The reference interval in higher-order stochastic dominance
Abstract
Given two random variables taking values in a bounded interval, we study whether one dominates the other in higher-order stochastic dominance depends on the reference interval in the model setting. We obtain two results. First, the stochastic dominance relations get strictly stronger when the reference interval shrinks if and only if the order of stochastic dominance is larger than three. Second, for mean-preserving stochastic dominance relations, the reference interval is irrelevant if and only if the difference between the degree of the stochastic dominance and the number of moments is no larger than three. These results highlight complications arising from using higher-order stochastic dominance in economic applications.
Keywords: Higher-order stochastic dominance; prudence; temperance; expected utility; mean-preserving stochastic dominance
1 Introduction
Stochastic dominance is a widely used concept in economics, finance, and decision-making under uncertainty, providing a robust method for comparing distributions of uncertain outcomes. This concept is essential in evaluating risk preferences without relying on a specific utility function or preference model, which allows for broad applications across various fields (Levy (2015); Shaked and Shanthikumar (2007)).
First-order stochastic dominance (FSD) and second-order stochastic dominance (SSD) are the most popular stochastic dominance rules. More recently, the application of higher-order stochastic dominance has become increasingly significant, providing deeper insights into risk behavior that extend beyond mere risk aversion; see Eeckhoudt and Schlesinger (2006); Crainich et al. (2013); Deck and Schlesinger (2014); Noussair et al. (2014); Liu and Neilson (2019).
Despite its widespread use, the definition of higher-order stochastic dominance lacks consistency across the literature, sometimes leading to interpretational ambiguity. Consider, for example, two distributions, and , each supported over the interval . At first glance, one might assume that the question of whether dominates in fourth-order stochastic dominance would yield a straightforward answer. However, the consequence can depend significantly on the choice of the evaluation interval. For instance, if we assess the dominance using only the interval , may not dominate . Yet, extending the interval to might flip the assessment, resulting in dominating .111For a detailed discussion, see Example 1, where the specific distributions of and with . This highlights a crucial aspect of higher-order stochastic dominance: It can vary with alterations in the interval considered. This issue has led to ambiguous formulations of higher-order stochastic dominance across various texts. For example, Definition 7 in Baiardi et al. (2020) and the related definitions in Section 2.3 of Denuit and Eeckhoudt (2010) both adopted an arbitrary interval that encompasses the support of the distribution, but the definition actually depends on the choice of the interval.
To be specific, two prevalent formulations of higher-order stochastic dominance are found in the literature. The first formulation, denoted as , can be applied to all distributions with bounded support and is defined as: dominates if for all , where is the higher-order cumulative function, as defined in (1); see e.g., Rolski (1976); Fishburn (1980); Shaked and Shanthikumar (2007). The second formulation was initially proposed by Jean (1980) and has been widely adopted in decision theory; see e.g., Eeckhoudt et al. (2009); Nocetti (2016); Baiardi et al. (2020). We denote this as , which specifically applies to distributions supported within the interval . This criterion requires that for all in , and also the boundary conditions at , i.e., for each from 1 to . Both formulations can be described by ordering distributions with their expected utility for some sets of utility functions.
We say that the two formulations are consistency if the ranking between distributions and supported in remains the same when assessed under or . To the best of our knowledge, although various papers hint at the inconsistency issue under different settings (see Section 4 for a review), the consistency of the two formulations of higher-order stochastic dominance was explicitly discussed only in Fang and Post (2022). In their Section 2.2, they contended that imposes a more stringent criterion than , suggesting that inconsistencies might arise when . We formally encapsulate these observations in our Proposition 1, providing a detailed analysis and illustrating the inconsistencies for cases where with a straightforward counterexample in Example 1.
Ranking inconsistencies can also arise when applying formulations across different intervals, such as and , when . Our Theorem 1 illustrates that these inconsistencies arise even when distributions are confined to a subset of the intersection of and , rather than the entire intersection. This observation highlights the profound influence that the choice of evaluation interval can exert on stochastic dominance assessments, underscoring the importance of meticulous interval selection in both theoretical analysis and practical implementation.
