The Manifold Of Variations:
hazard assessment of
short-term impactors
Abstract.
When an asteroid has a few observations over a short time span the information contained in the observational arc could be so little that a full orbit determination may be not possible. One of the methods developed in recent years to overcome this problem is based on the systematic ranging and combined with the Admissible Region theory to constrain the poorly-determined topocentric range and range-rate. The result is a set of orbits compatible with the observations, the Manifold Of Variations, a 2-dimensional compact manifold parametrized over the Admissible Region. Such a set of orbits represents the asteroid confidence region and is used for short-term hazard predictions. In this paper we review the Manifold Of Variations method and make a detailed analysis of the related probabilistic formalism.
1. Introduction
An asteroid just discovered has a strongly undetermined orbit, being it weakly constrained by the few available astrometric observations. This is called a Very Short Arc (VSA, Milani et al. (2004)) since the observations cover a short time span. As it is well-known, the few observations constrain the position and velocity of the object in the sky-plane, but leave almost unknown the distance from the observer and the radial velocity, respectively the topocentric range and range-rate. This means that the asteroid confidence region is wide in at least two directions instead of being elongated and thin. Thus one-dimensional sampling methods, such as the use of the Line Of Variations (LOV, Milani et al. (2005)), are not a reliable representation of the confidence region. Indeed, VSAs are often too short to allow a full orbit determination, which would make it impossible even to define the LOV. To overcome the problem three systems have been developed in recent years: Scout at the NASA JPL (Farnocchia et al., 2015), NEOScan at SpaceDyS and at the University of Pisa (Spoto et al., 2018; Del Vigna, 2018), and neoranger at the University of Helsinki (Solin and Granvik, 2018).
Scout111https://cneos.jpl.nasa.gov/scout/ and NEOScan222https://newton.spacedys.com/neodys2/NEOScan/ are based on the systematic ranging, an orbit determination method which explores a suitable subset of the topocentric range and range-rate space (Chesley, 2005). They constantly scan the Minor Planet Center NEO Confirmation Page (NEOCP), with the goal of identifying asteroids such as NEAs, MBAs or distant objects to confirm/remove from the NEOCP and to give early warning of imminent impactors. NEOScan uses a method based on the systematic ranging and on the Admissible Region (AR) theory (Milani et al., 2004) to include in the orbit determination process also the information contained in the short arc, although too little to constrain a full orbit. Starting from a sampling of the AR, a set of orbits compatible with the observations is then computed by a doubly constrained differential correction technique, which in turn ends with a sampling of the Manifold Of Variations (MOV, Tommei (2006)), a 2-dimensional manifold of orbits parametrized over the AR and representing a two-dimensional analogue of the LOV. This combination of techniques provided a robust short-term orbit determination method and also a two-dimensional sampling of the confidence region to use for the subsequent hazard assessment and for the planning of the follow-up activity of interesting objects.
In this paper we review the algorithm at the basis of NEOScan and examine in depth the underlying mathematical formalism, focusing on the short-term impact monitoring and the impact probability computation. In Section 2 we summarise the AR theory and the main definitions concerning the MOV. Section 3 contains the results for the derivation of the probability density function on an appropriate integration space, by assuming that the residuals are normally distributed and by a suitable linearisation. In Section 4 we show that without the linearisation assumed in the previous section we find a distribution known to be inappropriate for the problem of computing the impact probability of short-term impactors (Farnocchia et al., 2015). In Section 5 we give a probabilistic interpretation to the optimisation method used to define the MOV, namely the doubly constrained differential corrections. Lastly, Section 6 contains our conclusions and a possible application of the method presented in this paper to study in future research.
2. The Admissible Region and the Manifold Of Variations
As anticipated in the introduction, the systematic ranging method on which NEOScan is based makes a deep use of the Admissible Region. In this section we briefly recap its main properties and we refer the reader to relevant further references.
When in presence of a VSA, even when we are not able to fit a full least squares orbit, we are anyway able to compute the right ascension , the declination , and their time derivatives and , to form the so-called attributable (Milani et al., 2004). For the notation, we indicate the attributable as
where all the quantities are referred to the mean of the observational times. The AR has been introduced to constrain the possible values of the range and the range-rate that the attributable leaves completely undetermined. Among other things, we require that the observed object is a Solar System body, discarding the orbits corresponding to too small objects to be source of meteorites (the so-called shooting star limit).
