Towards Understanding How Transformers Learn In-context Through a Representation Learning Lens
Abstract
Pre-trained large language models based on Transformers have demonstrated remarkable in-context learning (ICL) abilities. With just a few demonstration examples, the models can implement new tasks without any parameter updates. However, it is still an open question to understand the mechanism of ICL. In this paper, we attempt to explore the ICL process in Transformers through a lens of representation learning. Initially, leveraging kernel methods, we figure out a dual model for one softmax attention layer. The ICL inference process of the attention layer aligns with the training procedure of its dual model, generating token representation predictions that are equivalent to the dual model’s test outputs. We delve into the training process of this dual model from a representation learning standpoint and further derive a generalization error bound related to the quantity of demonstration tokens. Subsequently, we extend our theoretical conclusions to more complicated scenarios, including one Transformer layer and multiple attention layers. Furthermore, drawing inspiration from existing representation learning methods especially contrastive learning, we propose potential modifications for the attention layer. Finally, experiments are designed to support our findings.
1 Introduction
Recently, large language models (LLMs) based on the Transformer architectures (Vaswani et al., 2017) has shown surprising in-context learning (ICL) capabilities (Brown et al., 2020; Wei et al., 2022; Dong et al., 2022; Liu et al., 2023). By prepending several training examples before query inputs without labels, the models can make predictions for the queries and achieve excellent performance without any parameter updates. This excellent capability enables pre-trained LLMs such as GPT models to be used in general downstream tasks conveniently. Despite the good performance of the ICL capabilities, the mechanism of ICL still remains an open question.
In order to better understand the ICL capabilities, many works began to give explanations from different aspects. Xie et al. (2021) propose a Bayesian inference framework to explain how ICL occurs between pretraining and test time, where the LLMs infers a shared latent concept among the demonstration examples. Garg et al. (2022) demonstrate through experiments that pre-trained Transformer-based models can learn new functions from in-context examples, including (sparse) linear functions, two-layer neural networks, and decision trees. Zhang et al. (2023b) adopt a Bayesian perspective and show that ICL implicitly performs the Bayesian model averaging algorithm, which is approximated by the attention mechanism. Li et al. (2023) define ICL as an algorithm learning problem where a transformer model implicitly builds a hypothesis function at inference-time and derive generalization bounds for ICL. Han et al. (2023) suggest that LLMs can emulate kernel regression algorithms and exhibit similar behaviors during ICL. These works have provided significant insights into the interpretation of ICL capabilities from various perspectives.
In addition to the above explorations, there are also some attempts to relate ICL capabilities to gradient descent. Inspired by the dual form of linear attention proposed in Aiserman et al. (1964) and Irie et al. (2022), the ICL process is interpreted as implicit fine-tuning in the setting of linear attention by Dai et al. (2022). However, there is still a certain noticeable gap between linear attention and the widely used softmax attention. Additionally, this comparison is more of a formal resemblance and the specific details of gradient descent, including the form of the loss function and training data, require a more fine-grained exploration. Akyürek et al. (2022) show that by constructing specific weights, Transformer layers can perform fundamental operations (mov, mul, div, aff), which can be combined to execute gradient descent. Von Oswald et al. (2023a) adopt another construction, such that the inference process on a single or multiple linear attention layers can be equivalently seen as taking one or multiple steps of gradient descent on linear regression tasks. Building upon this weight construction method, subsequent work has conducted a more in-depth exploration of the capabilities of ICL under a causal setting, noticing that the inference of such attention layers is akin to performing online gradient descent (Ding et al., 2023; Von Oswald et al., 2023b). However, these analyses are still conducted under the assumption of linear attention and primarily focus on linear regression tasks, adopting specific constructions for the input tokens (concatenated from features and labels) and model weights. This limits the explanation of the Transformer’s ICL capabilities in more general settings. Thus, the question arises: Can we relate ICL to gradient descent under the softmax attention setting, rather than the linear attention setting, without assuming specific constructions for model weights and input tokens?
Motivated by the aforementioned challenges and following these works that connect ICL with gradient descent, we explore the ICL inference process from a representation learning lens. First, by incorporating kernel methods, we establish a connection between the ICL inference process of one softmax attention layer and the gradient descent process of its dual model. The test prediction of the trained dual model will be equivalent to the ICL inference result. We analyze the training process of this dual model from the perspective of representation learning and compare it with existing representation learning methods. Then, we derive a generalization error bound of this process, which is related to the number of demonstration tokens. Our conclusions can be easily extended to more complex scenarios, including a single Transformer layer and multiple attention layers. Furthermore, inspired by existing representation learning methods especially contrastive learning, we propose potential modifications to the attention layer and experiments are designed to support our findings.
2 Preliminaries
2.1 In-context Learning with Transformers
The model we consider is composed of many stacked Transformer decoder layers, each of which is composed of an attention layer and a FFN layer. For simplicity, we have omitted structures such as residual connections and layer normalization, retaining only the most essential parts. We consider the standard ICL scenario, where the model’s input consists of demonstrations followed by query inputs, that is, the input can be represented as , where denotes demonstration tokens, and denotes query tokens. Here, we focus more on how tokens interact during model inference while ignoring the internal structure of demonstration tokens. For the query input at position , its output after one layer of Transformer can be represented as
| (1) |
| (2) |
where are parameters for key, query, value projections and ,, are FFN parameters. Our concern is how the query token learns in-context information from demonstrations. Unlike previous work (Von Oswald et al., 2023a; Zhang et al., 2023a; Bai et al., 2023), here we do not make additional assumptions about the structure of input matrix and parameters to study the Transformer’s ability to implement some specific algorithms. Instead, we adopt the same setting as (Dai et al., 2022) to study more general cases.
2.2 Self-Supervised Representation Learning Using Contrastive Loss Functions
Representation learning aims to learn embeddings of data to preserve useful information for downstream tasks. One class of methods most relevant to our work is probably contrastive learning methods without negative samples (Chen and He, 2021; Grill et al., 2020; Caron et al., 2020; Tian et al., 2021). Contrastive learning is a significant approach of self-supervised learning (SSL) which aims at learning representations by minimizing the distance between the augmentations of the same data point (positive samples) while maximizing the distance from different data points (negative samples) (He et al., 2020; Chen et al., 2020b; Oord et al., 2018; Oh Song et al., 2016). To alleviate the burden of constructing a sufficient number of negative samples while avoiding representational collapse, some works propose architectures for contrastive learning without negative samples, which mainly use weight-sharing network known as Siamese networks (Chen and He, 2021; Grill et al., 2020; Caron et al., 2020; Tian et al., 2021). The architecture takes two augmentations from the same data as inputs, which will be processed by online network and target network respectively to obtain the corresponding representations, that is, . The two encoder networks share weights directly or using Exponential Moving Average (EMA). Then, will be input into a predictor head to obtain the predictive representation . Finally, we minimize the distance between the predictive representation and target representation, that is, where means is treated as a constant during backpropagation. For , we often choose the cosine similarity or the -norm as a measure of distance, although they are equivalent when the vector is normalized. Another class similar to our work is kernel contrastive learning (Esser et al., 2024). Given an anchor and its positive and negative samples , it aims to optimize the loss function , where and is the feature mapping for some kernel. We will consider the gradient descent process corresponding to the inference process of ICL from the perspective of representation learning and compare it with the two aforementioned representation learning patterns.
2.3 Gradient Descent on Linear Layer is the Dual Form of Linear Attention
It has been found that the linear attention can be connected to the linear layer optimized by gradient descent (Aiserman et al., 1964; Irie et al., 2022; Dai et al., 2022), that is, the gradient descent on linear layer can be seen as the dual form 111It should be clarified that the term ”dual” here is different from the one in mathematical optimization theory. Instead, it follows the terminology used in previous works (Irie et al., 2022; Dai et al., 2022), where the forward process of the attention layer and backward process on some model are referred to as a form of ”dual”. of linear attention. A simple linear layer can be defined as where is the projection matrix. Given training inputs with their labels , a linear layer can output the predictions where and then compute certain loss for training. Backpropagation signals will be produced to update in gradient descent process where if we set as the learning rate. During test time, the trained weight matrix can be represented by its initialization and the updated part , that is,
| (3) |
where denotes the outer product according to the chain rule of differentiation. On the other hand, this process can be viewed from the perspective of linear attention. Let denote the key and value vectors constituting matrices respectively. For a given query input , linear attention is typically defined as the weighted sum of these value vectors
Then, we can rewrite the output of a linear layer during test time as
| (4) |
where and are stacked by backpropagation signals and training inputs respectively. We can find from Eq (4) that the trained weight records all training datapoints and the test prediction of the linear layer indicates which training datapoints are chosen to activate using where can be considered as values while as keys and as the query. This interpretation uses gradient descent as a bridge to connect predictions of linear layers with linear attention, which can be seen as a simplified softmax attention used in Transformers.
Inspired by this relationship, Dai et al. (2022) understand ICL as implicit fine-tuning. However, this interpretation based on linear attention deviates from the softmax attention used in practical Transformers. Furthermore, this alignment is also ambiguous as the specific details of the gradient descent process, including the form of loss function and dataset, have not been explicitly addressed. In addition, Von Oswald et al. (2023a); Ding et al. (2023) also connect ICL with gradient descent for linear regression tasks using weight construction methods, where parameters , and of the self-attention layer need to roughly adhere to a specific constructed form. However, these analyses rely on the setting of linear regression tasks and assumptions about the form of input tokens (concatenated with features and labels), which limits the interpretability of ICL capabilities from the perspective of gradient descent. Thus, we attempt to address these issues in the following sections.
3 Connecting ICL with Gradient Descent
In this section, we will address two questions discussed above: (i) Without assuming specific constructions for model weights and input tokens, how to relate ICL to gradient descent in the setting of softmax attention instead of linear attention? (2) What are the specific forms of the training data and loss function in the gradient descent process corresponding to ICL? In addressing these two questions, we will explore the gradient descent process corresponding to ICL from the perspective of representation learning.
3.1 Connecting Softmax Attention with Kernels
Before we begin establishing the connection between ICL and gradient descent, we need to firstly rethink softmax attention with kernel methods. Dai et al. (2022) connect ICL with gradient descent under the linear attention setting. In fact, it is completely feasible to interpret ICL under softmax attention with the help of kernel methods. We define the attention block as
| (5) |
which can be viewed as the product of an unnormalized part and a normalizing multiplier , that is,
| (6) |
where is element-wise. Similar in (Choromanski et al., 2020), we define softmax kernel as where is the guassian kernel when the variance . According to Mercer’s theorem (Mercer, 1909), there exists some mapping function satisfying that . Thus, noting that when omitting the -renormalization and equivalently normalize key and value vectors in Eq (6), every entry in the unnormalized part can be seen as the output of softmax kernel defined for the mapping , which can be formulated as:
| (7) |
There have been many forms of mapping function used in linear Transformers research to approximate this non-negative kernel (Choromanski et al., 2020; Katharopoulos et al., 2020; Peng et al., 2021; Lu et al., 2021). For example, we can choose as positive random features which has the form to achieve unbiased approximation (Choromanski et al., 2020). Alternatively, we can also choose proposed by Katharopoulos et al. (2020).
