Towards Robust Out-of-Distribution
Generalization Bounds via Sharpness
Abstract
Generalizing to out-of-distribution (OOD) data or unseen domain, termed OOD generalization, still lacks appropriate theoretical guarantees. Canonical OOD bounds focus on different distance measurements between source and target domains but fail to consider the optimization property of the learned model. As empirically shown in recent work, the sharpness of learned minima influences OOD generalization. To bridge this gap between optimization and OOD generalization, we study the effect of sharpness on how a model tolerates data change in domain shift which is usually captured by "robustness" in generalization. In this paper, we give a rigorous connection between sharpness and robustness, which gives better OOD guarantees for robust algorithms. It also provides a theoretical backing for "flat minima leads to better OOD generalization". Overall, we propose a sharpness-based OOD generalization bound by taking robustness into consideration, resulting in a tighter bound than non-robust guarantees. Our findings are supported by the experiments on a ridge regression model, as well as the experiments on deep learning classification tasks.
1 Introduction
Machine learning systems are typically trained on a given distribution of data and achieve good performance on new, unseen data that follows the same distribution as the training data. Out-of-Distribution (OOD) generalization requires machine learning systems trained in the source domain to generalize to unseen data or target domains with different distributions from the source domain. A myriad of algorithms (Sun & Saenko, 2016; Arjovsky et al., 2019; Sagawa et al., 2019; Koyama & Yamaguchi, 2020; Pezeshki et al., 2021; Ahuja et al., 2021) aim to learn the invariant components along the distribution shifting. Optimization-based methods such as (El Ghaoui & Lebret, 1997; Duchi & Namkoong, 2018; Liu et al., 2021; Rame et al., 2022) focus on maximizing robustness by optimizing for worst-case error over an uncertainty distribution set. While these methods are sophisticated, they do not always perform better than Empirical Risk Minimization (ERM) when evaluated across different datasets (Gulrajani & Lopez-Paz, 2021; Wiles et al., 2022). This raises the question of how to understand the OOD generalization of algorithms and which criteria should be used to select models that are provably better (Gulrajani & Lopez-Paz, 2021). These questions highlight the need for more theoretical research in the field of OOD generalization (Ye et al., 2021).
To characterize the generalization gap between the source domain and the target domain, a canonical method (Blitzer et al., 2007) from domain adaptation theory decouples this gap into an In-Distribution (ID) generalization and a hypothesis-specific Out-of-Distribution (OOD) distance. However, this distance is based on the notion of VC-dimension (Kifer et al., 2004), resulting in a loose bound due to the large size of the hypothesis class in the modern overparameterized neural networks. Subsequent works improve the bound based on Rademacher Complexity (Du et al., 2017), whereas Germain et al. (2016) improves the bound based on PAC-Bayes. Unlike the present paper, these works did not consider algorithmic robustness, which has natural interpretation and advantages for distribution shifts In this work, we consider algorithmic robustness to derive the OOD generalization bound. The key idea is to partition the input space into non-overlapping subspaces such that the error difference in the model’s performance between any pair of points in each subspace is bounded by some constant . Within each subspace, any distributional shift is considered subtle for the robust model thus leading to less impact on OOD generalization. Figure 1 illustrates this with the two distributions where the target domain has a distributional shift from the source domain. Compared to existing non-robust OOD generalization bounds Zhao et al. (2018), our new generalization error does not depend on hypothesis size, which is more reliable in the overparameterized regime. Our goal is to measure the generalizability of a model by considering how it is robust to this shift and achieves a tighter bound than existing works.

Although robustness captures the tolerance to distributional shift, it is intractable to compute robustness constant due to the inaccessibility of target distribution. The robustness definition in Xu & Mannor (2012) indicates that the loss landscape induced by the model’s parameters is closely tied to its robustness. To gain a deeper understanding of robustness, we further study the learned model from an optimization perspective. As shown in (Lyu et al., 2022; Petzka et al., 2021), when the loss landscape is "flat", there is a good generalization, which is also observed in OOD settings (Izmailov et al., 2018; Cha et al., 2021). However, the relationship between robustness and this geometric property of the loss landscape, termed Sharpness, remains an open question. In this paper, we establish a provable dependence between robustness and sharpness for ReLU random neural network classes. It allows us to replace robustness constant with the sharpness of a learned model which is only computed from the training dataset that addresses the problem mentioned above. Our result of the interplay between robustness and sharpness can be applied to both ID and OOD generalization bounds. We also show an example to generalize our result beyond our assumption and validate it empirically.
Our main contributions can be summarized as follows:
-
•
We proposed a new framework for Out-of-distribution/ Out-of-domain generalization bounds. In this framework, we use robustness to capture the tolerance of distribution shift which leads to tighter upper bounds generally.
-
•
We reveal the underlying connection between the robustness and sharpness of the loss landscape and use this connection to enrich our robust OOD bounds under one-hidden layer ReLU NNs. This is the first optimization-based bound in Out-of-Distribution/Domain generalization.
-
•
We studied two cases in ridge regression and classification which support and generalize our main theorem well. All the experimental results corroborate our findings well.
2 Preliminary
Notations
We use to denote the integers set . We use to denote the -norm (Euclidean norm). In vector form, denotes the -th instance while the is the -th element of the vector and we use for the element-wise absolute value of vector . We use for the training set size and input dimension. is the Big-O notation.
2.1 Problem formulation
Consider a source domain and a target domain of the OOD generalization problem where we use , to represent the source and target distribution respectively. Let each be the probability measure of sample from sample space with . In the source domain, we have a training set while the target is to learn a model with and parameters where generalizes well. Given loss function , which is for short, the expected risk over the source distribution will be
We use as the shorthand. The OOD generalization is to measure between target domain expected risk and the source domain empirical risk which involves two parts: (1) In-domain generalization error gap between empirical risk and expected risk in the source domain. (2) Out-of-Domain distance between source and target domains. A model-agnostic example in Zhao et al. (2018) gave the following uniform bound:
Proposition 2.1 (Zhao et al. Zhao et al. (2018) Theorem 2 & 3.2).
With hypothesis class and pseudo dimension , unlabeled empirical datasets from source and target distribution and with size each, then with probability at least , for all ,
where and is the XOR operator. Specific form of is defined in Appendix C.6.
2.2 Algorithmic robustness
Definition 2.2 (Robustness, Xu & Mannor (2012)).
A learning model on training set is -robust, for , if can be partitioned into disjoint sets, denoted by , such that we have
This definition captures the robustness of the model in terms of the input. Within each partitioned set , the loss difference between any sample belonging to and training sample will be upper bounded by the robustness constant . The generalization result given by Xu & Mannor (2012) provides a framework to bound the empirical risk with algorithmic robustness which has been stated in Appendix C. Based on this framework, we are able to reframe the existing OOD generalization theory.
3 Main Results
In this section, we propose a new Out-of-Distribution (OOD) generalization bound for robust algorithms that have not been extensively studied yet. We then compare our result to the existing domain shift bound in Proposition 2.1 and discuss its implications for OOD and domain generalization problems by considering algorithmic robustness. To further explain the introduced robustness, we connect it to the sharpness of the minimum (a widely concerned geometric property in optimization) by showing a rigorous dependence between robustness and sharpness. This interplay will give us a better understanding of the OOD generalization problem, and meanwhile, provide more information on the final generalization bound. Detailed assumptions are clarified in Appendix B.1.
3.1 Robust OOD Generalization Bound
The main concern in OOD generalization is to measure the domain shift of a learned model. However, existing methods fail to consider the intrinsic property of the model, such as robustness. Definition 2.2 gives us a new robustness measurement to the model trained on dataset where the training set is a collection of i.i.d. data pair sampled from source distribution with size . The measurement provides an intuition that if a test sample from the target domain is similar to a specific group of training samples, their losses will be similar as well. In other words, the model’s robustness is a reflection of its ability to generalize to unseen data. Our first theorem shows that by utilizing the "robustness" measurement, we can more effectively handle domain shifts by setting a tolerance range for distribution changes. This robustness measurement, therefore, provides a useful tool for addressing OOD generalization.
Theorem 3.1.
Let be the empirical distribution of size drawn from . Assume that the loss is upper bounded by M. With probability at least (over the choice of the samples ), for every trained on satisfying -robust, we have
| (1) |
where the total variation distance for discrete empirical distributions is defined by:
| (2) |
and are the number of samples from and that fall into the set , respectively.
Remark.
The result can be decomposed into in-domain generalization and out-domain distance (please refer to Lemma C.1). Both of them depend on robustness .
