for simplicity); and let denote the (units of) risk-free asset that participant holds at time , and let denote the risk-free (interest) rate. Also note that all participants are allowed to trade stakes (with cash) only internally among themselves, whereas each participants can only exchange cash with an external source (say, a bank).
The decision for each participant at is hence a tuple . Let be the process of consumption, or cash flow of participant , which follows the dynamics below:
| (C1) |
with
| (C2) |
Set and for .
In (C1), if , the participant sells the risk-free asset to get cash either for buying stakes, or for consumption; if , the participant adds more risk-free asset. Thus, (C1) is a self-financing condition in which is the net change (in value of the risk-free asset held) used to finance new stakes and consumption . The requirements in (C2) are all in the spirit of disallowing shorting on either the risk free asset or the stakes . In some PoS blockchains, there is a minimum requirement for bidding (e.g. 32 ETHs for Ethereum). In this case, we can impose a lower bound on the process , to prevent it from falling below this threshold. The analysis will be similar. We also require that the trading strategy be bounded: there is such that
| (C3) |
The objective of participant is:
| (2.3) | ||||
where is a discount factor, a parameter measuring the risk sensitivity of participant ; and are two utility functions representing, respectively, the running profit and the terminal profit.
While generally following Merton’s consumption-investment framework, our formulation as presented above takes into account some distinct features of PoS blockchains and cryptocurrencies. One notable point is, the utilities and in the objective are expressed as functions of the number of stakes , as opposed to their total value . To the extent that is treated as exogenous (as explained above), this difference may seem to be trivial. Yet, it is a reflection of the more substantial fact that crypto-participants tend to mentally decouple the utility of holding stakes from their monetary value at any given time. For instance, holding ETH may be equivalent to for one person, and for another, and neither will be influenced by the ETH market price at the time, which could be say, about .
Throughout below, the following conditions will be assumed:
Assumption 2.1.
-
(i)
is increasing with , and .
-
(ii)
is increasing and .
-
(iii)
is increasing and .
3. The Consumption-Investment Problem
Here we study the consumption-investment problem for participant in (2.3). To lighten notation, omit the subscript , and write out the problem in full as follows, where (C0) is a repeat of the state dynamics in (2.2):
| (3.1) | ||||
| (C0) | ||||
| (C1) | ||||
| (C2) | ||||
| (C3) |
where .
Note that the expectation in the objective function is with respect to , which is involved in via (C1). Denote
| (3.2) |
Substituting the constraint (C1) into the objective function, and taking into account
along with (3.2), we have
| (3.3) | |||||
where is used in the last equality. Hence,
| (3.4) |
Next, suppose , a condition that will be assumed below (and readily justified as the risk premium associated with the valuation of any stake over the risk-free asset). Then, from the expression in (3.3), and taking into account as constrained in (C2), we have with the optimality binding at for all . Consequently, the problem in (3.1) is reduced to
| (3.5) |
where (C2’) is (C2) without the constraints on .
In summary, the key fact here is that the objective is separable in the control variables ; hence the problem in (3.1) is decomposed into two optimal control problems, one on the risk-free asset , and the other on the trading of stakes , as specified in (3.3) and (3.4). Moreover, under the condition , the consumption-investment problem is reduced to the one in (3.5), where the objective function – refer to (3.3) – takes the form of a tradeoff between the utility from holding stakes ( and ) and the dis-utility of reducing consumption (). Thus, the optimal trading strategy needs to strike a balance between these two opposing terms.
Before we present the optimal solution to the consumption-investment problem in (3.5), we make a digression to first study a simple degenerate case of . This special case removes the tradeoff mentioned above, so the solution becomes a one-sided strategy of always accumulating (or “hoarding”) the stakes at full capacity (). Yet, as the analysis below will show, there are still some interesting (and subtle) issues involved. More importantly, this special case provides a very accessible path to finding the optimal solution via dynamic programming and the HJB equation.
