Toward Ambient Intelligence: Federated Edge Learning with Task-Oriented Sensing, Computation, and Communication Integration
Abstract
With the breakthroughs in deep learning and contactless sensors, the recent years have witnessed a rise of ambient intelligence applications and services, spanning from healthcare delivery to intelligent home. Federated edge learning (FEEL), as a privacy-enhancing paradigm of collaborative learning at the network edge, is expected to be the core engine to achieve ambient intelligence. Sensing, computation, and communication (SC2) are highly coupled processes in FEEL and need to be jointly designed in a task-oriented manner for pursuing the best FEEL performance under the stringent resource constraints at the edge devices. However, this remains an open problem as there is a lack of theoretical understanding on how the SC2 resource jointly affect the FEEL performance. In this paper, we address the problem of joint SC2 resource allocation for FEEL via a concrete case study of human motion recognition based on wireless sensing in ambient intelligence. First, by analyzing the wireless sensing process in human motion recognition, we find that there exists a thresholding value for the sensing transmit power, exceeding which yields sensing data samples with approximately the same satisfactory quality. Then, the joint SC2 resource allocation problem is cast to maximize the convergence speed of FEEL, under the constraints on training time, energy supply, and sensing quality of each edge device. Solving this problem entails solving two subproblems in order: the first one reduces to determine the joint sensing and communication resource allocation that maximizes the total number of samples that can be sensed during the entire training process; the second one concerns the partition of the attained total number of sensed samples over all the communication rounds to determine the batch size at each round for convergence speed maximization. The first subproblem on joint sensing and communication resource allocation is converted to a single-variable optimization problem by exploiting the derived relation between different control variables (resources), which thus allows an efficient solution via one-dimensional grid search. For the second subproblem, it is found that the number of samples to be sensed (or batch size) at each round is a decreasing function of the loss function value attained at the round. Based on this relationship, the approximate optimal batch size at each communication round is derived in closed-form as a function of the round index. Finally, extensive simulation results are provided to validate the superiority of the proposed joint SC2 resource allocation scheme over baseline schemes in terms of FEEL performance.
Index Terms:
Federated edge learning, ambient intelligence, sensing-computation-communication resource allocation, integrated sensing and communicationI Introduction
With the continuous integration of information and communication technologies and the all-round penetration of artificial intelligence (AI), we can envision that the future 6G network will no longer serve only the single purpose of data transmission, but will need to support connected intelligence services and ubiquitous intelligence applications[1, 2]. One emerging technology of ubiquitous intelligence, called ambient intelligence, has shown significant potential in improving the efficiency of healthcare delivery and quality of life [3]. The goal of ambient intelligence is to build physical spaces that are sensitive and responsive to the inputs triggered by humans and to provide low-latency, high-accurate, scalable, and resilient services with the help of AI technologies and contactless sensors [4]. Therefore, in order to support ambient intelligence, the future 6G network needs to undergo a paradigm shift from a pure information delivery pipeline to an integrated sensing-computation-communication multi-functional platform.
Demand for low-latency in ambient intelligence has prompted the development of AI technologies at the network edge, leading to an emerging research area known as edge learning [5], which advocates local data processing at the edge and thus avoids the long delay resulting from the data transfer from the edge to the remote cloud server. Specifically, edge learning allows the edge devices to process the sensory data from their onboard sensors and makes full use of the computing power at the edge to learn AI models customized for specific tasks. Among the techniques in edge learning, federated edge learning (FEEL) is a popular collaborative distributed learning paradigm that trains a global machine learning (ML) model over wireless networks while helping to preserve data privacy [6, 7, 8]. In a typical training iteration of FEEL, a dedicated edge server first broadcasts the global ML model to the participating edge devices; next, the edge devices compute their respective model-updates using their local data and then upload them to the edge server for further aggregation and global model updating.
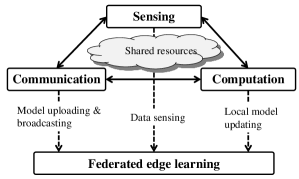
Since the ML model is transmitted over wireless links which could introduce training errors due to the limited radio resources (e.g., bandwidth), prior works on FEEL mainly focus on accelerating the learning process from the resource allocation perspective. For example, the work in [9] optimized the receive beamforming at the edge server to maximize the number of participated edge devices at each iteration of FEEL under peak power constraints. The works in [10, 11, 12] designed the power allocation of each edge device to maximize the convergence speed of FEEL under a total energy constraint. Besides power and energy constraints, the authors in [13] and [14] also took the latency constraint into consideration, and studied the problem of power allocation and device scheduling in FEEL. While interesting, the works in [6, 7, 9, 10, 11, 12, 13, 14] all took the learning error as the objective function. Instead, the work in [15] minimized total energy consumption under a latency constraint and learning performance guarantee. Last but not least, from a more practical consideration, the authors in [16] studied resource block allocation under imperfect channel state information. These prior works mainly focused on the communication and/or computation perspectives and assumed that the data used for training are readily available without considering the data sensing process, which could significantly affect the learning performance as sensing also competes with communication and computation for resources. As shown in Fig. 1, sensing, computation, and communication (SC2) are highly coupled in FEEL and thus need to be seamlessly integrated in a joint design to fully unleash the potential of FEEL. This thus calls for task-oriented SC2 resource management that takes the FEEL performance as the ultimate objective in the resulting optimization.
Among various contactless sensors used in ambient intelligence, wireless sensors are widely adopted inside office buildings, homes, and hospitals due to their unique advantages such as safety, reliability, portability, and affordability [17]. Wireless sensors sense the environmental information by analyzing the raw reflected radio signals from the sensing targets, and achieve the functions of detection, ranging, positioning, imaging, and so on. The fact that radio signals can not only be used for wireless communication but also for environmental sensing is particularly appealing as it allows the same radio hardware to be reused for dual functions. This has led to an increasingly popular research area known as integrated sensing and communication (ISAC) [18, 19]. The integration of both functions enjoys the benefit of a smaller form factor for the ISAC devices due to the shared hardware and better management of the shared radio resources, such as power and bandwidth. In view of its promising potential, ISAC is expected to support various ambient intelligence applications, ranging from indoor health monitoring to extended human sensing [20]. In these applications, fundamental differences in the data domain have driven the development of unique AI-based signal processing. In particular, sensing data is not inherently acquired as images, but mostly as complex time series with amplitudes and phases related to the electromagnetic scattering and kinematics of the sensed targets [21]. Hence, some preprocessing stages, e.g., filtering and time-frequency analysis, are required to transform the raw signals into the data samples as the inputs of ML models. Since the raw reflected signals are typically mixed with scatterings from the environment, it poses a significant challenge to generate data samples of approximately the same satisfactory quality over time, which is desirable for training a ML model.
