The Memory Perturbation Equation:
Understanding Model’s Sensitivity to Data
Abstract
Understanding model’s sensitivity to its training data is crucial but can also be challenging and costly, especially during training. To simplify such issues, we present the Memory-Perturbation Equation (MPE) which relates model’s sensitivity to perturbation in its training data. Derived using Bayesian principles, the MPE unifies existing sensitivity measures, generalizes them to a wide-variety of models and algorithms, and unravels useful properties regarding sensitivities. Our empirical results show that sensitivity estimates obtained during training can be used to faithfully predict generalization on unseen test data. The proposed equation is expected to be useful for future research on robust and adaptive learning.
1 Introduction
Understanding model’s sensitivity to training data is important to handle issues related to quality, privacy, and security. For example, we can use it to understand (i) the effect of errors and biases in the data; (ii) model’s dependence on private information to avoid data leakage; (iii) model’s weakness to malicious manipulations. Despite their importance, sensitivity properties of machine learning (ML) models are not well understood in general. Sensitivity is often studied through empirical investigations, but conclusions drawn this way do not always generalize across models or algorithms. Such studies are also costly, sometimes requiring thousands of GPUs [38], which can quickly become infeasible if we need to repeat them every time the model is updated.
A cheaper solution is to use local perturbation methods [21], for instance, influence measures that study sensitivity of trained model to data removal (Fig. 1(a)) [8, 7]. Such methods too fall short of providing a clear understanding of sensitivity properties for generic cases. For instance, influence measures are useful to study trained models but are not suited to analyze training trajectories [14, 54]. Another challenge is in handling non-differentiable loss functions or discrete parameter spaces where a natural choice of perturbation mechanisms may not always be clear [32]. The measures also do not directly reveal the causes of sensitivities for generic ML models and algorithms.
In this paper, we simplify these issues by proposing a new method to unify, generalize, and understand perturbation methods for sensitivity analysis. We present the Memory-Perturbation Equation (MPE) as a unifying equation to understand sensitivity properties of generic ML algorithms. The equation builds upon the Bayesian learning rule (BLR) [28] which unifies many popular algorithms from various fields as specific instances of a natural-gradient descent to solve a Bayesian learning problem. The MPE uses natural-gradients to understand sensitivity of all such algorithms. We use the MPE to show several new results regarding sensitivity of generic ML algorithms:
-
1.
We show that sensitivity to a group of examples can be estimated by simply adding their natural-gradients; see Eq. 6. Larger natural-gradients imply higher sensitivity and just a few such examples can often account for most of the sensitivity. Such examples can be used to characterize the model’s memory and memory-perturbation refers to the fact that the model can forget its essential knowledge when those examples are perturbed heavily.
-
2.
We derive Influence Function [8, 31] as a special case of the MPE when natural-gradients with respect to Gaussian posterior are used. More importantly, we derive new measures that, unlike influence functions, can be applied during training for all algorithms covered under the BLR (such as those used in deep learning and optimization). See Table 1.
-
3.
Measures derived using Gaussian posteriors share a common property: sensitivity to an example depends on the product of its prediction error and variance (Eq. 12). That is, most sensitive data lies where the model makes the most mistakes and is also least confident. In many cases, such estimates are extremely cheap to compute.
- 4.


2 Understanding a Model’s Sensitivity to Its Training Data
Understanding a model’s sensitivity to its training data is important but is often done by a costly process of retraining the model multiple times. For example, consider a model with a parameter vector trained on data by using an algorithm that generates a sequence for iteration that converges to a minimizer . Formally, we write
| (1) |
and we use the loss for and a regularizer . Because are all functions of or its subsets, we can analyze their sensitivity by simply ‘perturbing’ the data. For example, we can remove a subset to get a perturbed dataset, denoted by , and retrain the model to get new iterates , converging to a minimizer . If the deviation is large for most , we may deem the model to be highly sensitive to the examples in . This is a simple method for sensitive analysis but requires a costly brute-force retraining [38] which is often infeasible for long training trajectories, big models, and large datasets. More importantly, conclusions drawn from retraining are often empirical and may not hold across models or algorithms.
A cheaper alternative is to use local perturbation methods [21], for instance, influence measures that estimate the sensitivity without retraining (illustrated in Fig. 1(a) by the dashed red arrow). The simplest result of this kind is for linear regression which dates back to the 70s [7]. The method makes use of the stationarity condition to derive deviations in due to small perturbations to data. For linear regression, the deviations can be obtained in closed-form. Consider input-output pairs and the loss for and a regularizer . We can obtain closed-form expressions of the deviation due to the removal of the ’th example as shown below (a proof is included in App. A),
| (2) |
where we denote defined using the Hessian . We also denote the prediction error of by , and prediction variance of by .
The expression shows that the influence is bi-linearly related to both prediction error and variance, that is, when examples with high error and variance are removed, the model is expected to change a lot. These ideas are generalized using infinitesimal perturbation [21]. For example, influence functions [8, 32, 31] use a perturbation model with a scalar perturbation . By using a quadratic approximation, we get the following influence function,
| (3) |
This works for a generic differentiable loss function and is closely related to Eq. 2. We can choose other perturbation models, but they often exhibit bi-linear relationships; see App. A for details.
Despite their generality, there remain many open challenges with the local perturbation methods:
-
1.
Influence functions are valid only at a stationary point where the gradient is assumed to be 0, and extending them to iterates generated by generic algorithmic-steps is non-trivial [14]. This is even more important for deep learning where we may never reach such a stationary point, for example, due to stochastic training or early stopping [33, 53].
-
2.
Applying influence functions to a non-differentiable loss or discrete parameter spaces is difficult. This is because the choice of perturbation model is not always obvious [32].
-
3.
Finally, despite their generality, these measures do not directly reveal the causes of high influence. Does the bi-linear relationship in Eq. 2 hold more generally? If yes, under what conditions? Answers to such questions are currently unknown.
Studies to fix these issues are rare in ML, rather it is more common to simply use heuristics measures. Many such measures have been proposed in the recent years, for example, those using derivatives with respect to inputs [23, 2, 38], variations of Cook’s distance [17], prediction error and/or gradients [3, 51, 42, 40], backtracking training trajectories [16], or simply by retraining [13]. These works, although useful, do not directly address the issues. Many of these measures are derived without any direct connections to perturbation methods. They also appear to be unaware of bi-linear relationships such as those in Eq. 2. Our goal here is to address the issues by unifying and generalizing perturbation methods of sensitivity analysis.
3 The Memory-Perturbation Equation (MPE)
We propose the memory-perturbation equation (MPE) to unify, generalize, and understand sensitivity methods in machine learning. We derive the equation by using a property of conjugate Bayesian models which enables us to derive a closed-form expression for the sensitivity. In a Bayesian setting, data examples can be removed by simply dividing their likelihoods from the posterior [52]. For example, consider a model with prior and likelihood , giving rise to a posterior . To remove , say for all , we simply divide by those . This is further simplified if we assume conjugate exponential-family form for and . Then, the division between two distributions is equivalent to a subtraction between their natural parameters. This property yields a closed-form expression for the exact deviation, as stated below.
