Towards Fast Setup and High Throughput of GPU Serverless Computing
Abstract
Integrating GPUs into serverless computing platforms is crucial for improving efficiency. However, existing solutions for GPU-enabled serverless computing platforms face two significant problems due to coarse-grained GPU management: long setup time and low function throughput.
To address these issues, we propose SAGE, a GPU serverless framework with fast setup and high throughput. First, based on the data knowability of GPU function ahead of actual execution, SAGE first devises the parallelized function setup mechanism, which parallelizes the data preparation and context creation. In this way, SAGE achieves fast setup of GPU function invocations.Second, SAGE further proposes the sharing-based memory management mechanism, which shares the read-only memory and context memory across multiple invocations of the same function. The memory sharing mechanism avoids repeated data preparation and then unnecessary data-loading contention. As a consequence, the function throughput could be improved. Our experimental results show that SAGE reduces function duration by and improves function density by compared to the state-of-the-art serverless platform.
1 Introduction
Emerging clouds start to employ GPUs for the cloud applications (e.g., personal recommendation [1], medical service [2]). These applications often integrate AI or scientific computing components, which rely on GPUs for computation. Meanwhile, these cloud applications often experience unstable loads, which may have only a few to dozens of user requests per minute [3, 4, 5, 6]. In this case, if a traditional GPU-based inference system [7, 8, 9, 10, 11, 12] is adopted, the resources will be reserved for a long time, even if the load is low. Serverless computing [13, 14, 5] has been proven efficient for handling relatively low and unstable loads, benefitting from the high scalability.
Cloud providers have spent some efforts to integrate GPU capabilities into serverless computing platforms for processing compute-intensive applications. The well-established solutions for GPU-enabled serverless computing are Azure Function [13] and Alibaba Function Compute [15]. Both platforms adopt the way in Figure 1 to schedule GPU functions. Specifically, They launch size-fixed container instances with GPU calls wrapped in them to manage GPU functions. We refer to this mode as instance-fixed GPU serverless computing (denoted by FixedGSL), as the scheduled instances have predetermined memory and computing specifications.
Although FixedGSL enables GPU in serverless computing, its coarse-grained management brings the long setup time of GPU functions and low function throughput on the GPU.

Long setup time. Similar to CPU functions, execution of each GPU function in the FixedGSL requires launching a container first. However, GPU functions suffer from additional setup time beyond the setup stages experienced by CPU functions. Compared to CPU functions, there are two extra setup stages in GPU functions: GPU context preparation and GPU data preparation. Our experimental findings, as detailed in § 3.2.1, reveal that GPU context preparation requires approximately 280 milliseconds, while GPU data preparation consumes tens to hundreds of milliseconds.
Low function throughput. Our investigation in §3.2.2 demonstrates that FixedGSL’s supported function throughput is only 12.3% of theoretical peak throughput. There are two main reasons for this gap. On one hand, while size-fixed memory of FixedGSL facilitates memory management for cloud service providers, it also restricts the number of GPU functions residing on the GPU simultaneously. For instance, when the memory size of a function instance is set to 2GB, only 20 functions can reside on A100-40GB. On the other hand, concurrent function invocations all use the same data-loading path (network, disk, and PCIe) for data preparation. The contention of these data-loading paths further degrades the end-to-end latency of each function invocation, thus leading to low throughput.
Similar to the methods for optimizing CPU serverless frameworks [16, 17, 18], several intuitive approaches could be used. However, these approaches are still far from optimal for GPU serverless. For instance, preparing the GPU context in advance can alleviate long setup time by eliminating context-creating time. It does not handle the data preparation for launching GPU kernels and introduces additional GPU memory consumption (414MB for each pre-warmed function instance on A100). Besides, flexible memory allocation could allow more function invocations on a single GPU. Although it mitigates the insufficient function invocations, the contention of the data-loading path will increase, which further results in poorer throughput.
This paper proposes SAGE, the first GPU serverless framework that enables fast setup and high function throughput. Specifically, each function invocation could be processed with as little setup time as possible. Meanwhile, SAGE reduces the data-loading contention with flexible memory management. Under these cases, GPU’s computing resources are fully utilized, thus resulting in a high system throughput.
To tackle the long setup issue, the key insight of SAGE is that the massive data loaded through PCIe for a GPU function is knowable in advance of its actual execution. The information for the data retrieved from the host side is typically already stored within the metadata of the incoming request. This implies that the data preparation can be proactively performed for a GPU function without a pre-created GPU context. Based on this insight, SAGE proposes parallelized function setup mechanism to reduce the setup time by parallelizing the GPU context creation and data preparation.
The parallelized setup mechanism involves an unified memory daemon and a taxon shim. The memory daemon is designed to proactively load data for GPU functions. The shim is used for intercepting the GPU calls, and classifying them into memory calls and kernel calls. Specifically, the shim communicates with the unified memory daemon to get the actual GPU memory address when intercepting the memory call. Meanwhile, it also ensures that data is indeed ready on GPU when launching GPU kernels. Therefore, SAGE can quickly launch a GPU function without the pre-created GPU context and wasted GPU memory.
In fact, the unified memory daemon already enables flexible memory management for SAGE. SAGE now only needs to reduce the contention of the data-loading path for high throughput. We find another key insight that appropriate memory sharing can avoid repeated data preparation, thus reducing unnecessary data-loading contention. Fortunately, many memory allocations in GPU functions are read-only memory, e.g., the weight of DNN models. Such memory can be safely shared across invocations to the same GPU serverless function.
Based on this insight, we propose sharing-based memory management. SAGE first exposes the interface for users to specify the read-only memory. Then, it exploits the memory characteristics in two ways to reduce the data preparation of the invocations to the same GPU function. As for concurrent invocations, read-only memory and GPU context are directly shared. As for invocations comming adjacently, SAGE devises a multi-stage resource exit scheme. When an invocation finishes, its occupied resources are released in multiple stages according to the order of read-only data, GPU context, CPU context, and container. In these stages, as long as a request is coming in, the exit will stop, and the new invocation will reuse the unreleased resources. Therefore, SAGE is able to achieve high throughput with less memory access through the data-loading path. It is worth noting that context sharing here does not reduce data-loading contention but further saves setup time.
The main contributions of this paper are as follows:
-
1.
Identifying the root causes that lead to long setup and low throughput in existing GPU serverless systems. Based on the investigations, we propose SAGE with appropriate setup boost and fine-grained memory-sharing methods to address the issues.
-
2.
Designing an elegant mechanism that efficiently parallelizes data preparation and context creation. SAGE utilizes it in order to accelerate the setup of GPU functions, when there are no available resources for reuse.
-
3.