See proof in Appendix C. The last three terms on the RHS of (1) are distribution distance, robustness constant, and error term, respectively. Unlike traditional distribution measures, we partition the sample space and the distributional shift separately in the sub-groups instead of measuring it point-wisely. We argue that the can be zero measure if all small changes happen within the same partition where a 2D illustrative case is shown in Figure 1. Under the circumstances, our distribution distance term will be significantly smaller than Proposition 2.1 as the target distribution is essentially a perturbation of the source distribution. As a robust OOD generalization measure, our bound characterizes how robust the learned model is to negligible distributional perturbations. To prevent a bound that expands excessively, we also propose an alternate solution tailored for non-robust algorithms () as follows.
Corollary 3.2.
If , the domain shift bound can be replaced to the distribution distance in Proposition 2.1 where
| (3) |
where the pseudo dimension .
The proof is in Appendix C.1. As dictated in Theorem 3.1, when , the use infinite number of partitions on the data distribution leads to meaningless robustness. However, Eq. 25 suggests that our bound can be replaced by in the limit of infinite . This avoids computing a vacuous bound for non-robust algorithms. In summary, Theorem 3.1 presents a novel approach for quantifying distributional shifts by incorporating the concept of robustness. Our framework is particularly beneficial when a robust algorithm is able to adapt to local shifts in the distribution. Additionally, our data-dependent result remains valid and useful in the overparameterized regime, since does not depend on the model size.
3.2 Sharpness and Robustness
Clearly, robustness is inherently tied to the optimization properties of a model, particularly the curvature of the loss landscape. One direct approach to characterize this geometric curvature, referred to as "sharpness," involves analyzing the Hessian matrix (Foret et al., 2020; Cohen et al., 2021). Recent research (Petzka et al., 2021) has shown that the concept of “relative flatness", the sharpness in this paper, has a strong correlation with model generalization. However, the impact of relative flatness on OOD generalization remains uncertain, even within the convex setting. To address this problem, we aim to investigate the interplay between robustness and sharpness. With the following definition of sharpness, we endeavor to establish an OOD generalization bound rooted in optimization principles.
Definition 3.3 (Sharpness, Petzka et al. (2021)).
For a twice differentiable loss function , with a sample set , the sharpness is defined by
| (4) |
where is the Hessian matrix of loss w.r.t. with hypothesis set and input set .
As per Eq. 4, sharpness is characterized by the sum of all the eigenvalues of the Hessian matrix, scaled by the parameter norm. Each eigenvalue of the Hessian reflects the rate of change of the loss derivative in the corresponding eigenspace. Therefore the smaller value of indicates a flatter minimum. In Cha et al. (2021), they suggest that flatter minima will improve the OOD generalization, but fail to deliver an elaborate analysis of the Hessian matrix. In this section, we begin with the random ReLU Neural Networks parameterized by where is the trainable parameter. Let , the whole function class is defined as
| (5) |
where is the ReLU activation function and are random vectors uniformly distributed on -dim hypersphere whose surface is a manifold. We then define any convex loss function . The corresponding empirical minimizer in the source domain will be: With , we are interested in loss geometry over the sample domain ( for short). Intuitively, a flatter minimum on the loss landscape is expected to be more robust to varying input. Suppose the sample space can be partitioned into disjoint sets. For each set , the loss difference is upper bounded by . Given , we have
| (6) |
As an alternative form of robustness, the in (6) captures the "maximum" loss difference between any two samples in each partition and depends on the convexity and smoothness of the loss function in the input domain. Given a training set and any initialization , the robustness of a learned model will be determined. It explicitly reflects the smoothness of the loss function in each (pre-)partitioned set. Nevertheless, its connection to the sharpness of the loss function in parameter space still remains unclear. In order to address this gap, we establish a connection between sharpness and robustness in Eq. 7. Notably, this interplay holds implications not only for OOD but also for in-distribution generalization.
Theorem 3.4.
Assume for any , the loss function w.r.t. sample satisfies the -Hessian Lipschitz continuity (refer to Definition B.2) within every set . Let . Define to be the set of global minima in , suppose such that for some almost surely, then let , and , w.p over we have
| (7) |
Remark.
Given the training set , we can estimate factor that by comparing the maximum Hessian norm w.r.t. to the sum of all the Hessian norms over . Note that the smoothness condition only applies to every partitioned set (locally) where it is much weaker than the global requirement for the loss function to be satisfied We also discuss the difference between our results and Petzka et al. (2021) in Appendix F. The chosen family of loss functions that applied to our theorem can be found in Appendix B.1.
Corollary 3.5.
Let be the minimum value of . Suppose and is bounded by . If , taking expectation over all and all , we have
| (8) |
where is the minimum eigenvalue and is product constant of Gegenbauer polynomials (definition can be founded in Appendix B).
See proof in Appendix D. From Eq. 7 we can see, the robustness constant is (pointwise) upper bounded by the sharpness of the learned model, as measured by the quantity , and the parameter . It should be noted that the parameter depends on the partition, and as the number of partitions increases, the region of the input domain becomes smaller, thereby making sharpness the dominant term in reflecting the model’s robustness within the small local area. In Corollary 3.5, we show a stronger connection when the partition satisfies some conditions. Overall, this bound states that the larger the sharpness of the model , the larger the upper bound on the robustness parameter . This result aligns with the intuition that a sharper model is more prone to overfitting the training domain and is less robust in the unseen domain. While the dependency is not exact, it still can be regarded as an alternative approach that avoids the explicit computation of the intractable robustness term. By substituting this upper bound for into Theorem 3.1, we derive a sharpness-based OOD generalization bound. This implies that the OOD generalization error will have a high probability of being small if the learned model is flat enough. Unlike existing works, our generalization bound provides more information about how optimization property influences performance when generalizing to OOD data. It bridges the gap between robustness and sharpness which can also be generalized to non-OOD learning problems. Moreover, we provide a better theoretical grounding for an empirical observation that a flat minimum improves domain generalization (Cha et al., 2021) by pinpointing a clear dependence on sharpness.
3.3 Case Study
To better demonstrate the relationship between sharpness and robustness, we provide two specific examples: (1) linear ridge regression; (2) two-layer diagonal neural networks for classification.
Example 3.6.
In ridge regression models, has a reverse relationship to the regularization parameter . , the more probably flatter minimum and less sensitivity of the learned model could be. Following the previous notation, we have such that where has a smaller order than for large (proof refer to Appendix E.1).
As suggested in Ali et al. (2019), let’s consider a generic response model where . The least-square empirical minimizer of the ridge regression problem will be:
| (9) |
Let be the training set. It’s trivial to get the sharpness of a quadratic loss function where
| (10) |
It’s obvious that both of the above two equations depend on the same matrix . For fixed training samples , we have in the limit of . Then it’s clear that a higher penalty leads to a flatter minimum. This intuition is rigorously proven in Appendix E.1. According to Theorem 3.1 and Eq. 7, a flatter minimum probably associates with lower robustness constant . Thus it enjoys a lower OOD generalization error gap. In ridge regression, this phenomenon can be reflected by the regularization coefficient . Therefore, in general, the larger is, the lower the sharpness and variance are. As a consequence, larger learns a more robust model resulting in a lower OOD generalization error gap. This idea is later verified in the distributional shift experiments, shown as Figure 3.
Example 3.7.
We consider a classification problem using a 2-layer diagonal linear network with exp-loss. The robustness has a similar relationship in Eq. 7. Given training set , after iterations , , .
In addition to the regression and linear models, we have obtained a similar relationship for 2-layer diagonal linear networks, which are commonly used in the kernel and rich regimes as well as in intermediate settings (Moroshko et al., 2020). Example 3.7 demonstrates that the relationship also holds true when the model is well-trained, even exp-loss does not satisfy the PŁ condition. By extending our theorems to these more complex frameworks, we go beyond our initial assumptions and offer insights into broader applications. Later experiments on non-linear NN also support our statements. However, we still need a unified theorem for general function classes with fewer assumptions.
4 Related Work
Despite various methods (Sun & Saenko, 2016; Sagawa et al., 2019; Shi et al., 2021; Shafieezadeh Abadeh et al., 2015; Li et al., 2018; Cha et al., 2021; Du et al., 2020; Zhang et al., 2022) that have been proposed to overcome the poor generalization brought by unknown distribution shifts, the underlying principles and theories still remain underexplored. As pointed out in Redko et al. (2020); Miller et al. (2021), different tasks that address distributional shifts, such as domain adaptation, OOD, and domain generalization, are collectively referred to as "transfer transductive learning" and share similar generalization theories. In general, the desired generalization bound will be split into In-Distribution/Domain (ID) generalization error and Out-of-Distribution/Domain (OOD) distance. Since Blitzer et al. (2007) establish a VC-dimension-based framework to estimate the domain shift gap by a divergence term, many following works make the effort to improve this term in the following decades, such as Discrepancy (Mansour et al., 2009), Wasserstein measurement (Courty et al., 2017; Shen et al., 2018), Integral Probability Metrics (IPM) (Zhang et al., 2019b; Ye et al., 2021) and -divergence (Germain et al., 2016). Among them, new generalization tools like PAC-Bayes, Rademacher Complexity, and Stability are also applied. However, few of them discuss how the sharpness reacts to data distributional shifts.
