11email: {uchida,iwana}@ait.kyushu-u.ac.jp
Towards Book Cover Design via Layout Graphs
Abstract
Book covers are intentionally designed and provide an introduction to a book. However, they typically require professional skills to design and produce the cover images. Thus, we propose a generative neural network that can produce book covers based on an easy-to-use layout graph. The layout graph contains objects such as text, natural scene objects, and solid color spaces. This layout graph is embedded using a graph convolutional neural network and then used with a mask proposal generator and a bounding-box generator and filled using an object proposal generator. Next, the objects are compiled into a single image and the entire network is trained using a combination of adversarial training, perceptual training, and reconstruction. Finally, a Style Retention Network (SRNet) is used to transfer the learned font style onto the desired text. Using the proposed method allows for easily controlled and unique book covers.
Keywords:
Generative model Book cover generation Layout graph1 Introduction
Book covers are designed to give potential readers clues about the contents of a book. As such, they are purposely designed to serve as a form of communication between the author and the reader [drew2005by]. Furthermore, there are many aspects of the design of a book cover that is important to the book. For example, the color of a book cover has shown to be a factor in selecting books by potential readers [gudinavivcius2018choosing], the objects and photographs on a book cover are important for the storytelling [kratz1994telling], and even the typography conveys information [tschichold1998new, el2018representing]. Book covers [iwana2016judging, Lucieri_2020] and the objects [jolly2018how] on book covers also are indicators of genre.
While book cover design is important, book covers can also be time-consuming to create. Thus, there is a need for easy-to-use tools and automated processes which can generate book covers quickly. Typically, non-professional methods of designing book covers include software or web-based applications. There are many examples of this, such as Canva [canva], fotor [fotor], Designhill [designhill], etc. These book cover designers either use preset templates or builders where the user selects from a set of fonts and images. The issue with these methods is that the design process is very restrictive and new designs are not actually created. It is possible for multiple authors to use the same images and create similar book covers.
Recently, there has been an interest in machine learning-based generation. However, there are only a few examples of book cover-based generative models. In one example, the website deflamel [deflamel] generates designs based on automatically selected background and foreground images and title font. The images and font are determined based on a user-entered description of the book plus a “mood.” The use of Generative Adversarial Networks (GAN) [goodfellow2014gan] have been used to generate books [Lucieri_2020, booksby]. Although, in the previous GAN-based generation methods, the created book covers were uncontrollable and generate gibberish text and scrambled images.
The problem with template-based methods is that new designs are not created and the problem with GAN-based methods is that it is difficult to control which objects are used and where they are located. Thus, we propose a method to generate book covers that addresses these problems. In this paper, we propose the use of a layout graph as the input for users to draw their desired book cover. The layout graph, as shown in Fig. 1, indicates the size, location, positional relationships, and appearance of desired text, objects, and solid color regions. The advantage of using the layout graph is that it is easy to describe a general layout for the proposed method to generate a book cover image from.

In order to generate the book cover image, the layout graph is provided to a generative network based on scene graph-based scene generators [Johnson_2018, Ashual_2019]. In Fig. 2, the layout graph is fed to a Graph Convolution Network (GCN) [Scarselli_2009] to learn an embedding of the layout objects (i.e. text objects, scene objects, and solid regions). This embedding is used to create mask and bounding-box proposals using a mask generator and box regression network, respectively. Like [Ashual_2019], the mask proposals are used with an appearance generator to fill in the masks with contents. The generated objects are then aggregated into a single book cover image using a final generator. These generators are trained using four adversarial discriminators, a perception network, and L1 loss to a ground truth image. Finally, the learned text font is transferred to the desired text using a Style Retention Network (SRNet) [Wu_2019].

The main contributions of this paper are summarized as follows:
-
•
As far as the authors know, this is the first instance of using a fully generative model for creating book cover images while being able to control the elements of the cover, such as size, location, and appearance of the text, objects, and solid regions.
-
•
We propose a method of using a combination of a layout graph-based generator and SRNet to create user-designed book cover images.
