Towards Decentralized Human-Swarm Interaction by Means of Sequential Hand Gesture Recognition
Abstract
In this work, we present preliminary work on a novel method for Human-Swarm Interaction (HSI) that can be used to change the macroscopic behavior of a swarm of robots with decentralized sensing and control. By integrating a small yet capable hand gesture recognition convolutional neural network (CNN) with the next-generation Robot Operating System ros2, which enables decentralized implementation of robot software for multi-robot applications, we demonstrate the feasibility of programming a swarm of robots to recognize and respond to a sequence of hand gestures that capable of correspond to different types of swarm behaviors. We test our approach using a sequence of gestures that modifies the target inter-robot distance in a group of three Turtlebot3 Burger robots in order to prevent robot collisions with obstacles. The approach is validated in three different Gazebo simulation environments and in a physical testbed that reproduces one of the simulated environments.
I INTRODUCTION
As the price of low-power computing devices continues to decrease, the robotics community recognizes the increasing viability of robotic swarms for a multitude of applications. The emphasis on scalability and hardware redundancy in robotic swarms, however, makes developing robust and stable management and control tools difficult. In addition, a human-in-the-loop approaches for managing a fleet of robots leads to cognitive overload by operators impairing their ability to continue working [1]. Our work seeks to solve this issue in Human-Swarm Interfaces (HSI) by attempting to remove the interface. Instead, a human operator may give commands through a sequence of hand gestures and have their commands relayed to an entire swarm or team of robots.
Yet before this can happen, further progress is required in Human-Swarm interfaces and control. Past work in the field has expanded upon control using a variety of different control interfaces which are often referred to as Human-Swarm Interfaces. Kolling et al. provide an essential survey of the HSI field as it currently stands [2]. As mentioned earlier in [1], one of the most difficult aspects of human-swarm control is burdening the user with cognitive overload. Managing multiple robots is a difficult task, and, therefore, HSI systems are designed with this premise. Abstracting complex swarm behavior is essential to discretizing the tasks into manageable and comprehensible feedback to the human user. Lin et al. were able to generate artificial task functions capable of abstracting a swarm in real-time to assist users [3]. After abstracting complex swarm behavior, [4] and [5] mapped the different abstracted behaviors onto single gesture inputs for tablet interfaces. However, both these methods require a centralized server to function because of their robot’s low computational power, and they require the difficult development of an external mobile application.
Various approaches have been attempted to control multi-robot systems by other physical means, including wearable devices using haptic feedback as seen in [6][7] and Electroencephalogram brain-computer interfaces (BCI) as reported by Karavas et al. [8]. However, both these approaches are hindered by the necessity of wearable hardware to function and cumbersome application process to read noisy EEG signals, respectively. These issues make the their applicability in everyday usage more difficult.
In this work, we present preliminary research into a human-swarm control paradigm capable of future use in decentralized control of a robotic swarm through human input that is realizable with the current generation of computer hardware. By decentralized, we mean that the robots’ systems are independent of one another but are capable of inter-communication. With the advent of accelerated training in machine learning and advances in computer vision, many complex classification tasks are scalable to less computationally powerful devices. We seek to utilize this by combining advances in decentralized robotic systems using ros2 [9] with specialized convolutional neural networks (CNN) capable of recognizing hand gestures. We hypothesize that concatenating a series of different hand gestures produces more refined control of a particular swarm task specified by a user.
In Section II, we establish a simplified system composed of a CNN and simplified swarm behavior to validate our hypothesis. Next, we test our approach using a simplified swarm behavior on a small swarm size (three robots) in various simulation testbeds. The system is further validated through physical experimentation using three robots in a re-creation of the final simulated testbed. Finally, we expand upon the results of the experiments and discuss the future applicability of this approach towards a decentralized swarm controlled by a human-in-the-loop. As of time of writing, this is the only known work that formulates sequential hand gestures for controlling multiple robots using CNNs in a semi-decentralized manner.