3.2 The Gradient Descent Process of ICL
Now, we begin to establish the connection between the ICL inference process of a softmax attention layer and gradient descent. We focus on a softmax attention layer in a trained Transformer model, where the parameters have been determined and the input has the form introduced in Section 2.1. Then, after the inference by one attention layer, the query token at position will have the form formulated by Eq (1).
On the other hand, given a specific softmax kernel mapping function that satisfies Eq (7), we can define the dual model for the softmax attention layer as
| (8) |
where is parameters. We assume that the dual model obtains its updated weights after undergoing one step of gradient descent with some loss function . Subsequently, when we take as the test input, we can obtain its test prediction as
We will show that in Eq (1), is strictly equivalent to the above test prediction , which implies that the inference process of ICL involves a gradient descent step on the dual model. This can be illustrated by the following theorem:
Theorem 3.1.
The query token obtained through ICL inference process with one softmax attention layer, is equivalent to the test prediction obtained by performing one step of gradient descent on the dual model . The form of the loss function is:
| (9) |
where is the learning rate and is a constant.
Proof can be found in Appendix A. Theorem 3.1 demonstrates the equivalence between the ICL inference process and gradient descent. Below, we delve into more detailed discussions:
Training Set and Test Input: In fact, once the attention layer has already been trained, that is, has been determined, the demonstration tokens will be used to construct a training set for the dual model. Specifically, the training data has the form where as inputs and as their labels. During training stage, for each input , the dual model outputs its prediction . Then, the loss function Eq (9) can be rewritten as which can be regarded as the cosine similarity. Then, using this loss function and the training data, we can perform one step of Stochastic Gradient Descent (SGD) on the dual model and obtain the updated . Finally, during the testing stage, we take as the test input to get its prediction which will be consistent with the ICL result , that is, . This process can be illustrated in Figure 1. Demonstration tokens provide information about the training data points and the weight matrix is optimized to learn sufficient knowledge about demonstrations. This gradient descent process using the loss function applied to can be seen as the dual form of the ICL inference process of the attention layer.




Representation Learning Lens: Even though we have now clarified the details of the gradient descent process of ICL, what does this process more profoundly reveal to us? In fact, for a encoded demonstration token , the key and value mapping will generate a pair of features and that exhibit a certain distance from each other, akin to positive samples in contrastive learning. And then, projects into a higher-dimensional space to capture deeper features. Finally, the weight matrix , which maps back to the original space, is trained to make the mapped vector as close as possible to . This process is illustrated in Figure 2. Below, we attempt to understand this process from the perspective of existing representation learning methods introduced in Section 2.2, although we emphasize that there are certain differences between them.
Comparison with Contrastive Learning without Negative Samples: If we consider the key and value mapping as two types of data augmentation, then from the perspective of contrastive learning without negative samples, this process can be similarly formalized as
where is naturally applicable because there are no learning parameters involved in the generation process of the representation . However, it’s important to note that the representation learning process of ICL is much simpler: Firstly, the online and target networks are absent while the augmentations are directly used as online and target representations respectively. Secondly, the predictor head is useful and not discarded, which is then used during test stage.
Comparison with Contrastive Kernel Learning: Given an anchor data and its positive and negative samples , , contrastive kernel learning aims to optimize the loss function where . There are significant differences in the representation learning process of ICL: Firstly, it does not involve negative samples. Secondly, there is no corresponding processing for positive samples, leading to parameter updates being solely dependent on the processing of the anchor.
Extension to More Complicated Scenarios: Theorem 3.1 can be naturally extended to one single Transformer layer and multiple attention layers. As for one Transformer layer formed in Section 2.1, its dual model introduces an additional bias and only is trained while remains fixed. In addition, the labels of training set will be where has potential low-rankness property induced by . As for multiple attention layers, the ICL inference process will be equivalent to sequentially performing gradient descent and making predictions on the dual model sequence. We provide more details in Appendix B.
Compared to Dai et al. (2022) considering the connection under linear attention setting, Theorem 3.1 gives explanation for more generally used softmax attention and offers a more detailed exploration of the training process. Additionally, unlike Von Oswald et al. (2023a, b); Ding et al. (2023)’s focus on particular linear regression task and specific configurations of token and parameters, we aim to explain the process of token interactions during ICL inference in a more general setting.
3.3 Generalization Bound of the dual gradient descent process for ICL
In this part, we are interested in the generalization bound of the ICL gradient process. When ICL inference is performed for some task , we cannot provide all demonstrations related to task limited by the length of input tokens. We denote as all possible tokens for the task and assume that these tokens will be selected according to the distribution . During a particular instance of ICL inference, let represent the example tokens we selected. We define the function class as where denotes the Frobenius norm. Generally, ignoring constant term in Eq (9), we consider the representation learning loss as
| (10) |
where and is the distribution for some ICL task . Correspondingly, the empirical loss will be formulated as and we have . In addition, we denote the kernel matrix of demonstration tokens as where , that is, the inner product of the feature maps after projection between the -th token and -th token. We state our theorem as follows:
Theorem 3.2.
Define the function class as and let the loss function defined as Eq (10). Consider the given demonstration set as where and is all possible demonstration tokens for some task . With the assumption that , then for any , the following statement holds with probability at least for any
| (11) |
Proof of 3.2 can be found in Appendix C. Theorem 3.2 provides the generalization bound of the optimal dual model trained on a finite selected demonstration set under a mild assumption that is bounded. Intuitively, as the number of demonstration (and therefore the number of demonstration tokens) increases, the generalization error decreases, which is consistent with existing experimental observations (Xie et al., 2021; Garg et al., 2022; Wang et al., 2024).
4 Attention Modification Inspired by the Representation Learning Lens
Analyzing the dual gradient descent process of ICL from the perspective of representation learning inspires us to consider that: Do existing representation learning methods, especially contrastive learning methods, also involve a dual attention inference process? Alternatively, can we modify the attention mechanism by drawing on existing methods? In fact, since there are lots of mature works in representation learning especially contrastive learning, it is possible for us to achieve this by drawing on these works (He et al., 2020; Chen et al., 2020c; Wu et al., 2018; Chen et al., 2020a; Chen and He, 2021). We will provide some simple perspectives from the loss function, data augmentations and negative samples to try to adjust attention mechanism. It is worth noting that these modifications are also applicable to the self-attention mechanism, and we will explore these variants in experiments. More details can be seen in Appendix D.
Attention Modification inspired by the Contrastive Loss: It can be observed that the unnormalized similarity in Eq (9) allows to be optimized to infinity if we ignore the Layer Normalization (LN) layer to prevent this. As for one single attention layer without LN layer, to address this issue, we can introduce regularization term to constrain the norm of , specifically by
| (12) |
where is a hyperparameter. Equivalently, the attention output Eq (1) will be modified as
| (13) |
This modification is equivalent to retaining less prompt information for query token during aggregation and relatively more demonstration information will be attended to.
Attention Modification inspired by the Data Augmentation: If we analogize the key and value mappings to data augmentations in contrastive learning, then for the representation learning process of ICL, these overly simple linear augmentations may limit the model’s ability to learn deeper representations. Thus, more complicated augmentations can be considered. Denoting these two augmentations as and , the loss function will be modified as
Correspondingly, the attention layer can be adjusted as,
| (14) |
where and will be column-wise here. Here we add augmentations for all tokens instead of only demonstration ones to maintain uniformity in the semantic space. In experiments, we simply select MLP for and . It’s worth noting that here we only propose the framework, and for different tasks, the augmentation approach should be specifically designed to adapt them.
Attention Modification inspired by the Negative Samples: Negative samples play a crucial role in preventing feature collapse in contrastive learning methods while the representation learning process of ICL only brings a single pair of features closer, lacking the modeling of what should be pushed apart, which could potentially limit the model’s ability to learn representations effectively. Therefore, we can introduce negative samples to address this:
where is the set of the negative samples for and is a hyperparameter. Correspondingly, the attention layer is modified as
| (15) |
where . Here we simply use other tokens as negative samples and we emphasize that for specific tasks, an appropriate design of negative samples will be more effective.




5 Experiments
In this section, we design experiments on synthetic tasks to support our findings and more experiments including on more realistic tasks can be seen in Appendix E. The questions of interest are: (i) Is the result of ICL inference equivalent to the test prediction of the trained dual model? (ii) Is it potential to improve the attention mechanism from the perspective of representation learning?
Linear Task Setting: Inspired by Von Oswald et al. (2023a), to validate the equivalence and demonstrate the effectiveness of the modifications, we firstly train one softmax self-attention layer using linear regression tasks. We generate the task by where every element of is sampled from a normal distribution and from uniform distribution . We set and . Then, at each step, we use generated to form the input matrix where the last token will be used as the query token and the label part will be masked, that is, . Here we consider only one query token () and we denote to maintain consistency of notation in Section 2.1. Finally, the attention layer is trained to predict to approximate the true label using mean square error (MSE) loss.
Model Setting: It is worth noting that to facilitate direct access to the dual model, we use positive random features as kernel mapping functions (Performer architecture (Choromanski et al., 2020)) to approximate the standard softmax attention, that is, where . We set the dimension of the random features as to obtain relatively accurate estimation. After training, the weights of the attention layer have been determined. Thus, given specified input , we can construct the dual model and its corresponding training data and test input according to Theorem 3.1.
We perform three experiments under different random seeds for linear regression tasks with the results of one presented in Figure 3. In addition, we also conduct more experiments including these on trigonometric, exponential synthetic regression tasks and more realistic tasks. More details of experiments setting and results can be found in Appendix E. We mainly discuss the results on the linear regression task as follows.
Equivalence Between ICL and Gradient Descent: To answer the first question, we generate the test input using the same method as training and obtain the ICL result of the query token . On the other hand, we use to train the dual model according to Theorem 3.1 and get the test prediction . The result is shown in the left part part of Figure 3. It can be observed that after epochs training on the dual model, the test prediction is exactly equivalent to the ICL inference result by one softmax attention layer, which aligns with our analysis in Theorem 3.1. More detailed experiments can be seen in Appendix E.1.
Analysis on the Modifications: In Section 4, we discussed different modifications to the attention mechanism from perspectives of contrastive loss, data augmentation and negative samples. Here we call these modifications regularized models, augmented models and negative models respectively. More details of modifications for self-attention mechanism can be seen in Appendix D.