Furthermore, we show that Proposition 1 can be extended to a broader class of stochastic dominance rules known as th degree -mean preserving stochastic dominance (Liu (2014)). This framework includes higher-order stochastic dominance, th degree mean-preserving stochastic dominance (Denuit and Eeckhoudt (2013)), and th degree risk increase (Ekern (1980)) as special cases.
One implication of our results is that, since stochastic domination relations (with ) get strictly stronger when the reference interval shrinks, it affects both their applications and characterization results. For instance, a stochastic dominance relation is easier to hold when we enlarge the reference interval, which are usually harmless for real-data applications. The results also illustrate a drawback of the higher-order stochastic dominance relations: As stochastic dominance is mostly used as a robust tool for ordering risks without assuming specific preferences, the fact that they depend on a reference interval — a subjective choice of the modeler — jeopardizes their robustness interpretation.
2 Main results
For with , denote by the set of all bounded random variables taking values in . For simplicity, we write . We use capital letters, such as and , to represent random variables, and and for distribution functions. For , we write for the expectation of . Let denote the distribution function of . We use to represent the point-mass at . For a real-valued function , let and be the left and right derivative of , respectively, and denote by the th derivative for . Whenever we use the notation , and , it is understood that they exist. Denote by with . In this paper, all terms like “increasing”, “decreasing”, “convex”, and “concave” are in the weak sense.
For a distribution function , denote by and define
| (1) |
It is well-known that is connected to the expectation of (see e.g., Proposition 1 of Ogryczak and Ruszczyński (2001)):
where for .
As introduced earlier, we now detail the two formulations of th-order stochastic dominance.
Definition 1.
[Shaked and Shanthikumar (2007)] Let . For , we say that dominates in the sense of th-order stochastic dominance on (), denoted by or if
or equivalently,
Definition 2.
[Jean (1980)] Let with and . For , we say that dominates in the sense of th-order stochastic dominance on (), denoted by or if
or equivalently,
For , SD corresponds to the well-known first, second, third and fourth-order stochastic dominance. Risk aversion, which includes aversion to mean-preserving spreads, aligns with second-order stochastic dominance as described in Rothschild and Stiglitz (1970). Higher orders of stochastic dominance, specifically third and fourth orders, cater to decision makers with more refined risk preferences. Third-order stochastic dominance reflects prudence (Kimball (1990)), while fourth-order dominance corresponds to temperance (Kimball (1992)). The characterizations of these preferences, as detailed by Eeckhoudt and Schlesinger (2006), extend from the traditional concept of mean-preserving spreads to a broader framework of risk apportionment.
For two random variables , both and can be used to rank their order. This raises a natural question of whether these ranking relations are consistent. To examine this, we define two sets of utility functions that are regular -increasing concave (Denuit and Eeckhoudt (2013)) over different domains:222 From the definition in Liu (2014), the utility functions in exhibit th-degree risk aversion for . Letting , becomes the set of all completely monotone functions, which is well studied in the mathematics literature and is closely linked to Laplace–Stieltjes transforms (see, e.g., Schoenberg (1938)). In this case, utility functions express mixed risk aversion, as discussed in Caballé and Pomansky (1996).
and
Denote as the closure of with respect to pointwise convergence. This gives the class of all the utilities such that for and is increasing and concave on . The following proposition provides an answer to the above question of consistency and reveals that the answer is negative for .
Proposition 1.
Let with and . For , we have
| (i) | (ii) | |||||
| (iv) | (v) |
and (i) (iv) always holds true. But (iv) (i) holds for all if and only if .
The equivalence of (i) and (ii) was well-established; see e.g., Eeckhoudt et al. (2009), Denuit and Eeckhoudt (2013) and Theorem 3.6 of Levy (2015). Specifically, the implication (i) (ii) can be shown by using integration by parts. Note that (ii) (v) is trivial. Once the equivalence of (iv) and (v) is established, it follows that (i) (iv) holds. This implication suggests that provides a more stringent criterion than when comparing random variables defined over the space . Additionally, Proposition 1 demonstrates that a prudent decision maker’s preferences remain consistent whether employing or SD. Consequently, this allows for the uniform application of SD to rank random variables. However, preferences of a temperate decision maker may vary when transitioning from the criterion to .
Below, we present a specific example involving two random variables . This example demonstrates that and , serving as a counterexample to the implication (iii) (i) in Proposition 1.
