TR-LLM: Integrating Trajectory Data for Scene-Aware LLM-Based Human Action Prediction
Abstract
Accurate prediction of human behavior is crucial for AI systems to effectively support real-world applications, such as autonomous robots anticipating and assisting with human tasks. Real-world scenarios frequently present challenges such as occlusions and incomplete scene observations, which can compromise predictive accuracy. Thus, traditional video-based methods often struggle due to limited temporal and spatial perspectives. Large Language Models (LLMs) offer a promising alternative. Having been trained on a large text corpus describing human behaviors, LLMs likely encode plausible sequences of human actions in a home environment. However, LLMs, trained primarily on text data, lack inherent spatial awareness and real-time environmental perception. They struggle with understanding physical constraints and spatial geometry. Therefore, to be effective in a real-world spatial scenario, we propose a multimodal prediction framework that enhances LLM-based action prediction by integrating physical constraints derived from human trajectories. Our experiments demonstrate that combining LLM predictions with trajectory data significantly improves overall prediction performance. This enhancement is particularly notable in situations where the LLM receives limited scene information, highlighting the complementary nature of linguistic knowledge and physical constraints in understanding and anticipating human behavior.
Project page:
https://sites.google.com/view/trllm?usp=sharing
Github repo:
https://github.com/kojirotakeyama/TR-LLM/blob/main/readme.md
I INTRODUCTION
Predicting human behavior is essential for AI systems to integrate seamlessly into our lives and provide effective support. This capability is particularly crucial for applications like support robots, which need to anticipate human actions and proactively perform tasks in a home environment. While traditional approaches have relied heavily on video data for action prediction, they often fall short due to their limited temporal and spatial scope. Human behavior is influenced by complex environmental and personal factors that extend beyond what can be captured in video footage. These include temporal elements like time of day, environmental conditions such as room temperature, the state and position of objects in the scene, and human-specific attributes including personal characteristics, action history, and the relationship with others present in the room. These factors exert significant influence on human behavior as exemplified by the contrast between retrieving an item from a fridge during a time-constrained morning routine versus during a more leisurely evening meal preparation or the contrast between weekday vs weekend routines. To truly understand and predict human behavior, we must take into account this broader contextual landscape, moving beyond the constraints of conventional video-based methods.

Our work addresses the challenge by leveraging the capabilities of Large Language Models (LLMs), which possess broad knowledge of human behaviors and actions in home environments, and encodes the ability to plausibly predict human actions by considering diverse scene contexts, even in unseen scenarios.
However, observable scene contexts in the real world are often insufficient for predicting a person’s intentions accurately. For instance, scene context derived from sensor data (e.g., cameras, microphones) frequently suffers from limitations in coverage, sensitivity, or resolution, leading to increased uncertainty in predictions. This presents an inherent limitation in LLM-based action predictions.
To tackle the issue, we propose a multi-modal prediction framework that integrates physical constraints with LLM-based action prediction. Specifically, we use a person’s past trajectory to infer their likely destination, which imposes physical constraints on the person’s next target object, helping to narrow down potential actions (Fig.1). Since the target area prediction is intricately influenced by factors such as room layout and the person’s location and speed, we leverage an indoor human locomotion dataset to learn these relationships, allowing us to reliably derive a probabilistic distribution of target areas. To summarize our approach, we introduced a novel multi-modal action prediction method that integrates physical and semantic spaces. The key idea is to observe human actions from two spatially distinct perspectives—physical and semantic factors—which compensates for the limitations of each perspective and effectively refine the prediction. We believe that our multi-modal approach unlocks new potential for human action prediction in real-world applications.
The contribution of our work is described as follows.
(i) Incorporating LLMs to human action anticipation considering a wide variety of semantic scene context
(ii) Proposing a multi-modal action prediction framework incorporating LLMs with trajectory that imposes physical constraints on the person’s next target object, helping to narrow down potential actions.
(iii) Building an evaluation dataset for our multi-modal approach, which includes scene map, trajectory, and scene contexts.
(iv) Demonstrating that the integration of LLM and trajectory data synergistically enhances performance, with the improvement being particularly pronounced when the LLM has limited scene information as input.
