Toward Degree Bias in Embedding-Based
Knowledge Graph Completion
Abstract.
A fundamental task for knowledge graphs (KGs) is knowledge graph completion (KGC). It aims to predict unseen edges by learning representations for all the entities and relations in a KG. A common concern when learning representations on traditional graphs is degree bias. It can affect graph algorithms by learning poor representations for lower-degree nodes, often leading to low performance on such nodes. However, there has been limited research on whether there exists degree bias for embedding-based KGC and how such bias affects the performance of KGC. In this paper, we validate the existence of degree bias in embedding-based KGC and identify the key factor to degree bias. We then introduce a novel data augmentation method, KG-Mixup, to generate synthetic triples to mitigate such bias. Extensive experiments have demonstrated that our method can improve various embedding-based KGC methods and outperform other methods tackling the bias problem on multiple benchmark datasets. 111The code is available at https://github.com/HarryShomer/KG-Mixup
1. Introduction
Knowledge graphs (KGs) are a specific type of graph where each edge represents a single fact. Each fact is represented as a triple that connects two entities and with a relation . KGs have been widely used in many real-world applications such as recommendation (Cao et al., 2019), drug discovery (Mohamed et al., 2020a), and natural language understanding (Liu et al., 2020). However, the incomplete nature of KGs limits their applicability in those applications. To address this limitation, it is desired to perform a KG completion (KGC) task, i.e., predicting unseen edges in the graph thereby deducing new facts (Rossi et al., 2021). In recent years, the embedding-based methods (Bordes et al., 2013; Dettmers et al., 2018a; Balažević et al., 2019; Schlichtkrull et al., 2018) that embed a KG into a low-dimensional space have achieved remarkable success on KGC tasks and enable downstream applications.

However, a common issue in graph-related tasks is degree bias (Tang et al., 2020; Kojaku et al., 2021), where nodes of lower degree tend to learn poorer representations and have less satisfactory downstream performance. Recent studies have validated this issue for various tasks on homogeneous graphs such as classification (Tang et al., 2020; Zhao et al., 2021c; Liu et al., 2021) and link prediction (Kojaku et al., 2021). However, KGs are naturally heterogeneous with multiple types of nodes and relations. Furthermore, the study of degree bias on KGs is rather limited. Therefore, in this work, we ask whether degree bias exists in KGs and how it affects the model performance in the context of KGC.
To answer the aforementioned question, we perform preliminary studies to investigate how the degree affects the KGC performance. Take a triple as one example. The in-degree of entity is the number of triples where is the tail entity. Furthermore, we define the tail-relation degree as the number of triples where and the relation co-occur as the tail and relation (Eq. (2)). An example in Figure 1 is the tail-relation pair (Germany, Has Country). Since the pair only co-occurs as a relation and tail in one triple, their tail-relation degree is 1. Our preliminary studies (Section 3) suggest that when predicting the tail entity , the in-degree of and especially the tail-relation degree of plays a vital role. That is, when predicting the tail for a triple , the number of triples where the entity and relation co-occur as an entity-relation pair correlates significantly with performance during KGC. Going back to our example, since Germany and Has Country only co-occur as a relation and tail in one triple their tail-relation degree is low, thus making it difficult to predict Germany for the query (Europe, Has Country, ?).
Given the existence of degree bias in KGC, we aim to alleviate the negative effect brought by degree bias. Specifically, we are tasked with improving the performance of triples with low tail-relation degrees while maintaining the performance of other triples with a higher tail-relation degree. Essentially, it is desired to promote the engagement of triples with low tail-relation degrees during training so as to learn better embeddings. To address this challenge, we propose a novel data augmentation framework. Our method works by augmenting entity-relation pairs that have low tail-relation degrees with synthetic triples. We generate the synthetic triples by extending the popular Mixup (Zhang et al., 2018) strategy to KGs. Our contributions can be summarized as follows:
-
•
Through empirical study, we identify the degree bias problem in the context of KGC. To the best of our knowledge, no previous work has studied the problem of degree bias from the perspective of entity-relation pairs.
-
•
We propose a simple yet effective data augmentation method, KG-Mixup, to alleviate the degree bias problem in KG embeddings.
-
•
Through empirical analysis, we show that our proposed method can be formulated as a form of regularization on the low tail-relation degree samples.
-
•
Extensive experiments have demonstrated that our proposed method can improve the performance of lower tail-relation degree triples on multiple benchmark datasets without compromising the performance on triples of higher degree.
2. Related Work
KG Embedding: TransE (Bordes et al., 2013) models the embeddings of a single triple as a translation in the embedding space. Multiple works model the triples as a tensor factorization problem, including (Nickel et al., 2011; Yang et al., 2015; Balažević et al., 2019; Amin et al., 2020). ConvE (Dettmers et al., 2018a) learns the embeddings by modeling the interaction of a single triple via a convolutional neural network. Other methods like R-GCN (Schlichtkrull et al., 2018) modify GCN (Kipf and Welling, 2017) for relational graphs. Imbalanced/Long-Tail Learning: Imbalanced/Long-Tail Learning considers the problem of model learning when the class distribution is highly uneven. SMOTE (Chawla et al., 2002), a classic technique, attempts to produce new synthetic samples for the minority class. Recent work has focused on tackling imbalance problems on deeper models. Works such as (Ren et al., 2020; Tan et al., 2020; Lin et al., 2017) address this problem by modifying the loss for different samples. Another branch of work tries to tackle this issue by utilizing ensemble modeling (Wang et al., 2020; Zhou et al., 2020; Wang et al., 2021). Degree Bias: Mohamed et al. (2020b) demonstrate the existence of popularity bias in popular KG datasets, which causes models to inflate the score of entities with a high degree. Bonner et al. (2022) show the existence of entity degree bias in biomedical KGs. Rossi et al. (2021) demonstrate that the performance is positively correlated with the number of source peers and negatively with the number of target peers. Kojaku et al. (2021) analyze the degree bias of random walks. To alleviate this issue, they propose a debiasing method that utilizes random graphs. In addition, many studies have focused on allaying the effect of degree bias for the task of node classification including (Tang et al., 2020; Zhao et al., 2021c; Liu et al., 2021). However, there is no work that focuses on how the intersection of entity and relation degree bias effects embedding-based KGC. Data Augmentation for Graphs There is a line of works studying data augmentation for homogeneous graphs (Zhao et al., 2021a, 2022). Few of these works study the link prediction problem (Zhao et al., 2021b) but they do not address the issues in KGs. To augment KGs, Tang et al. (2022) generate synthetic triples via adversarial learning; Wang et al. (2018) use a GAN to create stronger negative samples; Li et al. (2021) use rule mining to identify new triples to augment the graph with. However, all these methods do not augment with for the purpose of degree bias in KGs and hence are not applicable to the problem this paper studies.