Despite the fact that wireless sensor outputs may not include photos or video, some wireless sensing applications can nevertheless create enormous volumes of data that may contain private information about the users, such as the number of occupants, health conditions, and room sizes. The wealth of sensing data at the network edge should also be leveraged without under fear of privacy leakage. Fortunately, FEEL as a privacy-enhancing learning framework can be applied with wireless sensing in ambient intelligence [22]. In this work, we investigate the joint SC2 resource allocation in FEEL by considering a concrete case study, i.e., human motion recognition. Specifically, we consider an ISAC-based FEEL system in which multiple ISAC devices obtain their own local datasets for human motion recognition by wireless sensing, and communicate with the server to exchange model-updates over wireless channels. Then each ISAC device updates its local model using only the latest sensed data samples, the number of which gives its batch size for the current round. Under this online FEEL setting, the SC2 resources include the transmit power and time for sensing and communication, as well as the batch size to be computed at each round. In this setting, we address two challenges for the considered system: 1) how to generate data samples with approximately the same satisfactory quality for FEEL over time by wireless sensing; 2) how to jointly allocate the SC2 resources in an task-oriented manner so as to yield the best learning performance. The findings and the contributions of this work are as follows:
-
•
Sensing quality analysis: We present the pipeline of wireless sensing in human motion recognition, empirically analyze the sensing process, and find that the sensing quality does not improve much when the sensing transmit power exceeds a threshold value. This finding suggests that it is sufficient to sense with the said threshold power value for generating data samples of approximately the same satisfactory quality over time, which addresses the first challenge above.
-
•
Problem formulation and splitting for joint SC2 resource allocation: We formulate the joint SC2 resource allocation problem in FEEL, which aims to maximize the convergence speed under total latency and energy constraints. To solve this challenging non-convex problem, we split it into two subproblems without loss of optimality: the one concerns sensing and communication resource allocation to maximize the number of total sensed data samples in the training process; the other concerns the partition of the total sensed data samples over rounds to determine the batch size to be computed at each round for convergence speed maximization.
-
•
Optimal joint SC2 resource allocation: To tackle the first subproblem of joint sensing and communication resource allocation, we first analyze the coupled relations between different control variables, by exploiting which, the challenging multi-variable optimization problem is transformed to a single variable problem. This thus allows an efficient solution via one-dimensional grid search. The second subproblem cannot be solved directly due to the lack of an explicit objective function. Instead, we derive an approximate solution in closed-form for the optimal batch sizes at different rounds, based on a theoretical finding that the optimal batch size should be adaptive and increase as the training loss value decreases in the course of training. The solutions of the two subproblems together address the second challenge above.
-
•
Performance evaluation: We conduct extensive simulations based on a concrete wireless sensing task of human motion recognition over a high-fidelity wireless sensing simulator [23] to evaluate the performance of our proposed joint SC2 resource allocation scheme. The superiority of the proposed scheme over other baseline joint SC2 resource management schemes is demonstrated.
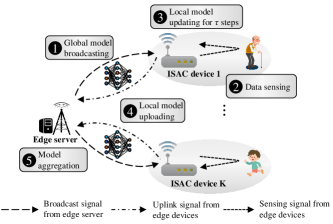
The remainder of this paper is organized as follows. Sec. II presents the system model, including FEEL specification, communication and sensing models. Sec. III analyzes the communication rate and sensing quality in this setting. Sec. IV formulates the SC2 resource allocation problem of FEEL under total latency and energy constraints. The optimal power allocation of communication and sensing and batch size updating policy are characterized in Sec. V. Simulation results are given in Sec. VI, followed by conclusions in Sec. VII.
II System Model
II-A Federated Edge Learning
As shown in Fig. 2, we consider an ISAC-assisted FEEL system comprising ISAC devices, denoted by a set , and a single edge server. Each ISAC device is equipped with a single-antenna ISAC transceiver that can switch between the sensing mode and communication mode as needed in a time-devision manner using a shared radio-frequency front-end circuit111A practical implementation of such an ISAC device via software-defined radio platform has been demonstrated in [24]. [24]. Specifically, in the sensing mode, dedicated radar waveform known as frequency-modulated continuous-wave (FMCW) consisting of multiple up-chirps is transmitted [17]. Then, by processing the received radar echo signals, sensing data that contain the motion information of the human target can be attained at ISAC devices (see Sec. III-B for more details of the sensing processing). On the other hand, in the communication mode, constant-frequency carrier modulated by communication data using digital modulation scheme (e.g., QAM) is transmitted. This mode is used for the necessary information exchange between the ISAC device and edge server in the course of FEEL as elaborated in Sec. II-B. For better illustration, the time-frequency diagram for the considered time-switching ISAC waveforms is depicted in Fig. 3. Besides, each ISAC device is equipped with certain computation power and can perform local computations for training and inference of ML models, e.g., convolutional neural network (CNN). The goal of this ISAC-assisted FEEL system is to train222After the model training stage is completed, each device will deploy the model locally for inference. In this work, we only focus on the optimization in the training stage. an ML model tailored for specific sensing applications, e.g., human motion recognition, using the data wirelessly sensed by the ISAC devices.
In FEEL, a shared ML model, represented by , is trained collaboratively over all the ISAC devices with the coordination of the edge server. Specifically, we seek to find such a model that can minimize the objective function,
| (1) |
where is the local loss function at device ; is a random seed whose realization represents a batch of samples.
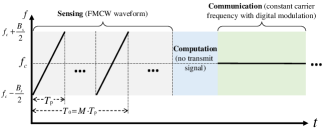
The FEEL training process proceeds iteratively over multiple communication rounds. In an arbitrary round , mainly five steps are executed as elaborated as follows (see Fig. 2):
-
1.