For regularized models, we vary different to investigate the impact on pretraining performance under the same setting, as shown in the center left part of Figure 3. It can be observed that when , the regularized models converges to a poorer result while when , the model converges faster and achieves final results comparable to the normal model without regularization (). At least for this setting, this is a little contrary to our initial intention of applying regularization to the contrastive loss where should be positive. We explain it that the appropriate contributes to achieving a full-rank attention matrix as stated in Appendix D, preserving information and accelerating convergence.
For augmented models, we simply choose a single-layer MLP for and as data augmentations to enhance the value and key embeddings respectively in Eq (14) and we choose GELU (Hendrycks and Gimpel, 2016) as the activation function. It can be observed in the center right part of Figure 3 that when we only use , that is, only provide augmentation for keys, the model actually shows slightly faster convergence than other cases. Furthermore, when we use two-layer MLP as as a more complicated augmentation function, the result indicates that although the model initially converges slightly slower due to the increased number of parameters, it eventually accelerates convergence and achieves a better solution. This indicates that appropriate data augmentation indeed have the potential to enhance the capabilities of the attention layer.
For negative models, we select the tokens with the lowest attention scores as negative samples for each token. From Eq (15), we can see that it is equivalent to subtracting a certain value from the attention scores corresponding to those negative samples. We vary the number of negative samples and in Eq (15) and the results are shown in the right part of Figure 3. It can be found that the model has the potential to achieve slightly faster convergence with appropriate settings ( and ). In fact, it can be noted that in the original attention mechanism, attention scores are always non-negative, indicating that some irrelevant information will always be preserved to some extent. However, in the modified structure, attention scores can potentially become negative, which makes the model more flexible to utilize information. Certainly, as we discussed in Section 4, for different tasks, more refined methods of selecting augmentations and constructing negative samples may be more effective and we also leave these aspects for future.
6 Related Work
Since Transformers have shown remarkable ICL abilities (Brown et al., 2020), many works have aimed to analyze the underlying mechanisms (Garg et al., 2022; Wang et al., 2023). To explain how Transformers can learn new tasks without parameter updates given few demonstrations, an intuitive idea is to link ICL with (implicit) gradient updates. The most relevant work to ours is that of Dai et al. (2022), which utilizes the dual form to understand ICL as an implicit fine-tuning (gradient descent) of the original model under a linear attention setting (Aiserman et al., 1964; Irie et al., 2022). They design a specific fine-tuning setting where only the parameters for the key and value projection are updated and the causal language modeling objective is adopted. In this context, they find ICL will have common properties with fine-tuning. Based on this, Deutch et al. (2024) investigate potential shortcomings in the evaluation metrics used by Dai et al. (2022) in real model assessments and propose a layer-causal GD variant that performs better in simulating ICL. As a comparison, our research also uses the dual form to analyze the nonlinear attention layer and explores the specific form of the loss used in the training process. However, we link ICL to the gradient descent performed on the dual model rather than fine-tuning the original model. The former process utilizes a self-supervised representation learning loss formalized as Eq (9) determined by the attention structure itself while performing supervised fine-tuning on the original model is often determined by task-specific training objectives (or manually specified causal language modeling objective Dai et al. (2022)). A more formal and detailed comparison can be found in Appendix F.
Additionally, many other works also link ICL with gradient descent, aiming to explore the Transformer’s ability to perform gradient descent algorithms to achieve ICL (Bai et al., 2023; Schlag et al., 2021). Akyürek et al. (2022) reveal that under certain constructions, Transformer can implement simple basic operations (mov, mul, div and aff), which can be combined to further perform gradient descent. Von Oswald et al. (2023a) provide a simple and appealing construction for solving least squares solutions in the linear attention setting. Subsequently, Zhang et al. (2023a); Ahn et al. (2023); Mahankali et al. (2023) provide theoretical evidence showing that the local or global minima will have a form similar to this specific construction proposed by Von Oswald et al. (2023a) under certain assumptions. These works, both experimentally and theoretically, often focus on specific linear regression tasks () and specific structured input format where each token takes the form consisting of the input part and the label part . In addition, the label part of the final query to be predicted is masked, represented as . Subsequent works have expanded this exploration under more complicated setups, including examining nonlinear attention instead of linear attention(Cheng et al., 2023; Collins et al., 2024), using unstructured inputs rather than structured ones(Xing et al., 2024), and considering casual or autoregressive setting(Ding et al., 2023; Von Oswald et al., 2023b). As a comparison to these works, our work does not target specific tasks like linear regression; therefore, we do not make detailed assumptions about the model weights (simply treated as weights after pre-training) or specific input forms. Instead, we aim to view the ICL inference process from the perspective of representation learning in the dual model. However, we would like to point out that under these specific weight and input settings, an intuitive explanation can also be provided from a representation learning perspective (see Appendix F). We also notice that Shen et al. (2023) experimentally show that there may exist differences between ICL inference in LLMs and the fine-tuned models in real-world scenarios from various perspectives and assumptions used in previous works may be strong. As mentioned earlier, our analysis primarily focus on linking ICL with gradient descent on the dual model of a simplified Transformer rather than fine-tuning the original model. Analyzing more realistic models will also be our future directions.
7 Conclusion and Impact Statements
In this paper, we establish a connection between the ICL process of Transformers and gradient descent of the dual model, offering novel insights from a representation learning lens. Based on this, we propose modifications for the attention layer and experiments under our setup demonstrate their potential. Although we have made efforts in understanding ICL, there are still some limitations in our analysis: (1) our work primarily focuses on the simplified Transformer and the impact of structures like layer normalization, residual connections, and others requires more nuanced analysis; (2) for more tasks and settings, the proposed model modifications may require more nuanced design and validation. We leave these aspects for future exploration. And we believe that this work mainly studies the theory of in-context learning, which does not present any foreseeable societal consequence.
8 Acknowledgements
We sincerely appreciate the anonymous reviewers for their helpful suggestions and constructive comments. This research was supported by National Natural Science Foundation of China (No.62476277, No.6207623), Beijing Natural Science Foundation (No.4222029), CCF-ALIMAMA TECH Kangaroo Fund (No.CCF-ALIMAMA OF 2024008), and Huawei-Renmin University joint program on Information Retrieval. We also acknowledge the support provided by the fund for building worldclass universities (disciplines) of Renmin University of China and by the funds from Beijing Key Laboratory of Big Data Management and Analysis Methods, Gaoling School of Artificial Intelligence, Renmin University of China, from Engineering Research Center of Next-Generation Intelligent Search and Recommendation, Ministry of Education, from Intelligent Social Governance Interdisciplinary Platform, Major Innovation & Planning Interdisciplinary Platform for the “DoubleFirst Class” Initiative, Renmin University of China, from Public Policy and Decision-making Research Lab of Renmin University of China, and from Public Computing Cloud, Renmin University of China.
References
- Ahn et al. [2023] Kwangjun Ahn, Xiang Cheng, Hadi Daneshmand, and Suvrit Sra. Transformers learn to implement preconditioned gradient descent for in-context learning. Advances in Neural Information Processing Systems, 36:45614–45650, 2023.
- Aiserman et al. [1964] MA Aiserman, Emmanuil M Braverman, and Lev I Rozonoer. Theoretical foundations of the potential function method in pattern recognition. Avtomat. i Telemeh, 25(6):917–936, 1964.
- Akyürek et al. [2022] Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models. arXiv preprint arXiv:2211.15661, 2022.
- Amari [1993] Shun-ichi Amari. Backpropagation and stochastic gradient descent method. Neurocomputing, 5(4-5):185–196, 1993.
- Bai et al. [2023] Yu Bai, Fan Chen, Huan Wang, Caiming Xiong, and Song Mei. Transformers as statisticians: Provable in-context learning with in-context algorithm selection. arXiv preprint arXiv:2306.04637, 2023.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Caron et al. [2020] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. Advances in neural information processing systems, 33:9912–9924, 2020.
- Chen et al. [2020a] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020a.
- Chen et al. [2020b] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020b.
- Chen and He [2021] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15750–15758, 2021.
- Chen et al. [2020c] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020c.
- Cheng et al. [2023] Xiang Cheng, Yuxin Chen, and Suvrit Sra. Transformers implement functional gradient descent to learn non-linear functions in context. arXiv preprint arXiv:2312.06528, 2023.
- Choromanski et al. [2020] Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. arXiv preprint arXiv:2009.14794, 2020.
- Collins et al. [2024] Liam Collins, Advait Parulekar, Aryan Mokhtari, Sujay Sanghavi, and Sanjay Shakkottai. In-context learning with transformers: Softmax attention adapts to function lipschitzness. arXiv preprint arXiv:2402.11639, 2024.
- Dai et al. [2022] Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Zhifang Sui, and Furu Wei. Why can gpt learn in-context? language models secretly perform gradient descent as meta optimizers. arXiv preprint arXiv:2212.10559, 2022.
- Deutch et al. [2024] Gilad Deutch, Nadav Magar, Tomer Natan, and Guy Dar. In-context learning and gradient descent revisited. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1017–1028, 2024.
- Ding et al. [2023] Nan Ding, Tomer Levinboim, Jialin Wu, Sebastian Goodman, and Radu Soricut. Causallm is not optimal for in-context learning. arXiv preprint arXiv:2308.06912, 2023.
- Dong et al. [2022] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. A survey for in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- Esser et al. [2024] Pascal Esser, Maximilian Fleissner, and Debarghya Ghoshdastidar. Non-parametric representation learning with kernels. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 11910–11918, 2024.
- Garg et al. [2022] Shivam Garg, Dimitris Tsipras, Percy S Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes. Advances in Neural Information Processing Systems, 35:30583–30598, 2022.
- Grill et al. [2020] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33:21271–21284, 2020.
- Guo et al. [2022] Jianyuan Guo, Kai Han, Han Wu, Yehui Tang, Xinghao Chen, Yunhe Wang, and Chang Xu. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12175–12185, 2022.
- Han et al. [2023] Chi Han, Ziqi Wang, Han Zhao, and Heng Ji. In-context learning of large language models explained as kernel regression. arXiv preprint arXiv:2305.12766, 2023.
- He et al. [2021] Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning. arXiv preprint arXiv:2110.04366, 2021.
- He et al. [2020] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020.
- Hendrycks and Gimpel [2016] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- Irie et al. [2022] Kazuki Irie, Róbert Csordás, and Jürgen Schmidhuber. The dual form of neural networks revisited: Connecting test time predictions to training patterns via spotlights of attention. In International Conference on Machine Learning, pages 9639–9659. PMLR, 2022.
- Katharopoulos et al. [2020] Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. pages 5156–5165, 2020.
- Kenton and Toutanova [2019] Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of naacL-HLT, volume 1, page 2. Minneapolis, Minnesota, 2019.
- Li et al. [2023] Yingcong Li, M. Emrullah Ildiz, Dimitris Papailiopoulos, and Samet Oymak. Transformers as algorithms: Generalization and stability in in-context learning. arXiv preprint arXiv:2301.07067, 2023.
- Liu et al. [2023] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9):1–35, 2023.
