Kartik Ahuja††thanks: Equal Contribution \Email[email protected]
\addrMila - Quebec AI Institute, Université de Montréal.
and \NameDivyat Mahajan11footnotemark: 1 \Email[email protected]
\addrMila - Quebec AI Institute, Université de Montréal.
and \NameVasilis Syrgkanis \Email[email protected]
\addrMicrosoft Research, New England
and \NameIoannis Mitliagkas \Email[email protected]
\addrMila - Quebec AI Institute, Université de Montréal.
Towards efficient representation identification in supervised learning
Abstract
Humans have a remarkable ability to disentangle complex sensory inputs (e.g., image, text) into simple factors of variation (e.g., shape, color) without much supervision. This ability has inspired many works that attempt to solve the following question: how do we invert the data generation process to extract those factors with minimal or no supervision? Several works in the literature on non-linear independent component analysis have established this negative result; without some knowledge of the data generation process or appropriate inductive biases, it is impossible to perform this inversion. In recent years, a lot of progress has been made on disentanglement under structural assumptions, e.g., when we have access to auxiliary information that makes the factors of variation conditionally independent. However, existing work requires a lot of auxiliary information, e.g., in supervised classification, it prescribes that the number of label classes should be at least equal to the total dimension of all factors of variation. In this work, we depart from these assumptions and ask: a) How can we get disentanglement when the auxiliary information does not provide conditional independence over the factors of variation? b) Can we reduce the amount of auxiliary information required for disentanglement? For a class of models where auxiliary information does not ensure conditional independence, we show theoretically and experimentally that disentanglement (to a large extent) is possible even when the auxiliary information dimension is much less than the dimension of the true latent representation.
keywords:
disentanglement, non-linear independent component analysis1 Introduction
Representation learning (Bengio et al., 2013) aims to extract low dimensional representations from high dimensional complex datasets. The hope is that if these representations succinctly capture factors of variation that describe the high dimensional data (e.g., extract features characterizing the shape of an object in an image), then these representations can be leveraged to achieve good performance on new downstream tasks with minimal supervision. Large scale pre-trained language models demonstrate the major success of representation learning based approaches (Brown et al., 2020; Wei et al., 2021; Radford et al., 2021). However, we should look at these results with a dose of caution, as neural networks have also been shown to fail often at out-of-distribution generalization (Beery et al., 2018; Geirhos et al., 2020; Peyrard et al., 2021). To address out-of-distribution generalization failures, recent works (Schölkopf, 2019; Schölkopf et al., 2021; Wang and Jordan, 2021) have argued in favour of incorporating causal principles into standard training paradigms—supervised (Arjovsky et al., 2019) and unsupervised (von Kügelgen et al., 2021). The issue is that the current deep learning paradigm does not imbibe and exploit key principles of causality (Pearl, 2009; Schölkopf, 2019)—invariance principle, independent causal mechanisms principle, and causal factorization. This is because the traditional causal inference requires access to structured random variables whose distributions can be decomposed using causal factorization, which is impossible with complex datasets such as images or text. Therefore, to leverage the power of deep learning and causal principles, we first need to disentangle raw datasets to obtain the causal representations that generated the data, and then exploit tools from causal structure learning to pin down the relationships between the representations. (Ke et al., 2019; Brouillard et al., 2020).
It has been shown that the general process of disentanglement is impossible in the absence of side knowledge of the structure of the data generation process (Hyvärinen and Pajunen, 1999; Locatello et al., 2019). However, under additional structural assumptions on the data generation process, it is possible to invert the data generation process and recover the underlying factors of variation (Hyvarinen and Morioka, 2016). Recently, there have been works (Hyvarinen et al., 2019; Khemakhem et al., 2020a) which present a general framework that relies on auxiliary information (e.g., labels, timestamps) to disentangle the latents. While existing works (Hyvarinen et al., 2019; Khemakhem et al., 2020a) have made remarkable progress in the field of disentanglement, these works make certain key assumptions highlighted below that we significantly depart from.
Labels cause the latent variables. In supervised learning datasets, there are two ways to think about the data generation process—a) labels cause the latent variables and b) latent variables cause the labels. (Schölkopf et al., 2012) argue for the former view, i.e., labels generate the latents, while (Arjovsky et al., 2019) argue for the latter view, i.e., latents generate the label (see Figure 1). Current non-linear ICA literature (Khemakhem et al., 2020a; Hyvarinen et al., 2019) assumes the label knowledge renders latent factors of variation conditionally independent, hence it is compatible with the former perspective (Schölkopf et al., 2012). But the latter view might be more natural for the setting where a human assigns labels based on the underlying latent factors. Our goal is to enable disentanglement for this case when the latent variables cause the labels (Arjovsky et al., 2019).
Amount of auxiliary information. Existing works (Khemakhem et al., 2020a) (Theorem 1), Khemakhem et al. (2020b) require a lot of auxiliary information, e.g., the number of label classes should be twice the total dimension of the latent factors of variation to guarantee disentanglement. We seek to enable disentanglement with lesser auxiliary information.
Contributions. We consider the following data generation process – latent factors generate the observations (raw features) and the labels for multiple tasks, where the latent factors are mutually independent. We study a natural extension of the standard empirical risk minimization (ERM) (Vapnik (1992)) paradigm. The most natural heuristic for learning representations is to train a neural network using ERM and use the output from the representation layer before the final layer. In this work, we propose to add a constraint on ERM to facilitate disentanglement – all the components of the representation layer must be mutually independent. Our main findings for the representations learned by the constrained ERM are summarized below.