The AR turns out to be a compact subset of and
to have at most two connected components. Commonly the AR has one
component and the case with two components indicates the possibility
for the asteroid to be distant. Since the AR is compact we can sample
it with a finite number of points, and we use two different sampling
techniques depending on the geometric properties of the AR and on the
existence of a reliable least squares orbit. A nominal solution is an
orbit obtained by unconstrained (i.e. full) differential
corrections, starting from a preliminary orbit as first guess. Indeed
it does happen that the available observations are enough to constrain
a full orbit: it essentially depends on the quality of the observed
arc, which can be measured by the arc type and the signal-to-noise
ratio of the geodesic curvature of the arc on the celestial sphere
(Milani et al., 2007). We say that the nominal orbit is reliable
if the latter is . If this is the case we anyway compute a
sampling of orbits compatible with the observations to use to make
predictions, but instead of considering the entire AR we exploit the
knowledge of the least squares orbit, and in particular of its
covariance.
Grid sampling. When a reliable nominal solution does not exist
or it is not reliable, the systematic ranging is performed by a
two-step procedure and in both steps it uses rectangular grids over
the AR. In the first step a grid covers the entire AR, with the sample
points for spaced either uniformly or with a logarithmic scale
depending on the geometry of the AR (see Figure 1,
left). The corresponding sampling of the MOV is then computed, with
the doubly constrained differential corrections procedure described
below. Then we are able to identify the orbits which are more
compatible with the observations by computing their value
(see Equation (2.2)), and we can restrict the grid to the
region occupied by such orbits. Thus the grid used in the second step
typically covers a smaller region and thus it has a higher resolution
than the first one (see Figure 1, right).
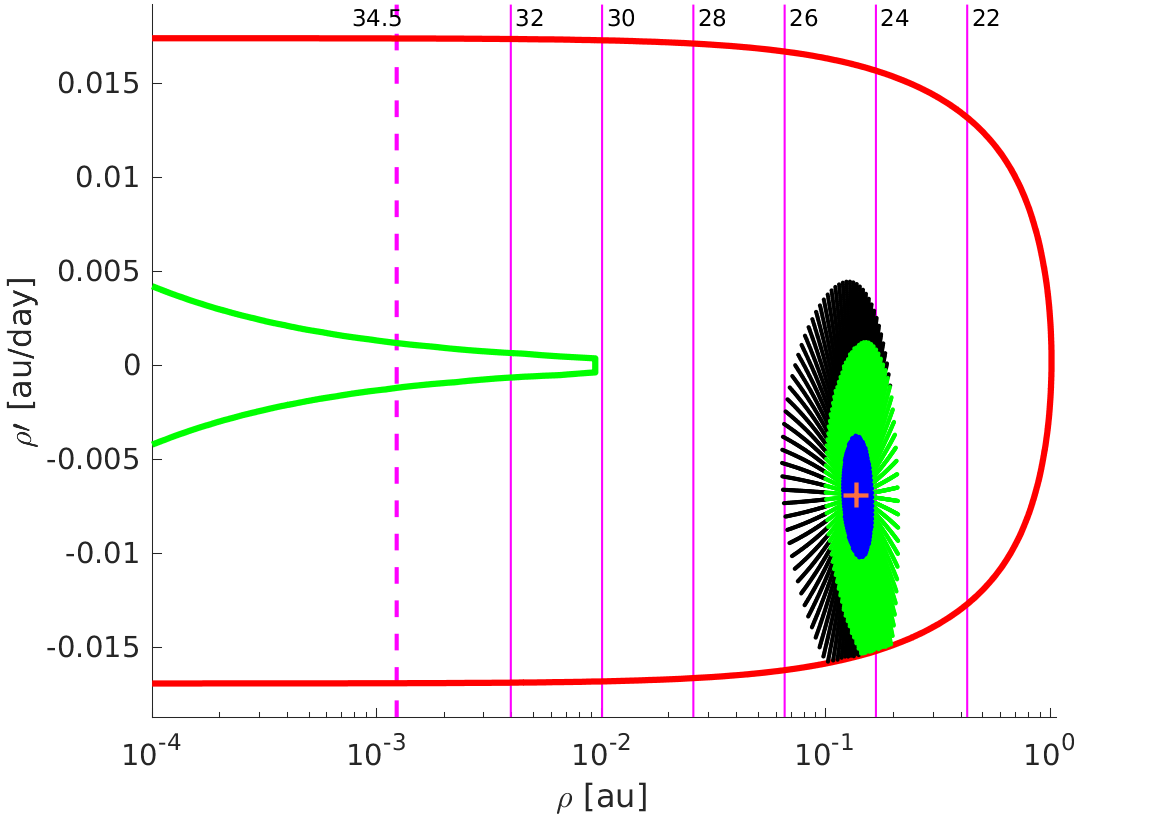
Cobweb sampling. If a reliable nominal orbit exists,
instead of using a grid we compute a spider web sampling in a suitable
neighbourhood of the nominal solution. This is obtained by following
the level curves of the quadratic approximation of the target function
used to minimise the RMS of the observational residuals (see
Figure 2).