II Related works
II-A Vision-based action prediction
Previous works have primarily focused on vision-based human action prediction. One line of research has focused on video-based action prediction, utilizing the recent past sequence of video frames to forecast future actions. Given the availability of large-scale action video datasets (e.g., Ego4D [2], Human3.6M [9], Home Action Genome [1]), many researchers have adopted machine-learning-based approaches [8, 7, 5, 4], often employing sequential models such as LSTM [6] or transformers [15, 14]. Some studies have integrated multimodal models to improve performance, combining video with other modalities (e.g., video-acoustic models [3], video-LLM models [11, 10]). Others have focused on object-based cues within the video to predict future actions [12, 13]. Another research direction involves predicting future motions from past motions, using only the human body’s pose data. For instance, [19] introduced a stochastic model for predicting diverse future actions with probability, while [17, 18] incorporated graph convolutional networks with attention mechanisms to improve prediction accuracy. Additionally, [16] proposed the use of a diffusion model to account for multi-person interactions.
In existing video-based action prediction research, a limitation lies in the spatial and temporal restrictions of scene context. Most studies focus on information within the limited field of view of ego-centric or third-person cameras, which only provides localized data. This narrow perspective hinders understanding of broader, more complex behaviors in real-world environments. Additionally, privacy concerns restrict the observation of individuals’ daily activities over extended periods in uncontrolled settings, limiting the ability to capture a diverse range of daily action patterns from existing datasets. To overcome these constraints, we propose leveraging large language models (LLMs), which encode vast everyday knowledge in natural language. By integrating LLMs, we remove spatial and temporal limitations, enabling a more flexible and generalized approach to action prediction that captures broader patterns applicable to diverse real-world scenarios.
II-B LLM-based action prediction
With the rise of large language models (LLMs), many studies have leveraged LLMs to analyze social human behaviors. Notably, [23, 22] made a significant impact on the field by simulating town-scale, multi-agent human daily life, incorporating social interactions between agents throughout the entire pipeline using LLMs. This work has inspired subsequent efforts to extend the scale and complexity of such simulations [24, 25, 26]. However, a notable gap exists between their work and ours, as their focus is primarily on macroscopic-scale social behavior simulations. Additionally, their approach centers on intention-conditioned action generation within these simulations, which contrasts with our goal of predicting human actions in real-world scenarios.
To the best of our knowledge, only two studies have explored LLM-based human action prediction. [20] utilized an LLM to predict the next human activity by identifying the object in the environment that the person is most likely to interact with. [21] focused on LLM-based human action prediction to enable a robot to plan corresponding supportive actions. In their approach, they provided the LLM with object layouts and action history to predict the next human action. However, their problem settings are relatively simple, relying on limited cues for predicting the next target object. Moreover, while they account for scene context, they do not consider physical constraints such as human motion or the spatial structure of the environment.
III Method
III-A Problem definition
In daily life, individuals perform sequential actions while interacting with various objects. For instance, one might take a glass from a cupboard, fill it with a drink from the fridge, and then sit on the couch to drink. In this study, we focus on predicting the transition between these sequential actions, specifically forecasting the next action as a person moves toward the target object. We assume the scene is a room-scale home environment with two persons performing separate actions, where we can observe various scene states except for the persons’ internal states (Fig.2).

III-B Method overview
Fig.1 illustrates an overview of our approach. We propose a multi-modal action prediction framework that incorporates both an LLM and human trajectories. The core idea is to integrate two different perspectives—physical and semantic factors—through an object-based action prediction framework. Our framework consists of two primary steps: target object prediction (III-C) and action prediction (III-D). In the target object prediction step, we first utilize a LLM to predict a person’s target object based on the input scene context, generating a probability distribution over potential objects in the room from a semantic perspective (III-C1). Subsequently, we incorporate the person’s past trajectory to infer their likely destination, applying physical constraints to refine the prediction of the next target object (III-C2).
In the action prediction phase, the individual’s subsequent action is predicted using a LLM, based on the identified target object.
Further details of the approach are provided in the following sections.
