The statistical spread of transmission outages on a fast protection time scale based on utility data
Abstract
When there is a fault, the protection system automatically removes one or more transmission lines on a fast time scale of less than one minute. The outaged lines form a pattern in the transmission network. We extract these patterns from utility outage data, determine some key statistics of these patterns, and then show how to generate new patterns consistent with these statistics. The generated patterns provide a new and easily feasible way to model the overall effect of the protection system at the scale of a large transmission system. This new generative modeling of protection is expected to contribute to simulations of disturbances in large grids so that they can better quantify the risk of blackouts. Analysis of the pattern sizes suggests an index that describes how much outages spread in the transmission network at the fast timescale.
I Introduction
We present observed utility outage data that shows patterns in line outages at the time scale of less than one minute, at which the protection system acts. The line outages occurring during each minute mostly appear on the network as single lines or small tree subnetworks. The protection system routinely limits the outages to simple patterns, most frequently to outages involving one or two lines. However, much rarer but more impactful patterns with many line outages also appear in the data.
We extract and analyze such patterns from historical line outage data for two transmission systems. We compute key statistics of these observed patterns that describe how outages propagate on the network at the fast protection time scale. These statistics are then used to calibrate a model capable of generating new patterns consistent with those statistics that can start from any initial line outage. This amounts to novel data-driven generative modeling of the effects of protection at the transmission system level.
The new systems-level statistical modeling of fast protection actions is significant for two reasons: First, it provides an alternative to detailed modeling that is based on real data and is relatively easy to apply. This new alternative is promising since it is difficult to model the intricate details of the protection system for an entire transmission system; the barriers include access to the detailed protection data for an entire system, coordinating protection models and models for transmission system statics and dynamics, and the many ways that the protection system can act when operating as intended, operating in an unusual network condition, or misoperating [1, 2]. Second, there is a need to model protection at the transmission system scale: The protection system contributes to the risk of cascading or extreme weather causing blackouts, so that giving a practical way to model the effects of the protection system at the transmission system scale is useful. It is also generally worthwhile to extract and characterize the actual overall protection system behavior from utility data at the transmission system scale. This helps to further ground the subject in reality and can help guide the development and validation of detailed models.
Our approach to reproducing observed protection operation patterns is conceptually close to the generative modeling techniques employed in recommendation systems and online discussion threads [3]. Rather than only obtaining a set of descriptive statistics of the observed data, generative models contrast with descriptive methods by their ability to generate synthetic observations.
In summary, the main contributions of this paper are:
-
•
Extract and present observed utility data showing the patterns of how line outages did propagate at the fast protection time scale in two transmission networks.
-
•
Compute key statistics describing the size and form of the patterns. In particular, we find that the pattern size has a heavy tailed distribution.
-
•
Show how to generate patterns on the network that match the key statistics. This is a new data-driven statistical model of outage propagation at the fast time scale that applies at the transmission system level.
-
•
Assess the data-driven generative model performance in terms of a distance between generated patterns and observed patterns.
-
•
Suggest a new index that measures how much outages spread in a transmission system due to protection.
II Literature review
Models of protection system backup operation and misoperation can be used to identify multiple N–k contingencies to be included in lists of initial contingencies that are used to evaluate transmission system robustness or to initiate cascading failure simulations. Indeed, the previous work most nearly related to the overall approach of this paper is Zhou et al. [4], which finds spatial patterns of initial contingencies in utility data called contingency motifs. Contingency motifs occur much more frequently in practice than multiple outages chosen randomly with equal probability from the utility network. Contingency lists using these more frequent patterns are much more effective in capturing the probability of multiple contingencies [4]. This paper and [4] both analyze patterns in utility data, but the thrust of the analysis is quite different: [4] takes the patterns as given and analyzes their frequency to find the motifs and improve contingency lists, whereas we estimate key statistics of patterns and use these to generate similar patterns. [4] only analyzes patterns initiating cascades and includes disconnected patterns, while we analyze all the connected patterns appearing at the fast time scale. The smaller patterns that we study in this paper are also frequent enough to be contingency motifs but we also analyze and generate the larger patterns that are too rare to be motifs.
There is also detailed protection system modeling aimed at improving contingency lists. Chen and McCalley [5] model protection groups and stuck breakers to trace the higher probability series of events online under different substation and maintenance conditions to alert operators to higher probability contingencies. Yang et al. [6] analyze hidden stuck breaker failures in a 24-bus system to find critical contingencies. Jiang et al. [7] use a Markov chain to determine the steady state probabilities of NERC standard categories of contingencies. The failure and repair rates are estimated from utility data.
There is extensive literature assessing the cascading risk of large transmission system blackouts by simulating models as surveyed in [8, 9]. Most of this literature outages lines without any detailed consideration of the protection system. However, there are advances in modeling some aspects of the protection system in this context.
