Towards Automated Machine Learning Research
Abstract
This paper explores a top-down approach to automating incremental advances in machine learning research through component-level innovation, facilitated by Large Language Models (LLMs). Our framework systematically generates novel components, validates their feasibility, and evaluates their performance against existing baselines. A key distinction of this approach lies in how these novel components are generated. Unlike traditional AutoML and NAS methods, which often rely on a bottom-up combinatorial search over predefined, hardcoded base components, our method leverages the cross-domain knowledge embedded in LLMs to propose new components that may not be confined to any hard-coded predefined set. By incorporating a reward model to prioritize promising hypotheses, we aim to improve the efficiency of the hypothesis generation and evaluation process. We hope this approach offers a new avenue for exploration and contributes to the ongoing dialogue in the field.
Introduction
Efficient hypothesis generation, validation, and evaluation are critical, yet resource-intensive, components of scientific discovery. In many scientific fields, these processes require substantial manual effort, as they often involve intricate experiments and extensive data collection. The ability to streamline these tasks could significantly accelerate the pace of innovation.
Machine learning offers a unique opportunity in this regard. Unlike other scientific domains, hypothesis validation in machine learning can be automated through code, with effectiveness measured numerically using objective criteria such as loss or accuracy. This capability makes machine learning an ideal field for exploring automation in research.
Building on this potential, we propose a framework that leverages a top-down methodology using Large Language Models (LLMs) to generate high-level hypotheses. Although our approach is not intended to replace bottom-up methods such as AutoML-Zero(Real et al. 2020) or MetaQNN(Santoro et al. 2016), it offers a complementary path by introducing cross-domain innovation and a broader exploration of potential solutions. By formulating and testing hypotheses in natural language, our method lowers the barrier to entry for a wider range of researchers, fostering interdisciplinary collaboration and the integration of diverse knowledge from various fields. This combination of top-down and bottom-up strategies improves the research pipeline, providing a more comprehensive and innovative approach to automated machine learning research.
In this paper, we contribute by:
-
•
Proposing and evaluating viable components: Generating viable hypotheses to replace neural network components and achieve competitive performance with known alternatives.
-
•
Training a reward model: Learning patterns between the content of a hypothesis and its downstream performance.
-
•
Efficient Hypothesis Generation: Using the reward model to prune and prioritize hypotheses, improving the efficiency of generation, validation, and evaluation.
Caveats
-
1.
This work does not make any assumptions about the inherent capabilities of LLMs to reason or have a deep understanding of ML topics. Even a random string generator can yield a meaningful hypothesis given unlimited attempts, akin to the infinite monkey theorem, which suggests that a monkey hitting keys at random on a typewriter for an infinite amount of time will almost surely type a given text, such as the complete works of Shakespeare. Our assumptions on the state of LLMs and ML are as follows.
-
(a)
LLMs are good enough at generating feasible outputs, thus narrowing down our search space meaningfully from a set of random outputs.
-
(b)
LLMs (and ML models in general) are good enough in pattern recognition. Therefore, training a reward model on performance would allow the model to identify common patterns among successful hypotheses.
In short, we solely explore if LLMs can identify what would ”look like” a good hypothesis based on the patterns that it has seen in previous examples.
-
(a)
-
2.
In this work, we solely lay the foundation and do not claim that our automated research necessarily would yield state-of-the-art (SOTA) results in machine learning research. We explore the feasibility of operationalizing steps involved in ML research to a level where the current state of LLMs can generate feasible hypotheses efficiently.
-
3.
This work was conducted using the authors’ personal time and resources, limiting the scope to a small set of datasets and experiments. We hope that larger-scale experiments conducted at research labs interested in exploring this topic could further solidify this framework.

This work assumes an existing baseline solution and explores incremental innovations in its components, focusing on one component at a time. For example, in a neural network, the component of interest might be an activation function. We generate a set of viable alternatives (hypotheses) and evaluate their performance against baseline components.
The framework includes a generator for hypothesis creation, a validator to ensure basic validity, and an evaluator to measure success metrics such as validation loss. A reward model is trained to prioritize hypotheses that perform well compared to baselines, reducing computational burden while maintaining a high probability of discovering valuable new hypotheses.
While we manually verified and adjusted the validator and evaluator functions, the generation of hypotheses was not manually reviewed, highlighting the potential for fully automated research. This framework aims to accelerate innovation and make advanced machine learning techniques more accessible, with potential applications in various scientific discovery tasks.
Related Work
The field of automated machine learning (AutoML)(Liang et al. 2019) has rapidly advanced, automating processes such as data pre-processing, model selection, and hyperparameter tuning. Google’s AutoML and Auto-Keras (Jin, Song, and Hu 2019) have made machine learning more accessible. AutoML-Zero (Real et al. 2020) and MetaQNN (Baker et al. 2016) take a bottom-up combinatorial approach to model construction, evolving algorithms, and network architectures from basic operations. In contrast, our work uses a top-down method, leveraging large language models (LLMs) to start with high-level concepts, allowing for broader exploration and the potential for cross-domain innovation.
Meta-Learning has also made significant strides, with foundational methods like MAML enabling fast task adaptation (Finn, Abbeel, and Levine 2017). Matching Networks (Vinyals et al. 2016) and Prototypical Networks (Snell, Swersky, and Zemel 2017) advanced few-shot learning, while optimization-based methods (Ravi and Larochelle 2016) and Memory-Augmented Neural Networks (Santoro et al. 2016) enhanced meta-learning capabilities. Simplified approaches like first-order meta-learning (Nichol, Achiam, and Schulman 2018) and Probabilistic MAML (Finn, Xu, and Levine 2018) further refined the field.