III-C Target object prediction
III-C1 LLM-based prediction
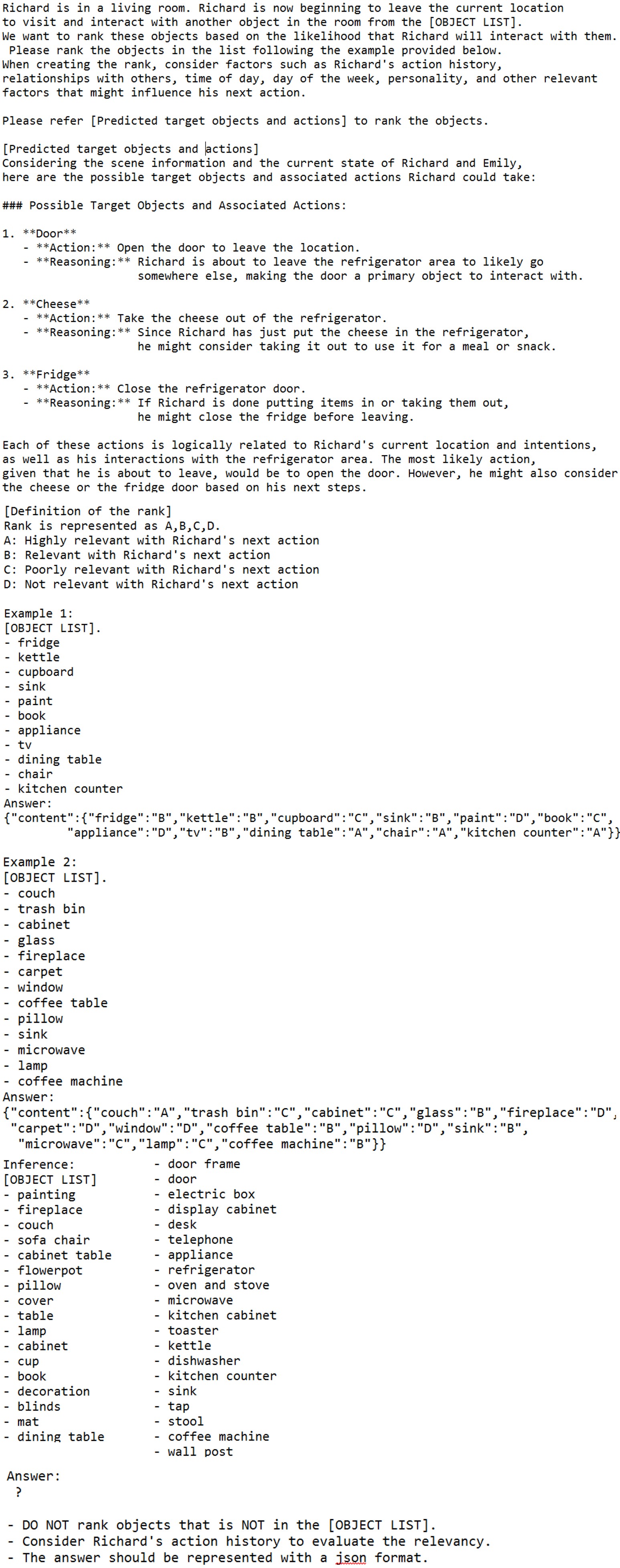
Fig.3 shows the pipeline of LLM-based target object prediction. In the initial step, various scene contexts—such as time of day, the person’s state (including location, action history, and conversation), and a list of objects—are provided as a text prompt and input into the LLM. Additionally, an order prompt is used to guide the LLM in generating a comprehensive, free-form list of potential target objects and their associated actions. This intermediate step facilitates the identification of probable target objects by considering their corresponding actions. Consequently, we derive a ranking of objects in the environment based on the target object candidates given in the previous step and the initial scene context prompt. The ranking is divided into four probability levels: A (high probability), B (moderate probability), C (low probability), and D (very low probability). The output from the LLM is subsequently converted into numerical scores and normalized into probabilities that sum to 1. In this study, scores of 15, 10, 5, and 1 were assigned to categories A, B, C, and D, respectively.