Rios et al. [10] model protection system misoperation by a constant probability when a fault lies in the vulnerability region of a relay. Chen et al. [11] model hidden protection failure of a line exposed by a neighboring outage with a probability that changes according to the line loading. Yu and Singh [12] obtain probabilities of failure to operate and the undesired trip from a steady state Markov chain and then use these probabilities to simulate cascades in a 24-bus power system. Dobson et al. [1] model the protection system in some detail and account for stuck breakers when cosimulating protection and power system dynamics in a 130-bus power system. Another application where detailed protection modeling has been applied is assessing resilience to the risk of extreme weather. Ciapessoni et al. [13] assess this risk in an 80-bus power system, and their models include busbar and double circuit faults and stuck breakers.
Except for [4], all these studies advance the detailed modeling of specific mechanisms of protection operation and misoperation. These studies complement and have a different scope than our investigation of all the outage spreading that actually occurred at the fast time scale. Detailed modeling of specific mechanisms allows the effect of that mechanism to be assessed in simulations of blackout risk in small transmission system networks, whereas our approach based on observed data faithfully reflects the combined effect of all the mechanisms in large-scale transmission systems.
Generative modeling of general cascading outages is used by Kelly-Gorham et al. [14, 15] as part of modeling transmission system resilience in the CRISP Computing Resilience of Infrastructure Simulation Platform. Starting from a random initial line outage, successive line outages are chosen according to the observed distribution of cascade size and the observed distribution of distances between successive line outages in resilience events. The line and generator restoration times are also sampled from their observed lognormal distributions. The generative modeling of line outages in CRISP has a similar overall objective to this paper: to generate outages consistent with the statistical patterns of observed events. However, it models all the cascading and outage processes combined and does not separately consider protection processes at the fast time scale. As this paper shows, fast protection processes have a special structure different from cascading or weather-induced outages in general. Most notably, outage propagation at the fast protection time scale produces small connected subnetworks that are mostly trees, whereas general cascading or weather-induced outages propagate locally, as well as more globally to disconnected sets of lines. This explains why this paper controls how the new lines are directly attached to the evolving patterns, whereas CRISP samples new lines according to their network distance from the initial line outage.
While the only previous generative models we know in power transmission systems are in CRISP [14, 15], generative models of cascading phenomena have been used in other applications. Generative models have been used to model cascades of product recommendations in social networks and in discussion forums [16, 17]. For example, Leskovec et al. examine the topology of blog posts when some of them become popular and observe that the cascade size distribution presents a heavy tail and follows a Zipf distribution. They develop a generative model based on contagion dynamics that is able to accurately model the statistics of the observed cascades [16]. Gomez et al. introduce a more sophisticated model based on preferential attachment [17]. They derive a likelihood function used for parameter estimation and they fit their model to four different blogging communities. The model can replicate observed statistics, and also, the fitted parameters are used to draw conclusions about communication habits. A later review of generative models for online discussion threads points out the successes and diverse uses of these models, such as comparison of discussion platforms, predicting user behavior, and evaluation of platform design [3].
III Utility data
The main part of the Bonneville Power Administration (BPA) transmission system is in Washington and Oregon states. We analyze 19 years of historical outage data recorded by BPA and publicly available at [18]. The New York State Independent System Operator (NYISO) transmission system outage records cover New York State and parts of neighboring states and Canadian provinces, with more network detail in New York State. The NYISO outage data is publicly accessed from its website [19], and 12 years of data from 2008 to 2020 are processed according to the method in [20].
After data cleaning, mainly standardizing bus names, the power transmission network is deduced from the outage data itself using the method in [21], which ensures that the outaged lines can be easily located on the network. Any isolated portions of the network are removed to ensure a connected network. Outages of lines outside the main component and outages of the Pacific DC intertie in the BPA network are removed. This yields a network of 608 lines for BPA, including multiple circuits, and 1238 lines for NYISO. The BPA network can be reduced to a single-line network of 468 lines by combining the multiple circuits into single lines. Fig. 1 shows the single-line BPA and NYISO networks. We will find the outage patterns in the single line networks in Fig. 1 and account for the multiple circuits in the BPA network as a final step.


For both transmission systems, the automatic line outage data include the outaged line specified by its sending and receiving end buses and the line outage times at a one-minute granularity. Other details of the outage data that are not used in this paper are described in [22] and [20]. Then, the automatic line outages are grouped together into the lines that outage within the time span of the same minute111Repeats of outages of the same line in the same group are removed.. Each group of lines is called a “generation” of line outages in [22, 21, 4], although these references use a slightly different definition of generation222References [22, 21, 4] define a generation as groups of outages that are separated by at least 1 minute, giving generations that sometimes include more outages. For example, if outages occur in each of 2 successive minutes, outages in each minute would be a generation in this paper, whereas all these outages would be included in one generation as defined in [22, 21, 4]. . Our outage time data has one-minute granularity, so the group is simply the outages with that minute recorded. Most of the groups of outages in one minute are a connected subnetwork of the transmission system network, and in that case the pattern is that group of outages. For a small fraction of cases (2.6% for BPA and 1.1% for NYISO), there is more than one connected component in the group. In that case, we consider each of the components in the group as a pattern, as combined failures stemming from fast protection actions can be assumed to result in a connected pattern.
