Towards Assessment of Randomized Smoothing Mechanisms for Certifying Adversarial Robustness
Abstract
As a certified defensive technique, randomized smoothing has received considerable attention due to its scalability to large datasets and neural networks. However, several important questions remain unanswered, such as (i) whether the Gaussian mechanism is an appropriate option for certifying -norm robustness, and (ii) whether there is an appropriate randomized (smoothing) mechanism to certify -norm robustness. To shed light on these questions, we argue that the main difficulty is how to assess the appropriateness of each randomized mechanism. In this paper, we propose a generic framework that connects the existing frameworks in [1, 2], to assess randomized mechanisms. Under our framework, for a randomized mechanism that can certify a certain extent of robustness, we define the magnitude of its required additive noise as the metric for assessing its appropriateness. We also prove lower bounds on this metric for the -norm and -norm cases as the criteria for assessment. Based on our framework, we assess the Gaussian and Exponential mechanisms by comparing the magnitude of additive noise required by these mechanisms and the lower bounds (criteria). We first conclude that the Gaussian mechanism is indeed an appropriate option to certify -norm robustness. Surprisingly, we show that the Gaussian mechanism is also an appropriate option for certifying -norm robustness, instead of the Exponential mechanism. Finally, we generalize our framework to -norm for any . Our theoretical findings are verified by evaluations on CIFAR10 and ImageNet.
1 Introduction
The past decade has witnessed tremendous success of deep learning in handling various learning tasks like image classification [3], natural language processing [4], and game playing [5]. Nevertheless, a major unresolved issue of deep learning is its vulnerability to adversarial samples, which are almost indistinguishable from natural samples to humans but can mislead deep neural networks (DNNs) to make wrong predictions with high confidence [6, 7]. This phenomenon, referred to as adversarial attack, is considered to be one of the most significant threats to the deployment of many deep learning systems. Thus, a substantial amount of effort has been devoted to developing defensive techniques against it. However, a majority of existing defenses are of heuristic nature (i.e., without any theoretical guarantees), implying that they may be ineffective against stronger attacks. Recent work [8, 9, 10] has confirmed this concern by showing that most of those heuristic defenses actually fail to defend against strong adaptive attacks. This forces us to shift our attention to certifiable defenses as they can classify all the samples in a predefined neighborhood of the natural samples with a theoretically-guaranteed error bound. Among all the existing certifiable defensive techniques, randomized smoothing is becoming increasingly popular due to its scalability to large datasets and arbitrary networks. [1] first relates adversarial robustness to differential privacy, and proves that adding noise is a certifiable defense against adversarial examples. [2] connects adversarial robustness with the concept of Rényi divergence, and improves the estimate on the lower bounds of the robust radii. Recently, [11] successfully certifies accuracy on the original ImageNet dataset under adversarial perturbations with norm less than .
Despite these successes, there are still several unanswered questions regarding randomized (smoothing) mechanisms***In this paper, “randomized mechanism” is an abbreviation for “randomized smoothing mechanism”.. One such question is, why should we use the Gaussian mechanism for randomized smoothing to certify -norm robustness, or is there any more appropriate mechanism than the Gaussian mechanism? Another important question is regarding the ability of this method to certify -norm robustness. If randomized smoothing can certify -norm robustness, what mechanism is an appropriate choice? All these questions motivate us to develop a framework to assess the appropriateness of a randomized mechanism for certifying -norm robustness.
In this paper, we take a promising step towards answering the above questions by proposing a generic and self-contained framework, which applies to different norms and connects the existing frameworks in [1, 2], for assessing randomized mechanisms. Our framework employs the Maximal Relative Rényi (MR) divergence as the probability distance measurement, and thus, the definition of robustness under this measurement is referred to as robustness. Under our framework, we define the magnitude (i.e., the expected -norm) of the noise required by a mechanism to certify a certain extent of robustness as the metric for assessing the appropriateness of this mechanism. To be specific, a more “appropriate” randomized mechanism under this definition refers to a mechanism that can certify a certain extent of robustness with “less” additive noise. Given this definition, it is natural to define the assessment criteria as the lower bounds on the magnitude of the noise required to certify -norm () robustness, in that we can judge whether a mechanism is an appropriate option based on the gap between the magnitude of noise needed by the mechanism and the lower bounds.
Inspired by the theory regarding the lower bounds on the sample complexity to estimate one-way marginals in differential privacy, we prove lower bounds on the magnitude of additive noise required by any randomized smoothing mechanism to certify -norm and -norm robustness. We demonstrate the gap between the magnitude of Gaussian noise required by the Gaussian mechanism and the lower bounds is only for both -norm and -norm, where is the dimensionality of the data. Note that this gap is small for datasets like CIFAR-10 and ImageNet, which indicates that the Gaussian mechanism is an appropriate option for certifying -norm or -norm robustness. Moreover, we also show that the Exponential mechanism is not an appropriate option for certifying -norm robustness since the gap scales in . To summarize, our contribution is four-fold:
- •
-
•
We define a metric for assessing randomized mechanisms, i.e., the magnitude of the additive noise to certify adversarial robustness, and we derive the lower bounds on the magnitude of the additive noise to certify -norm and -norm robustness as the criteria for the assessment. Also, we extend this assessment framework to -norm for any in Appendix, which indicates the curse of dimensionality on randomized smoothing for certifying -norm () robustness.
-
•
We assess the Gaussian mechanism and the Exponential mechanism based on the metric and the lower bounds (i.e., the criteria). We conclude that the Gaussian mechanism is an appropriate option to certify -norm and -norm robustness, and the Exponential mechanism is not an appropriate option for certifying -norm robustness here.
- •
Due to the space limit, all the omitted proofs and some experimental results are included in Appendix (in the supplementary material).
2 Related Work
To our knowledge, there are mainly three approaches to certify adversarial robustness standing out. The first approach formulates the task of adversarial verification as an optimization problem and solves it by tools like convex relaxations and duality [12, 13, 14]. Given a convex set (usually an ball) as input, the second approach maintains an outer approximation of all the possible outputs at each layer by various techniques, such as interval bound propagation, hybrid zonotope, abstract interpretations, and etc. [15, 16, 17, 18, 19]. The third approach uses randomized smoothing to certify robustness, which is the main focus of this paper. Randomized smoothing for certifying robustness becomes increasingly popular due to its strong scalability to large datasets and arbitrary networks [1, 20, 11, 12, 21]. For this approach, [1] first proves that randomized smoothing can certify the and -norm robustness using the differential privacy theory. [20] derives a tighter lower bound on the -norm robust radius based on a lemma on Rényi divergence. [11] further obtains a tight guarantee on the -norm robustness using the Neyman-Pearson lemma. [22] proposes a new framework based on f-divergence that applies to different measures. [21] combines [11] with adversarial training, and [23] extends the method in [11] to the top-k classification setting. We note that, compared with [11], the frameworks proposed in [1, 2] are more general. In the following, we briefly review the basic definitions and theorems in the frameworks of [1, 2], which helps us demonstrate the inherent connections between our framework and those two frameworks [1, 2].
