There Is No Data Like More Data – Datasets for Deep Learning in Earth Observation
Abstract
Carefully curated and annotated datasets are the foundation of machine learning, with particularly data-hungry deep neural networks forming the core of what is often called Artificial Intelligence (AI). Due to the massive success of deep learning applied to Earth Observation (EO) problems, the focus of the community has been largely on the development of ever-more sophisticated deep neural network architectures and training strategies largely ignoring the overall importance of datasets. For that purpose, numerous task-specific datasets have been created that were largely ignored by previously published review articles on AI for Earth observation. With this article, we want to change the perspective and put machine learning datasets dedicated to Earth observation data and applications into the spotlight. Based on a review of the historical developments, currently available resources are described and a perspective for future developments is formed. We hope to contribute to an understanding that the nature of our data is what distinguishes the Earth observation community from many other communities that apply deep learning techniques to image data, and that a detailed understanding of EO data peculiarities is among the core competencies of our discipline.
I Introduction
Deep learning techniques have enabled drastic improvements in many scientific fields, especially in those dedicated to the analysis of image data, e.g. computer vision or remote sensing. While it was possible to train shallow learning approaches on comparably small datasets, deep learning requires large-scale datasets to reach the desired accuracy and generalization performance. Therefore, the availability of annotated datasets has become a dominating factor for many cases of modern Earth observation data analysis that develops and evaluates powerful, deep learning-based techniques for the automated interpretation of remote sensing data.
The main goal of general computer vision is the analysis of optical images, such as photos, which contain everyday objects, e.g., furniture, animals, or road signs. Remote sensing involves a larger variety of sensor modalities and image analysis tasks than conventional computer vision, rendering the annotation of remote sensing data more difficult and costly. Besides classical optical images, multi- or hyperspectral sensors and different kinds of infrared sensors, active sensor technologies such as laser scanning, microwave altimeters, and synthetic aperture radar (SAR) are regularly used, too. The fields of application range from computer vision-like tasks, such as object detection and classification, to semantic segmentation (mainly for land cover mapping) to specialized regression tasks grounded in the physics of the used remote sensing system. To provide an illustrative example, a dataset for biomass regression from interferometric SAR data will adopt imagery and annotations very different from the ones needed for the semantic segmentation of urban land cover types from multispectral optical data. Thus, while extensive image databases, such as ImageNet111As a prime example for an annotated computer vision dataset, ImageNet contains more than 14 million images depicting objects from more than 20,000 categories., have been created already more than ten years ago and form the backbone of many modern machine learning developments in computer vision, there is still no similar dataset or backbone network in remote sensing. This lack of generality renders the generation of an ImageNet-like general EO dataset extremely complicated and thus costly: Instead of photographs openly accessible in the internet, many different – and sometimes quite expensive – sensor data would have to be acquired, and instead of mechanical turks (see box) trained EO experts would have to be hired to link these different sensor data to the multitude of different, domain- and task-specific annotations. Therefore, until now the trend in machine learning applied to EO data is characterized by the generation of numerous remote sensing datasets, each consisting of a particular combination of sensor modalities, applications, and geographic locations. Yet, a review of these developments is still missing in the literature. The only papers that make a small step towards a general review of benchmark datasets are [1, 2, 3, 4]. All of them provide some sort of review, but always limited to a very narrow aspect, e.g. object detection or scene classification. Furthermore, their focus is on machine learning approaches and their corresponding datasets, while the historical evolution of datasets is neither discussed in detail, nor from a sensor- and task-agnostic point-of-view.
The Mechanical Turk
The name mechanical turk comes from a fraudulent chess-playing machine developed in the 18th century. Chess-players were made to believe they played against the machine, but were in fact competing against a person hidden inside it. Today, the term mostly refers to Amazon Mechanical Turk (MTurk), a crowdsourcing website run by the corporation Amazon. On MTurk, users can hire remotely located crowd-workers to perform desired tasks. MTurk is frequently used to create manual annotations for supervised machine learning tasks.
As an extension of our IGARSS 2021 contribution [5], this paper intends to close this gap by
-
•
reviewing current developments in the creation of datasets for deep learning applications in remote sensing and Earth observation,
-
•
structuring existing datasets and discussing their properties,
-
•
providing a perspective on future requirements.
In this context, we additionally present the Earth Observation Database (EOD) [6], which is the result of the effort and cooperation of voluntary scientists within the Image Analysis and Data Fusion (IADF) Technical Committee of IEEE GRSS. This database aims to function as a centralized tool that organizes the meta information about existing datasets in a community-driven manner.
II Evolution of EO-oriented Machine Learning Datasets
II-A Historical Development

High-quality benchmark datasets have played an increasingly important role in Earth observation for quite some time and are one of the driving factors for the recent success of deep learning approaches to analyze remote sensing data. As such, they can be seen as a tool complementary to methodological advancements to push accuracy, robustness, and generalizability. This section reviews and summarizes the historical development of EO-oriented Machine Learning (ML) datasets to provide insights into the evolution of this ”tool”, ranging from its historical beginnings to the current state of the art.
The beginnings of ML applied to remote sensing focused on specific applications. Datasets were mainly built by considering a very localized study site, a few specific sensor modalities, and a relatively small number of acquired samples. Therefore, the first datasets are relatively small compared to what is now considered a benchmarking dataset. Training, validation, and testing samples were often taken from the same image. Even with the use of sophisticated shallow learning models, but especially since the advent of deep learning, such small datasets were no longer sufficient for proper training and evaluation. The need for extended datasets led to the creation of larger datasets containing multiple images, often acquired at different geographic locations.
How to Measure the Size of a Dataset
In this paper, we look at the size of datasets from two perspectives:
•
Size: Data volume in terms of the number of spatial pixels. We count the number of pixels in the highest available image resolution while ignoring multi-band, multi-channel, and multi-sensor data. In other words, pixels are only counted once in the spatial coverage provided by the dataset.
•
Volume: Data volume in terms of storage. The amount of disk space required for a dataset is a proxy for image resolution and provided modalities (e.g., multiple bands and sensor types).
Fig. 1 highlights the different factors that affect the volume and size of a dataset: The number of bits per pixel (radiometric resolution), the number of spectral bands (spectral resolution, i.e., RGB, multispectral, or hyperspectral), the number of images during a specific time period (temporal resolution), and the number of pixels per unit area (spatial resolution). As mentioned above, the size is directly related to the unique number of ground projected resolution cells. A larger dataset in terms of size corresponds to images with higher resolutions or broader coverage.
Fig. 2 illustrates the evolution of benchmark datasets for ML in EO by showing this temporal development.
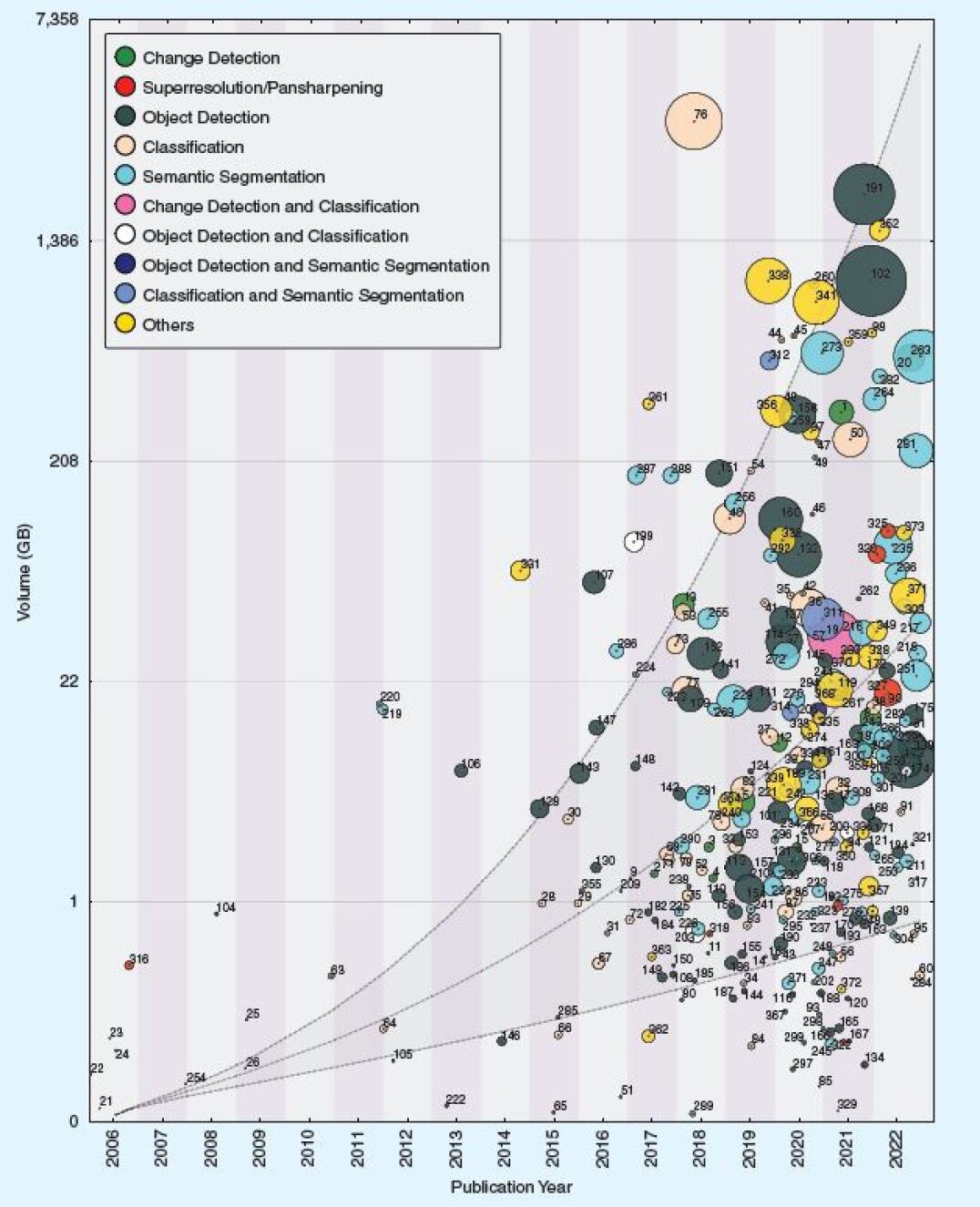
To provide a broad view about the recent evolution of benchmarking datasets, we gathered an extensive list of datasets available in the EO community, resulting in a large collection with currently 400 (i.e., 380 image-based and 20 point-cloud-based datasets) entries (see Tab. II), including related metadata. We point out that, while being extensive, this list is far from being complete due to the fact that a large amount of new datasets are published every year. Furthermore, the metadata required to generate the plot of Fig. 2 are available only for a subset of 290 datasets (roughly 73%). In the horizontal axis we indicate the year of publication. The vertical axis shows the volume of a dataset, while the circle radius reflects the number of spatial pixels covered by a dataset. For a more detailed explanation of how we measure dataset size, please refer to Fig. 1 and the corresponding box. Fig. 2 provides a straightforward overview of the proportion between size, spatial dimension and, therefore, about the overall information content given by features such as resolution, sensor modalities, number of bands/channels, etc. Each circle is accompanied by an index, allowing to identify the dataset in the database (see Tab. II) that provides further information. As there are a few datasets published before 2006, the first column denotes the time of 2006 and earlier (denoted as 2006). Note that we use the category ”Others” for datasets that do not belong to any of the other categories and are too rare to form their own category. Examples for the ”Others” category are datasets on cloud removal visual question answering and parameter estimation tasks such as hurricane wind speed prediction, satellite pose estimation, and vegetation phenological change monitoring. The dashed line illustrates an exponential growth of benchmark datasets created by and for the EO community.
This map on the evolution of remote sensing datasets offers several interesting insights:
-
1.
The Beginnings
Additionally to the first IEEE GRSS Data Fusion Contest in 2006 (Tab. II-#316), there are a few other pioneering datasets that have fostered ML research applied to remote sensing data in its early stages, e.g.-
•
Hyperspectral datasets (Indian Pines, Salinas Valley, and Kennedy Space Center, (Tab. II-#21, #22, and #24)): Published before 2005, these datasets triggered the ML era in remote sensing. Covering a very small area on the ground and having a very small number of pixels, such datasets are not suitable for training DL models (or have to be used with excessive caution). On the other hand, due to their rich hyperspectral information, they are still being used for tasks such as dimensionality reduction and feature extraction.
- •
- •
- •
All of those pioneering datasets have seen massive use in the early machine-learning-oriented Earth observation literature. It is interesting to note that pan-sharpening, scene classification, semantic segmentation, and object detection were the first topics in remote sensing to be addressed with machine learning based methodologies.
-
•
-
2.
The Deep Learning Boom As discussed by several review articles on deep learning and artificial intelligence applied to Earth observation [11, 12, 13], the year 2015 marked the beginning of the deep learning boom in the EO community. This is well reflected by a significantly rising number of datasets published from that year onwards. It is furthermore confirmed by the fact that the dataset sizes both in terms of spatial pixels and data volume started to increase significantly from about that time.
-
3.
The Diversity of Tasks From the early days on, machine learning-oriented Earth observation datasets were designed for a multitude of different tasks. The historical evolution depicted in Fig. 2 further shows that object detection and semantic segmentation are the most popular tasks, with a significant increase of datasets dedicated to minority categories (denoted by ”Others”) from about 2019 on. This indicates that the rise of deep learning in Earth observation broadens the overall application scope of the discipline.