IV Observed patterns and their statistics
Patterns observed in the BPA and NYISO data are shown in Figs. 3 and 5, together with their bus degrees and a count of how many times those bus degrees appear in the data. (Recall that the bus degree is the number of lines incident at each bus and that the list of bus degrees is known as the degree sequence in network theory.) Most of the patterns are small trees, with only a few patterns with loops. For BPA, there are 11836 patterns (623 patterns per year) of which 93% have one line, 5% have two lines, and 2% have 3 or more lines. For NYISO, there are 7362 patterns (609 patterns per year) of which 93% have one line, 6% have two lines, and 1% have 3 or more lines.
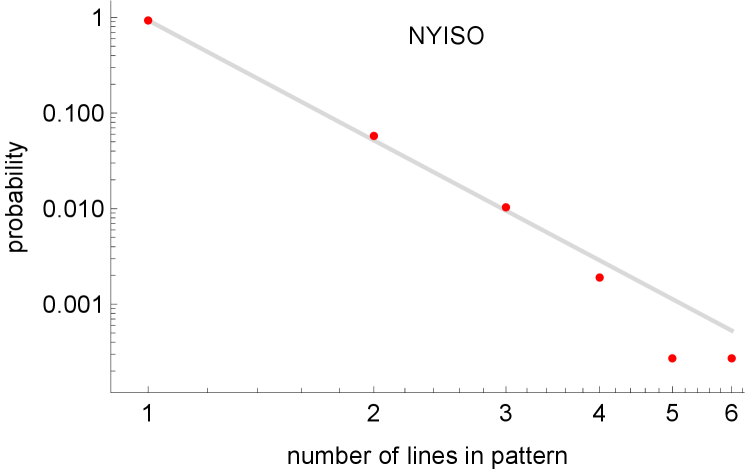
The simpler patterns in Figs. 3 and 5 are much more common than the more complicated patterns, many of which only occur once or twice. This is expected in a well-engineered protection system, as it is designed to quickly halt the propagation of outages. The distributions of the number of lines in the patterns are shown by the red dots in the log-log plots in Fig. 2. These observed data in Fig. 2 can be fit with a Zipf distribution using the maximum likelihood method in [23]. The Zipf distribution (often called the zeta distribution or discrete Pareto distribution) is a heavy-tailed probability distribution on the positive integers with
| (1) |
where is the Riemann zeta function. The discrete probabilities (1) lie on a straight line of slope on a log-log plot. For Fig. 2, so that the slope of the line is . This is a heavy-tailed distribution for which the probability of a large number of lines in a pattern decreases quite sharply as the number of lines increase, but the decrease is slower than exponential. In particular, implies that the probability is multiplied by when the number of lines in the pattern doubles. The Zipf distribution (1) in effect extrapolates the observed data to allow arbitrarily large patterns; one could alternatively use a truncated Zipf distribution with an upper bound on pattern size.





The observed patterns can be reproduced by starting with a single line out and successively adding lines. The key statistical features of the patterns describe the number of lines in the pattern and where the lines were attached to form the pattern. The number of lines in the pattern should match the Zipf distribution (1) that fits the distribution of number of lines in the observed patterns. While forming the pattern, lines can be attached at buses of degree 1 in the pattern or at buses of degree in the pattern. The probability of lines attached at buses of degree 1 should match the corresponding probability in the observed patterns.
The single line pattern ![]() can add a line at one of its buses to become the pattern
can add a line at one of its buses to become the pattern ![]() .
Further line additions at buses with degree starting from
.
Further line additions at buses with degree starting from ![]() can yield the star patterns such as
can yield the star patterns such as ![]() and
and ![]() .
And line additions starting from
.
And line additions starting from ![]() at buses of degree 1 can yield linear patterns such as
at buses of degree 1 can yield linear patterns such as ![]() and
and ![]() .
Other patterns such as
.
Other patterns such as ![]() result from adding lines at buses both of degree and of degree 1.
A particular pattern can be formed in multiple ways.
For example,
result from adding lines at buses both of degree and of degree 1.
A particular pattern can be formed in multiple ways.
For example, ![]() can be formed by either attaching a line to the degree 2 bus of
can be formed by either attaching a line to the degree 2 bus of ![]() followed by a line to a degree 1 bus of
followed by a line to a degree 1 bus of ![]() , or by attaching a line to a degree 1 bus of
, or by attaching a line to a degree 1 bus of ![]() followed by a line to a degree 2 bus of
followed by a line to a degree 2 bus of ![]() .
The observed ways to successively add a line to obtain the BPA patterns are shown in Fig. 7.
.
The observed ways to successively add a line to obtain the BPA patterns are shown in Fig. 7.
Since each line joins 2 buses, the total number of lines in pattern is
| (2) |
For example, ![]() with degree sequence has (2+1+1)/2=2 lines.
with degree sequence has (2+1+1)/2=2 lines.
Where lines have been attached in forming a pattern can be estimated from the degree sequence of the pattern. First, consider the case of a pattern , which is a tree. Then, all the patterns that evolved from ![]() to are also trees.
Each addition of a line
attaches one end at some bus in the evolving pattern, and since all the evolving patterns are trees, the other end is not attached to the evolving pattern. In particular,
each line addition at a bus of degree 1 changes the corresponding 1 in the degree sequence to 2 and appends a new 1 to the degree sequence.