Global model broadcasting: Each ISAC device downloads the global FL model from the server via the wireless broadcast channel.
-
2.
Data sensing: Each ISAC device switches to the sensing mode, and transmits dedicated FMCW signals (as shown in Fig. 3) for sensing. Then, a batch of sensing data, i.e., , can be attained at each ISAC device by processing its received echo signals as mentioned. This batch of data with size will be used for local computation in the following Step 3. The batch size can vary adaptively over different rounds, but keep unchanged within any particular round333The size of batch can also vary adaptively among different devices in each communication round to reduce the waiting time [25]. In this work, we focus on adjusting batch size over different communication rounds by designing the sensing strategy to accelerate the convergence speed of FEEL..
-
3.
Local model updating for steps: Each device updates its model by running steps of stochastic gradient decent (SGD) from , i.e.,
where is the learning rate; is the stochastic gradient.
-
4.
Local model uploading: Each ISAC device switches to communication mode and uploads its local model after local updates, i.e., , to the server via the uplink wireless channel.
-
5.
Global aggregation: Once the server receives the models from all the devices, it aggregates them to obtain a new global ML model, i.e.,
II-B Communication Model
We assume that each device occupies a non-overlapping communication frequency subcarrier, and the transmissions of the devices are interference-free from each other. The received baseband signal from device at time is given by
where denotes the channel from device to the server, is the communication transmit power, is the communication transmit signal, and is additive Gaussian white noise. Since the latency for transmitting a model to the server is typically much longer than the channel coherence time, we assume that the communication channels from the devices to the server are fast Rayleigh fading channel [26]. Specifically, the channel propagation coefficient between the server and device is generally modeled as444The time index will be omitted for simplicity hereafter, unless necessary. ; here, describes the large-scale propagation effects, including path loss and shadowing effect, and represents the small-scale fading modeled as independent and identically distributed (i.i.d.) circularly symmetric complex Gaussian (CSCG) random variables with zero mean and unit variance, i.e., . We assume that the large-scale propagation coefficient remains unchanged during the whole uplink transmission, while the small-scale fading varies from one coherence time block to another. Moreover, we assume that the channel coefficients are only known at the server by channel estimation. The ergodic capacity, instead of instantaneous capacity, of device , is used to quantify the capacity of the fast Rayleigh fading channel between device and the server [26], which is represented as a function of :
| (2) |
where is the bandwidth of each subcarrier, and is the noise power spectral density.
| (3) |
II-C Sensing Model
The FMCW signal for sensing of device is denoted as . The bandwidth of sensing signal is denoted as , and the duration of each chirp is , as shown in Fig. 3. Moreover, we focus on sensing/recognizing dynamic targets such as moving humans in this work. We consider the scenario that the devices are geometrically separated at different locations with sufficient distance between each other, such that all the devices can sense the environment over the same bandwidth and will not be interfered with each other555This is well justified by the fact that the range of the sensing applications such as human/object recognition is usually small, typically less than 20 meters [20]..
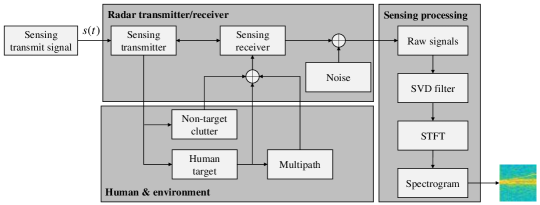
We use a primitive-based method [27] to model the scattering from the entire human body to the device sensing receiver as a linear time varying system. The scattering along -th path is approximated using superposition of the returns from body primitives as given by (3) at the bottom of next page, where is the sensing transmit power of device at time , is a constant related to the gain of the antenna, is the complex amplitude proportional to the radar-cross sections (RCS) of the -th primitive at time along the -th path, is the distance from the -th primitive to the sensing receiver along the -th path, is the light speed, and is the scattering along -th path normalized by the square root of the sensing transmit power.
Then, the received signal from the environment at the sensing receiver of device is given by
| (4) | ||||
where is the normalized scattering along first-order (direct) reflected path, and is summation of the normalized scattering along higher-order (indirect) reflected paths, and is additive term because of the ground clutter and receiver noise. We assume that the additive ground clutter and receiver noise components are zero-mean complex Gaussian distributed [28]. In practice, the ground clutter is small enough to be ignored in a space where no other dynamic objects exist except one moving target.
III Communication and Sensing Analysis
In this section, we analyze the ergodic communication rate and obtain its closed-form expression. Moreover, we also look into the wireless sensing process in human motion recognition and analyze the sensing quality.
III-A Communication Rate Analysis
To get a closed-form expression of in (2), it is rewritten as
where and are the probability density function and cumulative distribution function of the random variable , respectively. It can be verified that follows an exponential distribution, i.e., . Hence, we have . Then, can be calculated as
According to [29, Section 8.212], for real number and , , where is the exponential integral function. Then, can be rewritten in closed-form as follows:
| (5) |
It can be verified that is an increasing function of .
III-B Sensing Quality Analysis
In this subsection, we analyze the quality of sensing samples for human motion recognition. Micro-Doppler signature is a characteristic of motion, which can be used for recognizing human motions. A common technique for micro-Doppler analysis is the time-frequency representation, such as spectrograms [30]. Thus, the received sensing signal as in (4) needs to be further preprocessed in order to obtain the spectrograms as the sensing data samples. Each spectrogram is generated from a long sequence of the received signal spanning a duration of , called unit sensing time, which consists of chirps, as shown in Fig. 3. We assume that the sensing transmit power will remain unchanged during the duration. The sampling rate is denoted as . The received raw signal as shown in (4) after sampling in -th duration can be reconstructed as a 2D sensing data matrix, i.e., , which is the superposition of first-order scattering, higher-order scattering, and the clutter and receiver noise in 2D format as follows:
where , , , , represents the fast time index, and represents the slow time index.