3.1. Stake-hoarding
As motived above, here the problem for participant is reduced to the following (again, omit the subscript ):
| (3.6) | ||||
Below, we denote for the optimal control process, for the corresponding state process, and for the exit time.
Proposition 3.1.
Denote
| (3.7) |
We have:
-
(i)
If , then . The optimal control is for , the optimal state process is for , and .
-
(ii)
If , set
Assume further that
(3.8) Then, . The optimal strategy is for (and for ), the optimal state process is for (and for ), and .

Deferring the proof, we first make a few comments on the above proposition. Note that as specified in (3.7) is identified as the optimal state process , which is the number of stakes given . It is easy to see that the participant’s share of stakes, , is increasing in , leading to centralization regardless of how the rewarding scheme is designed (although large rewards may slow down the speed towards concentration). The interesting point of the above theorem is in its part (ii), where the required condition (3.8) is a technical one, to ensure the optimality of . The more substantive fact is , when , i.e., the participant has accumulated all stakes available in the system, leading to the extreme situation of monopoly (or “dictatorship”); and this is done before the end of the horizon, i.e., forcing a pre-matured exit time. See Figure 1 for an illustration.
The following corollary illustrates further this extreme phenomenon, with the polynomial family defined by (2.1), and with a long time horizon ().
Corollary 3.2.
Proof.
Note that
| (3.10) |
As , the dominant term in is if , and is if ; and the dominant term in is . It then suffices to compare to , and the rest of the corollary is immediate. ∎
This corollary shows a sharp phase transition towards monopoly in terms of the rewarding schemes. For (increasing reward), there is a threshold for , only above which monopoly may occur, and below which the share of stakes increases towards the value on the right side of (3.9). For (constant or decreasing reward), monopoly always occurs. Thus, these results have practical implications in the design of the PoS protocol. For instance, if/when certain participants have large capacities, adopting a suitable increasing reward scheme will counter the effect of concentration.
Now, returning to the proof of Proposition 3.1, we use the standard machinery of dynamic programming and the HJB equation. Consider the following problem, where is the “value-to-go” function, for and :
Clearly, the solution to the above problem concerning , for all and , will yield the desired solution to in (3.6), since . The following lemma identifies an HJB equation (with terminal and boundary conditions), to which. is a solution.
Lemma 3.3.
Let . Then is the (unique) viscosity solution to the following HJB equation:
| (3.11) |
Proof.
What remains is to pin down the term in the HJB equation, i.e., to identify the maximizing . Given the intuitive solution that (a “conjecture,” so far), the HJB equation in 3.11 is expected to be
| (3.13) |
which is a transport equation with variable coefficients. Now we solve the transport equation (3.13) by the method of characteristics. For and , let be the solution to the following equation:
| (3.14) |
A direct computation yields
| (3.15) |
Under the regularity conditions in Assumption 2.1, it is standard that (see e.g. [2, 12])
| (3.16) |
where . We will next show that given by (3.16) indeed solves the HJB equation (3.11), which then proves Proposition 3.1.
Proof of Proposition 3.1.
Case 1: If , then and hence, . By the regularity conditions in Assumption 2.1, we get
where the non-negativity follows from the fact that and are increasing.
Case 2: If , then , and hence . As a result,
So, in both cases, we have . Thus, defined by (3.16) is a classical solution and hence, a viscosity solution to the HJB equation in (3.11). By Lemma 3.3, we conclude , and the optimal control is for . Specializing to yields the results in Proposition 3.1 (and defined by (3.7) is just ). ∎
3.2. Main theorem and proof
We are now ready to present the main result of this section, the optimal solution to in (3.5) and hence to in (3.1).
Theorem 3.4.
Proof.