3. Preliminary Study



In this section we empirically study the degree bias problem in KGC. We focus on two representative embedding based methods ConvE (Dettmers et al., 2018a) and TuckER (Balažević et al., 2019).
We first introduce some notations. We denote as a KG with entities , relations , and edges . Each edge represents two entities connected by a single relation. We refer to an edge as a triple and denote it as where is referred to as the head entity, the tail entity, and the relation. Each entity and relation is represented by an embedding. We represent the embedding for a single entity as and the embedding for a relation as , where and are the dimensions of the entity and relation embeddings, respectively. We further define the degree of an entity as and the in-degree () and out-degree () as the number of triples where is the tail and head entity, respectively.
Lastly, KGC attempts to predict new facts that are not found in the original KG. This involves predicting the tail entities that satisfy and the head entities that satisfy . Following (Dettmers et al., 2018b), we augment all triples with its inverse . As such, predicting the head entity of is analogous to predicting the tail entity for . Under such a setting, KGC can be formulated as always predicting the tail entity. Therefore, in the remainder of this work, we only consider KGC as predicting the tail entities that satisfy .
In the following subsections, we will explore the following questions: (1) Does degree bias exist in typical KG embedding models? and (2) Which factor in a triple is related to such bias? To answer these questions, we first study how the head and tail entity degree affect KGC performance in Section 3.1. Then, we investigate the impact of the frequency of entity-relation pairs co-occurring on KGC performance in Section 3.2.
3.1. Entity Degree Analysis
We first examine the effect that the degree of both the head and tail entities have on KGC performance. We perform our analysis on the FB15K-237 dataset (Toutanova and Chen, 2015), a commonly used benchmark in KGC. Since a KG is a directed graph, we postulate that the direction of an entity’s edges matters. We therefore split the degree of each entity into its in-degree and out-degree. We measure the performance using the mean reciprocal rank (MRR). Note that the degree metrics are calculated using only the training set.
Figure 2(a) displays the results of TuckER (see Section 6.1.4 for more details) on FB15K-237 split by both entities and degree type. From Figure 2(a) we observe that when varying the tail entity degree value, the resulting change in test MRR is significantly larger than when varying the degree of head entities. Furthermore, the MRR increases drastically with the increase of tail in-degree (blue line) while there is a parabolic-like relationship when varying the tail out-degree (orange line). From these observations we can conclude: (1) the degree of the tail entity (i.e. the entity we are trying to predict) has a larger impact on test performance than the degree of the head entity; (2) the tail in-degree features a more distinguishing and apparent relationship with performance than the tail out-degree. Due to the page limitation, the results of ConvE are shown in Appendix A.4, where we have similar observations. These results suggest that KGC displays a degree bias in regards to the in-degree. Next, we will examine which factors of a triple majorly contribute to such degree bias.
3.2. Entity-Relation Degree Analysis
In the previous subsection, we have demonstrated the relationship between the entity degree and KGC performance. However, it doesn’t account for the interaction of the entities and relation. Therefore, we further study how the presence of both the relation and entities in a triple together impact the KGC performance. We begin by defining the number of edges that contains the relation and an entity as the relation-specific degree:
| (1) |
Based on the results in Section 3.1, we posit that the main indicator of performance is the in-degree of the tail entity. We extend this idea to our definition of relation-specific degree by only counting co-occurrences of an entity and relation when the entity occurs as the tail. For simplicity we refer to this as the tail-relation degree and define it as:
| (2) |
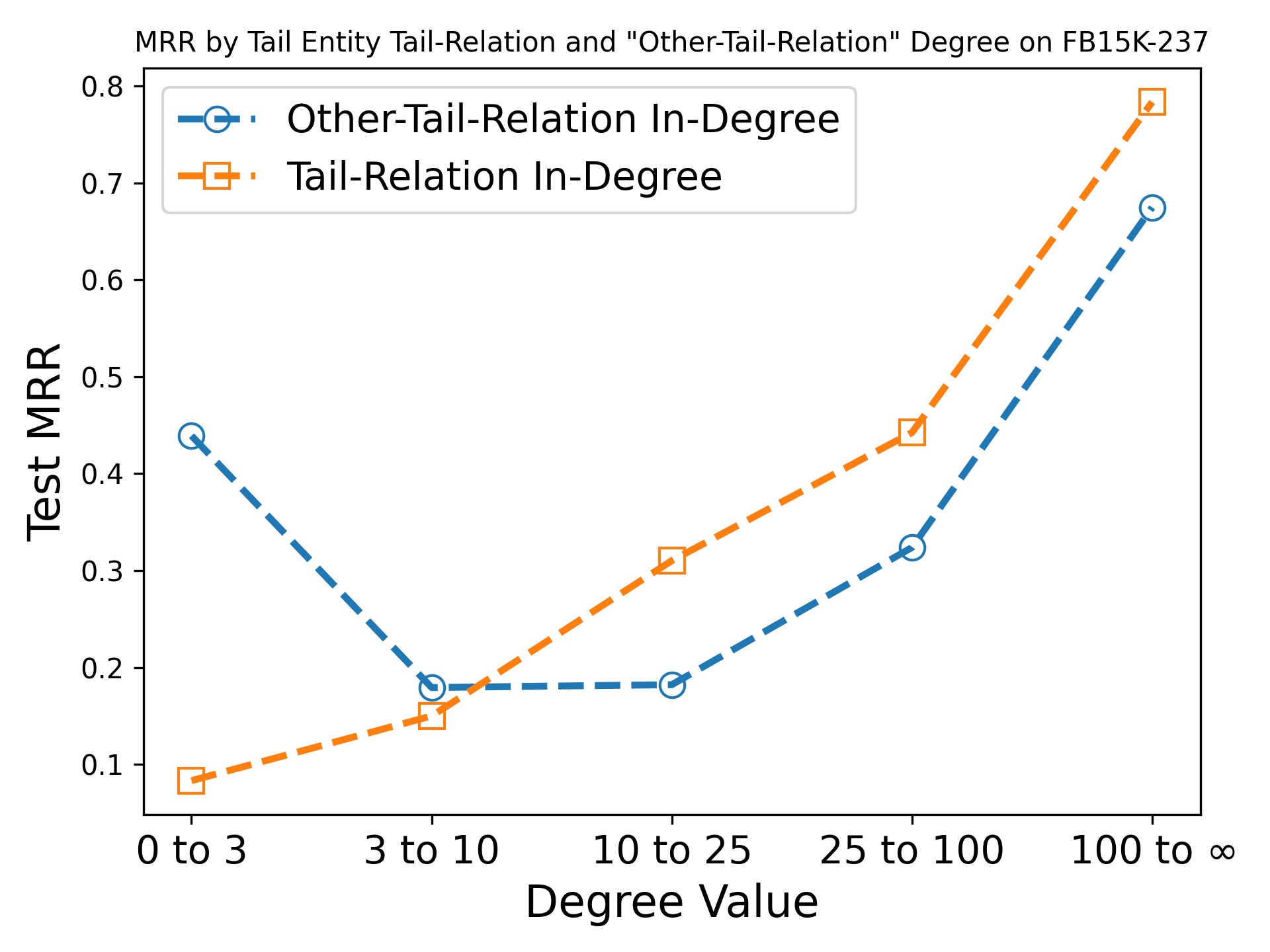
The tail-relation degree can be understood as the number of edges that an entity shares with , where occupies the position we are trying to predict (i.e. the tail entity). We further refer to the number of in-edges that doesn’t share with as “Other-Tail Relation” degree. This is calculated as the difference between the in-degree of entity and the tail-relation degree of and relation , i.e. . It is easy to verify that the in-degree of an entity is the summation of the tail-relation degree and “Other-Tail Relation” degree. We use Figure 1 as an example of the tail-relation degree. The entity Sweden co-occurs with the relation Has Country on one edge. On that edge, Sweden is the tail entity. Therefore the tail-relation degree of the pair (Sweden, Has Country) is one. We note that a special case of the tail-relation degree is relation-level semantic evidence defined by Li et al. (2022).