This bus degree of 2 can be further incremented by the addition of other lines, but these further additions are all to a bus of degree .
Therefore, the total number of additions of lines at a bus of degree 1 in forming a tree pattern is given by
to are also trees.
Each addition of a line
attaches one end at some bus in the evolving pattern, and since all the evolving patterns are trees, the other end is not attached to the evolving pattern. In particular,
each line addition at a bus of degree 1 changes the corresponding 1 in the degree sequence to 2 and appends a new 1 to the degree sequence.
This bus degree of 2 can be further incremented by the addition of other lines, but these further additions are all to a bus of degree .
Therefore, the total number of additions of lines at a bus of degree 1 in forming a tree pattern is given by
| (3) |
A large majority of the observed patterns are trees. However, if the pattern is not a tree, the line additions forming include a line addition that joins two buses of the evolving pattern to form a loop in the pattern. When counting the number of additions of lines at a bus of degree 1, (3) remains valid if only one of the joined buses has degree 1. However, if both of the joined buses have degree 1, then (3) will count that single line addition twice. For example, according to (3), . This double counting can be corrected for some simple non-tree patterns by defining
| (4) |
as special cases. This gives an exact answer for the observed NYISO patterns. However, the situation is more complicated for more elaborate non-tree patterns in BPA because there are many possible orders in which the pattern can be assembled, and only the orders in which the line forming the loop is attached to join buses of degree 1 in the evolving pattern have double counting. Since there are only two more elaborate non-tree patterns for the observed patterns in BPA and none for NYISO, and there is an overcount by one in only some of the possible assembly orders, it is an underestimate that is a good approximation for the purpose of estimating in (5) below to define by (3) together with the special cases (4).
Note that we do not know from our data the initial line of each observed pattern or the order in which lines were added to obtain each observed pattern.
Consider all the patterns with 3 or more lines, all of which are produced by adding lines to ![]() .
.
Each pattern in added lines to ![]() .
Hence there are a total of line additions to
.
Hence there are a total of line additions to ![]() to produce all the patterns .
to produce all the patterns .
Each pattern in has had line additions to a bus of degree 1 starting from ![]() and line additions to a bus of degree 1 starting from
and line additions to a bus of degree 1 starting from ![]() .
Therefore, in producing the patterns starting from
.
Therefore, in producing the patterns starting from ![]() , the observed empirical probability of adding a line to a bus of degree 1 is
, the observed empirical probability of adding a line to a bus of degree 1 is
| (5) |
Since lines must be added at either a bus of degree 1 or a bus of degree , the empirical probability of adding a line to a bus of degree in producing is .
For patterns observed in BPA, , and for patterns observed in NYISO, .
The BPA network sometimes has multiple circuits joining the same two buses, and we now account for the possibility of a second circuit outaging when there are multiple circuits. The probability of an additional circuit outaging in a line with multiple circuits is estimated as the number of generations with multiple circuit outages divided by the number of generations with outages of a line with multiple circuits. For the BPA network, .
V Generative model of fast protection patterns
This section describes the fast protection modeling of probabilistically and successively adding lines to an initial single line outage to generate patterns. We first consider multiple circuits joining the same two buses to be single circuits (i.e. consider the network to be simple) and account for the possible outages of the other circuits as the last step.
The patterns are formed by starting with a single line out and successively adding lines until the process stops. The process is probabilistic so that it can be repeatedly sampled to produce a range of patterns that reproduce some key statistical features of the observed patterns. This process is only intended to reproduce these key statistical features of the observed patterns and is not intended to reflect the order of outages when the pattern is produced by the protection system. It aims to represent the statistics of the overall effect observed after the protection mechanisms have acted.
The sampling procedure to match the key statistics of the patterns developed in section IV is as follows:
(1) The assumed initial single line outage ![]() is chosen at random. The single-line outage can be caused by various factors such
as bad weather or a fault. In system risk simulations, it is common to assume a uniform or length-dependent
line outage probability that is applied to the lines in the network.
is chosen at random. The single-line outage can be caused by various factors such
as bad weather or a fault. In system risk simulations, it is common to assume a uniform or length-dependent
line outage probability that is applied to the lines in the network.
(2) We determine how many lines are in the pattern according to the Zipf distribution fitting the data in Fig. 2. A simple way to do this is to sample from the positive integers with weights given by the Zipf distribution. A more accurate and efficient method would be to use stratified sampling as in [15] with each positive integer up to a bound as a stratum. The first seven numerical values of the Zipf distribution probabilities are shown in Table I.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| BPA | 0.92911 | 0.05451 | 0.01038 | 0.00320 | 0.00128 | 0.00061 | 0.00032 |
| NYISO | 0.93336 | 0.05179 | 0.00954 | 0.00287 | 0.00113 | 0.00053 | 0.00028 |
(3) We describe where an additional line is added to an evolving pattern.
(3a) If another outaged line is added to the initial outaged line ![]() to form
to form ![]() , the new outaged line is attached at one of the two buses of
, the new outaged line is attached at one of the two buses of ![]() . This is always possible since the network is connected.
If several neighboring lines are available to be added, one of these neighboring lines is selected with equal probability.