Our codes are shown at https://github.com/Touyuki/Cover_generation
2 Related Work
2.1 Document Generation
There are many generative models for documents. For example, automatic text and font generation is a key task in document generation. In the past, models such as using interpolation between multiple fonts [Campbell_2014, Uchida_2015] and using features from examples [Suveeranont_2010] have been used. More recently, the use of GANs have been used for font generation [Abe_2017, Hayashi_2019] and neural font style transfer [Atarsaikhan_2017] has become an especially popular topic in document generation. There have also been attempts at creating synthetic documents using GANs [Bui_2019, Rusticus_2019] and document layout generation using recursive autoencoders [Patil_2020]. Also, in a similar task to the proposed method, Hepburn et al. used a GAN to generate music album covers [hepburn2017album].
However, book cover generation, in particular, is a less explored area. Lucieri et al. [Lucieri_2020] generated book covers using a GAN for data augmentation and the website Booksby.ai [booksby] generated entire books, including the cover, using GANs. However, while the generated book covers have features of book covers and have the feel of book covers, the objects and text are completely unrecognizable and there is little control over the layout of the cover.
2.2 Scene Graph Generation
The proposed layout graph is based on scene graphs for natural scene generation. Scene graphs are a subset of knowledge graphs that specifically describe natural scenes, including objects and the relationships between objects. They were originally used for image retrieval [Johnson_2015] but were expanded to scene graph-based generation [Johnson_2018]. In scene graph generation, an image is generated based on the scene graph. Since the introduction of scene graph generation, there has been a huge boom of works in the field [xu2020survey]. Some examples of scene graph generation with adversarial training, like the proposed method, include Scene Graph GAN (SG-GAN) [klawonn2018generating], the scene generator by Ashual et al. [Ashual_2019], and PasteGAN [li2019pastegan]. These methods combine objects generated by each node of the scene graph and use a discriminator to train the scene image as a whole. As far as we know, we are the first to propose the use of scene graphs for documents.
3 Book Cover Generation
In this work, we generate book covers using a combination of two modules. The first is a Layout Generator. The Layout Generator takes a layout graph and translates it into an initial book cover image. Next, the neural font style transfer method, SRNet [Wu_2019], is used to edit the generated placeholder text into a desired book cover text or title.
3.1 Layout Generator
The purpose of the Layout Generator is to generate a book cover image including natural scene objects, solid regions (margins, headers, etc.), and the title text. To do this, we use a layout graph-based generator which is based on scene graph generation [Johnson_2018, Ashual_2019]. As shown in Fig. 2, the provided layout graph is given to a comprehensive model of an embedding network, four generators, four discriminators, and a perceptual consistency network. The output of the Layout Generator is a book cover image based on the layout graph.
3.1.1 Layout Graph.
The input of the Layout Generator is a layout graph, which is a directed graph with each object represented by a node , where is a class vector and is the location vector of the object. The class vector contains a 128-dimensional embedding of the class of the object. The location vector is a 35-dimensional binary vector that includes the location and size of the object. The first 25 bits of describe the location of the object on a grid and the last 10 bits indicate the size of the desired object on a scale of 1 to 10.
The edges of the layout graph are the positional relations between the objects. Each edge contains a 128-dimensional embedding of six relationships between every possible pairs of nodes and . The six relationships include “right of”, “left of”, “above”, “below”, “surrounding” and “inside”.
3.1.2 Graph Convolution Network.
The layout graph is fed to a GCN [Scarselli_2009], , to learn an embedding of each object . Where a traditional Convolutional Neural Network (CNN) [lecun1998gradient] uses a convolution of shared weights across an image, a GCN’s convolutional layers operate on graphs. They do this by traversing the graph and using a common operation on the edges of the graph.
To construct the GCN, we take the same approach as Johnson et al. [Johnson_2018] which constructs a list of all of the nodes and edges in combined vectors and then uses a multi-layer perceptron (MLP) on the vectors, as shown in Fig. 3. Vector consists of a concatenation of an edge embedding and the two adjacent vertices and and vertex embeddings and . The GCN is consists of two sub-networks. The GCN (Edge) network in Fig. 3a takes in vector and then performs the MLP operation. The output is then broken up into temporary object segments and and further processed by individual GCN (Vertex) networks for each object. The result of GCN (Vertex) is a 128-dimensional embedding for each object, which is used by the subsequent Box Regression Network and Mask Generator.


