Towards Deployment-Efficient Reinforcement Learning: Lower Bound and Optimality
Abstract
Deployment efficiency is an important criterion for many real-world applications of reinforcement learning (RL). Despite the community’s increasing interest, there lacks a formal theoretical formulation for the problem. In this paper, we propose such a formulation for deployment-efficient RL (DE-RL) from an “optimization with constraints” perspective: we are interested in exploring an MDP and obtaining a near-optimal policy within minimal deployment complexity, whereas in each deployment the policy can sample a large batch of data. Using finite-horizon linear MDPs as a concrete structural model, we reveal the fundamental limit in achieving deployment efficiency by establishing information-theoretic lower bounds, and provide algorithms that achieve the optimal deployment efficiency. Moreover, our formulation for DE-RL is flexible and can serve as a building block for other practically relevant settings; we give “Safe DE-RL” and “Sample-Efficient DE-RL” as two examples, which may be worth future investigation.
1 Introduction
In many real-world applications, deploying a new policy to replace the previous one is costly, while generating a large batch of samples with an already deployed policy can be relatively fast and cheap. For example, in recommendation systems (Afsar et al., 2021), education software (Bennane et al., 2013), and healthcare (Yu et al., 2019), the new recommendation, teaching, or medical treatment strategy must pass several internal tests to ensure safety and practicality before being deployed, which can be time-consuming. On the other hand, the algorithm may be able to collect a large amount of samples in a short period of time if the system serves a large population of users. Besides, in robotics applications (Kober et al., 2013), deploying a new policy usually involves operations on the hardware level, which requires non-negligible physical labor and long waiting periods, while sampling trajectories is relatively less laborious. However, deployment efficiency was neglected in most of existing RL literatures. Even for those few works considering this important criterion (Bai et al., 2020; Gao et al., 2021; Matsushima et al., 2021), either their settings or methods have limitations in the scenarios described above, or a formal mathematical formulation is missing. We defer a detailed discussion of these related works to Section 1.1.
In order to close the gap between existing RL settings and real-world applications requiring high deployment efficiency, our first contribution is to provide a formal definition and tractable objective for Deployment-Efficient Reinforcement Learning (DE-RL) via an “optimization with constraints” perspective. Roughly speaking, we are interested in minimizing the number of deployments under two constraints: (a) after deploying times, the algorithm can return a near-optimal policy, and (b) the number of trajectories collected in each deployment, denoted as , is at the same level across deployments, and it can be large but should still be polynomial in standard parameters. Similar to the notion of sample complexity in online RL, we will refer to as deployment complexity.
To provide a more quantitative understanding, we instantiate our DE-RL framework in finite-horizon linear MDPs111Although we focus on linear MDPs, the core idea can be extended to more general settings such as RL with general function approximation (Kong et al., 2021). (Jin et al., 2019) and develop the essential theory. The main questions we address are:
Q1: What is the optimum of the deployment efficiency in our DE-RL setting?
Q2: Can we achieve the optimal deployment efficiency in our DE-RL setting?
When answering these questions, we separately study algorithms with or without being constrained to deploy deterministic policies each time. While deploying more general forms of policies can be practical (e.g., randomized experiments on a population of users can be viewed as deploying a mixture of deterministic policies), most previous theoretical works in related settings exclusively focused on upper and lower bounds for algorithms using deterministic policies (Jin et al., 2019; Wang et al., 2020b; Gao et al., 2021). As we will show, the origin of the difficulty in optimizing deployment efficiency and the principle in algorithm design to achieve optimal deployment efficiency are generally different in these two settings, and therefore, we believe both of them are of independent interests.
As our second contribution, in Section 3, we answer Q1 by providing information-theoretic lower bounds for the required number of deployments under the constraints of (a) and (b) in Def 2.1. We establish and lower bounds for algorithms with and without the constraints of deploying deterministic policies, respectively. Contrary to the impression given by previous empirical works (Matsushima et al., 2021), even if we can deploy unrestricted policies, the minimal number of deployments cannot be reduced to a constant without additional assumptions, which sheds light on the fundamental limitation in achieving deployment efficiency. Besides, in the line of work on “horizon-free RL” (e.g., Wang et al., 2020a), it is shown that RL problem is not significantly harder than bandits (i.e., when ) when we consider sample complexity. In contrast, the dependence in our lower bound reveals some fundamental hardness that is specific to long-horizon RL, particularly in the deployment-efficient setting. 222Although (Wang et al., 2020a) considered stationary MDP, as shown in our Corollary 3.3, the lower bounds of deployment complexity is still related to . Such hardness results were originally conjectured by Jiang & Agarwal (2018), but no hardness has been shown in sample-complexity settings.
After identifying the limitation of deployment efficiency, as our third contribution, we address Q2 by proposing novel algorithms whose deployment efficiency match the lower bounds. In Section 4.1, we propose an algorithm deploying deterministic policies, which is based on Least-Square Value Iteration with reward bonus (Jin et al., 2019) and a layer-by-layer exploration strategy, and can return an -optimal policy within deployments. As part of its analysis, we prove Lemma 4.2 as a technical contribution, which can be regarded as a batched finite-sample version of the well-known “Elliptical Potential Lemma”(Carpentier et al., 2020) and may be of independent interest. Moreover, our analysis based on Lemma 4.2 can be applied to the reward-free setting (Jin et al., 2020; Wang et al., 2020b) and achieve the same optimal deployment efficiency. In Section 4.2, we focus on algorithms which can deploy arbitrary policies. They are much more challenging because it requires us to find a provably exploratory stochastic policy without interacting with the environment. To our knowledge, Agarwal et al. (2020b) is the only work tackling a similar problem, but their algorithm is model-based which relies on a strong assumption about the realizability of the true dynamics and a sampling oracle that allows the agent to sample data from the model, and how to solve the problem in linear MDPs without a model class is still an open problem. To overcome this challenge, we propose a model-free layer-by-layer exploration algorithm based on a novel covariance matrix estimation technique, and prove that it requires deployments to return an -optimal policy, which only differs from the lower bound by a logarithmic factor. Although the per-deployment sample complexity of our algorithm has dependence on a “reachability coefficient” (see Def. 4.3), similar quantities also appear in related works (Zanette et al., 2020; Agarwal et al., 2020b; Modi et al., 2021) and we conjecture that it is unavoidable and leave the investigation to future work.
Finally, thanks to the flexibility of our “optimization with constraints” perspective, our DE-RL setting can serve as a building block for more advanced and practically relevant settings where optimizing the number of deployments is an important consideration. In Appendix F, we propose two potentially interesting settings: “Safe DE-RL” and “Sample-Efficient DE-RL”, by introducing constraints regarding safety and sample efficiency, respectively.
1.1 Closely Related Works
We defer the detailed discussion of previous literatures about pure online RL and pure offline RL to Appendix A, and mainly focus on those literatures which considered deployment efficiency and more related to us in this section.
To our knowledge, the term “deployment efficiency” was first coined by Matsushima et al. (2021), but they did not provide a concrete mathematical formulation that is amendable to theoretical investigation. In existing theoretical works, low switching cost is a concept closely related to deployment efficiency, and has been studied in both bandit (Esfandiari et al., 2020; Han et al., 2020; Gu et al., 2021; Ruan et al., 2021) and RL settings (Bai et al., 2020; Gao et al., 2021; Kong et al., 2021). Another related concept is concurrent RL, as proposed by Guo & Brunskill (2015). We highlight the difference with them in two-folds from problem setting and techniques.
As for the problem setting, existing literature on low switching cost mainly focuses on sub-linear regret guarantees, which does not directly implies a near-optimal policy after a number of policy deployments333Although the conversion from sub-linear regret to polynominal sample complexity is possible (“online-to-batch”), we show in Appendix A that to achieve accuracy after conversion, the number of deployments of previous low-switching cost algorithms has dependence on , whereas our guarantee does not. . Besides, low switching-cost RL algorithms (Bai et al., 2020; Gao et al., 2021; Kong et al., 2021) rely on adaptive switching strategies (i.e., the interval between policy switching is not fixed), which can be difficult to implement in practical scenarios. For example, in recommendation or education systems, once deployed, a policy usually needs to interact with the population of users for a fair amount of time and generate a lot of data. Moreover, since policy preparation is time-consuming (which is what motivates our work to begin with), it is practically difficult if not impossible to change the policy immediately once collecting enough data for policy update, and it will be a significant overhead compared to a short policy switch interval. Therefore, in applications we target at, it is more reasonable to assume that the sample size in each deployment (i.e., between policy switching) has the same order of magnitude and is large enough so that the overhead of policy preparation can be ignored.
More importantly, on the technical side, previous theoretical works on low switching cost mostly use deterministic policies in each deployment, which is easier to analyze. This issue also applies to the work of Guo & Brunskill (2015) on concurrent PAC RL. However, if the agent can deploy stochastic (and possibly non-Markov) policies (e.g., a mixture of deterministic policies), then intuitively—and as reflected in our lower bounds—exploration can be done much more deployment-efficiently, and we provide a stochastic policy algorithm that achieves an deployment complexity and overcomes the lower bounds for deterministic policy algorithms (Gao et al., 2021).
2 Preliminaries
Notation
Throughout our paper, for , we will denote . denotes the ceiling function. Unless otherwise specified, for vector and matrix , denotes the vector -norm of and denotes the largest singular value of . We will use standard big-oh notations , and notations such as to suppress logarithmic factors.
2.1 Episodic Reinforcement Learning
We consider an episodic Markov Decision Process denoted by , where is the state space, is the finite action space, is the horizon length, and and denote the transition and the reward functions. At the beginning of each episode, the environment will sample an initial state from the initial state distribution . Then, for each time step , the agent selects an action , interacts with the environment, receives a reward , and transitions to the next state . The episode will terminate once is reached.
A (Markov) policy at step is a function mapping from , where denotes the probability simplex over the action space. With a slight abuse of notation, when is a deterministic policy, we will assume . A full (Markov) policy specifies such a mapping for each time step. We use and to denote the value function and Q-function at step , which are defined as:
We also use and to denote the optimal value functions and use to denote the optimal policy that maximizes the expected return . In some occasions, we use and to denote the value functions with respect to as the reward function for disambiguation purposes. The optimal value functions and the optimal policy will be denoted by , respectively.