Neural Architecture Search (NAS) has progressed with approaches like NASNet (Zoph et al. 2018), ENAS (Pham et al. 2018), and DARTS (Liu, Simonyan, and Yang 2019), which introduced scalable and efficient architecture search methods. Auto-Keras (Jin, Song, and Hu 2019) and ProxylessNAS (Cai, Zhu, and Han 2019) made NAS more accessible and practical, while AmoebaNet (Real et al. 2019), MnasNet (Tan et al. 2019), and FBNet (Wu et al. 2019) pushed the boundaries of mobile and hardware-aware optimization.
Hyperparameter Optimization has evolved with Bayesian optimization (Bergstra et al. 2011), later improved by Snoek et al. (Snoek, Larochelle, and Adams 2012). Random search (Bergstra and Bengio 2012) provided a simpler alternative, while Hyperband (Li et al. 2018) and BOHB (Falkner, Klein, and Hutter 2018) optimized resource allocation. Gradient-based methods (Maclaurin, Duvenaud, and Adams 2015) and automated tuning for neural networks (Mendoza et al. 2016) further advanced the field.
The objective of our work aligns with ongoing efforts in AutoML, meta-learning, NAS, and hyperparameter optimization, however, it goes beyond those capabilities as our framework proposes and evaluates new components in a top-down approach and builds on the baseline state of the art.
Framework
The scope of this work begins when a specific area of machine learning research is selected, such as the development of a new activation function. The researcher selects this area and constructs a baseline set of solutions that represent the current state-of-the-art or commonly used approaches. The goal is to generate a set of viable alternatives to these baselines. Each proposed hypothesis is generated such that it can replace a component in the baseline solutions, such as substituting a new activation function in place of the standard ReLU in a neural network. This structured approach ensures that the generated hypotheses are directly relevant and potentially beneficial to the chosen area of research.
Our approach for generating and measuring the performance of each of the proposed hypotheses involves a generator, a validator, and an evaluator. A reward model is then trained to map the hypotheses to their success metrics measured by the evaluator. This reward is then used to improve the efficiency of the system by prioritizing more promising hypotheses solely by their content. In what follows we provide more details on each of these components.
The Generator
The generator is the mechanism through which a feasible hypothesis is reached and sent for validation and evaluation. Here, it is a language model prompted by natural language, optionally followed by a reward model. In the activation function case study, these hypotheses take the form of novel activation functions. LLMs are trained on a comprehensive corpus of existing activation functions and related mathematical formulations, enabling them to propose viable functions.
We experiment with two types of base prompts. The first type encourages the model to discover incremental proposed blocks, to which we refer to as Incrementality Encouraging Prompting (IEP for short). The following is an example of such a prompt, used for generating activation function blocks.
”define a python class that inherits from pytorch nn.Module. I should be able to use it as an activation function. Make sure if it has any parameters, all of them are set to default values so I can initialize without specifying any parameters. Try to come up with something that combines characteristics of Sigmoid/Tanh, ReLU, and ELU.”
The second type of base prompt aims to reduce the likelihood of trivial incrementality. We refer to this as Novelty Encouraged Prompting (NEP) prompting. An example of such a prompt for activation function is as follows.
”define a python class that inherits from pytorch nn.Module. I should be able to use it as an activation function. Make sure if it has any params, all of them are set to default values so I can initialize without specifying any params. This function should not resemble common activation functions like ReLU, ELU, Sigmoid, or Tanh, and should explore unusual mathematical operations, combinations, or transformations. The expression can involve basic arithmetic, trigonometric functions, exponentials, or other non-linear operations, but avoid straightforward or commonly used forms in neural networks.”
The generator then involves a few wrappers around this base prompt, to request the implementation code for the proposed hypothesis in a parsable way.
Code 1 is an example of an activate function generated using the incrementality-encouraging base prompt. As prompted, the model clearly borrows characteristics from two commonly used activation functions of ReLU and Sigmoid.
Code 2 shows another activation function generated using the novelty-encouraged prompt. The model avoids directly using existing activation functions, adhering meaningfully to the instructions. While further exploration in prompt engineering is beyond this work’s scope, we believe it could significantly reduce LLMs’ inductive bias towards state-of-the-art methods, minimize borrowing from existing literature, and encourage the proposal of less explored functions.
Figure 2 visualizes the shape of the proposed activation functions.


For more examples, please refer to the Appendix.
The Validator
Each proposed hypothesis is first passed through a validator function, denoted . This function checks the validity of the hypothesis, ensuring it meets necessary criteria before further evaluation. For a proposed activation function , the validator function returns a binary value indicating whether is a valid activation function (that is, ).
For our case study on activation functions, we implement the validator manually and as a unittest111Fully automating this function is very feasible, but out of the scope of this effort.. The validator checks if inherits from nn.Module, has the required initialization and forward functions, all its parameters have default values, and can pass a few basic test cases. We provide code snippets of this validator in the Appendix section Code 9.
The Evaluator
Valid hypotheses are fully evaluated using an evaluation function, denoted . The goal of this function is to replace a baseline component with an alternative hypothesis and measure the performance of the model in the task(s) of interest. For our case, this translates to integrating the hypothesis into a machine learning model and measuring its performance, specifically its loss on the validation split of the dataset (val-loss). To streamline the process, we perform a single iteration of forward and backward passes to obtain a preliminary loss value, rather than conducting a full training and evaluation cycle. Formally, for a model and an activation function , the val loss is calculated as .
In our experiments, we hard-coded the architecture to a 2-layer MLP, and used cross-entropy and MSE loss for a set of classification and regression tasks. We also define the problem as solving the classification and regression instances in a one-pass learning setup (only one epoch) to reduce the computation required for each and enable more extensive exploration across a larger set of hypotheses.
