Towards Evaluating Adaptivity of
Model-Based Reinforcement Learning
Abstract
In recent years, a growing number of deep model-based reinforcement learning (RL) methods have been introduced. The interest in deep model-based RL is not surprising, given its many potential benefits, such as higher sample efficiency and the potential for fast adaption to changes in the environment. However, we demonstrate, using an improved version of the recently introduced Local Change Adaptation (LoCA) evaluation methodology , that well-known model-based methods such as PlaNet and DreamerV2 perform poorly in their ability to adapt to local environmental changes. Combined with prior work that made a similar observation about the other popular model-based method, MuZero, a trend appears to emerge, suggesting that current deep model-based methods have serious limitations. We dive deeper into the causes of this poor performance, by identifying elements that hurt adaptive behavior and linking these to underlying techniques frequently used in deep model-based RL. We empirically validate these insights in the case of linear function approximation by demonstrating that a modified version of linear Dyna achieves effective adaptation to local changes.
1 Introduction
While model-free reinforcement learning (RL) is still the dominant approach in deep RL, more and more research on deep model-based RL appears (wang2019benchmarking; moerland2020model). This is hardly surprising, as model-based RL (MBRL), which leverages estimates of the reward and transition model , could hold the key to some persistent challenges in deep RL, such as sample efficiency and effective adaptation to environment changes.
Although deep model-based RL has gained momentum, there are questions to be raised about the proper way to evaluate its progress. A common performance metric is sample-efficiency in a single task (wang2019benchmarking), which has several disadvantages. First, it conflates progress due to model-based RL with other factors such as representation learning. More importantly, it is unclear whether in an single-task setting, model-based RL is always more sample-efficient than model-free RL because learning a policy directly is not necessarily slower than learning a model and planning with the model. By contrast, when it comes to solving multiple tasks that share (most of) the dynamics, it is arguable that model-based RL has a clear advantage.
Instead of measuring the sample-efficiency of an algorithm in a single task, vanseijen-LoCA developed the Local Change Adaptation (LoCA) task configuration and corresponding evaluation methodology to measure the agent’s ability to adapt when the task changes. This approach, inspired by approaches used in neuroscience for measuring model-based behavior in humans and rodents, is designed to measure how quickly an RL algorithm can adapt to a local change in the reward using its learned environment model. They used this to show that the deep model-based method MuZero schrittwieser2019mastering, which achieves great sample-efficiency on Atari, was not able to effectively adapt to a local change in the reward, even on simple tasks.
This paper builds out this direction further. First, we improve the original LoCA evaluation methodology, such that it is less sensitive to hyperparameters and can be more easily applied to stochastic environments. Our evaluation methodology is designed to make a binary classification of model-based methods: those that can effectively adapt to local changes in the environment and those that cannot.
We apply our improved methodology to the MuJoCo Reacher domain and use it to evaluate two continuous-control model-based methods, PlaNet and DreamerV2 hafner2019learning; hafner2019dream; hafner2020mastering. Both methods turn out to adapt poorly to local changes in the environment. Combining these results with the results from vanseijen-LoCA, which showed a similar shortcoming of MuZero, a trend appears to emerge, suggesting that modern deep model-based methods are unable to adapt effectively to local changes in the environment.
We take a closer look at what separates model-based methods that adapt poorly from model-based methods that adapt effectively, by evaluating various tabular model-based methods. This leads us to define two failure modes that prohibit adaptivity. The two failure modes are linked to MuZero, potentially justifying its poor adaptivity to local changes. Further analysis of the Planet and the DreamerV2 methods enables us to identify two more failure modes that are unique to approximate (i.e., non-tabular) model-based methods.
Using the insights about important failure modes, we set off to design adaptive model-based methods that rely on function approximation. We demonstrate that by making small modifications to the classical linear Dyna method. The resulting algorithm adapts effectively in a challenging setting (sparse reward and stochastic transitions).
2 Measuring Adaptivity of Model-Based Methods
In this section, we present the LoCA task configuration introduced by vanseijen-LoCA and an improved version of the corresponding LoCA evaluation methodology. The LoCA task configuration consists of two different tasks based on the same environment and the LoCA evaluation methodology measures how effective a method is in adapting from the first to the second task. This methodology is inspired by how model-based behavior is identified in behavioral neuroscience (e.g., see daw2011model). The LoCA task configuration only specifies some specific features that the environment should have. In practise, many different domains can be used as the basis for a LoCA environment, ranging from tabular environments with discrete actions to environments with high-dimensional, continuous state and action spaces.
2.1 LoCA task configuration and training procedure

The LoCA configuration considers two different tasks (i.e., reward functions) in the same environment. In addition, two different initial state distributions are used during training (see Figure 1).
A LoCA environment contains two terminal states, T1 and T2. Around T1 is a local area that, once entered, the agent is unable to move out of without terminating the episode, regardless of its policy. We refer to this local area as the T1-zone. The boundary of the T1-zone can be viewed as a one-way passage. The reward function for task A, , and task B, , are 0 everywhere, except upon transitions to a terminal state. A transition to T1 results in a reward of 4 under and 1 under ; transitioning to T2 results in a reward of 2 under both and . The discount factor is the same for task A and task B. Note that, while and only differ locally, the optimal policy changes for almost all states: for task A, the optimal policy points towards T1 for the majority of the state-space, while for task B it points towards T2 (except for states within the T1-zone).
An experiment consists of three different training phases (with our improved evaluation methodology, the third phase is optional). During Phase 1, the reward function is ; upon transitioning to Phase 2, the reward function changes to and remains unchanged upon transitioning to Phase 3. Crucially, the initial-state distribution during training changes across the phases as well. In Phases 1 and 3, the initial state is drawn uniformly at random from the full state space111Other initial-state distributions are possible too, as long as the distribution enables experiences from across the full state-space.; in Phase 2, it is drawn from the T1-zone.
The key question that determines adaptivity is whether or not a method can adapt effectively to the new reward function during phase 2. That is, can it change its policy from pointing towards T1 to pointing towards T2 across the state-space, while only observing samples from the local area around T1.