Example 1.
Let with
It holds that
Hence. .
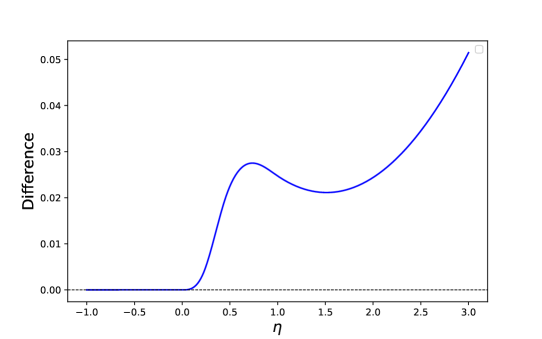
By standard calculation, one can check that for all (see Figure 1 for an intuitive illustration), which implies that . Moreover,
Hence, we also have .
The next result examines the consistency of when applied across various intervals. Notably, does not depend on as long as is smaller than the left endpoint of the support of the random variables to compare. For simplicity, we assume that the left endpoint of all intervals is the same in the following theorem.
Theorem 1.
Theorem 1 illustrates that the ranking of two random variables can be inconsistent when applying SD across different intervals when . Specifically, when two stochastic dominance relations, defined over intervals and such that the right endpoint of exceeds that of , this inconsistency arises. Importantly, such inconsistencies occur even when only considering random variables whose support is confined to a sub-interval of , not necessarily the entire intersection.
In practice, the exact interval that bounds all possible values of wealth may not be known, and decision makers typically set a sufficiently large range based on historical data. Suppose that there are two risk analysts using 4SD to rank the stock returns in one year. One chooses as the reference interval, and one chooses as the reference interval. Consider two stock returns, denoted by and , evaluated based on their historical performance, both taking values between . The first analyst may conclude that dominates in 4SD, and the second may conclude that the domination does not hold. In this example, although both analysts choose very large upper bound for the interval that surely contains all possible values of and , it is unclear which value of is the right one to choose, and this subjective choice affects their conclusion on domination. In extreme scenarios, where a new observation shows that the upper bound is not large enough to cover all risks of interest, the analysts must enlarge their interval, and may arrive at different domination relations even for those return variables that are within the originally chosen interval.
Proposition 1 can be generalized to include a broader category of stochastic dominance rules known as th degree -mean preserving stochastic dominance (Liu (2014)), denoted as . Specifically, for , dominates in if and for all , with equality holding for all . This concept can be extended to the set of all bounded random variables, denoted as , where dominates if and for each . The higher-order stochastic dominance is a particular instance of th degree -mean preserving stochastic dominance with . If , this dominance criterion corresponds to th degree mean-preserving stochastic dominance as introduced in Denuit and Eeckhoudt (2013). When , it aligns with the notion of th degree risk increase as originally defined by Ekern (1980).
For the above two formulations of th degree -mean preserving stochastic dominance, we have the following result about the consistency that extends Proposition 1.
Theorem 2.
Theorem 2 shows that the th degree mean-preserving stochastic dominance rules are consistent for . Furthermore, the th degree risk increase rules are always consistent across different intervals. This finding indicates that when a decision maker uses the th-degree risk increase rule to compare uncertain outcomes, she can uniformly apply its counterpart on , making it suitable for all bounded uncertainty outcomes.
3 Proofs
3.1 Proof of Proposition 1
Note that is the closure of with respect to pointwise convergence. We only need to consider the statements (i), (ii), (iv) and (v). Below we will prove Proposition 1 by three steps.
-
(a)
Prove (i) (iv) for .
-
(b)
Prove (i) (ii) (iv) (v) for .
-
(c)
For any with and , there exist such that and .
In Step (b), the equivalence of (i) and (ii) was well-established, as discussed in Section 2. Specifically, the implication (i) (ii) can be shown by using integration by parts, greatly facilitated by the condition for derived from . This condition, however, is absent in the analysis of the implication (iv) (v). In fact, the implication (iv) (v) can be verified by the insight that every is a positive linear combination of singularity functions in the set ; see Williamson (1956). We provide a self-contained proof based on the integration by parts.
Before showing the proofs, we present an auxiliary lemma for later use.
