Time Series Generative Learning with Application to Brain Imaging Analysis
Abstract
This paper focuses on the analysis of sequential image data, particularly brain imaging data such as MRI, fMRI, CT, with the motivation of understanding the brain aging process and neurodegenerative diseases. To achieve this goal, we investigate image generation in a time series context. Specifically, we formulate a min-max problem derived from the -divergence between neighboring pairs to learn a time series generator in a nonparametric manner. The generator enables us to generate future images by transforming prior lag-k observations and a random vector from a reference distribution. With a deep neural network learned generator, we prove that the joint distribution of the generated sequence converges to the latent truth under a Markov and a conditional invariance condition. Furthermore, we extend our generation mechanism to a panel data scenario to accommodate multiple samples. The effectiveness of our mechanism is evaluated by generating real brain MRI sequences from the Alzheimer’s Disease Neuroimaging Initiative. These generated image sequences can be used as data augmentation to enhance the performance of further downstream tasks, such as Alzheimer’s disease detection.
keywords:
Time series, Generative learning, Brain imaging, Markov property, data augmentation1 Introduction
Time series data is not limited to numbers; it can also include images, texts, and other forms of information. This paper specifically focuses on the analysis of image time series, driven by the goal of understanding brain aging process with brain imaging data, such as magnetic resonance imaging (MRI), computer tomography (CT), etc. Understanding the brain aging process holds immense value for a variety of applications. For instance, insights into the brain aging process can reveal structural changes within the brain (Tofts,, 2005) and aid in the early detection of degenerative diseases such as Alzheimer’s Disease (Jack et al.,, 2004). Consequently, the characterization and forecasting of brain image time series data can play a crucial role in the fight against age-related neurodegenerative diseases (Cole et al.,, 2018; Huizinga et al.,, 2018).
Time series analysis, a classic topic in statistics, has been extensively studied, with numerous notable works such as autoregression (AR), autoregressive moving-average (ARMA, Brockwell and Davis, 1991), autoregressive conditional heteroskedasticity (ARCH, Engle, 1982; Bollerslev, 1986), among others. The classic scalar time series model has been expanded to accommodate vectors (Stock and Watson,, 2001), matrices (Chen et al.,, 2021; Han et al.,, 2023; Chang et al.,, 2023), and even tensors (Chen et al., 2022a, ) in various contexts. Furthermore, numerous time series analysis methods have been adapted to high-dimensional models, employing regularization techniques, such as Basu and Michailidis, (2015); Guo et al., (2016). Beyond linear methods, nonlinear time series models have also been explored in the literature, e.g., Fan and Yao, (2003); Tsay and Chen, (2018), etc. We refer to Tsay, (2013) for a comprehensive review of time series models. In recent years, with the advent of deep learning, various deep neural network architectures have been applied to sequential data modeling, including recurrent neural network (RNN)-based methods (Pascanu et al.,, 2013; Lai et al.,, 2018) and attention-based methods (Li et al.,, 2019; Zhou et al.,, 2021). These deep learning models have demonstrated remarkable success in addressing nonlinear dependencies, resulting in promising forecasting performances. However, in spite of these advances, image data typically contains rich spatial and structural information along with substantially higher dimensions. Time series methods designed for numerical values are not easily applicable to image data analysis.
In recent years, imaging data analysis has attracted significant attention in both statistics and machine learning community. Broadly speaking, existing work in the statistical literature can be divided into two categories. The first category typically involves converting images into vectors and analyzing the resulting vectors with high-dimensional statistical methods, such as Lasso (Tibshirani,, 1996) or other penalization techniques, Bayesian approaches (Kang et al.,, 2018; Feng et al.,, 2019), etc. Notably, this type of approach may generate ultra high-dimensional vectors and face heavy computational burdens when dealing with high resolution images. The second category of approaches treats image data as tensor inputs and employs general tensor decomposition techniques, such as Canonical polyadic decomposition (Zhou et al.,, 2013) or Tucker decomposition (Li et al.,, 2018; Luo and Zhang,, 2023). Recently, Kronecker product based decomposition has been applied in image analysis and its connections to Convolutional Neural Network (CNN, LeCun et al., 1998) has been explored in the literature (Wu and Feng,, 2023; Feng and Yang,, 2023). Indeed, Deep neural networks (DNN), particularly CNNs, have arguably emerged as the most prevalent approach for image data analysis across various contexts.
Owing to the success of DNNs, generative models have become an immense active area, achieving numerous accomplishments in image analysis and computer vision. In particular, variational autoencoder (Kingma and Welling,, 2013), generative adversiral networks (GAN, Goodfellow et al., 2014) and diffusion models (Ho et al.,, 2020) have gained substantial attention and have been applied to various imaging tasks. Moreover, statisticians have also made tremendous contributions to the advancement of generative models. For example, Zhou et al., 2023a introduced a deep generative approach for conditional sampling, which matches appropriate joint distributions using Kullback-Liebler divergence. Zhou et al., 2023b introduced a non-parametric test for the Markov property in time series using generative models. Chen et al., 2022b proposed an inferential Wasserstein GAN (iWGAN) model that fuses autoencoders and GANs, and established the generalization error bounds for the iWGAN. Although generative models have achieved remarkable success, their investigation in the context of image time series analysis has been much less explored, to the best of our knowledge. Ravi et al., (2019) introduced a deep learning approach to generate neuroimages and simulate disease progression, while Yoon et al., (2023) employed a conditional diffusion model for generating sequential medical images. In fact, handling medical imaging data can present additional challenges, such as limited sample sizes, higher image resolutions, and subtle differences between images. Consequently, conventional generative approaches might not be sufficient for generating medical images.
Motivated by brain imaging analysis, this paper considers image generation problem in a time series context. Suppose that a time series of images of dimension is observed from to and we are interested in generating the next points, i.e., . Our goal is to generate a sequence which follows the same joint distribution as , i.e.,
| (1) |
In this paper, we show that under a Markov and a conditional invariance condition, such generation is possible by letting
| (2) |
where is certain unknown measurable function, i.e., generator, that need to be estimated, is a -dimensional random vector that is drawn i.i.d. from a reference distribution such as Gaussian. If (1) could be achieved, not only would any subset of the generated sequence follows the same distribution as that of , but the dependencies between and also maintain consistency with the existing relationships between and . We refer to the generation (2) as “iteration generation” as is generated iteratively. Additionally, we consider a “s-step” generation that allows us to generate directly from :
| (3) |
where is the target function that to be learned.
To guarantee the generation (2) achieves distribution matching (1), in this paper, we first establish the existence of the generator . Given its existence, we formulate a min-max problem that derived from the -divergence between the pairs and to estimate the generator . With the learned , we prove that under a mild distribution condition on , not only does the pairwise distribution of converge in expectation to for any , but more important, the joint distribution of the generated sequence converges to that of . The lag-1 generation in (2) could be further extended to a lag-k time series context with similar distribution matching guarantees. Furthermore, we generalize our framework to a panel data scenario to accommodate multiple samples. Finally, The effectiveness of our generation mechanism is evaluated by generating real brain MRI sequences from the Alzheimer’s Disease Neuroimaging Initiative (ADNI).
The rest of this paper is organized as follows. In Section 2, we establish the existence of the generator and formulate the estimation of iterative and s-step generation. In Section 3, we prove the weak convergence of joint and pairwise distribution for the generation. We extend our theoretical analysis to a lag-k time series context in Section 4. Section 5 generalize the framework to a panel data scenario with multiple samples. We conduct simulation studies in Section 6 and generate real brain MRI sequences in ADNI in Section 7. The detailed proof and implementation of our approach are deferred to the supplementary material.