III-C2 Trajectory-based prediction
We utilize past trajectory data and scene map information to constrain the target area of a person. Since the target area prediction is heavily influenced by factors such as room layout, the person’s location, and speed, we leverage the LocoVR dataset[32] to learn these intricate relationships. The LocoVR dataset consists of over 7,000 human trajectories captured in 131 indoor environments, with each trajectory segment spanning from a randomly assigned start to a goal location within the room. We employed a simple U-Net model to learn how to specify the possible target area based on the past trajectory and scene map (see Appendix-B2). Once the model predicts the probabilistic distribution of the target area, we calculate the overlap between this predicted distribution and the spatial location of objects in the scene to estimate the probability of each object being the target.
Fig.4 illustrates the process of trajectory-based prediction. In an early stage of trajectory (left image), the potential target area is broadly distributed. As the person progresses, the predicted target area and potential target objects are progressively narrowed down (center and right images). This refinement is based on a learned policy reflecting typical human behavior: when moving toward a specific goal, individuals generally avoid retracing their steps or taking unnecessary detours.

Since both LLM-based prediction and trajectory-based prediction assign probabilities to each object, we integrate these by multiplying their respective probabilities. This approach allows us to refine and identify target object candidates that are highly probable from both semantic and physical perspectives.
III-D Action prediction
At this stage, we employ the LLM to predict the action corresponding to the target object identified in the previous step. The input to the LLM includes the scene context and the predicted target object, and the LLM outputs the most plausible action the person is likely to perform within the given scene context.
IV Experiment
IV-A Evaluation data
To evaluate our multimodal method, we required input data with a text prompt describing the scene context, trajectory, and scene map. As no existing dataset met these criteria, we constructed a new dataset for evaluation.
Fig.5 illustrates the pipeline we employed to generate the evalution dataset. We utilized the Habitat-Matterport 3D Semantics Dataset (HM3DSem) [27] to obtain scene map and object data in home environments. HM3DSem provides a diverse set of 3D models of home environments, with semantic labels. From HM3DSem, we extracted scene maps represented as binary grids, where a value of 1 indicates areas walkable areas (within 0.3 meters of the floor height), and 0 corresponds to all other regions. These maps have dimensions of 256 x 256 pixels, mapping to a physical space of 10m x 10m. Additionally, we identified the pixel regions corresponding to each object within the scene map.
Furthermore, we manually designed daily action scenarios, detailing factors such as day/time, persona, current location, target object, subsequent actions, conversations, and more. These scenarios were transformed into text prompts for input to the LLM. We generated a trajectory from the current location to the target object by leveraging a model trained on the LocoVR dataset[32], which incorporates the scene map to guide the path (see Appendix-C2 for details).
Finally, we obtained 67 data pairs from the combination of 10 action scenarios and 9 scene maps. The total number of pairs is lower than the combination count because cases where objects from the action scenarios were absent in the scene maps were excluded.

IV-B Experimental setup
We employed ChatGPT-4 to evaluate prediction performance using three types of input data to assess the model’s robustness under degraded conditions: (1) full scene context, (2) scene context without conversation, and (3) scene context without conversation and past action history. These variations simulate real-world scenarios where certain information is unavailable. The evaluation focuses on how our method mitigates this degradation to improve performance.
IV-C Evaluation metric
We conducted evaluations on both target object prediction and action prediction tasks.
Target object prediction: The goal of this task is to identify the correct target object from a set of 30-40 objects in each scene. In this evaluation, we considered the prediction correct if the groundtruth object appeared within the top three predicted objects.
Action prediction: This task involves predicting the action based on the target object and the scene contexts. We evaluated the similarity between the predicted and groundtruth actions, classifying them as correct or incorrect (see Appendix-B1 for details). Note that if the target object prediction was incorrect, the action prediction was also deemed incorrect, as it relied on the predicted target object.
For both tasks, we calculated accuracy as the percentage of correct predictions across all scenarios. To ensure reproducibility, we conducted three trials for each evaluation and used the average of these trials as the final result.
