TinySeg: Model Optimizing Framework for
Image Segmentation on Tiny Embedded Systems
Abstract.
Image segmentation is one of the major computer vision tasks, which is applicable in a variety of domains, such as autonomous navigation of an unmanned aerial vehicle. However, image segmentation cannot easily materialize on tiny embedded systems because image segmentation models generally have high peak memory usage due to their architectural characteristics. This work finds that image segmentation models unnecessarily require large memory space with an existing tiny machine learning framework. That is, the existing framework cannot effectively manage the memory space for the image segmentation models.
This work proposes TinySeg, a new model optimizing framework that enables memory-efficient image segmentation for tiny embedded systems. TinySeg analyzes the lifetimes of tensors in the target model and identifies long-living tensors. Then, TinySeg optimizes the memory usage of the target model mainly with two methods: (i) tensor spilling into local or remote storage and (ii) fused fetching of spilled tensors. This work implements TinySeg on top of the existing tiny machine learning framework and demonstrates that TinySeg can reduce the peak memory usage of an image segmentation model by 39.3% for tiny embedded systems.
1. Introduction

Image segmentation is one of the major computer vision tasks, which is being used in various domains, including autonomous navigation of an unmanned aerial vehicle (Minaee et al., 2022). Image segmentation is to classify each pixel of the input image in an object category. For example, in autonomous driving, image segmentation can be used to detect cars, pedestrians, roads, and traffic signs (Cordts et al., 2016). Since image segmentation provides more detailed information about objects than object detection, image segmentation has become an attractive but challenging task for computer vision researchers.
Although image segmentation can be helpful for many applications, image segmentation cannot easily materialize on tiny embedded systems because of its high peak memory usage. Popular image segmentation networks (Ronneberger et al., 2015; Milletari et al., 2016; Cao et al., 2023) have an hourglass-like architecture where the early computation results are concatenated with the later results. Then, the early results have to be stored in memory until the later results become available, which is the primary reason why image segmentation models generally have high peak memory usage. Since tiny embedded systems have limited memory of less than 1 megabyte, image segmentation models can hardly run on the systems, limiting the potential of intelligent embedded systems.
To demonstrate that image segmentation models unnecessarily take up large memory space, this work analyzes the memory consumption of image segmentation models on top of an existing tiny machine learning framework, TensorFlow Lite for Microcontrollers (TFLM) (tfl, 2023). The existing framework uses a large global buffer, named arena, and lets tensors share the memory space depending on their lifetimes. This work figures out that long-living tensors and large interim tensors for concatenation occupy lots of memory space. This work also finds that the existing tiny machine learning framework cannot effectively identify and handle the issues with the image segmentation models.
Based on the analysis, this work proposes TinySeg, a new model optimizing framework that enables memory-efficient image segmentation on tiny embedded systems. TinySeg analyzes the cold (idle) ranges of tensors in the target image segmentation model and identifies tensors that have long cold ranges. Then, TinySeg optimizes the peak memory usage of the target model mainly with two methods: (i) tensor spilling into local or remote storage to take cold tensors aside and (ii) fused fetching of spilled tensors to remove large interim tensors. At run-time, TinySeg efficiently implements tensor spilling and fetching through dynamic tensor compression and asynchronous block operation.
To demonstrate the effectiveness of the proposed framework, this work develops the TinySeg framework on top of the existing tiny machine learning framework, TensorFlow Lite for Microcontrollers, with new operators for tensor spilling and fused fetching. This work also designs a tiny image segmentation model to enable image segmentation on a small microcontroller board with a main memory of 1 megabyte. This work evaluates the TinySeg framework in terms of peak memory usage, network latency, and power consumption. The evaluation results show that TinySeg can reduce the peak memory usage of the image segmentation model by 39.3% at most, enabling more intelligent image segmentation on low-power embedded systems.
The contributions of this work are:
-
•
A new model optimizing framework, called TinySeg, for image segmentation on tiny embedded systems.
-
•
Design of the TinySeg model optimizer and the TinySeg runtime with a variety of optimization methods.
-
•
Implementation and evaluation of the TinySeg framework on top of an existing machine learning framework.
2. Background & Motivation
2.1. Image Segmentation Networks
In recent years, the computer vision community has developed various neural network architectures for accurate image segmentation. Image segmentation is to classify every pixel of an input image into a certain category, corresponding to the object that the pixel belongs to. U-Net is one of the most popular image segmentation networks, which is originally designed for medical image segmentation (Ronneberger et al., 2015). Many state-of-the-art image segmentation networks, including V-Net (Milletari et al., 2016) and Swin-Unet (Cao et al., 2023), have similar architectural structures to U-Net.
U-Net is said to have an hourglass-like structure as illustrated in Figure 1. Going downwards, it repeatedly applies convolutions and poolings, and then activations become smaller in height and width but deeper with more channels. Then, going upwards, it repeatedly applies transposed convolutions and normal convolutions, and then activations recover the original resolution. Meanwhile, the early activations are concatenated with the later activations via long skip connections for the final prediction.
2.2. TensorFlow Lite for Microcontrollers
TensorFlow Lite for Microcontrollers (TFLM) (David et al., 2021) is a tiny machine learning framework that facilitates deploying neural network models on low-power microcontrollers, such as Arduino microcontroller boards. TFLM provides a C++ programming interface to load and run a neural network model on bare-metal microcontrollers. TFLM represents a neural network model as a graph of operators and tensors, where each operator takes input tensors, performs calculations, and returns output tensors, like in Figure 2.