Similar to the dynamic programming/HJB approach that proves Lemma 3.3 and Proposition 3.1 above, here we consider
so that . By the same dynamic programming argument as above, solves in the viscosity sense the HJB equation in (3.19), which can be expressed as , with
It is readily checked that under Assumption 2.1 and the Liptschiz condition in (3.18), the inequality in (3.12) holds. Thus, as identified above is the unique viscosity to the HJB equation in (3.19). The rest of the theorem is straightforward. ∎
Comparing the HJB equations in (3.11) and in (3.19), we see the nonlinear term changes from in the stake-hoarding problem, to in the stake-trading problem, the latter being the general consumption-investment problem. The more general HJB equation in (3.19) does not have a closed-form solution, and neither does the optimal trading strategy . This calls for numerical methods; see e.g. [19, 23].
4. Linear and Convex Utilities
4.1. Linear utility
Consider the special case of linear utility, and , for some given (positive) constants and . In this case we can derive a closed-form solution to the HJB equation in (3.19), and then derive the optimal strategy (in terms of ).
To start with, the HJB equation in (3.19) now specializes to the following, with (as before, refer to Lemma 3.3):
| (4.1) |
For the nonlinear term , we have if , and if .
Next, presuming that , and ignoring the boundary conditions, the HJB equation in (4.1) becomes
which has the (classical) solution
| (4.2) |
where
| (4.3) |
Similarly, presuming that and neglecting the boundary conditions turns the HJB equation in (3.19) into the following form:
which has the solution
| (4.4) |
where
| (4.5) |
The key observation is that
| (4.6) |
and , notably independent of , is decreasing in :
| (4.7) |
This suggests that (buy all the time) if ; and (sell all the time) if . Various other scenarios are also possible, such as first buy then sell, or first sell then buy, and so forth.
The following proposition classifies all possible optimal strategies corresponding to as specified above, which we will comment on later.
Proposition 4.1.
Let and with , and satisfy Assumption 2.1 (i). Assume that satisfies the Lipschitz condition in (3.18), and that satisfies the following:
| (4.8) |
Then, the following results hold:
-
(i)
Suppose stays constant, i.e., for all , .
-
(a)
If , then for all . That is, the participant sells at all time at full capacity.
-
(b)
If , then . That is, the participant purchases at all time at full capacity.
-
(c)
If , then
where is the unique point in such that with defined in (4.6). That is, the participant first buys and after some time sells, both at full capacity.
-
(a)
-
(ii)
Suppose that is increasing in .
-
(a)
If , then for all . That is, the participant sells all the time at full capacity.
-
(b)
If , then . That is, the participant purchases all the time at full capacity.
-
(c)
If and , then
where is the unique point of intersection of and on . That is, the participant first buys and after some time sells, both at full capacity.
-
(a)
-
(iii)
Suppose that is decreasing in .
-
(a)
If , then the participant first sells, and may then buy, etc, always (buy or sell) at full capacity, according to the crossings of and in .
-
(b)
If , then the participant first buys, and may then sell, etc, always (buy or sell) at full capacity, according to the crossings of and in .
-
(a)
Proof.
Recall that is the state process (number of stakes) corresponding to the optimal strategy , which, as stipulated in the rest of the proposition, will be equal to either or . The condition in (4.8) then ensures that for all , so (i.e., there will no forced early exit).
Thus, it suffices to find the optimal strategy from
(i) and (ii). Since is decreasing and is either constant or increasing, is decreasing. Hence, we have the following cases (for both (i) and (ii)).
(a) If , then for all ; hence, , and .
(b) Similarly, if , then for all ; hence, , and .
(c) Otherwise, there will be a unique point for (which is decreasing in ) to cross from above, and let denote the crossing point. This implies that for , and for ; and
Part (iii) is similarly argued, the only complication is that is now non-monotone, and hence, there will be multiple points when it crosses . ∎
Several remarks are in order. First note that the condition in (4.8) is to guarantee the constraint (C2’) not activated prior to ; that is, to exclude the possibility of monopoly/dictatorship that will trigger a forced early exit. This condition may well be removed, but then we would expect another condition similar to the one in (3.8) to guarantee the optimality of a strategy when an early exit occurs.