The Reward
Passing the set of hypotheses to the evaluator function results in the collection of pairs of generated hypotheses (activation functions) and their corresponding validation losses, in the form of . We define the reward as the win rate of the proposed hypothesis over the baselines. Specifically, we measure two metrics:
Baseline Win Rate (B-WR): This metric measures the percentage of times outperforms any given baseline across different tasks and over different runs. Formally, it measures .
Baseline State-of-the-Art Win Rate (BSOTA-WR): This metric measures the win rate of the proposed hypothesis over the best runs of the entire baseline set in each task / dataset. Formally, it is defined as . Please note that the minimum operation is done on the average loss of different runs for each baseline, thus the best baseline run still contains a distribution of losses (resulting from several runs / random initialization), allowing for calculating a probabilistic win rate.
The reward model is then trained as a ranking model mapping the content of the hypothesis to its downstream performance (i.e. loss). In other words, this model is aimed to looking at the content of a proposed component (i.e. code of an activation function), and be able to predict how well it is likely to perform in terms of winning over the baseline set. Intuitively, the reward model learns patterns in the content of the proposed activation functions, leading to better performance.
Closing the Loop
In the initial round of hypothesis generation, every hypothesis is evaluated using a brute-force approach, where each one is passed through the validator and evaluator in a fully exploratory iteration. This process allows for comprehensive data collection, yielding the success metrics B-WR and BSOTA-WR for each validated and evaluated hypothesis. We employ three LLMs to generate a dataset of 2000 validated and evaluated hypotheses for each component type.
Once this initial data is collected, the second iteration leverages a trained reward model to streamline the process. The reward model is used to prune the newly generated hypotheses, filtering them to select the top- candidates based on their predicted performance. These top- hypotheses, expected to be the most promising, are the only ones that proceed to the full evaluation phase, which involves more intensive computational resources.
Experiments
We aim to identify novel components that improve a simple neural network’s performance across various tasks using a one-pass learning setup, where the model is trained for a single epoch. This approach enables rapid iteration and evaluation of numerous hypotheses.
Experimental Setup
Downstream Tasks and Datasets
To validate the effectiveness of our framework, we performed experiments on six tasks using four well-known datasets, covering both classification and regression.
Iris Dataset: Classification task with 150 instances, 4 features, and 3 classes.
Wine Dataset: Used for both classification (3 classes) and regression, with 178 instances and 13 features.
Breast Cancer Dataset: Binary classification task with 569 instances and 30 features.
Diabetes Dataset: Regression task with 442 instances, each with 10 baseline variables, such as age, sex, body mass index (BMI), average blood pressure, and six blood serum measurements. The goal is to predict the progression of the disease one year after baseline.
Generated Hypothesis Dataset
Each hypothesis is evaluated to generate a dataset of 36,000 (hypothesis, reward) tuples over two iterations of 18,000 each. These are further divided into 3 LLMs, 3 component types, and 2 prompt types, with each combination generating 1,000 samples.
Components
We experimented with three component types: activation functions, regularization functions, and preprocessing functions. Detailed prompts for each type are provided in the appendix.
Language Models and Prompts
We used three language models: GPT-3.5 Turbo, GPT-4o and Gemini, to generate components, using two prompt types: incrementality-encouraging and novelty-encouraging (as described in Section The Generator).
Architecture
We employed a 2-layer fully-connected neural network with 64 and 16 units for all datasets for simplification.
Quantitative Results and Analysis
Our goal is to generate viable and high-performing proposed components, efficiently. In the following, we provide details on how we measure success in these aspects.
Performance: Component Evaluation
As mentioned in the Reward Section The Reward, we use the two key metrics of Baseline Win-rate (B-WR for short), and Baseline State-of-the-art win-rate (BSOTA-WR for short) to assess the effectiveness of each proposed block. Both metrics, BSOTA-WR and B-WR, are designed to provide a holistic view of the proposed method’s performance, highlighting its potential to advance the state of the baseline set by setting new benchmarks and consistently outperforming the baseline set. Table. 1, contains the metrics for the set of components generated through the pipeline. We also report the success rate of the Validator, indicating the fraction of generated hypotheses that had the valid format. Please note that all of these metrics are averaged over the whole dataset of hypotheses generated in the first iteration (2000 samples generated for each component type). The performance of the individual components can be seen in the scatter plots provided in Figure. 10. As can be observed, in the majority of cases the generated hypotheses have a low win rate compared to the baseline set, however, there are components with win rates very close to 1, indicating that they always outperform every single baseline individually and also the baseline state of the art.

| - | Inc | Nov | ||||||
|---|---|---|---|---|---|---|---|---|
| Activation |
|
|
||||||
| Preprocessor |
|
|
||||||
| Regularizer |
|
|
Reward model Evaluation
As mentioned earlier, the goal of the reward model is to learn to predict the performance of a proposed hypothesis solely from its content (code). To train such a model, we extract three different code embedding features from the content of the implementation code generated, namely CodeBERT(Feng et al. 2020), GraphCodeBert(Guo et al. 2020), and CodeGen(Nijkamp et al. 2022). We report the results on ranking models trained on the concatenation of all three features in table 2. In the Appendix, we also provide ablation on the same metrics for each feature type, and also for preprocessors and regularizers.