3 Preliminaries
In this section, we first introduce several basic definitions and notations. In general, we denote any randomized mechanism by , which outputs a random variable depending on the input. We represent any deterministic classifier that outputs a prediction label by . A commonly-used randomized classifier can be constructed by . We denote a data sample and its label by and , respectively. An -norm ball centered at with radius is represented by . We say a data sample is in the iff . Next, we can detail the frameworks in [1] and [2], i.e., PixelDP and Rényi Divergence-based Bound.
PixelDP
To the best of our knowledge, PixelDP [1] is the first framework to prove that randomized smoothing is a certified defense by connecting the concepts of adversarial robustness and differential privacy. The definition of adversarial robustness in the framework of PixelDP can be stated as follows:
Definition 1 (PixelDP [1])
For any and , if a randomized mechanism satisfies
| (1) |
where denotes the output space of . Then we can say is -PixelDP (in ).
[1] connects PixelDP with adversarial robustness by the following lemma.
Lemma 1 (Robustness Condition [1])
Suppose is randomized K-class classifier defined by that satisfies -PixelDP (in ). For class , if
| (2) |
then the classification result is robust‡ ‣ 4.3 in , i.e., , .
Note that the definition of the randomized classifier is different from the definition of since the output of is a scalar not a vector (prediction label). is more popular in the follow-up works such as [2, 11]. [1] mainly utilizes two mechanisms, i.e., the Laplace mechanism and Gaussian mechanism, to guarantee PixelDP. Specifically, adding Laplace noise (i.e., ) to the data samples can certify -PixelDP in for any , and adding Gaussian noise (i.e., ) can certify -PixelDP in for any .
Rényi Divergence-based Bound
Lemma 2 (Rényi Divergence Lemma [2])
Let and be two multinomial distributions. If the indices of the largest probabilities do not match on and , then the Rényi divergence between and , i.e., †††For , is defined as ., satisfies
where and refer to the largest and the second largest probabilities in , respectively.
If the Gaussian mechanism is applied to certify -norm robustness, then we have the following bound of the robust radii.
Lemma 3 ([2])
Let be any deterministic classifier and be its corresponding randomized classifier for sample , where . Then , , i.e., is robust in , and the robust radii that could be certified is given by
| (3) |
and refer to the largest and the second largest probabilities in , where is the probability that returns the -th class, i.e., .
4 Framework Overview
In this section, we present a generic framework based on the Definition 2, 3, and 4, for assessing randomized mechanisms. According to Definition 3, our framework applies to different norms. Moreover, we show that our proposed framework connects the existing general frameworks in [1, 2] by Theorem 4.1 & 4.2. Also, we note that it is difficult to involve the framework in [11] since [11] restricts the additive noise of the randomized mechanism to be isotropic such as Gaussian noise, while in our framework, we do not need to specify the type of additive noise.
4.1 Main Definitions
Under our framework, the definition of adversarial robustness is induced by maximal relative Rényi divergence (MR divergence), namely robustness, so we start from introducing the definition of MR divergence.
Definition 2 (Maximal Relative Rényi Divergence)
The Maximal Relative Rényi Divergence of distributions and is defined as
| (4) |
where is the Rényi Divergence between and . Using as the probability measure, we can define adversarial robustness as follows:
Definition 3 ( Robustness)
We say a randomized (smoothing) mechanism is -robust if for any and ,
| (5) |
If a randomized smoothing classifier satisfies the above condition, we can say it is a -robust classifier or it certifies -robustness.
A property of robustness we use throughout this paper is its postprocessing property, which can be stated as follows:
Corollary 1 (Postprocessing Property)
Let be a randomized classifier, where is any deterministic function (classifier). is -robust if is -robust.
This postprocessing property can be easily proved by for any [24]. This property allows us to only concentrate on the randomized mechanism without considering the specific form of the deterministic classifier , and therefore makes the framework applicable to an arbitrary neural network.
4.2 Connections between robustness and the existing frameworks
The framework defined by Definition 2 & 3 is generic since it is closely connected with the existing ones [1, 2]. Here we demonstrate the connections by the following two theorems.
Theorem 4.1 ( Robustness & PixelDP)
If is -robust, then is also -PixelDP in for any .
We note that the opposite of Theorem 4.1 holds only when , which indicates our framework is a relaxed version of the PixelDP framework. But this should not be a surprise since most of the following frameworks [2, 11, 22] can somehow be considered more relaxed than the PixelDP framework and thus yield tighter certified bounds. Similarly, our framework can provide the same bound on the robust radius as in [2], which is tighter than the bound in [1] (Theorem 4.2).
Theorem 4.2 ( Robustness & Rényi Divergence-based Bound)
If a randomized classifier is -robust, then we have , as long as
| (6) |
where and also refer to the largest and the second largest probabilities in , and is the probability that returns the -th class, i.e., . Based on the above theorem, we can derive the same robust radius as in Lemma 3 [2]. We will detail how to derive the robust radius after Theorem 5.1 in Section 5.
An interpretation of Theorem 4.1 and 4.2 is that, as long as we can use a randomized mechanism with a certain amount of noise to certify robustness, we can use the same mechanism with the same amount of noise to certify PixelDP and the Rényi Divergence-based bound. Thus, Theorem 4.1 and 4.2 indicate the assessment results based on the metric defined in Section 4.3 is very likely to generalize to the other frameworks.
4.3 Assessment of Randomized Mechanisms
Since there are infinite randomized mechanisms, a natural problem is to determine whether a certain randomized mechanism is an appropriate option to certify adversarial robustness. However, we note that all the previous work [2, 11, 21] overlook this problem and assume the Gaussian mechanism to be an appropriate mechanism for certifying -norm robustness without sufficient assessment. While in this paper, we attempt to provide a solution to this problem under our proposed framework. Specifically, we define a metric to assess randomized mechanisms as follows:
Definition 4
Specify a -norm, a robust radius , and an epsilon , the magnitude (expected -norm) of the additive noise required by a randomized mechanism to certify -robustness is defined as the metric to assess the appropriateness of .