Non-Markov Policies
While we focus on Markov policies in the above definition, some of our results apply to or require more general forms of policies. For example, our lower bounds apply to non-Markov policies that can depend on the history (e.g., for deterministic policies); our algorithm for arbitrary policies deploys a mixture of deterministic Markov policies, which corresponds to choosing a deterministic policy from a given set at the initial state, and following that policy for the entire trajectory. This can be viewed as a non-Markov stochastic policy.
2.2 Linear MDP Setting
We mainly focus on the linear MDP (Jin et al., 2019) satisfying the following assumptions:
Assumption A (Linear MDP Assumptions).
An MDP is said to be a linear MDP with a feature map if the following hold for any :
-
•
There are unknown signed measures over such that for any .
-
•
There exists an unknown vector such that for any , .
2.3 A Concrete Definition of DE-RL
In the following, we introduce our formulation for DE-RL in linear MDPs. For discussions of comparison to existing works, please refer to Section 1.1.
Definition 2.1 (Deployment Complexity in Linear MDPs).
We say that an algorithm has a deployment complexity in linear MDPs if the following holds: given an arbitrary linear MDP under Assumption A, for arbitrary and , the algorithm will return a policy after deployments and collecting at most trajectories in each deployment, under the following constraints:
-
(a)
With probability , is -optimal, i.e. .
-
(b)
The sample size is polynominal, i.e. . Moreover, should be fixed a priori and cannot change adaptively from deployment to deployment.
Under this definition, the goal of Deployment-Efficient RL is to design algorithms with provable guarantees of low deployment complexity.
Polynomial Size of
We emphasize that the restriction of polynomially large is crucial to our formulation, and not including it can result in degenerate solutions. For example, if is allowed to be exponentially large, we can finish exploration in deployment in the arbitrary policy setting, by deploying a mixture of exponentially many policies that form an -net of the policy space. Alternatively, we can sample actions uniformly, and use importance sampling (Precup, 2000) to evaluate all of them in an off-policy manner. None of these solutions are practically feasible and are excluded by our restriction on .
3 Lower Bound for Deployment Complexity in RL
In this section, we provide information-theoretic lower bounds of the deployment complexity in our DE-RL setting. We defer the lower bound construction and the proofs to Appendix B. As mentioned in Section 2, we consider non-Markov policies when we refer to deterministic and stochastic policies in this section, which strengthens our lower bounds as they apply to very general forms of policies.
We first study the algorithms which can only deploy deterministic policy at each deployment.
Theorem 3.1.
[Lower bound for deterministic policies, informal] For any and any algorithm that can only deploy a deterministic policy at each deployment, there exists a linear MDP satisfying Assumption A, such that the deployment complexity of in is .
The basic idea of our construction and the proof is that, intuitively, a linear MDP with dimension and horizon length has “independent directions”, while deterministic policies have limited exploration capacity and only reach direction in each deployment, which result in deployments in the worst case.
In the next theorem, we will show that, even if the algorithm can use arbitrary exploration strategy (e.g. maximizing entropy, adding reward bonus), without additional assumptions, the number of deployments still has to depend on and may not be reduced to a constant when is large.
Theorem 3.2.
[Lower bound for arbitrary policies, informal] For any and any algorithm which can deploy arbitrary policies, there exists a linear MDP satisfying Assumption A, such that the deployment complexity of in is .
The origin of the difficulty can be illustrated by a recursive dilemma: in the worst case, if the agent does not have enough information at layer , then it cannot identify a good policy to explore till layer in 1 deployment, and so on and so forth. Given that we enforce to be polynomial, the agent can only push the “information boundary” forward by layers per deployment. In many real-world applications, such difficulty can indeed exist. For example, in healthcare, the entire treatment is often divided into multiple stages. If the treatment in stage is not effective, the patient may refuse to continue. This can result in insufficient samples for identifying a policy that performs well in stage .
Stationary vs. non-stationary dynamics
Since we consider non-stationary dynamics in Assump. A, one may suspect that the -dependence in the lower bound is mainly due to such non-stationarity. We show that this is not quite the case, and the -dependence still exists for stationary dynamics. In fact, our lower bound for non-stationary dynamics directly imply one for stationary dynamics: given a finite horizon non-stationary MDP , we can construct a stationary MDP by expanding the state space to so that the new transition function and reward function are stationary across time steps. As a result, given arbitrary and , we can construct a hard non-stationary MDP instance with dimension and horizon , and convert it to a stationary MDP with dimension and horizon . If there exists an algorithm which can solve in deployments, then it can be used to solve in no more than deployments. Therefore, the lower bounds for stationary MDPs can be extended from Theorems 3.1 and 3.2, as shown in the following corollary:
Corollary 3.3 (Extension to Stationary MDPs).
For stationary linear MDP with and , suppose , the lower bound of deployment complexity would be for deterministic policy algorithms, and for algorithms which can deploy arbitrary policies.
As we can see, the dependence on dimension and horizon will not be eliminated even if we make a stronger assumption that the MDP is stationary. The intuition is that, although the transition function is stationary, some states may not be reachable from the initial state distribution within a small number of times, so the stationary MDP can effectively have a “layered” structure. For example, in Atari games (Bellemare et al., 2013) (where many algorithms like DQN (Mnih et al., 2013) model the environments as infinite-horizon discounted MDPs) such as Breakout, the agent cannot observe states where most of the bricks are knocked out at the initial stage of the trajectory. Therefore, the agent still can only push forward the “information frontier” a few steps per deployment. That said, it is possible reduce the deployment complexity lower bound in stationary MDPs by adding more assumptions, such as the initial state distribution providing good coverage over the entire state space, or all the states are reachable in the first few time steps. However, because these assumptions do not always hold and may overly trivialize the exploration problem, we will not consider them in our algorithm design. Besides, although our algorithms in the next section are designed for non-stationary MDPs, they can be extended to stationary MDPs by sharing covariance matrices, and we believe the analyses can also be extended to match the lower bound in Corollary 3.3.
4 Towards Optimal Deployment Efficiency
In this section we provide algorithms with deployment-efficiency guarantees that nearly match the lower bounds established in Section 3. Although our lower bound results in Section 3 consider non-Markov policies, our algorithms in this section only use Markov policies (or a mixture of Markov policies, in the arbitrary policy setting), which are simpler to implement and compute and are already near-optimal in deployment efficiency.
Inspiration from Lower Bounds: a Layer-by-Layer Exploration Strategy The linear dependence on in the lower bounds implies a possibly deployment-efficient manner to explore, which we call a layer-by-layer strategy: conditioning on sufficient exploration in previous time steps, we can use deployments to sufficiently explore the -th time step, then we only need deployments to explore the entire MDP. If we can reduce the deployment cost in each layer from to or even , then we can achieve the optimal deployment efficiency. Besides, as another motivation, in Appendix C.4, we will briefly discuss the additional benefits of the layer-by-layer strategy, which will be useful especially in “Safe DE-RL”. In Sections 4.1 and 4.2, we will introduce algorithms based on this idea and provide theoretical guarantees.
4.1 Deployment-Efficient RL with Deterministic Policies
In this sub-section, we focus on the setting where each deployed policy is deterministic. In Alg 1, we propose a provably deployment-efficient algorithm built on Least-Square Value Iteration with UCB (Jin et al., 2019)444In order to align with the algorithm in reward-free setting, slightly different from (Jin et al., 2019) but similar to (Wang et al., 2020b), we run linear regression on instead of . and the “layer-by-layer” strategy. Briefly speaking, at deployment , we focus on exploration in previous layers, and compute by running LSVI-UCB in an MDP truncated at step . After that, we deploy to collect trajectories, and complete the trajectory after time step with an arbitrary policy. (In the pseudocode we choose uniform, but the choice is inconsequential.) In line 19, we compute with samples and use it to judge whether we should move on to the next layer till all layers have been explored. The theoretical guarantee is listed below, and the missing proofs are deferred to Appendix C.
Theorem 4.1 (Deployment Complexity).
For arbitrary , and arbitrary , as long as , where is an absolute constant, by choosing
| (1) |
Algorithm 1 will terminate at iteration and return us a policy , and with probability , .
As an interesting observation, Eq (1) reflects the trade-off between the magnitude of and when is small. To see this, when we increase and keep it at the constant level, definitely increases while will be lower because its dependence on decreases. Moreover, the benefit of increasing is only remarkable when is small (e.g. we have if , while if ), and even for moderately large , the value of quickly approaches the limit . It is still an open problem that whether the trade-off in Eq.1 is exact or not, and we leave it for the future work.
Another key step in proving the deployment efficiency of Alg. 1 is Lem. 4.2 below. In fact, by directly applying Lem. 4.2 to LSVI-UCB (Jin et al., 2019) with large batch sizes, we can achieve deployment complexity in deterministic policy setting without exploring in a layer-by-layer manner. We defer the discussion and the additional benefit of layer-by-layer strategy to Appx. C.4.
Lemma 4.2.
[Batched Finite Sample Elliptical Potential Lemma] Consider a sequence of matrices with and , where and . We define: . For arbitrary , and arbitrary , if , by choosing , where is an absolute constant independent with , we have
Extension to Reward-free setting
4.2 Deployment-Efficient RL with Arbitrary Policies
From the discussion of lower bounds in Section 3, we know that in order to reduce the deployment complexity from to , we have to utilize stochastic (and possibly non-Markov) policies and try to explore as many different directions as possible in each deployment (as opposed to direction in Algorithm 1). The key challenge is to find a stochastic policy—before the deployment starts—which can sufficiently explore independent directions.
In Alg. 2, we overcome this difficulty by a new covariance matrix estimation method (Alg. 6 in Appx. E). The basic idea is that, for arbitrary policy 555Here we mainly focus on evaluating deterministic policy or stochastic policy mixed from a finite number of deterministic policies, because for the other stochastic policies, exactly computing the expectation over policy distribution may be intractable., the covariance matrix can be estimated element-wise by running policy evaluation for with as a reward function, where and denotes the -th component of vector .