If the number of tasks is at least equal to the dimension of the latent variables, and the latent variables are not Gaussian, then we can recover the latent variables up to permutation and scaling.
If we only have a single task and the latent variables come from an exponential family whose log-density can be expressed as a polynomial, then under further constraints on both the learner’s inductive bias and the function being inverted, we can recover the latent variables up to permutation and scaling.
To implement constrained ERM, we propose a simple two-step approximation. In the first step, we train a standard ERM based model, and in the subsequent step we carry out linear ICA (Comon, 1994) on the representation extracted from ERM. We carry out experiments with the above procedure for regression and classification. Our experiments show that even with the approximate procedure, it is possible to recover the true latent variables up to permutation and scaling when the number of tasks is smaller than the latent dimension.
2 Related work
Non-linear ICA with auxiliary information. We first describe the works in non-linear ICA where the time index itself serves as auxiliary information. Hyvarinen and Morioka (2016) showed that if each component of the latent vector evolves independently and follows a non-stationary time series without temporal dependence, then identification is possible for non-linear ICA. In contrast, Hyvarinen and Morioka (2017) showed that if the latent variables are mutually independent, with each component evolving in time following a stationary time series with temporal dependence, then also identification is possible. (Khemakhem et al., 2020a; Hyvarinen et al., 2019; Khemakhem et al., 2020b) further generalized the previous results. In these works, instead of using time, the authors require observation of auxiliary information. Note that (Hyvarinen and Morioka, 2017; Hyvarinen et al., 2019; Khemakhem et al., 2020a) have a limitation that the auxiliary information renders latent variables conditionally independent. This assumption was relaxed to some extent in (Khemakhem et al., 2020b), however, the model in (Khemakhem et al., 2020b) is not compatible with the data generation perspective that we consider, i.e., latent variables cause the labels. Recently, (Roeder et al., 2020) studied representation identification for classification and self-supervised learning models, where it was shown that if there are sufficient number of class labels (at least as many as the dimension of the latent variables), then the representations learned by neural networks with different initialization are related by a linear transformation. Their work does not focus on recovering the true latent variables and instead studies whether neural networks learn similar representations across different seeds.
Other works. In another line of work (Locatello et al., 2020; Shu et al., 2019), the authors study the role of weak supervision in assisting disentanglement. Note this line of work is different from us, as these models do not consider labelled supervised learning datasets, bur rather use different sources of supervision. For example, in (Locatello et al., 2020) the authors use multiple views of the same object as a form of weak supervision.
3 Problem Setup

3.1 Data generation process
Before we describe the data generation process we use, we give an example of the data generation process that is compatible with the assumptions in (Khemakhem et al., 2020a).
| (1) |
where is the uniform Bernoulli distribution over , is normal distribution, is the vector that together with the label selects the mean of the latent , is a dimensional identity matrix, is a bijection that generates the observations . In Figure 1 (a), we show the causal directed acyclic graph (DAG) corresponding to the above data generation process, where the labels cause the latent variables (Schölkopf et al., 2012). Most of the current non-linear ICA models are only compatible with this view of the data generation process. This may be valid for some settings, but it is not perfectly suited for human labelled datasets where a label is assigned based on the underlying latent factors of variations. Hence, we focus on the opposite perspective (Arjovsky et al., 2019) when the latent variables generate the labels. The assumptions regarding the data generation process studied in our work are defined formally ahead.
Assumption 1
The data generation process for regression is described as
| (2) |
where is noise, generates (the components of latent variable are mutually independent, non-Gaussian, and have finite second moments), is a bijection that generates the observations , is a matrix that generates the label and is the noise vector ( is independent of and ).
Note that is the dimension of the latent representation, and corresponds to the number of tasks. We adapt the data generation process to multi-task classification as follows by changing the label generation process.
| (3) |
where corresponds to the sigmoid function applied elementwise to and outputs the probabilities of the tasks, and operates on these probabilities elementwise to generate the label vector for the tasks.
We also contrast the DAGs of the two data generation processes in Figure 1. The nature of the auxiliary information (labels) in the data generation process we study (Assumption 1) is very different from the one in prior works (equation 1); conditioning on the auxiliary information (labels) in our data generation process does not make the latent variables independent. Our setting could be interpreted as multi-task supervised learning, where the downstream task labels serve as the auxiliary information generated from shared latent variables.
Remark. The classic non-identifiability results in Locatello et al. (2019) and Hyvärinen and Pajunen (1999) assumed that the latent factors of variation are all mutually independent. These results implied that without some knowledge, e.g., auxiliary information (labels), it is impossible to disentangle the latent variables. While (Khemakhem et al., 2020a) showed that it is possible to succeed in the presence of auxiliary information, their data generation process assumes that the latent variables are not mutually independent and thus is not consistent with assumptions in (Locatello et al., 2019) and (Hyvärinen and Pajunen, 1999). Whereas our work shows that the auxiliary information helps in the case considered in (Locatello et al., 2019) and (Hyvärinen and Pajunen, 1999), since the auxiliary information is introduced downstream of the latent variables.
3.2 Identifiability
Our objective is to learn the model (or the generator ) from the observed data and labels pairs , such that for new observations we can recover the latent variables that generated . We can not always learn the exact latent variables but may only identify them to some degree. Let us denote the model learned as (with its inverse ). We now describe a general notion (commonly used in the literature) of identification for the learned map with respect to the true map .
Definition 3.1.
Identifiability up to . If the learned map and the true map are related by some bijection , such that (or equivalently ), then is said to learn up to bijections in . We denote this .