IV-D Results
IV-D1 Quantitative result
Fig.6(a) illustrates the accuracy of target object prediction. While the accuracy of LLM-based predictions decreases as input scene information is limited, our method significantly mitigates this degradation. Furthermore, it is noteworthy that our method outperforms both the standalone performance of the LLM and the trajectory-based predictions, demonstrating a synergistic improvement in performance through the integration of LLM and trajectory data. Fig.6(b) presents the accuracy of action prediction based on the predicted target object. A similar trend is observed as in the target object prediction. Note that overall accuracy is lower than that of target object prediction because it is a subsequent process dependent on the target object prediction.
Fig.7(a) and 7(b) show the performance of target object prediction and action prediction as a function of the observed past trajectory length. The results demonstrate that performance improves for both tasks with longer observed trajectories. This is attributed to the increasing availability of cues for refining the target area as the trajectory progresses.




IV-D2 Qualitative result
In this section, we present the qualitative performance of target object prediction using the LLM, trajectory, and our method through two sample scenarios.
LLM-based target object prediction: Fig.8 illustrates the results of target object prediction by the LLM, where the probabilities of each object are visualized on a map. Scenario 1 involves filling water at the sink to water a plant, while scenario 2 involves get a dirty glass at the table and take it to the sink. The results demonstrate that the objects relevant to the next action in each scenario are appropriately highlighted, despite a certain degree of uncertainty remaining in the predictions. This uncertainty arises from the limitation of predicting a person’s intention based on scene context from a semantic perspective.
Trajectory-based target object prediction: Fig.9 shows the results of target object prediction using trajectory data. The yellow distribution represents the predicted target area based on the observed trajectory, with each object color-coded from blue to red according to the degree of overlap with the predicted area (blue: low probability, red: high probability). In both scenario 1 and 2, the predicted target area initially covers a wide range shortly after the person starts from the sink. However, as the trajectory progresses, the target area becomes more focused, highlighting objects near the groundtruth. While the prediction roughly narrows down the target object region, it remains a significant challenge to precisely identify the groundtruth target object.
Target object prediction with our method: Fig.10 presents the results of target object prediction using our proposed method. In contrast to predictions using either the LLM or trajectory data alone, which retain some uncertainty, our method demonstrates a faster and more accurate narrowing of the target object. This indicates that by leveraging the complementary perspectives of the LLM’s semantic understanding and the trajectory’s physical context, the groundtruth target object is more effectively identified.



V Limitation and Futurework
Introducing Full-Body Motion: While this study focused on trajectories as the primary form of physical information, future work could explore full-body motion, which may provide more refined and highly available cues for action prediction. Incorporating signals such as hand, foot, head, and gaze movements could serve as valuable indicators for predicting actions even during periods without locomotion.
Application to Larger Environments: The experiments in this study were conducted in private home environments within a 10-meter-square area. However, applying the proposed method to larger public spaces, such as schools, offices, stores, and stations, could yield greater temporal advantages in predictions through our framework. This would expand the potential for a wider range of service applications.
Performance enhancement: Further improvement in prediction accuracy is expected by independently enhancing both the LLM and trajectory prediction components. The refinement of each component would offer greater benefits through the integration of the two modalities.
Application to Service Development: A promising application of the proposed method lies in the development of intelligent systems that leverage LLMs to deliver context-aware and adaptive services tailored to predicted human actions. By anticipating user behavior, these systems could provide more timely and relevant responses, significantly enhancing user experience across various domains.
VI Conclusion
We leverage LLM to predict human actions incorporating diverse scene contexts in home environments. To improve the robustness against insufficient scene observations, we propose a multimodal prediction framework that combines LLM-based action prediction with physical constraints derived from human trajectories. The key idea is to integrate two different perspectives—physical and semantic factors—through an object-based action prediction framework, which compensates for the limitations of each perspective and effectively refine the prediction. Our experiments show that integrating LLM predictions with trajectory data markedly enhances prediction performance, especially in scenarios where the LLM has limited access to scene information. This improvement underscores the complementary roles of linguistic knowledge and physical constraints in comprehending and anticipating human behavior.