Theorem 1
Assuming a conjugate exponential-family model, the posterior (with natural parameter ) can be written in terms of (with natural parameter ), as shown below:
| (4) |
where all exponential families are defined by using inner-product with natural parameters and sufficient statistics . The natural parameter of is denoted by .
The deviation is obtained by simply adding for all . Further explanations and examples are given in App. B, along with some elementary facts about exponential families. We use this result to derive an equation that enables us to estimate the sensitivity of generic algorithms.
Our derivation builds on the Bayesian learning rule (BLR) [28] which unifies many algorithms by expressing their iterations as inference in conjugate Bayesian models [26]. This is done by reformulating Eq. 1 in a Bayesian setting to find an exponential-family approximation . At every iteration , the BLR updates the natural parameter of an exponential-family which can equivalently be expressed as the posterior of a conjugate model (shown on the right),
| (5) |
where is the natural gradient with respect to defined using the Fisher Information Matrix of , and is the learning rate. For simplicity, we denote , and assume to be conjugate. The conjugate model on the right uses a prior and likelihood both of which, by construction, belong to the same exponential-family as . By choosing an appropriate form for and making necessary approximations to , the BLR can recover many popular algorithms as special cases. For instance, using a Gaussian , we can recover stochastic gradient descent (SGD), Newton’s method, RMSprop, Adam, etc. For such cases, the conjugate model at the right is often a linear model [25]. These details, along with a summary of the BLR, are included in App. C. Our main idea is to study the sensitivity of all the algorithms covered under the BLR by using the conjugate model in Eq. 5.
Let be the posterior obtained with the BLR but without the data in . We can estimate its natural parameter in a similar fashion as Eq. 4, that is, by dividing by the likelihood approximation at the current . This gives us the following estimate of the deviation obtained by simply adding the natural-gradients for all examples in ,
| (6) |
where is an estimate of the true . We call this the memory-perturbation equation (MPE) due to a unique property of the equation: the deviation is estimated by a simple addition and characterized solely by the examples in . Due to the additive nature of the estimate, examples with larger natural-gradients contribute more to it and so we expect most of the sensitivity to be explained by just a few examples with largest natural gradients. This is similar to the representer theorem where just a few support vectors are sufficient to characterize the decision boundary [29, 47, 10]. Here, such examples can be seen as characterizing the model’s memory because perturbing them can make the model forget its essential knowledge. The phrase memory-perturbation signifies this.
The equation can be easily adopted to handle an arbitrary perturbation. For instance, consider perturbation . To estimate its effect, we divide by the likelihood approximations raised to , giving us the following variant,
| (7) |
where we denote all in by . Setting in the left reduces to Eq. 6 which corresponds to removal. The example demonstrates how to adopt the MPE to handle arbitrary perturbations.
3.1 Unifying the existing sensitivity measures as special cases of the MPE
The MPE is a unifying equation from which many existing sensitivity measures can be derived as special cases. We will show three such results. The first result shows that, for conjugate models, the MPE recovers the exact deviations given in Thm. 1. Such models include textbook examples [6], such as, mixture models, linear state-space models, and PCA. Below is a formal statement.
Theorem 2
The result holds because, for conjugate models, one-step of the BLR is equivalent to Bayes’ rule and therefore (see [24, Sec. 5.1]). A proof is given in App. D along with an illustrative example on the Beta-Bernoulli model. We note that a recent work in [49] also takes inspiration from Bayesian models, but their sensitivity measures lack the property discussed above. See also [15] for a different approach to sensitivity analysis of variational Bayes with a focus on the posterior mean. The result above also justifies setting to 1, a choice we will often resort to.
Our second result is to show that the MPE recovers the influence function by Cook [7].
Theorem 3
The proof in App. E relies on two facts: first, the natural parameter is , and second, the natural gradients for a Gaussian with mean can be written as follows,
| (8) |
where and . This is due to [28, Eqs. 10-11], but a proof is given in Eq. 27 of App. C. The theorem then directly follows by plugging in Eq. 6. This derivation is much shorter than the classical techniques which often require inversion lemmas (see Sec. A.1). The estimated deviations are exact, which is not a surprise because linear regression is a conjugate Gaussian model. However, it is interesting (and satisfying) that the deviation in naturally emerges from the deviation in .
Our final result is to recover influence functions for deep learning, specifically Eq. 3. To do so, we use a Gaussian posterior approximation obtained by using the so-called Laplace’s method [34, 50, 37]. The Laplace posterior can be seen a special case of the BLR solution when the natural gradient is approximated with the delta method [28, Table 1]. Remarkably, using the same approximation in the MPE, we recover Eq. 3.
Theorem 4
A proof is in App. F. We note that Eq. 3 can be justified as a Newton-step over the perturbed data but in the opposite direction [32, 31]. In a similar fashion, Eqs. 6 and 7 can be seen as natural-gradient steps in the opposite direction. Using the natural-gradient descent, as we have shown, can recover a variety of existing perturbation methods as special cases.
3.2 Generalizing the perturbation method to estimate sensitivity during training
Influence measures discussed so far assume that the model is already trained and that the loss is differentiable. We will now present generalizations to obtain new measures that can be applied during training and do not require differentiability of the loss. We will focus on Gaussian but the derivation can be extended to other posterior forms. The main idea is to specialize Eqs. 6 and 7 to the algorithms covered under the BLR, giving rise to new measures that estimate sensitivity by simply taking a step over the perturbed data but in the opposite direction.
We first discuss sensitivity of an iteration of the BLR yielding a Gaussian . The natural parameter is the pair . Using Eq. 8 in Eq. 6, we get
| (9) |
Plugging from the second equation into the first one, we can recover the following expressions,
| (10) |
For the second equation, we omit the proof but it is similar to App. F, resulting in preconditioning with . For computational ease, we will approximate even in the first equation. We will also approximate the expectation at a sample or simply at the mean . Ultimately, the suggestion is to use as the sensitivity measure, or variations of it, for example, by using a Monte-Carlo average over multiple samples.
Based on this, a list of algorithms and their corresponding measures is given in Table 1. All of the algorithms can be derived as special instances of the BLR by making specific approximations (see Sec. C.3). The measures are obtained by applying the exact same approximations to Eq. 10. For example, Newton’s method is obtained when , , and expectations are approximated by using the delta method at (similarly to Thm. 4). With these, we get
| (11) |
which is the measure shown in the first row of the table. In a similar fashion, we can derive measures for other algorithms that use a slightly different approximations leading to a different preconditioner. The exact strategy to update the preconditioners is given in Eqs. 31, 32, 33 and 34 of Sec. C.3. For all, the sensitivity measure is simply an update step for the ’th example but in the opposite direction.
| Algorithm | Update | Sensitivity |
|---|---|---|
| Newton’s method | ||
| Online Newton (ON) [28] | ||
| ON (diagonal+minibatch) [28] | ||
| iBLR (diagonal+minibatch) [35] | ||
| RMSprop/Adam [30] | ||
| SGD |
Table 1 shows an interplay between the training algorithm and sensitivity measures. For instance, it suggests that the measure is justifiable for Newton’s method but might be inappropriate otherwise. In general, it is more appropriate to use the algorithm’s own preconditioner (if they use one). The quality of preconditioner (and therefore the measure) is tied to the quality of the posterior approximation. For example, RMSprop’s preconditioner is not a good estimator of the posterior covariance when minibatch size is large [27, Thm. 1], therefore we should not expect it to work well for large minibatches. In contrast, the ON method [28] explicitly builds a good estimate of during training and we expect it to give better (and more faithful) sensitivity estimates.