In the above definition, if was the set of all the permutation maps , then denotes identification up to permutations. Permutation identification guarantees that we learn the true latent vector but do not learn the indices of the true latent, which is not important for many downstream tasks. In other words, identification up to permutations of the latent variables is the gold standard for identification. Our aim is to identify the latent variables by inverting the data generating process (learning ) up to permutations.
4 Identification via independence constrained ERM
The previous section established our objective of learning the model (or the generator ) from the observed data . We first train a supervised learning model to predict the labels from .
For the rest of the work, we will assume that the predictor we learn takes the form , where is a linear predictor that operates on the representation . As a result, the hypothesis space of the functions that the learner searches over has two parts: corresponding to the hypothesis class of linear maps, and , where corresponds to the hypothesis class over the representations. We measure the performance of the predictor on an instance using the loss (mean square error for regression, cross-entropy loss for classification). We define the risk achieved by a predictor as , where the expectation is taken with respect to the data .
Independence Constrained ERM (IC-ERM): The representations () learnt by ERM as described above have no guarantee of recovering the true latent variables up to permutations. Hence, we propose a new objective where we want the learner to carry out constrained empirical risk minimization, where the constraint is placed on the representation layer that all components of the representation are mutually independent. We provide the formal definition of mutual independence for the convenience of the reader below.
Definition 4.1.
Mutual independence. A random vector is said to be mutually independent if for each subset we have .
We state the proposed independence constrained ERM (IC-ERM) objective formally as follows:
| (4) |
We now state theorems that show the IC-ERM learning objective would recover the true latent variables up to permutations under certain assumptions. It is intuitive that more auxiliary information/numbers of tasks () should help us to identify the latent variables as they are shared across these different tasks. Hence, we first state identification guarantees for IC-ERM when we have sufficient tasks, and then discuss the difficult cases when we have few tasks.
4.1 Identification when number of tasks is equal to the latent data dimension
We first study the setting when the number of tasks is equal to the dimension of the latent variables . Before we describe the theorem, we state assumptions on the hypothesis class of the representations () and the classifier ().
Assumption 2
Assumption on and . For the true solutions (, ), we have and . For the case when , the set corresponds to the set of all invertible matrices.
The above assumption ensures that the true solutions and are in the respective hypothesis classes that the learner searches over. Also, the invertibility assumption on the hypothesis in is needed to ensure that we do not have redundant tasks for the identification of the latent variables. Under the above assumption and the assumptions of our data generation process (1), we state the following identification result for the case when k=d.
Theorem 1.
The proof for the same is available in Appendix Section A. This implies that for the DAGs in Figure 1 (b), it is possible to recover the true latents up to permutation and scaling. This result extends the current disentanglement guarantees (Khemakhem et al., 2020b) that exist for models where labels cause the latent variables (latent variables are conditionally independent) to the settings where latent variables cause the label (latent variables are not conditionally independent). In multi-task learning literature (Caruana, 1997; Zhang and Yang, 2017), it has been argued that learning across multiple tasks with shared layers leads to internal representations that transfer better. The above result states the conditions when the ideal data generating representation shared across tasks can be recovered.
Remark. Since we use a linear model for the label generation process, one can ask what happens if we apply noisy linear ICA techniques (Davies, 2004; Hyvarinen, 1999) on the label itself (when ) to recover followed by a regression to predict from . Noisy linear ICA require the noise distribution to be Gaussian and would not work when is not a Gaussian. Since we do not make such distributional assumptions on , we cannot rely on noisy linear ICA on labels.
4.2 Identification when the number of tasks is less than the dimensions of the latent
In this section, we study the setting when the number of tasks is equal to one. Since this setting is extreme, we need to make stronger assumptions to show latent identification guarantees. Before we lay down the assumptions, we provide some notation. Since we only have a single task, instead of using the matrix , we use to signify the coefficients that generate the label in the single task setting. We assume each component of is non-zero. In the single task setting for regression problems, the label generation is written as , and the rest of the notation is the same as the data generation process in Assumption 1. We rewrite the data generation process in Assumption 1 for the single task case in terms of normalized variables .
Assumption 3
The data generation process for regressions is described as
| (5) |
where , where . We assume that all the components of are mutually independent and identically distributed (i.i.d.).
Note that is invertible since is invertible and each element of is also non-zero. Hence, for simplicity, we can deal with the identification of . If we identify up to permutation and scaling, then is automatically identified up to permutation and scaling. The predictor we learn is a composition of linear predictor and a representation , which is written as . The learner searches for in the set , where consists of linear predictors with all non-zero components, and in the set .
We can further simplify the predictor as follows: , where is component-wise multiplication expressed as . Therefore, instead of searching over such that all components of are non-zero, we can fix and carry out the search over representations only. For the rest of the section, without loss of generality, we assume the predictor is of the form . We restate the IC-ERM (4) with this parametrization and an additional constraint that all components are now required to be independent and identically distributed (i.i.d.). We provide a formal definition for the convenience of the reader below, where denotes identical in distribution.
Definition 3.
Independent & Identically Distributed (i.i.d.). A random vector is said to be i.i.d. if 1) 2) .
The reparametrized IC-ERM (4) constraint is stated as follows.
| (6) |
Next, we state the assumptions on each component of (recall each component of is i.i.d. from Assumption 3) and under which we show that the reparametrized IC-ERM objective (equation (6)) recovers the true latent variables up to permutations. We assume each component of is a continuous random variable with probability density function (PDF) . Define the support of each component of as . Define a ball of radius as .
