The Interpolation Phase Transition in Neural Networks:
Memorization and Generalization under Lazy Training
Abstract
Modern neural networks are often operated in a strongly overparametrized regime: they comprise so many parameters that they can interpolate the training set, even if actual labels are replaced by purely random ones. Despite this, they achieve good prediction error on unseen data: interpolating the training set does not lead to a large generalization error. Further, overparametrization appears to be beneficial in that it simplifies the optimization landscape. Here we study these phenomena in the context of two-layers neural networks in the neural tangent (NT) regime. We consider a simple data model, with isotropic covariates vectors in dimensions, and hidden neurons. We assume that both the sample size and the dimension are large, and they are polynomially related. Our first main result is a characterization of the eigenstructure of the empirical NT kernel in the overparametrized regime . This characterization implies as a corollary that the minimum eigenvalue of the empirical NT kernel is bounded away from zero as soon as , and therefore the network can exactly interpolate arbitrary labels in the same regime.
Our second main result is a characterization of the generalization error of NT ridge regression including, as a special case, min- norm interpolation. We prove that, as soon as , the test error is well approximated by the one of kernel ridge regression with respect to the infinite-width kernel. The latter is in turn well approximated by the error of polynomial ridge regression, whereby the regularization parameter is increased by a ‘self-induced’ term related to the high-degree components of the activation function. The polynomial degree depends on the sample size and the dimension (in particular on ).
1 Introduction
Tractability and generalization are two key problems in statistical learning. Classically, tractability is achieved by crafting suitable convex objectives, and generalization by regularizing (or restricting) the function class of interest to guarantee uniform convergence. In modern neural networks, a different mechanism appears to be often at work [NTS15, ZBH+16, BHMM19]. Empirical risk minimization becomes tractable despite non-convexity because the model is overparametrized. In fact, so overparametrized that a model interpolating perfectly the training set is found in the neighborhood of most initializations. Despite this, the resulting model generalizes well to unseen data: the inductive bias produced by gradient-based algorithms is sufficient to select models that generalize well.
Elements of this picture have been rigorously established in special regimes. In particular, it is known that for neural networks with a sufficiently large number of neurons, gradient descent converges quickly to a model with vanishing training error [DZPS18, AZLS19, OS20]. In a parallel research direction, the generalization properties of several examples of interpolating models have been studied in detail [BLLT20, LR20, HMRT19, BHX19, MM21, MRSY19]. The present paper continues along the last direction, by studying the generalization properties of linear interpolating models that arise from the analysis of neural networks.
In this context, many fundamental questions remain challenging. (We refer to Section 4 for pointers to recent progress on these questions.)
-
Q1.
When is a neural network sufficiently complex to interpolate data points? Counting degrees of freedom would suggest that this happens as soon as the number of parameters in the network is larger than . Does this lower bound predict the correct threshold? What are the architectures that achieve this lower bound?
-
Q2.
Assume that the answer to the previous question is positive, namely a network with the order of parameters can interpolate data points. Can such a network be found efficiently, using standard gradient descent (GD) or stochastic gradient descent (SGD)?
-
Q3.
Can we characterize the generalization error above this interpolation threshold? Does it decrease with the number of parameters? What is the nature of the implicit regularization and of the resulting model ?
Here we address these questions by studying a class of linear models known as ‘neural tangent’ models. Our focus will be on characterizing test error and generalization, i.e., on the last question Q3, but our results are also relevant to Q1 and Q2.
We assume to be given data with i.i.d. -dimensional covariates vectors (we denote by the sphere of radius in dimensions). In addressing questions Q1 and Q2, we assume the labels to be arbitrary. For Q3 we will assume , where are independent noise variables with and . Crucially, we allow for a general target function under the minimal condition . We assume both the dimension and sample size to be large and polynomially related, namely for some small constant .
A substantial literature [DZPS18, AZLS19, ZCZG20, OS20, LZB20] shows that, under certain training schemes, multi-layer neural networks can be well approximated by linear models with a nonlinear (randomized) featurization map that depends on the network architecture and its initialization. In this paper, we will focus on the simplest such models. Given a set of weights , we define the following function class with parameters :
| (1) |
In other words, to a vector of covariates , the NT model associates a (random) features vector
| (2) |
The model then computes a linear function . We fit the parameters via minimum -norm interpolation:
| minimize | (3) | |||
| subj. to |
We will also study a generalization of min -norm interpolation which is given by least-squares regression with ridge penalty. Interpolation is recovered in the limit in which the ridge parameter tends to .
As mentioned, the construction of model (1) and the choice of minimum -norm interpolation (3) are motivated by the analysis of two-layers neural networks. In a nutshell, for a suitable scaling of the initialization, two-layer networks trained via gradient descent are well approximated by the min-norm interpolator described above.
While our focus is not on establishing or expanding the connection between neural networks and neural tangent models, Section 5 discusses the relation between model (1) and two-layer networks, mainly based on [COB19, BMR21]. We also emphasize that the model (1) is the neural tangent model corresponding to a two-layer network in which only first-layer weights are trained. If second-layer weights were trained as well, this model would have to be slightly modified (see Section 5). However, our proofs and results would remain essentially unchanged at the cost of substantial notational burden. The reason is intuitively clear: in large dimensions, the number of second layer weights is negligible compared to the number of first-layer weights .
We next summarize our results. We assume the weights to be i.i.d. with . In large dimensions, this choice is closely related to one of the most standard initialization of gradient descent, that is . In the summary below denotes constants that can change from line to line, and various statements hold ‘with high probability’ (i.e., with probability converging to one as ).
- Interpolation threshold.
-
Considering —as mentioned above— feature vectors , and arbitrary labels we prove that, if then with high probability there exists that interpolates the data. Namely for all .
Finding such an interpolator amounts to solving the linear equations , in the unknowns , which parametrize , cf. Eq. (1). Hence the function can be found efficiently, e.g. via gradient descent with respect to the square loss.
- Minimum eigenvalue of the empirical kernel.
-
In order to prove the previous upper bound on the interpolation threshold, we show that the linear system , has full row rank provided . In fact, our proof provides quantitative control on the eigenstructure of the associated empirical kernel matrix.
Denoting by the matrix whose -th row is the -th feature vector , the empirical kernel is given by . We then prove that, for , tightly concentrates around its expectation with respect to the weights , which can be interpreted as the kernel associated to an infinite-width network. We then prove that the latter is well approximated by , where is a polynomial kernel of constant degree , and is bounded away from zero, and depends on the high-degree components of the activation function. This result implies a tight lower bound on the minimum eigenvalue of the kernel as well as estimates of all the other eigenvalues. The term acts as a ‘self-induced’ ridge regularization.
- Generalization error.
-
Most of our work is devoted to the analysis of the generalization error of the min-norm NT interpolator (3). As mentioned above, we consider general labels of the form , for a target function with finite second moment. We prove that, as soon as , the risk of NT interpolation is close to the one of polynomial ridge regression with kernel and ridge parameter .
The degree of the effective polynomial kernel is defined by the condition for or for (in particular our result does not cover the case for an integer , but they cover for any non-integer ).
Remarkably, even if the original NT model interpolates the data, the equivalent polynomial regression model does not interpolate and has a positive ‘self-induced’ regularization parameter .
From a technical viewpoint, the characterization of the generalization behavior is significantly more challenging than the analysis of the eigenstructure of the kernel at the previous point. Indeed understanding generalization requires to study the eigenvectors of , and how they change when adding new sample points.
These results provide a clear picture of how neural networks achieve good generalizations in the neural tangent regime, despite interpolating the data. First, the model is nonlinear in the input covariates, and sufficiently overparametrized. Thanks to this flexibility it can interpolate the data points. Second, gradient descent selects the min-norm interpolator. This results in a model that is very close to a polynomial of degree at ‘most’ points (more formally, the model is close to a polynomial in the sense). Third, because of the large dimension , the empirical kernel matrix contains a portion proportional to the identity, which acts as a self-induced regularization term.
The rest of the paper is organized as follows. In the next section, we illustrate our results through some simple numerical simulations. We formally present our main results in Section 3. We state our characterization of the NT kernel, and of the generalization error of NT regression. In Section 4, we briefly overview related work on interpolation and generalization of neural networks. We discuss the connection between GD-trained neural networks and neural tangent models in Section 5. Section 6 provides some technical background on orthogonal polynomials, which is useful for the proofs. The proofs of the main theorems are outlined in Sections 7 and 8, with most technical work deferred to the appendices.
2 Two numerical illustrations
2.1 Comparing NT models and Kernel Ridge Regression


In the first experiment, we generated data according to the model , with , , , and
| (4) |
Here is a fixed unit norm vector (randomly generated and then fixed throughout), and are orthonormal Hermite polynomials, e.g. , (see Section 6 for general definitions). We fix , and compute the min -norm NT interpolator for ReLU activations , and random weights . We average our results over repetitions.


From Figure 1, we observe that the minimum eigenvalue of the kernel becomes strictly positive very sharply as soon as , as a consequence, the train error vanishes sharply as crosses . Both phenomena are captured by our theorems in the next section, although we require the condition which is suboptimal by a polylogarithmic factor.
From Figure 2, we make the following observations and remarks.
-
1.
The number of samples and the number of parameters play a strikingly symmetric role. The test error is large when (the interpolation threshold) and decreases rapidly when either or increases (i.e. moving either along horizontal or vertical lines). In the context of random features model, a form of this symmetry property was established rigorously in [MMM21]. For the present work, we only focus on the overparametrized regime .
-
2.
The test error rapidly decays to a limit value as grows at fixed . We interpret the limit value as the infinite-width limit, and indeed matches the risk of kernel ridge(–less) regression with respect to the infinite-width kernel (dashed lines); see Theorem 3.3.
-
3.
Considering the most favorable case, namely , the test error appears to remain bounded away from zero even when . This appears to be surprising given the simplicity of the target function (4). This phenomenon can be explained by Theorem 3.3, in which we show that for with an integer, NT regression is roughly equivalent to regression with respect to degree- polynomials. In particular, for it will not capture components of degree larger than 2 in the target of Eq. (4).
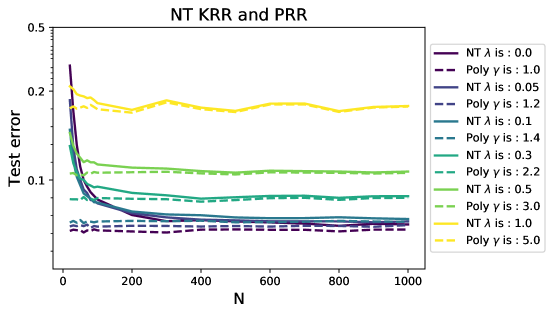

2.2 Comparing NT regression and polynomial regression
In the second experiment, we generated data from a linear model . As before, , , , and is a fixed unit norm vector (randomly generated and then fixed throughout). In Figure 3, We fix and , and vary the number of neurons \seqsplit. In Figure 4, we fix and , and vary the sample size \seqsplit. The results are averaged over repetitions.