2.2 Original LoCA evaluation methodology
The LoCA evaluation methodology introduced by vanseijen-LoCA only evaluates a method during Phase 3. Good adaptivity in Phase 2 implies optimal performance in Phase 3 right out of the gate; by contrast, a method that adapts poorly in Phase 2 will require additional training time in Phase 3 to obtain optimal performance. The amount of additional training needed is used to quantify how far off the behavior of a method is from ideal adaptive behavior. A method is evaluated by freezing learning periodically during training (i.e., not updating its weights, internal models or replay buffer), and executing its policy for a number of episodes. During evaluation, an initial-state distribution is used that covers a small area of the state-space roughly in the middle of T1 and T2. The fraction of episodes the agent ends up in the high-reward terminal (T2 for Phase 3) within a certain time-limit is used as measure for how good its policy is. This measure is called the top-terminal fraction and its values are always between 0 (poor performance) and 1 (good performance). The regret of this metric during Phase 3 with regards to optimal performance is called the LoCA regret. A LoCA regret of 0 implies the agent has a top-terminal fraction of 1 out of the gate in Phase 3 and means the agent adapts effectively to local changes.
The original evaluation procedure has a number of disadvantages. It involves various hyperparameters, such as the exact placement of the initial-state distribution for evaluation and the cut-off time for reaching T2 that can affect the value of the LoCA metric considerably. Furthermore, in stochastic environments, even an optimal policy could end up at the wrong terminal by chance. Hence, in stochastic environments a LoCA regret of 0 is not guaranteed even for adaptive methods.
Finally, measuring the amount of training needed in Phase 3 to determine how far off a method is from ‘ideal’ behavior is questionable. Adaptivity in Phase 2 is fundamentally different from adaptivity in Phase 3. Adaptivity in Phase 2 requires a method to propagate newly observed reward information to parts of the state-space not recently visited such that the global policy changes to the optimal one under the new reward function, an ability classically associated with model-based learning. By contrast, adaptivity in Phase 3, where the agent observes samples throughout the full state-space, is a standard feature of most RL algorithms, regardless whether they are model-based or not. And while leveraging a learned environment model can reduce the amount of (re)training required, so do many other techniques not unique to model-based learning, such as representation learning or techniques to improve exploration. So beyond determining whether a method is adaptive (LoCA regret of 0) or not (LoCA regret larger than 0), the LoCA regret does not tell much about model-based learning.
2.3 Improved LoCA evaluation methodology
To address these shortcomings, we introduce an improved evaluation methodology. In this improved version we evaluate performance during both Phases 1 and 2 by simply measuring the average return over the evaluation episodes and comparing it with the average return of the corresponding optimal policy. Furthermore, as initial-state distribution, the full state-space is used instead of some area in between T1 and T2. Under this new methodology, we call a method (locally) adaptive if its performance is close-to-optimal in both Phases 1 and 2; if it is close-to-optimal in Phase 1, but not in Phase 2, we call the method non-adaptive. Keep in mind that both phases have a different optimal expected return due to the different reward functions. Finally, if the performance in phase 1 is not close-to-optimal, we do not make an assessment of its adaptivity.
With our improved evaluation methodology, Phase 3 is no longer required to evaluate the adaptivity of a method. However, it can be useful to rule out two—potentially easily fixable—causes for poor adaptivity in Phase 2. First, a method might simply not be able to get close-to-optimal performance in task B regardless of the samples it observes. Second, some methods are designed with the assumption of a stationary environment and cannot adapt to any changes in the reward function. This could happen, for example, if a method decays exploration and/or learning rates such that learning becomes less effective over time. In both cases, tuning learning hyperparameters or making minor modifications to the method might help.
3 Adaptive Versus Non-Adaptive MBRL
The single-task sample efficiency of a method says little about its ability to adapt effectively to local changes in the environment. Moreover, seemingly small discrepancies among different MBRL methods can greatly affect their adaptivity. In Section 3.1, we will illustrate both these points by evaluating three different tabular MBRL methods in the GridWorldLoCA domain (Figure 2(a)), introduced by vanseijen-LoCA, using LoCA. In Section 3.2 we discuss in more detail why some of the tabular MBRL methods fail to adapt effectively. The code of all of the experiments presented in this paper is available at https://github.com/chandar-lab/LoCA2.
3.1 Tabular MBRL Experiment
Each of the three methods we introduce learns an estimate of the environment model (i.e., the transition and reward function). We consider two 1-step models and one 2-step model. The 1-step model consists of and that estimate the 1-step transition and expected reward function, respectively. Upon observing sample , this model is updated according to:
with the (fixed) learning rate and a one-hot encoding of state . Both and are vectors of length , the total number of states. Planning consists of performing a single state-value update at each time step based on the model estimates.222This is a special case of asynchronous value iteration, as discussed for example in Section 4.5 of sutton2018reinforcement. For a 1-step model:
We evaluate two variations of this planning routine: mb-1-r, where the state that receives the update is selected at random from all possible states; and mb-1-c, where the state that receives the update is the current state. Action selection occurs in an -greedy way, where the action-values of the current state are computed by doing a lookahead step using the learned model and bootstrapping from the state-values.
We also evaluate mb-2-r, which is similar to mb-1-r except that it uses a 2-step model, which estimates—under the agent’s behavior policy—a distribution of the state 2 time steps in the future and the expected discounted sum of rewards over the next 2 time steps. The update equations for this method, as well as further experimental details, can be found in Section B.1.
A summary of the methods we evaluate is shown in Table 1. Besides these methods, we also test the performance of the model-free method Sarsa() with .
| Method | Model | State receiving value update |
|---|---|---|
| mb-1-r | 1-step | Randomly selected |
| mb-1-c | 1-step | Current state |
| mb-2-r | 2-step | Randomly selected |


We use a stochastic version of the GridWorldLoCA domain, where the action taken results with 25% probability in a move in a random direction instead of the preferred direction. The initial-state distribution for training in Phases 1 and 3, as well as the initial-state distribution for evaluation is equal to the uniform random distribution across the full state-space; the initial-state distribution for training in phase 2 is equal to the uniform random distribution across the T1-zone.
Figure 2 shows the performance of the various methods, averaged over 10 independent runs. While all three MBRL methods have similar performance in Phase 1 (i.e., similar single-task sample-efficiency), their performance in Phase 2 (i.e., their adaptivity to local changes in the environment) is very different. Specifically, even though the methods are very similar, only mb-1-r is able to change its policy to the optimal policy of task B during Phase 2. By contrast, mb-1-c and mb-2-r lack the flexibility to adapt effectively to the new task. Note that Sarsa() achieves a higher average return in phase 2 than mb-1-c and mb-2-r. This may seem to be odd, given that it is a model-free method. There is however a simple explanation: the policy of Sarsa() in phase 2 still points to T1, which now results in a reward of 1 instead of 4. By contrast, the policy changes for mb-1-c and mb-2-r are such that the agent neither moves to T1 nor T2 directly, instead, it mostly moves back and forth during the evaluation period, resulting in a reward of 0 most of time.