3.1.3 Mask Generator and Discriminator.
The purpose of the Mask Generator is to generate a mask of each isolated object for the Appearance Generator. The Mask Generator is based on a CNN. The input of the Mask Generator is the object embedding learned from the GCN and the output is a shape mask of the target object. This mask is only the shape and does not include size information. Furthermore, since the Mask Generator creates detailed masks, a variety of shapes should be used. To do this, a 64-dimensional random vector is concatenated with the object embedding before being given to the Mask Generator.
In order to produce realistic object masks, an adversarial Mask Discriminator is used. The Mask Discriminator is based on a conditional Least Squares GAN (LS-GAN) [mao2017least] with the object class as the condition. It should be noted that the object class is different than the 128-dimensional class vector in the layout graph. The GAN loss is:
| (1) |
where is the Mask Generator and is a real mask. Accordingly, the Mask Discriminator is trained to minimize .
3.1.4 Box Regression Network.
The Box Regression Network generates a bounding box estimation of where and how big the object should be placed in the layout. Just like the Mask Generator, the Box Regression Network receives the object embedding . The Box Regression Network is an MLP that predicts the bounding box coordinates for each object .
To generate the layout, the outputs of the Mask Generator and the Box Regression Network are combined. In order to accomplish this, the object masks from the Mask Generator are shifted and scaled according to bounding boxes. The shifted and scaled object masks are then concatenated in the channel dimension and used with the Appearance Generator to create a layout feature map for the Book Cover Generator.
3.1.5 Appearance Generator.
The objects’ appearances that are bound by the mask are provided by the Appearance Generator . The Appearance Generator is a CNN that takes real images of cropped objects of ( resolution and encodes the appearance into a 32-dimension appearance vector. The appearance vectors represent objects within the same class and changing the appearance vectors allows the appearance of the objects in the final generated result to be controlled. This gives the network to provide a variety of different object appearances even with the same layout graph. A feature map is created by compiling the appearance vectors to fill the masks that were shifted and scaled by the bounding boxes.
3.1.6 Book Cover Generator.
The Book Cover Generator is based on a deep Residual Network (ResNet) [he2016deep] and it generates the final output. The network has three parts. The first part is the contracting path made of strided convolutions which encodes the features from the feature map . The second part is a series of 10 residual blocks and the final part is an expanding path with transposed convolutions to upsample the features to the final output image .
3.1.7 Perception Network.
In order to enhance the quality of output of the Book Cover Generator a Perception Network is used. The Perception Network is a pre-trained very deep convolutional network (VGG) [simonyan2014very] that is only used to establish a perceptual loss [johnson2016perceptual]. The perceptual loss:
| (2) |
is the content consistency between the extracted features of the VGG network given the generated layout image and a real layout image . In Eq. (2), is a layer in the set of layers and is a feature map from at layer .
3.1.8 Layout Discriminator.
The Layout Discriminator is a CNN used to judge whether the layout image appears realistic given the layout . In this way, through the compound adversarial loss , the generated layout will be trained to be more indistinguishable from images of real layout images and real layout feature maps . The loss is defined as:
| (3) | ||||
where is a second layout with the bounding box, mask, and appearance attributes taken from a different, incorrect ground truth image with the same objects. This is used a poor match despite having the correct objects. The aim of the Layout Discriminator is to help the generated image with ground truth layout to be indistinguishable from real image .
3.1.9 Book Cover Discriminator.
The Book Cover Discriminator is an additional discriminator that is used to make the generated image look more like a book. Unlike the Layout Discriminator, the Book Cover Discriminator only compares the generated image to random real book covers . Specifically, an adversarial loss:
| (4) |
where is the Book Cover Discriminator, is added to the overall loss.
