The Sound of Bounding-Boxes
Abstract
In the task of audio-visual sound source separation, which leverages visual information for sound source separation, identifying objects in an image is a crucial step prior to separating the sound source. However, existing methods that assign sound on detected bounding boxes suffer from a problem that their approach heavily relies on pre-trained object detectors. Specifically, when using these existing methods, it is required to predetermine all the possible categories of objects that can produce sound and use an object detector applicable to all such categories. To tackle this problem, we propose a fully unsupervised method that learns to detect objects in an image and separate sound source simultaneously. As our method does not rely on any pre-trained detector, our method is applicable to arbitrary categories without any additional annotation. Furthermore, although being fully unsupervised, we found that our method performs comparably in separation accuracy.
I Introduction
In the world around us numerous sounds exist at the same time such as the sound of people speaking, the engine sound of cars going by, and the roar of planes flying overhead. Humans have the capability to identify and isolate individual sounds in such environments, and this is particularly true when we are able to see the objects emitting the sound. This task of separating sounds given visual guidance but in an automatic manner is called audio-visual sound source separation and has been studied in the field of computer vision and signal processing. More specifically, in this task, given an image with multiple sound-producing objects and the corresponding monaural audio as input, the objective is to locate each sound-producing object in the image and to separate the monaural audio into individual sounds associated with the objects.
One promising direction for audio-visual sound source separation is the usage of pre-trained object detectors to identify sound-producing objects prior to separating the sound source. However, in this case, an abundant amount of annotated data is required to train the detector, and moreover, categories whose annotations are not available can not be handled.
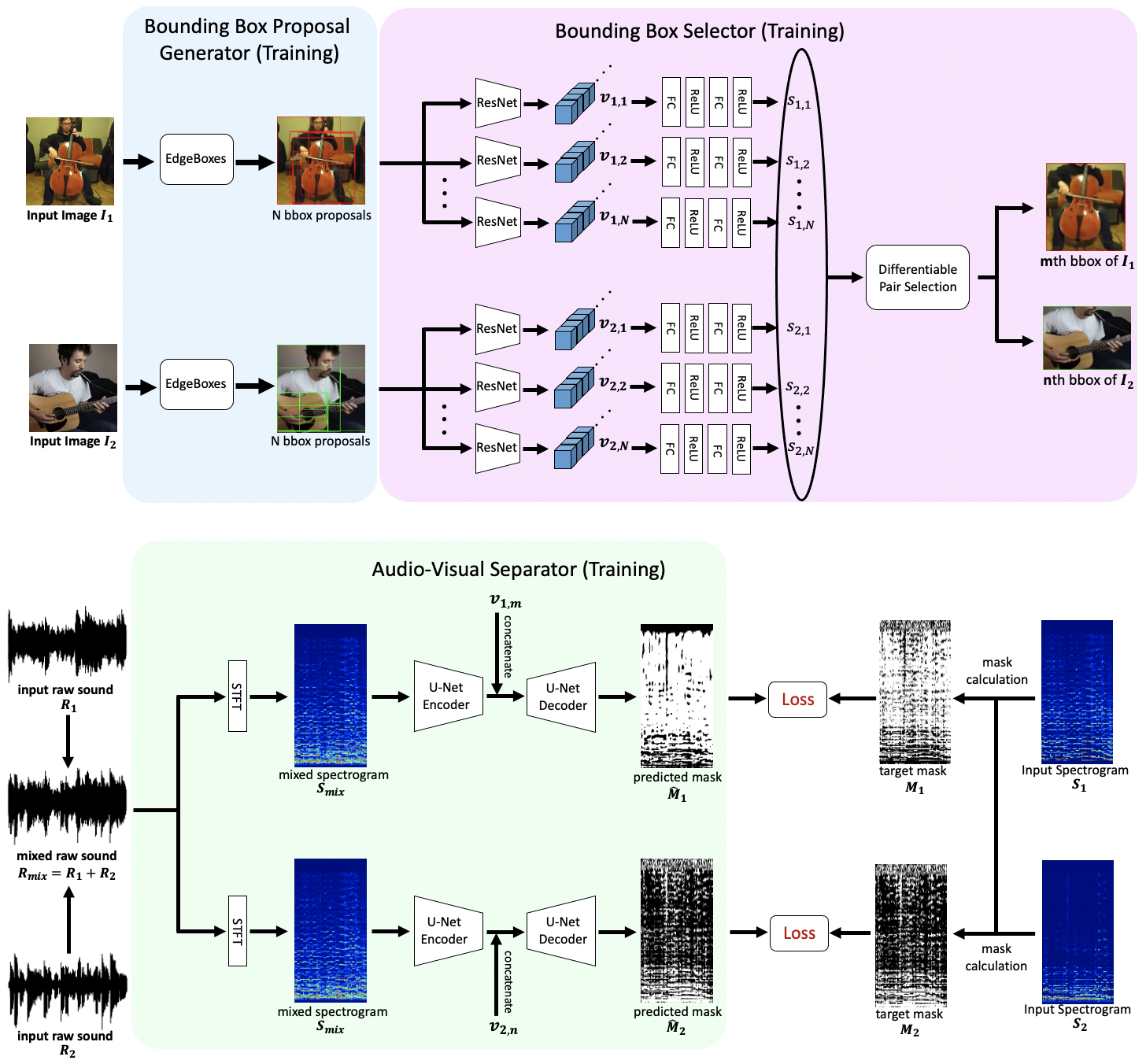
To tackle this problem, we propose a fully unsupervised method that learns to detect objects in an image and separate sound source simultaneously. Unlike existing methods, our method can be trained in an end-to-end manner including the object detection process. As shown in Fig. 1, our proposed method is composed of 3 modules: the bounding box proposal generator, the bounding box selector, and the audio-visual separator. The bounding box proposal generator takes an image as input and returns bounding box proposals. For this module, we leverage EdgeBoxes [1] which has been used in conventional object detection models (e.g. R-CNN [2]). The bounding box selector is a novel module, which takes the bounding box proposals as input and returns the indices of the selected bounding boxes. Intuitively, this module learns to select bounding boxes that are likely to produce sound. The audio-visual separator takes the image features of the selected bounding boxes and the sound source as inputs and returns the separated sound for each bounding box. To make the overall architecture differentiable and trainable, we used a categorical reparameterization trick called Straight-Through Gumbel Softmax [3] for the bounding box selector. Owing to this technique, our model can be trained end-to-end including the object detector. In contrast to the pre-trained detector based method which fundamentally can not handle categories whose annotations are not available, by design our model is applicable to such categories. In our experiments, we compared separation accuracy with the pre-trained detector based method, and found that our proposed model performs comparably when validated on known categories for the pre-trained detector.

