Towards Analyzing and Mitigating Sycophancy in Large Vision-Language Models
Abstract
Large Vision-Language Models (LVLMs) have shown significant capability in vision-language understanding. However, one critical issue that persists in these models is sycophancy, which means models are unduly influenced by leading or deceptive prompts, resulting in biased outputs and hallucinations. Despite the progress in LVLMs, evaluating and mitigating sycophancy is yet much under-explored. In this work, we fill this gap by systematically analyzing sycophancy on various VL benchmarks with curated leading queries and further proposing a text contrastive decoding method for mitigation. While the specific sycophantic behavior varies significantly among models, our analysis reveals the severe deficiency of all LVLMs in resilience of sycophancy across various tasks. For improvement, we propose Leading Query Contrastive Decoding (LQCD), a model-agnostic method focusing on calibrating the LVLMs’ over-reliance on leading cues by identifying and suppressing the probabilities of sycophancy tokens at the decoding stage. Extensive experiments show that LQCD effectively mitigate sycophancy, outperforming both prompt engineering methods and common methods for hallucination mitigation. We further demonstrate that LQCD does not hurt but even slightly improves LVLMs’ responses to neutral queries, suggesting it being a more effective strategy for general-purpose decoding but not limited to sycophancy.
Introduction
Large Vision-Language Models (LVLMs) have attracted significant attention for their ability to understand and generate multimodal data by integrating textual and visual information. These models have been applied in diverse domains, showcasing impressive capabilities that push the boundaries of artificial intelligence (Zhang et al. 2024; Cui et al. 2024).
Despite their success, LVLMs are widely criticized for the hallucination problem (Liu et al. 2024b; Xiao et al. 2024), of which sycophancy (Sharma et al. 2024; Perez et al. 2023) is a key factor but has rarely been analyzed. Sycophancy refers to the phenomenon where a model tends to agree with the statement in input queries in unwanted ways (Sharma et al. 2024; Perez et al. 2023). It is a sort of model susceptibility, meaning that models are unduly influenced by text interference or deceptive prompts. As such, sycophancy often results in performance decreasing, bias and hallucination (Cui et al. 2023; Qian et al. 2024), as shown in Figure 1. In practice, sycophancy can lead to AI violating human ethics under deliberate inducement, causing biased and discriminatory output and severely impact the widespread real-world application of LVLMs. Thus, the need to evaluate and mitigate sycophancy in LVLMs is paramount.

While existing benchmarks focus on evaluating various types of hallucination of LVLMs, they typically employ neutral queries, and thus fail to assess the model’s robustness against sycophancy (Li et al. 2023b, 2024; Yu et al. 2024). Although some research has examined sycophancy in LLMs and find that finetuning and alignment techniques based on human feedback likely bring sycophancy in models (Sharma et al. 2024; Cui et al. 2023; Qian et al. 2024), studies about sycophancy in LVLMs are missing. Sycophancy in LVLMs is more complex than in LLMs due to the integration of visual knowledge. The additional visual and cross-modal fusion module often increase the instability of the model’s output and can also interfere with the results generated by the language module. For instance, the model’s attention to visual information often differs from the attention to texts, which adds the complexity of analyzing sycophantic behavior. Additionally, there is a notable absence of work for mitigating sycophancy in LVLMs.
This work thus conducts the first systematic analysis to sycophancy in LVLMs and additionally proposes a new method to mitigate sycophancy. We begin by curating leading queries for the popular VL datasets, such as POPE (Li et al. 2023b), AMBER (Wang et al. 2023a), RealwordQA (x.ai 2024), ScienceQA (Lu et al. 2022) and MM-Vet (Yu et al. 2024). Specifically, the leading queries are obtained by appending deceptive prompts to the original standard queries by prompting GPT-4V, accompanied with manula check and correction as needed. Note that we keep unchanged the original answers and ensure the deceptive prompts do not leak the answers.
With the edited queries, we extensively evaluate sycophancy of five prominent LVLMs, including Qwen-VL (Bai et al. 2023), CogVLM2 (Wang et al. 2023b), InternVL-1.5 (Chen et al. 2024a), LLaVA-NeXT (Liu et al. 2024a) and mPLUG-Owl-2.1 (Ye et al. 2024). The results reveal that leading query significantly exacerbates the sycophancy issue in these models. Concretely, all models show high chance of hallucination and their performance decline significantly. We also devise several new metrics to help discern the specific sycophantic behavior and find that different models exhibit varying characteristics of sycophancy. For example, the specific results of flipped predictions significantly vary among models when affected by the same sycophancy. Additionally, through sentiment analysis of the text, we find that for some models, leading queries with higher sentiment intensity are more likely to induce sycophancy.
To mitigate sycophancy, we propose Leading Query Contrastive Decoding (LQCD), a model-agnostic and training-free technique that highlights a corrective mechanism to calibrate the models’ over-reliance on leading cues. Specifically, LQCD suppresses the selection probability of hallucinatory tokens caused by sycophancy, by contrasting output token distributions of neutral and leading query during decoding. Through experiments and analysis, we show that LQCD effectively alleviates sycophancy for all LVLMs. Its performance on leading queries even surpasses that on neutral queries. Also, compared with popular prompt engineering techniques (e.g., chain-of-thought) and common methods for hallucination mitigation (e.g., Volcano (Lee et al. 2023)), LQCD shows superior performance with stronger robustness and less hallucination. Further studies demonstrate that LQCD does not degrade but even slightly improve performance in the context of neutral queries, showcasing it being a more effective approach for generation-purpose decoding but not limited to sycophancy.
To summarize our contributions:
-
•
We conduct the first study to sycophancy in LVLMs and construct datasets to facilitate study.
-
•
We systematically analyze the sycophancy phenomenon in top-performing LVLMs, revealing their severe deficiency in resilience of sycophancy and providing insights towards specific behaviors.