. This is always possible since the network is connected.
If several neighboring lines are available to be added, one of these neighboring lines is selected with equal probability.
(3b) Consider that the evolving pattern already has lines, and another line in the network is to be added to the pattern. If there are lines in the network available to add at either a bus of degree 1 in the evolving pattern or at a bus of degree in the evolving pattern, then the line is added to a bus of degree 1 in the evolving pattern with probability , and added to a bus of degree with probability . However, for a modest fraction of evolving patterns, the network constrains which lines are available in the network to add to the pattern. If there are only lines in the network available to add at a bus of degree 1 in the evolving pattern, then the line is added at a bus of degree 1 in the evolving pattern. If there are only lines in the network available to add at a bus of degree in the evolving pattern, then the line is added at a bus of degree in the evolving pattern. If the network allows several choices of lines to add to the evolving pattern in one of these ways, then select one of the choices with equal probability. The calculation of is explained in section VII.
(4) For the BPA network, if any line in the pattern has multiple circuits in parallel, outage one of the other parallel circuits with probability .
Note that the objective is not to reproduce the observed patterns exactly but to be able to generate new patterns that are credible because they are statistically similar in key respects. If one wanted to use the exact patterns, then this could also be done directly from the specific historical patterns observed, but this lacks flexibility in the number and variety of samples, and since the larger patterns are rare, the historical patterns are only a limited sample of the possibilities. Our model is able to generate rare large patterns in new locations. There is a uniformity assumption that the same generative algorithm applies uniformly across the network, but this assumption is reasonable for this first generative model.
VI Protection Event Propagation System Index
The empirical distribution of the number of outaged lines in a pattern on a log-log plot is fit with a straight line in Fig. 2 for both BPA and NYISO. The magnitude of the slope of the line is the parameter of the fitted Zipf distribution (1). We suggest using as a Protection Event Propagation Slope Index (PEPSI). For example, the slope magnitude of the BPA fitted line in Fig. 2 is given by . For NYISO, . Using the fitted line smooths the more erratic data points caused by the sparse data for the larger patterns.
A lower value of PEPSI indicates a shallower slope and an increased probability of outages propagating to form larger patterns on the fast time scale. More quantitatively, we can use PEPSI to estimate the probabilities of large patterns. These probabilities are conditional on an initial automatic outage happening. Define a large pattern as having 4 or more outages (different cut-offs can be chosen). Then, substituting PEPSI for in (1), we can compute the probability
For example, for , , and for , .
VII Accounting for how evolving patterns fit into the network
Generating the patterns requires a value of , which is the probability of adding a line to a bus of degree 1 in the evolving pattern when there is a choice available in the network between adding a line at a bus of degree 1 in the evolving pattern and adding a line at a bus of degree in the evolving pattern.
The patterns are generated by successively adding outaged lines to a randomly chosen initial outage. And whether a line will be added to buses of degree 1 in an evolving pattern with more than one line should match the observed probability . However, for some of the evolving patterns that are unfavorably positioned in the network it can happen that the network does not have any line available to attach to a bus of degree 1 in the pattern, or the network only has lines available to attach to a bus of degree 1 in the pattern. This section computes a value of accounting for this effect.
We assume a known distribution of initial outages, which here is taken to be a uniform distribution. We generate 1 000 000 patterns assuming a value of starting from the distribution of initial outages. From these patterns, we empirically determine the probability , which is the probability of lines being attached at a bus of degree 1 in an evolving pattern with at least 2 lines. Then we repeat this calculation of , adjusting the value of until matches the corresponding quantity observed in the utility data. This calculation yields for the BPA network and for the NYISO network.
VIII Evaluating generative model results
To evaluate the generative model, we introduce a distance metric that quantifies the difference between the observed data and the generative model results. Such distance metrics have been used to evaluate generative models in neuroscience, astrophysics, X-ray images, and other scientific settings [26]. To construct this distance, we first define a distance between degree sequences of patterns based on the number of edges that need to be added or removed to convert one into another. Then we use the Wasserstein metric to define the distance between distributions of degree sequences of patterns. Given the Wasserstein distance, we can not only quantify how close the generated patterns are to the observed patterns but also statistically test whether the degree sequences of the generated and observed patterns can be considered to be samples from the same probability distribution.
VIII-A Distance between degree sequences of patterns
The distance between the degree sequence of pattern and the degree sequence of pattern is defined as the minimum number of line additions and subtractions to transform the degree sequence into the degree sequence . This can be considered a restricted case of the graph edit distance or Hamming distance [27]. For instance, if the degree sequence of a pattern can be transformed to the degree sequence of by adding or removing one line, then .
To compute the pattern distance, it is convenient to form a graph with all the degree sequences of interest as nodes of the graph. The degree sequences nodes are connected by an edge of the graph if they are distance one apart. Examples of such a graph, but only showing the observed degree sequences, are shown in Figs. 7 and 8.
To form the graph, we start with the degree sequence 1,1 of ![]() and successively add lines one at a time to obtain new degree sequences with each new degree sequence joined by an edge of the graph to its preceding degree sequence.