II Related Work
In this section, we will go over previous studies on audio-visual sound source separation, and sound source localization which is a closely related task.
Sound source localization
Sound source localization is a traditional problem in robotics and signal processing that uses audio information from multiple microphones to determine the direction and position of a sound source. In the field of computer vision, sound source localization is regarded as the prediction of the location of sound sources in an image and is also sometimes called audio-visual sound source localization.
There have been many sound source localization methods in the field of computer vision, e.g. mutual information and CCA [4, 5], CAM-based [6, 7], attention mechanism based [8, 9, 10, 11], those that utilize motion information [12, 13, 14]. Sound source localization and audio-visual sound source separation are closely related because it is necessary to identify the position of the sound source in an image in order to perform audio-visual sound source separation. Inevitably, sound source localization must be performed prior to audio-visual source separation.
Audio-visual sound source separation.
Audio-visual sound source separation is the task of separating sound sources using visual information. There are many methods for audio-visual sound source separation, e.g. NMF [15, 16, 17], subspace method [18, 19], mix-and-separate method [20, 6, 21, 22, 13, 14, 23, 24], use of facial information [25, 26, 27, 28], use of facial information without lip movements [23], use of the visual structure of the scene as graph [24].
In audio-visual sound source separation, it is essential to identify the location of the sound sources in advance, and therefore several existing methods identify the location of the sound source using bounding boxes via pre-trained detectors [22, 25]. For example, Gao & Grauman [22] train an object detection model using the samples in the instrument categories of the Open Images dataset [29]. However, in order to adapt the model to new categories, it is necessary to prepare new annotations for these additional categories and retrain the object detection model.
Alternatively, there are methods that do not assign sound to bounding boxes but instead assign sounds to pixels [13, 20]. These methods are trained in an unsupervised manner and do not require annotations. One drawback of these methods is that the locations of the sound sources are not explicitly identified. Also, when the sound of each sound source is desired, the pixel that best represents the actual sound is ambiguous. In contrast to these methods, our method can explicitly identify the location of the sound sources using bounding boxes.