3.2 Discussion
The tabular MBRL experiment illustrates two different reasons why a model-based method may fail to adapt effectively.
Failure Mode #1: Planning relies on a value function, which only gets updated for the current state.
This applies to mb-1-c. A local change in the environment or reward function can results in a different value function across the entire state-space. Since mb-1-c only updates the value of the current state, during phase 2 only states within the T1-zone are updated. And because evaluation uses an initial-state distribution that uses the full state-space, the average return will be low.
Failure Mode #2: The prediction targets of the learned environment model are implicitly conditioned on the policy used during training.
This is the case for mb-2-r, as the model predicts the state and reward 2 time steps in the future, using only the current state and action as inputs. Hence, there is an implicit dependency on the behavior policy. For mb-2-r, the behavior policy is the -greedy policy with regards to the state-values, and during the course of training in Phase 1, this policy converges to the (epsilon-)optimal policy under reward function . As a consequence, the environment model being learned will converge to a version that is implicitly conditioned on an optimal policy under as well. During training in Phase 2, this dependency remains for states outside of the T1-zone (which are not visited during Phase 2), resulting in poor performance.
These two failure modes, while illustrated using tabular representations, apply to linear and deep representations as well, as the underlying causes are independent of the representation used. In fact, we believe that these two failure modes are in part responsible for the poor adaptivity of MuZero, as shown in vanseijen-LoCA. MuZero relies on a value function that gets updated towards -step returns, which are implicitly conditioned on the policy used during training. This has a similar effect as when using multi-step update targets for learning the model, which underlies Failure Mode #2: the value function that results from the planning updates is not able to fully adapt to the new reward function. In addition, the -step returns bootstrap from target values that are computed only for the visited states from an episode-trajectory, which is similar to Failure Mode #1, as we explain in more detail in Appendix B.2.
4 Evaluating PlaNet and DreamerV2
In this section, we evaluate the adaptivity of two deep model-based methods, PlaNet hafner2019learning and the latest version of Dreamer, called DreamerV2 hafner2020mastering, using a modified version of LoCA in a variant of the Reacher domain, which involves a continuous-action domain with dimensional (pixel-level) states.
4.1 The ReacherLoCA Domain
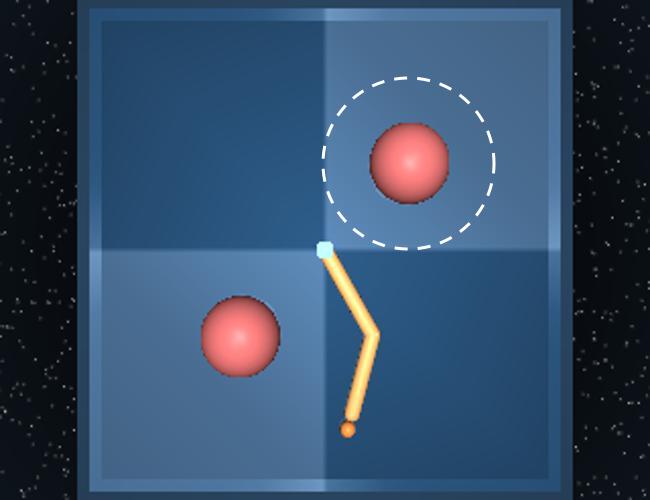
We introduce a variation on the Reacher environment (the easy version) available from the DeepMind Control Suite tassa2018deepmind. The Reacher environment involves controlling the angular velocity of two connected bars in a way such that the tip of the second bar is moved on top of a circular target. The reward is 1 at every time step that the tip is on top of the target, and 0 otherwise. An episode terminates after exactly 1000 time steps. The target location and the orientation of the bars are randomly initialized at the start of each episode.
In our modified domain, ReacherLoCA, we added a second target and fixed both target locations in opposite corners of the domain (Figure 3). Furthermore, we created a one-way passage around one of the targets. Staying true to the original Reacher domain, episodes are terminated after exactly 1000 time steps. While this means the target locations are strictly speaking not terminal states, we can apply LoCA to this domain just the same, interpreting the target location with the one-way passage surrounding it as T1 and the other one as T2. Rewards and are applied accordingly. The advantage of staying as close as possible to the original Reacher environment (including episode termination after 1000 time steps) is that we can copy many of the hyperparameters used for PlaNet and DreamerV2 applied to the original Reacher environment and only minor fine-tuning is required.







4.2 Experiment
Note that both PlaNet and DreamerV2 learn from transitions sampled from a large experience replay buffer (they call it experience dataset) that contains all recently visited transitions. When evaluating these algorithms in the ReacherLoCA domain, such a strategy could hurt the agent’s ability of adaptation, because in early stage of Phase 2, most of the data that the agent learns from are still from Phase 1 and it takes a long time before all of the task A data in the buffer get removed, if the replay buffer is large. Therefore a natural question to ask is, in practice, whether the agent can adapt well, with some stale data in the replay buffer. The other interesting question to ask would be, if the agent somehow knows the change of the task and reinitializes its replay buffer when it observes such a change, does the agent perform well in Phase 2?
To answer the above two questions, we tested two variants of each of these two algorithms. For both variants, we used a sufficiently large replay buffer that could contain all the transitions produced during training. For one variant, we reinitialized the replay buffer between two phases by first clearing the replay buffer and then filling replay buffer with certain number of episodes generated by following a random policy. This variant of algorithm requires to know when the environment changes and could therefore take advantage of this prior knowledge to remove outdated data. For the other variant, no modification to the replay buffer was applied between two phases. For both DreamerV2 and PlaNet, we did a grid search only over the critical hyperparameters suggested by the corresponding papers. Unless specified otherwise, other hyperparameters were chosen to be the same as those found to be the best by the corresponding papers in the original Reacher environment. Details of the experiment setup are summarized in Sections C.1 and C.4. Complete empirical results are presented in Sections C.3 and C.6.
For each variant of each of the two algorithms, we drew a learning curve (Figure 3) corresponding to the best hyperparameter setting found by a grid search (see Sections C.2 and C.5 for details). The reported learning curves suggest that neither DreamerV2 nor PlaNet effectively adapted their policy in Phase 2, regardless of the replay buffer being reinitialized or not. Further, when the replay buffer was not reinitialized, both DreamerV2 and PlaNet performed poorly in Phase 3. To obtain a better understanding of the failure of adaptation, we plotted in Figure 4 the reward predictions of DreamerV2’s world model at the end of each phase. The corresponding results for PlaNet is similar and are presented in Section C.6. This time, our empirical results provide affirmative answers to the above two questions.