We define this metric for assessing randomized mechanisms because the accuracy of neural networks tends to decrease as the magnitude of the noise added to the inputs increases. Note that if the magnitude of the noise required by a randomized classifier is too large, the accuracy of its predictions on clean samples will be very low, then robustness will be useless‡‡‡Certified robustness only guarantees the predictions of the perturbed samples and the predictions of their clean samples are the same.. Given the above metric, we also need criteria to assess the (relative) appropriateness of a randomized mechanism. In this paper, we employ the lower bounds on the magnitude of the noise required by any randomized mechanism to certify -robustness as the criteria. We consider a randomized mechanism as an appropriate option if the gap between the magnitude of the additive noise required by this mechanism and the corresponding lower bound is small. In the following, we will provide the lower bounds for -norm and -norm, i.e., the two most popular norms, and assess the appropriateness of the Gaussian and Exponential mechanisms for certifying -norm and -norm robustness. In Appendix, we generalize our framework to -norm for any .
5 Assessing Mechanisms for Certifying -norm Robustness
In this section, we first elaborate on how the Gaussian mechanism certifies robustness, and then provide the lower bound on the magnitude of the additive noise required by any randomized mechanism () to certify -norm robustness. By comparing the magnitude of the additive noise required by the Gaussian mechanism with the lower bound, we conclude that the Gaussian mechanism is an appropriate option to certify -norm robustness.
Theorem 5.1 (Gaussian Mechanism for Certifying -norm robustness)
Let be any deterministic classifier and be its corresponding randomized classifier for sample , where with . Then, is -robust.
According to Theorem 4.2, if we substitute with , can be given by which is same as the bound of the robust radii in [2] (Lemma 3). To provide a criterion for the assessment of randomized mechanisms in the -norm case, we prove a lower bound on the magnitude of the additive noise required by any randomized mechanism to ensure that (as well as ) is -robust. As mentioned in Section 4.3, if the magnitude of the additive Gaussian noise is close to the lower bound, then the Gaussian mechanism is considered as an appropriate option. The lower bound is given by the following theorem.
Theorem 5.2 (-norm Criterion for Assessment)
For any , if there is an -robust randomized mechanism that satisfies
| (7) |
for some , then it must be true that . In another word, is the lower bound of the (expected) magnitude of the additive random noise.
Note that proving this theorem on is non-trivial, which is detailed in Appendix. Theorem 5.2 indicates that the magnitude (expected -norm) of the additive noise should be at least to certify -robustness. For the Gaussian mechanism, the expected -norm of the additive noise is according to [25], which is to guarantee -robustness, according to Theorem 5.1. This means the gap between the magnitude of the noise required by the Gaussian mechanism and the lower bound is bounded by .
Remark 1
We say Gaussian mechanism is an appropriate option because the gap is small for most commonly-used datasets. For instance, for CIFAR-10 (), , and for ImageNet (), .
Equivalently, if we fix the expected -norm of the additive noise as , the radius that can be certified by any -robust randomized mechanism is upper bounded by , according to Theorem 5.2. For the Gaussian mechanism, since , the certified robust radius is §§§The theoretical results of the scales of the robust radii are verified by experiments., according to Theorem 5.1. This means the gap between the upper bound of the robust radius and the radius certified by the Gaussian mechanism is also .
6 Assessing Mechanisms for Certifying -norm Robustness
In this section, we first discuss the possibility of using the Exponential mechanism, an analogue of the Gaussian mechanism in the -norm case, to certify -norm robustness. Then, we prove the lower bound on the magnitude of the additive noise required by any randomized mechanism to certify -norm robustness. By comparing the magnitude of the noise required by the Exponential mechanism with the lower bound, we conclude that the Exponential mechanism is not an appropriate option to certify -norm robustness. Surprisingly, we find that the Gaussian mechanism is a more appropriate option than the Exponential mechanism to certify -norm robustness.
We first recall the form of the density function of Gaussian noise: . Based on this, we conjecture that, to certify -norm robustness, we can sample the noise using the Exponential mechanism, an analogue of the Gaussian mechanism in the -norm case:
| (8) |
We show in the following theorem that randomized smoothing using the Exponential mechanism can certify -robustness, which is seemingly an extension of the -norm case. However, its required magnitude of noise is , which implies it is unscalable to high-dimensional data, i.e., The Exponential mechanism should not be an appropriate mechanism to certify -norm robustness. This conclusion is further verified by our assessment method, which will be detailed later.
Theorem 6.1 (Exponential Mechanism for Certifying -norm Robustness)
Let be any deterministic classifier and be its corresponding randomized classifier for sample , where with sampled from the Exponential mechanism. Then, is -robust and also -robust.
According to Theorem 4.2, if we substitute with or , then can be given by or Comparing this result and Theorem 5.1, we can see that randomized smoothing via the Exponential mechanism certifies a similar form of the radius as that certified by the Gaussian mechanism in the -norm case, indicating similarity in their robustness guarantees. However, the following corollary shows that the magnitude of the noise required by the Exponential mechanism is much larger than that of the Gaussian mechanism in the -norm case.
Corollary 2
For the Exponential mechanism that can guarantee Theorem 6.1,
Equivalently, if we fix the expected -norm of the additive noise as , according to Theorem 6.1 & Corollary 2, the robust radius certified by the Exponential mechanism is § ‣ 5. The following theorem shows that there is a huge gap between the additive noise required by the Exponential mechanism and the lower bound, indicating that the Exponential mechanism is indeed not an appropriate option for certifying -norm robustness here.
Theorem 6.2 (-norm Criterion for Assessment)
For any , if there is an -robust mechanism that satisfies
| (9) |
for some , then it must be true that . In another word, is the lower bound of the (expected) magnitude of the additive random noise.
According to Corollary 2 and Theorem 6.1, for the Exponential mechanism, its required magnitude of noise is or to certify -robustness. Compared with Theorem 6.2, we can see that the gap between the magnitude of the noise required by the Exponential mechanism and the lower bound is , which can be very large for high-dimensional datasets. Therefore, we can conclude that the Exponential mechanism is probably not an appropriate mechanism for certifying -norm robustness. Surprisingly, the following theorem shows that the Gaussian mechanism is an appropriate choice for certifying -robustness.
Theorem 6.3 (Gaussian Mechanism for Certifying -norm robustness)
Let be some fixed number and with . Then, is -robust, and is upper bounded by .
From Theorem 6.2 and 6.3, we can see that the gap between the magnitude of the noise required by the Gaussian mechanism and the lower bound is also . Thus, we can say the Gaussian mechanism is an appropriate option to certify -norm robustness (see Remark 1). Equivalently, if we fix the expected -norm of the additive noise as , the certified robust radius is § ‣ 5.
Remark 2
Note that in the previous sections, we only consider -norm and -norm and the corresponding mechanisms because they are the two most important norms. But actually, we can extend our framework to -norm for any . See Section D in Appendix.