As shown in Fig. 4, similar to [23], we extract the useful first-order scattering666The higher-order scattering can be utilized as a diverse source to improve the sensing performance [31], which, however, makes the processing more complicated. In this work, the high-order scattering signals are treated as interference to the first-order scattering when generating the spectrograms. from via singular value decomposition (SVD) based filter. Suppose that the SVD of is denoted as777The index for each duration is omitted for simplicity, since the signal at each duration will be preprocessed in the same way. where and are complex unitary matrices, and is rectangular diagonal matrix with singular values on the diagonal. The signal after filtering is , where and are pre-determined hyperparameters. It is equivalent to write as
where and . Denote , , and . Then, is rewritten as
Next, short-time Fourier transform (STFT) with a sliding window function of length is adopted to generate the range-Doppler-time (RDT) cube in order to obtain time-frequency features of . The RDT cube of after STFT is given by
where is the number of overlapping points; and are the frequency and temporal shift indexes, respectively. Then, we non-coherently integrate within all the range bins and obtain the integrated STFT of as
Due to the linearity of STFT and summation operation, can be given by
| (6) |
where , , and are integrated STFT of , , and , respectively. The first-order scattering related term represents useful information in the spectrogram; the higher-order scattering related term and the clutter and noise related term corrupt the spectrogram as interference.
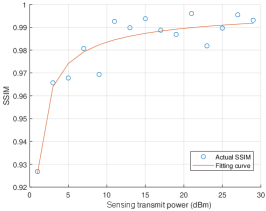
Remark 1 (Impact of sensing transmit power to the quality of spectrograms).
From (6), we can see that the quality of spectrograms will improve as we increase the sensing transmit power. Moreover, when the sensing transmit power is large enough such that the effects of clutter and noise is ignorable compared with that of high-order scattering, the quality of spectrogram will no longer improve. This is also validated by the experimental result in Fig. 5. We use the structural similarity (SSIM) index888SSIM is a metric that measures the perceptual difference between two similar images, which is widely used in image compression and computer vision. It is a full reference metric that requires two images from the same image capture, i.e., a reference image and a processed image. to visualize the quality of spectrogram [32]. Therefore, we can set a threshold for transmit power, say , and if we choose the transmit power as , each device can generate data samples (spectrograms) with approximately the same satisfactory quality.
IV Problem Formulation
In this paper, we aim at accelerating the training process, i.e., minimizing the global loss function in (1), under the constraints on latency, energy, and peak power. In the following, these three kinds of constraints are formulated.
IV-A Latency Constraints
The latency for each device in a communication round comprises four parts: the global model downloading time, sensing time, local computation time, and local model uploading time, as shown in Fig. 6. Since the server broadcasts the same global model to all the devices over the entire frequency band, and the server usually has greater transmit power than the devices, we can ignore the global downloading time in a communication round. In the next, we formulate the other three parts.
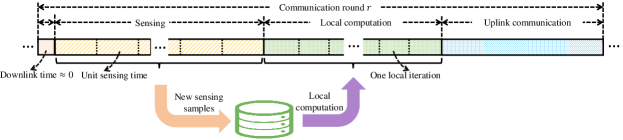
IV-A1 Sensing time
Recall that the unit sensing time, i.e., the time for generating a sensing sample, is , and the number of samples generated at communication round is . Thus, the sensing time of device at round is given by
| (7) |
IV-A2 Local computation time
Let denote the CPU cycles that required for executing the computation of a single sample in the local update. Then, the local computation time of device at communication round can be expressed as
| (8) |
where is the CPU frequency (cycles/s) of each device.
IV-A3 Local model uploading time
Since the dimensions of the local model are fixed for all devices, the data size in bits that each device needs to be uploaded is a constant, which is denoted by . Then, the local model uploading time of device are equal over all the communication rounds and should satisfy that
where is the ergodic capacity in (2).
We consider synchronous aggregation at the server, i.e., the aggregation happens until the local model from all the devices are received. Then, the latency for round is given by
| (9) |
Accordingly, the total latency is constrained by
where is the total number of communication rounds in the training process, and is the total latency constraint.
IV-B Energy Constraint
The energy consumption of each device comes from three parts: energy for sensing, energy for local computation, and energy for local model uploading, which are formulated one by one as follows:
IV-B1 Energy for sensing
The energy consumption for sensing of device at round is
| (10) |
IV-B2 Energy for local computation
According to [33], the energy consumption for local computation is formulated as
| (11) |
where is effective switched capacitance that depends on the chip architecture of the device.
IV-B3 Energy for local model uploading
The energy consumption for local model uploading of device at round is calculated as
| (12) |
From practical consideration, the ISAC devices have limited battery life, and the total energy consumption to complete a training task should be under constrained, i.e.,
where is the total energy constraint.
IV-C Peak Power Constraints
Limited by the transmitter, the communication transmit power should be constrained by
where is the peak communication transmit power. Moreover, according to Remark 1, the sensing transmit power should be constrained by
where is the peak sensing transmit power.
IV-D Problem Formulation
Under the three kinds of constraints above, the problem of accelerating the training process can be formulated as
| s.t. |
It is challenging to solve Problem (P1) due to: (i) The loss function at communication round has no exact analytical expression; (ii) Generally, we need to find an expression of learning error with adaptive batch size over communication rounds in order to solve Problem (P1), which is also a non-trivial task; (iii) The constraints (C2) and (C3) are non-convex. Moreover, although has a closed-form expression in (5), it involves special function which is non-trivial for analysis. In this work, we will derive an upper bound of the learning error for tractability, instead of the exact loss function in Problem (P1), which is beneficial for jointly allocating SC2 resource.
V Joint SC2 Resource Allocation
In this section, we first present an error upper bound with fixed batch size, based on which we split the original Problem (P1) into two separate subproblems, one optimizing the sensing and communication transmit power and the communication time to maximize the total sensed data samples, and the other optimizing the batch sizes for each round under given maximized total sensed data samples.
V-A Error Upper Bound Analysis
To facilitate the analysis, the following commonly adopted assumptions on local loss functions are made [34, 35, 36, 37].
Assumption 1 (Smoothness).
The global loss function ’s is -smooth: for all and , .
Assumption 2 (Unbiased gradient with bounded variance).
Stochastic gradient of each ISAC device is unbiased with -uniformly bounded variance in norm, namely
where is the batch size in calculating gradient .
Assumption 3 (Lower bounded).
The global loss function is lower bounded by , i.e., , .
Under the above assumptions, the following theorem gives an upper bound on the average-squared gradient norm of FL with fixed batch size.