Notice that in all of these experiments . The theory developed below (see in particular Theorem 3.3 and Corollary 3.2) implies that the risk of NT ridge regression should be well approximated by the risk polynomial ridge regression, although with an inflated ridge parameter. For , the polynomial degree is . If denotes the regularization parameter in NT ridge regression, the equivalent regularization in polynomial regression is predicted to be
| (5) |
where .
In Figures 3 and 4 we fit NT ridge regression (NT) and polynomial ridge regression of degree (Poly). We use different pairs of regularization parameters (for NT) and (for Poly), satisfying Eq. (5). We observe a close match between the risk of NT regression and polynomial, in agreement with the theory established below.
We also trained a two-layer neural network to fit this linear model. Under specific initialization of weights, the test error is well aligned with the one from NT KRR and polynomial ridge regression. Details can be found in the appendix.
3 Main results
3.1 Notations
For a positive integer, we denote by the set . The norm of a vector is denoted by . We denote by the sphere of radius in dimensions (sometimes we simply write ).
Let be a matrix. We use to denote the -th largest singular value of , and we also denote and . If is a symmetric matrix, we use to denote its -th largest eigenvalue. We denote by the operator norm, by the maximum norm, by the Frobenius norm, and by the nuclear norm (where is the -th singular value). If is a square matrix, the trace of is denoted by . Positive semi-definite is abbreviated as p.s.d.
We will use and for the standard big- and small- notation, where is the asymptotic variable. We write for scalars if there exists such that for . For random variables and , if for any , there exists and such that
Similarly, if converges to in probability. Occasionally, we use the notation and : we write if there exists a constant such that , and similarly we write if there exists a constant such that . We may drop the subscript if there is no confusion in a context.
For a nonnegative sequence , we write if there exists a constant such that .
Throughout, we will use to refer to constants that do not depend on . In particular, for notational convenience, the value of may change from line to line.
Most of our statement apply to settings in which all grow to , while satisfying certain conditions. Without loss of generality, one can thing that such sequences are indexed by , with functions of .
Recall that we say that happens with high probability (abbreviated as w.h.p.) if its probability tends to one as (in whatever way is specified in the text). In certain proofs, we will say that an event happens with very high probability if for every , we have (again, we think of when in whatever way prescribed in the text).
3.2 Definitions and assumptions
Throughout, we assume and . To a vector of covariates , the NT model associates a (random) features vector as per Eq. (2). We denote by the matrix whose -th row contains the feature vector of the -th sample, and by the corresponding empirical kernel:
The entries of the kernel matrix take the form
| (6) |
The infinite-width kernel matrix is given by
| (7) |
In terms of the featurization map , an NT function reads
| (8) |
where .
Assumption 3.1.
Given an arbitrary integer , and a small constant , we assume that the following hold for a sufficiently large constant (depending on , , and on the activation )
| (9) | ||||
| (10) |
Throughout, we assume that the activation function satisfies the following condition. Note that commonly used activation functions, such as ReLU, sigmoid, tanh, leaky ReLU, satisfy this condition. Low-degree polynomials are excluded from this assumption. We denote by the -th coefficient in the Hermite expansion of ; see its definition in Section 6, especially Eqn. 39.
Assumption 3.2 (polynomial growth).
We assume that is weakly differentiable with weak derivative satisfying for some finite constant , and that .
Note that this condition is extremely mild: it is satisfied by any activation function of practical use. The existence of the weak derivative is needed for the NT model to make sense at all. The assumption of polynomial growth for ensures that we can use harmonic analysis on the sphere to analyze its behavior. Finally the condition is satisfied if is not a polynomial of degree .
3.3 Structure of the kernel matrix
Given points , has full row rank, i.e. if and only if for any choice of the labels or responses , there exists a function interpolating those data, i.e. for all . This of course requires . Our first result—which is a direct corollary of Theorem 3.1 that we present below—shows that this lower bound is roughly correct.
Corollary 3.1.
Assume , and , and let , be fixed. Then, there exist constants such that the following holds.
Remark 1.
Note that any NT model (1) can be approximated arbitrarily well by a two-layer neural network with neurons. This can be seen by taking in . As a consequence, in the above setting, a -neurons neural network can interpolate data points with arbitrarily small approximation error with high probability provided .
To the best of our knowledge, this is the first result of this type for regression. The concurrent paper [Dan20] proves a similar memorization result for classification but exploits in a crucial way the fact that in classification it is sufficient to ensure . Regression is considered in [BELM20] but the number of required neurons depends on the interpolation accuracy.
While we stated the above as an independent result because of its interest, it is in fact an immediate corollary of a quantitative lower bound on the minimum eigenvalue of the kernel , stated below. Given , we let denote its -th Hermite coefficient (here , ); see also Section 6, Eq. 39.
Theorem 3.1.
Assume , and , and let , be fixed. Then, there exist constants such that the following holds.
Remark 2.
In the case , the eigenvalue lower bound is simply where .
The only earlier result comparable to Theorem 3.1 was obtained in [SJL18] which, in a similar setting, proved that, with high probability, for a strictly positive constant , provided .
The proof of Theorem 3.1 is presented in Section 7. The key is to show that the NT kernel concentrates to the infinite-width kernel for large enough .
For any constant , we define an event as follows.
| (12) |
This event only involves (formally speaking, it lies in the sigma-algebra generated by ). We will show that, if is a constant no larger than , then the event happens with very high probability under Assumption 3.2, provided . Below we will use to mean the probability over the randomness of (equivalently, conditional on ).
Theorem 3.2 (Kernel concentration).
Assume , and . Let . Then, there exist constants such that the following holds. Under Assumption 3.2, the event holds with very high probability, and on the event , for any constant ,
As a consequence, if (i.e. the upper bound in Assumption 3.1 holds), with the same as in Assumption 3.2, then with very high probability,
| (13) |
When the right-hand side of (13) is , it is clear that the eigenvalues of are bounded from below, since
| (14) |
If we further have , for and a sufficiently large constant , then we can take here.
Remark 3.
If is not a polynomial, then holds with high probability as soon as for some constant . Hence, in this case, the stronger assumption is not needed for the second part of this theorem.
3.4 Test error
In order to study the generalization properties of the NT model, we consider a general regression model for the data distribution. Data are i.i.d. with and where . Here, is the space of functions on which are square integrable with respect to the uniform measure. In matrix notation, we let denote the matrix whose -th row is , , and . We then have
| (15) |
The noise variables are assumed to have zero mean and finite second moment, i.e., .
We fit the coefficients of the NT model using ridge regression. Namely
| (16) |
where is defined as per Eq. (1). Explicitly, we have
| (17) |
We evaluate this approach on a new input that has the same distribution as the training input. Our analysis covers the case , in which case we obtain the minimum -norm interpolator.
The test error is defined as
| (18) |
We occasionally call this ‘generalization error’, with a slight abuse of terminology (sometimes this term is referred to the difference between test error and the train error .)
Our main results on the generalization behavior of NT KRR establish its equivalence with simpler methods. Namely, we perform kernel ridge regression with the infinite-width kernel . Let be any ridge regularization parameter. The prediction function fitted by the data alongside its associated risk is given by
We also define the polynomial ridge regression as follows. The infinite-width kernel can be decomposed uniquely in orthogonal polynomials as , where is the Gegenbauer polynomial of degree (see Lemma 1). We consider truncating the kernel function up to the degree- polynomials:
| (19) |
The superscript refers to the name “polynomial”. We also define
| (20) |
For example, in the case , we have equivalence (the kernel of linear regression with an intercept). The prediction function fitted by the data and its associated risk are
Kernel ridge regression and polynomial ridge regression are well understood. Our next result establishes a relation between these risks: the neural tangent model behaves as the polynomial model, albeit with a different value of the regularization parameter.
Theorem 3.3.
Assume , and . Recall and let , be fixed. Then, there exist constants such that the following holds.
Example: .
Suppose Assumptions 3.1 and 3.2 hold with , i.e. . In this case, Theorem 3.3 implies that NT regression can only fit the linear component in the target function . In order to simplify our treatment, we assume that the target is linear: .
Consider ridge regression with respect to the linear features, with regularization :
| (21) | ||||
| (22) |
Note that is essentially the same as , with the minor difference that we are not fitting an intercept. The scaling factor is specially chosen for comparison with NT KRR. Theorem 3.3 implies the following correspondence.
Corollary 3.2 (NT KRR for linear model).
Remark 4.
In particular, the ridgeless NT model at corresponds to linear regression with regularization . Note that the denominator in (24) is due to the different scaling for the linear term (cf. Eq. 19). Since and from the formulas (28) and (29), we find that the error term of order in Eq. (23) is negligible for . We leave to future work the problem of obtaining optimal bounds on the error term.
3.5 An upper bound on the memorization capacity
In the regression setting, naively counting degrees of freedom would imply that the memorization capacity of a two-layer network with neurons is at most given by the number of parameters, namely . More careful consideration reveals that, as long as the data are in generic positions neurons are sufficient to achieve memorization within any fixed accuracy, using a ‘sawlike’ activation function.
These constructions are of course fragile and a non-trivial upper bound on the memorization capacity can be obtained if we constrain the weights. In this section, we prove such an upper bound. We state it for binary classification, but it is immediate to see that it implies an upper bound on regression which is of the same order.
To simplify the argument, we assume (which is very close to the setting ) and . Consider a subset of two-layers neural networks, by constraining the magnitude of the parameters:
To get binary outputs from , we take the sign. In particular, the label predict on sample is .
The value is referred to the margin for input . In regression we require (the latter equality holds for labels), while in classification we ask for . The next result states that must be roughly of order in order for a neural network to fit a nontrivial fraction of data with margin.
Proposition 3.1.
Let Assumptions 3.1 and 3.2 hold, and further assume . Fix constants , and let , be general functions of . Then there exists a constant such that the following holds.
Assume that, with probability larger than , there exists a function such that
| (30) |
(In words, achieves margin in at least a fraction of the samples.)
Then we must have .
If and are upper bounded by a polynomial of , then this result implies an upper bound on the network capacity of order . This matches the interpolation and invertibility thresholds in Corollary 3.1, and Theorem 3.1 up to a logarithmic factor. The proof follows a discretization–approximation argument, which can be found in the appendix.
Remark 5.
Notice that the memorization capacity upper bound tends to infinity when the margin vanishes . This is not an artifact of the proof. As mentioned above, if we allow for an arbitrarily small margin, it is possible to construct a ‘sawlike’ activation function such that the corresponding network correctly classifies points with binary labels despite . Note that our result is different from [YSJ19, BHLM19] in which the activation function is piecewise linear/polynomial.
Remark 6.
While we stated Proposition 3.1 for classification, it has obvious consequences for regression interpolation. Indeed, considering , the interpolation constraint implies .
4 Related work
As discussed in the introduction, we addressed three questions: Q1: What is the maximum number of training samples that a network of given width can interpolate (or memorize)? Q2: Can such an interpolator be found efficiently? Q3: What are the generalization properties of the interpolator? While questions Q1 and Q2 have some history (which we briefly review next), much less is known about Q3, which is our main goal in this paper.
In the context of binary classification, question Q1 was first studied by Tom Cover [Cov65], who considered the case of a simple perceptron network () when the feature vectors are in a generic position, and the labels are independent and uniformly random. He proved that this model can memorize training samples with high probability if , and cannot memorize them with high probability if . Following Cover, this maximum number of samples is sometimes referred to as the network capacity but, for greater clarity, we also use the expression network memorization capacity.