Figure 2(b) displays the MRR when varying the value of the tail-relation and “Other-Tail Relation” degree of the tail entity. From the results, we note that while both degree metrics correlate with performance, the performance when the other-tail-relation degree in the range is quite high. Since both metrics are highly correlated, it is difficult to determine which metric is more important for the downstream performance. Is the “Other-Tail Relation” the determining factor for performance or is it the tail-relation degree? We therefore check the performance when controlling for one another. Figure 2(c) displays the results when varying the “Other-Tail Relation” degree for specific sub-ranges of the tail-relation degree. From this figure, we see that the tail-relation degree exerts a much larger influence on the KGC performance as there is little variation between bars belonging to the same subset. Rather the tail-relation degree (i.e. the clusters of bars) has a much larger impact. Therefore, we conclude that for a single triple, the main factor of degree bias is the tail-relation degree of the tail entity.
Remark. Our analysis differs from traditional research on degree bias. While previous works focus only on the degree of the node, we focus on a specific type of frequency among entity-relation pairs. This is vital as the frequencies of both the entities and relations are important in KGs. Though we only analyze KGs, findings from our analysis could be applicable to other types of heterogeneous graphs.
4. The Proposed Method
Grounded in the observations in Section 3.2, one natural idea to alleviate the degree bias in KGC is to compensate the triples with low tail-relation degrees. Based on this intuition, we propose a new method for improving the KGC performance of triples with low tail-relation degrees. Our method, KG-Mixup, works by augmenting the low tail-relation degree triples during training with synthetic samples. This strategy has the effect of increasing the degree of an entity-relation pair with a low tail-relation degree by creating more shared edges between them. Therefore, KG-Mixup is very general and can further be used in conjunction with any KG embedding technique.
4.1. General Problem
In Section 3.2 we showed that the tail-relation degree of the tail entity strongly correlates with higher performance in KGC. As such we seek to design a method that can increase the performance of such low-degree entity-relation pairs without sacrificing the performance of high-degree pairs.
To solve this problem, we consider data augmentation. Specifically, we seek to create synthetic triples for those entity-relations pairs with a low tail-relation degree. In such a way we are creating more training triples that contain those pairs, thereby “increasing” their degree. For each entity-relation pair with a tail-relation degree less than , we add synthetic samples, which can be formulated as follows:
| (3) |
where are the original training triples with the relation and the tail entity , is a synthetic sample, and is the new set of triples to use during training.
Challenges. We note that creating the synthetic samples as shown in Eq. (3) is non-trivial and there are a number of challenges:
-
(1)
How do we produce the synthetic samples for KG triples that contain multiple types of embeddings?
-
(2)
How do we promote diversity in the synthetic samples ? We want them to contain sufficient information from the original entity and relation embeddings we are augmenting, while also being distinct from similar triples in .
-
(3)
How do we achieve such augmentation in a computationally efficient manner?
These challenges motivate us to design a special data augmentation algorithm for knowledge graph completion and we detail its core techniques in the next subsection.
4.2. KG-Mixup
We now present our solution for producing synthetic samples as described in Eq. (3). Inspired by the popular Mixup (Zhang et al., 2018) strategy, we strive to augment the training set by mixing the representations of triples. We draw inspiration from mixup as (1) it is an intuitive and widely used data augmentation method, (2) it is able to promote diversity in the synthetic samples via the randomly drawn value , and (3) it is computationally efficient (see Section 4.4).
We now briefly describe the general mixup algorithm. We denote the representations of two samples as and and their labels and . Mixup creates a new sample and label by combining both the representations and labels via a random value drawn from such that:
| (4) | ||||
| (5) |
We adapt this strategy to our studied problem for a triple where the tail-relation degree is below a degree threshold, i.e. . For such a triple we aim to augment the training set by creating synthetic samples . This is done by mixing the original triple with other triples .
However, directly adopting mixup to KGC leads to some problems: (1) Since each sample doesn’t contain a label (Eq. 5) we are unable to perform label mixing. (2) While standard mixup randomly selects samples to mix with, we may want to utilize a different selection criteria to better enhance those samples with a low tail-relation degree. (3) Since each sample is composed of multiple components (entities and relations) it’s unclear how to mix two samples. We go over these challenges next.
4.2.1. Label Incorporation in KGC
We first tackle how to incorporate the label information as shown in Eq. (5). Mixup was originally designed for classification problems, making the original label mixing straightforward. However, for KGC, we have no associated label for each triple. We therefore consider the entity we are predicting as the label. For a triple where we are predicting , the label would be considered the entity .
4.2.2. Mixing Criteria
Per the original definition of Mixup, we would then mix with a triple belonging to the set . However, since our goal is to predict we wish to avoid mixing it. Since we want to better predict , we need to preserve as much tail (i.e. label) information as possible. As such, we only consider mixing with other triples that share the same tail and belong to the set . Our design is similar to SMOTE (Chawla et al., 2002), where only samples belonging to the same class are combined. We note that while it would be enticing to only consider mixing with triples containing the same entity-relation pairs, i.e. , this would severely limit the number of possible candidate triples as the tail-relation degree can often be as low as one or two for some pairs.
