[table]capposition=bottom
Towards Open-World Grasping with
Large Vision-Language Models
Abstract
The ability to grasp objects in-the-wild from open-ended language instructions constitutes a fundamental challenge in robotics. An open-world grasping system should be able to combine high-level contextual with low-level physical-geometric reasoning in order to be applicable in arbitrary scenarios. Recent works exploit the web-scale knowledge inherent in large language models (LLMs) to plan and reason in robotic context, but rely on external vision and action models to ground such knowledge into the environment and parameterize actuation. This setup suffers from two major bottlenecks: a) the LLM’s reasoning capacity is constrained by the quality of visual grounding, and b) LLMs do not contain low-level spatial understanding of the world, which is essential for grasping in contact-rich scenarios. In this work we demonstrate that modern vision-language models (VLMs) are capable of tackling such limitations, as they are implicitly grounded and can jointly reason about semantics and geometry. We propose OWG, an open-world grasping pipeline that combines VLMs with segmentation and grasp synthesis models to unlock grounded world understanding in three stages: open-ended referring segmentation, grounded grasp planning and grasp ranking via contact reasoning, all of which can be applied zero-shot via suitable visual prompting mechanisms. We conduct extensive evaluation in cluttered indoor scene datasets to showcase OWG’s robustness in grounding from open-ended language, as well as open-world robotic grasping experiments in both simulation and hardware that demonstrate superior performance compared to previous supervised and zero-shot LLM-based methods. Project material is available at https://gtziafas.github.io/OWG_project/.
Keywords: Foundation Models for Robotics, Open-World Grasping, Open-Ended Visual Grounding, Robot Planning
1 Introduction
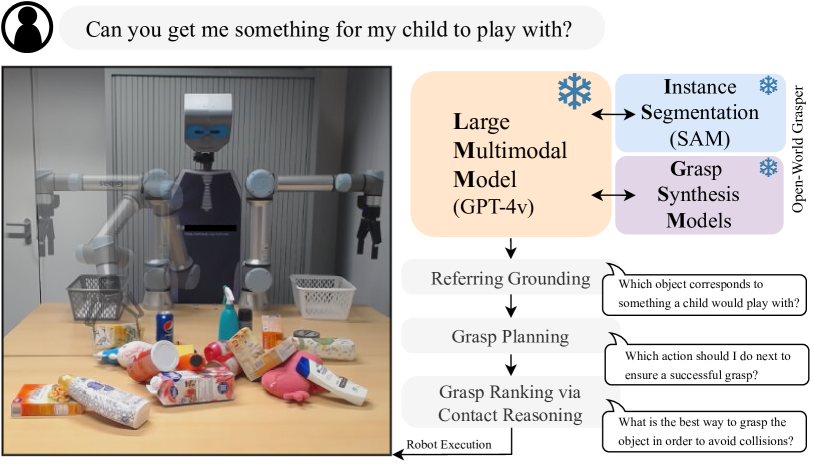
Following grasping instructions from free-form natural language in open-ended environments is a multi-faceted problem, posing several challenges to robot agents. Consider the example of Fig. 1: The robot has to decipher the semantics of the user instruction (i.e., “what would a child want to play with?”), recognize the appearing objects and ground the target (i.e., the white toy), reason about the feasibility of the grasp to generate an appropriate plan (i.e., first remove the blocking juice box), and finally select a suitable grasp based on the object geometry and potential collisions. It becomes clear that to deal with the full scope of open-world grasping, agents should integrate high-level semantic with low-level physical-geometric reasoning, while doing so in a generalizable fashion.
In recent years, Large Language Models (LLMs) [1, 2, 3, 4, 5], have emerged as a new paradigm in robotics and embodied AI, due to their emergent general knowledge, commonsense reasoning and semantic understanding of the world [6, 7, 8, 9, 10]. This has led to a multitude of LLM-based approaches for zero-shot robotic task planning [11, 12, 13, 14, 15], navigation [16, 17, 18, 19] and manipulation [20, 21, 22, 23, 24, 25], where the LLM decomposes a high-level language instruction into a sequence of steps, therefore tackling complex, long-horizon tasks by composing primitive skills. However, a notorious limitation of LLMs is their lack of world grounding — they cannot directly reason about the agent and environment physical state [26], and lack deep knowledge when it comes to low-level, physical properties, such as object shapes, precise 3D geometry, contact physics and embodiment constraints [27]. Even when equipped with external visual modules for perceiving the world, the amount of information accessed by the LLM is bottlenecked by the visual model’s interface (e.g. open-vocabulary detectors [28, 29, 30] cannot reason about object relations such as contacts). Recently, Large Vision-Language Models (LVLMs) integrate visual understanding and language generation into a unified stream, allowing direct incorporation of perceptual information into the semantic knowledge acquired from language [31, 32, 33, 34]. Preliminary explorations with LVLMs [35] have illustrated two intriguing phenomena, namely: a) by combining LVLMs with segmentation models and constructing suitable visual prompts, LVLMs can unleash extraordinary open-ended visual grounding capabilities [26], and b) effective prompting strategies like chain-of-thought [36] and in-context examples [1] seem to also emerge in LVLMs. Motivated by these results, we perform an in-depth study of the potential contributions of LVLMs in open-ended robotic grasping. In this paper, we propose Open World Grasper (OWG): an integrated approach that is applicable zero-shot for grasping in open-ended environments, object catalogs and language instructions. OWG combines LVLMs with segmentation [37] and grasp synthesis models [38], which supplement the LVLM’s semantic knowledge with low-level dense spatial inference. OWG decomposes the task in three stages: open-ended referring segmentation, where the target object is grounded from open-ended language, (ii) grounded grasp planning, where the agent reasons about the feasibility of grasping the target and proposes a next action, and (iii) grasp ranking, where the LVLM ranks grasp proposals generated from the grasp synthesizer based on potential contacts.
In summary, our contributions are threefold: a) we propose a novel algorithm for grasping from open-ended language using LVLMs, b) we conduct extensive comparisons and ablation studies in real cluttered indoor scenes data [39, 40], where we show that our prompting strategies enable LVLMs to ground arbitrary natural language queries, such as open-vocabulary object descriptions, referring expressions and user-affordances, while outperforming previous zero-shot vision-language models by a significant margin, and c) we integrate OWG with a robot framework and conduct experiments both in simulation and in the real world, where we illustrate that LVLMs can advance the performance of zero-shot approaches in the open-world setup.