-
•
We propose the leading query contrastive decoding method. The method is model-agnostic and training-free; it can be integrated into different LVLMs for improving robustness towards sycophancy.
Related Work
Large Vision-Language Models
Inspired by the significant achievements of LLMs, researchers have developed a series of LVLMs by integrating them with visual pretraining models. A typical architecture consists of a visual encoder, an LLM, and a modality alignment module. The visual encoder often employs popular visual pretraining models (Han et al. 2022), while the LLM can utilize various popular models like Vicuna and LLaMA. The modality alignment module is finetuned using paired image-text data, endowing the model with visual dialogue capabilities. Some of the representative models that have garnered widespread attention include Qwen-VL, LLaVA, and CogVLM (Wang et al. 2023b; Liu et al. 2024a; Bai et al. 2023), and these are also baselines in our experiments. Due to issues related to network architecture, the quality of training data, and inherent problems within LLMs themselves, LVLMs face numerous challenges.
Hallucination of LVLMs and Sycophancy
Among the many flaws of LVLMs, the most prominent is the hallucination problem, which also exists in LLMs and is particularly severe in LVLMs. Existing research has analyzed the causes of hallucination (Liu et al. 2024b). Numerous new benchmarks are also proposed to evaluate the hallucination in LVLMs (Li et al. 2023b; Wu et al. 2024; Guan et al. 2024). Different types of hallucination exhibit different manifestations and require various mitigation strategies. Currently, research on alleviating hallucination in LVLMs focuses on three primary approaches: the first is prompt engineering (Mündler et al. 2024; Lee et al. 2023), the second is enhancing the model itself (Liu et al. 2023a; Jiang et al. 2023), and the third is post-processing of the results. This post-processing could involve new decoding strategies or using external tools like GroundingDINO (Liu et al. 2023b) to detect and eliminate hallucinations (Leng et al. 2024; Huang et al. 2024; Chen et al. 2024b).
Sycophancy is a significant cause of model hallucination. Some studies have reported that leading queries or prompts that are biased can interfere with the responses of LVLMs, indicating that the models often do not verify the prior statements in the queries and tend to agree with users (Cui et al. 2023; Qian et al. 2024). However, evaluating and mitigating for sycophancy are rarely studied. It remains unknown whether the aforementioned methods that have shown effective for alleviating object/attribute hallucinations, are capable of solving hallucinations in the context of leading queries. This gap thus underscores the need on related investigation, which is also the goal of this work.
Contrastive Decoding
The main idea of contrastive decoding is a commonly employed in image and text generation. For instance, in classifier-free diffusion models, a contrastive objective is used to estimate diffusion models (Ho and Salimans 2022). In text generation, there is often a significant performance difference between the two models being compared, such as an expert LLM and an amateur LLM (Li et al. 2023a). This method suppresses the amateur model’s errors to enhance overall performance. Similarly, in LVLMs, some works compare the results of the original image and a distorted image through contrastive decoding to mitigate the issue of hallucinations (Leng et al. 2024). The key difference in our approach is that we do not employ multiple models nor do we perform any processing on the images. Instead, we achieve better performance by constructing differences between texts, thereby alleviating the sycophancy problem.
Dataset Construction
Benchmarks Task Type Size POPE Object Hallucination 9,000 AMBER Attribute & Relation Hallucination 1,4000 RealworldQA Realworld Understanding 765 ScienceQA Knowledge & Reasoning 2,017 MM-Vet Integrated Capabilities 218
In this section, we construct specifically datasets to comprehensively and systematically evaluate sycophancy phenomenon in LVLMs. We select five popular Visual Question Answering (VQA) datasets, and then edit and extend the question text to inject leading and deceptive information for sycophancy evaluation.
Data Source.
We select and extend five datasets to evaluate sycophancy in LVLMs, as shown in Table 1. Considering that sycophancy is an factor of hallucination, we select two popular datasets POPE (Li et al. 2023b) and AMBER (Wang et al. 2023a) which are proposed to evaluate hallucination. Meanwhile, we also select three VQA datasets RealworldQA (x.ai 2024), ScienceQA (Lu et al. 2022) and MM-Vet (Yu et al. 2024) to evaluate the effect of sycophancy on commonsense comprehension and complex multimodal tasks. POPE (Li et al. 2023b) is designed to assess object hallucination in LVLMs through yes-or-no questions regarding the presence of objects in images. POPE is divided into three settings: random, popular, and adversarial, indicating different methods of sampling hallucination objects. AMBER (Wang et al. 2023a) is a comprehensive benchmark designed to evaluate the hallucination performance of LVLMs. In our experiments, AMBER is mainly used for analyzing the attribute hallucination and relation hallucination. RealworldQA (x.ai 2024) is designed to evaluate the real-world spatial understanding capabilities of large multimodal models. ScienceQA (Lu et al. 2022) is designed for evaluating multimodal reasoning in science question answering. MM-Vet (Yu et al. 2024) is designed to assess the integrated capabilities of LVLMs based on 16 complex multimodal tasks, focusing on six core vision-language capabilities: recognition, optical character recognition (OCR), knowledge, language generation, spatial awareness, and math.

Leading Query Generation.
Queries in these above-mentioned datasets are neutral without explicit misleading cues. Thus, the neutral queries are incapable of assessing the specific impact of sycophancy. In this work, we edit and expand the dataset with specially designed leading queries to inject misleading information, as shown in Figure 2. For POPE and AMBER datasets, the questions are closed, requiring a binary YES or NO answer, such as “Is there a dog in the image?”. We simply add a biased and misleading supplementary clause, for example, “Is there a dog in the image? It seems like there isn’t.”, transforming the original neutral query into a corresponding leading query.
