\ul
Towards No.1 in CLUE Semantic Matching Challenge: Pre-trained Language Model Erlangshen with Propensity-Corrected Loss
Abstract
This report describes a pre-trained language model Erlangshen with propensity-corrected loss, the No.1 in CLUE Semantic Matching Challenge111https://www.cluebenchmarks.com/sim.html. In the pre-training stage, we construct a dynamic masking strategy based on knowledge in Masked Language Modeling (MLM) with whole word masking. Furthermore, by observing the specific structure of the dataset, the pre-trained Erlangshen applies propensity-corrected loss (PCL) in the fine-tuning phase. Overall, we achieve points in F1 Score and points in Accuracy on the test set. Our code is publicly available at: https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/hf-ds/fengshen/examples/clue_sim.
1 Background
1.1 Semantic Matching
With the development of data science applications, semantic matching plays a fundamental role in Natural Language Processing (NLP). These applications, such as information retrieval, often require semantic matching to combine data from multiple sources prior to further analysis Li et al. (2021). It is natural to think of semantic matching as a binary classification issue. Given a pair of sentences, the artificial intelligent system is required to determine if two sentences provide the same meaning.
1.2 CLUE Semantic Matching Challenge
To up the challenge of this problem, the CLUE team Xu et al. (2020) releases CLUE Semantic Matching Challenge. In detail, the QBQTC (QQ Browser Query Title Corpus) challenge dataset includes three labels, which are {, irrelevant or not matching; , some correlation; , high relevant}, instead of only two. Furthermore, QBQTC dataset is designed as a learning-to-rank (LTR) dataset that integrates relevance, authority, content quality, timeliness and other dimensional annotations, which is widely used in QQ search engine business scenarios222https://browser.qq.com/. In additional, this challenge is included in CLUE benchmark, which is widely evaluated in Chinese NLP community.
2 Introduction
In Chines Natural Language Understanding (NLU) tasks, Pre-trained Language Models (PLMs) have proven to be effective, such as BERT Devlin et al. (2019), MacBERT Cui et al. (2020) and ALBERT Lan et al. (2020). MacBERT and RoBERTa improve the pre-training tasks of BERT and ALBERT by considering Chinese grammatical structure Cui et al. (2020). However, those models only randomly masks tokens, which leads to a simple pre-training task. Therefore, we introduce Knowledge-based Dynamic Masking (KDM) method to mask semantically rich tokens. Moreover, we pre-train Erlangshen in a large-scale Chinese corpus and optimize the pre-training settings such as employing pre-layer normalization Xiong et al. (2020) method. In addition, several designed prompts are assigned into surprised datasets for processing surprised pre-training tasks.
As a specific Chinese NLU task, the CLUE Semantic Matching Challenge has higher difficulty than binary classification semantic matching. By our observation, the QBQTC dataset has serious data imbalance problem, which includes a imbalance label distribution with severe bias. The large number of negative samples drives the model to ignore learning difficult positive samples under the effect of popular cross-entropy. Therefore, the poor prediction on positive samples directly leads to a low F1 score. This problem comes from the nature of cross-entropy, which treats each sample equally and tries to push them to positive or negative. An workable loss to address unbalanced samples is Dice loss Li et al. (2020). In classification scenario, we only need to concern a probability instead of an extract probability when it is a negative sample. Although Dice loss achieves the success of data imbalance, it only consider target categories while ignoring non-target categories. Therefore, this method is susceptible to the influence of a single sample. Inspired by Label-smoothing Szegedy et al. (2016), we propose Propensity-Corrected Loss (PCL) to correct the propensity of the system to predict the labels.
Through extensive experiments on the benchmark, we demonstrate that our approach achieve state-of-the-art (SOTA) performance. Ablation studies reveal that Erlangshen model and PCL are the key components to the success of understanding semantic matching. Our contributions are as follows.
-
•
We apply a powerful PLM Erlangshen on a Chinese semantic matching task.
-
•
Our proposed PCL teaches the model well in an imbalance dataset.
-
•
Our approach win the No.1 over the existing SOTA models on CLUE Semantic Matching Challenge.
3 Approach
In this section, we introduce the Pre-trained Language Model (PLM) Erlangshen (Section 3.1) and a new Propensity-Corrected Loss (PCL) (Section 3.2) to address a semantic matching problem.
3.1 PLM: Erlangshen
To improve BERT Devlin et al. (2019) in Chinese tasks, we release a new PLM, Erlangshen. Note that we can not explain the details of Erlangshen, such as training implementation and detailed methods. This advanced Chinese PLM follows the private policy and company agreement of IDEA333https://idea.edu.cn/. Fortunately, we are allowed to describe the idea of the design and the basic structure. Although Erlangshen is kept under wraps, we open-source its weights in Huggingface444https://huggingface.co/IDEA-CCNL for accessible use in custom tasks.
