ThinTact: Thin Vision-Based Tactile Sensor by Lensless Imaging
Abstract
Vision-based tactile sensors have drawn increasing interest in the robotics community. However, traditional lens-based designs impose minimum thickness constraints on these sensors, limiting their applicability in space-restricted settings. In this paper, we propose ThinTact, a novel lensless vision-based tactile sensor with a sensing field of over 200 mm2 and a thickness of less than 10 mm. ThinTact utilizes the mask-based lensless imaging technique to map the contact information to CMOS signals. To ensure real-time tactile sensing, we propose a real-time lensless reconstruction algorithm that leverages a frequency-spatial-domain joint filter based on discrete cosine transform (DCT). This algorithm achieves computation significantly faster than existing optimization-based methods. Additionally, to improve the sensing quality, we develop a mask optimization method based on the generic algorithm and the corresponding system matrix calibration algorithm. We evaluate the performance of our proposed lensless reconstruction and tactile sensing through qualitative and quantitative experiments. Furthermore, we demonstrate ThinTact’s practical applicability in diverse applications, including texture recognition and contact-rich object manipulation.
Index Terms:
Tactile sensing, lensless imaging, mask optimization, real-time reconstructionI Introduction
Tactile sensing plays a crucial role in robot manipulation by providing necessary contact information [1, 2, 3, 4]. Vision-based tactile sensors transform the contact properties into images and have the advantages of high spatial resolution, low fabrication cost, and compatibility with learning-based computer vision techniques [5, 6]. Utilizing vision-based tactile sensors, successful examples of robot manipulation are emerging [1, 2, 7, 8].
However, in most unstructured environments where tactile sensing is necessary, objects or devices are typically designed for human use. As a result, they are well suited to the dimensions of human fingertips, which generally range from 15 to 20 mm in diameter. This poses significant challenges for vision-based tactile sensors because most of them use lens systems for image capturing, whose thickness is constrained by the minimum focusing distance [9, 10, 11]. This constraint significantly limits the potential applications of tactile sensors, such as parallel gripper grasping in cluttered scenarios, manipulating daily objects and integration with multi-finger hands.

In this work, we aim to overcome the thickness constraint by eliminating the dependence of lens system. We propose ThinTact, a novel vision-based tactile sensor with a thickness of 9.6 mm, which utilizes the amplitude-mask-based lensless imaging technique to map the contact information to CMOS signals. Fig. 1 shows the sensor and its capabilities. Due to our use of the lensless imaging technique, the CMOS signal does not present a clear RGB image. For utilization, we first reconstruct the RGB image from the CMOS signal and then compute the contact geometry and marker displacements. Our sensor has high sensitivity, enabling it to reconstruct the detailed geometries of different textures and detect small contact forces during object grasping. Its thin profile also enables contact-rich object manipulation in confined spaces.
Incorporating lensless imaging into tactile sensors presents unique challenges. Firstly, lensless imaging requires a computational algorithm to reconstruct a clear image of the scene. The need for computational efficiency in closed-loop and reactive control of robot manipulation makes existing optimization-based approaches inapplicable. To address this, we propose a real-time lensless reconstruction algorithm. This algorithm employs a frequency-spatial-domain joint filter based on the Discrete Cosine Transform (DCT) to separate components in captured measurement images and reconstructs the scene using an analytical solution. The entire computation time is less than 2 ms, significantly faster than optimization-based methods [12]. Secondly, constructing a thin tactile sensor with a large sensing field necessitates that the distance between the scene and the CMOS image sensor is smaller than the CMOS size, which is rare in most lensless applications. This makes traditional Maximum-Length-Sequence-based (MLS-based) masks [13] unsuitable for the proposed sensor. To overcome this, we propose a mask optimization method based on fast lensless imaging simulation and the genetic algorithm (GA). The optimized mask yields reconstructed images with improved uniformity and quality compared to those based on MLS. Additionally, we propose a corresponding calibration algorithm for the optimized mask. Lastly, we employ the Real2Sim method [14] on ThinTact to improve ThinTact’s surface deformation measurement accuracy.
To validate the effectiveness of ThinTact, we first characterize the resolution of ThinTact’s tactile image. Secondly, we evaluate the surface deformation measurement accuracy quantitatively. Lastly, we demonstrate the practicability of ThinTact in many applications, including texture recognition, grasping of delicate objects and contact-rich object manipulation in confined spaces.
In summary, the contributions of this work are as follows:
-
1.
We propose a novel lensless vision-based tactile sensor design, which overcomes the thickness constraint imposed by the lens system and achieves 9.6 mm thickness.
-
2.
We propose a real-time lensless reconstruction algorithm, which is significantly faster than optimization-based counterparts.
-
3.
We propose a mask optimization which improves the reconstruction quality. Correspondingly, we design a calibration algorithm to compute system matrices of the optimized mask.
-
4.
We conduct qualitative and quantitative experiments to validate the effectiveness of our proposed method and demonstrate the usefulness of our tactile sensor in various robot tasks.
The remainder of this article is structured as follows. Section II reviews the relevant literature on tactile sensors and lensless imaging. Section III describes the design of the proposed tactile sensor and the methodology for image reconstruction and tactile sensing. Section IV presents the detailed fabrication process of the sensor. Section V evaluates the performance of the lensless imaging subsystem, and Section VI demonstrates the capabilities of the tactile sensor. Section VII examines the proposed tactile sensor’s practicability in various robot applications. Finally, Section VIII concludes this work.
II Related Work
II-A Vision-Based Tactile Sensing
Tactile sensing has been increasingly applied in robot manipulation, especially for contact-rich scenarios [15]. According to Wang et al.’s review [16], tactile sensors’ principle can be categorized into the following modes: resistive, capacitive, piezoelectric, frictional, and optical mechanisms. Vision-based tactile sensors, a type of sensor that operates on optical mechanisms, have recently attracted significant attention. Their advantages lie in their superior spatial resolution, robustness against electromagnetic interference, cost-effectiveness, and the ability to capture rich contact information including simultaneous measurement of normal and tangential forces [5, 6]. The GelSight sensor represents a notable example of vision-based tactile sensors [17, 9, 18, 19]. It captures high-resolution color images of the deformed elastomer surface which is illuminated from various angles. These images provide rich information of the contact surface, including 3D geometries and deformation. Aside from GelSight, there are other vision-based tactile sensors which can also provide rich contact information [20, 10, 21, 22]. However, the common limitation of these vision-based tactile sensors is their large thickness and volume, which restricts the application in cluttered scenes and integration with dexterous grippers.
II-B Compact Tactile Sensor Design
To address the aforementioned issue, compact tactile sensors have been developed. A common approach involves the use of mirrors to fold the optical path, as seen in systems like GelSlim [23] and GelSight Wedge [24]. However, despite that the camera is relocated, constraints in sensor integration persist due to the considerable scene-to-CMOS distance. Several studies have comprehensively designed robotic fingers or grippers with tactile sensing [25, 26, 27, 28, 29]. These designs allocate substantial space for optical transmission. Consequently, altering their form factor for integration into other robotic components poses a significant challenge. Other works have developed sensors based on small-sized cameras [30] or wide-angle cameras [19] and achieve impressive results. However, the resulting thickness still exceeds that of human fingers. In summary, none of these sensors have a thickness of less than 20 mm, making it challenging to achieve human-level dexterity.
Recently, several vision-based tactile sensors have adopted multi-lens imaging systems instead of the traditional single-lens models [31, 32, 33, 34, 35]. Despite the flexibility offered by multi-lens systems, most of them still possess a bulky size. Therefore, our focus is on the work of Chen et al. [35], who proposed a tactile sensor with only 5 mm thickness. The sensor utilizes microfabricated micro-lens arrays (MLA) for imaging. However, each micro-lens still adheres to the constraints of object distance, image distance, and magnification ratio, leading to overlapping sub-image areas and a low utilization rate of the image sensor. Additionally, the process of fabricating the MLA and preventing crosstalk introduces higher manufacturing costs.
