TinyDefectNet: Highly Compact Deep Neural Network Architecture for High-Throughput Manufacturing Visual Quality Inspection
Abstract
A critical aspect in the manufacturing process is the visual quality inspection of manufactured components for defects and flaws. Human-only visual inspection can be very time-consuming and laborious, and is a significant bottleneck especially for high-throughput manufacturing scenarios. Given significant advances in the field of deep learning, automated visual quality inspection can lead to highly efficient and reliable detection of defects and flaws during the manufacturing process. However, deep learning-driven visual inspection methods often necessitate significant computational resources, thus limiting throughput and act as a bottleneck to widespread adoption for enabling smart factories. In this study, we investigated the utilization of a machine-driven design exploration approach to create TinyDefectNet, a highly compact deep convolutional network architecture tailored for high-throughput manufacturing visual quality inspection. TinyDefectNet comprises of just 427K parameters and has a computational complexity of 97M FLOPs, yet achieving a detection accuracy of a state-of-the-art architecture for the task of surface defect detection on the NEU defect benchmark dataset. As such, TinyDefectNet can achieve the same level of detection performance at 52 lower architectural complexity and 11 lower computational complexity. Furthermore, TinyDefectNet was deployed on an AMD EPYC 7R32, and achieved 7.6 faster throughput using the native Tensorflow environment and 9 faster throughput using AMD ZenDNN accelerator library. Finally, explainability-driven performance validation strategy was conducted to ensure correct decision-making behaviour was exhibited by TinyDefectNet to improve trust in its usage by operators and inspectors.
1 Introduction
The promises of the new era for machine learning have motivated different industries to augment and enhance the capabilities and efficiency of their existing workforce with artificial intelligence (AI) applications that automate highly-repetitive and time-consuming processes. In particular, the advances in deep learning have led to promising results in different applications ranging from computer vision tasks [1, 2] such as image classification [1] and video object segmentation [2] to natural language processing tasks [3] such as language translation [4] and question-answering [5]. However, much of success in adopting deep learning in real-world applications have been in newer technology sectors such as e-commerce and social media where the tasks are inherently automation-friendly without human intervention under a controlled environment (e.g., product/content recommendation), with very limited adoption in traditional industrial sectors such as manufacturing where the tasks are currently done manually by human agents in unconstrained environments.
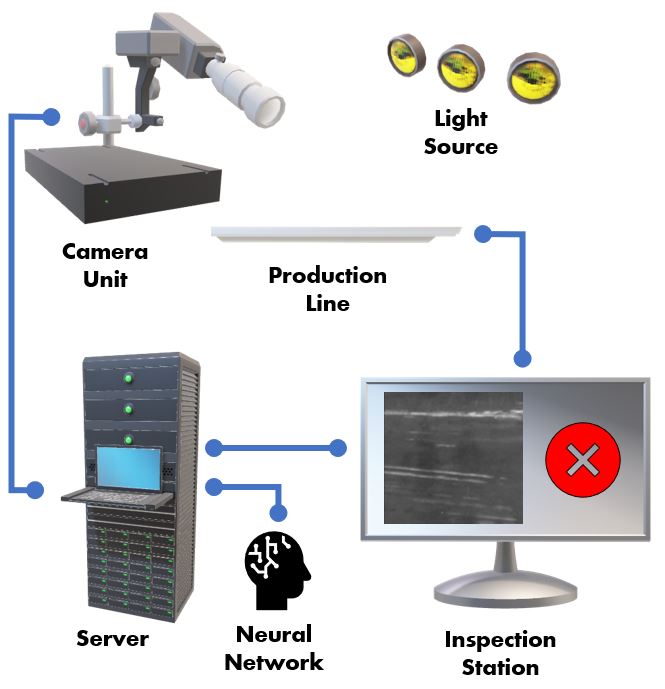
As an example, the visual quality inspection of manufactured components to identify defects and flaws is a critically important task in manufacturing that is very laborious and time-consuming (See Figure 1 for example of a surface defect visual inspection system). As such, automating this process would result in significant cost savings and significantly improved production efficiencies. However, there are a number of key challenges that make it very difficult to adopt deep learning for visual quality inspection in a real-world production setting, including: i) small data problem: the availability of annotated data is limited and thus makes building highly accurate deep learning models a challenge, and ii) highly constrained operational requirements: designing high-performance deep learning models that satisfy very constrained operational requirements with regards to inference speed and size is very challenging especially in high-throughput manufacturing scenarios.