Proposing approaches that reduce contention of the data-loading path for maximizing the overall throughput of GPU serverless. SAGE achieves the goal through fine-grained memory sharing, especially the multi-stage resource exit scheme.
We have implemented and deployed SAGE on a cluster with A100 GPUs. We also evaluated it using DL tasks [19, 20, 21, 22, 23, 24, 25, 26] and scientific benchmarks [2]. Our experimental results show that SAGE reduces the function duration by , and improves function density by compared with the state-of-art serverless frameworks.
2 Related Works
The usable GPU serverless platforms are available in Alibaba Cloud [15] and Microsoft Azure [13]. For tradeoffs between GPU accessibility and the portability of existing serverless platforms, they schedule the GPU function at the granularity of size-fixed GPU instances (FixedGSL). ORSCA [27], DGSF [28] provided GPU functions on CPU-only nodes with pre-created GPU context on remote GPUs. It is achieved through API-remoting. The high memory overhead for pre-warming and high communication overhead make these works not applicable in the production environment. We compare SAGE with FixedGSL and DGSF in § 7. In Molecule [29], a shim layer is proposed to unify the usage of various devices such as DPU, GPUs, and other accelerators in serverless computing. Molecule is orthogonal to SAGE’s goal, and they can be combined together for optimizations.
Some prior works support fine-grained memory and computation management through hijacking driver-level API, such as Alibaba cGPU [30], Tencent qGPU [31], vCUDA [32], qCUDA [33] and GPUshare [34]. These technologies provide isolated GPU memory and computing capacity. NVIDIA also has its own GPU fine-grained resource-sharing solutions, such as MPS [35]. There are also some works that have proposed GPU-sharing solutions in fixed scenarios, such as deep learning applications [36, 37, 38]. These techniques are not aware of the characteristics of GPU serverless and do not help accelerate the setup and increase the function density for existing GPU serverless frameworks. However, they can be integrated into SAGE to provide the mechanism of better memory and computation isolation.
There are also many prior works on optimizing the startup time in serverless computing [14, 39, 40, 6, 41, 42]. Replayable Execution [43], Firecracker [17], and Catalyzer [44] are snapshot and fork-based optimizations. SAND [16] used a multi-level sandboxing mechanism to improve the performance of the application. These works only accelerate the host-side operations, making GPU functions still suffer from long setup and extra memory consumption.
3 Background and Motivation
In this section, we first present state-of-the-art GPU serverless frameworks and the used benchmarks. Then, we analyze the inefficiencies of existing serverless frameworks and the reasons behind them.
3.1 GPU Serverless and Benchmarks
| Task | Task Type | ||
|---|---|---|---|
|
Computer Vision | ||
| deepspeech [20], seq2seq [25] | Speech Recognition | ||
| bert [19] | Natural Language Processing | ||
| lbm, mrif, tpacf [2] | Scientific Computing |
GPU container toolkit [45] is often used to integrate GPU into existing serverless frameworks seamlessly. The GPU calls of functions are forwarded to the underlying GPU driver by the GPU container toolkit. The container toolkit also provides the memory and computing resource partition to meet the multi-tenant requirements of GPUs in serverless computing. Both GPU-enabled Azure Functions [13] and Alibaba Function Compute [15] use the toolkit. With the help of the GPU container toolkit, they are designed with the FixedGSL rules for the convenience of management. That is, each GPU function is wrapped into the container equipped with GPU instances. These GPU instances have limited specifications, and the memory allocation granularity is 1 Gigabyte.
Considering that GPU serverless is suitable for a variety of fields, we also use multiple scientific computing tasks as the benchmarks in addition to the DL inference tasks. We use seven DNN models concerned by the DL inference system [46] and three scientific tasks from Parboil [2] as our GPU function benchmarks. Table 1 presents the benchmark details. The DL models cover computer vision, speech recognition, and natural language processing. The scientific computing tasks include fluid mechanics (), medical assistance (), and astrophysics ().
We run the benchmarks on a node with one NVIDIA A100 (40GB memory) GPU and use FixedGSL to manage the GPU resources. Upon each new request, FixedGSL allocates memory for the function in 1 Gigabyte granularity. Specifically, the function’s memory usage is rounded up from the real memory usage. The detailed hardware and software configurations are described in Table 3 of § 7.1.
3.2 Inefficiency of FixedGSL
In this subsection, we measure the response latencies of the benchmarks, and the system throughput with FixedGSL. The experiments show that FixedGSL results in long response latency and low system throughput. The long response latency comes from the extra setup stages for preparing the GPU functions. The low function density is attributed to the resource contention in the data preparation stages.
3.2.1 Long Setup Time

We first measure the end-to-end duration of a GPU function using FixedGSL, and breakdown the duration. The function invocations are generated in a close-loop manner, eliminating the impact of queuing and resource contention.
Figure 2 shows the duration breakdown of all the benchmarks with FixedGSL. The end-to-end duration for GPU functions can be segmented into eight stages, including container creation, CPU context preparation, CPU data preparation, GPU context preparation, GPU data preparation, function computation, and result return. Both data preparation stages incorporate memory allocation and corresponding data transfer. For CPU data preparation, GPU functions load data from the database through Disk or Network. For GPU data preparation, GPU functions transfer data from CPU memory to GPU memory through PCIe. We refer to the five stages before computation as setup stages.
The experimental results reveal that the computation time only accounts for of the end-to-end duration on average, with a maximum of . GPU functions are suffering from long setup time. Among these setups, container creation is the most time-consuming ( of end-to-end latency on average). As for the container creation, we have two observations here. First, there is no difference in startup time between GPU container and CPU container. Secondly, the calling commands of the two containers are very similar. GPU container creation time can be optimized using the pre-warm techniques proposed for CPU container [15, 14, 39].
When the container creation time is optimized away, the overall time of all functions is reduced. In this case, the computation time takes up 12.1% of the overall time, and the preparation time takes up 86.3%. Among these setups, GPU context preparation and data preparation (CPU/GPU data loading) consume the most time (86.1% of the overall time). Because GPU context is created implicitly and GPU data loading relies on created GPU context, GPU functions are executing these GPU-related setups in serial. Therefore, GPU functions are suffering long setup time.
3.2.2 Low System Throughput
This experiment reports the achievable system throughput of all benchmarks with FixedGSL. In this experiment, requests are generated with a Poisson distribution and are scheduled in an open-loop manner. Such experiment configuration can maximize the actual loads to the GPU. In order to obtain the peak system throughput, we gradually increase the load until FixedGSL fails to process the received requests stably.