In this work, we propose a novel, compact, vision-based tactile sensor that utilizes lensless imaging principles. This approach eliminates the constraints in traditional imaging systems and results in a sensor with a thickness of less than 10 mm and a sensing field of over 200 mm2. By employing a simple binary mask composed of a glass substrate and a thin chrome film, our sensor offers ease of manufacturing and cost-effectiveness.
II-C Lensless Imaging
In a lensless camera, an optical encoder replaces the traditional lens to encode scene information into sensor measurements. The scene is later recovered using appropriate algorithms. We refer to [36] for a comprehensive review of lensless imaging. In the context of tactile sensing, the appealing advantages of lensless imaging include reduced camera size and large field of view (FOV), because lensless imaging breaks the constraint between working distance and FOV in traditional lens-based imaging.
Designing a lensless imaging system is a systematic task, as the imaging conditions, the choice and design of the optical encoder, the reconstruction algorithm, are closely coupled. To make lensless imaging applicable in tactile sensing, several issues must be addressed. Firstly, the computational burden should be minimized to ensure real-time measurement. Secondly, to design a tactile sensor with a large sensing area and low thickness, the scene-to-CMOS distance is smaller than the CMOS size, which is uncommon in traditional lensless imaging applications.
With these considerations in mind, we delve into the field of lensless imaging. One method to reduce the computational burden is to use a convolutional imaging model, such as DiffuserCam [37] and PhlatCam [38]. This method requires the point spread function (PSF) to be spatially invariant across the entire scene. However, this assumption does not hold when the scene-to-CMOS distance is smaller than the CMOS size. Although [39] proposed a model to account for this situation, it cannot be solved efficiently in real time. Another method to realize real-time reconstruction is to use a separable amplitude mask, known as FlatCam [13]. Adams et al. have extended FlatCam to close-up imaging situations [12], but the corresponding imaging model cannot be solved analytically and efficiently. In this work, we adopt the separable amplitude mask and propose a novel filter to decompose the sensor measurements and obtain the coding component, enabling efficient real-time scene reconstruction. It is noteworthy that recent studies have suggested the application of deep neural networks for lensless image reconstruction [40, 41, 42, 43]. However, in the context of compact tactile sensors, it is difficult to gather scene-measurement-paired datasets for training. Furthermore, these learning-based methods often encounter hallucination artifacts that lack high-fidelity [41]. Therefore, in this work, we have designed the proposed filter based on mathematical and physical properties. This approach not only ensures its generalizability but also guarantees a lower computational burden compared to deep neural networks.
III Methodology
To address the inherent thickness limitations of lens-based imaging systems in existing vision-based tactile sensors, we present a novel tactile sensor called ThinTact. Our proposed approach leverages lensless imaging techniques to capture and map contact information into CMOS signals. In the left part of Fig. 2, we illustrate the design of our tactile sensor. It consists of a transparent elastomer covered by a reflective membrane, a separable amplitude mask, a CMOS sensor and LEDs of different colors. Light emitted from the LEDs is reflected on the membrane, constructing a colored 2D “scene” . Subsequently, the light transports through the mask and reaches the CMOS, forming a measured RGB image . In lensless imaging, the R, G and B channels can be handled separately, therefore in next discussions we neglect the channel dimension for simplicity, i.e., , .
Fig. 2 illustrates the workflow of ThinTact. When an object comes into contact with the sensor, the sensing surface deforms, which leads to the change of the scene and the measurement . We first describe the lensless imaging model that transforms into in Sec. III-A. In order to reconstruct from efficiently in real time, we propose a novel non-iterative reconstruction algorithm (Sec. III-B), which is approximately 1000 times faster than the optimization-based reconstruction algorithm [12]. However, we observed that our proposed algorithm’s reconstruction quality deteriorates for typical separable masks [13], when the distance between the scene and the CMOS is small. As our sensor operates under such conditions, we address this issue by presenting a mask pattern optimization algorithm (Sec. III-C). The calibration process of the lensless system matrices is presented in Sec. III-D. Once the scene is reconstructed, the surface deformation can be computed by photometric stereo and marker tracking (Sec. III-E).
III-A Lensless Imaging Model
In this work, we choose to use a 2D separable amplitude mask as the coded aperture, which has the advantage of better computational efficiency and lower fabrication cost. The binary mask pattern is constructed by:
| (1) |
where are two vectors, each entry of which is either -1 or +1. In this work, we assume . An example of the separable mask is shown in Fig. 2.
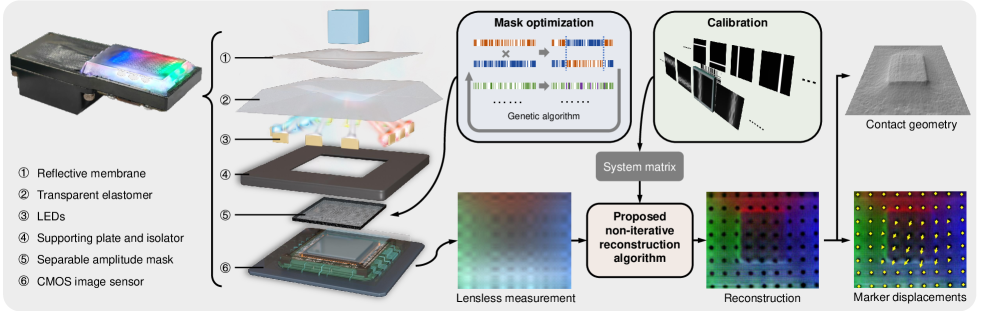
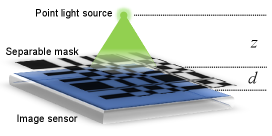
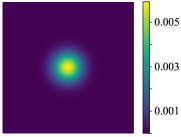
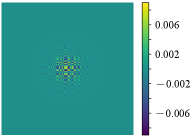
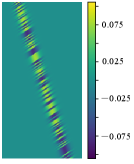
Due to the limited thickness of our proposed tactile sensor, the distance between the scene and the CMOS sensor is small. Consider a point light source present in the scene (Fig. 3). The light source casts a portion of the mask pattern onto the CMOS (Fig. 3), which is referred to as the Point Spread Function (PSF). The PSF can be decomposed into two components: The first component (Fig. 3) corresponds to the term in the mask. This component approximates the response of the CMOS when it is exposed to an “open” mask, i.e., a mask without any apertures. The second component (Fig. 3) corresponds to the term in the mask. This component represents the coding effect of the mask and captures the features introduced by the mask pattern.
Because the measurement is a superposition of the PSFs of all the points in the scene , the imaging model can be expressed as
| (2) |
where , , and are the system matrices, and the subscripts “o” and “c” denote “open” and “coding”, respectively. We present some typical system matrices in Fig. 3 and Fig. 3. This model is known as the Texas Two-Step (T2S) model [12].

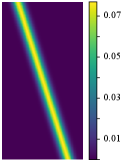
Given the imaging model, the scene can be reconstructed by solving the following optimization problem:
| (3) |
where is the regularization coefficient. Unfortunately, there are no computationally feasible analytical solutions at present. Instead, it can be solved using iterative methods, such as Nesterov gradient method [44] as introduced in [12], whose time consumption typically ranges from a fraction of a second to a few seconds on GPU, which makes it inapplicable in tactile sensing. To address this issue, in the next subsection, we propose a non-iterative reconstruction algorithm to greatly decrease the computational time and enable real-time image reconstruction.