Beyond this canonical framework, Ye et al. (2021) reformulate the OOD generalization problem and provide a generalization bound using the concepts of "variation" and "informativeness." The causal framework proposed in Peters et al. (2017); Rojas-Carulla et al. (2018) focuses on the impact of interventions on robust optimization over test distributions. However, none of these frameworks consider the optimization process of a model and how it affects OOD generalization. Inspired by previous investigation on the effect of sharpness on ID generalization (Lyu et al., 2022; Petzka et al., 2021), recent work in Cha et al. (2021) found that flatter minima can also improve OOD generalization. Nevertheless, they lack a sufficient theoretical foundation for the relationship between the "sharpness" of a model and OOD generalization, but end with a union bound of Blitzer et al. (2007)’s result. In this paper, we aim to provide a rigorous examination of this relationship.
5 Experiments
In light of space constraints, we present only a portion of our experimental results to support the validity of our theorems and findings. For comprehensive results, please refer to the Appendix G
5.1 Ridge regression in distributional shifting
Following Duchi & Namkoong (2021), we investigated the ridge regression on distributional shift. We randomly generate in spherical space, and data from the following generating process: . To simulate distributional shift, we randomly generate a perpendicular unit vector to . Let be the basis vectors, then shifted ground-truth will be computed from the basis by . For the source domain, we use as our training distribution. We randomly sample 50 data points and train a linear classifier with a gradient descent of 3000 iterations. By minimizing the objective function in (9), we can get the empirical optimum . Then we gradually shift the distribution by increasing to get different target domains. Along distribution shifting, the test loss will increase. As shown in Figure 3, the test loss will culminate in around rads due to the maximum distribution shifting. Comparing different levels of regularization, we found that the larger L2-penalty brings lower OOD generalization error which is shown as darker purple lines. This plot bears out our intuition in the previous section. As stated in the aforementioned case, the sharpness of ridge regression should inversely depend on . Correspondingly, we compute sharpness using the definition equation (4) by averaging ten different results. For each trial, we use the same training and test data for every . The sharpness of each ridge regressor is shown in the legend of Figure 3. As we can see, larger leads to less sharpness.

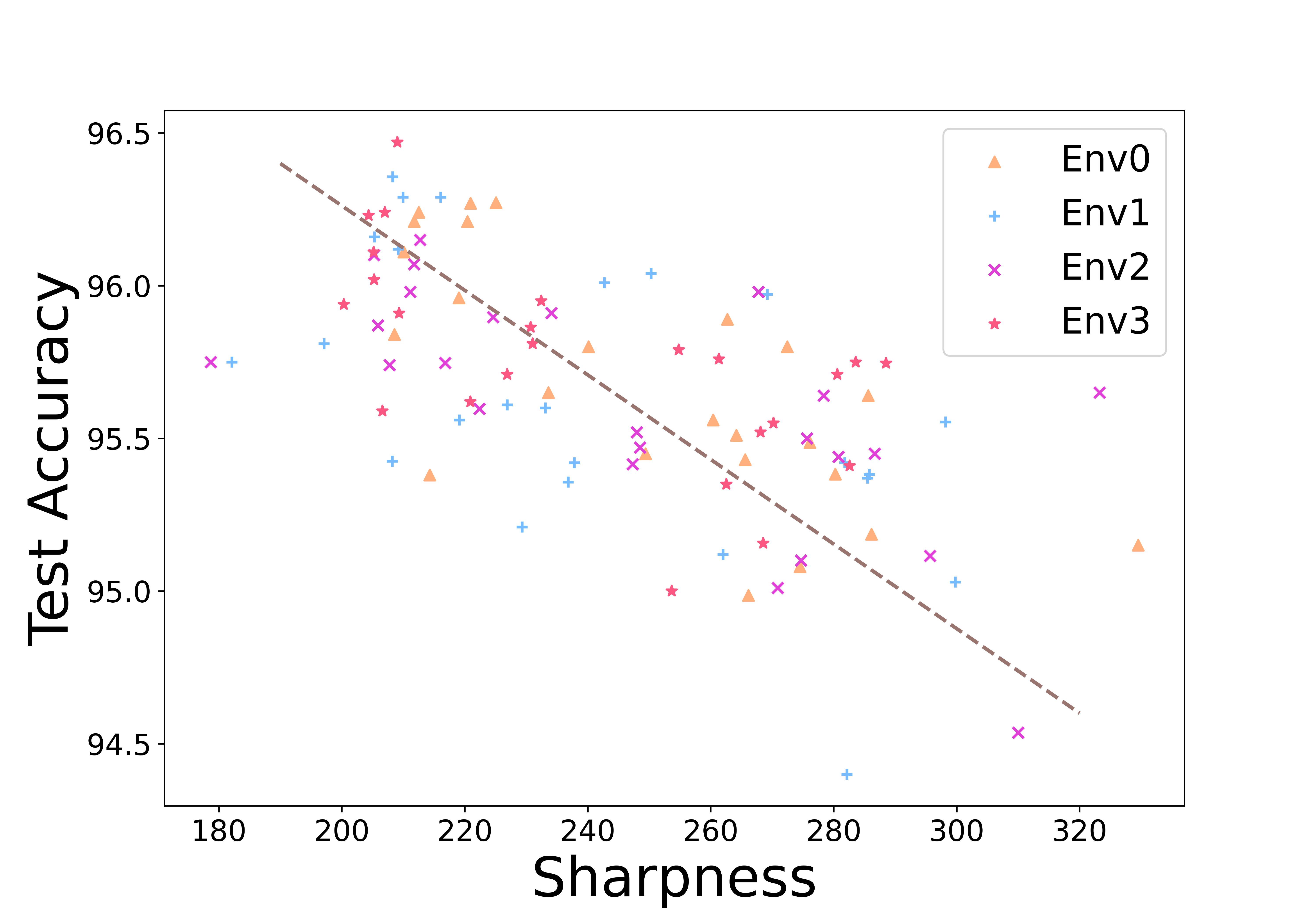
5.2 Sharper minimum hurts OOD generalization
In our results, we proved that the upper bound of OOD generalization error involves the sharpness of the trained model. Here we empirically verified our theoretical insight. We follow the experiment setting in DomainBed (Gulrajani & Lopez-Paz, 2021). To easily compute the sharpness, we choose the 4-layer MLP on RotatedMNIST dataset where RotatedMNIST is a rotation of MNIST handwritten digit dataset (LeCun, 1998) with different angles ranging from . In this codebase, each environment refers to selecting a domain (a specific rotation angle) as the test domain/OOD test dataset while training on all other domains. After getting the trained model of each environment, we compute the sharpness using all domain training sets based on the implementation of Petzka et al. (2021). To this end, we plot the performances of Empirical Minimization Risk (ERM), SWAD (Cha et al., 2021), Mixup (Yan et al., 2020) and GroupDRO (Sagawa et al., 2019) with 6 seeds of each. Then we measure the sharpness of all these minima. Figure 3 shows the relationship between model sharpness and out-of-domain accuracy. The tendency is clear that flat minima give better OOD performances. In general, different environments can not be plotted together due to different training sets. However, we found the middle environments are similar tasks and thus plot them together for a clearer trend. In addition, different algorithms lead to different feature scales which may affect the scale of the sharpness. To address this, we align their scales when putting them together. For more individual results, please refer to Figure 8 in the appendix.
5.3 Comparison of generalization bounds
To analyze our generalization bounds, we follow the toy example experiments in Sagawa et al. (2020). In this experiment, the distribution shift terms and generalization error terms can be explicitly computed. Furthermore, their synthetic experiment considers the spurious correlation across distribution shifts which is now a general formulation of OOD generalization (Wald et al., 2021; Aubin et al., 2021; Yao et al., 2022). Consider data that consist of two features: core feature and spurious feature. The features are generated from the following rule:
where is the label, and is the spurious attribute. Data with forms the majority group of size , and data with forms minority group of size . Total number of training points . The spurious correlation probability, defines the probability of in training data. In testing, we always have . The metric, worst-group error Sagawa et al. (2019) is defined as
where is the loss in binary classification. Here we compare the robustness of our proposed OOD generalization bound and the baseline in Proposition 2.1. We also give the comparison to other baselines, like PAC-Bayes DA bound in the Appendix G.