References
- [1] N. Rai, H. Chen, J. Ji, R. Desai, K. Kozuka, S. Ishizaka, E. Adeli, and J. C. Niebles, ”Home action genome: Cooperative compositional action understanding,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2021, pp. 11184-11193.
- [2] K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, M. Martin, T. Nagarajan, I. Radosavovic, S. K. Ramakrishnan, F. Ryan, J. Sharma, M. Wray, M. Xu, E. Z. Xu, C. Zhao, S. Bansal, D. Batra, V. Cartillier, S. Crane, T. Do, M. Doulaty, A. Erapalli, C. Feichtenhofer, A. Fragomeni, Q. Fu, A. Gebreselasie, C. González, J. Hillis, X. Huang, Y. Huang, W. Jia, W. Khoo, J. Kolář, S. Kottur, A. Kumar, F. Landini, C. Li, Y. Li, Z. Li, K. Mangalam, R. Modhugu, J. Munro, T. Murrell, T. Nishiyasu, W. Price, P. Ruiz, M. Ramazanova, L. Sari, K. Somasundaram, A. Southerland, Y. Sugano, R. Tao, M. Vo, Y. Wang, X. Wu, T. Yagi, Z. Zhao, Y. Zhu, P. Arbeláez, D. Crandall, D. Damen, G. M. Farinella, C. Fuegen, B. Ghanem, V. K. Ithapu, C. V. Jawahar, H. Joo, K. Kitani, H. Li, R. Newcombe, A. Oliva, H. S. Park, J. M. Rehg, Y. Sato, J. Shi, M. Z. Shou, A. Torralba, L. Torresani, M. Yan, and J. Malik, ”Ego4D: Around the world in 3,000 hours of egocentric video,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2022, pp. 18995-19012.
- [3] Z. Zhong, D. Schneider, M. Voit, R. Stiefelhagen, and J. Beyerer, ”Anticipative feature fusion transformer for multi-modal action anticipation,” in Proc. IEEE/CVF Winter Conf. Appl. Comput. Vis., 2023, pp. 6068-6077.
- [4] E. V. Mascaró, H. Ahn, and D. Lee, ”Intention-conditioned long-term human egocentric action anticipation,” in Proc. IEEE/CVF Winter Conf. Appl. Comput. Vis., 2023, pp. 6048-6057.
- [5] Y. Wu, L. Zhu, X. Wang, Y. Yang, and F. Wu, ”Learning to anticipate egocentric actions by imagination,” IEEE Trans. Image Process., vol. 30, pp. 1143-1152, 2020.
- [6] A. Furnari and G. M. Farinella, ”Rolling-unrolling LSTMs for action anticipation from first-person video,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 43, no. 11, pp. 4021-4036, 2020.
- [7] B. Fernando and S. Herath, ”Anticipating human actions by correlating past with the future with Jaccard similarity measures,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2021, pp. 13224-13233.
- [8] D. Surís, R. Liu, and C. Vondrick, ”Learning the predictability of the future,” CoRR, vol. abs/2101.01600, 2021. [Online]. Available: https://arxiv.org/abs/2101.01600.
- [9] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu, ”Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 7, pp. 1325-1339, 2013.
- [10] H. Mittal, N. Agarwal, S.Y. Lo, and K. Lee, ”Can’t make an omelette without breaking some eggs: Plausible action anticipation using large video-language models,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 18580-18590.
- [11] Q. Zhao, S. Wang, C. Zhang, C. Fu, M. Q. Do, N. Agarwal, K. Lee, and C. Sun, ”AntGPT: Can large language models help long-term action anticipation from videos?,” arXiv preprint arXiv:2307.16368, 2023.
- [12] C. Zhang, C. Fu, S. Wang, N. Agarwal, K. Lee, C. Choi, and C. Sun, ”Object-centric video representation for long-term action anticipation,” in Proc. IEEE/CVF Winter Conf. Appl. Comput. Vis., 2024, pp. 6751-6761.
- [13] R.G. Pasca, A. Gavryushin, M. Hamza, Y.L. Kuo, K. Mo, L. Van Gool, O. Hilliges, and X. Wang, ”Summarize the past to predict the future: Natural language descriptions of context boost multimodal object interaction anticipation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 18286-18296.