However, a new challenge emerging is that, because the transition is stochastic, in order to guarantee low evaluation error for all possible policies , we need an union bound over all policies to be evaluated, which is challenging if the policy class is infinite. To overcome this issue, we discretize the value functions in Algorithm 5 (see Appendix E) to allow for a union bound over the policy space: after computing the Q-function by LSVI-UCB, before converting it to a greedy policy, we first project it to an -net of the entire Q-function class. In this way, the number of policy candidates is finite and the projection error can be controlled as long as is small enough.
Using the above techniques, in Lines 2-2, we repeatedly use Alg 6 to estimate the accumulative covariance matrix and further eliminate uncertainty by calling Alg 5 to find a policy (approximately) maximizing uncertainty-based reward function . For each , inductively conditioning on sufficient exploration in previous layers, the errors of Alg 6 and Alg 5 will be small, and we will find a finite set of policies to cover all dimensions in layer . (This is similar to the notion of “policy cover” in Du et al. (2019); Agarwal et al. (2020a).) Then, layer can be explored sufficiently by deploying a uniform mixture of and choosing large enough (Lines 2-2). Also note that the algorithm does not use the reward information, and is essentially a reward-free exploration algorithm. After exploring all layers, we obtain a dataset and can use Alg 4 for planning with any given reward function satisfying Assump. A to obtain a near-optimal policy.
Deployment complexity guarantees
We first introduce a quantity denoted as , which measures the reachability to each dimension in the linear MDP. In Appendix E.8, we will show that the is no less than the “explorability” coefficient in Definition 2 of Zanette et al. (2020) and is also lower bounded by the maximum of the smallest singular value of matrix .
Definition 4.3 (Reachability Coefficient).
Now, we are ready to state the main theorem of this section, and defer the formal version and its proofs to Appendix E. Our algorithm is effectively running reward-free exploration and therefore our results hold for arbitrary linear reward functions.
Proof Sketch
Next, we briefly discuss the key steps of the proof. Since can be chosen to be very small, we will ignore the bias induced by when providing intuitions. Our proof is based on the induction condition below. We first assume it holds after deployments (which is true when ), and then we try to prove at the -th deployment we can explore layer well enough so that the condition holds for .
Condition 4.5.
[Induction Condition] Suppose after deployments, we have the following induction condition for some , which will be determined later:
| (2) |
The l.h.s. of Eq.(2) measures the uncertainty in previous layers after exploration. As a result, with high probability, the following estimations will be accurate:
| (3) |
where denotes the entry-wise maximum norm. This directly implies that:
where is the target value for to approximate. Besides, recall that in Algorithm 5, we use as the reward function, and the induction condition also implies that:
As a result, if and the resolution are small enough, would gradually reduce the uncertainty and (also ) will decrease. However, the bias is at the level , and therefore, no matter how small is, as long as , it is still possible that the policies in do not cover all directions if some directions are very difficult to reach, and the error due to such a bias will be at the same level of the required accuracy in induction condition, i.e. . This is exactly where the “reachability coefficient” definition helps. The introduction of provides a threshold, and as long as is small enough so that the bias is lower than the threshold, each dimension will be reached with substantial probability when the breaking criterion in Line 9 is satisfied. As a result, by deploying and collecting a sufficiently large dataset, the induction condition will hold till layer . Finally, combining the guarantee of Alg 4, we complete the proof.
5 Conclusion and Future Work
In this paper, we propose a concrete theoretical formulation for DE-RL to fill the gap between existing RL literatures and real-world applications with deployment constraints. Based on our framework, we establish lower bounds for deployment complexity in linear MDPs, and provide novel algorithms and techniques to achieve optimal deployment efficiency. Besides, our formulation is flexible and can serve as building blocks for other practically relevant settings related to DE-RL. We conclude the paper with two such examples, defer a more detailed discussion to Appendix F, and leave the investigation to future work.
Sample-Efficient DE-RL
In our basic formulation in Definition 2.1, we focus on minimizing the deployment complexity and put very mild constraints on the per-deployment sample complexity . In practice, however, the latter is also an important consideration, and we may face additional constraints on how large can be, as they can be upper bounded by e.g. the number of customers or patients our system is serving.
Safe DE-RL
In real-world applications, safety is also an important criterion. The definition for safety criterion in Safe DE-RL is still an open problem, but we believe it is an interesting setting since it implies a trade-off between exploration and exploitation in deployment-efficient setting.
Acknowledgements
JH’s research activities on this work were completed by December 2021 during his internship at MSRA. NJ acknowledges funding support from ARL Cooperative Agreement W911NF-17-2-0196, NSF IIS-2112471, and Adobe Data Science Research Award.
References
- Abbasi-yadkori et al. (2011) Yasin Abbasi-yadkori, Dávid Pál, and Csaba Szepesvári. Improved algorithms for linear stochastic bandits. In Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc., 2011.
- Afsar et al. (2021) M Mehdi Afsar, Trafford Crump, and Behrouz Far. Reinforcement learning based recommender systems: A survey. arXiv preprint arXiv:2101.06286, 2021.
- Agarwal et al. (2020a) Alekh Agarwal, Mikael Henaff, Sham Kakade, and Wen Sun. Pc-pg: Policy cover directed exploration for provable policy gradient learning. arXiv preprint arXiv:2007.08459, 2020a.
- Agarwal et al. (2020b) Alekh Agarwal, Sham Kakade, Akshay Krishnamurthy, and Wen Sun. Flambe: Structural complexity and representation learning of low rank mdps, 2020b.
- Agrawal et al. (2021) Priyank Agrawal, Jinglin Chen, and Nan Jiang. Improved worst-case regret bounds for randomized least-squares value iteration. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 6566–6573, 2021.
- Agrawal & Jia (2017) Shipra Agrawal and Randy Jia. Posterior sampling for reinforcement learning: worst-case regret bounds. In Advances in Neural Information Processing Systems, pp. 1184–1194, 2017.
- Antos et al. (2008) András Antos, Csaba Szepesvári, and Rémi Munos. Learning near-optimal policies with bellman-residual minimization based fitted policy iteration and a single sample path. Machine Learning, 71(1):89–129, 2008.
- Azar et al. (2017) M. G. Azar, Ian Osband, and R. Munos. Minimax regret bounds for reinforcement learning. In ICML, 2017.
- Bai et al. (2020) Yu Bai, Tengyang Xie, Nan Jiang, and Yu-Xiang Wang. Provably efficient q-learning with low switching cost, 2020.
- Bellemare et al. (2013) Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47:253–279, 2013.
- Bellemare et al. (2016) Marc G. Bellemare, Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, and Remi Munos. Unifying count-based exploration and intrinsic motivation, 2016.
- Bennane et al. (2013) Abdellah Bennane et al. Adaptive educational software by applying reinforcement learning. Informatics in Education-An International Journal, 12(1):13–27, 2013.
- Burda et al. (2018) Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation, 2018.
- Campero et al. (2020) Andres Campero, Roberta Raileanu, Heinrich Küttler, Joshua B Tenenbaum, Tim Rocktäschel, and Edward Grefenstette. Learning with amigo: Adversarially motivated intrinsic goals. arXiv preprint arXiv:2006.12122, 2020.
- Carpentier et al. (2020) Alexandra Carpentier, Claire Vernade, and Yasin Abbasi-Yadkori. The elliptical potential lemma revisited, 2020.
- Chen & Jiang (2019) Jinglin Chen and Nan Jiang. Information-theoretic considerations in batch reinforcement learning. In International Conference on Machine Learning, pp. 1042–1051. PMLR, 2019.
- Dann et al. (2018) Christoph Dann, Nan Jiang, Akshay Krishnamurthy, Alekh Agarwal, John Langford, and Robert E Schapire. On oracle-efficient pac rl with rich observations. Advances in neural information processing systems, 31, 2018.
- Du et al. (2019) Simon Du, Akshay Krishnamurthy, Nan Jiang, Alekh Agarwal, Miroslav Dudik, and John Langford. Provably efficient rl with rich observations via latent state decoding. In International Conference on Machine Learning, pp. 1665–1674. PMLR, 2019.
- Ecoffet et al. (2019) Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O Stanley, and Jeff Clune. Go-explore: a new approach for hard-exploration problems. arXiv preprint arXiv:1901.10995, 2019.
- Esfandiari et al. (2020) Hossein Esfandiari, Amin Karbasi, Abbas Mehrabian, and Vahab Mirrokni. Regret bounds for batched bandits, 2020.
- Fujimoto & Gu (2021) Scott Fujimoto and Shixiang Shane Gu. A minimalist approach to offline reinforcement learning, 2021.
- Gao et al. (2021) Minbo Gao, Tianle Xie, Simon S. Du, and Lin F. Yang. A provably efficient algorithm for linear markov decision process with low switching cost, 2021.
- Gu et al. (2021) Quanquan Gu, Amin Karbasi, Khashayar Khosravi, Vahab Mirrokni, and Dongruo Zhou. Batched neural bandits, 2021.
- Guo & Brunskill (2015) Zhaohan Guo and Emma Brunskill. Concurrent pac rl. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 29, 2015.
- Han et al. (2020) Yanjun Han, Zhengqing Zhou, Zhengyuan Zhou, Jose Blanchet, Peter W. Glynn, and Yinyu Ye. Sequential batch learning in finite-action linear contextual bandits, 2020.
- Hazan et al. (2019) Elad Hazan, Sham M. Kakade, Karan Singh, and Abby Van Soest. Provably efficient maximum entropy exploration, 2019.
- Jiang & Agarwal (2018) Nan Jiang and Alekh Agarwal. Open problem: The dependence of sample complexity lower bounds on planning horizon. In Conference On Learning Theory, pp. 3395–3398. PMLR, 2018.
- Jiang & Li (2016) Nan Jiang and Lihong Li. Doubly robust off-policy value evaluation for reinforcement learning. In International Conference on Machine Learning, pp. 652–661. PMLR, 2016.