As microcontrollers have limited memory of less than a megabyte, memory management is a crucial part of the framework. In general, neural network models need to have two types of data in memory:
-
•
Parameters: Some neural network operators include parameters (weights), which are used to perform calculations, such as convolution filters. For example, in Figure 2, conv2d_1:filter and conv2d_1:bias are the parameters of Conv2D. The memory usage for parameters is usually static because the parameter values do not change after training in general.
-
•
Activations: During execution, neural network operators generate intermediate outputs (feature maps), which become the inputs of other operators. For example in Figure 2, conv2d_1:Conv2D is the activations defined by the Conv2D operator and used by the Concatenation operator. The memory usage for activations is usually dynamic because it depends on how memory space is shared among tensors.
TFLM uses a fixed-size global memory buffer called arena and stores the activations in the global buffer from when they are created to when they are last used (i.e., during their lifetimes). TFLM analyzes the lifetime of each tensor and generates a memory plan considering the lifetimes and sizes of tensors. TFLM allows tensors with non-overlapping lifetimes to share the same memory space so that it can minimize the peak memory usage for running a network model.
When loading the model, TFLM checks whether the peak memory usage of a model will be larger than the arena size specified by the user. If so, TFLM returns an out-of-memory error, and the model cannot run on the target system. That is, depending on the dynamic memory usage, the model may fail to run on the target system.


2.3. Memory Usage of Image Segmentation Models
This work analyzes the memory usage of an image segmentation model on top of the TFLM framework and compares the model with a typical convolutional neural network model for image classification, provided by the framework (per, 2023).
Figure 3(3(a)) shows the memory usage of the classification and segmentation models for both their parameters and activations. The graph reveals that the segmentation model requires much more memory for activations than parameters, while the classification model requires much less memory for activations. Then, the segmentation model is 2.18 smaller than the classification model in binary, but it requires 5.76 more memory for execution.
This work finds that the high peak memory usage of the image segmentation model comes from two major issues: (i) long-living tensors that remain idle for a long time in memory and (ii) large interim tensors for concatenation that are used only for a short time.
First, this work figures that in image segmentation models, long-living tensors unnecessarily take up large memory space. As shown in Figure 1, image segmentation networks have long skip connections to incorporate early (concrete) information for the final prediction. Accordingly, the early activations have to be stored in memory for a long time until they are concatenated with the later activations. That is, even though the early activations are not accessed for a long time, large memory space is reserved for the activations, increasing the peak memory usage of the models.
Figure 3(3(b)) illustrates the memory plan for an image segmentation model generated by the default memory planner of TFLM. The graph shows which part of memory space (i.e., arena) each tensor occupies over time. For example, tensor 0 occupies 115.2 kilobytes in the bottom of the arena from time 0 to time 1. The graph demonstrates that there exist large long-living tensors such as tensor 3 and tensor 6, occupying the memory space for a long time.
This work also discovers that large interim tensors, especially for concatenation, also contribute to high peak memory usage. In Figure 3(3(b)), a concatenation operator reads tensor 3 and tensor x and writes to tensor y. Then, a convolution operator reads tensor y and writes to tensor z. Here, the interim tensor y is used only for a short time just to concatenate tensor 3 and tensor x but its memory usage is not negligible.

3. TinySeg: Model Optimizing Framework
This work proposes TinySeg, an optimizing framework for memory-efficient image segmentation of which models are likely to have high peak memory usage. The TinySeg framework consists of the TinySeg model optimizer and the TinySeg runtime as illustrated in Figure 4. The TinySeg model optimizer analyzes and transforms the input model to reduce its peak memory usage. The TinySeg runtime provides efficient custom operators to execute the optimized model.
The TinySeg model optimizer includes two main components for memory optimization: cold range analyzer and graph transformer. The cold range analyzer identifies the longest cold range of each tensor in the input model where the tensor is stored in memory without being accessed. Next, the graph transformer modifies the model graph based on the analysis to handle long-living tensors and large interim tensors that contribute to peak memory usage.
The entire optimization process is summarized in Algorithm 1. At every iteration, the model optimizer analyzes the cold ranges of the tensors in the model, transforms the model based on the analysis, and generates a new memory plan to check the peak memory usage of the transformed model. This is because the memory plan of the model may change every time the graph transformer modifies the model and updates the lifetimes of tensors. If no further optimization is possible, the model optimizer stops optimizing the model and returns the optimized model.
Note that the TinySeg model optimizing framework imposes no restriction on the type of the input model. Thus, the TinySeg framework can process any machine learning model even though it is most effective on image segmentation models that have long skip connections.
4. The TinySeg Model Optimizer
4.1. Cold Range Analyzer
The cold range analyzer traverses the model graph from the root node and tracks where each tensor is defined and used to generate the cold range information. The cold range information for a tensor includes the following three integers:
-
•
start: the identifier of the operator at the start of the longest cold range
-
•
end: the identifier of the operator at the end of the longest cold range
-
•
last: the identifier of the operator that last uses the tensor
Note that the identifier of the start operator is always less than or equal to the identifier of the end operator.
Algorithm 2 describes how the cold range analyzer builds the cold range information to be used in graph transformation. Basically, it iterates over the entire list of operators in the input graph and updates the (longest) cold ranges of the tensors. For each operator, it first checks the output tensors of the operator and initializes the cold range of each output tensor (from Line 2 to Line 2). In the model graph, each tensor is defined only once, so it is safe to initialize the cold range information when it is defined by an operator.
Next, it checks the input tensors of the operator and updates the cold range of each input tensor (from Line 2 to Line 2). If a tensor is an input of an operator, it means that the tensor is used by the operator. It also indicates the end of the current cold range and the start of the new cold range. Since the code range analyzer aims to find the longest cold range, it first checks whether the current cold range () is longer than the tentative longest cold range (). If so, it updates the longest cold range and then the last operator.

