Towards Universal Text-driven CT Image Segmentation
Abstract
Computed tomography (CT) is extensively used for accurate visualization and segmentation of organs and lesions. While deep learning models such as convolutional neural networks (CNNs) and vision transformers (ViTs) have significantly improved CT image analysis, their performance often declines when applied to diverse, real-world clinical data. Although foundation models offer a broader and more adaptable solution, their potential is limited due to the challenge of obtaining large-scale, voxel-level annotations for medical images. In response to these challenges, prompting-based models using visual or text prompts have emerged. Visual-prompting methods, such as the Segment Anything Model (SAM), still require significant manual input and can introduce ambiguity when applied to clinical scenarios. Instead, foundation models that use text prompts offer a more versatile and clinically relevant approach. Notably, current text-prompt models, such as the CLIP-Driven Universal Model, are limited to text prompts already encountered during training and struggle to process the complex and diverse scenarios of real-world clinical applications. Instead of fine-tuning models trained from natural imaging, we propose OpenVocabCT, a vision-language model pretrained on large-scale 3D CT images for universal text-driven segmentation. Using the large-scale CT-RATE dataset, we decompose the diagnostic reports into fine-grained, organ-level descriptions using large language models for multi-granular contrastive learning. We evaluate our OpenVocabCT on downstream segmentation tasks across nine public datasets for organ and tumor segmentation, demonstrating the superior performance of our model compared to existing methods. All code, datasets, and models will be publicly released at https://github.com/ricklisz/OpenVocabCT.
Contrastive Learning, Medical Image Segmentation, Vision Language Model
1 Introduction
In clinical practice, computed tomography (CT) is widely used for detailed anatomical visualization and precise segmentation of organs-at-risk and tumor lesions. With the advent of deep learning models such as convolutional neural networks (CNNs) [1, 2, 3] and vision transformers (ViTs) [4, 5], medical image segmentation has shown significant promise in CT image analysis. While many purpose-built models achieve remarkable precision for specific tasks [6, 7, 8, 9], their effectiveness is often limited when dealing with the generalizability observed in diverse multimodal clinical data or handling various imaging tasks.

Foundation models, on the other hand, are designed to provide a broad base of capabilities that can be adapted to many tasks without extensive retraining [11]. With the substantial increase in the availability of annotated imaging datasets, numerous studies have been conducted on building foundation segmentation models for 3D CT images [12, 13, 14]. However, obtaining abundant voxel-level annotations for medical images remains time-consuming and expensive. As a result, prompting-based foundation models are being explored as a more data-efficient solution [15, 16, 17]. These models leverage either visual prompts (points or bounding boxes) or text prompts (natural language) to guide the segmentation process. While visual-prompting methods such as the Segment Anything Model (SAM) [18] are widely used for various tasks, they still face challenges when applied to medical settings due to: 1) SAM requires significant image-level annotations for training and considerable manual prompting for inference, which is not a scalable solution for clinical settings; 2) visual prompts lack the necessary clinical details to guide accurate segmentation. These limitations reduce the clinical utility of visual-prompting methods and underscore the importance of vision-language models, as both visual and textual features are essential for effective segmentation to facilitate the diagnosis, treatment planning, and treatment response assessment.
Text-prompting models have emerged as a promising solution for building foundation segmentation models in CT [19, 16]. Recent developments in learning visual representations from text supervision have shown tremendous success in computer vision [20] and medical imaging [21]. However, prior works primarily focus on 2D medical images, such as chest X-rays [22, 23], which limits their application to the more widely used volumetric CT imaging for individual segments of the whole-body. Additionally, text-driven segmentation methods for 3D CT scans often rely on text embeddings from pretrained text encoders, with limited or insufficient use of image-text alignment strategies [24, 19, 16]. This insufficient alignment can restrict the model’s ability to generalize effectively to diverse unseen clinical text prompts or varying medical vocabularies, hindering its utility in real-world clinical settings.
In real-world practice, healthcare professionals use varied prompts to describe or annotate specific organs, making generalization particularly important for achieving universal organ segmentation. Furthermore, radiology reports frequently contain detailed but lengthy diagnostic information, qualitatively deduced from the images, some of which is unrelated to organs or lesions, which poses challenges for efficient image-to-text alignment. To address these challenges, we developed a dedicated image-text supervision framework for 3D CT that generalizes to diverse and unseen text prompts, and that can be applied to text-prompt segmentation tasks. Our main contributions are summarized as follows:
1). We generated detailed organ-level image-text pairs from CT radiology reports by applying large language models (LLMs) on the large-scale paired CT and radiology report dataset, CT-RATE (n = 50,188) [10].
2). We propose a pretraining framework that leverages organ-level and report-level textual information to align the vision-language model using a multi-label contrastive loss, outperforming other existing methods.
3). We evaluate method on eight public datasets for organ and tumor segmentation, demonstrating its robustness across various text prompts and multi-target segmentation tasks. Compared to vision-only segmentation models, our approach achieves comparable performance while enhancing usability by allowing clinicians to interact with the model using natural language. Moreover, compared to text-driven models, it delivers superior performance in single-target segmentation tasks and generalizes effectively to diverse text prompts.
2 Related Work
2.1 Medical image segmentation
Deep learning-based methods [1, 2] have been widely applied for organ segmentation and tumor segmentation and detection, yielding promising results. However, these methods are often task-specific or organ-specific, such as organ segmentation [25] or tumor detection [26, 27]. Recently, there has been a growing interest in building foundation segmentation models for various organs and tumors [13, 19, 28], and for this reason adapting SAM for ’universal’ segmentation [15, 29]; however, SAM’s interactive nature still requires considerable manual input, limiting its applicability in clinical settings [30]. Additionally, since SAM was developed using natural images, it may lack the medical semantic understanding to differentiate between healthy organs and tumors. In contrast, our method integrates medical professional’s knowledge from radiology reports into a text model, which is more practical than visual prompting for clinical usage.