Fig. 3 provides further insights into the size distribution of available datasets in terms of the (1) number of pixels and (2) data volume in GB for typical remote sensing tasks. Illustrating these two different aspects allows a further understanding of the nature of the data. For example, datasets counting a similar number of spatial pixels may differ in data volume, which can, for example, indicate the use of multimodal imagery. Object detection offers the largest data volume among the existing benchmarking datasets, which again confirms its popularity in deep learning-oriented remote sensing research. However, in terms of number of pixels, semantic segmentation takes the lead, indicating that a larger spatial coverage is usually involved for this type of application.

II-B Platforms
A direct overview of the occurrence of a type of platform and sensor is given in Fig. 4. Satellite platforms are the most common, followed by airborne platforms and drones. Optical data cover more than half of the datasets, while all other sensors are almost equally distributed. Interestingly, of the datasets provide time series, while the rest are single-temporal acquisitions. Complementing this, Fig. 5 highlights the distribution of tasks between sensors and platforms. The inner ring indicates the platform type, which then splits into different sensor types in the middle ring, and finally denotes the targeted tasks in the outer ring, respectively. This graph shows that the datasets acquired by UAVs and aircrafts are mainly dedicated to optical sensors, while satellite-based Earth observation has a much wider and more homogeneous distribution across all sensor and application types.




Fig. 6(a) and Fig. 6(b) further specify the previous findings by showing how the datasets acquired by different platforms are distributed across both tasks and sensors. While the former provides an overview, the latter adds a temporal aspect by showing the corresponding applications per year. The x- and y-axes represent tasks and sensors, respectively, while the different markers indicate the type of acquisition platforms. From these plots we can affirm that object detection and classification tasks are mainly performed on optical images. At the same time, semantic segmentation is fairly evenly distributed between optical, multispectral, and other sensor combinations. SAR images are mainly acquired from satellite platforms, while hyperspectral datasets are almost always acquired from airborne systems. UAVs mainly carry optical sensors in the context of semantic segmentation. Some tasks, such as super-resolution, naturally make use of multimodal data, e.g., optical and hyperspectral imagery. The year-by-year graph in Fig. 6(b) shows that super-resolution datasets, together with UAV-based acquisitions, have received more attention in recent years. On the other hand, the EO community has not seen many new hyperspectral datasets since 2018. Optical sensors were the most common source of information, while after 2020 an increasing number of datasets were also acquired from other sensors, such as SAR or hyperspectral systems.
Figures 4, 5, and 6(a) show that the number of datasets acquired from ”multiple” platforms or sensors is still the minority which provides evidence for the earlier statement that state-of-the-art datasets are usually designed to respond to a specific task in EO applications. These figures also show which combination of EO tasks, platforms, and sensors is currently underrepresented. In particular Fig. 6(a) shows three main gaps: (1) SAR change detection, (2) SAR super-resolution, and (3) hyperspectral super-resolution. From a sensor perspective alone, the lack of airborne SAR datasets and drone-based hyperspectral benchmarks are other obvious gaps.

II-C Geographic Diversity
The geographic diversity and spatial distribution of the Earth observation imagery is an important attribute of a benchmark dataset as it is directly related to the geographic generalization performance of data-driven models. Fig. 8 shows the geographic distribution of datasets (i.e. of roughly 300 datasets (75%) from Tab. II that provided (or where we could find) their geographic information). Many of the datasets are globally distributed (Global) and contain images from around the world, while others cover a limited set of multiple cities or countries (Multiple Locations). Maybe surprisingly, synthetic datasets show a dominating presence as well, illustrating the benefits of being able to control image acquisition parameters (such as viewing angle), environmental factors (such as atmospheric conditions, illumination, and cloud cover), and scene content (e.g. type, size, shape, and number of objects). Fig 8 illustrates an important and within the EO community seldom discussed issue: There exists a strong geographic bias within the available EO datasets. While 25% of the datasets contain samples from globally distributed locations, nearly 40% of available datasets are covering regions in Europe (21%) and North America (18%) only. Asia is still covered by 10%, however, Africa (5%), South America (4%), and Australia (1%) are barely included. This raises the question whether many of the findings and conclusions in corresponding research articles would generalize to these geographic areas. In any case, the need for more spatially diverse datasets becomes apparent, in particular covering also underdeveloped countries.