We use established ranking metrics, including Kendall’s Tau (), Spearman correlation coefficient (SCC), and Pearson correlation coefficient (PCC), as reported in Tables 2, 3, and 2 for activation functions, preprocessing functions, and regularization functions respectively. From table 2, for activation, preprocessing, and regularization functions, respectively. These metrics show successful generalization of the ranking models across components generated by different language models. While reward models perform best on the datasets they were trained on, the consistently positive correlations across different language models demonstrate their robustness and generalization capability. Even when correlation values are modest, they remain directionally positive, indicating meaningful ranking performance.
| train test | gpt-3.5-turbo | gpt-4o-mini | gemini-pro | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gpt-3.5-turbo |
|
|
|
|||||||||
| gpt-4o-mini |
|
|
|
|||||||||
| gemini-pro |
|
|
|
Efficienct Hypothesis Evaluation
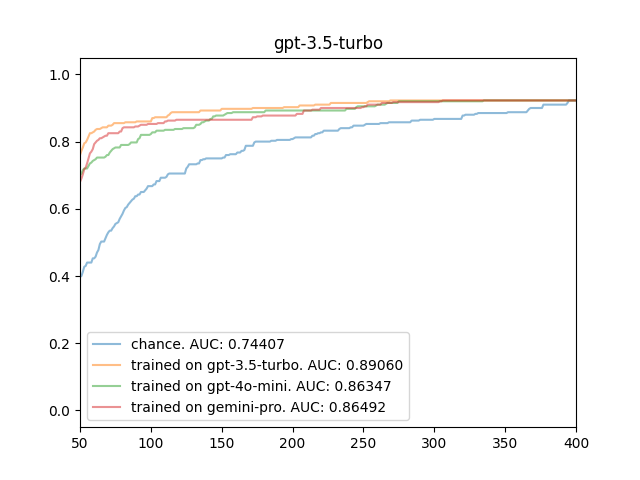
We also evaluate the efficiency of the reward model in terms of prioritizing the candidates in the second iteration. That means that we measure the performance of the top 50 candidates at each step if we were to sort the candidates based on their predicted reward. Intuitively, a good reward model would sort them in an order in which the top k candidates are more likely to be on the top of the list, therefore discovering the promising hypotheses earlier, resulting in a curve with a higher AUC. Figure. 12 visualize the efficiency curves for the activation function on the datasets generated by the different LLMs separately. We provide similar curves for the datasets generated for other components (preprocessor and regularizer) in Figures 11 and 13 of the appendix. The x-axis in these figures shows the number of steps, and the y-axis is the reward (linear addition of BSOTA-WR + B-WR) for the top 50 hypotheses if they were to be prioritized by the reward model of interest. In all graphs, the blue curve shows how fast the pipeline reaches the high top-50 accuracies if there is no reward model used (chance/random reward). As it can be observed, all reward models for the activation functions lead to a faster discovery of better hypotheses, leading to higher AUC values.



Risks and Limitations
Given that this work is the first in the lane. here we cover some potential risks and limitations for this line of research. These risks may be even more prominent once models are trained or fine-tuned end-to-end in a closed-loop setup with minimal human involvement.
Shortcuts: Given the empirical nature of this approach, there’s a possibility that the model might exploit existing shortcuts rather than genuinely innovative solutions. This could lead to overfitting to specific datasets or tasks without contributing to broader advancements.
Reward Collapse: During our experiments, we observed a significant issue with the generation of redundant and highly similar hypotheses, particularly when using GPT-3.5-turbo to generate activation functions. As illustrated in Figure 5, the top-12 activation functions often exhibit striking similarities, indicating a lack of diversity in the generated hypotheses. This phenomenon, known as reward collapse, occurs when the reward model becomes overly focused on specific patterns, leading to a narrow exploration of the hypothesis space. The right side of the figure, shows the pairwise similarity between the top-12 candidates, it can be observed that the one difference component (highlighted in red) completely stands out both in terms of the shape of its activation function, and also in terms of its similarity to others in the embeddings space. Given this phenomenon, we did a preliminery exploration on whether we can construct a set of diverse activation functions by constructing a set iteratively and greedily as a trade-off of win rate and diversity.
This greedy and iterative approach encourages the selection of hypotheses that are both high-performing and diverse, thereby promoting a broader and more thorough exploration of the hypothesis space. By balancing the exploitation of known successful solutions with the exploration of novel and potentially superior alternatives, this method helps mitigate the risk of reward collapse. The effectiveness of this approach is demonstrated in Figure 6, where the top-12 activation functions constructed with this method exhibit a greater diversity compared to the initial set. This suggests the possibility of preventing collapse in case of finetuning the generator (future work).
SOTA Inductive Bias and unintended plagiarism: LLMs, trained on vast datasets, risk generating outputs that closely resemble existing works, leading to unintended plagiarism and a bias toward state-of-the-art (SOTA) methodologies. This limits innovation, as models may favor incremental changes over novel ideas. To address this, it’s essential to build careful baseline sets and implement strong credit assignment. Prompt design also plays a key role; novelty-focused prompts yield more diverse outputs, while those targeting incremental improvements often mirror existing literature. Refining prompts to avoid reliance on known solutions and explore new areas can reduce plagiarism and SOTA bias, encouraging truly innovative contributions.
Optimizing for incremental short term improvements: The empirical focus of this work, combined with the absence of strong theoretical constraints, creates a risk of prioritizing short-term, incremental gains over more significant, long-term advancements. This approach may lead to the discovery of surface-level improvements that offer marginal benefits, while potentially overlooking opportunities for groundbreaking innovations that could drive substantial progress in the field.


Future Work
Future research could focus on expanding the framework to other types of machine learning components beyond activation functions, preprocessors and regularizers, and including more complex architectures and diverse datasets. Additionally, refining the reward model to balance novelty and performance more effectively, and incorporating stronger theoretical constraints, could help mitigate risks like reward collapse and incremental bias. An intriguing direction for future work is fine-tuning the language model based on the reward signal, which could guide the model towards generating higher-quality and more innovative hypotheses. Moreover, ensuring that the embeddings extracted from the generated hypotheses are consistent with those of the backbone model could open the possibility for fully differentiable training, further enhancing the integration and efficiency of the framework. Further experiments could also explore constrcuting prompt engineering practices to reduce unintended plagiarism and inductive bias. And last but not least, a proper credit assignment framework would be a necessity for improviong this line of research.