Along model size
We plot the generalization error of the random feature logistic regression along the model size increases in Figure 4(a). In this experiment, we follow the hyperparameter setup of Sagawa et al. (2020) by setting the number of points , data dimension with on each feature. majority fraction and noises . The worst-group error turns out to be nearly the same as the model size increases. However, in Figure 4(b), the error term in domain shift bound Proposition 2.1(A) will keep increasing when the model size is increasing. In contrast, our domain shift bound at order is independent of the model size which addresses the limitation of their bound. We follow Kawaguchi et al. (2022) to compute in an inverse image of the -covering in a randomly projected space (see details in appendix). We set the same value in our experiment. Different from the baseline, is data dependent and leads to a constant concentration error term along with model size increases. Analogously, our OOD generalization bound will not explode as model size increases (shown in Figure 4(c)).
Along distribution shift
In addition, we are interested in characterizing OOD generalization when test distribution shifts from train distribution by varying the correlation probability during data generation. As shown in Figure 4(d), when , there is no distributional shift between training and test data due to no spurious features correlated to training data. Thus, the training and test distributions align closer and closer when and increase, resulting in an initial decrease in the test error for the worst-case group. However, as and deviates from 0.5, introducing the spurious features, a shift in the distribution occurs. This deviation is likely to impact the worst-case group differently, leading to an increase in the test error. As displayed in Figure 4(e) and Figure 4(f), our distribution distance and generalization bound can capture the distribution shifts but are tighter than the baseline.
6 Conclusion
In this paper, we provide a more interpretable and informative theory to understand Out-of-Distribution (OOD) generalization Based on the notion of robustness, we propose a robust OOD bound that effectively captures the algorithmic robustness in the presence of shifting data distributions. In addition, our in-depth analysis of the relationship between robustness and sharpness further illustrates that sharpness has a negative impact on generalization. Overall, our results advance the understanding of OOD generalization and the principles that govern it.
7 Acknowledgement
This research/project is supported by the National Research Foundation, Singapore under its AI Singapore Programme (AISG Award No: AISG-GC-2019-001-2A), (AISG Award No: AISG2-TC-2023-010-SGIL) and the Singapore Ministry of Education Academic Research Fund Tier 1 (Award No: T1 251RES2207). We would appreciate the contributions of Fusheng Liu, Ph.D. student at NUS.
References
- Ahuja et al. (2021) Kartik Ahuja, Ethan Caballero, Dinghuai Zhang, Jean-Christophe Gagnon-Audet, Yoshua Bengio, Ioannis Mitliagkas, and Irina Rish. Invariance principle meets information bottleneck for out-of-distribution generalization. Advances in Neural Information Processing Systems, 34:3438–3450, 2021.
- Ali et al. (2019) Alnur Ali, J Zico Kolter, and Ryan J Tibshirani. A continuous-time view of early stopping for least squares regression. In The 22nd international conference on artificial intelligence and statistics, pp. 1370–1378. PMLR, 2019.
- Arjovsky et al. (2019) Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization. arXiv preprint arXiv:1907.02893, 2019.
- Aubin et al. (2021) Benjamin Aubin, Agnieszka Słowik, Martin Arjovsky, Leon Bottou, and David Lopez-Paz. Linear unit-tests for invariance discovery. arXiv preprint arXiv:2102.10867, 2021.
- Bandi et al. (2018) Peter Bandi, Oscar Geessink, Quirine Manson, Marcory Van Dijk, Maschenka Balkenhol, Meyke Hermsen, Babak Ehteshami Bejnordi, Byungjae Lee, Kyunghyun Paeng, Aoxiao Zhong, et al. From detection of individual metastases to classification of lymph node status at the patient level: the camelyon17 challenge. IEEE Transactions on Medical Imaging, 2018.
- Ben-David et al. (2010) Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman Vaughan. A theory of learning from different domains. Machine learning, 79:151–175, 2010.
- Blitzer et al. (2007) John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman. Learning bounds for domain adaptation. Advances in neural information processing systems, 20, 2007.
- Bourin et al. (2013) Jean-Christophe Bourin, Eun-Young Lee, and Minghua Lin. Positive matrices partitioned into a small number of hermitian blocks. Linear Algebra and its Applications, 438(5):2591–2598, 2013.
- Cha et al. (2021) Junbum Cha, Sanghyuk Chun, Kyungjae Lee, Han-Cheol Cho, Seunghyun Park, Yunsung Lee, and Sungrae Park. Swad: Domain generalization by seeking flat minima. Advances in Neural Information Processing Systems, 34:22405–22418, 2021.
- Cohen et al. (2021) Jeremy M Cohen, Simran Kaur, Yuanzhi Li, J Zico Kolter, and Ameet Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. arXiv preprint arXiv:2103.00065, 2021.
- Courty et al. (2017) Nicolas Courty, Rémi Flamary, Amaury Habrard, and Alain Rakotomamonjy. Joint distribution optimal transportation for domain adaptation. Advances in Neural Information Processing Systems, 2017.
- Du et al. (2017) Simon S Du, Jayanth Koushik, Aarti Singh, and Barnabás Póczos. Hypothesis transfer learning via transformation functions. Advances in neural information processing systems, 30, 2017.
- Du et al. (2020) Yingjun Du, Xiantong Zhen, Ling Shao, and Cees GM Snoek. Metanorm: Learning to normalize few-shot batches across domains. In International Conference on Learning Representations, 2020.
- Duchi & Namkoong (2018) John Duchi and Hongseok Namkoong. Learning models with uniform performance via distributionally robust optimization. arXiv preprint arXiv:1810.08750, 2018.
- Duchi & Namkoong (2021) John C Duchi and Hongseok Namkoong. Learning models with uniform performance via distributionally robust optimization. The Annals of Statistics, 49(3):1378–1406, 2021.
- El Ghaoui & Lebret (1997) Laurent El Ghaoui and Hervé Lebret. Robust solutions to least-squares problems with uncertain data. SIAM Journal on matrix analysis and applications, 1997.
- Foret et al. (2020) Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware minimization for efficiently improving generalization. arXiv preprint arXiv:2010.01412, 2020.
- Germain et al. (2013) Pascal Germain, Amaury Habrard, François Laviolette, and Emilie Morvant. A pac-bayesian approach for domain adaptation with specialization to linear classifiers. In International conference on machine learning. PMLR, 2013.
- Germain et al. (2016) Pascal Germain, Amaury Habrard, François Laviolette, and Emilie Morvant. A new pac-bayesian perspective on domain adaptation. In International conference on machine learning. PMLR, 2016.
- Gulrajani & Lopez-Paz (2021) Ishaan Gulrajani and David Lopez-Paz. In search of lost domain generalization. In International Conference on Learning Representations, 2021.
- Izmailov et al. (2018) Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights leads to wider optima and better generalization. arXiv preprint arXiv:1803.05407, 2018.
- Kawaguchi et al. (2022) Kenji Kawaguchi, Zhun Deng, Kyle Luh, and Jiaoyang Huang. Robustness implies generalization via data-dependent generalization bounds. In International Conference on Machine Learning. PMLR, 2022.
- Kifer et al. (2004) Daniel Kifer, Shai Ben-David, and Johannes Gehrke. Detecting change in data streams. In VLDB, volume 4, pp. 180–191. Toronto, Canada, 2004.
- Koh et al. (2021) Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. Wilds: A benchmark of in-the-wild distribution shifts. In International Conference on Machine Learning, pp. 5637–5664. PMLR, 2021.
- Koyama & Yamaguchi (2020) Masanori Koyama and Shoichiro Yamaguchi. Out-of-distribution generalization with maximal invariant predictor. 2020.
- LeCun (1998) Yann LeCun. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/, 1998.
- Li et al. (2017) Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M Hospedales. Deeper, broader and artier domain generalization. In Proceedings of the IEEE international conference on computer vision, pp. 5542–5550, 2017.
- Li et al. (2018) Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy Hospedales. Learning to generalize: Meta-learning for domain generalization. In Proceedings of the AAAI conference on artificial intelligence, 2018.
- Liu et al. (2021) Jiashuo Liu, Zheyuan Hu, Peng Cui, Bo Li, and Zheyan Shen. Heterogeneous risk minimization. In International Conference on Machine Learning, pp. 6804–6814. PMLR, 2021.
- Lyu et al. (2022) Kaifeng Lyu, Zhiyuan Li, and Sanjeev Arora. Understanding the generalization benefit of normalization layers: Sharpness reduction. In Advances in Neural Information Processing Systems, 2022.
- Mansour et al. (2009) Yishay Mansour, Mehryar Mohri, and Afshin Rostamizadeh. Domain adaptation: Learning bounds and algorithms. arXiv preprint arXiv:0902.3430, 2009.
- Mei & Montanari (2022) Song Mei and Andrea Montanari. The generalization error of random features regression: Precise asymptotics and the double descent curve. Communications on Pure and Applied Mathematics, 75(4):667–766, 2022.