For RealworldQA and ScienceQA, the questions are multiple-choice, requiring a definitive answer from a set of given options. For these types of queries, we similarly construct leading queries by providing a specific biased option. For example, given a query “How many pedestrians are there?”, we can give a specific wrong answer “How many pedestrians are there? It looks like there are 5.” as the corresponding leading query. For MM-Vet VQA tasks, considering the questions of MM-Vet VQA tasks are open without options, we construct a why-question containing an incorrect answer. The why-question bring misleading and deceptive information in a implicit way, which is more natural to verify whether the LVLM will be influenced by the prior information embedded in the leading query. For instance, for the original question “How many ducks are there in the image?” and the answer six, we create a leading query “Why are there five ducks in the image?” to test whether the model will detect the mistakes in the question. We designed specific prompt templates and use GPT-4 to transform neutral queries into leading queries. All leading queries are crafted to be misleading in the opposite direction of the ground truth. We also ensure a rich variety in tone and wording through few-shots prompt engineering.
Leading Query Contrastive Decoding
In this section, we propose a method called Leading Query Contrastive Decoding to alleviate sycophancy. Sycophancy can be problematic as it biases the output, potentially leading to less accurate or relevant results. Leading query can aggravate sycophancy since a leading query essentially amplifies language priors in a certain fixed direction, thereby reducing the model’s sensitivity to visual perception. Thus, to mitigate sycophancy in LVLMs, we need to calibrates the model’s over-reliance on language priors of leading queries. To achieve this goal, it is necessary to suppress the token probability of incorrect answers caused by sycophancy. Inspired by (Li et al. 2023a; Leng et al. 2024), we designed this suppress mechanism based on contrastive decoding, and propose Leading Query Contrastive Decoding. During decoding stage of LVLMs, LQCD contrasts output token distributions of generated neutral query and leading query, as shown in Figure 3. Therefore, the over-reliance on language priors of leading queries can be removed, so as to suppress the token probability of sycophancy answers and highlight the expected neutral answers.
Contrastive Objective

Specifically, given a textual leading query and a visual input , we firstly generate transformed neutral query corresponding to by using LLM. Then LVLM model generates two distinct output distribution conditioned on the leading query and conditioned on the transformed neutral query . The contrastive probability distribution of LQCD is computed by exploiting the differences between the two obtained distributions, formulated as:
where is a weight hyperparameter, is the resulting token distribution, denotes the model parameters. Larger value signifies a greater amplification of disparity between the two distributions (where = 0 corresponds to regular decoding). The objective enhance token probability favored by the neutral query output and suppress token probability favored by leading query output.
Adaptive Plausibility Constraint
However, leading query output are not always mistaken: except the hallucination caused by sycophancy, the output still capture many simple aspects of grammar and common sense. Thus, penalizing all tokens from leading query output indiscriminately would penalize these simple aspects that are correct (For example, due to tokenization, the probability of the word ”is” in ”The color is red” is close to 1 under both neutral and leading query output, but the contrast may be very closed to 0, which is much lower than bad continuation). In order to promote the generation of plausible tokens, we truncate the vocabulary:
where is the output vocabulary of LVLMs and is a hyperparameters in for controlling the truncation of the next token distribution. Larger entails more aggressive truncation and smaller allows tokens of lower probabilities to be generated. Combining the above two formulations, we can obtain the full formulation:
It is worth mentioning that the decoding method presented in this paper can be directly applied to regular prompts, not just limited to leading prompts that induce sycophancy. Considering that regular prompts are often neutral by nature, the distribution obtained from the transformed neutral prompts will be consistent with or close to the original regular prompts, thus not interfering with the decoding result for the original regular query.
Experiments
Overview
Our experiments answer three research questions: Q1: To what extent are the current LVLM’s capabilities interferenced by sycophancy? Q2: Do different models exhibit same behavior under the influence of sycophancy? Q3: How effective is the proposed LQCD for mitigating sycophancy? Related code of the experiments can be found in supplementary materials.
LVLMs.
We select five popular LVLMs to perform the experiments, including Qwen-VL (Bai et al. 2023), CogVLM2 (Wang et al. 2023b), InternVL (Chen et al. 2024a) , LLaVA-NeXT (Liu et al. 2024a) and mplug-Owl (Ye et al. 2024). These LVLMs vary in parameter sizes from 7B to 34B, and cover different architectures of vision encoders, LLM module and modality fusion architecture, as shown in Table 2. The chosen models are diverse and represent a broad spectrum of architectures. For all five models, we conducted evaluations on the aforementioned five extended datasets.
Model Vision Encoder LLM #Params Qwen-VL ViT-G/14 Qwen-7B 7B CogVLM2 EVA2-CLIP-E LLaMA-3-8B 19B InternVL-1.5 InternViT InternLM2-20B 25.5B LLaVA-NeXT ViT-L/14 Hermes-Yi-34B 34B mPLUG-Owl2.1 ViT-G/14 Qwen-7B 9.8B
Experimental Settings.
Throughout our experiments, we set for all baselines and datasets. The hyperparameter settings used in these experiments are empirical selected. For a consistent comparison, our baseline decoding strategy follow standard protocol (num_beams is set to 1 and do_sample is set to True).
Results and Analysis
Q1:To what extent are the current LVLM’s capabilities interference by sycophancy?
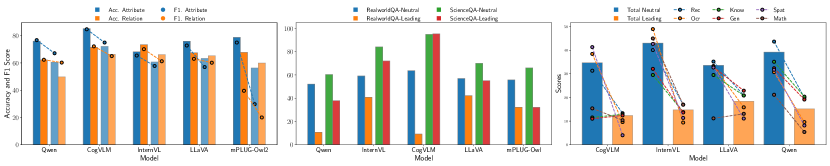
As shown in Figure 4 and left of Figure 5, the leading queries in both POPE and AMBER severely damage the performance of all LVLMs. The accuracy of all models on the POPE dataset decreased by 12% to 42%, while the F1 score showed a more significant decline, ranging from 15% to 88%. The results indicate that all models exhibited varying degrees of sycophancy, leading to performance degradation and exacerbating the issue of hallucinations.
