Towards Communication Efficient and Fair Federated Personalized Sequential Recommendation
Abstract
Federated recommendations leverage the federated learning (FL) techniques to make privacy-preserving recommendations. Though recent success in the federated recommender system, several vital challenges remain to be addressed: (i) The majority of federated recommendation models only consider the model performance and the privacy-preserving ability, while ignoring the optimization of the communication process; (ii) Most of the federated recommenders are designed for heterogeneous systems, causing unfairness problems during the federation process; (iii) The personalization techniques have been less explored in many federated recommender systems.
In this paper, we propose a Communication efficient and Fair personalized Federated Sequential Recommendation algorithm (CF-FedSR) to tackle these challenges. CF-FedSR introduces a communication-efficient scheme that employs adaptive client selection and clustering-based sampling to accelerate the training process.
A fairness-aware model aggregation algorithm that can adaptively capture the data and performance imbalance among different clients to address the unfairness problems is proposed. The personalization module assists clients in making personalized recommendations and boosts the recommendation performance via local fine-tuning and model adaption. Extensive experimental results show the effectiveness and efficiency of our proposed method.
Index Terms:
federated learning, sequential recommendation, fairnessI Introduction
Sequential recommendations become a crucial task in our daily recommendation scenarios. It is able to learn from a series of correlated browse sequences (e.g., a person may buy shirts, pants, shoes, etc. together), and recommend some new items given the sequence. Recent years have witnessed a significant advance and success in sequential recommendation. The prosperity of neural networks (NN) motivates the community to design NN-based sequential recommendation models [1, 2].
Recently, user privacy has drawn more concerns, and regulations such as General Data Protection Regulation (GDPR)111https://gdpr-info.eu/ and California Consumer Privacy Act (CCPA)222https://oag.ca.gov/privacy/ccpa are set to protect user privacy. To further preserve users’ privacy, Federated Learning (FL) techniques [3], as a new privacy-preserving paradigm, are incorporated with the recommender system. Prior works of federated recommendation tackle the privacy problem by incorporating FL [4, 5, 6, 7]. Among them, [4] combines the FL with collaborative filtering as a basic paradigm for the federated recommendation. Reference [5] propose federated matrix factorization for making privacy-preserving recommendations. Reference [6] resort to tacking the real situation problem by incorporating the sequential recommendation model GRU4REC [1] with FL.
However, current federated recommender systems are facing some challenges. Firstly, the majority of federated recommendation models only consider the model performance and the privacy-preserving ability, while ignoring the optimization of the communication process. Thus the communication overhead could be a heavy burden for the system. Secondly, most of the federated recommenders are designed for heterogeneous systems, causing unfairness problems during the federation process. For example, the clients with a large data size would normally share a higher weight in the model aggregation process, then the aggregated model would turn to prefer this client. The model performance in these clients may be obviously better than those of small clients. Besides, a large proportion of current federated sequential recommender systems do not sufficiently consider personalized recommendations. In other words, all clients share the model with the same parameters. This could degrade the model performance since different clients may have different interests.
To tackle the aforementioned challenges, we hereby propose a Communication efficient and Fair Federated personalized Sequential Recommendation algorithm (CF-FedSR), which is a model agnostic algorithm and thus could be fit to other tasks with appropriate adjustments. Specifically, we first perform client selection and sampling based on client clustering. The client is clustered according to the latent representation thus similar clients could benefit from each other for faster training. Secondly, we propose a fairness-aware algorithm for model aggregation. Here we consider the heterogeneity among different clients, and fairness is achieved by designing an adaptive aggregation algorithm to eliminate the impact. Detailedly, we add the fairness coefficient when aggregating the models. Moreover, the personalized is achieved by local fine-tuning and model adaption. Our extensive experiments over real-world datasets show the effectiveness of our proposed algorithms, efficiency in time and computing resources, and a tradeoff between privacy and recommendation performance.
Overall, the main contributions of this work are summarized as follows.