The first question is addressed by analyzing the predicted rewards without reinitializing the replay buffer. In this case, the predicted reward of T1 overestimates the actual reward (1) in both Phases 2 and 3. Such an overestimation shows that learning from stale data in the replay buffer apparently hurts model learning. In addition, the corresponding learning curves in Phases 2 and 3 show that the resulting inferior model could be detrimental for planning. The second question is addressed by analyzing the predicted rewards with reinitializing the replay buffer. In this case, the values for T1 at the end of Phase 2 are correct now, but the estimates for the rest of the state space are completely incorrect. This result answers our second question – with replay buffer reinitialization, the agent had no data outside of the T1-zone to rehearse in Phase 2 and forgot the learned reward model for states outside the T1-zone. Such an issue is called catastrophic forgetting, which was originally coined by mccloskey1989catastrophic. Overall, we conclude that DreamerV2 achieved poor adaptivity to local changes due to two additional failure modes that are different from those outlined in Section 3.
Failure Mode #3: Learning from large replay buffers cause interference from the old task.
Failure Mode #4: If the environment model is represented by neural networks, learning from small replay buffers cause model predictions for areas of the state space not recently visited to be off due to catastrophic forgetting.
Remark: Note that there is a dilemma between the above two failure modes. Also, note that as long as one uses a large replay buffer in a non-stationary environment, failure mode #3 is inevitable. This suggests that, when using neural networks, solving the catastrophic forgetting problem is an indispensable need for LoCA and the more ambitious continual learning problem. Over the past 30 years, significant progress was made towards understanding and solving the catastrophic forgetting problem (french1991using; robins1995catastrophic; french1999catastrophic; goodfellow2013empirical; kirkpatrick2017overcoming; kemker2018measuring). However, a satisfying solution to the problem is still not found and the problem itself is still actively studied currently.
5 Adaptive MBRL Algorithm with Function Approximation

In this section, we identify an algorithm that does not fall into the four aforementioned failure modes and understand its behavior using LoCA in a variant of the MountainCar domain (moore1990efficient). This algorithm, called adaptive linear Dyna, is a modified version of the linear Dyna algorithm (Algorithm 4 by sutton2012dyna). To overcome the unsolved catastrophic forgetting problem with neural networks, this algorithm takes a step back by using linear function approximation with sparse feature vectors. We provide empirical evidence showing that this algorithm is adaptive in the MountainCarLoCA domain. Additional empirical results show that a nonlinear (neural networks) extension of the linear algorithm did not adapt equally well in the same setup, due to the inferior learned model resulting from catastrophic forgetting or interference from the old task.
Sutton et al.’s linear Dyna algorithm applies value iteration with a learned linear expectation model, which predicts the expected next state, to update a linear state-value function. Using expectation models in this way is sound because value iteration with an expectation model is equivalent to it with an aligned distribution model when using a linear state-value function (wan2019planning). The algorithm does not fall into Failure Mode #2 because the expectation model is policy-independent. The algorithm does not fall into the Failure Modes #3 and #4 because the model is learned online and the algorithm uses linear function approximation with sparse tile-coded (sutton2018reinforcement) feature vectors. Limiting feature sharing alleviates the catastrophic forgetting problem because learning for one input influences predicting for only few other inputs.
Sutton et al.’s linear Dyna algorithm does fall into something similar to Failure Mode #1 because planning is not applied to any of the real feature vectors. Specifically, planning uses tabular feature vectors (one bit on in each vector), while real feature vectors (feature vectors corresponding to real states) are binary vectors with multiple bits on. It is thus unclear if planning with these unreal feature vectors could produce a good policy. In Figure 5, we empirically show that original linear Dyna leads to failure of adaptation in Phase 2.
A natural modification of the algorithm to improve its adaptivity, is to change the way of generating feature vectors for planning. We choose to randomly sample these feature vectors from a buffer containing feature vectors corresponding to recently visited states. We call this buffer the planning buffer because feature vectors stored in the buffer are used for planning. While the modification itself is small and simple, the effect of the modification is significant – the modified algorithm can almost achieve the optimal value in Phase 2. The pseudo code of the algorithm is shown in Appendix E.
We tested our algorithm on a variant of the MountainCar domain. Our variant of the MountainCar domain extends the variant of the same domain used by vanseijen-LoCA, by introducing stochasticity. Specifically, with probability , the agent’s action is followed and with probability , the state evolves just as a random action was taken. We tested . The discount factor is 0.99. Other details of the experiment setup are summarized in Section D.1.
The first experiment was designed to test if the adaptive linear Dyna algorithm can adapt well with proper choices of hyperparameters. To this end, for each level of stochasticity, we did a grid search over the algorithm’s hyperparameters and showed the learning curve corresponding to the best hyperparameter setting in Figure 5. The figure also shows, for different levels of stochasticity, learning curves of Sarsa() with the best hyperparameter setting as baselines. The best hyperparameter setting is the one that performs the best in Phase 2, among those that perform well in Phase 1 (See Section D.2 for details). Further, we show a learning curve of linear Dyna by sutton2012dyna. A hyperparameter study of these algorithm is presented in Section D.3.
The learning curves show that for all different levels of stochasticity tested here, adaptive linear Dyna performed well in Phase 1 and adapted quickly and achieved near-optimal return in Phase 2. The learning curve for Sarsa() coincides with our expectation. It performed well in Phase 1, but failed to adapt its policy in Phase 2. Linear Dyna also performed well in Phase 1, but failed to adapt in Phase 2, which is somewhat surprising because the unreal tabular feature vectors were used in both phases. A deeper look at our experiment data (Figure D.4 and D.5) shows that in Phase 1, although the policy is not apparently inferior, the estimated values are inferior. The estimated values are even worse in Phase 2. We hypothesize that such a discrepancy between Phases 1 and 2 is due to the fact that the model-free learning part of the linear Dyna algorithm helps obtaining a relatively accurate value estimation for states over the entire state space in Phase 1, but only for states inside the T1-zone in Phase 2.
The other observation is that when stochasticity = 0.5, Sarsa() is worse than adaptive linear Dyna. Note that there is a very high variance in the learning curve of Sarsa(). On the contrary, adaptive linear Dyna achieved a much lower variance, potentially due to its planning with a learned model, which induces some bias and reduces variance. Comparing the two algorithms shows that when the domain is highly stochastic, the variance can be an important factor influencing the performance and planning with a learned model can reduce the variance.