- Miller et al. (2021) John P Miller, Rohan Taori, Aditi Raghunathan, Shiori Sagawa, Pang Wei Koh, Vaishaal Shankar, Percy Liang, Yair Carmon, and Ludwig Schmidt. Accuracy on the line: on the strong correlation between out-of-distribution and in-distribution generalization. In International Conference on Machine Learning. PMLR, 2021.
- Mohri et al. (2018) Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar. Foundations of machine learning. MIT press, 2018.
- Moroshko et al. (2020) Edward Moroshko, Blake E Woodworth, Suriya Gunasekar, Jason D Lee, Nati Srebro, and Daniel Soudry. Implicit bias in deep linear classification: Initialization scale vs training accuracy. Advances in neural information processing systems, 33:22182–22193, 2020.
- Peters et al. (2017) Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. Elements of causal inference: foundations and learning algorithms. The MIT Press, 2017.
- Petzka et al. (2021) Henning Petzka, Michael Kamp, Linara Adilova, Cristian Sminchisescu, and Mario Boley. Relative flatness and generalization. Advances in Neural Information Processing Systems, 34:18420–18432, 2021.
- Pezeshki et al. (2021) Mohammad Pezeshki, Oumar Kaba, Yoshua Bengio, Aaron C Courville, Doina Precup, and Guillaume Lajoie. Gradient starvation: A learning proclivity in neural networks. Advances in Neural Information Processing Systems, 34:1256–1272, 2021.
- Rame et al. (2022) Alexandre Rame, Corentin Dancette, and Matthieu Cord. Fishr: Invariant gradient variances for out-of-distribution generalization. In International Conference on Machine Learning, pp. 18347–18377. PMLR, 2022.
- Redko et al. (2020) Ievgen Redko, Emilie Morvant, Amaury Habrard, Marc Sebban, and Younès Bennani. A survey on domain adaptation theory: learning bounds and theoretical guarantees. arXiv preprint arXiv:2004.11829, 2020.
- Robbins (1955) Herbert Robbins. A remark on stirling’s formula. The American mathematical monthly, 62(1):26–29, 1955.
- Rojas-Carulla et al. (2018) Mateo Rojas-Carulla, Bernhard Schölkopf, Richard Turner, and Jonas Peters. Invariant models for causal transfer learning. The Journal of Machine Learning Research, 2018.
- Sagawa et al. (2019) Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. arXiv preprint arXiv:1911.08731, 2019.
- Sagawa et al. (2020) Shiori Sagawa, Aditi Raghunathan, Pang Wei Koh, and Percy Liang. An investigation of why overparameterization exacerbates spurious correlations. In International Conference on Machine Learning. PMLR, 2020.
- Shafieezadeh Abadeh et al. (2015) Soroosh Shafieezadeh Abadeh, Peyman M Mohajerin Esfahani, and Daniel Kuhn. Distributionally robust logistic regression. Advances in Neural Information Processing Systems, 2015.
- Shen et al. (2018) Jian Shen, Yanru Qu, Weinan Zhang, and Yong Yu. Wasserstein distance guided representation learning for domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, 2018.
- Shi et al. (2021) Yuge Shi, Jeffrey Seely, Philip HS Torr, N Siddharth, Awni Hannun, Nicolas Usunier, and Gabriel Synnaeve. Gradient matching for domain generalization. arXiv preprint arXiv:2104.09937, 2021.
- Sun & Saenko (2016) Baochen Sun and Kate Saenko. Deep coral: Correlation alignment for deep domain adaptation. In European conference on computer vision, pp. 443–450. Springer, 2016.
- Wald et al. (2021) Yoav Wald, Amir Feder, Daniel Greenfeld, and Uri Shalit. On calibration and out-of-domain generalization. Advances in neural information processing systems, 2021.
- Wiles et al. (2022) Olivia Wiles, Sven Gowal, Florian Stimberg, Sylvestre-Alvise Rebuffi, Ira Ktena, Krishnamurthy Dj Dvijotham, and Ali Taylan Cemgil. A fine-grained analysis on distribution shift. In International Conference on Learning Representations, 2022.
- Xu & Mannor (2012) Huan Xu and Shie Mannor. Robustness and generalization. Machine learning, 86(3):391–423, 2012.
- Yan et al. (2020) Shen Yan, Huan Song, Nanxiang Li, Lincan Zou, and Liu Ren. Improve unsupervised domain adaptation with mixup training. arXiv preprint arXiv:2001.00677, 2020.
- Yao et al. (2022) Huaxiu Yao, Yu Wang, Sai Li, Linjun Zhang, Weixin Liang, James Zou, and Chelsea Finn. Improving out-of-distribution robustness via selective augmentation. arXiv preprint arXiv:2201.00299, 2022.
- Ye et al. (2021) Haotian Ye, Chuanlong Xie, Tianle Cai, Ruichen Li, Zhenguo Li, and Liwei Wang. Towards a theoretical framework of out-of-distribution generalization. Advances in Neural Information Processing Systems, 2021.
- Zhang et al. (2019a) Xiao Zhang, Yaodong Yu, Lingxiao Wang, and Quanquan Gu. Learning one-hidden-layer relu networks via gradient descent. In The 22nd international conference on artificial intelligence and statistics, pp. 1524–1534. PMLR, 2019a.
- Zhang et al. (2022) Xingxuan Zhang, Linjun Zhou, Renzhe Xu, Peng Cui, Zheyan Shen, and Haoxin Liu. Towards unsupervised domain generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4910–4920, 2022.
- Zhang et al. (2019b) Yuchen Zhang, Tianle Liu, Mingsheng Long, and Michael Jordan. Bridging theory and algorithm for domain adaptation. In International Conference on Machine Learning. PMLR, 2019b.
- Zhao et al. (2018) Han Zhao, Shanghang Zhang, Guanhang Wu, José MF Moura, Joao P Costeira, and Geoffrey J Gordon. Adversarial multiple source domain adaptation. Advances in neural information processing systems, 31, 2018.
- Zhong et al. (2017) Kai Zhong, Zhao Song, Prateek Jain, Peter L Bartlett, and Inderjit S Dhillon. Recovery guarantees for one-hidden-layer neural networks. In International conference on machine learning, pp. 4140–4149. PMLR, 2017.
Appendix A Additional Experiments
A.1 Sharpness v.s. OOD Generalization on PACS and Wilds-Camelyon17


To evaluate our theorem more deeply, we examine the relationship between our defined sharpness and OOD generalization error on larger-scale real-world datasets, Wilds-Camelyon17 Bandi et al. (2018); Koh et al. (2021) and PACS Li et al. (2017). Wilds-Camelyon17 dataset includes 455,954 tumor and normal tissue slide images from five hospitals (environments). One of the hospitals is assigned as the test environment by the dataset publisher. Distribution shift arises from variations in patient population, slide staining, and image acquisition. PACS dataset contains 9,991 images of 7 objects in 4 visual styles (environments): art painting, cartoon, photo, and sketch. Following the common setup in Gulrajani & Lopez-Paz (2021), each environment is used as a test environment in turn. We follow the practice in Petzka et al. (2021) to compute the sharpness using the Hessian matrix from the last Fully-Connected (FC) layer of each model. For the Wilds-Camelyon17 dataset, we test the sharpness of 18 ERM models trained with different random seeds and hyperparameters. Figure 6 shows the result. For the PACS dataset, we run 60 ERM models with different random seeds and hyperparameters for each test environment. To get a clearer correlation, we align the points from 4 environments by their mean performance. Figure 6 shows the result. From the two figures, we can observe a clear correlation between sharpness and out-of-distribution (OOD) accuracy. Sharpness tends to hurt the OOD performance of the model. The result is consistent with what we report in Figure 3. It shows that the correlation between sharpness and OOD accuracy can also be observed on large-scale datasets.
Appendix B Notations and Definitions
Notations
We use denote the integers set . represents -norm for short. Without loss of generality, we use for the loss function of model on data pair , which is denoted as and we use for training set size and input dimension. Note that we generally follow the notations in the original papers.
-
•
: expected risk of the source domain and target domain, respectively. The corresponding empirical version will be
-
•
: partitions on sample space and denotes each partitioned set.
-
•
: distributions of source and target domain. Their sampled dataset will be denoted as accordingly.
-
•
: In our setting, denotes the model parameters where is the trainable parameters and are the random features (we also use for short notation in many places). is the minimizer of empirical loss.
-
•
: upper bound of the loss function.
-
•
: training data of size .
Definition B.1 (Robustness, Xu & Mannor (2012)).
A learning algorithm on training set is -robust, for , if can be partitioned into disjoint sets, denoted by , such that for all we have
Definition B.2 (Hessian Lipschitz continuous).
For a twice differentiable function , it has -Lipschitz continuous Hessian for domain are vectors in if
where depends on input domain and is norm. Then for all domains , let be the uniform Lipschitz constant, so we have
which is uniformly bounded with .
Lemma B.3 (Hessian Lipschitz Lemma).