2 Existence and estimation
We consider a time series that satisfies the following two assumptions
Markov and conditional invariance property are commonly imposed in the time series analysis. Here we restrict our attention to a lag-1 time series , further generalization to lag-k scenarios will be considered in Section 4. Notably, Zhou et al., 2023b proposed a nonparametric test for the Markov property using generative learning. The proposed test could even allow us to infer the order of a Markov model. We omit the details here and refer interested readers to their paper for further details.
Suppose that the time series is observed from to and we are interested in generating the next points, i.e., . In particular, we aim to generate a sequence that follows the same joint distribution as . More aggressively, we aim to achieve
| (4) |
The target (4) is aggressive. If it holds true, then not only does any subset of the generated sequence follows the same distribution as that of , but the dependencies between and also remain consistent with those existing between and .
In this paper, we show that such a generation is possible by letting
| (5) |
where is certain unknown measurable function, is a sequence of -dimensional Gaussian vector that is independent of .
The existence of target function is based on the following proposition.
Theorem 1.
Let be a sequence of random variables which satisfy:
for any . Suppose and be a sequence of independent -dimensional Gaussian vector. Then there exist a a measurable function such that the sequence
| (6) |
satisfies that for any ,
| (7) |
Theorem 1 could be proved using the following noice-outsourcing lemma.
Lemma 1.
(Theorem 5.10 in Kallenberg, (2021))
Let be a random vector. Suppose random variables and which is independent of . Then there exist a random variable and a measurable function such that and .
We refer to the generation mechanism (6) as “iterative generation” since it is produced iteratively, one step at a time. Theorem 1 proves the existence of such iterative generation process. Besides iterative generation, an alternative approach is to directly generate the outcomes after steps. Specifically, we consider the -step generation of the following form
| (8) |
with being the target function.
Theorem 2.
Let be a sequence of random variables which satisfy:
for any . Let be a sequence of independent -dimensional Gaussian vector. Further let be the target function in Theorem 1. Then there exist a measurable function such that the sequence
| (9) |
satisfies
| (10) |
and
| (11) |
Remark 2.1.
Unlike Theorem 1, the sequence does not necessarily achieve the target property (7) on the joint distribution. Instead, Theorem 2 could only guarantee the distributional match on the marginals as in (10). The major difference is that in the s-step generation, the conditional distribution varies with . Consequently, the mutual dependencies between could not be kept in the generation.
Remark 2.2.
Due to the connection between and in (11), could be considered as an extended function of that includes an extra forecasting lag variable .
Given Theorem 1 on the existence of , now we consider the estimation of function . For any given period , we consider the following -GAN (Nowozin et al.,, 2016) type of min-max problem for the iterative generation:
| (12) | |||
| (13) |
where is the convex conjugate of , and are spaces of continuous and bounded functions.
The -divergence includes many commonly used measures of divergence, such as Kullback-Leibler (KL) divergence, divergence as special cases. In our analysis, we consider the general divergence. From a technique perspective, we assume that is a convex function and satisfies . We further assume that there exists constants and such that,
| (14) |
The assumption (14) is rather mild. For instance, the KL divergence, defined by , meets the requirement of (14) with and . Similarly, the divergence, described by , satisfies (14) with and .
Now we define the pseudo dimension and global bound of and , which will be used in later analysis. Let be a class of functions from to . The pseudo dimension of , written as , is the largest integer for which there exists such that for any there exists such that . Note that this definition is adopted from Bartlett et al., (2017). Furthermore, the global bound of is defined as .
The min-max problem (12) is derived from the -divergence between the pairs and . For any two probability distributions with densities and , let be their -divergence. Denote the -divergence between and as :
| (15) |
A variational formulation of -divergence (Keziou,, 2003; Nguyen et al.,, 2010) is based on the Fenchel conjugate. Let
| (16) |
Then we have . The equality holds if and only if , where and denote the distribution of and , respectively. If for , then by Theorem 1, there exists a function such that
Consequently, a function exists such that
For the -step generation, we consider a similar min-max problem of the following form:
| (17) | |||
| (18) | |||
| (19) |
Similar to , here and are the spaces of continuous and bounded functions. As the s-step generation allows us to generate outcomes after -steps for an arbitrary , the includes all the available pairs before the observation time . As a comparison, in iterative generation, the pairs are restricted to neighbors. The -step generation is related to the following average of -divergence a
| (20) |
As in iterative generation, we also consider the following variational form
| (21) | |||||
| (22) |
Similarly, we have .
On the other hand, the solution of s-step generation (17) and iterative generation (12) could also be connected as in the following proposition.
Thus, the property (11) on the target function and could also be inherited by the estimated solution and .
3 Convergence analysis for Lag-1 time series
3.1 General bounds for iterative generation
In this section, we prove that the time series obtained by iterative generation matches the true distribution as in (4) asymptotically. To achieve this goal, we impose the following condition on .
Asumption 1.
The probability density funtion of , denoted as , converges in , i.e., there exists a funtion such that:
| (23) |
where is a constant.
Assumption 1 requires that the density converges in , and the convergence rate is controlled by . Under many scenarios, such a rate is rather mild and can be achieved easily. For example, if we consider the following Gaussian distribution family, the convergence rate will be controlled by , a smaller order of .
Example 1.
Let be time series which satisfy:
where , is symmetric matrix and its largest singular value is less than . is independent of . Let . Then there exists a density function such that
| (24) |
In classical time series analysis, stationary conditions are usually imposed for desired statistical properties. For example, A time series is said to be strictly stationary or strongly stationary if
for all and for all , where is the distribution function of . Clearly, the strictly stationary condition implies Assumption 1. In other words, Assumption 1 is a much weaker condition, since the convergence condition is imposed only on the marginal densities, with no requirement placed on the joint distribution.
Given the convergence condition, we are ready to state the main theorem for the iterative generations. Let be the solution to (12) and be the generated sequence, i.e.,
Then, the joint density of converge to the corresponding truth in expectation as in Theorem 4 below.
Theorem 4.
(iterative generation) Let be a sequence of random variables which satisfy the Markov and Conditional invariance condition as in Theorem 1. Suppose Assumption 1 holds. Let be the solution to the f-GAN problem (12) with f satisfying (14). Then,
| (25) |
where
Moreover, for the pairwise distribution, we have
| (26) |
Corollary 1.
When follows a Gaussian distribution family as in Example 1, the statistical error could be further optimized to
where is a certain constant.
Theorem 4 establishes the convergence of joint and pairwise distribution for the iterative generations. The distance between and the true sequence could be bounded by four terms, including the statistical errors , and approximation errors , . In particular, it is clear that converge to 0 when . While for to , we prove their converge in Section 3.3 when and are chosen to be spaces of deep neural networks. As a result of Theorem 4, the main objective (4) can be ensured asymptotically. In other words, the generated sequence follows approximately the same distribution as the truth with sufficient samples.
Remark 3.1.
The statistical error depends on and , the convergence speed of . Clearly, we may omit the term in as is of smaller order of . We include in because it controls the difference between joint distribution and pairwise distribution bound. See Proposition 5 below. In addition, the term is obtained by estimating a carefully constructed quantity in Proposition 6 below.
Proposition 5.
For any ,
| (27) | |||||
| (28) |
Proposition 6.
For any , define
| (29) | |||||
| (31) | |||||
then we have
| (32) |
Remark 3.2.