Figure 5 illustrates an example cold range analysis for a single tensor. When tensor 1 is defined by Operator 1, the analyzer initializes the cold range information of the tensor. Next, when the tensor is used for the first time, the analyzer updates the cold range information to commit the first cold range, which is from Operator 1 to Operator 2. Then, when the tensor is used again by Operator 9, the analyzer compares the current cold range, which is from Operator 2 to Operator 9, with the longest cold range. Since the current cold range is longer than the longest cold range, the analyzer updates the cold range information. In this way, the cold range analyzer builds the cold range information for all the tensors in the input model graph.
4.2. Graph Transformer
The graph transformer modifies the graph of the target model based on the cold range analysis with two methods: (i) tensor spilling into local or remote storage to take cold tensors aside and (ii) fused fetching to remove large interim tensors. Algorithm 3 briefly describes the overall transformation process.
4.2.1. Tensor Spilling
To avoid unnecessary memory usage by long-living tensors, the model optimizer spills long-living tensors into local or remote storage if it is expected to be beneficial. For a given model graph, the graph transformer finds a tensor to spill and modifies the graph by spilling the tensor. To choose the victim tensor, it finds the tensors associated with peak memory usage. Among the tensors, the graph transformer selects the tensor with the longest cold range as the victim tensor (Line 3 in Algorithm 3).
After selecting the victim tensor, the optimizer checks if the size of the victim tensor is larger than the target amount of memory reduction. If so, it means that spilling the entire tensor is unnecessary to achieve the target memory reduction. To partially spill the victim tensor, the optimizer inserts additional operators that split the victim tensor into two sub-tensors and concatenate the sub-tensors (from Line 3 to Line 3 in Algorithm 3). Then, one of the sub-tensors becomes the new victim tensor, and the start and end operators are updated accordingly. In this way, the optimizer can decrease the size of the tensor to be spilled, reducing the unnecessary overhead of tensor spilling and fetching.
| Operator | Type | Name | Description |
| Spill | Input | victim | Tensor to spill |
| Option | id | Identifier of the victim tensor | |
| Fetching | Input | tensors | List of tensors to concatenate |
| Option | victim | Identifier of the tensor to fetch | |
| Option | nth | Position of the victim tensor | |
| Option | axis | Axis along which to concatenate | |
| Output | output | Concatenated tensor |
Next, the graph transformer inserts operators that implement tensor spilling to the start and end of the cold range (from Line 3 to Line 3 in Algorithm 3). TinySeg provides two custom operators for tensor spilling: Spill and Fetching operators. The Spill operator transfers tensor data to local or remote storage. The Fetching operator fetches the tensor from local or remote storage and concatenates it with the input tensor(s) if any.
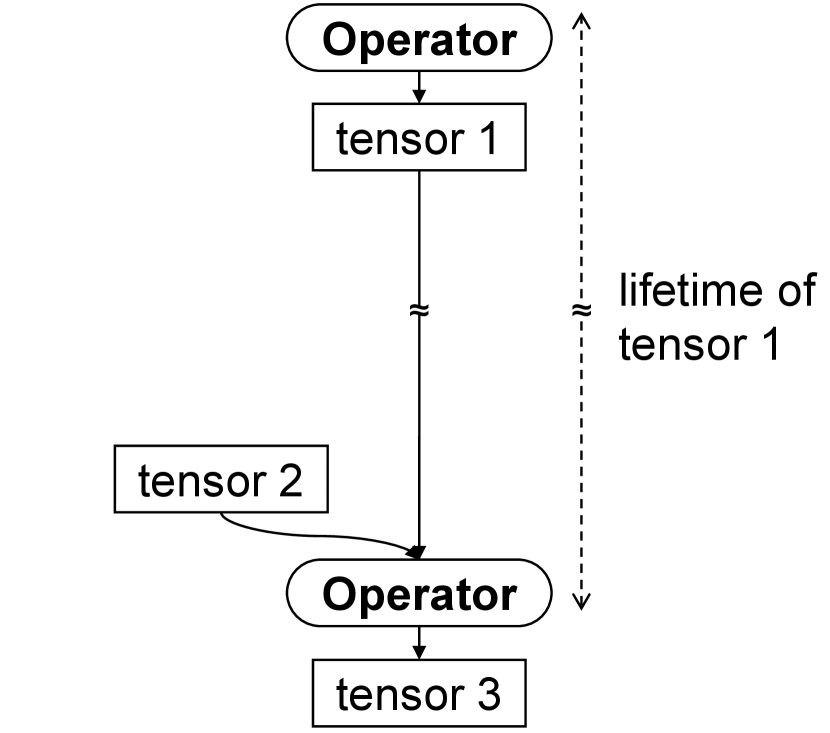
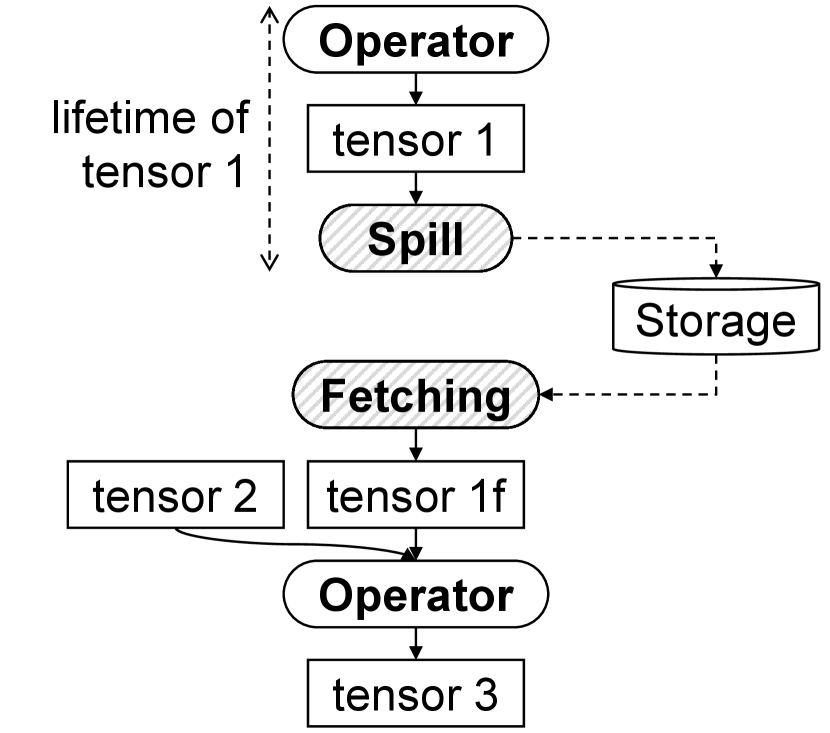
Figure 6 briefly illustrates how a model graph changes after tensor spilling. First, the graph transformer inserts the Spill operator at the start of the cold range. The Spill operator takes the victim tensor (e.g., tensor 1 in the figure) as its input and returns no output tensor. Next, the graph transformer inserts the Fetching operator at the end of the cold range. In the end, the lifetime of the victim tensor shortens because the tensor no longer has to be in memory during its cold range as shown in the figure. Then, the memory space occupied by the tensor can be shared with the other tensors.
Figure 7 describes how a model graph changes in the case of partial spilling. When partial spilling is allowed, the optimizer inserts a Split operator to divide the victim tensor into two sub-tensors. Then, the optimizer inserts a Concatenation operator to restore the original tensor with the two sub-tensors. Then, as one sub-tensor (i.e., tensor 1b in the figure) becomes the new victim tensor, the optimizer inserts the Spill and Fetching operators like in Figure 6.