If is twice differentiable and has -Lipschitz continuous Hessian, then
Gegenbauer Polynomials
We briefly define Gegenbauer polynomials here whose details can be found in Appendix of Mei & Montanari (2022). First, we denote as the uniform spherical distribution with the radius on manifold. Let be the probability measure on and and the inner product in functional space denoted as and :
For any function , where is the distribution of , the orthogonal basis forms the Gegenbauer polynomial of degree , its spherical harmonics coefficients can be expressed as:
then the Gegenbauer generating function holds in sense
where is the normalized factor depending on the norm of input.
B.1 Assumptions
We discuss and list all assumptions we used in our theorems. The purposes are to offer clarity regarding the specific assumptions required for each theorem and ensure that the assumptions made in our theorems are well-founded and reasonable, reinforcing the validity and reliability of our results.
OOD Generalization
(Setting): Given a full sample space , source and target distributions are two different measures over this whole sample domain . The purpose is to study the robust algorithms in the OOD generalization setting.
(Assumptions): For any sample , the loss function is bounded . This assumption generally follows the original paper Xu & Mannor (2012). While it is possible to relax this assumption and derive improved bounds, our primary objective is to formulate a framework for robust OOD generalization and establish a clear connection with the optimization properties of the model.
Robustness and Sharpness
(Setting): In order to give a fine-grained analysis, we follow the common choice where a two-layer ReLU Neural Network function class is widely analyzed in most literature, i.e. Neural Tangent Kernel, non-kernel (rich) regime Moroshko et al. (2020) and random feature models. Among them, we select the following random feature models as our function class:
where is the hidden size and contains random vectors uniformly distributed on -dim hypersphere whose surface is a manifold. denotes the ReLU activation function and is the indicator function. is the trainable parameter. We choose the common loss functions: (1) Homogeneity in regression; (2) (Binary) Cross-Entropy Loss; (3) Negative Log Likelihood (NLL) loss;
(Assumptions):
(i) Let be any set from whole partitions , we assume , the loss function satisfies -Hessian Lipschitz for all (See details in Definition B.2). Note that we only require this assumption to hold within each partition, instead of holding globally. In general, the smoothness and convexity condition is actually equivalent to locally convex which is a weak assumption for most function classes.
(ii) Consider an optimization problem in each partition . Let one of the training points be the initial point and is the corresponding nearest local minima where is the local minima set of partition . For some , we assume holds a.s.. It ensures the hessian norm has the lower bound. Similar conditions and estimations can be found in Zhang et al. (2019a).
(iii) To simplify the computation of probability, we assume obeys a rotationally invariant distribution.
(iv) For Corollary 3.5, we make additional assumptions that loss function satisfied a bounded condition where the second derivative with respect to its argument should be bounded by . Note, we consider the case where the data while is to ensure the positive definiteness of almost surely.
Appendix C Proof to Domain shift
Lemma C.1.
Let be the empirical distribution of size drawn from . The loss is upper bounded by M. With probability at least (over the choice of the samples), for every trained on , we have
| (11) |
where
| (12) |
and are the number of samples from and that fall into the set , respectively.
Proof.
In the following generalization statement, we use to denote the error obtained with input and hypothesis function for better illustration. By definition we have,
| (13) |
Then we make the partitions for source distribution . Let be the size of collection set of points fall into the partition where is the i.i.d.multinomial random variable with . We use parallel notation for target distribution with . Since
| (14) | ||||
and thus we have
| (15) | ||||
If we sample empirical distribution of size each drawn from and , respectively. are the i.i.d. random variables belongs to . We use the parallel notation for target distribution.
| (16) |
Further, we have
| (17) | ||||
With Breteganolle-Huber-Carol inequality we have
| (18) |
To integrate these two inequalities, we have
| (19) | ||||
In summary with probability we have
| (20) |
which completes the proof. ∎
With the result of the domain (distribution) shift and the relationship between sharpness and robustness, we can move forward to the final OOD generalization error bound. First, we state the context of ID robustness bound in Xu & Mannor (2012) as follows.
Lemma C.2 (Xu et al.Xu & Mannor (2012)).
Assume that for all and , the loss is upper bounded by i.e., . If the learning algorithm is -robust, then for any , with probability at least over an iid draw of samples , it holds that:
As the conclusive results, we briefly prove the following result by summarizing Lemma C.2 and Lemma C.1.
Theorem C.3 (Restatement of Theorem 3.1).
Let be the empirical distribution of size drawn from . The loss is upper bounded by M. With probability at least (over the choice of the samples), for every trained on , we have
| (21) |
Proof.
Here is the robustness constant that we can replace with any sharpness measure.
C.1 Proof to Corollary 3.2
Definition C.4.
and is defined as:
where is the XOR operator e.g. .
Lemma C.5 (Lemma 2 Zhao et al. (2018)).
If , then .
Proposition C.6 (Zhao et al. (2018)).
Let be a hypothesis class with pseudo dimension . If is the empirical distributions generated with i.i.d.. samples from source domain, and is the empirical distribution on the target domain generated from samples without labels, then with probability at least , for all , we have:
| (23) | ||||
where is the total error of best hypothesis over source and target domain.
Proof.
With Lemma 4 (Zhao et al., 2018), we have
where
Lemma 6 (Zhao et al., 2018), which is actually Lemma 1 in (Ben-David et al., 2010), shows the following results
As suggested in Zhao et al. (2018), is at most . Further, with Theorem 2 (Ben-David et al., 2010), we have at probability at least
| (24) | ||||
Using in-domain generalization error Lemma 11.6 (Mohri et al., 2018), with probability at least the result is
Note in Zhao et al. (2018), the for the normalized regression loss. Combine them all, we conclude the proof. ∎
Corollary C.7.
If , domain shift bound will be reduced to (Empirical div Error) in Proposition C.6 where
| (25) |
Appendix D Sharpness and Robustness
Lemma D.1 (positive definiteness of Hessian).
Let be the minimum value of and . For any denote be the minimum eigenvalue, where is the polynomial product constant. If , the hessian can be lower bound by
| (29) |
Proof.
As suggested in Lemma D.6 of (Zhong et al., 2017), we have a similar result to bound the local positive definiteness of Hessian. By previous definition, the Hessian w.r.t. has a following partial order
| (30) | ||||
For the ReLU activation function, we further have
| (31) |
We extend the (where is the distribution of ) by Gegenbauer polynomials that
| (32) |
Let . We assume . Lemma C.7 in (Mei & Montanari, 2022), suggests that
| (33) |
which shows matrix is a positive definite matrix. Similarly, taking the expectation over , terms in RHS of (30) bracket can be rewritten as
| (34) | ||||
Besides, we have the following property of Gegenbauer polynomials,
-
1.
For
-
2.
For
where spherical harmonics forms an orthonormal basis which gives the following results
| (35) | ||||
Hence, we have
| (36) |
Since , and are i.i.d, then . Let we have
| (37) |
∎
Lemma D.2.
Let be the whole domain, the notion of -robustness is described by
Define be the set of global minima in , where
suppose for some maximum training loss point
there where
such that almost surely hold for any and for any , is -Hessian Lipschitz continuous. Then the can be bounded by
Proof.
Let be a collection of from the training set and denote any collection from the set . We define local minima set (which is the global minima set of ). Assume that for some maximum point , there exists a almost surely for all such that
| (38) |
By definition, can be rewritten as
| (39) | ||||
According to Lemma B.3, we have
| (40) | ||||
where support by the fact . With Lipschitz continuous Hessian we have
| (41) |
Overall, we have
| (42) | ||||
which completes the proof. ∎
Lemma D.3 (Lemma 2.1 Bourin et al. (2013)).
For every matrix in partitioned into blocks, we have a decomposition
for some unitaries .
Lemma D.4.
Then, given an arbitrary partitioned positive semi-definite matrix,
for all symmetric norms.
Proof.
In lemma D.3 we have
for some unitaries . The result then follows from the simple fact that symmetric norms are non-decreasing functions of the singular values where , we have
∎
Lemma D.5.
For and are some vector with norm , we have
| (43) |
Proof.
We can replace the unit vector of with by
| (44) |
Similarly, we can replace by unit vector such that
| (45) |
Solving , we get
| (46) |
In this case, the probability will converge to as increases. As is known to us, surface area of equals
| (47) |
An area of the spherical cap equals
| (48) |
where .
1) When , almost surely we have
| (49) |
2) When , we have where is a circle and the probability is the angle between how much the vectors span within the circle where
| (50) |
3) When , the probability equals
| (51) |
where is the remaining area of cutting the hyperspherical caps in half of the sphere,
| (52) | ||||
3-a) If is even then , so
| (53) |
Robbins’ bounds (Robbins, 1955) imply that for any positive integer
| (54) |
So we have
| (55) | ||||
So the probability will be
| (56) |
Suppose , we have
| (57) |
3-b) Similarly, if is odd, then , so
| (58) |
If then
| (59) |
If then Robbins’ bounds imply that
| (60) |
Thus, the probability will be at least
| (61) |
To simplify the result, we compare the minimum probability that for
| (62) | ||||
Overall, we have ,
| (63) |
∎
D.1 Proof to Eq. 7
Proof.