III Proposed Framework
Following existing studies on audio-visual sound source separation, we adopt different procedures for the training phase and the inference phase. In the training phase, a pair of videos that each contains a single sound-producing object is used as input, e.g. a video of a guitar being played and a video of a violin being played. The accompanying monaural audio of each video are mixed into a single audio to artificially create an audio environment containing multiple objects. The task at hand during training is to locate the sound-producing object in each video via bounding boxes, and to separate the mixed audio into individual audio that matches the located objects, i.e. reconstruct the original single audio. The detailed process of the training phase is shown in Fig. 2. In the inference phase, the difference is that the input is a single video containing multiple sound-producing objects. Therefore, multiple sound-producing objects are detected in the single input video, unlike the training phase where only a single object can be found in each video. The detailed process of the inference phase is shown in Fig. 3. The rationale for adopting different procedures for training and inference is that, for videos with multiple sound-producing objects, obtaining the ground-truth audio for each object is impractical.
III-A Bounding Box Proposal Generator
The bounding box proposal generator is a module that takes an image as input and returns a set of possible bounding boxes. For this module, we simply employed EdgeBoxes [1], a conventional algorithm that has been used for training object detection models. In training phase, N bounding boxes are obtained for both images (, ). In inference phase, M bounding boxes are obtained for the duet image (), i.e. an image containing multiple sound-producing objects. In both phases, the images are cropped using these bounding boxes and passed on to the bounding box selector.
III-B Bounding Box Selector
Training phase In training phase, the bounding box selector takes 2N cropped images. First, DilatedResNet18 [30] is applied to the input images, and the image features are obtained from the first image and the image features are obtained from the second image. Here, denotes the dimension of the image features. Then, positive scalar values are obtained from each image features, by applying fully-connected layers (FC) as shown below:
| (1) |
| (2) |
Intuitively, and indicate how likely it is that sound is being produced from the region of the corresponding bounding box. After that, the pair of bounding boxes that are most likely to produce sound can be selected by the following equation:
| (3) |
However, Eq. 3 itself is not differentiable, so it can not be used in training. To solve this problem, we made the process differentiable by introducing a categorical reparameterization trick, which will be explained in the next section.
Differentiable Pair Selection
To make the process in Eq. 3 differentiable, We first calculated
| (4) |
Then, a categorical reparameterization trick called Straight-Through (ST) Gumbel Softmax [3] is leveraged to make discrete.
| (5) |
Finally, the image features corresponding to the selected bounding boxes (, ) can be obtained by the following equation, in a differentiable manner.
| (6) |
| (7) |
Inference phase In inference phase, the bounding box selector takes M cropped images. Same as the training phase, DilatedResNet18 is applied to the input images and the image features are obtained. Then, positive scalar values are obtained by
| (8) |
After that, the pair of non-overlapping bounding boxes that is most likely to produce sound is selected by
| (9) |
Here, NO is decided by the following condition.
| (10) |
Finally, the image features corresponding to the selected bounding boxes (, ) are used as the input of the audio-visual separator.
III-C Audio-Visual Separator
Training phase In training phase, the audio-visual separator takes an artificially mixed raw sound and the image features (, ) as inputs. Here, can be calculated by , where and denote an input raw sound pair. First, Short-Time Fourier Transform (STFT) is applied to and the spectrogram is obtained. Then, the spectrogram is used as the input of the U-Net and each of the image features (, ) are concatenated with the intermediate features of the U-Net. The output of the U-Net is the spectrogram masks (, ) corresponding to each of the image features. Finally, per-pixel cross entropy loss is calculated between the predicted masks (, ) and the target masks (, ), where and are calculated by
| (11) |
| (12) |
These masks are called “binary mask” in existing studies, and are empirically known to work well. The per-pixel cross entropy loss is the only loss used to train the model.
Inference phase
In inference phase, the audio-visual separator takes a raw sound and the image features (, ) as inputs. First, same as training phase, STFT is applied to , and the spectrogram is obtained. Then, the spectrogram is used as the input of the U-Net, and each of the image features (, ) are concatenated with the intermediate features of the U-Net. The output of the U-Net is the spectrogram masks (, ) corresponding to each of the image features. These masks are multiplied with the input spectrogram, and then the predicted spectrograms for both bounding boxes (, ) are obtained. Finally, inverse STFT is applied to the predicted spectrograms and the separated raw sound (, ) is obtained.
III-D Constraint on predicted masks using softmax function
We found our method can be easily improved by introducing a simple constraint that forces the sum of the predicted masks to be equal to 1. Specifically, we replaced the sigmoid layer, which is used as the final activation function in the U-Net, with a softmax layer. When using the sigmoid layer, the masks are calculated by
| (13) |
, where and are the outputs of the U-Net decoder prior to the last activation function. On the other hand, when using the softmax layer, the masks are calculated as follows.
| (14) |
| (15) |
Because of the softmax function, it is obvious that the sum of the predicted masks is equal to 1. It should be noted that the sum of the separated sound is always equal to the original sound in such a situation.
III-E Hyperparameters
For the hyperparameters of audio-visual separator and DilatedResNet18, we followed the official implementation of Pixelplayer [20], except that the number of the frames in video is 1. For the hyperparameters of bounding box selector, we used , , C = 32. The number of the hidden layers in FCs of the bounding box selector is 128.
IV Experiments
| Example pair 1 | Example pair 2 | Example pair 3 | ||||||
| Input images |