II METHODOLOGY
Our system is primary composed of two parts: (1) a deep neural network classifying various hand gestures, and (2) a simplified swarm cohesion model for a small swarm size. This paper will provide a validation of sequential hand gestures as a means of controlling a swarm. Therefore, we do not formulate the algorithm as a generalized model for scalable swarm sizes, which we leave to future work.
II-A Deep Neural Network
Since low-powered, small computationally powerful devices, such as the Raspberry Pi and other ARM devices, are common among swarm robotics hardware architecture, most conventional and state-of-the-art neural network models are unusable or difficult to implement. To circumvent this issue, a special neural network named a SqueezeNet was deployed for hand gesture recognition [10]. The SqueezeNet model is capable of performing as well, or even surpassing, classification rates of many the most popular model types with only a fraction of the parameters, thus reducing the model size to roughly MB. This substantial reduction in model size makes this model ideal for use in hardware typically found in swarm robotics applications.
II-A1 Dataset and Preprocessing
A training set consisting of six different gestures and images was utilized for training the SqueezeNet model [11]. The images are silhouettes of the gestures in black and white. A gesture set, , containing all possible gestures for classification and available in the training data is defined as:
| (1) |
Figure 1 contains examples of the gestures found in the dataset. The dataset was expanded to ensure more robust classification of gestures during real-time operation. The data augmentation began with inverting the images horizontally to resemble the gesture but with the opposite hand. The original image and the inverted image are used to generate three new images, respectively. One rotated by clockwise, another counter-clockwise, and an image flipped upside-down. Therefore, seven new images are generated for each image in the original dataset.
To ensure that the model is capable of real-time performance, a seventh gesture was added to the dataset: ‘None’. Since the user’s hand is not consistently in the frame, the image is classified as ‘None’ and awaits a gesture to come into the frame. A dataset containing blank images is generated during preprocessing consisting of black images and black images containing Gaussian noise to add to SqueezeNet model’s classification capabilities.
Further preprocessing was performed before training to ensure optimal results. Images in the dataset were cropped from their original size of to . The images were then scaled to . This final image size is big enough to ensure adequate real-time classification of gestures without increasing computational cost.

II-A2 Training
The SqueezeNet model was programmed and trained using the TensorFlow API version [12] running on a development box containing four Nvidia RTX 2080 graphics cards. The model was trained for epochs with a Stochastic Gradient Descent optimizer, which had a learning rate , a coefficient of momentum , and a learning rate decay . The batch size was set to two images to prevent memory issues due to the images’ size. The dataset was split into a training and validation set consisting of and of the images, respectively.
II-B Gesture Driven Controller
We first consider a waypoint system in which a finite number of robots, , plot a straight motion to a desired goal position from an initial starting position . To help validate the applicability of sequential gesture control, we will only focus on one direction, , and keep the values arbitrary. For example, if the initial position of a robot is and the desired position is set to be , the desired position is considered achieved if only the robot’s x-coordinate matches the desired value. A set of waypoints, , for each robot is thus generated from augmenting by , which is calculated from a user-defined number of waypoints, .
| (2) | ||||
| (3) |
Each robot, , moves from one waypoint to another in the set until it reaches the final desired position .
With the waypoints generated, we define to be the cohesion of the swarm, that is, a metric measuring the inter-robot distance of a swarm, where is the robot ’s position and is the cohesion factor. is a binary variable that represents an increase in cohesion if or a decrease in cohesion if . To increase the cohesion of a swarm is to reduce the distance between each robot, and to decrease the cohesion is to increase the distance between each robot. Additionally, we consider a small swarm size of three agents in a line separated by an offset in the direction. The cohesion of this small swarm is best represented by a constant addition or subtraction of a small, static offset . An individual robot, , applies a cohesion change by the following piecewise formula:
| (4) |
Next, we consider a differential drive capable of driving from one waypoint to the next based on the unicycle model [13] as defined by the following state-space formulation, where and are the robot’s position and is its angle.
| (5) |
Here, and is the robot’s linear and angular velocity, respectively. Since we choose to apply a constant linear velocity, the dynamics of the robot using the unicycle model are represented primarily by . To control the robot’s motion from one point to another reference point, the difference between a desired angle, , and the robot’s current angle, , is calculated and used as the error
| (6) |
To prevent singularities from arising and restrict the error between and , we update the calculated error using
| (7) |
Finally, our control input into the robot is applied with a proportional gain .
| (8) |
This forms the basis for the control of the swarm using sequential hand gestures.