2.2 Vision-language model for medical imaging
Vision-language models such as CLIP [20] have demonstrated the ability to learn transferable visual features through language supervision, without manual image annotations. In medical imaging, where diagnostic radiology-founded reports complement imaging data, CLIP-based models have shown promise across various tasks, including organ segmentation [19], disease classification [22], and image-text retrieval [31]. However, adapting CLIP to medical imaging presents unique challenges. Unlike natural images, which can often be summarized in a few sentences, medical images like CT scans contain complex diagnostic information, resulting in detailed radiology reports. This complexity demands improved local-level alignment between image and text. Another significant challenge is data scarcity. While CLIP is ideal for large-scale datasets, medical image-text datasets are relatively limited, which requires a more label-efficient approach. Our method addresses this by curating a radiology-specific corpus of image-text pairs, designed to supplement the radiology-specific knowledge that conventional CLIP training lacks.
2.3 Text-driven segmentation model
Prompt engineering has demonstrated strong performance improvements in both natural language processing and computer vision tasks. By utilizing pre-trained vision-language models [20], text prompting methods results in open-vocabulary segmentation [32, 33] and referring segmentation [34] tasks. Previous studies demonstrate that pretrained CLIP models are effective for 2D medical image segmentation tasks [35, 17]. Li et al. propose a text-augmented segmentation model that utilizes medical text annotations and pseudo labels in a semi-supervised framework [24]. However, extending these approaches to 3D vision-language models for CT segmentation remains an active research area due to the limited availability of paired CT image-text datasets. Recent efforts have centered on developing text-prompted universal models for segmenting various organs and tumors in 3D volumes. Liu et al. proposed to leverage CLIP’s text embeddings to guide the segmentation model for partially-labeled datasets [19]. Zhao et al. introduced SAT, a large-scale segmentation model with a knowledge-enhanced text encoder for multimodal organ and tumor segmentation [16]. However, no existing approach fully leverages a vision-language-aligned model like CLIP for 3D medical image segmentation tasks. Given CLIP’s strong grounding capabilities, we argue that vision-language alignment is essential for building robust text-driven segmentation models. To address this, we propose a pre-trained vision-language model trained on a large-scale CT image-report dataset, incorporating diverse captions for each organ and region.
3 Method

3.1 Preliminary
In recent years, language supervision methods such as CLIP [20] and SigLIP [36] have been shown to be effective in learning transferable representations. Concretely, given a batch of images {,,···,} and paired text descriptions {,,···,}, CLIP leverages an image encoder to extract the image embedding and a text encoder to extract the text embedding :
| (1) |
The extracted image embedding and text embedding are used to compute InfoNCE loss, in which paired image-text samples are considered as positives and the unpaired ones as negatives. The image-to-text loss can be formulated as:
| (2) |
where cos⟨·,·⟩ denotes the cosine similarity and is a learnable temperature parameter. The final bidirectional total loss can be formulated as .
3.2 Improving image-text alignment with language models
While CLIP has demonstrated promising results on natural images using large-scale datasets, it still faces considerable challenges in medical data due to the significant domain gap between them. First, paired medical image and text data are much more limited compared to natural images, necessitating the use of image-level and text-level data augmentations. Second, medical text typically comes in the form of diagnostic reports made by radiologists, which are much longer and more complex than the concise captions found in natural image datasets. While diagnostic reports contain abundant information about the patient, they may lack the granular, organ-level details essential for effective text-driven segmentation. Also, directly training the model with these lengthy reports may cause it to overgeneralize, attempting to encompass all organs and abnormalities in a single image without distinguishing among them.
Recognizing these challenges, we propose to leverage existing LLMs to generate granular text descriptions relating to organs and abnormalities from each CT image’s radiology report. As in-context learning shows great promise in aligning LLM’s responses to human gold standards, we also leverage this technique to generate organ-level descriptions. First, we generate some few-shot examples of concise organ-level captions from the radiology impressions (Figure 1). We then prompt GPT-4 and Llama-3 APIs with ”You are a medical expert. You will read radiology reports from various physicians on CT images. Given the following radiology report, generate shorter captions describing each organ or disease.” to generate target texts. The LLMs will receive the few-shot examples as context and the radiology report as input data, returning the generated organ-level descriptions. By using in-context learning, we ensure the model maintains consistency in its response and preserves the semantic details in the original caption. Finally, observing that the generated captions may contain redundant information, we followed MetaCLIP’s [37] approach to filter out low-quality captions via substring matching. We utilize a radiology-specific text corpus RadLex, which provides an agreed set of named entities for radiology procedures, as our text metadata. We then apply sub-string matching on the granular captions with the metadata entries, which identifies high-quality captions that contain any of the metadata entries, filtering the various types of noise that the LLM may introduce. By addressing these challenges, we aim to enhance the training process and expand the benefits of augmentation to the text inputs, leading to improved performance and a more comprehensive learning framework.
3.3 Multi-granularity contrastive learning
Having generated and filtered the image captions, we can improve the image-text alignment via a multi-granularity contrastive learning framework. The main difference between our approach and CLIP’s is that our approach leverages multiple granular captions as text augmentation. Given the granular captions , we implement a simple random sampling strategy to gather short captions:
| (3) |
where refers to the -th caption of -th sample from the short caption set. The multi-granular contrastive text-to-image loss becomes:
| (4) |
where refers to the text embedding of , and denotes the number of randomly sampled short captions (K=3 in our implementation). We formulate the bi-directional multi-granular contrastive loss: . By introducing short captions as text augmentations, we increase the diversity of the training data, resulting in a more complete and aligned representation of both images and text.