The case of two-layers network was studied by Baum [Bau88] who proved that, again for any set of points in general positions, the memorization capacity is at least . Upper bound of the same order were proved, among others, in [Sak92, Kow94]. Generalizations to multilayer networks were proven recently in [YSJ19, Ver20]. Can these networks be found efficiently? In the context of classification, the recent work of [Dan19] provides an efficient algorithm that can memorize all but a fraction of the training samples in polynomial time, provided the . For the case of Gaussian feature vectors, [Dan20] proves that exact memorization can be achieved efficiently provided .
Here we are interested in achieving memorization in regression, which is more challenging than for classification. Indeed, in binary classification a function memorizes the data if for all . On the other hand, in our setting, memorization amounts to for all . The techniques developed for binary classification exploit in a crucial way the flexibility provided by the inequality constraint, which we cannot do here.
In concurrent work, [BELM20] studied the interpolation properties of two-layers networks. Generalizing the construction of Baum [Bau88], they show that, for there exists a two-layers ReLU network interpolating points in generic positions. This is however unlikely to be the network produced by gradient-based training. They also construct a model that interpolates the data with error , provided . In contrast, we obtain exact interpolation provided From a more fundamental point of view, our work does not only construct a network that memorizes the data, but also characterizes the eigenstructure of the kernel matrix. While our paper is under review, more papers on memorization are posted, including [VYS21, PLYS21] that study the effect of depth.
As discussed in the introduction, we focus here on the lazy or neural tangent regime in which weights change only slightly with respect to a random initialization [JGH18]. This regime attracted considerable attention over the last two years, although the focus has been so far on its implications for optimization, rather than on its statistical properties.
It was first shown in [DZPS18] that, for sufficiency overparametrized networks, and under suitable initializations, gradient-based training indeed converges to an interpolator that is well approximated by an NT model. The proof of [DZPS18] required (in the present context) , where is the infinite width kernel of Eq. (7). This bound was improved over the last two years [DZPS18, AZLS19, LXS+19, ZCZG20, OS20, LZB20, WCL20]. In particular, [OS20] prove that, for , gradient descent converges to an interpolator. The authors also point out the gap between this result and the natural lower bound .
A key step in the analysis of gradient descent in the NT regime is to prove that the tangent feature map at the initialization (the matrix ) or, equivalently, the associated kernel (i.e. the matrix ) is nonsingular. Our Theorem 3.1 establishes that this is the case for . As discussed in Section 5, this implies convergence of gradient descent under the near-optimal condition , under a suitable scaling of the weights [COB19]. More generally, our characterization of the eigenstructure of is a foundational step towards a sharper analysis of the gradient descent dynamics.
As mentioned several times, our main contribution is a characterization of the test error of minimum norm regression in the NT model (1). We are not aware of any comparable results.
Upper bounds on the generalization error of neural networks based on NT theory were proved, among others, in [ADH+19, AZLL19, CG19, JT19, CCZG19, NCS19]. These works assume a more general data distribution than ours. However their objectives are of very different nature from ours. We characterize the test error of interpolators, while most of these works do not consider interpolators. Our main result is a sharp characterization of the difference between test error of NT regression (with a finite number of neurons ) and kernel ridge regression (corresponding to ), and between this and polynomial regression. None of the earlier work is sharp enough to provide to control these quantities. More in detail:
-
•
The upper bound of [ADH+19] applies to interpolators but controls the generalization error by which, in the setting studied in the present paper, is a quantity of order one.
-
•
The upper bounds of [AZLL19, CG19] do not apply to interpolators since SGD is run in a one-pass fashion. Further they require large overparametrization, namely in [CG19] and depending on the generalization error in [AZLL19]. Finally, they bound generalization error rather than test error, and do not bound the difference between NT regression and kernel ridge regression.
- •
Results similar to ours were recently obtained in the context of simpler random features models in [HMRT19, GMMM21, MM21, MRSY19, GMMM20, MMM21]. The models studied in these works corresponds to a two-layer network in which the first layer is random and the second is trained. Their analysis is simpler because the featurization map has independent coordinates.
Finally, the closest line of work in the literature is one that characterizes the risk of KRR and KRR interpolators in high dimensions [Bac17, LR20, GMMM21, BM19, LRZ20, MMM21]. It is easy to see that the infinite width limit ( at fixed), NT regression converges to kernel ridge(–less) regression (KRR) with the rotationally invariant kernel . Our work address the natural open question in these studies: how large should be for NT regression to approximate KRR with respect to the limit kernel? By considering scalings in which are all large and polynomially related, we showed that NT performs KRR already when .
5 Connections with gradient descent training of neural networks
In this section we discuss in greater detail the relation between the NT model (1) studied in the rest of the paper, and fully nonlinear two-layer neural networks. For clarity, we will adopt the following notation for the NT model:
| (31) |
We changed the normalization purely for aesthetic reasons: since the model is linear, this has no impact on the min-norm interpolant. We will compare it to the following neural network
| (32) |
Note that the network has hidden units and the second layer weights are fixed. We train the first-layer weights using gradient flow with respect to the empirical risk
| (33) |
We use the following initialization:
| (34) |
Under this initialization, the network evaluates to at . Namely, for all . Let us also emphasize that the weights in the NT model (31) are chosen to match the ones in the initialization (34): in particular, we can take to recover the neural tangent model treated in the rest of the paper. This symmetrization is a standard technique [COB19]: it simplifies the analysis because it implies . We refer Remark 7 for explanations.
The next theorem is a slight modification of [BMR21, Theorem 5.4] which in turn is a refined version of the analysis of [COB19, OS20].
Theorem 5.1.
Consider the two-layer neural network of (32) trained with gradient flow from initialization (34), and the associated NT model of Eq. (31). Assume , the activation function to have bounded second derivative , and its Hermite coefficients to satisfy for all for some constant . Further assume are i.i.d. with and to be -subgaussian.
Then there exist constants , depending uniquely on , such that if , as well as
| (35) |
then, with probability at least , the following holds.
-
1.
Gradient flow converges exponentially fast to a global minimizer. Specifically, letting , we have, for all ,
(36) In particular the rate is lower bounded as by Theorem 3.1.
-
2.
The model learned by gradient flow and min- norm interpolant are similar on test data. Namely, writing and , we have
(37) for the coefficients of the min- norm interpolant of Eq. (3).
Notice that any generic activation function satisfies the condition for all . For instance a sigmoid or smoothed ReLU with a generic offset satisfy the assumptions of this theorem.
The only difference with respect to [BMR21, Theorem 5.4] is that we assume while [BMR21] assumes . However, it is immediate to adapt the proof of [BMR21], in particular using Theorem 3.1 to control the minimum eigenvalue of the kernel at initialization.
Note that Theorem 5.1 requires the activation function to be smoother than other results in this paper (it requires a bounded second derivative). This assumption is used to bound the Lipschitz constant of the Jacobian uniformly over . We expect that a more careful analysis could avoid assuming such a strong uniform bound.
The difference in test errors between the neural network (32) trained via gradient flow and the min-norm NT interpolant studied in this paper can be bounded using Eq. (37) by triangular inequality. Also, while we focus for simplicity on gradient flow, similar results hold for gradient descent with small enough step size.
A few remarks are in order.
Remark 7.
Even among two-layer fully connected neural networks, model (32) presents some simplifications:
-
Second-layer weights are not trained and fixed to . If second-layer weights are trained, the NT model (31) needs to be modified as follows
(38) The new model has parameters . Notice that, for large dimension, the additional number of parameters is negligible. Indeed, going through the proofs reveals that our analysis can be extended to this case at the price of additional notational burden, but without changing the results.
-
The specific initialization (34) is chosen so that identically. If this initialization was modified (for instance by taking independent ) two main elements would change in the analysis. First, the target model should be replaced by the difference between target and initialization . Second, and more importantly, the approximation results in Theorem 5.1 become weaker: we refer to [BMR21] for a comparison.
Remark 8.
Within the setting of Theorem 5.1 (in particular being -subgaussian), the null risk is of order one, and therefore we should compare the right-hand side of Eq. (37) with . We can point at two specific regimes in which this upper bound guarantees that :
-
First letting grow, the this upper bound vanishes. More precisely, it becomes much smaller than one provided . By training the two-layer neural network with a large scaling parameter , we obtain a model that is well approximated by the NT model as soon as the overparametrization condition is satisfied.
This role of scaling in the network parameters, and its generality were first pointed out in [COB19]. It implies that the theory developed in this always applied to nonlinear neural networks under a certain specific initialization and training scheme.
-
A standard initialization rule suggests to take . In this case, the right-hand side of Eq. (37) becomes small for wide enough networks, namely . This condition is stronger than the overparametrization condition under which we carried our analysis of the NT model.
This means that, for and , we can apply our analysis to neural tangent models but not to actual neural networks. On the other hand, the condition in Theorem 5.1 is likely to be a proof artifact, and we expect that it will be improved in the future. In fact we believe that the refined characterization of the NT model in the present paper is a foundational step towards such improvements.
Remark 9.
Theorem 5.1 relates the large-time limit of GD trained neural networks to the minimum -norm NT interpolators, corresponding to the case of Eq. (17). The review paper [BMR21] proves a similar bound relating the NN and NT models, trained via gradient descent, at all times . Our main result, Theorem 3.3 characterizes the test error of NT regression with general . Going through the proof [BMR21, Theorem 5.4], it can be seen that a non-vanishing corresponds to regularizing GD training of the two-layer neural network by the penalty .
6 Technical background
This subsection provides a very short introduction to Hermite polynomials and Gegenbauer polynomials. More background information can be found in [AH12, CC14, GMMM21] for example. Let be standard Gaussian measure on , namely . The space is a Hilbert space with the inner product .
The Hermite polynomials form a complete orthogonal basis of . Throughout this paper, we will use normalized Hermite polynomials :
where is Kronecker delta, namely if and if . For example, the first four Hermite polynomials are given by and . For any function , we have decomposition
In particular, if , we denote and have
| (39) |
Let be the uniform probability measure on , be the probability measure of where , and be the probability measure of . The Gegenbauer polynomials form a basis of (for simplicity, we may write it as unless confusion arises) where is a polynomial of degree of and the they satisfy the normalization
where is a dimension parameter that is monotonically increasing in and satisfies . This normalization guarantees . The following are some properties of Gegenbauer polynomials we will use.
-
For ,
(40) -
For ,
(41) where are normalized spherical harmonics of degree ; more precisely, each is a polynomial of degree and they satisfy
(42) -
Recurrence formula. For ,
(43) -
Connection to Hermite polynomials. If , then
(44)
Note that point and the Cauchy-Schwarz inequality implies . If the function satisfies , then we can decompose using Gegenbauer polynomials:
| (45) | |||
| (46) |
We also have . We sometimes drop the subscript if no confusion arises.
7 Kernel invertibility and concentration: Proof of Theorems 3.1 and 3.2
Our analysis starts with a study of the infinite-width kernel . In our setting, we will show that is essentially a regularized low-degree polynomial kernel plus a small ‘noise’. Such a decomposition will play an essential role in our analysis of the generalization error.