The throughput of each application over a period using FixedGSL is also collected and denoted as . We also calculate the theoretical throughput in Equation 1, which simply considers the application’s computation time . Based on the , the normalized throughput performance of each application is further calculated.
| (1) | ||||

Figure 3 shows the normalized throughput performance of each application. On average, the actual throughput is only 12.3% of its theoretical value. One straightforward reason for the poor performance is the fixed memory allocation, which restricts GPU from serving more application queries. Furthermore, we find that another reason for the low throughput is the resource contention in the data loading paths.

Figure 4 shows the average data loading time of all applications under FixedGSL. This time is normalized to the data loading time without any resource contention in Figure 2. As shown in the figure, each application suffers 34.9 data loading time under FixedGSL. Specifically, loading data to CPU memory from database and copying data to GPU memory through PCIe encounter severe resource contention. As a consequence, FixedGSL has the low throughput problem.
In summary, FixedGSL encounters long setup time and low system throughput. The long setup time comes from the extra setup stages of the GPU function compared to the CPU function. The low system throughput comes with resource contention in the data loading paths.
4 Design Overview
Faced with the above problems, we propose SAGE, a GPU serverless framework that enables fast function setup and high function throughput. In this section, we illustrate the architecture of SAGE and corresponding programming model.
4.1 SAGE Architecture
Figure 5 shows the overview of SAGE and its corresponding programming interface. As shown in the right part of Figure 5, SAGE comprises four modules: the per-function engine, the taxon shim, the unified memory daemon, and the kernel executor. SAGE proposes two innovative mechanisms to enhance the function latency and throughput performance for the GPU serverless system, which are parallelized function setup and sharing-based memory management.
When the upper cluster scheduler assigns a GPU function request to SAGE runtime, SAGE first starts a container with GPU capability. Inside the container, a per-function engine is then initialized. The engine first extracts the data that can be loaded in advance and notifies the memory daemon to perform data preparation. After that, the engine continues to trigger the execution of the function. Because the memory daemon works independently, the data preparation and the context preparation inside the engine are parallelized.

When the function handler is being executed, taxon shim intercepts all GPU calls and dispatches them respectively. Specifically, if it is a memory-related call, the shim forwards it to the memory daemon. The memory daemon returns the actual device memory address of preloaded data to the function handler. GPU Kernel-emitting calls are forwarded by the shim to the kernel executor. The kernel executor then communicates with the memory daemon to ensure that related GPU memory is correctly prepared.
SAGE deploys only one memory daemon on a single GPU. The memory daemon and the function engine collaboratively support the sharing-based memory management mechanism. When multiple invocations of the same function are scheduled to the same GPU, the read-only data will be only loaded upon the first invocation. The other invocations could share the same copy, which reduces the data loading requirement and the resource contention in the data loading paths. As a consequence, the function throughput is improved.
In addition, the per-function engine is also shared with the latter invocations. SAGE keeps the engine alive within a period. To enhance the sharing efficiency, the lifecycle of the launched per-function engine ends with a multi-stage exit method, rather than terminating directly upon the completion of the invocation’s execution. Specifically, the occupied resources of a function engine are released in multiple stages according to the order of read-only data, GPU context, CPU context, and container.
4.2 Programming Model
The left part of Figure 5 presents an example of SAGE’s programming interface. Our current implementation of SAGE only supports C++ language runtime. It should be trivial to provide other language bindings (e.g., Python), as GPU relies on C++ to provide its functionality. The provided interfaces follow the design pattern of the existing serverless framework AWS Lambda [47] that supports C++ runtime.
The developer wraps the GPU function code within the function handler with a pre-defined signature. SAGE also requires developers to store metadata of the data loaded from external sources when defining Request struct, which is detailed in § 5.1. The read-write attribute of data also needs to be designated to ascertain whether it can be shared as read-only data. SAGE’s runtime can then identify them for setup parallelization and memory sharing.
SageInit() and SageRun() are two APIs provided to initialize the SAGE’s runtime and invoke the function execution upon an incoming request. These two APIs do not need user definition. Later, we will present the interface details about how SAGE parallelizes the context creation and data preparation. Besides, we will also give an example of how to utilize our interface to transform the original GPU application into a GPU function for SAGE.
5 Parallelized Function Setup
In this section, we present our methods for optimizing function setup, while the function is first invocated on the GPU. These methods are crucial in accelerating the function setup process and the end-to-end latency.
5.1 Parallelizing data and context

We outline the simplified execution flow of the GPU functions in Figure 6, which consists of seven stages. (1) The GPU scheduler creates a container for the GPU function. (2) The GPU function establishes its own CPU context and corresponding function engine. (3) The GPU function requests CPU-side memory and loads data from a designated database based on the invocation request. (4) The GPU function generates its own GPU context and initializes the corresponding library. (5) The GPU function requests GPU memory and transfers the data from CPU to GPU. (6) The GPU function starts computing. (7) Upon completion of computing, the GPU function returns the result.
Among these stages, stage-3 and stage-4 could be executed in any order for no dependency. Meanwhile, stage-5 and stage-6 can also occur in any order because the GPU memory allocation and the GPU kernel launch could happen at any time. However, developers usually prioritize preparing the data first before launching a series of GPU kernels. In this way, kernel launching overhead is hidden, and GPU utilization is improved. This means that the first five stages are executed sequentially prior to the computation stage. As a result, the GPU function experiences a long setup.


After a deeper analysis of Figure 6, we have two observations. First, GPU functions always load data from external sources. For instance, DL inference services commonly read model inputs and weights from databases, while scientific computing services require input data or updated data to be sourced from databases.
Secondly, both CPU and GPU support inter-process communication. CPU and GPU could use data from other processes for computation. Corresponding experimental results show that a GPU function can compute correct results through the exclusive use of data from other processes. This means that context and data are not firmly intertwined.
Based on these two observations, we have a key insight: GPU data preparation can be delegated to another process, enabling parallel preparation of both the GPU data and GPU context. Further, we reconsider the execution flow of a GPU function and have three findings. (1) Container creation, CPU context creation, and GPU context creation must be performed in a strict sequence. (2) There is no strong bond between the GPU data and GPU context, and GPU data loading depends on CPU data loading. (3) GPU computation depends on both GPU context and GPU data.
We reconstruct the dependency graph for the GPU function setup stages. As shown in Figure 6, we could divide the function setup stages into two distinct parts, namely GPU context preparation and GPU data preparation. The function engine is designated with GPU context preparation, whereas the memory daemon handles GPU data preparation from external sources. They are executed in parallel.
To implement the aforementioned process, the function engine must communicate the data-loading information with the memory daemon ahead of actual execution. To this end, we devise a data structure to store the positional details of the external data required by a request, as illustrated in Figure 8.
Specifically, Request contains all the data that require loading from the databases. The database information is stored in the key of the Data structure. When the memory daemon receives a request from the function engine, it immediately initiates the data-loading process. After the data loading is finished, the data_dptr could used to perform the computation. Leveraging this approach, GPU context preparation and GPU data preparation can occur concurrently, thereby enabling the fast function setup.