For SGD, our approach suggests using the gradient. This goes well with many existing approaches [40, 42, 51, 3] but also gives a straightforward way to modify them when the training algorithm is changed. For instance, the TracIn approach [42] builds sensitivity estimates during SGD training by tracing for many examples and . When the algorithm is switched, say to the ON method, we simply need to trace . Such a modification is speculated in [42, Sec 3.2] and the MPE provides a way to accomplish exactly that. It is also possible to mix and match algorithms with different measures but caution is required. For example, to use the measure in Eq. 11, say within a first-order method, the algorithm must be modified to build a well-conditioned estimate of the Hessian. This can be tricky and can make the sensitivity measure fragile [5].
Extensions to non-differentiable loss functions and discontinuous parameter spaces is straightforward. For example, when using a Gaussian posterior, the measures in Eq. 10 can be modified to handle non-differentiable loss function by simply replacing with , which is a simple application of the Bonnet theorem [44] (see App. G). The resulting approach is more principled than [32] which uses an ad-hoc smoothing of the non-differentiable loss: the smoothing in our approach is automatically done by using the posterior distribution. Handling of discontinuous parameter spaces follows in a similar fashion. For example, binary variables can be handled by measuring the sensitivity through the parameter of the Bernoulli distribution (see App. D).
3.3 Understanding the causes of high sensitivity estimates for the Gaussian case
The MPE can be used to understand the causes of high sensitivity-estimates. We will demonstrate this for Gaussian but similar analysis can be done for other distributions. We find that sensitivity measures derived using Gaussian posteriors generally have two causes of high sensitivity.
To see this, consider a loss where is an exponential-family distribution with expectation parameter , is the model output for the ’th example, and is an activation function, for example, the softmax function. For such loss functions, the gradient takes a simple form: [6, Eq. 4.124]. Using this, we can approximate the deviations in model outputs by using a first-order Taylor approximation,
| (12) |
where we used which is based on the measure in the first row of Table 1. Similarly to Eq. 2, the deviation in the model output is equal to the product of the prediction error and (linearized) prediction variance of [25, 20]. The change in the model output is expected to be high, whenever examples with high prediction error and variance are removed.
We can write many such variants with a similar bi-linear relationship. For example, Eq. 12 can be extended to get deviations in predictions as follows:
| (13) |
Eq. 12 estimates the deviation at one example and at a location , but we could also write them for a group of examples and evaluate them at the mean or at any sample . For example, to remove a group of size , we can write the deviation of the model-output vector ,
| (14) |
where is the vector of labels and we used the sensitivity measure in Eq. 10. An example for sparse Gaussian process is in App. H. The measure for SGD in Table 1 can also be used which gives which is similar to the scores used in [40]. The list in Table 1 suggests that such scores can be improved by using or , essentially, replacing the gradient norm by an estimate of the prediction variance. Additional benefit can be obtained by further employing samples from instead of using a point estimate or ; see an example in App. H.
It is also clear that all of the deviations above can be obtained cheaply during training by using already computed quantities. The estimation does not add significant computational overhead and can be used to efficiently predict the generalization performance during training. For example, using Eq. 12, we can approximate the leave-one-out (LOO) cross-validation (CV) error as follows,
| (15) |
The approximation eliminates the need to train models to perform CV, rather just uses and which are extremely cheap to compute within algorithms such as ON, RMSprop, and SGD. Leave-group-out (LGO) estimates can also be built, for example, by using Eq. 14, which enables us to understand the effect of leaving out a big chunk of training data, for example, an entire class for classification. The LOO and LGO estimates are closely related to marginal likelihood and sharpness, both of which are useful to predict generalization performance [22, 12, 19]. Estimates similar to Eq. 15 have been proposed previously [43, 4] but none of them do so during training.
4 Experiments
We show experimental results to demonstrate the usefulness of the MPE to understand the sensitivity of deep-learning models. We show the following: (1) we verify that the estimated deviations (sensitivities) for data removal correlate with the truth; (2) we predict the effect of class removal on generalization error; (3) we estimate the cross-validation curve for hyperparameter tuning; (4) we predict generalization during training; and (5) we study evolution of sensitivities during training. All details of the experimental setup are included in App. I and the code is available at https://github.com/team-approx-bayes/memory-perturbation.
Estimated deviations correlate with the truth: Fig. 2 shows a good correlation between the true deviations and their estimates , as shown in Eq. 13. We show results for three datasets, each using a different architecture but all trained using SGD. To estimate the Hessian and compute , we use a Kronecker-factored (K-FAC) approximation implemented in the laplace [11] and ASDL [39] packages. Each marker represents a data example. The estimate roughly maintains the ranking of examples according to their sensitivity. Below each panel, a histogram of true deviations is included to show that the majority of examples have extremely low sensitivity and most of the large sensitivities are attributed to a small fraction of data. The high-sensitivity examples often include interesting cases (possibly mislabeled or simply ambiguous), some of which are visualized in each panel along with some low-sensitivity examples to show the contrast. High-sensitivity examples characterize the model’s memory because perturbing them leads to a large change in the model. Similar trends are observed for removal of groups of examples in Fig. 6 of Sec. I.2.



Predicting the effect of class removal on generalization: Fig. 3(a) shows that the leave-group-out estimates can be used to faithfully predict the test performance even when a whole class is removed. The x-axis shows the test negative log-likelihood (NLL) on a held-out test set, while the y-axis shows the following leave-one-class-out (LOCO) loss on the set of a left-out class,
The estimate uses an approximation: , which is similar to Eq. 12, but uses an additional approximation to reduce the computation due to matrix-vector multiplications (we rely on the same K-FAC approximation used in the previous experiment). Results might improve when this approximation is relaxed. We show results for two models: MLP and LeNet. Each marker corresponds to a specific class whose names are indicated with the text. The dashed lines indicate the general trends, showing a good correlation between the truth and estimate. The classes Shirt, Pullover are the most sensitive, while the classes Bag, Trousers are least sensitive. A similar result for MNIST is in Fig. 11(d) of Sec. I.3.





Predicting generalization for hyperparameter tuning: We consider the tuning of the parameter for the -regularizer of form . Fig. 4 shows an almost perfect match between the test NLL and the estimated LOO-CV error of Eq. 15. Additional figures with the test errors visualized on top are included in Fig. 7 of Sec. I.4 where we again see a close match to the LOO-CV curves.