- Lu et al. [2021] Jiachen Lu, Jinghan Yao, Junge Zhang, Xiatian Zhu, Hang Xu, Weiguo Gao, Chunjing Xu, Tao Xiang, and Li Zhang. Soft: Softmax-free transformer with linear complexity. Advances in Neural Information Processing Systems, 34:21297–21309, 2021.
- Mahankali et al. [2023] Arvind Mahankali, Tatsunori B Hashimoto, and Tengyu Ma. One step of gradient descent is provably the optimal in-context learner with one layer of linear self-attention. arXiv preprint arXiv:2307.03576, 2023.
- Maurer [2016] Andreas Maurer. A vector-contraction inequality for rademacher complexities. In Algorithmic Learning Theory: 27th International Conference, ALT 2016, Bari, Italy, October 19-21, 2016, Proceedings 27, pages 3–17. Springer, 2016.
- Mercer [1909] J. Mercer. Functions of positive and negative type, and their connection with the theory of integral equations. Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character, 209:415–446, 1909. ISSN 02643952. URL http://www.jstor.org/stable/91043.
- Mohri et al. [2018] Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar. Foundations of machine learning. MIT press, 2018.
- Oh Song et al. [2016] Hyun Oh Song, Yu Xiang, Stefanie Jegelka, and Silvio Savarese. Deep metric learning via lifted structured feature embedding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4004–4012, 2016.
- Oord et al. [2018] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Peng et al. [2021] Hao Peng, Nikolaos Pappas, Dani Yogatama, Roy Schwartz, Noah A Smith, and Lingpeng Kong. Random feature attention. arXiv preprint arXiv:2103.02143, 2021.
- Reid et al. [2023] Isaac Reid, Krzysztof Marcin Choromanski, Valerii Likhosherstov, and Adrian Weller. Simplex random features. In International Conference on Machine Learning, pages 28864–28888. PMLR, 2023.
- Roberts et al. [2019] Adam Roberts, Colin Raffel, Katherine Lee, Michael Matena, Noam Shazeer, Peter J. Liu, Sharan Narang, Wei Li, and Yanqi Zhou. Exploring the limits of transfer learning with a unified text-to-text transformer. Technical report, Google, 2019.
- Saunshi et al. [2019] Nikunj Saunshi, Orestis Plevrakis, Sanjeev Arora, Mikhail Khodak, and Hrishikesh Khandeparkar. A theoretical analysis of contrastive unsupervised representation learning. In International Conference on Machine Learning, pages 5628–5637. PMLR, 2019.
- Schlag et al. [2021] Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber. Linear transformers are secretly fast weight programmers. In International Conference on Machine Learning, pages 9355–9366. PMLR, 2021.
- Shen et al. [2023] Lingfeng Shen, Aayush Mishra, and Daniel Khashabi. Do pretrained transformers really learn in-context by gradient descent? arXiv preprint arXiv:2310.08540, 2023.
- Tian et al. [2021] Yuandong Tian, Xinlei Chen, and Surya Ganguli. Understanding self-supervised learning dynamics without contrastive pairs. In International Conference on Machine Learning, pages 10268–10278. PMLR, 2021.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Von Oswald et al. [2023a] Johannes Von Oswald, Eyvind Niklasson, Ettore Randazzo, João Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. pages 35151–35174, 2023a.
- Von Oswald et al. [2023b] Johannes Von Oswald, Eyvind Niklasson, Maximilian Schlegel, Seijin Kobayashi, Nicolas Zucchet, Nino Scherrer, Nolan Miller, Mark Sandler, Max Vladymyrov, Razvan Pascanu, et al. Uncovering mesa-optimization algorithms in transformers. arXiv preprint arXiv:2309.05858, 2023b.
- Wang [2018] Alex Wang. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
- Wang et al. [2023] Lean Wang, Lei Li, Damai Dai, Deli Chen, Hao Zhou, Fandong Meng, Jie Zhou, and Xu Sun. Label words are anchors: An information flow perspective for understanding in-context learning. arXiv preprint arXiv:2305.14160, 2023.
- Wang et al. [2024] Xinyi Wang, Wanrong Zhu, Michael Saxon, Mark Steyvers, and William Yang Wang. Large language models are latent variable models: Explaining and finding good demonstrations for in-context learning. Advances in Neural Information Processing Systems, 36, 2024.
- Wei et al. [2022] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022.
- Wolf [2019] T Wolf. Huggingface’s transformers: State-of-the-art natural language processing. arXiv preprint arXiv:1910.03771, 2019.
- Wu et al. [2018] Zhirong Wu, Yuanjun Xiong, Stella X Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3733–3742, 2018.
- Xie et al. [2021] Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in-context learning as implicit bayesian inference. arXiv preprint arXiv:2111.02080, 2021.
- Xing et al. [2024] Yue Xing, Xiaofeng Lin, Namjoon Suh, Qifan Song, and Guang Cheng. Benefits of transformer: In-context learning in linear regression tasks with unstructured data. arXiv preprint arXiv:2402.00743, 2024.
- Yu et al. [2016] Felix Xinnan X Yu, Ananda Theertha Suresh, Krzysztof M Choromanski, Daniel N Holtmann-Rice, and Sanjiv Kumar. Orthogonal random features. Advances in neural information processing systems, 29, 2016.
- Zhang et al. [2023a] Ruiqi Zhang, Spencer Frei, and Peter L Bartlett. Trained transformers learn linear models in-context. arXiv preprint arXiv:2306.09927, 2023a.
- Zhang et al. [2023b] Yufeng Zhang, Fengzhuo Zhang, Zhuoran Yang, and Zhaoran Wang. What and how does in-context learning learn? bayesian model averaging, parameterization, and generalization. arXiv preprint arXiv:2305.19420, 2023b.
Appendix A Details of Theorem 3.1
We repeat Theorem 3.1 as follows and provide proof and more discussion for it.
Theorem A.1.
The query token obtained through ICL inference process with one softmax attention layer, is equivalent to the test prediction obtained by performing one step of gradient descent on the dual model . The form of the loss function is:
| (16) |
where is the learning rate and is a constant.
Proof.
The derivative of with respect to should be:
Thus, after one step of gradient descent , the learned will be
| (17) |
where is the initialization of the reference model and is the learning rate. So the test prediction will be
| (18) |
On the other hand, from the perspective of ICL process with one attention layer, with Eq (7) in our mind, we can rewrite Eq (1) as
where we use , , for simplify and is a constant to normalize the equivalent attention block. Further, we expand the above equation to connect the inference process of ICL using softmax attention with the gradient descent as follows
where and are the -th column vetors respectively.
Then, in Eq (18), when setting the initialization and the constant , we will find that
| (19) |
which means is strictly equivalent to . Thus, we have completed our proof. ∎
Given a reference model , by comparing Eq (19) and Eq (4), we can easily observe that the gradient descent on the loss function applied to is the dual form of the inference process of ICL, where , and play the roles of backpropagation signals, training inputs and test inputs respectively. Recalling the form of Eq (4), we can interpret the as the initialization of the weight matrix which provide the information under the zero-shot case while the second part in Eq (19) shows that the demonstration examples in ICL acts as the training samples in gradient descent. The reference model , initialized with , will have test prediction after training. This is also why we refer to it as the dual model of the softmax attention layer. We also note that for different demonstrations, even though the model has the same query input, the different given demonstrations will result in different output results. This is equivalent to the dual model performing gradient descent in different directions from the same initialization.
Appendix B Extensions to more complex scenarios
In Theorem 3.1, we provided the dual form of gradient descent for the ICL of one softmax attention layer. Here, we extend the conclusion to more complex scenarios, including one Transformer layer (attention layer plus one FFN layer) and multiple attention layers.
B.1 Extension to one Transformer Layer
As for one Transformer layer introduced in Section 2.1, we define the new dual model as
| (20) |
We will show that after performing gradient descent on , the test output will be equivalent to . Our theorem is given as follows.
Theorem B.1.
The output of ICL inference process with one Transformer layer, is strictly equivalent to the test prediction of its dual model , where is trained under the loss function formed as
| (21) |
where is the learning rate, is a constant, and will be determined once the specified pre-trained model, demonstrations and query tokens are given.
Proof.
Recalling the proof of Theorem 3.1, we can rewrite Eq (1) as
| (22) |
where is a constant to normalize the attention scores and . Furthermore, will be taken as input for the FFN sublayer and the Eq (2) can be rewritten as
where is a diagonal matrix whose -th diagonal element will be one if otherwise be zero. We need to note that this process is reasonable: for given demonstration and query tokens, once the parameters of the Transformer layer are fixed after training, will be determined implicitly (otherwise, would be a function that varies with these settings). For simplify, we rewrite as
where and . Furthermore, expanding in the above Equation, we get:
| (23) | ||||
On the other hand, we define a reference model:
where is exactly the mapping function satisfying Eq (7) to approximate the softmax kernel. Given the loss formed in Eq (21), we can note that the right part in is exactly the output of this reference model when taking as input, that is,
We can calculate the derivative of with respect to as
Suppose that the weight matrix in the reference model is initialized as , then using one step of stochastic gradient descent (SGD) [Amari, 1993] with learning rate , the weight matrix will be updated as
Compared to Eq (23), we can set , and take as test input. Then, after one step update to , the output of the reference model will be
which implies that if we initialize the reference model with , , then after one step of gradient descent for , the test output of will be identical to the ICL result of one Transformer layer. Thus, we call the reference model with setting , as the dual model corresponding to the ICL inference process. Finally, we complete our proof. ∎
Now, we discuss Theorem B.1 from the following perspectives:
-
•
Training set and test input: In fact, we can observe that the loss function can be seen as the sum of inner products of vector-pairs. In Eq (21), the right vector happens to be the predicted output of the dual model for training input . Correspondingly, the vector on the left can be regarded as the true label . In other words, it can be seen that the dual model performs one step SGD given training set on using the loss :
And then taking as test input, it finally output the prediction , which achieves the ICL result . Compared to Theorem 3.1, after introducing the FFN layer, the main difference is that the labels of the training data become instead of . Additionally, compared to , an extra bias is introduced in the new dual model , which also have a different initialization rather than . We also need to note that in the dual model , only is trained, while remains unchanged after initialization.
-
•
Potential Low-rankness of : Noting that where , , (here we assume that for simplify), the rank of will satisfy
We observe that is a diagonal matrix with elements being zero or one, and its rank is determined by the number of non-zero elements. Here, we can make a mild assumption that we can set . This assumption is quite mild as even for any random square matrix as it will be non-singular with probability 1. In addition, we also assume which is consistent with settings in practice. Therefore, we get , and the upper bound of will be
Thus, we can find that if we want to avoid losing information, should strive to maintain which will be more easily achieved as becomes larger than . Otherwise, is likely to gradually decrease with an increase in the number of Transformer layers. This explains the necessity of setting in practice. In some cases where , meaning that the number of non-zero elements in or positive elements in is less than , the upper bound of will be and the lower bound of will be given as
which implies the rank of will exactly equal to . We should note that this condition, i.e., , is easily satisfied when or when is slightly larger than (for example, in an expected sense). Thus, we conclude that has the potential low-rank property.