5.2 Supporting Prallelization with Taxon Shim
Loading data proactively through the unified memory daemon can invalidate the execution of the original GPU program. Previously the program interacts with the GPU directly, the GPU’s built-in scheduler ensures the correctness of memory operation, kernel launching, etc. With the unified memory daemon, there has to be a consolidated design to achieve exactly the same functionality. Then, the taxon shim is designed in response to the particular need.
5.2.1 Programming of Function Handle
The taxon shim first provides APIs to access the address of the previously prepared memory by the memory daemon. For loading data from external resources, SAGE designs an interface termed SageLoadToGPU(), which returns the actual memory address. For saving data to external destinations, SAGE also designs a similar interface called SageDumpToDB(). Developers use these two APIs for loading and returning data inside the function handler. When it comes to common GPU function calls like cudaMalloc() and kernel launching, the taxon shim intercepts both of them. The difference is that a memory call will be forwarded to the daemon, while a kernel call will be forwarded to the kernel executor.
Figure 7-(a) depicts an illustrative example of using the programming interface. As shown in the figure, a function handler may utilize either SageLoadToGPU() for data loading or cudaMalloc() for straightforward allocation. When the GPU function calls SageLoadToGPU(), the memory daemon returns a pointer to the function. Notably, SageLoadToGPU() is an asynchronous operation, and the data loading may not finish after invoking it. Kernel entry is then also intercepted. At the end of the handler, SageDumpToDB() returns the result to the memory daemon, which is responsible for dumping the data into the database.
5.2.2 Ensuring Function Correctness
Figure 7-(b) demonstrates how taxon shim interacts with memory daemon and kernel executor. It is easy to see that the taxon shim forwards all GPU calls based on their categories. All memory-related calls are forwarded to the memory daemon, and all kernel calls are forwarded to the kernel executor. This is because we need a central memory coordinator to ensure that the pre-loaded data is correctly prepared.
As the taxon shim forwards the GPU calls one by one, the memory daemon also processes the memory calls one by one. When the kernel executor receives the kernel, it only needs to communicate with the memory daemon to verify whether all the data required by the kernel has been prepared. If all data is ready, the kernel executor can directly launch the kernel to the GPU. Based on these processes, the taxon shim could support the parallelized cold setup without any faults.
6 Sharing-based Memory Management
Following optimizing the function setup time, it is imperative that we further reduce the resource contention in the data loading paths and address the low function throughput attributed to existing GPU serverless solutions. In this section, we present our sharing-based memory management method, which solves the above issue.
6.1 Memory Usage Analysis
To reduce resource contention in the data loading paths, we initially conduct experiments to investigate the memory usage of mainstream GPU functions. Our investigation reveals that GPU function memory usage can be divided into three categories: context memory, read-only memory, and writeable memory. Context memory is implicitly allocated during the initial execution of the GPU application and is utilized to store the runtime data. Read-only memory represents the read-only data of GPU function execution. Writeable memory, on the other hand, denotes the writable data of GPU function execution.
| benchmark | context | read-only | writable | explicit |
|
||
| bert | 414 | 1282.5 | 60.1 | 1342,6 | 95.5 | ||
| deepspeech | 414 | 24.8 | 6.9 | 31.7 | 78.8 | ||
| inception3 | 414 | 91.1 | 11.7 | 102.8 | 88.6 | ||
| nasnet | 414 | 20.3 | 11.8 | 32.1 | 63.5 | ||
| resnet50 | 414 | 97.7 | 11.9 | 109.6 | 89.2 | ||
| seq2seq | 414 | 6.1 | 0.1 | 6.2 | 98.9 | ||
| vgg11 | 414 | 506.8 | 38.0 | 544.8 | 93.0 | ||
| lbm | 414 | 0 | 330 | 330 | 0 | ||
| mrif | 414 | 0 | 22 | 22 | 0 | ||
| tpacf | 414 | 0.1 | 28.3 | 28.3 | 0.4 |
Table 2 demonstrates the memory usage allocation of all GPU functions. These functions are implemented by Rammer [46] and Parboil [2]. As observed from the table, context memory occupies the maximum memory usage of all functions except Bert, accounting for an average of 79.0% of the overall memory usage. Although context memory occupies a large amount of memory, corresponding experimental results show that the context creation time does not change when multiple function invocations create their contexts. This implies that context creation for function invocations does not interfere with each other.
In addition to context memory, explicit memory accounts for 21.0% of the overall memory usage. As demonstrated in § 3.2.2, concurrent function invocations encounter severe resource contention during data loading. The benchmark functions suffer 34.9 data loading time compared to the solo-run case. Meanwhile, we observe from this table that read-only memory may occupy more than 90% of explicit memory usage. Optimizing the data loading process for read-only memory can substantially mitigate memory contention issues in data loading paths.
6.2 Read-only Memory Sharing
Existing GPUs only offer basic data transfer APIs through PCIe, which could only handle data transfer tasks sequentially. Meanwhile, the disk and network bandwidth used by CPU loading are also limited. There lack sophisticated interfaces to manage the data transmission of multiple invocations to maximize the efficiency of data loading. Under these circumstances, we find that multiple invocations of the same function can safely share the read-only memory.
While read-only memory remains unmodified during the function execution, the read-only memory sharing between multiple invocations does not cause correctness issues or performance problems. It should be noted that multiple function invocations perform the same computation, which comes from the same service provider. There will also be no malicious memory attack on the GPU. In this case, read-only memory sharing can effectively reduce data loading, which further reduces the resource contention in the data loading paths. Therefore, the overall throughput can be improved.
To support the read-only memory sharing between multiple invocations, the memory daemon needs to identify read-only data in the function. Since function developers could easily distinguish read-only data from writable data, we require the function developers to indicate the data attributes in the data structure shown in LABEL:fig:request. If a data is read-only, the Type in the Data structure should be set to ReadOnly. Otherwise, it should be set to Writable.
It is worth noting that read-only memory is not limited to the weight of ML inference tasks. The benchmark in astrophysics also has read-only memory. Any read-only data in the GPU function could be shared by multiple invocations.
6.3 Multi-stage Resource Exit
Another commonly used sharing method involves reusing launched containers and keeping them warm for periods of time. Although the initial function call must complete all necessary prerequisite setups (referred to as a cold start), subsequent calls may be processed by the warm container, thereby mitigating undesired startup latency. Leading serverless platforms, including OpenWhisk [48] and AWS Lambda [49], mostly offer support for container reuse.