II-D Source of the Reference Data
Another important aspect is the source of the reference data. While most scientific papers introducing a new benchmark dataset are very detailed regarding source and properties of the provided image data, they often contain only sparse information about the exact process of how the reference data was obtained. However, knowledge about the source of the reference data as well as about measures for quality assessment and quality control are essential to judge the potential of the benchmark and how to interpret obtained results. For example, achieving a high ”accuracy” on a dataset that contains a high amount of annotation errors in its reference data only means that the model is reproducing the same bias as the method used to annotate the data but is not actually producing accurate results. Furthermore, information about the source of the reference data is not only scarce but also very heterogeneous. Examples include manual annotation for semantic segmentation (e.g. OpenEarthMap (Tab-II-#253)) or object detection (e.g. BIRDSAI (Tab-II-#127), DroneCrowd (Tab-II-#138), the use of keywords in image search engines for classification (e.g. AIDER (Tab-II-#34)), leveraging existing resources (e.g. BigEarthNet (Tab-II-#40) uses the CORINE LULC map, MapInWild (Tab-II-#264) uses the World Database of Protected Areas, AI-TOD (Tab-II-#162) uses other existing datasets, ship detection datasets usually use AIS data, OpenSentinelMap (Tab-II-#282) uses OSM), automatic reference methods (e.g. HSI Oil Spill (Tab-II-#211) and Sen12MS-CR-TS (Tab-II-#98), or a mixture of these (e.g. RSOC (Tab-II-#117) uses existing datasets (DOTA, Tab-II-#109) as well as manual annotations for new images). The quality of class definitions varies among different datasets, often depending on whether a dataset is designed for a specific real-world application (in which class definitions are driven by the application context) or whether it is just an example dataset to train and evaluate a machine-learning based approach (in which case class definitions are more arbitrary). If human interaction is involved (e.g. via manual annotations), annotation protocols or precise class definitions are often not shared (if they even exist). With the evolution of datasets, the quality of the meta-information about the reference data needs to increase together with the quality and quantity of the image data.
II-E Applications and Tasks
Finally, we analyze a last aspect concerning the distribution of some characteristics of the datasets, namely the number of classes and images. In Fig. 7, we show on the left side the evolution of the number of classes per publication year. On the right side, we plot the number of classes against the number of images in the dataset. In both plots, the radius indicates the size of the image (width or height), while the color indicates the type of task. We can see that there is no clear trend or correlation between the year of publication and the number of classes in a dataset. Instead, we find that more recently published datasets increase the variety in the number of classes, again highlighting an increased interest in using benchmarking datasets in a wider range of applications. Furthermore, although there is no clear correlation, we can confirm that increasing the number of classes reduces the size of the images and increases the number of images. More populated datasets, in terms of number of images, also have smaller image sizes and typically consider a smaller number of classes. Conversely, larger images are found in less populated datasets.
This overview is a snapshot of the currently published benchmarking datasets. Although the list of datasets is constantly growing, we believe that the observed trends will not change much over the next few years. Instead, we expect long-term developments that lead to two divergent aspects of datasets: specificity and generality. This will be further discussed in Section V.
Point-cloud datasets are another large group of benchmark data that are widely used in the literature and industry. Within EO the most common source for point-cloud data are LiDAR (Light Detection and Ranging) sensors that use light in the form of laser pulses to measure the distance to the surface. The primary sources are Airborne, Terrestrial, and Mobile Laser Scanning devices (i.e., ALS, TLS, and MLS, respectively). Other sources of point clouds and 3D data include photogrammetric methods (Structure from Motion, Multi-View Stereo, dense matching approaches) and tomographic synthetic aperture radar (TomoSAR). Since 3D data typically comes with features very different to 2D image data, such datasets are beyond the scope of this paper. Nevertheless, Tab. I provides a short list of example LiDAR/point-cloud datasets for interested readers.
| Task | Platform | Time stamps | Name | Pub. Date | Point Density (pts/m2) | #Classes | #Points | Volume (MB) |
|---|---|---|---|---|---|---|---|---|
| Change Detection | ALS | Multiple | Abenberg ALS | 2013 | 16 | - | 5400000 | 258 |
| Classification | ALS | Single | NEWFOR | 2015 | varies | 4 | - | 97 |
| Classification | ALS | Single | DFC19 | 2019 | - | 6 | 167400000 | 613 |
| Classification | ALS | Single | ISPRS 3D Vaihingen | 2014 | 8 | 9 | 780879 | |
| Classification | Multiple | Single | ArCH | 2020 | varies | 10 | 136138423 | - |
| Classification / Semantic Segmentation | ALS | Single | DublinCity | 2019 | 240 to 348 | 13 | 260000000 | 3000 |
| Filtering | ALS | Single | OpenGF | 2021 | 6 and 14 | 3 | 542100000 | 2280 |
| Object Detection /Semantic Segmentation | TLS | Single | LiSurveying | 2021 | varies | 54 | 2450000000 | - |
| Others | ALS | Single | RoofN3D | 2018 | 4.72 | 3 | 118100 | - |
| Semantic Segmentation | ALS | Single | LASDU | 2020 | 3-4 | 6 | 3120000 | - |
| Semantic Segmentation | ALS | Single | DALES | 2020 | 50 | 8 | 505000000 | 4000 |
| Semantic Segmentation | ALS | Single | DALES Object | 2021 | 50 | 8 | 492000000 | 5000 |
| Semantic Segmentation | Drone | Single | Campus3D | 2020 | varies | 24 | 937000000 | 2500 |
| Semantic Segmentation | Drone | Multiple | Hessigheim 3D | 2021 | 800 | 11 | 73909354 | 5950 |
| Semantic Segmentation | Drone | Single | WildForest3D | 2022 | 60 | 6 | 7000000 | 81 |
| Semantic Segmentation | MLS | Single | Toronto3D | 2020 | 1000 | 8 | 78300000 | 1100 |
| Semantic Segmentation | MLS | Multiple | HelixNet | 2022 | - | 9 | 8850000000 | 235700 |
| Semantic Segmentation | Photogrammetry | Single | SensatUrban | 2020 | - | 13 | 2847000000 | 36000 |
| Semantic Segmentation | Photogrammetry | Single | STPLS3D | 2022 | - | 20 | - | 36600 (images:700000) |
| Semantic Segmentation | TLS | Single | Semantic 3D | 2017 | - | 8 | 4000000000 | 23940 |
| Index | Task | Platform | Sensor Type | Name | Pub. Date | Timestamps | #Images | Img. Size | Size | #Classes | Volume (MB) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Change Detection | Aerial | Multiple | DFC21-MSD | 2021 | Multiple | 2250 | 4000 | 36000000000 | 15 | 325000 |
| 10 | Change Detection | Satellite | Multiple | DFC09 | 2009 | Multiple | 2 | 98 | |||
| 11 | Change Detection | Satellite | Multispectral | OneraCD | 2018 | Multiple | 24 | 600 | 8640000 | 2 | 489 |
| 15 | Change Detection | Satellite | Optical | LEVIR-CD | 2020 | Single | 637 | 1024 | 667942912 | 1 | 2700 |
| 21 | Classification | Aerial | Hyperspectral | Indian Pines | 2000 | Single | 1 | 145 | 21025 | 16 | 6 |
| 22 | Classification | Aerial | Hyperspectral | Salinas | 2000 | Single | 1 | 365 | 111104 | 16 | 27 |
| 24 | Classification | Aerial | Hyperspectral | Kennedy Space Center | 2005 | Single | 1 | 550 | 311100 | 13 | 57 |
| 34 | Classification | Drone | Optical | AIDER | 2019 | Single | 2645 | 240 | 152352000 | 4 | 275 |
| 40 | Classification | Satellite | Multiple | BigEarthNet-MM | 2019 | Single | 590326*12 | 120 | 1.02E+11 | 19 | 121000 |
| 52 | Classification | Satellite | Multispectral | EuroSAT | 2018 | Single | 27000*13 | 64 | 1437696000 | 10 | 1920 |
| 63 | Classification | Satellite | Optical | UC Merced | 2010 | Single | 2100 | 256 | 137625600 | 21 | 317 |
| 69 | Classification | Satellite | Optical | AID | 2017 | Single | 10000 | 600 | 3600000000 | 30 | 2440 |
| 76 | Classification | Satellite | Optical | FMoW | 2018 | Single | 523846 | - | 1.08E+12 | 63 | 3500000 |
| 98 | Cloud Removal | Satellite | Multiple | SEN12MS-CR-TS | 2021 | Multiple | 53 | 4000 | 848000000 | - | 649000 |
| 105 | Object Detection | Aerial | Optical | SZTAKI AirChange | 2012 | Multiple | 13 | 800 | 7920640 | 2 | 42 |
| 109 | Object Detection | Aerial | Optical | DOTA v1.0 | 2018 | Single | 2806 | 4000 | 44896000000 | 15 | 18000 |
| 114 | Object Detection | Aerial | Optical | DOTA v2.0 | 2020 | Single | 11268 | 4000 | 1.80E+11 | 18 | 34280 |
| 117 | Object Detection | Aerial | Optical | RSOC | 2020 | Single | 3057 | 2500 | 3621481392 | 4 | - |
| 127 | Object Detection | Drone | Multispectral | BIRDSAI | 2020 | Multiple | 162000 | 640 | 49766400000 | - | 43200 |
| 138 | Object Detection | Drone | Optical | DroneCrowd | 2022 | Multiple | 33600 | 1920 | 69672960000 | 1 | 10400 |
| 151 | Object Detection | Satellite | Optical | SpaceNet-4 | 2018 | Single | 60000 | 900 | 48600000000 | 186000 | |
| 162 | Object Detection | Satellite | Optical | AI-TOD | 2020 | Single | 28036 | - | - | - | 22000 |
| 191 | Object Detection | Satellite | SAR | xView3-SAR | 2021 | Single | 991*2 | 27000 | 1.42E+12 | 2 | 2000000 |
| 204 | Object Detection/Classification | Satellite | SAR | FUSAR-Ship | 2020 | Single | 5000 | 512 | 1310720000 | 113 | |
| 208 | Semantic Segmentation | Aerial | Hyperspectral | DFC08 | 2008 | Single | 5 | 194 | |||
| 211 | Semantic Segmentation | Aerial | Hyperspectral | HOSD | 2022 | Single | 18*224 | 1700 | 3622355072 | 1 | 2200 |
| 212 | Semantic Segmentation | Aerial | Multiple | DFC13 | 2013 | Single | 145 | 16 | 1000 | ||
| 213 | Semantic Segmentation | Aerial | Multiple | DFC14 | 2014 | Single | 7 | ||||
| 214 | Semantic Segmentation | Aerial | Multiple | DFC15 | 2015 | Single | 7 | 10000 | 700000000 | ||
| 215 | Semantic Segmentation | Aerial | Multiple | DFC18 | 2018 | Single | 1 | 20 | 19763 | ||
| 217 | Semantic Segmentation | Aerial | Multiple | DFC22-SSL | 2022 | Single | 5000 | 2000 | 20000000000 | 14 | 42000 |
| 219 | Semantic Segmentation | Aerial | Multispectral | ISPRS 2D - Potsdam | 2011 | Single | 38 | 6000 | 1368000000 | 6 | 16000 |
| 220 | Semantic Segmentation | Aerial | Multispectral | ISPRS 2D - Vaihingen | 2011 | Single | 33 | 2200 | 156750000 | 6 | 17000 |
| 246 | Semantic Segmentation | Multiple | Multiple | DFC17 | 2017 | Multiple | 17 | ||||
| 247 | Semantic Segmentation | Multiple | Multiple | SpaceNet-6 | 2020 | Single | 3401 | 900 | 2754810000 | 1 | 368 |
| 253 | Semantic Segmentation | Multiple | Optical | OpenEarthMap | 2022 | Single | 5000 | 1024 | 5242880000 | 8 | 9100 |
| 254 | Semantic Segmentation | Satellite | Multiple | DFC07 | 2007 | Single | 1 | 787 | 619369 | 19 | |
| 257 | Semantic Segmentation | Satellite | Multiple | DFC20 | 2020 | Single | 180662 | 17 | 19200 | ||
| 261 | Semantic Segmentation | Satellite | Multiple | DFC21-DSE | 2021 | Single | 6000 | 16 | 1536000 | 4 | 18000 |
| 264 | Semantic Segmentation | Satellite | Multiple | MapInWild | 2022 | Single | 1018*8 | 1920 | 30022041600 | 11 | 365000 |
| 282 | Semantic Segmentation | Satellite | Multispectral | OpenSentinelMap | 2022 | Multiple | 137045 | 192 | 5052026880 | 15 | 445000 |
| 286 | Semantic Segmentation | Satellite | Optical | SpaceNet-1 | 2016 | Single | 9735 | 650 | 4113037500 | 1 | 31000 |
| 287 | Semantic Segmentation | Satellite | Optical | SpaceNet-2 | 2017 | Single | 24586 | 650 | 10387585000 | 1 | 182200 |
| 288 | Semantic Segmentation | Satellite | Optical | SpaceNet-3 | 2017 | Single | 3711 | 1300 | 6271590000 | 1 | 182200 |
| 292 | Semantic Segmentation | Satellite | Optical | SpaceNet-5 | 2019 | Single | 2369 | 1300 | 4003610000 | 1 | 84103 |
| 294 | Semantic Segmentation | Satellite | Optical | SpaceNet-7 | 2020 | Multiple | 1525 | 1024 | 1599078400 | 1 | 20582 |
| 301 | Semantic Segmentation | Satellite | Optical | SpaceNet-8 | 2022 | Multiple | 1200 | 1200 | 3456000000 | 2 | 6800 |
| 312 | Semantic Segmentation, Classification | Satellite | Multiple | SEN12MS | 2019 | Single | 180662 | 256 | 11839864832 | - | 510000 |
| 313 | Semantic Segmentation, Classification | Satellite | Multiple | DFC23 | 2023 | Single | 12 | ||||
| 316 | Super Resolution, Pan-Sharpening | Aerial | Multispectral | DFC06 | 2006 | Single | 6 | 5000 | 637500000 | - | 390 |
| 318 | Super Resolution, Pan-Sharpening | Satellite | Multispectral | Proba-V Super Resolution | 2018 | Single | 1160 | 384 | 171048960 | - | 692 |
| 319 | Super Resolution, Pan-Sharpening | Satellite | Multispectral | PAirMAX (Airbus) | 2021 | Single | - | - | - | - | 153 |
| 324 | Super Resolution, Pan-Sharpening | Satellite | Optical | PAirMAX (MAXAR) | 2021 | Single | 14 | - | - | - | 386 |
| 325 | Super Resolution, Pan-Sharpening | Satellite | Optical | WorldStrat | 2022 | Single | 3928 | 1054 | 4363678048 | - | 107000 |
| 340 | Others | Multiple | Multiple | DFC19 | 2019 | Single | |||||
| 360 | Others | Satellite | Optical | DFC16 | 2016 | Multiple |
III Exemplary Datasets
This section provides short descriptions of a selection of Earth Observation datasets for various tasks: semantic segmentation, classification, object detection, change detection, and super-resolution/pan-sharpening. Given the vast amount of publicly available EO datasets, it is only possible to present some of them in this paper. Thus, this selection cannot be comprehensive and certainly follows a subjective view influenced by the experience of the authors. However, the selected datasets are representative for their respective tasks and were selected based on their observed relevance: They either are the largest in terms of size (see Section II for a definition), the first to be introduced for a given task, or the most popular dataset for the chosen application. The popularity was determined based on the number of citations the original paper introducing the dataset received.
The popularity of a dataset is influenced by multiple factors. One is certainly the size of a dataset, i.e. larger datasets are often preferred. However, there are exceptions. For instance, Functional Map of the World (FMoW) (Tab-II-#76), introduced in 2018 [14], is the largest dataset for remote sensing scene classification in terms of the number of images (1 million), but has yet to gain a high level of popularity (with 200 citations and 128 GitHub stars, compared to EuroSAT (Tab. II-#52) with 796 citations and 276 GitHub stars, or AID (Tab. II-#69) with 1000 citations, which are all published in 2018). Several other factors affect the popularity of a dataset, too, such as ease of access to the hosting servers (Google Drive, IEEE Dataport, Amazon AWS, University/Personal servers, etc.), accompanying documentation and presentation (standard metadata format, detailed description, availability of template code and support, suitable Search Engine Optimization, etc), or ease of downloading the data (temporary or permanent links, the bandwidth of hosting server, sign in/up requirements, etc.). Last but not least, an already established dataset is more likely to be used in new studies to enable comparison to related prior works, even if newer (and potentially better) datasets might exist.
Along with brief descriptions, this section provides insights into the different dataset characteristics.
III-A Semantic Segmentation

Semantic segmentation refers to assigning a class label to each pixel in the image. Partitioning the image into semantically meaningful parts creates a more detailed map of the input image and provides a foundation for further analysis such as land use land cover (LULC) classification, building footprint extraction, landslide mapping, etc. [15]. Fig. 9 shows the relative volume of corresponding benchmark datasets and illustrates a wide spread of dataset sizes. Here, we present two examples: SEN12MS (focusing on medium-resolution satellite data and weak annotations) and the ISPRS Vaihingen dataset (focusing on very-high-resolution airborne data with high-quality annotations).
1) SEN12MS222https://github.com/schmitt-muc/SEN12MS is among the most popular and largest datasets (Tab. II-#312) in terms of volume of data as shown in Fig. 2. A total of 541,986 image patches of size pixels with high spectral information content is present in this dataset [16]. It contains dual-polarimetric SAR image patches from Sentinel-1, multispectral image patches from Sentinel-2, and MODIS land cover maps (Fig. 10). The image patches are acquired at random locations around the globe and cover the four meteorological seasons of the northern hemisphere. The patches were further processed to ensure that the images did not contain any clouds, shadows, and artifacts. In addition to the images and the land cover maps, the results of two baseline CNN classifiers (ResNet50 and DenseNet121) are also discussed to demonstrate the usefulness of the dataset for land cover applications [17].

2) ISPRS Vaihingen333https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx is the earliest semantic segmentation dataset for identifying land cover classes in aerial images [18] as shown in Fig. 2 (Tab. II-#220). This dataset contains a subset of images acquired by aerial cameras during the test of digital aerial cameras carried out by the German Association of Photogrammetry and Remote Sensing (DGPF) [19]. The dataset was prepared as part of a 2D semantic labeling contest organized by the International Society for Photogrammetry and Remote Sensing (ISPRS). The dataset contains images acquired over Vaihingen in Germany. In total, orthorectified images of varying sizes and a digital surface model (DSM) are provided for 33 patches covering the city of Vaihingen (Fig. 11). The ground sampling distance for the images and DSM is 9 cm. The three channels of the orthorectified images contain infrared, red, and green bands as acquired by the camera. The images are manually labeled for six common land cover classes: impervious surfaces, buildings, low vegetation, tree, car, and clutter/background.

III-B Scene Classification

Remote sensing scene classification is closely related to semantic segmentation, and has been used in various application domains such as urban planning [20], environment monitoring [21], LULC estimation [22], etc. The main difference is that instead of pixel-wise classification and resolution-preserving maps as output, in scene classification only one or more global labels are predicted for a given input image, aiming at a more comprehensive, generalized and context-aware understanding of the underlying scene. Similar to image classification, which has been the driving force behind the early days of deep learning in computer vision, research on remote sensing scene classification has led to the creation of more diverse and large-scale high-resolution image datasets. Fig. 12 shows the relative volume distribution of remote sensing scene classification datasets. This section covers EuroSAT as one of the earliest and fMoW as one of the largest datasets (representing roughly 50% of the available data in this task category), as well as BigEarthNet-MM that introduces an additional interesting aspect by providing multiple labels for each image.
1) EuroSAT444https://github.com/phelber/EuroSAT is one of the earliest large-scale datasets tailored for training deep neural networks for LULC classification tasks as Fig. 2 shows (Tab. II-#52). The dataset includes ten land cover classes (Fig. 13), each containing 2,000-3,000 images, for 27,000 annotated and geo-referenced images with 13 different spectral bands of pixels. It contains multispectral images with a single label acquired from Sentinel-2 satellite images of cities in 34 European countries [23, 24]. This dataset has been widely used for classification tasks. However, it may be used in a variety of real-world Earth observation applications, such as detecting changes in land use and land cover, as well as improving geographical maps as Sentinel-2 images are freely available [23, 25, 26].

2) BigEarthNet-MM555https://bigearth.eu/ (Tab. II-#40) is a benchmark archive that introduced an alternative nomenclature for images as compared to the traditional CORINE Land Cover (CLC) map for multi-label image classification and image retrieval tasks. The CLC Level-3 nomenclature is arranged into 19 classes for semantically coherent and homogenous land cover classes. This archive is created using Sentinel-1 SAR and Sentinel-2 multispectral satellite images acquired between June 2017 and May 2018 over ten countries of Europe [27]. The first version of the BigEarthNet only included Sentinel-2 image patches. It has been augmented with Sentinel-1 image patches to form a multi-modal benchmark archive (also called BigEarthNet-MM). The archive comprises 590,326 image patches with 12 spectral and two polarimetric bands. As shown in Fig. 14, each image patch is annotated with several land-cover classes (multi-labels). One of the key features of the BigEarthNet dataset is its large number of classes and images, which makes it suitable for training deep learning models. However, because it is a multi-label dataset, the complexity of the problem is significantly increased compared to single-label datasets [28].