For the formal definition of the AR and the proof of its
properties the reader can refer to Milani et al. (2004). The operative
definition used in NEOScan and a detailed explanation of the sampling
techniques can be found in Spoto et al. (2018) and
Del Vigna (2018).


We now describe the Manifold Of Variations, a sample of orbits compatible with the observational data set. In general, to obtain orbits from observations we use the least squares method. The target function is
where are the orbital elements to fit, is the number of observations used, is the vector of the observed-computed debiased astrometric residuals, and is the weight matrix. As explained in the introduction, in general a full orbit determination is not possible for short arcs. Nevertheless, from the observational data set it is possible to compute an attributable . The AR theory has been developed to obtain constraints on the values of , so that we can merge the information contained in the attributable with the knowledge of an AR sampling. The basic idea of this method is to fix and at some specific values obtained from the AR sampling, compose the full orbit , and fit only the attributable part to the observations with a suitable differential corrections procedure.
Definition 2.1.
Given a subset of the AR, we define the Manifold Of Variations to be the set of points such that and is the local minimum of the function , when it exists. We denote the Manifold Of Variations with .
Remark 2.2.
In general is a 2-dimensional manifold, since the differential of the map from the space to has rank (see Lemma 3.2).
The set is the intersection of a rectangle with the AR in the case of the grid sampling, whereas is an ellipse around in the cobweb case, where is the reliable nominal orbit. To fit the attributable part we use the doubly constrained differential corrections, which are usual differential corrections but performed on a 4-dimensional space rather than on a 6-dimensional one. The normal equation is
where
| (2.1) |
We call the subset of on which the doubly constrained differential corrections converge, giving a point on .
Definition 2.3.
For each orbit we define the -value to be
| (2.2) |
where is the minimum value of the target function over , that is . The orbit for which this minimum is attained is denoted with and referred to as the best-fitting orbit.
The standard differential corrections are a variant of the Newton method to find the minimum of a multivariate function, the target function (Milani and Gronchi, 2010). The uncertainty of the result can be described in terms of confidence ellipsoids (optimisation interpretation) as well as in the language of probability (probabilistic interpretation). In Section 5 we give a probabilistic interpretation to the doubly constrained differential corrections procedure.
3. Derivation of the probability density function
Starting from Spoto et al. (2018) we now give the proper mathematical formalism to derive the probability density function on a suitable space which we define below. Upon integration this will lead to accurate probability estimates, the most important and urgent of which is the impact probability computation for a possible imminent impactor.
Our starting point is a probability density function on the residuals space, to propagate back to . In particular, we assume the residuals to be distributed according to a Gaussian random variable , with zero mean and covariance , that is
Without loss of generality, we can assume that
| (3.1) |
where is the identity matrix. This is obtained by using the normalised residuals in place of the true residuals (see for instance Milani and Gronchi (2010)). For the notation, from now on we will use to indicate the normalised residuals. Note that with the use of normalised residuals the target function becomes .
3.1. Spaces and maps
Let us introduce the following spaces.
-
(i)
is the sampling space, which is if the sampling is uniform in , if the sampling is uniform in , and in the cobweb case.
-
(ii)
has already been introduced in Section 2, and it is the subset of the points of the AR on which the doubly constrained differential corrections achieved convergence.
-
(iii)
is the orbital elements space in attributable coordinates, where is the attributable space and is the range/range-rate space.
-
(iv)
is the Manifold Of Variations, a 2-dimensional submanifold of .
-
(v)
is the residuals space, whose dimension is since the number of observations must be .
We now define the maps we use to propagate back the density . First, the residuals are a function of the fit parameters, that is , with being a differentiable map. The second map goes from the AR space to the MOV space.
Definition 3.1.
The map is defined to be
where is the best-fit attributable obtained at convergence of the doubly constrained differential corrections.
Lemma 3.2.