III-B Non-Iterative Real-Time Lensless Image Reconstruction
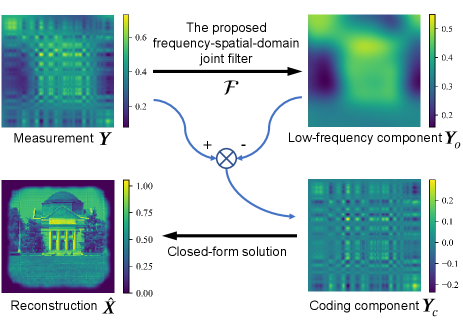
In this section, we propose a non-iterative real-time reconstruction algorithm. It first utilizes a frequency-spatial-domain joint filter to remove the term. The remaining term is then solved analytically. Fig. 4 shows the proposed algorithm.
III-B1 Frequency-spatial-domain joint filter
In contrast to the T2S model, the imaging model in [13] can be solved analytically. However, the reduced model is only applicable to situations with large scene-to-CMOS distances and cannot be used for scene reconstruction in our tactile sensor. The key of the proposed method is a filter which obtains the low-frequency component from the measurement so that the coding component can be obtained by subtraction:
| (4) | ||||
| (5) |
where denotes and denotes . From the mapping ’s effect we know that it is linear, and therefore we should design a linear filter to ensure generalizability.
To design , we look into its physical characteristics. As previously discussed in Sec. III-A, the term approximates the response in the absence of a mask, while the term reflects the modulation introduced by the mask. Consequently, primarily contains low-frequency components. On the other hand, although mainly contains high-frequency components, it also includes low-frequency components. These can intermingle with , with the mixture ratio varying spatially and determined by the mask. Therefore, the design of the filter should take into account both the frequency and spatial domains.
Based on the above discussion, we design the following two basic units to form a frequency-spatial-domain joint filter. The frequency-domain filter unit is:
| (6) |
The spatial-domain filter unit is:
| (7) |
where is the parameter matrix of the frequency-domain filter, and stand for Discrete Cosine Transform (DCT) and its inverse transform, is element-wise product; is the parameter matrix of the spatial-domain filter. DCT is widely adopted in image and video compression, and is known for its excellent energy compaction [45]. We also empirically find that DCT performs better than Discrete Fourier Transform (DFT) in this case.
By cascading them together, we obtain the proposed frequency-spatial-domain joint linear filter:
| (8) |
Theoretically, when the arrangement of a separable-mask-based lensless imaging system is determined, the four system matrices , , and are also determined correspondingly and can be obtained through calibration, thereby determining the filter parameters and . However, in practice, it is difficult to obtain the filter parameters through the system matrices analytically. Therefore, this paper uses the system matrices and multiple scene images to generate a virtual dataset, and performs gradient descent training on the proposed filter to obtain optimal and .
III-B2 The closed-form solution of the scene
Using the previously introduced filter, we obtain the coding component . Then, the reconstruction of the scene can be calculated using a closed-form solution [13]. Here we briefly provide the solution. For detailed derivation, please refer to [13].
Reconstruction of the scene is formulated as the following optimization problem:
| (9) |
which can be solved by differentiating it and letting the gradient be zero:
| (10) |
To solve (10), first calculate the Singular Value Decomposition (SVD) of , : , , and use and to denote the vectors formed by the diagonal elements of and . The final solution can be written as
| (11) |
where is element-wise division of matrices. Note that only is obtained from from the image sensor in real time, while all other matrices can be calculated in advance. Therefore, fast reconstruction is possible using this closed-form solution.
III-C Mask Pattern Optimization
In existing separable-mask-based lensless imaging systems, masks are typically designed based on vectors with specific mathematical properties, such as MLS [13]. The advantage of MLS is that, the transfer matrix of the mask it forms will have large and slowly-decaying singular values, which is beneficial for image reconstruction. However, when the scene is close to the CMOS sensor, the system matrices begin to exhibit difference properties because the PSF only covers a small area. This change can result in reconstructed scenes suffering from nonuniform intensity or low Signal-to-Noise Ratio (SNR). To this end, we propose to generate the optimal mask pattern for such scenario using the genetic algorithm. Since the time consumption of the genetic algorithm largely depends on the time of each generation, we develop a method that directly generates corresponding system matrices from the vector, which significantly accelerates the optimization process.
III-C1 Mask optimization using genetic algorithm
Given the assumption of mask symmetry in our work, the objective of mask optimization is to search for the optimal vector . Since each element of the vector is binary, we choose the genetic algorithm [46] to solve the mask optimization problem. Here we present some critical design choices:
Definition of genes. The vector naturally becomes the gene. During optimization, the length of is fixed to be and each of its element can be 1 or -1.
The crossover operator. When performing crossover, we randomly select two corresponding loci on two gene sequences, and then exchange the gene fragments between the two loci.
The mutation operator. When performing mutation, we randomly select loci on the gene sequence, and then invert them. The value of is determined based on the length of the gene.
The fitness function. We use the quality of the simulated reconstructed image as the fitness function. For a certain ground truth scene image , because our proposed reconstruction algorithm does not rely on the low-frequency component , its simulated measurement image under the mask corresponding to the gene can be calculated as:
| (12) |
where and are the system matrices generated from the gene and is the pixel-wise noise. The method for directly generating the system matrices will be described in the following subsection. The next step is to use (11) to reconstruct the scene from and obtain the simulated reconstructed image . Because a regularization coefficient is introduced when calculating the reconstructed image, the noise resistance of the system matrix can be judged by the quality of the reconstructed image. Two commonly used indicators in image quantitative evaluation indicators - Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM) - are used to evaluate the quality of the reconstructed image,
| (13) | ||||
| (14) |
In order to avoid the nonuniform intensity phenomenon in the reconstructed image, an additional gradient-based evaluation indicator is added for the reconstruction of a pure white image :
| (15) | ||||
where and represent the gradient matrix in both directions. The selection of specific parameters will be introduced in the experiment section.
III-C2 Direct generation of system matrices
[41] introduced a method to generate randomized system matrices for network training, as shown in Fig. 5. However, it cannot accommodate the imaging scenarios in our tactile sensor, and the values in the generated system matrix are randomized and thus cannot be used for simulation. In this work, we first extend the method to accommodate close-up imaging situations. Second, we ensure that the values in the generated system matrices are physically reasonable, enabling us to directly simulate the reconstructed scenes.

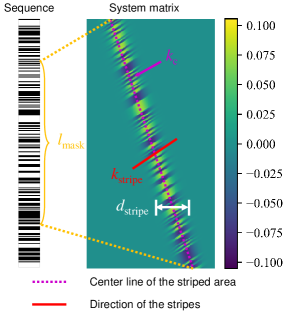
Without loss of generalizability, we take as an example to explain the properties of the system matrices in separable-mask-based lensless imaging. As shown in Fig. 5, a vector to form the separable mask and the corresponding system matrix are shown. An important characteristic of the system matrix is the gradual fading of the striped area at its boundary, rather than covering the entire matrix. This unique aspect distinguishes the close-up imaging scenario. The fading effect is attributed to the limited response of each CMOS pixel when the light source is close to the CMOS. To approximate this fading effect in practice, we employ a sigmoid function. The width of the striped area, denoted as , is experimentally determined to align with the actual system matrix. For other important parameters, as shown in Fig. 5, let denote the slope of the center line of the stripe area, denote the slope of the direction of stripes and denote the effective physical length of the mask, corresponding to the center line in the system matrix. These values can be calculated as:
| (16) | ||||
| (17) | ||||
| (18) |
where is the pixel spacing of the image sensor, is the pixel size of the reconstructed scene, is the mask-to-CMOS distance, is the scene-to-mask distance, is the height of the measurement image for . After obtaining the above relations, we can use affine transformation to generate system matrices based on the vectors that form the mask pattern.
III-D Calibration of Lensless System Matrices
The objective of calibration is to obtain the system matrices , , and . In [12], since the MLS vector satisfies , the corresponding columns of and are orthogonal. Thus, an SVD-based calibration method is adopted.