We propose a Communication efficient and Fair Federated personalized Sequential Recommendation algorithm. To reduce the communication overhead, we utilize adaptive client selection and sampling based on client clustering to accelerate the training process.
We investigate the fairness and personalization problem in the federated sequential recommendation, and propose an adaptive model aggregation and personalization algorithm as the solution. The fairness is ensured by adaptively aggregating the uploaded model parameters according to the client feature and performance, and the personalization is achieved by local fine tunes and model adaption.
Evaluation on real-world datasets demonstrates the superiority of the proposed model over representative methods. The proposed model brought 9.12% improvement over competing methods on average while requiring less communication round.
II Problem Formulation and Definition
In this section, we formally formulate the federated sequential recommendations task and state the current approaches’ shortcomings. Also, we define fairness in the federated recommender system.
The federated sequential recommendations task is to train a global recommendation model for a server and many distributed and privacy concerning clients while not disclosing the raw data from the clients. However, current approaches care less about the communication efficiency, fairness, and personalization of the federated recommenders. We hope to bridge this gap in this paper. Here we also define the fairness of the federated recommender system as the variance between different clients. For client , with corresponding model performance , then .
III Proposed Method
In this section, we first describe the overall system architecture, then we detailed introduce our proposed method, including client selection, sampling based on client clustering, fairness-aware model aggregation, and personalization module.
III-A Overall System Architecture
A typical example of federated recommender system is illustrated in Fig. 1. Here each client has a local recommender engine to recommend items to local users. The local recommender engine performs local model training, exchanges models with the recommendation server, and makes local recommendations. The recommendation server gathers information from all the clients and distributes the aggregated learning model to the clients. In this way, the server and the clients exchange models instead of raw data, which preserves the users’ privacy.
Based on the standard FL algorithm as described beforehand. We try to improve it by designing a communication efficient and fair federated learning algorithm for the sequential recommendation, termed CF-FedSR.

III-B Communication efficient and Fair Federated Sequential Recommendation Algorithm (CF-FedSR)
This section introduces our proposed Communication efficient and Fair Federated Sequential Recommendation algorithm (CF-FedSR). To enhance the model performance, improve the fairness and reduce the communication overhead simultaneously, we specifically design client selection, sampling based on client clustering, fairness-aware model aggregation, and a personalization module. The client selection module introduces the adaptive selector to select appropriate clients to participate in training. Then sampling relies on client clustering to adaptively select representative clients. Also, the parameter aggregation module performs fairness-aware parameter aggregation. Moreover, the personalization module uses fine-tune techniques for personalized recommendations.
III-B1 Client selection
Federated learning requires lots of transmissions of model parameters between servers and clients. However, we find not all communication is necessary. In the beginning stage, the global model performance is limited due to random initialization. Allowing all the clients to participate in all training rounds may be suboptimal since small clients may negatively affect the model performance in the beginning stage. Since for small clients, due to their limited data sizes or low learning rates, they may not contribute enough to improve the model. Instead, the updates by these small clients may even negatively affect the model aggregation.
To cope with this problem, an adaptive selector is adopted on the server-side to save training time and computing power, as well as to improve the performance. We introduce two criteria for selecting appropriate clients: (i) the number of data samples in client exceeds a threshold , or (ii) the training epoch of client exceeds a threshold . If a client satisfy either of the two criteria, we select it to participate in the training. In this way, the system can get rid of the interference from the updates from small clients in the beginning stage. Through adaptive client selection, the server can train the global model faster and achieve better performance.
III-B2 Sampling based on client clustering
We also propose client clustering to reduce the communication and computation complexity further. Each client is represented by short-term and long-term interest, as illustrated in Figure 2, which is represented by the concatenate of the recent interacted item embeddings. Specifically, we choose the recent items to represent the user’s short-term interest and the recent items to represent the user’s long-term interest. Obviously we have . Then we calculate the average embeddings of the selected items. After that, we concatenate the long-term and short-term interests to form the client representation. Several clustering techniques can be adapted to cluster similar users, such as K-means [8] and Mean shift [9]. We sample clients proportionally from each cluster; thus, the sampled clients should be more representative than the randomly sampled.