The statistical error depends only on the time period and the structure of function spaces and . In subsection 3.3, we show that goes to 0 when and are taken as neural network spaces of appropriate sizes. The is obtained by estimating the Rademacher complexity of in Proposition 7 below. Under the time series setting, are highly correlated. Conventional techniques to bound Rademacher complexity does not work. In our proof, we adopt a new technique introduced by McDonald and Shalizi, (2017) that allows us to handle correlated variables. We defer to the supplementary material for more details.
Proposition 7.
Let be the Rademacher random variables. For , define
| (34) | |||||
Further let be the Rademacher complexity of ,
| (35) |
Then we have
| (36) |
Moreover, could be further bounded using the pseudo dimension and global bound of and .
3.2 General bounds for -step generation
In this subsection, we provide theoretical guarantees for the -step generation. Let be the solution to (17) and be the generated sequence, i.e.,
Now we show that the pairwise distance between and could be guaranteed as in Theorem 8 below.
Theorem 8.
(-step generation) Let be a sequence of random variables which satisfy the Markov and Conditional invariance condition as in Theorem 1. Suppose Assumption 1 holds. Let be the solution to the f-GAN problem (17) with f satisfying (14). Then,
| (37) |
where
In particular, when ,
| (38) |
where and are the quantities in Theorem 4.
Theorem 8 demonstrates the convergence of pairwise distribution for the -step generation. It states that the distribution distance between and for any can be bounded by the sum of two statistical errors and two approximation errors. In the following subsection, similar to Theorem 4, we will show that all s approach to 0 when and are chosen to be spaces of deep neural networks. Upon comparing Theorem 8 with Theorem 4, it can be observed that the term in does not appear in . As discussed in Remark 3.1, the term controls the difference between joint and pairwise distribution, and it is no longer needed in Theorem 8.
Remark 3.3.
Unlike Theorem 4, the convergence for joint distribution may not be guaranteed for s-step generated sequence . As discussed in Theorem 2, there is no assurance regarding the existence of to attain the joint distribution match. The major issue for s-step generation is that varies with . Thus the mutual dependencies between could not be kept in the generation. As a comparison, in iterative generation, the joint distribution match could be achieved as the conditional distribution of adjacent generations does not vary with , i.e.,
3.3 Analysis of deep neural network spaces
Neural networks have been extensively studied in recent years due to its universal approximation power. In this subsection, we consider DNN to approximate the generator in our model. In particular, we show that both statistical and approximation errors converge to zero when , , , are taken to be the space of Rectified Linear Unit (ReLU) neural network functions. To avoid redundancy, we concentrate on the spaces of and , with generalizations to and being straightforward.
Recall that the input and reference are of dimension and , respectively. We consider the generator in the space of ReLU neural networks with width , depth , size and global bound . Specifically, let denote the number of hidden units in layer with being the dimension of input layer. Then the width is the maximum dimension, the depth is the number of layers, the size is the total number of parameters, and the global bound satisfies for all . Similarly, we may define a ReLU network space for the discriminator as .
Then, by Bartlett et al., (2017), we may bound the pseudo dimension of (and ) and consequently as in Proposition 9 below.
Proposition 9.
Let be the ReLU network space with width , depth , size and global bound . Then we have
Consequently,
By Proposition 9, it is clear that goes to 0 with appropriate size of ReLU network spaces, e.g. and are of smaller order of . Moreover, as when regardless of network structure, we can conclude that the statistical error in Theorem 4 converge to 0.
Now we consider the approximation errors and . The approximation power of DNN has been intensively studied in the literature under different conditions, such as smoothness assumptions. For instance, the early work by Stone, (1982) established the optimal minimax rate of convergence for estimating a -smooth function. While more recently, Yarotsky, (2017) and Lu et al., (2020) considered target functions with continuous -th derivatives. Jiao et al., (2021) assumed -Hölder smooth functions with . Moreover, studies including Shen et al., (2021), Schmidt-Hieber, (2020), and Bauer and Kohler, (2019), have sought to enhance the convergence rate by assuming that the target function possesses certain compositional structure. Here, we adopt Theorem 4.3 in Shen et al., (2019) and show that the approximation error in Theorem 4 converge to 0 with a particular structure of neural networks.
Proposition 10.
Let be a ReLU network space with depth and width . Further let be a ReLU network with depth and width . Then as , we have
4 Generalizations to lag-k time series
In this section, we generalize the lag-1 time series studied in Section 2 and 3 to a lag-k setting. Specifically, we consider a time series that satisfies the following lag-k Markov assumption
| (39) |
Moreover, assume that is conditionally invariant
| (40) |
In other words, the conditional density function of does not depend on .
Given a lag-k time series , we aim to generate a sequence that not only follows the same joint distribution as , but also maintains the dependencies between and . In other words, we aim to achieve
| (41) |
we show that such generation is possible by the following iterative generation
where is the target function to be estimated and is i.i.d. Gaussian vectors of dimension . Moreover, we may also consider the -step generation:
The following proposition suggests that, analogous to the lag-1 case, there exist a function for iterative generation to achieve the joint distribution matching. Furthermore, for the s-step generation, a function exists to attain the marginal distribution matching.
Proposition 11.
Let satisfies the lag-k Markov property (39) and conditional invariance condition (40). Let and be independent -dimensional Gaussian vectors which are independent of . Then for iterative generation, there exists a measurable function such that the sequence
| (42) |
satisfies that for any ,
| (43) |
Moreover, for -step generation, the sequence
| (44) |
satisfies
| (45) |
Now we consider the estimation of and in lag-k time series. For any sequence and positive integer , denote as the set . Then we consider the following min-max problem for the estimation of s-step generation:
| (46) | |||||
| (48) | |||||
| (49) |
where , are the spaces of continuous and bounded functions. As in the lag-1 case, the generator and discriminator in the lag-k iterative generation can be obtained by letting
Asumption 2.
The probability density funtion of , denoted by , converges in , i.e., there exists a funtion such that:
| (50) |
where is certain positive constant.
Given Assumption 2, we can derive theoretical guarantees for the distribution matching of lag-k time series. Now let be the iteratively generated sequence, i.e.,
| (51) | ||||
| (52) |
Further let be the s-step generated sequence, i.e.,
| (53) | ||||
| (54) |
Then we have the following convergence theorem for iterative and s-step generated sequences.
Theorem 12.
Let satisfies the lag-k Markov property (39) and conditional invariance condition (40). Suppose Assumption 2 holds. Let be the solution to the f-GAN problem (77) with f satisfying (14). Then, for the iterative generations in (51), we have
| (55) |
and
| (56) |
where
Moreover, for -step generations in (53), we have
| (57) |
In particular, when ,
| (58) |
where
Remark 4.1.
Analogous to the lag-1 case, the , , , and in the lag-k time series are defined as below:
| (59) | |||||
| (61) | |||||
| (62) | |||||
| (64) | |||||
When and are approximated by appropriate deep neural networks, the to and to will all converge to 0. Consequently, the joint distribution matching for the iterative generation and pairwise distribution matching for the s-step generation could be guaranteed in lag-k time series.
5 Further generalizations to panel data
In this section, we extend our analysis for image time series to a panel data setting. In particular, we consider a scenario with subjects, and for each subject , we observe a sequence of images . Here we allow the time series length for each subject to be different. Clearly, this type of setting is frequently encountered when analyzing medical image data. Our objective is to generate images for each subject at future time points.
In the panel data setting, we assume that satisfies the following Markov condition for all subject
| (65) |
We further assume the following invariance condition
| (66) |
In other words, we assume the same conditional distribution for different subjects and time point .