6 Discussion and Conclusion
We introduced an improved version of the LoCA evaluation methodology, which is more flexible and easier to use. We then studied the adaptivity of two deep MBRL methods using this methodology. Our empirical results, combined with those from vanseijen-LoCA, suggest that several popular modern deep MBRL methods adapt poorly to local changes in the environment. This is surprising as the adaptivity should be one of the major strengths of MBRL (in behavioral neuroscience, adaptivity to local changes is one of the characteristic features that differentiates model-based from model-free behavior, e.g., see daw2011model).
Besides that, we studied the challenges involved with building adaptive model-based methods and identified four important failure modes. These four failure modes were then linked to three modern MBRL algorithms, justifying why they didn’t demonstrate adaptivity in experiments using LoCA. The first three of these failure modes can be overcome by using appropriate environment models and planning techniques. The fourth failure mode is tied to catastrophic forgetting, which is a challenging open problem. The most common mitigation technique to the problem, using a large experience replay buffer, is not an option in our case, as our experiments show that this precludes effective adaptation in non-stationary environments. Hence, we conclude that the path towards adaptive deep MBRL involves tackling the challenging catastrophic forgetting problem.
Appendix A Related Work
LoCA is an evaluation methodology designed to measure the adaptivity of an algorithm. It serves as a preliminary yet important step towards the ambitious continual learning problem (khetarpal2020towards). In the continual learning problem, the agent interacts with an non-stationary environment. LoCA specifies a particular kind of continual learning problem, which involves fully observable environment and only one environment change.
LoCA is also closely related to the well-known transfer learning problem (taylor2009transfer; lazaric2012transfer; zhu2020transfer) because they both need the agent to solve for multiple tasks. Nevertheless, LoCA should not be viewed as a special case of transfer learning. In transfer learning, the agent is informed of which task it is solving, while in LoCA it does not.
There are several ways in which an algorithm may potentially adapt quickly when the environment changes. For example, the learned feature representation (konidaris2012transfer; barreto2016successor), the discovered options (sutton1999between; barto2003recent; bacon2018temporal), or some general meta-knowledge (finn2017model; huisman2021survey) obtained from the old environment may be useful for learning and planning in the new environment. LoCA focuses on evaluating if the agent’s fast adaptation relies on its planning with a learned model.
On the other hand, there are also some existing works developing MBRL algorithms for the continual learning problem or the transfer learning problem (huang2020continual; boloka2021knowledge; zhang2019solar; nguyen2012transferring; lu2020reset). Although these algorithms have shown great performance in various experiments, none of these algorithms directly resolve the fundamental catastrophic forgetting issue and therefore, generally speaking, they are not likely to demonstrate adaptivity in LoCA.
Appendix B Supplementary Details for Experiments in Section 3
B.1 Details of the Tabular Experiment
| Initial distributions | Phase 1 training | Uniform distribution over the entire state space |
| Phase 1 evaluation | Uniform distribution over the entire state space | |
| Phase 2 training | Uniform distribution over states within T1-zone | |
| Phase 2 evaluation | Uniform distribution over the entire state space | |
| Phase 3 training | Uniform distribution over the entire state space | |
| Phase 3 evaluation | Uniform distribution over the entire state space | |
| Training steps | Phase 1 steps | |
| Phase 2 steps | ||
| Phase 3 steps | ||
| Other details | Training steps between two evaluations | 500 |
| Number of runs | 10 | |
| Number of evaluation episodes | 100 |
For the GridWorldLoCA domain, we used the same discount factor as used in (vanseijen-LoCA), , but used stochastic transitions. In particular, with 25% probability the action outcome is that of a random action instead of the selected action.
For all methods, we used an -greedy behavior policy with . In addition, we used optimistic initialization to encourage high exploration during initial training in Phase 1. Specifically, for Sarsa() we set the initial action-values to (twice the value of the maximum reward in Phase 1). And for all model-based methods, we set the initial state-values and initial reward-function estimates to 8. For Sarsa(), we used . We roughly optimized the step-size for each method. This resulted in a step-size of 0.2 for all model-based method and a step-size of 0.03 for Sarsa(). The reason the best step-size for Sarsa() is substantially lower than the one for the model-based methods is that a of 0.95 combined with the relatively high environment stochasticity leads to high variance updates for Sarsa(). Hence, to counter this variance and get accurate estimates a small step-size is needed.
B.2 MuZero and its relation to Failure Mode #1 and #2
We start by summarizing some key elements of MuZero’s implementation. At its core, MuZero learns a 1-step model that takes as input a hidden state (derived from past observations) and action , and outputs an estimate of the reward and next hidden state . Simultaneously, it learns a value-function that maps a hidden state to an estimate of the expected return. At every time step, a MCTS routine is performed starting from the current hidden state, by leveraging the learned model as the agent does not have access to the true environment model. MCTS is performed up to a certain maximum horizon k (k=5 for the Atari domain). At the leaf nodes of the tree, MuZero’s MCTS bootstraps from rather than performing a sample rollout, as normally occurs in MCTS. The output of MuZero’s MCTS routine is a (local) policy , according to which action is selected, and a target value . This target value is an improved estimate of , as it is computed from the bootstrapped MCTS routine. The target value is stored in a replay buffer, in addition to the current observation , action , reward and policy . The value function is updated by selecting a past trajectory, computing the hidden state for some time step within the trajectory and updating its value using the -step return . Crucially, the -step return bootstraps not from , but from the target value of the corresponding time step, . These target values are not updated once they are in the replay buffer. Hence, despite that MuZero employs experience replay to update the value function , during Phase 2 the update targets outside the T1-zone remain the same and do not adapt to the newly observed reward. This can be viewed as a variation of Failure Mode #1. Finally, an -step update target is used, whose value is implicitly conditioned on the behavior policy during training. This has a similar effect as when using multi-step update targets for learning the model—which underlies Failure Mode #2–as the planning update uses the model estimate as well as value function.
Appendix C Supplementary Details and Results for Experiments in Section 4
C.1 Setup of the DreamerV2 Experiment
| Initial distributions | Phase 1 training | Uniform distribution over the entire state space |
| Phase 1 evaluation | Uniform distribution over the entire states outside T1-zone | |
| Phase 2 training | Uniform distribution over states within T1-zone | |
| Phase 2 evaluation | Uniform distribution over the entire states outside T1-zone | |
| Phase 3 training | Uniform distribution over the entire state space | |
| Phase 3 evaluation | Uniform distribution over the entire states outside T1-zone | |
| Training steps | Phase 1 steps | Planet: , DreamerV2: |
| Phase 2 steps | Planet: , DreamerV2: | |
| Phase 3 steps | Planet: , DreamerV2: | |
| Other details | Training steps between two evaluations | PlaNet: , DreamerV2 |
| Number of runs | 5 | |
| Number of evaluation episodes | 5 |
In the ReacherLoCA domain, if the agent is within the T1-zone and chooses an action that takes it out of the T1-zone, the agent’s state remains unchanged. In general, T1-zone can be implemented without touching native domain code as long as the domain code offers an API function to set or reload the state. A wrapper around the domain can be implemented that resets the state to the previous one whenever the agent takes an action that moves it out of the T1-zone.