III-B3 Fairness aware parameter aggregation
Firstly, we review the FedAvg [10], which is a commonly used federation aggregation strategy. The formula is denoted as:
| (1) |
where is the model parameter in time , and is the sample size for client . According to the formula, a larger sample size would result in a more significant contribution to the global model for clients.
However, the FedAvg algorithm suffers from several problems. Though the overall model performance may be satisfactory, the local model performance for each client may not be promising. The main reason is that the data for clients are Non-IID, then the local datasets are usually heterogeneous between clients in terms of size and distribution. Therefore, it is unfair for some clients since they may have a small data sample size and are largely ignored in the parameter aggregation process.
To tackle the heterogeneous problem, we design a weighting strategy to encourage a more fair distribution in this work. Firstly, we propose a fairness-aware parameter aggregation method to deal with the varying model performance among clients. To start with, we represent the performance for client as . For federated recommendation scenarios, commonly adopted evaluation metrics are Hit Rate (HR) and Normalized Discounted Cumulative Gain (NDCG). Thus we use the sum of evaluation metrics to represent the performance, denoted as:
| (2) |
Then we normalize it:
| (3) |
After that, we apply an activation function. The activation function should satisfy decreasing in range . In this work, the activation function is .
| (4) |
Then we normalize it again,
| (5) |
where the is the fairness-aware factor.
Secondly, we alleviate the impact of the data sample size. For the unfairness caused by the imbalance sample size, one way to eliminate this effect is to reduce the impact of the parameter of data sampling size. In this way, the aggregation formula is denoted as:
We set the weight parameter as . Intuitively, it is denoted as:
| (6) |
Then we use an activation function. The activation function should satisfies increasing in range . In this work, the activation function is .
| (7) |
Then we have:
| (8) |
Lastly, we combine these two factors and form the final parameter aggregation function:
| (9) | |||
| (10) |
where is the global model at time , and are two hyper-parameters.
III-B4 Personalization
Prior researches show that FL could be used to train a high-performing global model for federated recommendation [11, 12]. The trained model, however, is more of generality but lacks personalization. Therefore, we fine-tune the global model with the client’s local data to make personalized recommendations. We aggregate the global and fine-tuned model to balance generality and personalization. Thus the client could benefit from the personalization process. We denote the process as:
| (11) | |||
| (12) |
where is a hyper-parameter. The model could adaptively balance the generalizable and personalization by adjusting the hyper-parameters. Additionally, note we only transmit the embedding layer in the training process, as the skeleton network, while letting the remaining part of the network be trained localized.
IV Experiments and Analysis
This section presents our experimental results over three real datasets by comparing our proposed algorithms’ performance against other reasonable baselines. Besides, we demonstrate the effectiveness for each component through an ablation study. We also analyze the impact of different experimental settings, such as embedding size and different numbers of clusters. Our experiments are designed to answer the following Research Questions (RQs):
RQ1: Does CF-FedSR show superiority of existing methods in federated sequential recommendation in terms of model performance, communication cost, and fairness?
RQ2: What is the influence of various components in the CF-FedSR framework? Are those components necessary?
RQ3: What is the impact of the hyper-parameters settings in CF-FedSR?
IV-A Experiment Setup
IV-A1 Dataset Description
We have conducted experiments using real-world datasets to evaluate our proposed method. A detailed description of the total number of user clicks, the number of items and clicks, and the average number of clicks is listed in Table I. These datasets vary in domains, platforms, and sparsity. Here we give the detailed description of the datasets.
Amazon: A series of datasets introduced in [13], comprising large corpora of product reviews crawled from Amazon.com. Top-level product categories on Amazon are treated as separate datasets. We consider two categories, Beauty and Video. This dataset is notable for its high sparsity and variability.