Assumption 4
Each component of is a continuous random variable from the exponential family with probability density . is a polynomial with degree (where is odd) written as
where the absolute value of the coefficients of the polynomial are bounded by , i.e., for all , and the absolute value of the coefficient of the highest degree term is at least , i.e., . The support of is sufficiently large that it contains , i.e., . Also, the moment generation function of each component of , , exists for all .
Remark on the PDFs under the above assumption. The above assumption considers distributions in the exponential family, where the log-PDF can be expressed as a polynomial. Note that as long as the support of the distribution is bounded, every polynomial with bounded coefficients leads to a valid PDF (i.e., it integrates to one) and we only need to set the value of appropriately.
We now state our assumptions on the hypothesis class that the learner searches over. Observe that can be written as (since ). We write the set of all the maps constructed from composition of and as . Define , where is the determinant, is the Jacobian of computed at . The set of all the ’s obtained from all is denoted as
Assumption 5
consists of analytic bijections. For each , the moment generating function of each component , , denoted as exists for all . Each is a finite degree polynomial with degree at most , where the absolute values of the coefficients in the polynomial are bounded by .
Define , where is the maximum number of non-zero coefficients in any polynomial , is small constant (see Appendix C).
Theorem 2.
Proof sketch. The complete proof is available in Appendix Section C and we provide an overview here. We use the optimality condition that the prediction made by the learned model, , exactly matches the true mean, , along with the constraints that each component of are i.i.d. and each component of are i.i.d., to derive that the distributions of and are the same.
We substitute this condition in the change of variables formula that relates the densities of and . Using the Assumption 5, we can show that if the highest absolute value of and the highest absolute value of are not equal, then the term with the highest absolute value among and will dominate, leading to contradiction in the identity obtained by change of variables formula.
Based on this, we can conclude that the highest absolute value of and the highest absolute value of must be equal. We iteratively apply this argument to show that all the absolute values of and are related by permutation. We can extend this argument to the actual values instead of absolute values. Since is analytic we argue that the relationship of permutation holds in a neighborhood. Then we use properties of analytic functions (Mityagin, 2015) to conclude that the relationship holds on the entire space.
Why does the bound on grow linearly in ? We provide some geometric intuition into why the degree of the polynomial () of the log-PDF () needs to be large. If the dimension of the latent space is large, then the second term in dominates, i.e., has to grow linearly in . The simplification in the proof yields that the mapping must satisfy the following condition – for all , where is the norm. Hence, is a bijection that preserves all norms up to the norm. If is dimensional, then the a bijection that preserves the norm and the norm is composed of permutations and sign-flips. In general, since is dimensional, we need at least constraints on in the form and thus , which ensure that the only map that satisfies these constraints is composed of permutations and sign-flips.
Significance and remarks on Theorem 2. Theorem 2 shows that if we use IC-ERM principle, i.e., constraint the representations to be independent, then we continue to recover the latents even if the number of tasks is small. We can show that the above theorem also extends to binary classification. We admit that strong assumptions were made to arrive at the above result, while other assumptions such as bound on growing linearly in seem necessary, but we would like to remind the reader that we are operating in the extreme single task regime. In the previous section, when the number of tasks was equal to the dimension of the latent (when we have sufficiently many tasks), we had shown the success of the IC-ERM (4) objective (Theorem 1) for identification of latent variables with much fewer assumptions.
In contrast, in Theorem 2, we saw that with more assumptions on the distribution we can guarantee latent recovery with even one task. If we are in the middle, i.e., when the number of tasks is between one and the dimension of the latent, then the above Theorem 2 says we only require the assumptions (Assumptions 3, 4, 5) to hold for at least one task.
Note on the case kd: We did not discuss the case when the number of tasks is greater than the dimension of the latent variables. This is because we can select a subset of tasks, such that and then proceed in a similar fashion as Theorem 1. This question arises commonly in linear ICA literature, and selecting a subset of tasks is the standard practice.
5 ERM-ICA: Proposed implementation for independence constrained ERM
In the previous section, we showed the identification guarantees with the IC-ERM objective. However, solving this objective is non-trivial, since we need to enforce independence on the representations learnt. We propose a simple two step procedure as an approximate approach to solve the above problem. The learner first carries out standard ERM stated as
| (7) |
The learner then searches for a linear transformation that when applied to yields a new representation with mutually independent components. We state this as follows. Find an invertible such that
| (8) |
Note that a solution to the above equation (8) does not always exist. However, if we can find a that satisfies the above (8), then the classifier and the representation together solve the IC-ERM (4) assuming and . To find a solution to the equation (8) we resort to the approach of linear ICA (Comon, 1994). The approach has two steps. We first whiten . 111For simplicity, we assume is zero mean, although our analysis extends to the non-zero mean case as well. We also assume has finite second moments. Define to be the covariance matrix of . If the covariance is invertible, 222If it is not invertible, then we first need to project into the range space of then the eigendecomposition of is given as . We obtain the whitened data as follows . Consider a linear transformation of the whitened data and denote it as and construct another vector such that its individual components are all independent and equal in distribution to the corresponding components in . Our goal is to find an such that the mutual information between and is minimized. To make dependence on explicit, we denote the mutual information between and as . We state this as the following optimization
| (9) |
We denote the above two step approximation method as ERM-ICA and summarize it below:
-
•
ERM Phase: Learn by solving the ERM objective (Eq: 7).
-
•
ICA Phase: Learn by linear ICA (Eq: 9) on the representation from ERM Phase ().