Conclusion
This work introduces a framework for automating machine learning research by leveraging large language models to generate, validate, and evaluate novel components. While the approach shows promise in enhancing the efficiency of hypothesis generation and evaluation, it also presents challenges, such as the risk of reward collapse and the tendency to prioritize incremental improvements. Addressing these issues through careful design, fine-tuning strategies, and future refinements—such as consistent embedding integration for fully differentiable training—will be key to realizing the full potential of this automated research paradigm.
References
- Baker et al. (2016) Baker, B.; Gupta, O.; Naik, N.; and Raskar, R. 2016. Designing neural network architectures using reinforcement learning. arXiv preprint arXiv:1611.02167.
- Bergstra et al. (2011) Bergstra, J.; Bardenet, R.; Bengio, Y.; and Kégl, B. 2011. Algorithms for hyper-parameter optimization. Advances in neural information processing systems, 24.
- Bergstra and Bengio (2012) Bergstra, J.; and Bengio, Y. 2012. Random search for hyper-parameter optimization. Journal of machine learning research, 13(2).
- Cai, Zhu, and Han (2019) Cai, H.; Zhu, L.; and Han, S. 2019. ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware. In International Conference on Learning Representations.
- Falkner, Klein, and Hutter (2018) Falkner, S.; Klein, A.; and Hutter, F. 2018. BOHB: Robust and efficient hyperparameter optimization at scale. In International conference on machine learning, 1437–1446. PMLR.
- Feng et al. (2020) Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. 2020. Codebert: A pre-trained model for programming and natural languages. arXiv preprint arXiv:2002.08155.
- Finn, Abbeel, and Levine (2017) Finn, C.; Abbeel, P.; and Levine, S. 2017. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, 1126–1135. PMLR.
- Finn, Xu, and Levine (2018) Finn, C.; Xu, K.; and Levine, S. 2018. Probabilistic model-agnostic meta-learning. Advances in neural information processing systems, 31.
- Guo et al. (2020) Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. 2020. Graphcodebert: Pre-training code representations with data flow. arXiv preprint arXiv:2009.08366.
- Jin, Song, and Hu (2019) Jin, H.; Song, Q.; and Hu, X. 2019. Auto-keras: An efficient neural architecture search system. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 1946–1956.
- Li et al. (2018) Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; and Talwalkar, A. 2018. Hyperband: A novel bandit-based approach to hyperparameter optimization. Journal of Machine Learning Research, 18(185): 1–52.
- Liang et al. (2019) Liang, J.; Meyerson, E.; Hodjat, B.; Fink, D.; Mutch, K.; and Miikkulainen, R. 2019. Evolutionary neural automl for deep learning. In Proceedings of the genetic and evolutionary computation conference, 401–409.
- Liu, Simonyan, and Yang (2019) Liu, H.; Simonyan, K.; and Yang, Y. 2019. DARTS: Differentiable Architecture Search. In International Conference on Learning Representations.
- Maclaurin, Duvenaud, and Adams (2015) Maclaurin, D.; Duvenaud, D.; and Adams, R. 2015. Gradient-based hyperparameter optimization through reversible learning. In International conference on machine learning, 2113–2122. PMLR.
- Mendoza et al. (2016) Mendoza, H.; Klein, A.; Feurer, M.; Springenberg, J. T.; and Hutter, F. 2016. Towards automatically-tuned neural networks. In Workshop on automatic machine learning, 58–65. PMLR.
- Nichol, Achiam, and Schulman (2018) Nichol, A.; Achiam, J.; and Schulman, J. 2018. On first-order meta-learning algorithms. arXiv preprint arXiv:1803.02999.
- Nijkamp et al. (2022) Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; and Xiong, C. 2022. Codegen: An open large language model for code with multi-turn program synthesis. arXiv preprint arXiv:2203.13474.
- Pham et al. (2018) Pham, H.; Guan, M. Y.; Zoph, B.; Le, Q. V.; and Dean, J. 2018. Efficient Neural Architecture Search via Parameter Sharing. In International Conference on Machine Learning, 4095–4104. PMLR.
- Ravi and Larochelle (2016) Ravi, S.; and Larochelle, H. 2016. Optimization as a model for few-shot learning. In International conference on learning representations.
- Real et al. (2019) Real, E.; Aggarwal, A.; Huang, Y.; and Le, Q. V. 2019. Regularized Evolution for Image Classifier Architecture Search. In Proceedings of the AAAI conference on artificial intelligence, volume 33, 4780–4789.
- Real et al. (2020) Real, E.; Liang, C.; So, D.; and Le, Q. 2020. Automl-zero: Evolving machine learning algorithms from scratch. In International conference on machine learning, 8007–8019. PMLR.
- Santoro et al. (2016) Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; and Lillicrap, T. 2016. Meta-learning with memory-augmented neural networks. In International conference on machine learning, 1842–1850. PMLR.
- Snell, Swersky, and Zemel (2017) Snell, J.; Swersky, K.; and Zemel, R. 2017. Prototypical networks for few-shot learning. Advances in neural information processing systems, 30.
- Snoek, Larochelle, and Adams (2012) Snoek, J.; Larochelle, H.; and Adams, R. P. 2012. Practical bayesian optimization of machine learning algorithms. Advances in neural information processing systems, 25.
- Tan et al. (2019) Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; and Le, Q. V. 2019. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2820–2828.
- Vinyals et al. (2016) Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; and Wierstra, D. 2016. Matching Networks for One Shot Learning. In Advances in Neural Information Processing Systems, 3630–3638.