All the possible line additions that maintain a connected graph with no multiple lines are considered. Since the edges of the graph join degree sequences that differ by one line, the minimum graph distance between two degree sequences is the distance between the degree sequences, and can be computed with Dijkstra’s algorithm assuming the weight of every edge to be 1.
and successively add lines one at a time to obtain new degree sequences with each new degree sequence joined by an edge of the graph to its preceding degree sequence.
All the possible line additions that maintain a connected graph with no multiple lines are considered. Since the edges of the graph join degree sequences that differ by one line, the minimum graph distance between two degree sequences is the distance between the degree sequences, and can be computed with Dijkstra’s algorithm assuming the weight of every edge to be 1.
The detail of forming the graph is as follows: We regard the degree sequences as padded on the right with zeros to allow new buses to be added. Then adding a line changes the degree sequence by adding 1 to two of the bus degrees. The new line either connects two existing buses or joins a new bus to an existing bus. All possible degree sequences produced by such line additions are considered, except that degree sequences corresponding to multiple lines joining the same two buses are excluded using the test for a simple graph from the Havel and Hakimi theorem [28].
VIII-B Distance between distributions of degree sequences
Next, to establish a distance between distributions of degree sequences, we use the Wasserstein metric or Earth Mover’s Distance. By taking the union of all the degree sequences, and dividing the number of occurrences of each degree sequence by the total number of degree sequences, we can construct the empirical probability mass distribution for the degree sequences of both the observed and generated patterns
Here, are the degree sequences of patterns, and , and are the corresponding probabilities. The Wasserstein metric between these two discrete distributions computes the minimal transport plan that is required to convert one distribution into another based on the distance between degree sequences. For this particular case, the Wasserstein metric is the solution of a linear program
| (6) |
subject to for all , for all , and for all . Here is the transportation matrix or transportation plan. There are several open source libraries that implement this calculation, and we use the Python Optimal Transport library (POT) [29].
The Wasserstein distance between two distributions of degree sequences can be interpreted as the fraction of lines that have to be changed to convert one distribution of degree sequences into the other [30]. If the two distributions were obtained from the same number of degree sequences, then the Wasserstein distance times the number of degree sequences can be interpreted as number of lines that have to be changed to convert one set of degree sequences into the other.
VIII-C Distance between the degree sequences of observed and generated patterns
We evaluate the distance between the observed patterns and the same number of samples of the generated patterns by computing the Wasserstein distance between the distributions of their degree sequences. Because the generative model produces different sets of patterns every time it runs, there is variance in the evaluation of this distance. Thus, we perform this evaluation 100 times and compute statistics of the result.
For the BPA system, the mean distance between the generated and observed patterns is 0.0086 while its variance is 0.0016. The Wasserstein distance of 0.0086 corresponds to changing lines to change the 11836 generated pattern degree sequences into those observed. For the NYISO system, the mean distance of the generated and observed data is 0.0131 while its variance is 0.0027. The Wasserstein distance of 0.0131 corresponds to changing lines to change the 7362 generated pattern degree sequences into those observed.
VIII-D Statistical testing of the observed and generated patterns
We statistically test whether the generated patterns and the observed patterns are from the same underlying probability distribution using a permutation test [31] with the test statistic of distance between the distributions of the degree sequences of the observed and generated patterns. Permutation tests are applied in [32] to test generative models, and have been proposed to validate synthetic datasets in finance, healthcare, and other fields [33].
The generative model is used to produce 100 sets of patterns, with each set containing the same number of patterns as those observed (11836 patterns for BPA and 7362 patterns for NYISO). A permutation test is run on each of the 100 sets of patterns to test the null hypothesis that each set of patterns is from the same underlying distribution as the observed patterns. Each permutation test samples 10000 permutations. The p-value for each test is the estimated probability that the distance of the generated set of patterns from the observed set of patterns exceeds the calculated distance. We do not reject the hypothesis that the set of patterns is from the same underlying distribution if the p-value.
This testing procedure gives 100 p-values for each transmission system. For BPA, the median p-value is 0.3565, and 98 p-values exceed 0.05, and for NYISO, the median p-value is 0.0983 and 73 p-values exceed 0.05. These results indicate that in most cases the samples from our generative model are indistinguishable from the observed data, thus strengthening the case that our model is able to capture the underlying statistical structure of the outage propagation.
IX Discussion and Conclusions
We show how to extract network patterns in transmission line outages from utility outage data at the fast protection time scale and the large transmission system scale. The utility data is routinely collected by transmission operators and includes the bus names at each end of the line and the outage start times to the nearest minute. Given unique bus names, it is straightforward to form the network topology directly from the utility outage data itself so that the patterns of outages can be easily located on the network [21]. The outage patterns are easily extracted by noting which outages occur in the same minute.
We extract the fast time scale outage patterns for two transmission systems. This appears to be the first publication of such data, and it is informative to see the multiple outage patterns that actually occurred together with their frequencies. The patterns at this fast time scale are quite different than the patterns formed by outages that occur at a slower time scale due to extreme weather and cascading [21]. The outage patterns at the fast time scale are almost all connected, whereas the outage patterns at the slower time scale tend to be disconnected. We do suggest that separately analyzing the fast protection time scale and the slower time scales in analyzing extreme weather and cascading is valuable. Examining real data is a sound basis for these analyses, and this paper contributes to this at the fast protection time scale.