7 Experiments
Datasets and Models
Our theories are verified on two widely-used datasets, i.e., CIFAR10 and ImageNet¶¶¶Pixel value range is . We follow [11, 21] to use a 110-layer residual network and a ResNet-50 as the base models for CIFAR10 and ImageNet. The certified accuracy for radius is defined as the fraction of the test set whose certified radii are larger than , and predictions are correct. We note that the lower bounds (criteria) are not verifiable by experiments since we are still not sure if there exist any randomized mechanism that can achieve those lower bounds. So in the following, we mainly verify the theoretical results regarding the Gaussian mechanism and the Exponential mechanism. We provide more details about the numerical method (to compute the robust radii) and more experimental results compared to the other frameworks in Appendix in the supplementary material.
Empirical Results
In the following, we verify our framework by comparing our theoretical results of the robust radii with the radii at which the Gaussian/Exponential mechanism can certify accuracy in the experiments. Note that in the previous literature, robust accuracy is considered as a reasonably good performance [26, 11]. Besides, selecting another reasonable accuracy does not affect the verification results too much because what our theories characterize are the asymptotic behaviors rather than the exact values of the robust radii.
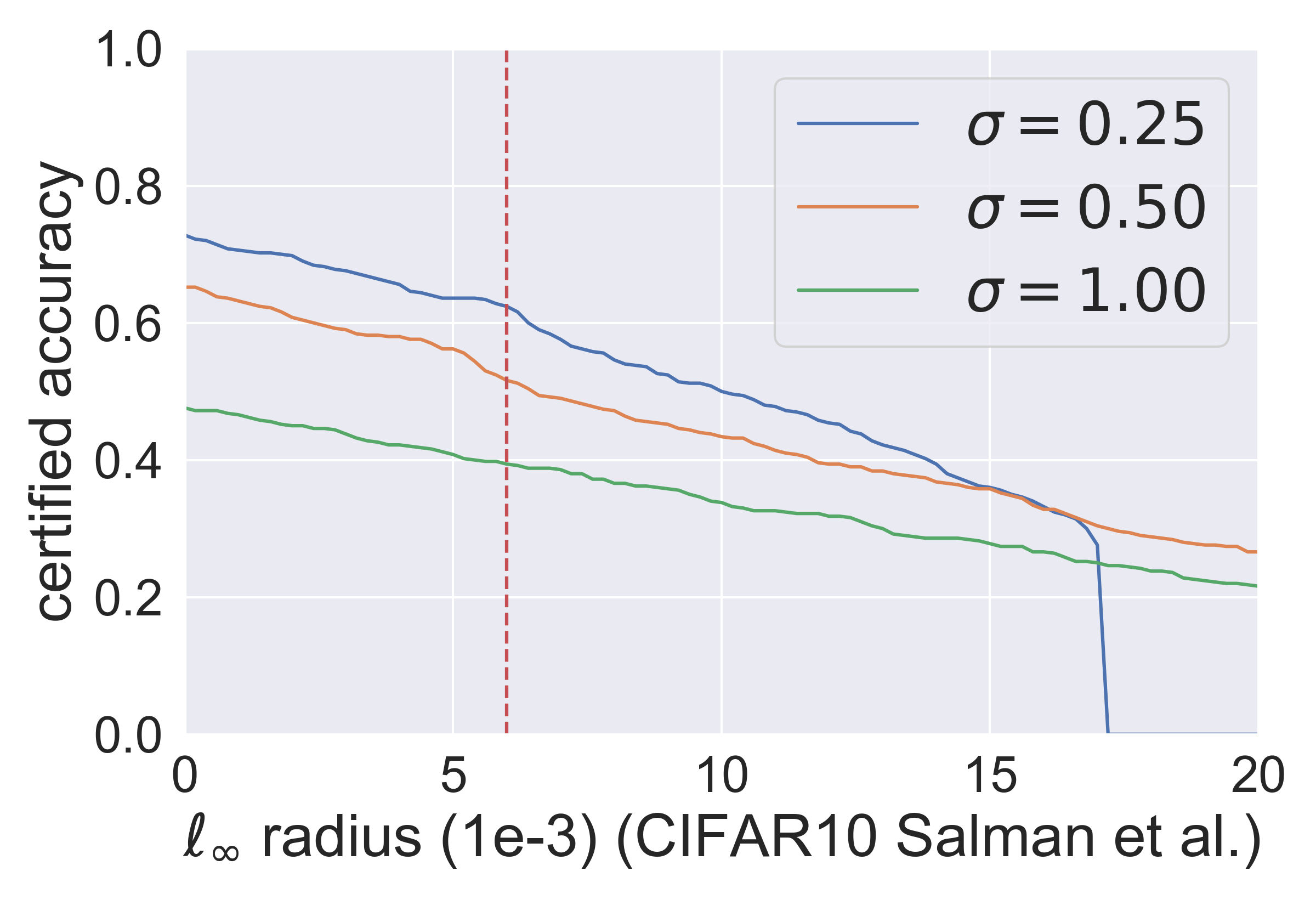
In Fig. 1, we demonstrate the results of the Gaussian mechanism for certifying -norm robustness. The red dashed lines show that the Gaussian mechanism can certify accuracy at (CIFAR-10, ) and (ImageNet, ), i.e., approximately . These results verify that the radius certified by the Gaussian mechanism is ∥∥∥, and (equality can hold).. We also argue that, is the scale of the largest certified radius (i.e., [11]) in the previous literature since the -norm of the Gaussian noise is . This argument is verified by Fig. 3 & 4 in Appendix.
Fig. 2 (1&3 subfigures) shows that the Gaussian mechanism certifies accuracy at on CIFAR-10 () and on ImageNet (), i.e., approximately . These results verify that the radius certified by the Gaussian mechanism is . Fig. 2 (2&4 subfigures) also shows that the Exponential mechanism certifies approximately accuracy at on CIFAR-10 and on ImageNet, i.e., approximately . These results verify that the robust radius certified by the Exponential mechanism scales in or . If we compare the performance of the Gaussian mechanism and the Exponential mechanism in Fig. 2, we can see that the Gaussian mechanism is a much more appropriate option for certifying -norm robustness. It is worth noting that the performance of the Gaussian mechanism can be better with the bound proved in [11], which is comparable to the other state-of-the-art approaches introduced in Section 2. We detail some results regarding the comparison in Appendix.