|

|
|
|
|
|
||
| mixed spectrogram |

|
|
|
|||||
| Predicted spectrogram |

|

|
|
|
|
|
||
| Ground truth spectrogram |

|

|
|
|
|
|
||
IV-A Dataset and Data Preprocessing
For the training and evaluation, we collected 655 videos from the MUSIC dataset’s [20] YouTube video IDs. The MUSIC dataset contains 20 categories, where 11 categories are of a single instrument (solo), and 9 categories are of two instruments (duet). We used 408 solo videos for training, 102 solo videos for validation, and 145 duet videos for testing. We split train/validation so that the proportion of the number of samples in each category is the same. The validation set is used to evaluate the separation accuracy, as the test set samples do not have ground truth sound of individual objects. The test set is used for the qualitative evaluation.
IV-B Configurations
To evaluate the separation accuracy of our model, we make a comparison with Co-separation [22] which is an audio-visual sound source separation model that locates sound-producing objects using bounding boxes in a supervised manner. In addition, we made a comparison with Pixelplayer [20], which assigns sound to every pixel in the given image and is trained in an unsupervised manner. Although Pixelplayer does not explicitly identify the location of the sound-producing object and hence is tackling a slightly different problem, a comparison in separation accuracy can be made in the validation setting. Because Co-separation depends on an object detector pre-trained on the Open Images V4 Dataset [29], comparison with Co-separation can only be made on the categories included in this dataset. Specifically, we used 7 out of 11 single instrument categories in the MUSIC dataset. The excluded categories are ‘clarinet’, ‘erhu’, ‘tuba’, and ‘xylophone’. On the other hand, a comparison with Pixelplayer can be performed using all categories of the MUSIC dataset. Furthermore, we experimented both with and without the softmax constraint for our model and Co-separation. However for Pixelplayer, since the softmax constraint can not be applied in inference phase as sounds are assigned to every pixel in the image, the softmax constraint is not tested. When excluding the softmax constraint, the final activation function is simply a sigmoid. For all models, the same loss function is used to ensure a fair comparison.
IV-C Evaluation
For evaluation we employed SDR (Source to Distortion Ratio), SIR (Source to Interference Ratio) and SAR (Source to Artifacts Ratio). It should be noted that SDR is considered as the overall metric that can evaluate the sound separation quality.
IV-D Results and Analysis
Quantitative evaluation
| SDR | SIR | SAR | |
|---|---|---|---|
| Ours (sigmoid) | 7.78 | 12.78 | 11.52 |
| Ours (softmax) | 8.40 | 13.39 | 11.99 |
| Co-Separation (sigmoid) | 8.00 | 13.14 | 11.69 |
| Co-separation (softmax) | 8.59 | 13.77 | 11.94 |
| PixelPlayer (sigmoid) | 7.76 | 12.96 | 11.07 |
| SDR | SIR | SAR | |
|---|---|---|---|
| Ours (sigmoid) | 8.77 | 15.18 | 11.83 |
| Ours (softmax) | 9.62 | 16.38 | 12.26 |
| PixelPlayer (sigmoid) | 8.41 | 15.81 | 10.92 |
We reported SDR/SIR/SAR of our model, Pixelplayer [20] and Co-separation [22], in Table I and Table II. As can be seen in Table I, our model performs comparably as Co-separation with only 0.22 (sigmoid) and 0.19 (softmax) performance degradation in SDR. These results show that our fully unsupervised model is capable of separating sounds at similar quality as Co-separation, even though being validated on categories that were used for pre-training of the object detector in Co-separation.
Moreover, as can be seen in Table I and Table II, when used with the softmax constraint, our model performs better than Pixelplayer, the existing fully unsupervised method, by 1.21 (all categories) and 0.66 (limited categories) in SDR. From these results we can deduce that the softmax constraint, which enforces the sum of the separated sound to be equal to the original sound, largely enhances the separation accuracy. It should be noted that this constraint can not be incorporated in Pixelplayer.
Qualitative evaluation of our model
| Example 1 | Example 2 | Example 3 | Example 4 | Example 5 | |
| Ours |