Let . We consider the random ReLU NN function class to be
where . The empirical minimizer of the source domain is
| (64) |
Then with the chain rule, the first derivative of any input at will be
| (65) | ||||
where a short notation denotes the first order directional derivative of is the Jacobian matrix w.r.t. input . Apparently, the second order derivative is represented as , thus the Hessian will be
| (66) | ||||
Similarly, we have
| (67) |
where is the sign function. ∗ holds under our choice of the family of loss functions.
-
1.
Homogeneity in regression, i.e. L1, MSE, MAE, Huber Loss, we have ;
-
2.
(Binary) Cross-Entropy Loss:
-
3.
Negative Log Likelihood (NLL) loss: .
Besides, as a convex loss function, . Hence, the range of will be .
To combine with robustness, we denote . Therefore, the Hessian of will be
| (68) |
With Lemma D.4, the spectral norm of Hessian will be bounded by
| (69) |
The first term in (69) can be further bounded by
| (70) | ||||
where the convexity of loss functions supports the last equation. The right term has the facts that
| (71) |
In summary, we have the following inequality:
| (72) | ||||
In Lemma D.2, it depends on some that
| (73) | ||||
where , the is a smaller order term compared to first term, since . Last equality, the maximum can be taken as we find maximum . Because is one of the training sample , there must exist that
| (74) | ||||
Recall that the sharpness of parameter is defined by
| (75) | ||||
Let the and the expectation of where is some rotationally invariant distribution, i.e. uniform or normal distribution. Under this circumstance, the sample mean of still obeys the same family distribution as . Thus, we have
| (76) | ||||
With Eq. 43, we have at least a probability at
| (77) |
the following inequality holds,
| (78) | ||||
∎
D.2 Proof to Corollary 3.5
Corollary D.6 (Restatement of Corollary 3.5).
Let be the minimum value of . Suppose and is bounded by . If , for any , taking expectation over all in , we have
| (79) |
where is the minimum eigenvalue and is product constant of Gegenbauer polynomials
Proof.
In our main theorem, with some probability, we have the following relation
So, we are concerned about the relation between the second term. If , we may say the RHS is dominated by sharpness term as well as the main effect is taken by the sharpness. As suggested in Lemma D.1, we have
| (80) |
where is the global minimum over the whole set. As defined in (38), the following condition holds true
| (81) |
and with Hessian Lipschitz, the relation is almost surely for arbitrary that
| (82) | ||||
Obviously, . Following Lemma A.2 of Zhang et al. (2019a), for , we have a similar result that
| (83) |
where denotes the minimum singular value. With Lemma D.2, we know that
| (84) |
We also have another condition that
| (85) |
Combine all these results, we finally have
| (86) | ||||
Recall the definition of in the main theorem that
| (87) |
Look at the second sum, we have
| (88) | ||||
Suppose and are i.i.d. from , let , we have a well-known result that
| (89) | ||||
Therefore, in (88),
| (90) |
and we have (based on proof of main theorem),
| (91) | ||||
∎
Appendix E Case Study
To better illustrate our theorems, we here give two different cases for clearly picturing intuition. The first case is the very basic model, ridge regression. As is known to us, ridge regression provides a straightforward way (by punishing the norm of the weights) to reduce the "variance" of the model in order to avoid overfitting. In this case, this mechanism is equivalent to reducing the model’s sharpness.
Example E.1.
In ridge regression models, the robustness constant has a reverse relationship to regularization parameter where , the more probably flatter minimum and less sensitivity of the learned model could be. Follow the previous notation that denotes the robustness and is the sharpness on training set , then we have
where is a much smaller order than .
E.1 Ridge regression
We consider a generic response model as stated in Ali et al. (2019).
ridge regression minimization problem is defined by
| (92) |
The least-square solution of ridge regression is
| (93) |
With minimizer , we now focus on its geometry w.r.t. . Let be the training set, be a measure space. Consider the bounded sample set such that
| (94) |
The can be partitioned into disjoint sets . By definition, we have robustness defined by each partition ,
| (95) |
For this convex function , we have the following upper bound in the whole sample domain
| (96) | ||||
where the are the global minimum point in and whole domain , respectively. is a training data point that has the maximum loss difference from the optimum. Specifically, it as well as the augmented form of can be expressed as
Then the loss difference can be rewritten as
It is a convex function with regards to such that
| (97) | ||||
where the second equality is supported by convexity and the third equality is due to . Further, with Lemma D.4, we have
| (98) |
In (97), we can also bound the norm of the input difference by
| (99) |
and then for simplicity, assume we have
| (100) | ||||
where is the dominate term for large . Now, let’s look at the relation to sharpness. By definition,
| (101) |
Since
| (102) |
so we have
| (103) |
As is known to us, the "variance" of ridge estimator Ali et al. (2019) can be defined by
| (104) |
Note that is a PSD with , thus it has only one eigenvalue .
| (105) |
By definition, the covariance matrix is a diagonal matrix with entries of . Averagely, we have
| (106) | ||||
where and are simultaneously diagonalizable and commutable. Therefore, the greater is, the smaller is.
Conclusions
From our above analysis, we have the following conditions.
-
•
Upper bound of robustness
-
•
Sharpness expression
-
•
Variance expression
1) First, let’s discuss how influences sharpness.
| (107) | ||||
As dictated in above equation, the where sharpness holds an inverse relationship to .
2) Now, it’s trivial to get the relationship between robustness and sharpness by combining the first two points. Because in supermum is one of the training samples there exists a constant and such that
| (108) | ||||
This relation is consistent with Eq. 7 where the robustness is upper bounded by times sharpness . Besides, the relation is simpler here, where robustness only depends on sharpness without other coefficients before .
3) Finally, the relation between and robustness will be
| (109) | ||||
where the somehow is the order of in the limit of . It’s clear to us that the greater is, the less sensitive (more robust) model we can get. In practical, we show that "over-robust" may hurt the model’s performance (we show the detail empirically in Figure 7).
E.2 2-layer Diagonal Linear Network Classification
However, our main theorem assumes the loss function satisfying Polyak-Łojasiewicz (PŁ) condition. To extend our result to a more general case, here we study a 2-layer diagonal linear network classification problem whose loss is exponential-based and not satisfied the PŁ condition.
Example E.2.
We consider a classification problem using a 2-layer diagonal linear network with exp-loss. The robustness has a similar relationship in Eq. 7. Given training set , after iterations , , .
Given a training set . A depth- diagonal linear networks with parameters specified by:
We consider exponential loss where and . It has the same tail behavior and thus similar asymptotic properties as the logistic or cross-entropy loss. WLOG, we assume such that . Suggest by Moroshko et al. (2020), we have
where and . Note that
| (110) |
where .
Part i, sharpness. First derivative and Hessian can be obtained by
| (111) | ||||
With the definition of sharpness, we can get
| (112) |
Part ii, robustness. Now, let’s use the same discussion of the robustness constant in the previous case. Follow the previous definition of , after some iteration number it is defined by
| (113) |
where is the (denormalized) point-wise loss of and denotes the minimum loss of point . There exists , we have
| (114) |
Let , the above equation
| (115) | ||||
Part iii, connection. Compare the last part of (112) and (115), we found that robustness and sharpness depend on the same term. Further, we can say that for any step , will have the upper bound.
From Lemma 11 of Moroshko et al. (2020), we have the following inequality,
| (116) |
where . Then, we can bound the via:
| (117) |
Note that In summary, we have
| (118) |
where is a constant.
Part iv, sanity check– asymptotic. Asymptotically, as , while will be explode. So if sharpness , then it will fail to imply robustness.
| (119) | ||||
Let be a upper bound of at any time step . The dynamics will be
| (120) | ||||
As , we have , thus it is easy to converge that
| (121) |
As we can see, the dynamics of the derivative of is decreasing to as which means the sharpness will be upper bounded by a converged number . So sharpness will not explode.
Appendix F Comparison to feature robustness
F.1 Their results
Definition F.1 (Feature robustness Petzka et al. Petzka et al. (2021)).
Let denote a loss function, and two positive (small) real numbers, a finite sample set, and a matrix. A model with is called -feature robust, if for all . More generally, for a probability distribution on perturbation matrices in , we define
and call the model -feature robust on average over , if for
Theorem F.2 (Theorem 5 Petzka et al. Petzka et al. (2021)).