- Jiang et al. (2017a) Nan Jiang, Akshay Krishnamurthy, Alekh Agarwal, John Langford, and Robert E Schapire. Contextual decision processes with low bellman rank are pac-learnable. In International Conference on Machine Learning, pp. 1704–1713. PMLR, 2017a.
- Jiang et al. (2017b) Nan Jiang, Akshay Krishnamurthy, Alekh Agarwal, John Langford, and Robert E. Schapire. Contextual decision processes with low Bellman rank are PAC-learnable. In Doina Precup and Yee Whye Teh (eds.), Proceedings of the 34th International Conference on Machine Learning, volume 70, pp. 1704–1713, 2017b.
- Jin et al. (2018) Chi Jin, Zeyuan Allen-Zhu, Sebastien Bubeck, and Michael I. Jordan. Is q-learning provably efficient?, 2018.
- Jin et al. (2019) Chi Jin, Zhuoran Yang, Zhaoran Wang, and Michael I. Jordan. Provably efficient reinforcement learning with linear function approximation, 2019.
- Jin et al. (2020) Chi Jin, Akshay Krishnamurthy, Max Simchowitz, and Tiancheng Yu. Reward-free exploration for reinforcement learning, 2020.
- Jin et al. (2021a) Chi Jin, Qinghua Liu, and Sobhan Miryoosefi. Bellman eluder dimension: New rich classes of rl problems, and sample-efficient algorithms. Advances in Neural Information Processing Systems, 34, 2021a.
- Jin et al. (2021b) Ying Jin, Zhuoran Yang, and Zhaoran Wang. Is pessimism provably efficient for offline rl? In International Conference on Machine Learning, pp. 5084–5096. PMLR, 2021b.
- Kober et al. (2013) Jens Kober, J Andrew Bagnell, and Jan Peters. Reinforcement learning in robotics: A survey. The International Journal of Robotics Research, 32(11):1238–1274, 2013.
- Kong et al. (2021) Dingwen Kong, R. Salakhutdinov, Ruosong Wang, and Lin F. Yang. Online sub-sampling for reinforcement learning with general function approximation. ArXiv, abs/2106.07203, 2021.
- Krishnamurthy et al. (2016) Akshay Krishnamurthy, Alekh Agarwal, and John Langford. Pac reinforcement learning with rich observations. Advances in Neural Information Processing Systems, 29:1840–1848, 2016.
- Kumar et al. (2020) Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. arXiv preprint arXiv:2006.04779, 2020.
- Laroche et al. (2019) Romain Laroche, Paul Trichelair, and Remi Tachet Des Combes. Safe policy improvement with baseline bootstrapping. In International Conference on Machine Learning, pp. 3652–3661. PMLR, 2019.
- Lee et al. (2021) Jongmin Lee, Wonseok Jeon, Byung-Jun Lee, Joelle Pineau, and Kee-Eung Kim. Optidice: Offline policy optimization via stationary distribution correction estimation. arXiv preprint arXiv:2106.10783, 2021.
- Liu et al. (2018) Qiang Liu, Lihong Li, Ziyang Tang, and Dengyong Zhou. Breaking the curse of horizon: Infinite-horizon off-policy estimation. arXiv preprint arXiv:1810.12429, 2018.
- Liu et al. (2020) Yao Liu, Adith Swaminathan, Alekh Agarwal, and Emma Brunskill. Provably good batch off-policy reinforcement learning without great exploration. Advances in Neural Information Processing Systems, 33:1264–1274, 2020.
- Matsushima et al. (2021) Tatsuya Matsushima, Hiroki Furuta, Yutaka Matsuo, Ofir Nachum, and Shixiang Gu. Deployment-efficient reinforcement learning via model-based offline optimization. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=3hGNqpI4WS.
- Misra et al. (2020) Dipendra Misra, Mikael Henaff, Akshay Krishnamurthy, and John Langford. Kinematic state abstraction and provably efficient rich-observation reinforcement learning. In International conference on machine learning, pp. 6961–6971. PMLR, 2020.
- Mnih et al. (2013) Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
- Modi et al. (2021) Aditya Modi, Jinglin Chen, Akshay Krishnamurthy, Nan Jiang, and Alekh Agarwal. Model-free representation learning and exploration in low-rank mdps. arXiv preprint arXiv:2102.07035, 2021.
- Moskovitz et al. (2021) Ted Moskovitz, Jack Parker-Holder, Aldo Pacchiano, Michael Arbel, and Michael I. Jordan. Tactical optimism and pessimism for deep reinforcement learning, 2021.
- Munos & Szepesvári (2008) Rémi Munos and Csaba Szepesvári. Finite-time bounds for fitted value iteration. Journal of Machine Learning Research, 9(5), 2008.
- Nachum et al. (2019) Ofir Nachum, Bo Dai, Ilya Kostrikov, Yinlam Chow, Lihong Li, and Dale Schuurmans. Algaedice: Policy gradient from arbitrary experience. arXiv preprint arXiv:1912.02074, 2019.
- Nair et al. (2021) Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online reinforcement learning with offline datasets, 2021.
- Pertsch et al. (2020) Karl Pertsch, Youngwoon Lee, and Joseph J Lim. Accelerating reinforcement learning with learned skill priors. arXiv preprint arXiv:2010.11944, 2020.
- Precup (2000) Doina Precup. Eligibility traces for off-policy policy evaluation. Computer Science Department Faculty Publication Series, pp. 80, 2000.
- Ruan et al. (2021) Yufei Ruan, Jiaqi Yang, and Yuan Zhou. Linear bandits with limited adaptivity and learning distributional optimal design, 2021.
- Russo & Van Roy (2013) Daniel Russo and Benjamin Van Roy. Eluder dimension and the sample complexity of optimistic exploration. In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger (eds.), Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc., 2013.
- Tropp (2015) Joel A. Tropp. An introduction to matrix concentration inequalities, 2015.
- Uehara et al. (2020) Masatoshi Uehara, Jiawei Huang, and Nan Jiang. Minimax weight and q-function learning for off-policy evaluation. In International Conference on Machine Learning, pp. 9659–9668. PMLR, 2020.
- Wang et al. (2020a) Ruosong Wang, Simon S. Du, Lin F. Yang, and Sham M. Kakade. Is long horizon reinforcement learning more difficult than short horizon reinforcement learning?, 2020a.
- Wang et al. (2020b) Ruosong Wang, Simon S. Du, Lin F. Yang, and Ruslan Salakhutdinov. On reward-free reinforcement learning with linear function approximation, 2020b.
- Wang et al. (2020c) Ruosong Wang, Ruslan Salakhutdinov, and Lin F Yang. Reinforcement learning with general value function approximation: Provably efficient approach via bounded eluder dimension. arXiv preprint arXiv:2005.10804, 2020c.
- Xie et al. (2021a) Tengyang Xie, Ching-An Cheng, Nan Jiang, Paul Mineiro, and Alekh Agarwal. Bellman-consistent pessimism for offline reinforcement learning. arXiv preprint arXiv:2106.06926, 2021a.
- Xie et al. (2021b) Tengyang Xie, Nan Jiang, Huan Wang, Caiming Xiong, and Yu Bai. Policy finetuning: Bridging sample-efficient offline and online reinforcement learning, 2021b.
- Yang et al. (2020) Mengjiao Yang, Ofir Nachum, Bo Dai, Lihong Li, and Dale Schuurmans. Off-policy evaluation via the regularized lagrangian. arXiv preprint arXiv:2007.03438, 2020.
- Yu et al. (2019) Chao Yu, Jiming Liu, and Shamim Nemati. Reinforcement learning in healthcare: A survey. arXiv preprint arXiv:1908.08796, 2019.
- Yu et al. (2020) Tianhe Yu, Garrett Thomas, Lantao Yu, Stefano Ermon, James Zou, Sergey Levine, Chelsea Finn, and Tengyu Ma. Mopo: Model-based offline policy optimization. arXiv preprint arXiv:2005.13239, 2020.
- Zanette & Brunskill (2019) Andrea Zanette and Emma Brunskill. Tighter problem-dependent regret bounds in reinforcement learning without domain knowledge using value function bounds. In International Conference on Machine Learning, pp. 7304–7312. PMLR, 2019.
- Zanette et al. (2020) Andrea Zanette, Alessandro Lazaric, Mykel J Kochenderfer, and Emma Brunskill. Provably efficient reward-agnostic navigation with linear value iteration. arXiv preprint arXiv:2008.07737, 2020.
- Zhang et al. (2021) Tianjun Zhang, Paria Rashidinejad, Jiantao Jiao, Yuandong Tian, Joseph Gonzalez, and Stuart Russell. Made: Exploration via maximizing deviation from explored regions. arXiv preprint arXiv:2106.10268, 2021.
Appendix A Extended Related Work
Online RL
Online RL is a paradigm focusing on the challenge of strategic exploration. On the theoretical side, based on the “Optimism in Face of Uncertainty”(OFU) principle or posterior sampling techniques, many provable algorithms have been developed for tabular MDPs (Jin et al., 2018; Azar et al., 2017; Zanette & Brunskill, 2019; Agrawal & Jia, 2017; Agrawal et al., 2021), linear MDPs (Jin et al., 2019; Agarwal et al., 2020a), general function approximation (Wang et al., 2020c; Russo & Van Roy, 2013), or MDPs with structural assumptions (Jiang et al., 2017b; Du et al., 2019). Moreover, there is another stream of work studying how to guide exploration by utilizing state occupancy (Hazan et al., 2019; Zhang et al., 2021). Beyond the learning in MDPs with pre-specified reward function, recently, Jin et al. (2020); Wang et al. (2020b); Zanette et al. (2020) provide algorithms for exploration in the scenarios where multiple reward functions are of interest. On the practical side, there are empirical algorithms such as intrinsically-motivated exploration (Bellemare et al., 2016; Campero et al., 2020), exploration with hand-crafted reward bonus (RND) (Burda et al., 2018), and other more sophisticated strategies (Ecoffet et al., 2019). However, all of these exploration methods do not take deployment efficiency into consideration, and will fail to sufficiently explore the MDP and learn near-optimal policies in DE-RL setting where the number of deployments is very limited.