Second, combines , which measures the participant’s sensitivity towards risk, with the stake price . Thus, the monotone properties of , which classify the three parts (i)-(iii) in Proposition 4.1, naturally connect to martingale pricing: being a constant in (i) makes the process a martingale; whereas increasing or decreasing, respectively in (ii) and (iii), makes a sub-martingale or a super-martingale.
On the other hand, the function represents the rate of return of the participant’s utility (from holding of stakes, ); and interestingly, in the linear utility case, this return rate is independent of while decreasing in . Thus, the trading strategy is completely determined by comparing this return rate with the participant’s risk-adjusted stake price (or, valuation) : if , then the participant will buy (resp. sell) stakes.
Specifically, following (i) and (ii) of Proposition 4.1, for a constant or an increasing (corresponding to a risk-neutral or risk-seeking participant), there are only three possible optimal strategies: buy all the time, sell all the time, or first buy then sell. (The first-buy-then-sell strategy echoes the general investment practice that an early investment pays off in a later day.) See Figure 2 for an illustration.


4.2. A special case
In part (iii) of Proposition 4.1, when is decreasing in , like , the multiple crossings between the two decreasing functions can be further pinned down when there’s more model structure. Consider, for instance, when follows a geometric Brownian motion (GBM):
| (4.9) |
where denotes the standard Brownian motion; and and are the two parameters of the GBM model, representing the rate of return and the volatility of . From the second equation in (4.9), we have ; hence, . Then, a decreasing corresponds to . From (4.6), we can derive
and hence,
| (4.10) |
Let denote for defined by (2.1). The following proposition gives the conditions under which is monotone in the regime , and optimal strategies are derived accordingly.
Proposition 4.2.
Suppose the assumptions in Proposition 4.1 hold, with and specified by (4.9) with . As , we have the following results:
-
•
If for some ,
(4.11) then is increasing on .
-
•
If for some ,
(4.12) then is decreasing on .
Consequently, we have:
- (a)
-
(b)
If and (4.11) holds, then for and for , where is the unique point of intersection of and on . That is, the participant first sells (before ) and then buys (after ), both at full capacity.
-
(c)
If and (4.12) holds, then for and for , where is the unique point of intersection of and on . That is, the participant first buys (before ) and then sells (after ), both at full capacity.
- (d)
Proof.
Note that , and
where is the incomplete Gamma function. As , we have
which together with (4.6) and (4.10) implies that
| (4.13) | ||||
Multiplying the RHS of (4.13) by , we get
Clearly, the sum of all the terms above is lower bounded by
which implies that , and hence, is increasing.
Moreover, the term is upper bounded by
which implies that , and hence, is decreasing.
(a) If and (4.11) holds, then and is increasing. If and (4.12) holds, then and is decreasing. In both cases, we have for all .
(b) (c) (d) follow the same argument as (a). ∎
See Figure 3 below for an illustration of the results in the above proposition. Also note that the connection to the participant’s risk sensitivity as remarked at the end of §4.1 can also be made more explicit when the price process follows the GBM model in (4.9), for which we have . Then, the three cases in Proposition 4.1 correspond to (martingale), (sub-martingale), and (super-martingale). According to the three ranges of , they can be viewed as representing the participant as risk-neutral, risk-seeking and risk-averse.

4.3. Convex utility
It is possible to extend the above results to more general, non-linear utility functions and , by following the same approach as above that leads to and in (4.2) and (4.4).
Specifically, considering the two cases of , and , we can derive
| (4.14) | |||
| (4.15) |
Note that both and depend on (as well as on ), via and . This dependence makes it necessary to take a closer look at and , since the involved in both depends on the control before (and up to) . We have the following cases: for ,
| (4.18) | |||||
| (4.19) |
In other words, corresponds to both before and after , whereas corresponds to both before and after . The other two cases are similar:
| (4.20) | |||||
| (4.21) |
where corresponds to before (and up to) and after , and corresponds to the other way around.