Empirically, we find that image-text pretraining may not result in optimal finetuning performance for dense prediction tasks like segmentation. To enhance the model’s dense prediction capability, we first pretrained the image encoder on TotalSegmentator for segmentation for 500 epochs, providing a good initialization for the image encoder. We then initialized the image encoder with the pretrained model’s weights before image-text alignment. During image-text contrastive learning, we locked the image encoder and only tuned the text encoder to align the text embeddings with the vision embeddings.
For the final pretraining objective, we combine the original CLIP loss using the full radiology report with the proposed loss using the generated short captions:
| (5) |
This approach helps the model to capture detailed connections between images and text while keeping the broader context provided in the radiology reports, improving its ability to generalize to a variety of image-text pairs.
4 Experiments
4.1 Datasets and evaluation metrics
4.1.1 Vision-language pretraining dataset
We leverage a large-scale chest CT dataset CT-RATE [10], that have 21,304 patients and 50,188 image-radiology report pairs. The CT images were obtained using a range of reconstruction techniques. The radiology reports have four sections: 1. clinical information inlcuding symptoms and history, 2. imaging technique and acquisition protocol, 3. imaging findings (anatomical/pathological observations), and 4. impression/diagnosis.
4.1.2 Segmentation datasets
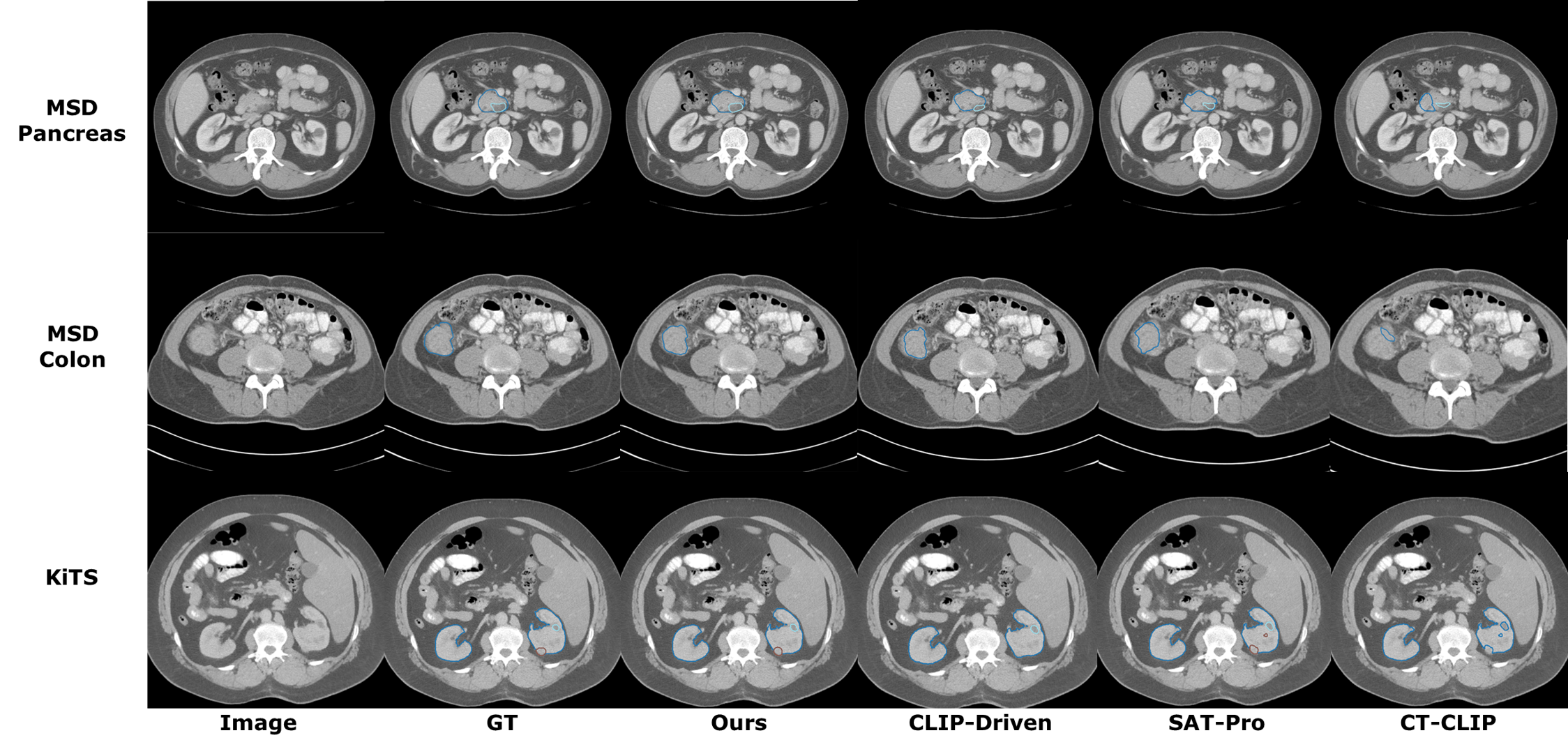
For finetuning on segmentation datasets, we connect our pretrained encoder to STUNet decoder and finetuned on a variety of datasets: TotalSegmentator [38], MSD Lung, MSD Pancreas, MSD Hepatic Vessel, MSD Colon, MSD Liver [39], KiTS23 [40]. For each dataset, we used 80% for training, and 20% for testing. We also evaluate the segmentation model’s generalization capabilities on the FLARE22 and SegTHOR datasets. Dice Similarity Coefficient (DSC) is utilized to quantitatively evaluate organ/tumor segmentation performance.