To ease notations, we will henceforth write the target function simply as .
7.1 Infinite-width kernel decomposition
Recall that we denote by the Gegenbauer polynomials in dimensions, and denote by the normalized spherical harmonics of degree in dimensions. We denote by the degree- spherical harmonics evaluated at data points, and denote by the concatenation of these matrices of degree no larger than ; namely,
Lemma 1 (Harmonic decomposition of the infinite-width kernel).
The kernel can be decomposed as
| (47) |
with coefficients:
| (48) |
where the coefficients are defined in (46). The convergence in (47) takes place in any of the following interpretations: As functions in ; Pointwise, for every ; In operator norm as integral operators .
Finally, and for we have , where we recall that is the -th coefficient in the Hermite expansion of .
The use of spherical harmonics and Gegenbauer polynomials to study inner product kernels on the sphere (the case) is standard since the classical work of Schoenberg [Sch42]. Several recent papers in machine learning use these tools [Bac17, BM19, GMMM21]. On the other hand, quantitative properties when both the sample size and the dimension are large are much less studied [GMMM21]. The finite width case is even more challenging since the kernel is no longer of inner-product type.
Proof.
Recall the Gegenbauer decomposition of in (45), implying that the following holds in (we omit indicating the measure when this is uniform). For any fixed (and writing ):
We thus obtain, for fixed , :
Here, is due to the the orthogonality of and for as well as Lemma 24 (exchanging summation with expectation), and is due to the property (40).
Thus, we obtain
We use the recurrence formula to simplify the above expression.
| (49) |
We thus proved that Eq. (47) holds pointwise for every . Calling the sum of the first terms on the right hand side, we also obtain by an application of Fatou’s lemma. Finally the last norm coincides with Hilbert-Schmidt norm, when we view these kernels as operators, and hence implies convergence in operator norm.
The asymptotic formulas for follow by the convergence of Gegenbauer expansion to Hermite expansion discussed in Section 6. ∎
Lemma 2 (Structure of infinite-width kernel matrix).
Assume , and the activation function to satisfy Assumption 3.2. Then we can decompose as follows
| (50) |
where and
Here, and (we denote ).
Further there exists a constant such that, for , the remainder term satisfies, with very high probability,
Finally, if , with very high probability,
| (51) |
In the case , the above upper bound can be replaced by .
Proof of Lemma 2.
Using Lemma 1, and using property (41) to express
for , we obtain the decomposition (50), where
and . Note that
The last equality involves interchanging the limit with the summation. We explain the validity as follows. For any integer ,
By first taking and then , we obtain
Here in the last line we recall that is the standard Gaussian measure, and we used dominated convergence to show that . By Proposition E.1, we have with very high probability,
Thus, satisfies
Finally, denote . The matrix has i.i.d. rows, denote them by , , where
| (52) |
By orthonormality of the spherical harmonics (42), the covariance of these vectors is . Further, for any , we have
| (53) |
By [Ver18][Theorem 5.6.1 and Exercise 5.6.4], we obtain
| (54) |
with probability at least . The claim follows by setting , and noting that . ∎
7.2 Concentration of neural tangent kernel: Proof of Theorem 3.2
Let be a sufficiently large constant (which is determined later). Define the truncated function
For , we also define matrices , and truncated kernels and as
| (55) | ||||
| (56) |
Note that by definition and the assumption on the activation function, namely Assumption 3.2, we have .
Note that is a very high probability event as a consequence of Lemma 2. We shall treat as deterministic vectors such that the conditions in the event holds.
Step 1: The effect of truncation is small. First, we realize that
By the fact that uniform spherical random vector is subgaussian [Ver10][Sect. 5.2.5], we pick sufficiently large such that
| (57) |
Thus, with very high probability, .
Furthermore, for , we have
where . For the first term, we derive
where (i) is due to , (ii) is due to Hölder’s inequality, and (iii) follows from the polynomial growth assumption on . By (57), we can choose large enough such that . Similarly, we can prove that . Thus,
| (58) |
Since we work on the event , this implies
| (59) |
Step 2: Concentration of truncated kernel. Next, we will use matrix concentration inequality [Ver18][Thm. 5.4.1] for . First, we observe that (58) implies that . Together with the bound on and the deterministic bound on , we have a deterministic bound on .
where is a sufficiently large constant. This also implies . We will make use of the following simple fact: if are p.s.d. that satisfy , then . We use this on and find
Taking the expectation , we get
This implies
Now we apply the matrix Bernstein’s inequality [Ver18][Thm. 5.4.1] to the matrix sum . We obtain
| (60) |
where
We choose a sufficient large constant and set
so that the right-hand side of (60) is no larger than . This proves that with very high probability,
| (61) |
7.3 Smallest eigenvalue of neural tangent kernel: Proof of Theorem 3.1
By Lemma 2, we have, with high probability,
where the second inequality is because by Assumption 3.1, , so . We choose the constant to be larger than . So by Weyl’s inequality,
Note that is always p.s.d., and it has rank at most if and if . So
and we can strengthen the inequalities to equalities in (i), (ii) if . By Theorem 3.2 and Eq. (14) in its following remark,
We conclude that and that the inequality can be replaced by an equality if .
8 Generalization error: Proof outline of Theorem 3.3
In this section outline the proof our main result Theorem 3.3, which characterize the test error of NT regression. We describe the main scheme of proof, and how we treat the bias term. We refer to the appendix where the remaining steps (and most of the technical work) are carried out.
Throughout, we will assume that the setting of that theorem (in particular, Assumption 3.1 and 3.2) hold. We will further assume that Eq. (10) in Assumption 3.1 holds for the case as well. In Section C we will refine our analysis to eliminate logarithmic factors for .
In NT regression the coefficients vector is given by Eq. (16) and, more explicitly, Eq. (17). The prediction function can be written as
where we denote . Define and . We now decompose the generalization error into three errors.
In the kernel ridge regression, the prediction function is
Similarly, we can decompose the associated generalization error into three errors.
The first part of Theorem 3.3, establishing that NT regression is well approximated by kernel ridge regression for overparametrized models, is an immediate consequence of the next statement.
Theorem 8.1 (Reduction to kernel ridge regression).
There exists a constant such that the following holds. If , then for any , with high probability,
| (62) | |||
| (63) |
As a consequence, we have .
Recall the decomposition of the infinite-width kernel into Gegenbauer polynomials introduced in Lemma 1. In Section 3.4 we defined the polynomial kernel by truncating to the degree- polynomials. Namely:
| (64) |
We also define the matrix and vector as in Eq. (20). In polynomial ridge regression, the prediction function is
Its associated generalization error into also decomposed into three errors.
The second part of Theorem 3.3 follows immediately from the following result.
Theorem 8.2 (Reduction to polynomial ridge regression).
There exists a constant such that the following holds. For any , with high probability,
| (65) | |||
| (66) |
As a consequence, we have .
8.1 Proof of Theorem 8.1: Bias term
In this section we prove the first inequality in Eq. (62). Since both sides are homogeneous in , we will assume without loss of generality that .
First let us decompose . Define
Then,
where we define
We also decompose , where
Our goal is to show that and are close, and that and are close. Let us pause here to explain the challenges and our proof strategy:
-
•
First, our concentration result controls but not , so it is crucial to balance the matrix differences as we do in the decomposition introduced below.
-
•
Second, the relation between eigenvalues of and is not sufficient to control the generalization error (which is evident in the term ). We will therefore characterize the eigenvector structure as well.
-
•
Third our bound of does not allow us to control from our previous analysis. We develop a new approach that exploits the independence of .
For the purpose of later use, we need a slightly general setup: let be a function and a random vector. We begin the analysis by defining the following differences.
We notice that
so we only need to bound these delta terms. Below we state a lemma for this general setup. Note that satisfies the assumption on the random vector therein, because by the law of large numbers , so with high probability.
Lemma 3.
Suppose that, for a constant, we have , and that is a random vector that satisfies with high probability. Then, there exists a constant such that the following bounds hold with high probability.
| (67) | |||
| (68) | |||
| (69) | |||
| (70) | |||
| (71) |
Here, we denote . As a consequence, we have, with high probability,
| (72) |
We handle the other two terms and in a different way. Denote
The function satisfies with high probability by the following lemma, which we will prove in Section B.3.
Lemma 4.
Define or, equivalently,
| (73) |
Then, with high probability,
| (74) | |||
| (75) |
We can rewrite and as
Note that is always nonnegative. We calculate and bound , , and , so that we obtain bounds on and with high probability.
Lemma 5.
Suppose that, for a constant, we have , and that is a random vector that satisfies with high probability.
Let be independent copies of . Then we have
| (76) | |||
| (77) | |||
| (78) |
where are given by
Moreover, it holds that with high probability,
As a consequence, with high probability, we have
9 Conclusions
We studied the neural tangent model associated to two-layer neural networks, focusing on its generalization properties in a regime in which the sample size , the dimension , and the number of neurons are all large and polynomially related ( for some small constant ), while in the overparametrized regime . We assumed an isotropic model for the data , and noisy label with a general target (with independent noise).
As a fundamental technical step, we obtained a characterization of the eigenstructure of the empirical NT kernel in the overparametrized regime. In particular for non-polynomial activations, we showed that, the minimum eigenvalue of is bounded away from zero, as soon as . Further, for , , concentrates around a value that is explicitly given in terms of the Hermite decomposition of the activation.
An immediate corollary is that, as soon as , the neural network can exactly interpolate arbitrary labels.
Our most important result is a characterization of the test error of minimum -norm NT regression. We prove that, for the test error is close to the one of the limit (i.e. of kernel ridgeless regression with respect to the expected kernel). The latter is in turn well approximated by polynomial regression with respect degree- polynomials as long as .
Our analysis offers several insight to statistical practice:
-
1.
NT models provide an effective randomized approximation to kernel methods. Indeed their statistical properties are analogous to the one of more standard random features methods [RR08], when we compare them at fixed number of parameters [MMM21]. However, the computational complexity at prediction time of NT models is smaller than the one of random feature models if we keep the same number of parameters.
-
2.
The additional error due to the finite number of hidden units is roughly bounded by .
-
3.
In high dimensions, the nonlinearity in the activation function produces an effective ‘self-induced’ regularization (diagonal term in the kernel) and as a consequence interpolation can be optimal.
Finally, our characterization of generalization error applies to two-layer neural networks (under specific initializations) as long as the neural tangent theory provides a good approximation for their behavior. In Section 5 we discussed sufficient conditions for this to be the case, but we do not expect these conditions to be sharp.
Acknowledgements
We thank Behrooz Ghorbani and Song Mei for helpful discussion. This work was supported by NSF through award DMS-2031883 and from the Simons Foundation through Award 814639 for the Collaboration on the Theoretical Foundations of Deep Learning. We also acknowledge NSF grants CCF-1714305, IIS-1741162, and the ONR grant N00014-18-1-2729.
Appendix A Additional numerical experiment
The setup of the experiment is similar to the second experiment in Section 2: we fit a linear model where covariates satisfy and the noises satisfy , . We fix and , and vary the sample size .