Substituting these four cases into and in (4.16) and (4.17) further splits the latter two into four cases:
| (4.22) | |||
| (4.23) |
All four are now functions of only, as has been replaced by either or .
Now, suppose and are both smooth, convex (and increasing) functions. Hence, and , and both are increasing functions. Then, it is readily verified:
-
(i)
Both and are decreasing in , and so is ; whereas could be both increasing and decreasing (i.e., non-monotone).
-
(ii)
Furthermore, for all .
For instance, for in (i), consider
| (4.25) | |||||
where follows from in both the first and last terms on the RHS. The other two cases, and , are similarly verified.
As in the case of linear utility, the properties above can be used to compare against to identify the optimal trading strategy. Consider the case of being a constant, for all , as in part (i) of Proposition 4.1. If for all , then the optimal strategy is to buy all the time and at rate . If for all , then it is optimal to sell all the time, at full capacity.
On the other hand, since corresponds to sell first (before ) and then buy, this clearly cannot be optimal, as it is impossible for before and after , since is decreasing in . Similarly, corresponds to buy first (before ) and then sell, which can be optimal provided if is decreasing in .
The details are stated in the following proposition; and see Figure 4 for an illustration.
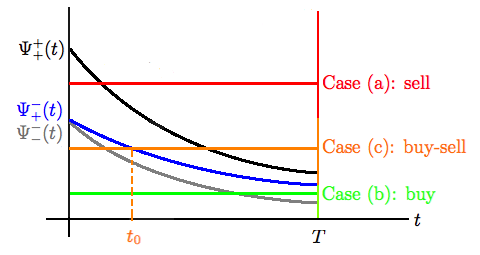
Proposition 4.3.
Assume that and are twice continuously differentiable, convex, and satisfy the conditions in Assumption 2.1. Assume that stays constant, i.e. for all . Further assume the condition (4.8), and that is decreasing then
-
(a)
If , then for all . That is, the participant sells at all time at full capacity.
-
(b)
If , then for all . That is, the participant buys at all time at full capacity.
-
(c)
If and , then
where is the unique point in such that . That is, the participant first buys and after some time sells, both at full capacity.
-
(d)
If , then
-
(1)
if , then for all . That is, the participant sells at all time at full capacity.
-
(2)
if , then then
where is the unique point in such that . That is, the participant first buys and after some time sells, both at full capacity.
-
(1)

5. Extension: Risk Control
In the previous sections, we have focused on profit seeking objectives in which a participant’s utility increases with getting more stakes, or consuming more. In the modern finance literature, Markowitz [16] pioneered the idea of balancing return and risk in any investment, which is particularly relevant for cryptocurrency trading, which often involves substantial volatility. In this spirit, here we add to the utility objective two “cost” terms that penalize the deviation of participant ’s holding of stakes from the average of all others. The idea is, to extent this deviation measures risk (analogous to the variance in the Markowitz model), it should be the price to be paid for the utility (in holding stakes) that wants to maximize. (The same idea has been used in [13] in the context of stochastic games.) Specifically, the deviation of participant ’s holding from the average all others can be expressed as , taking into account . Hence, the new objective function is:
| (5.1) | ||||
| (C0) | ||||
| (C1) | ||||
| (C2) | ||||
| (C3) |
where is a discount factor (which may or may not be equal to ), and and are symmetric, and increasing on (a typical example is and with ).
The theorem below follows the same argument as Theorem 3.4.
Theorem 5.1.
Let the assumptions in Theorem 3.4 hold for the problem (5). Assume that are symmetric, and increasing on . Then where is the unique viscosity solution to the following HJB equation:
| (5.2) |
Moreover, the optimal strategy is and for (if it exists), where achieves the supremum in (3.19), and solves with , and .