Lemma 1 (Error upper bound with fixed batch size [34]).
Proof:
See Appendix of Theorem 1 in [34]. ∎
Remark 2.
To accelerate the training convergence, one needs to minimize the error upper bound in Lemma 1. Obviously, increasing the batch size can accelerate the convergence. The explanation is straightforward that larger batch size leads to smaller stochastic gradient noise, which makes the training converge faster [37].
V-B Problem Splitting
This subsection shows that Problem (P1) can be split into two subproblems equivalently to make Problem (P1) tractable.
First, substituting (7), (8), and (9) into (C2), it follows that
| (14) |
After proper manipulation, we can rewrite (14) as
| (15) |
where . Similarly, we substitute (10), (11), and (12) into (C3) and can have that
| (16) |
Therefore, the original Problem (P1) can be rewritten as
| s.t. | |||
Before we split Problem (P2), the following corollary is given to unveil how can affect the convergence speed.
Corollary 1.
Under the given total latency and energy constraint, larger leads to smaller average-squared gradient norm, i.e., faster convergence speed.
Proof:
From Lemma 1, the average-squared gradient norm after one communication round, say the -th communication round, is upper bounded by
It follows that larger batch size leads to smaller average-squared gradient norm after the training of the -th communication round. Assume that the optimal batch size of the -th communication round is . Obviously, if there exists , one can always find a set of batch sizes such that and for any . Therefore, compared with , can lead to smaller average-squared gradient norm, i.e., faster convergence speed, which completes the proof. ∎
Intuitively, is the summation of the batch sizes at all the communication rounds for each device, and also the number of data samples generated/sensed by each device in the training process. From Corollary 1, the devices needs to generate as many data samples as possible to accelerate the convergence speed. However, on the other hand, generating more data samples means greater consumption of the time and energy resources. Since the devices are time and energy constrained, the total number of generated data samples is limited.
Obviously, only depends on the constraints in Problem (P2). From Corollary 1, we need to find maximum under the constraints in Problem (P2) in order to maximize the convergence speed. Therefore, Problem (P2) can be equivalently solved by: (i) first optimizing , , and to maximize under the constraints in Problem (P2); (ii) then optimizing given maximum to maximize the convergence speed.
V-C Maximization of Total Sensed Data Samples
In the following, we solve the first subproblem above to maximize the total sensed data samples, i.e., , subject to all the constraints in Problem (P2), which is formulated as
| s.t. |
Problem (P3) is challenging to solve due to: (i) Constraints (C1), (15), and (16) are non-convex; (ii) Constraints (C1), (15), and (16) involves in (5), which has complex special function. It is generally impossible to solve Problem (P3) by using standard techniques for convex optimization. In the following, we first give the optimal sensing transmit power , and then simplify Problem (P3) such that we can use grid search efficiently to find the optimal solutions.
From Constraint (16) we have that
which gives an upper bound of . Moreover, this upper bound is decreasing with . Combined with Constraint (C5), we can obtain that the optimal sensing transmit power in Problem (P3) is .
Then, Constraint (16) in Problem (P3) becomes
| (17) |
Constraint (15) can also be transformed into
| (18) |
Then, (17) and (18) can be combined as
| (19) |
Proposition 1.
Constraint (C1) in Problem (P3) is equivalent to
| (20) |
Proof:
If the equality in (C1) is not satisfied, i.e., , it follows from (19) that one can always decease and thus increase . ∎
Then, substituting (20) into (19) yields
| (21) |
where
| (22) |
which is a function of . With the above results, Problem (P3) reduces to a single variable optimization problem regarding to as follows
| s.t. |
Since are independent with each other for , it can be verified that the optimal communication transmit power is given by
| (23) |
It is still challenging to obtain from (23) directly, since is still complicated. In this work, we tend to find by grid search in . After we have , the optimal is obtained by substituting into (19), i.e.,
| (24) |
It follows from (20) that the optimal communication time is given by
| (25) |
Remark 3 (Energy-limited and latency-limited scenarios).
When the energy constraint is large enough, the FEEL system will be latency-limited, and the latency constraint will be tight, i.e., in (22) reduces to . Since is an increasing function of , also increases with . Thus, the optimal communication transmit power in this case is . Alternatively, when the latency constraint is large enough, the FEEL system will be energy-limited, and the energy constraint will be tight, and in (22) reduces to . However, it is difficult to verify the monotonicity of in this case, and we can only find optimal by grid search.
V-D Adaptive Batch Size Optimization
After obtaining the maximum number of total sensed data samples, i.e., , we tend to solve the second subproblem, which optimizes under given to maximize the convergence speed.
For given , Problem (P2) becomes
| s.t. |
Problem (P5) is equivalent to allocating batch size over different communication rounds given the total sensed data samples. It is generally not possible to obtain the exact expression of the loss function at each round, not to mention that the analytical relation between the loss function and the batch size at each round. The common method is to replace the loss function with an error upper bound; however, we need to find a expression of learning error that can be represented by an function of adaptive batch size over communication rounds, which is also non-trivial as mentioned earlier. Thus, Problem (P5) cannot be solved directly. Instead, in this work, we propose an alternative approach to approximately optimize the adaptive batch size at each communication round based on the following proposition.
Proposition 2 (Error upper bound for given total sensed samples).
It can be verified that, to minimize the error upper bound in Proposition 2, i.e., the right-hand side of (26), the optimal batch size is given by
| (27) |
The result in (27) can be applied in the design of adaptive batch size to accelerate the convergence speed. According to (27), the best choice of in the -st communication round should be
| (28) |
For the -th communication round, it can be viewed that each device restarts the training at a new initial point . Similarly, the best choice of at the -th communication round should be
| (29) |
Combining the results in (28) and (29), and approximating by , it yields that999Since we consider a classification task, the loss value typically approximates when the training converge, which is also validated by experiments in Sec. VI.
| (30) |
Remark 4 (Adaptive batch size).
The results in (30) simply reveals an updating rule for the batch size from one communication round to the next. That is, the batch size should increase as the value of loss function gets smaller.