We tried two variants of the DreamerV2 algorithm. One reinitializes the replay buffer at the beginning of Phase 2 and the other one does not. When initializing (at the beginning of Phase 1) or reinitializing the replay buffer, the agent performs 50 episodes following a uniformly random policy and stores these episodes in the buffer (the same initialization strategy is also adopted in DreamerV2, although fewer number of episodes are produced there). We found that increasing the number of random episodes helps the agent to find the optimal target, not the sub-optimal one.
We searched over the KL loss scale , the actor entropy loss scale , and the discount factor . Note that the discount factor tested here is not the problem’s discount factor (the problem’s discount factor is 1). Instead, it is part of the solution method.
C.2 Additional Information about the DreamerV2 Result Shown in the Middle Panel of Figure 3
The hyperparameters used to generate the plotted learning curves are chosen in the following way. We first collect the set of hyperparameter settings that, in both Phases 1 and 3, result in average returns (over the last five evaluation runs) being more than 80% of the optimal average returns. If the set of hyperparameter settings is empty, we chose the setting that achieved the highest average return in Phase 3 (over the last five evaluation runs). Otherwise, from the set of hyperparameter settings, we picked the setting that achieved the highest average return over all evaluation runs in Phase 2. Each point in a learning curve is the average of undiscounted cumulative reward over 5 evaluation episodes. The shading area shows the standard error.
The best hyperparamerter setting for DreamerV2 with replay buffer reinitialization is , , and . Without replay buffer reinitialization, none of the runs achieved more than 80% of optimal average return in Phase 3 over the last five evaluation runs. The setting that achieved the highest performance in Phase 3 is , , and .
C.3 Additional DreamerV2 Results
Figure C.3 shows DreamerV2’s (no reinitialization) performance with longer training in Phase 3. We observe that even with a much longer training in Phase 3, the agent did not escape from the sub-optimal target.
C.4 Setup of the PlaNet Experiment
PlaNet uses the cross-entropy method (CEM) for planning. We empirically found that some of the runs would get stuck in the local optima at the end of Phase 1 when using the suggested hyperparameters. Through more experiments, we found that increasing the CEM hyperparameters avoids poor performance in phase 1 for all the random seeds. We increased the horizon length to 50, optimization iterations to 25, and candidate samples to 4000.
Just like the two tested DreamerV2 variants, the two tested PlaNet variants are one that reinitializes the replay buffer and one that does not. The reinitializing strategy is the same as what we apply to DreamerV2 shown in Section C.1.
We searched over the KL-divergence scale , and the step-size .
C.5 Additional Information about the PlaNet Result Shown in the Right Panel of Figure 3
The best hyperparameter setting for PlaNet with buffer reinitialization is , and the step-size . For PlaNet without buffer reinitialization, similar to DreamerV2, none of the runs achieved more than 80% of optimal average return in Phase 3. The setting that achieved the highest average return in Phase 3 is , and the step-size .
C.6 Additional PlaNet Results
Figure C.5 shows learning curves with different hyperparameter settings for PlaNet.





Appendix D Supplementary Details and Results for Experiments in Section 5
D.1 Setup of the Adaptive Linear Dyna Experiment
The MountainCarLoCA domain has two terminal states, one of which locates at the top of the mountain (position , velocity ) and the other one locates at the valley ). The dynamics of the environment is described in Section LABEL:sec:_The_MountainCarLoCA_Domain. The small region where the agent is initialized during evaluation is roughly at the middle of the two terminal states ( position , velocity ).
The linear Dyna algorithm we tested is basically Algorithm 4 by sutton2012dyna. However, we found that Algorithm 4 takes too much memory and computation, making it difficult for testing. To reduce the memory and computation usage, the tested linear Dyna algorithm slightly modifies Algorithm 4 in the following two ways. First, while Algorithm 4 does not specify the maximum size of the priority queue, our algorithm sets that maximum to be 400000 (maximum training steps) and removes 20% oldest elements in the queue whenever the queue is full. Second, in each planning step, Algorithm 4 updates for all predecessor features of the first element in the priority queue and add all predecessor features to the priority queue, our algorithm only updates 5 randomly chosen predecessor features and adds them to the queue. These two modifications we made significantly reduce memory usage and computation.
We summarize in Table D.1 tested hyperparameters for linear Dyna and adaptive linear Dyna.
| Number of Tilings and Tiling Size | [3, 18 by 18; 5, 14 by 14; 10, 10 by 10] |
|---|---|
| Exploration parameter | [0.1, 0.5, 1.0] |
| Stepsize | [0.001, 0.005, 0.01, 0.05, 0.1] / number of tilings |
| Model Stepsize | [0.001, 0.005, 0.01, 0.05, 0.1] / number of tilings |
| Number of planning steps | 5 |
| Size of the planning buffer (adaptive linear Dyna) | [10000, 200000, 4000000] |
For Sarsa(), the tile coding setups and the choices of stepsize are the same as those used for adaptive linear Dyna. The exploration parameter was fixed to be 0.1. We also tested three values: 0, 0.5, and 0.9.
Table D.2 shows the experiment setup used to test linear Dyna, adaptive linear Dyna (Algorithm 1), and Sarsa().
| Initial distributions | Phase 1 training | Uniform distribution over the entire state space |
| Phase 1 evaluation | Uniform distribution over a small region | |
| Phase 2 training | Uniform distribution over states within T1-zone | |
| Phase 2 evaluation | Uniform distribution over a small region | |
| Training steps | Phase 1 steps | |
| Phase 2 steps | ||
| Other details | Training steps between two evaluations | |
| Number of runs | 10 | |
| Number of evaluation episodes | 10 |
D.2 Additional Information about the Result Shown in Figure 5
The hyperparameter setting chosen to draw curves in Figure 5 was chosen in the following way. We first collected hyperparameter settings that achieved 90% of the optimal average return over the last 5 evaluations in Phase 1. From these hyperparameter settings, we picked one that achieved the highest average return over the last 5 evaluations in Phase 2 and drew its learning curve. For stochasticity = 0.5, no hyperparameter setting for Sarsa() achieved 90% optimal performance in the first phase and we picked the one that achieved more than 80% optimality in the first phase.