8 Conclusion
In this paper, we present a generic and self-contained framework, which applies to different norms and connects the existing frameworks such as [1, 2], for assessing randomized mechanisms. Under our framework, we define the magnitude of the noise added by a randomized mechanism to certify a certain extent of robustness as the metric for assessing this mechanism. We also provide the general lower bounds on the magnitude of the additive noise as the assessment criteria. Comparing the noise required by the Gaussian and Exponential mechanism and the lower bounds, we conclude that (i) The Gaussian mechanism is an appropriate option to certify -norm and -norm robustness. (ii) The Exponential mechanism is not an appropriate mechanism to certify -norm robustness. Moreover, we extend our assessment framework to -norm for any .
References
- [1] Mathias Lecuyer, Vaggelis Atlidakis, Roxana Geambasu, Daniel Hsu, and Suman Jana. Certified robustness to adversarial examples with differential privacy. arXiv preprint arXiv:1802.03471, 2018.
- [2] Bai Li, Changyou Chen, Wenlin Wang, and Lawrence Carin. Certified adversarial robustness with additive noise. In Advances in Neural Information Processing Systems, pages 9459–9469, 2019.
- [3] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
- [4] Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
- [5] David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature, 529(7587):484–489, 2016.
- [6] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013.
- [7] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- [8] Warren He, James Wei, Xinyun Chen, Nicholas Carlini, and Dawn Song. Adversarial example defense: Ensembles of weak defenses are not strong. In 11th USENIX Workshop on Offensive Technologies (WOOT 17), 2017.
- [9] Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. arXiv preprint arXiv:1802.00420, 2018.
- [10] Jonathan Uesato, Brendan O’Donoghue, Pushmeet Kohli, and Aaron Oord. Adversarial risk and the dangers of evaluating against weak attacks. In International Conference on Machine Learning, pages 5032–5041, 2018.
- [11] Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. Certified adversarial robustness via randomized smoothing. In International Conference on Machine Learning, pages 1310–1320, 2019.
- [12] Krishnamurthy Dvijotham, Robert Stanforth, Sven Gowal, Timothy A Mann, and Pushmeet Kohli. A dual approach to scalable verification of deep networks. In UAI, pages 550–559, 2018.
- [13] Aditi Raghunathan, Jacob Steinhardt, and Percy Liang. Certified defenses against adversarial examples. arXiv preprint arXiv:1801.09344, 2018.
- [14] Eric Wong and Zico Kolter. Provable defenses against adversarial examples via the convex outer adversarial polytope. In International Conference on Machine Learning, pages 5283–5292, 2018.
- [15] Matthew Mirman, Timon Gehr, and Martin Vechev. Differentiable abstract interpretation for provably robust neural networks. In International Conference on Machine Learning, pages 3575–3583, 2018.
- [16] Shiqi Wang, Kexin Pei, Justin Whitehouse, Junfeng Yang, and Suman Jana. Efficient formal safety analysis of neural networks. In Advances in Neural Information Processing Systems, pages 6367–6377, 2018.
- [17] Sven Gowal, Krishnamurthy Dvijotham, Robert Stanforth, Rudy Bunel, Chongli Qin, Jonathan Uesato, Timothy Mann, and Pushmeet Kohli. On the effectiveness of interval bound propagation for training verifiably robust models. arXiv preprint arXiv:1810.12715, 2018.
- [18] Huan Zhang, Hongge Chen, Chaowei Xiao, Bo Li, Duane Boning, and Cho-Jui Hsieh. Towards stable and efficient training of verifiably robust neural networks. arXiv preprint arXiv:1906.06316, 2019.
- [19] Mislav Balunovic and Martin Vechev. Adversarial training and provable defenses: Bridging the gap. In International Conference on Learning Representations, 2020.
- [20] Bai Li, Changyou Chen, Wenlin Wang, and Lawrence Carin. Second-order adversarial attack and certifiable robustness. arXiv preprint arXiv:1809.03113, 2018.
- [21] Hadi Salman, Jerry Li, Ilya Razenshteyn, Pengchuan Zhang, Huan Zhang, Sebastien Bubeck, and Greg Yang. Provably robust deep learning via adversarially trained smoothed classifiers. In Advances in Neural Information Processing Systems, pages 11289–11300, 2019.
- [22] KD Dvijotham, J Hayes, B Balle, Z Kolter, C Qin, A Gyorgy, K Xiao, S Gowal, and P Kohli. A framework for robustness certification of smoothed classifiers using f-divergences. In International Conference on Learning Representations, 2020.
- [23] Jinyuan Jia, Xiaoyu Cao, Binghui Wang, and Neil Zhenqiang Gong. Certified robustness for top-k predictions against adversarial perturbations via randomized smoothing. arXiv preprint arXiv:1912.09899, 2019.
- [24] Tim Van Erven and Peter Harremos. Rényi divergence and kullback-leibler divergence. IEEE Transactions on Information Theory, 60(7):3797–3820, 2014.
- [25] Francesco Orabona and Dávid Pál. Optimal non-asymptotic lower bound on the minimax regret of learning with expert advice. arXiv preprint arXiv:1511.02176, 2015.
- [26] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017.
- [27] Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data analysis. In Theory of cryptography conference, pages 265–284. Springer, 2006.
- [28] Ilya Mironov. Rényi differential privacy. In 2017 IEEE 30th Computer Security Foundations Symposium (CSF), pages 263–275. IEEE, 2017.
- [29] Thomas Steinke and Jonathan Ullman. Between pure and approximate differential privacy. Journal of Privacy and Confidentiality, 7(2), 2016.
- [30] Mark Bun and Thomas Steinke. Concentrated differential privacy: Simplifications, extensions, and lower bounds. In Theory of Cryptography Conference, pages 635–658. Springer, 2016.
- [31] Thomas Steinke and Jonathan Ullman. Between pure and approximate differential privacy. arXiv preprint arXiv:1501.06095, 2015.
To make the paper more readable, we first review some definitions about differential privacy [27].
Definition 5
Given a data universe , we say that two datasets are neighbors if they differ by only one entry, which is denoted by . A randomized algorithm is -differentially private (DP) if for all neighboring datasets and all events the following holds
Definition 6
A randomized algorithm is -Rényi differentially private (DP) if for all neighboring datasets the following holds
Appendix A Omitted Proofs in Section 4
Proof [Proof of Theorem 4.1] According to Definition 2, for a fixed , we have and any ,
Therefore, satisfies -Rényi DP (, and, ). According to the following lemma, i.e.,
Lemma 4 ([28])
If a randomized mechanism is -Rényi DP, then it is -DP for any (we substitude with ),
Appendix B Omitted Proofs in Section 5
Proof [Proof of Theorem 5.1] By the postprocessing property we just need to show is robust.
Fix any , we have for any and
Proof [Proof of Theorem 5.2] We first show that, in order to prove Theorem 5.2, we only need to prove Theorem B.1. Then we show that, to prove Theorem B.1, we only need to prove Theorem B.2. Finally, we give a formal proof of Theorem B.2.