The map is a global parametrization of as a -dimensional manifold.
Proof.
The set is a subset of with non-empty interior, the map is at least and its Jacobian matrix is
| (3.2) |
from which is clear that it is full rank on . ∎
The last map to introduce is that from the sampling space to the AR space .
Definition 3.3.
The map is defined according to the sampling technique:
-
(i)
if the sampling is uniform in , is the identity map;
-
(ii)
if the sampling is uniform in , we have and ;
-
(iii)
if we are in the cobweb case, and the map is given by
where are the eigenvalues of the matrix , the latter being the restriction of the covariance matrix to the space, and is the unit eigenvector corresponding to .
We then consider the following chain of maps
and we use it to compute the probability density function on obtained by propagating back.
3.2. Conditional density of a Gaussian on an affine subspace
In this section we establish general results about the conditional probability density function of a Gaussian random variable on an affine subspace. Let and be two positive integers, with . Let a matrix with full rank, that is . Consider the affine -dimensional subspace of given by
We can also assume that is orthogonal to , that is , otherwise it is possible to subtract the component parallel to . Given the random variable with the Gaussian distribution on as in (3.1), we want to find the conditional probability density of on . Let be a rotation matrix and let be the affine map
Throughout this section, we use the notation , with and . We choose in such a way that
| (3.3) |
Lemma 3.4.
Condition (3.3) holds for all if and only if there exists an invertible matrix such that .
Proof.
Let . Since is invertible
there exists such that
. Then
, hence
.
Condition (3.3) implies that for all
there exists such
that
. Since the multiplication by is
injective, such is unique. Therefore there
exists a well-defined map such that
. The map is linear and
injective since , thus it is a
bijection. If is the matrix associated to
, there easily follows
.
∎
Lemma 3.5.
Let . Then the following holds:
-
(i)
and the map is a bijection;
-
(ii)
for some .
Proof.
(i) The inclusion is trivial. For the other
one, let , then there exists
such that
. From Lemma
3.4 we have
.
(ii) Since and is an isometry,
we have ,
where the last equality follows from (i).
∎∎
Theorem 3.6.
The conditional probability density of is , that is
Proof.
By the standard propagation formula for probability density functions under the action of a continuous function, we have that
The conditional probability density of the variable on (see Lemma 3.5-(i)) is obtained by using that and Lemma 3.5-(ii). We have
where we have used that for all . Now the thesis follows by noting that the random variable coincides with . ∎∎
Corollary 3.7.
The conditional probability density of on is
where .
3.3. Computation of the probability density
We first derive the probability density function on the Manifold Of Variations from that on the normalised residuals space. The computation is based on the linearisation of the map around the best-fitting orbit. In Section 4 we will instead show the result of the full non-linear propagation of the probability density function and discuss the reason for which this approach, although correct, is not a suitable choice for applications.
Theorem 3.8.
Let be the random variable of . By linearising around the best-fitting orbit , the conditional probability density of on is given by
| (3.4) |
Proof.
The map is differentiable of class at least and the Jacobian matrix of is the design matrix . Since the doubly constrained differential corrections converge to , the matrix is full rank. It follows that the map is a local parametrization of
in a suitable neighbourhood of . The set is thus a 2-dimensional submanifold of the residuals space . Consider the differential
where is a 2-dimensional affine subspace of . We claim that is orthogonal to : since is a local minimum of the target function
that is . By applying Corollary 3.7 we have that
for . The differential map is continuous and invertible (since it is represented by the matrix , as in Lemma 3.4), thus we can use the standard formula for the transformations of random variables to obtain
for , where is the normal matrix of the differential corrections converging to . Furthermore, in the approximation used, we have
so that for
Now the thesis follows by normalising the density just obtained. ∎∎
We now complete the derivation of the probability density function on the space . In particular, to obtain the density on the space we use the notion of integration over a manifold because we want to propagate a probability density on a manifold to a probability density over the space that parametrizes the manifold itself (see Theorem 3.9). Then the last step involves two spaces with the same dimension, namely and , thus we simply apply standard propagation results from probability density functions (see Theorem 3.10).
Theorem 3.9.
Let be the random variable on the space . Assuming (3.4) to be the probability density function on , the probability density function of is
where and is the Gramian determinant
Moreover, neglecting terms containing the second derivatives of the residuals multiplied by the residuals themselves, for all we have
Proof.