Figure 5 illustrates the relation between the NT, 2-layer NN, and polynomial ridge regression. We train a two-layer neural network with ReLU activations using the initialization strategy of [COB19]. Namely, we draw , and set , . We use Adam optimizer to train the two-layer neural network with parameters initialized by . This guarantees that the output is zero at initialization and the parameter scale is much larger than the default, so that we are in the lazy training regime. We compare its generalization error with the one of PRR, and with the theoretical prediction of Remark 4. The agreement is excellent.

Appendix B Generalization error: Proof of Theorem 3.3
This section finishes the proof of our main result, Theorem 3.3, which was initiated in Section 8. We use definitions and notations introduced in that section.
B.1 Proof of Theorem 8.1: Variance term and cross term
By homogeneity we can and will assume, without loss of generality, .
We handle and in a way similar to that of (mostly following the same proof with set to instead of ). First we observe that
Note that by the law of large numbers, and therefore with high probability. Applying Lemma 3 with set to , we obtain the following holds with high probability.
| (79) | |||
| (80) | |||
| (81) |
This implies that and w.h.p. Moreover, denoting
we express as
Applying Lemma 5 in which we set , we obtain w.h.p.,
This implies that w.h.p. as well. This proves the bound on the variance term in Theorem 8.1.
Now for the cross term, we observe that
For the first term , we further decompose:
From Eqs. (67) and (71) in Lemma 3 (setting and ), we have w.h.p. By Lemma 5 Eq. (76) (setting to ), w.h.p.,
so with high probability . Thus we proved .
Finally, we further decompose as follows.
By Lemma 3 (in which we set to ) and Eqs. (79)–(81), we have and w.h.p. Moreover, denoting
we express as
In Lemma 5 Eq. (76), we set to obtain ; and we set to obtain . For , we use
Note that w.h.p., so applying Lemma 5 Eq. (78) with leads to w.h.p. This proves w.h.p. and therefore w.h.p. Hence, we have proved the bound on the cross term in Theorem 8.1.
B.2 Proof of Lemma 3
Throughout this subsection, given a sequence of random variables , we write if and only if for any and , we have . We also assume that
for a sufficiently large such that we can use the following inequalities by Lemma 2 and Theorem 3.2:
| (82) |
In Section C we will refine our analysis to eliminate logarithmic factors for .
We start with the easiest bounds in Lemma 3.
Proof of Lemma 3, Eqs. (69)–(71).
The first two bounds follow from the observation
From the invertibility of and , with high probability,
We conclude that Eq. (69) and (70) hold with high probability.
Next, we will show that w.h.p.,
| (83) | |||
| (84) |
Once these are proved, then, w.h.p.,
In order to show (83), we observe that
From Theorem 3.2, we know that w.h.p. It also implies
Also, we notice that
These bounds then lead to the desired bound in (83). In order to show (84), we recall the notation . We also write where are independent conditional on and . We calculate
| (85) | ||||
| (86) | ||||
| (87) |
where (i) is due to
Recall the notations in the proof of Theorem 3.2, cf. Eqs. (55), (56).
Before proving the more difficult inequalities (67), (68), we establish some useful properties of the eigenstructure of . For convenience, we write if are diagonal matrices and ; we also write if are diagonal matrices and . Denote .
Lemma 6 (Kernel eigenvalue structure).
The eigen-decomposition of and can be written in the following form:
| (88) | |||
| (89) |
where are diagonal matrices that contain eigenvalues of respectively, columns of are the corresponding eigenvectors and correspond to the other eigenvectors (in particular ).
The eigenvalues in have the following structure.
| (90) | |||
| (91) |
Moreover, the remaining components satisfy and .
Proof of Lemma 6.
For convenience, for a symmetric matrix , we denote by the vector of eigenvalues of . We write if . From Lemma 2, we can decompose as
We claim that
| (92) |
To prove this claim, first note that (82) implies . Observe that has rank at most . Define such that its columns are the left singular vectors of . We only need to show
| (93) |
In order to prove the above claim, we use the eigenvalue min-max principle to express the -th eigenvalue of . We sort the diagonal entries of in the descending order and denote the ranks by (break ties arbitrarily). Define the subspaces , and . Note that has full rank, so and .
Similarly,
Finally, we recall that . This then leads to the claim (92).
In the equality , we view as the perturbation added to . By Weyl’s inequality,
This proves (90) about the eigenvalues of .
Finally, from the kernel invertibility result (i.e. Theorem 3.2), we have for some . This implies
So all eigenvalues of are up to a factor of compared with those of . This implies that the eigenvalue structure of is similar to that of . ∎
Lemma 6 indicates that the eigenvalues of and exhibit a group structure: roughly speaking, for every , there are eigenvalues centered around . It is convenient to partition the eigenvectors according to such group structure.
We define
We further define and such that they contain the remaining eigenvectors and eigenvalues of , , respectively. We also denote groups of eigenvectors/eigenvalues of by
| (94) |
and the remaining eigenvectors/eigenvalues are and . The following is a useful result about the kernel eigenvector structure.
Lemma 7 (Kernel eigenvector structure).
Let . Denote for and .
-
(a)
Suppose that . Then,
-
(b)
Recall defined in (88). Then,
Proof of Lemma 7.
First, we prove a useful claim, which is a consequence of classical eigenvector perturbation results [DK70]. We will give a short proof for completeness. For a diagonal matrix , we denote by the smallest interval that covers all diagonal entries in . If , then
| (95) |
To prove this, we observe that
Left-multiplying both sides by and re-arranging the equality, we obtain
Denote for simplicity. Without loss of generality, we assume . Let be the top left/right singular vector of . Then,
This proves the claim (95). By the kernel eigenvalue structure (Lemma 6),
| (96) |
By the assumptions on and , with very high probability,
| (97) |
By the kernel invertibility, Theorem 3.2, we have
Since has the same eigenvectors as , we have
| (98) |
Similarly,
| (99) |
We also note that
Therefore, we deduce
| (100) |
Combining (97) and (100), we have shown that with very high probability,
which proves . Now in order to show , we view as a perturbation of , cf. Eq. (88). Hence,
| (101) |
(The first inequality is proved in the same way as (95).) By Weyl’s inequality, . Therefore, if , then
If , then from a trivial bound we have
as well. In either way,
∎
We state and prove two useful lemmas. Let be the canonical basis. For an integer , define the projection matrix .
Lemma 8.
Suppose that , where are constants. Then there exists such that with very high probability,
Proof of Lemma 8.
Let the singular value decomposition of be where . By the concentration result (51) we have . By definition, . Left-multiplying both sides by and rearranging, we have
We use the concentration result (51) to (where we view as the dimension) and get . This then leads to
| (102) |
So with very high probability, . Since and span the same column space, we can find an orthogonal matrix such that . Thus, with very high probability. ∎
Lemma 9.
Suppose that are two matrices with orthonormal column vectors. Let be any orthogonal projection matrix, and . Then, we have
Proof of Lemma 9.
By the variational characterization of singular values and the triangle inequality,
This proves the lemma. ∎
Suppose is a positive integer that satisfies where is a constant. Denote . Let us sample new data which are i.i.d. and have the same distribution as . We introduce the augmented kernel matrix as follows. We define
| (103) |
where have size , , , respectively. Under this definition, clearly . Note that we can express as (recalling that ):
So we can reduce our problem using .
where (i) follows from Jensen’s inequality, and (ii) is due to
where denotes the top left matrix block of . Similarly, we define the augmented vector
| (104) |
and by Jensen’s inequality, we have
Hence, proving Eqs. (67) and (68) is reduced to studying and , which can be analyzed by making use of the kernel eigenstructure.
Lemma 10.
Proof of Lemma 10.
Step 1. First we prove (105) and (106). Fix the constant . We apply Lemma 6 to the augmented matrix (where is replaced by ) and find that its eigenvalues can be partitioned into groups, with the first groups corresponding to eigenvalues. These groups, together with the group of the remaining eigenvalues, are centered around
| (109) |
These values may be unordered and have small gaps (so that Lemma 7 does not directly apply). So we order them in the descending order and denote the ordered values by . Let their corresponding group sizes be . Let be the largest index such that . (If such does not exist, then with very high probability, and thus (105) and (106) follow.) Let the eigen-decomposition of be
so that we only keep eigenvalues/eigenvectors in the largest groups in , and the remaining eigenvalues are in (in particular ). Therefore
and satisfies
| (110) |
(where is a constant). Taking the square, we have
where satisfies .
For convenience, we denote to be the size of (i.e., number of eigenvalues in the main part of ). Also denote by the submatrix of formed by its top-/bottom- rows respectively. Using this eigen-decomposition, we have
| (111) | ||||
| (112) |
Since (or equivalently ) has smallest eigenvalue bounded away from zero with very high probability by Theorem 3.2, we can see that the two terms in the second line (112) are bounded with very high probability. To handle the term on the right-hand side of (111), we use the identity
| (113) |
where are nonsingular symmetric matrices and is a symmetric matrix. Define , which is strictly positive definite with very high probability (since by definition, ). We set , and , and it holds that , and with very high probability by the above. Therefore, with very high probability,
| (114) |
where (i) is because , (ii) is because by the identity (156) in Lemma 23 we have
and (iii) is due to .
Similarly, we have
It is clear that the second term on the last line is bounded by with very high probability, by Eq. (110). For the first term, with very high probability,
| (115) | ||||
| (116) |
By and the law of large numbers, holds with very high probability, so (114) and (116) indicate that we only need to prove that .
Step 2. We next prove a the claimed lower bound on . We will make use of the augmented infinite-width kernel
Notice that the eigen-decomposition of takes the same form as the one of as given in Lemma 6 (with the change that should be replaced by ). We denote by the groups of eigenvectors that correspond to in that lemma and have the same eigenvalue structure as . Namely, in the eigen-decomposition of , we keep eigenvalues from the largest groups in (109) and let columns of be the corresponding eigenvectors. We can express and as groups of eigenvectors.
| (117) |
The remaining groups of eigenvectors are denoted by , and . Note that
Define . We apply Lemma 9 where we set , , , and . This yields
| (118) |
Now we invoke Lemma 7 (a) for the pair where and . By the definition of , the assumption of Lemma 7 (a) is satisfied, so . Thus,
Moreover, we have
where and uses the fact that (where is a vector) since has orthonormal columns.
Finally, we claim that
| (119) |
with very high probability where is a small constant. We defer the proof of this claim to Step 4. Once it is proved, from Eqs. (118), we deduce that . From (114) and (116), we conclude that, with very high probability,
Step 3. We only prove (107) since (108) is similar. For simplicity, we denote . We know by Theorem 3.2 that there exists a constant such that with very high probability. Let be the same constant as in Eq. (105). For any , we also notice that the following event happens with very high probability
| (120) |
(Note that the left-hand side is a random variable depending on and .) Indeed, for any , By Markov’s inequality,
Thus, we proved that (120) happens with high probability. Let be the event such that both and (120) happen. By the assumption on , namely Assumption 3.2, on the event , a deterministic (and naive) bound on is . So on , we get
Thus, on the event ,
Therefore, for some .