2 Related Works
Visual Prompting for Vision-Language Models Several works investigate how to bypass fine-tuning VLMs, instead relying on overlaying visual/semantic information to the input frame, a practise commonly referred to as visual prompting. Colorful prompting tuning (CPT) is the first work that paints image regions with different colors and uses masked language models to “fill the blanks” [41]. Other methods try to use CLIP [42] by measuring the similarity between a visual prompt and a set of text concepts. RedCircle [43] draws a red circle on an image, forcing CLIP to focus on a specific region. FGVP [44] further enhances the prompt by specifically segmenting and highlighting target objects. Recent works explore visual prompting strategies for LVLMs such as GPT-4v, by drawing arrows and pointers [35] or highlighting object regions and overlaying numeric IDs [26]. In the same vein, in this work we prompt GPT-4v to reason about visual context while being grounded to specific spatial elements of the image, such as objects, regions and grasps.
LLMs/LVLMs in Robotics Recent efforts use LLMs as an initialization for vision-language-action models [45, 46], fine-tuned in robot demonstration data with auxiliary VQA tasks [46, 45, 47]. Such end-to-end approaches require prohibitive resources to reproduce, while still struggling to generalize out-of-distribution, due to the lack of large-scale demonstration datasets. Alternatively, modular approaches invest on the current capabilities of LLMs to decompose language instructions into a sequence of high-level robot skills [48, 11, 12, 22, 14], or low-level Python programs composing external vision and action models as APIs [13, 23, 21, 22, 25, 49]. Such approaches mostly focus on the task planning problem, showcasing that the world knowledge built in LLMs enables zero-shot task decomposition, but require external modules [28, 29, 30, 42] to ground plan steps to the environment and reason about the scene. Recent works study the potential of LVLMs for inherently grounded task planning [27, 50, 51]. In [50], the authors use GPT-4v to map videos of human performing tasks into symbolic plans, but do not consider it for downstream applications. VILA [27] feeds observation images with text prompts to an LVLM to plan without relying on external detectors. However, produced plans are expressed entirely in language and assume an already obtained skill library to execute the plans. MOKA [51] proposes a keypoint-based visual prompting scheme to parameterize low-level motions, but still relies on external vision models to perform grounding, and does not consider referring expressions and clutter.. In our work, we use visual marker prompting to leverage LVLMs for the full stack of the open-world grasping pipeline, including grounding referring expressions, task planning and low-level motion parameterization via grasp ranking.
Semantics-informed Grasping Most research on grasping assumes golden grounding, i.e., the target object is already segmented from the input scene. Instead, they focus on proposing 4-DoF grasps from RGB-D views [52, 53, 54, 38, 55, 56, 57], or 6-DoF poses from 3D data [58, 59, 60, 61, 62, 63, 64]. Recently, several works study language-guided grasping in an end-to-end fashion, where a language model encodes the user instruction to provide conditioning for grasping [65, 66, 39]. However, related methods typically train language-conditioned graspers that struggle to generalize outside the training distribution. Another similar line of works is that of task-oriented grasping [67, 68], where recent LLM-based methods [69] exploit the vast knowledge of LLMs to provide additional semantic context for selecting task-oriented grasps, but do not consider the grounding problem, clutter or referring expressions. Further, none of the above approaches consider the planning aspect, typically providing open-loop graspers that do not incorporate environment feedback. In this work, we leverage LVLMs to orchestrate a pipeline for language-guided grasping in clutter, exploiting it’s multimodal nature to jointly ground, reason and plan.
3 Method
3.1 Prerequisites and Problem Statement
Large Vision-Language Models VLMs receive a set of RGB images of size : and a sequence of text tokens , and generate a text sequence of length : from a fixed token vocabulary , such that: . The images-text pair input is referred to as the prompt, with the text component typically being a user instruction or question that primes the VLM for a specific task.
Grasp Representations We represent a grasp via an end-effector gripper pose , with for 4-DoF and for 6-DoF grasping. Such representation contains a 3D position and either a yaw rotation or a full SO(3) orientation for 4-DoF and 6-DoF respectively. 4-DoF grasps assume that the approach vector is calibrated with the camera extrinsics, and hence can be directly drawn as rectangles in the 2D image plane (see bottom of Fig. 2), which happens to be a favorable representation for VLMs, as grasp candidates can be interpreted as part of the input image prompt. A motion primitive is invoked to move the arm to the desired gripper pose , e.g. via inverse-kinematics solvers. 111More sophisticated motion planning algorithms, e.g. with integrated obstacle avoidance, can be utilized orthogonal to our approach.
Problem Statement Given an RGB-D observation , and an open-ended language query , which conveys an instruction to grasp a target object, the goal of OWG is to provide a policy . Assuming the objects that appear in the scene and the target object, then at each time step , the policy outputs a pose for grasping an object: , where the last step always maps to grasping the target object: . We refer to the function as the grasp generation function, which corresponds to a pretrained grasp synthesis network from RGB-D views [38] 222Other point-cloud [59] or voxel-based [62] methods for 3D grasp generation can be utilized orthogonal to our approach, which uses single RGB-D view. We note that our policy outputs directly the actual gripper pose , and the object-centric abstraction is used implicitly (details in next sections).
We wish to highlight that in most grasp synthesis pipelines [38, 55, 53, 57, 56], it’s always and , which corresponds to an open-loop policy attempting to grasp the object of interest once. Our formulation for allows the VLM to close the loop by re-running after each step, which enables visual feedback for planning and recovery from failures / external disturbances.