The warmed container exempts the invocation from some setup stages, which include container creation, context creation, and data loading. However, simply applying the warm strategy to GPU functions may not be a good choice. Specifically, maintaining a warm container for extended periods requires extra memory usage, such as GPU context memory and read-only memory. While GPU memory is scarce, maintaining a warm container for GPU function may cause a decrease in function density.
To solve this problem, we leverage the CPU-side context as a suitable intermediary layer for GPU functions. Given that multiple prerequisite stages are required for the computation of the GPU function, we design a multi-stage resource exit mechanism. Figure 9 shows our multi-stage exit mechanism.

In the first stage, the GPU function retains all GPU context and read-only data. In the second stage, the GPU function preserves the GPU context, yet caches the read-only data to CPU memory. This is because CPU memory typically boasts larger storage capacity, lower cost, and faster PCIe transfer times. In the third stage, the GPU function discards the GPU context but still retains the CPU memory and CPU context. In the fourth stage, the GPU function discards the CPU memory and CPU context but retains the container to minimize the start time of subsequent requests. Finally, after the container has served its purpose, it is destroyed.
Leveraging the multi-stage exit mechanism outlined above, we are able to attain a more flexible management of the tradeoff between GPU resource cost and warm containers. Moreover, it is noteworthy that the time interval of each stage is adjustable. For instance, configuring each stage’s interval to the previous time interval would enable the GPU function to maintain a longer warm state at a lower cost. Alternatively, configuring the overall duration of the three stages to the previous time interval would allow the serverless platform to support a similar warm effect at a lesser cost. In this paper, SAGE configures each stage’s interval to the previous time interval, which is set as 30 seconds[14, 18].
6.4 Context Memory Sharing
Note that, while context memory sharing does not mitigate the resource contention in the data loading paths, it still brings considerable context creation time and memory usage. Therefore, we also support the context memory sharing between multiple invocations of the same function. Using the context memory sharing, the function invocations could benefit from the shorter function setup and less memory usage. The shorter function setup further improves the system throughput, and the less memory usage enables the GPU to keep more functions warm on the GPU. Similarly, the invocations of the same function perform the same computation, there will be no malicious attack about the context.

7 Evaluation
7.1 Implementaion and Experimental Setup
| Configuration | |||
|---|---|---|---|
| CPU |
|
||
| GPU |
|
||
| Software |
|
||
| Container |
|
We implement SAGE with all components described in § 4. Our system uses Docker [50] for the application sandbox, GRPC [51] for the message passing, and MongoDB [52] for the database. All components of SAGE are implemented as independent processes based on C++.
We use FixedGSL, FixedGSL-F, and DGSF as the baselines. FixedGSL is only capable of allocating memory for functions at a granularity of 1 Gigabyte. We extend FixedGSL to FixedGSL-F, which supports flexible memory allocation for functions. Additionally, we also choose DGSF, a state-of-the-art serverless system, as another baseline. Each function in DGSF has four pre-created GPU contexts, eliminating GPU context preparation time. Invocations to the same function share these four contexts using a First-Come-First-Serve queue [28]. Note that, to better distinguish our effect from previous works on the CPU side [16, 17, 18], we enhance all the systems with the pre-warmed container. Therefore, there is no container creation overhead for GPU functions.
To evaluate the effectiveness of SAGE, we use seven DNN applications from Rammer [46] and three scientific computing applications from Parboil [2] as our benchmark suite. These applications cover diverse domains such as object recognition, speech generation, natural language processing, fluid mechanics, and real-time medical imaging. Detailed information about the benchmarks can be found in Table 1 of § 3. Besides, we replay the workload trace from Microsoft Azure Functions (MAF) [53] for 2 hours in all experiments. After we adapt the benchmarks to GPU functions using our interfaces, we could conduct the experiments.
The experiments described in § 7.2 to § 7.7 are executed on the Nvidia A100 GPU. All the experiment setups are shown in Table 3. First, the experiments in § 7.2 demonstrate the function latency performance and the system throughput performance of SAGE. Second, the experiments in § 7.3 are performed to compare with the theoretical performance. Third, the experiments in § 7.4 prove the performance of SAGE with more functions. Then, we conduct the ablation study for the multi-stage resource exit mechanism and read-only memory sharing scheme in § 7.6 and § 7.7. Finally, SAGE is deployed on a small cluster containing 4 Nvidia A100 GPUs to prove the scalability in § 7.8.
7.2 Latency and Throughput


Figure 10 illustrates the average latency of ten applications for FixedGSL, FixedGSL-F, DGSF, and SAGE. On average, SAGE outperforms FixedGSL, FixedGSL-F, and DGSF by 193.4, 391.5, and 13.3, respectively. SAGE outperforms FixedGSL, FixedGSL-F, and DGSF on the minimum by 26.3, 52.4, and 1.21, respectively. Besides, we also collect the 99%-ile latency of ten applications, which are not shown due to page limitation. For the 99%-ile latency, SAGE outperforms FixedGSL, FixedGSL-F, and DGSF by 54.1, 109.2, and 25.4, respectively.
The improved latency performance of SAGE comes from two aspects. Firstly, SAGE accelerates the processing of cold invocations by paralleling its context preparation and data preparation. Secondly, sharing read-only memory and existing context also shortens the end-to-end latency of warm (invocations to the same GPU function).
As a comparison, FixedGSL and FixedGSL-F do not prioritize the latency performance of functions. They only schedule the function invocations with the memory usage in a fixed granularity. Although multiple invocations from the same function in DGSF could enjoy the pre-created GPU contexts, DGSF ignores the resource contention in the data loading path, thus still suffering long data preparation. Our proposed method, SAGE, takes both of these factors into account and has been shown to be highly effective in reducing latency.
Figure 11 illustrates the system throughput of FixedGSL, FixedGSL-F, DGSF, and SAGE during this period. SAGE’s system throughput outperforms FixedGSL, FixedGSL-F, and DGSF by 8.9, 10.3, and 1.22, respectively. The throughput improvement comes from the memory sharing of SAGE. The read-only memory sharing between multiple invocations could mitigate the resource contention in the data preparation stages. Thus, all the invocations could finish the computation in a short time, which contributes to higher system throughput.
It should be noted that FixedGSL-F shows worse performance compared with FixedGSL both in latency and throughput. This is because FixedGSL does not concern the resource contention in the data preparation stages. While FixedGSL-F could launch more function invocations on the GPU, it suffers more serious and unrestrained contention of the data-loading paths than FixedGSL.
Figure 12 illustrates the memory usage of FixedGSL, FixedGSL-F, DGSF, and SAGE during this period. The average memory usage of SAGE only accounts for 18.7% of FixedGSL, 21.7% of FixedGSL-F, and 37.5% of DGSF. The improved memory usage also comes from the memory sharing of SAGE. SAGE could achieve better latency and throughput performance using at most 37.5% memory of the baseline systems. Note that while SAGE uses less memory, it could hold more cold functions on the GPU, thus further improving the function latency performance.