Note that the optimizer determines the split size considering the target amount of memory reduction. For example, assuming that the size of the victim tensor is , the optimizer splits the victim tensor into one sub-tensor with the size of and another sub-tensor with the size of , which becomes the new victim tensor. The optimizer applies the alignment according to the shape and data type of the victim tensor.


4.2.2. Fused Fetching
After spilling a tensor, the model optimizer tries to fuse the Fetching operator with the following operator if it is possible and beneficial. First, operator fusion may not be possible if the framework does not support an efficient fused operation. Second, operator fusion may not be beneficial if the interim tensor is smaller than the input and output tensors. If the interim tensor is smaller than the input and output tensors, the peak memory usage may increase after fusion. After the fusion, the fused operator would perform original calculations while fetching the spilled tensor from local or remote storage.
Especially, when the following operator is Concatenation, the optimizer merges the Concatenation operator into the Fetching operator. As the Fetching operator can internally perform concatenation, it is not necessary to have another Concatenation operator. Then, the Fetching and following Concatenation operators become a new Fetching operator after the fusion. For the other types of operators, the optimizer creates a new fused operator that performs two operations at the same time.
Figure 8 briefly illustrates how a model graph changes after an operator fusion. The graph transformer fuses the two operators and removes the interim tensor because the tensor is no longer needed after fusion. Here, it is assumed that tensor 2 is larger than either tensor 1 or tensor 3. The peak memory usage before fusion is
and then the peak memory usage becomes
after operator fusion. Since tensor 2 is larger than either tensor 1 or tensor 3, the modified graph would have lower peak memory usage than the original graph. In this way, the memory optimizer can further optimize the memory usage of the target model.


5. The TinySeg Runtime
The TinySeg runtime is in charge of implementing tensor spilling and fetching at run-time. The TinySeg runtime uses various optimization methods to reduce the performance overhead, which are described in this section.
5.1. Dynamic Tensor Compression
The TinySeg runtime transfers tensor data for tensor spilling and fetching at run-time. To reduce data transfer overhead, this work designs a simple yet effective (compressed) tensor representation, which removes the duplicate occurrences of the most frequent value. As illustrated in Figure 9(9(a)), it consists of a representative value, an array of the other values, and a bitmap to indicate the positions of the other values. For example in the figure, the most frequent value of the tensor is and the bitmap indicates the position of each value that is not equal to the most frequent value.
Although Compressed Sparse Row (CSR) (Buluç et al., 2009) is a widely-used representation for sparse tensors, it is more complicated and more suitable when the sparsity of tensors is high (i.e., when there are many zeros in the tensor data). However, this work finds that tensors in a sample image segmentation model often contain one very frequent non-zero value that occupies around 50% of tensors. Figure 9(9(b)) shows the proportion of the most frequent value for each tensor in the sample image segmentation model. The graph shows that except for a couple of tensors, the representative values are dominant in the corresponding tensors.




5.2. Asynchronous Block Operation
Depending on the specification of the target storage, tensor spilling and fetching may incur non-negligible overhead, largely increasing the total network latency. Especially when using on-device flash memory, it could be more expensive because block erases are necessary before overwriting tensor data. In addition, block erase is known to take much longer than block write or read in typical flash memory.