3.2 Pipeline Overview
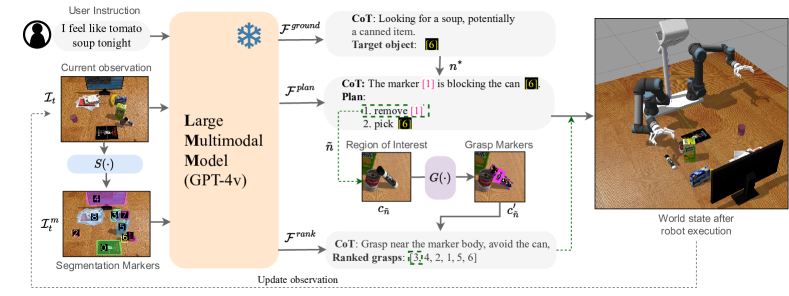
OWG combines VLMs with pretrained 2D instance segmentation and grasp synthesis models. Segmentation methods like SAM [37] and its variants [70, 71] have demonstrated impressive zero-shot performane. Similarly, view-based grasp synthesis networks [56, 55, 38, 53, 57] have also shown to be transferable to unseen content, as they are trained without assumptions of objectness or semantics in their training objectives. The zero-shot capabilities of these models for low-level dense spatial tasks is complementary to the high-level semantic reasoning capabilities of VLMs, while both use images as the underlying representation, hence offering a very attractive coupling for tackling the open-world grasping problem. The overall pipeline can be decomposed in three subsequent stages: (i) open-ended referring segmentation, (ii) grounded grasp planning, and (iii) grasp generation and ranking. A schematic of OWG is shown in Fig. 2 and described formally in Algorithm 1. Prompt implementation details can be found in Appendix A.

Open-ended referring segmentation In this stage, the target object of interest must be segmented from the input RGB image given the instruction . To enable this, we first run our segmentation model and then draw the generated masks with additional visual markers in a new frame . This step aims to exploit the VLM’s OCR capabilities and link each segment in the frame with a unique ID that the VLM can use to refer to it. After augmenting the image with visual markers, we pass the prompt to the VLM. We refer to this VLM generation as , such that: where the target object and its segmentation mask. We note that can contain free-form natural language referring to a target object, such as open object descriptions, object relations, affordances etc.
Grounded grasp planning This stage attempts to leverage VLM’s visual reasoning capabilities in order to produce a plan that maximizes the chances that the target object is graspable. If the target object is blocked by neighboring objects, the agent should remove them first by picking them an placing them in free tabletop space. Similar to [27], we construct a text prompt that describes these two options (i.e., remove neighbor or pick target) as primitive actions for the VLM to compose plans from. We provide the marked image together with the target object (from the previous grounding stage) to determine a plan: . Each corresponds to the decision to grasp the object with marker ID . As motivated earlier, in order to close the loop, we take the target of the first step of the plan and move to the grasping stage of our pipeline.
Grasp generation and ranking After determining the current object to grasp , we invoke our grasp synthesis model to generate grasp proposals. To that end, we element-wise multiply the mask with the RGB-D observation, thus isolating only object in the input frames: . The grasp synthesis network outputs pixel-level quality, angle and width masks which can be directly transformed to 4-DoF grasps [56, 55, 38], where the total number of grasp proposals. Then, we crop a small region of interest around the bounding box of the segment in the frame , from its mask . We draw the grasp proposals as 2D grasp rectangles within the cropped image and annotate each one with a numeric ID marker, similar to the grounding prompt. We refer to the marked cropped frame as . Then, we prompt the VLM to rank the drawn grasp proposals: where the prompt instructs the VLM to rank based on each grasp’s potential contacts with neighboring objects. Finally, the grasp ranked best by the VLM is selected and sent to our motion primitive for robot execution.
4 Experiments
In this section, we compare the open-ended grounding capabilities of OWG vs. previous zero-shot methods in indoor cluttered scenes (Sec. 4.1). Then, we demonstrate its potential for open-world grasping both in simulation and in hardware (Sec. 4.2). Finally, we investigate the effect of several components of our methodology via ablation studies (Sec. 4.3).
4.1 Open-Ended Grounding in Cluttered Scenes
| Method |
|
Name | Attribute |
|
|
|
Affordance |
|
Avg. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ReCLIP [72] | CLIP [42] | 71.4 | 57.7 | 27.3 | 47.4 | 46.2 | 62.5 | 20.8 | 47.6 | ||||||||||
| RedCircle [43] | CLIP [42] | 52.4 | 53.9 | 18.2 | 42.1 | 46.2 | 18.9 | 12.5 | 34.8 | ||||||||||
| FGVP [44] | CLIP [42] | 50.0 | 53.9 | 33.3 | 36.9 | 53.8 | 43.8 | 29.1 | 43.0 | ||||||||||
| FGVP∗ [44] | CLIP [42] | 65.7 | 65.4 | 33.3 | 42.1 | 69.2 | 56.2 | 29.1 | 51.8 | ||||||||||
| QWEN-VL-2 [31] | QWEN [31] | 64.3 | 60.9 | 52.4 | 44.0 | 47.1 | 11.9 | 42.1 | 46.1 | ||||||||||
| SoM [26] | GPT-4v [73] | 54.8 | 42.3 | 54.6 | 57.9 | 53.9 | 62.5 | 45.8 | 53.1 | ||||||||||
| OWG (Ours) | GPT-4v [73] | 85.7 | 80.8 | 75.8 | 73.7 | 76.9 | 93.8 | 79.2 | 80.8 |
In order to evaluate the open-ended potential of OWG for grounding, we create a small subset of OCID-VLG test split [39], which we manually annotate for a broad range of grasping instructions. As we strive for zero-shot usage in open scenes, we mostly experiment with previous visual prompting techniques for large-scale VLMs, such as CLIP [43, 44, 72], as well as the recent Set-of-Mark prompting methodology for GPT-4v [26], which constitutes the basis of our method. We also include comparisons with open-source visually-grounded LVLM QWEN-VL-2 [31]. Please see Appendix C for details on the test dataset, baseline implementations and more comparative ablations and qualitative results.
We observe that both CLIP-based visual prompting techniques and open-source LVLMs are decent in object-based but fail to relate objects from the visual prompts. Even GPT-4v-based SoM prompting method is not directly capable of handling cluttered tabletop scenes from depth cameras, as is evident by the averaged mIoU across all query types. Overall, our OWG-grounder achieves an averaged mIoU score of , which corresponds to a delta from the second best approach. Importantly, OWG excels at semantic and affordance-based queries, something which is essential in human-robot interaction applications but is missing from modern vision-language models. We identify two basic failure modes: a) the LVLM confused the target description with another object, e.g. due to same appearance or semantics, and b) the LVLM reasons correctly about the object and where it is roughly located, but chooses a wrong numeric ID to refer to it.