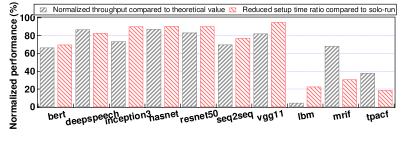
7.3 Supported Peak Results

In this section, we use the same experimental setup as § 3 to evaluate the theoretical throughput ratio for SAGE. The gray bars in Figure 13 shows the throughput ratio of each application using SAGE. On average, the system throughput is 65.1% of its theoretical value. These results demonstrate that SAGE has better performance than the baseline systems. The improved performance of SAGE comes from the fast setup and memory sharing of function invocations.
The red bars in Figure 13 show the normalized reduced time of each application using SAGE compared to the solo-run case. SAGE reduces the setup time of function invocations by 66.8% on average. While the function invocation could get the data ready in a short period, the system throughput could be improved. Note that, there is a significant gap between SAGE and the theoretical value because of the resource contention. Although SAGE could reduce the data loading pressure by sharing the read-only memory in the GPU function, some data preparation could not be avoided. Furthermore, some tasks like could not benefit from the read-only memory sharing.
7.4 Efficiency with More functions
In this subsection, we use 30 functions to further demonstrate the effectiveness of SAGE. While the system is required to handle more functions, the memory-sharing capability between multiple invocations of the same function is reduced. Specifically, we use 10 benchmarks in Section 7.1 to simulate 30 benchmarks. For example, we use , , to represent different benchmarks.
Figure 14 shows the average latency of 30 functions under FixedGSL, DGSF, and SAGE. On average, SAGE outperforms FixedGSL and DGSF by 211.9 and 5.9, respectively. Additionally, SAGE outperforms FixedGSL and DGSF with the tail latency by 49.6 and 4.6, respectively. While more functions on one GPU node mean a low load for each function, the memory-sharing opportunity between multiple invocations of the same function is reduced. However, SAGE still could rely on the parallel setup method and multi-stage resource exit method to optimize the function latency. With these two methods, the function’s invocations could still benefit from reduced setup time and a warm context environment.
At the same time, experimental results also show that SAGE outperforms FixedGSL and DGSF in terms of system throughput by 9.7 and 1.19, respectively. This also comes from the possible read-only memory sharing and multi-stage resource exit methods. While the memory sharing opportunity is reduced, SAGE could still utilize it to improve the system throughput. In addition, the multi-stage resource exit mechanism could keep the resources warm for a longer time, which also helps to improve the system throughput.
7.5 Effectiveness of parallelized setup mechnaism

To evaluate the effectiveness of the parallelized function setup mechanism, we measure the end-to-end duration of the GPU functions like the experiment in §3.2.1. The function invocations are generated in a close-loop manner.
Figure 15 shows the duration breakdown of all the benchmark functions with SAGE. Compared with the results in Figure 2, SAGE reduces the setup time of all the functions by 20.8% on average. This result could also be observed from the figure. As for the benchmark functions, they either have the GPU context preparation time or the data preparation time. This is because the parallelized function setup mechanism hides another setup stage, which improves the function setup performance. Benefiting from the parallelized function setup mechanism, SAGE could improve the 99%-ile latency of all the benchmark functions.
7.6 Effectiveness of multi-stage mechnaism
| Time (ms) | Baseline | stage 1 | stage 2 | stage 3 | stage 4 | cold |
| end-to-end | 399.4 | 28.9 | 49.7 | 309.5 | 309.5 | 310.5 |
| return data | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| compute | 24.3 | 24.3 | 24.3 | 24.3 | 24.3 | 24.3 |
| GPU data | 21.7 | 0.9 | 21.7 | 21.7 | 21.7 | 21.7 |
| GPU context | 285.1 | 0 | 0 | 285.1 | 285.1 | 285.1 |
| CPU data | 67.2 | 3.6 | 3.6 | 3.6 | 67.2 | 67.2 |
| CPU context | 1 | 0 | 0 | 0 | 0 | 1 |
As shown in Table 4, the invocations could be in four stages or in a cold state. We use Resnet50 as the representative benchmark to show the breakdown in different stages. Compared with the traditional method which only includes warm state and cold state, SAGE contains five stages for fine-grained resource management. As shown in the table, the bold values and the zero values are hidden by the Italic value in the mechanism. For example, the GPU data loading time (67.2) and the CPU data loading time (21.7) are hidden by the GPU context creation time (285.1) in stage 4.
SAGE improves the function’s latency by an average of 6.1 in the other four states compared to the cold state (baseline), with a minimum of 1.3. All other benchmarks show similar results. The experimental results show that SAGE reduces 91.7% of the queries in the cold state. Therefore, the multi-stage resource exit mechanism could improve the function’s 99%-ile latency.
7.7 Effectiveness of read-only memory sharing
In this subsection, we disable the read-only memory sharing of SAGE (denoted as SAGE-NR), and compare its latency and system throughput with DGSF and SAGE. In this experiment, we extend DGSF to destroy the context while there are no function invocations in 30 seconds.
Figure 16 shows the average latency of 10 functions under DGSF, SAGE-NR, and SAGE. On average, SAGE outperforms SAGE-NR and DGSF by 8.2 and 13.3, respectively. Without the read-only memory sharing method, SAGE-NR still needs to suffer resource contention in the data loading paths. Meanwhile, although DGSF could eliminate the context creation time using pre-created context, it still suffers from context creation time when there is no created context. While SAGE-NR could utilize the multi-stage resource exit and parallelized setup preparation methods, SAGE-NR could perform better than DGSF. Furthermore, SAGE-NR has a similar memory usage with DGSF. SAGE-NR’s memory usage is only 38.3% of SAGE. s
7.8 Scaling SAGE Out

To assess SAGE’s scalability, we conduct the performance tests on a cluster with 4 A100 devices on 4 nodes. Figure 17 illustrates the average latency of ten applications using FixedGSL, DGSF, and SAGE on the cluster. On average, SAGE surpasses FixedGSL and DGSF by 207.1 and 12.5, respectively. Experimental results also show that SAGE delivers a 10.3 and 1.18 increase in system throughput compared to FixedGSL, and DGSF, respectively.
Based on the aforementioned data, it can be deduced that SAGE has excellent scalability. Although we dispatch the function invocations to GPU randomly, SAGE could still improve the overall system’s average latency and system throughput. This is because the proposed optimization methods of SAGE are orthogonal to the task distribution strategy at the cluster level. SAGE can integrate any cluster-level scheduling strategies proposed for specific scenarios to further achieve performance improvements.