Similar to previous sections, we aim to find a common function such that for all subjects , the generated sequence
| (67) |
achieves distribution matching
| (68) |
By Theorem 1, such a function clearly exist. To estimate , we consider the following min-max problem.
| (69) | |||
| (70) |
where as before, are spaces of continuous and uniformly bounded functions. To prove the convergence of the generated sequence, we consider two different settings: 1) approaches infinity, while may either go to infinity or be finite; 2) is finite, while approaches infinity.
5.1 Convergence analysis for
In this subsection, we consider the case that , while may either go to infinity or be finite. We consider the following sequences
| (71) |
Now we are ready to present the convergence theorem for the generated sequences.
Theorem 13.
Whether is finite or approaches infinity, Theorem 13 demonstrates the convergence of the generated sequence when . We shall note that the usual independence assumption between subjects is not necessary in Theorem 13. This implies that convergence can be guaranteed even when the observations are dependent.
5.2 Convergence analysis for and is finite
In this subsection, we consider the case that , while is finite. Without loss of generality, we assume that . In addition, the following assumption is needed in our analysis.
Asumption 3.
For all , the starting point follows the same distribution as , i.e.,
| (73) |
By combining Assumption 3 with the Markov and conditional invariance conditions, we could have that the sequences for all follow the same joint distribution. Consequently, we can reach the following convergence theorem.
Theorem 14.
Remark 5.1.
The independence assumption is necessary for convergence in Theorem 14, whereas it is not required in Theorem 13. In a panel data setting where the time series length is finite, we cannot rely on a sufficiently long time series to achieve convergence. In particular, the Proposition 5 could no longer be employed to control the difference between joint and pairwise distribution bounds. Thus the proof for Theorem 14 differs significantly from previous sections.
6 Simulation studies
In this section, we conduct comprehensive simulation studies to assess the performance of our generations. We begin in Section 6.1 to consider the generation of a single image time series, then in Section 6.2 generalize to the panel data scenario.
6.1 Study I: Single Time Series
We consider matrix valued time series to mimic the setting of real image data. Specifically, we consider the following three cases:
-
Case 1. Lag-1 Linear
-
Case 2. Lag-1 Nonlinear
-
Case 3. Lag-3 Nonlinear
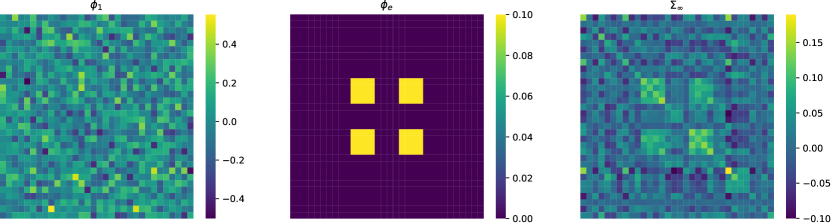
Here and represent target image and independent noise matrices, respectively, with the image size fixed to be . In all three cases, we let the noise matrix consists of i.i.d. standard normal entries. Moreover, the initialization in Cases 1 and 2 and , , and in Case 3 are also taken to the matrices with i.i.d. standard normal entries. It is worth noting that under Case 1 setting, is column-wise independent, and each column of converges to , where satisfies . In this simulation, we let be a normalized Gaussian matrix with the largest eigenvalue modulus less than 1, is a fixed matrix with block shape patterns. Given and , then could be solved easily. We plot the , and in the supplementary material. Moreover, in Case 2, we set , in a similar manner as Case 1, but certainly, the normal convergence would no longer hold. While in Case 3, we let both and be normalized Gaussian matrices, and fix as before.
We consider the time series with two different lengths, and for training. We set the horizon , i.e., generate images in a maximum of steps. We aim to generate a total of image points in a “rolling forecasting” style. Specifically, for any , we let the -step generation (denoted as “s-step GTS”) be
where and superscript indicting the j-th generation. Here is estimated using 10,000 randomly selected pairs from the training data. While for iteration generation (denoted as “iter GTS”), we let
where is the -times composition of the function .
The for s-step generation (and for iterative generation) are estimated for KL divergence (i.e., ) using neural networks in the simulation. Specifically, in Case 1 and 2, the input initially goes through two fully connected layers, each with ReLU activation functions. Afterward, it is combined with the random noise vector . This combined input is then passed through a single fully connected layer. The discriminator has two separate processing branches that embed and into low-dimensional vectors, respectively. These vectors are concatenated and further processed to produce an output score. The details of network structure can be found in Table 1. While for Case 3, in the generator network, , , and are each processed independently using three separate fully-connected layers. Afterward, they are combined with a random noise vector and passed through another fully-connected layer before producing the output. The discriminator in this case follows the same process as in Cases 1 and 2.
Different from supervised learning, generative learning does not have universally applicable metrics for evaluating the quality of generated samples (Theis et al.,, 2015; Borji,, 2022). Assessing the visual quality of produced images often depends on expert domain knowledge. Meanwhile, the GANs literature has seen significant efforts in understanding and developing evaluation metrics for generative performance. Several quantitative metrics have been introduced, such as Inception Score (Salimans et al.,, 2016), Frechet Inception Distance (Heusel et al.,, 2017), and Maximum Mean Discrepancy (Bińkowski et al.,, 2018), among others.
| Layer | Type | ||
|---|---|---|---|
| 1 | fully connected layer (in dims = 1024, out dims = 256) | ||
| 2 | ReLU | ||
| generator | 3 | fully connected layer (in dims = 256, out dims = 128) | |
| 4 | ReLU | ||
| 5 | concatenate with random vector | ||
| 6 | fully connected layer (in dims = 148, out dims = 1024) | ||
| discriminator | |||
| Cases | Methods | |||||
| OLS | (0.002) | (0.003) | (0.004) | |||
| case 1 | Naive Baseline | 1.563 (0.039) | 1.932 (0.043) | 1.408 (0.098) | ||
| iter GTS | (0.038) | 0.891 (0.050) | 0.985 (0.064) | |||
| s-step GTS | (0.038) | (0.047) | (0.062) | |||
| OLS | 0.973 (0.060) | 1.000 (0.021) | 0.995 (0.008) | |||
| 1000 | case 2 | Naive Baseline | 1.462 (0.129) | 1.455 (0.152) | 1.373 (0.178) | |
| iter GTS | (0.053) | (0.064) | (0.075) | |||
| s-step GTS | (0.053) | (0.057) | (0.061) | |||
| OLS | 0.608 (0.021) | 0.609 (0.021) | 0.609 (0.020) | |||
| case 3 | Naive Baseline | 0.845 (0.034) | 0.843 (0.034) | 0.844 (0.033) | ||
| iter GTS | (0.020) | (0.020) | (0.020) | |||
| s-step GTS | (0.020) | (0.020) | (0.020) | |||
| OLS | (0.001) | (0.002) | (0.002) | |||
| case 1 | Naive Baseline | 1.563 (0.040) | 1.932 (0.043) | 1.408 (0.099) | ||
| iter GTS | (0.098) | 0.717 (0.163) | 0.851 (0.226) | |||
| s-step GTS | (0.098) | (0.167) | (0.079) | |||
| OLS | 0.973 (0.060) | 1.001 (0.021) | 0.995 (0.007) | |||
| 5000 | case 2 | Naive Baseline | 1.468 (0.132) | 1.452 (0.157) | 1.377 (0.181) | |
| iter GTS | (0.046) | (0.056) | (0.066) | |||
| s-step GTS | (0.046) | (0.048) | (0.054) | |||
| OLS | 0.608 (0.020) | 0.610 (0.021) | 0.609 (0.020) | |||
| case 3 | Naive Baseline | 0.845 (0.032) | 0.846 (0.032) | 0.850 (0.033) | ||
| iter GTS | (0.020) | (0.020) | (0.020) | |||
| s-step GTS | (0.020) | (0.020) | (0.021) |
Nonetheless, achieving a consensus regarding the evaluation of generative models remains an unresolved issue. In our approach, we compute the mean of the generated samples and present the results as the normalized root mean squared error (NRMSE) of the mean estimation. Specifically, for a given step , let and be the estimated mean of the s-step and iterative generated samples, respectively. The NRMSE of the iterative generation is defined as
where denotes the Frobenius norm. The NRMSE of the s-step generation can be defined similarly.