3.1.10 Object Discriminator.
The Object Discriminator is another CNN used to makes each object images look real. is an object image cut from the generated image by the generated bounding box and is a real crop from the ground truth image. The object loss is:
| (5) |
3.1.11 Training.
The entire Layout Generator with all the aforementioned networks are trained together end-to-end. This is done using a total loss:
| (6) | ||||
where each is a weighting factor for each loss. In addition to the previously described losses, Eq. (6) contains a pixel loss and two additional perceptual losses and . The pixel loss is the L1 distance between the generated image and the ground truth image . The two perceptual losses and are similar to (Eq. 2), except instead of a separate network, the feature maps of all of the layers of discriminators and are used, respectively.
3.2 Solid Region Generation
The original scene object generation is designed to generate objects in natural scenes that seem realistic. However, if we want to use it in book cover generation we should generate more elements that are unique to book covers, such as the solid region and the title information.

We refer to solid regions as regions on a book with simple colors. They can be a single solid color, gradients, or subtle designs. As shown in Fig. 8, they are often used for visual saliency, backgrounds, and text regions. Except for some text information, usually, there are no other elements in these regions. To incorporate the solid regions into the proposed model, we prepared solid regions as objects in the Layout Graph. In addition, the solid regions are added as an object class to the various components of the Layout Generator as well as added to the ground truth images and layout feature maps . To make sure we can generate realistic solid regions, in our experiment, we used solid regions cut from real book covers.
3.3 Title Text Generation
Text information is also an important part of the book covers. It contains titles, sub-titles, author information, and other text. In our experiment, we only consider the title text. Unlike other objects, like trees, the text information cannot be random variations and has to be determined by the user. However, the text still needs to maintain a style and font that is suitable for the book cover image.

Thus, we propose to generate the title text in the image using a placeholder and use font style transfer to transfer the placeholder’s font to the desired text. Fig. 5 shows our process of transferring the font style to the title text. To do this, we use SRNet [Wu_2019]. SRNet is a neural style transfer method that uses a skeleton-guided network to transfer the style of text from one image to another. In SRNet, there are two inputs, the desired text in a plain font and the stylized text. The two texts are fed into a multi-task encoder-decoder that generates a skeleton image and a stylized image of the desired text. Using SRNet, we can generate any text using the style learned by the Layout Generator and use it to replace the placeholder.
To train the Layout Generator, we use a placeholder text, “Lorem Ipsum,” to represent the title. Similar to the solid region object, the title object is also added as an object class. For the ground truth images , a random font, color, and location are used. However, the purpose of the Book Cover Discriminator is to ensure that the combination is realistic as books.
4 Experimental Results
4.1 Dataset
To train the proposed method two datasets are required. The first is the Book Cover Dataset111https://github.com/uchidalab/book-dataset. This dataset is used to train the Book Cover Discriminator so that the generated images appear more book-like. From the Book Cover Dataset, 2,000 random book covers are used. For the second dataset, a natural scene object dataset with semantic segmentation information is required. For this, we use 5,000 images from the COCO222https://cocodataset.org/ dataset. For the ground truth images and layouts, random solid regions and titles are added. The cropped parts of COCO is used with the Mask Discriminator and the Object Discriminator, and modified images of MSCOCO are used for the Layout Discriminator and Perception Network. All of the images are resized to .
4.2 Settings and Architecture
The networks in the Layout Generator are trained end-to-end using Adam optimizer [kingma2014adam] with and an initial learning rate of 0.001 for 100,000 iterations with batch size 6. For the losses, we set , , and . The hyperparameters used in the experiments are listed in Table 1. For SRNet, we used a pre-trained model333https://github.com/Niwhskal/SRNet.