In general, the HJB equation (5.2) does not have a closed-form solution even when are linear, and are quadratic. Again it requires numerical methods to solve the HJB equation, and then find the optimal strategy . Nevertheless, there is one exception where the participant is only concerned with the risk entailed by the stakes. The objective is to solve the stake parity problem:
| (5.3) | ||||
| (C0) | ||||
| (C2’) | ||||
| (C3) |
Since attain the minimum at , if , then the participant sells at full capacity until hitting the average ; if if , then the participant purchases at full capacity until hitting the average . We record this simple fact in the following proposition.
Proposition 5.2.
Assume that are symmetric, and increasing on for the stake parity problem (5.3). Let be defined by (3.7), and
| (5.4) |
and
| (5.5) |
Then, the following results hold.
-
(i)
If , then the optimal strategy is for all , and .
-
(ii)
If , then the optimal strategy is
and .
-
(iii)
If , then the optimal strategy is
and .
-
(iv)
If , the the optimal strategy is for all , and .
Proof.
(i) If , we have for all . By a comparison argument, we get for all given any feasible strategy . Since are increasing on , we obtain
which yields the desired result.
(ii) If , we have for and . Again by the comparison argument, for given any strategy. Thus,
which permits to conclude.
(iii) and (iv) follow the same argument as (1) and (2). ∎
6. Conclusion
We have developed in this paper a continuous-time control approach to the optimal trading under the PoS protocol, formulated as a consumption-investment problem. We present general solutions to the optimal control via dynamic programming and the HJB equations, and in the case of linear and utility functions, close-form solutions in the form of bang-bang controls. Furthermore, we bring out the explicit connections between the rate of return in trading/holding stakes and the participant’s risk-adjusted valuation of the stakes, such that the participant’s risk sensitivity is explicitly accounted for in the trading strategy. We have also studied a risk-control version of the consumption-investment problem, and for a special case, the “stake-parity” problem, we show a mean-reverting strategy is the optimal solution.
While our focus here is entirely on an individual participant’s trading strategy in a PoS protocol, it is possible to study the interactions among the participants, and formulate the problem of trading in a PoS protocol as a game (deterministic or stochastic), and to study issues such as equilibrium, social welfare, and the inclusion of a trusted third party (or market maker). This will be our focus of a follow-up paper.
Acknowledgement: W. Tang gratefully acknowledges financial support through NSF grants DMS-2113779 and DMS-2206038, and through a start-up grant at Columbia University. David Yao’s work is part of a Columbia-CityU/HK collaborative project that is supported by InnotHK Initiative, The Government of the HKSAR and the AIFT Lab.
References
- [1] H. Alsabah and A. Capponi. Pitfalls of Bitcoin’s Proof-of-Work: R&D arms race and mining centralization. 2020. SSRN:3273982.
- [2] L. Ambrosio. Transport equation and Cauchy problem for non-smooth vector fields. In Calculus of variations and nonlinear partial differential equations, volume 1927 of Lecture Notes in Math., pages 1–41. Springer, Berlin, 2008.
- [3] N. Arnosti and S. M. Weinberg. Bitcoin: A natural oligopoly. Management Science, 2022.
- [4] C. Bertucci, L. Bertucci, J.-M. Lasry, and P.-L. Lions. Mean field game approach to Bitcoin mining. 2020. arXiv:2004.08167.
- [5] C. Bertucci, L. Bertucci, J.-M. Lasry, and P.-L. Lions. How resilient is the Bitcoin protocol? 2022. SSRN:3907822.
- [6] V. Buterin. Toward a -second block time. 2014. Available at https://blog.ethereum.org/2014/07/11/toward-a-12-second-block-time.
- [7] J. Chiu and T. V. Koeppl. The economics of cryptocurrencies–Bitcoin and beyond. 2017. SSRN:3048124.