4.2.3. How to Mix?
We now discuss how to perform the mixing of two samples. Given a triple of low tail-relation degree we mix it with another triple that shares the same tail (i.e. label) such that . Applying Eq. (4) to and , a synthetic triple is equal to:
| (6) | ||||
| (7) | ||||
| (8) |
where and represent the entity and relation embeddings, respectively. We apply the weighted sum to the head, relation, and tail, separately. Each entity and relation are therefore equal to:
| (9) | ||||
| (10) | ||||
| (11) |
We use Figure 1 to illustrate an example. Let (Europe, Has Country, Germany) be the triple we are augmenting. We mix it with another triple with the tail entity Germany. We consider the triple (Belgium, Borders, Germany). The mixed triple is represented as . As contains the continent that Germany belongs to and has the country it borders, we can understand the synthetic triple as conveying the geographic location of Germany inside of Europe. This is helpful when predicting Germany in the original triple , since the synthetic sample imbues the representation of Germany with more specific geographic information.
4.3. KG-Mixup Algorithm for KGC
We utilize the binary cross-entropy loss when training each model. The loss is optimized using the Adam optimizer (Kingma and Ba, 2014). We also include a hyperparameter for weighting the loss on the synthetic samples. The loss on a model with parameters is therefore:
| (12) |
where is the loss on the original KG triples and is the loss on the synthetic samples. The full algorithm is displayed in Algorithm 1. We note that we first pre-train the model before training with KG-Mixup, to obtain the initial entity and relation representations. This is done as it allows us to begin training with stronger entity and relation representations, thereby improving the generated synthetic samples.
4.4. Algorithmic Complexity
We denote the algorithmic complexity of a model (e.g. ConvE (Dettmers et al., 2018a) or TuckER (Balažević et al., 2019)) for a single sample as . Assuming we generate negative samples per training sample, the training complexity of over a single epoch is:
| (13) |
where is the number of training samples. In KG-Mixup, in addition to scoring both the positive and negative samples, we also score the synthetic samples created for all samples with a tail-relation degree below a threshold . We refer to that set of samples below the degree threshold as . We create synthetic samples per . As such, our algorithm scores an additional samples for a total of samples per epoch. Typically the number of negative samples . Both ConvE and TuckER use all possible negative samples per training sample while we find works well. Furthermore, by definition, rendering . We can thus conclude that . We can therefore express the complexity of KG-Mixup as:
| (14) |
This highlights the efficiency of our algorithm as its complexity is approximately equivalent to the standard training procedure.
5. Regularizing Effect of KG-Mixup
In this section, we examine the properties of KG-Mixup and show it can be formulated as a form of regularization on the entity and relation embeddings of low tail-relation degree samples following previous works (Carratino et al., 2020; Zhang et al., 2021).
We denote the mixup loss with model parameters over samples as . The set contains those samples with a tail-relation degree below a threshold (see line 10 in Algorithm 1). The embeddings for each sample is mixed with those of a random sample that shares the same tail. The embeddings are combined via a random value as shown in Eq. (9), thereby producing the synthetic sample . The formulation for is therefore:
| (15) |
where synthetic samples are produced for each sample in , and is the mixed binary label. Following Theorem 1 in Carratino et al. (2020) we can rewrite the loss as the expectation over the synthetic samples as,
| (16) |
where and . The distribution and the set contains all samples with tail . Since the label for both samples and are always 1, rendering , we can simplify Eq. (16) arriving at:
| (17) |
For the above loss function, we have the following theorem.
Theorem 5.1.
The mixup loss defined in Eq. (17) can be rewritten as the following where the loss function is the binary cross-entropy loss, is the loss on the original set of augmented samples , and and are two regularization terms,
| (18) |
The regularization terms are given by the following where each mixed sample is composed of a low tail-relation degree sample and another sample with the same tail entity :
| (19) | ||||
| (20) |
with , , , is the sigmoid function, and is the score function.
We provide the detailed proof of Theorem 5.1 in Appendix A.6. Examining the terms in Eq (18), we can draw the following understandings on KG-Mixup:
-
(1)
The inclusion of implies that the low tail-relation degree samples are scored an additional time when being mixed. This can be considered as a form of oversampling on the low tail-relation degree samples.
-
(2)
If the probability is very high, i.e. , both and cancel out. This is intuitive as if the current parameters perform well for the original low-degree sample, there is no need to make any adjustments.
-
(3)
We can observe that and enforce some regularization on the derivatives as well as the difference between the embeddings and . This motivates us to further examine the difference between the embeddings. In Section 6.3, we find that our method does indeed produce more similar embeddings, indicating that our method exerts a smoothing effect among mixed samples.
6. Experiment
Model Method FB15K-237 NELL-995 CoDEx-M MRR H@1 H@10 MRR H@1 H@10 MRR H@1 H@10 ConvE Standard 33.04 23.95 51.23 50.87 44.14 61.48 31.70 24.34 45.60 + Over-Sampling 30.45 21.85 47.81 48.63 40.99 60.78 27.13 20.17 40.11 + Loss Re-weighting 32.32 23.32 50.19 50.89 43.83 62.17 28.38 21.12 42.68 + Focal Loss 32.08 23.29 50.09 50.43 44.00 60.70 27.99 20.93 41.48 + KG-Mixup (Ours) 34.33 25.00 53.11 51.08 43.52 63.22 31.71 23.49 47.49 TuckER Standard 35.19 26.06 53.47 52.11 45.51 62.26 31.67 24.46 45.73 + Over-Sampling 34.77 25.48 53.53 50.36 44.04 60.40 29.97 22.27 44.19 + Loss Re-weighting 35.25 26.08 53.34 51.91 45.76 61.05 31.58 24.32 45.41 + Focal Loss 34.02 24.79 52.48 49.57 43.28 58.91 31.47 24.05 45.60 + KG-Mixup (Ours) 35.83 26.37 54.78 52.24 45.78 62.14 31.90 24.15 46.54
Model Method FB15K-237 NELL-995 CoDEx-M Zero Low Medium High Zero Low Medium High Zero Low Medium High ConvE Standard 7.34 12.35 34.95 70.97 35.37 57.16 65.99 91.90 8.38 7.97 34.64 65.29 + Over-Sampling 8.37 12.45 33.01 68.75 36.67 57.33 56.09 79.57 8.09 7.52 29.51 54.80 + Loss Re-weighting 5.03 9.89 30.56 63.34 36.16 57.96 63.69 89.52 8.79 7.09 29.09 58.10 + Focal Loss 7.52 11.89 33.96 68.75 34.72 58.00 65.60 90.89 6.78 6.80 33.42 56.96 + KG-Mixup (Ours) 10.90 13.92 35.74 70.72 35.38 59.56 65.41 90.64 9.74 8.96 32.63 64.38 TuckER Standard 10.41 14.65 38.49 71.39 37.02 58.21 69.17 90.55 9.99 8.29 35.23 63.94 + Over-Sampling 12.25 14.28 36.79 70.50 34.50 55.46 65.68 93.47 10.98 7.76 32.50 60.25 + Loss Re-weighting 10.61 14.40 37.66 72.28 36.59 59.00 67.19 91.17 10.44 8.62 35.00 63.39 + Focal Loss 10.84 13.53 37.00 69.28 34.18 53.60 62.67 91.02 9.68 8.17 33.95 64.13 + KG-Mixup (Ours) 11.83 15.61 39.45 70.86 36.12 60.73 71.67 92.27 9.14 8.70 32.38 65.28
In this section we conduct experiments to demonstrate the effectiveness of our approach on multiple benchmark datasets. We further compare the results of our framework to other methods commonly used to address bias. In particular we study if KG-Mixup can (a) improve overall KGC performance and (b) increase performance on low tail-relation degree triples without degrading performance on other triples. We further conduct studies examining the effect of the regularization terms, ascertaining the importance of each component in our framework, and the ability of KG-Mixup to improve model calibration.