In our case, because our mask is optimized through the genetic algorithm and does not have such constraint, the calibration algorithm in [12] is not applicable. This section presents our calibration algorithm.
III-D1 Collection of calibration images
The calibration images are the measurement images of a scanning horizontal slit and a scanning vertical slit, which are the same as [12]. Take the measurement images of a scanning horizontal slit as an example. A horizontal slit is a scene of which only the th row is activated, i.e., , where is a column vector of zeros with only the th element to be 1. The corresponding measurement image can be written as
| (19) | ||||
where and are the th columns of and , respectively, and and are the sums of rows of and , respectively. Note that and remain constant when changes. This property is important for the calibration algorithm. For a scanning vertical slit, we also obtain
| (20) |
where and are the th columns of and , respectively, and and are the sums of rows of and , respectively.
III-D2 Algorithm to obtain the system matrices
Because and are not necessarily orthogonal in our case, we cannot use SVD to decompose and compute , , and . Instead, we employ an iterative approach to solve the system matrices. From the definition of , , the sums of rows of and nearly maintain a constant value, as shown in Fig. 3. Conversely, the sums of rows of and exhibit varying values, as shown in Fig. 3. This property allows us to generate initial estimates for and , and then use these estimates to progressively solve each column of the system matrices. This process is repeated iteratively to achieve the final calibration results. The full calibration algorithm consists of Algorithm 1, 2 and 3, which are introduced as follows:
Algorithm 1 calculates and given a list of calibration images and , . Note that when this algorithm is used to calculate , , the input calibration images are the horizontal ones . It can also be used to get and , simply by transposing all the vertical calibration images to .
Then, we define Algorithm 2 to generate the initial estimates of the system matrices. We first assume and get the initial . From the calibration image , we can get the estimate of , and then obtain the initial . We use because the slit is positioned at the vertical center of the scene, and therefore its emitted light should mostly be captured by the CMOS sensor, making it easier to estimate . After , are obtained, we call Algorithm 1 to get the initial and .
Once the initial estimates of all system matrices are ready, we can progressively refine the system matrices, as shown in Algorithm 3. In each iteration, the system matrices are scaled to have equal Frobenius norms to avoid divergence.
III-E Interpretation of Tactile Information
In this subsection, we introduce the method for reconstructing the contact geometry (i.e., the depth map) from the reconstructed tactile images. Further, we adopt a Real2Sim method to transfer the real tactile images into the simulation domain to improve the depth reconstruction quality. Finally, we introduce the method for interpreting marker displacements.
Reconstruction of contact geometry. In the proposed design of the tactile sensor, the contact geometry is reconstructed using the photometric stereo method [47, 9]. The key idea of photometric stereo is to map the surface gradient into color intensities, and then the depth map can be computed using the Poisson equation. Typically, the mapping from color intensities to gradient values can be modelled in two ways: using a Look-Up Table (LUT) [9] or using a neural network [48, 24]. In this work, we adopt the LUT method.
Real2Sim method for improving depth reconstruction. In real sensors, several non-ideal properties can impact the accuracy of photometric stereo, such as non-uniform illumination, inter-reflections, shadows and artifacts existing in lensless reconstruction. To address these issues, we employ a Real2Sim transfer method based on CycleGAN [49] to mitigate the non-ideal factors present in reality. This method has been validated on standard GelSight sensors in our previous work [14]. In the experiment section, we will demonstrate that this method is also applicable to the proposed tactile sensor.
Interpreting marker displacements. Markers are frequently employed in vision-based tactile sensors to detect shear deformation and forces. In order to interpret the displacements of these markers, we establish a correspondence between consecutive frames by applying marker detection and the nearest-neighbor algorithm. By cascading this correspondence, we can obtain the current marker displacements relative to the initial reference frame. The displacement fields derived from the markers can then be leveraged for manipulation tasks.
IV Experiment: Sensor Fabrication
In Sec. III and Fig. 2, we present the conceptual design of ThinTact. In this section, the detailed fabrication process of ThinTact will be introduced.
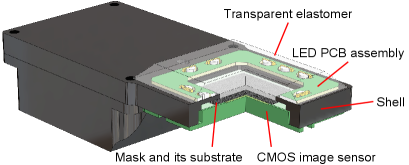
Fig. 6 presents the CAD model of ThinTact without the reflective membrane. To fabricate ThinTact, we start with constructing the lensless imaging subsystem. It comprises the following steps:
-
(1)
Prepare the sensor shell. The shell is made of aluminum alloy through CNC machining, which is shown in black in Fig. 6.
-
(2)
Place the separable amplitude mask. The mask pattern is created using a thin chrome film on a 1-mm-thick piece of soda glass. The feature size of the mask , which equals the unit size of the mask pattern, is 20 µm.
-
(3)
Install the CMOS sensor. Beneath the mask is the CMOS sensor, which is fixed to the sensor shell by screws. We have modified a JAI GO-5000C-USB industrial camera to construct our lensless camera. The GO-5000C-USB camera has a 1” optical format and a resolution of 25602048. To reduce the amount of data, we do not perform demosaicing on the raw image. Instead, we extract the red, blue pixels respectively, and average the two green pixels in each Bayer filter unit to form a 3-channel, 12801024 image.
-
(4)
Attach the LED PCB assembly. The LEDs provide illumination of different colors from different directions, which is required by Photometric Stereo. We use 10 side-illuminating LEDs and place them around the mask, as shown in Fig. 6. Their colors are red, green, blue, and white, respectively.
-
(5)
Cast the transparent elastomer. Following DIGIT [30], we use Smooth-On Solaris silicone rubber as the elastomer’s material. The elastomer is directly cast onto the shell, the soda glass and the LED PCB assembly, using a CNC-machined aluminum mold. The thickness of the elastomer is 3 mm.
After constructing the lensless imaging subsystem, we perform calibration to obtain the system matrices and conduct experiments to validate its performance, which will be presented in Sec. V. Later, we complete ThinTact’s fabrication by sequentially applying thin layers of opaque elastomer and laser-cutting the markers. The details are as follows:

-
(1)
Prepare white and black paint mixtures. We follow the process of DIGIT [30] for this step. Firstly, we mix an equal part A/B solution of Smooth-On EcoFlex 00-10. Then, we add Smooth-On White (Black) Silicone Pigment such that it is 3% of the total weight of the previous mixture. Finally, we thin out the mixture to 20% of the total weight using Smooth-On NOVOCS Matte.
-
(2)
Apply the white paint mixture. We use an air brush to spray the white paint mixture onto the transparent elastomer’s surface and form a thin layer.
-
(3)
Laser-cut the markers. We use a laser-cutting machine to form small holes on the white layer. The diameter of the holes is 0.5 mm. The holes have a 1.5 mm spacing.
-
(4)
Apply the black paint mixture. We use another air brush to spray the black paint mixture onto the surface. It provides the black color for the markers and eliminates the influence of environmental light.
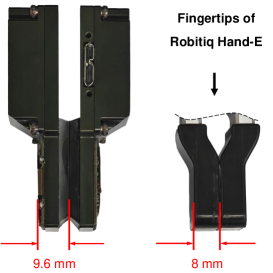
After all the fabrication process is completed, the sensor is shown in Fig. 7. Fig. 7 presents the thickness of ThinTact and compares it with the fingertips of Robotiq Hand-E. Despite providing a sensing field of over 200 mm2, ThinTact maintains a slim profile. At only 9.6 mm thick, it is slightly thicker than a typical robotic fingertip and thinner than human fingers.