We have already proved that the map is a global parametrization of . From the definition of integral of a function over a manifold we have
and the thesis follows since from Equation (3.2)
The equation for is proved in Spoto et al. (2018), Appendix A, but for the sake of completeness we repeat the argument here. Let . By definition, the point is a zero of the function defined to be
The function is continuously differentiable and we have
where we neglected terms containing the second derivatives of the residuals multiplied by the residuals themselves. The matrix is invertible because , which means that the doubly constrained differential corrections did not fail. By applying the implicit function theorem, there exists a neighbourhood of , a neighbourhood of , a continuously differentiable function such that, for all it holds
and
| (3.5) |
The derivative is already computed above. For we have
The thesis now follows from Equation (3.5). ∎∎
The final step in the propagation of the probability density function consists in applying the map , where is the portion of the sampling space mapped onto .
Theorem 3.10.
Let be the random variable on the space . Assuming (3.4), the probability density function of is
| (3.6) |
where we used the compact notation , , and is the Gramian of the columns of , so that
Proof.
Equation (3.6) directly follows from the transformation law for random variables between spaces of the same dimension, under the action of the continuous function : it suffices to change the variables from the old ones to the new ones and multiply by the modulus of the determinant of the Jacobian of the inverse transformation, that is . ∎∎
The determinant depends on the sampling technique and it is explicitly computed in Spoto et al. (2018), Appendix A. In particular, the straightforward computation yields the following:
-
(i)
if the sampling is uniform in then for all ;
-
(ii)
if the sampling is uniform in the logarithm of then for all ;
-
(iii)
in the case of the spider web sampling for all .
For the sake of completeness, we now recall how the density is used for the computation of the impact probability of a potential impactor. Each orbit of the MOV sampling is propagated for 30 days, recording each close approach as a point on the Modified Target Plane (Milani and Valsecchi, 1999), so that we are able to identify which orbits are impactors. Let be the subset of impacting orbits, so that is the corresponding subset of sampling variables. The impact probability is then computed as
Of course the above integrals are evaluated numerically as finite sums over the integration domains: since they are subsets of we use the already available sampling described in Section 2. In particular, we limit the sums to the sample points corresponding to MOV orbits with a -value less than . As pointed out in Spoto et al. (2018), this choice guarantees to NEOScan to find all the impacting regions with a probability , the so-called completeness level of the system (Del Vigna et al., 2019).
4. Full non-linear propagation
In this section we compute the probability density function on the space obtained by a full non-linear propagation of the probability density on the residuals space. In particular, the map is not linearised around as we did in Theorem 3.10. This causes the inclusion in Equation (3.4) of the contribution of the normal matrix as it varies along the MOV and not the fixed contribution coming from the orbit with the minimum value of . With the inclusion of all the non-linear terms the resulting density of has the same form as the Jeffreys’ prior and is thus affected by the same pathology discussed in Farnocchia et al. (2015). This is the motivation for which we adopted the approach presented in Section 3.3.
Theorem 4.1.
The probability density function of the variable resulting from a full non-linear propagation of the probability density of is
where and is the restriction of the covariance matrix to the space.
Proof.
The map is a global parametrization of . From the properties of the map it is easy to prove that the map is a global parametrization of the 2-dimensional manifold . From the notion of integration on a manifold we have
and by the chain rule
so that the Gramian matrix becomes
where the matrices , , , and are the restrictions of the normal matrix to the corresponding subspace. From Theorem 3.9 we have
so that the previous expression becomes
where the last equality is proved in Milani and Gronchi (2010), Section 5.4. ∎∎
5. Conditional density on each attributable space
In this section we prove that the conditional density of the attributable given is Gaussian, providing a probabilistic interpretation to the doubly constrained differential corrections.
Once has been fixed, consider the fibre of with respect to the projection from to , so that
The fibre is diffeomorphic to and thus is a -dimensional submanifold of , actually a 4-dimensional affine subspace, and the collection is a 4-dimensional foliation of . Theorem 5.1 gives a probability density function on each leaf of this foliation. Moreover, let us denote by the canonical diffeomorphism between and , that is for all .
Theorem 5.1.
Let be the random variable of the space . For each , the conditional probability density function of given is
where we have used the compact notation .
Proof.