6.1. Experimental Settings
6.1.1. Datasets
We conduct experiments on three datasets including FB15K-237 (Toutanova and Chen, 2015), CoDEx-M (Safavi and Koutra, 2020), and NELL-995 (Xiong et al., 2017). We omit the commonly used dataset WN18RR (Dettmers et al., 2018a) as a majority of entities have a degree less than or equal to 3, and as such does not exhibit any degree bias towards triples with a low tail-relation degree. The statistics of each dataset is shown in Table 6.
6.1.2. Baselines
We compare the results of our method, KG-Mixup, with multiple popular methods proposed for addressing imbalanced problems. Such methods can be used to mitigate bias caused by the initial imbalance. In our case, an imbalance in tail-relation degree causes algorithms to be biased against triples of low tail-relation degree. Specifically, we implement: (a) Over-Sampling triples below a degree threshold . We over-sample times, (b) Loss Re-Weighting (Yuan and Ma, 2012), which assigns a higher loss to triples with a low tail-relation degree, (c) Focal Loss (Lin et al., 2017), which assigns a higher weight to misclassified samples (e.g. low degree triples).
6.1.3. Evaluation Metrics
To evaluate the model performance on the test set, we report the mean reciprocal rank (MRR) and the Hits@k for . Following (Bordes et al., 2013), we report the performance using the filtered setting.
6.1.4. Implementation Details
In this section, we detail the training procedure used to train our framework KG-Mixup. We conduct experiments on our framework using two different KG embedding models, ConvE (Dettmers et al., 2018a) and TuckER (Balažević et al., 2019). Both methods are widely used to learn KG embeddings and serve as a strong indicator of our framework’s efficacy. We use stochastic weight averaging (SWA) (Izmailov et al., 2018) when training our model. SWA uses a weighted average of the parameters at different checkpoints during training for inference. Previous work (Rebuffi et al., 2021) has shown that SWA in conjunction with data augmentation can increase performance. Lastly, the synthetic loss weighting parameter is determined via hyperparameter tuning on the validation set.
6.2. Main Results
In this subsection we evaluate KG-Mixup on multiple benchmarks, comparing its test performance against the baseline methods. We first report the overall performance of each method on the three datasets. We then report the performance for various degree bins. The top results are bolded with the second best underlined. Note that the Standard method refers to training without any additional method to alleviate bias.
Table 1 contains the overall results on each method and dataset. The performance is reported for both ConvE and TuckER. KG-Mixup achieves for the best MRR and Hits@10 on each dataset for ConvE. For TuckER, KG-Mixup further achieves the best MRR on each dataset and the top Hits@10 for two. Note that the other three baseline methods used for alleviating bias, on average, perform poorly. This may be due to their incompatibility with relational structured data where each sample contains multiple components. It suggests that we need dedicated efforts to handle the degree bias in KGC.
We further report the MRR of each method for triples of different tail-relation degree. We split the triples into four degree bins of zero, low, medium and high degree. The range of each bin is [0, 1), [1, 10], [10, 50), and [50, ), respectively. KG-Mixup achieves a notable increase in performance on low tail-relation degree triples for each dataset and embedding model. KG-Mixup increases the MRR on low degree triples by 9.8% and 5.3% for ConvE and TuckER, respectively, over the standard trained models on the three datasets. In addition to the strong increase in low degree performance, KG-Mixup is also able to retain its performance for high degree triples. The MRR on high tail-relation degree triples degrades, on average, only 1% on ConvE between our method and standard training and actually increases 1% for TuckER. Interestingly, the performance of KG-Mixup on the triples with zero tail-relation degree isn’t as strong as the low degree triples. We argue that such triples are more akin to the zero-shot learning setting and therefore different from the problem we are studying.
Lastly, we further analyzed the improvement of KG-Mixup over standard training by comparing the difference in performance between the two groups via the paired t-test. We found that for the results in Table 1, are statistically significant (p¡0.05). Furthermore, for the performance on low tail-relation degree triples in Table 2, all results () are statistically significant. This gives further justification that our method can improve both overall and low tail-relation degree performance.
6.3. Regularization Analysis
In this subsection we empirically investigate the regularization effects of KG-Mixup discussed in Section 5. In Section 5 we demonstrated that KG-Mixup can be formulated as a form of regularization. We further showed that one of the quantities minimized is the difference between the head and relation embeddings of the two samples being mixed, and , such that and . Here is the low tail-relation degree sample being augmented and is another sample that shares the same tail. We deduce from this that for low tail-relation degree samples, KG-Mixup may cause their head and relation embeddings to be more similar to those of other samples that share same tail. Such a property forms a smoothing effect on the mixed samples, which facilitates a transfer of information to the embeddings of the low tail-relation degree sample.
We investigate this by comparing the head and relation embeddings of all samples that are augmented with all the head and relation embeddings that also share the same tail entity. We denote the set of all samples below some tail-relation degree threshold as and all samples with tail entity as . Furthermore, we refer to all head entities that are connected to a tail as and all such relations as . For each sample we compute the mean euclidean distance between the (1) head embedding and all and (2) the relation embedding and all . For a single sample the mean head and relation embedding distance are given by and , respectively. Lastly, we take the mean of both the head and relation embeddings mean distances across all ,
| (21) | |||
| (22) |
Both and are shown in Table 3 for models fitted with and without KG-Mixup. We display the results for ConvE on FB15K-237. For both the mean head and relation distances, KG-Mixup produces smaller distances than the standardly-trained model. This aligns with our previous theoretical understanding of the regularization effect of the proposed method: for samples for which we augment during training, their head and relation embeddings are more similar to those embeddings belonging to other samples that share the same tail. This to some extent forms a smoothing effect, which is helpful for learning better representations for the low-degree triplets.
| Embedding Type | Head Entity | Relation |
| w/o KG-Mixup | 1.18 | 1.21 |
| KG-Mixup | 1.09 | 1.13 |
| % Decrease | -7.6% | -6.6% |
6.4. Ablation Study
In this subsection we conduct an ablation study of our method on the FB15K-237 dataset using ConvE and TuckER. We ablate both the data augmentation strategy and the use of stochastic weight averaging (SWA) separately to ascertain their effect on performance. We report the overall test MRR and the low tail-relation degree MRR. The results of the study are shown in Table 4. KG-Mixup achieves the best overall performance on both embedding models. Using only our data augmentation strategy leads to an increase in both the low degree and overall performance. On the other hand, while the SWA-only model leads to an increase in overall performance it degrades the low degree performance. We conclude from these observations that data augmentation component of KG-Mixup is vital for improving low degree performance while SWA helps better maintain or even improve performance on the non-low degree triples.