7.9 Overhead of SAGE

The overhead of SAGE arises from the runtime interception of functions and the communication between the kernel executor and memory daemon. Since the runtime interception of functions has been widely used in the past decade, its overhead is very small. At the same time, we use shared memory to support the communication between the executor and daemon. The communication overhead is microsecond-level. Therefore, the overhead of SAGE is negligible.
7.10 Other Lessons Learned
We have got some other lessons during the research.
Lesson-1: The fine-grained GPU memory management also enables the fine-grained pricing model for GPU serverless. While memory is crucial for GPUs, it is more reasonable to charge the users based on both the memory usage (the size of memory hours) and computation usage. In this case, the pricing model of traditional FixedGSL is not reasonable as a GPU function may not need 1GB memory.
Lesson-2: While a GPU often has many streaming multiprocessors (SMs), SAGE can be extended to explicitly allocate SM allocation to GPU functions or adjust the processing order of GPU serverless functions. The functionality can be done through the shim module and provides better control over the progress of concurrent GPU functions.
Lesson-3: While SAGE’s fine-grained memory management enables GPU to have more memory available, it could be extended to use a cache replacement strategy for container warm-up. For a new-coming function, we can use a cache replacement strategy to replace long-inactive GPU functions. Meanwhile, while there are no new GPU functions arriving, existing GPU functions could always reside in GPU memory.
8 Conclusion
In this paper, we propose SAGE, an efficient serverless system with fast setup and high throughput for GPU functions. SAGE proposes two innovative mechanisms to enhance the function latency and throughput performance for the GPU serverless system, which are parallelized function setup and sharing-based memory management. The parallelized function setup mechanism enables the fast function setup by parallelizing data preparation and context creation. Meanwhile, the sharing-based memory management allows multiple invocations of the same function to share the read-only memory and context memory. This reduces the resource contention in the datapaths and then improves the system throughput. Our experimental results show that SAGE improves function throughput by and reduces function duration by , compared with state-of-the-art solutions.
References
- [1] Liu Ke, Udit Gupta, Mark Hempstead, Carole-Jean Wu, Hsien-Hsin S Lee, and Xuan Zhang. Hercules: Heterogeneity-aware inference serving for at-scale personalized recommendation. In 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pages 141–154. IEEE, 2022.
- [2] John A Stratton, Christopher Rodrigues, I-Jui Sung, Nady Obeid, Li-Wen Chang, Nasser Anssari, Geng Daniel Liu, and Wen-mei W Hwu. Parboil: A revised benchmark suite for scientific and commercial throughput computing. Center for Reliable and High-Performance Computing, 127:27, 2012.
- [3] Peter Elger and Eóin Shanaghy. AI as a Service: Serverless machine learning with AWS. Manning Publications, 2020.
- [4] Josef Spillner, Cristian Mateos, and David A Monge. Faaster, better, cheaper: The prospect of serverless scientific computing and hpc. In Latin American High Performance Computing Conference, pages 154–168. Springer, 2018.
- [5] Simon Eismann, Joel Scheuner, Erwin Van Eyk, Maximilian Schwinger, Johannes Grohmann, Nikolas Herbst, Cristina L Abad, and Alexandru Iosup. Serverless applications: Why, when, and how? IEEE Software, 38(1):32–39, 2020.
- [6] Erwin Van Eyk, Alexandru Iosup, Simon Seif, and Markus Thömmes. The spec cloud group’s research vision on faas and serverless architectures. In Proceedings of the 2nd International Workshop on Serverless Computing, pages 1–4, 2017.
- [7] Hao Wang, Di Niu, and Baochun Li. Distributed machine learning with a serverless architecture. In IEEE INFOCOM 2019-IEEE Conference on Computer Communications, pages 1288–1296. IEEE, 2019.
- [8] Joao Carreira, Pedro Fonseca, Alexey Tumanov, Andrew Zhang, and Randy Katz. A case for serverless machine learning. In Workshop on Systems for ML and Open Source Software at NeurIPS, volume 2018, 2018.
- [9] Vatche Ishakian, Vinod Muthusamy, and Aleksander Slominski. Serving deep learning models in a serverless platform. In 2018 IEEE International Conference on Cloud Engineering (IC2E), pages 257–262. IEEE, 2018.
- [10] Ahsan Ali, Riccardo Pinciroli, Feng Yan, and Evgenia Smirni. Batch: Machine learning inference serving on serverless platforms with adaptive batching. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–15. IEEE, 2020.
- [11] Ahsan Ali, Riccardo Pinciroli, Feng Yan, and Evgenia Smirni. Optimizing inference serving on serverless platforms. Proceedings of the VLDB Endowment, 15(10):2071–2084, 2022.
- [12] Jie Li, Laiping Zhao, Yanan Yang, Kunlin Zhan, and Keqiu Li. Tetris: Memory-efficient serverless inference through tensor sharing. In 2022 USENIX Annual Technical Conference (USENIX ATC 22), 2022.
- [13] Gpu-enabled docker image to host a python pytorch azure function. https://github.com/puthurr/python-azure-function-gpu. Accessed: 2023-01-08.
- [14] Zijun Li, Linsong Guo, Quan Chen, Jiagan Cheng, Chuhao Xu, Deze Zeng, Zhuo Song, Tao Ma, Yong Yang, Chao Li, et al. Help rather than recycle: Alleviating cold startup in serverless computing through Inter-Function container sharing. In 2022 USENIX Annual Technical Conference (USENIX ATC 22), pages 69–84, 2022.
- [15] Best practices for gpu-accelerated instances. https://www.alibabacloud.com/help/en/function-compute/latest/development-guide. Accessed: 2023-01-08.
- [16] Istemi Ekin Akkus, Ruichuan Chen, Ivica Rimac, Manuel Stein, Klaus Satzke, Andre Beck, Paarijaat Aditya, and Volker Hilt. SAND: Towards high-performance serverless computing. In 2018 Usenix Annual Technical Conference (USENIX ATC 18), pages 923–935, 2018.
- [17] Alexandru Agache, Marc Brooker, Alexandra Iordache, Anthony Liguori, Rolf Neugebauer, Phil Piwonka, and Diana-Maria Popa. Firecracker: Lightweight virtualization for serverless applications. In 17th USENIX symposium on networked systems design and implementation (NSDI 20), pages 419–434, 2020.
- [18] Zijun Li, Jiagan Cheng, Quan Chen, Eryu Guan, Zizheng Bian, Yi Tao, Bin Zha, Qiang Wang, Weidong Han, and Minyi Guo. Rund: A lightweight secure container runtime for high-density deployment and high-concurrency startup in serverless computing. In 2022 USENIX Annual Technical Conference, USENIX ATC 2022, Carlsbad, CA, USA, July 11-13, 2022, pages 53–68. USENIX Association, 2022.