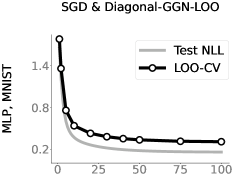
Predicting generalization during training: As discussed earlier, existing influence measures are not designed to analyze sensitivity during training and care needs to be taken when using ad-hoc strategies. We first show results for our proposed measure in Eq. 10 which gives reliable sensitivity estimates during training. We use the improved-BLR method [35] which estimates the mean and a vector preconditioner during training. We can derive an estimate for the LOO error at the mean following a derivation similar to Eqs. 14 and 15,
| (16) |
where and .
The first panel in Fig. 5 shows a good match between the above LOO estimate and test NLL. For comparison, in the next two panels, we show results for SGD training by using two ad-hoc measures obtained by plugging different Hessian approximations in Eq. 11. The first panel approximates with a diagonal Generalized Gauss-Newton (GGN) matrix, while the second panel uses a K-FAC approximation. We see that diagonal-GGN-LOO does not work well at all and, while K-FAC-LOO improves this, it is still not as good as the iBLR result despite using a non-diagonal Hessian approximation. Not to mention, the two measures require an additional pass through the data to compute the Hessian approximation, and also need a careful setting of a damping parameter.
A similar result for iBLR is shown in Fig. 1(b) where we use the larger ResNet–20 on CIFAR10, and more such results are included in Fig. 8 of Sec. I.5. We also find that both diagonal-GGN-LOO or K-FAC-LOO further deteriorate when the model overfits; see Fig. 9. Results for the Adam optimizer are included in Fig. 10, where we again see that using ad hoc measures may not always work. Overall, these results show the difficulty of estimating sensitivity during training and suggest to take caution when using measures that are not naturally suited to analyze the training algorithm.



Evolution of sensitivities during training: Fig. 3(b) shows the evolution of sensitivities of examples as the training progresses. We use the iBLR algorithm and approximate the deviation as where and are obtained similarly to Eq. 16. The x-axis corresponds to examples sorted from least sensitive to most sensitive examples at convergence. The y-axis shows the histogram of sensitivity estimates. We observe that, as the training progresses, the distribution concentrates around a small fraction of the data. At the top, we visualize a few examples with high and low sensitivity estimates, where the high-sensitivity examples included interesting cases (similarly to Fig. 2). The result suggests that the model concentrates more and more on a small fraction of high-sensitivity examples, and therefore such examples can be used to characterize the model’s memory. Additional experiments of this kind are included in Fig. 11 of Sec. I.6, along with other experiment details.
5 Discussion
We present the memory-perturbation equation by building upon the BLR framework. The equation suggests to take a step in the direction of the natural gradient of the perturbed examples. Using the MPE framework, we unify existing influence measures, generalize them to a wide variety of problems, and unravel useful properties regarding sensitivity. We also show that sensitivity estimation can be done cheaply and use this to predict generalization performance. An interesting avenue for future research is to apply the method to larger models and real-world problems. We also need to understand how our generalization measure compares to other methods, such as those considered in [22]. We would also like to understand the effect of various posterior approximations. Another interesting direction is to apply the method to non-Gaussian cases, for example, to study ensemble methods in deep learning with mixture models.
Acknowledgements
This work is supported by the Bayes duality project, JST CREST Grant Number JPMJCR2112.
References
- [1] Vincent Adam, Paul Chang, Mohammad Emtiyaz Khan, and Arno Solin. Dual Parameterization of Sparse Variational Gaussian Processes. Advances in Neural Information Processing Systems, 2021.
- [2] Chirag Agarwal, Daniel D’Souza, and Sara Hooker. Estimating Example Difficulty using Variance of Gradients. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2022.
- [3] Devansh Arpit, Stanisław Jastrzębski, Nicolas Ballas, David Krueger, Emmanuel Bengio, Maxinder S Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, and Simon Lacoste-Julien. A Closer Look at Memorization in Deep Networks. In International Conference on Machine Learning, 2017.
- [4] Gregor Bachmann, Thomas Hofmann, and Aurélien Lucchi. Generalization Through The Lens of Leave-One-Out Error. In International Conference on Learning Representations, 2022.
- [5] Samyadeep Basu, Phil Pope, and Soheil Feizi. Influence Functions in Deep Learning Are Fragile. In International Conference on Learning Representations, 2021.
- [6] Christopher M. Bishop. Pattern Recognition and Machine Learning. Springer, 2006.
- [7] R Dennis Cook. Detection of Influential Observation in Linear Regression. Technometrics, 1977.
- [8] R Dennis Cook and Sanford Weisberg. Characterizations of an Empirical Influence Function for Detecting Influential Cases in Regression. Technometrics, 1980.
- [9] R Dennis Cook and Sanford Weisberg. Residuals and Influence in Regression. Chapman and Hall, 1982.
- [10] Corinna Cortes and Vladimir Vapnik. Support-Vector Networks. Machine learning, 1995.
- [11] Erik Daxberger, Agustinus Kristiadi, Alexander Immer, Runa Eschenhagen, Matthias Bauer, and Philipp Hennig. Laplace Redux-Effortless Bayesian Deep Learning. Advances in Neural Information Processing Systems, 2021.
- [12] Gintare Karolina Dziugaite and Daniel M Roy. Computing Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters Than Training Data. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, 2017.
- [13] Vitaly Feldman and Chiyuan Zhang. What Neural Networks Memorize and Why: Discovering the Long Tail via Influence Estimation. In Advances in Neural Information Processing Systems, 2020.
- [14] Wing K Fung and CW Kwan. A Note on Local Influence Based on Normal Curvature. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 1997.
- [15] Ryan Giordano, Tamara Broderick, and Michael I Jordan. Covariances, robustness and variational Bayes. Journal of Machine Learning Research, 19(51), 2018.
- [16] Satoshi Hara, Atsushi Nitanda, and Takanori Maehara. Data Cleansing for Models Trained with SGD. In Advances in Neural Information Processing Systems, 2019.
- [17] Hrayr Harutyunyan, Alessandro Achille, Giovanni Paolini, Orchid Majumder, Avinash Ravichandran, Rahul Bhotika, and Stefano Soatto. Estimating Informativeness of Samples with Smooth Unique Information. In International Conference on Learning Representations, 2021.
- [18] James Hensman, Nicolo Fusi, and Neil D Lawrence. Gaussian Processes for Big Data. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, 2013.
- [19] Alexander Immer, Matthias Bauer, Vincent Fortuin, Gunnar Rätsch, and Mohammad Emtiyaz Khan. Scalable Marginal Likelihood Estimation for Model Selection in Deep Learning. In International Conference on Machine Learning, 2021.
- [20] Alexander Immer, Maciej Korzepa, and Matthias Bauer. Improving Predictions of Bayesian Neural Nets via Local Linearization. International Conference on Artificial Intelligence and Statistics, 2021.
- [21] Louis A Jaeckel. The Infinitesimal Jackknife. Technical report, Bell Lab., 1972.
- [22] Yiding Jiang, Behnam Neyshabur, Hossein Mobahi, Dilip Krishnan, and Samy Bengio. Fantastic Generalization Measures and Where To Find Them. In International Conference on Learning Representations, 2020.
- [23] Angelos Katharopoulos and Francois Fleuret. Not All Samples Are Created Equal: Deep Learning with Importance Sampling. In International Conference on Machine Learning, 2018.