Method ConvE TuckER Low Overall Low Overall Standard 12.35 33.04 14.65 35.19 + SWA 12.27 33.69 14.18 35.77 + Augmentation 13.99 33.67 15.64 35.62 KG-Mixup (Ours) 13.92 34.33 15.61 35.83
6.5. Parameter Study
In this subsection we study how varying the number of generated synthetic samples and the degree threshold affect the performance of KG-Mixup. We consider the values and . We report the MRR for both TuckER and ConvE on the CoDEx-M dataset. Figure 3(a) displays the performance when varying the degree threshold. Both methods peak at a value of and perform worst at . Figure 3(b) reports the MRR when varying the number of synthetic samples generated. Both methods peak early with ConvE actually performing best at . Furthermore, generating too many samples harms performance as evidenced by the sharp drop in MRR occurring after .


6.6. Model Calibration
In this subsection we demonstrate that KG-Mixup is effective at improving the calibration of KG embedding models. Model calibration (Guo et al., 2017) is concerned with how well calibrated a models prediction probabilities are with its accuracy. Previous work (Pleiss et al., 2017) have discussed the desirability of calibration to minimize bias between different groups in the data (e.g. samples of differing degree). Other work (Wald et al., 2021) has drawn the connection between out-of-distribution generalization and model calibration, which while not directly applicable to our problem is still desirable. Relevant to our problem, Thulasidasan et al. (2019) has shown that Mixup is effective at calibrating deep models for the tasks of image and text classification. As such, we investigate if KG-Mixup is helpful at calibrating KG embedding models for KGC.
We compared the expected calibration error (see Appendix A.5 for more details) between models trained with KG-Mixup and those without on multiple datasets. We report the calibration in Table 5 for all samples and those with a low tail-relation degree. We find that in every instance KG-Mixup produces a better calibrated model for both ConvE and TuckER. These results suggest another reason for why KG-Mixup works; a well-calibrated model better minimizes the bias between different groups in the data (Pleiss et al., 2017). This is integral for our problem where certain groups of data (i.e. triples with low tail-relation degree) feature bias.
Model Method FB15K-237 NELL-995 CoDEx-M Low Overall Low Overall Low Overall ConvE Standard 0.19 0.15 0.34 0.27 0.28 0.26 KG-Mixup 0.08 0.05 0.08 0.08 0.02 0.09 TuckER Standard 0.20 0.35 0.63 0.56 0.05 0.34 KG-Mixup 0.07 0.1 0.26 0.20 0.01 0.06
7. Conclusion
We explore the problem of degree bias in KG embeddings. Through empirical analysis we find that when predicting the tail for a triple , a strong indicator performance is the number of edges where and co-occur as the relation and tail, respectively. We refer to this as the tail-relation degree. We therefore propose a new method, KG-Mixup, that can be used in conjunction with any KG embedding technique to improve performance on triples with a low tail-relation degree. It works by augmenting lower degree entity-relation pairs with additional synthetic triples during training. To create synthetic samples we adapt the Mixup (Zhang et al., 2018) strategy to KGs. Experiments validate its usefulness. For future work we plan on expanding our method to path-based techniques such as NBFNet (Zhu et al., 2021).
Acknowledgements.
This research is supported by the National Science Foundation (NSF) under grant numbers CNS1815636, IIS1845081, IIS1928278, IIS1955285, IIS2212032, IIS2212144, IOS2107215, and IOS2035472, the Army Research Office (ARO) under grant number W911NF-21-1-0198, the Home Depot, Cisco Systems Inc, Amazon Faculty Award, Johnson&Johnson and SNAP.References
- (1)
- Amin et al. (2020) Saadullah Amin, Stalin Varanasi, Katherine Ann Dunfield, and Günter Neumann. 2020. LowFER: Low-rank bilinear pooling for link prediction. In International Conference on Machine Learning. PMLR, 257–268.
- Balažević et al. (2019) Ivana Balažević, Carl Allen, and Timothy M Hospedales. 2019. Tucker: Tensor factorization for knowledge graph completion. arXiv preprint arXiv:1901.09590 (2019).
- Bonner et al. (2022) Stephen Bonner, Ian P Barrett, Cheng Ye, Rowan Swiers, Ola Engkvist, Charles Tapley Hoyt, and William L Hamilton. 2022. Understanding the performance of knowledge graph embeddings in drug discovery. Artificial Intelligence in the Life Sciences (2022), 100036.
- Bordes et al. (2013) Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. Advances in neural information processing systems 26 (2013).
- Cao et al. (2019) Yixin Cao, Xiang Wang, Xiangnan He, Zikun Hu, and Tat-Seng Chua. 2019. Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences. In The world wide web conference. 151–161.
- Carratino et al. (2020) Luigi Carratino, Moustapha Cissé, Rodolphe Jenatton, and Jean-Philippe Vert. 2020. On mixup regularization. arXiv preprint arXiv:2006.06049 (2020).
- Chawla et al. (2002) Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. 2002. SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research 16 (2002), 321–357.
- Dettmers et al. (2018a) Tim Dettmers, Pasquale Minervini, Pontus Stenetorp, and Sebastian Riedel. 2018a. Convolutional 2d knowledge graph embeddings. In Thirty-second AAAI conference on artificial intelligence.
- Dettmers et al. (2018b) Tim Dettmers, Pasquale Minervini, Pontus Stenetorp, and Sebastian Riedel. 2018b. Convolutional 2d knowledge graph embeddings. In Proceedings of the AAAI conference on artificial intelligence, Vol. 32.
- Guo et al. (2017) Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. 2017. On calibration of modern neural networks. In International conference on machine learning. PMLR, 1321–1330.
- Izmailov et al. (2018) Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. 2018. Averaging Weights Leads to Wider Optima and Better Generalization. arXiv preprint arXiv:1803.05407 (2018).
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Kipf and Welling (2017) Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In International Conference on Learning Representations (ICLR).
- Kojaku et al. (2021) Sadamori Kojaku, Jisung Yoon, Isabel Constantino, and Yong-Yeol Ahn. 2021. Residual2Vec: Debiasing graph embedding with random graphs. Advances in Neural Information Processing Systems 34 (2021).