We also evaluated sycophancy on datasets related to Real-world Understanding and Science Knowledge on RealworldQA and ScienceQA. As shown in middle of Figure 5, almost all model performance deteriorate significantly on both datasets. An exception is CogVLM on ScienceQA, which performance does not shrink but even improved slightly.

Similar experimental results can be observed on MM-Vet which can measure different integrated capabilities. As shown in right of Figure 5, almost all models have a performance drops on all six capabilities. Except that CogVLM did not exhibit sycophancy effects in the Knowledge domain, which is consistent with our observations in ScienceQA. And LLaVA does not influenced by sycophancy in Math ability either.
In summary, sycophancy is common in existing LVLMs, making models easily influenced by deceptive prompts in various capabilities, which alters their originally correct judgments. Specifically, LLaVA and InternVL exhibit slightly better resistance to sycophancy, with less performance degradation compared to Qwen and mPLUG-Owl. It may be because these two models have larger parameter sizes, making them relatively less susceptible to sycophancy. Additionally, CogVLM did not exhibit sycophancy effects in the Knowledge domain in both ScienceQA and MM-Vet. We believe this is due to CogVLM’s use of LLaMA-3-8B, which conduct specialized adversarial training for knowledge-related content.
Q2: Do different models exhibit same behavior under the influence of sycophancy?
In this section, we conduct a more detailed analysis of sycophancy based on dissecting the flipped predictions. By comparing the original results from neutral queries with those from the leading queries, for a given sample in the dataset, if sycophancy occurs, it can result in four possible outcomes: true positive changes to false negative (TP2FN), true negative changes to false positive (TN2FP), false negative changes to true positive (FN2TP), and false positive changes to true negative (FP2TN). Based on this, we define the following metrics:
-
1.
Consistency Transformation Rate (CTR). This metric measures the consistency of the model’s predictions between the original and leading queries. A higher CTR indicates that the model’s performance is less stable and sycophancy is more severe. refers to total sample size of the dataset.
-
2.
Error Introduction Rate (EIR). This metric measures the proportion of new errors introduced by the model under the leading query settings. A higher EIR indicates that the model is more prone to making incorrect predictions when influenced by sycophancy.
-
3.
Error Correction Rate (ECR). This metric measures the proportion of incorrect predictions that the model corrects under the leading query settings, i.e. sycophancy accidentally leading to correct predictions. This could be due to intentional adversarial training on leading questions during the model’s training phase. Higher values essentially indicate the model’s instability.
-
4.
Prediction Imbalance Rate (PIR). This metric measures whether the shifts in answers from Yes to No and No to Yes under the influence of sycophancy are balanced. When PIR deviates from 0.5, it suggests that the prediction results are imbalanced and the model’s performance exhibits bias.
Model CTR EIR ECR PIR p-value Qwen-VL 0.46 0.48 0.37 0.98 CogVLM2 0.31 0.36 0.03 0.75 InternVL-1.5 0.39 0.37 0.45 0.55 0.99 LLaVA-NeXT 0.23 0.21 0.32 0.46 0.07 mPLUG-Owl2.1 0.42 0.44 0.33 0.09
The results of evaluation are shown in Table 3. First, From the CTR and EIR metric, it can be seen that different models exhibit varying degrees of sensitivity to sycophancy, with larger models being less sensitive to sycophancy. Second, it can be observed that the PIR values significantly vary among different models. Among them, Qwen-VL is easily guided to answer No, while mPLUG-Owl2.1, on the contrary, is more susceptible to being influenced to answer Yes, whereas InternVL-1.5 and LLaVA-NeXT are relatively balanced. Models with relatively balanced PIR may have been intentionally trained with a balanced approach to positive and negative samples. Third, InternVL-1.5 and LLaVA-NeXT exhibited high ECR values. ECR indicates a phenomenon opposite to sycophancy where the model originally answered incorrectly, but chose the opposite of the leading query after introducing a leading query, and happened to answer correctly. We suspect this is due to the intentional introduction of adversarial samples during the training phase of InternVL-1.5 and LLaVA-NeXT. In contrast, CogVLM2 achieved the lowest ECR value, indicating that it has a high level of confidence in its own correct answers, suggesting that there may have been special design during its training.
On this basis, we performed sentiment analysis on the leading queries. We divided the leading query texts into two groups based on whether sycophancy occurred in each sample. A RoBERTa-based language model was used to predict the sentiment intensity of the leading texts, yielding corresponding probability values. We then applied the Mann-Whitney U Test to these two sets of values to conduct hypothesis testing, determining whether there is a significant difference in sentiment between the leading queries that led to sycophancy and those that did not. The p-values from the Mann-Whitney U Test are reported in the table, with a p-value of less than 0.05 indicating a significant difference. It can be observed that Qwen, CogVLM, and mPLUG-Owl2 show significant differences between the two groups, indicating that for these models, stronger sentiment in the tone of the leading queries makes them more prone to sycophancy. These models may be developed on biased data, leading to significant deviations in handling leading queries with different sentiments. We suspect that some models might prioritize accuracy while neglecting other issues, leading to biases in sycophancy.