After the necessary declarations, we introduce our basic ideas for constructing Erlangshen. Our Erlangshen employs the similar multi-layer transformer architecture as BERT. By following the pre-training and fine-tuning paradigm, Erlangshen is pre-trained with Masked Language Modeling (MLM) Devlin et al. (2019) and Sentence-Order Prediction (SOP) Cui et al. (2021) task. When considering the linguistic characteristics of Chinese, we apply Whole Word Masking (WWM) Cui et al. (2021) to process whole Chinese words instead of individual Chinese characters in WordPiece. Furthermore, since the original MLM strategy only randomly masks tokens, the language model can easily recover common tokens such as “I am”. To address this issue, we propose a Knowledge-based Dynamic Masking (KDM) method to mask semantically rich tokens such as entities and events. Besides understanding intra-sentence information, we apply SOP task to learn inter-sentence information instead of next sentence prediction task. The main reason is that SOP is much more effective than NSP Cui et al. (2021); Lan et al. (2020). After pre-training on large-scale unsupervised data, Erlangshen and its variants are released in Huggingface.
In fine-tuning phase, we add a classifier layer on the top of Erlangshen and predict its label. In detail, given a pair of sentences and , we generate the input () with special tokens in BERT Devlin et al. (2019) as follows:
| (1) |
Then, we fed [CLS] as the global feature into the classifier for generating the final answer.
3.2 Propensity-Corrected Loss
By observing the QBQTC dataset with three labels, it suffer data imbalance problem (Details in Section 4.1). Since the label occupies the majority of samples, we focus on the correlation between different categories. We introduce the Propensity-Corrected Loss (PCL) to encourage the model to predict the dominant categories, which corrects the predicting propensity.
We consider a label set {, irrelevant or not matching; , some correlation; , high relevant}. Given a pair of sentences ( and ), we argue that the model must take care of the “distance” of labels. For example, if it is a not-matching pair, the penalty for the model to misclassify it as label must be larger than as label . Because label is closer to label in “distance” than label . If the opposite occurs, a loss bonus (which reduces the original loss) is provided. Similarly, this case also works with misclassifying labels into labels or . Note that the label represents irrelevant; the penalty for assigning the label to the label is also greater than assigning it to the label .
In detail, considering simple implementation, we apply PCL based on all samples. Let to be the ground truth set. Since PCL considers multiple conditions, we compute and as follow.