V Experiment: Lensless Imaging Subsystem
V-A Configuration of ThinTact’s Lensless Imaging Subsystem
The fabrication of the lensless imaging subsystem has been introduced in Sec. IV. Lensless imaging experiments are conducted before the transparent elastomer is covered with the refractive membrane. The calibration setup is shown in Fig. 8. The calibration images are displayed using a 5.5” 38402160 LCD monitor, which is tightly attached to the transparent elastomer. The pixel size of the monitor is 31.5 µm, and therefore the pixel size of the reconstructed image is also 31.5 µm. The resolution of the reconstructed images is determined to be 512400, which corresponds to an area of 16.112.6 mm2. The key technical specifications of the lensless imaging system are summarized in Table I.


| Name | Value |
|---|---|
| CMOS resolution | 25602048 |
| CMOS pixel size | 5 µm |
| CMOS size | 12.8 mm10.24 mm |
| measurement resolution | 12801024 |
| effective pixel size of measurement | 10 µm |
| reconstruction resolution | 512400 |
| pixel size of reconstruction | 31.5 µm |
| area size of reconstruction | 16.1 mm12.6 mm |
| mask feature size | 20 µm |
| scene-to-mask distance (estimated) | 4.8 mm |
| mask-to-CMOS distance (estimated) | 1 mm |
V-B Comparison of the Optimized Mask and the MLS-based Mask



To generate an optimized mask, the vector ’s length is set to 770. We run the genetic algorithm with 2000 generations and 200 individuals in each generation. The crossover and mutation probability are set to be 0.8 and 0.1, respectively. In each mutation operation, 10 random loci in are inverted. To evaluate each individual’s fitness, we choose the pure white image (the 1st row in Fig. 9) and the reshaped USAF test image (the 3rd row in Fig. 9), and the fitness score of gene is calculated as:
| (21) | ||||
Finally, the individual with the highest fitness score is selected. The corresponding optimized mask pattern is shown in Fig. 10. It covers an area of 15.415.4 mm2, sufficient to overlay the full extent of the CMOS underneath.
For comparison, we choose the MLS-based mask in [13] as the baseline. We use a 255-length MLS and repeat it 3 times to be a 765-length sequence. Then, we use (1) to form a 15.315.3 mm2 mask (Fig. 10), as the baseline.
The experimental setup is the same as the calibration setup introduced in V-A, as shown in Fig. 8. The ground-truth images are displayed on the monitor, and the measurement images are obtained by averaging 100 frames from the CMOS. SSIM and PSNR are used as the quantitative metrics to evaluate the reconstruction quality.
In Fig. 9, we present the comparison results. Fig. 9 presents three representative scenes. From qualitative comparison and quantitative metrics, we draw the conclusion that our proposed algorithm has largely improved the reconstruction qualities compared with the MLS-based mask, especially in terms of uniformity. Another significant advantage is the larger usable FOV provided by the optimized mask. The reason is as follows: In lensless imaging, a point at the FOV boundary only casts a small PSF area on the CMOS. With the MLS-based mask, the CMOS collects minimal information about these boundary points, resulting in decaying intensities in the reconstructed images’s boundary due to the regularization term in (9). In contrast, the optimized mask takes this factor into account, leading to a larger usable FOV. These advantages will considerably enhance subsequent tactile sensing.
V-C Comparison of Lensless Reconstruction Algorithms
A reconstruction algorithm with high computational efficiency and good quality is crucial in the application of tactile sensing. Therefore, we conduct experiments to compare the proposed non-iterative reconstruction and the traditional optimization-based reconstruction algorithm. Specifically, for the optimization-based reconstruction algorithm, we use Nesterov gradient method to solve (3).
In Fig. 11, we present the comparison results of two representative scenes. From qualitative comparison and quantitative metrics, we draw the conclusion that our proposed algorithm has reconstruction qualities similar to the traditional optimization-based method.
We further compare the reconstruction speed by computing the average time of reconstructing 100 images. For the optimization-based method, we have tuned the parameters so that it only takes 800 iterations to converge. Both algorithms are implemented in PyTorch. We used a NVIDIA RTX 3080 Ti GPU and an Intel Core i7-13700K CPU for the experiment. Table II summarizes the results, which clearly reveals that the proposed algorithm is about 3 orders of magnitude faster than the optimization-based counterpart. Our algorithm can achieve real-time reconstruction up to hundreds of frames per second on a desktop GPU, providing enough efficiency for most robotic tactile applications.
| Reconstruction algorithm | CPU time (s) | GPU time (s) |
|---|---|---|
| The optimization-based method [12] | 46.1 | 2.01 |
| The proposed non-iterative method | 0.0585 | 0.00150 |
VI Experiment: Tactile Sensor Performance
In this section, we first compare the compactness of ThinTact with several typical vision-based tactile sensors with straight optical paths in Sec.VI-A. Sec. VI-B discusses the sensor’s lateral resolution. ThinTact utilizes photometric stereo with Real2Sim for depth reconstruction, which is presented in Sec. VI-C. As an application of the high-resolution images, we showcase ThinTact’s capability to recognize fine fabric textures from a single static touch in Sec. VI-D.
VI-A Compactness Comparison
| Imaging principle | Lens-based | Micro-lens-based | Lensless | |||
|---|---|---|---|---|---|---|
| Sensor name | GelSight Mini [50] | GelSlim3.0 [19] | DIGIT [30] | DTact [51] | Chen et al. [35] | ThinTact (ours) |
| Sensing field (mm2) | 18.6×14.3 | 27×25 | 19×16 | 24×24 | 9×8 | 16.1×12.6 |
| Thickness (mm) | 28 | 20 | 28* | 45* | 5 | 9.6 |
| Scene-to-CMOS distance (mm) | 21 | 17* | 18* | 40* | 4** | 5.8 |
| 0.34 | 1.69 | 0.39 | 0.28 | 2.88 | 2.20 | |
| 0.60 | 2.34 | 0.94 | 0.36 | 4.50 | 6.03 | |
-
•
* measured from CAD models
-
•
** estimated by assuming its CMOS PCB assembly is 1 mm thick
In Table III, we present a comparison of several typical vision-based tactile sensors with straight optical paths. We introduce a dimensionless metric, which is the sensing area divided by the square of the thickness, to quantify the compactness of the sensor. The table considers two types of thickness: the actual physical thickness of the sensor and the scene-to-CMOS distance which signifies the minimal possible thickness. The table reveals that the majority of vision-based tactile sensors possess a thickness exceeding 20 mm. However, ThinTact and the MLA-based sensor manage to maintain a thickness of less than 10 mm. In terms of the compactness metric, both ThinTact and the MLA-based sensor significantly outperform the others. It’s important to note that the CMOS we utilized has a thickness of over 4 mm, which contributes to the relatively larger physical thickness of ThinTact. Nonetheless, when considering the scene-to-CMOS distance, ThinTact still holds an advantage over the MLA-based sensor.
VI-B Lateral Resolution
Vision-based tactile sensors are widely recognized for their superior resolution in comparison to tactile sensors using other sensing principles. Typically, the resolution referred to in this context is the lateral resolution, which bears a close relation to the high resolution of the CMOS image sensor. In this study, tactile images are reconstructed from raw measurements. It’s important to note that the actual resolution might differ from the resolution of the reconstructed images. In this subsection, we characterize ThinTact’s lateral resolution from two aspects.
First, we figure out the optical resolution from the standard resolution test chart. As shown in Fig. 12, the minimum spacing of white rectangles that ThinTact can recognize is about 0.18 mm. Second, we measure the actual tactile resolution by testing its ability to identify small depth fluctuations. As Shown in Fig. 12, a screw is pressed against the sensor and its screw thread can be clearly seen. The screw’s major diameter is 1 mm and its pitch is 0.25 mm (Fig. 12). The reason that the tactile resolution is lower than the optical resolution is due to the presence of the reflect membrane on the sensor surface, which degrades the transmission and detection of fine geometry details. Fig. 12 shows the tactile image from GelSight Mini [50], which has a higher resolution than our tactile sensor. This can be attributed to not only the lens system, but also higher camera resolution, softer elastomer, better illumination, and thinner reflect membrane.