We approximate the observed distribution of the number of outages in each pattern with a Zipf distribution. The heavy-tailed nature of the Zipf distribution has the practical implication that the larger patterns, although rare, can be expected to occur. The Zipf distribution is characterized by its slope on a log-log plot, and the magnitude of this slope provides a Protection Event Propagation Slope Index that describes how much outages spread in the network at the fast timescale.
The patterns with 3 lines can be evolved by starting with two adjacent line outages and adding lines. We show how to estimate from the observed final patterns and the network structure the probability that a line was added to buses already attached to only one line. This probability controls whether the pattern evolves tending towards linear strings of lines or tending towards stars in which multiple lines are attached to one bus. This probability, together with the statistics of the number of lines in a pattern, are key statistics describing the observed patterns.
These key statistics can be sampled to generate representative sets of outage patterns consistent with the observed statistics. Indeed, this amounts to a novel generative model of the protection system’s overall effects at the transmission system scale.
The ability to generate representative outage patterns from any given starting line outage, caused, for instance, by weather or by equipment failure, is important because the historical outages alone will not cover the full range of credible possibilities when assessing the risk of future outages. Since they are based on utility data, the generated patterns incorporate the common cases of routine operation as well as the rare, but more impactful complicated cases (protection backup, substation design, stuck breaker, hidden failure, common mode etc.) in which outages quickly spread further in the network. The patterns of outages on the network can be generated according to their statistics without getting involved in the various mechanisms for their cause and the formidable difficulties in practice of obtaining and representing the details of the protection system and substations across an entire transmission system.
We show sample results of the generated patterns. To test these generated patterns quantitatively, we define distances between sets of patterns and show that the generated patterns are close to the observed patterns. Moreover, we consider whether the generated patterns are from a different probability distribution than the observed patterns when differences in their distance are evaluated. A statistical permutation test shows that it is unlikely that the generated patterns are from a different underlying probability distribution than the observed patterns.
This paper is devoted to analyzing observed utility data and developing a new generative model of patterns of outages at the large transmission network scale and the fast protection system time scale. Promising future applications for the new generative model that further motivate its development include contributing a practical statistical model of the effects of protection that can be included in Monte Carlo simulations to help assess blackout risk at the transmission system scale, as well as providing observed data and statistics to validate or help guide the development of detailed protection models.


References
- [1] I. Dobson, A. Flueck, S. Aquiles-Perez, S. Abhyankar, J. Qi, Towards incorporating protection and uncertainty into cascading failure simulation and analysis, Probability Methods Applied to Power Systems Conf., Boise, Idaho USA, June 2018.
- [2] A.J. Flueck, I. Dobson, Z. Huang, N.E. Wu, R. Yao, G. Zweigle, Dynamics and protection in cascading outages, IEEE Power and Energy Society General Meeting, Montreal CA, August 2020.
- [3] P. Aragón, V. Gómez, D. García, A. Kaltenbrunner, Generative models of online discussion threads: state of the art and research challenges, Journal of Internet Services and Applications, vol. 8, Oct. 2017.
- [4] K. Zhou, I. Dobson, Z. Wang, The most frequent N-k line outages occur in motifs that can improve contingency selection, IEEE Trans. Power Systems, vol. 39, no. 1, pp. 1785-1796, Jan. 2024.
- [5] Q. Chen, J.D. McCalley, Identifying high risk N-k contingencies for online security assessment, IEEE Trans. Power Systems, vol. 20, no. 2, pp. 823-834, May 2005.
- [6] F. Yang, S. Meliopoulos, J. Cokkinides, Q.B. Dam, Bulk power system reliability assessment considering protection system hidden failures, Proc. IREP Symp., Aug. 2007, pp. 3408–3421.
- [7] Y. Jiang et al., Contingency probability estimation for risk-based planning studies using NERC’s outage data and standard TPL-001-4, in Proc. IEEE North American Power Symp., 2021, pp. 1–6.
- [8] IEEE PES CAMS Task Force on Understanding, Prediction, Mitigation and Restoration of Cascading Failures, Initial review of methods for cascading failure analysis in electric power transmission systems, IEEE PES General Meeting, Pittsburgh, PA USA July 2008.
- [9] IEEE Working Group on understanding, prediction, mitigation and restoration of cascading failures, Benchmarking and validation of cascading failure analysis tools, IEEE Trans. Power Systems, vol. 31, no. 6, November 2016, pp. 4887-4900.
- [10] M.A. Rios, D. S. Kirschen, D. Jayaweera, D.P. Nedic, R.N. Allan, Value of security: modeling time-dependent phenomena and weather conditions, IEEE Trans. Power Systems, vol. 17, no. 3, pp. 543-548, Aug. 2002.
- [11] J. Chen, J.S. Thorp, I. Dobson, Cascading dynamics and mitigation assessment in power system disturbances via a hidden failure model, Intl. J. Elect. Power & Energy Sys., 2005, vol. 27, no. 4, pp. 318-326.
