The Why, When, and How to Use Active Learning in Large-Data-Driven 3D Object Detection for
Safe Autonomous Driving: An Empirical Exploration
Abstract
Active learning strategies for 3D object detection in autonomous driving datasets may help to address challenges of data imbalance, redundancy, and high-dimensional data. We demonstrate the effectiveness of entropy querying to select informative samples, aiming to reduce annotation costs and improve model performance. We experiment using the BEVFusion model for 3D object detection on the nuScenes dataset, comparing active learning to random sampling and demonstrating that entropy querying outperforms in most cases. The method is particularly effective in reducing the performance gap between majority and minority classes. Class-specific analysis reveals efficient allocation of annotated resources for limited data budgets, emphasizing the importance of selecting diverse and informative data for model training. Our findings suggest that entropy querying is a promising strategy for selecting data that enhances model learning in resource-constrained environments.
Note to Practitioners—Data-driven systems continue to show state-of-the-art performance across perception tasks in autonomous driving systems. However, the annotation of such data can be prohibitively expensive, with the annotation of non-informative data contributing to wasted labor and computational resources. Active learning systems, like the one we introduce in this paper, allow for the reduction of datasets to the most informative samples, such that the same perception performance can be reached at a limited labeling budget. We relate this data budget to hours of labor to illustrate the importance of this efficiency gain. In this paper, we especially show that these performance effects actually serve a dual purpose, providing enhanced perception of minority classes on limited data. Minority classes stochastically appear most rarely while driving, and safety-critical events occur with such rarity (“long-tail problem") that it is critical to fully utilize such data during model training to improve safety outcomes.
Index Terms:
active learning, safe autonomous driving, 3D object detection, entropy querying, data-driven perception systemsI Introduction
Many autonomous driving tasks rely on supervised learning, and task performance under such methods is heavily dependent on accurate, high-volume data annotation. The conventional approach for most autonomous driving tasks, such as 3D object detection [1, 2, 3, 4, 5], is to ask humans to label (or supervise the labeling of) all data collected in driving, then train learning machines using the labeled data.

However, such annotation often requires meticulous treatment and expensive labor from expert human annotators [6]. When the volume of the data grows faster than the available human resources, annotating data becomes a challenging bottleneck to better-performing models. This is especially the case for autonomous driving, where the data itself can be collected quickly and diversely from fleets or even a single vehicle [7]. In fact, a German study in autonomous vehicle data estimated the annotation cost to produce direct statistical evidence of reliable AI-perception ranges in the scale of 1.16 trillion to 51,800 trillion Euro – 14,800 times Germany’s gross domestic product! [8, 9] In this research, we explore and evaluate an entropy-based querying active learning solution to this annotation bottleneck with consideration to the multimodal, multitask, and safety-critical nature of intelligent vehicle learning systems.

I-A Redundancy and Data Imbalance
As a motivating example, consider a fleet which seeks to gather data in a particular region. By the nature of our roadway system, over time, vehicles will likely encounter the same roads in the same conditions and same context multiple times (e.g. a 5 o’clock rush hour traffic jam on southbound I5 near Exit 26B). For this reason, many data points collected for autonomous driving may be redundant or similar between capture sessions.
Why is this redundancy, or data imbalance, a problem to begin with? When nearly-identical, highly-repeated samples are used to train a model (and distinct samples are significantly less present), the data imbalance can cause the model to overfit parameters to be sensitive to the minor deviations in the over-represented data instead of solving the intended problem – an issue addressed with active learning [10] [11]. Additionally, in a well-designed model trained on a sufficiently diverse dataset, the model learns a latent space which interpolates between encoded samples, allowing the model to generalize to noisy data in the wild [12]. While collecting large amounts of data is important, there comes a point when further data collection of similar samples becomes redundant as the learning of the latent space sufficiently covers the real-world pattern for similar samples. This is especially the case when it comes to safety for autonomous driving, as it is not the familiar which poses a risk, but rather encounters with unexpected or novel situations, so-called “long-tail" (infrequent) driving events. At a practical level, because ML systems optimize over a loss function summed over each training sample, in cases of severe class imbalance, catering to the “majority" serves to place the learner in a comfortable local minimum of loss. Further, when it comes to safe autonomy, these non-majority cases are often the most significant from a safety standpoint. This challenge is shared with biomedical research, earning the name curse of rarity, referring to the difficulty of gathering samples of events that are most likely to cause system safety failures [13]. This is also referred to as the “long-tail problem".
Data sampling methods are commonly used to overcome data imbalance, such as random under-sampling (to remove majority cases from training data), and random over-sampling (having under-represented classes appear more frequently during training). In principle, standard data augmentation serves this same purpose, but on the basis that the collected data under-represents the variance of the complete population of data. Naturally, augmentation methods can be applied to minority-class data to build a stronger representation within a training dataset. However, here we seek solutions which add more to a model’s knowledge than crafted re-use of existing training data, such that a system can continually learn from new examples, finding “useful novelty" through examining the entropy of considered data [14].
I-B Dealing with High-Dimensional Data
In addition to data imbalance, data for intelligent vehicle tasks tends to be high-dimensional. For example, a typical testbed may be collecting data along dimensions of time, arrays of pixels from 2D spatial cameras, sweeps of 3D spatial lidar measurements, and a variety of additional sensors such as GPS, INS, and CAN.
By learning an expansive low-to-high-level feature set, this scale and variety of information has proven to be helpful towards a variety of tasks such as lane detection [15], vehicle and VRU detection and tracking [16], traffic sign and light classification [17, 18, 19], trajectory prediction [20, 21], vehicle landmark identification [22], driving maneuver and driver style classification [23]; such tasks are important not only towards autonomous driving, but also towards effectiveness of ADAS systems [24]. While this data provides a wealth of information to learn from, the infamous “curse of dimensionality" puts systems at risk of improperly fitting models to complex data (requiring exponential amount of increased data with each new dimension introduced). Further, even annotating this data at a high-quality, frame-by-frame, pixel-by-pixel, voxel-by-voxel level is a monumental task, near impossible to complete exhaustively given resource constraints and costs in human annotation, discussed further in later sections.