- Li et al. (2021) Guangyao Li, Zequn Sun, Lei Qian, Qiang Guo, and Wei Hu. 2021. Rule-based data augmentation for knowledge graph embedding. AI Open 2 (2021), 186–196.
- Li et al. (2022) Ren Li, Yanan Cao, Qiannan Zhu, Guanqun Bi, Fang Fang, Yi Liu, and Qian Li. 2022. How Does Knowledge Graph Embedding Extrapolate to Unseen Data: a Semantic Evidence View. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2022.
- Lin et al. (2017) Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. 2017. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision. 2980–2988.
- Liu et al. (2020) Weijie Liu, Peng Zhou, Zhe Zhao, Zhiruo Wang, Qi Ju, Haotang Deng, and Ping Wang. 2020. K-bert: Enabling language representation with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 2901–2908.
- Liu et al. (2021) Zemin Liu, Trung-Kien Nguyen, and Yuan Fang. 2021. Tail-GNN: Tail-Node Graph Neural Networks. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 1109–1119.
- Mohamed et al. (2020b) Aisha Mohamed, Shameem Parambath, Zoi Kaoudi, and Ashraf Aboulnaga. 2020b. Popularity agnostic evaluation of knowledge graph embeddings. In Conference on Uncertainty in Artificial Intelligence. PMLR, 1059–1068.
- Mohamed et al. (2020a) Sameh K Mohamed, Vít Nováček, and Aayah Nounu. 2020a. Discovering protein drug targets using knowledge graph embeddings. Bioinformatics 36, 2 (2020), 603–610.
- Nickel et al. (2011) Maximilian Nickel, Volker Tresp, and Hans-Peter Kriegel. 2011. A three-way model for collective learning on multi-relational data. In Icml.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Eds.). Curran Associates, Inc., 8024–8035. http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf
- Pleiss et al. (2017) Geoff Pleiss, Manish Raghavan, Felix Wu, Jon Kleinberg, and Kilian Q Weinberger. 2017. On fairness and calibration. Advances in neural information processing systems 30 (2017).
- Rebuffi et al. (2021) Sylvestre-Alvise Rebuffi, Sven Gowal, Dan Andrei Calian, Florian Stimberg, Olivia Wiles, and Timothy A Mann. 2021. Data augmentation can improve robustness. Advances in Neural Information Processing Systems 34 (2021), 29935–29948.
- Ren et al. (2020) Jiawei Ren, Cunjun Yu, Xiao Ma, Haiyu Zhao, Shuai Yi, et al. 2020. Balanced meta-softmax for long-tailed visual recognition. Advances in neural information processing systems 33 (2020), 4175–4186.
- Rossi et al. (2021) Andrea Rossi, Denilson Barbosa, Donatella Firmani, Antonio Matinata, and Paolo Merialdo. 2021. Knowledge graph embedding for link prediction: A comparative analysis. ACM Transactions on Knowledge Discovery from Data (TKDD) 15, 2 (2021), 1–49.
- Safavi and Koutra (2020) Tara Safavi and Danai Koutra. 2020. CoDEx: A Comprehensive Knowledge Graph Completion Benchmark. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 8328–8350.
- Schlichtkrull et al. (2018) Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne Van Den Berg, Ivan Titov, and Max Welling. 2018. Modeling relational data with graph convolutional networks. In European semantic web conference. Springer, 593–607.
- Tan et al. (2020) Jingru Tan, Changbao Wang, Buyu Li, Quanquan Li, Wanli Ouyang, Changqing Yin, and Junjie Yan. 2020. Equalization loss for long-tailed object recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11662–11671.
- Tang et al. (2020) Xianfeng Tang, Huaxiu Yao, Yiwei Sun, Yiqi Wang, Jiliang Tang, Charu Aggarwal, Prasenjit Mitra, and Suhang Wang. 2020. Investigating and mitigating degree-related biases in graph convoltuional networks. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 1435–1444.
- Tang et al. (2022) Zhenwei Tang, Shichao Pei, Zhao Zhang, Yongchun Zhu, Fuzhen Zhuang, Robert Hoehndorf, and Xiangliang Zhang. 2022. Positive-Unlabeled Learning with Adversarial Data Augmentation for Knowledge Graph Completion. arXiv preprint arXiv:2205.00904 (2022).
- Thulasidasan et al. (2019) Sunil Thulasidasan, Gopinath Chennupati, Jeff A Bilmes, Tanmoy Bhattacharya, and Sarah Michalak. 2019. On mixup training: Improved calibration and predictive uncertainty for deep neural networks. Advances in Neural Information Processing Systems 32 (2019).
- Toutanova and Chen (2015) Kristina Toutanova and Danqi Chen. 2015. Observed versus latent features for knowledge base and text inference. In Proceedings of the 3rd workshop on continuous vector space models and their compositionality. 57–66.
- Wald et al. (2021) Yoav Wald, Amir Feder, Daniel Greenfeld, and Uri Shalit. 2021. On calibration and out-of-domain generalization. Advances in neural information processing systems 34 (2021), 2215–2227.
- Wang et al. (2018) Peifeng Wang, Shuangyin Li, and Rong Pan. 2018. Incorporating gan for negative sampling in knowledge representation learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 32.
- Wang et al. (2020) Tao Wang, Yu Li, Bingyi Kang, Junnan Li, Junhao Liew, Sheng Tang, Steven Hoi, and Jiashi Feng. 2020. The devil is in classification: A simple framework for long-tail instance segmentation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16. Springer, 728–744.
- Wang et al. (2021) Xudong Wang, Long Lian, Zhongqi Miao, Ziwei Liu, and Stella Yu. 2021. Long-tailed Recognition by Routing Diverse Distribution-Aware Experts. In International Conference on Learning Representations.
- Xiong et al. (2017) Wenhan Xiong, Thien Hoang, and William Yang Wang. 2017. DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 564–573.
- Yang et al. (2015) Bishan Yang, Scott Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. 2015. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the International Conference on Learning Representations (ICLR) 2015.
- Yuan and Ma (2012) Bo Yuan and Xiaoli Ma. 2012. Sampling+ reweighting: Boosting the performance of AdaBoost on imbalanced datasets. In The 2012 international joint conference on neural networks (IJCNN). IEEE, 1–6.
- Zhang et al. (2018) Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. 2018. mixup: Beyond Empirical Risk Minimization. In International Conference on Learning Representations.
- Zhang et al. (2021) L Zhang, Z Deng, K Kawaguchi, A Ghorbani, and J Zou. 2021. How Does Mixup Help With Robustness and Generalization?. In International Conference on Learning Representations.
- Zhao et al. (2022) Tong Zhao, Wei Jin, Yozen Liu, Yingheng Wang, Gang Liu, Stephan Günneman, Neil Shah, and Meng Jiang. 2022. Graph Data Augmentation for Graph Machine Learning: A Survey. arXiv preprint arXiv:2202.08871 (2022).