A common practice to the development of custom deep learning models for new industrial applications is to take advantage of off-the-shelf generic models published in research literature such as ResNet [1] and MobileNet [6] architectures and apply transfer learning [7] to learn a new task given the available training data samples. While this approach enables rapid prototyping of models to understand feasibility of the task at hand, such generic off-the-shelf models are not tailored for specific industrial tasks and are often unable to meet operational requirements related to speed and size for real-world industrial deployment. As such, it makes it very challenging to adopt off-the-shelf generic models for tackling visual quality inspection applications under real-world manufacturing scenarios.
A very promising strategy for the creation of highly-customized deep learning models tailored for manufacturing visual quality inspection applications is machine-driven design exploration, where the goal is to automatically identify deep neural network architecture designs based on operational requirements. One path towards machine-driven design exploration is neural architecture search (NAS) [8, 9, 10], where the problem is formulated as a large-scale, high-dimensional search problem and solved using algorithms such as reinforcement learning and evolutionary algorithms. While they have shown promising results in designing new deep neural network architectures [10], they are very computationally intensive and require very large-scale computing resources over long search times [10]. More recently, another path towards machine-driven design exploration is the concept of generative synthesis [11], where the problem is formulated as a constrained optimization problem and the approximate solution is found in an iterative fashion using a generator-inquisitor pair. This approach has been demonstrated to successfully generate deep neural network architectures tailored for different types of tasks across different fields and applications [12, 13, 14].
In this study, we explore the efficacy of machine-driven design exploration for the design of deep neural network architectures tailored for high-throughput manufacturing visual quality inspection. Leveraging this strategy and a set of operational requirements, we introduce TinyDefectNet, a highly compact deep convolutional network architecture design automatically tailored around visual surface quality inspection. Furthermore, we evaluate the capability of the ZenDNN accelerator library for AMD processors in further reducing the run-time latency of the generated TinyDefectNet for high-throughput inspection.
2 Methodology
The macro- and micro-architectures of the proposed TinyDefectNet are designed by leveraging the concept of generative synthesis for the purpose of machine-driven design exploration. The concept of generative synthesis revolves around the formulation of the design exploration problem as a constrained optimization problem. More specifically, we wish to find an optimal generator given a set of seeds which can generate networks architectures that maximize a universal performance function , with constraints defined by a predefined set of operational requirements formulated via an indicator function ,
| (1) |
| Model | ACC | Parameters | FLOPs | Inference Speed (s) |
| ResNet-50 | 98% | 24,136,710 | 1,115,962,374 | 0.01881 |
| TinyDefectNet | 98% | 427,776 | 97,263,435 | 0.00247 |
| Improvement | – | 56 | 11 | 7.6 |
Finding in a direct manner is computationally infeasible. As such, we find the approximate solution to through an iterative optimization process, where in each step the previous generator solution is evaluated by an inquisitor via its newly generated architectures , and this evaluation is used to produce a new generator solution. The initiation of this iterative optimization process is conducted based on a prototype, , and .
In this study, we define a residual design prototype based on the principles proposed in [1], define based on [15], and define the indicator function with the following operational constraint: number of floating-point operations (FLOPs) is within 5% of 100M FLOPs to account for high-throughput manufacturing visual inspection scenarios.
