The Hermes BFT for Blockchains
Abstract
The performance of partially synchronous BFT-based consensus protocols is highly dependent on the primary node. All participant nodes in the network are blocked until they receive a proposal from the primary node to begin the consensus process. Therefore, an honest but slack node (with limited bandwidth) can adversely affect the performance when selected as primary. Hermes decreases protocol dependency on the primary node and minimizes transmission delay induced by the slack primary while keeping low message complexity and latency.
Hermes achieves these performance improvements by relaxing strong BFT agreement (safety) guarantees only for a specific type of Byzantine faults (also called equivocated faults). Interestingly, we show that in Hermes equivocating by a Byzantine primary is unlikely, expensive and ineffective. Therefore, the safety of Hermes is comparable to the general BFT consensus. We deployed and tested Hermes on Amazon instances. In these tests, Hermes’s performance was comparable to the state-of-the-art BFT protocol for blockchains (when the network size is large) in the absence of slack nodes. Whereas, in the presence of slack nodes Hermes outperformed the state-of-the-art BFT protocol by more than in terms of throughput as well as in terms of latency.
Index Terms:
Blockchains, Byzantine Fault Tolerance, Consensus, Performance, Scalability, Security, Throughput.1 Introduction
Scaling of a consensus protocol to support a large number of participants in the network is a desired feature. It not only allows more participants to join the network but also improves decentralization [1]. Additionally, reliability of a consensus protocol also depends on the actual number of faults it can tolerate [2, 3]. In a BFT-based (Byzantine Fault Tolerant) protocol if the total number of participating nodes is then the number of faults that can be tolerated is bounded by [4]. Therefore, to improve the fault tolerance a scalable protocol has to be designed so that it can operate well with larger values of . However, the increase in number of nodes generally results in higher message complexity which adversely affects the BFT performance [5, 6, 7]. Recent works have tried to address the scalability issues in the BFT protocols [8, 9, 10, 11, 12].
In BFT-based protocols the primary node acts as a serializer for requests. The consensus epoch begins as the primary proposes request batch/block to nodes in the network. The epoch ends after nodes agree on a block and add it to their chain. In practice, usually the size of the block proposed by the primary may range from several Kilobytes to several Megabytes. Therefore, by increasing the number of participants/nodes in the network the primary node with limited bandwidth has to spend most of its time broadcasting the block to a large number of nodes. Moreover, consensus nodes are blocked until they receive the proposal from the primary. Inversely, a primary node will be blocked until it receives at least responses from other nodes before proposing the next block. By designing a protocol that shortens this blocking time, BFT-based consensus protocol performance can be improved.
The Hermes protocol design has two new elements. The first design element includes proposing a block to a subset of nodes of size and having a round of message exchange among this subset to make sure no request (block) equivocation has taken place by the primary. This design element helps us to achieve two goals namely: High performance despite slack primary nodes; and Efficient Optimistic Responsiveness. The second design element involves removing a round (phase) of message exchange among all nodes (equivalent to first phase of PBFT) from happy case execution (normal mode) and adding a recovery step to the view change mode. This design element helps Hermes to achieve design goal Latency. In addition, we make use of a design element in [13] in order to achieve design goal Scalability. This element involves node communication through a subset of nodes of size also called the impetus committee.
Although the use of a committee to improve BFT performance has been done previously [13, 14, 15, 16], we use the impetus committee for completely different design goals ( through ). Moreover, a novel combination of the above three design elements to improve the overall BFT performance is something that to our best knowledge has not been done before.
Below we present key design goals of Hermes BFT that have pushed the performance to a next level especially for a blockchain setup.
1: High performance despite slack primary nodes. Slack nodes are honest nodes that have lower upload bandwidth compared to other nodes in the network. Lower upload bandwidth increases transmission delay (which is the time taken to put packets on the wire/link). On the contrary, prompt nodes have higher upload bandwidth and have lower transmission delay. In normal BFT based protocols [17, 18, 19] the primary has to broadcast a block to all nodes in the network of size . Whereas in Hermes the primary broadcasts a block only to a small subset of nodes of size (also called impetus nodes). In Hermes the growth of is sub-linear to , therefore increase in will not have significant impact on , and hence on performance of Hermes. This leads to another interesting property that we call Efficient Optimistic Responsiveness.