|

|

|

|

|
| Co-Separation [22] |

|

|

|

|

|
We show examples of the separation and the detection results on the validation set in Fig. 4. As can be seen in Fig. 4, our model is applicable to various types of categories, including the ones that are not included in the Open Images V4 Dataset. From the comparison between the predicted and ground truth spectrograms, we can confirm that the separation is properly performed. For the separation and detection results on the test set, please refer to the supplementary video.
Limitation of our model
We show some examples of the detection result of our model and Co-separation in Fig. 5. While Co-separation, which is based on a pre-trained detector, successfully detects the region of the instruments, our model sometimes detects slightly larger or smaller regions. This can be because our model has no explicit constraint that induces the model to detect the exact region. Specifically, if the selected bounding box includes the region that enables the type of object to be identified, the model can reduce the defined loss.
V Discussion & Conclusion
In this paper, we proposed a fully unsupervised method for audio-visual sound source separation that learns to both detect objects in an image and separate sound sources. While existing methods rely on a pre-trained object detector, our method can be trained in an end-to-end manner including the object detection part. Therefore, unlike the existing methods that rely on a pre-trained detector, our method is applicable to categories whose annotations are not available. Moreover, even though our method does not use any annotations, our method performs comparably in terms of separation accuracy as the method that is based on a pre-trained detector. Additionally, our method performs much better than the existing fully unsupervised method by introducing a simple constraint, which enforces the sum of the separated sound to be equal to the original sound. For future work, we believe it is valuable to try to make audio-visual models applicable to images in which a large number of sound-producing objects are present.
Acknowledgements This research was fully supported by JST Mirai Program No. JPMJMI19B2, and JSPS KAKENHI Nos. 19H01129, 19H04137, 21H0504.
References
- [1] C. Lawrence Zitnick and Piotr Dollár. Edge boxes: Locating object proposals from edges. In European Conference on Computer Vision (ECCV), 2014.
- [2] Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Computer Vision and Pattern Recognition (CVPR), 2014.
- [3] Eric Jang, Shixiang Gu, and Ben Poole. Categorical Reparameterization with Gumbel-Softmax. arXiv preprint arXiv:1611.01144, 2016.
- [4] John R. Hershey and Javier R. Movellan. Audio vision: Using audio-visual synchrony to locate sounds. In Neural Information Processing Systems (NIPS), 1999.
- [5] Einat Kidron, Yoav Y. Schechner, and Michael Elad. Pixels that sound. In Computer Vision and Pattern Recognition (CVPR), 2005.
- [6] Andrew Owens and Alexei A. Efros. Audio-visual scene analysis with self-supervised multisensory features. In European Conference on Computer Vision (ECCV), 2018.
- [7] Bruno Korbar, Du Tran, and Lorenzo Torresani. Cooperative learning of audio and video models from self-supervised synchronization. In Neural Information Processing Systems (NIPS), 2018.
- [8] Relja Arandjelović and Andrew Zisserman. Objects that sound. In European Conference on Computer Vision (ECCV), 2018.
- [9] Arda Senocak, Tae-Hyun Oh, Junsik Kim, Ming-Hsuan Yang, and In So Kweon. Learning to localize sound source in visual scenes. In Computer Vision and Pattern Recognition (CVPR), 2018.
- [10] Honglie Chen, Weidi Xie, Triantafyllos Afouras, Arsha Nagrani, Andrea Vedaldi, and Andrew Zisserman. Localizing visual sounds the hard way. In Computer Vision and Pattern Recognition (CVPR), 2021.