Weeks of Annotation % of nuScenes dataset in Training Pool 1 2.52% 2 5.04% 3 7.56% 4 10.08% 5 12.60% 6 15.12% 7 17.64% 8 20.16% 9 22.68% 10 25.20%
In essence, much of machine learning involves reducing the dimensionality of data from its high-dimensional observed form to a task-useful form. Sometimes we do this before the data enters the learning mechanism (e.g. pre-processing the data by selecting features to learn from), sometimes we do this inside the learning mechanism (e.g. an early bottleneck layer in a neural network, which learns lower-dimensional encodings of feature combinations). Sometimes we do this explicitly (e.g. extract particular features, such as one color channel for a task like brake light extraction [22]), often termed selecting, other times letting the system learn the features (e.g. neural network which outputs a low-dimensional vector for system inference [28]), often termed mapping.
| Active Learning Methods | Datasets | Modalities | Insights |
|---|---|---|---|
| Entropy, Monte Carlo dropout, ensemble learning | KITTI | Camera, LiDAR | Can save up to 60% of labeling efforts for same performance [29] |
| Class Entropy and Spatial Uncertainty | Private | LiDAR | Importance of both classification and spatial uncertainty [30] |
| Kernel coding rate | KITTI, Waymo | LiDAR | 44% box-level annotation costs savings without compromising performance [31] |
| Sensor consistency-based selection score, LiDAR guidance as semi-supervision for monocular detection | KITTI, Waymo | Camera | 17% savings in labeling costs, top performance in BEV monocular object detection official benchmarks with 2.02 AP gain [32, 33] |
| 3D consistency of bounding box predictions in both semi-supervised and active learning | KITTI | LiDAR | Improves from baseline by more than 60% with only 1500 annotated frames [34] |
| Consensus score variation ratio, sequential region-of-interest matching | KITTI | Camera, LiDAR | Saves 35% of labeling efforts [35] |
| Bi-domain active learning, diversity-based sampling | KITTI | LiDAR | Gains on cross-domain settings; retraining Waymo-trained model on just 5% of KITTI data outperforms 100% KITTI-trained model [36] |
| Uncertainty sampling | Astyx | Radar, Camera, LiDAR | Semi-automatic labeling for efficient dataset creation [37] |
| Augmentation, dropout, insertion, deletion | KITTI | LiDAR | Practical method for fast annotation [38] |
| Semi-supervised co-training on prediction disagreement | KITTI, Waymo | Camera | Semi-supervised co-training clearly boosts detection accuracy in regimes where the training size is just 5-10% of the pool [39] |
| Ego-pose distance-based sampling | Navya3DSeg | LiDAR | Heuristic-free method; outperform random sampling [40] |
| Bayesian surprise (KL divergence) | AGV Anomaly Dataset | LiDAR | Effective in warehouse environment anomaly detection; may be applied as AL to identify novel data [41] |
| Uncertainty sampling | Private | LiDAR, Camera | Effective for identifying road damage [42] |
| Spatial and temporal diversity-based sampling | NuScenes | LiDAR | Annotation costs vary between scenes; diversity methods are effective and allow warm start [43] |
| Classification Entropy Querying | NuScenes | LiDAR, Camera | Outperforms random sampling, reduces intra-class performance difference, learning of minority classes (this research) |
In addition to implications toward the theoretical limits of a systems ability to learn, high-dimensional data also contributes to a lack of explainability in systems, and complicates the process of safety regulation on a practical level. Techniques in intelligent data selection and feature extraction help to resolve these challenges, but as information is discarded, a tradeoff is induced between system performance and system explainability. Pes et al. [11] categorize three types of feature selection methods:
-
•
Filter methods, which remove data according to some non-learned criteria,
-
•
Wrapper methods, which essentially search over different feature subsets to optimize performance, and
-
•
Embedded methods, which, critically, make use of learning algorithm internal information in the process of searching for optimal features. For example, while a wrapper method might make use of system accuracy over a test set to select a best feature set, an embedded method may examine the uncertainty values of logits during classification to drive its selection criteria.
As expected, filter methods bear the least computational cost, but show the most constrained performance (albeit, sometimes this constrained performance may be sufficient towards a task). In this research, we explore an embedded method, accepting increased computational complexity to enhance model performance.
I-C Using Active Learning
Active learning is the process by which a learning system interactively selects which data points should be added from the unlabeled data pool to the labeled training set, assisted by the intervention of a human expert providing associated annotations. Within this framework, in the case of classification tasks, we consider the information gain of a new datum to be a measure of the decrease in entropy when that datum is added to the training set.
This problem is therefore twofold: (1) for model cost and performance, a large set of these non-informative data points increases the time and decreases effectiveness of the training process and model tuning, and (2) for annotation cost, in situations where a data corpus has high levels of redundancies, annotating all collected data may waste a lot of human resources on non-informative samples.
II Related Research
Cohn et al. engage in a particular style of active learning as concept learning via queries, by which the learner requests from an oracle a label for a particular sample [10]. In particular, their work examines the effectiveness of such methods in improving generalization behavior. One of the goals in active learning is to label a small subset of collected unlabeled data so as to maintain or achieve better performance given the cost of labeling or requesting human oracle. Conventional query strategies usually evaluate informativeness based on handcrafted functions or heuristic selection methods, such as query-by-committee [44], uncertainty sampling [45, 46], region of uncertainty and version space [10], and expected model change [47]. Empirical studies [48, 49] have shown that the best strategy or informativeness measure may be application specific. Moreover, the effectiveness of such heuristic methods is limited and varies across different datasets.
Due to the variability in datasets, models, and query selection methods, it is difficult to form a noticeable consensus for the state of the art in active learning. Accordingly, through this paper, we show the clear utility of one such method towards the detection safety goals of autonomous driving systems. Early works in the literature applying active learning in autonomous driving tasks mostly utilized handcrafted features such as Haar wavelets and the histogram of oriented gradients on SVMs or Adaboost [50, 51, 52]. As deep learning became a dominant approach in computer vision [53], more works have resorted to DNNs as models in active learning to further boost performance. In [54], four active learning methods (sum of entropy, maximum entropy, average entropy, and Monte Carlo dropout) are applied to the Apollo Synthetic dataset and Waymo Open dataset on 2D object detection and instance segmentation tasks, using R-CNNs appropriate for each task, and finding that active learners beat baselines in these autonomous driving tasks, and that summation-entropy learners tend to bring forward samples with the most instances, which seem to have the strongest effect on learning. While these insights are valuable, in this research, we focus on the task of 3D object detection, reflecting the need for vehicles to recognize an object’s relative position for purposes of safe planning; accordingly, our discussion of related works will continue with active learning towards this task. We highlight relevant literature towards effective detection and efficient annotation of such datasets in Table III, and discuss particular methods in the following paragraphs.