Q3: How effective is the proposed LQCD for mitigating sycophancy?
| Model | Query Type/ Method | POPE | AMBER | RealworldQA. Acc | ScienceQA. Acc | ||||||||
| Random | Popular | Adversarial | Attribute | Relation | |||||||||
| Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | ||||
| Qwen-VL | Neutral | 89.8 | 89.2 | 87.1 | 86.7 | 82.2 | 82.6 | 76 | 77.2 | 62.2 | 62.7 | 52.12 | 60.34 |
| Leading | 52.3 | 11.7 | 50.5 | 10.5 | 49 | 10.6 | 60.5 | 67.5 | 49.8 | 60.6 | 10.72 | 37.88 | |
| CoT | 53 | 12.4 | 52.7 | 11.4 | 52.7 | 12.6 | 60.1 | 67 | 47.7 | 60.4 | 18.56 | 41.35 | |
| Detailed | 50.2 | 1.3 | 49.4 | 1.8 | 49.2 | 1 | 60.1 | 58 | 51.3 | 62.1 | 4.58 | 27.62 | |
| Volcano | 44.9 | 10.3 | 39.8 | 11.2 | 40.1 | 9.8 | 54.2 | 59.8 | 49 | 56.5 | 13.07 | 30.99 | |
| LQCD | 87.8 | 86.2 | 86.9 | 85.4 | 85.1* | 83.7* | 77.2* | 78* | 58.8 | 64.4* | 48.37 | 63.66* | |
| LQCD Oracle | 87.8 | 86.3 | 87 | 85.5 | 85.1* | 83.7* | 82.1* | 83.1* | 57.4 | 65.2* | 52.55* | 64.4* | |
| CogVLM | Neutral | 90.4 | 89.6 | 88.5 | 87.8 | 86.8 | 86.1 | 85.2 | 85.2 | 71.5 | 72.6 | 63.66 | 94.79 |
| Leading | 66.7 | 52.9 | 60.6 | 48.8 | 57 | 46 | 72.1 | 75.4 | 66.3 | 65.4 | 9.15 | 95.29 | |
| CoT | 72.9 | 64.5 | 69.4 | 62.4 | 66.2 | 59.4 | 74.7 | 75 | 64.5 | 66.7 | 15.82 | - | |
| Detailed | 45.9 | 0.1 | 37.4 | 0.3 | 36.1 | 2.1 | 61.5 | 70.4 | 65.7 | 67.3 | 3.53 | - | |
| Volcano | 64 | 60.9 | 56.6 | 55.7 | 53.9 | 54.4 | 56.7 | 47.2 | 63 | 54.4 | 17.39 | - | |
| LQCD | 90.6* | 89.9* | 89.3* | 88.6* | 87.6* | 87* | 84.7 | 84.6 | 70.6 | 72.2 | 30.07 | - | |
| LQCD Oracle | 91.4* | 90.7* | 89.2* | 88.5* | 88.3* | 87.6* | 84.8 | 84.7 | 69.5 | 71.2 | 66.8* | - | |
| InternVL | Neutral | 82.8 | 82.5 | 81.5 | 81.6 | 78.8 | 79.5 | 68.2 | 65.8 | 73.4 | 70.5 | 59.08 | 84.09 |
| Leading | 63.7 | 61.7 | 61.2 | 60.8 | 59 | 58.9 | 60.7 | 58.1 | 66.1 | 61.6 | 40.78 | 71.99 | |
| CoT | 63.5 | 62.6 | 63 | 61.7 | 62.3 | 60.8 | 56.6 | 47.5 | 62.7 | 48.7 | 39.61 | 49.33 | |
| Detailed | 69.5 | 65.5 | 65.7 | 62.5 | 65.9 | 63 | 63.5 | 62.3 | 66.7 | 63.7 | 38.95 | 66.24 | |
| Volcano | 71.1 | 68.4 | 67.8 | 65.3 | 64.8 | 62.5 | 61.2 | 61.4 | 69.5 | 69 | 28.1 | 61.03 | |
| LQCD | 81.5 | 81.7 | 80.2 | 80.7 | 77.8 | 78.9 | 66.5 | 58.7 | 73.9* | 65.9 | 50.65 | 80.32 | |
| LQCD Oracle | 86.7* | 86.7* | 83.6* | 83.8* | 82.7* | 83.3* | 69.4* | 63.3 | 76* | 68.4 | 62.22* | 82.7 | |
| LLaVA | Neutral | 90.5 | 90.3 | 87 | 87 | 84.6 | 85 | 75.9 | 73.2 | 67.5 | 63.4 | 56.86 | 69.91 |
| Leading | 80.2 | 79.9 | 74.3 | 74.6 | 70.9 | 72.6 | 63.3 | 57.3 | 65.3 | 60.5 | 42.22 | 55.03 | |
| CoT | 73.3 | 74.2 | 73.4 | 74.4 | 68.4 | 71.4 | 62.6 | 55.1 | 63.9 | 55.6 | 43.79 | 49.58 | |
| Detailed | 72.7 | 71.7 | 69.1 | 69.2 | 66.9 | 67.8 | 62.5 | 58.2 | 63.7 | 57.4 | 34.9 | 55.97 | |
| Volcano | 69.6 | 65 | 69.2 | 65.8 | 65.4 | 62.6 | 57.4 | 57.8 | 59.5 | 63.1 | 39.22 | 49.83 | |
| LQCD | 91.9* | 91.6* | 89.1* | 89.1* | 84.8* | 85.4* | 77.7* | 75.9* | 70.8* | 68.3* | 54.51 | 68.77 | |
| LQCD Oracle | 91.9* | 91.7* | 88.7 | 88.7 | 85.3* | 85.8* | 77.6* | 75.9* | 67.7* | 65.5* | 58.04* | 70.8* | |
| mPLUG | Neutral | 87.6 | 87.3 | 83.9 | 84.1 | 80 | 81 | 78.7 | 75.4 | 67.7 | 39.8 | 55.69 | 65.99 |
| Leading | 55.6 | 67.3 | 50.4 | 64.9 | 51.5 | 65.3 | 78.7 | 75.4 | 59.9 | 20.1 | 32.16 | 32.13 | |
| CoT | 52.3 | 66.6 | 54.6 | 67.8 | 55.1 | 67.9 | 52.7 | 16.6 | 58.8 | 4.2 | 53.73 | 15.57 | |
| Detailed | 66.5 | 59 | 59.6 | 55.8 | 55.1 | 51.4 | 57.6 | 50.8 | 61.3 | 57.7 | 21.31 | 25.09 | |
| Volcano | 51.4 | 56.1 | 45.8 | 52.5 | 44.7 | 52.8 | 53.1 | 36.5 | 58.8 | 28 | 32.03 | 34.41 | |
| LQCD | 88* | 87.6* | 85.2* | 85.1* | 81.3* | 81.8* | 76.2 | 72.9 | 69.4* | 45.4* | 38.04 | 61.18 | |
| LQCD Oracle | 88.1* | 87.7* | 85.2* | 85.1* | 81.4* | 82* | 79.9* | 77.6* | 69.6* | 45.7* | 56.21* | 63.91 | |
As illustrated in Figure 3, when asked, “What color is the traffic light in this scene?” the probability of the correct token “green” significantly decreases under the influence of a leading question, leading to the erroneous output of the token “red” and causing a hallucination. By applying contrastive decoding of the leading question and the neutral question, we obtain a calibrated probability, which allows the model to correctly output the intended result. Additional examples can be found in the supplementary materials. We compared our proposed LQCD with several other commonly used techniques. First is Chain-of-Thought (CoT) (Wei et al. 2022), a method that involves generating intermediate reasoning steps to enhance model performance. The second is to use more detailed and specific guiding prompts (Qian et al. 2024). We also evaluated Volcano, a self-feedback-based hallucination mitigation method (Lee et al. 2023). Due to the potential for errors in the generated process of reverting leading queries to neutral queries, we also conducted Oracle experiments which directly used the original neutral queries and leading queries for contrastive decoding, representing the upper limit of our method’s performance.