- Wu et al. (2019) Wu, B.; Dai, X.; Zhang, P.; Wang, Y.; Sun, F.; Wu, Y.; Tian, Y.; Vajda, P.; Jia, Y.; and Keutzer, K. 2019. FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10734–10742.
- Zoph et al. (2018) Zoph, B.; Vasudevan, V.; Shlens, J.; and Le, Q. V. 2018. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 8697–8710.
Appendix
Performance of the generated components
As mentioned in section Quantitative Results and Analysis we present a scatter plot visualization to compare the two success metrics for the hypotheses generated across different block types. Figure 10 illustrates the scatter plots for the pre-processor, activation, and regularization block types, respectively.


Reward Model Efficiency
Here we provide efficiency curves for the preprocessor and regularize blocks in figure 11 and 13 respectively. It can be observed that similar to activation functions, the reward ranking model trained on the preprocessor blocks can effectively speed up the discovery of the most promising proposed components. However, when it comes to the regularizers, the trained reward models, especially the ones trained on the Gemini-pro dataset, fail to generalize to other datasets. We also provide the metrics for the rewards models in tables 3 and 4 respectively.





| train test | gpt-3.5-turbo | gpt-4o-mini | gemini-pro | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gpt-3.5-turbo |
|
|
|
|||||||||
| gpt-4o-mini |
|
|
|
|||||||||
| gemini-pro |
|
|
|
| Train Test | 3000_gpt-3.5-turbo | 3000_gpt-4o-mini | 3000_gemini-pro | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3000_gpt-3.5-turbo |
|
|
|
|||||||||
| 3000_gpt-4o-mini |
|
|
|
|||||||||
| 3000_gemini-pro |
|
|
|
Component Examples
In the following, we provide some auto-generated justification for why one of the hypotheses that has worked well, is a good option.
Sigmoid-ELU (SigELU): An activation function generated through IEP
Definition
The Sigmoid-ELU (SigELU): An Activation Function is a hybrid activation function that combines the Sigmoid function for non-negative inputs and the Exponential Linear Unit (ELU) function for negative inputs.
Formula
The activation function is defined as:
where and is a hyperparameter that controls the scaling for negative inputs.
Justification
The name Sigmoid-ELU Activation (SigELU) reflects the combination of the Sigmoid function for non-negative inputs and the ELU function for negative inputs:
-
•
Sigmoid for Non-Negative Inputs: The Sigmoid function is well-known for its smooth, bounded output between 0 and 1. It is particularly useful for squashing input values to a manageable range, which can help stabilize the training process and make the model’s output more interpretable in certain contexts.
-
•
ELU for Negative Inputs: ELU (Exponential Linear Unit) is effective for handling negative inputs. It produces non-zero outputs for negative values, which helps to alleviate the vanishing gradient problem often encountered with ReLU in deep networks. The parameter allows for controlling the steepness of the negative part, adding flexibility to the function.
-
•
Smooth Transition: The activation function ensures a smooth transition between the positive and negative parts, which can contribute to better gradient flow and more stable training.
Differentiability Analysis
-
•
Sigmoid Function for Non-Negative Inputs: The Sigmoid function, defined as , is a smooth and differentiable function for all real numbers. Its derivative is given by:
-
•
ELU-like Function for Negative Inputs: The ELU-like function defined as is also smooth and differentiable for all real numbers. Its derivative is:
-
•
Combination of Both Functions: The combination of these functions using a piecewise definition ensures that the function is differentiable. Since both components are differentiable, and the transition between them occurs at , the overall function is differentiable at .
-
•
Continuity at : At , both functions yield the same value if we choose :
Therefore, if , the function value is continuous at .
-
•
Smooth Transition: The derivative at for both functions should also match for smooth transition:
Therefore, the function transitions smoothly if we ensure the parameters are set appropriately.
Given these properties, the Sigmoid-ELU activation function is fully differentiable and suitable for use in neural networks.
ScaledSinusoidalDecay: An activation function generated through NEP
Activation functions play a crucial role in neural networks by introducing nonlinearity, allowing the model to learn complex patterns in data. The ScaledSinusoidalDecay activation function is a novel approach that combines sinusoidal transformations with exponential decay, modulated by user-defined scaling and shifting parameters. This function is designed to introduce controlled non-linearity, making it a versatile choice for various deep-learning architectures.
Formal Definition
The ScaledSinusoidalDecay activation function is defined as follows:
Given an input , the output of the activation function is calculated as:
where:
-
•
scale is a parameter that controls the amplitude of the sinusoidal component.
-
•
introduces a periodic, oscillatory behavior to the activation function.
-
•
is an exponential decay function that diminishes the output as the magnitude of the input increases.
-
•
shift is a parameter that shifts the output, providing additional flexibility in the function’s range.
Why ScaledSinusoidalDecay is a Good Activation Function
The ScaledSinusoidalDecay activation function offers several advantages that make it a strong candidate for deep learning applications:
-
•
Controlled Non-linearity: The sine component introduces periodic non-linearity, which can be beneficial for learning complex patterns that are not purely linear. This is particularly useful in applications where the relationship between input features and the output is oscillatory or involves repeated cycles.
-
•
Attenuation of Large Inputs: The exponential decay term serves to attenuate the influence of large input values, preventing them from dominating the output. This can lead to better stability during training, especially in scenarios where the input data contains large outliers.
-
•
Parameter Flexibility: The inclusion of the scale and shift parameters allows for fine-tuning the function’s behavior to suit specific tasks. For instance, adjusting the scale can amplify or reduce the overall impact of the activation, while the shift can move the activation range to better align with the desired output.