Step 4. We now prove the claim (119), namely which was used in Step 2. We use a similar strategy as in Step 2. Let contain the normalized spherical harmonics evaluated on . Similar to (117), in the eigen-decomposition of , we keep eigenvalues from the largest groups in (109) and let be those eigenvalues and columns of be the corresponding eigenvectors. Then we partition into groups:
The remaining groups of eigenvectors are denoted by . Define . We apply Lemma 9 again, in which we set , , , and . This yields
By Lemma 8, we have with very high probability for certain constant . Because of the gap , we can apply Lemma 7: for and , we have
Further by Lemma 6. Thus,
| (121) |
Moreover, . Combining the lower bounds on , and the upper bound (121), we obtain
with very high probability. This proves the claim. ∎
B.3 Proof of Lemma 4
By homogeneity, we will assume, without loss of generality .
Recall that, by Lemma 1, we have (where we replaced by an independent copy for notational convenience). We derive
where in (i) we used and convergence in -spaces (Lemma 24), and in (ii) we used the identity (40). Note that
Using the identity (41), we have . Thus, we can express as
| (122) |
where satisfies, by Proposition E.1, with high probability,
Using the decomposition of in (122) and from Lemma 2, we have
Now we use the identity (113), in which we set , and . It holds that , and with high probability. So with high probability,
where (i) follows from the identity (156) and (ii) follows form (82). This completes the proof of (74).
B.4 Proof of Lemma 5
Proof of Lemma 5.
Step 1: Proving (76)–(78). Define, for ,
so we have . We derive
where we used independence of (conditional on ) and . Note that
and that
This proves the the bound on in (76). A similar bound, namely (77), holds for , in which we replace with .
Step 2: proving the bounds on . We define the function as follows.
We observe that, for any unit vector ,
where we used Hölder’s inequality and
| (123) | |||
| (124) |
Since is independent of , it follows that
Using this function, we express as
Let be any vector, then
where we used for a p.s.d. matrix . This shows . The proof for is similar.
We also define :
By definition, is p.s.d. for all . For any and unit vector ,
where we used the Cauchy-Schwarz inequality and (123)–(124). This implies
For any vector , we derive
where we used for p.s.d. matrices . This proves .
Step 3: Proving the “as a consequence” part. Now we derive bounds on and . By assumption, is bounded by a constant.
Also, by assumption with high probability. Therefore
Similar bounds hold for and . Note that is always nonnegative. By Markov’s inequality, we have w.h.p.,
Combining the last two bounds then leads to the bound on . ∎
B.5 Proof of Theorem 8.2
By homogeneity we can and will assume, without loss of generality, . It is convenient to introduce the following matrix
| (125) |
We further define or, equivalently,
| (126) |
We will use the following lemma.
Lemma 11.
Suppose that is a constant and that are random vectors that satisfy with high probability. Then, there exists a constant such that the following bounds hold with high probability.
| (127) | |||
| (128) |
Proof of Theorem 8.2.
First we observe that
In Lemma 11 Eqs. (127) and (128), we set , which yields . For the variance term, we apply Lemma 11 Eq. (127) with , which yields .
For the cross term, we observe that
We apply Lemma 11 with and . This leads to , which completes the proof. ∎
Proof of Lemma 11.
Define differences
We have
We observe that
It follows that
| (129) | |||
| (130) |
Therefore, with high probability,
| (131) | ||||
| (132) | ||||
| (133) |
where in (i), (ii) we used Proposition E.1. Also, note that , so we must have . Thus, w.h.p.,
In the identity (113), we set , , and . It holds that w.h.p., , . Thus, w.h.p.,
where we used Lemma 4 Eq. (74). Combining the upper bounds on and , we arrive at the first inequality in the lemma.
Next, we bound . With high probability,
where (i) follows from the Cauchy-Schwarz inequality, (ii) follows from (130), (iii) is because w.h.p. by assumption and , and (iv) follows from Proposition E.1. Finally,
where in (i) we used , Eq. (131), and Lemma 4 Eq. (75). Combining the upper bounds on and , we arrive at the second inequality of this lemma. ∎
Appendix C Generalization error: improved analysis for
We will show that for the case , we can relax the condition
The proof of the generalization error under this relaxed condition follows mostly the proof in Section B.2, with modifications we show in this subsection.
Throughout, we suppose that and correspondingly . The matrix is given by
An important difference under the relaxed condition is that does not necessarily converge to (cf. Eq. 51). (In fact, if satisfy , the spectra of is characterized by the Marchenko-Pastur distribution.) Nevertheless, if where is sufficiently large, we have a good control of .
Lemma 12.
For any constant , there exists certain such that the following holds. If , then with very high probability,
| (134) |
Fix the constant . Let be the constant in Lemma 12. First, we establish some useful results under the condition
| (135) |
for a sufficiently large such that the following inequalities hold by Lemma 2, 12 and Theorem 3.2: in the decomposition , we have
| (136) |
We strengthen Lemma 6 for the case .
Lemma 13 (Kernel eigenvalue structure: case ).
Assume that Eq. (135) holds and set and . Then the eigen-decomposition of and can be written in the following form:
| (137) | |||
| (138) |
where are diagonal matrices that contain eigenvalues of respectively, columns of are the corresponding eigenvectors and correspond to the other eigenvectors (in particular ).
Further defining
the eigenvalues have the following structure:
| (139) | |||
| (140) |
Here, denotes entrywise comparisons ( if and only if for all ). Moreover, the remaining components satisfy and .
Proof of Lemma 13.
In the proof of Lemma 6, instead of claiming (93), we will show that the following modified claim holds.
To prove this claim, we note that Lemma 12 implies that and with very high probability. Following the notations in the proof of Lemma 6, we have
Similarly,
We omit the rest of proof, as it follows closely the proof of Lemma 6. ∎
We prove a slight modification of Lemma 7 for the case .
Lemma 14 (Kernel eigenvector structure: case ).
Proof of Lemma 14.
Instead of Eqs. (96)–(97), we have
By the assumptions on and , with very high probability,
Also, instead of Eqs. (98)–(99), we have
Similarly,
These inequalities lead to
which results in the same conclusion as in Lemma 7 (a). To show the modified inequality in (b), we only need to notice that
The proof is complete. ∎
Recall that we denote the projection matrix , and that the top- eigenvectors of form . The next lemma adapts Lemma 8 to the present case.
Lemma 15.
Suppose that , where are constants. Also suppose that the condition (135) is satisfied. Then there exist such that if , then with very high probability,
Proof of Lemma 15.
Following the proof of Lemma 8, we have
By (136), we have . Let be the matrix formed by the top- rows of . Note that
where the last equality holds since . It suffices to show for certain constant with very high probability.
Let , and note that
By concentration of the norm of subgaussian vectors, we have with very high probability. By concentration of the eigenvalues of empirical covariance matrices [Ver18], we have with very high probability. Further, by the Cauchy-Schwarz inequality,
It follows from the above bounds that with very high probability, provided we choose a large enough constant. Since , this implies the desired lower bound. ∎
Consider the condition . We choose to be the smallest integer such that . As defined in (103), the augmented kernel matrix has size , where is guaranteed to satisfy .
Lemma 16.
We note that the remaining proof of Lemma 3 is the same as before. Once Lemma 3 is proved, we will obtain Theorem 3.3 under the relaxed condition for .
Proof of Lemma 16.
Following the proof of Lemma 16, we have with very high probability,
As in the proof of Lemma 16, it suffices to show
| (143) |
for certain constant . In the case , the assumptions in Lemma 13, 14, 15 are satisfied. Following the proof of Lemma 16, we have
| (144) |
Below we consider the case . One difficulty is that we cannot apply Lemma 15; moreover, if , then the matrix is not full rank, so we do not expect (144) to hold.
In order to resolve this issue, we first notice that if , then (143) holds with very high probability. In fact,
From now on, we assume . Conforming to our notations in the previous proof, we denote the top eigenvector (which corresponds to the eigenvalue closest to ) of , respectively, by . Also, denote where .
First, we make a claim about . There exists a constant such that if , then for certain constant , with very high probability,
| (145) |
To prove this claim, we express as
where each row of is a uniform vector in . Evaluating the maximization problem at and , we obtain
Since with very high probability, we have
where are some constants. Thus, we obtain
We observe that
where in (i) we used the fact for any projection matrix . Thus, we deduce that
where in (i) we used for , and in (ii) is certain small constant. Therefore, if , then . This proves the claim (145).
In order to bound the smallest eigenvalue in (143), we consider two cases.
Case 1: . We have
Case 2: . We derive two lower bounds on its variational form. Let by any vector, and we denote . The first lower bound is
| (146) |
where we used the claim (145) in (i). The second lower bound is
| (147) |
where is certain small constant, and in the last inequality we used our assumption . If , then by the first lower bound (146), we have
If instead, then the second lower bound (147) implies that the left-hand side above is lower bounded by a constant. Combining the two cases, we obtain
This proves the desired inequality (143). The remaining proof is similar proof of Lemma 16. ∎
Appendix D Generalization error for linear model: proof of Corollary 3.2
Throughout this subsection, let the assumptions of Corollary 3.2 hold. Denote . First, we state and prove a lemma. We will use the simple identity
multiple times.
Lemma 17.
There exist constants such that the following holds. With high probability,
Proof of Lemma 17.
Since with very high probability (by Lemma 21), if , we have
where in the last inequality we used for a constant so . If , we observe that
Since and with high probability due to Lemma 21, we get
In either case, the first inequality of the lemma holds with high probability. Next, we notice that
By re-arranging the equality, we get
which proves the lemma. ∎
Building on this lemma, we prove some useful bounds. For convenience, we define
| (148) |
Lemma 18.
We have
| (149a) | |||
| (149b) | |||
| (149c) |
Proof of Lemma 18.
In this proof, we will use the bounds on the singular values of from Lemma 21. To prove the two bounds in (149a), we observe that
where in (i) we used Lemma 17. So by the triangle inequality, we have
If for any constant , then by Lemma 21 with high probability for certain constant . Since , we also have and with high probability. Thus,
| (150) | |||
where in (i) we used for matrices . If instead, then , and . In either cases, the two bounds in (149a) are true. To prove the two bounds in (149b), we note that
where we used the bound (150) in (i). This leads to . Also, the rank of is at most , so
To prove the two bounds in (149c), we let the eigenvalue decomposition of be and we find
The diagonal entries are all no larger than , so this proves the first bound in (149c). Moreover,
which proves the second bound. ∎
To study the risk in the linear case, we first notice that . Thus, we have
where the second equality is due to . Now we break down the risk.
The expressions for the bias/variance/cross terms are given below.
To simplify these expressions, we notice that we can assume to be uniformly random on a sphere with given radius : . To understand why this is the case, let us denote the risk to emphasize its dependence on , . Let be a random orthogonal matrix with uniform (Haar) distribution. Then,
The first equality follows from straightforward calculation, and the distributional equivalence holds because the distribution of is orthogonally invariant. Considering therefore, without loss of generality, , it is easy to further simplify the terms . Indeed, we expect these terms to concentrate around their expectation with respect to , . This is formally stated in the next lemma.
Lemma 19 (Concentration to the trace).
We have
| (151a) | |||
| (151b) | |||
| (151c) | |||
| (151d) |
To further simplify the terms, we will show the following lemma.
Lemma 20.