As shown in Table 4, the experimental results demonstrate that LQCD method is highly effective in addressing the sycophancy problem. Whether in the oracle setting or the generated setting of LQCD, the performance can approach or even exceed that of the model in the neutral setting. It can also be observed that, in In RealworldQA and ScienceQA, more complex queries impose higher demands on prompt engineering, resulting in a significant performance gap between the Oracle results and those based on prompt engineering. More cases and analysis can be found in supplementary material. Additionally, the experiments reveal the deficiency of common techniques oriented for hallucination in addressing sycophancy. Some test reveal that, they may even exacerbate the sycophancy phenomenon. For POPE dataset, compared to the leading query, CoT, detailed prompt, and Volcano methods do not significantly mitigate the model’s sycophancy, with CoT only slightly enhancing the model’s accuracy and score, but not substantially. Moreover, different methods exhibit significant performance variations across different models, resulting in large performance variance. The proposed method effectively mitigates the sycophancy phenomenon, bringing the performance in the leading query setting close to that in the neutral setting. The performance of oracle setting even exceeds the original neutral setting. Similar to POPE, the proposed method outperforms others in fighting attribute and relation hallucination with leading queries in the evaluation of AMBER. However, detailed prompt and Volcano methods do not lead to a significant improvement in the final performance.
Robustness Analysis and Ablation Experiments
We conduct robustness analysis and ablation experiments to validate two aspects.

First, we analyze whether LQCD causes significant performance degradation when addressing neutral problems. As shown in Figure 6, by comparing the results of “Neutral” and “Neutral+LQCD”, it can be observed that using LQCD for neutral queries does not result in a performance decline. This aligns with the theoretical foundation of our method and demonstrates its generalizability, proving it to be effective beyond merely addressing sycophancy issues. Second, to ensure that the LQCD is the key factor in performance enhancement, we conduct experiments by removing LQCD and solely using prompt engineering to transform the leading query to a neutral query. Comparing the results of “Leading+PE” and “Leading+PE+CD”, the proposed LQCD reduces the variance of results while improving the performance in terms of accuracy and score, demonstrating its effectiveness.
Conclusion
We systematically analyzed the behavior of various LVLMs when faced with sycophantic prompts in a range of perception and reasoning challenges, highlighting the severe inadequacy of these models in mitigating sycophantic hallucinations. In response, we introduced Leading Query Contrastive Decoding (LQCD), a training-free decoding method that effectively reduces sycophancy by adjusting the models’ reliance on language priors corresponding to the leading cues. We conduct extensive experiments to validate the effectiveness of LQCD, showcasing its strength over existing relevant techniques. We hope our work provide a solid foundation for evaluating and mitigating sycophancy in LVLMs.
References
- Bai et al. (2023) Bai, J.; Bai, S.; Yang, S.; Wang, S.; Tan, S.; Wang, P.; Lin, J.; Zhou, C.; and Zhou, J. 2023. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966.
- Chen et al. (2024a) Chen, Z.; Wu, J.; Wang, W.; Su, W.; Chen, G.; Xing, S.; Zhong, M.; Zhang, Q.; Zhu, X.; Lu, L.; et al. 2024a. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 24185–24198.
- Chen et al. (2024b) Chen, Z.; Zhao, Z.; Luo, H.; Yao, H.; Li, B.; and Zhou, J. 2024b. HALC: Object Hallucination Reduction via Adaptive Focal-Contrast Decoding. In Forty-first International Conference on Machine Learning.
- Cui et al. (2024) Cui, C.; Ma, Y.; Cao, X.; Ye, W.; Zhou, Y.; Liang, K.; Chen, J.; Lu, J.; Yang, Z.; Liao, K.-D.; et al. 2024. A survey on multimodal large language models for autonomous driving. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 958–979.
- Cui et al. (2023) Cui, C.; Zhou, Y.; Yang, X.; Wu, S.; Zhang, L.; Zou, J.; and Yao, H. 2023. Holistic analysis of hallucination in gpt-4v (ision): Bias and interference challenges. arXiv preprint arXiv:2311.03287.
- Guan et al. (2024) Guan, T.; Liu, F.; Wu, X.; Xian, R.; Li, Z.; Liu, X.; Wang, X.; Chen, L.; Huang, F.; Yacoob, Y.; et al. 2024. HallusionBench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14375–14385.