Wikipedia: This dataset contains one month of edits on Wikipedia [14]. The editors who made at least 5 edits and the 1,000 most edited pages are filtered out as users and items for recommendation. This dataset contains 157,474 interactions in total.
| Dataset | # of user | # of item | # of click | Avg. length |
|---|---|---|---|---|
| Beauty | 52204 | 57289 | 394908 | 7.56 |
| Video | 31013 | 23715 | 287107 | 9.26 |
| Wikipedia | 8227 | 1000 | 157474 | 19.14 |
IV-A2 Baselines
We aim to explore the performance of federated learning in a deep learning model for sequential recommendations. We use the GRU4REC [1] as the backbone sequential recommendation model. The model combines RNNs to model user sequences for the sequential recommendation. We compare our proposed CF-FedSR algorithm with the popular FedAvg [10] method. FedAvg is a classical federated learning algorithm that allows many clients to train a global model collaboratively. Recall that CF-FedSR is designed to improve FedAvg in communication efficiency, fairness, and personalization. Also, we compare them with centralized training settings.
IV-A3 Evaluation Metrics
We use the following two metrics to evaluate the performance of our proposed algorithms and existing algorithms.
1) Hit Rate (HR). To calculate the proportion of predicted items that are accurate. In this work, we evaluate the top-5 and top-10 items for comparison.
2) Normalized Discounted Cumulative Gain (NDCG). To calculate the ranking position of correctly predicted items. When the rank list is predicted correctly, the NDCG is high. If predicted item ranks exceed the recommended limit (5 or 10 in our settings), the NDCG value is zero.
IV-A4 Experiment Settings
For performance evaluation, we use the leave-one-out strategy, following [2, 15]. For each user, we held out their latest interaction for the test set, the second last for validation and the remaining data for training.
Also, we adopt a commonly used negative sampling method to reduce heavy computation, in accordance to [2, 15]. Specifically, we randomly sample 100 negative items, and rank these items together with the ground-truth item.
| Beauty | Video | Wikipedia | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | HR@5 | NDCG@5 | HR@10 | NDCG@10 | HR@5 | NDCG@5 | HR@10 | NDCG@10 | HR@5 | NDCG@5 | HR@10 | NDCG@10 |
| Central | 0.3223 | 0.2435 | 0.4482 | 0.2835 | 0.3283 | 0.2648 | 0.4922 | 0.2848 | 0.8982 | 0.8767 | 0.9181 | 0.8828 |
| FedAvg | 0.2651 | 0.1828 | 0.3740 | 0.2173 | 0.2720 | 0.1858 | 0.3987 | 0.2259 | 0.7842 | 0.7606 | 0.8077 | 0.7681 |
| CF-FedSR | 0.2869 | 0.2036 | 0.4073 | 0.2509 | 0.2951 | 0.2008 | 0.4223 | 0.2517 | 0.8469 | 0.8199 | 0.8722 | 0.8279 |
| Impro. | 8.22% | 11.38% | 8.90% | 15.46% | 8.49% | 8.07% | 5.92% | 11.42% | 8.00% | 7.80% | 7.99% | 7.79% |
IV-A5 Implementation Details
The number of users used in each round of model training is 128, and the total number of the epoch is 200. The ratio of dropout is 0.3. Adam [16] is selected as the optimizer, and the default learning rate is 0.001. We tune hyper-parameters using the validation set, and terminate training if validation performance doesn’t improve for five successive epochs. Unless stated otherwise, we use the same hyper-parameters of FedAvg and CF-FedSR. We report the average performance scores over the five repetitions.
Our evaluation target is to compare the recommendation performance in a federated context, thus we don’t compare it to other centralized algorithms since they’re not well suited to federated settings.
IV-B Performance Comparison (RQ1)
IV-B1 Evaluation on model performance
We have compared different methods’ performances in Table II. We have the following observations:
Our proposed CF-FedSR significantly outperforms the state-of-the-art federated recommender systems in all datasets. Compared with FedAvg, CF-FedSR achieves on average 7.92% and 10.32% relative improvements on HR and NDCG, respectively. Several advantages of CF-FedSR support its superiority: (1) client selection and sampling helps to find more representative and useful clients to participate in training; (2) fairness aware aggregation algorithm help to bridge the gap between clients with various data distribution and facilitate the training.