-
•
Representation Learning Lens: For a encoded demonstration representation , the key and value projections will generate a pair of feature and to create a certain distance between data representations in space. And then, on the one hand, a potential low-rank transformation is applied to the , attempting to compress some information which increases the difficulty of contrastive learning and forces the model to learn better features; on the other hand, projects into a higher-dimensional space to capture deeper-level features. Finally, we need to train the weight matrix , which maps back to the original space, aiming to make the mapped vector as close as possible to . This interpretation is illustrated in Figure 4.


B.2 Extension to Multiple Attention Layers
In this part , we extend Theorem 3.1 to multiple attention layers. Here we adopt the attention layer based on PrefixLM [Roberts et al., 2019], where the query tokens can compute attention with all preceding tokens (including itself), while for demonstration ones, attention can be computed between themselves, excluding the query tokens. Existing work [Ding et al., 2023] has theoretically and experimentally explained that PrefixLM achieves better results than CasualLM. In this paper, we assume we have only one query token, that is, there is no query input before the considered query token. With the assumption that , to maintain notational simplicity, we use to represent the query token here instead of and the input will be . We assume that there are attention layers and the output of the -th layer can be expressed as:
where we set as the initial input. And the final output of the query token is . Here, we assume that after training, the parameters are fixed and we set .
Next, we extend Theorem 3.1 to the case of multiple softmax attention layers. Formally, we present our result in the following theorem.
Theorem B.2.
Given softmax attention layers whose parameters are fixed after training, the ICL output of these layers is equivalent to sequentially performing one step gradient descent on a sequence of dual models , where the loss function for the -th dual model is:
| (24) |
where is the output of the -th attention layer for the -th token, is the learning rate and is a constant. The input for the -th dual model is generated by the trained -th dual model.

Proof.
Given as the input for the -th attention layer, the inference process of is
where is a constant to normalize the attention scores and . According to Theorem 3.1, we can easily get the dual model where the initialization is . Given the loss function formed as Equation 24 and training set where and , we perform one step SGD with learning rate on weight matrix and will get trained dual model:
Taking test input as , the prediction will exactly equal to .
Next, we will show how to obtain through the trained dual model . And after projections, will constitute the training set as well as the test input for the next dual model .
Keeping the initialized dual model and the trained one in mind, we can compute the demonstration token output () of -th attention layer as
| (25) | ||||
where is a constant to normalize the attention scores for . Therefore, once we obtain the trained dual model , we can use the Eq (25) to get the demonstration token output . These demonstration token outputs, along with the output for query tokens, will together constitute the training set and test input for the next dual model . This process continues layer by layer until we obtain the ultimate ICL output . In summary, the ICL inference process across attention layers is equivalent to performing gradient descent on dual models sequentially. Thus, we complete our proof. ∎
This theorem is a natural extension of Theorem 3.1: when considering the stacking of multiple attention layers, a sequence of dual models is correspondingly generated. Although these dual models have the same form , they have different initializations and datasets. As the ICL inference process progresses layer by layer between attention layers, we equivalently perform gradient descent on the dual models one by one. The input for each attention layer, including demonstration tokens and query tokens, can be obtained from the test output of the dual models. This can be illustrated in Figure 5.
Appendix C Proof of the Generalization bound
C.1 Proof of Theorem 3.2
In this part, we provide the proof regarding the generalization boundary in Theorem 3.2. We restate our theorem as follows:
Theorem C.1.
Define the function class as and let the loss function defined as Eq (10). Consider the given demonstration set as where and is all possible demonstration tokens for some task . With the assumption that , then for any , the following statement holds with probability at least for any
| (26) |
Proof.
Our proof is similar to the Lemma 4.2 in Saunshi et al. [2019], but here we focus on a different function class. Firstly, we consider the classical generalization bound based on the Rademacher complexity of the function class which can refer to Theorem 3.1 in Mohri et al. [2018]. For a real function class whose functions map from a set to and for any , if is a training set composed by iid samples , then with probability at least , for all
| (27) |
where is the traditional Rademacher complexity. By setting exactly the demonstration set and , we can apply this bound to our case.
Then, we construct a function class whose functions map from to . Next, we will first prove and to do this, we need to use the following Lemma:
Lemma C.2 (Corollary 4 in Maurer [2016]).
Let be any set, and . Let be a class of functions and be -Lipschitz. For all , let . Then
| (28) |
where .
We apply Lemma C.2 to our case by setting , to be exactly the demonstration set, to be the function class we constructed and . We also use where and thus we have . We can find that and the left side of inequality (28) is exactly .
Then we can see that is -Lipschitz with the assumption that and we have . Now using Lemma C.2 and the classical generalization bound (27), we have that with probability at least
| (29) |
Let . According to Hoeffding’s inequality, with probability at least , we have that . Combining this with (29), the fact that and applying a union bound, we can get that
| (30) |
Next, we give the upper bound for .
| (Definition of Rademacher complexity) | ||||
| ( is independent of ) | ||||
| (By Cauchy-Schwartz inequality) | ||||
| (Using the fact that ) | ||||
| (By Jensen’s inequality) | ||||
Substituting the upper bound of into (30), we will get that
| (31) |
Thus we finish our proof. ∎
C.2 Extension to negative models:
One may also wonder whether the ratio of negative samples mentioned in Section 4 will affect the generalization bounds. In fact, after introducing negative samples and ignoring constant term in Eq (9), we consider the following representation loss:
where we consider sampling negative samples for each and denotes the -th negative sample for token . Correspondingly, the empirical loss will be considered as where is the -th negative sample for . Then, by retaining the other definitions in Section 3.3, corresponding to Theorem 3.2, we can obtain the generalization bound as
where is excatly the the ratio of the number of negative samples. It can be observed that as the ratio of negative samples increases, the generalization error decreases. However, we also notice that thus the former term dominates, which means the reduction in generalization error due to an increased proportion of negative samples is limited. Nevertheless, we do not rule out the possibility of a tighter generalization bound, which is a promising direction for future research.
Proof Sketch.
The proof process is similar to that of Theorem 3.2. The main difference lies in the fact that we should firstly define the function class to use the classical bound. In addition, we define whose functions map from to . Similarly, when using Lemma C.2, we set , be the above function class and . We also use defined as . Then we notice that
| (32) | ||||
With the assumption that , we can get that the Frobenius norm of the Jocabian of has . Thus we get that is -Lipschitz. The rest of the proof process is similar to that of Theorem 3.2. Ultimately, we will obtain the aforementioned generalization error. ∎
Appendix D Details and More Discussions for Section 4
In this section, we provide a more detailed discussion on improving the model structure from the perspective of representation learning especially contrastive learning, which is presented in Section 4 of the main body. And we also point out the corresponding modifications in the self-attention mechanism, which are adopted in our experiments.
D.1 More Discussion on the Contrastive Loss
Although we have figured out the representation learning loss of the implicit gradient updates, it can be observed that this loss function has a flaw: due to the lack of normalization for and when calculating the cosine distance, the loss can theoretically be optimized to negative infinity. To address this issue, we introduce regularization to constrain the norm of , that is,
where is a hyperparameter to balance the two parts. As a result, we can see that the gradient update for will be in an exponentially smoothed manner meaning that a portion of the initial part will be discarded at every step, that is,
Equivalently, the inference process of ICL can be seen as the first step of the aforementioned update, and the attention mechanism will be correspondingly adjusted as,
which means more demonstration information will be attended to. This will directly result in Eq 13.
This result can be easily extended to self-attention mechanism. As for a self-attention layer, if all other tokens adopt the same modification, the self-attention layer will become
which leads to the model structure incorporating an operation similar to skip connections. Furthermore, to ensure numerical stability, we normalize the attention scores yielding:
where is performed column-wise to ensure that the attention scores sum to . The above modification reduce the attention score of each token to its own information during aggregation. It is worth noting that, although our initial intention is to impose regularization on the contrastive loss where to prevent it from diverging to negative infinity, we find in experiments that this modification remains effective even when is less than . We interpret this as possibly stemming from the fact that an appropriate helps the attention block become full-rank, thereby better preserving information, which can be illustrated by Lemma D.1:
Lemma D.1.
Let the attention block . There exists some such that, for any , the attention block will become full-rank.
Proof.
Define , which is a polynomial of degree in . Then, has only finitely roots. Let be the non-zero roots of . Now, consider . For , we can claim that . Thus, becomes non-singular (full-rank) and we complete the proof. ∎
Lemma D.1 provides one possible case for appropriate . In fact, the selection of can be quite flexible; for instance, similarly, when and holds, also remains full-rank. Our experimental results related to regularized models will further illustrate the effectiveness of an appropriate in enhancing model performance.
We also acknowledge that our modification is relatively straightforward and may not be optimal. However, we believe that it may be a good choice to make structural improvements to the model from the perspective of the loss function, or more generally, from an optimization standpoint. For example, to address the issue of non-normalized and , we can also modify the loss function from the perspective of ridge regression as:
And the optimal will be
Correspondingly, the attention mechanism will be modified to
| (33) |
where we neglect the normalization operation. This result is very similar to the mesa-layer proposed by Von Oswald et al. [2023b], which optimizes linear attention layers under the auto-regressive setting. Here, we presented its form on softmax self-attention setting using kernel methods and explained it from the perspectives of contrastive loss and ridge regression. Although the matrix inversion calculation in Eq (33) can be computationally expensive, effective methods for computing Eq (33), including both forward computation and backward propagation, have been thoroughly researched in Von Oswald et al. [2023b], which contributes to making the above modification practically applicable.
D.2 More Discussion on the Data Augmentation
In addition to discussing the loss function, the contrastive learning paradigm also offers our some insights. In the corresponding representation learning process of ICL, we can easily notice that "data augmentation" is performed using a simple linear mapping, which may be not sufficient for learning deeper-level features. To address this, we can employ more complicated nonlinear functions for more complex augmentations. Denoting these two augmentations as and , consequently, the process of contrastive learning will be modified as follows
Correspondingly, the gradient update for will become
And from the perspective of ICL, correspondingly, the last token will be updated as
And by reformulating the above equation we will get Eq (14) in the main body.
Correspondingly, the modification for self-attention layer can be adjusted as,
where and will be column-wise here. It is worth noting that here we have only presented the framework of using nonlinear functions as data augmentations to modify the self-attention layer and in the simplest case, we can set and as MLPs (Multi-Layer Perceptrons). However, in practice, it is encouraged to use data augmentation functions that are tailored to specific data structures. For example, in the case of CMT [Guo et al., 2022], the used Convolutional Neural Networks (CNNs) can be considered as a form of "strong data augmentations" suitable for image datas within our framework. We consider the exploration of various augmentation methods tailored to different types of data as an open question for future research.