- [11] Takashi Oya, Shohei Iwase, Ryota Natsume, Takahiro Itazuri, Shugo Yamaguchi, and Shigeo Morishima. Do we need sound for sound source localization? In Asian Conference on Computer Vision (ACCV), 2020.
- [12] Yapeng Tian, Jing Shi, Bochen Li, Zhiyao Duan, and Chenliang Xu. Audio-visual event localization in unconstrained videos. In European Conference on Computer Vision (ECCV), 2018.
- [13] Hang Zhao, Chuang Gan, Wei-Chiu Ma, and Antonio Torralba. The sound of motions. In International Conference on Computer Vision (ICCV), 2019.
- [14] Chuang Gan, Deng Huang, Hang Zhao, Joshua B. Tenenbaum, and Antonio Torralba. Music gesture for visual sound separation. In Computer Vision and Pattern Recognition (CVPR), 2020.
- [15] Sanjeel Parekh, Slim Essid, Alexey Ozerov, Ngoc Duong, Patrick Pérez, and Gaël Richard. Motion informed audio source separation. In International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017.
- [16] Farnaz Sedighin, Massoud Babaie-Zadeh, Bertrand Rivet, and Christian Jutten. Two multimodal approaches for single microphone source separation. In European Signal Processing Conference (EUSIPCO), 2016.
- [17] Ruohan Gao, Rogerio Feris, and Kristen Grauman. Learning to separate object sounds by watching unlabeled video. In European Conference on Computer Vision (ECCV), 2018.
- [18] Paris Smaragdis and Michael Casey. Audio/visual independent components. In International Conference on Independent Component Analysis and Signal Separation (ICA), 2003.
- [19] Jie Pu, Yannis Panagakis, Stavros Petridis, and Maja Pantic. Audio-visual object localization and separation using low-rank and sparsity. In International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017.
- [20] Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick, Josh McDermott, and Antonio Torralba. The sound of pixels. In European Conference on Computer Vision (ECCV), 2018.
- [21] Andrew Rouditchenko, Hang Zhao, Chuang Gan, Josh McDermott, and Antonio Torralba. Self-supervised audio-visual co-segmentation. In International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019.
- [22] Ruohan Gao and Kristen Grauman. Co-separating sounds of visual objects. In International Conference on Computer Vision (ICCV), 2019.
- [23] Ruohan Gao and Kristen Grauman. Visualvoice: Audio-visual speech separation with cross-modal consistency. In Computer Vision and Pattern Recognition (CVPR), 2021.
- [24] Moitreya Chatterjee, Jonathan Le Roux, Narendra Ahuja, and Anoop Cherian. Visual scene graphs for audio source separation. In International Conference on Computer Vision (ICCV), 2021.
- [25] Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, and Michael Rubinstein. Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. In Special Interest Group on Computer GRAPHics and Interactive Techniques (SIGGRAPH), 2018.
- [26] Aviv Gabbay, Asaph Shamir, and Shmuel Peleg. Visual speech enhancement. In International Speech Communication Association (INTERSPEECH), 2018.
- [27] Triantafyllos Afouras, Joon Son Chung, and Andrew Zisserman. The conversation: Deep audio-visual speech enhancement. In International Speech Communication Association (INTERSPEECH), 2018.
- [28] Anna Llagostera Casanovas, Gianluca Monaci, Pierre Vandergheynst, and Rémi Gribonval. Blind audiovisual source separation based on sparse redundant representations. Transactions on Multimedia, 12(5):358–371, 2010.
- [29] Ivan Krasin, Tom Duerig, Neil Alldrin, Vittorio Ferrari, Sami Abu-El-Haija, Alina Kuznetsova, Hassan Rom, Jasper Uijlings, Stefan Popov, Andreas Veit, Serge Belongie, Victor Gomes, Abhinav Gupta, Chen Sun, Gal Chechik, David Cai, Zheyun Feng, Dhyanesh Narayanan, and Kevin Murphy. Openimages: A public dataset for large-scale multi-label and multi-class image classification. Dataset available from https://github.com/openimages, 2017.
- [30] Fisher Yu, Vladlen Koltun, and Thomas Funkhouser. Dilated residual networks. In Computer Vision and Pattern Recognition (CVPR).