III SIMULATIONS
A series of 3D simulations were designed to test the viability of sequential gesture-based control of a swarm. To formalize the experimental simulations, the following assumptions were made. First, the simulations are limited to three robots. Though it may seem like a small swarm size, we believe that this size provides a viable minimal benchmark for how our algorithm will actually work. Second, odometry is provided by the simulation environment and not by internal (i.e. encoders) or external (i.e. GPS, cameras, etc.) sensors. Finally, a black background is used when reading images from the gestures to streamline classifications.
III-A Structure
The simulation was developed using ros2, the next-generation of the Robot Operating System (ROS). Compared to the original ROS, ros2 provides an enhanced middleware programming environment, the removal of a ROS Master to make multi-robot decentralized approaches easier, and expanded platform and architecture support. Gazebo, a 3D robot simulation environment, is used to render the experiment. Gazebo is a project developed in tandem with ROS/ros2, and comes with many ROS drivers to simplify development of robots by providing a simulation environment that functions similarly to a physical one. The experiment is run using the Turtlebot3 Burger robot by ROBOTIS [14] who provide 3D Gazebo models for use in simulation.
Each robot runs two separate nodes: one that contains drivers to connect to Gazebo to simulate differential drive control, sensor readings, etc., and another that is the primary motion controller as defined in Section II-B. The robots do not intercommunicate and only subscribe to messages from one external node that tells them what gestures were classified. This external node reads information from a generic webcam running the SqueezeNet model. Additionally, images captured by the webcam are modified to reflect those used for training, which were silhouette images of the different hand gestures.
The captured camera images are cropped from the resolution to resolution and then scaled to , which is the input size for our SqueezeNet model. The images are then converted to greyscale and a slight Gaussian blur is applied to prevent fine details in the image from causing artifacts when converted to a binary image. Finally, the image is converted using a binary filter and inputted into the SqueezeNet model. The predicted gesture is then published to all the robots. This message is not unique to each robot.
III-B Gestures
For this experiment, the number of gestures used have been reduced to the following five:
| (9) |
These gestures are mapped to the subsequent actions the swarm may undergo:
-
•
Palm: Stop movement of the swarm
-
•
Peace: Resume movement of the swarm
-
•
Fist: Read cohesion action
-
•
C Sign: Increase
-
•
L Sign: Decrease
Additionally, there is a sixth classified gesture is None, which, as stated in Section II-A1, means that there is no gesture recognized and no swarm action applicable. Palm (Stop) and Peace (Resume) are the only two gestures capable of controlling the swarm alone. The rest require the user to give a sequence of gestures for the swarm to read. One a gesture pertaining to the swarm behavior (cohesion) the user wishes to modify and the next is a gesture mapped to a modification variable (increase or decrease).
In the simulation, we will rely on two sequences used to modify the cohesion of the swarm to help negotiate an obstacle. The first is increasing the cohesion of the swarm, , which means that the swarm will group closer to one another. This is done by giving the following commands in this order:
| (10) |
This sequence is explained as “stop the swarm, read my cohesion command, increase cohesion by one step size, and resume moving.” The second would be to decrease the cohesion of the swarm, , resulting in a increase in distance between the robots. This is done using the same hand gestures but with the decrease cohesion command.