VI-C Depth Accuracy




As mentioned in Sec. III-E, we employ a Real2Sim transfer method to mitigate the non-ideal factors present in reality and improve the depth reconstruction quality.
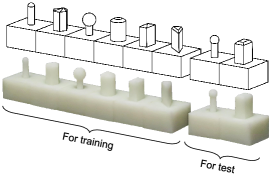
First, we follow [14] to collect the unpaired synthetic and real data. We design 8 indenters with various shapes, as depicted in Fig. 13. For the real dataset, the tactile sensor remains fixed, while an indenter is secured on a 4-DoF stage (3 translational DoF and 1 rotational DoF), as shown in Fig. 13. For each indenter, we randomize its position and rotation, and set its indentation depths to 0.25 mm, 0.50 mm, 0.75 mm, and 1.00 mm, respectively. We collect 50×4=200 images per indenter. For the simulation, we generate the surface depth map by intersecting the indenter mesh with the surface mesh. The depth map is then processed using Gaussian filters to approximate the deformation of the elastomer [52]. Subsequently, we employ Phong’s Shading to generate ideal tactile images that perfectly meet the requirements of photometric stereo. These simulated images are then blended with the background of the real images. For each indenter, we also generate 50×4=200 images with 4 indentation depths, with randomized positions that are not aligned with the real dataset. Several real and simulated images are displayed in Fig. 13.
We use 6 indenters for training CycleGAN and the remaining 2 indenters for test. Calibration of the LUT is performed in advance using a 3 mm sphere indenter, and the calibration procedure is performed separately using real images and the Real2Sim images. We present several Real2Sim tactile images in Fig. 13. As can be seen in the figure, real tactile images suffer from a noisy background and non-uniform illumination. In contrast, the Real2Sim images exhibit more idealness than the real ones. We further evaluate our sensor’s depth reconstruction accuracy quantitatively. To calculate the depth error, we generate the ground-truth depth using simulation and apply thresholding to select the area for error calculation. The depth error is calculated by first calculating the root-mean-squared error of all the pixels in the aforementioned area in each image, and then averaging the errors across all the tactile images. The results are summarized in Table IV. The data shows that direct reconstruction from real tactile images results in a large depth error due to non-ideal conditions. In contrast, the Real2Sim method achieves an error of 0.13 mm and improves the depth accuracy by approximately 60%.
| Indenter name | Indentation depth | Real | Real2Sim |
|---|---|---|---|
| chamfered prism | 0.25 mm | 0.248 mm | 0.065 mm |
| 0.50 mm | 0.341 mm | 0.090 mm | |
| 0.75 mm | 0.407 mm | 0.098 mm | |
| 1.00 mm | 0.447 mm | 0.142 mm | |
| 4 mm sphere | 0.25 mm | 0.262 mm | 0.169 mm |
| 0.50 mm | 0.324 mm | 0.172 mm | |
| 0.75 mm | 0.365 mm | 0.156 mm | |
| 1.00 mm | 0.365 mm | 0.109 mm |
VI-D Fabric Texture Classification
To evaluate the capability of ThinTact to capture fine details, we conduct an experiment of fabric texture classification, where we use a robot arm to press the tactile sensor against various fabric materials. A deep neural network is trained to classify the reconstructed tactile images.
Fabric materials. We select 47 kinds of fabrics for fabric texture classification. These fabrics are composed of diverse materials such as cotton, linen, silk, polyester, spandex, or wool, resulting in nuances of tactile signals. As shown in Fig. 14, ThinTact is able to reconstruct the subtle fabric texture geometries.


Data Collection and Network. To construct the dataset, we collect 100 images for each texture and divide them into three subsets: a training set, a validation set, and a testing set, with a ratio of 6:2:2. As shown in Fig. 15, we affix ThinTact to the end of a ROKAE xMate3-pro robotic arm. Starting from a corner, the arm is programmed to move along horizontal and vertical directions with a step size of 8 mm and rotate 5° on the surface of each fabric sample. The size of each fabric sample is 10 cm 10 cm. The applied pressure remains approximately constant across all fabric samples. After each contact, a measurement image was captured and reconstructed to produce a tactile image with a resolution of .
We use ResNet-50 image classification network [53], and train the network for 100 epochs with a batch size of 64 and a learning rate of 1e-3.
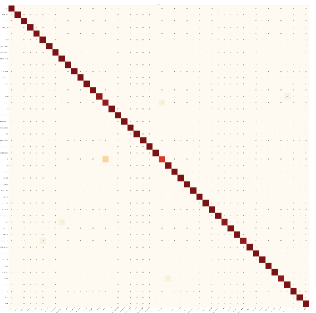
Results and data analysis. The classification precision on the test set is 98.96%. Fig. 15 shows the confusion matrix, where most fabrics have a 100% classification accuracy, demonstrating the sensor’s ability to recognize subtle surface texture features.
VII Application in Manipulation
Tactile sensing offers significant benefits for robots, particularly in terms of the ability to interact with unstructured environments. In these settings, objects and devices are typically designed for human use, and thus, are well-suited to the dimensions of human fingertips, which generally range from 15 to 20 millimeters in diameter. Consequently, tactile sensors with larger dimensions may struggle to accommodate such constrained spaces. In this section, we first present ThinTact’s sensitivity when handling delicate objects, and then present several instances where tactile sensing is essential and space is limited, to prove the advantages of ThinTact. Demonstrations are available in the supplementary video associated with this article.
VII-A Grasping of Delicate Objects


To demonstrate the sensitivity of ThinTact, we conduct experiments to grasp two delicate objects: a 0.5 mm pencil lead and a potato chip. In the experiment, the fingertips of the parallel gripper gradually closes, and the gripper will immediately stop once a tactile sensor detects contact. Fig. 16 shows that these two delicate objects are successfully grasped and lifted by ThinTact. The corresponding tactile images are also shown in Fig. 16. We use a high-precision force sensor (Rtec MFT-5000) with a resolution of 1.5 mN to measure the force applied when the sensor detects contact. The result shows that the force is 0.16 N when a contact is detected, demonstrating the high sensitivity of our proposed tactile sensor.

VII-B Insertion of Test Tubes
Using ThinTact for perception and feedback control, we are able to accomplish tasks such as precisely inserting test tubes into a test tube rack, where the diameter of the tube is 20 mm, the diameter of the hole is 22 mm, the distance between two tubes is only 12 mm, and the clearance of the hole is 1 mm. As shown in Fig.17, we utilize a Robotiq 2F-140 gripper fixed at the end of a ROKAE xMate3-pro robotic arm for grasping. Two ThinTacts are installed on both sides of the gripper.
To simulate the positioning errors from vision perception or human handover, we introduce a random offset to the initial pose of the test tube. When the test tube makes contact with the rack during the placement, we capture the marker displacements from the sensors and fit them to derive the direction of the force exerted on the test tube. Subsequently, we adjust the gripper’s pose in the opposite direction, allowing the test tube to be precisely inserted into the hole. For a detailed demonstration, please refer to the accompanying video.
VII-C Daily Object Manipulation
Grasp a plate. In this experiment, the object of interest is a flat plate with a height of only 16 mm. To grasp such a thin plate, a slim fingertip is required. As depicted in Fig. 18, ThinTact successfully inserts itself into the gap at the edge of the plate. In contrast, GeiSight Mini fails to do so due to its thickness exceeding the height of the plate. While GelSight Wedge [24] can also be inserted into the gap, its insertion depth is limited compared to ours. This limitation is due to the mirror angle, which cannot be further reduced to provide the appropriate reflection into the camera at the bottom. Tactile sensing is employed to determine the plate’s position and trigger the gripping action. The gripper, Robotiq Hand-E, initially moves along the tabletop towards the plate until ThinTact detects contact with the plate. Subsequently, the gripper closes, enabling the robot to lift the plate.