| Network | Layers | Activation | Norm. |
| GCN (Edge) | FC, 512 nodes | ReLU | |
| FC, 1,152 nodes | ReLU | ||
| GCN (Vertex) | FC, 512 nodes | ReLU | |
| FC, 128 nodes | ReLU | ||
| Box Regression Network | FC, 512 nodes | ReLU | |
| FC, 4 nodes | ReLU | ||
| Mask Generator | Conv. (), 192 filters, stride 1 | ReLU | Batch norm |
| Conv. (), 192 filters, stride 1 | ReLU | Batch norm. | |
| Conv. (), 192 filters, stride 1 | ReLU | Batch norm. | |
| Conv. (), 192 filters, stride 1 | ReLU | Batch norm. | |
| Conv. (), 192 filters, stride 1 | ReLU | Batch norm. | |
| Appearance Generator | Conv. (), 64 filters, stride 2 | LeakyReLU | Batch norm. |
| Conv. (), 128 filters, stride 2 | LeakyReLU | Batch norm. | |
| Conv. (), 256 filters, stride 2 | LeakyReLU | Batch norm. | |
| Global Average Pooling | |||
| FC, 192 nodes | ReLU | ||
| FC, 64 nodes | ReLu | ||
| Book Cover Generator | Conv. (), 64, stride 1 | ReLU | Inst. norm. |
| Conv. (), 128 filters, stride 2 | ReLU | Inst. norm. | |
| Conv. (), 256 filters, stride 2 | ReLU | Inst. norm. | |
| Conv. (), 512 filters, stride 2 | ReLU | Inst. norm. | |
| Conv. (), 1,024 filters, stride 2 | ReLU | Inst. norm. | |
| ( residual blocks) | Conv. (), 1,024 filters, stride 1 | ReLU | Inst. norm. |
| Conv. (), 1,024 filters, stride 1 | ReLU | Inst. norm. | |
| T. conv. (), 512 filters, stride 2 | ReLU | Inst. norm. | |
| T. conv. (), 256 filters, stride 2 | ReLU | Inst. norm. | |
| T. conv. (), 128 filters, stride 2 | ReLU | Inst. norm. | |
| T. conv. (), 64 filters, stride 2 | ReLU | Inst. norm. | |
| Conv. (), 3 filters, stride 1 | Tanh | ||
| Mask Discriminator | Conv. (), 64 filters, stride 2 | LeakyReLU | Inst. norm. |
| Conv. (), 128 filters, stride 2 | LeakyReLU | Inst. norm. | |
| Conv. (), 256 filters, stride 1 | LeakyReLU | Inst. norm. | |
| Conv. (), 1 filters, stride 1 | LeakyReLU | ||
| Ave. Pooling (), stride 2 | |||
| Layout Discriminator | Conv. (), 64 filters, stride 2 | LeakyReLU | |
| Conv. (), 128 filters, stride 2 | LeakyReLU | Inst. norm. | |
| Conv. (), 256 filters, stride 2 | LeakyReLU | Inst. norm. | |
| Conv. (), 512 filters, stride 2 | LeakyReLU | Inst. norm. | |
| Conv. (), 1 filter, stride 2 | Linear | ||
| Conv. (), 64 filters, stride 2 | LeakyReLU | ||
| Conv. (), 128 filters, stride 2 | LeakyReLU | Inst. norm. | |
| Conv. (), 256 filters, stride 2 | LeakyReLU | Inst. norm. | |
| Conv. (), 512 filters, stride 2 | LeakyReLU | Inst. norm. | |
| Conv. (), 1 filter, stride 2 | Linear | ||
| Ave. Pooling (), stride 2 | |||
| Book Cover Discriminator | Conv. (), 64 filters, stride 2 | LeakyReLU | |
| Conv. (), 128 filters, stride 2 | LeakyReLU | Batch norm. | |
| Conv. (), 256 filters, stride 2 | LeakyReLU | Batch norm. | |
| Conv. (), 512 filters, stride 2 | LeakyReLU | Batch norm. | |
| Conv. (), 512 filters, stride 2 | LeakyReLU | Batch norm. | |
| Conv. (), 1 filter, stride 2 | Sigmoid | ||
| Object Discriminator | Conv. (), 64 filters, stride 2 | LeakyReLU | |
| Conv. (), 128 filters, stride 2 | LeakyReLU | Batch norm. | |
| Conv. (), 256 filters, stride 2 | LeakyReLU | Batch norm. | |
| Global Average Pooling | |||
| FC, 1024 nodes | Linear | ||
| FC, 174 nodes | Linear | ||
| Perception Network | Pre-trained VGG [simonyan2014very] | ||
| Font Style Transfer | Pre-trained SRNet [Wu_2019] |















4.3 Generation Results
Examples of generated book covers are shown in Fig. 6. We can notice that not only the object images can be recognizable, but also the solid regions make the results resemble book covers. In addition, for most of the results, the generated titles are legible. While not perfect, these book covers are a big step towards book cover generation. We also shows some images with poor quality in Fig. 7. In these results the layout maps are reasonable, but the output is still poor. This is generally due to having overlapping objects such as “grass” on the “title” or objects overlapping the solid regions.