- Han et al. (2022) Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. 2022. A survey on vision transformer. IEEE transactions on pattern analysis and machine intelligence, 45(1): 87–110.
- Ho and Salimans (2022) Ho, J.; and Salimans, T. 2022. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598.
- Huang et al. (2024) Huang, Q.; Dong, X.; Zhang, P.; Wang, B.; He, C.; Wang, J.; Lin, D.; Zhang, W.; and Yu, N. 2024. Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13418–13427.
- Jiang et al. (2023) Jiang, C.; Xu, H.; Dong, M.; Chen, J.; Ye, W.; Yan, M.; Ye, Q.; Zhang, J.; Huang, F.; and Zhang, S. 2023. Hallucination Augmented Contrastive Learning for Multimodal Large Language Model. arXiv:2312.06968.
- Lee et al. (2023) Lee, S.; Park, S. H.; Jo, Y.; and Seo, M. 2023. Volcano: mitigating multimodal hallucination through self-feedback guided revision. arXiv preprint arXiv:2311.07362.
- Leng et al. (2024) Leng, S.; Zhang, H.; Chen, G.; Li, X.; Lu, S.; Miao, C.; and Bing, L. 2024. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13872–13882.
- Li et al. (2024) Li, B.; Ge, Y.; Ge, Y.; Wang, G.; Wang, R.; Zhang, R.; and Shan, Y. 2024. SEED-Bench: Benchmarking Multimodal Large Language Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13299–13308.
- Li et al. (2023a) Li, X. L.; Holtzman, A.; Fried, D.; Liang, P.; Eisner, J.; Hashimoto, T. B.; Zettlemoyer, L.; and Lewis, M. 2023a. Contrastive Decoding: Open-ended Text Generation as Optimization. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 12286–12312.
- Li et al. (2023b) Li, Y.; Du, Y.; Zhou, K.; Wang, J.; Zhao, W. X.; and Wen, J.-R. 2023b. Evaluating Object Hallucination in Large Vision-Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 292–305.
- Liu et al. (2023a) Liu, F.; Lin, K.; Li, L.; Wang, J.; Yacoob, Y.; and Wang, L. 2023a. Aligning Large Multi-Modal Model with Robust Instruction Tuning. arXiv preprint arXiv:2306.14565.
- Liu et al. (2024a) Liu, H.; Li, C.; Li, Y.; and Lee, Y. J. 2024a. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 26296–26306.
- Liu et al. (2024b) Liu, H.; Xue, W.; Chen, Y.; Chen, D.; Zhao, X.; Wang, K.; Hou, L.; Li, R.; and Peng, W. 2024b. A survey on hallucination in large vision-language models. arXiv preprint arXiv:2402.00253.
- Liu et al. (2023b) Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Li, C.; Yang, J.; Su, H.; Zhu, J.; et al. 2023b. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499.
- Lu et al. (2022) Lu, P.; Mishra, S.; Xia, T.; Qiu, L.; Chang, K.-W.; Zhu, S.-C.; Tafjord, O.; Clark, P.; and Kalyan, A. 2022. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems, 35: 2507–2521.
- Mündler et al. (2024) Mündler, N.; He, J.; Jenko, S.; and Vechev, M. 2024. Self-contradictory Hallucinations of Large Language Models: Evaluation, Detection and Mitigation. In The Twelfth International Conference on Learning Representations.
- Perez et al. (2023) Perez, E.; Ringer, S.; Lukosiute, K.; Nguyen, K.; Chen, E.; Heiner, S.; Pettit, C.; Olsson, C.; Kundu, S.; Kadavath, S.; et al. 2023. Discovering Language Model Behaviors with Model-Written Evaluations. In Findings of the Association for Computational Linguistics: ACL 2023, 13387–13434.
- Qian et al. (2024) Qian, Y.; Zhang, H.; Yang, Y.; and Gan, Z. 2024. How easy is it to fool your multimodal llms? an empirical analysis on deceptive prompts. arXiv preprint arXiv:2402.13220.
- Sharma et al. (2024) Sharma, M.; Tong, M.; Korbak, T.; Duvenaud, D.; Askell, A.; Bowman, S. R.; DURMUS, E.; Hatfield-Dodds, Z.; Johnston, S. R.; Kravec, S. M.; et al. 2024. Towards Understanding Sycophancy in Language Models. In The Twelfth International Conference on Learning Representations.
- Wang et al. (2023a) Wang, J.; Wang, Y.; Xu, G.; Zhang, J.; Gu, Y.; Jia, H.; Yan, M.; Zhang, J.; and Sang, J. 2023a. An llm-free multi-dimensional benchmark for mllms hallucination evaluation. arXiv preprint arXiv:2311.07397.
- Wang et al. (2023b) Wang, W.; Lv, Q.; Yu, W.; Hong, W.; Qi, J.; Wang, Y.; Ji, J.; Yang, Z.; Zhao, L.; Song, X.; et al. 2023b. Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079.
- Wei et al. (2022) Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q. V.; Zhou, D.; et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 24824–24837.
- Wu et al. (2024) Wu, M.; Ji, J.; Huang, O.; Li, J.; Wu, Y.; Sun, X.; and Ji, R. 2024. Evaluating and Analyzing Relationship Hallucinations in Large Vision-Language Models. In Forty-first International Conference on Machine Learning.
- x.ai (2024) x.ai. 2024. RealWorldQA: A Benchmark for Real-World Spatial Understanding. https://x.ai/blog/grok-1.5v. Accessed: 2024-07-09.
- Xiao et al. (2024) Xiao, J.; Huang, N.; Qin, H.; Li, D.; Li, Y.; Zhu, F.; Tao, Z.; Yu, J.; Lin, L.; Chua, T.-S.; and Yao, A. 2024. VideoQA in the Era of LLMs: An Empirical Study. arXiv preprint arXiv:2408.04223.