The centralized models perform better than those decentralized models. Compared with CF-FedSR, centralized models achieves in average 10.25% and 15.20% relative improvements in HR and NDCG, respectively. There are two reasons: (1) centralized models models are better as they can directly train the model without noise or pseudo-labeled items. In the meantime, the federated learning framework achieves better privacy-preserving ability than centralized training because clients do not reveal raw data to the server. It could be viewed as the tradeoff of the recommendation performance to privacy. (2) though FL theoretically would have similar performance with the centralized settings. However, due to the data heterogeneous, distributed systems are harder to train since they lack the capacity to model the global data structures.
| Model | HR@10 | NDCG@10 | Converge round |
|---|---|---|---|
| FedAvg | 0.3740 | 0.2173 | 7̃5 |
| CF-FedSR | 0.4073 | 0.2509 | 6̃7 |
| Impro. | 8.90% | 15.46% | -10.67% |
IV-B2 Evaluation on communication efficiency
We evaluate the converge speed together with the model performance in Table III. We observe that the CF-FedSR converges much more quickly than FedAvg. Thus the communication cost is saved by transmitting less round. The reason is that we adopt several techniques to reduce communication loss. We strictly limit the participation of small clients at the beginning stage of training, which prevents the inference from these small clients. Additionally, we carefully select representative clients to participate through clustering, making the system converge faster. In a nutshell, CF-FedSR can enhance the model performance while boosting communication efficiency.
IV-B3 Evaluation on fairness
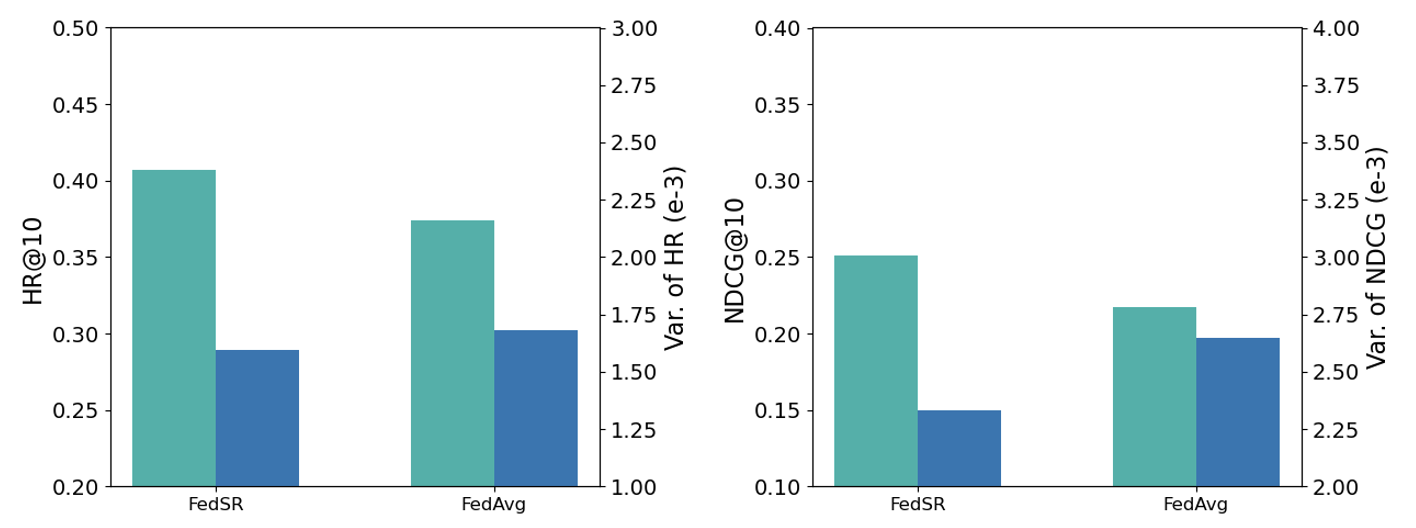
Recall that we define the fairness as the variance among clients in Section II. A lower value of variance means the system is more fair. The experimental results is shown in Figure 4. The result demonstrate that our proposed method could decrease the variance and boost the model performance in the meanwhile, showing the effectiveness of our proposed method. The superiority of our proposed method come from our specially designed adaptive aggregation algorithm.