4.4 Creating Variations in Book Covers
As mentioned previously, the advantage of using a layout graph is that each node contains information about the object, location, and appearance embedding. This allows for the ease of book cover customization using an easy to use interface. Thus, we will discuss some of the effects of using the layout graph to make different book cover images.
4.4.1 Location on the solid region.
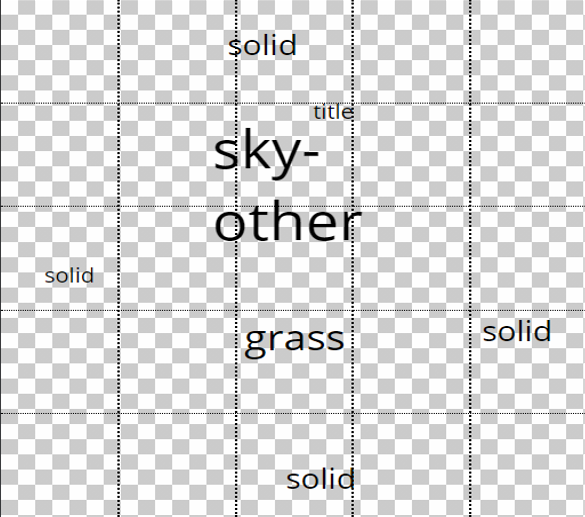
Along with the scene objects, the title text and the solid region can be moved on the layout graph. Fig. 8 shows examples of generated book covers with the same layout graph except for the “Solid” nodes. By moving the “Solid” node to have different relationship edges with other nodes, the solid regions can be moved. In addition, multiple “Solid” nodes can be added to the same layout graph to construct multiple solid regions.









4.4.2 Variation in the appearance vector.
Due to each node in the layout graph containing its own appearance vector, different variations of generated book covers can be created from the same layout graph. Fig. 9 shows a layout graph and the effects of changing the appearance vector of individual nodes. In the figure, only one node is changed and all the rest are kept constant. However, even though only one element is being changed in each sub-figure, multiple elements are affected. For example, in Fig. 9 (c) when changing the “Grass” node, the generated grass area changes and the model automatically changes the “Solid” and “Sky” regions to match the appearance of the “Grass” region. As it can be observed from the figure, the solid bar on the left is normally contrasted from the sky and the grass. This happens because each node is not trained in isolation and the discriminators have a global effect on multiple elements and aim to generate more realistic compositions.


































“Giraffe” “Sheep” “Summer” “Winter Day” “Color”
4.5 Effect of Text Style Transfer
The SRnet is used to change the placeholder text to the desired text in the generated image. In Fig. 10, we show a comparison of book covers before and after using SRNet. As can be seen from the figure, SRNet is able to successfully transfer the font generated by the Layout Generator and apply it to the desired text. This includes transferring the color and font features of the placeholder. In addition, even if the title text is short like “Sheep” or “Color,” SRNet was able to still erase the longer placeholder text. However, “Winter Day” appears to erroneously overlap with the solid region, but that is due to the predicted bounding box of the text overlapping with the solid region. Thus, this is not a result of a problem with SRNet, but with the Box Regression Network.
5 Conclusion
We proposed a book cover image generation system given a layout graph as the input. It comprises an image generation model and a font style transfer network. The image generation model uses a combination of a GCN, four generators, four discriminators, and a perception network to a layout image. The font style transfer network then transfers the style of the learned font onto a replacement with the desired text. This system allows the user to control the book cover elements and their sizes, locations, and appearances easily. In addition, users can write any text information and fonts fitting the book cover will be generated. Our research is a step closer to automatic book cover generation.
Acknowledgement
This work was in part supported by MEXT-Japan (Grant No. J17H06100 and Grant No. J21K17808).