The loss function value can be easily obtained in the training process, and the only problem is to determine the initial batch size at the 1-st communication round such that . One way to get the value of is to perform one-dimensional grid search over all possible values of , which is inefficient. In the following, we propose a heuristic scheme, but efficient and practical for implementation. From empirical results, the value of loss function decreases approximately in an order of when training with SGD [38]. It follows from (30) that the optimal batch size at communication round should increase in an order of , and it can be approximated by
| (31) |
where is a hyperparameter that determines the batch size at the initial communication round, and is a constant such that holds. Then, we have that
Thus, is calculated by
| (32) |
Substituting (32) into (31), and considering that ’s are integers, we can approximate by
| (33) |
V-E Overall joint SC2 resource allocation scheme
In general, the joint SC2 resource allocation scheme by solving Problem (P1) consists of two steps as follows:
-
•
Step 1: We optimize the sensing and communication transmit power and the communication time to obtain the maximum total sensed samples , where the optimal sensing power is given by , the optimal communication power is obtained by solving the problem in (23), the optimal communication time is obtained from (25), and the maximum total sensed samples is obtained from (24);
-
•
Step 2: We determine the batch size of each communication round following (33) with from Step 1.
VI Simulation Results
In this section, we present the simulation results to validate the proposed joint SC2 resource allocation scheme. The simulation parameters are summarized in Table I.
VI-A Simulation Setup
| Parameter | Value |
|---|---|
| Number of ISAC devices, | |
| Maximum communication transmit power, | dBm |
| Minimum sensing transmit power, | dBm |
| Variance of shadow fading, | 8 dB |
| Noise power spectral density, | -174 dBm/Hz |
| Communication bandwidth for each device, | 0.5 MHz |
| CPU frequency, | cycles/s |
| CPU cycles for one sample, | |
| Effective switched capacitance of CPU, | |
| Number of local updates, | 10 |
| Total communication rounds, | 300 |
| Bandwidth for sensing, | MHz |
| Carrier frequency, | GHz |
| Chirp duration, | |
| Chirp numbers per frame, | 25 |
| Unit sensing time, | s |
| Sampling rate, | MHz |
VI-A1 FEEL system
In this experiment, we consider a FEEL network consisting of an edge server and ISAC devices. The devices are randomly located in a circular area of radius meters. The large-scale propagation coefficient in dB from device to the server is modeled as , where ( is the distance in kilometer) is the path loss in dB, and is the shadow fading in dB [39]. In this simulation, is Gauss-distributed random variable with mean zero and variance .
VI-A2 Sensing task
We apply the wireless sensing simulator in [23] to simulate various high-fidelity human motions and generate human motion datasets. In our simulation, the sensing task is to identify five different human motions, i.e., child walking, child pacing, adult walking, adult pacing, and standing. The heights of children and adults are uniformly distributed in interval and , respectively. The speed of standing, walking, and pacing are m/s, m/s, and m/s, respectively, where is the height value. The heading of the moving human is set to be uniformly distributed in . Some example data samples of each human motion are shown in Fig. 7.
VI-A3 Learning model
We apply widely used ResNet-10 (4,900,677 model parameters in total) with batch normalization as the classifier model [40]. The learning rate is .
VI-B Baselines
In the simulations, we evaluate our proposed joint SC2 resource allocation scheme as summarized in Sec. V-E by comparing with the following baseline schemes:
Baseline 1: (I-BS-MaxPower) This scheme naively uses maximum communication transmit power in Step 1, and the obtained total sensing samples is denoted as . However, increasing batch size of is considered in Step 2 as same as (33) in our proposed scheme. By comparing with this baseline, we evaluate the validity of Step 1 in our proposed scheme.
Baseline 2: (E-BS-OptimalPower) This schemes optimizes each transmit power in Step 1 as same as in our proposed scheme, but considers equal batch size in Step 2. Specifically, the batch size at communication round is calculated as . By comparing with this baseline, we evaluate the validity of Step 2 in our proposed scheme.
Baseline 3: (D-BS-OptimalPower) The only difference with Baseline 2 is that this scheme considers decreasing batch size instead in Step 2. Specifically, the batch size at communication round is calculated as . By comparing with this baseline, we also evaluate the validity of Step 2 in our proposed scheme.
VI-C Simulation Results
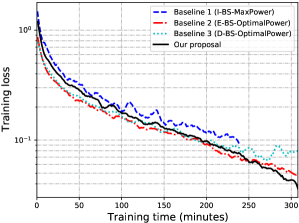
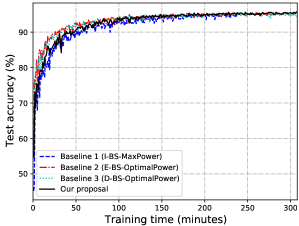
VI-C1 Selection of hyperparameter
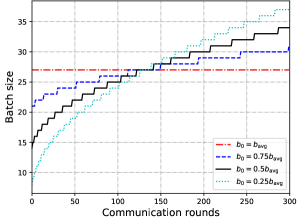
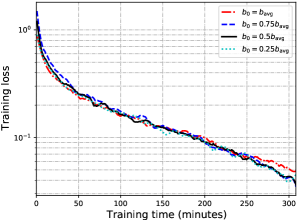
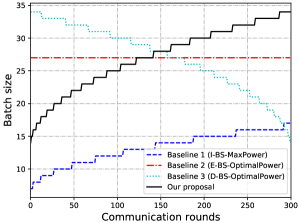
In our proposed scheme, we need to choose the hyperparameter , which determines the batch size at the initial communication round. Since the batch size should be increasing with the communication round, should be smaller than the average batch size . In this experiment, we evaluate four different values of , i.e., , , , and . Note that the batch size of each communication round is equal when . Fig. 8 depicts the batch size at each communication round under different . Fig. 9 represents the training speed (loss value versus training time) under different . It can be observed from Fig. 9 that the training speeds are almost the same when , and , but significantly faster than the case when in the later stage of the training process. Therefore, in the following experiments, we will randomly choose .