We summarize in Table D.3 the best hyperparameter settings under different level of stochasticities for each algorithm tested in Section 5.
| Algorithm | Hyperparameter | Deterministic | Stochasticity = 0.3 | Stochasticity = 0.5 |
| Adaptive linear Dyna | Exploration parameter () | 0.5 | 1.0 | 1.0 |
| Step-size () | 0.05 | 0.05 | 0.1 | |
| Step-size () | 0.01 | 0.01 | 0.01 | |
| Number of tilings | 5 | 5 | 5 | |
| Size of the planning buffer | 4000000 | 4000000 | 4000000 | |
| Sarsa() | Step-size () | 0.1 | 0.05 | 0.05 |
| 0.5 | 0.5 | 0.9 | ||
| Number of tilings | 10 | 10 | 10 | |
| Linear Dyna | Exploration parameter () | 0.5 | ||
| Step-size () | 0.5 | |||
| Number of tilings | 5 |
D.3 Additional Results of the Adaptive Linear Dyna Experiment



To demonstrate adaptive linear Dyna’s sensitivity to a hyperparameter, we fixed all of the hyperparameters, except the one being tested, to be those in the best hyperparameter setting (Table D.3). We then varied the tested hyperparameter and plotted the corresponding learning curves. Learning curves for stochasticity = 0, 0.3, and 0.5 are shown in Figure D.1, Figure D.2, and Figure D.3 respectively.
We now use Figure D.1 as an example to understand the algorithm’s sensitivity to its hyperparameters. Sub-figure (a) shows that the algorithm needs a sufficiently large replay buffer to achieve fast adaptation. This is not surprising because the collected data in Phase 2 would only cover a small region of the state space. The Phase 2 data quickly occupy the entire planning buffer, after which planning in Phase 2 would only update states in that small region. Sub-figure (b) shows that the algorithm worked well when a relatively large exploration parameter is used. performed well in the second phase but it was not close to optimality in the first phase. A deeper look at the experimental data (not shown here) suggested that, when , for most of runs, the agent only moved to the sub-optimal terminal state in the first phase, presumably as a result of weak exploration. The sub-optimal terminal state in Phase 1 is the optimal terminal state in Phase 2 and thus the agent didn’t have to change its policy to adapt to the task change. A first look at Sub-figure (c) seems to suggest that the algorithm only adapted well when the number of tilings is small (3 or 5). By checking experimental results of more hyperparameter settings, we found that the failure when is actually a result of other hyperparameters being chosen to be the best for . There are also quite a few hyperparameter settings that achieved fast adaptation in Phase 2 for (not shown here). In fact, Figure D.2, and D.3 show that performed pretty well for stochasticity = 0.3 and 0.5. Sub-figure (g) shows the sensitivity of the algorithm to the stepsize. As one would expect, lower stepsize results in slower learning in both Phases 1 and 2. Sub-figure (h) is particularly interesting. It shows that when the model stepsize is large (equal or larger than 0.05/5) the performance in Phase 2 has a high variance. The model stepsize can not be too small either: with the agent didn’t learn to move to the right terminal in the first phase.

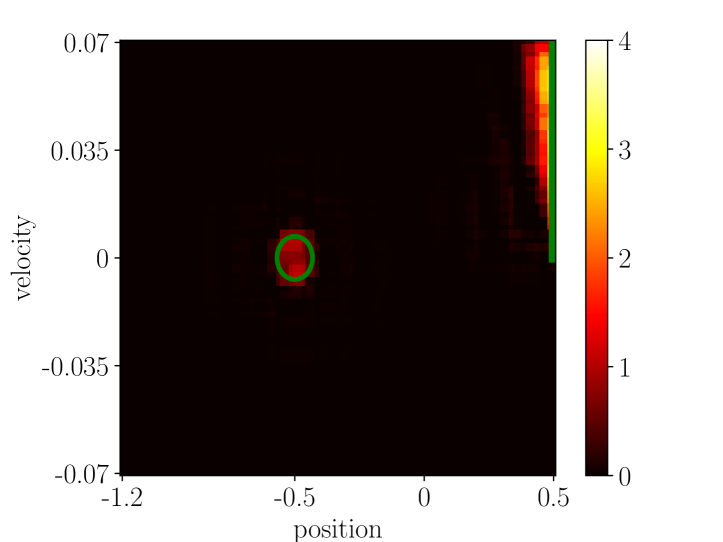

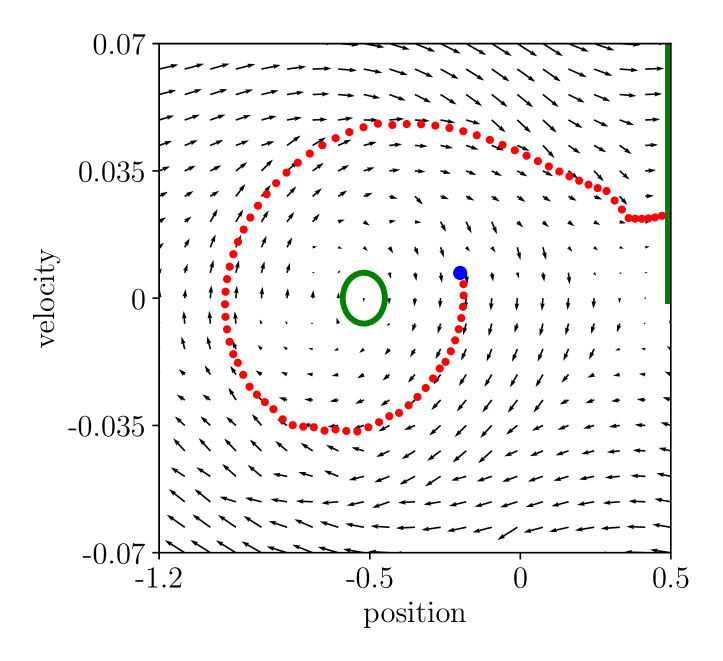




















For better understanding of the tested linear algorithms, we plotted their learned values, policies, reward model, and predicted next value for adaptive linear Dyna (Figure D.4) and linear Dyna (Figure D.5). Plots for Sarsa() are summarized in Figure D.6. We also plotted learned values and policies by the Sarsa() algorithm in the two tasks when the algorithm is applied for sufficiently long.