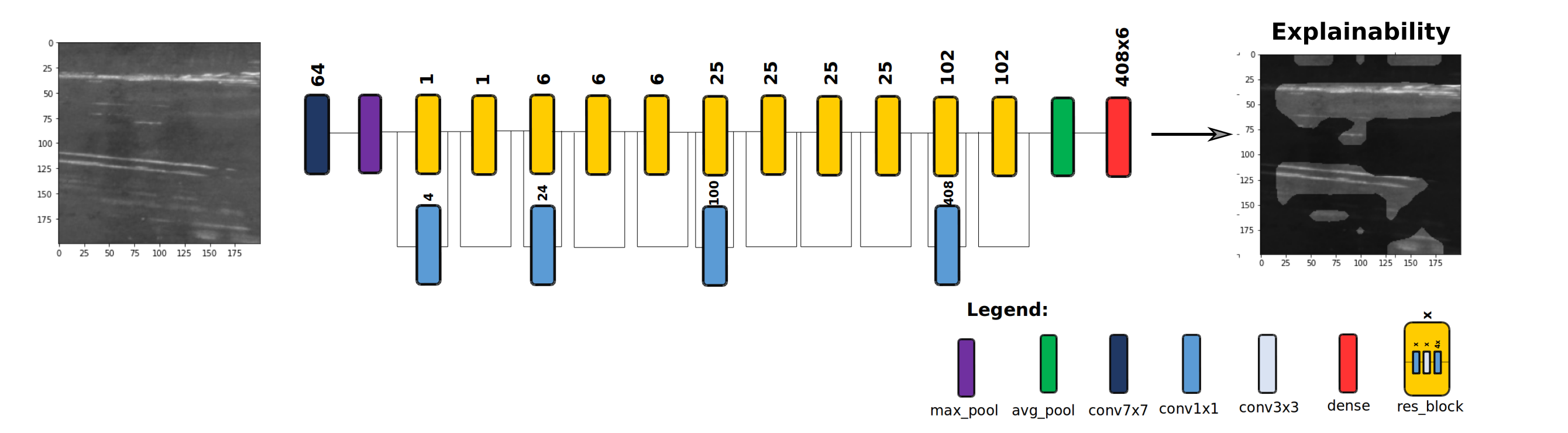
The network architecture of TinyDefectNet is demonstrated in Figure 2, and there are two key observations worth highlighting in more detail. First, it can be observed that the micro- and macro-architecture designs of the proposed TinyDefectNet possess heterogeneous, lightweight characteristics that strike a strong balance between representational capacity and model efficiency. Second, it can also be observed that TinyDefectNet has a shallower macro-architecture design to facilitate for low latency, making it well-suited for high-throughput inspection scenarios. These architectural traits highlight the efficacy of leveraging a machine-driven design exploration strategy in the creation of high-performance customized deep neural network architectures tailored around task and operational requirements needed for a given application.
3 Results & Discussion
The generated TinyDefectNet architecture is evaluated using the NEU-Det benchmark dataset [16] for surface defect detection, with the performance of the off-the-shelf ResNet-50 architecture [1] also evaluated for comparison purposes. Both architectures were implemented in Keras with a Tensorflow-backend.
 |
 |
 |
| (a) | (b) | (c) |
 |
 |
 |
| (d) | (e) | (f) |
The NEU-Det [16] benchmark dataset used in this study is a metallic surface defect dataset comprising of 6 different defects including rolled-in scale (RS), patches (Pa), crazing (Cr), pitted surface (PS), inclusion (In) and scratches (Sc) (See Figure 3 for examples of surface defects). The dataset contains 1,800 grayscale images with equal number of samples from each classes; from 300 images of each class, 240 images are assigned for training and 60 images for testing. The input image size to the evaluated deep learning models is .
3.1 Performance Analysis
Table 1 shows the quantitative performance results of the proposed TinyDefectNet. It can be observed that the proposed TinyDefectNet network architecture comprises of only 427K parameters, which is 56 smaller compared to an off-the-shelf ResNet-50 architecture. Furthermore, in terms of computational complexity, the proposed TinyDefectNet architecture requires only 97M FLOPs to process the input data compared to 1.1B FLOPs required by the ResNet-50 architecture with the same input size, and thus requires 11 fewer number of FLOPs in comparison. This high efficiency is highly desirable especially given that the proposed TinyDefectNet architecture performs with the same accuracy as ResNet50 architecture.