| (11) |
Just like the increase cohesion sequence, this sequence is similarly explained as “stop the swarm, read my cohesion command, decrease cohesion by one step size, and resume moving.” As described earlier, the cohesion of the swarm is set as steps. Specifically, each call to increase or decrease the swarm cohesion decreases or increases the distance between the robots by a calculated , respectively. If an obstacle requires the user to change the swarms cohesion by multiple steps of , the user does not need to repeat the whole sequence twice but can concatenate the swarm command multiple times. For example, if the swarm cohesion is needed to increase by two steps, a user would provide the following command:
| (12) |
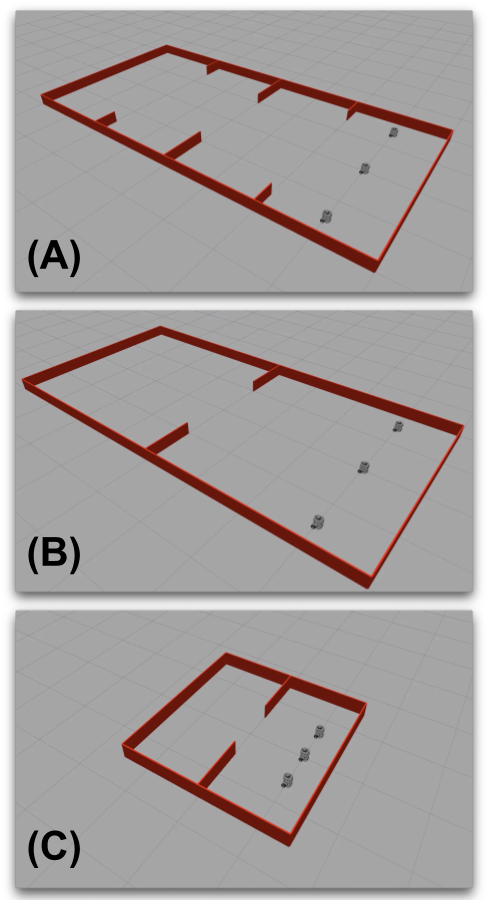
III-C Simulated Environment
The three robots are placed in a line within three simulated testbeds, shown in Figure 2. The first contains a series of two types of openings: one small-sized opening in the middle and two intermediate-sized openings located on both ends of the testbed. The second testbed has only one small-sized opening. Each testbed provides a different validation for the capability of our sequential gesture control scheme. The first demonstrates how individual commands can be given at the onset of an obstacle, and the other shows how for more difficult obstacles a user is capable of stringing together multiple gesture actions into one command. The first two testbeds are in size. Each robot is placed from the end of the testbed and spread to have an inter-robot distance of between one another. To complete each task, the robots will have to move forward and reach the other end of the testbed. The swarm of robots will need to negotiate the obstacles before them by relying on a user’s sequential gesture input.
The third testbed is a recreation of a real testbed used in the physical experiment section of the paper. Compared to the large surface area of the other testbeds, this testbed is significantly smaller at . Additionally, the initial inter-robot distance is reduced to and the robots are placed from the end. The testbed contains a sized opening a meter from the robots starting position. Like the other testbeds, the robots will have to negotiate this obstacle using a single sequence of gestures to increase cohesion. After going through the obstacle, a different sequence is used to decrease the cohesion. This testbed’s results act as validation for the success of this experiment using real robots. Figure 3 provides a brief overview of the robots increasing and then decreasing their cohesion to negotiate a small opening.

IV PHYSICAL EXPERIMENTS

To validate the use of sequential hand gesture control of a swarm in a physical setting, an analogous physical testbed to the third simulated testbed was built as shown in Figure 4. The experiment was set up in the same manner as the simulated one. For this paper, the individual robot controller and gesture recognition code was written with the intention of interchangeability between the simulated and physical experiments. The only difference were parameter files which provided environmental constraints and individual robot attributes depending on the environment the test is being run.
However, certain aspects of the simulation were not available for use in our physical experiments. Odometry within simulation is accurately calculated by the Gazebo environment, but getting this same information in a physical experiment required use of an overhead camera and ArUco fiducial markers [15] [16] to calculate each individual robot’s pose. A ros2 node was developed to track individual robot position from the overhead camera and calculate poses from a marker placed atop each robot that was detected. This odometry information is then published to the robots for use in their controller node’s.
During simulation, all the ros2 individual robot nodes and gesture node were run on the same computer. The physical experiment distributes the computation over a wireless network. Each robot runs their respective controller on their hardware, but do not communicate to one another. The only communication they receive are from two external sources: the node calculating individual robot odometry from a central overhead camera and the node reading and classifying the sequential gestures from the user. Each of these nodes are also run on separate computers due to convenience rather than the inability of running both on the same one. This decentralization comes with a cost, however, in the form an approximately delay. Even though the individual robots were capable of running the gesture detection node, we chose to keep the node running on a separate computer to keep the test runs between the simulation and physical experiments similar.