- [14] J. Wang, G. Chen, Y. Huang, L. Wang, and T. Lu, ”Memory-and-anticipation transformer for online action understanding,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2023, pp. 13824-13835.
- [15] R. Girdhar and K. Grauman, ”Anticipative video transformer,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2021, pp. 13505-13515.
- [16] J. Tanke, L. Zhang, A. Zhao, C. Tang, Y. Cai, L. Wang, P.C. Wu, J. Gall, and C. Keskin, ”Social diffusion: Long-term multiple human motion anticipation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2023, pp. 9601-9611.
- [17] W. Mao, M. Liu, and M. Salzmann, ”History repeats itself: Human motion prediction via motion attention,” in Proc. Comput. Vis. ECCV 2020: 16th Eur. Conf., Glasgow, U.K., Aug. 2020, pp. 474-489.
- [18] W. Mao, M. Liu, M. Salzmann, and H. Li, ”Multi-level motion attention for human motion prediction,” Int. J. Comput. Vis., vol. 129, no. 9, pp. 2513-2535, 2021.
- [19] S. Aliakbarian, F. S. Saleh, M. Salzmann, L. Petersson, and S. Gould, ”A stochastic conditioning scheme for diverse human motion prediction,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2020, pp. 5223-5232.
- [20] M. A. Graule and V. Isler, ”GG-LLM: Geometrically grounding large language models for zero-shot human activity forecasting in human-aware task planning,” in 2024 IEEE Int. Conf. Robot. Autom. (ICRA), 2024, pp. 568-574.
- [21] Y. Liu, L. Palmieri, S. Koch, I. Georgievski, and M. Aiello, ”Towards human awareness in robot task planning with large language models,” arXiv preprint arXiv:2404.11267, 2024.
- [22] J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, ”Generative agents: Interactive simulacra of human behavior,” in Proc. 36th Annu. ACM Symp. User Interface Softw. Technol., 2023, pp. 1-22.
- [23] J. S. Park, L. Popowski, C. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, ”Social simulacra: Creating populated prototypes for social computing systems,” in Proc. 35th Annu. ACM Symp. User Interface Softw. Technol., 2022, pp. 1-18.
- [24] C. Gao, X. Lan, Z. Lu, J. Mao, J. Piao, H. Wang, D. Jin, and Y. Li, ”S3: Social-network simulation system with large language model-empowered agents,” arXiv preprint arXiv:2307.14984, 2023.
- [25] S. Li, J. Yang, and K. Zhao, ”Are you in a masquerade? Exploring the behavior and impact of large language model driven social bots in online social networks,” arXiv preprint arXiv:2307.10337, 2023.
- [26] K. Zhao, M. Naim, J. Kondic, M. Cortes, J. Ge, S. Luo, G. R. Yang, and A. Ahn, ”Lyfe agents: Generative agents for low-cost real-time social interactions,” arXiv preprint arXiv:2310.02172, 2023.
- [27] K. Yadav, R. Ramrakhya, S. K. Ramakrishnan, T. Gervet, J. Turner, A. Gokaslan, N. Maestre, A. X. Chang, D. Batra, M. Savva, and others, ”Habitat-Matterport 3D Semantics Dataset,” arXiv preprint arXiv:2210.05633, 2022. [Online]. Available: https://arxiv.org/abs/2210.05633.
- [28] D. P. Kingma and J. Ba, ”Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [29] N. Tax, ”Human activity prediction in smart home environments with LSTM neural networks,” in 2018 14th Int. Conf. Intell. Environ. (IE), 2018, pp. 40-47.
- [30] M.J. Tsai, C.L. Wu, S. K. Pradhan, Y. Xie, T.Y. Li, L.C. Fu, and Y.C. Zeng, ”Context-aware activity prediction using human behavior pattern in real smart home environments,” in 2016 IEEE Int. Conf. Autom. Sci. Eng. (CASE), 2016, pp. 168-173.