- [8] J. Chod, N. Trichakis, G. Tsoukalas, H. Aspegren, and M. Weber. On the financing benefits of supply chain transparency and blockchain adoption. Management Science, 66(10):4378–4396, 2020.
- [9] F. Donovan. Healthcare blockchain could save industry $100b annually by 2025. HIT Infrastructure, 2019. Available at https://hitinfrastructure.com/news/healthcare-blockchain-could-save-industry-100b-annually-by-2025.
- [10] W. Duggan and F. Powell. What is Ethereum 2.0? understanding the merge. Avalialbe at https://www.forbes.com/uk/advisor/investing/cryptocurrency/what-is-ethereum-2/, year=2022,.
- [11] W. H. Fleming and H. M. Soner. Controlled Markov processes and viscosity solutions, volume 25 of Stochastic Modelling and Applied Probability. Springer, New York, second edition, 2006.
- [12] F. Golse. Mean field kinetic equations. 2013. Available at http://www.cmls.polytechnique.fr/perso/golse/M2/PolyKinetic.pdf.
- [13] X. Guo, W. Tang, and R. Xu. A class of stochastic games and moving free boundary problems. SIAM J. Control Optim., 60(2):758–785, 2022.
- [14] S. King and S. Nadal. Ppcoin: Peer-to-peer crypto-currency with proof-of-stake. 2012. Available at https://decred.org/research/king2012.pdf.
- [15] Z. Li, A. M. Reppen, and R. Sircar. A mean field games model for cryptocurrency mining. 2019. arXiv:1912.01952.
- [16] H. M. Markowitz. Portfolio selection: Efficient diversification of investments. Cowles Foundation for Research, Monograph 16. John Wiley & Sons, Inc., New York, 1959.
- [17] C. Mora, R. L. Rollins, K. Taladay, M. B. Kantar, M. K. Chock, M. Shimada, and E. C. Franklin. Bitcoin emissions alone could push global warming above 2 c. Nat. Clim. Change, 8(11):931–933, 2018.
- [18] S. Nakamoto. Bitcoin: A peer-to-peer electronic cash system. Decentralized Business Review, page 21260, 2008.
- [19] S. Osher and C.-W. Shu. High-order essentially nonoscillatory schemes for Hamilton-Jacobi equations. SIAM J. Numer. Anal., 28(4):907–922, 1991.
- [20] M. Platt, J. Sedlmeir, D. Platt, P. Tasca, J. Xu, N. Vadgama, and J. I. Ibañez. Energy footprint of blockchain consensus mechanisms beyond proof-of-work. 2021. arXiv:2109.03667.
- [21] I. Roşu and F. Saleh. Evolution of shares in a proof-of-stake cryptocurrency. Manag. Sci., 67(2):661–672, 2021.
- [22] F. Saleh. Blockchain without waste: Proof-of-stake. The Review of Financial Studies, 34(3):1156–1190, 2021.
- [23] P. E. Souganidis. Approximation schemes for viscosity solutions of Hamilton-Jacobi equations. J. Differential Equations, 59(1):1–43, 1985.
- [24] W. Tang. Stability of shares in the Proof of Stake protocol – concentration and phase transitions. 2022. arXiv:2206.02227.
- [25] W. Tang and D. D. Yao. Polynomial voting rules. 2022. arXiv:2206.10105.
- [26] Q. Wang, R. Li, Q. Wang, and S. Chen. Non-fungible token (NFT): Overview, evaluation, opportunities and challenges. 2021. arXiv:2105.07447.
- [27] A. Wood. West Virginia secretary of state reports successful blockchain voting in 2018 midterm elections. 2018. Avalialbe at https://cointelegraph.com/news/west-virginia-secretary-of-state-reports-successful-blockchain-voting-in-2018-midterm-elections.
- [28] G. Wood. Ethereum: A secure decentralised generalised transaction ledger. Ethereum Project Yellow Paper, 151:1–32, 2014.