- [24] Mohammad Emtiyaz Khan. Variational Bayes Made Easy. Fifth Symposium on Advances in Approximate Bayesian Inference, 2023.
- [25] Mohammad Emtiyaz Khan, Alexander Immer, Ehsan Abedi, and Maciej Korzepa. Approximate Inference Turns Deep Networks into Gaussian Processes. Advances in Neural Information Processing Systems, 2019.
- [26] Mohammad Emtiyaz Khan and Wu Lin. Conjugate-Computation Variational Inference: Converting Variational Inference in Non-Conjugate Models to Inferences in Conjugate Models. In International Conference on Artificial Intelligence and Statistics, 2017.
- [27] Mohammad Emtiyaz Khan, Didrik Nielsen, Voot Tangkaratt, Wu Lin, Yarin Gal, and Akash Srivastava. Fast and Scalable Bayesian Deep Learning by Weight-Perturbation in Adam. In International Conference on Machine Learning, 2018.
- [28] Mohammad Emtiyaz Khan and Håvard Rue. The Bayesian Learning Rule. Journal of Machine Learning Research, 2023.
- [29] George S Kimeldorf and Grace Wahba. A Correspondence Between Bayesian Estimation on Stochastic Processes and Smoothing by Splines. The Annals of Mathematical Statistics, 1970.
- [30] Diederik Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. In International Conference on Learning Representations, 2015.
- [31] Pang Wei Koh, Kai-Siang Ang, Hubert Teo, and Percy S Liang. On the Accuracy of Influence Functions for Measuring Group Effects. In Advances in Neural Information Processing Systems, 2019.
- [32] Pang Wei Koh and Percy Liang. Understanding Black-Box Predictions via Influence Functions. In International Conference on Machine Learning, 2017.
- [33] Aran Komatsuzaki. One Epoch is All You Need. ArXiv e-Prints, 2019.
- [34] Pierre-Simon Laplace. Mémoires de Mathématique et de Physique. Tome Sixieme, 1774.
- [35] Wu Lin, Mark Schmidt, and Mohammad Emtiyaz Khan. Handling the Positive-Definite Constraint in the Bayesian Learning Rule. In International Conference on Machine Learning, 2020.
- [36] Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. International Conference on Learning Representations, 2019.
- [37] David JC MacKay. Information Theory, Inference and Learning Algorithms. Cambridge University Press, 2003.
- [38] Roman Novak, Yasaman Bahri, Daniel A Abolafia, Jeffrey Pennington, and Jascha Sohl-Dickstein. Sensitivity and Generalization in Neural Networks: An Empirical Study. In International Conference on Learning Representations, 2018.
- [39] Kazuki Osawa, Satoki Ishikawa, Rio Yokota, Shigang Li, and Torsten Hoefler. ASDL: A Unified Interface for Gradient Preconditioning in PyTorch. In NeurIPS Workshop Order up! The Benefits of Higher-Order Optimization in Machine Learning, 2023.
- [40] Mansheej Paul, Surya Ganguli, and Gintare Karolina Dziugaite. Deep Learning on a Data Diet: Finding Important Examples Early in Training. In Advances in Neural Information Processing Systems, 2021.
- [41] Daryl Pregibon. Logistic Regression Diagnostics. The Annals of Statistics, 1981.
- [42] Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. Estimating Training Data Influence by Tracing Gradient Descent. In Advances in Neural Information Processing Systems, 2020.
- [43] Kamiar Rahnama Rad and Arian Maleki. A Scalable Estimate of the Out-of-Sample Prediction Error via Approximate Leave-One-Out Cross-Validation. Journal of the Royal Statistical Society Series B: Statistical Methodology, 2020.
- [44] Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In International Conference on Machine Learning, 2014.
- [45] Hugh Salimbeni, Stefanos Eleftheriadis, and James Hensman. Natural Gradients in Practice: Non-Conjugate Variational Inference in Gaussian Process Models. In International Conference on Artificial Intelligence and Statistics, 2018.
- [46] Frank Schneider, Lukas Balles, and Philipp Hennig. DeepOBS: A Deep Learning Optimizer Benchmark Suite. In International Conference on Learning Representations, 2019.
- [47] Bernhard Schölkopf, Ralf Herbrich, and Alex J Smola. A Generalized Representer Theorem. In International Conference on Computational Learning Theory, 2001.
- [48] Saurabh Singh and Shankar Krishnan. Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020.
- [49] Ryutaro Tanno, Melanie F Pradier, Aditya Nori, and Yingzhen Li. Repairing Neural Networks by Leaving the Right Past Behind. Advances in Neural Information Processing Systems, 2022.
- [50] Luke Tierney and Joseph B Kadane. Accurate Approximations for Posterior Moments and Marginal Densities. Journal of the American Statistical Association, 1986.
- [51] Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Bengio, and Geoffrey J. Gordon. An Empirical Study of Example Forgetting during Deep Neural Network Learning. In International Conference on Learning Representations, 2019.
- [52] Robert Weiss. An Approach to Bayesian Sensitivity Analysis. Journal of the Royal Statistical Society Series B: Statistical Methodology, 1996.
- [53] Fuzhao Xue, Yao Fu, Wangchunshu Zhou, Zangwei Zheng, and Yang You. To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis. ArXiv e-Prints, 2023.
- [54] Hongtu Zhu, Joseph G. Ibrahim, Sikyum Lee, and Heping Zhang. Perturbation Selection and Influence Measures in Local Influence Analysis. The Annals of Statistics, 2007.
Appendix A Influence Function for Linear Regression
We consider input-output pairs . The feature matrix containing as rows is denoted by and the output vector of length is denoted by . The loss is for . The regularizer is assumed to be . The minimizer is given by
| (17) |
We define a perturbation model as follows with :
For , it corresponds to example removal. An arbitrary simply weights the example accordingly. The solution has a closed-form expression,
| (18) |
where is the Hessian of . We first derive a closed-form expressions for , and then specialize them for different .
A.1 Derivation of the leave-one-out (LOO) deviation
We denote and use the Sherman-Morrison formula to write
| (19) |
In line 3 we substitute and and in the last step we use .
We define which is the prediction error of ,
| (20) |
Therefore, we get the following expressions for the deviation,
These expressions can be written in the form of Eq. 2 by left-multiplying with ,
A.2 Derivation of the infinitesimal perturbation approach
We differentiate in Eq. 19 to get
| (21) |
yielding the following expressions:
| (22) |
The second equation in Eq. 22 follows from the chain rule. We get a bi-linear relationship of the influence measure with respect to and prediction error . It is also possible to evaluate Eq. 21 at representing an infinitesimal perturbation about the LOO estimate, From this and Eq. 22, we can interpret Eq. 2 as the average derivative over the interval [9] or the derivative evaluated at some (via an application of the mean value theorem) [41].