In [29], Feng et al. use active learning to find the fewest number of labeled training samples to improve the performance of 3D object detection by convolutional neural networks (CNNs) trained on LiDAR point clouds, using Monte Carlo Dropout and Deep Ensembles to measure entropy in predictive labels and mutual information between model weights and class predictions. Moses et al. [30] coin a “LOCAL" acquisition function, utilizing both classification and localization-based uncertainty and summing values across all objects in a sample as inclusion criteria. They adapt the exclusive Basic Sequential Algorithmic Scheme (BSAS) clustering scheme for per-object matching to allow for entropy calculation, and use variance of spatial estimation as measure of spatial uncertainty. However, their training and evaluation is carried out on a limited 41 LiDAR point clouds of data from a private, government-owned airborne-collected dataset, and they point out the important difference in scale compared to autonomous driving datasets such as KITTI [55], Waymo, and nuScenes. Luo et al. [31] show that maximizing the kernel coding rate as criteria for data selection can strongly outperform most generic (task-agnostic) active learning methods, and marginally improves over task-specific active learning methods for 3D detection, at lower running time than near performers. Hekimoglu et al. [56] use active learning on a monocular-input for the 3D detection task, quantifying uncertainty using (1) the variance of predicted Gaussian localizations, and (2) the variance in predicted position when an image undergoes a variety of intensity and sharpness transforms to form a query-by-committee, and perform experiments using a fixed training size, showing that the combinations of data augmentation query-by-committee and heatmap uncertainty lead to clear improvement over random sampling. Hekimoglu et al. are later the first to use a teacher-student paradigm for active learning data selection and semi-supervised training, this time combining LiDAR measurement with monocular images to form this teacher-student relation, and setting a new state of the art for “monocular" (since the LiDAR is technically used without label) 3D object detection on KITTI [33]. Hwang et al. [34] exploit the ability to localize 3D objects under flips, rotations, and scalings so that unlabeled data can be used to train the model to be consistent in assessing object locations, using this value as both an additional training term and uncertainty measurement towards active learning. These papers are all united on the theme that active learning leads to higher 3D detection performance at lower data budgets, shown in a general sense on a limited number of object classes.
From our search, Liang and et al. [43] provide the only prior investigation of active learning on the nuScenes dataset. While we study uncertainty-based active learning in this research, Liang et al. study diversity-based active learning, finding that spatial and temporal diversity of samples are effective strategies. They importantly highlight the differences of annotation costs being variable between scenes, due to the varying number of objects that may appear in each; accordingly, they define the annotation budget by a combined scene-object formulation. They also hypothesize that these entropy-based methods may introduce redundant samples in a scene, since having a high-entropy class at any one pooling round would likely identify all members of that class to be high entropy, when a smaller representative amount would suffice for learning. Further, their diversity-based active learning approach allows for a “warm start" to their base training pool, as the diversity criteria can be established without a trained model. Under their annotation budget, the entropy-based method appears to underperform compared to random sampling (and, this makes sense given that a scene’s entropy is formed by the sum of the detected object entropies). However, we do recommend that entire scenes be annotated at once (even if highly crowded), due to the difficult task of the model to identify all objects within any annotated scene; state-of-the-art models are not trained to look for single objects in a field of many, but rather to identify all instances simultaneously, and the task of identifying instances within a crowd warrants appropriate data. Accordingly, we show that at the scene-sampling level budget, entropy-driven active learning actually does exceed a random baseline.
We point out key differences between our research and the research of [29], [31], [56], [33], [34], and [43]:
- •
-
•
Accordingly, while the KITTI and Waymo-based approaches [29, 31, 56, 33, 34] divide objects into five or less classes (for example, small vehicle, human, truck, tram, and miscellaneous), we divide objects into 10 classes111Pedestrian, Bicycle, Car, Bus, Construction Vehicle, Motorcycle, Barrier, Traffic Cone, better capturing the distribution of minority classes and the effects of active learning on less-represented data.
-
•
Some of the above prior works do not include orientation [29, 43] or classification [56] of objects in their detection. These attributes are important for the purposes of understanding possible direction-of-travel and behavioral patterns for an object [58]. We include and evaluate these predictions in our network output.
-
•
[29] uses ground-truth and pre-trained image 2D detectors in their 3D detection pipeline, while [31, 34, 43] utilize LiDAR only and [56] utilizes monocular camera only. By contrast, we train our image-based 2D detector as part of a two-stage (image + LiDAR) network; thus, active learning decisions influence the complete network performance.
We create an active learning framework for autonomous driving to jointly minimize redundant, expensive annotation while avoiding the risk introduced by domain adaptations and overfitting. Such an approach allows autonomous vehicles to efficiently learn new knowledge for unseen environments under constrained resources.
II-A How long does it take to annotate 3D bounding boxes?
3D object detection is a very relevant and important task to autonomous driving because unlike 2D object detection, the object’s position and orientation in space is inferred. However, the task of drawing 3D bounding boxes to train models for such tasks can be more time consuming than 2D annotation. In this section, we highlight just how expensive this data can be to make a case for active learning as a cost-reducing measure so these systems can be developed safely at scale.
To assist in this annotation task, tools such as Zimmer et al.’s 3D-BAT [25] have been developed for semi-automatic labelling. In the 3D-BAT test case, they find that the most efficient expert human annotator is able to use the system to annotate approximately 57 objects per minute, and the average among users is approximately 40 objects per minute. However, IoU with ground truth is very low for these fast annotations, with the best annotator reaching only around 20%. Lee et al. design a system where annotators provide object anchor clicks to generate instance segmentation results in 3D, reporting 3.7 seconds per bounding box [26]. To motivate their auto-labelling system MAP-Gen, Liu et al. report statistics that an experienced annotator takes around 114 seconds per 3D bounding box, and those using a 3D object detector assistant around 30 seconds [27]. While auto-labelling may eventually be a viable solution toward massive data annotation, here we emphasize the importance of expert annotators in the loop for the purpose of human-validated safety in such a risky domain.