D.3 More discussion on the Negative Samples
Although the gradient descent process corresponding to ICL exhibits some similarities with traditional contrastive learning approaches without negative samples, there are also significant differences: In traditional Siamese networks, the augmented representations as positive pairs are further learned through target and online network that share weights (or at least influence each other using EMA). The output of the target network is then passed through a predictor to compute the contrastive loss. In contrast, the representation learning pattern corresponding to ICL indeed performs more simply, which may potentially limit the ability of the dual model to learn representations fully without negative samples. To address this, similar to most contrastive learning approaches, we can introduce negative samples forcing the model to separate the distances between positive and negative samples at the same time, that is,
where , is the set of the negative samples for and is a hyperparameter. As a result, the gradient descent on will be modified as
Correspondingly, the ICL process for will be
And this will directly result in Eq (15) in the main body.
As for a self-attention layer, similarly, we can get the corresponding modification as
| (34) |
where . In corresponding experiments, for each token, we simply choose other the least relevant tokens as its negative samples, i.e., the tokens with the lowest attention scores. Noting that here we simply use other token representations as negative samples for . However, there are more ways to construct negative samples that are worth exploring (for instance, using noise vectors or tokens with low semantic similarity as negative samples). For specific data structures and application scenarios, customizing the selection or construction of negative samples may be more effective.
Appendix E More Experiments
E.1 More details of Experiments on Linear Task
In this part, we will discuss our experimental setup in more details and provide more results on linear regression task.
Inspired by Garg et al. [2022] and Von Oswald et al. [2023a], we choose to pretrain a softmax attention layer before exploring the equivalence proposed by Theorem 3.1. In fact, pretraining is not mandatory since our theoretical analysis does not depend on any specific weight construction. In other words, the inference results of ICL and the test prediction of the dual model will still remain consistent for an attention layer with arbitrary weights or even random initialization. However, for the convenience of further investigating the impact of subsequent modifications to the model structure and to better align with real-world scenarios, we still opted for pretraining to let the model acquire some task-specific knowledge. Additionally, our experiments are conducted in a self-attention setting. When we focus only on the last token, this is equivalent to considering the case with only one query token () in Section 2.1. The experiments are completed on a single 24GB NVIDIA GeForce RTX 3090 and the experiments can be completed within one day.
For the linear regression task, we generate the task by where every element of is sampled from a normal distribution and is sampled from a Gaussian distribution . To facilitate more accurate estimation of attention matrices using random features and considering the limited learning capacity of a single attention layer, we only set a small value for and . Then, at each step, we use generated to form the input matrix while the label part of the query token is masked to be zero, that is, where we consider only one query token and we denote to maintain consistency of notation in Section 2.1. The softmax attention layer is expected to predict to approximate the ground truth value . We use mean square error (MSE) as the loss function, that is, for each epoch,
where and are the prediction and ground truth value at -th step and is the number of steps. We set for which means the total number of tokens remains . We choose stochastic gradient descent (SGD) [Amari, 1993] as the optimizer and we set the learning rate to 0.003 for normal and regularized models, while the remaining experiments to . We also attempt the multi-task scenario, where the input token at each step is generated from a different task. However, we find it challenging for a single attention layer to effectively learn in this setting, resulting in disordered predictions. Therefore, our experiments are currently limited to single-task settings, and the multi-task scenario is worth further investigation in the future.










It is worth noting that we approximate the attention matrix calculation using random features as kernel mapping function instead of using the traditional softmax function in the self-attention layer [Choromanski et al., 2020]. The mapping function has the form of where . Orthogonal random features [Yu et al., 2016, Choromanski et al., 2020] or simplex random features [Reid et al., 2023] can be chosen to achieve better performance theoretically. We investigate the impact of changing the dimension of random features on the approximation of attention matrices and output, using Mean Squared Error (MSE) and Mean Absolute Error (MAE) as evaluation metrics, where we conduct repeated experiments and calculated the average values for each value of , as shown in Figure 8. It can be observed that as the dimension of random features increases, the approximation performance gradually improves, with both errors reaching a low level in the end. We visualize the exact attention matrix and compare it with the estimated attention matrices obtained using different values of , as shown in Figure 6. Again, it can be seen that as increases, the approximation of the true attention matrix improves gradually and similar results can be observed for the analysis of output matrices in Figure 7.
To obtain a more accurate estimation of the attention matrix, we set the output dimension of the mapping function to be 100 times the input dimension, that is, . Furthermore, we visualize the exact attention matrix and the output with the approximation results, which are shown in the Figure 9. As we can see, although some larger values are not estimated accurately due to the limited dimension of the random features we select, the majority of the information is still estimated comprehensively well. These findings indicate that our choice of using positive random features as mapping functions to estimate the true softmax attention and conduct experiments is relatively feasible.




After the weights , , of the attention layer have been determined, we generate test tokens in the same way where the part of the -th token is also set to be zero and finally input the test tokens into the attention layer to obtain the corresponding predicted . Here, we also use to maintain the notation consistency in Section 2.1.
On the other hand, we construct a dual model where is strictly equivalent to the kernel mapping function used in the attention layer. We transform the first tokens as the training set according to Theorem 3.1 and train the dual model using the loss formed by Eq (9). In fact, according to Theorem 3.1, after we perform one step of gradient descent on this training set, the test prediction of the dual model will strictly equal .
We conduct experiments under the same setup using different random seeds to explore the effects of various model modifications. The data for all three experiments are generated under identical conditions. One set of experimental results is presented in the main text, while the results of the other two sets are shown in the Figure 10. Similar to the discussion in the main text, we can achieve better performance than the normal model with appropriate parameter settings.





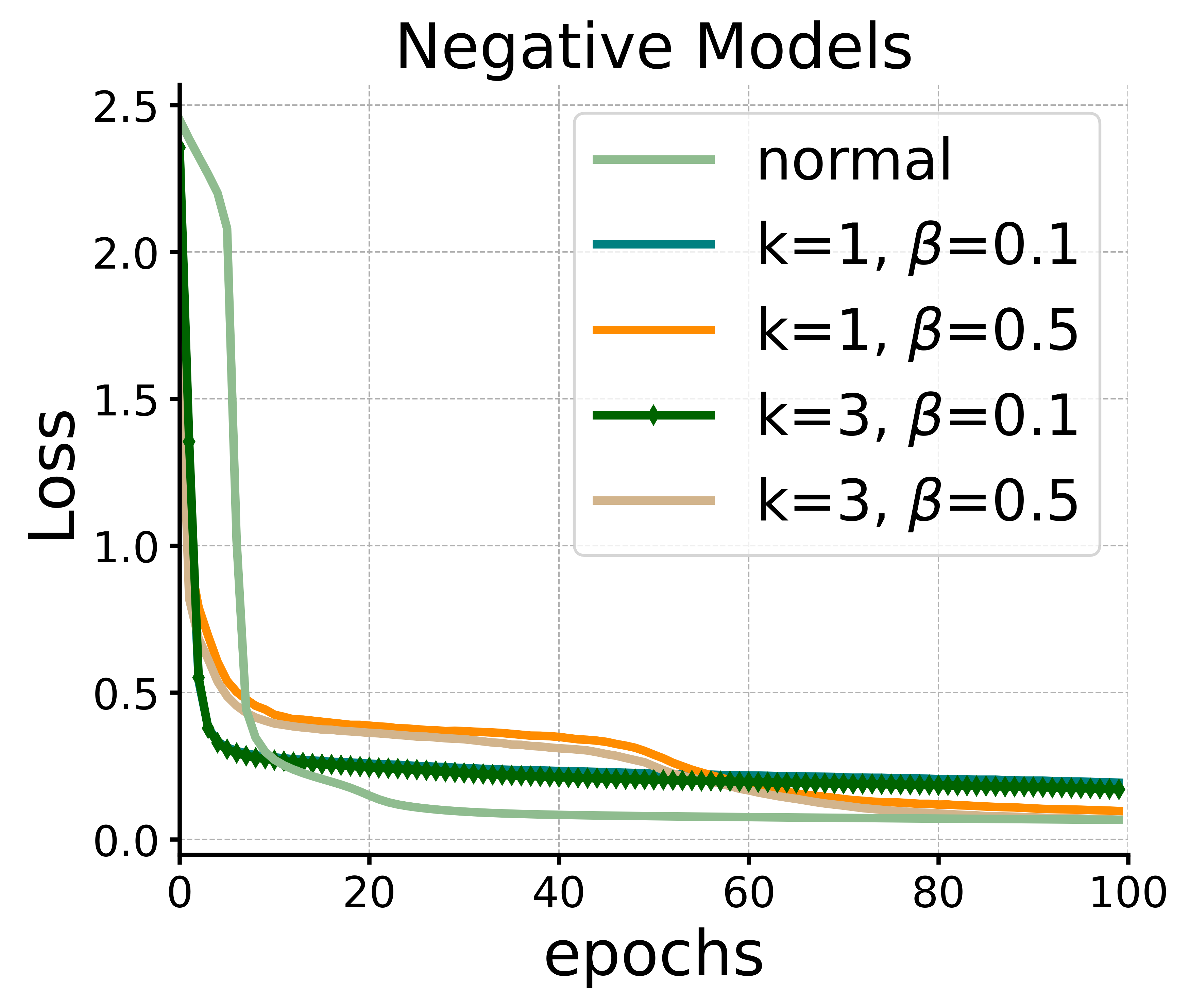
E.2 More details of Experiments on Different Tasks
In addition to conducting experiments on linear regression tasks, we also extended our experiments to involve trigonometric and exponential tasks.
E.2.1 More details of Experiments on Trigonometric Tasks




For trigonometric task, we generate the task by where is element-wise, is sampled from the normal distribution while is sampled from the uniform distribution . In experiments, we found that for one softmax attention layer, learning higher-dimensional tasks is challenging. Therefore, we only set and . At each step, we use tokens and the total number of tokens remains unchanged at . Compared to the setting of linear tasks, we observed that for more complex tasks, the attention layer needs to use more tokens to provide information at each training step. Similarly, we mask the label part of the last token, that is, and use mean square error (MSE) loss to train the attention layer. We choose SGD as the optimizer and the learning rate is set as 0.005. The rest of the settings remain consistent with those used in the linear task. The result for trigonometric regression task is shown in Figure 11.
Firstly, as shown in the left part of Figure 11, the inference results is of ICL is strictly equivalent to the prediction of the dual model, that is, as well as the label part , aligning with our analysis in Theorem 3.1.