4.2 Implementation details
4.2.1 Pretraining
Our OpenVocabCT is composed of an image encoder, a text encoder and a segmentation decoder. For pretraining, we use the STUNet-Large [13] as the backbone for our image encoder due to its excellent performance in various benchmarks. We use BIOLORD [41] as our text encoder, which was pretrained on both clinical sentences and biomedical concepts. The text encoder’s latent feature is projected to the image encoder’s latent feature dimension using a simple MLP. We preprocessed CT images by resampling them to an isotropic spacing of 1.5 mm × 1.5 mm × 1.5 mm and padding them to a size of 220 × 220 × 220. For image captions, we randomly sample three granular captions from the filtered dataset, along with the findings section from the original report. Pretraining is conducted on four NVIDIA A100 GPUs, with a batch size of 32 per GPU.
(2). Finetuning on segmentation datasets: We directly use the aligned image encoder and text encoder from pretraining. We then connect the pretrained image encoder to the decoder of STUNet-Large. To avoid catastrophic forgetting, we freeze the weights of both image encoder and text encoder and only tune the segmentation decoder. For text-driven segmentation, we generate organ prompts such as ’Liver’ or ’Left kidney’ and feed the tokenized prompts to the text encoder similar to [19, 16]. The text features are further processed through a text-guidance connector to generate query embeddings, which are then multiplied with the image features to produce segmentation maps. In our ablation study, we explored various strategies for designing the text-guidance connector.
4.3 Comparison with other methods
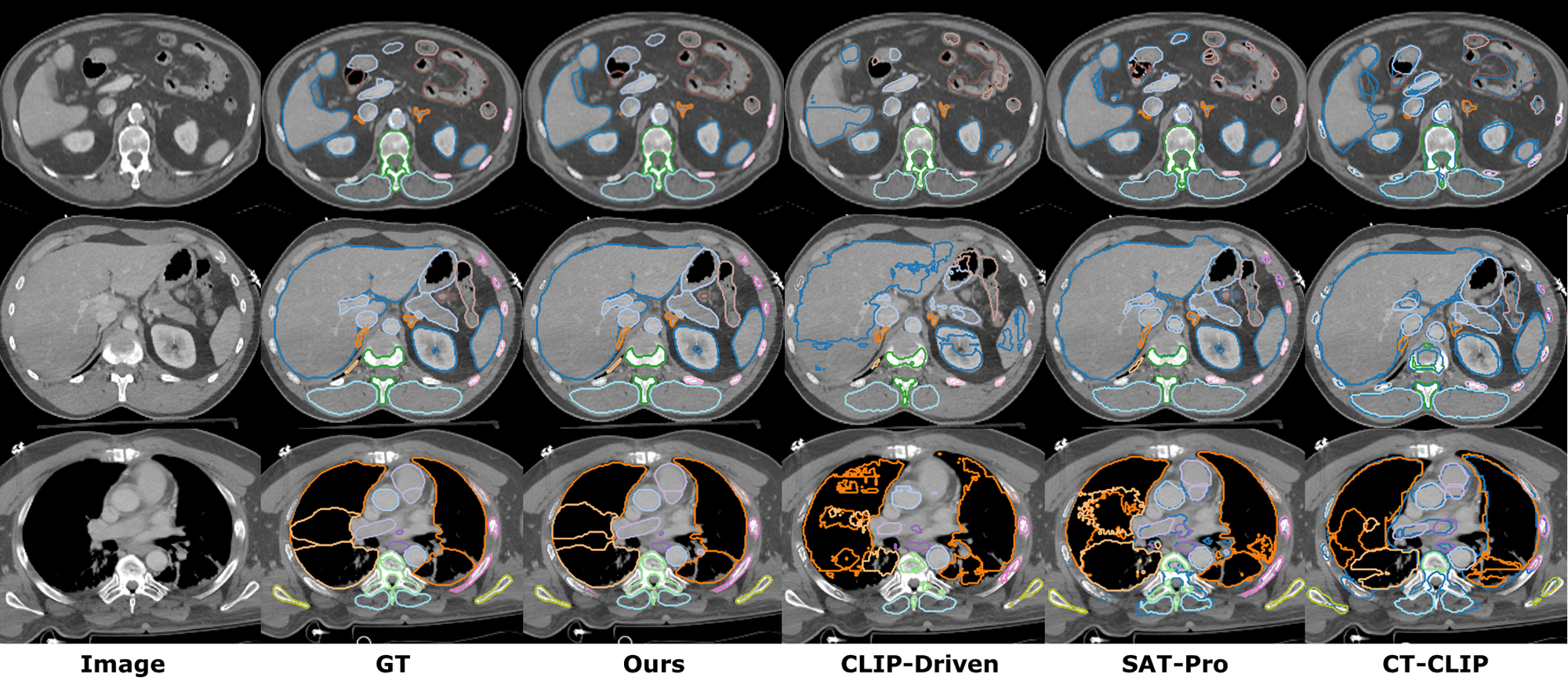
We compare our method with both vision-only segmentation models and text-driven segmentation frameworks. For vision-only methods, we compare with nnUNetv2 [2] and UniMiSS [28]. For text-driven approaches, we compare with CLIP-Driven Universal Model [19], SAT-Pro [16], and CT-CLIP [10]. As shown in Table 1, our method is able to achieve better performance than both the previous SOTA image-only methods and the text-driven SOTA methods on TotalSegmentator dataset. Compared to the best image-only method UniMISS, our method outperforms by 2.7% DSC. Compared to the best text-driven method, i.e., SAT, our method outperforms by 3.1% DSC. We also visualize the organ segmentation results in (Figure 3). This shows that our method can effectively segment the majority of organs with superior performance. For tumor segmentation tasks, as shown in Table 2, our method achieves comparable performance as the best text-driven method Universal model and outperforms the best vision-only method nnUNet by 4.3% on average.