| (2) |
| (3) |
where is the sample number of the dataset and is a scaling ratio.
Then, the PCL () can be calculated as:
| (4) |
where represents the Label-smoothing loss. Condition 1 tends to encourage the model, e.g., the model misclassify label into label , which is better than label . Condition 2 tends to punish the model, e.g., the model misclassifies label into label . Condition 3 considers the cases where no correction propensity is required.
3.3 Discussion
Interestingly, PCL can be computed within a batch rather than across all samples. Therefore, as a future work, we will consider PCL in local level and global level.
4 Experiment
4.1 Experimental Setup
We summarize QBQTC dataset splits in Table 1. We further investigate the average number of words for and , average token number after organization and the label ratio. The dataset details are shown in Table 2.
Train Dev Test_public Test 180,000 20,000 5,000
Train Dev Test_public Avg. 9.6 8.60 9.7 Avg. 25.4 25.6 25.3 Avg. Token 33.9 34.1 33.8 Label Ratio 2 : 5 : 1 2 : 5 : 1 2 : 5 : 1
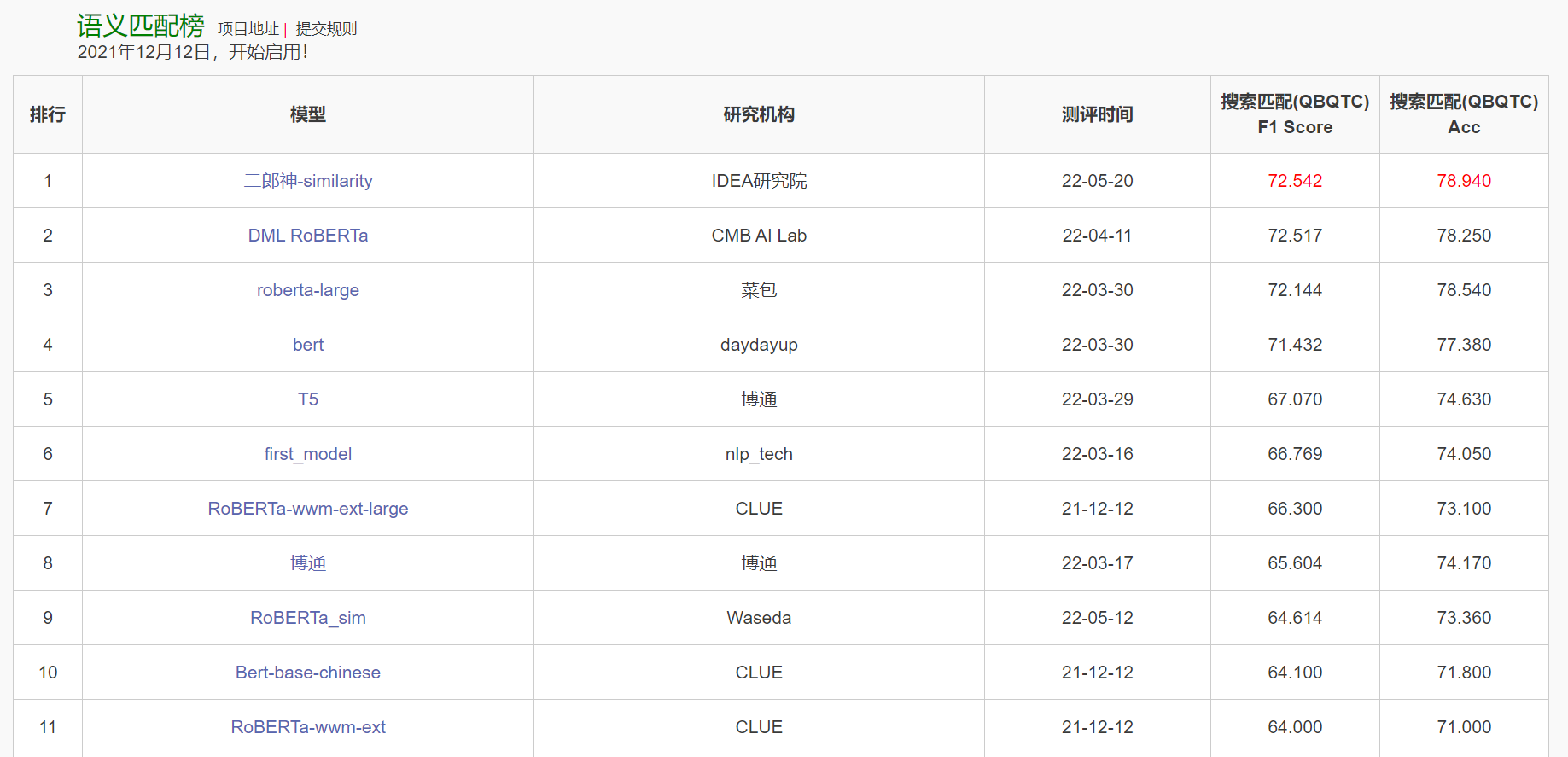
Model Research Institute F1 Score Accuracy Erlangshen IDEA 72.54 78.94 DML RoBERTa CMB AI Lab 72.52 78.25 roberta-large CaiBao 72.14 78.54 bert daydayup 71.43 77.38 T5 BoTong 67.07 74.63 first_model nlp_tech 66.77 74.05 RoBERTa-wwm-ext-large CLUE 66.30 73.10 BoTong BoTong 65.60 74.17 Bert-base-chinese CLUE 64.10 71.80 RoBERTa-wwm-ext CLUE 64.00 71.00
In all our experiments, we apply the variant “Erlangshen-MegatronBert-1.3B-Similarity”555https://huggingface.co/IDEA-CCNL/Erlangshen-MegatronBert-1.3B-Similarity as “Erlangshen”. The detailed settings are followed the open-sourced code666https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/hf-ds/fengshen/examples/clue_sim. We tune the models in train and dev set, and evaluate them in test_public set for easy analysis.
4.2 Challenge Results
After submitting our prediction files to the CLUE official website, the comparison with existing SOTA performance is listed in Table 3. Our proposed Erlangshen with PCL outperforms all models, which achieves points in F1 Score and points in Accuracy.
Label smoothing PCL F1 Score Accuracy F1 Score Accuracy RoBERTa-wwm 67.94 75.02 70.03 (+2.09) 77.02 (+2.00) MacBERT 69.18 76.58 71.78 (+2.60) 78.38 (+1.80) Erlangshen 72.24 79.10 72.74 (+0.50) 80.00 (+0.90)
4.3 Ablation Studies
To verify the effectiveness of our Erlangshen and Propensity-Corrected Loss (PCL), we conduct ablation studies on Test_public set, as shown in Table 9.
We first verified the effectiveness of our PLM Erlangshen. Regardless of the loss employed, our model outperform widely used MacBERT and RoBERTa-wwm. For label smoothing loss, our Erlangshen improve points on F1 Score and points on Accuracy over MacBERT.