The above ERM-ICA procedure outputs a classifier and representation that is an approximate solution to the IC-ERM problem (4). While the proposed ERM-ICA procedure is a simple approximation, we do not know of other works that have investigated this approach theoretically and experimentally for recovering the latents. Despite its simplicity, we can prove (similar to Theorem 1) that when the number of tasks is equal to the dimension of the latent variable, ERM-ICA can recover the latent variables up to permutation and scaling.
Theorem 3.
The proof of the above theorem can be found in Appendix Section B. We leave the theoretical analysis of the ERM-ICA approach for the single task case for future work, but we do show its performance empirically for such scenarios in the evaluation section ahead. We believe that building better approximations to directly solve the IC-ERM, which do not involve a two-step approach like ERM-ICA approach is a fruitful future work.
6 Evaluation
6.1 Experiment Setup
6.1.1 Data generation process
Regression. We use the data generation process described in Assumption 1. The components of are i.i.d. and follow discrete uniform distribution. Each element of the task coefficient matrix is i.i.d. and follows a standard normal distribution. The noise in the label generation is also standard normal. We use a 2-layer invertible MLP to model and follow the construction used in Zimmermann et al. (2021).333\urlhttps://github.com/brendel-group/cl-ica/blob/master/main_mlp.py We carry out comparisons for three settings, , and vary tasks from . The dataset size used for training and test is data points, along with a validation set of data points for hyper parameter tuning.
Classification. We use the data generation process described in Assumption 1. We use the same parameters and dataset splits as regression, except the labels are binary and sampled as follows:
. Also, the noise in the sampling is set to a higher value (10 times that of a standard normal), as otherwise the Bayes optimal accuracy is much smaller.
6.1.2 Methods, architecture, and other hyperparameters
We compare our method against two natural baselines. a) ERM. In this case, we carry out standard ERM (7) and use the representation learned at the layer before the output layer. b) ERM-PCA. In this case, we carry out standard ERM (7) and extract the representation learned at the layer before the output layer. We then take the extracted representation and transform it using principal component analysis (PCA). In other words, we analyze the representation in the eigenbasis of its covariance matrix. c) ERM-ICA. This is the main approach ((7), (8)) that approximates the IC-ERM objective (4). Here we take the representations learnt using ERM (7) and transform them using linear independent component analysis (ICA) (9).
We define mean square error and cross-entropy as our loss objectives for the regression and classification task respectively. In both settings, we use a two layer fully connected neural network and train the model using stochastic gradient descent. The architecture and the hyperparameter details for the different settings are provided in Appendix D. Also, the code repository can be accessed from the link 444Our Code Repository: \urlhttps://github.com/divyat09/ood_identification in the footnote.




6.1.3 Metrics
The models are evaluated on the test dataset using the following two metrics.
Label () prediction performance. We use the average (coefficient of determination) and the average accuracy across tasks in the regression and classification task respectively. For the ERM-PCA and ERM-ICA, we take final representations learnt by these methods and train a linear/logistic regression model to predict the label for the regression/classification task. We check this metric to ensure that the representations do not lose any information about the label.
Latent () prediction performance. We use mean correlation coefficient (MCC), a standard metric used to measure permutation and scaling based identification (refer (Hyvarinen and Morioka, 2017; Zimmermann et al., 2021) for further details). The metric is computed by first obtaining the correlation matrix () between the recovered latents and the true latents . Let’s define as the absolute values of the correlation matrix. Then we find a matching (assign each row to a column in ) such that the average absolute correlation is maximized and return the optimal average absolute correlation. Intuitively, we find the optimal way to match the components of the predicted latent representation () and components of the true representation (). Notice that a perfect absolute correlation of one for each matched pair of components would imply identification up to permutations.
6.2 Results
Regression. Figure 2 and 3 show a comparison of the performance of the three approaches across and for various tasks. The results for the case of are in the Appendix E.1 (due to space limits). In both cases, we find that the method ERM-ICA is significantly better than the other approaches in terms of guaranteeing permutation and scaling based identification. All three approaches have similar label prediction performance. We observe a similar trend for the case of shown in the Appendix E.1.
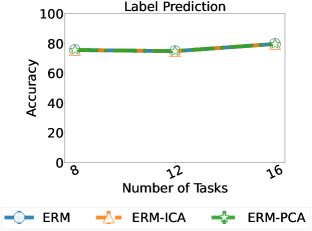
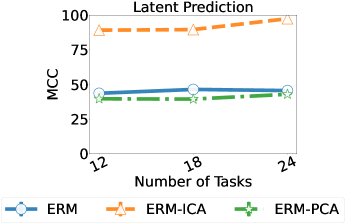
Classification. Figure 4 and 5 show a comparison of the performance of the three approaches across and for various tasks. In both cases, we find that the method ERM-ICA is better than the other approaches in terms of guaranteeing permutation and scaling based identification, except in the case of 24 data dimensions with a total of 12 tasks. All three approaches have similar label prediction performance. For classification, unlike regression, the improvements are smaller and we do not see improvement for (comparisons for the case of are in the Appendix E.2). We see a worse performance in the classification setting because the ERM model does not learn the Bayes optimal predictor unlike regression.
Discussion. We have shown that ERM-ICA achieves significant improvement in latent recovery with much fewer tasks (up to ). However, in our theory we proved that under certain assumptions solving the reparametrized IC-ERM objective (Eq (6)) can achieve identification even with a single task. Note that we only approximate equation (6) with ERM-ICA, and if we build better approximations of the ideal approach (IC-ERM), then we can witness gains with even fewer tasks. We believe that building such approximations is a fruitful future work.