We have
| (152a) | |||
| (152b) | |||
| (152c) |
Once these bounded are proved, then by Lemma 23 we have
| (153a) | |||
| (153b) | |||
| (153c) |
where we recall and denote . Hence, we derive
where the last equality is due to . Also,
This proves that
| (154) |
Similar to the decomposition of the risk and Lemma 20, we can show that has a similar variance-bias decomposition and that the components concentrate to their respective trace, which yield Eqs. (25)–(27). Combining these with Theorem 3.3 and (154), we arrive at the claims in Corollary 3.2.
Proof of Lemma 20.
To show the claim (152a), first we notice that
where we used Lemma 17. Further,
where in (i) we used Lemma 17 and , in (ii) we used from Lemma 18. Similarly, we have
which proves (152a). Next,, we have
where we used Lemma 17. Also,
where we used Lemma 17 and 18 in the last inequality. Similarly, we can also prove
which proves (152b). Finally, we observe
Thus we get
which proves (152c). ∎
Proof of Lemma 19.
Step 1. We will use the variance calculation of quadratic forms from [MM21]: suppose is a vector of i.i.d. random variables which have zero mean and variance , and is another vector of i.i.d. random variables with zero mean and variance , then for matrices ,
| (155) |
In particular, if is symmetric and , then the second variance is bounded by . In order to apply these identities, we use the Gaussian vector as a surrogate for , which only incurs small errors since Gaussian vector norm concentrates in high dimensions. We use to denote the surrogate terms after we replace by in the definitions of . By homogeneity, we assume that without loss of generality.
Using Lemma 18, we have
Also, using Lemma 18 and Lemma 20,
Combining the two bounds proves
Similar to this, we derive
Combining these two bounds give
Step 2. Finally, to prove the desired results, we connect back to . By definition, and have the same distribution, so there is no loss of generality by writing
And also because there is no involved. By concentration of Gaussian vector norms [Ver10, vH14], we have . We observe that
by Chebyshev’s inequality, and thus . The same argument applies to the term which leads to the bound . Also, by a similar argument,
Therefore, we deduce
Note that and are exactly the trace quantities in the statement of Lemma 19. Also note that are bounded by a constant due to Lemma 20 and Eqs. (153a)–(153c). This completes the proof.
∎
Appendix E Supporting lemmas and proofs
E.1 Basic lemmas
Lemma 21.
Fix any constant . With very high probability, , , and .
Proof of Lemma 21.
Let be a matrix of i.i.d. standard normal variable, and . By [Ver10][Corollary 5.35], with probability at least . By the subgaussian concentration, with probability at least . Taking the union bound, we deduce that with probability at least ,
where we used concentration of Gaussian vector norms [Ver10, vH14] in the last inequality. This finishes the proof. ∎
Lemma 22.
Let be any constant, be fixed, and . Then holds with very high probability.
Proof of Lemma 22.
By orthogonal invariance, we assume without loss of generality that . It suffices to prove that holds with very high probability. Note that where . From basic concentration results [Ver10], we know and with very high probability. This then proves the desired result. ∎
Lemma 23.
Let be a matrix and . Then,
| (156) |
This simple lemma is straightforward to check (left-multiplying and right-multiplying ).
Lemma 24.
Let be an space and be the associated inner product. If for , and , , then .
This is a simple convergence result of spaces.
E.2 An operator norm bound
Recall that is the degree- Gegenbauer polynomial in dimensions. The next lemma states that when the degree is high, the Gegenbauer inner-product kernels are very close to the identity matrices. Throughout this subsection, we assume that .
Proposition E.1.
Denote . Then, there exists a constant such that with very high probability,
This lemma is a quantitative refinement of [GMMM21][Prop. 3]. Difference from the moment method employed in [GMMM21][Prop. 3], the proof of this lemma uses a specific matrix concentration inequality, namely the matrix version of Freedman’s inequality for martingales, first established by [T+11] (see also [Oli09]).
Theorem E.1.
Consider a matrix-valued martingale with respect to the filtration . The values of are symmetric matrices with dimension . Let for all . Assume that almost surely for all . Then, for all and ,
where is defined as .
First, we fix and treat it as a constant. We also suppress the dependence on if there is no confusion. Define a filtration and random matrices as follows. We define to be the -algebra generated by ; particularly, is the trivial -algebra. We also define the truncated version of .
| (157) |
By a simple concentration result (Lemma 22), we have, with very high probability,
Note always holds. So holds with very high probability. Define
In other words, is a Doob martingale with respect to the filtration , and is the resulting martingale difference sequence. Note that trivially , . Using this definition, we can express as
| (158) |
By construction, . It is not difficult to show that ; see Lemma 25 below. Crucially, we claim that the matrix is a rank- matrix plus a small perturbation (namely, a matrix with very small operator norm). The perturbation term is due to the effect of truncation.
Lemma 25.
Let be a constant. Then we have decomposition
| (159) |
Here is certain matrix that satisfies almost surely, and satisfies almost surely. In addition, .
Proof of Lemma 25.
Let be indices. Since is symmetric, there is no loss of generality in only considering that (note if ). If , then so . Next we consider . Observe that
where in (i) we used (160), in (ii) we used the Cauchy-Schwarz inequality, and in (iii) we used (160) and Lemma 22. This implies
| (161) |
Together, these bounds imply . Finally, consider . A similar argument gives
Combining the three cases, we derive the expression (159). The residual satisfies
where the last inequality is due to . Note that (161) also implies
By the property (44) of the Gegenbauer polynomials, we know that the coefficients of are of constant order, so we have the deterministic bound
Since , this gives and thus
This completes the proof. ∎
Before applying the matrix concentration inequality to the sum , let us define
Using Lemma 25, we obtain deterministic bounds on and , as stated below.
Lemma 26.
The following holds almost surely.
| (162) | |||
| (163) |
Proof of Lemma 26.
The first inequality follows directly from Lemma 25:
To prove the second inequality, we use the decomposition (159).
where is given by
Note that we used in the above calculation. Using the deterministic bounds on and , we get
We also note that is a diagonal matrix with its diagonal entries bounded by . Thus, we get
| (164) |
where the last inequality is because
due to the assumption . To further simplify (164), we note that
Now we consider the case where and .
where we used the identity (40) in the last equality. We write and use the Cauchy-Schwarz inequality to derive
where in (i) we used the inequality , and in (ii) we used Lemma 22. Therefore,
Thus, we obtain
This completes the proof. ∎
Once this lemma is established, we apply Theorem E.1 to the martingales and (where we simply set for ), and we obtain the following result. For any and ,
where is the upper bound on in (162). This inequality implies a probability tail bound on .
| (165) |
By taking slightly larger the “typical” values of , we can make the probability very small, which can be bounded by a tail probability of according to (163). This leads to a recursive inequality between tail probabilities. By abuse of notations, in the next lemma we assume that constant is chosen to be no smaller than those that appeared in Lemma 25 and 26 (so that we can invoke both results).
Lemma 27.
Proof of Lemma 27.
If satisfies (166), then we derive
where (i) is because . By Lemma 26 Eq. (163), we get
By the assumption on , we have
This leads to . Also, , so
This proves the inequality (167). We note that there is a naive deterministic bound
We apply (167) in which is set to one of } where . Summing these inequalities and using the naive deterministic bound, we obtain
Since happens with high probability, the above inequality implies that also happens with very high probability. ∎
Finally, we are in a position to prove Proposition E.1. Note that Lemma 27 already gives the right bound on for a constant . For very large , we resort to a different approach.
Proof of Proposition E.1.
Let be a constant integer. Our goal is to prove
| (168) |
for certain sufficiently large constant .
Appendix F Proof for network capacity upper bound
Proof of Theorem 3.1.
We denote by the collection of neural network parameters and by the associated function.
Let be a positive integer to be specified later. We define the discretization set and
| (171) | |||
| (172) |
Each is associated with an .
(1) Lower bound on discretized parameter space. We make the following claim. If with probability at least , there exists certain such that at least examples are correctly classified, i.e.,
| (173) |
then we have .
To prove this claim, we treat the input as deterministic. We derive
| (174) | |||
where denotes a Bernoulli random variable with mean . Here, (i) used the union bound and (ii) used the following bound on the cardinality of
which is proved via the covering number argument (see Lemma 28). By Hoeffding’s inequality, we have
Since we assume that the probability of the event in (174) is at least , we take the logarithm and deduce
It then follows that .
(2) Projecting onto the discretized set. For any , let and be the elements in such that the distances to are the smallest one and the second smallest one (break ties in an arbitrary way). For a given , define a random variable by
This definition ensures that . Indeed, and have the opposite signs, so
Denote and for all and (they are independent random variables), and . Then is a random projection of onto the discretized set .
(3) Bounding the approximation error. By assumption, with probability greater than , there exists (which depends on the data and ) such that it gives more than margin on at least examples. Denote by the set of indices such that . Then, the assumption is equivalent to with probability great than .
We claim
| (175) |
Here we emphasize that is the probability measure over all random variables (namely the data , and also ). Once this claim is proved, we can immediately prove the desired result. In fact, for a given , let us define the indicator variable
We observe that
where (i) is because the mean is no larger than the maximum and (ii) is because takes value or . Combining this with (175), we deduce that with probability at least , there exists an such that for all where satisfies .
We use the fact that for arbitrary events to deduce that with probability at least , there exists an such that for all , and in the meantime . By the triangle inequality, for every ,
Note that . Therefore, the assumption of the discretized case, namely (1), is satisfied; and hence we obtain the desired lower bound.
Below we prove the claim (175). Denote and . By the triangle inequality,
| (176) |
where we used Cauchy-Schwarz inequality in (i).
i) Bounding . Conditioning on and , the random variable is independent across , has zero mean, and satisfies . So we can use Hoeffding’s inequality to control the first term in (176).
Taking yields the bound
with probability at least , where we used the assumption that .
ii) Bounding . By assumption, has weak derivatives, so we have
Since with probability at least , we have . Thus
Recall the Assumption 3.2 on the activation function . We have . Therefore,
By standard random matrix theory [Ver10, Cor. 5.35], with probability at least . Also, . So we get
| (177) |
Let be the set of such that
Recall the definition . Then, with probability at least , we have . Indeed, if this is the not true, then the set of that does not satisfy the above inequality will exceed and thus (177) will be violated.
Now, conditioning on , we can view as a weighted sum of independent sub-gaussian variables . By Hoeffding’s inequality for sub-gaussian variables, we have
We take where is a sufficiently large constant so that the above probability upper bound (right-hand side) is smaller than . Denote the event as
We have proved for . Conditioning on , we obtain, by Markov’s inequality,
Let be the set of such that the complement holds. Then with probability at least , we have , and for every ,
iii) Bounding . By the assumption on , we can write
Similarly as before, with probability at least , we have and similarly for all and . This leads to
By the assumption on , we have . Therefore, we can bound as follows. For each ,
with probability at least . This is because holds with probability ; and also, since each entry of is independent and bounded by ,
| (178) |
which is a consequence of Bernstein’s inequality (see [Ver10] Thm. 5.39 for example). Taking the union bound over , (178) holds for all with probability at least .
(iv) Combining three bounds. Finally, combining the bounds on , , and , we obtain that with probability at least ,
| (179) |
Under the asymptotic assumption , we have , so there exists a sufficient large such that if . We choose (where the has the same value as in Eq. 179) and get
with probability . This proves the claim. Note that with this choice of , so the lower bound is obtained.