The physical experimental procedure is nearly identical to the simulation except for the software structure changes presented in this section. There are a few small changes in comparison to the simulation; however, we do not believe it reduces the validity of our physical experiment. One additional change to this experiment was the linear velocity of each robot was reduced due to the half-second network lag in the system.
V DISCUSSION
We have successfully demonstrated our hypothesis by showcasing a simplified cohesion control model for both simulated and physical testbeds. The supplemental video attached provides the results of a single run on each simulated and physical testbed. Each simulated test completed successfully and the controller responded correctly to the properly classified sequential gesture commands given from the SqueezeNet model in real-time. As mentioned in Section III-A, the run corresponding to Testbed demonstrated the ability for the systems to read multiple instances of the same increase cohesion gesture sequence in one input. Results from that run show that the provided input sequence was easily registered and enacted by the robots. Additionally, the physical experiment was able to finish successfully even with the network delay present in the system. We believe that re-creations of bigger testbeds, such as Testbed and in our simulations, would yield successful runs. Although the system is semi-decentralized due to odometry calculations and having the gesture recognition node running separate from the robots, these results of these tests show the feasibility of a human operator interacting with a decentralized robot swarm by showing a robot a sequence of hand gestures.
Although all the experiments were successful, we did run into a minor classification issue during test runs. The SqueezeNet CNN would sporadically misclassify the hand gesture upon the subject’s hand leaving the camera’s viewing area or when switching between hand gestures. We believe that this issue is likely due to gestures created during the hand’s motion unable to be classified. To help reduce this error, publishing of the predicted gesture was limited to once every half second instead of one every tenth of a second, which is the refresh rate of the ros2 node that classified the gestures.
VI FUTURE WORK
As stated in the beginning of Section II, the experiments shown were not generalized, but future work hopes to encompass multiple, generalized swarm behaviors. Research by Harriott et al. gives an interesting breakdown of numerous biologically-inspired swarm behavior metrics [17] as possible future behaviors employable by our system. A further expanded repertoire of behaviors would increase the feasibility of this system for everyday work with human operators.
Although this light-weight SqueezeNet model is capable of being run on low-powered hardware such as the Raspberry Pi due to its size (approximately MB), the model proved very sensitive to lighting conditions and cluttered backgrounds. Generating the silhouette images is very difficult in more dynamic backgrounds, which we believe is necessary if a gesture recognition system were to be placed on each robot. Therefore, all of our tests were run with a static black background. As of time of writing, the team at Google AI has developed algorithms for more robust hand gesture recognition without the need for silhouette images capable of running on Android and iOS devices [18]. These algorithms are capable of running on hardware similar to that of the Turtlebot3 and is able to classify a larger set of hand gestures. Our future work seeks to explore this and other algorithms capable of recognizing hand gestures in more dynamic and cluttered backgrounds.
Finally, we intend this work to help us pursue human-swarm interaction capable of rewarding a swarm for the actions or tasks it accomplishes. Specifically, a form of dynamic on-line reinforcement learning (RL) on a decentralized swarm. Work by Nam et al. show the feasibility in applying RL to predict or learn a human operators “trust” is in the swarm they are operating [19] [20]. We hope that future work allows more unique and novel methods for human and swarm to learn from one another in different environments.
VII CONCLUSION
Our paper provides preliminary work into using a sequence of hand gestures to control swarm behavior. This system is a combination of a small sized CNN model capable of recognizing silhouette images of hand gestures in real-time and a decentralized robot development environment, ros2. We test this control strategy in a semi-decentralized manner in three simulated testbeds using three Turtlebot3 Burger robots. The system is further tested on a physical testbed with the same robots. Both environments yielded successful runs using a single swarm metric (cohesion of the swarm). In the future, we intend to expand upon this work and create a fully realized, decentralized swarm system controllable by a human operator with no external equipment by giving a sequence of commands to control the whole swarm.