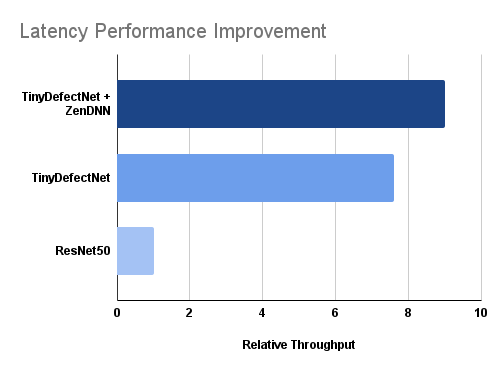
To further evaluate the efficiency of the proposed TinyDefectNet model, its running time latency is examined (at a batch size of 1024) on an AMD CPU (in this study, an AMD EPYC 7R32 processor) and compared with the ResNet-50 architecture. As shown in Table 1, the proposed TinyDefectNet architecture can process an input image in 2.5 ms, which is a 7.6 speed gains when compared to the ResNet-50 architecture which needs 19 ms to process the same image. The significant speed gains, complexity reductions demonstrated by the proposed TinyDefectNet over off-the-shelf architectures while achieving high accuracy makes it highly suited for high-throughput manufacturing inspection scenarios and speaks to the efficacy of leveraging a machine-driven design exploration strategy for producing highly tailored deep neural network architectures catered specifically for industrial tasks and applications.
| Flag | Value |
| ZENDNN PRIMITIVE CACHE CAPACITY | 4 |
| ZENDNN BLOCKED FORMAT | 0 |
| ZENDNN MEMPOOL ENABLE | 1 |
| ZENDNN TENSOR POOL LIMIT | 1 |
| ZENDNN TF CONV ADD FUSION SAFE | 0 |
| OMP NUM THREADS | 8 |
| GOMP CPU AFFINITY | 0-7 |
3.2 ZenDNN Acceleration
In this section we analyze the impact of ZenDNN accelerator library for AMD processors on the performance of the proposed TinyDefectNet. ZenDNN [17] is a run-time accelerator library that is easy to use as it does not require model re-compilation or conversion and can be applied to different models for different tasks.
To further improve the running time latency of the proposed TinyDefectNet to improve throughput performance, we perform inference of TinyDefectNet within the ZenDNN environment. The optimal parameters for the ZenDNN variables are reported in Table 2. As shown in Figure 4, leveraging the ZenDNN accelerator improves the performance of the proposed TinyDefectNet on an AMD CPU by 1.2 (i.e., 2ms). As such, the proposed TinyDefectNet when running with ZenDNN can perform inference 9 faster when compared to the ResNet-50 architecture in a native Tensorflow environment.
3.3 Explainability-driven Performance Validation
The proposed TinyDefectNet was audited using an explainability-driven performance validation strategy to gain deeper insights into its decision-making behaviour when conducting visual quality inspection and ensure that its decisions are driven by relevant visual indicators associated with surface defects. In particular, we leverage the quantitative explainability strategy proposed in [18], which has been shown to provide good quantitative explanations that better reflect decision-making processes than other approaches in literature, and has been shown to be effective at not only model auditing [14] but also identifying hidden data issues [19]. An example of an input surface image and the corresponding quantitative explanation corresponding explanation are shown in Figure 2. It can be observed based on the quantitative explanation that TinyDefectNet correctly decided that this particular surface image exhibit scratch defects by correctly leveraging the different scratch defects found on the surface during its decision-making process. In addition to ensuring correct model behaviour, conducting this explainability-driven performance validation process helps to improve trust in its deployment and usage by human operators and inspectors.
4 Conclusion
In this study we introduced TinyDefectNet, a highly effective and efficient deep neural network architecture for the high-throughput manufacturing visual quality inspection. We take advantage of generative synthesis for machine-driven design exploration to design micro- and macro-architectures of the proposed TinyDefectNet architecture in an automated manner. Experimental results show that the proposed model is highly efficient which can perform 9 faster when it runs with ZenDNN accelerator on an AMD CPU compared to an off-the-shelf ResNet-50 architecture in a native Tensorflow environment. This is very desirable especially since the proposed TinyDefectNet performs with 98% accuracy at the same level as ResNet-50 architecture. Explainability-driven performance validation strategy was conducted in this study to ensure correct decision-making behaviour was exhibited by TinyDefectNet to improve trust in its deployment and usage. Future work involves leveraging this machine-driven design exploration strategy for producing high-performing, highly efficient deep neural network architectures for other critical manufacturing tasks such as component localization and defect segmentation.