3) Functional Map of the World (fMoW)666https://github.com/fMoW/dataset (Tab. II-#76) is the largest dataset (Fig. 2) for remote sensing scene classification in terms of the number of images [14]. The fMoW dataset is composed of approximately one million satellite images, along with metadata and multiple temporal views, as well as subsets of the dataset that are classified into 62 classes, which are used for training, evaluation, and testing. Each image in the dataset comes with one or multiple bounding boxes indicating the regions of interest. Some of these regions may be present in multiple images acquired at different times, adding a temporal dimension to the dataset. The fMoW dataset is available to the public in two image formats: the fMoW-Full and the fMoW-RGB. The fMoW-Full is in TIFF format and contains 4-band and 8-band multispectral imagery with a high spatial resolution resulting in 3.5TB of data, while the fMoW-RGB has a much smaller size of 200GB and includes all multispectral data converted to RGB in JPEG format. Examples of the classes in the dataset include flooded roads, military facilities, airstrips, oil and gas facilities, surface mines, tunnel openings, shipyards, ponds, and towers (see Fig. 15 for some examples). The fMoW dataset has a number of important characteristics, such as global diversity, multiple images per scene captured at different times, multispectral imagery, and metadata linked to each image.

III-C Object Detection

The aim of object detection is to locate and identify the presence of one or more objects within an image, including objects with clear boundaries, such as vehicles, ships, and buildings, as well as those with more complex or irregular boundaries, for example LULC parcels [29]. As seen in Fig. 3, object detection is one of the most widely studied research tasks. Fig. 16 shows the relative volume of the corresponding datasets. The xView3-SAR is by far the largest one. On the other hand, the family of DOTA datasets has a pioneering role in this field, placing them among the most popular datasets for object recognition tasks from remote sensing images.
1) The xView3-SAR777https://iuu.xview.us/ Ship Detection dataset is the largest labeled dataset (Tab. II-#191), as Fig. 2 shows, for training machine learning models to detect and classify ships in SAR images. The dataset includes nearly 1,000 analysis-ready SAR images from the Sentinel-1 mission, which are annotated using a combination of automated and manual analysis (see Fig. 17 for some image samples). The images are accompanied by co-located bathymetry and wind state rasters, and the dataset is intended to support the development and evaluation of machine learning approaches for detecting ”dark vessels” not visible in conventional monitoring systems.

2) DOTA888https://captain-whu.github.io/DOTA/ is one of the most popular and largest object detection datasets (Tab. II-#109/114) in terms of labeled object instances. It includes 2,806 images acquired from Google Earth and the China Center for Resources Satellite Data and Application [30, 31, 32]. The DOTA dataset is available in three different versions: DOTA-v1.0, DOTA-v1.5, and DOTA-v2.0. The image size in the initial version ranges from pixels to pixels, with 188,282 object instances with various scales and angular orientations and a total of 15 object categories. DOTA-v1.5 adds various small objects (less than 10 pixels) and a new container crane category with 402,089 instances, whereas DOTA-v2.0 adds two categories, airport and helipad, with 11,268 images and 1,793,658 instances, respectively. Some image samples of the DOTA dataset are presented in Fig. 18.

III-D Change Detection

Change detection (CD) in remote sensing aims to identify temporal changes by analyzing multi-temporal satellite images of the same location. CD is a popular task in Earth observation, as it fosters monitoring environmental changes through artificial or natural phenomena. Fig. 3 shows that the number of dedicated change detection datasets is small compared to other applications. Fig. 19 shows that the available data is dominated by the DFC20 dataset (Track MSD) which focuses on semantic change detection, followed by xView2 tackling building damage assessment in the context of natural disasters. We chose LEVIR-CD as a recent dataset example and the Onera Satellite Change Detection Dataset as one of the first large-scale datasets.
1) LEVIR-CD999https://justchenhao.github.io/LEVIR/ is one of the most recent and largest change detection datasets as seen in Fig. 2 (Tab. II-#15). It is mainly developed for the evaluation of deep learning algorithms on building-related changes, including building growth (the transition from soil/grass/hardened ground, building under construction to new build-up regions) and building decline [33]. The dataset comprises 637 optical image patch pairings extracted from Google Earth (GE) with a resolution of pixels, acquired over a time span of 5 to 14 years. LEVIR-CD covers various structures, including villa residences, tall apartments, small garages, and large warehouses, from 20 distinct regions in multiple Texas cities. The fully annotated LEVIR-CD dataset comprises 31,333 distinct change-building instances, some of which are illustrated in Fig. 20 generated from the bi-temporal images by remote sensing image interpretation specialists.

2) Onera Satellite Change Detection101010https://rcdaudt.github.io/oscd/ is one of the first, larger change detection datasets, as Fig 2 shows (Tab. II-#11), containing multispectral image pairs from Sentinel-2. This dataset includes 24 pairs of multispectral images acquired from Sentinel-2 satellites between 2015 and 2018, focusing on urban changes such as new buildings or roads [34]. The locations are selected from around the world, including Brazil, the United States, Europe, the Middle East, and Asia. The reference data for pixel-level change is provided for all 14 training and 10 test image pairs. As illustrated in Fig. 21, the annotated changes are primarily associated with urban changes, such as new buildings or roads.

III-E Super Resolution/Pansharpening
Pansharpening is one of the oldest data fusion approaches in remote sensing and aims to increase the spatial resolution of a multispectral image by combining it with a panchromatic image. Due to the resolution difference between panchromatic and multispectral sensors, pansharpening is an exciting topic in remote sensing as it can provide a means to obtain higher-resolution data without better sensor technology. We select the Proba-V, PAirMax, and WorldStrat datasets as examples to showcase the peculiarities of datasets designed for that particular application.
1) Proba-V111111https://kelvins.esa.int/proba-v-super-resolution/data/ is the earliest dataset available for super-resolution [35] as Fig. 2 shows (Tab. II-#318). This dataset contains radiometrically and geometrically corrected Top-Of-Atmosphere reflectances in Plate Carre projection from the PROBA-V mission of the European Space Agency (Fig. 22). The RED and NIR spectral band data at 300 m and 100 m resolution are collected for 74 selected regions across the globe. Super-resolution might be affected by the presence of pixels with clouds, cloud shadows, and ice/snow cover. Therefore, this dataset contains a quality map indicating pixels affected by clouds that should not be considered for super-resolution. The dataset contains one 100 m resolution image and several 300 m resolution images of the same scene.

2) PAirMax121212https://perscido.univ-grenoble-alpes.fr/datasets/DS353 is a recently published (Tab. II-#319/324) yet popular dataset for pansharpening. It contains 14 multispectral and panchromatic image pairs from six sensors onboard satellite constellations of Maxar Technologies and Airbus [36]. As seen in Fig. 23, most images are acquired over urban areas, highlighting several challenges for pan-sharpening (such as high contrast features and adjacent regions with different spectral features). The work [36] also discusses the best practices to be followed in preparing high-quality full-resolution and reduced-resolution images for pan-sharpening applications. In this dataset, the panchromatic band has times more pixels than the multispectral bands. The multispectral bands are near the visible infra-red region. The dataset also contains nine reduced-resolution test cases per Wald’s protocol.

3) WorldStrat131313https://worldstrat.github.io/ is a recently introduced dataset for super-resolution [37] and the largest in terms of volume (107 GB) as Fig.2 shows (Tab. II-#325). This dataset contains high-resolution images from Airbus 6/7 along with temporally matched 16 low-resolution images from Sentinel-2 satellites. The high resolution images are over five spectral bands: Panchromatic band at 1.5 m/pixel resolution and Red, Green, Blue, and Near Infrared bands at 6 m/pixel. The low resolution ranges from 10 m/pixel to 60 m/pixel (Figure 24). In total, the dataset covers an area of around 10,000 km2 and attempts to represent all types of land-use across the world. Notably, the dataset contains non-settlement and under-represented locations such as illegal mining sites, settlements of persons at risk, etc.

IV Working with Remote Sensing Datasets
This section provides guidance on how to leverage available datasets to their full potential. Two of the main difficulties caused by information asymmetry (i.e. the information imbalance between the data providers and the data users) [5] are finding suitable datasets and easy prototyping of machine learning approaches using such datasets. Here we discuss resources to gain an overview of existing datasets and download actual data, but also provide examples of Earth observation-oriented machine learning programming libraries.
IV-A Data Availability
Data availability covers two distinct aspects: On the one hand, access to the curated benchmark datasets, i.e. how such datasets are made available to the public. This section provides several examples of the most common data sources below. On the other hand, the actual non-curated measurements as acquired by the different sensors such as satellites, planes, and UAVs are often available, too. Many data providers offer either their complete database for public access (e.g. the European Copernicus Open Access Hub141414https://scihub.copernicus.eu/) or at least parts of their image acquisitions (e.g. via Open Data Programs such as those from Maxar151515https://www.maxar.com/open-data and Capella Space161616https://registry.opendata.aws/capella_opendata/ or through scientific proposals as possible for TerraSAR-X/TanDEM-X data171717https://sss.terrasar-x.dlr.de/). In principle, these data sources are highly valuable as they offer free access to petabytes of EO data that can either be used to compile benchmark datasets by augmenting it with reference data for a specific task or being leveraged for modern training paradigms such as self-supervised learning. An important aspect that is unfortunately sometimes ignored is the licensing of the corresponding data products: While direct usage (at least for scientific purposes) is usually free, redistribution of this data is often prohibited. Nevertheless, such image data finds its way into public benchmark datasets essentially causing copyright infringements. Additionally to being in direct conflict with scientific integrity, such behavior is likely to be less tolerated in the future given the rising commercial value of EO imagery. Creators of future benchmark datasets should be fully aware of the license under which the leveraged EO data is accessible and how it limits its use in public datasets. In parallel, data providers should consider a licensing scheme that allows non-commercial redistribution for scientific / educational purposes to further facilitate the development and evaluation of modern machine-learning techniques.

1) IEEE DataPort181818https://ieee-dataport.org is a valuable and easily accessible data platform that enables users to store, search, access, and manage data. The platform is designed to accept all formats and sizes of datasets (up to 2TB), and it provides both downloading capabilities and access to datasets in the Cloud. Both individuals and institutions can indefinitely store and make datasets easily accessible to a broad set of researchers, engineers, and industry. In particular, most of the datasets used for the past IEEE GRSS Data Fusion Contests have been published on this platform. However, unless being a dataset associated with a competition or being submitted as open access, an IEEE account is required to access and download.
2) Radiant MLHub191919https://mlhub.earth enables users to access, store, register, and share high-quality open datasets for training ML models in EO. It’s designed to encourage widespread collaboration and the development of trustworthy applications. The available datasets in this platform cover research topics like crop type classification, flood detection, tropical storm estimation, etc.
3) Euro Data Cube (EDC)202020https://eurodatacube.com provides a global archive of analysis-ready data (Sentinel, Landsat, MODIS, etc.), where users can search and order data using the graphical interface EDC Browser (see Fig. 25). It also enables users to store, analyze, and distribute user-contributed data content with simple APIs.