To hide the block erase overhead, the TinySeg runtime enables asynchronous block operation using dual-core processing. Recently, many microcontrollers come with multiple processing cores. Since block erase has no dependence on the following computations within a single model execution, the runtime can use another core to asynchronously erase flash blocks. Therefore, as illustrated in Figure 10, the runtime invokes an asynchronous remote procedure call to another core so that block erase can run in parallel.
5.3. Temporary Tensor Quantization
On top of dynamic tensor compression and asynchronous block operation, this work finds another memory optimization opportunity in the existing framework (tfl, 2023). For some operators, the framework allocates and uses temporary tensors as scratch buffers. However, in the case of certain operators like TransposeConv, temporary tensors could be even larger than its input and output tensors, increasing the peak memory usage. Thus, this work further quantizes large temporary tensors (from 32-bit to 16-bit) if possible.
6. Evaluation
6.1. Experimental Setup
This work implements the prototype of TinySeg on top of the open-source TensorFlow Lite framework (tfl, 2023). This work develops the cold range analyzer and graph transformer conforming to the TensorFlow Lite model format for applicability. In addition, this work extends the framework with three new TensorFlow Lite operators to support tensor spilling and fused fetching: Spill, Fetching, and FetchingConv2D, considering the operators used in typical image segmentation models. The source code of the prototype implementation is available at https://github.com/coslab-kr/tinyseg.
This work also designs a new tiny image segmentation network, called Tiny U-Net to enable image segmentation on tiny embedded devices. The new network is a miniaturized version of U-Net (Ronneberger et al., 2015) with smaller convolution layers and fewer skip connections. To demonstrate its usefulness, this work trains the network from scratch and obtains a comparable validation accuracy for an existing image segmentation dataset (car, 2023). More specifically, the Tiny U-Net model obtained 87.7% accuracy while the original U-Net with around 200 parameters obtained 92.9% for the validation set. Table 2 summarizes the characteristics of the network.
| Characteristic | Value |
|---|---|
| Input tensor shape | |
| Output tensor shape | |
| Number of model parameters | 109,725 |
| Binary size (w/ 8-bit integer quantization) | 138,040 bytes |
| Validation accuracy (w/ Carvana (car, 2023) dataset) | 87.7% |
To show the effectiveness of the TinySeg framework, this work applies the optimization methods to the original Tiny U-Net model (with 8-bit integer quantization) step by step and evaluates the optimized models in terms of memory usage, network latency, and power consumption. To compare the power consumption of the original and optimized models, this work measures the electric current flowing into the target device using a Keysight U1232A digital multimeter of which the current measurement resolution is 0.01 A.
For tensor spilling, this work investigates these three options:
-
•
spilling a tensor into the on-device internal flash memory, on the microcontroller chip
-
•
spilling a tensor into the on-device external flash memory, connected to the microcontroller
-
•
spilling a tensor into the remote storage by transferring the tensor through serial communication
Note that using a different spilling option does not affect the peak memory usage of the model, but the latency of the model.
This work measures the peak memory usage of the original and optimized models with the default memory planner of the existing framework called GreedyMemoryPlanner (tfl, 2023). In addition, this work measures the network latency of each model on a commercial low-power microcontroller board, Arduino Nicla Vision (ard, 2023), which uses the STM32H757AII6 microcontroller equipped with dual ARM Cortex-M7/M4 cores, 2 MB internal flash memory, and 1 MB main memory, and connected with 16 MB external QSPI flash memory.
6.2. Results
6.2.1. Memory Usage

This work measures the peak memory usage of the original and optimized models with the prototype TinySeg optimizing framework. This work applies the three optimization methods to the original model in the following order: (1) temporary tensor quantization, (2) tensor spilling, and (3) fused fetching. During the optimization, the model optimizer selects one tensor (tensor 3 in Figure 3(3(b))) for tensor spilling as the optimizer finds that spilling another tensor will be no more beneficial. After tensor spilling, the model optimizer fuses two operators, Fetching and Conv2D, which then become FetchingConv2D after fusion.
Figure 11 shows how the memory usage of the model changes when each optimization method is applied in the aforementioned order. Then, the bar at the bottom represents the memory usage of the final optimized model. As shown in the graph, the binary model size (i.e., the memory usage for parameters) changes little in each step. After tensor spilling or fused fetching, the optimized model will have new operators in its graph. However, the new operators require only a few parameters such as the tensor identifier for tensor spilling, so they hardly increase the model binary size.
Regarding dynamic memory usage for activations, which is more critical for execution, the graph shows that each optimization method can contribute to reducing the peak memory usage of the model. First, quantizing temporary tensors largely reduces the peak memory usage by 24.1%, freeing some buffer space used by scratch buffers like tensor F in Figure 3(3(b)). Then, spilling a long-living tensor further reduces the peak memory usage by 15.9% (36.2% compared with the original model) by shortening the lifetime of the long-living tensor. In the end, the final optimized model has 39.3% lower peak memory usage than the original model.

Figure 12 illustrates the memory plan of the final optimized model, showing what changes in the memory plan result in the lower peak memory usage of the model, compared with the original one in Figure 3(3(b)). First, the figure shows that the lifetime of the long-living tensor (tensor 3) shortens so that the tensor can be placed in the low part of the memory space, leaving free memory space for other tensors. Second, the figure shows that the large interim tensor (tensor y between tensor x and tensor z in Figure 3(3(b))) is not present in the new memory plan because the interim tensor is no longer used by any operator with fused fetching. As a result, the new memory plan can better utilize the memory space than the original plan for image segmentation.