NuScenes contains 1.4M camera images and 390k LIDAR sweeps of driving data, originally labeled by expert annotators from an annotation partner. 1.4M objects are labelled with a 3D bounding box, semantic category (among 23 classes), and additional attributes. In Table I, we form estimates of the portion of nuScenes dataset that annotators utilizing above-described methods could annotate in 40 hours, again noting that the quality of annotation for some of these methods is substandard.

| Class | Frequency (%) |
|---|---|
| Car | 42.30 |
| Pedestrian | 19.05 |
| Barrier | 13.04 |
| Traffic Cone | 8.40 |
| Truck | 7.59 |
| Trailer | 2.13 |
| Bus | 1.4 |
| Construction Vehicle | 1.26 |
| Motorcycle | 1.08 |
| Bicycle | 1.02 |
Though this paper demonstrates the utility of active learning towards the task of 3D object detection, we would like to stress that this paper is not about improved 3D object detection, but rather about systematically selecting data in a way that improves model learning under limited resources. There are many additional tasks in autonomous driving beyond 3D object detection; for example, Motional has accompanying semantic visual and LiDAR segmentation tasks, which are even more time-intensive during annotation (for example, Schmidt estimates up to 90 minutes to fully segment an autonomous vehicle domain image [59]). The benefits demonstrated on our sample task are applicable towards other tasks; active learning is used to increase efficient utility of data towards improving any task model, especially in the cases of multi-task active learning frameworks [32, 60].
III Data Methods
Because the rate of newly collected data is faster than the rate of annotation, prioritizing data for learning new knowledge is expected to boost performance in a more optimal rate per datum. Therefore, we formulate the autonomous driving tasks as pool-based active learning problems [61]. We assume that large collections of unlabeled data are collected continuously in the pool and associate queries for the accurate annotation by expert human annotators with some costs. To minimize the total cost while maximizing the autonomous driving performance, our proposed algorithms only request humans to annotate data points when they are novel to the existing dataset and influential to the current model. The other data points are assigned with the label generated by the current model or have their annotation delayed. For evaluation, the model is trained with a few steps in each cycle based on the union of the requested labels and a subset of assigned labels of data points.
III-A Active Learning for NuScenes
NuScenes comprises 1000 scenes. In order to maintain complete control over the scenes within the dataset, we will be making slight adjustments to the fundamental database setup. These modifications are necessary to accommodate the presence of unlabeled data and the computations associated with active learning queries. The specific adjustments will depend on the selected method. This alteration is a crucial step in the process of sampling underrepresented data from the current labeled pool.
Towards reproducability of our methods, throughout the training and testing of the chosen model we will use the trainval split of the dataset, which containes 850 scenes. We will split this into labeled, unlabeled and validation subsets, where the validation set will contain 150 scenes used to evaluate and test the model. We will discard the provided test subset for our experiments, as the labels are not provided by the creators.
The remainder of the scenes in trainval will initially be part of the unlabeled subset and iteratively be sampled approximately 5% at the time into the labeled set. This process will proceed until models have been trained on the labeled subset containing up to 50% of the original scenes present in the trainval dataset.
III-B Baseline: Random Sampling
We create a baseline budget using the average of the statistics surveyed in Table I, or 2.52% of the nuScenes dataset annoted with a 40-person-hour labelling budget. We create 10 iterative batches of such labels, representing in a figurative sense the amount that one (very dedicated) annotator might label over 10 weeks, shown in Table II.
For each baseline trial, we randomly sample a percentage of scenes described in Table II and train the model to N epochs. We will start with 10.08% scenes and add 5.04% for every round representing a start with 4 weeks worth of work and an increase of 2 weeks worth of work for every sampling round.
III-C Active Learning Method: Entropy Querying
We aim to investigate the implications of utilizing a commonly employed uncertainty measure for sampling from an unlabeled data pool [29], [56], [33], [34].
While certain methods, like "least confidence" and "smallest margin," derive their acquisition function based on individual or paired confidence values across all semantic classes, our specific focus lies on the "entropy querying" method. This method takes into account a model’s uncertainty across all conceivable classes. Our objective is to uncover potential enhancements that the entropy query method could bring about, given that the informativeness measure is determined by comparing a sample’s probability of belonging to a class across all possible classes. [62]
This process starts by conducting inference on the unlabeled subset and strategically selecting samples found to be the most informative. The criterion for informativeness is determined by the entropy scores associated with each sample. These scores are calculated, generally, using the formula expressed in Equation 1.
| (1) |
In the equation, represents the entropy score for a given sample . The calculation involves the summation over all possible class labels , where represents the probability of class given the input . The resulting entropy score serves as a quantitative measure of uncertainty, guiding the selection of samples for active learning.
By adopting the entropy sampling approach, we aim to enhance our understanding of its impact on the selection process within the context of 3D datasets. The utilization of entropy scores provides a nuanced perspective on uncertainty, enabling the selection of samples that contribute most significantly to the model’s learning process.
Round Pool mAP mATE mASE mAOE mAVE mAAE NDS Random Entropy Random Entropy Random Entropy Random Entropy Random Entropy Random Entropy Random Entropy 1 10% 0.3095 0.3106 0.4665 0.4588 0.3494 0.3669 1.108 1.030 1.236 1.420 0.3794 0.3187 0.3353 0.3409 2 15% 0.3419 0.3639 0.4392 0.4144 0.3397 0.3386 0.9418 0.8909 1.223 1.347 0.3095 0.3074 0.3679 0.3868 3 20% 0.380 0.4041 0.4041 0.3994 0.3503 0.3270 0.8296 0.8131 1.317 1.060 0.3017 0.2955 0.4014 0.4185 4 25% 0.4236 0.4217 0.3921 0.3786 0.3136 0.3319 0.7685 0.6780 0.8695 0.9803 0.277 0.2942 0.4497 0.4446 5 30% 0.4494 0.4557 0.3713 0.3552 0.3112 0.3169 0.6989 0.6563 0.7764 0.7106 0.2485 0.2287 0.4841 0.5011 6 35% 0.4474 0.4676 0.3498 0.3679 0.3168 0.3066 0.6569 0.6152 0.8830 0.6354 0.2941 0.2324 0.4736 0.5181 SOA 100.00% 0.750 - - - - - 0.761
III-D BEVFusion Model for 3D Object Detection
For the purpose of designing and experimenting on data selection and learning schemes, in this paper we consider the fundamental driving task of 3D object detection. This is an essential task for obstacle avoidance and path planning.