IV-C Ablation Study (RQ2)
Specifically, we repeat the experiment by removing one module from the proposed CF-FedSR model and test the performance. The detailed information of variants is listed as follows.
CF-FedSR-Variation 1 (w/o client selection & sampling): The proposed CF-FedSR without the client selection & sampling component.
CF-FedSR-Variation 2 (w/o fair aggregation): The proposed CF-FedSR without fair aggregation component.
CF-FedSR-Variation 3 (w/o personalization): The proposed CF-FedSR without the personalization module.
From Table IV, we observe that the CF-FedSR achieves the best results on all datasets, which verifies the importance of each critical module. Among them, the experimental results of CF-FedSR-Variation 3 drop sharply, which proves that the lack of personalization could significantly decrease the learning ability of the framework.
| Wikipedia | ||||
|---|---|---|---|---|
| Model | HR@5 | NDCG@5 | HR@10 | NDCG@10 |
| CF-FedSR | 0.8469 | 0.8199 | 0.8722 | 0.8279 |
| CF-FedSR-Variation 1 | 0.8039 | 0.7631 | 0.8396 | 0.7751 |
| CF-FedSR-Variation 2 | 0.8259 | 0.7968 | 0.8610 | 0.8083 |
| CF-FedSR-Variation 3 | 0.7984 | 0.7703 | 0.8358 | 0.7801 |
| Dataset | Beauty | |||
|---|---|---|---|---|
| Dimension | HR@5 | NDCG@5 | HR@10 | NDCG@10 |
| d=10 | 0.2631 | 0.1986 | 0.3689 | 0.2296 |
| d=20 | 0.2726 | 0.2003 | 0.3821 | 0.2389 |
| d=50 | 0.2869 | 0.2036 | 0.4073 | 0.2509 |
| d=100 | 0.2965 | 0.2073 | 0.4124 | 0.2516 |
| Dataset | Beauty | |||
|---|---|---|---|---|
| # clusters | HR@5 | NDCG@5 | HR@10 | NDCG@10 |
| k=3 | 0.2846 | 0.2013 | 0.4029 | 0.2453 |
| k=5 | 0.2869 | 0.2036 | 0.4073 | 0.2509 |
| k=10 | 0.2912 | 0.2065 | 0.4068 | 0.2527 |
Without the client selection & sampling module, the performance of the framework still decreases obviously. Throughout these three ablation experiments, it turns out that each module improves the model performance from different aspects and is meaningful.
IV-D Hyper-parameter study (RQ3)
IV-D1 Sensitivity of CF-FedSR to embedding size
Table V illustrates the analysis of the effect of embedding on the Beauty dataset. We repeat the experiment with default parameters and with different values for the number of embedding size, i.e. with . We find that performance is continually improved with the increase of embedding size. Presumably, this is because higher dimension of item embedding could bring more information from different aspect. However, a larger embedding size would have a higher communication cost. Thus it is a tradeoff between the communication cost and the model performance.
IV-D2 Sensitivity of CF-FedSR to number of clusters
This experiment demonstrates the sensitivity of CF-FedSR to the number of clusters hyper-parameter. We ran CF-FedSR using the default parameters in subsection 5.1 but with different values for the number of clusters, i.e. with . The result of this experiment is presented in Table VI. We observe that its performance improves and then drops when the number of cluster increases from 3 to 10.