Offline RL
Different from the online setting, where the agents are encouraged to explore rarely visited states to identify the optimal policy, the pure offline RL setting serves as a framework for utilizing historical data to learn a good policy without further interacting with the environment. Therefore, the core problem of offline RL is the performance guarantee of the deployed policy, which motivated multiple importance-sampling based off-policy policy evaluation and optimization methods (Jiang & Li, 2016; Liu et al., 2018; Uehara et al., 2020; Yang et al., 2020; Nachum et al., 2019; Lee et al., 2021), and the “Pessimism in Face of Uncertainty” framework (Liu et al., 2020; Kumar et al., 2020; Fujimoto & Gu, 2021; Yu et al., 2020; Jin et al., 2021b; Xie et al., 2021a) in contrast with OFU in online exploration setting. However, as suggested in Matsushima et al. (2021), pure offline RL can be regarded as constraining the total number of deployments to be .
Bridging Online and Offline RL; Trade-off between Pessimism and Optimism
As pointed out by Xie et al. (2021b); Matsushima et al. (2021), there is a clear gap between existing online and offline RL settings, and some efforts have been made towards bridging them. For example, Nair et al. (2021); Pertsch et al. (2020); Bai et al. (2020) studied how to leverage pre-collected offline datasets to learn a good prior to accelerate the online learning process. Moskovitz et al. (2021) proposed a learning framework which can switch between optimism and pessimism by modeling the selection as a bandit problem. None of these works give provable guarantees in our deployment-efficiency setting.
Conversion from Linear Regret in Gao et al. (2021) to Sample Complexity
Gao et al. (2021) proposed an algorithm with the following guarantee: after interacting with the environments for times (we use to distinguish with in our setting), there exists a constant such that the algorithm’s regret is
where we denote , and use to refer to the log terms. Besides, in there are only policy switching.
As discussed in Section 3.1 by Jin et al. (2018), such a result can be convert to a PAC guarantee that, by uniformly randomly select a policy from , with probability at least 2/3, we should have:
In order to make sure the upper bound in the r.h.s. will be , we need:
and the required policy switching would be:
In contrast with our results in Section 4.1, there is an additional logarithmic dependence on and . Moreover, since their algorithm only deploys deterministic policies, their deployment complexity has to depend on , which is much higher than our stochastic policy algorithms in Section 4.2 when is large.
Investigation on Trade-off between Sample Complexity and Deployment Complexity
| Methods | R-F? | Deployed Policy |
|
|
|||
|
Deterministic | ||||||
|
✓ | Deterministic | |||||
|
✓ | Deterministic | |||||
|
Deterministic | ||||||
|
Deterministic | ||||||
|
✓ | Stochastic | |||||
| Alg. 1 [ Ours] | Deterministic | ||||||
| Alg. 3 + 4[ Ours] | ✓ | Deterministic | |||||
| Alg. 2[ Ours] | ✓ | Stochastic | |||||
In Table 1, we compare our algorithms and previous online RL works which did not consider deployment efficiency to shed light on the trade-off between sample and deployment complexities. Besides algorithms that are specialized to linear MDPs, we also include results such as Zanette et al. (2020), which studied a more general linear approximation setting and can be adapted to our setting. As stated in Def. 2 of Zanette et al. (2020), they also rely on some reachability assumption. To avoid ambiguity, we use to refer to their reachability coefficient (as discussed in Appx E.8, is no larger than and can be much smaller than our ). Because they also assume that (see Thm 4.1 in their paper), their results have an implicit dependence on . In addition, by using the class of linear functions w.r.t. , Q-type OLIVE (Jiang et al., 2017a; Jin et al., 2021a) has sample complexity and deployment complexity. Its deployment complexity is close to our deterministic algorithm, but with additional dependence on . We also want to highlight that OLIVE is known to be computationally intractable (Dann et al., 2018), while our algorithms are computationally efficient. With the given feature in linear MDPs and additional reachability assumption (not comparable to us), we can use a simplified version of MOFFLE (Modi et al., 2021) by skipping their LearnRep subroutine. Though this version of MOFFLE is computationally efficient and its deployment complexity does not depend on , it has much worse sample complexity ( is their reachability coefficient) and deployment complexity. On the other hand, PCID (Du et al., 2019) and HOMER (Misra et al., 2020) achieve deployment complexity in block MDPs. However, block MDPs are more restricted than linear MDPs and these algorithms have worse sample and computational complexities.
It is worth to note that all our algorithms achieve the optimal dependence on (i.e., ) in sample complexity. For algorithms that deploy deterministic policies, we can see that our algorithm has higher dependence on and in the sample complexity in both reward-known and reward-free setting, while our deployment complexity is much lower. Our stochastic policy algorithm (last row) is naturally a reward-free algorithm. Comparing with Wang et al. (2020b) and Zanette et al. (2020), our sample complexity has higher dependence on and the reachability coefficient , while our algorithm achieves the optimal deployment complexity and better dependence on .
Appendix B On the Lower Bound of Deployment-Efficient Reinforcement Learning
B.1 A Hard MDP Instance Template
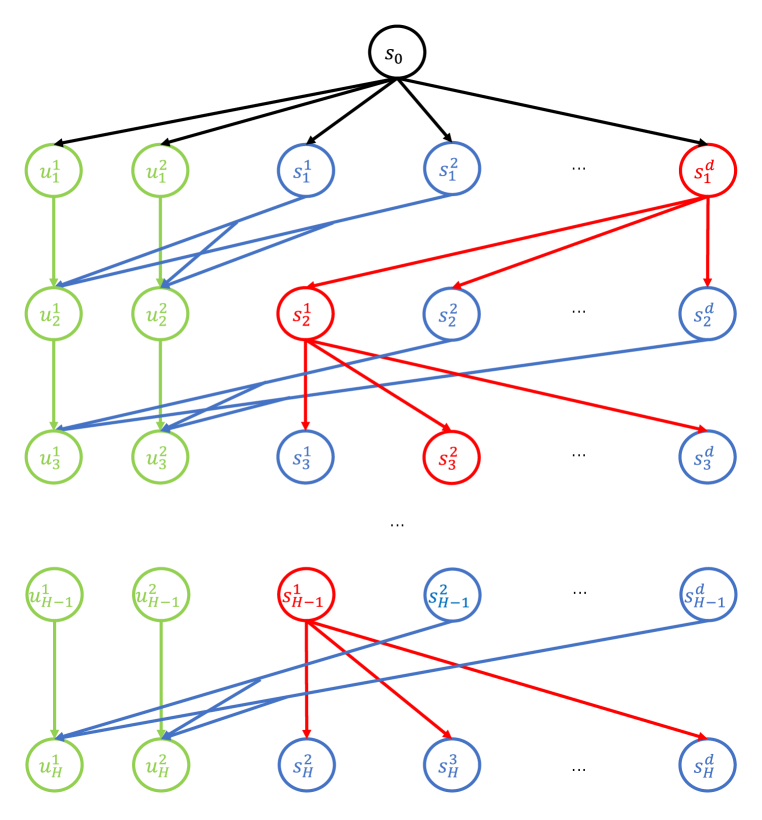
In this sub-section, we first introduce a hard MDP template that is used in further proofs. As shown in Figure 1, we construct a tabular MDP (which is a special case of linear MDP) where the horizon length is and in each layer except the first one, there are states and different state action pairs. The initial state is fixed as and there are different actions. It is easy to see that we can represent the MDP by linear features with at most dimensions, and construct reward and transition function satisfying Assumption A. As a result, it is a linear MDP with dimension and horizon length . Since there is only a constant-level blow up of dimension, the dimension of these MDPs is still , and we will directly use instead of in the rest of the proof. The states in each layer can be divided into three groups and we introduce them one-by-one in the following.
Group 1: Absorbing States (Green Color)
The first group consists of two absorbing states and , which can only take one action at each state and and transit to and with probability 1, respectively. The reward function is defined as for all and , .
Group 2: Core States (Red Color)
The second group only contains one state, which we call it core state and denote it as . For example, in Figure 1, we have and . In the “core state”, the agent can take actions and transit deterministically to . Besides, the reward function is for all .
Group 3: Normal States (Blue Color)
The third group is what we call “normal states”, and each state can only take one action and will transit randomly to one of the absorbing states in the next layer, i.e. . Besides, the reward function is for arbitrary , and the transition function is , except for a state action pair at layer with index , such that and and . In the following, we will call the “optimal state” and “optimal action” in this MDP. Note that the “optimal state” can not be the core state.
We will use with to denote the MDP whose optimal state is at layer and indexed by , and the core states in each layer are . As we can see, the only optimal policy should be the one which can generate the following sequence of states before transiting to absorb states at layer :
and the optimal value function would be . In order to achieve -optimal policy, the algorithm should identify , which is the main origin of the difficulty in exploration.
Remark B.1 (Markov v.s. Non-Markov Policies).
As we can see, the core states in each layer are the only states with #actions 1, and for each core state, there exists and only exists one deterministic path (a sequence of states, actions and rewards) from initial state to it, which implies that for arbitrary non-Markov policy, there exists an equivalent Markov policy. Therefore, in the rest of the proofs in this section, we only focus on Markov policies.
B.2 Lower bound for algorithms which can deploy deterministic policies only
In the following, we will state the formal version of the lower bound theorem for deterministic policy setting and its proof. The intuition of the proof is that we can construct a hard instance, which can be regarded as a multi-arm bandit problem, and we will show that in expectation the algorithm need to “pull arms” before identifying the optimal one.
Theorem B.2 (Lower bound for number of deployments in deterministic policy setting).
For the linear MDP problem with dimension and horizon , given arbitrary algorithm ( can be deterministic or stochastic), which can only deploy a deterministic policy but can collect arbitrary number of samples in each deployment, there exists a MDP problem where the optimal deterministic policy is better than all the other deterministic policies, but the estimate policy (which is also a deterministic policy) of the best policy output by after deployments must have unless the number of deployments .