-
•
Smooth Gradients: The combination of sine and exponential functions ensures that the gradients of the ScaledSinusoidalDecay activation function are smooth and continuous. This is advantageous for optimization algorithms like gradient descent, as it helps in avoiding issues related to vanishing or exploding gradients.
-
•
Regularization Effect: The exponential decay can act as a regularizer by suppressing the influence of extreme values. This can lead to more robust models that generalize better to unseen data, particularly in deep networks where overfitting is a concern.
Conclusion
The ScaledSinusoidalDecay activation function is a versatile and powerful tool in the design of neural networks. By combining sinusoidal non-linearity with exponential decay, and allowing for adjustable scaling and shifting, this function offers a unique blend of flexibility and control. It is particularly well-suited for tasks that require the learning of complex, cyclical patterns, or where the attenuation of large inputs is beneficial. Its smooth gradients and regularization properties further enhance its utility, making it a strong candidate for a wide range of deep learning applications.
NormalizedPCA: A Preprocessing Function generated through IEP
In the realm of data preprocessing, the ‘NormalizedPCA‘ function provides a robust method for scaling and dimensionality reduction. This function combines two essential preprocessing steps: feature normalization and Principal Component Analysis (PCA). In this section, we introduce the ‘NormalizedPCA‘ function, explain its benefits, and formalize its operations.
Introduction
The ‘NormalizedPCA‘ function is designed to preprocess data by first normalizing the features and then applying PCA for dimensionality reduction. This two-step process ensures that the data is appropriately scaled and transformed, allowing for more effective analysis and modeling.
Function Overview
Given a dataset , where is the number of samples and is the number of features, the ‘NormalizedPCA‘ function performs the following operations:
1. **Feature Normalization:** The feature normalization step involves standardizing the features to have zero mean and unit variance. This is achieved using the StandardScaler:
where is the normalized feature value, is the original feature value, is the mean of the -th feature, and is the standard deviation of the -th feature.
2. **Dimensionality Reduction with PCA:** After normalization, PCA is applied to reduce the dimensionality while preserving the maximum variance. PCA transforms the data to a lower-dimensional space:
where contains the principal components (eigenvectors) corresponding to the largest eigenvalues of the covariance matrix of .
Benefits of the ‘NormalizedPCA‘ Function
1. **Effective Scaling:** Normalizing features ensures that all features contribute equally to the PCA, avoiding bias towards features with larger magnitudes. This scaling step is crucial because PCA is sensitive to the scale of the input features.
2. **Improved Dimensionality Reduction:** By applying PCA after normalization, the function effectively reduces the dimensionality while retaining the most significant variance. This results in a lower-dimensional representation that captures the essential structure of the data.
3. **Enhanced Model Performance:** Proper normalization and dimensionality reduction improve the performance of machine learning models by reducing overfitting and speeding up convergence. Normalized data allows PCA to perform a more accurate reduction, leading to better generalization.
4. **Consistency and Interpretation:** The combination of scaling and PCA provides a consistent and interpretable transformation of the data. Normalized features ensure that PCA components represent the true variance, making the results more meaningful and actionable.
Formalization
Let be the input data matrix. The preprocessing steps are as follows:
-
1.
**Normalize the Data:**
where each feature is scaled to have zero mean and unit variance.
-
2.
**Apply PCA:**
where PCA reduces the dimensionality based on the specified number of components or variance threshold.
In summary, the ‘NormalizedPCA‘ function provides a comprehensive preprocessing solution by combining scaling and PCA. This approach ensures that the data are properly prepared for subsequent analysis, improving the effectiveness of dimensionality reduction and enhancing overall model performance.
SineSquaredDecay Transformation: A pre-processing function generated through NEP
In the realm of data preprocessing for machine learning, the choice of feature transformations can significantly impact model performance. One such transformation, which we term SineSquaredDecay, introduces a combination of non-linear operations and noise to the input data, creating a robust and diverse feature set. The SineSquaredDecay function is designed to transform input features in a way that captures complex patterns while also adding a degree of regularization to prevent overfitting.
Formal Definition
The SineSquaredDecay transformation is applied to each feature in the input data and can be formalized by the following equations:
Given an input feature matrix , the transformation for each feature in the training set train_X and validation set val_X is defined as:
where:
-
•
applies a non-linear, periodic transformation to the input feature.
-
•
introduces an exponential decay, which diminishes the influence of large feature values, ensuring that no single feature dominates the input space.
-
•
represents the noise_scale parameter, which controls the magnitude of the added Gaussian noise.
-
•
is a Gaussian noise term drawn from a normal distribution , added to the transformed features to enhance feature diversity and regularization.
Why SineSquaredDecay is a Good Choice for Preprocessing
The SineSquaredDecay transformation offers several advantages for preprocessing, particularly in scenarios where non-linear relationships and feature regularization are critical:
-
•
Capturing Complex Patterns: The use of the sine function, squared, introduces non-linear and periodic behavior into the features, which can help capture complex underlying patterns in the data. This is particularly useful in situations where the relationship between features and the target variable is not purely linear.
-
•
Feature Scaling and Regularization: The exponential decay term ensures that the transformed features do not become excessively large, which can help in preventing certain features from overpowering others. This acts as an inherent regularization mechanism, making the feature set more balanced.
-
•
Noise Augmentation: The addition of Gaussian noise controlled by the noise_scale parameter serves as a regularizer by slightly perturbing the input data. This prevents the model from overfitting to specific patterns in the training set, thereby improving generalization to unseen data.
-
•
Diverse Feature Representations: The combined effect of non-linear transformation and noise addition results in a rich and diverse feature set. This diversity can be particularly advantageous in ensemble models or in scenarios where the model benefits from a wide variety of input features.