VI-C2 Optimal communication transmit power
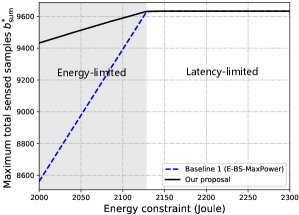
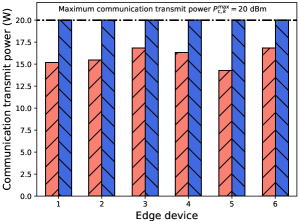
For exposition, we fix the latency constraint as seconds and evaluate the maximum total sensed samples under different energy constraints in Fig. 10. We compare our proposed scheme with Baseline 1 (I-BS-MaxPower) to validate the necessity of optimizing communication transmit power in Step 1. With different energy constraints and latency constraints , the FEEL system can be energy-limited or latency-limited, as explained in Remark 3. From Fig. 10, we have the following two observations. First, in both schemes, when the energy constraint is relatively small, the FEEL system will be energy-limited, and the maximum total sensed samples increases with ; when is large enough, the system will be latency-limited, and will no longer increase with . Moreover, it can be observed from Fig. 11 that the optimal communication transmit power of each device does not reach the maximum power constraint in the energy-limited case, which means that optimizing communication transmit power is necessary in an energy-limited FEEL system. Second, in the energy-limited case, our proposed scheme can lead to much larger than Baseline 1 (I-BS-MaxPower), especially when is small. These results suggest the superiority of our proposed scheme in allocating communication transmit power.
VI-C3 Adaptive batch size
Fig. 13 shows the comparison of the learning performance among different schemes in the energy-limited case. Since all devices transmit with maximum communication power in the latency-limited case, the optimal will be the same for all the schemes in this case. Thus, it is not necessary to evaluate the latency-limited case. Compared with Baseline 1 (I-BS-MaxPower), our proposed scheme can achieve a faster convergence speed while attaining a higher learning accuracy at the same time. The reason is that our proposed scheme brings larger , and thus a larger batch of samples can be used for SGD at each communication round (see Fig. 12). Moreover, the training process stops before the time constraint in Baseline 1 (I-BS-MaxPower), as it uses maximum communication transmit power at each communication round without allocating the energy properly and runs out of energy early. Baseline 2 (E-BS-OptimalPower) and Baseline 3 (D-BS-OptimalPower) both obtain the the optimal as same as our proposed scheme, but adopt a different batch size updating rule (see Fig. 12). It can be observed that Baseline 2 (E-BS-OptimalPower) achieves a slower convergence speed compared with our proposed scheme, and Baseline 3 (D-BS-OptimalPower) cannot even converge. One important observation is that in our proposed scheme the training converges a little slower but speeds up in the later stage of the training process. This result suggests the superiority of our proposed scheme in adopting adaptive batch size across different communication rounds.
VII Conclusion
In this paper, we investigated the issue of joint SC2 resource allocation for FEEL to enhance the ambient intelligence. The significance of the work is two-fold. First, we have characterized the sensing process in ambient intelligence for a concrete case study, namely human motion recognition, and discovered that sensing with a threshold power is adequate for generating data samples of approximately the same satisfactory quality, which is useful for FEEL. Second, we have proposed a joint SC2 resource allocation scheme that specifies the optimal transmit power and time for communication and sensing, and batch size to be computed at each communication round. This work opens several future directions for further investigation. More practical cases could be considered, such as ISAC devices with heterogeneous computation power, and adaptive total communication rounds. In addition, there are many different kinds of sensors for ambient intelligence, such as cameras, depth sensors, and radio sensors, which generate data samples of different modalities. Thus, how to deal with multi-modality in ambient intelligence together with joint SC2 resource allocation for FEEL is also a promising direction.
References
- [1] K. B. Letaief, Y. Shi, J. Lu, and J. Lu, “Edge artificial intelligence for 6G: Vision, enabling technologies, and applications,” IEEE J. Sel. Areas Commun., vol. 40, no. 1, pp. 5–36, Nov. 2021.
- [2] W. Saad, M. Bennis, and M. Chen, “A vision of 6G wireless systems: Applications, trends, technologies, and open research problems,” IEEE Netw., vol. 34, no. 3, pp. 134–142, Oct. 2019.
- [3] H. Albert, M. Arnold, and F.-F. Li, “Illuminating the dark spaces of healthcare with ambient intelligence,” Nature, vol. 585, no. 7824, pp. 193–202, Sep. 2020.
- [4] R. Dunne, T. Morris, and S. Harper, “A survey of ambient intelligence,” ACM Comput. Surveys, vol. 54, no. 4, pp. 1–27, May 2021.
- [5] G. Zhu, D. Liu, Y. Du, C. You, J. Zhang, and K. Huang, “Toward an intelligent edge: Wireless communication meets machine learning,” IEEE Commun. Mag., vol. 58, no. 1, pp. 19–25, 2020.
- [6] G. Zhu, Y. Wang, and K. Huang, “Broadband analog aggregation for low-latency federated edge learning,” IEEE Trans. Wireless Commun., vol. 19, no. 1, pp. 491–506, Jan. 2019.
- [7] M. Chen, D. Gündüz, K. Huang, W. Saad, M. Bennis, A. V. Feljan, and H. V. Poor, “Distributed learning in wireless networks: Recent progress and future challenges,” IEEE J. Sel. Areas Commun., Oct. 2021.
- [8] S. Wang, C. Li, Q. Hao, C. Xu, D. W. K. Ng, Y. C. Eldar, and H. V. Poor, “Federated deep learning meets autonomous vehicle perception: Design and verification,” arXiv preprint arXiv:2206.01748, Jun. 2022.
- [9] K. Yang, T. Jiang, Y. Shi, and Z. Ding, “Federated learning via over-the-air computation,” IEEE Trans. Wireless Commun., vol. 19, no. 3, pp. 2022–2035, Mar. 2020.
- [10] X. Cao, G. Zhu, J. Xu, Z. Wang, and S. Cui, “Optimized power control design for over-the-air federated edge learning,” IEEE J. Sel. Areas Commun., vol. 40, no. 1, pp. 342–358, Jan. 2021.
- [11] X. Wei and C. Shen, “Federated learning over noisy channels: Convergence analysis and design examples,” IEEE Trans. Cogn. Commun. Netw., Jan. 2022.
- [12] M. M. Amiri and D. Gündüz, “Federated learning over wireless fading channels,” IEEE Trans. Wireless Commun., vol. 19, no. 5, pp. 3546–3557, May 2020.