| Method | Vertebrae | Cardiac | Muscles | Organs | Ribs | Avg |
|---|---|---|---|---|---|---|
| CLIP-Driven | 81.1 | 84.5 | 88.8 | 86.4 | 82.1 | 84.6 |
| SAT Pro | 85.4 | 89.2 | 88.0 | 87.7 | 83.7 | 87.6 |
| CT-CLIP | 76.6 | 78.1 | 81.2 | 79.1 | 74.2 | 77.8 |
| UniMiSS | 85.1 | 88.9 | 92.8 | 88.5 | 84.5 | 88.0 |
| nnUNet | 87.0 | 88.7 | 85.1 | 87.5 | 86.1 | 86.9 |
| OpenVocabCT | 90.4 | 90.3 | 90.0 | 91.3 | 91.6 | 90.7 |
| Method | MSD Lung | MSD Pancreas | MSD Hepatic Vessel | MSD Colon | ||||
|---|---|---|---|---|---|---|---|---|
| Lung Tumor | Pancreas | Pancreas Tumor | Avg | Hepatic Vessel | Hepatic Vessel Tumor | Avg | Colon Tumor | |
| CLIP-Driven | 67.1 | 82.7 | 60.8 | 71.7 | 62.6 | 69.4 | 66.0 | 62.1 |
| SAT Pro | 61.8 | 76.2 | 41.6 | 58.9 | 65.2 | 61.8 | 63.5 | 32.4 |
| CT-CLIP | 52.9 | 68.3 | 33.2 | 50.8 | 52.9 | 55.0 | 53.9 | 28.1 |
| nnUNet | 68.2 | 81.6 | 53.1 | 67.4 | 67.7 | 72.1 | 69.9 | 49.2 |
| OpenVocabCT | 70.3 | 81.9 | 60.0 | 71.0 | 67.3 | 70.2 | 68.8 | 62.8 |
| Method | MSD Liver | KiTS23 | Avg | |||||
|---|---|---|---|---|---|---|---|---|
| Liver | Liver Tumor | Avg | Kidneys | Kidney Cysts | Kidney Tumor | Avg | ||
| CLIP-Driven | 96.5 | 71.9 | 84.2 | 95.2 | 76.4 | 84.7 | 85.4 | 75.4 |
| SAT Pro | 92.7 | 59.7 | 76.2 | 93.2 | 52.8 | 68.2 | 71.4 | 64.1 |
| CT-CLIP | 86.7 | 51.8 | 63.5 | 85.4 | 42.6 | 52.2 | 60.1 | 55.4 |
| nnUNet | 93.8 | 66.0 | 79.9 | 96.1 | 58.0 | 84.4 | 79.5 | 71.8 |
| OpenVocabCT | 96.6 | 68.5 | 82.6 | 96.4 | 78.0 | 86.9 | 87.1 | 76.2 |
4.4 Generalizability to diverse text prompts
Compared to vision-only models, text-driven segmentation models are more flexible by parsing a wide range of clinical descriptions to guide the segmentation process. This allows text-driven models to generalize to partially labeled data that are incomplete or inconsistent as compared to training data. In real-world scenarios where healthcare professionals use varied prompts to describe or annotate specific organs, this generalization capability becomes particularly valuable for achieving universal organ segmentation. To assess these generalization capabilities, we evaluate how well the text-driven segmentation model handles two categories of training invisible prompts: 1) prompts obtained by merging multiple organs and 2) prompts that are synonymous terms for the target organ. Specifically, for category 1, we obtain these prompts by merging various suborgans used in training (i.e. left lung is obtained by merging the lung upper lobe left, lung lower lobe left classes in TotalSegmentator). For category 2, we take the training visible prompt and substitute it for a synonym. For example, renal organs is synonym for kidney and hepatic system is synonym for liver.
Generalization results to merged suborgans is shown in Table 3. Compared to the CLIP-Driven Universal Model, SAT Pro, and CT-CLIP, our method consistently achieves superior performance on merging simple left and right organs (e.g. left and right lungs, left and right kidneys). These results highlight the model’s ability to interpret novel combinations of suborgans effectively. Generalization results to synonyms is shown in Table 4. Notably, our method also achieves significantly higher performance in challenging cases (e.g., cervical vertebrae, lumbar vertebrae, thoracic vertebrae, veins, arteries) without explicitly being trained on such prompts. Our method consistently outperforms the existing text-driven methods, achieving the highest average performance (73.2% DSC) across all categories.
We visualize the segmentation results of generalization study in axial view (Figure 5) and coronal view (Figure 6). As shown in Figure 5 rows 1, 3, and 4, our model performs resonably well when merging left and right organs in both the chest region (lung) and the abdominal region (kidney, autochthon). In row 2, the model demonstrates its flexibility by accurately segmenting organs described using synonyms, such as ”hepatic system” for the liver and ”renal organs” for the kidneys. Additionally, for bones and vertebrae, our method effectively segments merged categories like left ribs, right ribs, lumbar vertebrae, and thoracic vertebrae (Figure 5). This demonstrates the superior ability of our model to handle diverse and unseen clinical terminology as text prompts, suitable for real-world deployment in diverse clinical environments.