Consider a model as above, a loss function and a sample set , and let denote the set of orthogonal matrices. Let be a positive (small) real number and denote parameters at a local minimum of the empirical risk on a sample set . If the labels satisfy that for all and all , then is -feature robust on average over for .
Proof sketch
-
1.
With assumption that for all and all , feature perturbation around is
-
2.
Since Taylor expansion for local minimum will only remains second order term, thus
-
3.
With basic algebra, one can easily get
F.2 Comparison to our results
We first summarize the commonalities and differences between their results and ours:
-
•
Both of us consider the robustness of the model. But they define the feature robustness while we study the loss robustness Xu & Mannor (2012) which has been studied for many years.
-
•
They consider a non-standard generalization gap by decomposing it into representativeness and the expected deviation of the loss around the sample points. But we strive to integrate sharpness into the general generalization guarantees.
For point 1, their defined feature robustness trivially depends on the sharpness. Because the sharpness (the curvature information) is just defined by the robust perturbation areas around the desired point. From step 2 in the above proof sketch we can see, the hessian w.r.t. is exactly the second expansion of perturbed expected risk. So we think this definition provides less information about the optimization landscape. In contrast, we consider the loss robustness for two reasons: 1) it is easy to get in practice without finding the orthogonal matrices first. 2) we highlight its dependence on the data manifold.
For point 2, we try to integrate this optimization property (sharpness) into the standard generalization frameworks in order to get a clearer interplay. Unlike feature robustness, the robustness defined by loss function will be easier analyzed in generalization tools, because it’s hard and vague to define the "feature" in general. Besides, our result will also benefit the data-dependent bounds Xu & Mannor (2012); Kawaguchi et al. (2022).
Appendix G Experiments and details
G.1 Ridge regression with distributional shifting
As we stated before, we followed the Duchi & Namkoong (2021) to investigate the ridge regression on distributional shift. We randomly generate in spherical space, and data from
| (122) |
To simulate distributional shift, we randomly generate a perpendicular unit vector to . Let be the basis vectors, then shifted ground-truth will be computed from the basis by . For the source domain, we use as our training distribution. We randomly sample 50 data points and train a linear classifier with a gradient descent of 3000 iterations. Starting from , we gradually increase the to generate different distributional shifts.
From the left panel in Figure 7 we can see that a larger penalty suffers from lower loss increasing when ranges from to . Since we consider a cycling shift of label space, corresponds to the maximum shift thus leading to the highest loss increase. According to our analysis of ridge regression, larger means a flatter minimum and more robustness, resulting in a better OOD generalization. This experiment verifies our theoretical analysis. However, it is important to note that too large a coefficient of regularization will hurt the performance. As shown in Figure 7 (right panel), the curse of underfitting (indicated by brown colors) appears when .

G.2 Additional results on sharpness
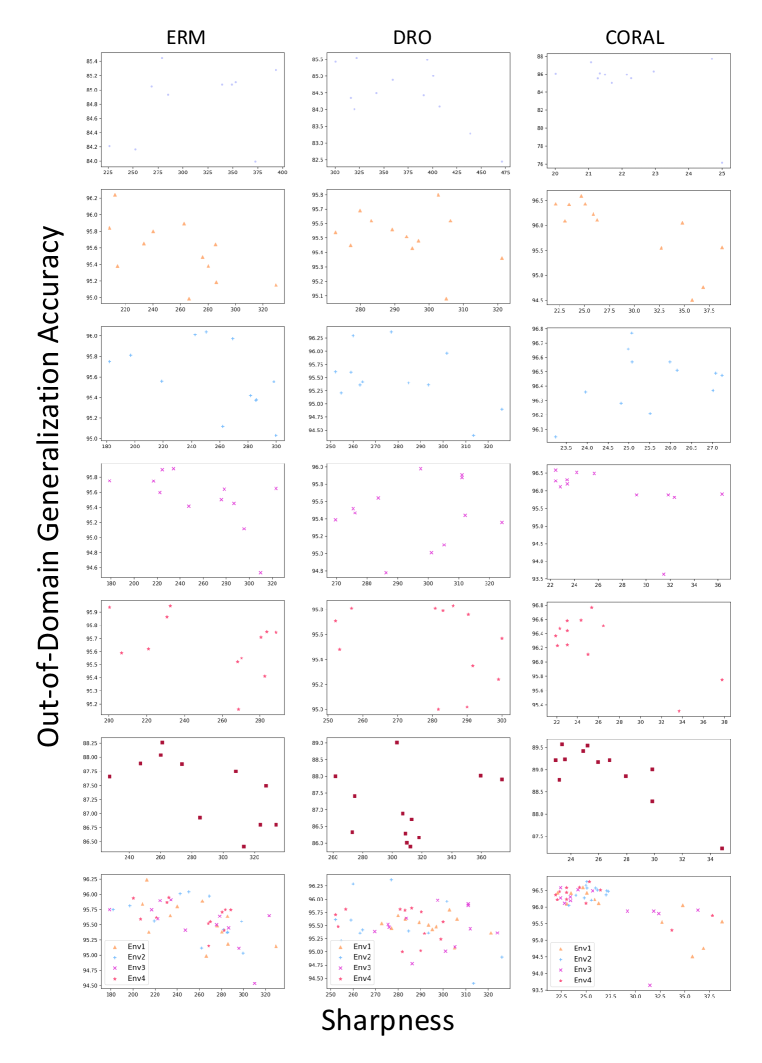
Here we show more experimental results on RotatedMNIST which is a rotation of MNIST handwritten digit dataset with different angles ranging from (6 domains/distributions). For each environment, we select a domain as a test domain and train the model on all other domains. Then OOD generalization test accuracy will be reported on the test domain. In our experiments, we run each algorithm with different seeds, thus getting trained models of different minima. Then we compute the sharpness (see Algorithm 1) for all these models and then plot them in Figure 8. For algorithms, we choose Empirical Risk Minimization (ERM), and Stochastic Weight Averaging (SWA) as the plain OOD generalization algorithm which is shown in the first column. In robust optimization algorithms, we choose Group Distributional Robust Optimization Sagawa et al. (2019). We also choose CORALSun & Saenko (2016) as a multi-source domain generalization algorithm. Among these different types of out-of-domain generalization algorithms, we can conclude that sharpness will affect the test accuracy on the OOD dataset.
Experimental configurations are listed in Table 1. For each model, we run the iterations and choose the last model as the test model. To ease the computational burden, we choose the -layer MLP to compute the sharpness.
| Algorithms | Optimizer | lr | WD | batch size | MLP size | eta | MMD |
| ERM(SWA) | Adam | 0.001 | 0 | 64 | 265*3 | - | - |
| DRO | Adam | 0.001 | 0 | 64 | 265*3 | 0.01 | - |
| CORAL | Adam | 0.001 | 0 | 64 | 265*3 | - | 1 |
From Figure 8 we can see, the sharpness has an inverse relationship with the out-of-domain generalization performance for every model in each individual environment. To make it clear, we plot similar tasks from environment to as the last row. Thus, we can see a clearer tendency in all algorithms. It verified our Theorem 3.1. Note that all algorithms have different feature scales. One may need to normalize the results of different algorithms when plotting them together.
G.3 Compare our robust bound to other OOD generalization bounds
G.3.1 Computation of our bounds
First, we follow Kawaguchi et al. (2022) to compute the in an inverse image of the covering in a randomly projected space. The main idea is to partition input space in a projected space with transformation matrix . The specific steps will be (1) To generate a random matrix , we i.i.d. sample each entry from the Uniform Distribution . (2) Each row of the random matrix is then normalized so that , i.e. (3) After generating a random matrix , we use the -covering of the space of to define the pre-partition .
G.3.2 Computation of PAC-Bayes bound
We follow the definition to compute expected in Germain et al. (2013) where
Definition G.1.
Let be a hypothesis class. For any marginal distributions and over , any distribution on , the domain disagreement between and is defined by,
Since the is defined as the expected distance, we can compute its empirical version according to their theoretical upper bound as follows.
Proposition G.2 (Germain et al. Germain et al. (2013) Theorem 3).
For any distributions and over , any set of hypothesis , any prior distribution over , any , and any real number , with a probability at least over the choice of , for every on , we have
. With , we can then compute the final generalization bound by the following inequality
with is the best target posterior, and .
Note that we ignore the expected errors over the best hypothesis by assuming the . We apply the same operation in of Proposition C.6 as well.
G.3.3 Comparisons
In this section, we add some additional experiments on comparing to other baselines, i.e. PAC-Bayes bounds Germain et al. (2013). As shown in the first row of Figure LABEL:fig_app:spurious_features, our robust framework has a smaller distribution distance in the bound compared to the two baselines when increasing the model size. In the second row, we have similar results in final generalization bounds. From the third and fourth rows we can see, our bound is tighter than baselines when suffering distributional shifts.