Proof.
First of all, we introduce how we construct hard instances.
Construction of Hard Instances
We consider a set of MDPs , where for each MDP in that set, the core states (red color) in each layer are fixed to be and the only optimal states which has different probability to transit to absorbing states are randomly selected from normal states (blue color). Easy to see that, .
Because of the different position of optimal states, the optimal policies for each MDP in (i.e. the policy which can transit from to optimal state) is different. We will use to refer to those different policies and use with to denote the MDP in where is the optimal policy. For convenience, we will use to denote the MDP where all the normal states have equal probability to transit to different absorbing states, i.e., all states are optimal states. Based on the introduction above, we define and use the MDPs in as hard instances.
Lower Bound for Average Failure Probability
Next, we try to lower bound the average failure probability, which works as a lower bound for the maximal failure probability among MDPs in . Since any randomized algorithm is just a distribution over deterministic ones, and it therefore suffices to only consider deterministic algorithms (Krishnamurthy et al., 2016).
Given an arbitrary algorithm and , we use to denote the policy taken by at the -th deployment (which is a random variable). Besides, we denote as the output policy.
For arbitrary , we use with to denote the probability that takes policy at deployment when running on , and use to denote the probability that the algorithm returns policy as optimal arm after running with deployments under MDP . We are interested in providing an upper bound for the expected success rate:
where we assume that all the policies in are optimal policies.
In the following, we use to denote the event that the policy has been deployed at least once in the first deployments and to denote the probability of an event when running algorithm under MDP .
Next, we prove that, for arbitrary ,
| (4) |
First of all, it holds for , because at the beginning has’t observe any data, and all its possible behavior should be the same in both and , and therefore . Next, we do induction. Suppose we already know it holds for , then consider the case for . Because behave the same if the pre-collected episodes are the same, which is the only information it will use for decision, we should have:
| (5) |
The second equality is due to each trajectory has the same probability under and by the construction. Notice that in this induction step, we only consider the trajectory with first episodes because define the whole sample space and event only based on the first episodes.
This implies that,
B.3 Proof for Lower Bound in Arbitrary Setting
In the following, we provide a formal statement of the lower bound theorem for the arbitrary policy setting and its proof.
Theorem B.3 (Lower bound for number of deployments in arbitrary setting).
For the linear MDP problem with given dimension and horizon , , and arbitrary given algorithm . Unless the number of deployments , for any , there exists an MDP such that the output policy is not -optimal with probability at least . Here can be deterministic or stochastic. The algorithm can deploy arbitrary policy but can only collect samples in each deployment.
Proof.
Since any randomized algorithm is just a distribution over deterministic ones, it suffices to only consider deterministic algorithms in the following proof (Krishnamurthy et al., 2016). The crucial part here is notice that a deployment means we have a fixed distribution (occupancy) over the state space and such distribution only depends on the prior information.
Construction of Hard Instances
We have instances by enumerating the location of core state from level 1 to and the optimal normal state at level . We assign as the core state at level if is the optimal state. Notice that for this hard instance class, we only consider the case that the optimal state is in level . We use to denote this hard instance class.
We make a few claims and later prove these claims and the theorem. We will use the notation to denote the event that at least one state at level is reached by the -th deployment. Also we notice that in all the discussion an event is just a set of trajectories. For all related discussion, the state at level does not include the state in the absorbing chain. In addition, we will use to denote the distribution of trajectories when executing algorithm and uniformly taking an instance from the hard instance class.
Claim 1.
Assume . Then for any deterministic algorithm , we have
Claim 2.
Assume . We have that for any deterministic algorithm ,
Proof of Claim 1
By the nature of the deterministic algorithm, we know that for any deterministic algorithm , the deployment is the same at the first time for all instances. The reason is that the agent hasn’t observed anything, so the deployed policy has to be the same.
Let denote the probability of the first deployment policy to choose action at node at level under the first deployment policy. We know that for is the same under all instances.
Note that there is a one to one correspondence between an MDP in the hard instance class and the specified locations of core states in the layer and the optimal state at level . Therefore, we can use to denote any instance in the hard instance class, where refers to the location of the core states and refers to the location of the optimal state. From the construction, we know that for instance , to arrive at level at level , the path as to be . Therefore the probability of a trajectory sampled from to reach state is
Here we use denotes the probability of taking action at to transit to and similarly for others. In the deployment, draws episodes, so the probability of executing to reach any state at level during the first deployment is no more than .
Calculating the sum over and gives us
| (6) |
Therefore we have the following equation about
Proof of Claim 2
Let denote any possible concatenation of the first episodes we get in the first deployments. In this claim, it suffices to consider the episodes because the event only depends on the first episodes. Therefore the sample space and the event will be defined on any trajectory with episodes. For any , we know that will output the -th deployment policy solely based on the and this map is deterministic (we use to denote the to episodes in ). In other words, will map to a fixed policy to deploy at the -th time.
We have the following equation for any
Notice that this equality does not generally hold for probability distribution .
Then we fix , such that . We also fix , and consider two instances and . Therefore, we have that (from the construction of , and the property of deterministic algorithm ). We use to denote the instance class that has fixed , , but different . In addition, we use to denote the instance class that has fixed , but different and .
Since we have already fixed here, is also fixed (for all ). Also notice that we are considering the probability of episodes . Therefore, we can follow Claim 1 and define for , which represents the probability of choosing action at node at level under the -th deployment policy. In the -th deployment, draws episodes, so the probability of executing to reach any state at level under instance is
Following the same step in Eq (6) by summing over and gives us
Now, we sum over all possible and take the average. For any fixed we have
Moreover, summing over all , gives us
In the second equality, we use because for any fixed and all , are the same.
Finally, we have
Proof of the Theorem
We can set and . Then for , we get and
Let event denote the event (a set of length episodes trajectories) that any state at level is not hit. Then we have . We use to denote the instance class that has fixed core states but different optimal states .
Consider any fixed . Similar as the proof in the prior claims, by the property of deterministic algorithm, we can define for , which represents the probability of the output policy under trajectory to choose action at node at level . Then we have
Summing over gives us
In the second equality, we notice that for all instance , are the same, so this probability distribution essentially depends on . In the third inequality, we change the order of the summation.
Finally, summing over and taking average yields that
| ( does not depend on the optimal state) | ||||
Therefore, we get the probability of not choosing the optimal state is
From the construction, we know that any policy that does not choose optimal state (thus also does not choose the optimal action associated with the optimal state) is sub-optimal. This implies that with probability at least , the output policy is at least sub-optimal. ∎
Appendix C Deployment-Efficient RL with Deterministic Policies and given Reward Function
C.1 Additional Notations
In the appendix, we will frequently consider the MDP truncated at , and we will use:
to denote the value function in truncated MDP for arbitrary , and also extend the definition in Section 2 to , for optimal policy setting and , for reward-free setting.
C.2 Auxiliary Lemma
Lemma C.1 (Elliptical Potential Lemma; Lemma 26 of Agarwal et al. (2020b)).
Consider a sequence of positive semi-definite matrices with and define . Then
Lemma C.2 (Abbasi-yadkori et al. (2011)).
Suppose are two positive definite matrices satisfying , then for any , we have:
Next, we prove a lemma to bridge between trace and determinant, which is crucial to prove our key technique in Lemma 4.2.
Lemma C.3.
[Bridge between Trace and Determinant] Consider a sequence of matrices with and , where . We have
Proof.
Consider a more general case, given matrix , we have the following inequality
By replacing with in the above inequality, we have:
By assigning and , and applying Lemma C.2, we have:
which finished the proof. ∎
See 4.2
Proof.
Suppose we have , by applying Lemma C.3 we must have:
| () |
which implies that,
Therefore,
which implies that, conditioning on , we have:
Now, we are interested in find the mimimum , under the constraint that . To solve this problem, we first choose an arbitrary , and find a such that,
In order to guarantee the above, we need:
The first constraint can be satisfied easily with for some constant . Since usually , the second constraint can be directly satisfied if:
Recall , it can be satisfied by choosing
| (7) |
where is an absolute constant. Therefore, we can find an absolute number such that,
to make sure that
Since in Eq.(7), it’s required that , we should constraint that and therefore, . Because the dependence of are decreasing as increases, by assigning and , will be minimized when . Then, we finished the proof. ∎
C.3 Analysis for Algorithms
Next, we will use the above lemma to bound the difference between and . We first prove a lemma similar to Lemma B.3 in (Jin et al., 2019) and Lemma A.1 in (Wang et al., 2020b).
Lemma C.4 (Concentration Lemma).
Proof.
The proof is almost identical to Lemma B.3 in (Jin et al., 2019), so we omit it here. The only difference is that we have an inner summation from to and we truncate the horizon at in iteration . ∎
Lemma C.5 (Overestimation).
On the event in Lemma C.4, which holds with probability , for all and ,
where recall that is the function computed at iteration in Alg.1 and denote the optimal value function in the MDP truncated at layer and is the optimal policy in the truncated MDP.
Besides, we also have:
Proof.
Now we are ready to prove the following theorem restated from Theorem 4.1 in a more detailed version, where we include the guarantees during the execution of the algorithm.
Theorem C.6.
[Deployment Complexity] For arbitrary , and arbitrary , as long as , where is an absolute constant and independent with , by choosing
| (8) |
Algorithm 1 will terminate at iteration and return us a policy , and with probability , (1) . (2) for each , there exists an iteration , such that but , and is an -optimal policy for the MDP truncated at step ;
Proof.
As stated in the theorem, we use to denote the number of deployment after which the algorithm switch the exploration from layer to layer , i.e. and . According to the definition and the algorithm, we must have , and for arbitrary , (if , then it means is small enough and the algorithm directly switch the exploration to the next layer, and we can skip the discussion below ). Therefore, for arbitrary , during the -th deployment, there exists , such that,
where the second inequality is because the average is less than the maximum. The above implies that
| (9) |
According to Lemma 4.2, there exists constant , such that by choosing according to Eq.(10) below, the event in Eq.(9) will not happen more than times at each layer .
| (10) |
Recall that and the covariance matrices in each layer is initialized by . Therefore, at the first deployment, although the computation of does not consider the layers , Eq.(9) happens in each layer . We use to denote the total number of times events in Eq.(9) happens for layer previous to deployment , as a result,
where we minus because such event must happen at the first deployment for each and we should remove the repeated computation; and we add another back is because there are times we waste the samples (i.e. for those such that ). Therefore, we must have .