Theorem B.1
For any , if there is a randomized (smoothing) mechanism such that for any ,
for some . Then it must be true that .
For any , in Theorem B.1, we only consider the expected -norm of the noise added by on . Thus, the in Theorem B.1 should be less than or equal to the in Theorem 5.2 (on ). Therefore, the lower bound for the in Theorem B.1 (i.e., ) is also a lower bound for the in Theorem 5.2. That is to say, if Theorem B.1 holds, then Theorem 5.2 also holds true.
Theorem B.2
For any , if there is a -robust randomized (smoothing) mechanism ******This mechanism might not be simply since it must involve operations to clip the output into such that for any
for some . Then it must be true that .
For any considered in Theorem B.1, there exists a -robust randomized mechanism considered in Theorem B.2 such that for all
To prove the above statement, we first let and , where is a coordinate-wise operator. Now we fix the randomness of (that is is deterministic), and we assume that , . If , then by the definitions, we have . If , then we have . Since and , . . Thus, .
Then, we let where is also a coordinate-wise operator. We can use a similar method to prove that . Also, we can see that , which means is also -robust randomized mechanism due to the postprocessing property.
Since , and is a randomized mechanism satisfying the conditions in Theorem B.2, the in Theorem B.2 should be less than or equal to the in Theorem B.1. Therefore, the lower bound for the in Theorem B.2 (i.e., ) is also a lower bound for the in Theorem B.1. That is to say, if Theorem B.2 holds, then Theorem B.1 also holds.
Finally, we give a proof of Theorem B.2.
Since is -robust on , and for any , (i.e., ), is -PixelDP on , according to Theorem 4.1. Thus, we also have is DP on the database .
Then let us take use of the above condition by connecting the lower bound of the sample complexity to estimate one-way marginals (i.e., mean estimation) for DP mechanisms with the lower bound studied in Theorem B.2. Suppose an -size dataset , the one-way marginal is , where is the -th row of . In particular, when , one-way marginal is just the data point itself, and thus, the condition in Theorem B.2 can be rewritten as
| (10) |
Based on this connection, we first prove the case where , and then generalize it to any . For , the conclusion reduces to . To prove this, we employ the following lemma, which provides a one-way margin estimation for all DP mechanisms.
Lemma 5 (Theorem 1.1 in [29])
For any , every and every , if is -DP and , then we have
Setting in Lemma 5, we can see that if , then we must have
where the last inequality is due to the fact that , since . Therefore, we have the following theorem,
Theorem B.3
For any , if there is a -robust randomized mechanism satisfies that for all
| (11) |
for some . Then , i.e., .
Appendix C Omitted Proofs in Section 6
Proof [Proof of Theorem 6.1] We first prove that for all . Since , for any ,
Since
, is -robust. Also, based on the following lemma,
Lemma 6 ([30])
Let and be two probability distributions satisfying and . Then, ,
we have , i.e., is -robust.
Proof [Proof of Corollary 2] Define the distribution on to be , meaning for , where is defined in Eq.(8). The probability density function of is given by
which is obtained by integrating the probability density function in Eq. (8) over the infinity ball of radius with surface area . is the Gamma distribution with shape and mean , and thus .
Proof [Proof of Theorem 6.2] Similar to the proof of Theorem 5.2, in order to prove Theorem 6.2, we only need to prove the following theorem:
Theorem C.1
For any , if there is a robust randomized (smoothing) mechanism such that for any , the following holds
for some . Then it must be true that .
Since is -robust on , and for any , (i.e., ), is -PixelDP on , according to Theorem 4.1. Thus, we also have is DP on the database .
We first consider the case where . By setting and in Lemma 5, we have a similar result as in Theorem B.3:
Theorem C.2
For any , if there is a -robust randomized mechanism satisfies that for all
| (13) |
for some . Then .
Appendix D Extension to -norm robustness for Any
In previous sections, we studied -norm and -norm robustness. As we mentioned earlier, our framework can be applied to general norm. In this section, we will study the general -norm robustness with . Just as the previous sections, here we first investigate the -norm criteria for assessment.
Theorem D.1
Given , for any , if there is a randomized (smoothing) mechanism such that
for some . Then it must be true that . Note that when , according to Theorem 6.2,
Proof [Proof of Theorem D.1] The proof is also almost the same as that of Theorem 5.2. Following the proof of Theorem 5.2, we can only constrain on the case where .
Since is -robust on , and for any , (i.e., ), is -PixelDP on , according to Theorem 4.1. Thus, we can also say is DP on the database .
We first consider the case where , then we extend to the general case. When , by setting and in Lemma 5, we have the following theorem, similar to Theorem B.3.
Theorem D.2
For any , if a -robust randomized mechanism satisfies that for all
| (14) |
for some . Then .
For general , similar to the proof of Theorem B.2, we substitute with and construct as . Since satisfies
then we have
Also, is -robust since is -robust. This is because , and since for any . Considering in Theorem D.1 with , we have
Thus we have .
Remark 3
First, we can see that when , Theorem D.1 is the same as Theorem 5.2. Thus, we can see it as a generalization of the previous theorems. Second, Theorem D.1 indicates that, to certify a certain extent of robustness, the magnitude of the noise we add should be at least , which can be quite large for high dimensional datasets. This means that for -norm robustness with , as a defensive method, the random smoothing method is not very scalable to high dimensional data, i.e.,, we can call it as the curse of dimensionality on randomized smoothing for certifying robustness. Note that if , then the as . Therefore, the lower bound is useful when .
In the following theorem, based on the above criteria for -norm, we show that the Gaussian mechanism is an appropriate option for certifying -norm robustness. This is because the gap between the criteria and the magnitude of the additive noise required by the Gaussian mechanism is bounded by .
Theorem D.3 (Gaussian Mechanism for Certifying -norm robustness)
Let be some fixed number and with . Then, is -robust, and is upper bounded by .
Appendix E Additional Details & Results
E.1 Numerical Method
We first detail the numerical method for the experiments in the following. The core algorithm is detailed in Alg. 1. We follow [11] to conduct evaluations on 500 testing samples from CIFAR10 and ImageNet, and we set for CIFAR-10 and for ImageNet in Alg. 1. Also, we refer the interested readers to our code for more technical details.
Here we highlight the sampling method for the Exponential mechanism, which is not detailed in [2, 11]. Due to the high dimensionality of samples in real world applications, directly sampling as in Eq. 8 by the Markov Chain Monte Carlo (MCMC) algorithm requires a large number of random-walks that can incur high computational cost. To alleviate this issue, we adopt an efficient sampling method from [31] that first samples from and then samples from uniformly. The complexity of this sampling algorithm is only .