This work also compares the prototype framework with existing tiny machine learning frameworks for microcontrollers, as summarized in Table 3. In addition to TFLM, this work tries to optimize the same Tiny U-Net model with two recent frameworks: STM32Cube.AI (stm, 2023) and Pex (Liberis and Lane, 2023). Unfortunately, STM32Cube.AI fails to process the network raising an internal memory error due to a concatenation operator in the model. Although Pex is able to process the network, it generates exactly the same model after optimization, without enhancing the peak memory usage of the model.
| Framework | Reference | Peak Memory Usage |
|---|---|---|
| TFLM (David et al., 2021; tfl, 2023) (Baseline) | Commit 384dd27 | 318.4 KB |
| STM32Cube.AI (stm, 2023) | Version 8.1.0 | Internal memory error |
| Pex (Liberis and Lane, 2023; pex, 2023) | Commit 08709f1 | 318.4 KB |
| This work | - | 193.4 KB |
Furthermore, this work applies the optimizations to large network models even though they do not fit in tiny embedded systems. This work selects three image segmentation models that can be converted to TensorFlow Lite models. Table 4 summarizes the peak memory usages of the original and optimized models. The results show that the framework can successfully optimize the memory usages of other image segmentation models that have long skip connections.
6.2.2. Network Latency
This work measures the total end-to-end network latency of the original and optimized models on the commercial low-power microcontroller board with internal, external, and remote spilling options:
-
•
Internal Spilling: The runtime stores the victim tensor in the internal flash memory of the microcontroller. Note that when using the both processing cores, the 2 MB internal flash is partitioned for the cores.
-
•
External Spilling: The runtime uses the external 16 MB flash memory of the board, which is connected to the microcontroller and shared by the two cores.
-
•
Remote Spilling: The runtime transfers the victim tensor to the host and retrieves the tensor from the host when needed.
Table 5 summarizes the latency of each model with internal, external, or remote spilling. After quantizing temporary tensors, the network latency actually slightly increases, unexpectedly. This work presumes the reason for the increase is that memory operations are more optimized for 32-bit operations than for 16-bit operations in the system. After applying tensor spilling, the latency increases due to the data transfer overhead. With dynamic tensor compression, the latency decreases because it reduces the amount of data to transfer with little compression and decompression overhead. Finally, the overhead of internal or external spilling is largely reduced by asynchronous block operation.
Regarding the different spilling options, internal spilling achieves the best latency among the three options at the end. Before applying synchronous block operation, internal spilling results in doubling the total latency of the model. This work finds that, especially for the internal flash memory, block write takes much less time than block erase. On the other hand, for the external flash memory, block write is almost as slow as block erase. Then, by hiding the overhead of block erase, internal spilling can obtain the best performance among the different spilling options.
| Model | Latency | ||
|---|---|---|---|
| Internal | External | Remote | |
| Original model | 1190 ms | ||
| + Temp. tensor quant. | 1199 ms | ||
| + Tensor spilling | 2421 ms | 2494 ms | 1583 ms |
| + Fused fetching | 2430 ms | 2511 ms | 1587 ms |
| + Tensor compression | 2333 ms | 2046 ms | 1470 ms |
| + Async. block operation | 1270 ms | 1718 ms | N/A |

Figure 13 shows the breakdown of the latency of the final model for each spilling option. The graph demonstrates that tensor spilling takes much more time with external spilling as block write is much slower with the external flash memory than the internal flash memory. For remote spilling, tensor spilling takes much less time than tensor fetching because the tensor data can be asynchronously buffered in the host for tensor spilling. In addition, the graph shows that tensor compression and decompression incurs almost no overhead compared to the total network latency.
This work also measures how the memory usage and latency change with partial spilling. As explained in Section 4, if the memory requirement is met, it is not necessary to spill the entire tensor, which would increase the runtime overhead. Figure 14 shows the memory usage and network latency when spilling a different percentage of the victim tensor. 100% spilling means spilling the entire tensor, and 0% spilling means no spilling. As the percentage of spilling decreases, the peak memory usage increases but the network latency decreases due to the reduced transfer overhead. Interestingly, the peak memory usage increases slowly when the percentage of spilling is high. That is, partial spilling could be more cost effective than entire spilling when the memory requirement is not very strict.
In summary, the evaluation results demonstrate that the TinySeg framework can successfully reduce the memory requirement of an image segmentation model, enabling tiny embedded systems to implement smarter image segmentation. Although the current implementation incurs some performance overhead for data transfer, the network latency can be further optimized by using a faster storage or communication interface.


6.2.3. Power Consumption
This work evaluates the power consumption of the original and optimized models by measuring the current flowing into the microcontroller board. Figure 15 shows how the amount of current changes over time when executing the original and optimized models. For the optimized model, the internal flash memory is used for tensor spilling. On average, the board consumes less power when executing the original model than executing the optimized model. The average power consumption of the original model is 418.2 mW, while the average power consumption of the optimized model is 420.6 mW in the experiments.
The main reason for the increase is the use of another processing core. As explained in Section 5, the runtime uses another core to perform asynchronous block erase. When executing the original model, the runtime uses only one main core by default. However, the processing cores are heterogeneous (i.e., one Cortex-M7 core at up to 480 MHz and one Cortex-M4 core at up to 240 MHz), using the Cortex-M4 core does not increase the power consumption a lot.


7. Related Work
7.1. Framework-level Memory Optimization
Previous work has proposed various framework-level methods for memory-efficient model execution on embedded systems (Liberis and Lane, 2023; stm, 2023; Lin et al., 2021; Lee et al., 2023; Ji et al., 2021).