References
- [1] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [2] A. Robinson, F. J. Lawin, M. Danelljan, F. S. Khan, and M. Felsberg, “Learning fast and robust target models for video object segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 7406–7415.
- [3] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding. arxiv 2018,” arXiv preprint arXiv:1810.04805, pp. 0–85 083 815 650, 2021.
- [4] S. Ranathunga, E.-S. A. Lee, M. P. Skenduli, R. Shekhar, M. Alam, and R. Kaur, “Neural machine translation for low-resource languages: A survey,” arXiv preprint arXiv:2106.15115, 2021.
- [5] S. Rongali, B. Liu, L. Cai, K. Arkoudas, C. Su, and W. Hamza, “Exploring transfer learning for end-to-end spoken language understanding,” arXiv preprint arXiv:2012.08549, 2020.
- [6] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4510–4520.
- [7] F. Zhuang, Z. Qi, K. Duan, D. Xi, Y. Zhu, H. Zhu, H. Xiong, and Q. He, “A comprehensive survey on transfer learning,” Proceedings of the IEEE, vol. 109, no. 1, pp. 43–76, 2020.
- [8] H. Liu, K. Simonyan, and Y. Yang, “Darts: Differentiable architecture search,” arXiv preprint arXiv:1806.09055, 2018.
- [9] M. Tan, B. Chen, R. Pang, V. Vasudevan, M. Sandler, A. Howard, and Q. V. Le, “Mnasnet: Platform-aware neural architecture search for mobile,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2820–2828.
- [10] P. Ren, Y. Xiao, X. Chang, P.-Y. Huang, Z. Li, X. Chen, and X. Wang, “A comprehensive survey of neural architecture search: Challenges and solutions,” ACM Computing Surveys (CSUR), vol. 54, no. 4, pp. 1–34, 2021.
- [11] A. Wong, M. J. Shafiee, B. Chwyl, and F. Li, “Ferminets: Learning generative machines to generate efficient neural networks via generative synthesis,” arXiv preprint arXiv:1809.05989, 2018.
- [12] A. Wong, M. Famouri, M. Pavlova, and S. Surana, “Tinyspeech: Attention condensers for deep speech recognition neural networks on edge devices,” arXiv preprint arXiv:2008.04245, 2020.
- [13] S. Abbasi, M. Famouri, M. J. Shafiee, and A. Wong, “Outliernets: Highly compact deep autoencoder network architectures for on-device acoustic anomaly detection,” arXiv preprint arXiv:2104.00528, 2021.
- [14] L. Wang, Z. Q. Lin, and A. Wong, “Covid-net: A tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images,” Scientific Reports, vol. 10, no. 1, pp. 1–12, 2020.
- [15] A. Wong, “Netscore: towards universal metrics for large-scale performance analysis of deep neural networks for practical on-device edge usage,” in International Conference on Image Analysis and Recognition. Springer, 2019, pp. 15–26.
- [16] K. Song and Y. Yan, “A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects,” Applied Surface Science, vol. 285, pp. 858–864, 2013.
- [17] “Zendnn.” [Online]. Available: https://developer.amd.com/zendnn/zendnn-archives/
- [18] Z. Q. Lin, M. J. Shafiee, S. Bochkarev, M. S. Jules, X. Y. Wang, and A. Wong, “Do explanations reflect decisions? a machine-centric strategy to quantify the performance of explainability algorithms,” arXiv preprint arXiv:1910.07387, 2019.
- [19] A. Wong, A. Dorfman, P. McInnis, and H. Gunraj, “Insights into data through model behaviour: An explainability-driven strategy for data auditing for responsible computer vision applications,” arXiv preprint arXiv:2106.09177, 2021.