Define the map . The differential of is represented by the design matrix introduced in (2.1). Consider the point , where is the best-fit attributable corresponding to , that exists since . Given that the doubly constrained differential corrections converge to , the matrix is full rank. It follows that the map is a global parametrization of
that turns out to be a 4-dimensional submanifold of the residuals space , at least in a suitable neighbourhood of . The map induces the tangent map between the corresponding tangent bundles
In particular we consider the tangent application
To use this map for the probability density propagation, we first need to have the probability density function on , that is an affine subspace of dimension 4 in . By Theorem 3.6 we have that the conditional probability density of on is . Let represent the rotation of the residuals space such that condition (3.3) holds, and let as in Lemma 3.4, so that the matrix represents the inverse map . By the transformation law of a Gaussian random variable under the linear map , we obtain a probability density function on the attributable space given by
where is the random variable on and
As a consequence, the normal matrix of the random variable is
which is in turn the normal matrix of the doubly constrained differential corrections leading to , computed at convergence. This completes the proof since and are diffeomorphic and thus the density is also the conditional density of given . ∎∎
6. Conclusions and future work
In this paper we considered the hazard assessment of short-term impactors based on the Manifold Of Variations method described in Spoto et al. (2018). This technique is currently at the basis of NEOScan, a software system developed at SpaceDyS and at the University of Pisa devoted to the orbit determination and impact monitoring of objects in the MPC NEO Confirmation Page. The aim of the paper was not to describe a new technique, but rather to provide a mathematical background to the probabilistic computations associated to the MOV.
Concerning the problem of the hazard assessment of a potential impactor, the prediction of the impact location is a fundamental issue. Dimare et al. (2020) developed a semilinear method for such predictions, starting from a full orbit with covariance. The MOV, being a representation of the asteroid confidence region, could be also used to this end and even when a full orbit is not available. The study of such a technique and the comparison with already existing methods will be subject of future research.
References
- Chesley (2005) Chesley, S. R., Feb. 2005. Very short arc orbit determination: the case of asteroid . In: Knežević, Z., Milani, A. (Eds.), IAU Colloq. 197: Dynamics of Populations of Planetary Systems. pp. 255–258.
- Del Vigna (2018) Del Vigna, A., Dec. 2018. On Impact Monitoring of Near-Earth Asteroids. Ph.D. thesis, Department of Mathematics, University of Pisa.
- Del Vigna et al. (2019) Del Vigna, A., Milani, A., Spoto, F., Chessa, A., Valsecchi, G. B., 2019. Completeness of Impact Monitoring. Icarus 321.
- Dimare et al. (2020) Dimare, L., Del Vigna, A., Bracali Cioci, D., Bernardi, F., 2020. Use of a semilinear method to predict the impact corridor on ground. Celestial Mechanics and Dynamical Astronomy 132.
- Farnocchia et al. (2015) Farnocchia, D., Chesley, S. R., Micheli, M., Sep. 2015. Systematic ranging and late warning asteroid impacts. Icarus 258, 18–27.
- Milani and Gronchi (2010) Milani, A., Gronchi, G. F., 2010. Theory of Orbit Determination. Cambridge University Press.
- Milani et al. (2004) Milani, A., Gronchi, G. F., De’ Michieli Vitturi, M., Kneẑević, Z., Apr. 2004. Orbit determination with very short arcs. I admissible regions. Celestial Mechanics and Dynamical Astronomy 90 (1-2), 57–85.
- Milani et al. (2007) Milani, A., Gronchi, G. F., Knežević, Z., Apr. 2007. New Definition of Discovery for Solar System Objects. Earth Moon and Planets 100, 83–116.
- Milani et al. (2005) Milani, A., Sansaturio, M., Tommei, G., Arratia, O., Chesley, S. R., Feb. 2005. Multiple solutions for asteroid orbits: Computational procedure and applications. Astronomy & Astrophysics 431, 729–746.
- Milani and Valsecchi (1999) Milani, A., Valsecchi, G. B., Aug. 1999. The Asteroid Identification Problem. II. Target Plane Confidence Boundaries. Icarus 140, 408–423.
- Solin and Granvik (2018) Solin, O., Granvik, M., 2018. Monitoring near-Earth-object discoveries for imminent impactors. Astronomy & Astrophysics 616.
- Spoto et al. (2018) Spoto, F., Del Vigna, A., Milani, A., Tommei, G., Tanga, P., Mignard, F., Carry, B., Thuillot, W., David, P., 2018. Short arc orbit determination and imminent impactors in the Gaia era. Astronomy & Astrophysics 614.
- Tommei (2006) Tommei, G., 2006. Impact Monitoring of NEOs: theoretical and computational results. Ph.D. thesis, University of Pisa.