The performance of our iterative and s-step generation are compared with two benchmark approaches. We first consider a naive baseline in which the prediction for is taken from the observation -steps ahead for a given , meaning that . In addition, we consider a simple linear estimator obtained using Ordinary Least Squares (OLS). Specifically, the linear coefficients are estimated with a correctly specified order of lag, i.e., for Cases 1 and 2, and for Case 3. Clearly, in Case 1, OLS is a suitable choice as the model is linear. However, for Cases 2 and 3, OLS is mis-specified.
We repeat the simulation for 100 times and report in Table 2 the mean and standard deviation of the NRMSE for using different approaches. It is clear that our s-step and iterative generations exhibit competitive performance across almost all settings, particularly in the nonlinear Cases 2 and 3. In Case 1, the original model is linear, and as expected, OLS achieves the minimum NRMSE. Moreover, as increases, the problem becomes more challenging. However, both s-step and iterative generation maintain robust performance across different . It is important to note that when , the iterative and s-step generation methods are equivalent. For , the s-step generation generally exhibits a slightly smaller NRMSE, though the difference is not significant.
6.2 Study II: Multiple Time Series
In this subsection, we consider a panel data setting with multiple time series. We consider two different sample sizes, while fixing the time series length . We set the horizon as before, i.e., generate images in a maximum of steps for each subject.
| Cases | Methods | |||||
| OLS | (0.001) | (0.002) | (0.003) | |||
| case 1 | Naive Baseline | 1.563 (0.039) | 1.925 (0.043) | 1.380 (0.097) | ||
| iter GTS | (0.036) | 0.813 (0.046) | 0.893 (0.056) | |||
| s-step GTS | (0.036) | (0.044) | (0.056) | |||
| OLS | 0.985 (0.029) | 1.000 (0.005) | 0.999 (0.001) | |||
| case 2 | Naive Baseline | 1.459 (0.107) | 1.478 (0.127) | 1.415 (0.156) | ||
| iter GTS | (0.049) | (0.060) | (0.071) | |||
| s-step GTS | (0.049) | (0.068) | (0.077) | |||
| OLS | 0.617 (0.018) | 0.620 (0.018) | 0.625 (0.015) | |||
| case 3 | Naive Baseline | 0.847 (0.032) | 0.845 (0.033) | 0.846 (0.034) | ||
| iter GTS | (0.019) | (0.020) | (0.020) | |||
| s-step GTS | (0.019) | (0.020) | (0.020) | |||
| OLS | (0.001) | (0.002) | (0.003) | |||
| case 1 | Naive Baseline | 1.564 (0.039) | 1.925 (0.043) | 1.379 (0.098) | ||
| iter GTS | (0.040) | 0.667 (0.053) | (0.072) | |||
| s-step GTS | (0.040) | (0.066) | 0.763 (0.056) | |||
| OLS | 0.985 (0.029) | 1.000 (0.005) | 0.999 (0.001) | |||
| case 2 | Naive Baseline | 1.458 (0.109) | 1.478 (0.128) | 1.414 (0.156) | ||
| iter GTS | (0.050) | (0.060) | (0.070) | |||
| s-step GTS | (0.050) | (0.069) | (0.080) | |||
| OLS | 0.617 (0.018) | 0.619 (0.018) | 0.625 (0.015) | |||
| case 3 | Naive Baseline | 0.847 (0.032) | 0.845 (0.033) | 0.846 (0.034) | ||
| iter GTS | (0.019) | (0.020) | (0.020) | |||
| s-step GTS | (0.019) | (0.020) | (0.021) |
Analogous to the single time series, we repeat the simulation for 100 times and report in Table 3 the mean and standard deviation of the NRMSE for using different approaches. Table 3 shows a similar pattern as Table 2. Both iterative and s-step generated images achieve the minimum NRMSE in Case 2 and 3. While under the linear Case 1, the OLS continues to achieve the lowest NRMSE. One notable difference in Table 3 is that the iterative generation achieves a lower NRMSE compared to the s-step generation in this case. One potential explanation for this is the increase in sample size. In comparison to the single time series setting, a sample size of or allows the iterative approach to obtain a better estimation, which in turn enhances the image generation process.
7 The ADNI study
Driven by the goal of understanding the brain aging process, we in this section study real brain MRI data from the Alzheimer’s Disease Neuroimaging Initiative (ADNI). Introduced by Petersen et al., (2010), ADNI aims to investigate the progression of Alzheimer’s disease (AD) by collecting sequential MRI scans of subjects classified as cognitively normal (CN), mildly cognitively impaired (MCI), and those with AD.
Our study focuses on analyzing the brain’s progression during the MCI stage. We include a total of 565 participants from the MCI group in our analysis, each having a sequence of T1-weighted MRI scans with lengths varying between 3 and 9. We approach this as an imaging time series generation problem with multiple samples. However, a significant challenge with the dataset is the short length of each sample (), a common issue in brain imaging analysis. Given the short length of these samples, we do not generate new images beyond a specific point , as it would be difficult to evaluate their quality. Instead, we divide the dataset into a training set consisting of 450 samples and a testing set comprising 115 samples. We then train the generator using the training set and generate image sequences for the testing set given the starting point . As in the simulation study, we also consider a naive baseline in which the prediction for is taken from the observation -steps ahead, meaning that . It is worth mentioning that OLS is not suitable for MRI analysis and, as such, is not included in this context.
In our study, all brain T1-weighted MRI scans are processed through a standard pipeline which begins with a spatial adaptive non-local means (SANLM) denoising filter (Manjón et al.,, 2010), then followed by resampling, bias-correction, affine-registration and unified segmentation (Ashburner and Friston,, 2005), skull-stripping and cerebellum removing. Each MRI is then locally intensity corrected and spatially normalized into the Montreal Neurological Institute (MNI) atlas space (Ashburner,, 2007). These procedures result in processed images of size . We further rescale the intensities of the resulting images to a range of . We select the central axial slice from each MRI and crop it to a size of by removing the zero-valued voxels.
Figure 1 plots the original, iterative and s-step generated MRI sequence along with their difference to for one subject in the test set. As shown by the original images, the brain changes gradually as age increases. This pattern is clearly captured by both iterative and s-step generations. To further assess the generated MRI images, we plot the starting image , true image after s step (i.e., ), iteratively and -step generated images (i.e., and ) for three subjects in Figure 2.