Appendix B Conjugate Exponential-Family Models
Exponential-family distributions take the following form:
where are the natural (or canonical) parameter for which the cumulant (or log partition) function is finite, strictly convex and differentiable over . The quantity is the sufficient statistics, is an inner product and is some function. A popular example is the Gaussian distribution, which can be rearranged to take an exponential-family form written in terms of the precision matrix ,
From this, we can read-off the quantities needed to define an exponential-form,
| (23) |
Both the natural parameter and sufficient statistics consist of two elements. The inner-product for the first elements is simply a transpose to get the term, while for the second element it is a trace which gives .
Conjugate Exponential-Family Models are those where both the likelihoods and prior can be expressed in terms of the same form of exponential-family distribution with respect to . For instance, in linear regression, both the likelihood and prior take a Gaussian form with respect to ,
Note that is a distribution over but it can also be expressed in an (unnormalized) Gaussian form with respect to . The sufficient statistics of both and correspond to those of a Gaussian distribution. Therefore, the posterior is also a Gaussian,
The third line follows because , as shown in Eq. 17.
These computations can be written as conjugate-computations [26] where we simply add the natural parameters,
In the same fashion, to remove the contributions of certain likelihoods, we can simply subtract their natural parameters from . These are the calculations which give rise to the following equation:
Appendix C The Bayesian Learning Rule
The Bayesian learning rule (BLR) aims to find a posterior approximation . Often, one considers a regular, minimal exponential-family , for example, the class of Gaussian distributions. The approximation is found by optimizing a generalized Bayesian objective,
where is the entropy of and is the class of exponential family approximation. The objective is equivalent to the Evidence Lower Bound (ELBO) when corresponds to the negative log-joint probability of a Bayesian model; see [28, Sec 1.2].
The BLR uses natural-gradient descent to find , where each iteration takes the following form,
| (24) |
where is the learning rate. The gradient is computed with respect to (through ), and we scale the gradient by the Fisher Information Matrix (FIM) defined as follows,
The second equality shows that, for exponential-family distribution, the above FIM is also the second derivative of the log-partition function .
C.1 The BLR of Eq. 5
The BLR in Eq. 5 is obtained by simplifying the natural-gradient using the following identity,
| (25) |
where is the expectation parameter. The identity works because of the minimality of the exponential-family which ensures that there is a one-to-one mapping between and , and also that the FIM is invertible. Using this, we can show that the natural gradient of is simply equal to ; see [28, App. B]. Defining , we get the version of the BLR shown in Eq. 5,
C.2 The conjugate-model form of the BLR given in Eq. 5
To express the update in terms of the posterior of a conjugate model, we simply take the inner product with and take the exponential to write the update as
| (26) |
The simplification of the second term on the left to happens when is a conjugate prior, that is, for some (see an example in App. B where we show that regularizer leads to such a choice). In such cases, we can simplify,
Using this in Eq. 26, we recover the conjugate model given in Eq. 5.
C.3 BLR for a Gaussian and the Variational Online Newton (VON) algorithm
By choosing an appropriate form for and making necessary approximations to , the BLR can recover many popular algorithms as special cases. We will now give a few examples for the case of a Gaussian which enables derivation of various first and second-order optimization algorithms, such as, Newton’s method, RMSprop, Adam, and SGD.
As shown in Eq. 23, for a Gausian , the natural parameter and sufficient statistics are shown below, along with the expectation parameters .
Using these, we can write the natural gradients as gradients with respect to , , and then using chain-rule to express them as gradients with respect to and ,
| (27) |
where in the last equation we define two quantities written in terms of and by using Price’s and Bonnet’s theorem [44],
| (28) |
Plugging these into the BLR update gives us the following update,
where and are quantities similar to before but now evaluated at the . The conjugate model can be written as follows,
The prior above is Gaussian and defined using and . The model uses likelihoods that are Gaussian distribution with information vector and information matrix . The likelihood is allowed to be an improper distribution, meaning that its integral is not one. This is not a problem as long as remains positive definite. A valid can be ensured by either using a Generalized Gauss-Newton approximation to the Hessian [27] or by using the improved BLR of [35]. The former strategy is used in [25] to express BLR iterations as linear models and Gaussian processes. Ultimately, we want to ensure that perturbation in the approximate likelihoods in yields a valid posterior and, as long as this is the case, the conjugate model can be used safely. For instance, in Thm. 4, this issue poses no problem at all.
The BLR update can be rearranged and written in a Newton-like form show below,
| (29) |
This is called the Variational Online Newton (VON) algorithm. A full derivation is in [27] with details on many of its variants in [28]. The simplest variant is the Online Newton (ON) algorithm, where we use the delta method,
| (30) |
Then denoting , we get the following ON update,
| (31) |
To reduce the cost, we can use a diagonal approximation where is a scale vector. Additionally, we can use minibatching to estimate the gradient and hessian (denoted by and ),
| ON (diagonal+minibatch): | (32) | |||
where indicates element-wise product two vectors and extracts the diagonal of a matrix.
Several optimization algorithms can be obtained as special cases from the above variants. For example, to get Newton’s method, we set in ON to get
| (33) |
RMSprop and Adam can be derived in a similar fashion [28].
In our experiments, we use the improved BLR or iBLR optimizer [35]. We use it to implement an improved version of VON [27, Eqs. 7–8] which ensures that the covariance is always positive-definite, even when the Hessian estimates are not. We use diagonal approximation , momentum and minibatching as proposed in [27, 35]. For learning rate , momentum the iterations are written as follows:
| (34) |
Here, is the -regularization parameter and , denote Monte-Carlo approximations of the expected stochastic gradient and diagonal Hessian under and minibatch . As suggested in [27, 35], we used the reparametrization trick to estimate the diagonal Hessian via gradients only. In practice, we approximate the expectations using a single random sample. We expect multiple samples to further improve the results.
Appendix D Proof of Thm. 2 and the Beta-Bernoulli Model
We will now show an example on Beta-Bernoulli model, which is a conjugate model. We assume the model to be where the prior is and likelihoods are with . This is a conjugate model and the posterior is Beta distribution, that is, it takes the same form as the prior. An expression is given below,
The posterior for the perturbed dataset is also available in closed-form:
Therefore the deviations in the posterior parameters can be simply obtained as follows:
| (35) |
This result can also be straightforwardly obtained using the MPE. For the Beta distribution , we have , therefore . For Beta distribution, and writing the likelihood in an exponential form, we get
therefore . Setting , we recover the result given in Eq. 35.
Appendix E Proof of Thm. 3
For linear regression, we have
Using these in Eq. 8, we get,
The natural parameter is . In a similar way, we can define and its natural parameter. Using these, we can write Eq. 6 as
Substituting the second equation into the first one, we get the first equation below,
The last equality is exactly Eq. 2. Since linear regression is a conjugate model, an alternate derivation would be to directly use the parameterization of (derived in App. B) and plug it in Thm. 2.
Appendix F Proof of Thm. 4
For simplicity, we denote
with as defined in Eq. 7 in the main text. For Gaussian distributions, the natural parameter comes in a pair . Its derivative with respect to at can be written as the following by using the chain rule:
Here, we use the fact that, as , we have and also assumed that the limit of the product is equal to the product of the individual limits. Next, we need the expression for the natural gradient, for which we will use Eq. 8 but approximate the expectation by using the delta approximation for any function , as shown below to define:
The claim is that if we set the perturbed we recover Eq. 3, that is, we set
Plugging the second equation into the first, the second term cancels and we recover Eq. 3.