V Conclusion
In this paper, we study the problem of the federated sequential recommendations and propose the CF-FedSR framework. The key component for CF-FedSR includes client selection, sampling based on client clustering, fairness-aware model aggregation, and a personalization module. These techniques are adopted to ensure fairness and personalization in the federated recommendation, boost the recommendation and ease the communication cost in the meanwhile. We conducted extensive experiments over real datasets and observed that our proposed framework effectively makes federated sequential recommender systems more accurate and reduces the communication overhead.
VI Acknowledgements
This work was supported in part by the Changsha Science and Technology Program International and Regional Science and Technology Cooperation Project under Grants kh2201026, the Hong Kong RGC grant ECS 21212419, the Technological Breakthrough Project of Science, Technology and Innovation Commission of Shenzhen Municipality under Grants JSGG20201102162000001, InnoHK initiative, the Government of the HKSAR, Laboratory for AI-Powered Financial Technologies, the Hong Kong UGC Special Virtual Teaching and Learning (VTL) Grant 6430300, and the Tencent AI Lab Rhino-Bird Gift Fund.
References
- [1] B. Hidasi, A. Karatzoglou, L. Baltrunas, and D. Tikk, “Session-based recommendations with recurrent neural networks,” arXiv preprint arXiv:1511.06939, 2015.
- [2] W.-C. Kang and J. McAuley, “Self-attentive sequential recommendation,” in 2018 IEEE International Conference on Data Mining (ICDM). IEEE, 2018, pp. 197–206.
- [3] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Artificial intelligence and statistics. PMLR, 2017, pp. 1273–1282.
- [4] M. Ammad-Ud-Din, E. Ivannikova, S. A. Khan, W. Oyomno, Q. Fu, K. E. Tan, and A. Flanagan, “Federated collaborative filtering for privacy-preserving personalized recommendation system,” arXiv preprint arXiv:1901.09888, 2019.
- [5] D. Chai, L. Wang, K. Chen, and Q. Yang, “Secure federated matrix factorization,” IEEE Intelligent Systems, 2020.
- [6] J. Han, Y. Ma, Q. Mei, and X. Liu, “Deeprec: On-device deep learning for privacy-preserving sequential recommendation in mobile commerce,” in Proceedings of the Web Conference 2021, 2021, pp. 900–911.
- [7] S. Luo, Y. Xiao, and L. Song, “Personalized federated recommendation via joint representation learning, user clustering, and model adaptation,” arXiv preprint arXiv:2208.09375, 2022.
- [8] J. A. Hartigan and M. A. Wong, “Algorithm as 136: A k-means clustering algorithm,” Journal of the royal statistical society. series c (applied statistics), vol. 28, no. 1, pp. 100–108, 1979.
- [9] D. Comaniciu and P. Meer, “Mean shift: A robust approach toward feature space analysis,” IEEE Transactions on pattern analysis and machine intelligence, vol. 24, no. 5, pp. 603–619, 2002.
- [10] J. Konečnỳ, H. B. McMahan, F. X. Yu, P. Richtárik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,” arXiv preprint arXiv:1610.05492, 2016.
- [11] C. Wu, F. Wu, Y. Cao, Y. Huang, and X. Xie, “FedGNN: Federated graph neural network for privacy-preserving recommendation,” arXiv preprint arXiv:2102.04925, 2021.
- [12] T. Qi, F. Wu, C. Wu, Y. Huang, and X. Xie, “Fedrec: Privacy-preserving news recommendation with federated learning,” arXiv preprint arXiv:2003.09592, 2020.
- [13] J. McAuley, C. Targett, Q. Shi, and A. Van Den Hengel, “Image-based recommendations on styles and substitutes,” in Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval, 2015, pp. 43–52.
- [14] G. Kossinets, “Processed wikipedia edit history,” 2012.
- [15] S. Luo, X. Zhang, Y. Xiao, and L. Song, “HySAGE: A hybrid static and adaptive graph embedding network for context-drifting recommendations,” arXiv preprint arXiv:2208.09586, 2022.
- [16] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.