More specifically, we consider the recent BEVFusion approach to 3D object detection [63]. At the time of writing, this method holds third place in the NuScenes tracking challenge and seventh place in the detection challenge, with newer variants of the BEVFusion architecture populating additional high rankings. While there are many techniques to find a unified representation of image and LiDAR data, LiDAR-to-Camera projection methods introduce geometric distortions, and Camera-to-LiDAR projections struggle with semantic-orientation tasks. BEVFusion is meant to create a unified representation which maintains both geometric structure and semantic density.
The Swin-Transformer [64] is used as the image backbone, while VoxelNet [65] is used as the LIDAR backbone. To create the bird’s-eye-view (BEV) features for images, first a Feature Pyramid Network (FPN) [66] is applied to fuse the multi-scale camera features. This produces a feature map 1/8 of the original size. After this, images are downsampled to 256x704 and the LiDAR point clouds are voxelized to 0.075m to get the BEV features needed for object detection. These two modalities are fused using a convolution-based BEV encoder to prevent local misalignment between LiDAR-BEV features and camera-BEV features under depth estimation uncertainty from the camera mode. The full architecture with active learning can be seen in 3.
III-E Explanation of nuScenes Metrics
We summarize here some common metrics in 3D object detection for conceptual description, and direct the reader to the nuScenes documentation for implementation thresholds and class-specific details:
-
•
Mean Average Precision (mAP): for the nuScenes dataset, AP is computed by taking the 2D center distance on the ground plane, filtering predictions beyond a certain threshold, and integrating the recall-precision curves for values over 0.1. These values are averaged over match thresholds of 0.5, 1, 2, 4 meters, and then averaged across classes.
-
•
Average Translation Error (ATE): Euclidean center distance in 2D in meters.
-
•
Average Scale Error (ASE): after aligning centers and orientation.
-
•
Average Orientation Error (AOE): Smallest yaw angle difference between prediction and ground-truth in radians.
-
•
Average Velocity Error (AVE): Absolute velocity error in m/s.
-
•
Average Attribute Error (AAE): Calculated as , where is the attribute classification accuracy.
These metrics are all positive (or zero) valued, and translation and velocity errors can grow unbounded. For metrics presented in this paper, we take a mean over all classes when presenting general statistics in Table V, and also examine per-class performance to observe the effects of active learning on minority classes in further analysis.
IV Experimental Evaluation
Experiments are conducted to test if entropy sampling performs better than random sampling. The initial dataset contains approximately 10% of the original dataset, we add approximately 5% of data for each subsequent round of training.
A single round involves training one model with six epochs on the current labeled training set. Following this training phase, the checkpoint file from the last round is employed to perform inference on the unlabeled dataset pool. Thereafter, the employed active learning method will be used on the obtained results. This process identifies the samples to be included in the labeled training dataset for the subsequent round. Each experiment will involve six rounds, as seen in Table V. We note that in general, the more training data sampled, the stronger the model learns to generalize to real-world test data.
The Active Learning strategy dominates on 26 of the 35 checkpoints and metrics in Table V. A sampling of qualitative examples are provided in Figure 7.
Data [%] 10 15 20 25 30 35 Random Entropy Random Entropy Random Entropy Random Entropy Random Entropy Random Entropy Car 31,940 32,488 42,308 42,942 56,415 53,760 71,209 64,451 88,131 74,933 108,562 82,911 Pedestrian 20,356 24,448 30,636 31,994 40,901 39,679 46,442 48,129 54,062 58,708 61,281 62,752 Barrier 7,915 15,224 24,166 20,335 28,904 22,117 34,338 28,117 38,903 34,791 44,906 38,639 Truck 7,972 6,128 11,467 10,184 14,354 15,555 18,267 19,871 21,503 22,796 25,908 25,926 Traffic Cone 3,767 6,165 10,283 8,921 12,539 10,225 15,628 13,028 18,584 15,179 20,584 18,007 Trailer 2,562 1,635 2,779 2,977 3,801 5,750 5,580 7,658 6,448 8,237 7,486 9,591 Bus 1,698 1,574 2,172 2,447 2,729 3,112 3,774 3,808 4,496 4,556 5,475 5,084 Construction Vehicle 1,262 1,401 2,138 2,253 2,877 2,903 3,678 3,634 4,595 4,366 5,145 4,752 Bicycle 762 954 1,468 1,427 2,090 1,750 2,378 2,042 2,659 2,508 2,967 2,917 Motorcycle 1,539 802 1,016 1,364 1,400 1,749 1,852 2,255 2,489 2,721 2,875 3,095


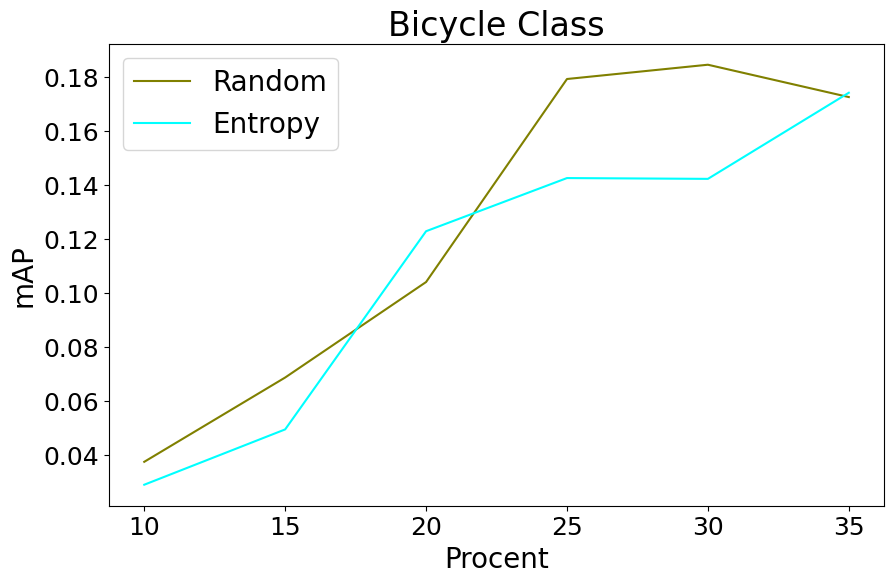




Table IV describes the class frequencies of appearance in the nuScenes dataset. We collapse the pedestrian class to contain adults, children, construction workers, those using personal mobility devices, wheelchairs, or strollers, and wearing construction or police uniforms. From Figure 4, we observe that the ordering of classes by highest-to-lowest mAP approximately matches the ordering of class appearance in Table IV (car, pedestrian, traffic cone, barrier, truck, bus, motorcycle, construction vehicle, trailer, bicycle). While this ordering is preserved by active learning, we notice that the gap between the lowest mAP and greatest mAP is smaller under active learning, and progressively tightens as more data is added to the pool. Class-specific comparisons are illustrated in Figure 5. In general, entropy-driven active learning shows improved precision over random selection on all classes, especially beyond early data pool sizes. The margin of performance varies by class.