2: Efficient Optimistic Responsiveness. Responsiveness is an important property of BFT state machine replication (SMR) protocols [20, 21]. In BFT SMR protocols with responsiveness the primary drives the protocol towards consensus in a time that depends on actual message delay, regardless of any upper bound on message delivery [17, 20]. A protocol is optimistically responsive if it achieves responsiveness when additional constrains are met. Hotsuff [17] is optimistically responsive in which the primary has to wait for responses to send next proposal. In Hermes during period of synchrony, a correct primary will only wait for responses (lower than responses) to propose next block that will make progress with high probability. After a round of agreement these nodes (also called impetus committee) if agreed, will forward the proposed block to all nodes in the network. In case of Hermes, conditions for optimistic responsiveness include receipt of responses by the primary. For different values of chosen in our experiments in Section 7 the probability of having at least one prompt node among a subset of size is approximately (when the number of prompt nodes are at least ). This means that with high probability there will be at least one prompt node in the impetus committee that can forward the block to the regular nodes efficiently. Therefore we call Hermes efficient optimistic responsive as messages in Hermes propagate to nodes with the wire speed comparable to the wire speed of prompt nodes.
3: Latency. BFT-based protocols [5, 11, 22] generally operate in two phases (excluding phase). In the first phase each node receives responses before moving to the second phase. The first phase has two objectives. First, it guarantees that the request is unique. We achieve this objective in Hermes with high probability through message exchange among a small subset of nodes of size in phase shown in Figure 1. Second, it guarantees that if a request is committed in the second phase by at least one node just before a view change, all other correct nodes will eventually commit this request. This means for Hermes the second objective of the first phase is only necessary when there is a view change. To save broadcast and processing latency (while achieving second objective), we remove this phase from happy case mode and instead add an additional recovery phase to view change sub protocol in Hermes.
4: Scalability. Hermes is using the impetus committee to maintain performance in the presence of a slack primary and achieve efficient optimistic responsiveness. Therefore, the same impetus committee can be leveraged to improve message complexity as done in Proteus [13]. Thus, we extend a single round of broadcast message where each node receives responses before committing a block into , and phases (as show in Figure 1). This reduces the message complexity from to .
The trade-off for improvements in Hermes is a relaxed safety guarantee (R-safety) in the presence of equivocated faults in which a Byzantine primary proposes multiple blocks for the same height just before a view change. Informally, R-safety can be defined as a block will never be revoked if it is committed by at least nodes or correct (honest) nodes. Whereas in Strong safety (S-safety) a block will never be revoked if it is committed by at least one correct node. Strong safety will not hold in the presence of equivocated faults. By making equivocation difficult we increase the likelihood of Hermes to be S-safe. Moreover we also show that the equivocation faults will not have any affect on clients. That means if a client receives commit approval for a transaction from network, then that transaction will never be revoked. Therefore, the main purpose of equivocation which is double spending attack is not possible. The only side affect of the equivocation faults is the network recovery cost from failure. We also show that due to the design of Hermes, equivocating faults are unlikely (the primary as well as the majority of the nodes in the impetus committee have to be Byzantine) and expensive for Byzantine primary and its acquaintances in the impetus committee (the primary as well as the Byzantine nodes in the impetus committee that have signed for two different blocks at the same height will lose their stake in the network or can be blacklisted). Therefore, a Byzantine primary finds equivocation unlikely, expensive and has no incentive to perform it.

Paper Outline. The paper is organized as follows. In Section 2 we give our system model and definitions. In Section 3 we present the overview of the Hermes protocol. Section 4 provides a detailed operation of Hermes protocol. Proof of correctness for Hermes appears in Section 5 and in Section 6 we describe Efficient Optimistic Responsiveness as protocol optimization. Section 7 contains the experimental analysis and in Section 8 we present related work . We conclude our work in Section 9.