4) NASA Earthdata212121https://www.earthdata.nasa.gov provides access to a wide range of remote sensing datasets, including satellite imagery, atmospheric data, and land cover data, and offers a number of programming APIs. For example, the Application for Extracting and Exploring Analysis Ready Samples (AppEEARS) API enables users to perform data access and transformation processes easily and efficiently.
5) Maxar Open Data Program222222https://www.maxar.com/open-data provides access to high-resolution remote sensing imagery collected since 2017, amounting to a total area of 1,834,152 square kilometers. It also features several programming APIs, such as the Maxar Catalog API and the Analysis-Ready Data API. In addition, this program seeks to assist the humanitarian community by furnishing essential and useful information to support response efforts when crises occur.
6) OpenAerialMap232323https://openaerialmap.org is a community-driven platform that provides access to openly licensed satellite and unmanned aerial vehicle imagery from across the globe, accompanied by programming APIs for data access and processing. The platform currently hosts 12,614 images captured by 721 sensors, and all images can be traced in OpenStreetMap242424https://openstreetmap.org.
7) EarthNets252525https://earthnets.nicepage.io is an interactive data-sharing platform with more than 400 publicly available datasets in the geoscience and remote sensing field, which covers essential EO tasks like land use/cover classification, change/disaster monitoring, scene understanding, climate change, and weather forecasting [38]. Each benchmark dataset provides detailed meta information like spatial resolution and volume. Besides, it also supports standard data loaders and codebases for different remote sensing tasks, which enables users to conduct a fair and consistent evaluation of deep learning methods on the benchmark datasets.
8) Earth Observation Database (EOD)262626https://eod-grss-ieee.com is an interactive online platform for cataloging different types of datasets leveraging remote sensing imagery, which is developed by IEEE GRSS Image Analysis and Data Fusion (IADF) Technical Committee [6]. The key feature of EOD is to build a central catalog that provides an exhaustive list of available datasets with their basic information, which can be accessed and extended by the community and queried in a structured and interactive manner (see Fig. 26 for an example of the user interface). For more information, please refer to the corresponding box.
The IEEE-GRSS Earth Observation Database
The core of the EOD is a database of user-submitted datasets. It can be searched by a combination of various queries, including location, as well as different combinations of sensors and tasks. Search results (as well as the whole database) can be viewed either in an illustrated list view or in an interactive map view indicating those datasets that cover only a specific location with a marker (see Fig. 26). Clicking on one of the markers in the map view will limit the list to datasets at this specific location. Clicking on a dataset in the list will open a new window displaying detailed information about this dataset which includes
•
Geographic location;
•
Sensor modality;
•
Task/application;
•
Data size;
•
URL to access the data;
•
Number of views;
•
A graphical representation;
•
A brief description of the dataset.
A helpful function is the compare option, which allows a direct side-to-side comparison of this information from two or more datasets in a newly opened window.
EOD is meant as a community-driven catalog maintained by GRSS IADF, i.e. adding datasets is neither limited to IADF members nor to the creators of the dataset but anybody with an interest that the visibility and accessibility of a certain dataset is increased can request to include it into EOD. The submission requests are reviewed by IADF for completeness and correctness before the dataset is added to the database and visible to the public.
IV-B EO-oriented ML Libraries
Most existing ML libraries are developed for classic computer vision tasks, where the input image is usually single-channel (grayscale) or with RGB bands. EO datasets are often of large volumes with highly diverse data types, different numbers of spectral bands, and spatial resolutions, as illustrated in Fig. 1. The code base for processing such data samples is often highly complex and difficult to maintain. One approach to increase readability, reusability, and maintainability is to modularize the code and encapsulating different tasks by decoupling processing the dataset (data loaders, visualization, pre-processing, etc.) and applying machine learning models (training, prediction, model selection, evaluation, etc.). A major challenge in training advanced ML models for EO tasks is the implementation of an easy-to-use, yet efficient data loader explicitly designed for geoscience data that loads and preprocesses a complex dataset and produces an iterable list of data samples in a customizable way.
This section introduces several well-known packages designed explicitly for geoscience and remote sensing data. Since PyTorch [39] and TensorFlow [40] (note that Keras is now a part of TensorFlow) are the most widely used deep learning frameworks, we mainly focus on the introduction for the existing libraries using these two deep learning frameworks as the backend.

1) TorchGeo272727https://github.com/microsoft/torchgeo is an open-source PyTorch-based library, which provides datasets, samplers, transforms, and pre-trained models specific to geospatial data [41]. The main goal of this library is to simplify the process of interacting with complex geospatial data and make it easier for researchers to train ML models for EO tasks. Fig. 27 provides an example of sampling pixel-aligned patch data from heterogeneous geospatial data layers using the TorchGeo package. Since different layers usually have different coordinate systems and spatial resolutions, patches sampled from these layers in the same area may not be pixel-aligned. Therefore, in a practical application scenario researchers need to conduct a series of preprocessing operations such as reprojecting and resampling of the geospatial data before training ML models, which is time-consuming and laborious. To address this challenge, TorchGeo provides data loaders tailored for geospatial data, which support transparently loading data from heterogeneous geospatial data layers with relatively simple code (an example is shown below).
A more detailed introduction about the supported geospatial datasets in TorchGeo can be found in [41].

2) RasterVision282828https://github.com/azavea/raster-vision is an open-source Python framework that aims to simplify the procedure in building deep learning-based computer vision models on satellite, aerial, and other types of geospatial data (including oblique drone imagery). It enables users to efficiently construct a deep learning pipeline, including training data preparation, model training, model evaluation, and model deployment, without any expert knowledge of ML. Specifically, RasterVision supports chip classification, object detection, and semantic segmentation with the PyTorch backend on both CPUs and GPUs with built-in support for running in the cloud using AWS. The framework is extensible to new data sources, tasks (e.g., instance segmentation), backends (e.g., Detectron2), and cloud providers. Fig. 28 provides the pipeline of the RasterVision package. A more comprehensive tutorial for this package can be found at https://docs.rastervision.io/.
3) Keras Spatial292929https://github.com/IllinoisStateGeologicalSurvey/keras-spatial provides data samplers and tools designed to simplify the preprocessing of geospatial data for deep learning applications with the Keras backend. It provides a data generator that reads samples directly from raster layers without creating small patch files before running the model. It supports loading raster data from local files or cloud services. Necessary preprocessing, like reprojecting and resampling, is also conducted automatically. Keras Spatial supports sample augmentation using a user-defined callback system to improve the flexibility of data management. A simple demo code using the SpatialDataGenerator class from Keras Spatial to prepare a training set for a deep learning model is given below:
IV-C Geospatial Computing Platforms
In addition to ML libraries, public geospatial computing platforms, such as Google Earth Engine (GEE), for EO tasks in practical application scenarios offer a series of benefits including:
-
•
Access to large-scale datasets: Geospatial computing platforms usually provide access to large and diverse geospatial datasets, such as satellite imagery, weather data, and terrain data. These datasets may be time-consuming and expensive to acquire on one’s own but can be easily accessed through a geospatial computing platform using the cloud service.
-
•
Scalability: Geospatial computing platforms are designed to address large-scale geospatial data processing and analysis. They usually provide cloud-based computing resources that can be easily scaled up or down to meet researchers’ needs. This makes it easier to perform complex geospatial analysis that would be difficult to do on local machines considering the limited computing resources.
-
•
Pre-built tools and APIs: Geospatial computing platforms usually provide pre-built tools and programming APIs for image processing, geocoding, and data visualization, making it much easier for researchers to work with geospatial data.
Several representative geospatial computing platforms are listed below.
1) Google Earth Engine (GEE)303030https://earthengine.google.com is a cloud-based platform designed for large-scale geospatial data analysis and processing. It provides a range of tools and APIs that allow users to analyze and visualize geospatial data, including raster and vector processing tools, machine learning algorithms, and geospatial modeling tools. In addition, GEE provides access to powerful computing resources, such as virtual machines and storage, to enable users to perform complex geospatial analyses. The GEE Data Catalog contains over forty years of historical imagery and scientific datasets for Earth science, which are updated and expanded daily. These datasets cover various topics such as climate, weather, surface temperature, terrain, and land cover. Notable datasets available on the GEE Data Catalog include Planet SkySat Public Ortho Imagery (collected for crisis response events) [42] and NAIP313131https://developers.google.com/earth-engine/datasets/catalog/USDA_NAIP_DOQQ (agricultural monitoring data in the USA).
2) Amazon Web Services (AWS)323232https://aws.amazon.com is a powerful platform for geospatial computing that offers a range of services for geospatial data storage, processing, and analysis. AWS hosts several representative geospatial datasets, including Digital Earth Africa333333https://www.digitalearthafrica.org (Landsat and Sentinel products over Africa), NOAA Emergency Response Imagery343434https://oceanservice.noaa.gov/hazards/emergency-response-imagery.html (LiDAR and hyperspectral data over the USA), and the datasets of the SpaceNet challenges (Tab. II-#134/264/298/299/300/304/306/312) [43]. Sharing data on AWS allows anyone to analyze it and build services using a broad range of computing and data analytical products like Amazon EC2, which enables data users to spend more time on data analysis rather than data acquisition.
3) Microsoft Planetary Computer353535https://planetarycomputer.microsoft.com provides access to a wide range of Earth observation data and powerful geospatial computing resources. The platform is specifically designed to support the development of innovative applications and solutions for addressing critical environmental challenges, such as climate change, biodiversity loss, and natural resource management. It offers cloud-based computing services that enable users to perform complex geospatial analyses efficiently. The Data Catalog in Planetary Computer provides access to petabytes of environmental monitoring data in a consistent and analysis-ready format. Some of the representative datasets available on the Planetary Computer Data Catalog include the HREA dataset363636https://planetarycomputer.microsoft.com/dataset/hrea (settlement-level measures of electricity access derived from satellite images) and the Microsoft Building Footprints dataset373737https://github.com/Microsoft/USBuildingFootprints.
4) Colab383838https://colab.research.google.com provides a flexible geospatial computing platform that offers users access to free GPU and TPU (Tensor Processing Units) computing resources for analyzing geospatial data. It provides a free Jupyter notebook environment that allows users to write and run Python code for accessing and processing geospatial data from various platforms (e.g., GEE Data Catalog). Colab notebooks can be easily shared and collaborated on with others, which is particularly useful for geospatial analysis projects that involve multiple team members.
5) Kaggle393939https://www.kaggle.com is an online platform that is widely used for data science and machine learning competitions. It provides a cloud-based computational environment that allows for reproducible and collaborative analysis in the field of geospatial computing. Kaggle also provides access to a variety of geospatial datasets, including satellite imagery, terrain data, and weather data, along with tools to analyze and visualize these datasets. Users can take advantage of the platform’s free GPU and TPU computing resources to train machine learning models and undertake complex geospatial analysis tasks.
V Open Challenges and Future Directions
The previous sections give an overview of existing benchmarking datasets, presenting their main features and describing their main characteristics, eventually providing a broad yet detailed picture of the current state-of-the-art. This section discusses existing gaps, open challenges and potential future trends.
V-A Where are we now?
The most prominent issue that new dataset releases aim to fix is lack of diversity. Many of the earlier datasets contain samples that are extremely limited in their spatial and temporal distribution, to the extreme of consisting of a single, small image only. Not only are such datasets prone to leading to biased evaluation protocols, where information from the training set leaks into the test set via spatial correlation, they are usually also not sufficient to train models that are able to generalize to other geographic areas or time points (e.g. different seasons). More modern datasets aim to increase diversity regarding scene content (e.g. more different object instances), environmental factors (e.g. seasons, light conditions, etc.), or aspects regarding image acquisition / processing (e.g. different look angles, resolutions, etc.). This increase of diversity was so far always connected to an increase in dataset size by including more images and/or larger scenes or even other modalities. While an increase in the provided image data is often easily possible, it is usually not feasible to have the same increase in the reference data. This lead to large scale datasets where the reference data is much less carefully curated as for early datasets, often based on other existing sources (e.g. OpenStreetMap), and containing more label noise. While many machine learning methods can handle a certain extent of label noise during training, its effects on the evaluation are barely understood and often ignored.
V-B Current trends: Specificity and generality
In this context, two main characteristics of a dataset for a given task will be the focus of the discussion: specificity and generality.
Earth Observation applications present numerous and diverse scenarios due to varying object types, semantic classes, sensor types and modalities, spatial, spectral, and temporal resolutions, and coverage (global, regional, or local).
High specificity refers to datasets that are strongly tailored towards a specific sensor-platform-task combination, maybe even being limited to certain acquisition modes, geographic regions, or meteorological seasons. These can hardly be used for anything beyond their original purpose. While different application domains, such as agriculture, urban mapping, military target detection, and bio-/geo-physical parameter extraction, do require different types of data, i.e., images, point measurements, tables, and metadata, the proliferation of different datasets specialized for every small task variation reduces the reusability of the datasets in a broader context and affects scientific transparency and reproducibility.
A high specificity also contributes to cluttered nomenclature causing different datasets to appear different while actually sharing very similar content. For example, a high level of detail in class semantics and terminology makes it difficult to compare reference data of different datasets. A typical example is land cover classification, where similar classes may be aggregated into different subcategories depending on the application. As a result, models trained on different application-specific datasets may actually approximate very similar functional relationships between image data and target variables.
Virtually all of the less recent and still most of the modern datasets aim for specificity. However, several of the more recent benchmarks follow another direction: generality, i.e. providing more sensor modalities than actually required plus large-scale, often noisy reference data for multiple tasks instead of small-scale and carefully curated annotations that only address a single task.
The contribution of such general datasets is manifold: First and foremost, the required number of (annotated) training samples for fully-supervised machine learning simply does not scale very well given the effort of data annotation and curation in remote sensing. Thus, such general, large-scale datasets introduce new factors that increase the relation to realistic application scenarios such as robustness to label noise (e.g. by leveraging existing semantic maps as reference data that are often outdated, misaligned, or of coarse resolution) and weakly-supervised learning (where the reference data has a lower level of detail than the actual target variable, e.g. training semantic segmentation networks with labels on image level). Large-scale datasets are the only option to realistically test the generalization capabilities of learning-based models, e.g. over different geographic regions, seasons, or other domain gaps. Furthermore, while multimodal datasets enable data-fusion and cross-modal approaches that leverage the different input sources, multi-task datasets allow exploiting the mutual overlap of related tasks regarding feature extraction and representation learning. Last but not least, the idea of loosening the previously tight relationship between input data and target variable in datasets (up to the point where a dataset might not offer reference data for any target variable) is to provide data that can be leveraged to learn powerful representations that are useful for a large variety of downstream tasks (as in pre-training or self-supervised learning).
However, there is not yet a single ”go-to” dataset that can be used for pre-training most newly developed models or for benchmarking specific tasks against state-of-the-art approaches. Collecting such a high-quality benchmark dataset that enables to pre-train models for as many downstream tasks as possible is of significant value for further pushing performance boundaries.
The ideal pre-training dataset
A dataset ideally suited for pre-training and/or self-supervised learning should adhere to as many of the following characteristics as possible:
•
Multiple platforms (vehicle, drone, airplane, satellite)
•
Multiple sensors (Planet, SPOT, WorldView, Landsat, Sentinel 1/2, etc.)
•
Several acquisition modalities (SAR, RGB, Hyperspectral, Multispectral, Thermal, LiDAR, Passive Microwave, etc.)
•
Diverse acquisition geometries (viewing angles, e.g., off-nadir conditions, spatial and temporal baselines in multiview data, e.g., InSAR)
•
Realistic distortion factors (cloud cover, dust, smog, fog, atmospheric influence, spatial misalignments and temporal changes in multi-view data, etc.)
•
Well distributed geographical locations (spatial distribution within the dataset, climate zones, socio-economic and cultural factors, different topographies)
•
Diverse land cover/use (urban, rural, forest, agricultural, water, etc.)
•
Varying spatial resolution (0.1-1 m, 3-10 m, 10-30 m, 100-500 m, scale distribution)
•
Well temporally distributed (seasonality, lighting condition, sun angle, nighttime imagery)
•
Diverse set of reference data that are well aligned with the EO measurements (semantic information, change, geo-/bio-physical parameters, etc.)