We make a few observations over these class performances. Most of the worst performing classes (trailer, construction vehicle, bicycle, motorcycle) perform better under entropy sampling than in random sampling. The trailer class performed the worst in random sampling and a little better in entropy sampling, and when looking at Table VI, it can be observed that entropy sampling focuses on querying trailer data for every round. The Construction Vehicle class is another class which did not do well in either entropy or random sampling, however, we again see in the table that entropy sampling still outperforms random sampling by a small margin in all rounds, even though the random sampling method draws more examples of this class beyond 30%, suggesting that the active learning algorithm was not finding better “informative" samples beyond this point (corroborated by random sampling’s greater sampling amount still not besting the performance of entropy querying). As a more classic case, in the motorcycle class, for the initial round the mAP result for this class is comparable to the lowest accuracies observed in other classes. But, under entropy querying, there is a rapid growth in the amount of samples present for this class and as a result the mAP performance consistently increases as the training pool grows.
To what extent does entropy querying resolve uncertainty by corrective sampling of minority classes? As shown in Figure 6, for each class in each graph, the entropy-driven method tends to pull the distribution to the right toward underrepresented classes as the training pool size increases. We observe the margin between methods for the majority class (car) being widened as the active learning method samples larger pool sizes, with this difference being distributed among the minority classes. The non-normalized data values are presented in Table VI.








V Concluding Remarks
Based on the observed results, it is evident that the integration of the entropy querying method with the Birds-Eye-View Fusion model constitutes a favorable combination, demonstrating the effectiveness of active learning.
One limitation of this analysis is the robustness of results, containing a single method with six iterations of training, each comprising six epochs. To address this limitation, it is recommended that future testing and analysis involve a more extensive approach, where several runs would be conducted for each method. Taking an average of these runs would yield more reliable and comprehensive results. Additionally, the decision to increase the number of epochs from six to ten in future experiments is motivated by the anticipation that a more distinct pattern which more closely matches the fine-tuned state of the art performance of such models may emerge with extended training. Specifically, this adjustment also aligns with the amount of epochs used in the BEVFusion paper, facilitating better direct comparisons with their outcomes.
V-A Future Research in Active Learning
Future research unexplored in active learning in this field includes the learning of query policies directly from autonomous driving tasks and data, instead of relying on handcrafted policies. This could be done using deep reinforcement learning approaches to learn the query policy in the active learning framework. Because the query selection has been shown as a decision process, reinforcement learning can be applied to learn the query [67]. Query strategies learned by reinforcement learning have been shown to outperform the heuristic selection methods such as uncertainty sampling and random sampling in a natural language processing task [67]. However, to the best of our knowledge, such data-driven query strategies have not been explored in autonomous driving. This is especially important considering the necessity of such systems to efficiently adapt to new environments [68, 69].
In conclusion, the findings in this research give an affirmation that entropy querying effectively samples the most informative instances from classes with lower accuracies and limited available data, showcasing its utility in the active learning framework, encouraging the adoption of active learning approaches to simultaneously reduce annotation costs and increase data efficiency in learned models for autonomous driving tasks.
Acknowledgments
The authors would like to acknowledge the support of Qualcomm through the Qualcomm Inovation Fellowship, and thank mentors Per Siden and Varun Ravi for their valuable feedback.
References
- [1] S. Wang, Y. Sun, Z. Wang, and M. Liu, “St-tracknet: A multiple-object tracking network using spatio-temporal information,” IEEE Transactions on Automation Science and Engineering, 2022.
- [2] H. Cai, Z. Zhang, Z. Zhou, Z. Li, W. Ding, and J. Zhao, “Bevfusion4d: Learning lidar-camera fusion under bird’s-eye-view via cross-modality guidance and temporal aggregation,” arXiv preprint arXiv:2303.17099, 2023.
- [3] Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. L. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” in 2023 IEEE international conference on robotics and automation (ICRA). IEEE, 2023, pp. 2774–2781.
- [4] Y. Chen, Z. Yu, Y. Chen, S. Lan, A. Anandkumar, J. Jia, and J. M. Alvarez, “Focalformer3d: focusing on hard instance for 3d object detection,” in Proceedings of the IEEE/CVF International Conference On Computer Vision, 2023, pp. 8394–8405.
- [5] Y. Xie, C. Xu, M.-J. Rakotosaona, P. Rim, F. Tombari, K. Keutzer, M. Tomizuka, and W. Zhan, “Sparsefusion: Fusing multi-modal sparse representations for multi-sensor 3d object detection,” arXiv preprint arXiv:2304.14340, 2023.
- [6] N. Kulkarni, A. Rangesh, J. Buck, J. Feltracco, M. M. Trivedi, N. Deo, R. Greer, S. Sarraf, and S. Sathyanarayana, “Create a large-scale video driving dataset with detailed attributes using amazon sagemaker ground truth: Lisa amazonmlsl vehicle attributes (lava) dataset,” AWS Machine Learning Blog, June 2021.
- [7] R. Greer, L. Rakla, S. Desai, A. Alofi, A. Gopalkrishnan, and M. Trivedi, “Champ: Crowdsourced, history-based advisory of mapped pedestrians for safer driver assistance systems,” arXiv preprint arXiv:2301.05842, 2023.