ACKNOWLEDGMENT
The authors would like to thank Shiba Biswal (ASU), Karthik Elamvazhuthi (UCLA), and Varun Nalam (ASU) for their assistance in this work.
References
- [1] Jessie Y. C. Chen and Michael J. Barnes. Human–Agent Teaming for Multirobot Control: A Review of Human Factors Issues. IEEE Transactions on Human-Machine Systems, 44(1):13–29, February 2014.
- [2] Andreas Kolling, Phillip Walker, Nilanjan Chakraborty, Katia Sycara, and Michael Lewis. Human Interaction With Robot Swarms: A Survey. IEEE Transactions on Human-Machine Systems, 46(1):9–26, February 2016.
- [3] Chao-Wei Lin, Mun-Hooi Khong, and Yen-Chen Liu. Experiments on Human-in-the-Loop Coordination for Multirobot System With Task Abstraction. IEEE Transactions on Automation Science and Engineering, 12(3):981–989, July 2015.
- [4] Nora Ayanian, Andrew Spielberg, Matthew Arbesfeld, Jason Strauss, and Daniela Rus. Controlling a team of robots with a single input. In 2014 IEEE International Conference on Robotics and Automation (ICRA), pages 1755–1762. IEEE, May 2014.
- [5] Yancy Diaz-Mercado, Sung G. Lee, and Magnus Egerstedt. Distributed dynamic density coverage for human-swarm interactions. In 2015 American Control Conference (ACC), pages 353–358. IEEE, July 2015.
- [6] Selma Music, Gionata Salvietti, Domenico Prattichizzo, and Sandra Hirche. Human-Multi-Robot Teleoperation for Cooperative Manipulation Tasks using Wearable Haptic Devices. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), page 8, 2017.
- [7] Eduardo Castelló Ferrer. A wearable general-purpose solution for Human-Swarm Interaction. In Proceedings of the Future Technologies Conference, pages 1059–1076. Springer, 2018.
- [8] George K. Karavas, Daniel T. Larsson, and Panagiotis Artemiadis. A hybrid BMI for control of robotic swarms: Preliminary results. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5065–5075, Vancouver, BC, September 2017. IEEE.
- [9] Open Source Robotics Foundation. ros2, 2019.
- [10] Forrest N Iandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William J Dally, and Kurt Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and 0.5mb model size. arXiv preprint arXiv:1602.07360, 2016.
- [11] Brenner Heintz. Training a neural network to detect gestures with opencv in python, 2018.
- [12] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org.
- [13] Ricardo Carona, A Pedro Aguiar, and Jose Gaspar. Control of unicycle type robots tracking, path following and point stabilization. 2008.
- [14] ROBOTIS. Turtlebot3, 2019.
- [15] Francisco Romero Ramirez, Rafael Muñoz-Salinas, and Rafael Medina-Carnicer. Speeded up detection of squared fiducial markers. Image and Vision Computing, 76, 06 2018.
- [16] Sergio Garrido-Jurado, Rafael Muñoz-Salinas, Francisco Madrid-Cuevas, and Rafael Medina-Carnicer. Generation of fiducial marker dictionaries using mixed integer linear programming. Pattern Recognition, 51, 10 2015.
- [17] Caroline E. Harriott, Adriane E. Seiffert, Sean T. Hayes, and Julie A. Adams. Biologically-Inspired Human-Swarm Interaction Metrics. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 58(1):1471–1475, September 2014.
- [18] Valentin Bazarevsky and Fan Zhang. On-device, real-time hand tracking with mediapipe, august 2019.
- [19] Changjoo Nam, Phillip Walker, Huao Li, Michael Lewis, and Katia Sycara. Models of Trust in Human Control of Swarms With Varied Levels of Autonomy. IEEE Transactions on Human-Machine Systems, pages 1–11, 2019.
- [20] Changjoo Nam, Phillip Walker, Michael Lewis, and Katia Sycara. Predicting trust in human control of swarms via inverse reinforcement learning. In 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), pages 528–533. IEEE, August 2017.