The performance of modified model during training process can be seen in the remaining parts of Figure 11. For regularized models, as seen in the center left part of figure 11, the models when converge slightly faster and reach better final results compared to the normal model (). For augmented models, we use as the same augmentation functions and as the ones in the linear regression task, that is, where is activation function. However, for , we use as the activation function. We can find from the center right part of Figure 11 that, compared to the normal model, using alone and using and simultaneously as data augmentations significantly degrade the model’s performance, including convergence speed and final results. However, using alone yields comparable result with the normal model. Particularly, when using , the model accelerates its convergence speed. However, for negative models, the performance with the selected number of negative samples and the parameter is worse than the normal model, which suggests that our simple approach of selecting those tokens low attention scores as negative samples is not a reasonable method. Just as we discussed in Section 4, for different tasks, a more refined strategy for selecting negative samples should be considered.
E.2.2 More details of Experiments on Exponential Tasks



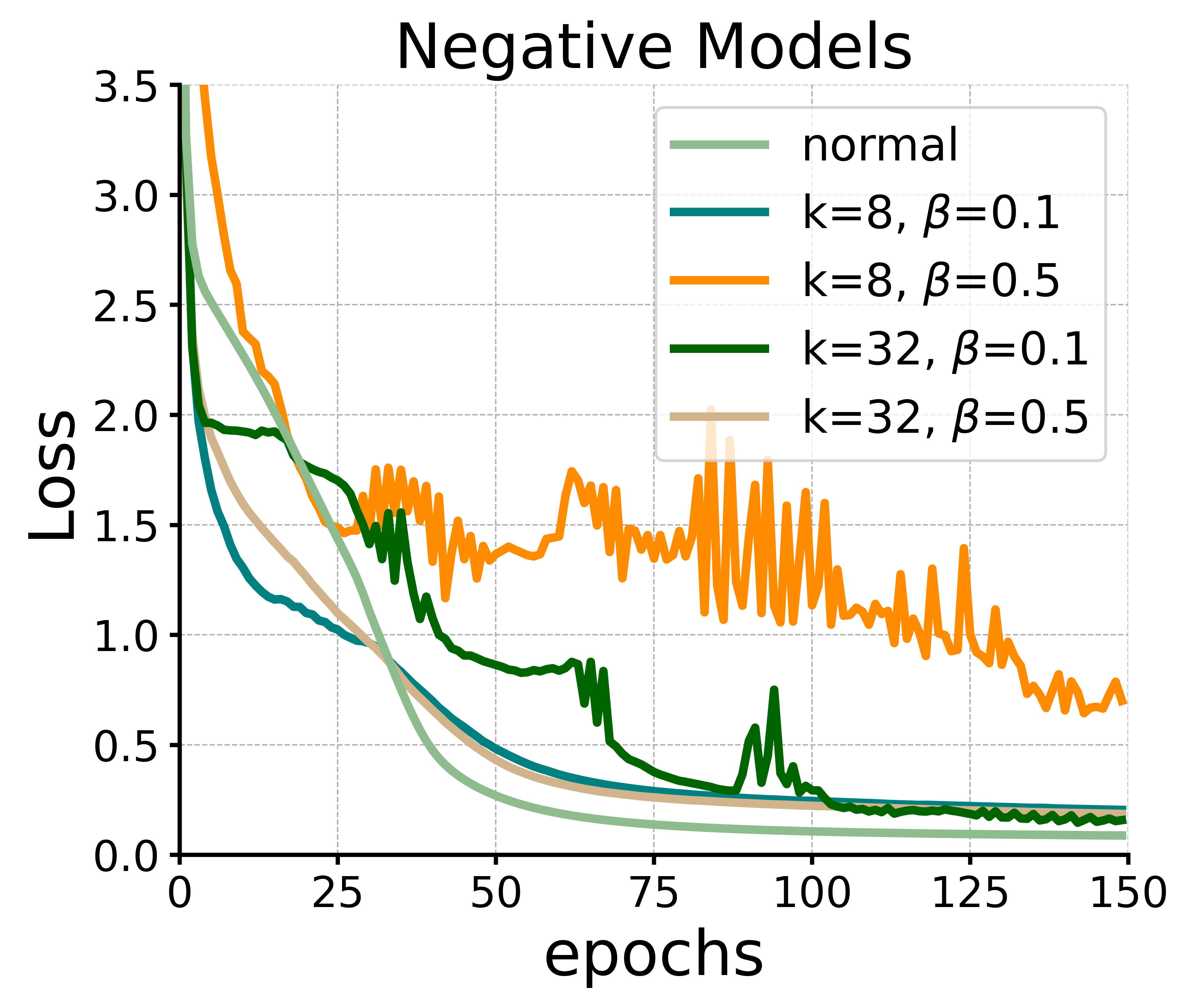
For exponential task, we generate the task by where is also element-wise, is sampled from the normal distribution while is sampled from the uniform distribution . We only set and considering the limited learning capacity of one softmax attention layer. At each training step, we use tokens and the total number of tokens remains unchanged at . Compared to the setting of linear tasks and of trigonometric tasks, we also find that for exponential tasks, the attention layer needs more tokens to provide in-context information at each training step. The rest of the settings remain consistent with those used in the trigonometric task. The result for exponential regression task is shown in Figure 12.
Similarly, as shown in the left part of Figure 12, the result of ICL inference is equivalent to the test prediction of the dual model after training, just as stated in Theorem 3.1. For regularized models, it can be observed that when , the model converges faster and achieves better result. For augmented models, using or alone as data augmentations results in better performance. However, when both and are used simultaneously, the training process becomes unstable, so we did not show it in the center right part of Figure 12. For negative model, similar to the case in the trigonometric task, the different combinations of negative samples’ number and parameter do not show a significant improvement over the normal model, highlighting the importance of the strategy for selecting negative samples. We leave the exploration of a more refined negative sample selection strategy when facing various tasks for future consideration.
E.3 More Experiments on Combinations
In addition, we also conduct experiments with their combinations on linear tasks, trigonometric tasks , and exponential tasks. The results are shown in Figure 13. For linear tasks, a combination of regularized and augmented modifications is sufficient. However, for the other two tasks, the results are actually worse than using regularized or augmented modification individually (compared to Figures 11 and 12). We think this may be due to the ineffective selection of negative samples, which is amplified when combined. Therefore, when the design of augmentation or negative sample improvement methods is not effective, we recommend using a single modification method.
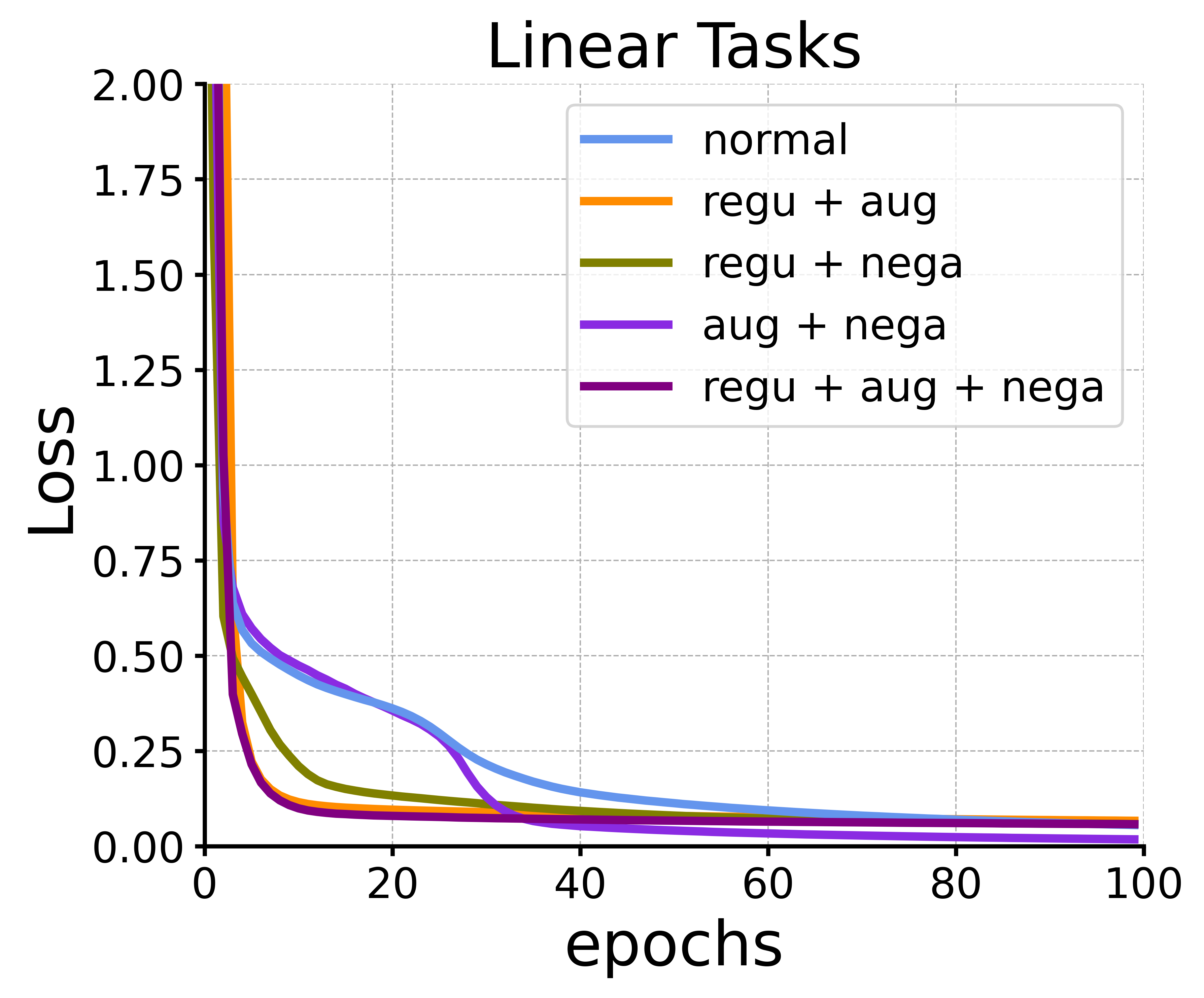


E.4 More Experiments on One Transformer Layer

Similar to the experiments with one softmax attention layer, we also conduct experiments on a Transformer layer (introducing one FFN layer after the attention layer) and trained its dual model based on Theorem B.1. As shown in Figure 14, the inference result of ICL remains equivalent to the test prediction of the trained dual model. Furthermore, to validate the potential low-rank property of matrix , we explore its upper bound of rank. Noting that where , , , the upper bound of is
where is equivalent to the number of non-zero elements in . We fix while varying the values of . We generate 1024 sets of for different tasks and repeat the experiments 5 times. Finally, we calculate the average upper bound of the rank of . The results are shown in the right part of Figure 14, indicating that when , the upper bound remains stable and equals . Otherwise, when is set to a smaller value, exhibits clear low-rank property.