Fig. 29 presents a schematic diagram of the properties of an ideal solution for a go-to EO benchmark dataset, covering diverse geo-locations, multiple modalities, different acquisition scenarios, and various applications. It is ideally acquired by different types of sensors and platforms with different viewing geometries to cover objects from different look-angles. The images are obtained from different electromagnetic spectrum bands, i.e., visible, infrared, thermal, and microwave, resulting in multi-/hyper-spectral, SAR, LiDAR, optical, thermal, and passive microwave measurements. The reference information or annotations are provided on a level that allows defining various tasks based on a single annotation. For example, an image with dense semantic annotations allows users to generate their desired object instance annotation files. Extending the dataset to multiple images of a scene with corresponding semantic labels enables not only semantic segmentation but also semantic change detection tasks.
In summary, we foresee a certain duality in the future development of EO-related datasets: On the one hand, following the paradigm of data-centric machine learning [44], i.e. moving against the current trend of creating performance gains merely by leveraging more training data but instead focusing on datasets tailored towards specific problems with well curated, high quality reference data (e.g. manually annotated or based on official sources). On the other hand, general datasets that cover as many in- and output modalities as possible to allow learning generic representations that are of value for a large number of possible downstream tasks.
V-C FAIR and ARD
Additional to the content, scope, and purpose of datasets their organization will gain importance. With only a dozen public datasets available prior to 2015, it was feasible that each is provided with its own data format and meta-information, hosted on individual web pages, and downloaded by everyone who wanted to work with them. With the hundreds of datasets available today and many more published every year, this cannot be maintained. Concepts such as FAIR (Findability, Accessibility, Interoperability, and Reuse, see, e.g., [45]) have already been proposed years ago and are still of high relevance. Data catalogs such as EOD (see Section IV) are a first step to structure datasets that are scattered among different data hosts. ARD (Analysis Ready Data, see, e.g., [46]), e.g. in the form of data cubes [47], and efforts to homogenize meta-information, e.g. in the form of datasheets [48], will continue to evolve into new standardized data formats. The trend of datasets growing in terms of size and volume (see Sec. II) as well as the need for global data products will soon put a stop on the current practice of downloading datasets and processing them locally. Working with data on distributed cloud services will create new requirements regarding data formats, but also lead to new standards and best practices for processing. Last but not least, the goal of any ML-centered dataset is to train an ML model. These models should be treated similar to the data they originated from, i.e. they should follow standardized data formats and FAIR principles.
VI Summary & Conclusion
This article discusses the relevance of machine-learning-oriented datasets in the technical disciplines of Earth observation and remote sensing. The analysis of the historical developments shows that the deep learning-boom has not only led to a rise in dataset numbers, but also large increase in size (as in spatial coverage and resolution but also with respect to multi-modal and multi-temporal imagery) and diversity of application tasks. This development has furthermore led to the implementation of dedicated software packages and metadatabases that help interested users to develop solutions for their applications. Eventually, we draw the conclusion that one of the critical challenges in dataset design for Earth observation tasks is the strong heterogeneity of possible sensors, data, and applications, which has led to a jungle of narrow-focused datasets. While one of the trends in deep learning certainly is the consideration of smaller, well-curated and task-specific datasets, another direction is the creation of a generic, nearly sensor- and task-agnostic database similar to the well-known ImageNet dataset used in Computer Vision. Such a generic dataset will especially be valuable in the pre-training of large high-capacity models with worldwide applicability.
The Role of the IEEE-GRSS Data Fusion Contests
The IEEE GRSS Data Fusion Contest (DFC) has been organized as an annual challenge since 2006 by the Image Analysis and Data Fusion Technical Committee (IADF TC) of the IEEE Geoscience and Remote Sensing Society (GRSS). GRSS is an IEEE society with the goal of bringing together researchers and practitioners to monitor and understand Earth’s ecosystems and to identify potential risks. IADF is one of seven GRSS technical committees aiming at technical contributions within the scope of geospatial image analysis (e.g., machine learning, deep learning, image and signal processing, and big data) and data fusion (e.g., multi-sensor, multi-scale, and multi-temporal data integration). In general, the contest promotes the development of methods for extracting geospatial information from large-scale, multi-sensor, multimodal, and multi-temporal data. It focuses on challenging problem settings and establishes novel benchmark datasets for open problems in remote sensing image analysis (see Table III).
Historically, the DFC developed from less formal activities related to the distribution of datasets between 2002 and 2006 by means of a collaboration between GRSS and the International Association of Pattern Recognition (IAPR). In 2006 the first DFC was organized by what was then called the Data Fusion Technical Committee of GRSS. It addressed the fusion of multispectral and panchromatic images, i.e., pan-sharpening, and provided one of the first public benchmark datasets for machine learning in remote sensing.
Since 2006 various sensors have played a role in the DFC, including optical (SPOT [49], DEIMOS-2 [50], WorldView-3 [51], aerial [52, 53, 54, 55, 56, 57]), multispectral (Landsat [58, 59, 60, 61], Worldview-2 [62, 63], Quickbird [63], Sentinel-2 [59, 64, 61], aerial [60]), as well as hyperspectral [65, 66, 55] images, SAR (ERS [58, 49], TerraSAR-X [63], Sentinel-1 [64, 61], Gaofeng [57]) and LiDAR [63, 66, 53, 54, 55, 67] data, but also less common sources of Earth Observation data such as thermal images [52], digital elevation models [56], video-from-space (ISS [50]), night-time images (VIIRS [61]), and Open Street Map [59]. Another meaningful change happened in 2017 when the DFC moved away from providing data over a single region only but instead allowed to train models over five cities worldwide (Berlin, Hong Kong, Paris, Rome, Sao Paulo) and testing on four other cities (Amsterdam, Chicago, Madrid, Xi’an.). This enabled creating models that generalize to new and unseen geographic areas instead of overfitting to a single location. This commendable trend was continued in 2020 by using SEN12MS (Tab. II-#87) [68] as training data [64], providing data for the whole state of Maryland, USA, in 2021 (Tab. II-#1/291) [60], in total 19 different conurbations in France in 2022 (Tab. II-#241) [56], and data from 17 cities across six continents in 2023 [57].
The tasks addressed by the DFC over the years are dominated by semantic mapping [58, 65, 66, 52, 53, 54, 59, 55, 51, 67, 61, 57], but also include pansharpening (Tab. II-#320) [69], change detection (in the context of floods) (Tab. II-#10) [49], and 3D reconstruction (Tab. II-#193) [51, 57], modern challenges such as weakly (Tab. II-#1/287/291) [64, 60] and semi-supervised learning (Tab. II-#241) [56], as well as open task contests [62, 63, 52, 50], which allowed the participants to freely explore the potential of new and uncommon EO data.
In 2006, seven teams from four different countries participated in the first DFC [69] despite public contests being a new concept within the EO community. Being organized by an internationally well-connected society, providing exciting challenges, and establishing new benchmarks led to a quick increase in popularity. From seven teams in four countries in 2006, participation jumped quickly to 21 teams in 2008, 42 teams in 2014, and reached its peak with 148 teams (distributed over four different tracks, though) in 2019. The peak of the popularity was around 2012, which attracted more than 1000 registrations for the contest from nearly 80 different countries. Influenced by different factors, including the overwhelming success of datasets (and connected contests) in the Computer Vision community404040Interestingly, the growing influence of Computer Vision on remote sensing, in particular due to deep learning, is also reflected by renaming the Data Fusion Technical Committee to the Image Analysis and Data Fusion (IADF) Technical Committee in 2014., an increasing amount of EO sensors with easier access to their data, as well as improved options for data hosting, the number of available benchmark datasets (that were not always but often connected to a contest) increased dramatically around 2015 (see also Figure 2). Since then, the participation in the DFC has been more or less constant (with a few positive outliers such as 2019), with around 40 teams from roughly 20 countries. Another commendable fact is that at the beginning the participants of the DFC were dominated by well-established scientists with solid experience in the respective fields. While this group still plays a vital role in more recent DFCs, a large number of participants (and winners!) are students. This shows that improved data availability helped to lower the starting threshold to analyze various Earth Observation data by standardizing data formats, easing access to theoretical knowledge, and open-sourcing software libraries and tools.
| Year | Data | Goal | Paper |
|---|---|---|---|
| 2023 | VHR optical and SAR satellite images | Classification, height estimation | [57] |
| 2022 | VHR aerial optical images, DEM | Semi-supervised learning | [56] |
| 2021 | Multi-temporal multispectral (aerial and Landsat 8) imagery | Weakly supervised learning | [60] |
| Multispectral (Landsat-8, Sentinel-2), SAR (Sentinel-1), night-time (VIIRS) images | Semantic segmentation | [61] | |
| 2020 | Multispectral (Sentinel-2) and SAR (Sentinel-1) imagery | Weakly supervised learning | [64] |
| 2019 | Optical (Worldview-3) images and LiDAR data | Semantic 3D reconstruction | [51, 67] |
| 2018 | Multispectral LiDAR data, VHR optical and hyperspectral imagery | Semantic segmentation | [55] |
| 2017 | Multispectral (Landsat, Sentinel-2) images and Open Street Map | Semantic segmentation | [59] |
| 2016 | Very high temporal resolution imagery (DEIMOS-2) and video from space (ISS) | Open for creative ideas | [50] |
| 2015 | Extremely high-resolution LiDAR and optical data | Semantic segmentation | [53, 54] |
| 2014 | Coarse resolution thermal/hyperspectral data and VHR color imagery | Semantic segmentation | [52] |
| 2013 | Hyperspectral imagery and LiDAR-derived DSM | Semantic segmentation | [66] |
| 2012 | VHR optical (QuickBird and WorldView-2), SAR (TerraSAR-X), and LiDAR data | Open for creative ideas | [63] |
| 2011 | Multi-angular optical images (WorldView-2) | Open for creative ideas | [62] |
| 2009-2010 | Multi-temporal optical (SPOT) and SAR (ERS) images | Change detection | [49] |
| 2008 | VHR hyperspectral imagery | Semantic segmentation | [65] |
| 2007 | Low-resolution SAR (ERS) and optical (Landsat) data | Semantic segmentation | [58] |
| 2006 | Multispectral and panchromatic images | Pan-sharpening | [69] |
References
- [1] G. Cheng, J. Han, and X. Lu, “Remote sensing image scene classification: Benchmark and state of the art,” Proc. IEEE, vol. 105, no. 10, pp. 1865–1883, 2017.
- [2] D. Hong, J. Hu, J. Yao, J. Chanussot, and X. X. Zhu, “Multimodal remote sensing benchmark datasets for land cover classification with a shared and specific feature learning model,” ISPRS J. Photogramm. Remote Sens., vol. 178, pp. 68–80, 2021.