- [12] X. Yu, C. Singh, A practical approach for integrated power system vulnerability analysis with protection failures, IEEE Trans. Power Systems, vol. 19, no. 4, pp. 1811–1820, Nov. 2004.
- [13] E. Ciapessoni, D. Cirio, G. Kjølle, S. Massucco, A. Pitto, M. Sforna, Probabilistic risk-based security assessment of power systems considering incumbent threats and uncertainties, IEEE Trans. Smart Grid, vol. 7, no. 6, pp. 2890-2903, Nov. 2016.
- [14] M.R. Kelly-Gorham, P.D.H. Hines, K. Zhou, I. Dobson, Using utility outage statistics to quantify improvements in bulk power system resilience, Power Systems Computation Conf., Porto, Portugal, June 2020 and Electric Power Systems Research, vol 189, 106676, Dec. 2020.
- [15] M.R. Kelly-Gorham, P.D.H. Hines, I. Dobson, Ranking the impact of interdependencies on power system resilience using stratified sampling of utility data, IEEE Trans. Power Systems, vol. 39, no. 1, Jan. 2024, pp. 1251-1262.
- [16] J. Leskovec, M. McGlohon, C. Faloutsos, N. Glance, M. Hurst, Cascading behavior in large blog graphs, April 2007. http://arxiv.org/abs/0704.2803
- [17] V. Gómez, H. Kappen, A. Kaltenbrunner, Modeling the structure and evolution of discussion cascades, Proc. 22nd ACM Conference Hypertext and Hypermedia, pp. 181-190, 2011.
- [18] “Bonneville power administration Transmission services Operations & reliability Operations information” 2024. [Online]. Available: www.bpa.gov/energy-and-services/transmission/operations-information
- [19] “New York independent system operator website,” 2024 [Online]. Available: http://mis.nyiso.com/public/P-54Blist.htm
- [20] N.K. Carrington, I. Dobson, Z. Wang, Transmission grid outage statistics extracted from a web page logging outages in Northeast America, in Proc. IEEE North Amer. Power Symp., 2021, pp. 1–6.
- [21] I. Dobson, B.A. Carreras, D.E. Newman, J.M. Reynolds-Barredo, Obtaining statistics of cascading line outages spreading in an electric transmission network from standard utility data, IEEE Trans. Power Systems, vol. 31, no. 6, November 2016, pp. 4831-4841.
- [22] I. Dobson, Estimating the propagation and extent of cascading line outages from utility data with a branching process, IEEE Trans. Power Systems, vol. 27, no. 4, pp. 2146-2155, 2012.
- [23] A. Clauset, C.R. Shalizi, M.E.J. Newman, Power-law distributions in empirical data, SIAM Review, vol. 51, no. 4, Nov. 2009, pp.661-703.
- [24] I. Dobson, Finding a Zipf distribution and cascading propagation metric in utility line outage data, arXiv:1808.08434 [physics.soc-ph], 2018.
- [25] S. Ekisheva, R. Rieder, J. Norris, M. Lauby, I. Dobson, Impact of extreme weather on North American transmission system outages, IEEE PES General Meeting, Washington DC USA, July 2021.
- [26] S. Bischoff et al., A practical guide to statistical distances for evaluating generative models in science, (arXiv,2024), https://arxiv.org/abs/2403.12636
- [27] C. Donnat, S. Holmes, Tracking network dynamics: A survey using graph distances, Annals Applied Statistics, vol. 12, June 2018.
- [28] N. Hartsfield, G. Ringel, Pearls in Graph Theory: A Comprehensive Introduction, Dover, NY 2013.
- [29] R. Flamary et al., POT: Python Optimal Transport, Journal Machine Learning Research, vol. 22, no. 78, pp. 1–8, 2021. [Online]. Available: http://jmlr.org/papers/v22/20-451.html
- [30] G. Bolt, S. Lunagómez, C. Nemeth, Distances for comparing multisets and sequences, arXiv:2206.08858v1 [stat.ME] 17 Jun 2022.
- [31] P. Good, Permutation tests: a practical guide to resampling methods for testing hypotheses, Springer Science & Business Media, 2013
- [32] D.J. Sutherland et al., Generative models and model criticism via optimized maximum mean discrepancy, Intl. Conf. Learning Representations, 2017. https://openreview.net/forum?id=HJWHIKqgl
- [33] G. Visani et al., Enabling synthetic data adoption in regulated domains, IEEE 9th Intl. Conf. Data Science & Advanced Analytics, 2022.
Government License (will be removed at publication): The submitted manuscript has been created by UChicago Argonne, LLC, Operator of Argonne National Laboratory (“Argonne”). Argonne, a U.S. Department of Energy Office of Science laboratory, is operated under Contract No. DE-AC02-06CH11357. The U.S. Government retains for itself, and others acting on its behalf, a paid-up nonexclusive, irrevocable worldwide license in said article to reproduce, prepare derivative works, distribute copies to the public, and perform publicly and display publicly, by or on behalf of the Government. The Department of Energy will provide public access to these results of federally sponsored research in accordance with the DOE Public Access Plan. http://energy.gov/downloads/doe-public-access-plan.