4.2 Open-World Grasping Robot Experiments

In this section we wish to evaluate the full stack of OWG, incl. grounding, grasp planning and grasp ranking via contact reasoning, in scenarios that emulate open-world grasping challenges. To that end, we conduct experiments in both simulation and in hardware, where in each trial we randomly place 5-15 objects in a tabletop and instruct the robot to grasp an object of interest. We conduct trials in two scenarios, namely: a) isolated, where all objects are scattered across the tabletop, b) cluttered, where objects are tightly packed together leading to occlusions and rich contacts. We highlight that object-related query trials contain distractor objects that share the same category with the target object.
| Setup | CROG [39] | SayCan-IM [12] | OWG (Ours) | |||
|---|---|---|---|---|---|---|
| seen | unseen | seen | unseen | seen | unseen | |
| Simulation () | ||||||
| -Isolated | ||||||
| -Cluttered | ||||||
| Real-World () | ||||||
| -Isolated | ||||||
| -Cluttered | ||||||
Baselines We compare with two baselines, namely: a) CROG [39], an end-to-end referring grasp synthesis model trained in OCID [40] scenes, and b) SayCan-IM [12], an LLM-based zero-shot planning method that actualizes embodied reasoning via chaining external modules for segmentation, grounding and grasp synthesis, while reasoning with LLM chain-of-thoughts [74]. Our choice of baselines aims at showing the advantages of using an LVLM-based method vs. both implicit end-to-end approaches, as well as modular approaches that rely solely on LLMs to reason, with visual processing coming through external tools. See details in baseline implementations in Appendix B.
Implementation Our robot setup consists of two UR5e arms with Robotiq 2F-140 parallel jaw grippers and an ASUS Xtion depth camera. We conduct 50 trials per scenario in the Gazebo simulator [75], using 30 unique object models. For real robot experiments, we conduct 6 trials per scenario having the initial scenes as similar as possible between baselines. In both SayCan-IM and our method, Mask-RCNN [76] is utilized for 2D instance segmentation while GR-ConvNet [38] pretrained in Jacquard [52] is used as the grasp synthesis module. Our robotic setup is illustrated in Fig. 4, while more details can be found in Appendix B. To investigate generalization performance, all method are evaluated in both scenarios, in two splits: (i) seen, where target objects and queries are present in the method’s training data or in-context prompts, and (ii) unseen, where the instruction refers to objects that do not appear in CROG’s training data or SayCan-IM’s in-context prompts. Averaged success rate per scenario is reported, where a trial is considered successful if the robot grasps the object and places it in a pre-defined container position.
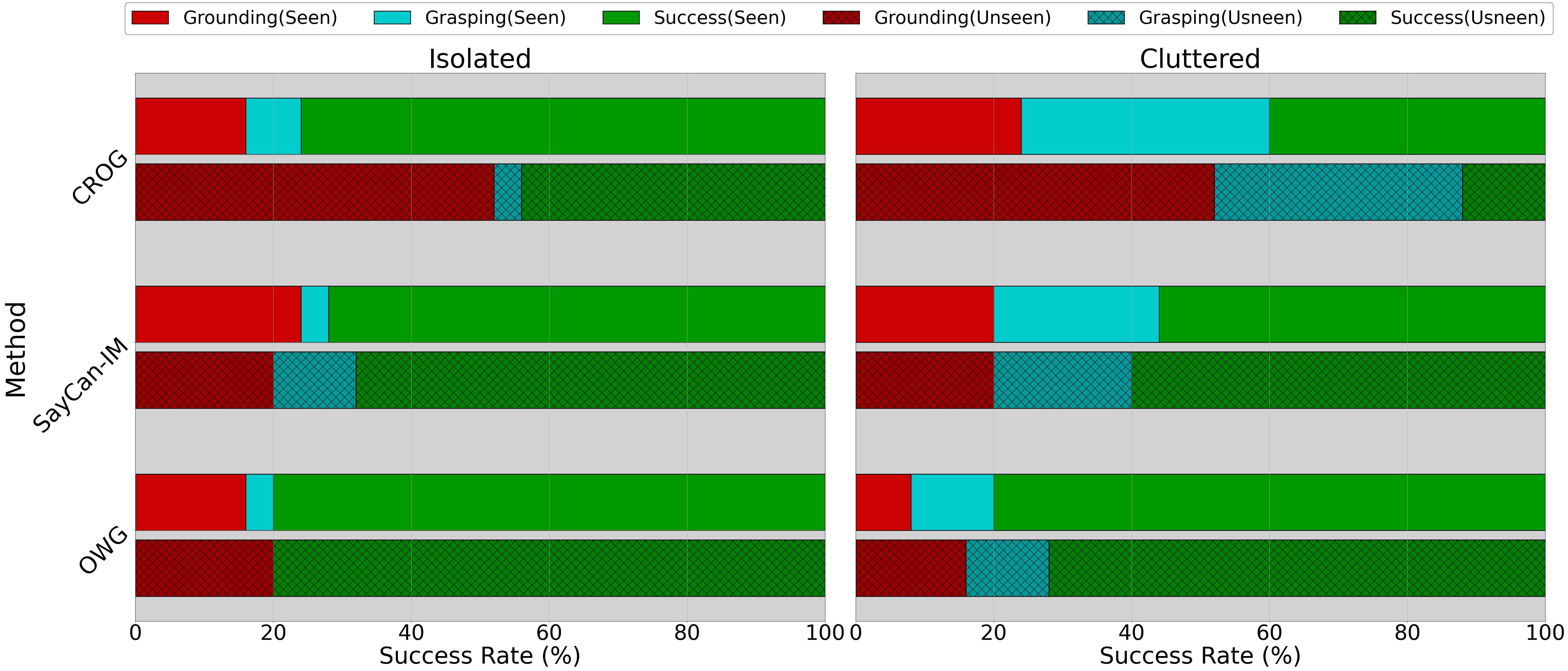
Results We observe that the supervised method CROG struggles when used at unseen data, in both scenarios. In contrary, both SayCan-IM and OWG demonstrate immunity to seen/unseen objects, illustrating the strong zero-shot capabilities of LLM-based approaches, which can naturally generalize the concepts of object categories/attributes/relations from language. SayCan-IM is limited by the external vision models and hence struggles in cluttered scenes, where its detector sometimes fails to perceive the target object, resulting in lower final success rates compared to OWG, especially in the real-world experiments. OWG consistently outperforms both baselines both in simulation and in the real robot, with an and improved averaged success rate respectively. In Fig. 5, we illustrate the decomposition of failures across grounding and grasping in our baselines for Gazebo trials per scenario, where we automatically test for the target object’s grounding results alongside success rate. We observe that OWG consistently reduces the error rates in both grasping and grasping compared to the baselines in all scenarios and test splits. We believe that these results are encouraging for the future of LVLMs in robot grasping.