- [8] T. Fingscheidt, H. Gottschalk, and S. Houben, Deep neural networks and data for automated driving: Robustness, uncertainty quantification, and insights towards safety. Springer Nature, 2022.
- [9] H. Gottschalk, M. Rottmann, and M. Saltagic, “Does redundancy in ai perception systems help to test for super-human automated driving performance?” arXiv preprint arXiv:2112.04758, 2021.
- [10] D. Cohn, L. Atlas, and R. Ladner, “Improving generalization with active learning,” Machine learning, vol. 15, pp. 201–221, 1994.
- [11] B. Pes, “Learning from high-dimensional biomedical datasets: the issue of class imbalance,” IEEE Access, vol. 8, pp. 13 527–13 540, 2020.
- [12] H. B. Lee, T. Nam, E. Yang, and S. J. Hwang, “Meta dropout: Learning to perturb latent features for generalization,” in Eighth International Conference on Learning Representations, ICLR 2020. International Conference on Learning Representations, 2020.
- [13] H. X. Liu and S. Feng, “" curse of rarity" for autonomous vehicles,” arXiv preprint arXiv:2207.02749, 2022.
- [14] S. Dubnov and R. Greer, Deep and shallow: Machine learning in music and audio. CRC Press, 2023.
- [15] H. Abualsaud, S. Liu, D. B. Lu, K. Situ, A. Rangesh, and M. M. Trivedi, “Laneaf: Robust multi-lane detection with affinity fields,” IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 7477–7484, 2021.
- [16] E. Haussmann, M. Fenzi, K. Chitta, J. Ivanecky, H. Xu, D. Roy, A. Mittel, N. Koumchatzky, C. Farabet, and J. M. Alvarez, “Scalable active learning for object detection,” in 2020 IEEE Intelligent Vehicles Symposium (IV), 2020, pp. 1430–1435.
- [17] R. Greer, J. Isa, N. Deo, A. Rangesh, and M. M. Trivedi, “On salience-sensitive sign classification in autonomous vehicle path planning: Experimental explorations with a novel dataset,” in 2022 Winter Conference on Applications of Computer Vision (WACV).
- [18] R. Greer, A. Gopalkrishnan, N. Deo, A. Rangesh, and M. Trivedi, “Salient sign detection in safe autonomous driving: Ai which reasons over full visual context,” 27th International Technical Symposium on the Enhanced Safety of Vehicles (ESV), 2023.
- [19] R. Greer, A. Gopalkrishnan, J. Landgren, L. Rakla, A. Gopalan, and M. Trivedi, “Robust traffic light detection using salience-sensitive loss: Computational framework and evaluations,” in 2023 IEEE Intelligent Vehicles Symposium (IV), 2023, pp. 1–7.
- [20] S. Lefevre, A. Carvalho, and F. Borrelli, “A learning-based framework for velocity control in autonomous driving,” IEEE Transactions on Automation Science and Engineering, vol. 13, no. 1, pp. 32–42, 2015.
- [21] R. Greer, N. Deo, and M. Trivedi, “Trajectory prediction in autonomous driving with a lane heading auxiliary loss,” IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4907–4914, 2021.
- [22] R. Greer, A. Gopalkrishnan, M. Keskar, and M. M. Trivedi, “Patterns of vehicle lights: Addressing complexities of camera-based vehicle light datasets and metrics,” Pattern Recognition Letters, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167865524000047
- [23] A. Doshi and M. M. Trivedi, “Examining the impact of driving style on the predictability and responsiveness of the driver: Real-world and simulator analysis,” in 2010 IEEE Intelligent Vehicles Symposium. IEEE, 2010, pp. 232–237.
- [24] A. Balachandran, M. Brown, S. M. Erlien, and J. C. Gerdes, “Predictive haptic feedback for obstacle avoidance based on model predictive control,” IEEE Transactions on Automation Science and Engineering, vol. 13, no. 1, pp. 26–31, 2015.
- [25] W. Zimmer, A. Rangesh, and M. Trivedi, “3d bat: A semi-automatic, web-based 3d annotation toolbox for full-surround, multi-modal data streams,” in 2019 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2019, pp. 1816–1821.
- [26] J. Lee, S. Walsh, A. Harakeh, and S. L. Waslander, “Leveraging pre-trained 3d object detection models for fast ground truth generation,” in 2018 21st International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2018, pp. 2504–2510.
- [27] C. Liu, X. Qian, X. Qi, E. Y. Lam, S.-C. Tan, and N. Wong, “Map-gen: An automated 3d-box annotation flow with multimodal attention point generator,” in 2022 26th International Conference on Pattern Recognition (ICPR). IEEE, 2022, pp. 1148–1155.
- [28] R. Greer, L. Rakla, A. Gopalkrishnan, and M. Trivedi, “Multi-view ensemble learning with missing data: Computational framework and evaluations using novel data from the safe autonomous driving domain,” arXiv preprint arXiv:2301.12592, 2023.
- [29] D. Feng, X. Wei, L. Rosenbaum, A. Maki, and K. Dietmayer, “Deep active learning for efficient training of a lidar 3d object detector,” in 2019 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2019, pp. 667–674.
- [30] A. Moses, S. Jakkampudi, C. Danner, and D. Biega, “Localization-based active learning (local) for object detection in 3d point clouds,” in Geospatial Informatics XII, vol. 12099. SPIE, 2022, pp. 44–58.
- [31] Y. Luo, Z. Chen, Z. Fang, Z. Zhang, M. Baktashmotlagh, and Z. Huang, “Kecor: Kernel coding rate maximization for active 3d object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 18 279–18 290.
- [32] A. Hekimoglu, P. Friedrich, W. Zimmer, M. Schmidt, A. Marcos-Ramiro, and A. Knoll, “Multi-task consistency for active learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3415–3424.
- [33] A. Hekimoglu, M. Schmidt, and A. Marcos-Ramiro, “Monocular 3d object detection with lidar guided semi supervised active learning,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 2346–2355.
- [34] S. Hwang, S. Kim, Y. Kim, and D. Kum, “Joint semi-supervised and active learning via 3d consistency for 3d object detection,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 4819–4825.
- [35] S. Schmidt, Q. Rao, J. Tatsch, and A. Knoll, “Advanced active learning strategies for object detection,” in 2020 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2020, pp. 871–876.