Although the differences are subtle, we can observe that the image and the generated images, and , are quite similar, but they all deviate from in several crucial regions. We highlight four of these regions in Figure 2, including: a) cortical sulci, b) ventricles, c) edge of ventricles, and d) anterior inter-hemispheric fissure. More specifically, we can observe (from subjects 1, 2, and 3, region a) that the cortical sulci widen as age increases. The widening of cortical sulci may be associated with white matter degradation (Drayer,, 1988; Walhovd et al.,, 2005). This phenomenon is also observed in patients with Alzheimer’s Disease (Migliaccio et al.,, 2012). Additionally, the brain ventricles expand from time to as suggested by subjects 1 and 3, region b. The enlargement of ventricles during the aging process is one of the most striking features in structural brain scans across the lifespan (MacDonald and Pike,, 2021). Moreover, we notice that the edge of the ventricles becomes softer (darker region of subject 1, region c), and there is an increased presence of low signal areas adjacent to the ventricles (subject 2, regions b and c). From a clinical perspective, this observation suggests the existence of periventricular interstitial edema, which is linked to reduced ependyma activity and brain white matter atrophy (Todd et al.,, 2018). Lastly, the anterior interhemispheric fissure deepens with aging, as demonstrated in subject 1, region d. In conclusion, the generated samples can potentially aid clinical analyses in identifying age-related brain issues.
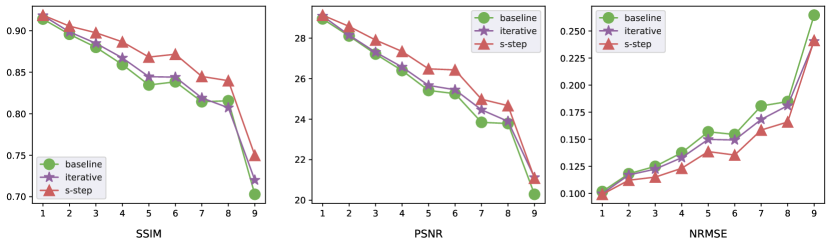
As discussed before, there is a lack of universally application metric for evaluating the quality of generated images. In this study, we consider three metrics to measure the difference between the target and our generations : structural similarity index measure (SSIM), peak signal-to-noise ratio (PSNR), along with the previously introduced NRMSE. More specifically, SSIM calculates the similarity score between two images by comparing their luminance, contrast, and structure. Given two images and , it is defined as
where , are the mean and variance of pixel values in and respectively. The is the covariance of and and , are constants, to be specified in the supplementary material. PSNR is a widely used engineering term for measuring the reconstruction quality for images subject to lossy compression. It is typically defined using the mean squared error:
where is the maximum pixel value among and . Clearly, better image generation performance is indicated by higher values of SSIM and PSNR, as well as smaller values of NRMSE.
In Figure 3, we present for each the mean SSIM, PSNR, and NRMSE over all subjects in the testing set. The results clearly indicate that both s-step and iterative generations outperform the benchmark in all three metrics across almost all the , providing strong evidence of the high quality of our generated images. As increases, the generation problem becomes more challenging. Consequently, we observe a decrease in both SSIM and PSNR for both iterative and s-step generations, indicating a decline in generation quality. On the other hand, the NRMSE for both approaches increase, suggesting a higher level of error in the generated images. When further comparing the iterative and s-step generation, the s-step generation shows a dominating performance in this study. The major reason is due to the limited sample size. With fewer than 500 subjects in training and the observed sequence for each subject being less than 9, a direct s-step generation approach proves advantageous compared to the iterative generation method.
In summary, this study further validates the effectiveness of our approach in generating image sequences. Incorporating the generated image sequences as data augmentation (Chen et al., 2022c, ) could further enhance the performance of downstream tasks, such as Alzheimer’s disease detection (Xia et al.,, 2022). As mentioned before, AD is the most prevalent neurodegenerative disorder, progressively leading to irreversible neuronal damage. The early diagnosis of AD and its syndromes, such as MCI, is of significant importance. We believe that the proposed image time series learning offers valuable assistance in understanding and identifying AD, as well as other aging-related brain issues.
References
- Anthony and Bartlett, (1999) Anthony, M. and Bartlett, P. L. (1999). Neural Network Learning: Theoretical Foundations. Cambridge University Press.
- Ashburner, (2007) Ashburner, J. (2007). A fast diffeomorphic image registration algorithm. Neuroimage, 38(1):95–113.
- Ashburner and Friston, (2005) Ashburner, J. and Friston, K. J. (2005). Unified segmentation. Neuroimage, 26(3):839–851.
- Bartlett et al., (2017) Bartlett, P. L., Harvey, N., Liaw, C., and Mehrabian, A. (2017). Nearly-tight vc-dimension and pseudodimension bounds for piecewise linear neural networks.
- Basu and Michailidis, (2015) Basu, S. and Michailidis, G. (2015). Regularized estimation in sparse high-dimensional time series models.
- Bauer and Kohler, (2019) Bauer, B. and Kohler, M. (2019). On deep learning as a remedy for the curse of dimensionality in nonparametric regression.
- Bińkowski et al., (2018) Bińkowski, M., Sutherland, D. J., Arbel, M., and Gretton, A. (2018). Demystifying mmd gans. arXiv preprint arXiv:1801.01401.
- Bollerslev, (1986) Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of econometrics, 31(3):307–327.
- Borji, (2022) Borji, A. (2022). Pros and cons of gan evaluation measures: New developments. Computer Vision and Image Understanding, 215:103329.
- Brockwell and Davis, (1991) Brockwell, P. J. and Davis, R. A. (1991). Time series: theory and methods. Springer science & business media.
- Chang et al., (2023) Chang, J., He, J., Yang, L., and Yao, Q. (2023). Modelling matrix time series via a tensor cp-decomposition. Journal of the Royal Statistical Society Series B: Statistical Methodology, 85(1):127–148.
- Chen et al., (2021) Chen, R., Xiao, H., and Yang, D. (2021). Autoregressive models for matrix-valued time series. Journal of Econometrics, 222(1):539–560.
- (13) Chen, R., Yang, D., and Zhang, C.-H. (2022a). Factor models for high-dimensional tensor time series. Journal of the American Statistical Association, 117(537):94–116.
- (14) Chen, Y., Gao, Q., and Wang, X. (2022b). Inferential wasserstein generative adversarial networks. Journal of the Royal Statistical Society Series B: Statistical Methodology, 84(1):83–113.
- (15) Chen, Y., Yang, X.-H., Wei, Z., Heidari, A. A., Zheng, N., Li, Z., Chen, H., Hu, H., Zhou, Q., and Guan, Q. (2022c). Generative adversarial networks in medical image augmentation: a review. Computers in Biology and Medicine, 144:105382.
- Cole et al., (2018) Cole, J. H., Ritchie, S. J., Bastin, M. E., Hernández, V., Muñoz Maniega, S., Royle, N., Corley, J., Pattie, A., Harris, S. E., Zhang, Q., et al. (2018). Brain age predicts mortality. Molecular psychiatry, 23(5):1385–1392.
- Drayer, (1988) Drayer, B. P. (1988). Imaging of the aging brain. part i. normal findings. Radiology, 166(3):785–796.
- Engle, (1982) Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica: Journal of the econometric society, pages 987–1007.
- Fan and Yao, (2003) Fan, J. and Yao, Q. (2003). Nonlinear time series: nonparametric and parametric methods, volume 20. Springer.
- Feng and Yang, (2023) Feng, L. and Yang, G. (2023). Deep kronecker network. Biometrika, page asad049.
- Feng et al., (2019) Feng, X., Li, T., Song, X., and Zhu, H. (2019). Bayesian scalar on image regression with nonignorable nonresponse. Journal of the American Statistical Association, pages 1–24.
- Goodfellow et al., (2014) Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. (2014). Generative adversarial nets. Advances in neural information processing systems, 27.