- [19] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [20] Awni Hannun, Carl Case, Jared Casper, Bryan Catanzaro, Greg Diamos, Erich Elsen, Ryan Prenger, Sanjeev Satheesh, Shubho Sengupta, Adam Coates, et al. Deep speech: Scaling up end-to-end speech recognition. arXiv preprint arXiv:1412.5567, 2014.
- [21] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2015.
- [22] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- [23] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V Le. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8697–8710, 2018.
- [24] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [25] Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks. Advances in neural information processing systems, 27, 2014.
- [26] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [27] Diana M Naranjo, Sebastián Risco, Carlos de Alfonso, Alfonso Pérez, Ignacio Blanquer, and Germán Moltó. Accelerated serverless computing based on gpu virtualization. Journal of Parallel and Distributed Computing, 139:32–42, 2020.
- [28] Henrique Fingler, Zhiting Zhu, Esther Yoon, Zhipeng Jia, Emmett Witchel, and Christopher J Rossbach. DGSF: Disaggregated gpus for serverless functions. In 2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 739–750. IEEE, 2022.
- [29] Dong Du, Qingyuan Liu, Xueqiang Jiang, Yubin Xia, Binyu Zang, and Haibo Chen. Serverless computing on heterogeneous computers. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, pages 797–813, 2022.
- [30] What is the cgpu service. https://www.alibabacloud.com/help/en/elastic-gpu-service/latest/what-is-the-cgpu-service. Accessed: 2023-01-08.
- [31] qgpu overview. https://www.tencentcloud.com/document/product/457/42973. Accessed: 2023-01-08.
- [32] Lin Shi, Hao Chen, Jianhua Sun, and Kenli Li. vcuda: Gpu-accelerated high-performance computing in virtual machines. IEEE Transactions on Computers, 61(6):804–816, 2011.
- [33] Yu-Shiang Lin, Chun-Yuan Lin, Che-Rung Lee, and Yeh-Ching Chung. qcuda: Gpgpu virtualization for high bandwidth efficiency. In 2019 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), pages 95–102. IEEE, 2019.
- [34] Anshuman Goswami, Jeffrey Young, Karsten Schwan, Naila Farooqui, Ada Gavrilovska, Matthew Wolf, and Greg Eisenhauer. Gpushare: Fair-sharing middleware for gpu clouds. In 2016 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pages 1769–1776. IEEE, 2016.
- [35] Nvidia multi-process service. https://docs.nvidia.com/deploy/mps/index.html. Accessed: 2023-01-08.
- [36] Wencong Xiao, Shiru Ren, Yong Li, Yang Zhang, Pengyang Hou, Zhi Li, Yihui Feng, Wei Lin, and Yangqing Jia. Antman: Dynamic scaling on gpu clusters for deep learning. In OSDI, pages 533–548, 2020.
- [37] Zhihao Bai, Zhen Zhang, Yibo Zhu, and Xin Jin. Pipeswitch: Fast pipelined context switching for deep learning applications. In Proceedings of the 14th USENIX Conference on Operating Systems Design and Implementation, pages 499–514, 2020.
- [38] Peifeng Yu and Mosharaf Chowdhury. Fine-grained gpu sharing primitives for deep learning applications. Proceedings of Machine Learning and Systems, 2:98–111, 2020.
- [39] Edward Oakes, Leon Yang, Dennis Zhou, Kevin Houck, Tyler Harter, Andrea Arpaci-Dusseau, and Remzi Arpaci-Dusseau. SOCK: Rapid task provisioning with serverless-optimized containers. In 2018 USENIX Annual Technical Conference (USENIXATC 18), pages 57–70, 2018.
- [40] Dmitrii Ustiugov, Plamen Petrov, Marios Kogias, Edouard Bugnion, and Boris Grot. Benchmarking, analysis, and optimization of serverless function snapshots. In Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, pages 559–572, 2021.
- [41] Michael Vrable, Justin Ma, Jay Chen, David Moore, Erik Vandekieft, Alex C Snoeren, Geoffrey M Voelker, and Stefan Savage. Scalability, fidelity, and containment in the potemkin virtual honeyfarm. In Proceedings of the twentieth ACM symposium on Operating systems principles, pages 148–162, 2005.
- [42] Anup Mohan, Harshad S Sane, Kshitij Doshi, Saikrishna Edupuganti, Naren Nayak, and Vadim Sukhomlinov. Agile cold starts for scalable serverless. HotCloud, 2019(10.5555):3357034–3357060, 2019.
- [43] Kai-Ting Amy Wang, Rayson Ho, and Peng Wu. Replayable execution optimized for page sharing for a managed runtime environment. In Proceedings of the Fourteenth EuroSys Conference 2019, pages 1–16, 2019.
- [44] Dong Du, Tianyi Yu, Yubin Xia, Binyu Zang, Guanglu Yan, Chenggang Qin, Qixuan Wu, and Haibo Chen. Catalyzer: Sub-millisecond startup for serverless computing with initialization-less booting. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 467–481, 2020.
- [45] Nvidia cloud native technologies documentation. https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/overview.html. Accessed: 2023-01-08.
- [46] Lingxiao Ma, Zhiqiang Xie, Zhi Yang, Jilong Xue, Youshan Miao, Wei Cui, Wenxiang Hu, Fan Yang, Lintao Zhang, and Lidong Zhou. Rammer: Enabling holistic deep learning compiler optimizations with rtasks. In Proceedings of the 14th USENIX Conference on Operating Systems Design and Implementation, pages 881–897, 2020.
- [47] C++ lambda runtime. https://aws.amazon.com/cn/blogs/compute/introducing-the-c-lambda-runtime/. Accessed: 2023-04-19.
- [48] Apache openwhisk is a serverless, open source cloud platform. https://openwhisk.apache.org. Accessed: 2023-01-08.
- [49] Aws lambda. https://aws.amazon.com/lambda/. Accessed: 2023-01-08.
- [50] Nvidia container toolkit. https://github.com/NVIDIA/nvidia-container-toolkit. Accessed: 2023-01-08.
- [51] Remote procedure call (rpc) framework. https://grpc.io/. Accessed: 2023-01-08.
- [52] Mongodb. https://www.mongodb.com. Accessed: 2023-10-18.
- [53] Mohammad Shahrad, Rodrigo Fonseca, Inigo Goiri, Gohar Chaudhry, Paul Batum, Jason Cooke, Eduardo Laureano, Colby Tresness, Mark Russinovich, and Ricardo Bianchini. Serverless in the wild: Characterizing and optimizing the serverless workload at a large cloud provider. arXiv preprint arXiv:2003.03423, 2020.