Moreover, because at iteration , we have , according to Hoeffding inequality, with probability , for each deployment , we must have:
| (11) |
Therefore, by choosing
| (12) |
we must have,
Therefore, after a combination of Eq.(10) and Eq.(12), we can conclude that, for arbitrary , there exists absolute constant , such that by choosing
the algorithm will stop at , and with probability (on the event of in C.4 and the Hoeffding inequality above), we must have:
and an additional benefits that for each , is an -optimal policy at the MDP truncated at step, or equivalently,
| (13) |
∎
C.4 Additional Safety Guarantee Brought with Layer-by-Layer Strategy
The layer-by-layer strategy brings another advantage that, if we finish the exploration of the first layers, based on the samples collected so far, we can obtain a policy , which is an -optimal in the MDP truncated at step , or equivalently:
We formally state these guarantees in Theorem C.6 (a detailed version of Theorem 4.1), Theorem D.4 and Theorem E.9 (the formal version of Theorem 4.4). Such a property may be valuable in certain application scenarios. For example, in “Safe DE-RL”, which we will discuss in Appendix F, can be used as the pessimistic policy in Algorithm 7 and guarantee the monotonic policy improvement criterion. Besides, in some real-world settings, we may hope to maintain a sub-optimal but gradually improving policy before we complete the execution of the entire algorithm.
If we replace Line 7-8 in LSVI-UCB (Algorithm 1) in Jin et al. (2019) with Line 13-18 in our Algorithm 1, the similar analysis can be done based on Lemma 4.2, and the same deployment complexity can be derived. However, the direct extension based on LSVI-UCB does not have the above safety guarantee. It is only guaranteed to return a near-optimal policy after deployments, but if we interrupt the algorithm after some deployments, there is no guarantee about what the best possible policy would be based on the data collected so far.
Appendix D Reward-Free Deployment-Efficient RL with Deterministic Policies
D.1 Algorithm
Similar to other algorithms in reward-free setting (Wang et al., 2020b; Jin et al., 2020), our algorithm includes an “Exploration Phase” to uniformly explore the entire MDP, and a “Planning Phase” to return near-optimal policy given an arbitrary reward function. The crucial part is to collect a well-covered dataset in the online “exploration phase”, which is sufficient for the batch RL algorithm (Antos et al., 2008; Munos & Szepesvári, 2008; Chen & Jiang, 2019) in the offline “planning phase” to work.
Our algorithm in Alg.3 and Alg.4 is based on (Wang et al., 2020b) and the layer-by-layer strategy. The main difference with Algorithm 1 is in two-folds. First, similar to (Wang et al., 2020b), we replace the reward function with of the bonus term. Secondly, we use a smaller threshold for comparing with Algorithm 1.
D.2 Analysis for Alg 3 and Alg 4
We first show a lemma adapted from Lemma C.4 for Alg 3. Since the proof is similar, we omit it here.
Lemma D.1 (Concentration for DE-RL in Reward-Free Setting).
Proof.
The proof is almost identical to Lemma 3.1 in (Wang et al., 2020b), so we omit it here. The only difference is that we have an inner summation from to and we truncate the horizon at in iteration . ∎
Lemma D.2 (Overestimation).
Proof.
We first prove the overestimation inequality.
Overestimation
First of all, similar to the proof of Lemma 3.1 in (Wang et al., 2020b), on the event of defined in Lemma C.4, which holds with probability , we have:
| (14) |
Then, we can use induction to show the overestimation. For , we have:
Suppose for some , we have
Then, , we have
where in the last inequality, we apply Eq.(14).
Relationship between and
where in the first inequality, we add and subtract , and in the second inequality, we use the following fact
∎ Next, we provide some analysis for Algorithm 4, which will help us to understand what we want to do in Algorithm 3
Lemma D.3.
On the event in Lemma D.1, which holds with probability , if we assign in Algorithm 4 and assign to be the samples collected till deployment , i.e. , then for arbitrary reward function satisfying the linear Assumption A, the policy returned by Alg 4 would satisfy:
| (15) |
where .
Proof.
By applying the similar technique in the analysis of in Lemma D.2 after replacing with , we have:
where denotes the value function returned by Alg 4 Besides,
then, we finish the proof. ∎
From Eq.(15) in Lemma D.3, we can see that, after exploring with Algorithm 3, the sub-optimality gap between and returned by Alg.4 can be bounded by the value of the optimal policy w.r.t. , which we will further bound in the next theorem.
Now we are ready to prove the main theorem.
Theorem D.4.
For arbitrary , by assigning for some , as long as
| (16) |
where is an absolute constant and independent with , then, Alg 3 will terminate at iteration and return us a dataset , such that given arbitrary reward function satisfying Assumption A, by running Alg 4 with and , with probability , we can obtain a policy satisfying .
Proof.
The proof is similar to Theorem 4.1. As stated in theorem, we use to denote the number of deployment when the algorithm switch the exploration from layer to layer , i.e. and . According to the definition and the algorithm, we must have , and for arbitrary , we must have (if , then it means is small enough and the algorithm directly switch the exploration to the next layer, and we can skip the discussion below). Therefore, for arbitrary , during the -th deployment, there exists , such that,
which implies that
| (17) |
According to Lemma 4.2, there exists an absolute constant , for arbitrary , by choosing according to Eq.(18) below, the events in Eq.(17) will not happen more than times at each layer .
| (18) |
We use to denote the total number of times Eq.(9) happens for layer till deployment . With a similar discussion as Theorem 4.1, we have:
Moreover, we must have for each , and according to Hoeffding inequality, with probability , for each step , we must have
Therefore, by choosing
| (19) |
we have,
For arbitrary , in Algorithm 4, if we assign and , note that , by applying Lemma D.2 and Lemma D.3 we have:
Therefore, after a combination of Eq.(18) and Eq.(19), we can conclude that, for arbitrary , there exists absolute constant , such that by choosing
Alg 3 will terminate at , and with probability (on the event in Lemma D.1 and Hoeffding inequality above), for each , if we feed Alg 4 with , and arbitrary linear reward function , the policy returned by Alg 4 should satisfy:
∎
Appendix E DE-RL with Arbitrary Deployed Policies
In the proof for this section, without loss of generality, we assume the initial state is fixed, which will makes the notation and derivation simpler without trivialize the results. For the case where initial state is sampled from some fixed distribution, our algorithms and results can be extended simply by considering the concentration error related to the initial state distribution.
E.1 Algorithms
We first introduce the definition for function:
Definition E.1 ( function).
Given vector or matrix as input, we have:
where is the ceiling function.
In Algorithm 6, we are trying to estimate the expected covariance matrix under policy by policy evaluation. The basic idea is that, the expected covariance matrix can be represented by:
where we use to denote a matrix whose element indexed by in row and in column is . In another word, the element in the covariance matrix indexed by is equal to the value function of policy with as reward function at the last layer (and use zero reward in previous layers), where denotes the -th elements of vector . Because the techniques rely on the reward is non-negative and bounded in , by leveraging the fact that , we shift and scale to obtain and use it for policy evaluation.
In Alg 5, we maintance two functions and . The learning of is based on LSVI-UCB, while is a “discretized version” for computed by discretizing (or at layer ) elementwisely with resolution , and will be used to compute for deployment. The main reason why we discretize is to make sure the number of greedy policies is bounded, so that we can use union bound and upper bound the error when using Alg 6 to estimate the covariance matrix. In Section E.5, we will analyze the error resulting from discretization, and we will upper bound the estimation error Alg. 6.
E.2 Function Classes and -Cover
We first introduce some useful function classes and their -cover.
Notation for Value Function Classes and Policy Classes
We first introduce some new notations for value and policy classes. Similar to Eq.(6) in (Jin et al., 2019), we define the greedy value function class
and the Q function class:
Besides, suppose we have a deterministic policy class with finite candidates (i.e. ), we use to denote:
Recall that in Alg.6, we will use a special reward function, and we need to consider it in the union bound. We denote:
and easy to check .
Moreover, if we have a Q function class , we will use to denote the class of greedy policies induced from , i.e.
Discretization with Resolution
In the following, we will use to denote the -cover for with , concretely,
where is the ceiling function.
Similarly, we will use to denote the -cover for matrix with
Easy to check that:
Recall the definition of function in Def. E.1, easy to check that:
-cover
Before we introduce our notations for -net, we first show a useful lemma:
Lemma E.2.
For arbitrary , denote and . Consider the following two functions and their greedy policies, where
then we have:
Proof.
After similar derivation as Eq.(28) in (Jin et al., 2019), we can show that
Because and are greedy policies, we have:
| ∎ |
Now, we consider the following Q function class and V function class,
based on Lemma E.2, and another important fact that , we know that is an -cover of , i.e. for arbitrary , there exists , such that . Similarly, is also an -cover of .
Besides, we will use to denote the collection of greedy policy induced from elements in .
We also define , which is an cover for .
Obviously, .
Besides, because is already a finite set, it is an -cover of itself.
E.3 Constraints in Advance
Induction Condition Related to Accumulative Error
Constraints for the Validity of the Algorithm
Besides, in order to make sure the algorithm can run successfully, we add the following constaints:
| (20) | ||||
| (21) | ||||
| (22) |
where constraint (22) for is to make sure the reward locates in interval.
Recall the definition of , therefore,
According to Lemma E.11, to make sure , we need the following constraint on
| (23) |
which is equivalent to .
As for , the constraint is equivalent to:
and can be rewritten to
| (24) |
E.4 Concentration Bound
Based on the notations above, we are already to claim that:
Claim 3.
Proof.