| Method | L. Lung | R. Lung | L&R Lung | L.Heart | R. Heart | L. and R. Kidney | L. and R. AG | Heart | L. Ribs | R. Ribs |
|---|---|---|---|---|---|---|---|---|---|---|
| CLIP-Driven | 80.8 | 50.1 | 21.0 | 42.3 | 64.0 | 45.7 | 40.4 | 63.1 | 0 | 10.3 |
| SAT Pro | 63.2 | 62.4 | 6.0 | 0 | 52.9 | 28.7 | 34.2 | 8.4 | 63.2 | 62.4 |
| CT-CLIP | 48.5 | 47 | 26.5 | 47.0 | 54.2 | 64.9 | 0 | 25.7 | 3.1 | 0 |
| OpenVocabCT | 95.4 | 92.8 | 85.6 | 51.3 | 68.2 | 89.3 | 77.3 | 54.2 | 68.1 | 66.7 |
| Method | Trachea and Esophgaus | L. Gluteus | R.Gluteus | Cervical V. | Lumbar V. | Thoracic V. | Veins | Arteries | Avg |
|---|---|---|---|---|---|---|---|---|---|
| CLIP-Driven | 69.0 | 50.0 | 19.8 | 20.3 | 5 | 21.1 | 36.1 | 63.1 | 39.0 |
| SAT Pro | 1.1 | 49.6 | 49.8 | 29 | 4.9 | 13.8 | 10.4 | 5 | 23.3 |
| CT-CLIP | 47.1 | 1.2 | 5.6 | 0 | 22.8 | 0 | 38.9 | 52.8 | 26.9 |
| OpenVocabCT | 67.1 | 78.1 | 77.5 | 66.2 | 31.6 | 43.0 | 62.8 | 63.3 | 68.8 |
| Method | Renal organs (kidney) | Hepatic system (liver) | Heart muscle (myocardium) | Aortic vessel (aorta) | Cerebrum (brain) | Small intestine (small bowel) | Avg |
|---|---|---|---|---|---|---|---|
| CLIP-Driven | 54.5 | 0 | 37.4 | 42.0 | 78.5 | 24.3 | 39.4 |
| SAT Pro | 0 | 74.7 | 76.5 | 83.6 | 0 | 76.2 | 51.8 |
| CT-CLIP | 23.6 | 45.7 | 65.1 | 57.9 | 72.5 | 19.3 | 47.4 |
| OpenVocabCT | 77.1 | 84.5 | 69.0 | 71.1 | 79.8 | 79.9 | 76.9 |


4.5 Ablation Study
4.5.1 Ablation study on pretraining
We conduct an ablation study on the effectiveness of our proposed pretraining strategy, shown in Table 5. Compared with a baseline model using random initialization, CLIP pretraining does not improve the finetuning performance, which corroborates our hypothesis that image-text alignment may not benefit a dense segmentation task. Incorporating our proposed MGCL on average improves the finetuning performance by 1.2% DSC and the generazaibility performance by 6.8% DSC and 12.4% DSC. We find that the optimal performance emerges when initializing the image encoder with pretrained weights and locking the image encoder, considerably improving finetuning score by 8.5% DSC and generalizability scores by 7.7% DSC for merging suborgans.
4.5.2 Ablation study on text-branch connector
We also conduct an ablation study on 2 architectures of the text-branch connector: Multi-Layer Perceptron (MLP) vs Cross-Attention mechanism in Table 5. Intriguingly, we find that the MLP connector achieves strong generalizability (61.1% DSC for merging and 73.1% DSC for synonyms) by efficiently aligning image and text without overfitting. In contrast, while cross-attention can result in a higher finetuning score of 85.6% DSC, it results in significantly lower generalizability, likely due to its reliance on specific text features. To mitigate this trade-off, our approach leveraging pretrained image encoder can provide a good initialization weight for our image-text alignment, achieving the best average performance, balancing the finetuing and generalizabitlity to diverse text prompts.
| Pretraining Strategy | Segmentation text-branch | Finetuning | Generalizability | |
| Merging | Synonyms | |||
| Random Init | MLP | 83.4 | - | - |
| CLIP Loss | MLP | 81.0 | 54.3 | 60.7 |
| Multi-Granularity Contrastive Loss | MLP | 82.2 | 61.1 | 73.1 |
| Multi-Granularity Contrastive Loss | Cross Attention | 85.6 | 43.4 | 49.4 |
| Pretrained Image Encoder + Multi-Granularity Contrastive Loss | MLP | 90.7 | 68.8 | 73.2 |
4.6 Generalization study
We further study the generalization capabilities to external datasets. Table 6 summarizes the performance on FLARE22 dataset. Compared to the other methods, our method consistently achieves superior generalization performances in 10 of 13 organs in the abdominal region. The second best performing model is the vision-only model nnUNet, which our method slightly outperforms by 0.4% DSC. Generalization performance for SegTHOR dataset is shown in table 7. Our method also achieves superior performance in esophagus, heart and aorta segmentation. For inferring the training unseen heart category, we prompt text-driven models with the prompt heart. Our method outperforms best existing text-driven models in heart segmentation by 9.4% DSC and 6% DSC on average. To further explore the generalization capability of nnUNet on the unseen heart category, we combined predictions for its sub-organ components (i.e., heart myocardium, heart ventricle, heart atrium, and pulmonary artery). Interestingly, nnUNet demonstrates comparable performance on this cardaic organ category, achieving results superior to most existing text-driven models (except ours). We hypothesize that this is because text-driven models may suffer from insufficient image-text alignment during training, limiting their ability to generalize effectively to unseen categories (heart in this case).