4.3 Ablation Studies
In out ablations we wish to answer the following questions: a) What is the bottleneck introduced by the segmentation model in the open-ended grounding performance?, b) What are the contributions of all the different visual prompt elements considered in our work?, and c) What is the contribution of the LVLM-based grasp planning and ranking in robot grasping experiments? The grounding ablations for the first two questions are organized in Table 3, while for the latter in Table 4.
Instance segmentation bottleneck We compare the averaged mIoU of our OWG grounder in a subset of our OCID-VLG evaluation data for three different segmentation methods and ground-truth masks. We employ: a) SAM [37], b) the RPN module of the open-vocabulary detector ViLD [28], and c) the RGB-D two-stage instance segmentation method UOIS [77], where we also provide the depth data as part of the input. ViLD-RPN and UOIS both achieve a bit above , which is a delta from ground-truth masks, while SAM offers the best baseline with a delta from ground-truth. Implementation details and related visualizations in Appendix C.
| Method | mIoU (%) |
|---|---|
| OWG (w/ Ground-Truth Mask) | |
| -w/o reference | |
| -w/o number overlay | |
| -w/o high-res | |
| -w/o self-consistency | |
| -w/ box | |
| -w/o CoT prompt | |
| -w/o mask fill | |
| SAM [37] | |
| ViLD-RPN [78] | |
| UOIS [77] |
Visual prompt components Visual prompt design choices have shown to significantly affect the performance of LVLMs. We ablate all components of our grounding prompt and observe the contribution of each one via its averaged mIoU in the same subset as above (see details in Appendix A.2). The most important prompt component is the reference image, provided alongside the marked image. Due to the high clutter of our test scenes, simply highlighting marks and label IDs in a single frame, as in SoM [26] hinders the recognition capabilities of the LVLM, with a mIoU drop from to . Further decluttering the marked image also helps, with overlaying the numeric IDs, using high-resolution images and highlighting the inside of each region mask being decreasingly important. Surprisingly, also marking bounding boxes leads to a mIoU drop compared to avoiding them, possibly due to occlusions caused by lots of boxes in cluttered areas. Finally, self-consistency and chain-of-thought prompting components that were added also improve LVLM’s grounding performance by and respectively, by ensembling multiple responses and enforcing step-by-step reasoning.
| Method | Isolated | Cluttered |
|---|---|---|
| OWG | ||
| -w/o planning | ||
| -w/o grasp ranking | ||
| -w/o both |
Grasp-Related Ablations We quantify the contribution of our grasp planning and ranking stages in the open-world grasping pipeline, by replicating trials as in the previous section and potentially skipping one or both of these stages. As we see in Table 4, the effect of these components is not so apparent in isolated scenes, as objects are not obstructed by surroundings and hence most proposed grasps are feasible. The effect becomes more prominent in the cluttered scenario, where the lack of grasp planning leads to a success rate decrease of . This is because without grasp planning the agent attempts to grasp the target immediately, which almost always leads to a collision that makes the grasp fail. Grasp ranking is less essential, as a lot of contact-related information is existent in the grasp quality predictions of our grasp synthesis network. However, it still provides an important boost in final success rate ( increase). When skipping both stages, the agent’s performance drops drastically in cluttered scenes, as it is unable to recover from grasp failures, and hence always fails when the first attempted grasp was not successful.
5 Conclusion, Limitations & Future Work
In this paper we introduce OWG, a novel system formulation for tackling open-world grasping. Our focus is on combining LVLMs with segmentation and grasp synthesis models, and visually prompt the LVLM to ground, plan and reason about the scene and the object grasps. Our works sets a foundation for enabling robots to ground open-ended language input and close-the-loop for effective grasp planning and contact reasoning, leading to significant improvements over previous zero-shot approaches, as demonstrated by empirical evaluations, ablation studies and robot experiments.
Limitations First, as OWG is a modular approach, it suffers from error cascading effects introduced by the segmentor and grasp synthesis models. However, improvements in these areas mean direct improvement to the OWG pipeline. Second, we currently use 4-DoF grasps to communicate them visually to GPT-4v, which constrains grasping to single view. In the future we would like to integrate 6-DoF grasp detectors and explore new prompting schemes to aggregate and rank grasp information visually. Third, our results suggest that LVLMs still struggle to ground complex object relationships. More sophisticated prompting schemes beyond marker overlaying, or instruct-tuning in grasp-related data, might be a future direction for dealing with this limitation.
References
- Brown et al. [2020] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, and et. al. Language models are few-shot learners. ArXiv, abs/2005.14165, 2020. URL https://api.semanticscholar.org/CorpusID:218971783.
- OpenAI [2023] OpenAI. Gpt-4 technical report,. 2023.
- Touvron et al. [2023a] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample. Llama: Open and efficient foundation language models. ArXiv, abs/2302.13971, 2023a. URL https://api.semanticscholar.org/CorpusID:257219404.
- Touvron et al. [2023b] H. Touvron, L. Martin, K. R. Stone, P. Albert, A. Almahairi, and Y. B. et. al. Llama 2: Open foundation and fine-tuned chat models. ArXiv, abs/2307.09288, 2023b. URL https://api.semanticscholar.org/CorpusID:259950998.
- Chowdhery et al. [2022] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, and A. R. et. al. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res., 24:240:1–240:113, 2022. URL https://api.semanticscholar.org/CorpusID:247951931.
- Gurnee and Tegmark [2023] W. Gurnee and M. Tegmark. Language models represent space and time. ArXiv, abs/2310.02207, 2023. URL https://api.semanticscholar.org/CorpusID:263608756.
- Jiang et al. [2019] Z. Jiang, F. F. Xu, J. Araki, and G. Neubig. How can we know what language models know? Transactions of the Association for Computational Linguistics, 8:423–438, 2019. URL https://api.semanticscholar.org/CorpusID:208513249.
- Petroni et al. [2019] F. Petroni, T. Rocktäschel, P. Lewis, A. Bakhtin, Y. Wu, A. H. Miller, and S. Riedel. Language models as knowledge bases? ArXiv, abs/1909.01066, 2019. URL https://api.semanticscholar.org/CorpusID:202539551.