- Guo et al., (2016) Guo, S., Wang, Y., and Yao, Q. (2016). High-dimensional and banded vector autoregressions. Biometrika, page asw046.
- Han et al., (2023) Han, Y., Chen, R., Zhang, C.-H., and Yao, Q. (2023). Simultaneous decorrelation of matrix time series. Journal of the American Statistical Association, pages 1–13.
- Heusel et al., (2017) Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. (2017). Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30.
- Ho et al., (2020) Ho, J., Jain, A., and Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851.
- Huizinga et al., (2018) Huizinga, W., Poot, D. H., Vernooij, M. W., Roshchupkin, G. V., Bron, E. E., Ikram, M. A., Rueckert, D., Niessen, W. J., Klein, S., Initiative, A. D. N., et al. (2018). A spatio-temporal reference model of the aging brain. NeuroImage, 169:11–22.
- Jack et al., (2004) Jack, C., Shiung, M., Gunter, J., O’brien, P., Weigand, S., Knopman, D. S., Boeve, B. F., Ivnik, R. J., Smith, G. E., Cha, R., et al. (2004). Comparison of different mri brain atrophy rate measures with clinical disease progression in ad. Neurology, 62(4):591–600.
- Jiao et al., (2021) Jiao, Y., Shen, G., Lin, Y., and Huang, J. (2021). Deep nonparametric regression on approximately low-dimensional manifolds. arXiv preprint arXiv:2104.06708.
- Kallenberg, (2021) Kallenberg, O. (2021). Foundations of modern probability. Probability Theory and Stochastic Modelling.
- Kang et al., (2018) Kang, J., Reich, B. J., and Staicu, A.-M. (2018). Scalar-on-image regression via the soft-thresholded gaussian process. Biometrika, 105(1):165–184.
- Keziou, (2003) Keziou, A. (2003). Dual representation of -divergences and applications. Comptes rendus mathématique, 336(10):857–862.
- Kingma and Welling, (2013) Kingma, D. P. and Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
- Lai et al., (2018) Lai, G., Chang, W.-C., Yang, Y., and Liu, H. (2018). Modeling long-and short-term temporal patterns with deep neural networks. In The 41st international ACM SIGIR conference on research & development in information retrieval, pages 95–104.
- LeCun et al., (1998) LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324.
- Li et al., (2019) Li, S., Jin, X., Xuan, Y., Zhou, X., Chen, W., Wang, Y.-X., and Yan, X. (2019). Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. Advances in neural information processing systems, 32.
- Li et al., (2018) Li, X., Xu, D., Zhou, H., and Li, L. (2018). Tucker tensor regression and neuroimaging analysis. Statistics in Biosciences, 10(3):520–545.
- Loshchilov and Hutter, (2017) Loshchilov, I. and Hutter, F. (2017). Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Lu et al., (2020) Lu, J., Shen, Z., Yang, H., and Zhang, S. (2020). Deep network approximation for smooth functions. arxiv e-prints, page. arXiv preprint arXiv:2001.03040.
- Luo and Zhang, (2023) Luo, Y. and Zhang, A. R. (2023). Low-rank tensor estimation via riemannian gauss-newton: Statistical optimality and second-order convergence. The Journal of Machine Learning Research, 24(1):18274–18321.
- MacDonald and Pike, (2021) MacDonald, M. E. and Pike, G. B. (2021). Mri of healthy brain aging: A review. NMR in Biomedicine, 34(9):e4564.
- Manjón et al., (2010) Manjón, J. V., Coupé, P., Martí-Bonmatí, L., Collins, D. L., and Robles, M. (2010). Adaptive non-local means denoising of mr images with spatially varying noise levels. Journal of Magnetic Resonance Imaging, 31(1):192–203.
- McDonald and Shalizi, (2017) McDonald, D. J. and Shalizi, C. R. (2017). Rademacher complexity of stationary sequences.
- Migliaccio et al., (2012) Migliaccio, R., Agosta, F., Possin, K. L., Rabinovici, G. D., Miller, B. L., and Gorno-Tempini, M. L. (2012). White matter atrophy in alzheimer’s disease variants. Alzheimer’s & Dementia, 8:S78–S87.
- Nguyen et al., (2010) Nguyen, X., Wainwright, M. J., and Jordan, M. I. (2010). Estimating divergence functionals and the likelihood ratio by convex risk minimization. IEEE Transactions on Information Theory, 56(11):5847–5861.
- Nowozin et al., (2016) Nowozin, S., Cseke, B., and Tomioka, R. (2016). f-gan: Training generative neural samplers using variational divergence minimization. Advances in neural information processing systems, 29.
- Pascanu et al., (2013) Pascanu, R., Gulcehre, C., Cho, K., and Bengio, Y. (2013). How to construct deep recurrent neural networks. arXiv preprint arXiv:1312.6026.
- Petersen et al., (2010) Petersen, R. C., Aisen, P. S., Beckett, L. A., Donohue, M. C., Gamst, A. C., Harvey, D. J., Jack, C. R., Jagust, W. J., Shaw, L. M., Toga, A. W., et al. (2010). Alzheimer’s disease neuroimaging initiative (adni): clinical characterization. Neurology, 74(3):201–209.
- Ravi et al., (2019) Ravi, D., Alexander, D. C., Oxtoby, N. P., and Initiative, A. D. N. (2019). Degenerative adversarial neuroimage nets: generating images that mimic disease progression. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 164–172. Springer.
- Salimans et al., (2016) Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., and Chen, X. (2016). Improved techniques for training gans. Advances in neural information processing systems, 29.
- Schmidt-Hieber, (2020) Schmidt-Hieber, J. (2020). Nonparametric regression using deep neural networks with relu activation function.
- Shen et al., (2021) Shen, G., Jiao, Y., Lin, Y., Horowitz, J. L., and Huang, J. (2021). Deep quantile regression: Mitigating the curse of dimensionality through composition. arXiv preprint arXiv:2107.04907.
- Shen et al., (2019) Shen, Z., Yang, H., and Zhang, S. (2019). Deep network approximation characterized by number of neurons. arXiv preprint arXiv:1906.05497.
- Stock and Watson, (2001) Stock, J. H. and Watson, M. W. (2001). Vector autoregressions. Journal of Economic perspectives, 15(4):101–115.
- Stone, (1982) Stone, C. J. (1982). Optimal global rates of convergence for nonparametric regression. The annals of statistics, pages 1040–1053.
- Theis et al., (2015) Theis, L., Oord, A. v. d., and Bethge, M. (2015). A note on the evaluation of generative models. arXiv preprint arXiv:1511.01844.
- Tibshirani, (1996) Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B (Methodological), pages 267–288.
- Todd et al., (2018) Todd, K. L., Brighton, T., Norton, E. S., Schick, S., Elkins, W., Pletnikova, O., Fortinsky, R. H., Troncoso, J. C., Molfese, P. J., Resnick, S. M., et al. (2018). Ventricular and periventricular anomalies in the aging and cognitively impaired brain. Frontiers in aging neuroscience, 9:445.
- Tofts, (2005) Tofts, P. (2005). Quantitative MRI of the brain: measuring changes caused by disease. John Wiley & Sons.
- Tsay, (2013) Tsay, R. S. (2013). Multivariate time series analysis: with R and financial applications. John Wiley & Sons.
- Tsay and Chen, (2018) Tsay, R. S. and Chen, R. (2018). Nonlinear time series analysis, volume 891. John Wiley & Sons.