Similar to this work, some recent work considers tiny embedded systems built with microcontrollers (Liberis and Lane, 2023; stm, 2023; Lin et al., 2021). Liberis and Lane (Liberis and Lane, 2023) introduce Pex, a partial execution compiler for memory-efficient deep learning on microcontrollers. Pex automatically identifies operators whose execution can be split along the channel dimension and generates memory-efficient execution schedules considering the operators. In addition, Pex applies structured pruning to the network model to further optimize the memory usage of the model.
STM32Cube.AI (stm, 2023) is a free tool from STMicroelectronics, which facilitates the optimization and deployment of neural network models for STM32 microcontrollers. It includes a memory optimizer for neural network models, which provides the visualization of model memory usage, the separation of model parameters for multiple storage, the reuse of input or output buffers for activations. It also includes a graph optimizer that supports various graph-level optimizations such as operator fusion and constant folding.
Lin et al. (Lin et al., 2021) propose an optimizing framework for executing neural network models on microcontrollers with limited memory. It reduces the peak memory usage of a model by processing the model patch by patch rather than processing the entire feature maps at a time. To efficiently implement the patch-by-patch execution, they introduce receptive field redistribution, which reduces the receptive field of the initial stage. It also optimizes memory consumption by jointly designing the system and the network through neural architecture search.
Other work focuses on relatively larger embedded systems such as Nvidia Jetson platforms, which can run neural network models on top of operating systems (Lee et al., 2023; Ji et al., 2021). Lee et al. (Lee et al., 2023) focus on reducing the memory burden on the embedded GPU during deep neural network inference. In the paper, they propose Occamy, a deep learning compiler that reduces the memory usage of network models without sacrificing accuracy by tensor coalescing, layer fusion, and memory access pattern analysis. It analyzes the liveness of tensors for layer fusion, merges input and output tensors to remove redundant tensors, and places tensors into memory pools to reduce memory management overhead.
Ji et al. (Ji et al., 2021) propose memory management schemes for model inference on edge-end embedded systems. First, they propose to load parameters in an incremental manner to reuse the memory space, enabling larger network models. Second, addressing the unnecessary memory consumption of blob and workspace tensors, they propose to reorganize the data layout of tensors in the middle of execution to better utilize the memory space.
Although the previous work demonstrates that their proposed methods can reduce the memory consumption of a given model for embedded systems, they do not consider long-living tensors and thus they cannot avoid storing the tensors in memory during their lifetimes. Therefore, their methods are relatively less effective for hourglass-like image segmentation models, while TinySeg is specially designed for image segmentation models with distinct architectural characteristics so that it can successfully optimize the models for better memory utilization.
7.2. Model Compression Techniques
Model compression is being widely studied in the artificial intelligence community, which is to reduce the memory consumption of a network model, generally for resource-constrained devices (Choi et al., 2017; Gupta et al., 2015; Jacob et al., 2018; Banner et al., 2019; Han et al., 2015; Li et al., 2017). Especially, post-training model compression is to compress neural network models without retraining, thus easily applicable to existing well-trained models (Jacob et al., 2018; Banner et al., 2019; Lazarevich et al., 2021; Shi et al., 2023).
Post-Training Quantization: Jacob et al. (Jacob et al., 2018) introduce an integer quantization scheme that quantizes both activations and weights as 8 bits with two quantization parameters (scale and zero point) and integer-only matrix multiplication based on the quantization scheme. The quantization scheme is the one used in the TensorFlow Lite framework. Banner et al. (Banner et al., 2019) propose a practical 4-bit post-training quantization scheme. It reduces the accuracy loss from quantization using analytical clipping, per-channel bit allocation, and etc.
Post-Training Pruning: Lazarevich et al. (Lazarevich et al., 2021) propose a method for post-training weight pruning that can obtain high sparsity rate but little accuracy drop. It selects layer-wise sparsity rates to achieve the global sparsity rate. More recently, Shi et al. (Shi et al., 2023) integrate pruning and quantization and optimize them considering the interaction between them under the post-training setting.
Since the optimization methods of TinySeg are orthogonal to the model compression techniques, the TinySeg optimizing framework can be applicable in combination with the techniques, further optimizing the target network model for tiny embedded systems.
8. Conclusion
This work proposes TinySeg, a new model optimizing framework that enables memory-efficient image segmentation on tiny embedded systems. TinySeg analyzes the lifetimes of tensors in the target model and identifies tensors idle for a long time. Then, TinySeg optimizes the peak memory usage of the target model with two methods: (i) tensor spilling into local or remote storage and (ii) fused fetching of spilled tensors. This work implements TinySeg on top of the existing tiny machine learning framework and demonstrates that TinySeg can reduce the peak memory usage of an image segmentation model by 39.3% for tiny embedded systems.
References
- (1)
- ard (2023) 2023. Arduino Nicla Vision. https://store.arduino.cc/products/nicla-vision.
- car (2023) 2023. Carvana Image Masking Challenge. https://www.kaggle.com/competitions/carvana-image-masking-challenge.
- per (2023) 2023. Sample TensorFlow Lite Models from TensorFlow Lite for Microcontrollers. https://github.com/tensorflow/tflite-micro/tree/main/tensorflow/lite/micro/models.
- stm (2023) 2023. STM32Cube.AI: Free tool for Edge AI developers. https://stm32ai.st.com/stm32-cube-ai/.
- tfl (2023) 2023. TensorFlow Lite for Microcontrollers. https://github.com/tensorflow/tflite-micro/tree/main.
- pex (2023) 2023. tflite-tools: TFLite model analyser & memory optimizer. https://github.com/eliberis/tflite-tools.
- Banner et al. (2019) Ron Banner, Yury Nahshan, and Daniel Soudry. 2019. Post training 4-bit quantization of convolutional networks for rapid-deployment. Curran Associates Inc., Red Hook, NY, USA.