- Ye et al. (2024) Ye, Q.; Xu, H.; Ye, J.; Yan, M.; Hu, A.; Liu, H.; Qian, Q.; Zhang, J.; and Huang, F. 2024. mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13040–13051.
- Yu et al. (2024) Yu, W.; Yang, Z.; Li, L.; Wang, J.; Lin, K.; Liu, Z.; Wang, X.; and Wang, L. 2024. Mm-vet: Evaluating large multimodal models for integrated capabilities. In International conference on machine learning. PMLR.
- Zhang et al. (2024) Zhang, D.; Yu, Y.; Li, C.; Dong, J.; Su, D.; Chu, C.; and Yu, D. 2024. Mm-llms: Recent advances in multimodal large language models. arXiv preprint arXiv:2401.13601.
Appendix A Appendix
Baselines
We selected six currently well-performing and state-of-the-art open-sourced LVLMs in the community and conducted comprehensive experimental evaluations on the selected and augmented datasets. The selected five LVLMs vary in parameter sizes from 8B to 34B and feature different model architectures. For instance, LLaVA uses multi-layer perceptron for token-level fusion to achieve feature alignment, while CogVLM incorporates a visual expert module in each Transformer layer to enable dual interaction and fusion between vision and language features. Additionally, Qwen utilizes a Q-Former with only 0.08B parameters for modality fusion. The chosen models are diverse and represent a broad spectrum of architectures.
Qwen-VL.
Qwen-VL is the multimodal version of Qwen large model series, proposed by Alibaba Cloud. Qwen-VL accepts image, text, and bounding box as inputs, outputs text, and bounding box. We use Qwen-VL-Chat in our experiment.
CogVLM.
CogVLM is a powerful open-source visual language model, supporting image understanding and multi-turn dialogue, proposed by Tsinghua University. We use the latest and best-performing version CogVLM2-LLaMA3-chat-19b.
InternVL.
InternVL is a state-of-the-art multimodal AI model to excel in visual-linguistic tasks like image classification, retrieval, and dialogue, proposed by Shanghai AI Lab(Chen et al. 2024a). It is open-source and designed for diverse applications, achieving top performance on multiple benchmarks. We use the latest and best-performing version InternVL-Chat-V1-5.
LLaVA.
LLaVA is an advanced multimodal model that integrates visual instruction tuning with large language models to achieve GPT-4 level capabilities(Liu et al. 2024a). LLaVA supports various model sizes and configurations, including quantized versions for efficient deployment. We use the latest and best-performing version LLaVA-v1.6-34b.
mPLUG-Owl2.
mPLUG-Owl2 is the multi-modal large lanaguage model proposed by DAMO Academy(Ye et al. 2024), and it is the first MLLM that achieves both state-of-the-art on pure-text and multi-modal datasets with remarkable improvement. We use mPLUG-Owl2.1 in the experiments.
Datasets
In our experiments, we selected and augmented the following five datasets to evaluate sycophancy in LVLMs:
POPE
POPE is a benchmark designed to assess object hallucination in LVLMs. The benchmark evaluates object-level hallucination through the use of yes-or-no questions regarding the presence of objects in images. The evaluation is conducted under various conditions, including random, popular, and adversarial settings, to measure the frequency and accuracy of object recognition. POPE ensures stability and fairness by simplifying the evaluation process, making it more efficient and reliable for determining the degree of hallucination in LVLMs. The performance is quantified using metrics such as accuracy, precision, recall, and score.
AMBER
AMBER is a comprehensive benchmark designed to evaluate the hallucination performance of LVLMs. AMBER offers a cost-effective and efficient solution by providing an LLM-free evaluation pipeline. This benchmark covers both generative and discriminative tasks and includes three types of hallucination: existence, attribute, and relation. In our experiments, AMBER is mainly used to complement the attribute hallucination and relation hallucination that POPE does not take care of.
RealworldQA
RealworldQA is a benchmark designed to evaluate the real-world spatial understanding capabilities of multimodal AI models. It assesses how well these models comprehend physical environments. The benchmark consists of over 700 images, each accompanied by a question and a verifiable answer. These images are drawn from various real-world scenarios, including those captured from vehicles. The goal is to advance AI models’ understanding of the physical world.
ScienceQA
ScienceQA is a benchmark designed for evaluating multimodal reasoning in science question answering. It comprises approximately 21,000 multiple-choice questions across diverse science topics, annotated with lectures and explanations to support reasoning. The dataset is collected from elementary and high school science curricula and includes questions with text and image contexts. ScienceQA aims to improve the interpretability and reasoning capabilities of AI models.
MM-Vet
MM-Vet is an evaluation benchmark designed to assess LVLMs on complex multimodal tasks.It addresses key challenges in evaluating LMMs, such as structuring and evaluating complex tasks and designing evaluation metrics that work across different question and answer types. MM-Vet defines six core vision-language capabilities: recognition, optical character recognition (OCR), knowledge, language generation, spatial awareness, and math. It examines the integration of these capabilities through 16 different tasks. MM-Vet employs an LLM-based evaluator to ensure thorough and unified assessment across various response formats, providing deeper insights into model performance beyond simple rankings.
Supplement Experimental Results



Appendix B Prompt Examples





Case Analysis
As shown in the Figure 15, we selected examples from our method and other mitigation methods across different datasets for demonstration. In the figure, we can observe that the original query, when influenced by a leading query, causes the model to output incorrect, leading content. While detailed prompt design aimed at helping the model better understand the question itself does not significantly alleviate sycophancy, a few cases, such as the AMBER Attribute example (the second example from the top), are answered correctly. CoT, similar to detailed query prompts, is effective in certain scenarios, but Volcano, despite generating more content, fails to make a clear judgment on the query and therefore does not effectively mitigate the sycophancy issue. Among the selected cases, our method achieved the most optimal results.