Lemma 1 (Proposition 6 of Ogryczak and Ruszczyński (2001)).
For and , we have
As a result, for and , implies .
Proof of Step (a).
The cases are trivial. Let now .
(i) (iv): It is straightforward to see that (i) implies for all and . For , we have
This yields (iv).
(iv) (i): It follows from Lemma 1 that (iv) implies . This completes the proof. ∎
Proof of Step (b).
The implication (i) (ii) has been verified in Theorem 1 of Eeckhoudt et al. (2009). The implication (ii) (v) is trivial. The implication (v) (iv) is supported by the fact that the mapping is contained in , and thus, it can be approximated by the functions in with respect to the pointwise convergence.
It remains to verify (iv) (v). To see this, suppose that . It follows from Lemma 1 that . First, we assume that , and the case that will be studied later. Using Lemma 1 again and noting that , there exists such that for all . For , using integration by parts yields
where the inequality follows from and . Using integration by parts repeatedly following a similar argument, we get
where the last inequality holds because for all , and is increasing as . Hence, we have if . Suppose now that . It is straightforward that for all . It follows from the previous arguments that . Note that as . This gives . Hence, we have completed the proof. ∎
Proof of Step (c).
Let us now focus on Step (c). To verify this step, it suffices to show that there exist with and such that and , and such example has been given in Example 1. To see this, suppose that are the random variables satisfying and . Then, we have for all . It follows from Lemma 1 that , and hence, implies . For with and , define and , where and . It is straightforward to see that , and implies . Additionally, we have
Therefore, we have concluded that , and , which confirms Step (c). Hence, we complete the proof. ∎
3.2 Proof of Theorem 1
We first present an auxiliary lemma.
Lemma 2.
Let with . There exists a sequence such that and for all , and .
Proof.
We assume without loss of generality that and . Let and be such that and . It holds that as . Define with
It is straightforward to check that for all . We aim to verify that if is sufficiently large. To see this, denote by for and . It is straightforward to see that for . By standard calculation, we have
where . One can check that the mapping is increasing on and . Hence, we have for . For sufficiently large , we have is small enough, and thus, for . Let us now consider the case . Denote by , and it holds that and as . By some standard calculations, we have
where we have calculated the minimum of a quadratic function in the the first inequality by noting that , which implies that for when is sufficiently large. Therefore, we have concluded that if is sufficiently large. Note that
where the convergence follows from and . This comletes the proof. ∎
Proof of Theorem 1.
The implication in (2) follows from the equivalence between (i) and (ii) in Proposition 1. Note that the equivalence between (i) and (iii) in Proposition 1 holds for , and thus, the backward implication of (2) also holds when . It remains to verify that the backward implication fails if . To see this, we assume without loss of generality that . Let be such that ,
where the existence is due to Lemma 2. Let , and define and . It holds that , ,
Therefore, we have
This implies that and for . Since is more stringent than for , we have completed the proof. ∎
3.3 Proof of Theorem 2
In this section, closure refers specifically to pointwise convergence. For , define the class of -concave functions on as follows
The set is a closed convex cone. For any , there exists a sequence such that on for all and pointwisely. Denote by , which is also a closed convex cone. The following result is straightforward to verify by sharing a similar proof of Proposition 1 (see also Theorem 1 of Liu (2014)).
Lemma 3.
Let with and with . For , dominates in if and only if for all .
Next, we aim to show that the backward implication of (3) holds if . To see this, suppose that satisfy that dominates in . The cases are trivial. Let now . It suffices to verify that . Since dominates in , we have . Also note that for . By Theorem 4.A.58 of Shaked and Shanthikumar (2007), either or holds, which further implies that . This completes the proof of the backward implication of (3) for .
It remains to verify that the backward implication of (3) fails when . Unlike in Proposition 1, where a counterexample is presented, here we seek to demonstrate this result through an alternative approach. Such an approach is based on the following lemma, which is a direct result from Corollary 3.8 of Müller (1997).
Lemma 4.
Let with , and let and be two closed convex cones of real-valued functions on . Suppose that and are two orderings on , which satisfy for and , if and only if for all . Then, the orderings and are equivalent if and only if .
We complete the proof by verifying that is a strictly more stringent rule than on , where with and with . Choose for . It is straightforward to see that . Note that and are both closed convex cone. Combining Lemmas 3 and 4, it suffices to verify that on for all . To see this, we assume by contradiction that there exists such that on . It holds that
| (4) |
Define for and . We have that is increasing and concave on for as with . Note that on , and thus, must be the constant on as it is increasing and concave. Further, the equation (4) implies for . Since for , we have for . This means that for . Note that for . This contradicts the fact that is increasing on . Hence, we have concluded that is a strictly more stringent rule than on , where and . This completes the proof.∎
4 Stochastic dominance on grids and sub-intervals
Many studies have explored stochastic dominance for distributions restricted to specific subsets of , with several exploring the consistency of these orderings across various subsets. This section discusses some of them.
Fishburn (1976) investigated stochastic dominance on a restricted interval , defined such that dominates if for all within 333The order can take any real value from ; however, for our purposes, we consider only integer .. Compared to , Fishburn’s criterion does not require the boundary condition at , making it less stringent than both and . Furthermore, Fishburn (1980) showed that stochastic dominance relations in Fishburn (1976) align with only for . In light of our Proposition 1, we conclude that , , and Fishburn’s criterion exhibit consistent for and . However, for orders , these criteria do not exhibit consistency.
The integral stochastic orderings (Whitt (1986); Müller (1997)) within a fixed subset of , specifying that dominants if for all functions , which is defined on the subset, in a particular class . Following this framework, Denuit et al. (1999) and subsequent works by Fishburn and Lavalle (1995) and Denuit and Lefevre (1997) explored stochastic orderings by setting the subset as a grid to compare discrete distributions. In particular, Denuit et al. (1999) showed that the ranking of two discrete distributions, each of the support is contained in a fixed grid, can become inconsistent when stochastic orderings are applied to the original grid and then extended to include an additional point. This inconsistency indicates that the choice of the grid significantly affects the ranking of random variables.
Denuit et al. (1998) and Denuit et al. (1999) studied -concave orderings within specific intervals, which correspond to increasing th-degree risk as introduced in Ekern (1980). These orderings are always consistent across different intervals (see our Theorem 2), enabling us to unify their use with the counterpart on . Notably, Denuit et al. (1998) mentioned the possibility of inconsistencies between and in their Remark 3.6, but they did not provide explicit counterexamples or a detailed analysis. Our research builds on these observations and directly addresses these gaps, providing clarification of these potential inconsistencies.
References
- Baiardi et al. (2020) Baiardi, D., Magnani, M. and Menegatti, M. (2020). The theory of precautionary saving: an overview of recent developments. Review of Economics of the Household, 18, 513–542.
- Caballé and Pomansky (1996) Caballé, J. and Pomansky, A. (1996). Mixed risk aversion. Journal of Economic Theory, 71(2), 485–513.
- Crainich et al. (2013) Crainich, D., Eeckhoudt, L. and Trannoy, A. (2013). Even (mixed) risk lovers are prudent. American Economic Review, 103(4), 1529–1535.
- Deck and Schlesinger (2014) Deck, C. and Schlesinger, H. (2014). Consistency of higher order risk preferences. Econometrica, 82(5), 1913–1943.
- Denuit and Eeckhoudt (2010) Denuit, M. and Eeckhoudt, L. (2010). Stronger measures of higher-order risk attitudes. Journal of Economic Theory, 145(5), 2027–2036.
- Denuit and Eeckhoudt (2013) Denuit, M. and Eeckhoudt, L. (2013). Risk attitudes and the value of risk transformations. Journal of Economic Theory, 9(3), 245–254.
- Denuit and Lefevre (1997) Denuit, M. and Lefevre, C. (1997). Some new classes of stochastic order relations among arithmetic random variables, with applications in actuarial sciences. Insurance: Mathematics and Economics, 20(3), 197–213.
- Denuit et al. (1998) Denuit, M., Lefevre, C. and Shaked, M. (1998). The -convex orders among real random variables, with applications. Mathematical Inequalities and Applications, 1(4), 585–613.
- Denuit et al. (1999) Denuit, M., Lefevre, C. and Utev, S. (1999). Stochastic orderings of convex/concave-type on an arbitrary grid. Mathematics of Operations Research, 24(4), 835–846.