- Buluç et al. (2009) Aydin Buluç, Jeremy T. Fineman, Matteo Frigo, John R. Gilbert, and Charles E. Leiserson. 2009. Parallel Sparse Matrix-Vector and Matrix-Transpose-Vector Multiplication Using Compressed Sparse Blocks. In Proceedings of the Twenty-First Annual Symposium on Parallelism in Algorithms and Architectures (Calgary, AB, Canada) (SPAA ’09). Association for Computing Machinery, New York, NY, USA, 233–244. https://doi.org/10.1145/1583991.1584053
- Cao et al. (2023) Hu Cao, Yueyue Wang, Joy Chen, Dongsheng Jiang, Xiaopeng Zhang, Qi Tian, and Manning Wang. 2023. Swin-Unet: Unet-Like Pure Transformer for Medical Image Segmentation. In Computer Vision – ECCV 2022 Workshops, Leonid Karlinsky, Tomer Michaeli, and Ko Nishino (Eds.). Springer Nature Switzerland, Cham, 205–218. https://doi.org/10.1007/978-3-031-25066-8_9
- Choi et al. (2017) Yoojin Choi, Mostafa El-Khamy, and Jungwon Lee. 2017. Towards the Limit of Network Quantization. In Proceedings of the 5th International Conference on Learning Representations (ICLR ’17).
- Cordts et al. (2016) Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. 2016. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/CVPR.2016.350
- David et al. (2021) Robert David, Jared Duke, Advait Jain, Vijay Janapa Reddi, Nat Jeffries, Jian Li, Nick Kreeger, Ian Nappier, Meghna Natraj, Shlomi Regev, Rocky Rhodes, Tiezhen Wang, and Pete Warden. 2021. TensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems. arXiv:2010.08678 [cs.LG]
- Diakogiannis et al. (2020) Foivos I. Diakogiannis, François Waldner, Peter Caccetta, and Chen Wu. 2020. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS Journal of Photogrammetry and Remote Sensing 162 (2020), 94–114. https://doi.org/10.1016/j.isprsjprs.2020.01.013
- Gupta et al. (2015) Suyog Gupta, Ankur Agrawal, Kailash Gopalakrishnan, and Pritish Narayanan. 2015. Deep Learning with Limited Numerical Precision. In Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37 (Lille, France) (ICML’15). JMLR.org.
- Han et al. (2015) Song Han, Jeff Pool, John Tran, and William J. Dally. 2015. Learning Both Weights and Connections for Efficient Neural Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1 (NIPS’15). MIT Press, Cambridge, MA, USA.
- Jacob et al. (2018) Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. 2018. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Ji et al. (2021) Cheng Ji, Fan Wu, Zongwei Zhu, Li-Pin Chang, Huanghe Liu, and Wenjie Zhai. 2021. Memory-efficient deep learning inference with incremental weight loading and data layout reorganization on edge systems. Journal of Systems Architecture 118 (2021), 102183. https://doi.org/10.1016/j.sysarc.2021.102183
- Lazarevich et al. (2021) Ivan Lazarevich, Alexander Kozlov, and Nikita Malinin. 2021. Post-training deep neural network pruning via layer-wise calibration. In 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). 798–805.
- Lee et al. (2023) Jaeho Lee, Shinnung Jeong, Seungbin Song, Kunwoo Kim, Heelim Choi, Youngsok Kim, and Hanjun Kim Kim. 2023. Occamy: Memory-efficient GPU Compiler for DNN Inference. In Proceedings of the 60th of Design Automation Conference. https://doi.org/10.1109/DAC56929.2023.10247839
- Li et al. (2017) Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. 2017. Pruning Filters for Efficient ConvNets. In Proceedings of the 5th International Conference on Learning Representations (ICLR ’17).
- Liberis and Lane (2023) Edgar Liberis and Nicholas D. Lane. 2023. Pex: Memory-efficient Microcontroller Deep Learning through Partial Execution. arXiv:2211.17246 [cs.LG]
- Lin et al. (2021) Ji Lin, Wei-Ming Chen, Han Cai, Chuang Gan, and Song Han. 2021. MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning. In Annual Conference on Neural Information Processing Systems (NeurIPS).
- Milletari et al. (2016) Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. 2016. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In 2016 Fourth International Conference on 3D Vision (3DV). 565–571. https://doi.org/10.1109/3DV.2016.79
- Minaee et al. (2022) Shervin Minaee, Yuri Boykov, Fatih Porikli, Antonio Plaza, Nasser Kehtarnavaz, and Demetri Terzopoulos. 2022. Image Segmentation Using Deep Learning: A Survey. IEEE Transactions on Pattern Analysis and Machine Intelligence 44, 7 (2022), 3523–3542. https://doi.org/10.1109/TPAMI.2021.3059968
- Oktay et al. (2018) Ozan Oktay, Jo Schlemper, Loic Le Folgoc, Matthew Lee, Mattias Heinrich, Kazunari Misawa, Kensaku Mori, Steven McDonagh, Nils Y Hammerla, Bernhard Kainz, Ben Glocker, and Daniel Rueckert. 2018. Attention U-Net: Learning Where to Look for the Pancreas. In Medical Imaging with Deep Learning.
- Ronneberger et al. (2015) Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015), Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi (Eds.). Springer International Publishing, Cham, 234–241. https://doi.org/10.1007/978-3-319-24574-4_28
- Shi et al. (2023) Yumeng Shi, Shihao Bai, Xiuying Wei, Ruihao Gong, and Jianlei Yang. 2023. Lossy and Lossless (L2) Post-training Model Size Compression. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV). 17500–17510.