Appendix G Extension to Non-Differentiable Loss function
For non-differentiable cases, we can use Eq. 28 to rewrite the BLR of Eq. 29 as
| (36) |
where . Essentially, we take derivative outside the expectation instead of inside which is valid because the expectation of a non-differentiable function is still differentiable (under some regularity conditions). The same technique can be applied to Eq. 8 to get
| (37) |
and proceeding in the same fashion we can write: . This is the extension of Eq. 10 to non-differentiable loss functions.
Appendix H Sensitivity Measures for Sparse Variational Gaussian Processes
Sparse variational GP (SVGP) methods optimize the following variational objective to find a Gaussian posterior approximation over function values where is the set of inducing inputs with :
where is the prior with as the covariance function evaluated at , is the posterior marginal of with and as the noise variance of conditioned on . The objective is also used to optimize hyperparameters and inducing input set .
We can optimize the objective using the BLR for which the resulting update is identical to the variational online-newton (VON) algorithm. We first write the natural gradients,
| (38) |
where we define
We define to be a matrix with as rows, and to be vectors of . Using these in the VON update, we simplify as follows:
| (39) | ||||
| (40) | ||||
For Gaussian likelihood, the updates in Eqs. 39 and 40 coincide with the method of [18], and for non-Gaussian likelihood they are similar to the natural-gradient method by [45], but we use the specific parameterization of [26]. An alternate update rule in terms of site parameters is given by [1] (see Eqs. 22-24).
We are now ready to write the sensitivity measure essentially substituting the gradient in Eq. 10),
| (41) |
We can also see the bi-linear relationship by considering the deviation in the mean of the posterior marginal ,
| (42) |
where is the marginal variance of .
Appendix I Experimental Details
I.1 Neural network architectures
Below, we describe different neural networks used in our experiments,
- MLP (500, 300):
-
This is a multilayer perceptron (MLP) with two hidden layers of 500 and 300 neurons and a parameter count of around (using hyperbolic-tangent activations).
- MLP (32, 16):
-
This is also an MLP with two hidden layers of 32 and 16 neurons, which accounts for around parameters (also using hyperbolic tangent activations).
- LeNet5:
-
This is a standard convolutional neural network (CNN) architecture with three convolution layers followed by two fully-connected layers, corresponding to around parameters.
- CNN:
-
This network, taken from the DeepOBS suite [46], consists of three convolution layers followed by three fully-connected layers with a parameter count of .
- ResNet–20:
-
This network has around parameters. We use filter response normalization (FRN) [48] as an alternative to batch normalization.
- MLP for USPS:
-
For the experiment on binary USPS in Fig. 6(a), we use an MLP with three hidden layers of 30 neurons each and a total of around parameters.
I.2 Details of “Do estimated deviations correlate with the truth?”
In Fig. 2, we train neural network classifiers with a cross-entropy loss to obtain . Due to the computational demand of per-example retraining, the removed examples are randomly subsampled from the training set. We show results over 1000 examples for MNIST and FMNIST and 100 examples for CIFAR10. In the multiclass setting, the expression yields a per-class sensitivity value. We obtain a scalar value for each example by summing over the absolute values of the per-class sensitivities. For training both the original model and the perturbed models , we use SGD with a momentum parameter of and a cosine learning-rate scheduler. To obtain , we retrain a model that is warmstarted at . Other details regarding the training setup are given in Table 2. For all models, we do not use data augmentation during training. The resulting for MNIST, FMNIST, and CIFAR10 have training accuracies of , , and , respectively. The test accuracies for these models are , and .
| Dataset | Model | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| MNIST | MLP (500, 300) | ||||||||
| FMNIST | LeNet5 | ||||||||
| CIFAR10 | CNN |
Additional group removal experiments:
We also study how the deviation for removing a group of examples in a set can be estimated using a variation of Eq. 14 for the deviation in predictions at convergence. Denoting the vector of for by , we get
| (43) |
where is a diagonal matrix containing all , is the prediction covariance of size where is the number of examples in , and is the vector of prediction errors. The last approximation above is done to avoid building the covariance, where we ignore the off-diagonal entries of .
In Fig. 6(a) we consider a binary USPS dataset consisting of the classes for the digits 3 and 5. Using = 16, we show the first and second approximations in Eq. 43 both correlate well with the truth obtained by removing a group and retraining the model. In Fig. 6(b) we do the same on MNIST with = 64, where we see similar trends. For the experiment on binary USPS in Fig. 6(a), we train a MLP with three hidden layers with neurons each. The original model is trained for epochs with a learning-rate of , a batch size of and a -regularization parameter . It has training accuracy and test accuracy. For the leave-group-out retraining to obtain , we initialize the model at , use a learning-rate of and train for epochs. For the MNIST result in Fig. 6(b) we use the MLP (500, 300) model with the same hyperparameters as for in Table 2. For , we initialize the model at and use a cosine schedule of the learning-rate from to over epochs. We do not use data augmentation. Similarly to the experiments on per-example removal, we use a K-FAC approximation.


| Dataset | Model | |||||
|---|---|---|---|---|---|---|
| MNIST | MLP (500, 300) | |||||
| MNIST | LeNet5 | |||||
| FMNIST | MLP (32, 16) | |||||
| FMNIST | LeNet5 |
I.3 Details of “Predicting the effect of class removal on generalization”
For the FMNIST experiment in Fig. 3(a), we use the MLP (32, 16) and LeNet5 models. For the MNIST experiment in Fig. 11(d), we use the MLP (500, 300) and LeNet5 models. The hyperparameters are given in Table 3. The MLP on MNIST has a training accuracy of and a test accuracy of . When using LeNet5, the training and test accuracies are and . On FMNIST, the LeNet5 has an accuracy of on the training set, and an accuracy of on the test set. On the same dataset, the MLP has a training accuracy of and a test accuracy of . For all models, we use a regularization parameter of 100 and a batch size of 256. The leave-one-class-out training is run for 1000 epochs and the rest of the training setup is same as the previous experiment.
I.4 Details of “Estimating the leave-one-out cross-validation curves for hyperparameter tuning”
The details of the training setup are in Table 2. Fig. 7 is the same as Fig. 4 but additionally shows the test errors. For visualization purposes, each plot uses a moving average of the plotted lines with a smoothing window. Other training details are similar to previous experiments. All models are trained from scratch where we use Adam for FMNIST, AdamW [36] for CIFAR10, and SGD with a momentum parameter of 0.9 for MNIST. We use a cosine learning-rate scheduler to anneal the learning-rate. The other hyperparameters are similar to the settings of the models trained on all data from the leave-one-out experiments in Table 2, except for the number of epochs for CIFAR10 where we train for 150 epochs. Similarly to Sec. I.2, we use a Kronecker-factored Laplace approximation for variance computation and do not employ data augmentation during training.
| Dataset | Model | Number of s | Range | Smoothing window |
|---|---|---|---|---|
| MNIST | MLP (500, 300) | 96 | 3 | |
| FMNIST | LeNet5 | 96 | 5 | |
| CIFAR10 | CNN | 30 | 3 |



I.5 Details of “Predicting generalization during the training”
Details of the training setup:
The experimental details, including test accuracies at the end of training, are listed in Table 5. We use a grid search to determine the regularization parameter . The learning-rate is decayed according to a cosine schedule. For diagonal-GGN-LOO and K-FAC-LOO, we use the SGD optimizer with an exception on the FMNIST dataset where we use the AdamW optimizer [36]. In that experiment, we use a weight decay factor of replacing the explicit -regularization term in the loss in Eq. 1. The regularizer is set to zero. We do not use training data augmentation. For all plots, the LOO-estimate is evaluated periodically during the training, which is indicated with markers.