Then, we explore the effectiveness of the proposed PCL. Among the models, PCL helps all models to achieve a better performance than the original label smoothing one. For MacBERT, PCL can provide up to points improvement in F1 score, and up to points improvement in accuracy. For Erlangshen, PCL can benefit up to points improvement in F1 score, and up to points improvement in accuracy. However, Erlangshen obtains less gain from PCL than other models. Our powerful Erlangen might already learn imbalance information in the dataset, so it has learned some propensity by itself rather than loss’ help.
5 Conclusion
In this work, we introduce Erlangshen with novel KDM method in MLM. Erlangshen also benefit from large-scale unlabeled data and prompted surprised datasets. By observing QBQTC dataset, we propose a new Propensity-Corrected Loss to encourage the model to predict the dominant categories, which corrects the predicting propensity. Our approach achieve the best results on CLUE Semantic Matching Challenge leaderboard. The ablation studies demonstrate the effectiveness of our designs.
In future, we plan to explore the Propensity-Corrected Loss in local and global level of the dataset. On the other hand, we will investigate the capability of Erlangshen in other NLP tasks.
Ethical Consideration
Natural language processing is an important technology in our society. It is necessary to discuss its ethical influence Leidner and Plachouras (2017). In this work, we develop a novel language model and the PCL loss. As discussed in Schramowski et al. (2022, 2019); Blodgett et al. (2020), language models might contain human-like biases from pre-trained datasets, which might embed in both the parameters of the models and outputs. In additional, we know that Erlangshen with PCL loss can be employed in similar applications, which may have potential to be abused and caused unexpected influence. We encourage open debating on its utilization, such as the task selection and the deployment, hoping to reduce the chance of any misconduct.
References
- Blodgett et al. (2020) Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna M. Wallach. 2020. Language (technology) is power: A critical survey of ”bias” in NLP. In ACL, pages 5454–5476. Association for Computational Linguistics.
- Cui et al. (2020) Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, and Guoping Hu. 2020. Revisiting pre-trained models for chinese natural language processing. In EMNLP (Findings), volume EMNLP 2020 of Findings of ACL, pages 657–668. Association for Computational Linguistics.
- Cui et al. (2021) Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, and Ziqing Yang. 2021. Pre-training with whole word masking for chinese bert. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3504–3514.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT (1), pages 4171–4186. Association for Computational Linguistics.
- Lan et al. (2020) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. ALBERT: A lite BERT for self-supervised learning of language representations. In ICLR. OpenReview.net.
- Leidner and Plachouras (2017) Jochen L. Leidner and Vassilis Plachouras. 2017. Ethical by design: Ethics best practices for natural language processing. In EthNLP@EACL, pages 30–40. Association for Computational Linguistics.
- Li et al. (2021) Han Li, Yash Govind, Sidharth Mudgal, Theodoros Rekatsinas, and AnHai Doan. 2021. Deep learning for semantic matching: A survey. Journal of Computer Science and Cybernetics, 37(4):365–402.
- Li et al. (2020) Xiaoya Li, Xiaofei Sun, Yuxian Meng, Junjun Liang, Fei Wu, and Jiwei Li. 2020. Dice loss for data-imbalanced NLP tasks. In ACL, pages 465–476. Association for Computational Linguistics.
- Schramowski et al. (2022) Patrick Schramowski, Cigdem Turan, Nico Andersen, Constantin A Rothkopf, and Kristian Kersting. 2022. Large pre-trained language models contain human-like biases of what is right and wrong to do. Nature Machine Intelligence, 4(3):258–268.
- Schramowski et al. (2019) Patrick Schramowski, Cigdem Turan, Sophie F. Jentzsch, Constantin A. Rothkopf, and Kristian Kersting. 2019. BERT has a moral compass: Improvements of ethical and moral values of machines. CoRR, abs/1912.05238.
- Szegedy et al. (2016) Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. 2016. Rethinking the inception architecture for computer vision. In CVPR, pages 2818–2826. IEEE Computer Society.
- Xiong et al. (2020) Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. 2020. On layer normalization in the transformer architecture. In ICML, volume 119 of Proceedings of Machine Learning Research, pages 10524–10533. PMLR.
- Xu et al. (2020) Liang Xu, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Yudong Li, Yechen Xu, Kai Sun, Dian Yu, Cong Yu, Yin Tian, Qianqian Dong, Weitang Liu, Bo Shi, Yiming Cui, Junyi Li, Jun Zeng, Rongzhao Wang, Weijian Xie, Yanting Li, Yina Patterson, Zuoyu Tian, Yiwen Zhang, He Zhou, Shaoweihua Liu, Zhe Zhao, Qipeng Zhao, Cong Yue, Xinrui Zhang, Zhengliang Yang, Kyle Richardson, and Zhenzhong Lan. 2020. CLUE: A Chinese language understanding evaluation benchmark. In Proceedings of the 28th International Conference on Computational Linguistics, pages 4762–4772, Barcelona, Spain (Online). International Committee on Computational Linguistics.