- Song et al. [2022] C. H. Song, J. Wu, C. Washington, B. M. Sadler, W.-L. Chao, and Y. Su. Llm-planner: Few-shot grounded planning for embodied agents with large language models. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2986–2997, 2022. URL https://api.semanticscholar.org/CorpusID:254408960.
- Ding et al. [2022] Y. Ding, X. Zhang, S. Amiri, N. Cao, H. Yang, C. Esselink, and S. Zhang. Robot task planning and situation handling in open worlds. ArXiv, abs/2210.01287, 2022. URL https://api.semanticscholar.org/CorpusID:252693004.
- Ahn et al. [2022] M. Ahn, A. Brohan, N. Brown, Y. Chebotar, O. Cortes, B. David, and C. F. et. al. Do as i can, not as i say: Grounding language in robotic affordances. In Conference on Robot Learning, 2022. URL https://api.semanticscholar.org/CorpusID:247939706.
- Huang et al. [2022] W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. R. Florence, A. Zeng, J. Tompson, I. Mordatch, Y. Chebotar, P. Sermanet, N. Brown, T. Jackson, L. Luu, S. Levine, K. Hausman, and B. Ichter. Inner monologue: Embodied reasoning through planning with language models. In Conference on Robot Learning, 2022. URL https://api.semanticscholar.org/CorpusID:250451569.
- Singh et al. [2022] I. Singh, V. Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg. Progprompt: Generating situated robot task plans using large language models. 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 11523–11530, 2022. URL https://api.semanticscholar.org/CorpusID:252519594.
- Huang et al. [2023] W. Huang, F. Xia, D. Shah, D. Driess, A. Zeng, Y. Lu, P. R. Florence, I. Mordatch, S. Levine, K. Hausman, and B. Ichter. Grounded decoding: Guiding text generation with grounded models for robot control. ArXiv, abs/2303.00855, 2023. URL https://api.semanticscholar.org/CorpusID:257279977.
- Lin et al. [2023] K. Lin, C. Agia, T. Migimatsu, M. Pavone, and J. Bohg. Text2motion: from natural language instructions to feasible plans. Autonomous Robots, 47:1345 – 1365, 2023. URL https://api.semanticscholar.org/CorpusID:257663442.
- Yu et al. [2023] B. Yu, H. Kasaei, and M. Cao. L3mvn: Leveraging large language models for visual target navigation. 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3554–3560, 2023. URL https://api.semanticscholar.org/CorpusID:258079021.
- Zhou et al. [2023] G. Zhou, Y. Hong, and Q. Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large language models. ArXiv, abs/2305.16986, 2023. URL https://api.semanticscholar.org/CorpusID:258947250.
- Rajvanshi et al. [2023] A. Rajvanshi, K. Sikka, X. Lin, B. Lee, H.-P. Chiu, and A. Velasquez. Saynav: Grounding large language models for dynamic planning to navigation in new environments. ArXiv, abs/2309.04077, 2023. URL https://api.semanticscholar.org/CorpusID:261660608.
- Lin et al. [2022] B. Lin, Y. Zhu, Z. Chen, X. Liang, J. zhuo Liu, and X. Liang. Adapt: Vision-language navigation with modality-aligned action prompts. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15375–15385, 2022. URL https://api.semanticscholar.org/CorpusID:249209579.
- Stone et al. [2023] A. Stone, T. Xiao, Y. Lu, K. Gopalakrishnan, K.-H. Lee, Q. H. Vuong, P. Wohlhart, B. Zitkovich, F. Xia, C. Finn, and K. Hausman. Open-world object manipulation using pre-trained vision-language models. ArXiv, abs/2303.00905, 2023. URL https://api.semanticscholar.org/CorpusID:257280290.
- Liang et al. [2022] J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. R. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9493–9500, 2022. URL https://api.semanticscholar.org/CorpusID:252355542.
- Zeng et al. [2022] A. Zeng, A. S. Wong, S. Welker, K. Choromanski, F. Tombari, A. Purohit, M. S. Ryoo, V. Sindhwani, J. Lee, V. Vanhoucke, and P. R. Florence. Socratic models: Composing zero-shot multimodal reasoning with language. ArXiv, abs/2204.00598, 2022. URL https://api.semanticscholar.org/CorpusID:247922520.
- Huang et al. [2023] S. Huang, Z. Jiang, H.-W. Dong, Y. J. Qiao, P. Gao, and H. Li. Instruct2act: Mapping multi-modality instructions to robotic actions with large language model. ArXiv, abs/2305.11176, 2023. URL https://api.semanticscholar.org/CorpusID:258762636.
- Vemprala et al. [2023] S. Vemprala, R. Bonatti, A. F. C. Bucker, and A. Kapoor. Chatgpt for robotics: Design principles and model abilities. ArXiv, abs/2306.17582, 2023. URL https://api.semanticscholar.org/CorpusID:259141622.
- Huang et al. [2023] W. Huang, C. Wang, R. Zhang, Y. Li, J. Wu, and L. Fei-Fei. Voxposer: Composable 3d value maps for robotic manipulation with language models. ArXiv, abs/2307.05973, 2023. URL https://api.semanticscholar.org/CorpusID:259837330.
- Yang et al. [2023] J. Yang, H. Zhang, F. Li, X. Zou, C. yue Li, and J. Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. ArXiv, abs/2310.11441, 2023. URL https://api.semanticscholar.org/CorpusID:266149987.
- Hu et al. [2023] Y. Hu, F. Lin, T. Zhang, L. Yi, and Y. Gao. Look before you leap: Unveiling the power of gpt-4v in robotic vision-language planning. ArXiv, abs/2311.17842, 2023. URL https://api.semanticscholar.org/CorpusID:265715696.
- Gu et al. [2021] X. Gu, T.-Y. Lin, W. Kuo, and Y. Cui. Open-vocabulary object detection via vision and language knowledge distillation. In International Conference on Learning Representations, 2021. URL https://api.semanticscholar.org/CorpusID:238744187.
- Minderer et al. [2022] M. Minderer, A. A. Gritsenko, A. Stone, M. Neumann, D. Weissenborn, A. Dosovitskiy, A. Mahendran, A. Arnab, M. Dehghani, Z. Shen, X. Wang, X. Zhai, T. Kipf, and N. Houlsby. Simple open-vocabulary object detection with vision transformers. ArXiv, abs/2205.06230, 2022. URL https://api.semanticscholar.org/CorpusID:248721818.