7 Conclusion
In this work, we analyzed the problem of disentanglement in a natural setting, where latent factors cause the labels, a setting not well studied in the ICA literature. We show that if ERM is constrained to learn independent representations, then we can have latent recovery from learnt representations even when the number of tasks is small. We propose a simple two step approximate procedure (ERM-ICA) to solve the constrained ERM problem, and show that it is effective in a variety of experiments. Our analysis highlights the importance of learning independent representations and motivates the development of further approaches to achieve the same in practice.
We thank Dimitris Koukoulopoulos for discussions regarding the proof for indentification under a single task. Kartik Ahuja acknowledges the support provided by IVADO postdoctoral fellowship funding program. Ioannis Mitliagkas acknowledges support from an NSERC Discovery grant (RGPIN-2019-06512), a Samsung grant, Canada CIFAR AI chair and MSR collaborative research grant.
References
- Arjovsky et al. (2019) Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization. arXiv preprint arXiv:1907.02893, 2019.
- Beery et al. (2018) Sara Beery, Grant Van Horn, and Pietro Perona. Recognition in terra incognita. In Proceedings of the European conference on computer vision (ECCV), pages 456–473, 2018.
- Bengio et al. (2013) Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence, 35(8):1798–1828, 2013.
- Brouillard et al. (2020) Philippe Brouillard, Sébastien Lachapelle, Alexandre Lacoste, Simon Lacoste-Julien, and Alexandre Drouin. Differentiable causal discovery from interventional data. arXiv preprint arXiv:2007.01754, 2020.
- Brown et al. (2020) Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- Caruana (1997) Rich Caruana. Multitask learning. Machine learning, 28(1):41–75, 1997.
- Comon (1994) Pierre Comon. Independent component analysis, a new concept? Signal processing, 36(3):287–314, 1994.
- Darmois (1953) George Darmois. General analysis of stochastic bonds: special study of linear factorial analysis. Journal of the International Statistical Institute, pages 2–8, 1953.
- Davies (2004) Mike Davies. Identifiability issues in noisy ica. IEEE Signal processing letters, 11(5):470–473, 2004.
- Feller (2008) Willliam Feller. An introduction to probability theory and its applications, vol 2. John Wiley & Sons, 2008.
- Geirhos et al. (2020) Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665–673, 2020.
- Hyvarinen (1999) Aapo Hyvarinen. Gaussian moments for noisy independent component analysis. IEEE signal processing letters, 6(6):145–147, 1999.
- Hyvarinen and Morioka (2016) Aapo Hyvarinen and Hiroshi Morioka. Unsupervised feature extraction by time-contrastive learning and nonlinear ica. Advances in Neural Information Processing Systems, 29:3765–3773, 2016.
- Hyvarinen and Morioka (2017) Aapo Hyvarinen and Hiroshi Morioka. Nonlinear ica of temporally dependent stationary sources. In Artificial Intelligence and Statistics, pages 460–469. PMLR, 2017.
- Hyvärinen and Pajunen (1999) Aapo Hyvärinen and Petteri Pajunen. Nonlinear independent component analysis: Existence and uniqueness results. Neural networks, 12(3):429–439, 1999.
- Hyvarinen et al. (2019) Aapo Hyvarinen, Hiroaki Sasaki, and Richard Turner. Nonlinear ica using auxiliary variables and generalized contrastive learning. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 859–868. PMLR, 2019.
- Ke et al. (2019) Nan Rosemary Ke, Olexa Bilaniuk, Anirudh Goyal, Stefan Bauer, Hugo Larochelle, Bernhard Schölkopf, Michael C Mozer, Chris Pal, and Yoshua Bengio. Learning neural causal models from unknown interventions. arXiv preprint arXiv:1910.01075, 2019.
- Khemakhem et al. (2020a) Ilyes Khemakhem, Diederik Kingma, Ricardo Monti, and Aapo Hyvarinen. Variational autoencoders and nonlinear ica: A unifying framework. In International Conference on Artificial Intelligence and Statistics, pages 2207–2217. PMLR, 2020a.
- Khemakhem et al. (2020b) Ilyes Khemakhem, Ricardo Pio Monti, Diederik P Kingma, and Aapo Hyvärinen. Ice-beem: Identifiable conditional energy-based deep models based on nonlinear ica. arXiv preprint arXiv:2002.11537, 2020b.
- Locatello et al. (2019) Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Raetsch, Sylvain Gelly, Bernhard Schölkopf, and Olivier Bachem. Challenging common assumptions in the unsupervised learning of disentangled representations. In international conference on machine learning, pages 4114–4124. PMLR, 2019.
- Locatello et al. (2020) Francesco Locatello, Ben Poole, Gunnar Rätsch, Bernhard Schölkopf, Olivier Bachem, and Michael Tschannen. Weakly-supervised disentanglement without compromises. In International Conference on Machine Learning, pages 6348–6359. PMLR, 2020.
- Mityagin (2015) Boris Mityagin. The zero set of a real analytic function. arXiv preprint arXiv:1512.07276, 2015.
- Pearl (2009) Judea Pearl. Causality. Cambridge university press, 2009.
- Peyrard et al. (2021) Maxime Peyrard, Sarvjeet Singh Ghotra, Martin Josifoski, Vidhan Agarwal, Barun Patra, Dean Carignan, Emre Kiciman, and Robert West. Invariant language modeling. arXiv preprint arXiv:2110.08413, 2021.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
- Roeder et al. (2020) Geoffrey Roeder, Luke Metz, and Diederik P Kingma. On linear identifiability of learned representations. arXiv preprint arXiv:2007.00810, 2020.