Open the drawer. In this task, the robot is required to locate the drawer’s handle and exert the necessary force to open it. The handle is designed with a downward opening, and the width of this opening is less than 20 mm, suitable for human use. To successfully open the drawer, the direction of contact should be outward to apply the correct forces, as illustrated in Fig. 19. Given these constraints, tactile sensors with a larger thickness, such as GelSight Mini, are unable to accomplish the task (Fig. 19). In contrast, ThinTact first detects contact with the handle through an upward movement, fits into the handle, and ultimately completes the task (Fig. 19).




VIII Discussion and Conclusion
In this work, we present ThinTact, a thin, vision-based tactile sensor with a substantial sensing area, powered by lensless imaging. Our extensive experiments demonstrate its ability to reconstruct contact geometries, recognize textures, and manipulate a variety of everyday objects. It performs comparably to traditional GelSight-type sensors, but with a significantly reduced thickness, making it suitable for integration into robots and use in confined spaces.
Despite the promising results, there are several limitations and directions for future investigation. First, the sensor is not thin enough to fully reveal the advantage of lensless imaging. This may be attributed to that the CMOS we use is over 4 mm thick itself, while current technology is already capable of fabricating large-area CMOS with thickness less than 1 mm, such as the ones used in smartphones. Second, although the part of the sensor beneath the sensing surface is thin, the sensor also has a thicker body part, which makes it currently unsuitable for integration into a dexterous hand. This issue could be addressed by developing customized, small-sized image processing units, or by considering all sensors in a dexterous hand and placing the multi-input image processing unit in an appropriate location. Finally, like other camera-based tactile sensors, ThinTact suffers from a limited sampling rate. To address this, one could consider incorporating other tactile sensing modalities, using high-end, fast CMOS sensors, or exploring event-based image sensors.
References
- [1] F. R. Hogan, J. Ballester, S. Dong, and A. Rodriguez, “Tactile dexterity: Manipulation primitives with tactile feedback,” in 2020 IEEE international conference on robotics and automation (ICRA). IEEE, 2020, pp. 8863–8869.
- [2] Y. She, S. Wang, S. Dong, N. Sunil, A. Rodriguez, and E. Adelson, “Cable manipulation with a tactile-reactive gripper,” The International Journal of Robotics Research, vol. 40, no. 12-14, pp. 1385–1401, 2021.
- [3] Y. Liu, X. Xu, W. Chen, H. Yuan, H. Wang, J. Xu, R. Chen, and L. Yi, “Enhancing generalizable 6d pose tracking of an in-hand object with tactile sensing,” IEEE Robotics and Automation Letters, 2023.
- [4] L. Bian, P. Shi, W. Chen, J. Xu, L. Yi, and R. Chen, “Transtouch: Learning transparent objects depth sensing through sparse touches,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 9566–9573.
- [5] A. Yamaguchi and C. G. Atkeson, “Recent progress in tactile sensing and sensors for robotic manipulation: can we turn tactile sensing into vision?” Advanced Robotics, vol. 33, no. 14, pp. 661–673, 2019.
- [6] S. Zhang, Z. Chen, Y. Gao, W. Wan, J. Shan, H. Xue, F. Sun, Y. Yang, and B. Fang, “Hardware technology of vision-based tactile sensor: A review,” IEEE Sensors Journal, 2022.
- [7] C. Wang, S. Wang, B. Romero, F. Veiga, and E. Adelson, “Swingbot: Learning physical features from in-hand tactile exploration for dynamic swing-up manipulation,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 5633–5640.
- [8] S. Dong, D. K. Jha, D. Romeres, S. Kim, D. Nikovski, and A. Rodriguez, “Tactile-rl for insertion: Generalization to objects of unknown geometry,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 6437–6443.
- [9] W. Yuan, S. Dong, and E. H. Adelson, “Gelsight: High-resolution robot tactile sensors for estimating geometry and force,” Sensors, vol. 17, no. 12, p. 2762, 2017.
- [10] B. Ward-Cherrier, N. Pestell, L. Cramphorn, B. Winstone, M. E. Giannaccini, J. Rossiter, and N. F. Lepora, “The tactip family: Soft optical tactile sensors with 3d-printed biomimetic morphologies,” Soft robotics, vol. 5, no. 2, pp. 216–227, 2018.
- [11] L. Zhang, Y. Wang, and Y. Jiang, “Tac3d: A novel vision-based tactile sensor for measuring forces distribution and estimating friction coefficient distribution,” arXiv preprint arXiv:2202.06211, 2022.
- [12] J. K. Adams, V. Boominathan, B. W. Avants, D. G. Vercosa, F. Ye, R. G. Baraniuk, J. T. Robinson, and A. Veeraraghavan, “Single-frame 3d fluorescence microscopy with ultraminiature lensless flatscope,” Science advances, vol. 3, no. 12, p. e1701548, 2017.
- [13] M. S. Asif, A. Ayremlou, A. Sankaranarayanan, A. Veeraraghavan, and R. G. Baraniuk, “Flatcam: Thin, lensless cameras using coded aperture and computation,” IEEE Transactions on Computational Imaging, vol. 3, no. 3, pp. 384–397, 2016.
- [14] W. Chen, Y. Xu, Z. Chen, P. Zeng, R. Dang, R. Chen, and J. Xu, “Bidirectional sim-to-real transfer for gelsight tactile sensors with cyclegan,” IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 6187–6194, 2022.
- [15] A. Billard and D. Kragic, “Trends and challenges in robot manipulation,” Science, vol. 364, no. 6446, p. eaat8414, 2019.
- [16] C. Wang, L. Dong, D. Peng, and C. Pan, “Tactile sensors for advanced intelligent systems,” Advanced Intelligent Systems, vol. 1, no. 8, p. 1900090, 2019.
- [17] R. Li, R. Platt, W. Yuan, A. Ten Pas, N. Roscup, M. A. Srinivasan, and E. Adelson, “Localization and manipulation of small parts using gelsight tactile sensing,” in 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2014, pp. 3988–3993.
- [18] D. Ma, E. Donlon, S. Dong, and A. Rodriguez, “Dense tactile force estimation using gelslim and inverse fem,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 5418–5424.
- [19] I. H. Taylor, S. Dong, and A. Rodriguez, “Gelslim 3.0: High-resolution measurement of shape, force and slip in a compact tactile-sensing finger,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 10 781–10 787.
- [20] K. Sato, K. Kamiyama, N. Kawakami, and S. Tachi, “Finger-shaped gelforce: sensor for measuring surface traction fields for robotic hand,” IEEE Transactions on Haptics, vol. 3, no. 1, pp. 37–47, 2009.
- [21] C. Sferrazza and R. D’Andrea, “Design, motivation and evaluation of a full-resolution optical tactile sensor,” Sensors, vol. 19, no. 4, p. 928, 2019.
- [22] R. Sui, L. Zhang, T. Li, and Y. Jiang, “Incipient slip detection method with vision-based tactile sensor based on distribution force and deformation,” IEEE Sensors Journal, vol. 21, no. 22, pp. 25 973–25 985, 2021.
- [23] E. Donlon, S. Dong, M. Liu, J. Li, E. Adelson, and A. Rodriguez, “Gelslim: A high-resolution, compact, robust, and calibrated tactile-sensing finger,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 1927–1934.
- [24] S. Wang, Y. She, B. Romero, and E. Adelson, “Gelsight wedge: Measuring high-resolution 3d contact geometry with a compact robot finger,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 6468–6475.
- [25] A. Padmanabha, F. Ebert, S. Tian, R. Calandra, C. Finn, and S. Levine, “Omnitact: A multi-directional high-resolution touch sensor,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 618–624.