| Method | Liver | RK | LK | LAG | RAG | Spleen | Pancreas | Gallbladder | Esophagus | Stomach | Duodenum | IVC | Aorta | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Universal | 95.0 | 87.9 | 88.3 | 83.1 | 83.7 | 88.1 | 79.3 | 87.8 | 84.5 | 93.5 | 66.7 | 91.4 | 90.6 | 86.2 |
| SAT-Pro | 97.9 | 91.1 | 90.9 | 84.4 | 81.6 | 95.1 | 81.4 | 90.1 | 85.1 | 95.3 | 73.8 | 93.7 | 93.5 | 88.8 |
| CT-CLIP | 86.7 | 76.2 | 75.7 | 71.0 | 71.5 | 83.3 | 74.7 | 78.7 | 75.0 | 89.8 | 67.3 | 82.3 | 81.2 | 78.0 |
| nnUNet | 97.5 | 92.5 | 93.1 | 85.0 | 84.8 | 98.0 | 83.6 | 90.0 | 82.3 | 95.9 | 76.6 | 94.1 | 95.1 | 89.9 |
| OpenVocabCT | 97.6 | 94.3 | 93.3 | 86.0 | 84.9 | 98.1 | 83.9 | 90.1 | 84.2 | 96.1 | 75.4 | 94.1 | 95.7 | 90.3 |
| Method | Esophagus | Heart∗ | Trachea | Aorta | Avg |
|---|---|---|---|---|---|
| Universal | 72.5 | 70.0 | 79.5 | 69.4 | 72.9 |
| SAT-Pro | 76.8 | 73.4 | 87.9 | 78.3 | 79.1 |
| CT-CLIP | 65.9 | 68.3 | 65.1 | 52.1 | 62.9 |
| nnUNet | 83.8 | 78.6 | 91.3 | 82.4 | 84.0 |
| OpenVocabCT | 85.8 | 82.8 | 88.9 | 82.9 | 85.1 |
5 Conclusion
In this paper, we propose a novel framework for pretraining and adapting vision-language models for universal text-driven CT image segmentation. Our approach introduces a multi-granular contrastive learning loss that effectively captures organ- and disease-specific information extracted from radiology reports. To ensure high-quality caption selection, we leverage a radiology corpus for generating informative and relevant text descriptions. We first show that our method achieves superior results on organ and lesion segmentation compared to both vision and vision-language models. We also show that our method can successfully generalize to training-unseen text prompts for universal organ segmentation, outperforming other methods. In our future work, we aim to extend this framework for other imaging modalities (such as PET and MRI) and also explore pretraining with more diverse CT image sites (such as abdominal, head and neck regions). We also plan to transfer our framework to real-world clinical data and demonstrate its effectiveness in other tasks such as tumor detection and image synthesis.
References
- [1] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer, 2015, pp. 234–241.
- [2] F. Isensee, P. F. Jaeger, S. A. Kohl, J. Petersen, and K. H. Maier-Hein, “nnu-net: a self-configuring method for deep learning-based biomedical image segmentation,” Nature methods, vol. 18, no. 2, pp. 203–211, 2021.
- [3] S. Roy, G. Koehler, C. Ulrich, M. Baumgartner, J. Petersen, F. Isensee, P. F. Jaeger, and K. H. Maier-Hein, “Mednext: transformer-driven scaling of convnets for medical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2023, pp. 405–415.
- [4] Y. Tang, D. Yang, W. Li, H. R. Roth, B. Landman, D. Xu, V. Nath, and A. Hatamizadeh, “Self-supervised pre-training of swin transformers for 3d medical image analysis,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 20 730–20 740.
- [5] H.-Y. Zhou, J. Guo, Y. Zhang, X. Han, L. Yu, L. Wang, and Y. Yu, “nnformer: Volumetric medical image segmentation via a 3d transformer,” IEEE Transactions on Image Processing, 2023.
- [6] H. H. Lee, S. Bao, Y. Huo, and B. A. Landman, “3d ux-net: A large kernel volumetric convnet modernizing hierarchical transformer for medical image segmentation,” in The Eleventh International Conference on Learning Representations, 2022.
- [7] X. Zhao, P. Zhang, F. Song, C. Ma, G. Fan, Y. Sun, Y. Feng, and G. Zhang, “Prior attention network for multi-lesion segmentation in medical images,” IEEE Transactions on Medical Imaging, vol. 41, no. 12, pp. 3812–3823, 2022.
- [8] A. Marcus, P. Bentley, and D. Rueckert, “Concurrent ischemic lesion age estimation and segmentation of ct brain using a transformer-based network,” IEEE Transactions on Medical Imaging, vol. 42, no. 12, pp. 3464–3473, 2023.
- [9] W. Ji, S. Yu, J. Wu, K. Ma, C. Bian, Q. Bi, J. Li, H. Liu, L. Cheng, and Y. Zheng, “Learning calibrated medical image segmentation via multi-rater agreement modeling,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 12 341–12 351.
- [10] I. E. Hamamci, S. Er, F. Almas, A. G. Simsek, S. N. Esirgun, I. Dogan, M. F. Dasdelen, O. F. Durugol, B. Wittmann, T. Amiranashvili et al., “Developing generalist foundation models from a multimodal dataset for 3d computed tomography,” 2024.
- [11] M. Moor, O. Banerjee, Z. S. H. Abad, H. M. Krumholz, J. Leskovec, E. J. Topol, and P. Rajpurkar, “Foundation models for generalist medical artificial intelligence,” Nature, vol. 616, no. 7956, pp. 259–265, 2023.
- [12] J. Silva-Rodríguez, J. Dolz, and I. B. Ayed, “Towards foundation models and few-shot parameter-efficient fine-tuning for volumetric organ segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2023, pp. 213–224.
- [13] Z. Huang, H. Wang, Z. Deng, J. Ye, Y. Su, H. Sun, J. He, Y. Gu, L. Gu, S. Zhang et al., “Stu-net: Scalable and transferable medical image segmentation models empowered by large-scale supervised pre-training,” arXiv preprint arXiv:2304.06716, 2023.
- [14] G. Wang, J. Wu, X. Luo, X. Liu, K. Li, and S. Zhang, “Mis-fm: 3d medical image segmentation using foundation models pretrained on a large-scale unannotated dataset,” arXiv preprint arXiv:2306.16925, 2023.
- [15] Y. Huang, X. Yang, L. Liu, H. Zhou, A. Chang, X. Zhou, R. Chen, J. Yu, J. Chen, C. Chen et al., “Segment anything model for medical images?” Medical Image Analysis, vol. 92, p. 103061, 2024.