- [3] K. Li, G. Wan, G. Chen, L. Meng, and J. Han, “Object detection in optical remote sensing images: A survey and a new benchmark,” ISPRS J. Photogramm. Remote Sens., vol. 159, pp. 296–307, 2020.
- [4] Y. Long, G.-S. Xia, S. Li, W. Yang, M. Y. Yang, X. X. Zhu, L. Zhang, and D. Li, “On creating benchmark dataset for aerial image interpretation: Reviews, guidances and million-AID,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 4205–4230, 2021.
- [5] M. Schmitt, S. A. Ahmadi, and R. Hänsch, “There is no data like more data - Current status of machine learning datasets in remote sensing,” in Proc. Int. Geosci. Remote Sens. Symp., 2021, pp. 1206–1209.
- [6] M. Schmitt, P. Ghamisi, N. Yokoya, and R. Hänsch, “EOD: The IEEE GRSS Earth observation database,” in Proc. Int. Geosci. Remote Sens. Symp., 2022, pp. 5365–5368.
- [7] Y. Yang and S. Newsam, “Bag-of-visual-words and spatial extensions for land-use classification,” in Proc. SIGSPATIAL Int. Conf. Adv. Geogr. Inf. Syst., 2010, pp. 270–279.
- [8] F. Rottensteiner, G. Sohn, J. Jung, M. Gerke, C. Baillard, S. Benitez, and U. Breitkopf, “The ISPRS benchmark on urban object classification and 3D building reconstruction,” ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci., vol. 1, no. 1, pp. 293–298, 2012.
- [9] P. Ghamisi and N. Yokoya, “IMG2DSM: Height simulation from single imagery using conditional generative adversarial net,” IEEE Geoscience and Remote Sensing Letters, vol. 15, no. 5, pp. 794–798, 2018.
- [10] C. Benedek, X. Descombes, and J. Zerubia, “Building development monitoring in multitemporal remotely sensed image pairs with stochastic birth-death dynamics,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 34, no. 1, pp. 33–50, 2011.
- [11] L. Zhang, L. Zhang, and B. Du, “Deep learning for remote sensing data: A technical tutorial on the state of the art,” IEEE Geoscience and Remote Sensing Magazine, vol. 4, no. 2, pp. 22–40, 2016.
- [12] X. X. Zhu, D. Tuia, L. Mou, G.-S. Xia, L. Zhang, F. Xu, and F. Fraundorfer, “Deep learning in remote sensing: A comprehensive review and list of resources,” IEEE Geoscience and Remote Sensing Magazine, vol. 5, no. 4, pp. 8–36, 2017.
- [13] Q. Yuan, H. Shen, T. Li, Z. Li, S. Li, Y. Jiang, H. Xu, W. Tan, Q. Yang, J. Wang et al., “Deep learning in environmental remote sensing: Achievements and challenges,” Remote Sensing of Environment, vol. 241, p. 111716, 2020.
- [14] G. Christie, N. Fendley, J. Wilson, and R. Mukherjee, “Functional map of the world,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 6172–6180.
- [15] I. Kotaridis and M. Lazaridou, “Remote sensing image segmentation advances: A meta-analysis,” ISPRS J. Photogramm. Remote Sens., vol. 173, pp. 309–322, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0924271621000265
- [16] M. Schmitt, L. H. Hughes, C. Qiu, and X. X. Zhu, “SEN12MS – A curated dataset of georeferenced multi-spectral Sentinel-1/2 imagery for deep learning and data fusion,” in ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci., vol. IV-2/W7, 2019, pp. 153–160.
- [17] M. Schmitt and Y.-L. Wu, “Remote sensing image classification with the sen12ms dataset,” in ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, vol. V-2-2021, 2021, pp. 101–106.
- [18] F. Rottensteiner, G. Sohn, M. Gerke, and J. D. Wegner, “ISPRS test project on urban classification and 3D building reconstruction- 2D semantic labeling - Vaihingen data,” https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx, 2013, accessed: 2022-10-14.
- [19] M. Cramer, “The DGPF-Test on digital airborne camera evaluation – Overview and test design,” in Photogrammetrie – Fernerkundung – Geoinformation 2, 2010.
- [20] Y. Wang and M. Li, “Urban impervious surface detection from remote sensing images: A review of the methods and challenges,” IEEE Geosci. Remote Sens. Mag., vol. 7, no. 3, pp. 64–93, 2019.
- [21] D. Wen, X. Huang, F. Bovolo, J. Li, X. Ke, A. Zhang, and J. A. Benediktsson, “Change detection from very-high-spatial-resolution optical remote sensing images: Methods, applications, and future directions,” IEEE Geosci. Remote Sens. Mag., vol. 9, no. 4, pp. 68–101, 2021.
- [22] A. Karpatne, Z. Jiang, R. R. Vatsavai, S. Shekhar, and V. Kumar, “Monitoring land-cover changes: A machine-learning perspective,” IEEE Geosci. Remote Sens. Mag., vol. 4, no. 2, pp. 8–21, 2016.
- [23] P. Helber, B. Bischke, A. Dengel, and D. Borth, “EuroSAt: A novel dataset and deep learning benchmark for land use and land cover classification,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 12, no. 7, pp. 2217–2226, 2019.
- [24] ——, “Introducing EuroSAT: A novel dataset and deep learning benchmark for land use and land cover classification,” in Proc. Int. Geosci. Remote Sens. Symp., 2018, pp. 204–207.
- [25] S. A. Yamashkin, A. A. Yamashkin, V. V. Zanozin, M. M. Radovanovic, and A. N. Barmin, “Improving the efficiency of deep learning methods in remote sensing data analysis: geosystem approach,” IEEE Access, vol. 8, pp. 179 516–179 529, 2020.
- [26] C. Broni-Bediako, Y. Murata, L. H. Mormille, and M. Atsumi, “Searching for CNN architectures for remote sensing scene classification,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–13, 2021.
- [27] G. Sumbul, A. De Wall, T. Kreuziger, F. Marcelino, H. Costa, P. Benevides, M. Caetano, B. Demir, and V. Markl, “Bigearthnet-mm: A large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval [software and data sets],” IEEE Geosci. Remote Sens. Mag., vol. 9, no. 3, pp. 174–180, 2021.
- [28] U. Chaudhuri, S. Dey, M. Datcu, B. Banerjee, and A. Bhattacharya, “Interband retrieval and classification using the multilabeled Sentinel-2 BigEarthNet archive,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 9884–9898, 2021.
- [29] G. Cheng and J. Han, “A survey on object detection in optical remote sensing images,” ISPRS J. Photogramm. Remote Sens., vol. 117, pp. 11–28, 2016. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0924271616300144
- [30] G.-S. Xia, X. Bai, J. Ding, Z. Zhu, S. Belongie, J. Luo, M. Datcu, M. Pelillo, and L. Zhang, “DOTA: A large-scale dataset for object detection in aerial images,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., June 2018.
- [31] J. Ding, N. Xue, Y. Long, G.-S. Xia, and Q. Lu, “Learning RoI transformer for detecting oriented objects in aerial images,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., June 2019.
- [32] J. Ding, N. Xue, G.-S. Xia, X. Bai, W. Yang, M. Yang, S. Belongie, J. Luo, M. Datcu, M. Pelillo, and L. Zhang, “Object detection in aerial images: A large-scale benchmark and challenges,” IEEE Trans. Pattern Anal. Mach. Intell., pp. 1–1, 2021.
- [33] H. Chen and Z. Shi, “A spatial-temporal attention-based method and a new dataset for remote sensing image change detection,” Remote Sens., vol. 12, no. 10, 2020. [Online]. Available: https://www.mdpi.com/2072-4292/12/10/1662
- [34] R. Caye Daudt, B. Le Saux, A. Boulch, and Y. Gousseau, “Urban change detection for multispectral earth observation using convolutional neural networks,” in Proc. Int. Geosci. Remote Sens. Symp., July 2018.
- [35] M. Märtens, D. Izzo, A. Krzic, and D. Cox, “Super-resolution of proba-v images using convolutional neural networks,” 2019. [Online]. Available: https://arxiv.org/abs/1907.01821
- [36] G. Vivone, M. Dalla Mura, A. Garzelli, and F. Pacifici, “A benchmarking protocol for pansharpening: Dataset, preprocessing, and quality assessment,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 6102–6118, 2021.
- [37] J. Cornebise, I. Orsolic, and F. Kalaitzis, “Open high-resolution satellite imagery: The worldstrat dataset – with application to super-resolution,” in Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022. [Online]. Available: https://openreview.net/forum?id=DEigo9L8xZA
- [38] Z. Xiong, F. Zhang, Y. Wang, Y. Shi, and X. X. Zhu, “EarthNets: Empowering AI in Earth observation,” arXiv preprint arXiv:2210.04936, 2022.
- [39] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “PyTorch: An imperative style, high-performance deep learning library,” Proc. Neural Inf. Process. Syst., vol. 32, 2019.
- [40] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard et al., “TensorFlow: A system for large-scale machine learning,” in Proc. USENIX Symp. Oper. Syst. Des. Implement., 2016, pp. 265–283.
- [41] A. J. Stewart, C. Robinson, I. A. Corley, A. Ortiz, J. M. L. Ferres, and A. Banerjee, “TorchGeo: Deep learning with geospatial data,” arXiv preprint arXiv:2111.08872, 2021.
- [42] H. Tamiminia, B. Salehi, M. Mahdianpari, L. Quackenbush, S. Adeli, and B. Brisco, “Google Earth Engine for geo-big data applications: A meta-analysis and systematic review,” ISPRS J. Photogramm. Remote Sens., vol. 164, pp. 152–170, 2020.
- [43] A. Van Etten, D. Lindenbaum, and T. M. Bacastow, “SpaceNet: A remote sensing dataset and challenge series,” arXiv preprint arXiv:1807.01232, 2018.
- [44] E. Strickland, “Andrew Ng, AI minimalist: The machine-learning pioneer says small is the new big,” IEEE Spectrum, vol. 59, no. 4, pp. 22–50, 2022.
- [45] M. D. Wilkinson, M. Dumontier, I. J. Aalbersberg, G. Appleton, M. Axton, A. Baak, N. Blomberg, J.-W. Boiten, L. B. da Silva Santos, P. E. Bourne et al., “The fair guiding principles for scientific data management and stewardship,” Scientific data, vol. 3, 2016.
- [46] J. L. Dwyer, D. P. Roy, B. Sauer, C. B. Jenkerson, H. K. Zhang, and L. Lymburner, “Analysis ready data: Enabling analysis of the landsat archive,” Remote Sensing, vol. 10, no. 9, 2018. [Online]. Available: https://www.mdpi.com/2072-4292/10/9/1363
- [47] G. Giuliani, B. Chatenoux, A. D. Bono, D. Rodila, J.-P. Richard, K. Allenbach, H. Dao, and P. Peduzzi, “Building an earth observations data cube: lessons learned from the swiss data cube (sdc) on generating analysis ready data (ard),” Big Earth Data, vol. 1, no. 1-2, pp. 100–117, 2017.
- [48] T. Gebru, J. Morgenstern, B. Vecchione, J. W. Vaughan, H. Wallach, H. Daumé, and K. Crawford, “Datasheets for datasets,” 2018. [Online]. Available: https://arxiv.org/abs/1803.09010
- [49] N. Longbotham, F. Pacifici, T. Glenn, A. Zare, M. Volpi, D. Tuia, E. Christophe, J. Michel, J. Inglada, J. Chanussot, and Q. Du, “Multi-modal change detection, application to the detection of flooded areas: Outcome of the 2009–2010 Data Fusion Contest,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 5, no. 1, pp. 331–342, 2012.
- [50] L. Mou, X. Zhu, M. Vakalopoulou, K. Karantzalos, N. Paragios, B. Le Saux, G. Moser, and D. Tuia, “Multitemporal very high resolution from space: Outcome of the 2016 IEEE GRSS Data Fusion Contest,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 10, no. 8, pp. 3435–3447, 2017.
- [51] S. Kunwar, H. Chen, M. Lin, H. Zhang, P. D’Angelo, D. Cerra, S. M. Azimi, M. Brown, G. Hager, N. Yokoya, R. Hänsch, and B. Le Saux, “Large-scale semantic 3-D reconstruction: Outcome of the 2019 IEEE GRSS Data Fusion Contest—Part A,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 922–935, 2021.
- [52] W. Liao, X. Huang, F. Van Coillie, S. Gautama, A. Pižurica, W. Philips, H. Liu, T. Zhu, M. Shimoni, G. Moser, and D. Tuia, “Processing of multiresolution thermal hyperspectral and digital color data: Outcome of the 2014 IEEE GRSS Data Fusion Contest,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 8, no. 6, pp. 2984–2996, 2015.
- [53] M. Campos-Taberner, A. Romero-Soriano, C. Gatta, G. Camps-Valls, A. Lagrange, B. Le Saux, A. Beaupère, A. Boulch, A. Chan-Hon-Tong, S. Herbin, H. Randrianarivo, M. Ferecatu, M. Shimoni, G. Moser, and D. Tuia, “Processing of extremely high-resolution lidar and rgb data: Outcome of the 2015 IEEE GRSS Data Fusion Contest–Part A: 2-D Contest,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 9, no. 12, pp. 5547–5559, 2016.
- [54] A.-V. Vo, L. Truong-Hong, D. F. Laefer, D. Tiede, S. d’Oleire Oltmanns, A. Baraldi, M. Shimoni, G. Moser, and D. Tuia, “Processing of extremely high resolution lidar and rgb data: Outcome of the 2015 IEEE GRSS Data Fusion Contest—Part B: 3-D Contest,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 9, no. 12, pp. 5560–5575, 2016.
- [55] Y. Xu, B. Du, L. Zhang, D. Cerra, M. Pato, E. Carmona, S. Prasad, N. Yokoya, R. Hänsch, and B. Le Saux, “Advanced multi-sensor optical remote sensing for urban land use and land cover classification: Outcome of the 2018 IEEE GRSS Data Fusion Contest,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 12, no. 6, pp. 1709–1724, June 2019.