- Zhao et al. (2021b) Tong Zhao, Gang Liu, Daheng Wang, Wenhao Yu, and Meng Jiang. 2021b. Counterfactual Graph Learning for Link Prediction. arXiv preprint arXiv:2106.02172 (2021).
- Zhao et al. (2021a) Tong Zhao, Yozen Liu, Leonardo Neves, Oliver Woodford, Meng Jiang, and Neil Shah. 2021a. Data augmentation for graph neural networks. In Proceedings of the aaai conference on artificial intelligence, Vol. 35. 11015–11023.
- Zhao et al. (2021c) Tianxiang Zhao, Xiang Zhang, and Suhang Wang. 2021c. Graphsmote: Imbalanced node classification on graphs with graph neural networks. In Proceedings of the 14th ACM international conference on web search and data mining. 833–841.
- Zhou et al. (2020) Boyan Zhou, Quan Cui, Xiu-Shen Wei, and Zhao-Min Chen. 2020. Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9719–9728.
- Zhu et al. (2021) Zhaocheng Zhu, Zuobai Zhang, Louis-Pascal Xhonneux, and Jian Tang. 2021. Neural bellman-ford networks: A general graph neural network framework for link prediction. Advances in Neural Information Processing Systems 34 (2021), 29476–29490.
Appendix A Appendix
A.1. Dataset Statistics
The statistics for each dataset can be found in Table 6.
| Statistic | FB15K-237 | NELL-995 | CoDEx-M |
| #Entities | 14,541 | 74,536 | 17,050 |
| #Relations | 237 | 200 | 51 |
| #Train | 272,115 | 149,678 | 185,584 |
| #Validation | 17,535 | 543 | 10,310 |
| #Test | 20,466 | 2,818 | 10,311 |
A.2. Infrastructure
All experiments were run on a single 32G Tesla V100 GPU and implemented using PyTorch (Paszke et al., 2019).
A.3. Parameter Settings
Each model is trained for 400 epochs on FB15K-237, 250 epochs on CoDEx-M, and 300 epochs on NELL-995. The embedding dimension is set to 200 for both methods except for the dimension of the relation embeddings in TuckER which is is tuned from . The batch size is set to 128 and the number of negative samples per positive sample is 100. The learning rate is tuned from , the decay from , the label smoothing from , and the dropout from {0, 0.1, 0.2, 0.3, 0.4, 0.5 }. For KG-Mixup we further tune the degree threshold from , the number of samples generated from , and the loss weight for the synthetic samples from {1e-2, 1e-1, 1 }. Lastly, we tune the stochastic weight averaging (SWA) initial learning rate from { 1e-5, 5e-4 }. The best hyperparameter values for ConvE and TuckER using KG-Mixup are shown in Figures 7 and 8, respectively.
A.4. Preliminary Study Results using ConvE
In Section 3 we conduct a preliminary study using TuckER (Balažević et al., 2019) on the FB15K-237 dataset (Toutanova and Chen, 2015). In this section we further include the corresponding results when using the ConvE (Dettmers et al., 2018a) embedding models. The plots can be found in Figure 4. We note that they show a similar pattern to those displayed by TuckER in Figure 2.
| Hyperparameter | FB15K-237 | NELL-995 | CoDEx-M |
| Learning Rate | |||
| LR Decay | None | None | None |
| Label Smoothing | 0 | 0.1 | 0.1 |
| Dropout #1 | 0.2 | 0.4 | 0.1 |
| Dropout #2 | 0.5 | 0.3 | 0.2 |
| Dropout #3 | 0.2 | 0.1 | 0.3 |
| Degree Threshold | 5 | 5 | 5 |
| # Generated | 5 | 5 | 5 |
| Synth Loss Weight | 1 | 1 | 1 |
| SWA LR |
| Hyperparameter | FB15K-237 | NELL-995 | CoDEx-M |
| Learning Rate | |||
| LR Decay | 0.99 | None | 0.995 |
| Label Smoothing | 0 | 0 | 0 |
| Dropout #1 | 0.3 | 0.3 | 0.3 |
| Dropout #2 | 0.4 | 0.3 | 0.5 |
| Dropout #3 | 0.5 | 0.2 | 0.5 |
| Rel Dim | 200 | 100 | 100 |
| Degree Threshold | 5 | 25 | 5 |
| # Generated | 5 | 5 | 5 |
| Synth Loss Weight | 1 | 1 | |
| SWA LR |


A.5. Expected Calibration Error
Expected calibration error (Guo et al., 2017) is a measure of model calibration that utilizes the model accuracy and prediction confidence. Following Guo et al. (2017), we first split our data into bins and define the accuracy (acc) and confidence (conf) on one bin as:
| (23) | |||
| (24) |
where is the true label for sample , is the predicted label, and the prediction probability for sample . A well-calibrated model should have identical accuracy and confidence for each bin. ECE is thus defined by Guo et al. (2017) as:
| (25) |
where is the total number of samples across all bins. As such, a lower ECE indicates a better calibrated model. For KGC we split the samples into bin by the tail-relation degree. Furthermore to calculate the accuracy score (acc) we utilize His@10 to denote a correct prediction. For the confidence score (conf) we denote as the prediction probability where is a KG embedding score function and is the sigmoid function. When calculating the ECE over all samples Eq. (25) is unchanged. When calculating ECE for just one bin of samples (e.g. low degree triples) it is defined as:
| (26) |
where is the expected calibration error for just bin .
A.6. Proof of Theorem 5.1
In this section we prove Theorem 5.1. Following recent work (Carratino et al., 2020; Zhang et al., 2021) we examine the regularizing effect of the mixup parameter . This is achieved by approximating the loss on a single mixed sample using the first-order quadratic Taylor approximation at the point near 0. Assuming is differentiable, we can approximate , with some abuse of notation as:
| (27) |
We consider the case where is the binary cross-entropy loss. Since the label is always true, it can be written as,
| (28) |
where is the sigmoid function and is the mixed sample. Since , we can rewrite the mixed sample as:
| (29) |
As such, setting doesn’t mix the two samples resulting in . The term is therefore equivalent to the standard loss over the samples . We can now compute the first derivative in Eq. (27). We evaluate via the chain rule,
| (30) |
where is evaluated via the multivariable chain rule to:
| (31) |
Evaluating :
| (32) | ||||
| (33) | ||||
| (34) |
where the term related to in Eq. (31) cancels out since . Since we are evaluating the expression near , we only consider the original sample in the score function, reducing the above to the following where , and ,
| (35) |
Plugging in and into Eq. (27) and rearranging the terms we arrive at:
| (36) |
where and are defined over all samples as:
| (37) | ||||
| (38) |
with where .