- [31] S. Choi, E. Kim, and S. Oh, ”Human behavior prediction for smart homes using deep learning,” in 2013 IEEE RO-MAN, 2013, pp. 173-179.
- [32] K. Takeyama, Y. Liu, and M. Sra, ”LocoVR: Multiuser Indoor Locomotion Dataset in Virtual Reality,” arXiv preprint arXiv:2410.06437, 2024.
-A Additional results
In the main paper, we defined target object prediction as correct if the ground truth object appeared within the top three predicted objects. In this section, we present results using alternative evaluation criteria, specifically considering the prediction correct if the ground truth object appears within the top one or top five predicted objects.
Fig.11-12 and Fig.13-14 present the results using top-1 and top-5 accuracy metrics, demonstrating a consistent trend with the findings reported in the main paper. Specifically, our method outperforms both standalone LLM and trajectory-based prediction approaches, with accuracy improving as the trajectory length increases.








-B Implementation details
-B1 LLM-based prediction
Here, we present the specific sequence of prompts input into the LLM. Fig.15 and Fig.16 illustrate the prompts used for LLM-based target object prediction, corresponding to the first and second prompts provided to the LLM as shown in Fig.3, respectively. Note that [predicted target objects and actions] defined in the Fig.16 is derived from the results provided by the order prompt shown in Fig.15.
Fig.17 shows the order prompt used to predict an action given a target object. It is designed to generate a concise description of the action expected to occur at the specified target object.
Additionally, Fig.18 presents the order prompt used for scoring the predicted action during the evaluation stage. It outputs 1 if the predicted action has a certain similarity to the groundtruth action, and 0 otherwise.



-B2 Trajectory-based prediction
Training data We employed LocoVR that includes over 7000 trajectories in 131 indoor environments to train the model. We split it into training (85%) and validation sets (15%).
Model and parameters We employed five layer U-Net model to predict the goal area from the past trajectory. Parameters for the model are shown as below.
In the U-Net models, time-series trajectory data is represented in a multi-channel image format. Specifically, the 2D coordinates of a trajectory point are plotted on a blank 256x256 pixel image using a Gaussian distribution, with time-series data encoded across multiple channels. Similarly, the goal position is encoded as an image and concatenated with the multi-channel trajectory image as input to the model.
We employed the Adam optimizer [28] to train the model, with a learning rate of 5e-5 and a batch size of 16. Each model is trained for up to 100 epochs on a single NVIDIA RTX 4080 graphics card with 8 GB of memory.
-
•
Input: (181HW)
-
–
Past trajectory of for 90 epochs (90HW)
-
–
Past heading directions of for 90 epochs (90HW)
-
–
Binary scene map (1HW)
-
–
-
•
Output: (1HW)
-
–
’s goal position (1HW)
-
–
-
•
Groundtruth: (1HW)
-
–
’s goal position (1HW)
-
–
-
•
Loss: BCELoss between the output and ground-truth
-
•
U-Net channels:
-
–
encoder: 256, 256, 512, 512, 512
-
–
decoder: 512, 512, 512, 256, 256
-
–
-
•
Calculation time for training: 30-35 hours on LocoVR
-C Evaluation data
-C1 Scenes
We converted the 3D models from HM3DSem [27] into two-dimensional scene maps, incorporating semantic labels and corresponding object pixelations. Fig.19 illustrates these scene maps along with their associated object labels. Each scene contains approximately 30 to 40 distinct objects, with each object represented by a unique color.

-C2 Trajectory synthesis
To evaluate the performance of our multimodal human action prediction model, we utilized evaluation data that includes human trajectory information. Given that our method predicts target areas based on observed trajectories, it is crucial that the trajectory data be realistic in terms of both spatial configuration and velocity profile. To ensure this, we employed a machine learning-based approach for trajectory generation. Using the LocoVR dataset, which provides comprehensive data on start positions, target positions, scene maps, and trajectories, the model was trained to learn the relationships between these elements. Specifically, the model takes start positions, target positions, and scene maps as inputs and predicts the corresponding trajectories. By incorporating both trajectory shape and velocity variations into the loss function, the model is able to generate realistic position-velocity sequences.