Conclusion
The SineSquaredDecay transformation is a powerful tool for preprocessing in machine learning pipelines. Its ability to introduce complex non-linearities, combined with an effective regularization mechanism through noise, makes it a robust choice for enhancing model performance. By using this transformation, practitioners can create a feature space that is both rich in diversity and resilient to overfitting, ultimately leading to more effective and generalizable models.
DropWeightL2: A Regularizer generated through IEP
The ‘DropWeightL2‘ regularization function introduces a novel method for regularizing neural network models by combining dropout-like behavior with the L2 weight penalty. This function aims to enhance model robustness and prevent overfitting through a dual-regularization approach. In this section, we describe the ‘DropWeightL2‘ function, justify its effectiveness, and formalize its operations.
Introduction
The DropWeightL2 regularization function integrates two distinct regularization techniques: dropout-like regularization applied directly to weights and L2 weight decay. By applying these methods simultaneously, DropWeightL2 seeks to improve model generalization and stability during training.
Function Overview
The DropWeightL2 function is defined as follows:
Benefits of DropWeightL2 Regularization
1. **Enhanced Model Robustness:** - **Dropout-Like Regularization:** Although dropout is typically applied to activations, applying a similar dropout-like effect to weights introduces noise into the weight parameters. This encourages the network to be less reliant on specific weights, promoting robustness, and reducing the risk of overfitting. - **Effect:** This technique helps in regularizing the model by preventing it from fitting too closely to the training data and improving generalization.
2. ** Effective weight decline: ** - ** L2 penalty: ** The term L2 weight penalty discourages large weights by adding a quadratic penalty to the loss function. This helps in controlling the complexity of the model and reducing overfitting. - **Effect:** Regularizing weights through L2 penalty improves model performance by constraining weight magnitudes, thereby simplifying the model and improving its generalization ability.
3. **Combination of Techniques:** - **Dual Regularization:** Combining dropout-like behavior with L2 regularization leverages the strengths of both methods. Dropout-like regularization introduces stochasticity into the weights, while L2 regularization ensures that weight magnitudes are kept in check. - **Effect:** This combination can lead to better generalization by balancing the benefits of both techniques.
Formalization
Let represent the weight matrix of a layer, where is the number of input features and is the number of output features. The regularization loss introduced by the DropWeightL2 function is formulated as:
| (1) |
where:
-
•
is the weight penalty coefficient (L2 regularization strength).
-
•
represents the weight value on the -th row and -th column.
-
•
represents the weight value after applying a dropout-like mechanism. Mathematically, it can be modeled as:
where is the dropout rate.
The total loss of regularization is accumulated in all layers of the model and the resulting value is added to the primary loss function during training.
where:
-
•
is the weight penalty coefficient (L2 regularization strength).
-
•
represents the weight value on the -th row and -th column.
-
•
is the dropout-like effect applied to the weight , introducing noise during regularization.
The total loss of regularization is accumulated in all layers of the model and the resulting value is added to the primary loss function during training.
Conclusion
The DropWeightL2 regularization function offers a unique approach by integrating dropout-like regularization with L2 weight penalty. This dual regularization strategy improves the robustness of the model, prevents overfitting, and improves generalization. By applying both methods simultaneously, ‘DropWeightL2‘ provides a comprehensive regularization solution that balances weight control with stochastic noise.
SineDecay: A regularizer generated through NEP
Regularization is a key technique in machine learning, particularly in deep learning, where it helps prevent overfitting and improves the generalization capabilities of models. The SineDecay Regularizer is a novel approach that combines sine transformations with exponential decay to regularize the parameters of a neural network. This regularizer introduces periodicity and attenuates large parameter values, providing a unique mechanism for controlling model complexity.
Formal Definition
The SineDecay Regularizer is applied to the parameters of a neural network model. The regularization loss, reg_loss, is computed by summing the sine-transformed and exponentially decayed values of the model’s parameters. Formally, the regularization loss is defined as follows:
where:
-
•
represents the -th parameter of the -th layer in the model.
-
•
is the number of layers in the model.
-
•
is the number of parameters in the -th layer.
-
•
scale is a hyperparameter that controls the amplitude of the sine transformation.
-
•
decay is a hyperparameter that determines the rate of exponential decay, attenuating the influence of large parameters.
Why SineDecay is a Good Regularizer
The SineDecay Regularizer offers several advantages that make it a valuable tool for enhancing the performance and robustness of neural network models:
-
•
Encouraging Smoothness and Periodicity: The sine transformation encourages the parameters to adopt smoother, periodic distributions. This can be particularly beneficial for models dealing with data that has inherent periodicity or cyclical patterns.
-
•
Attenuation of Large Parameters: The exponential decay component reduces the impact of large parameter values on the regularization loss. This helps in preventing overfitting by discouraging the development of overly large weights, which can dominate the model’s output.
-
•
Parameter Diversity: By combining sine and exponential decay, the regularizer introduces diversity in the parameter values, which can lead to a more robust and generalizable model. This is especially useful in complex models where standard regularizers like L1 or L2 might not be sufficient.
-
•
Flexibility with Hyperparameters: The scale and decay hyperparameters offer flexibility in tuning the regularizer’s effect. This allows practitioners to adjust the regularization strength to suit the specific needs of their model and dataset.
Implementation
The following is the implementation of the SineDecay Regularizer in Python using PyTorch:
Conclusion
The SineDecay Regularizer is a powerful and flexible tool for regularizing neural network models. Using the periodic nature of the sine function and the attenuating effect of exponential decay, this regularizer provides a unique approach to controlling model complexity and improving generalization. Its ability to encourage smooth, diverse parameter values while mitigating the risk of overfitting makes it a valuable addition to the regularization techniques available in deep learning.
Validator
An example of the validator function implemented to verify the validity of activation function hypotheses can be seen in the following: