The Name of the Title is Hope
Abstract.
Graphs are ubiquitous in many applications and graph neural networks (GNN) are the state-of-the-art method for predictive tasks on graphs. However, prediction accuracy is not the only objective and fairness needs to be traded off for accuracy. Although there are extensive studies on fair GNN, the generalizability of the accuracy-fairness trade-off from training to test graphs is less studied. In this paper, we focus on node classification on bipartite graphs, which have wide applications in spam detection and recommendation systems. We propose to balance the two objectives (accuracy and fairness) on the unseen test graph, using a novel focal fairness loss and data augmentation. We show that although each of the techniques can improve one objective, they can either pay the price of sacrificing one of the multiple objectives, or do not generalize the fairness-accuracy trade-off to the population distribution. The proposed integrated focal loss and data augmentation lead to generalizable well-balanced trade-offs. We verify that the method is agnostic about the underlying GNN architectures and can work both on vanilla GNN and edge-weighted GNNGuard.
1. Introduction
Existing fake reviews severely undermine the trustworthiness of online commerce websites that host the reviews (luca2016reviews). People have studied many detection methods to identify those reviews accurately. Among all methods, graph-based approaches (rayana2015collective; li2019spam) have shown great promise. However, most of the prior methods (dou2020enhancing; wu2020graph; wang2019semi; dou2020robust) focused exclusively on either accuracy or robustness of the fraud detectors, ignoring the detection fairness. Although several existing works studied fairness issues on graph-based classifiers against sensitive attributes, such as gender, age, and race (kang2020inform; ijcai2019p456; li2021dyadic; ma2021subgroup; dai2021say; agarwal2021towards). Restricted by the anonymity of the spammers, we have no access to the profile of users’ attributes to study any fairness problems towards traditional sensitive attributes. In fact, graph-based spam detectors suffer from another fairness problem: reviewers will receive unfavorable detection based on the number of historical posts (equal to the degree of the reviewer nodes). Existing reviewers and spammers receive slack regulations since their few spams are discreetly hidden behind loads of normal content. In contrast to that, new reviewers who have very few posts face a higher risk of false detection and strict regulation. Such discrimination harms user trust and leads to less engagement in online commerce activities. Formally, this type of fairness issue is caused by the variant graph topologies (burkholder2021certification). Growing efforts have been dedicated to enhancing fairness towards topological bias (burkholder2021certification; li2021dyadic; spinelli2021fairdrop; dai2021say; agarwal2021towards), yet few works of graph-based spam detection task prompt fairness against topological property.
Fig. 1 gives an example of our review graph (luca2016reviews; rayana2015collective) which contains user, review, and product nodes. Edges represent the events that a user post reviews on some products. We define users who post fewer reviews than a certain threshold as the “protected” users, denoted by the sensitive attribute . Other users are the ”favored” ones, denoted by . Comparing the computational graphs of spams and , many non-spams help dilute the information about the suspiciousness of after messages passing from the bottom up by GNN’s aggregation operation in Eq. (1). In this case, existing users with many reviews can reduce suspiciousness and evade detection, which is unfair to new users.
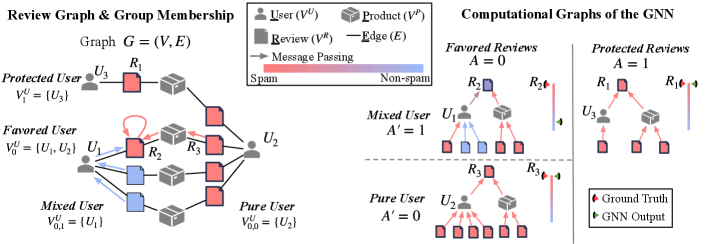
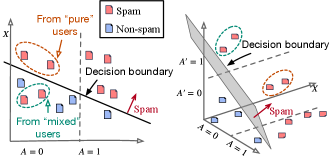
In fact, maintaining fairness between groups of users categorized only by node degree is imprecise. The detection fairness essentially depends on if two users have the same capability to hide their spamming reviews from their normal reviews. Two “favored” users can receive different treatment from the detector due to their heterogeneous behaviors, i.e., the various proportions of spams to non-spams across users. As for “protected” users, they post only a few reviews but belong to the same class, reflecting homogeneous user behaviors, whose reviews are treated equally by the detector. In order to ensure fairness in spam detection, the heterogeneous behavior of “favored” users must be accurately described by an additional sensitive attribute to indicate if their reviews are from the same class. In Fig. 1, user , named as the “mixed” user, denoted by , posts both spams and non-spams where spams deceive the detector by aggregating messages from non-spams. , named as the “pure” user, denoted by , posts only spams and thus receives no messages from non-spams to lower the suspiciousness calculated by the GNN model.. In order to get higher accuracy on the favored group, GNN will unfairly target spam reviews posted by pure users like since they are easier to detect. Once we let the spams from “mixed” users are easy to be caught as well, GNN will have better performance on detecting spams from “mixed” users without harming the detection accuracy of spams from “pure” user. As a result, distinguishing mixed users from pure users is crucial. Solving this problem involves three main challenges:
Define the subgroup structure. Most of the previous work studied the fairness problem with well-defined sensitive attributes. Studies including (ustun2019fairness; kearns2018preventing) utilize observable sensitive attributes and their combinations to divide the dataset into various groups. Others (celis2021fair; awasthi2020equalized; mehrotra2021mitigating) consider the fairness problem with unobserved or noisy sensitive attributes. In (chen2019fairness), researchers built probabilistic models to approximate the value of any well-defined sensitive attribute by using proxy information. For example, it infers race from the last name and geolocation. All of these methods are implemented on the I.I.D vector data with well-defined sensitive attributes. Unlike the above works, we enhance fairness by discovering a novel structural-based sensitive attribute and its approximation. Additionally, sensitive attributes in previous works (dwork2012fairness; hardt2016equality; zemel2013learning) have been treated as data characteristics, which are not determined by ground truth labels. We are looking for an undefined sensitive attribute that is both specific to graph-based spam detection and related to the ground truth of reviews.
Infer unknown subgroup membership.
We hypothesize that inferring helps resolve the unfairness among groups.
Indicating a user’s heterogeneous behavior by the subgroup indicator , either mixed or pure, helps clarify what users from the “favored” group genuinely benefit from their non-spams.
In this case, GNN can use the inferred indicator to strike a more equitable detection on spams posted by users from the “favored” group and then promote group fairness. (See Fig. 2).
Nevertheless, the indicator relates to the ground truth labels, which are unobservable for the test data and need to be inferred.
Even for the training data, labeling sufficient data and precisely identifying spams are great challenges that are expensive and time-consuming (qiu2020adaptive; tan2013unik; tian2020non).
Promote group fairness through subgroup information.
Considering fairness towards multiple sensitive attributes, the related works (kearns2018preventing; ustun2019fairness) formulated the optimization problem with several fairness constraints for each group of combinations.
These sensitive attributes must be precise and discrete in order to categorize data and ensure that those being discriminated against are fairly treated.
However, these premises are inapplicable to our inferred subgroup membership indicator , which is probabilistic rather than deterministic.
Meanwhile, constraints derived from thresholding noisy sensitive attributes can deteriorate optimization algorithms.
Fairness optimization is highly sensitive to group separation, so we avoid setting an uncertain threshold for converting membership from a probability to a concrete group.
The main contributions of this work are as follows:
-
[leftmargin=*]
-
•
In addition to well-known sensitive attributes, i.e., user node degree (burkholder2021certification) or node attributes (bose2019compositional; dai2021say; wu2021learning), we first define a new structural-based and label-related sensitive attribute in the fair spam detection task on graph.
-
•
We propose another GNN to infer the probability distribution of for the test users who have unlabelled reviews (i.e., unobserved user behaviors). Due to the insufficient training examples for the “favored” group and the “mixed” subgroup, we propose two fairness-aware data augmentation methods to synthesize nodes and edges. GNN will generate less biased representations of the minority groups and subgroups by using the re-balanced training datasets.
-
•
Rather than converting the estimated probability distribution of into concrete groups by any uncertain threshold, a joint training method is designed to let the detector directly use the inferred . Our proposed method is evaluated on three real-world Yelp datasets. The results demonstrate the unfairness inside the “favored” group and show group fairness can be enhanced by introducing the subgroup membership indicator . We show that regardless of what thresholds are used to split the group regarding , our joint method promotes group fairness by accurately inferring the distribution of during model training.
2. Preliminaries
2.1. Spam detection based on GNN
Our spam detection is on the review-graph defined as , where denotes the set of nodes and denotes the set of undirected edges. Each node has a feature vector with node index . contains three types of nodes: user, review, and product, where each node is from only one of the three types (see the example in Fig. 1 left). Let and denote the sets of user, review, and product nodes, respectively. has a set of neighboring nodes denoted by . The work focuses on detecting spammy users and reviews, and the task is essentially a node classification problem. GNN (kipf2016semi) is the state-of-the-art method for node classification (wu2020comprehensive). For our GNN detector , let be the learned representation of node at layer , where :
| (1) |
where AGGREGATE takes the mean over and messages passed from its neighboring nodes. UPDATE contains an affine mapping with parameters followed by a nonlinear mapping (ReLU in and Sigmoid in ). The input vector is the representation at layer 0. denotes the prediction probability of being spam. We minimize the cross-entropy loss for the training node set :
| (2) |
where is the class for . represents a collection of parameters in all the layers . The main notations are in Table 1.
2.2. Fairness regularizer
Group. We split users into the protected group whose degree is smaller than the -th percentile of all the users’ degrees, and the favored group for the remaining users (see Fig. 1 left). The subscript denotes the value of . The review nodes are divided into and following the group of their associated users. The fairness of the GNN detector is evaluated by the detection accuracies between two groups of spams and .
Fairness regularizer. Ranking-based metrics like NDCG are appropriate to evaluate the detector’s accuracy, as the highly skewed class distribution: most reviews are genuine. A larger NDCG score indicates that spams are ranked higher than non-spams, and a detector is more precise. NDCG can also be evaluated on the two groups and , separately. Hence, the group fairness can be evaluated by the NDCG gap between and , denoted as . In fact, NDCG on the “favored” group is always lower than that on the , since the detector performs preciser on group . For reducing by promoting the NDCG of without hurting that of , our detector starts with a fairness regularizer which takes negative NDCG of . We adopt a differentiable surrogate NDCG (burkholder2021certification) for
| (3) | ||||
| (4) |
where is the total number of pairs of spams and non-spams in the training . is the objective function for training by adding to in Eq. (2). is the importance of the fairness regularizer. Note that the fairness regularizer regularizes all the models referred to in this paper below.
| Notations | Definitions |
|---|---|
| Graph notations | |
| Review graph | |
| Nodes and Edges of graph | |
| Feature and label of node | |
| Set of direct neighbors of | |
| Cardinality of a set | |
| Training nodes and test nodes | |
| User, review, and product nodes | |
| Group notations | |
| Binary sensitive attributes (0/1) | |
| Review and user nodes from group of | |
| Review and user nodes from group of and | |
| Model notations | |
| GNNs with parameters and | |
| Output of for | |
| Representation of on layer | |
| Synthetic node by mixing-up and | |
| Label for the synthetic node | |
3. EXPERIMENTS
We seek to answer the following research questions:
RQ1: Do fairness issues exist between the “favored” and the “protected” groups, and between the “mixed” and the “pure” groups when using a GNN spam detector?
Will the inferred improve the group fairness?
RQ2: How to infer the subgroup memberships defined in Eq. (LABEL:eq._definition_for_A') with a shortage of training examples?
RQ3: Can the joint training method simultaneously promote the AUC of predicted and group fairness?
RQ4: Does the accuracy of predicting contribute to the improvement in group fairness?
3.1. Experimental Settings
Datasets. We used three Yelp review datasets (“Chi”, “NYC”, and “Zip” for short, see Table 2) which are commonly used in previous spam detection tasks (burkholder2021certification; dou2020enhancing). For the cutoff degree of user nodes (-th percentile in Section 2.2), we treat as a hyper-parameter distinguishing favored (top high-degree users, ) from protected groups (the remaining users, ). Reviews have the same value of as their associated users. The favored users are further split into pure () and mixed () users following Eq. (LABEL:eq._definition_for_A'). Users are divided into training (), validation (), and test () sets with their associated reviews.
| \multirow2*Name | Data Statistics | \multirow2* | |||||
| \multirow5*Chi | \multirow5* | ||||||
| PC | |||||||
| 20th | |||||||
| 15th | |||||||
| 10th | |||||||
| \multirow5*NYC | \multirow5* | ||||||
| PC | |||||||
| 20th | |||||||
| 15th | |||||||
| 10th | |||||||
| \multirow5*Zip | \multirow5* | ||||||
| PC | |||||||
| 20th | |||||||
| 15th | |||||||
| 10th | |||||||
Evaluation Metrics. (1) NDCG is to evaluate the detector’s accuracy, where a higher NDCG means that the detector tends to assign a higher suspiciousness to spams than non-spams. (2) To evaluate the ranking of spams within the group of , a metric called “Average False Ranking Ratio” is proposed to measure the average of relative ranking between spams from mixed and pure users
| (5) |
where denotes the subgroup membership. is the number of spams from a subgroup. denotes the reviews from a subgroup users. The ratio in the above equation calculates the proportion of non-spams ranked higher than spams over all the non-spams from the group of . The lower the AFRR, the fewer non-spams ranked higher than spams. Compared to NDCG, AFRR considers the non-spams across different subgroups and ignores the relative ranking of spams from the other subgroup. (3) AUC is to evaluate the performance of in predicting . The larger the AUC value, the more accurate given by .
Methods compared. Joint+GNN- denotes our method: Joint is the joint training for two GNNs ( and in Section LABEL:sec_3.3:_joint_training), GNN- is a GNN with our mixup method in Eq. (LABEL:eq:_mixup_second_node). “a+b” denotes a setting: “a” is one of a method for obtaining the value of ; “b” is a spam detector.
Baselines for obtaining the value of (selections for “a”):
-
[leftmargin=*]
-
•
w/o: has no definition of .
-
•
Random: randomly assigns to .
-
•
GT: assigns the ground truth of for users, which is the ideal case, as is unknown.
-
•
Pre-trained: is a variant of Joint that pre-training to infer and fixes the inferred when training .
Baselines for the spam detectors (selections for “b”):
-
[leftmargin=*]
-
•
FairGNN (dai2021say): is an adversarial method to get fair predictions for all groups defined by the known .
-
•
EDITS (dong2022edits): modifies the node attribute and the graph structure to debias the graph. FairGNN and EDITS consider as a known sensitive attribute and exclude any information about defined by our work.
-
•
GNN: is the vanilla GNN.
-
•
GNN- is a GNN with the mixup Case 2 in Eq. (LABEL:eq:_mixup_second_node).
-
•
GNN- is a GNN with the mixup Case 3 in Eq. (LABEL:eq:_mixup_second_node).
We set , , , weight decay for both and in Algorithm LABEL:alg:_joint_train, mixup weight . We have 10 training-validation-test splits of the three datasets. The following results are based on the aggregated performance on all splits.
| Detector | Metrics(%) | Chi | NYC | Zip | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| \multirow3*FairGNN (dai2021say) | NDCG() | 86.20.1 | 85.90.0 | 89.60.5 | ||||||
| NDCG() | 86.20.1 | 86.00.0 | 89.60.4 | |||||||
| \rowcolorgray!20 \cellcolorwhite | 53.72.1 | 20.71.1 | 36.44.6 | |||||||
| \multirow3*EDITS (dong2022edits) | NDCG() | 84.30.3 | 84.90.1 | 89.20.0 | ||||||
| NDCG() | 84.30.3 | 85.10.1 | 89.30.0 | |||||||
| \rowcolorgray!20 \cellcolorwhite | 50.92.3 | 32.71.5 | 39.410.6 | |||||||
| \multirow2*Detector | \multirow2*Metrics(%) | GNN | GNN | GNN | ||||||
| w/o | Pre-trained | Joint* | w/o | Pre-trained | Joint* | w/o | Pre-trained | Joint* | ||
| \multirow3*GNN | NDCG() | 84.50.9 | 83.21.5 | 83.32.2 | 85.20.8 | 85.10.8 | 85.20.5 | 88.41.4 | 87.61.5 | 88.61.0 |
| NDCG() | 84.70.9 | 83.51.3 | 83.62.1 | 85.1 0.8 | 85.30.8 | 85.20.5 | 88.41.4 | 87.61.5 | 88.61.0 | |
| \rowcolorgray!20 \cellcolorwhite | 51.22.1 | 51.03.0 | 50.73.5 | 21.97.0 | 21.87.8 | 21.38.9 | 36.310.4 | 34.310.8 | 34.811.1 | |
| \multirow3*GNN-* | NDCG() | 85.60.7 | 85.80.5 | 85.60.8 | 85.80.1 | 85.90.0 | 85.90.0 | 89.70.2 | 89.70.1 | 89.60.1 |
| NDCG() | 85.60.7 | 85.80.5 | 85.70.8 | 85.90.0 | 86.00.0 | 86.00.0 | 89.70.2 | 89.70.1 | 89.60.1 | |
| \rowcolorgray!20 \cellcolorwhite | 51.60.9 | 50.31.0 | 50.11.0 | 19.15.5 | 19.05.2 | 17.96.1 | 38.77.2 | 36.09.0 | 34.311.5 | |
| \multirow3*GNN- | NDCG() | 85.10.7 | 85.31.4 | 85.21.4 | 85.30.6 | 85.40.5 | 85.40.4 | 89.40.6 | 89.60.1 | 89.00.06 |
| NDCG() | 85.20.8 | 83.41.3 | 83.51.3 | 85.20.6 | 85.50.4 | 85.50.4 | 89.40.06 | 89.00.01 | 89.10.06 | |
| \rowcolorgray!20 \cellcolorwhite | 51.21.5 | 50.92.4 | 50.92.3 | 21.96.9 | 21.96.3 | 20.99.4 | 38.97.6 | 36.99.5 | 34.911.0 | |
| \multirow3*GNN- | NDCG() | 84.71.3 | 83.70.9 | 83.10.9 | 85.70.1 | 85.80.1 | 85.80.2 | 89.60.3 | 89.60.1 | 89.50.3 |
| NDCG() | 84.81.3 | 83.90.9 | 83.40.9 | 85.80.1 | 85.80.1 | 85.80.1 | 89.60.3 | 89.60.1 | 89.50.3 | |
| \rowcolorgray!20 \cellcolorwhite | 51.30.6 | 50.80.6 | 50.21.0 | 21.05.4 | 19.85.4 | 19.36.8 | 38.77.2 | 36.29.5 | 34.611.4 | |
| Detector | Metrics(%) | Chi | NYC | Zip | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| \multirow3*FairGNN (dai2021say) | NDCG() | 86.20.2 | 85.90.1 | 89.90.0 | ||||||
| NDCG() | 86.30.2 | 86.00.1 | 90.00.0 | |||||||
| \rowcolorgray!20 \cellcolorwhite | 45.81.7 | 20.02.4 | 31.02.7 | |||||||
| \multirow3*EDITS (dong2022edits) | NDCG() | 84.30.2 | 85.00.1 | 89.20.0 | ||||||
| NDCG() | 84.40.2 | 85.10.1 | 89.30.0 | |||||||
| \rowcolorgray!20 \cellcolorwhite | 43.82.6 | 32.41.5 | 34.43.5 | |||||||
| \multirow2*Detector | \multirow2*Metrics(%) | GNN | GNN | GNN | ||||||
| w/o | Pre-trained | Joint* | w/o | Pre-trained | Joint* | w/o | Pre-trained | Joint* | ||
| \multirow3*GNN | NDCG() | 84.31.3 | 84.30.9 | 84.40.9 | 85.70.2 | 84.50.4 | 84.60.5 | 89.50.2 | 88.90.6 | 88.90.6 |
| NDCG() | 84.61.1 | 84.70.7 | 84.80.7 | 85.8 0.2 | 84.60.4 | 84.60.5 | 89.50.2 | 88.90.6 | 88.90.7 | |
| \rowcolorgray!20 \cellcolorwhite | 41.82.4 | 40.93.7 | 40.94.0 | 16.33.9 | 15.82.7 | 15.26.1 | 26.13.4 | 26.62.5 | 25.92.7 | |
| \multirow3*GNN-* | NDCG() | 86.00.4 | 85.90.3 | 85.90.2 | 85.90.1 | 85.90.1 | 85.90.1 | 89.70.1 | 89.90.0 | 87.92.1 |
| NDCG() | 86.00.4 | 86.00.3 | 86.00.2 | 85.90.1 | 85.90.1 | 85.90.1 | 89.80.1 | 89.90.0 | 87.92.1 | |
| \rowcolorgray!20 \cellcolorwhite | 43.22.0 | 41.95.8 | 40.55.1 | 16.53.8 | 15.62.9 | 15.63.6 | 26.43.3 | 27.03.2 | 22.74.2 | |
| \multirow3*GNN- | NDCG() | 84.41.5 | 84.31.1 | 84.40.9 | 85.80.2 | 84.70.4 | 84.70.4 | 89.40.2 | 89.10.6 | 89.10.6 |
| NDCG() | 84.71.1 | 84.60.9 | 84.80. | 85.90.2 | 84.70.5 | 84.70.5 | 89.50.2 | 89.10.6 | 89.20.6 | |
| \rowcolorgray!20 \cellcolorwhite | 43.42.4 | 41.74.6 | 41.14.2 | 16.64.1 | 15.73.0 | 15.63.6 | 26.24.0 | 27.23.2 | 25.32.7 | |
| \multirow3*GNN- | NDCG() | 85.90.5 | 85.80.3 | 85.90.3 | 85.80.1 | 85.40.3 | 85.50.3 | 89.80.1 | 89.90.1 | 89.90.1 |
| NDCG() | 85.90.5 | 85.90.3 | 85.90.3 | 85.90.2 | 85.50.3 | 85.50.3 | 89.80.1 | 89.90.1 | 89.90.1 | |
| \rowcolorgray!20 \cellcolorwhite | 42.62.8 | 40.73.7 | 40.73.7 | 16.03.9 | 15.53.0 | 15.63.3 | 26.13.5 | 27.12.4 | 24.92.7 | |
| Detector | Metrics(%) | Chi | NYC | Zip | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| \multirow3*FairGNN (dai2021say) | NDCG() | 86.20.2 | 85.90.1 | 89.90.0 | ||||||
| NDCG() | 86.40.2 | 86.00.1 | 90.00.0 | |||||||
| \rowcolorgray!20 \cellcolorwhite | 33.85.4 | 22.41.9 | 24.81.6 | |||||||
| \multirow3*EDITS (dong2022edits) | NDCG() | 84.30.2 | 85.00.1 | 89.20.0 | ||||||
| NDCG() | 84.50.2 | 85.20.1 | 89.40.0 | |||||||
| \rowcolorgray!20 \cellcolorwhite | 37.12.0 | 30.01.2 | 28.91.3 | |||||||
| \multirow2*Detector | \multirow2*Metrics(%) | GNN | GNN | GNN | ||||||
| w/o | Pre-trained | Joint* | w/o | Pre-trained | Joint* | w/o | Pre-trained | Joint* | ||
| \multirow3*GNN | NDCG() | 85.40.5 | 84.71.3 | 84.91.4 | 84.80.4 | 84.50.3 | 84.60.4 | 89.70.3 | 89.60.6 | 88.90.6 |
| NDCG() | 85.70.4 | 85.30.8 | 85.40.9 | 84.8 0.4 | 84.60.3 | 84.70.4 | 89.80.3 | 89.60.6 | 89.80.4 | |
| \rowcolorgray!20 \cellcolorwhite | 34.71.5 | 33.92.5 | 34.71.5 | 19.71.6 | 19.11.6 | 18.72.0 | 25.01.8 | 23.71.7 | 23.61.7 | |
| \multirow3*GNN-* | NDCG() | 85.90.4 | 86.10.2 | 86.10.2 | 85.90.1 | 85.90.1 | 85.90.1 | 89.70.1 | 89.90.0 | 89.90.0 |
| NDCG() | 85.90.4 | 86.20.2 | 86.20.2 | 86.00.1 | 86.00.1 | 86.00.1 | 89.80.1 | 90.00.0 | 90.00.0 | |
| \rowcolorgray!20 \cellcolorwhite | 34.14.6 | 33.73.0 | 33.22.6 | 19.11.9 | 16.81.5 | 16.61.9 | 25.11.6 | 23.41.6 | 23.31.4 | |
| \multirow3*GNN- | NDCG() | 85.80.5 | 86.10.3 | 86.10.2 | 85.90.1 | 85.40.3 | 85.40.3 | 89.80.1 | 90.00.1 | 89.90.1 |
| NDCG() | 85.90.5 | 86.20.3 | 86.20.2 | 86.00.1 | 85.50.3 | 85.50.3 | 89.90.1 | 90.00.1 | 90.00.1 | |
| \rowcolorgray!20 \cellcolorwhite | 33.64.4 | 34.13.3 | 33.83.0 | 19.72.0 | 18.61.5 | 18.61.9 | 25.11.6 | 23.71.6 | 23.61.4 | |
| \multirow3*GNN- | NDCG() | 85.60.5 | 85.01.2 | 85.01.2 | 85.90.1 | 84.70.3 | 84.70.3 | 89.60.1 | 89.70.5 | 89.51.2 |
| NDCG() | 85.70.6 | 85.40.8 | 85.50.7 | 86.00.1 | 84.80.4 | 84.80.4 | 89.70.1 | 89.80.5 | 89.20.7 | |
| \rowcolorgray!20 \cellcolorwhite | 34.04.6 | 34.33.0 | 34.22.8 | 19.61.9 | 18.71.7 | 18.72.1 | 25.11.6 | 23.81.7 | 24.22.8 | |
3.2. Results
3.2.1. Group Fairness.
To answer RQ1, we take the difference in the NDCGs of reviews from groups of and as the group fairness metric, denoted by . Table 3, 4, and 5 show the NDCG values for the outputs of spam detectors with -th, -th, and -th percentile of user node degree as a cutoff for groups of , respectively. Each table has rows for six detectors in two sections. FairGNN and EDITS in the upper section ignore the attribute that we define. The remaining four detectors use where the columns under each dataset column are methods for obtaining the value of . These tree tables report the NDCG of all test reviews NDCG(), the NDCG of test reviews from the protected group NDCG(), and .
Large values of for FairGNN, EDITS, and w/o+GNN show the pervasive unfairness existing in the GNN-based models. FairGNN and EDITS have larger when improving NDCGs for the favored groups, meaning they worsen the fairness: the NDCGs are increased more on the favored groups than the protected groups. For any spam detector in the lower section, the proposed Joint method has the smallest in most cases. Comparing to Pre-trained, in Joint receives the additional gradient of from (see Eq. (LABEL:eq:_update_theta)). However, for detectors without the review and user augmentation (i.e., Joint+GNN), the additional gradient may lead to infer hurting the performance of . For any method obtaining the value of , the detector with our augmentation GNN- has the smallest almost in all cases. Since Chi and Zip contain fewer mixed users, maintaining the original distribution while mixing up is more complicated.
Explanation of improved group fairness. Fig. 5 shows the test AFRRs of pure and mixed subgroups across four methods {w/o+GNN, Joint+GNN-, Joint+GNN-, Joint+ GNN-}. It demonstrates the effect of adding on spams from subgroups and explains the improved NDCG on the protected group. w/o+GNN shows that spams from the mixed users have larger AFRRs than the pure users for all datasets. In other words, inside the favored group, the basic GNN tends to rank spams from pure users higher than those from mixed users. By introducing and applying the augmentation methods, AFRR is decreased for mixed users and sometimes for pure users. Our method (rightmost) improves the NDCG for the protected group by mainly raising the rank of spams from mixed users and sometimes the spams from pure users.
=0.5cm
\subfigbottomskip= -10pt
\subfigure[20-th Percentile of User Node Degree]
 \subfigbottomskip= -5pt
\subfigure[15-th Percentile of User Node Degree]
\subfigbottomskip= -5pt
\subfigure[15-th Percentile of User Node Degree]
 \subfigbottomskip= -5pt
\subfigure[10-th Percentile of User Node Degree]
\subfigbottomskip= -5pt
\subfigure[10-th Percentile of User Node Degree]

3.2.2. Evaluation of the Joint method on improving the quality of .
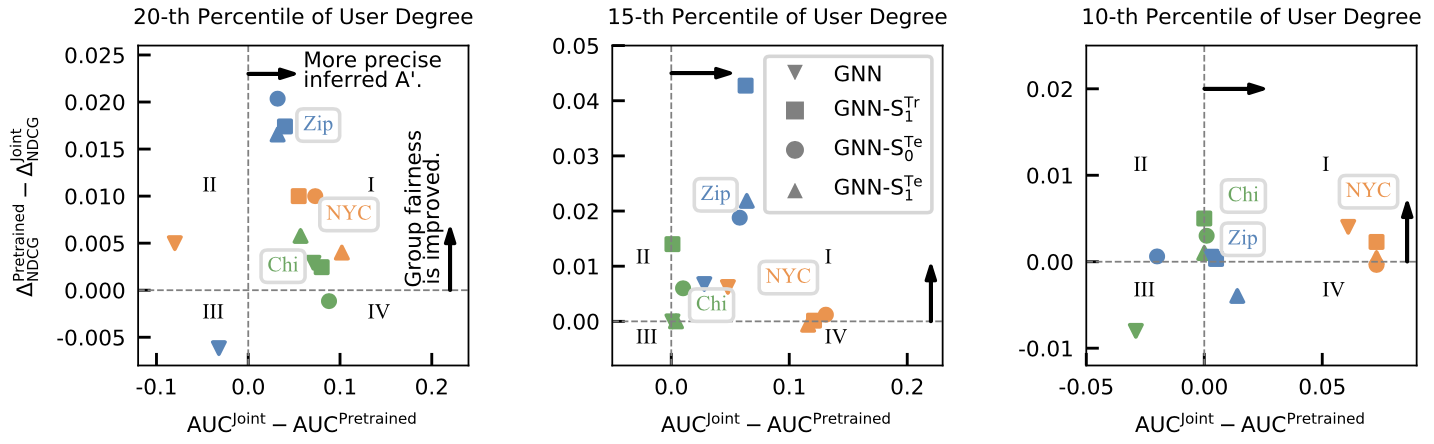
To answer RQ2 and RQ3, we study the relationship between the group fairness and the quality of inferred . Recall that in Table 3, 4, and 5, the Joint method has smaller than Pre-trained in most cases. To understand the advantage of Joint, Fig. 3 shows the AUC gap of given by (-axis) in these two settings with corresponding difference (-axis). Most models in the area I indicate that Joint simultaneously promotes the accuracy of and the fairness of . Since Joint updates using the gradient from (see Eq. (LABEL:eq:_update_theta)), our mixup strategies can mitigate the overfitting for with more gradients from the synthetic data.
=2pt
\subfigbottomskip= 2pt
\subfigcapskip= -5pt
\subfigure[20-th Percentile of User Node Degree]
 \subfigure[15-th Percentile of User Node Degree]
\subfigure[15-th Percentile of User Node Degree]
 \subfigure[10-th Percentile of User Node Degree]
\subfigure[10-th Percentile of User Node Degree]

3.2.3. Impact of the accurate on group fairness.
Since the quality of correlates with the group fairness, we further increase (i.e., Random method) or decrease (i.e., GT method) the noise in to see if this correlation holds to answer RQ4. Fig. 6 gives for detectors with different ways to assign value to which contain less and less noise moving from left to right in -axis. reduces as a detector receives a more accurate inference of the values of .
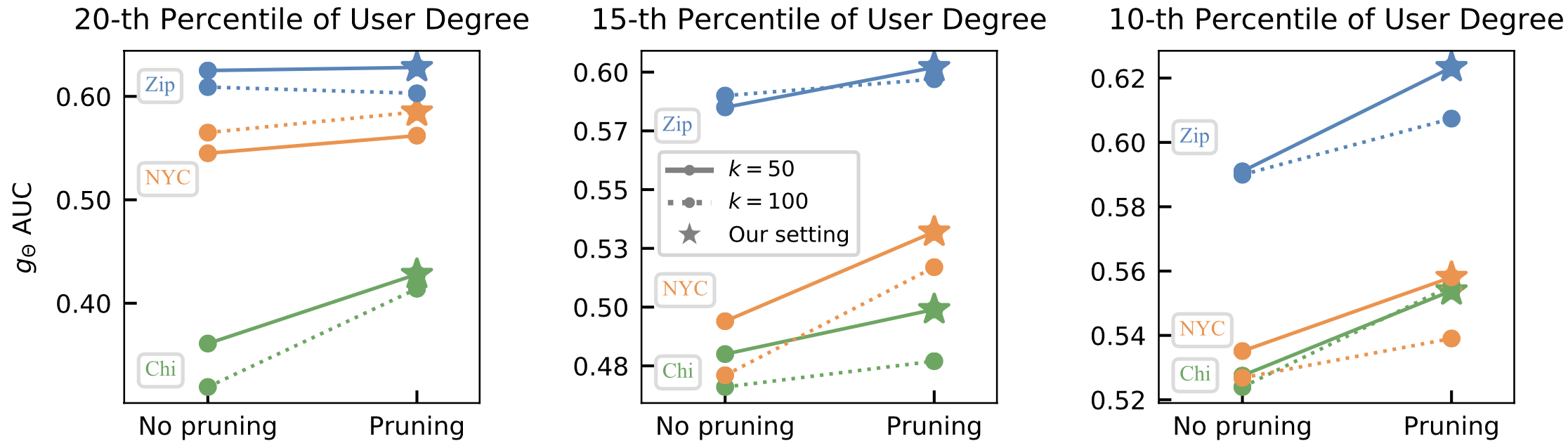
3.3. Sensitivity studies for the replication times and if pruning non-spam edges.
Fig. 4 shows the test AUCs of with replications and if pruning non-spams (see Section LABEL:sec:minor_user_augmentation). Pruning has better AUCs than No pruning except when on Zip. Additionally, AUCs for Chi and Zip decrease as increasing the number of . Since Chi and Zip have few mixed users, forcing the synthesized data to mimic the original node distribution is complex and easy to cause overfitting. Based on the validation set, we get the optimal for NYC and for Chi and Zip.