Algorithm 5: First we bound the norm of the weights in Algorithm 5. For arbitrary and , we have:
therefore, . Besides, according to Lemma E.11 and constraint (24), we have:
Recall and , the claim about Alg 5 is true.
Algorithm 6: The discussion about the value range of is similar to above. Therefore, all the value functions occurred in the previous layers would belong to , except that the last layer should belong to . Besides, since Alg 6 is only used to estimate the policies returned by Alg 5, we should have . As a result, the claim for Alg 6 is correct. ∎
Recall Lemma D.4 from (Jin et al., 2019), which holds for arbitrary with covering number and . Next, we state a slightly generalized version by replacing with , since in our Alg. 5 and Alg. 6 . This is also the main reason why we only need the coefficient of the bonus term instead of in Alg. 5 so that we can achieve better dependence on .
Lemma E.3 ((Revised) Lemma D.4 in (Jin et al., 2019)).
Let , be a stochastic process on state space with corresponding filtration . Let be an -valued stochastic process where and . Let . Then for any , with probability at least , for all , and any so that , we have:
where is the -covering number of w.r.t. the distance
Now we are ready to prove the main concentration result for Algorithm 2:
Theorem E.4.
Proof.
We consider the value function class:
and we have an -cover for it, which we denote as:
Besides, there exists , s.t.
By plugging into Lemma E.3 and considering the union bound over and (note that ), we have with probability ,
When , the first term will dominate, and there must exists such that
∎
E.5 Bias Analysis
Lemma E.5 (Overestimation in Alg 5).
Proof.
Lemma E.6 (Bias Accumulation in Alg 5).
Proof.
We will use to denote the optimal policy w.r.t. the function without discretization, although we do not deploy it in practice. According to Lemma E.2, we should have for arbitrary .
Lemma E.7 (Bias of Linear Regression in Alg 6).
The proofs for the above Lemma is based on Theorem E.4 and Claim 3 and is similar to Lemma 3.1 in (Wang et al., 2020b), so we omit it here.
Lemma E.8 (Policy Evaluation Error in Alg 6).
Proof.
E.6 Main Theorem and Proof
Now, we restate Theorem 4.4 in a formal version below:
Theorem E.9 (Formal Version of Theorem 4.4).
For arbitrary , there exists absolute constants and , such that by choosing ( used in Alg. 5 and 6, and used in Alg. 4)666 The ICLR 2022 version (and also the second version in arxiv) omitted that the bonus coefficients in Alg. 4 and in Alg. 5 and 6 should have different dependence on , which resulted in incorrect dependence on in the sample complexity upper bound. We thank Dan Qiao for calling this to our attention.
with probability , after deployments, by running Alg 4 with the collected dataset and arbitrary satisfying the linear assumption in A (in Line of Algorithm 2), we will obtain a policy such that .
As additional guarantees, after deployments, by running Alg 4 with the collected dataset and reward function , we will obtain a policy which is -optimal in the MDP truncated at step .
Proof.
We will use to denote the matrix which approximates in Alg. 2, and use to denote the reward function used in Alg 5 if the covariance matrix estimation is perfect (i.e. ).
The proof consists of three steps. In step 1, we try to show that the inner loop of Alg 2 will terminate and will contain a set of exploratory policies. In step 2, we will analyze the samples generated by a mixture of policies in . In the last step, we determine the choice of hyper-parameters and fill the gaps of pre-assumed constraints and induction conditions.
Step 1: Exploration Ability for Policies in
In the inner loop (line 5 - 12) in Algorithm 2, our goal is to find a set of policies , such that if the algorithm stops at iteration , the following uncertainty measure is as small as possible
| (28) |
To achieve this goal, we repeatedly use Alg 6 to estimate the covariance matrix of the policy and append it to as an approximation of , and use Alg 5 to find a near-optimal policy to maximizing the uncertainty-based reward function , by sampling trajectories with which we can reduce the uncertainty in Eq.(28).
First, we take a look at the estimation error of the accumulative covariance matrix when running Algorithm 2. On the conditions in Lemma E.8, we can bound the elementwise estimation error of :
As a result of Lemma E.11, we have:
| (29) |
where the last but two step is because we at most repeat it iterations at each layer , and we introduce the following constraint for during the derivation, to make sure the bias is small and all the iterms occurs in the derivation is well defined:
| (30) |
Next, we want to find a good choice of to make sure will not always be large and the for-loop will break for some . We first provide an upper bound for :
| (Lemma E.5) | ||||
| (; Lemma E.6) | ||||
| (bias of reward) | ||||
| (Constraints on in Eq.(30)) |
Next, we try to show that can not always be large. According to Elliptical Potential Lemma in Lemma C.1, we have:
where in the last step, we use the definition of . Therefore,
In order to guarantee , we require:
which can be satisfied by:
| (31) |
for some absolute constant .
Step 2: Policy Deployment and Concentration Error
For uniform mixture policy , by applying Lemma E.13, Lemma E.14 and the results above, we must have:
and this is the motivation of breaking criterion in Line 2 in Alg 2.
In the following, we will use to denote the matrix of sampled feature without regularization terms, according to Lemma E.10, with probability , we have:
Follow the same steps in the proof of Lemma E.14, we know that
As a result,
which implies that, as long as
| (32) |
we have
Therefore, for arbitrary , we have:
| () | ||||
As a result,
In order to make sure the induction conditions holds, we need
As long as we tighten the constraint in 32 to:
| (33) |
the induction conditions can be satisfied when
or equivalently,
Step 3: Determine Hyper-parameters
(1) Resolution
(2) Induction error
Choice of , and
Since , by plugging it into Eq.(26), we may choose to be:
The discussion about the choice of is similar to what we did for Alg. 3 and 4, and we can choose:
Now, we are ready to compute . When , we have:
and otherwise, we have:
Combining the additional constraint to control the concentration error in Eq.(33), the total number of complexity would at the level:
and therefore,
for some and .
Near-Optimal Guarantee
Under the events in Theorem E.4, considering the failure rate of concentration inequality in Step 2, we can conclude that the induction condition holds for with probability . Combining our discussion about choice of above, the probability that Alg 2 will return us an -optimal policy would be .
The additional guarantee in Theorem E.9 can be directly obtained by considering the induction condition at layer . ∎
E.7 Technical Lemma
Lemma E.10 (Matrix Bernstein Theorem (Theorem 6.1.1 in (Tropp, 2015))).
Consider a finite sequence of independent, random matrices with common dimension . Assume that
Introduce the random matrix
Let be the matrix variance statistic of the sum:
Then,
Furthermore, for all
Lemma E.11 (Matrix Perturbation).
Given a positive definite matrix and satisfying , define matrix , then for arbitrary with , we have:
which implies that
Moreover,
Proof.
First of all, easy to see that
and therefore we have
where we use and to denote the smallest and the largest sigular value, respectively, and use to refer to the Frobenius norm. Therefore,
and
Moreover,
∎
Next, we will try to prove that, with a proper choice of , Algorithm 2 will explore layer to satisfy the recursive induction condition.
Lemma E.12 (Random Matrix Estimation Error).
Denote . Based on the same induction condition 2, we have:
Lemma E.13.
Given a matrix with , and satisfies , then we have:
Proof.
Because , we have
Therefore,
∎
Lemma E.14.
Given a matrix , suppose , where is a constant, where is defined in Definition 4.3, we have:
E.8 More about our reachability coefficient
Recall the definition of reachability coefficient in (Zanette et al., 2020) is:
Easy to see that, for arbitrary with , we have
Therefore,
Besides, according to the min-max theorem, is also lower bounded by , to see this,
In fact, the value of is also related to the ”Well-Explored Dataset” assumption in many previous literature in offline setting (Jin et al., 2021b), where it is assumed that there exists a behavior policy such that the minimum singular value of the covariance matrix is lower bounded. Therefore, we can conclude that our reachability coefficient is also lower bounded by, e.g. in Corollary 4.6 in (Jin et al., 2021b).
Appendix F Extended Deployment-Efficient RL Setting
F.1 Sample-Efficient DE-RL
In applications such as recommendation systems, the value of cannot exceed the number of users our system serves during a period of time. Therefore, as an interesting extension to our framework, we can revise the constraint (b) in Definition 2.1 and explicitly assign an upper bound for . Concretely, we may consider the following alternatives: (b’) The sample size , where are some constant fixed according to the real situation. Under these revised constraints, the lower bound for may be different.
In fact, given constraints in the form of , our results in Section 4 already implies an upper bound for , since we can emulate 1 deployment of our algorithm that uses a large by deploying the same policy for times. However, this may result in sub-optimal deployment complexity since we are not adaptively updating our policy within those deployments. It would be an interesting open problem to identify the fine-grained trade-off between and in such a setting.
F.2 Safe DE-RL
Monotonic Policy Improvement Constraint
In many applications, improvement of service quality after policy update is highly desired, and can be incorporated in our formulation by adding an additional constraint into Def 2.1:
| (35) |
Because we require the deployed policy has substantial probability to visit unfamiliar states so that the agent can identify the near-optimal policy as shown in Def 2.1-(a), we relax the strict policy improvement with an small budget term for exploration.
Trade-off between Pessimism and Optimism
The balance between satisfying two contradictory constraints: (a) and (c), implies that a proper algorithm should leverage both pessimism and optimism in face of uncertainty. In Algorithm 7, we propose a simple but effective mixture policy srategy, where we treat pessimistic and optimistic algorithm as black boxes and mix the learned policies with a coefficient . One key property of the mixed policy is that:
Property F.1 (Policy improvement for mixture policy).
| (36) |
As a result, as long as the offline algorithm (which we treat as a black box here) has some policy improvement guarantee, such as (Kumar et al., 2020; Liu et al., 2020; Laroche et al., 2019), then Eq.(36) implies a substantial policy improvement if is chosen appropraitely. Besides, if we use Algorithms in Section 4.1 or 4.2, and collecting samples, the guarantees in Theorem 4.1 and Theorem 4.4 can be extended correspondingly. Therefore, Alg 7 will return us a near-optimal policy after deployments while satisfying the safety constraint (c) in (35).