- [16] Z. Zhao, Y. Zhang, C. Wu, X. Zhang, Y. Zhang, Y. Wang, and W. Xie, “One model to rule them all: Towards universal segmentation for medical images with text prompts,” arXiv preprint arXiv:2312.17183, 2023.
- [17] T. Koleilat, H. Asgariandehkordi, H. Rivaz, and Y. Xiao, “Medclip-sam: Bridging text and image towards universal medical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2024, pp. 643–653.
- [18] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015–4026.
- [19] J. Liu, Y. Zhang, J.-N. Chen, J. Xiao, Y. Lu, B. A Landman, Y. Yuan, A. Yuille, Y. Tang, and Z. Zhou, “Clip-driven universal model for organ segmentation and tumor detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 21 152–21 164.
- [20] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [21] S.-C. Huang, L. Shen, M. P. Lungren, and S. Yeung, “Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3942–3951.
- [22] C. Wu, X. Zhang, Y. Zhang, Y. Wang, and W. Xie, “Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 21 372–21 383.
- [23] Z. Wang, Z. Wu, D. Agarwal, and J. Sun, “Medclip: Contrastive learning from unpaired medical images and text,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022, pp. 3876–3887.
- [24] Z. Li, Y. Li, Q. Li, P. Wang, D. Guo, L. Lu, D. Jin, Y. Zhang, and Q. Hong, “Lvit: language meets vision transformer in medical image segmentation,” IEEE transactions on medical imaging, 2023.
- [25] S. Pan, C.-W. Chang, T. Wang, J. Wynne, M. Hu, Y. Lei, T. Liu, P. Patel, J. Roper, and X. Yang, “Abdomen ct multi-organ segmentation using token-based mlp-mixer,” Medical Physics, vol. 50, no. 5, pp. 3027–3038, 2023.
- [26] Z. Xue, P. Li, L. Zhang, X. Lu, G. Zhu, P. Shen, S. A. A. Shah, and M. Bennamoun, “Multi-modal co-learning for liver lesion segmentation on pet-ct images,” IEEE Transactions on Medical Imaging, vol. 40, no. 12, pp. 3531–3542, 2021.
- [27] C. Chen, K. Zhou, M. Zha, X. Qu, X. Guo, H. Chen, Z. Wang, and R. Xiao, “An effective deep neural network for lung lesions segmentation from covid-19 ct images,” IEEE Transactions on Industrial Informatics, vol. 17, no. 9, pp. 6528–6538, 2021.
- [28] Y. Xie, J. Zhang, Y. Xia, and Q. Wu, “Unimiss: Universal medical self-supervised learning via breaking dimensionality barrier,” in European Conference on Computer Vision. Springer, 2022, pp. 558–575.
- [29] J. Ma, Y. He, F. Li, L. Han, C. You, and B. Wang, “Segment anything in medical images,” Nature Communications, vol. 15, no. 1, p. 654, 2024.
- [30] P. Shi, J. Qiu, S. M. D. Abaxi, H. Wei, F. P.-W. Lo, and W. Yuan, “Generalist vision foundation models for medical imaging: A case study of segment anything model on zero-shot medical segmentation,” Diagnostics, vol. 13, no. 11, p. 1947, 2023.
- [31] S. Zhang, Y. Xu, N. Usuyama, H. Xu, J. Bagga, R. Tinn, S. Preston, R. Rao, M. Wei, N. Valluri et al., “Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs,” arXiv preprint arXiv:2303.00915, 2023.
- [32] F. Liang, B. Wu, X. Dai, K. Li, Y. Zhao, H. Zhang, P. Zhang, P. Vajda, and D. Marculescu, “Open-vocabulary semantic segmentation with mask-adapted clip,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7061–7070.
- [33] G. Ghiasi, X. Gu, Y. Cui, and T.-Y. Lin, “Scaling open-vocabulary image segmentation with image-level labels,” in European Conference on Computer Vision. Springer, 2022, pp. 540–557.
- [34] Z. Wang, Y. Lu, Q. Li, X. Tao, Y. Guo, M. Gong, and T. Liu, “Cris: Clip-driven referring image segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 686–11 695.
- [35] P. Müller, G. Kaissis, C. Zou, and D. Rueckert, “Radiological reports improve pre-training for localized imaging tasks on chest x-rays,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2022, pp. 647–657.
- [36] X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 11 975–11 986.
- [37] H. Xu, S. Xie, X. E. Tan, P.-Y. Huang, R. Howes, V. Sharma, S.-W. Li, G. Ghosh, L. Zettlemoyer, and C. Feichtenhofer, “Demystifying clip data,” arXiv preprint arXiv:2309.16671, 2023.
- [38] J. Wasserthal, H.-C. Breit, M. T. Meyer, M. Pradella, D. Hinck, A. W. Sauter, T. Heye, D. T. Boll, J. Cyriac, S. Yang et al., “Totalsegmentator: robust segmentation of 104 anatomic structures in ct images,” Radiology: Artificial Intelligence, vol. 5, no. 5, 2023.
- [39] M. Antonelli, A. Reinke, S. Bakas, K. Farahani, A. Kopp-Schneider, B. A. Landman, G. Litjens, B. Menze, O. Ronneberger, R. M. Summers et al., “The medical segmentation decathlon,” Nature communications, vol. 13, no. 1, p. 4128, 2022.
- [40] N. Heller, F. Isensee, D. Trofimova, R. Tejpaul, Z. Zhao, H. Chen, L. Wang, A. Golts, D. Khapun, D. Shats et al., “The kits21 challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase ct,” arXiv preprint arXiv:2307.01984, 2023.
- [41] F. Remy, K. Demuynck, and T. Demeester, “Biolord-2023: semantic textual representations fusing large language models and clinical knowledge graph insights,” Journal of the American Medical Informatics Association, p. ocae029, 2024.