- Kamath et al. [2021] A. Kamath, M. Singh, Y. LeCun, I. Misra, G. Synnaeve, and N. Carion. Mdetr - modulated detection for end-to-end multi-modal understanding. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 1760–1770, 2021. URL https://api.semanticscholar.org/CorpusID:233393962.
- Bai et al. [2023] J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. ArXiv, abs/2308.12966, 2023. URL https://api.semanticscholar.org/CorpusID:263875678.
- Dai et al. [2023] W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. A. Li, P. Fung, and S. C. H. Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. ArXiv, abs/2305.06500, 2023. URL https://api.semanticscholar.org/CorpusID:258615266.
- Liu et al. [2023] H. Liu, C. Li, Q. Wu, and Y. J. Lee. Visual instruction tuning. ArXiv, abs/2304.08485, 2023. URL https://api.semanticscholar.org/CorpusID:258179774.
- Zhu et al. [2023] D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. ArXiv, abs/2304.10592, 2023. URL https://api.semanticscholar.org/CorpusID:258291930.
- Yang et al. [2023] Z. Yang, L. Li, K. Lin, J. Wang, C.-C. Lin, Z. Liu, and L. Wang. The dawn of lmms: Preliminary explorations with gpt-4v(ision). ArXiv, abs/2309.17421, 2023. URL https://api.semanticscholar.org/CorpusID:263310951.
- Kojima et al. [2022] T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa. Large language models are zero-shot reasoners. ArXiv, abs/2205.11916, 2022. URL https://api.semanticscholar.org/CorpusID:249017743.
- Kirillov et al. [2023] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollár, and R. B. Girshick. Segment anything. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3992–4003, 2023. URL https://api.semanticscholar.org/CorpusID:257952310.
- Kumra et al. [2019] S. Kumra, S. Joshi, and F. Sahin. Antipodal robotic grasping using generative residual convolutional neural network. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9626–9633, 2019. URL https://api.semanticscholar.org/CorpusID:202558732.
- Tziafas et al. [2023] G. Tziafas, Y. XU, A. Goel, M. Kasaei, Z. Li, and H. Kasaei. Language-guided robot grasping: Clip-based referring grasp synthesis in clutter. In J. Tan, M. Toussaint, and K. Darvish, editors, Proceedings of The 7th Conference on Robot Learning, volume 229 of Proceedings of Machine Learning Research, pages 1450–1466. PMLR, 06–09 Nov 2023.
- Suchi et al. [2019] M. Suchi, T. Patten, and M. Vincze. Easylabel: A semi-automatic pixel-wise object annotation tool for creating robotic rgb-d datasets. 2019 International Conference on Robotics and Automation (ICRA), pages 6678–6684, 2019.
- Yao et al. [2021] Y. Yao, A. Zhang, Z. Zhang, Z. Liu, T. seng Chua, and M. Sun. Cpt: Colorful prompt tuning for pre-trained vision-language models. ArXiv, abs/2109.11797, 2021. URL https://api.semanticscholar.org/CorpusID:237635382.
- Radford et al. [2021] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. CoRR, abs/2103.00020, 2021. URL https://arxiv.org/abs/2103.00020.
- Shtedritski et al. [2023] A. Shtedritski, C. Rupprecht, and A. Vedaldi. What does clip know about a red circle? visual prompt engineering for vlms. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 11953–11963, 2023. URL https://api.semanticscholar.org/CorpusID:258108138.
- Yang et al. [2023] L. Yang, Y. Wang, X. Li, X. Wang, and J. Yang. Fine-grained visual prompting. ArXiv, abs/2306.04356, 2023. URL https://api.semanticscholar.org/CorpusID:259096008.
- Brohan et al. [2022] A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, J. Dabis, and C. F. et. al. Rt-1: Robotics transformer for real-world control at scale. ArXiv, abs/2212.06817, 2022. URL https://api.semanticscholar.org/CorpusID:254591260.
- Brohan et al. [2023] A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, K. Choromanski, T. Ding, D. Driess, C. Finn, P. R. Florence, and C. F. et. al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. ArXiv, abs/2307.15818, 2023. URL https://api.semanticscholar.org/CorpusID:260293142.
- Mu et al. [2023] Y. Mu, Q. Zhang, M. Hu, W. Wang, M. Ding, J. Jin, B. Wang, J. Dai, Y. Qiao, and P. Luo. Embodiedgpt: Vision-language pre-training via embodied chain of thought. ArXiv, abs/2305.15021, 2023. URL https://api.semanticscholar.org/CorpusID:258865718.
- Huang et al. [2022] W. Huang, P. Abbeel, D. Pathak, and I. Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. ArXiv, abs/2201.07207, 2022. URL https://api.semanticscholar.org/CorpusID:246035276.
- Jin et al. [2023] Y. Jin, D. Li, Y. A, J. Shi, P. Hao, F. Sun, J. Zhang, and B. Fang. Robotgpt: Robot manipulation learning from chatgpt. IEEE Robotics and Automation Letters, 9:2543–2550, 2023. URL https://api.semanticscholar.org/CorpusID:265608813.
- Wake et al. [2023] N. Wake, A. Kanehira, K. Sasabuchi, J. Takamatsu, and K. Ikeuchi. Gpt-4v(ision) for robotics: Multimodal task planning from human demonstration. ArXiv, abs/2311.12015, 2023. URL https://api.semanticscholar.org/CorpusID:265295011.
- Liu et al. [2024] F. Liu, K. Fang, P. Abbeel, and S. Levine. Moka: Open-world robotic manipulation through mark-based visual prompting. Robotics: Science and Systems XX, 2024. URL https://api.semanticscholar.org/CorpusID:268249161.
- Depierre et al. [2018] A. Depierre, E. Dellandréa, and L. Chen. Jacquard: A large scale dataset for robotic grasp detection. 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3511–3516, 2018.
- Ainetter and Fraundorfer [2021] S. Ainetter and F. Fraundorfer. End-to-end trainable deep neural network for robotic grasp detection and semantic segmentation from rgb. 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13452–13458, 2021.
- Jiang et al. [2011] Y. Jiang, S. Moseson, and A. Saxena. Efficient grasping from rgbd images: Learning using a new rectangle representation. 2011 IEEE International Conference on Robotics and Automation, pages 3304–3311, 2011.