- Schölkopf (2019) Bernhard Schölkopf. Causality for machine learning. arXiv preprint arXiv:1911.10500, 2019.
- Schölkopf et al. (2012) Bernhard Schölkopf, Dominik Janzing, Jonas Peters, Eleni Sgouritsa, Kun Zhang, and Joris Mooij. On causal and anticausal learning. arXiv preprint arXiv:1206.6471, 2012.
- Schölkopf et al. (2021) Bernhard Schölkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. Toward causal representation learning. Proceedings of the IEEE, 109(5):612–634, 2021.
- Shu et al. (2019) Rui Shu, Yining Chen, Abhishek Kumar, Stefano Ermon, and Ben Poole. Weakly supervised disentanglement with guarantees. arXiv preprint arXiv:1910.09772, 2019.
- Vapnik (1992) Vladimir Vapnik. Principles of risk minimization for learning theory. In Advances in neural information processing systems, pages 831–838, 1992.
- von Kügelgen et al. (2021) Julius von Kügelgen, Yash Sharma, Luigi Gresele, Wieland Brendel, Bernhard Schölkopf, Michel Besserve, and Francesco Locatello. Self-supervised learning with data augmentations provably isolates content from style. arXiv preprint arXiv:2106.04619, 2021.
- Wang and Jordan (2021) Yixin Wang and Michael I Jordan. Desiderata for representation learning: A causal perspective. arXiv preprint arXiv:2109.03795, 2021.
- Wei et al. (2021) Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- Zhang and Yang (2017) Yu Zhang and Qiang Yang. A survey on multi-task learning. arXiv preprint arXiv:1707.08114, 2017.
- Zimmermann et al. (2021) Roland S Zimmermann, Yash Sharma, Steffen Schneider, Matthias Bethge, and Wieland Brendel. Contrastive learning inverts the data generating process. arXiv preprint arXiv:2102.08850, 2021.
Appendix A Proof of Theorem 1: IC-ERM for the case k=d
Theorem 1.
Proof 1.
Consider we are in the regression setting for the data generation process in Assumption 1. Therefore, using and , the risk of a predictor can be written as follows:
| (10) |
From the above it is clear that for all functions . Since , and has all mutually independent components, satisfies the constraints in IC-ERM (4) and also achieves the lowest error possible, i.e., . Consider any solution to constrained ERM in (4). The solution must satisfy the following equality except over a set of measure zero.
| (11) |
Let us call and . Hence, the above equality becomes , where all the components of are independent (Eq: (4)) and all the components of are independent (Assumption 1). We will now argue that the matrix can be written as a permutation matrix times a scaling matrix. We first show that in each column of there is exactly one non-zero element. Consider column of denoted as . Since is invertible all elements of the column cannot be zero. Now suppose at least two elements and of are non-zero. Consider the corresponding components of . Since and are both independent and since and are both non-zero, from Darmois’ theorem (Darmois, 1953) it follows that is a Gaussian random variable. However, this leads to a contradiction as we assumed none of the random variables in follow a Gaussian distribution. Therefore, exactly one element in is non-zero. We can say this about all the columns of . No two columns will have the same row with a non-zero entry or otherwise would not be invertible. Therefore, can be expressed as a matrix permutation times a scaling matrix, where the scaling takes care of the exact non-zero value in the row and the permutation matrix takes care of the address of the element which is non-zero. This completes the proof.
Appendix B Proof of Theorem 3: ERM-ICA for the case k=d
Theorem 3.
Proof 3.
Although the initial half of the proof is identical to the proof of Theorem 1 we repeat it for clarity. Consider we are in the regression setting for the data generation process in Assumption 1. Therefore, using and , the risk of a predictor can be written as follows:
| (12) |
From the above it is clear that for all functions . Since , and has all mutually independent components, satisfies the constraints in IC-ERM (4) and also achieves the lowest error possible, i.e., .
Consider any solution to ERM in (7). The solution must satisfy the following equality except over a set of measure zero.
| (13) |
Since is a linear combination of independent latents with at least one latent non-Gaussian (and also the latents have a finite second moment). We can use the result from (Comon, 1994) that states that solves equation (9) relates to as follows
| (14) |
Substituting the above into (13) we get . This completes the proof.
We can also carry out the same proof for the multi-task classification case. In multi-task classification we can write the condition for optimality as
| (15) |
where sigmoid is applied separately to each element, and since the sigmoids are equal, this implies the individual elements are also equal. Therefore, and we can use the same analysis as the regression case from this point on. Also, note that we equated the sigmoids in first place, because the LHS corresponds to and RHS corresponds to true .
Appendix C Proof of Theorem 2: IC-ERM for the case k=1
Theorem 2.
Proof 2.
We write . We call and the vector .
Observe that since , we can use the same argument used in the proof of Theorem 1 to conclude that is a valid solution for the reparametrized IC-ERM objective (Eq: (6)). Notice that the terms and that appear in the proof of Theorem 1, they are equal to identity here due to the Assumption 3 and IC-ERM (6). Therefore, following the standard argument in Theorem 1, we can conclude that any solution of reparametrized IC-ERM (6) satisfies the following:
| (16) |
We write the moment generation function of a random variable as . We substitute the moment generating functions to get the following identity.
| (17) |
Since and , we can use and for all and simplify as follows:
| (18) | ||||
In the second step of the above simplification, we use the fact that the moment generating function is positive. In the third step, we use the fact that if moment generating functions exist and are equal, then the random variables are equal in distribution (Feller, 2008). Having established that the distributions are equal, we now show that the random variables are equal up to permutations.