- [26] B. Romero, F. Veiga, and E. Adelson, “Soft, round, high resolution tactile fingertip sensors for dexterous robotic manipulation,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 4796–4802.
- [27] D. F. Gomes, Z. Lin, and S. Luo, “Geltip: A finger-shaped optical tactile sensor for robotic manipulation,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 9903–9909.
- [28] H. Sun, K. J. Kuchenbecker, and G. Martius, “A soft thumb-sized vision-based sensor with accurate all-round force perception,” Nature Machine Intelligence, vol. 4, no. 2, pp. 135–145, 2022.
- [29] O. Azulay, N. Curtis, R. Sokolovsky, G. Levitski, D. Slomovik, G. Lilling, and A. Sintov, “Allsight: A low-cost and high-resolution round tactile sensor with zero-shot learning capability,” IEEE Robotics and Automation Letters, vol. 9, no. 1, pp. 483–490, 2023.
- [30] M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V. R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer et al., “Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation,” IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 3838–3845, 2020.
- [31] K. Shimonomura and H. Nakashima, “A combined tactile and proximity sensing employing a compound-eye camera,” in SENSORS, 2013 IEEE. IEEE, 2013, pp. 1–2.
- [32] C. Yu, M. Chen, M. D. I. Reyzabal, J. Back, D. Cao, and H. Liu, “Omsense: An omni tactile sensing principle inspired by compound eyes,” IEEE/ASME Transactions on Mechatronics, 2023.
- [33] L. Song, H. Zhu, Y. Zheng, M. Zhao, C. A. T. Tee, and F. Fang, “Bionic compound eye-inspired high spatial and sensitive tactile sensor,” IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1–8, 2021.
- [34] Y. Zhang, X. Chen, M. Y. Wang, and H. Yu, “Multidimensional tactile sensor with a thin compound eye-inspired imaging system,” Soft Robotics, vol. 9, no. 5, pp. 861–870, 2022.
- [35] X. Chen, G. Zhang, M. Y. Wang, and H. Yu, “A thin format vision-based tactile sensor with a microlens array (mla),” IEEE Sensors Journal, vol. 22, no. 22, pp. 22 069–22 076, 2022.
- [36] V. Boominathan, J. T. Robinson, L. Waller, and A. Veeraraghavan, “Recent advances in lensless imaging,” Optica, vol. 9, no. 1, pp. 1–16, 2022.
- [37] N. Antipa, G. Kuo, R. Heckel, B. Mildenhall, E. Bostan, R. Ng, and L. Waller, “Diffusercam: lensless single-exposure 3d imaging,” Optica, vol. 5, no. 1, pp. 1–9, 2018.
- [38] V. Boominathan, J. K. Adams, J. T. Robinson, and A. Veeraraghavan, “Phlatcam: Designed phase-mask based thin lensless camera,” IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 7, pp. 1618–1629, 2020.
- [39] G. Kuo, F. L. Liu, I. Grossrubatscher, R. Ng, and L. Waller, “On-chip fluorescence microscopy with a random microlens diffuser,” Optics express, vol. 28, no. 6, pp. 8384–8399, 2020.
- [40] K. Monakhova, J. Yurtsever, G. Kuo, N. Antipa, K. Yanny, and L. Waller, “Learned reconstructions for practical mask-based lensless imaging,” Optics express, vol. 27, no. 20, pp. 28 075–28 090, 2019.
- [41] S. S. Khan, V. Sundar, V. Boominathan, A. Veeraraghavan, and K. Mitra, “Flatnet: Towards photorealistic scene reconstruction from lensless measurements,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 4, pp. 1934–1948, 2020.
- [42] T. Zeng and E. Y. Lam, “Robust reconstruction with deep learning to handle model mismatch in lensless imaging,” IEEE Transactions on Computational Imaging, vol. 7, pp. 1080–1092, 2021.
- [43] D. Bagadthey, S. Prabhu, S. S. Khan, D. T. Fredrick, V. Boominathan, A. Veeraraghavan, and K. Mitra, “Flatnet3d: Intensity and absolute depth from single-shot lensless capture,” JOSA A, vol. 39, no. 10, pp. 1903–1912, 2022.
- [44] Y. Nesterov, “Efficiency of coordinate descent methods on huge-scale optimization problems,” SIAM Journal on Optimization, vol. 22, no. 2, pp. 341–362, 2012.
- [45] S. A. Khayam, “The discrete cosine transform (dct): theory and application,” Michigan State University, vol. 114, no. 1, p. 31, 2003.
- [46] M. Mitchell, An introduction to genetic algorithms. MIT press, 1998.
- [47] M. K. Johnson and E. H. Adelson, “Retrographic sensing for the measurement of surface texture and shape,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009, pp. 1070–1077.
- [48] J. Li, S. Dong, and E. H. Adelson, “End-to-end pixelwise surface normal estimation with convolutional neural networks and shape reconstruction using gelsight sensor,” in 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO). IEEE, 2018, pp. 1292–1297.
- [49] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2223–2232.
- [50] GelSight Inc., “Gelsight mini datasheet,” https://www.gelsight.com/wp-content/uploads/productsheet/Mini/GS_Mini_Product_Sheet_10.07.24.pdf.
- [51] C. Lin, Z. Lin, S. Wang, and H. Xu, “Dtact: A vision-based tactile sensor that measures high-resolution 3d geometry directly from darkness,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 10 359–10 366.
- [52] D. F. Gomes, P. Paoletti, and S. Luo, “Generation of gelsight tactile images for sim2real learning,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 4177–4184, 2021.
- [53] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c72e2157-b496-428f-a0a8-40a7355e0148/jingxu.png) |
Jing Xu received his Ph.D. in mechanical engineering from Tsinghua University, Beijing, China, in 2008. He was a Postdoctoral Researcher in the Department of Electrical and Computer Engineering, Michigan State University, East Lansing. He is currently an Associate Professor in the Department of Mechanical Engineering, Tsinghua university, Beijing, China. His research interests include vision-guided manufacturing, image processing, and intelligent robotics. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c72e2157-b496-428f-a0a8-40a7355e0148/cwh.jpg) |
Weihang Chen received his B.E. degree in mechanical engineering in 2018 from Tsinghua University, Beijing, China, where he is working toward his Ph.D. in the Department of Mechanical Engineering. His research interests include vision-based tactile sensing and Sim2Real for robotics. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c72e2157-b496-428f-a0a8-40a7355e0148/hongyuqian.jpg) |
Hongyu Qian is currently a Ph.D. student in the Department of Mechanical Engineering at Tsinghua University. He obtained his B.E. degree from Southwest Jiaotong University in 2023. His current research focuses on robotics and tactile sensors. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c72e2157-b496-428f-a0a8-40a7355e0148/x28.png) |
Dan Wu received the B.S., M.S., and Ph.D. degrees in mechanical engineering from Tsinghua University of Beijing, China in 1988, 1990, and 2008, respectively. Since 1990, she has been working in Tsinghua University. Now she is a Full Professor with the Department of Mechanical Engineering, Tsinghua University. She has authored or coauthored more than 160 papers. Her research interests include robotic manipulation, precision motion control, precision and ultra-precision machining. Prof. Wu is a member of American Society for Precision Engineering and a senior member of the Chinese Mechanical Engineering Society. Also, she is an associate editor of the Journal of Intelligent Manufacturing and Special Equipment. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c72e2157-b496-428f-a0a8-40a7355e0148/ruichen.jpg) |
Rui Chen is currently a research assistant professor in the Department of Mechanical Engineering, Tsinghua University. He received the Ph.D. degree in mechatronical engineering and the B.E. degree in mechanical engineering in 2020, 2014 from Tsinghua University, Beijing, China. His research interests include tactile sensing, three-dimensional computer vision, and robot learning. |