- [56] R. Hänsch, C. Persello, G. Vivone, J. C. Navarro, A. Boulch, S. Lefevre, and B. Saux, “The 2022 IEEE GRSS Data Fusion Contest: Semisupervised learning [technical committees],” IEEE Geosci. Remote Sens. Mag., vol. 10, no. 1, pp. 334–337, 2022.
- [57] C. Persello, R. Hänsch, G. Vivone, K. Chen, Z. Yan, D. Tang, H. Huang, M. Schmitt, and X. Sun, “2023 IEEE GRSS Data Fusion Contest: Large-Scale Fine-Grained Building Classification for Semantic Urban Reconstruction [Technical Committees],” IEEE Geosci. Remote Sens. Mag., vol. 11, no. 1, 2023.
- [58] F. Pacifici, F. Del Frate, W. J. Emery, P. Gamba, and J. Chanussot, “Urban mapping using coarse SAR and optical data: Outcome of the 2007 GRSS Data Fusion Contest,” IEEE Geosci. Remote Sens. Lett., vol. 5, no. 3, pp. 331–335, 2008.
- [59] N. Yokoya, P. Ghamisi, J. Xia, S. Sukhanov, R. Heremans, I. Tankoyeu, B. Bechtel, B. Le Saux, G. Moser, and D. Tuia, “Open data for global multimodal land use classification: Outcome of the 2017 IEEE GRSS Data Fusion Contest,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 11, no. 5, pp. 1363–1377, May 2018.
- [60] Z. Li, F. Lu, H. Zhang, L. Tu, J. Li, X. Huang, C. Robinson, N. Malkin, N. Jojic, P. Ghamisi, R. Hänsch, and N. Yokoya, “The outcome of the 2021 IEEE GRSS Data Fusion Contest—Track MSD: Multitemporal semantic change detection,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 15, pp. 1643–1655, 2022.
- [61] Y. Ma, Y. Li, K. Feng, Y. Xia, Q. Huang, H. Zhang, C. Prieur, G. Licciardi, H. Malha, J. Chanussot, P. Ghamisi, R. Hänsch, and N. Yokoya, “The outcome of the 2021 IEEE GRSS Data Fusion Contest - Track DSE: Detection of settlements without electricity,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 12 375–12 385, 2021.
- [62] F. Pacifici and Q. Du, “Foreword to the special issue on optical multiangular data exploitation and outcome of the 2011 GRSS Data Fusion Contest,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 5, no. 1, pp. 3–7, 2012.
- [63] C. Berger, M. Voltersen, R. Eckardt, J. Eberle, T. Heyer, N. Salepci, S. Hese, C. Schmullius, J. Tao, S. Auer, R. Bamler, K. Ewald, M. Gartley, J. Jacobson, A. Buswell, Q. Du, and F. Pacifici, “Multi-modal and multi-temporal data fusion: Outcome of the 2012 GRSS Data Fusion Contest,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 6, no. 3, pp. 1324–1340, 2013.
- [64] C. Robinson, K. Malkin, N. Jojic, H. Chen, R. Qin, C. Xiao, M. Schmitt, P. Ghamisi, R. Hänsch, and N. Yokoya, “Global land-cover mapping with weak supervision: Outcome of the 2020 IEEE GRSS Data Fusion Contest,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 3185–3199, 2021.
- [65] G. Licciardi, F. Pacifici, D. Tuia, S. Prasad, T. West, F. Giacco, C. Thiel, J. Inglada, E. Christophe, J. Chanussot, and P. Gamba, “Decision fusion for the classification of hyperspectral data: Outcome of the 2008 GRSS Data Fusion Contest,” IEEE Trans. Geosci. Remote Sens., vol. 47, no. 11, pp. 3857–3865, 2009.
- [66] C. Debes, A. Merentitis, R. Heremans, J. Hahn, N. Frangiadakis, T. van Kasteren, W. Liao, R. Bellens, A. Pižurica, S. Gautama, W. Philips, S. Prasad, Q. Du, and F. Pacifici, “Hyperspectral and lidar data fusion: Outcome of the 2013 GRSS Data Fusion Contest,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 7, no. 6, pp. 2405–2418, 2014.
- [67] Y. Lian, T. Feng, J. Zhou, M. Jia, A. Li, Z. Wu, L. Jiao, M. Brown, G. Hager, N. Yokoya, R. Hänsch, and B. L. Saux, “Large-scale semantic 3-d reconstruction: Outcome of the 2019 IEEE GRSS Data Fusion Contest—Part B,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 1158–1170, 2021.
- [68] M. Schmitt, L. H. Hughes, C. Qiu, and X. X. Zhu, “SEN12MS – A curated dataset of georeferenced multi-spectral sentinel-1/2 imagery for deep learning and data fusion,” in ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. IV-2/W7, 2019, pp. 153–160.
- [69] L. Alparone, L. Wald, J. Chanussot, C. Thomas, P. Gamba, and L. M. Bruce, “Comparison of pansharpening algorithms: Outcome of the 2006 GRSS Data Fusion Contest,” IEEE Trans. Geosci. Remote Sens., vol. 45, no. 10, pp. 3012–3021, 2007.
| Michael Schmitt ([email protected]) received his Dipl.-Ing. (Univ.) degree in geodesy and geoinformation, his Dr.-Ing. degree in remote sensing, and his habilitation in data fusion from the Technical University of Munich (TUM), Germany, in 2009, 2014, and 2018, respectively. Since 2021, he has been a Full Professor for Earth Observation at the Department of Aerospace Engineering of the University of the Bundeswehr Munich in Neubiberg, Germany. Before that, he was a professor for applied geodesy and remote sensing at the Munich University of Applied Sciences, Department of Geoinformatics. From 2015 to 2020, he was a senior researcher and deputy head at the Professorship for Signal Processing in Earth Observation at TUM; in 2019 he was additionally appointed as Adjunct Teaching Professor at the Department of Aerospace and Geodesy of TUM. In 2016, he was a guest scientist at the University of Massachusetts, Amherst. His research focuses on technical aspects of Earth observation, in particular image analysis and machine learning applied to the extraction of information from multi-sensor remote sensing observations. Among his core interests is remote sensing data fusion with a focus on SAR and optical data. He is a co-chair of the Working Group “Active Microwave Remote Sensing” of the International Society for Photogrammetry and Remote Sensing, and also of the Working Group “Benchmarking” of the IEEE-GRSS Image Analysis and Data Fusion Technical Committee. He frequently serves as a reviewer for a number of renowned international journals and conferences and has received several Best Reviewer awards. He is a Senior Member of the IEEE. |
| Seyed Ali Ahmadi received his B.Sc. degree in surveying engineering and M.Sc. degree in remote sensing from the Faculty of Geodesy and Geomatics, K. N. Toosi University of Technology, Tehran, Iran, in 2015 and 2017, respectively. He worked on image classification and segmentation techniques, machine learning algorithms, and LiDAR data processing. His thesis was focused on classifying hyperspectral and LiDAR datasets by combining spectral and spatial features in order to increase the classification accuracy. He is currently pursuing his Ph.D. thesis on building damage assessment with the K. N. Toosi University of Technology. His research interests include machine learning, deep learning, geospatial data analysis, image processing, and computer vision techniques for remote sensing and earth observation applications. He is a co-chair of Working Group “Benchmarking” of the IEEE-GRSS Image Analysis and Data Fusion Technical Committee; and frequently serves as a reviewer for a number of international journals and has received a Best Reviewer Award in 2018. |
| Yonghao Xu received the B.S. degree and the Ph.D. degree in Photogrammetry and Remote Sensing from Wuhan University, Wuhan, China, in 2016 and 2021, respectively. He is currently a post-doctoral researcher at the Institute of Advanced Research in Artificial Intelligence (IARAI), Austria. His research interests include remote sensing, computer vision, and machine learning. |
| Gulsen Taskin (SM’22-M’10) received the B.S. degree in Geomatics Engineering, the M.S. degree in Computational Science and Engineering (CSE), and the Ph.D. degree in CSE, from Istanbul Technical University (ITU), Turkey, in 2001, 2003, and 2011, respectively. She is currently an Associate Professor at the Institute of Disaster Management at Istanbul Technical University. She was a visiting scholar at the School of Electrical and Computer Engineering and the School of Civil Engineering at Purdue University from 2008 to 2009 and 2016 to 2017. She is a reviewer for Photogrammetric Engineering and Remote Sensing, IEEE Transactions on Geoscience and Remote Sensing, IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, IEEE Geoscience and Remote Sensing Letters, and IEEE Transactions on Image Processing. Her current interests include machine learning approaches in hyperspectral image analysis, dimensionality reduction, explainable AI, and sensitivity analysis. |
| Ujjwal Verma received his Ph.D. from Télécom ParisTech, University of Paris-Saclay, Paris, France, in Image Analysis and his M.S. (Research) from IMT Atlantique (France) in Signal and Image Processing. Dr. Verma is currently an Associate Professor and Head of the Department of Electronics and Communication Engineering at Manipal Institute of Technology, Bengaluru, India. His research interests include Computer Vision and Machine Learning, focusing on variational methods in image segmentation, deep learning methods for scene understanding, and semantic segmentation of aerial images. He is a recipient of the ”ISCA Young Scientist Award 2017-18” by the Indian Science Congress Association (ISCA), a professional body under the Department of Science and Technology, Government of India. Dr. Verma is also a recipient of the ”Young Professional Volunteer Award 2020” by IEEE Mangalore Sub-Section in recognition of his outstanding contribution to IEEE activities. Dr. Verma is the Co-Lead for the Working Group on Machine/Deep Learning for Image Analysis (WG-MIA) of the Image Analysis and Data Fusion Technical Committee (IADF TC) of the IEEE Geoscience and Remote Sensing Society. He is Guest Editor for Special Stream in IEEE Geoscience and Remote Sensing Letters and a reviewer for several journals (IEEE Transactions on Image Processing, IEEE Transactions on Geoscience and Remote Sensing, IEEE Geoscience and Remote Sensing Letters). He is also a Sectional Recorder for the ICT Section of the Indian Science Congress Association for 2020-24. |
| Francescopaolo Sica received the Laurea (M.S.) degree (summa cum laude) in Telecommunications Engineering and the Dr. Ing. (Ph.D.) degree in Information Engineering from the University of Naples Federico II, Italy, in 2012 and 2016, respectively. Since 2022, he is Deputy Head of the Earth Observation Laboratory at the Department of Aerospace Engineering of the University of the Bundeswehr Munich, Germany. Between 2016 and 2022, he was a researcher at the German Aerospace Center (DLR). His research interests cover a wide range of activities related to Synthetic Aperture Radar (SAR) technology, from mission design to SAR signal and image processing to end-user applications. Dr Sica received a Living Planet Postdoc Fellowship from the European Space Agency (ESA) for the HI-FIVE (High-Resolution Forest Coverage with InSAR & Deforestation Surveillance) project. He is co-chair of the Benchmarking Working Group of the IEEE-GRSS Image Analysis and Data Fusion Technical Committee (IADF) and is a regular reviewer for international journals and conferences. |
| Ronny Hänsch received the Diploma in computer science and the Ph.D. degree from the TU Berlin, Berlin, Germany, in 2007 and 2014, respectively. He is a scientist at the Microwave and Radar Institute of the German Aerospace Center (DLR) where he leads the Machine Learning Team in the Signal Processing Group of the SAR Technology Department. He continues to lecture at the TU Berlin in the Computer Vision and Remote Sensing Group. His research interest is computer vision and machine learning with a focus on remote sensing (in particular SAR processing and analysis). He serves as chair of the GRSS Image Analysis and Data Fusion (IADF) technical committee, co-chair of the ISPRS working group on Image Orientation and Fusion, editor of the GRSS eNewsletter, GRSS membership chair, associate editor of the Geoscience and Remote Sensing Letters and the ISPRS Journal of Photogrammetry and Remote Sensing, organizer of the CVPR Workshops EarthVision (2017-2023), Photogrammetric Computer Vision (2019,2023), the ML4RS Workshop at ICLR (2023), and the IGARSS Tutorial on Machine Learning in Remote Sensing (2017-2023). He has extensive experience in organizing remote sensing community competitions (e.g. the DFC 2018-2023), serves as the GRSS representative within SpaceNet, and was the technical lead of the SpaceNet 8 Challenge. |