- Denuit et al. (1999) Denuit, M., De Vylder, E. and Lefevre, C. (1999). Extremal generators and extremal distributions for the continuous s-convex stochastic orderings. Insurance: Mathematics and Economics, 24(3), 201–217.
- Eeckhoudt and Schlesinger (2006) Eeckhoudt, L. and Schlesinger, H. (2006). Putting risk in its proper place. American Economic Review, 96(1), 280–289.
- Eeckhoudt et al. (2009) Eeckhoudt, L., Schlesinger, H. and Tsetlin, I. (2009). Apportioning of risks via stochastic dominance. Journal of Economic Theory, 144(3), 994–1003.
- Ekern (1980) Ekern, S. (1980). Increasing th degree risk. Economics Letters, 6, 329–333.
- Fang and Post (2022) Fang, Y. and Post, T. (2022). Optimal portfolio choice for higher-order risk averters. Journal of Banking and Finance, 137, 106429.
- Fishburn (1976) Fishburn, P. C. (1976). Continua of stochastic dominance relations for bounded probability distributions. Journal of Mathematical Economics, 3(3), 295–311.
- Fishburn (1980) Fishburn, P. C. (1980). Continua of stochastic dominance relations for unbounded probability distributions. Journal of Mathematical Economics, 7(3), 271–285.
- Fishburn and Lavalle (1995) Fishburn, P. C. and Lavalle, I. H. (1995). Stochastic dominance on unidimensional grids. Mathematics of Operations Research, 20(3), 513–525.
- Jean (1980) Jean, W. H. (1980). The geometric mean and stochastic dominance. The Journal of Finance, 35(1), 151–158.
- Kimball (1990) Kimball, M. S. (1989). Precautionary saving in the small and in the large. Econometrica, 58(1), 53–73.
- Kimball (1992) Kimball, M. S. (1992). Precautionary motives for holding assets. In G. Hubbard (Ed.), Asymmetric Information, Corporate Finance, and Investment. University of Chicago Press.
- Levy (2015) Levy, H. (2015). Stochastic Dominance: Investment Decision Making under Uncertainty. Third Edition. Springer New York.
- Liu (2014) Liu, L. (2014). Precautionary saving in the large: th degree deteriorations in future income. Journal of Mathematical Economics, 52, 169–172.
- Liu and Neilson (2019) Liu, L. and Neilson, W. S. (2019). Alternative approaches to comparative th-degree risk aversion. Management Science, 65(8), 3824–3834.
- Müller (1997) Müller, A. (1997). Stochastic orders generated by integrals: A unified study. Advances in Applied probability, 29(2), 414–428.
- Nocetti (2016) Nocetti, D. C. (2016). Robust comparative statics of risk changes. Management Science, 62(5), 1381–1392.
- Noussair et al. (2014) Noussair, C. N., Trautmann, S. T. and Van de Kuilen, G. (2014). Higher order risk attitudes, demographics, and financial decisions. Review of Economic Studies, 81(1), 325–355.
- Ogryczak and Ruszczyński (2001) Ogryczak, W. and Ruszczyński, A. (2001). On consistency of stochastic dominance and mean–semideviation models. Mathematical Programming, 89, 217–232.
- Rolski (1976) Rolski, T. (1976). Order relations in the set of probability distribution functions and their applications in queueing theory. Dissertationes Mathematicae CXXXII. Warsaw, Poland: Polska Akademia Nauk, Instytut Matematyczny.
- Rothschild and Stiglitz (1970) Rothschild, M. and Stiglitz, J. (1970). Increasing risk: I. A definition. Journal of Economic Theory, 2(3), 225–243.
- Shaked and Shanthikumar (2007) Shaked, M. and Shanthikumar, J. G. (2007). Stochastic Orders. Springer New York.
- Schoenberg (1938) Schoenberg, I. J. (1938). Metric spaces and completely monotone functions. Annals of Mathematics, 39(4), 811–841.
- Whitt (1986) Whitt, W. (1986). Stochastic comparisons for non-Markov processes. Mathematics of Operations Research, 11(4), 608–618.
- Williamson (1956) Williamson, R. E. (1956). Multiply monotone functions and their Laplace transforms. Duke Mathematical Journal, 23(2), 189–207.