Additional details on hyperparameters of iBLR are as follows, where is the initialization of the Hessian:
-
•
MNIST, MLP (32, 16):
-
•
MNIST, LeNet5:
-
•
FMNIST, LeNet5:
-
•
CIFAR10, CNN:
-
•
CIFAR10, ResNet20:
We set and in all of those experiments. The magnitude of the prediction variance can depend on , which therefore can influence the magnitude of the sensitivities that are perturbing the function outputs in the LOO estimate of Eq. 16. We choose on a grid of four values [0.01, 0.05, 0.1, 0.5] to obtain sensitivities that result in a good prediction of generalization performance.
| Dataset | Model | Method | Test acc. | ||||
| MNIST | MLP (32, 16) | iBLR | |||||
| diag.-GGN-LOO | |||||||
| K-FAC-LOO | |||||||
| MNIST | LeNet5 | iBLR | % | ||||
| diag.-GGN-LOO | |||||||
| K-FAC-LOO | |||||||
| FMNIST | LeNet5 | iBLR | |||||
| diag.-GGN-LOO | |||||||
| K-FAC-LOO | |||||||
| CIFAR10 | CNN | iBLR | |||||
| diag.-GGN-LOO | |||||||
| K-FAC-LOO | |||||||
| CIFAR10 | ResNet–20 | iBLR |








Additional Results: In Fig. 8, we show additional results for MNIST and CIFAR10 that are not included in the main text. For MNIST, we evaluate both on a the MLP (32, 16) model and a LeNet5 architecture. For the additional CIFAR10 results, we use the CNN. In Fig. 9 we include an additional experiment where the model overfits. The K-FAC-LOO estimate deteriorates in this case, but we can still use the LOO as a diagnostic for detecting overfitting and as a stopping criterion. We train a LeNet5 on FMNIST with AdamW and predict generalization. The trend of the estimated NLL matches the trend of the test NLL in the course of training.
In Fig. 10, we include further results for sensitivity estimation with the Adam optimizer. We use the following update
where is the minibatch gradient, and are coefficients for the running averages, is a learning-rate, and a small damping to stabilize. We construct a diagonal matrix to estimate sensitivity with MPE as suggested in Table 1 ( is the number of training examples). Better results are expected by building better estimates of as discussed in [27]. As described in section 3.4 of [27], a smaller batch size should improve the estimate, which we also observe in the experiment.










| Dataset | Model | Method | Test acc. | ||||
|---|---|---|---|---|---|---|---|
| FMNIST | LeNet5 | diag., AdamW | |||||
| K-FAC, AdamW |
| Dataset | Model | Test acc. () | Test acc. () | |||
|---|---|---|---|---|---|---|
| MNIST | MLP (32, 16) | |||||
| MNIST | LeNet5 | |||||
| FMNIST | LeNet5 | |||||
| CIFAR10 | CNN |
I.6 Details of “evolution of sensitivities during training”
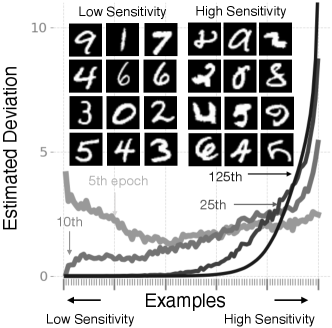



We use the MPE with iBLR for neural network classification on MNIST, FMNIST and CIFAR10, as well as MPE for logistic regression on MNIST. Experiment details are in Table 8.
| Dataset | Model | B | ||
|---|---|---|---|---|
| MNIST | MLP (500, 300) | 256 | 30 | 100 |
| FMNIST | LeNet5 | 256 | 60 | 100 |
| CIFAR10 | ResNet–20 | 512 | 35 | 300 |
For the experiment in Fig. 11(a), we consider Bayesian logistic regression. We set . The Hessian is always positive-definite due to the convex loss function therefore we use the VON algorithm given in Eq. 29. We use updates with batch-size , reaching a test accuracy of around using the mean . We use linear learning-rate decay from to for the mean and a learning-rate of for the precision . The expectations are approximated using 3 samples drawn from the posterior. We plot sensitivities at iteration . For this example, we use samples from to compute the prediction variance and error ( samples are used). We sort examples according to their sensitivity at iteration and then plot their average sensitivities in groups with examples in each group.
For the experiments in Fig. 3(b), Fig. 11(b) and Fig. 11(c), we consider neural network models on FMNIST, MNIST and CIFAR10. We do not use training data augmentation. For CIFAR10 we use a ResNet–20. The expectations in the iBLR are approximated using a single sample drawn from the posterior. For prediction, we use the mean . The test accuracies are for FMNIST, for MNIST and for CIFAR10. We use a cosine learning-rate scheduler with an initial learning-rate of 0.1 and anneal to zero over the course of training. Other experimental details are stated in Table 8. Similar to before, we use sampling to evaluate sensitivity ( samples are used).
Appendix J Author Contributions Statement
Authors list: Peter Nickl (PN), Lu Xu (LX), Dharmesh Tailor (DT), Thomas Moellenhoff (TM), Mohammad Emtiyaz Khan (MEK)
All co-authors contributed to developing the main idea. MEK and DT first discussed the idea deriving sensitivity measure based on the BLR. MEK derived the MPE and the results in Sec 3 and DT helped in connecting them to influence functions. PN derived the results in 3.3 and came up with the idea to predict generalization error with LOO-CV. LX adapted it to class-removal. PN wrote the code with help from LX. PN and LX did most of the experiments with some help from TM and regular feedback from everybody. TM did the experiment on the sensitivity evolution during training with some help from PN. All authors were involved in writing and proof-reading of the paper.
Appendix K Differences Between Camera-Ready Version and Submitted Version
We made several changes to take the feedback of reviewers into account and improve the paper.
-
1.
The writing and organization of the paper were modified to emphasize the generalization to a wide variety of models and algorithms and the applicability of MPE during training.
-
2.
The presentation was changed in Section 3 to emphasize the focus on the conjugate model. Detailed derivations were pushed to the appendices and more focus was put on big picture ideas. Arbitrary perturbations parts were made explicit. Table 1 was added and more focus was put on training algorithms.
-
3.
We added experiments using leave-one-out estimation to predict generalization on unseen test data during traininig. We also added results to study the evolution of sensitivities during training using MPE with iBLR.