∎
Lemma 28.
The cardinality of the discrete set defined in (172) have the bound
Proof.
Denote . Recall the definition of the packing number. We say the set is an -packing of if for every , . We define the packing number
By the volume argument, we have the bound
| (180) |
where in (i) we used the formula of the volume of a Euclidean ball and Stirling’s approximation.
Recall that . To apply this result to bounding , first we observe that
| (181) | ||||
| (182) |
Suppose lie in the set on the RHS of (181) and . Then, by the definition of , we must have . This means that the cardinality of the set on the RHS of (181) is bounded by the packing number . By (180), we get an upper bound on the cardinality
| (183) |
Similarly, we can bound the cardinality of each of the sets in (182) by
| (184) |
Recall that as , so in (183) can be replaced by . Combining (183) and (184), we obtain
∎
References
- [ADH+19] Sanjeev Arora, Simon Du, Wei Hu, Zhiyuan Li, and Ruosong Wang, Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks, International Conference on Machine Learning, PMLR, 2019, pp. 322–332.
- [AH12] Kendall Atkinson and Weimin Han, Spherical harmonics and approximations on the unit sphere: an introduction, vol. 2044, Springer Science, 2012.
- [AZLL19] Zeyuan Allen-Zhu, Yuanzhi Li, and Yingyu Liang, Learning and generalization in overparameterized neural networks, going beyond two layers, Advances in Neural Information Processing Systems 32 (2019), 6158–6169.
- [AZLS19] Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song, A convergence theory for deep learning via over-parameterization, International Conference on Machine Learning, 2019, pp. 242–252.
- [Bac17] Francis Bach, Breaking the curse of dimensionality with convex neural networks, The Journal of Machine Learning Research 18 (2017), no. 1, 629–681.
- [Bau88] Eric B Baum, On the capabilities of multilayer perceptrons, Journal of Complexity 4 (1988), no. 3, 193–215.
- [BELM20] Sébastien Bubeck, Ronen Eldan, Yin Tat Lee, and Dan Mikulincer, Network size and weights size for memorization with two-layers neural networks, arXiv:2006.02855 (2020).
- [BHLM19] Peter L Bartlett, Nick Harvey, Christopher Liaw, and Abbas Mehrabian, Nearly-tight vc-dimension and pseudodimension bounds for piecewise linear neural networks., J. Mach. Learn. Res. 20 (2019), 63–1.
- [BHMM19] Mikhail Belkin, Daniel Hsu, Siyuan Ma, and Soumik Mandal, Reconciling modern machine-learning practice and the classical bias–variance trade-off, Proceedings of the National Academy of Sciences 116 (2019), no. 32, 15849–15854.
- [BHX19] Mikhail Belkin, Daniel Hsu, and Ji Xu, Two models of double descent for weak features, arXiv:1903.07571, 2019.
- [BLLT20] Peter L Bartlett, Philip M Long, Gábor Lugosi, and Alexander Tsigler, Benign overfitting in linear regression, Proceedings of the National Academy of Sciences (2020).
- [BM19] Alberto Bietti and Julien Mairal, On the inductive bias of neural tangent kernels, arXiv:1905.12173 (2019).
- [BMR21] Peter L. Bartlett, Andrea Montanari, and Alexander Rakhlin, Deep learning: a statistical viewpoint, Acta Numerica 30 (2021), 87–201.
- [CC14] Efthimiou Costas and Frye Christopher, Spherical harmonics in dimensions, World Scientific, 2014.
- [CCZG19] Zixiang Chen, Yuan Cao, Difan Zou, and Quanquan Gu, How much over-parameterization is sufficient to learn deep relu networks?, arXiv:1911.12360 (2019).
- [CG19] Yuan Cao and Quanquan Gu, Generalization bounds of stochastic gradient descent for wide and deep neural networks, Advances in Neural Information Processing Systems 32 (2019), 10836–10846.
- [COB19] Lenaic Chizat, Edouard Oyallon, and Francis Bach, On lazy training in differentiable programming, Advances in Neural Information Processing Systems, 2019, pp. 2937–2947.
- [Cov65] Thomas M Cover, Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition, IEEE transactions on electronic computers (1965), no. 3, 326–334.
- [Dan19] Amit Daniely, Neural networks learning and memorization with (almost) no over-parameterization, arXiv preprint arXiv:1911.09873 (2019).
- [Dan20] , Memorizing gaussians with no over-parameterizaion via gradient decent on neural networks, arXiv:2003.12895 (2020).
- [DK70] Chandler Davis and W. M. Kahan, The rotation of eigenvectors by a perturbation. iii, SIAM Journal on Numerical Analysis 7 (1970), no. 1, pp. 1–46.
- [DZPS18] Simon S Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh, Gradient descent provably optimizes over-parameterized neural networks, International Conference on Learning Representations, 2018.
- [GMMM20] Behrooz Ghorbani, Song Mei, Theodor Misiakiewicz, and Andrea Montanari, When do neural networks outperform kernel methods?, arXiv:2006.13409 (2020).
- [GMMM21] Behrooz Ghorbani, Song Mei, Theodor Misiakiewicz, and Andrea Montanari, Linearized two-layers neural networks in high dimension, The Annals of Statistics 49 (2021), no. 2, 1029 – 1054.
- [HMRT19] Trevor Hastie, Andrea Montanari, Saharon Rosset, and Ryan J Tibshirani, Surprises in high-dimensional ridgeless least squares interpolation, arXiv:1903.08560 (2019).
- [JGH18] Arthur Jacot, Franck Gabriel, and Clément Hongler, Neural tangent kernel: Convergence and generalization in neural networks, Advances in neural information processing systems, 2018, pp. 8571–8580.
- [JT19] Ziwei Ji and Matus Telgarsky, Polylogarithmic width suffices for gradient descent to achieve arbitrarily small test error with shallow relu networks, International Conference on Learning Representations, 2019.
- [Kow94] Adam Kowalczyk, Counting function theorem for multi-layer networks, Advances in neural information processing systems, 1994, pp. 375–382.
- [LR20] Tengyuan Liang and Alexander Rakhlin, Just interpolate: Kernel “ridgeless” regression can generalize, Annals of Statistics 48 (2020), no. 3, 1329–1347.
- [LRZ20] Tengyuan Liang, Alexander Rakhlin, and Xiyu Zhai, On the multiple descent of minimum-norm interpolants and restricted lower isometry of kernels, Proceedings of Thirty Third Conference on Learning Theory (Jacob Abernethy and Shivani Agarwal, eds.), Proceedings of Machine Learning Research, vol. 125, PMLR, 2020, arXiv:1908.10292, pp. 2683–2711.
- [LXS+19] Jaehoon Lee, Lechao Xiao, Samuel Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington, Wide neural networks of any depth evolve as linear models under gradient descent, Advances in neural information processing systems 32 (2019), 8572–8583.
- [LZB20] Chaoyue Liu, Libin Zhu, and Mikhail Belkin, On the linearity of large non-linear models: when and why the tangent kernel is constant, Advances in Neural Information Processing Systems (H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, eds.), vol. 33, Curran Associates, Inc., 2020, pp. 15954–15964.
- [MM21] Song Mei and Andrea Montanari, The generalization error of random features regression: Precise asymptotics and double descent curve, Communications in Pure and Applied Mathematics (2021).
- [MMM21] Song Mei, Theodor Misiakiewicz, and Andrea Montanari, Generalization error of random features and kernel methods: hypercontractivity and kernel matrix concentration, arXiv:2101.10588 (2021).
- [MRSY19] Andrea Montanari, Feng Ruan, Youngtak Sohn, and Jun Yan, The generalization error of max-margin linear classifiers: High-dimensional asymptotics in the overparametrized regime, arXiv:1911.01544 (2019).
- [NCS19] Atsushi Nitanda, Geoffrey Chinot, and Taiji Suzuki, Gradient descent can learn less over-parameterized two-layer neural networks on classification problems, arXiv:1905.09870 (2019).
- [NTS15] Behnam Neyshabur, Ryota Tomioka, and Nathan Srebro, In search of the real inductive bias: On the role of implicit regularization in deep learning., ICLR (Workshop), 2015.
- [Oli09] Roberto Imbuzeiro Oliveira, Concentration of the adjacency matrix and of the laplacian in random graphs with independent edges, arXiv:0911.0600 (2009).
- [OS20] Samet Oymak and Mahdi Soltanolkotabi, Towards moderate overparameterization: global convergence guarantees for training shallow neural networks, IEEE Journal on Selected Areas in Information Theory (2020).
- [PLYS21] Sejun Park, Jaeho Lee, Chulhee Yun, and Jinwoo Shin, Provable memorization via deep neural networks using sub-linear parameters, Conference on Learning Theory, PMLR, 2021, pp. 3627–3661.
- [RR08] Ali Rahimi and Benjamin Recht, Random features for large-scale kernel machines, Advances in neural information processing systems, 2008, pp. 1177–1184.
- [Sak92] Akito Sakurai, n-h-1 networks store no less n*h+1 examples, but sometimes no more, [Proceedings 1992] IJCNN International Joint Conference on Neural Networks, vol. 3, 1992, pp. 936–941.
- [Sch42] Isaac J. Schoenberg, Positive definite functions on spheres, Duke Math. J. 9 (1942), 96––108.
- [SJL18] Mahdi Soltanolkotabi, Adel Javanmard, and Jason D Lee, Theoretical insights into the optimization landscape of over-parameterized shallow neural networks, IEEE Transactions on Information Theory 65 (2018), no. 2, 742–769.
- [T+11] Joel Tropp et al., Freedman’s inequality for matrix martingales, Electronic Communications in Probability 16 (2011), 262–270.
- [Ver10] Roman Vershynin, Introduction to the non-asymptotic analysis of random matrices, arXiv:1011.3027 (2010).
- [Ver18] , High-dimensional probability: An introduction with applications in data science, vol. 47, Cambridge university press, 2018.
- [Ver20] , Memory capacity of neural networks with threshold and relu activations, arXiv:2001.06938 (2020).
- [vH14] Ramon van Handel, Probability in high dimension, Tech. report, PRINCETON UNIV NJ, 2014.
- [VYS21] Gal Vardi, Gilad Yehudai, and Ohad Shamir, On the optimal memorization power of relu neural networks, arXiv preprint arXiv:2110.03187 (2021).
- [WCL20] E Weinan, Ma Chao, and Wu Lei, A comparative analysis of optimization and generalization properties oftwo-layer neural network and random feature models under gradient descent dynamics, Science China Mathematics 63 (2020), no. 7, 1235.
- [YSJ19] Chulhee Yun, Suvrit Sra, and Ali Jadbabaie, Small relu networks are powerful memorizers: a tight analysis of memorization capacity, Advances in Neural Information Processing Systems, 2019, pp. 15558–15569.
- [ZBH+16] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals, Understanding deep learning requires rethinking generalization, arXiv:1611.03530 (2016).
- [ZCZG20] Difan Zou, Yuan Cao, Dongruo Zhou, and Quanquan Gu, Gradient descent optimizes over-parameterized deep ReLU networks, Machine Learning 109 (2020), no. 3, 467–492.