Since the vector is an invertible transform of , where . We can write the pdf of in terms of as follows.
| (19) |
where corresponds to the pdf of (recall that pdfs of all components is the same). We take log on both sides of the above equation to get the following:
| (20) |
From Assumption 4, we substitute a polynomial for . From Assumption 5, we express this . We substitute these polynomials into the above equation to get the following:
| (21) |
In the proof, we first focus on comparing the largest absolute value among ’s and largest absolute value among ’s. Without loss of generality, we assume that for all ( is the largest absolute value among ’s) and for all ( is the largest absolute value among ’s). Consider the setting when (these points exist in the support because of the Assumption 4).
We can write , where .
There are three cases to further consider:
-
a)
-
b)
-
c)
We first start by analyzing the case b). Since all values of and are also strictly less than , we have the following:
-
•
such that
-
•
, where .
We divide the identity in equation (21) by and separate the terms in such a way that only the term is in the LHS and the rest of the terms are pushed to the RHS. We show further simplification of the identity below.
| (22) |
We analyze each of the terms in the RHS separately. The simplification of the first term yields the following expression.
| (23) | ||||
The simplification of the second term in the RHS of the last equation in (22) yields the following expression.
| (24) | ||||
The simplification of the third term in the RHS of the last equation in (22) yields the following expression.
| (25) | ||||
where corresponds to the number of non-zero terms in the polynomial expansion of the log-determinant. In the above simplification, we used the fact that and . Analyzing the RHS in equations (23)-(25), we see that if becomes sufficiently large, the RHS becomes less than . This contradicts the relationship in equation (22). Therefore, all cannot be strictly less than . This rules out case b).
We now derive the bounds on the value of as follows. Assume , i.e., the degree of the log-pdf of each component of is at least twice the degree of the log-determinant of the Jacobian of .
From the equation (23) we get the following bound on
| (26) |
From the equation (24) we get the following bound on
| (27) |
From the equation (25) we get the following bound on
| (28) |
From the above equations (26), (27), and (28), we get that if
| (29) |
then the sum of the terms in the RHS in equation (22) is at most and the term in the LHS in equation (22) is , which leads to a contradiction.
From the above expression, we gather that the second and third term should dominate in determining the lower bound for . From the second term, we gather that the lower bound increases linearly in the dimension of the latent, and from the third term we gather that must be greater than by a factor that grows logarithmically in the number of terms in the polynomial of the log determinant.
Let us now consider the case a) ( ) which is similar to the case b) analyzed above. Since values of are strictly less than and , and since , there exist a such that , , , where . We follow the same steps as done in the analysis for case b). We separate the equation so that only the term (obtained by dividing with ) is in the LHS and the rest on the RHS.
| (30) |
We analyze each of the terms in the RHS in equation (30) separately. The simplification of the first term in the RHS of the above yields the following upper bound.
| (31) | ||||
The simplification of the second term in the RHS of equation (30) yields the following upper bound.
| (32) | ||||
The simplification of the third term in the RHS of equation (30) yields the following upper bound.
| (33) | ||||
Analyzing the RHS in equation (31)-(33), we see that if becomes sufficiently large then the RHS becomes less than . This contradicts the relationship in equation (30). Therefore, there is no that is strictly larger than . This rules out case a). In fact from equations (31)-(33) we can get the same bound on as in case b).
Thus, the only possibility is case c), i.e., or . Consider the case when is odd. In that case, is the only option that works. We substitute in the equation (22) and repeat the same argument for the second highest absolute value, and so on. This leads to the conclusion that for each component there is a component of such that both of them are equal. Hence, we have established the relationship . For another sample where index corresponds to the highest absolute value and is in the neighbourhood of , the relationship must continue to hold. If this does not happen, then there would be another component where . However, if that were the case, then it would contradict the continuity of .
Therefore, the relationship (the match between index for and index for ) holds for a neighbourhood of values of vector . Since each component of is analytic, we can use the fact that the neighbourhood of vector of values of for which the relationship holds has a positive measure, and then from (Mityagin, 2015) it follows that this relationship would hold on the entire space. We can draw the same conclusion for all the components of and conclude that is a permutation map.
Appendix D Implementation Details
D.1 Model Architecture
-
•
Fully Connected Layer: (Data Dim, 100)
-
•
BatchNormalization(100)
-
•
LeakyReLU(0.5)
-
•
Full Connected Layer: (100, Data Dim)
-
•
BatchNormalization(Data Dim)
-
•
LeakyReLU(0.5)
-
•
Fully Connected Layer: (Data Dim, Total Tasks)
We consider the part of the network before the final fully connected layer as the representation network, and use the output from the representation network for training ICA/PCA after the ERM step.
D.2 Hyperparameters
We use SGD to train all the methods with the different hyperparameters across each task mentioned below. In every case, we select the best model during the course of training based on the validation loss, and also use a learning rate scheduler that reduces the existing learning rate by half after every 50 epochs. Also, regarding ICA, we use the FastICA solver in sklearn with maximum iterations and data whitening.
-
•
Regression: Learning Rate: , Batch Size: , Total Epochs: , Weight Decay: , Momentum:
-
•
Classification: Learning Rate: , Batch Size: , Total Epochs: , Weight Decay: , Momentum:
Appendix E Additional Experiments
E.1 Task: Regression

E.2 Task: Classification