- [13] M. Chen, Z. Yang, W. Saad, C. Yin, H. V. Poor, and S. Cui, “A joint learning and communications framework for federated learning over wireless networks,” IEEE Trans. Wireless Commun., vol. 20, no. 1, pp. 269–283, Jan. 2020.
- [14] K. Guo, Z. Chen, H. H. Yang, and T. Q. Quek, “Dynamic scheduling for heterogeneous federated learning in private 5G edge networks,” IEEE J. Sel. Topics Signal Process., Jan. 2021.
- [15] Z. Yang, M. Chen, W. Saad, C. S. Hong, and M. Shikh-Bahaei, “Energy efficient federated learning over wireless communication networks,” IEEE Trans. Wireless Commun., vol. 20, no. 3, pp. 1935–1949, Mar. 2020.
- [16] M. M. Wadu, S. Samarakoon, and M. Bennis, “Joint client scheduling and resource allocation under channel uncertainty in federated learning,” IEEE Trans. Commun., vol. 69, no. 9, pp. 5962–5974, Sep. 2021.
- [17] S. Z. Gurbuz and M. G. Amin, “Radar-based human-motion recognition with deep learning: Promising applications for indoor monitoring,” IEEE Sig. Process. Mag., vol. 36, no. 4, pp. 16–28, Jan 2019.
- [18] F. Liu, Y. Cui, C. Masouros, J. Xu, T. X. Han, Y. C. Eldar, and S. Buzzi, “Integrated sensing and communications: Toward dual-functional wireless networks for 6G and beyond,” IEEE J. Sel. Areas Commun., vol. 40, no. 6, pp. 1728–1767, 2022.
- [19] W. Yuan, Z. Wei, S. Li, J. Yuan, and D. W. K. Ng, “Integrated sensing and communication-assisted orthogonal time frequency space transmission for vehicular networks,” IEEE J. Sel. Topics Signal Process., vol. 15, no. 6, pp. 1515–1528, 2021.
- [20] Y. Cui, F. Liu, X. Jing, and J. Mu, “Integrating sensing and communications for ubiquitous IoT: Applications, trends and challenges,” IEEE Netw., vol. 35, no. 5, pp. 158–167, Dec. 2021.
- [21] I. Nirmal, A. Khamis, M. Hassan, W. Hu, and X. Zhu, “Deep learning for radio-based human sensing: Recent advances and future directions,” IEEE Commun. Surveys Tuts., vol. 23, no. 2, pp. 995–1019, Feb. 2021.
- [22] S. M. Hernandez and E. Bulut, “WiFederated: Scalable WiFi sensing using edge based federated learning,” IEEE Internet Things J., pp. 1–1, Dec. 2021.
- [23] G. Li, S. Wang, J. Li, R. Wang, X. Peng, and T. X. Han, “Wireless sensing with deep spectrogram network and primitive based autoregressive hybrid channel model,” in Proc. IEEE 22nd Int. Workshop Sig. Process. Advances Wireless Commun. (SPAWC). IEEE, Sep. 2021, pp. 481–485.
- [24] L. Han and K. Wu, “Joint wireless communication and radar sensing systems – state of the art and future prospects,” IET Microw. Antennas Propag., vol. 7, no. 11, pp. 876–885, May 2013.
- [25] Z. Ma, Y. Xu, H. Xu, Z. Meng, L. Huang, and Y. Xue, “Adaptive Batch Size for Federated Learning in Resource-Constrained Edge Computing,” IEEE Trans. Mobile Comput., vol. 1233, no. ii, pp. 1–16, 2021.
- [26] D. Tse and P. Viswanath, Fundamentals of wireless communication. Cambridge University Press, 2005.
- [27] S. S. Ram, C. Christianson, Y. Kim, and H. Ling, “Simulation and analysis of human micro-Dopplers in through-wall environments,” IEEE Trans. Geosci. Remote Sens., vol. 48, no. 4, pp. 2015–2023, 2010.
- [28] S. Sen, “Adaptive OFDM radar waveform design for improved micro-Doppler estimation,” IEEE Sensors J., vol. 14, no. 10, pp. 3548–3556, 2014.
- [29] I. S. Gradshteyn and I. M. Ryzhik, Table of integrals, series, and products. Academic press, 2014.
- [30] V. C. Chen and H. Ling, Time-frequency transforms for radar imaging and signal analysis. Artech house, 2002.
- [31] P. Zhang, G. Li, C. Huo, and H. Yin, “Exploitation of multipath micro-Doppler signatures for drone classification,” IET Radar, Sonar & Navigation, vol. 14, no. 4, pp. 586–592, 2019.
- [32] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE Trans. Image Process., vol. 13, no. 4, pp. 600–612, 2004.
- [33] Y. Mao, J. Zhang, and K. B. Letaief, “Dynamic computation offloading for mobile-edge computing with energy harvesting devices,” IEEE J. Sel. Areas Commun., vol. 34, no. 12, pp. 3590–3605, dec. 2016.
- [34] J. Wang and G. Joshi, “Cooperative SGD: A unified framework for the design and analysis of communication-efficient SGD algorithms,” arXiv preprint arXiv:1808.07576, 2018.
- [35] ——, “Adaptive communication strategies to achieve the best error-runtime trade-off in local-update SGD,” arXiv preprint arXiv:1810.08313, 2018.
- [36] M. K. Nori, S. Yun, and I.-M. Kim, “Fast federated learning by balancing communication trade-offs,” IEEE Trans. Commun., 2021.
- [37] L. Bottou, F. E. Curtis, and J. Nocedal, “Optimization methods for large-scale machine learning,” Siam Review, vol. 60, no. 2, pp. 223–311, 2018.
- [38] P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings et al., “Advances and open problems in federated learning,” arXiv preprint arXiv:1912.04977, 2019. [Online]. Available: https://arxiv.org/abs/1912.04977
- [39] Z. Yang, M. Chen, W. Saad, C. S. Hong, and M. Shikh-Bahaei, “Energy efficient federated learning over wireless communication networks,” IEEE Trans. Wireless Commun., vol. 20, no. 3, pp. 1935–1949, Nov. 2020.
- [40] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc IEEE Conf. Computer Vision Pattern Recognition (CVPR), Jun. 2016, pp. 770–778.