- [36] J. Yuan, B. Zhang, X. Yan, T. Chen, B. Shi, Y. Li, and Y. Qiao, “Bi3d: Bi-domain active learning for cross-domain 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15 599–15 608.
- [37] M. Meyer and G. Kuschk, “Automotive radar dataset for deep learning based 3d object detection,” in 2019 16th european radar conference (EuRAD). IEEE, 2019, pp. 129–132.
- [38] Q. Meng, W. Wang, T. Zhou, J. Shen, Y. Jia, and L. Van Gool, “Towards a weakly supervised framework for 3d point cloud object detection and annotation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 8, pp. 4454–4468, 2021.
- [39] G. Villalonga and A. M. L. Pena, “Co-training for on-board deep object detection,” IEEE Access, vol. 8, pp. 194 441–194 456, 2020.
- [40] A. Almin, L. Lemarié, A. Duong, and B. R. Kiran, “Navya3dseg-navya 3d semantic segmentation dataset design & split generation for autonomous vehicles,” IEEE Robotics and Automation Letters, 2023.
- [41] O. Çatal, S. Leroux, C. De Boom, T. Verbelen, and B. Dhoedt, “Anomaly detection for autonomous guided vehicles using bayesian surprise,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 8148–8153.
- [42] L. Chen, X. He, X. Zhao, H. Li, Y. Huang, B. Zhou, W. Chen, Y. Li, C. Wen, and C. Wang, “Gocomfort: Comfortable navigation for autonomous vehicles leveraging high-precision road damage crowdsensing,” IEEE Transactions on Mobile Computing, 2022.
- [43] Z. Liang, X. Xu, S. Deng, L. Cai, T. Jiang, and K. Jia, “Exploring diversity-based active learning for 3d object detection in autonomous driving,” arXiv preprint arXiv:2205.07708, 2022.
- [44] H. S. Seung, M. Opper, and H. Sompolinsky, “Query by committee,” in Proceedings of the fifth annual workshop on Computational learning theory, 1992, pp. 287–294.
- [45] D. D. Lewis and J. Catlett, “Heterogeneous uncertainty sampling for supervised learning,” in Machine learning proceedings 1994. Elsevier, 1994, pp. 148–156.
- [46] T. Scheffer, C. Decomain, and S. Wrobel, “Active hidden markov models for information extraction,” in International Symposium on Intelligent Data Analysis. Springer, 2001, pp. 309–318.
- [47] B. Settles, M. Craven, and S. Ray, “Multiple-instance active learning,” Advances in neural information processing systems, vol. 20, pp. 1289–1296, 2007.
- [48] A. I. Schein and L. H. Ungar, “Active learning for logistic regression: an evaluation,” Machine Learning, vol. 68, no. 3, pp. 235–265, 2007.
- [49] B. Settles and M. Craven, “An analysis of active learning strategies for sequence labeling tasks,” in Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, 2008, pp. 1070–1079.
- [50] S. Sivaraman and M. M. Trivedi, “A general active-learning framework for on-road vehicle recognition and tracking,” IEEE Transactions on Intelligent Transportation Systems, vol. 11, no. 2, pp. 267–276, 2010.
- [51] ——, “Active learning for on-road vehicle detection: A comparative study,” Machine vision and applications, vol. 25, no. 3, pp. 599–611, 2014.
- [52] R. K. Satzoda and M. M. Trivedi, “Multipart vehicle detection using symmetry-derived analysis and active learning,” IEEE Transactions on Intelligent Transportation Systems, vol. 17, no. 4, pp. 926–937, 2015.
- [53] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in neural information processing systems, vol. 25, pp. 1097–1105, 2012.
- [54] N. Singh, H. Hukkelås, and F. Lindseth, “Deep active learning for autonomous perception,” in NIKT: Norsk IKT-konferanse for forskning og utdanning 2020. Bibsys Open Journal Systems, 2020.
- [55] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in 2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012, pp. 3354–3361.
- [56] A. Hekimoglu, M. Schmidt, A. Marcos-Ramiro, and G. Rigoll, “Efficient active learning strategies for monocular 3d object detection,” in 2022 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2022, pp. 295–302.
- [57] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” CoRR, vol. abs/1903.11027, 2019. [Online]. Available: http://arxiv.org/abs/1903.11027
- [58] A. Møgelmose, M. M. Trivedi, and T. B. Moeslund, “Trajectory analysis and prediction for improved pedestrian safety: Integrated framework and evaluations,” in 2015 IEEE intelligent vehicles symposium (IV). IEEE, 2015, pp. 330–335.
- [59] F. A. Schmidt, Crowdproduktion von Trainingsdaten: Zur Rolle von Online-Arbeit beim Trainieren autonomer Fahrzeuge. Study der Hans-Böckler-Stiftung, 2019, no. 417.
- [60] C. Finn, K. Xu, and S. Levine, “Probabilistic model-agnostic meta-learning,” Advances in neural information processing systems, vol. 31, 2018.
- [61] D. D. Lewis and W. A. Gale, “A sequential algorithm for training text classifiers,” in SIGIR’94. Springer, 1994, pp. 3–12.
- [62] V. Nguyen, M. H. Shaker, and E. Hüllermeier, “How to measure uncertainty in uncertainty sampling for active learning,” https://doi.org/10.1007/s10994-021-06003-9, 2021.
- [63] Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” arXiv preprint arXiv:2205.13542v2, 2022.
- [64] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, , and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted window,” ICCV, 2021.
- [65] Y. Yan, Y. Mao, , and B. Li, “Second: Sparsely embedded convolutional detection,” Sensors, 2018.
- [66] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detectio,” CVPR, 2017.
- [67] M. Fang, Y. Li, and T. Cohn, “Learning how to active learn: A deep reinforcement learning approach,” arXiv preprint arXiv:1708.02383, 2017.
- [68] T. Lew, A. Sharma, J. Harrison, A. Bylard, and M. Pavone, “Safe active dynamics learning and control: A sequential exploration–exploitation framework,” IEEE Transactions on Robotics, vol. 38, no. 5, pp. 2888–2907, 2022.
- [69] C. S. Vallon and F. Borrelli, “Data-driven strategies for hierarchical predictive control in unknown environments,” IEEE Transactions on Automation Science and Engineering, vol. 19, no. 3, pp. 1434–1445, 2022.