E.5 More Experiments on More Realistic NLP Tasks
| Model Types | Dataset | CoLA | MRPC | STS-B | RTE |
| Normal | Bert-base-uncased | 56.82 | 90.24/86.27 | 88.29/87.96 | 68.23 |
| 0.0 | 79.01/68.87 | 57.23/60.16 | 52.71 | ||
| 61.42 | 83.17/74.02 | 85.28/85.22 | 57.04 | ||
| 58.06 | 89.50/85.05 | 88.71/88.27 | 65.70 | ||
| 58.34 | 90.59/86.76 | 88.12/87.81 | 64.98 | ||
| 27.01 | 83.56/73.28 | 85.25/85.03 | 59.93 | ||
| 0.0 | 81.22/68.38 | 52.07/55.60 | 47.29 | ||
|
Regularized
Models |
Local Best | 61.42 | 90.59/86.76 | 88.71/88.27 | 65.70 |
|
Augmented
Models |
/ | 59.85 | 88.11/83.33 | 88.56/88.22 | 68.59 |
| / | 56.51 | 90.88/87.01 | 88.96/88.60 | 71.12 | |
| / | 56.29 | 87.65/82.60 | 88.60/88.24 | 68.59 | |
| / | 58.85 | 87.74/82.60 | 88.68/88.32 | 70.40 | |
| / | 57.32 | 89.62/85.29 | 88.48/88.19 | 71.12 | |
| / | 58.30 | 90.40/86.52 | 88.83/88.45 | 68.95 | |
| Local Best | 59.85 | 90.88/87.01 | 88.96/88.60 | 71.12 | |
|
Negative
Models |
/ | 56.22 | 88.54/83.82 | 88.25/87.91 | 65.34 |
| / | 57.92 | 90.00/85.78 | 88.22/87.84 | 66.06 | |
| / | 57.92 | 89.31/84.80 | 88.26/87.90 | 67.15 | |
| / | 58.92 | 87.90/83.33 | 88.34/88.11 | 63.54 | |
| / | 57.13 | 87.87/83.09 | 88.59/88.27 | 64.98 | |
| / | 58.14 | 88.97/84.56 | 88.64/88.33 | 66.79 | |
| Local Best | 58.92 | 90.00/85.78 | 88.64/88.33 | 67.15 | |
|
Combined
Models |
Reg & Aug | 56.56 | 88.54/83.82 | 88.86/88.60 | 68.59 |
| Reg & Neg | 58.11 | 88.19/83.33 | 88.41/88.17 | 69.31 | |
| Aug & Neg | 59.07 | 90.49/86.76 | 88.59/88.21 | 70.76 | |
| Reg & Aug & Neg | 58.92 | 88.39/83.58 | 88.32/88.01 | 67.87 | |
| Local Best | 59.07 | 90.49/86.76 | 88.86/88.60 | 70.76 | |
| Global Best | 61.42 | 90.88/87.01 | 88.96/88.60 | 71.12 | |
We supplement our experiments on more more realistic NLP tasks. We choose the BERT-base-uncased model (can be downloaded from Huggingface library[Wolf, 2019], hereafter referred to as BERT[Kenton and Toutanova, 2019]) to validate the effectiveness of modifications to the attention mechanism and select four relatively smaller GLUE datasets (CoLA, MRPC, STS-B, RTE) [Wang, 2018]. We load the checkpoint of the pre-trained BERT model, where ’classifier.bias’ and ’classifier.weight’ are newly initialized, and then we fine-tune the model to explore the performance of three attention modifications as well as their combinations. In terms of more detailed experiment settings, we set the batch size to 32, the learning rate to 2e-5, and the number of epochs to 5 for all datasets. All experiments are conducted on a single 24GB NVIDIA GeForce RTX 3090. All experimental results are presented in Table 1. Below, we discuss the various modifications and their performance.
For the regularized modification, we consider different values of , specifically selected from . As can be observed in Table 1, except for RTE, the best regularized models outperform the original model on the other three datasets. However, we also note that when the absolute value of is too large, the model’s performance declines significantly, so we recommend using smaller absolute values for .
For the augmented modification, we also consider applying more complex “augmentation” functions to the linear key/value mappings. However, unlike the previous methods used in simulation tasks, we do not simply select and as MLPs, i.e., . This design is avoided because it could undermine the effort made during pre-training to learn the weights and , leading to difficulties in training and challenges in comparison. Instead, we adopt a parallel approach, i.e., , where is a hyperparameter to control the influence of the new branch, is the GELU activation function and the hidden layer dimension is set to twice the original size of . follows the same format.
Experimental results show that the best augmented models achieve better performance than the original model across all four datasets. Notably, augmentation on the value mapping (i.e., using alone) proves to be more effective than other methods, both in terms of performance and the amount of additional parameters introduced. Using both and introduces more parameters, which is particularly undesirable for larger models. Thus, under the augmentation methods and experimental settings we selected, using alone is recommended.
In addition, we do not rule out the possibility of more powerful and efficient augmentation methods. Our choice of and as parallel MLPs is primarily motivated by the desire to make better use of the pre-trained weights and . We have also noticed that this specific augmentation function design is structurally similar to the Parallel Adapter [He et al., 2021]. However, we would like to emphasize that our parallel design is just a specific case within this broader augmented modification framework and this is a new perspective for understanding the Parallel Adapter. As for practical implementation, the Parallel Adapter method focuses more on efficient training, so it uses fewer parameters, and the original and are freezed—only the newly introduced parameters are trained. In contrast, our approach aims to validate the benefits of introducing stronger nonlinear augmentation functions into the linear value/key mappings. Therefore, we set a higher hidden layer dimension (twice that of or ) and also train and simultaneously. This design is relatively general and does not take into account the specific characteristics of individual tasks. We still encourage the development of more task-specific augmentation strategies tailored to different tasks.
For the negative modification, we continue to select tokens with lower attention scores as negative samples. The parameter represents the proportion of tokens used as negative samples, while indicates the overall reduction in attention scores. We choose from and from . Under these combinations, the best negative models only outperform the original model on CoLA and STS-B, whereas their performance on MRPC and RTE is worse than the original one. This suggests that our simple approach of considering tokens with low attention scores as negative samples might be too coarse. A more effective method for constructing negative samples should be designed, which is a direction worth exploring in the future.
We also consider combining different modification methods. Specifically, we choose , and respectively as the basis for combining the three types of modifications, considering their overall performance across all datasets. The results indicate that under our settings, the combination of augmented and negative modification achieves the best performance on CoLA, MRPC, and RTE, while the combination of regularized and augmented modification achieves the best performance on STS-B. However, their optimal performance is slightly inferior to the best performance achieved with augmented models alone. Therefore, we conclude that using all three modifications simultaneously is not necessary. With appropriate hyperparameter choices, using augmented modification alone or in combination with one other modification is sufficient.
Overall, the experimental results show that our modifications inspired by the representation learning process are helpful in enhancing performance. This further validates the potential of our approach of thinking about and improving the attention mechanism from a representation learning perspective. In addition, we would like to reiterate that more validation across additional tasks and models, and the development of task-specific augmentation and negative sampling methods are all interesting directions worth exploring in the future.
Appendix F More Details about Related Work
In this section, we provide additional details about the related work in Section 6, especially those that involve formalization. Dai et al. [2022] interpret ICL as implicit fine-tuning: More specifically, let where denotes the demonstration tokens and be query tokens. On the one hand, for ICL, they consider the output of under the linear attention setting as
where is interpreted as the output in the zero-shot learning (ZSL) where no demonstrations are given. On the other hand, they consider a specific fine-tuning setting, which updates only the parameters for the key and value projection, that is,
where and denote the parameter updates and they are acquired by back-propagation from task-specific training objectives [Dai et al., 2022], which is a supervised learning process of the original model. Considering the similarity in form between and , their focus is on establishing a connection between ICL and implicit fine-tuning on the original model.
As a comparison, we turn our attention to establish a connection between ICL and the gradient descent process of the dual model, rather than the original model. More specifically, we consider the dual model of the nonlinear attention layer, where the weight are updated according to the following loss (presented as Eq (9) in Section 3.2):
where is the -th demonstration token. The prediction output of the trained dual model will be consistent with the ICL output of the attention layer. The gradient descent process of the dual model using this loss can be viewed from a self-supervised learning lens: unlike in supervised fine-tuning, where the original model is instructed to perform gradient descent using a given objective (loss), this loss formed as Eq (9) is determined (derived) by the attention mechanism itself and it also does not require additional "true label" to supervise each token (so called self-supervised). Therefore, modifications to this self-supervised learning loss will in turn cause modifications in the attention mechanism correspondingly, as we discussed in our work in Section 4. We believe this perspective offers several benefits:
-
•
By analyzing from the dual perspective, we can transform the forward inference process into an optimization process. Since optimization processes are well-known and have established theoretical tools (for example, generalization error as mentioned in Section 3.3), this transformation can provide reverse insights into analyzing the model mechanisms.
-
•
It can clearly observed that the dual model involves a self-supervised representation learning process from the dual perspective. Considering that there are lots of mature works in this area, we can draw on these works to reflect on the attention mechanism, which has also inspired attention modifications as illustrated in Section 4.
-
•
Intuitively, this explanation might be also reasonable as the original model is not explicitly instructed to provide the answer under some given objective (e.g., minimizing cross-entropy) during ICL inference process. Instead, the underlying criterion should be determined by the model’s own structure (self-supervised) as we mentioned above.
In addition, although we do not target specific tasks like linear regression as previous works mentioned in Section 6, we would like to point out that under those specific weight and input settings, an intuitive explanation can also be provided from a representation learning perspective. Here, we take the linear regression task as well as the weight constructions considered by Von Oswald et al. [2023a] as an example. Specifically, it assumes that the structured input is where is sampled from some linear task and the query token will be . And the considered linear self-attention layer will take the constructed weights and query output as:
| (35) | ||||
where is the underlying initial matrix. Then the label part of will has the form as , which is equivalent to the output (multiplied by ) of the linear layer where is initialized as after performing one step of gradient descent under mean squared loss .
In practice, the underlying initial weight matrix is set to be approximately thus the test input can be formed as [Von Oswald et al., 2023a]. In addition, when reading out the label , the test prediction will be multiplied again by , which can be done by a final projection matrix (or equivalently, ). In this case, we first note that the dual model of the linear attention layer can be written as where and similar to Eq (9), it will be trained under the loss below:
| (36) |
By substituting the corresponding weights in Eq (35) where we replace for the readout, the loss can be reformulated as:
| (37) |
Recalling that is sampled from some linear task , we assume that , it can then be easily seen that the optimal solution for Eq (37) will be
| (38) |
Furthermore, similar to Section 3.2, we take as the input where is constructed as Eq (35) and , the optimal dual model will output the result where the label part will be just the answer for the test query. Additionally, it would also be interesting to explore how these weights converge to the constructed form in Eq (35) or other forms under this special setting as previous works illustrated from the perspective of the dual model. Investigating this issue goes beyond the scope of this paper, and we will leave it for future exploration.