E.2 Additional Experiment Results
-norm Case
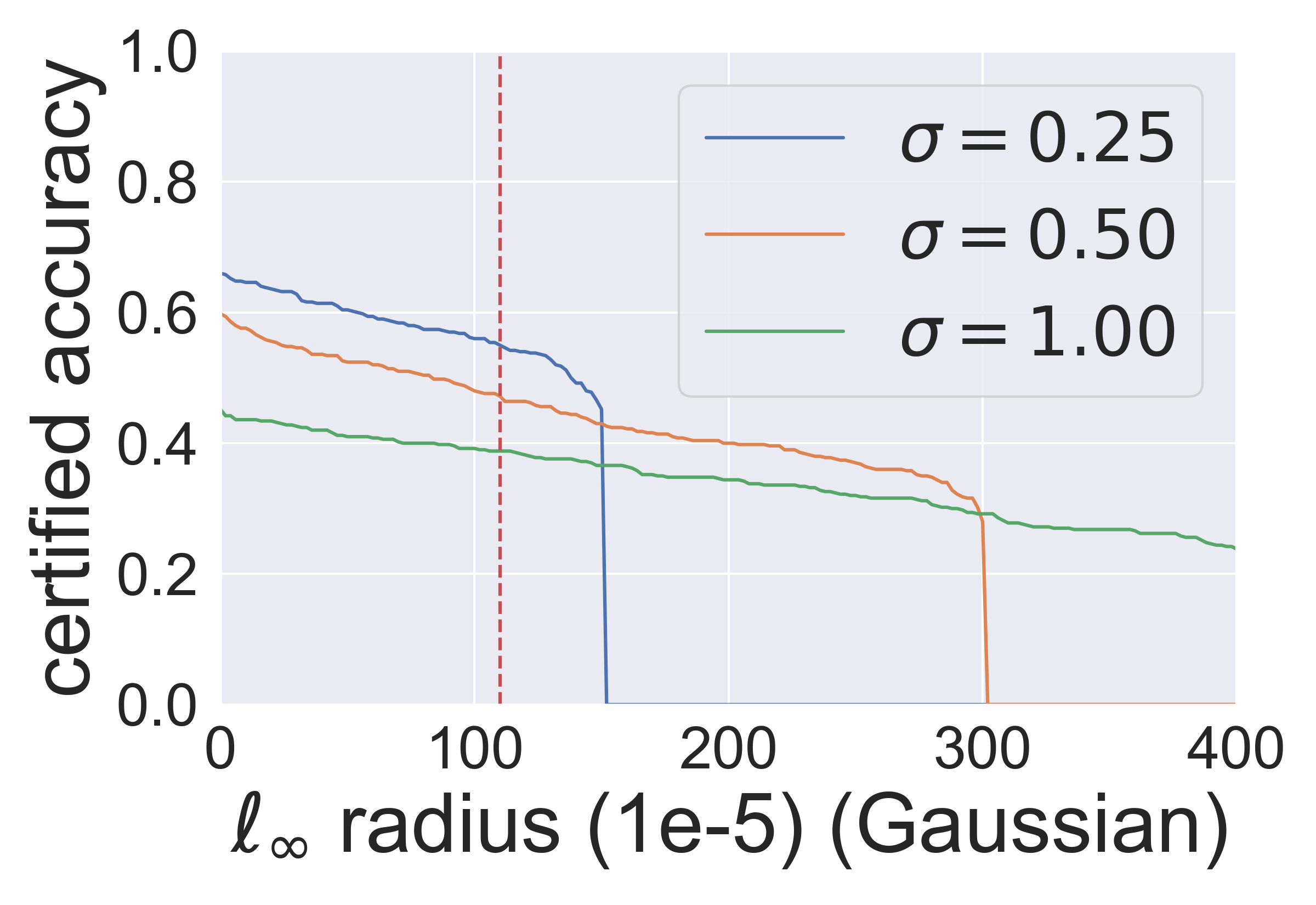
In Fig. 3, we can see that, although [11] proves a tighter bound than ours, it also certifies approximately accuracy at (CIFAR-10, ) and (ImageNet, ), i.e., . Even after using the advanced training method in [21], the scale of the robust radii is still , as shown in Fig. 4.


| Model | CIFAR-10 | (Original) ImageNet | ||
|---|---|---|---|---|
| Acc at 2/255 | Standard Acc | Acc at 1/255 | Standard Acc | |
| Cohen et al. [11] (Gaussian) | 47.0% | 74.8% () | 27.4% | 57.2% () |
| Framework (Gaussian) | 42.4% | 69.6% () | 24.6% | 45.2% () |
| Wong et al. [14] (Single model) | 53.9% | 68.3% | - | - |
| IBP [17] | 50.0% | 70.2% | - | - |
-norm Case
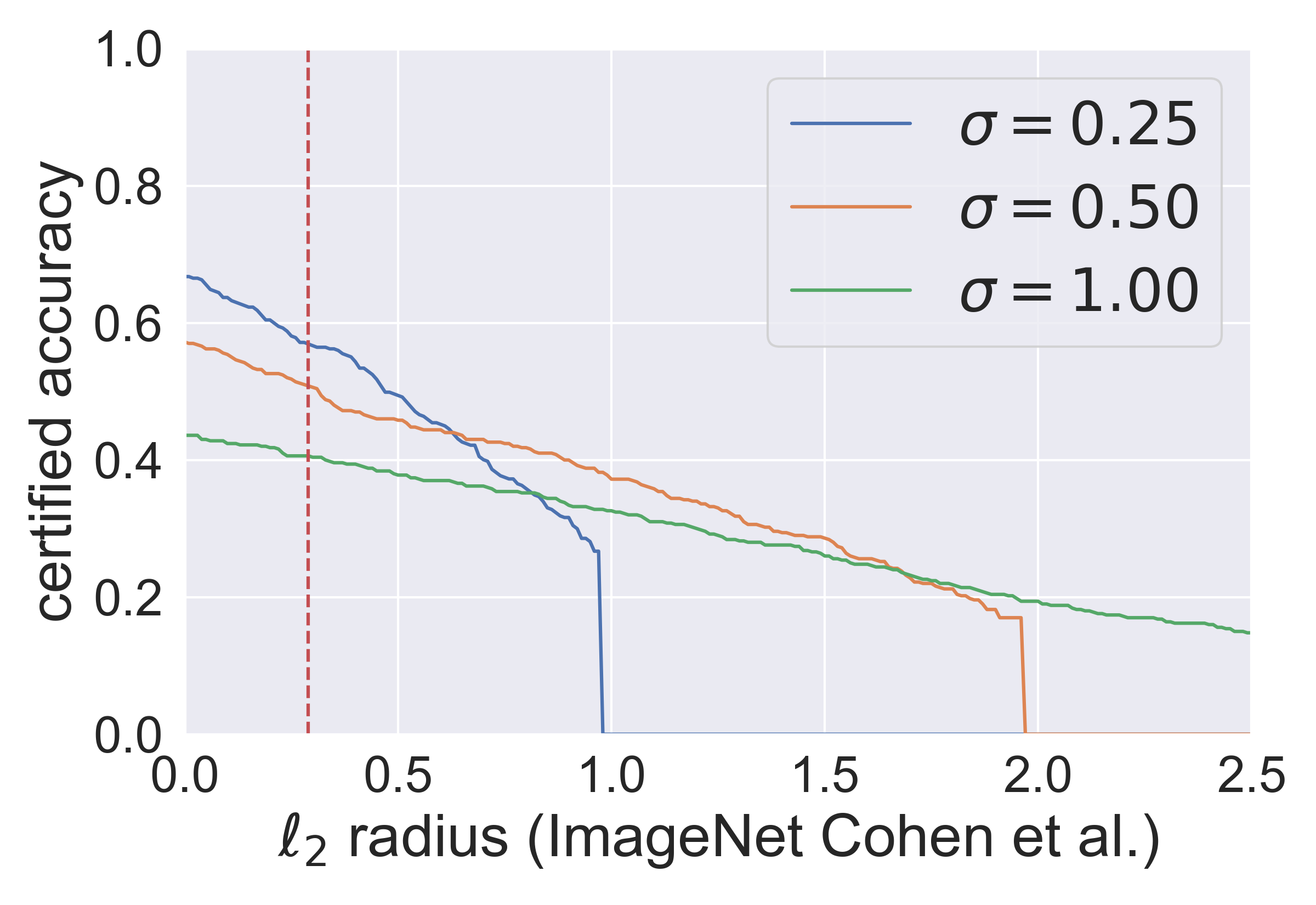
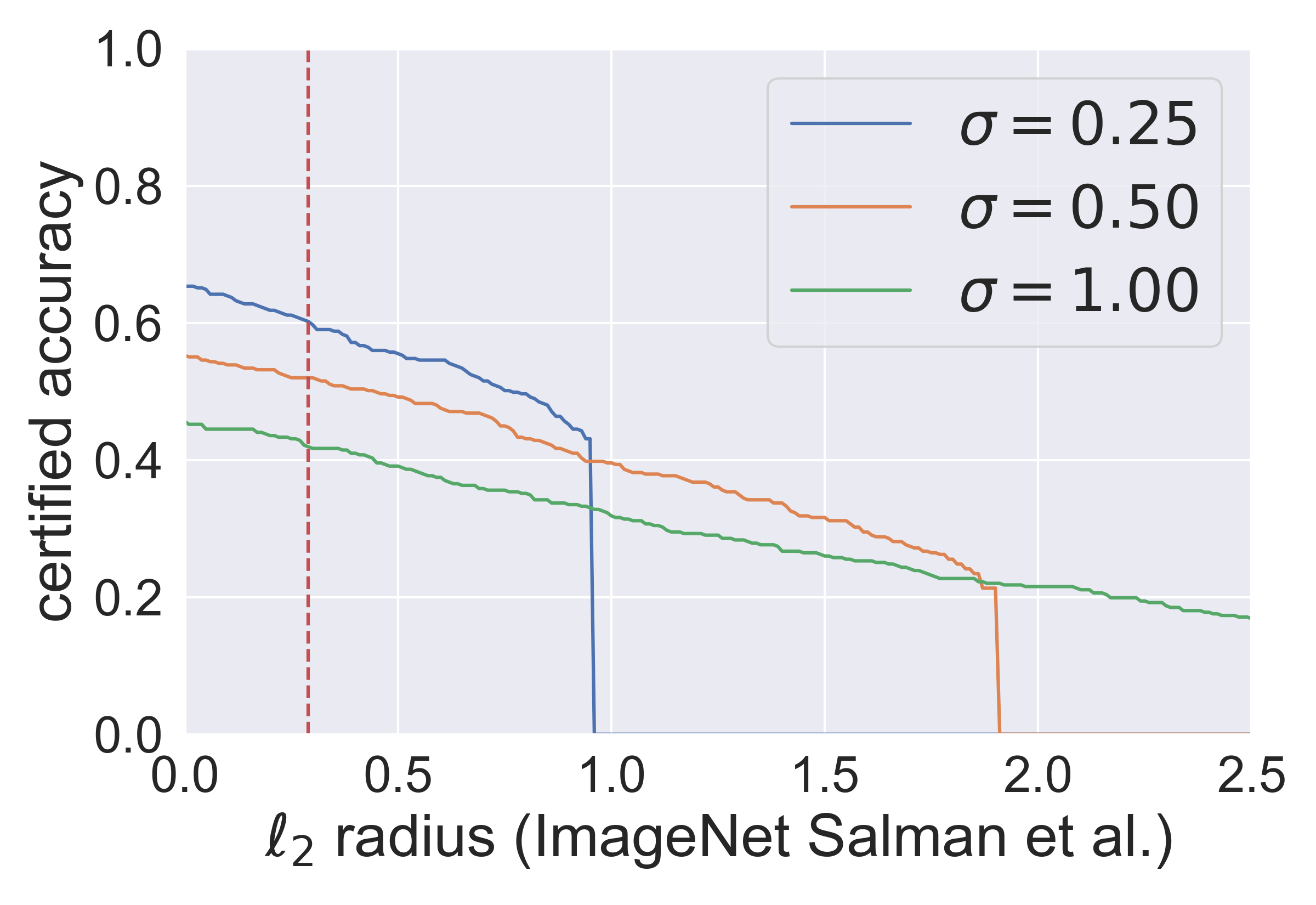
Note that it seems obvious that the Gaussian mechanism is an appropriate mechanism to certify -norm robustness since [11, 2, 21] have achieved the state-of-the-art certification results compared with the other methods in the -norm case. However, in the -norm case, it is a little counterintuitive that the Gaussian mechanism is also an appropriate choice, which performs much better than the Exponential mechanism. In the Table 1, we compare the -norm certification results of the Gaussian mechanism and the other two representative approaches. Although [11] and the framework perform slightly worse than [14] or [17] on CIFAR10, they are more scalable to high-dimensional datasets like ImageNet. So we can say their -norm certification results are comparable. Besides, in Fig. 5 & 6, we show that the Gaussian mechanism certifies approximately accuracy at on CIFAR-10 and on ImageNet, which are also approximately for both datasets.
All in all, the empirical results indicate the theorems proved under our framework are valid and very likely to generalize to the other frameworks.