- Morrison et al. [2018] D. Morrison, P. Corke, and J. Leitner. Closing the loop for robotic grasping: A real-time, generative grasp synthesis approach. ArXiv, abs/1804.05172, 2018. URL https://api.semanticscholar.org/CorpusID:4891707.
- Kumra et al. [2022] S. Kumra, S. Joshi, and F. Sahin. Gr-convnet v2: A real-time multi-grasp detection network for robotic grasping. Sensors (Basel, Switzerland), 22, 2022. URL https://api.semanticscholar.org/CorpusID:251706781.
- Xu et al. [2023] Y. Xu, M. M. Kasaei, S. H. M. Kasaei, and Z. Li. Instance-wise grasp synthesis for robotic grasping. ArXiv, abs/2302.07824, 2023.
- Mahler et al. [2017] J. Mahler, J. Liang, S. Niyaz, M. Laskey, R. Doan, X. Liu, J. A. Ojea, and K. Goldberg. Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics. ArXiv, abs/1703.09312, 2017. URL https://api.semanticscholar.org/CorpusID:6138957.
- Fang et al. [2020] H. Fang, C. Wang, M. Gou, and C. Lu. Graspnet-1billion: A large-scale benchmark for general object grasping. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11441–11450, 2020. URL https://api.semanticscholar.org/CorpusID:219964473.
- Eppner et al. [2020] C. Eppner, A. Mousavian, and D. Fox. ACRONYM: A large-scale grasp dataset based on simulation. In Under Review at ICRA 2021, 2020.
- Mousavian et al. [2019] A. Mousavian, C. Eppner, and D. Fox. 6-dof graspnet: Variational grasp generation for object manipulation. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2901–2910, 2019. URL https://api.semanticscholar.org/CorpusID:166228416.
- Breyer et al. [2021] M. Breyer, J. J. Chung, L. Ott, R. Y. Siegwart, and J. I. Nieto. Volumetric grasping network: Real-time 6 dof grasp detection in clutter. In Conference on Robot Learning, 2021. URL https://api.semanticscholar.org/CorpusID:230435660.
- Murali et al. [2019] A. Murali, A. Mousavian, C. Eppner, C. Paxton, and D. Fox. 6-dof grasping for target-driven object manipulation in clutter. 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 6232–6238, 2019. URL https://api.semanticscholar.org/CorpusID:208910916.
- Sundermeyer et al. [2021] M. Sundermeyer, A. Mousavian, R. Triebel, and D. Fox. Contact-graspnet: Efficient 6-dof grasp generation in cluttered scenes. 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13438–13444, 2021. URL https://api.semanticscholar.org/CorpusID:232380275.
- An et al. [2024] V. D. An, M. N. Vu, B. Huang, N. Nguyen, H. Le, T. D. Vo, and A. Nguyen. Language-driven grasp detection. ArXiv, abs/2406.09489, 2024. URL https://api.semanticscholar.org/CorpusID:270521942.
- Lu et al. [2023] Y. Lu, Y. Fan, B. Deng, F. Liu, Y. Li, and S. Wang. Vl-grasp: a 6-dof interactive grasp policy for language-oriented objects in cluttered indoor scenes. 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 976–983, 2023. URL https://api.semanticscholar.org/CorpusID:260351475.
- Ardón et al. [2019] P. Ardón, É. Pairet, R. P. A. Petrick, S. Ramamoorthy, and K. S. Lohan. Learning grasp affordance reasoning through semantic relations. IEEE Robotics and Automation Letters, 4:4571–4578, 2019. URL https://api.semanticscholar.org/CorpusID:195345691.
- Murali et al. [2020] A. Murali, W. Liu, K. Marino, S. Chernova, and A. K. Gupta. Same object, different grasps: Data and semantic knowledge for task-oriented grasping. In Conference on Robot Learning, 2020. URL https://api.semanticscholar.org/CorpusID:226306649.
- Tang et al. [2023] C. Tang, D. Huang, W. Ge, W. Liu, and H. Zhang. Graspgpt: Leveraging semantic knowledge from a large language model for task-oriented grasping. IEEE Robotics and Automation Letters, 8:7551–7558, 2023. URL https://api.semanticscholar.org/CorpusID:260154903.
- Zou et al. [2023] X. Zou, J. Yang, H. Zhang, F. Li, L. Li, J. Gao, and Y. J. Lee. Segment everything everywhere all at once. ArXiv, abs/2304.06718, 2023. URL https://api.semanticscholar.org/CorpusID:258108410.
- Li et al. [2023] F. Li, H. Zhang, P. Sun, X. Zou, S. Liu, J. Yang, C. Li, L. Zhang, and J. Gao. Semantic-sam: Segment and recognize anything at any granularity. arXiv preprint arXiv:2307.04767, 2023.
- Subramanian et al. [2022] S. Subramanian, W. Merrill, T. Darrell, M. Gardner, S. Singh, and A. Rohrbach. Reclip: A strong zero-shot baseline for referring expression comprehension. In Annual Meeting of the Association for Computational Linguistics, 2022. URL https://api.semanticscholar.org/CorpusID:248118561.
- GPT [2023] Gpt-4v(ision) system card. 2023. URL https://api.semanticscholar.org/CorpusID:263218031.
- Yao et al. [2022] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao. React: Synergizing reasoning and acting in language models. ArXiv, abs/2210.03629, 2022. URL https://api.semanticscholar.org/CorpusID:252762395.
- Koenig and Howard [2004] N. P. Koenig and A. Howard. Design and use paradigms for gazebo, an open-source multi-robot simulator. 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566), 3:2149–2154 vol.3, 2004.
- He et al. [2017] K. He, G. Gkioxari, P. Dollár, and R. B. Girshick. Mask r-cnn. 2017. URL https://api.semanticscholar.org/CorpusID:54465873.
- Xie et al. [2020] C. Xie, Y. Xiang, A. Mousavian, and D. Fox. Unseen object instance segmentation for robotic environments. IEEE Transactions on Robotics, 37:1343–1359, 2020. URL https://api.semanticscholar.org/CorpusID:220546289.
- Gu et al. [2021] X. Gu, T.-Y. Lin, W. Kuo, and Y. Cui. Open-vocabulary object detection via vision and language knowledge distillation. In International Conference on Learning Representations, 2021. URL https://api.semanticscholar.org/CorpusID:238744187.