First, we note that the model learning part of the adaptive linear Dyna algorithm with sparse tile-coded features does not suffer from catastrophic forgetting. This can be seen by comparing sub-figures (b) and (f) in Figure D.4 or those in Figure D.5. We also note that, in Phase 1, linear Dyna produced inferior value estimates (the upper part of sub-figure (a) should be less than 4 because of discounting while it is not) even though the greedy policy w.r.t. these values is not apparently inferior (sub-figure (d)). In Phase 2, the inferior values are even more significant, and the policy did not produce a trajectory that leads to T2. We believe that incorrect value estimate in Phase 1 is not as severe as it in Phase 2 because the model-free learning part of the linear Dyna algorithm helps value estimation for most of states in Phase 1, but only for states within T1-zone in Phase 2.
D.4 Nonlinear Dyna Q
Based on the adaptive linear Dyna algorithm, we propose the nonlinear Dyna Q algorithm (Algorithm 2), in which the value function and the model are both approximated using neural networks. Instead of trying to solve the catastrophic interference problem, we adopt the simple replay approach. Specifically, we maintain a learning buffer, in addition to the planning buffer, to store recently visited transitions and sample from the learning buffer to generate data for model learning. As discussed previously, this approach falls into a dilemma of learning from stale information (Failure Mode #3) or forgetting previously learned information (Failure Mode #4). To empirically verify if the dilemma is critical, we varied the size of the learning buffer as well as other hyperparameters to see if there is one parameter setting that supports adaptation. Further, we also tried two strategies of sampling from the learning buffer: 1) randomly sampling from the entire buffer, and 2) sampling half of the data randomly from the entire buffer and the rest randomly only from rewarding data (transitions leading to rewards). Our empirical results in the MountainCarLoCA domain presented in Section D.5 confirms that this dilemma is critical – the learned model is inferior, even with the best hyperparameter setting and sampling strategy.
The other important difference between the non-linear algorithm and the linear algorithm is the data used in model learning. The model in the non-linear algorithm is learned using off-line data sampled from a replay buffer, while it in the linear algorithm is learned using online data. Specifically, we maintain a learning buffer, in addition to the planning buffer, to store recently visited transitions and sample from the learning buffer to generate data for model learning.
D.5 Nonlinear Dyna Q Experiment
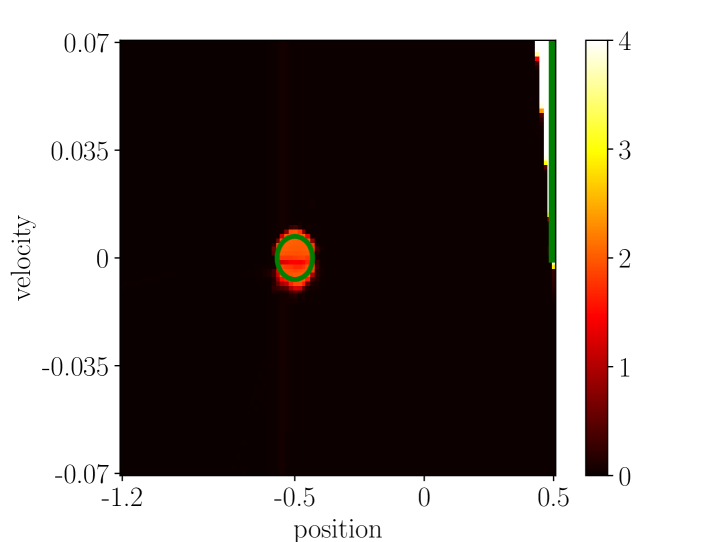
We performed an experiment to test if the nonlinear Dyna Q algorithm can successfully adapt in the deterministic MountainCarLoCA domain. Tested hyperparameters are specified in Table D.4. The hyperparameter setting used to generate the reported learning curve (Figure D.8(a)) chosen in a similar way as those chosen for the adaptive linear Dyna experiment.
The learning curve corresponding to the best hyperparameter setting is the one using a large learning buffer, and the sampling strategy that emphasizes rewarding transitions. Nevertheless, even the best hyperparameter setting only produced an inferior policy, as illustrated in the sub-figure (a) of Figure D.8. We picked one run with the best hyperparameter setting and plotted the estimated reward model at the end of Phase 2 in Figure D.8. Comparing the predicted rewards by the learned model with the true rewarding region marked by the green circle shows catastrophic forgetting severely influences model learning. In fact, we observed that if the model in Phase 2 is trained even longer, eventually T2’s reward model will be completely forgotten.
| Neural networks | Dynamics model | , tanh |
| Reward model | , tanh | |
| Termination model | , tanh | |
| Action-value estimator | , tanh | |
| Optimizer | Value optimizer | Adam, step-size |
| Model optimizer | Adam, step-size | |
| Other value and model optimizer parameters | Default choices in Pytorch (paszke2019pytorch) | |
| Other details | Exploration parameter () | |
| Target network update frequency () | 500 | |
| Number of model learning steps () | 5 | |
| Number of planning steps () | 5 | |
| Size of learning buffer () | ||
| Size of planning buffer () | ||
| Mini-batch size of model learning () | 32 | |
| Mini-batch size of planning () | 32 |
| Initial distributions | Phase 1 training | Uniform distribution over the entire state space |
| Phase 1 evaluation | Uniform distribution over a small region | |
| Phase 2 training | Uniform distribution over states within T1-zone | |
| Phase 2 evaluation | Uniform distribution over a small region | |
| Training steps | Phase 1 steps | |
| Phase 2 steps | ||
| Other details | Training steps between two evaluations | |
| Number of runs | ||
| Number of evaluation episodes |
The set of hyperparameters used to generate learning curves in Figure 5 is chosen in the way the set of hyperparameters chosen in the adaptive linear Dyna experiment. The best hyperparameter setting of nonlinear Dyna Q in this experiment is summarized in Table D.6.
| Optimizer | Value optimizer | Adam, step-size |
|---|---|---|
| Model optimizer | Adam, step-size | |
| Other hyperparameters | Exploration parameter () | |
| Size of learning buffer () |


Just as what we did for linear algorithm, we plot the estimated values, reward and termination models, as well as the learned policy in Figure D.9.
Comparing sub-figures (b) and (f) shows that the middle orange region changes to two smaller red regions, indicating that the algorithm forgets the reward model as more and more training goes on for the T1 part. Although sub-figure (e) still seems to be correct, but a deeper look at the learned policy shows that the trajectory generated by the policy (sub-figure (h)) is not optimal (c.f. sub-figure (h) in Figure D.4).







Appendix E Pseudo Code
We provide the pseudo code of the adaptive linear Dyna algorithm, and the nonlinear Dyna Q algorithm in Algorithm 1 and 2 respectively.