- Walhovd et al., (2005) Walhovd, K. B., Fjell, A. M., Reinvang, I., Lundervold, A., Dale, A. M., Eilertsen, D. E., Quinn, B. T., Salat, D., Makris, N., and Fischl, B. (2005). Effects of age on volumes of cortex, white matter and subcortical structures. Neurobiology of aging, 26(9):1261–1270.
- Wu and Feng, (2023) Wu, S. and Feng, L. (2023). Sparse kronecker product decomposition: a general framework of signal region detection in image regression. Journal of the Royal Statistical Society Series B: Statistical Methodology, 85(3):783–809.
- Xia et al., (2022) Xia, T., Sanchez, P., Qin, C., and Tsaftaris, S. A. (2022). Adversarial counterfactual augmentation: application in alzheimer’s disease classification. Frontiers in radiology, 2:1039160.
- Yarotsky, (2017) Yarotsky, D. (2017). Error bounds for approximations with deep relu networks. Neural Networks, 94:103–114.
- Yoon et al., (2023) Yoon, J. S., Zhang, C., Suk, H.-I., Guo, J., and Li, X. (2023). Sadm: Sequence-aware diffusion model for longitudinal medical image generation. In International Conference on Information Processing in Medical Imaging, pages 388–400. Springer.
- Zhang et al., (2019) Zhang, H., Goodfellow, I., Metaxas, D., and Odena, A. (2019). Self-attention generative adversarial networks. In International conference on machine learning, pages 7354–7363. PMLR.
- Zhang et al., (2018) Zhang, Z., Liu, Q., and Wang, Y. (2018). Road extraction by deep residual u-net. IEEE Geoscience and Remote Sensing Letters, 15(5):749–753.
- Zhou et al., (2013) Zhou, H., Li, L., and Zhu, H. (2013). Tensor regression with applications in neuroimaging data analysis. Journal of the American Statistical Association, 108(502):540–552.
- Zhou et al., (2021) Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., and Zhang, W. (2021). Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 11106–11115.
- (71) Zhou, X., Jiao, Y., Liu, J., and Huang, J. (2023a). A deep generative approach to conditional sampling. Journal of the American Statistical Association, 118(543):1837–1848.
- (72) Zhou, Y., Shi, C., Li, L., and Yao, Q. (2023b). Testing for the markov property in time series via deep conditional generative learning. arXiv preprint arXiv:2305.19244.
In the supplementary material, we provide proofs in the following order: Theorem 1, Theorem 2, Proposition 3, Example 1, Proposition 5, Proposition 6, Proposition 7, Theorem 8, Theorem 4, Theorem 14, Proposition 10. Moreover, we include three additional lemmas. Furthermore, we present more details on the numerical implementations.
Appendix A Proofs
A.1 Proof of Theorem 1
Proof A.1.
By Lemma 1, we can find a measurable function and random variable such that and . Then define for , we will use mathematical induction to prove that for .
Because the construction of makes , the conclusion is automatically held when .
For , suppose , we will prove that below.
Note that , then . Which means .
Because is independent of and , is independent of , then:
Because , combining the given conditions, we have:
which shows that:
Combining , therefore:
A.2 Proof of Theorem 2
Proof A.2.
We define the measurable function such that:
For , we apply Lemma 1 to and , there exist a measurable function such that:
Let , , then:
Therefore, such function satisfies the condition.
A.3 Proof of Proposition 3
A.4 Proof of Example 1
Proof A.4.
Obviously, for , follows gaussian distribution with mean . Suppose is the covariance matirx of , then the covariance matrices sequence satisfies the following recurrence relationship:
| (78) |
In addition, converges to a symmetric matrix , whose explicit expression is:
In (78), let , we have:
then,
By iteration:
Let . Because is symmetric, there exists an orthogonal matrix , such that:
where with , .
Denote , then:
let , then:
| (79) |
where is a constant.
Let be the density function of , then:
From (79), there exists a constant , such that:
then:
For , if , then:
if :
therefore,
Since , by (79), there exists a constant such that:
hence, for ,
therefore:
where is a constant.
Combining the above results, we have:
A.5 Proof of Proposition 5
A.6 Proof of Proposition 6
Proof A.6.
Then, for :
Therefore, let be an arbitrary integer, we have:
Let , then:
A.7 Proof of Proposition 7
A.8 Proof of Theorem 8
Proof A.8.
By Lemma 17:
After some calculations, we can decompose as:
Where
Then we only need to prove that:
where
Let:
then , and:
| (81) | |||
| (82) |
Let be the Rademacher random variables. For , denote the Rademacher complexity in as:
By Proposition 7, we have:
| (83) |
Fix , define empirical metric in such that:
Let be the -net of , be the covering number of -net, then by Lemma 15:
By assumption, can be bounded by a constant , we have:
By Theorem 12.2 in Anthony and Bartlett, (1999), the covering number can be bounded as:
The shown above is the Pseudo dimension of .
Let , therefore,
By Proposition 6, we have:
Finally, note that , then:
therefore,
A.9 Proof of Theorem 4
A.10 Proof of Theorem 14
A.11 Proof of Proposition 10
Proof A.11.
We first denote and is continuous on by assumption. Let , and in the Theorem 4.3 in Shen et al., (2019), there exists a ReLU network with depth and width , such that
where is the modulus of as defined in Shen et al., (2019). Then by continuity of ,
Similarly, let be continous function on . Setting , and in the Theorem 4.3 in Shen et al., (2019), there exists a ReLU network with depth and width , such that
where is the modulus of as defined in Shen et al., (2019). Let and , by the is continuous and integrable in , we have as . By the definition, can be rephrase as following
Therefore, by the continuity of (since is a differentiable convex function), we have
A.12 Additional lemmas
Lemma 15.
Let be the Rademacher random variables. For any , let . Then:
Proof A.12.
Let , we only need to prove that:
For arbitrary , by Jensen’s inequality:
Because , and , then applying Hoeffding’s inequality, we have:
Therefore,
Let , we have:
Lemma 16.
Suppose Assumption 1 holds. Then for and , the joint density function of and satisfy:
| (84) |
Proof A.13.
Let be the conditional density function of .
For and , the conditional density function of satisfies:
Then, for and , we have:
Combining Assumption 1, we have:
Lemma 17.
Suppose convex function satisfies . If equation (14) holds, then for any density functions and , we have:
| (85) |
Appendix B Implementations
B.1 Simulations
We present here the visualization of , , and of Case 1 in the simulation study.
B.2 The ADNI study
Given two images and , structural similarity index measure (SSIM) is defined as
where , are the mean and variance of pixel values in and respectively. The is the covariance of and . The where denotes the range of pixel values in the image. In the computing of , refers to the pixel range of .
Below are the specifics of the Generator and the Discriminator used in the ADNI study.
Generator: The Generator consists of two component: the Encoder and the Decoder . Initially, a 2D slice is fed into the , which generate an embedding vector of size 130, denoted as . Next we concatenate with age difference vector and use it as the input of . The output of is a generated image with the same dimension of . The structure of Encoder and Decoder are adopted from residual U-net proposed by Zhang et al., (2018).
Discriminator: The Discriminator consists of a encoder part () and a critic part (). At the encoder part, we obtain two latent features: and . Then we consider the combination of , and as the input of the critic , which produce a confident score. The encoder components and resemble the encoder in the generator, while the critic part is adopted from Zhang et al., (2019).
The number of training epochs was set to 500. We use AdamW optimizer Loshchilov and Hutter, (2017) for both networks with a learning rate and weight decay of . The size of mini-batches is set to 12.