2 Definitions and Model
Hermes operates under Byzantine fault model. Byzantine faults include but not limited to hardware failures, software bugs, and other malicious behavior. Our protocol can tolerate up to Byzantine nodes where the total number of nodes in the network is such that . The nodes that follow the protocol are referred to as correct nodes. In this model there can be up to number of slack nodes (, where is total number of slack nodes ).
Hermes is a permissioned blockchain. In permissioned blockchain nodes in the network are known to each other and have access to each other’s public key. In permissioned blockchains nodes can join the network through an access control list. In this model nodes are not able to break encryption, signatures and collision resistant hashes. We assume that all messages exchanged among nodes are signed. A message signed by the node is denoted by , a message with aggregated signature from impetus committee quorum (of size ) is denoted by , a message with aggregated signature from regular node quorum (of size ) is denoted by , and a message with aggregated signature from view change quorum (of size ) is denoted by .
As a state machine replication service Hermes needs to satisfy following properties.
Definition 1 (Relaxed Safety).
A protocol is R-safe against all Byzantine faults if the following statement holds: in the presence of Byzantine nodes, if nodes or correct nodes commit a block at the sequence (blockchain height) , then no other block will ever be committed at the sequence .
Definition 2 (Strong Safety).
A protocol is S-safe if the following statement holds: in the presence of Byzantine nodes, if a single correct node commits a block at the sequence (blockchain height) , then no other block will ever be committed at the sequence .
Definition 3 (Liveness).
A protocol is alive if it guarantees progress in the presence of at most Byzantine nodes.
Hermes guarantees liveness, R-safety as well as probabilistic S-safety. Liveness is achieved in asynchronous network by placing an upper bound on block generation time called timeout. Epoch identifies a period of time during which a block is generated. Each epoch can be associated with specific sequence or height of blockchain. Once a node receives a block it stops the timer for the expected block and starts its timer for the next block it is expecting from the impetus committee.
For ease of understanding first we describe and prove correctness of the basic Hermes protocol in which the primary proposes the next block once the current proposed block is committed. Then in Section 6 we discuss how Hermes can be optimized so that the primary can propose next block once it collects at least responses from the impetus committee (Efficient Optimistic Responsiveness).
3 Protocol Overview
In Hermes, the primary proposes a block to the impetus committee of size . The impetus committee is running an agreement phase based algorithm (Algorithm 1). If impetus committee nodes agree on the block proposed by the primary and regular nodes agree on the proposed block (which they received from the impetus committee), then the block is committed locally by a node and will be added to the blockchain. During normal execution of Hermes we use the same name for a message and its respective phase.
Normal execution of the protocol is shown in Figure 1 and can be summarized as follows:
-
1.
The primary proposes the block (which contains transactions send by clients) to the impetus committee ( message).
-
2.
Each impetus committee member verifies the block and makes sure that there is only one block proposed for the expected height (by collecting signatures from at least impetus committee members through messages).
-
3.
The block is then proposed using the message which includes primary signature along with aggregated signatures of impetus committee members from messages.
-
4.
Upon receipt of a block, regular nodes verify the aggregated signature and the transactions within the block.
-
5.
If the block is found to be valid, each regular node responds with the signed message.
-
6.
Upon receipt of messages from regular nodes, each impetus committee member as well as the primary commits the block. Each member of the impetus committee broadcasts approval of the majority nodes in the form of aggregated signatures from regular nodes in message.
-
7.
Upon receipt of approval, each regular node commits the block, which is then added to the local history.
-
8.
After committing locally, each node sends a message to the client. The client considers its transaction to be committed upon receipt of messages (or similar messages).
-
9.
Soon after committing a block the primary begins the next epoch (messages are shown in blue) and proposes a new block to the impetus committee using message. The impetus committee members begin the phase and the protocol progresses through each of its phases as described above.
3.1 Accountability
To discourage malicious primary as well as impetus committee nodes from equivocation, Hermes nodes will have to provide a fixed amount of stake while joining the network as done in Proof-of-Stake (PoS) protocols [23, 19]. But this amount will be equal for every participant in the network. Since every participant has equal stake therefore the probability of being selected as primary node or member of the impetus committee is same for every node. Alternatively, any node involved in equivocation can be blacklisted in the network.
3.2 Selecting Impetus Committee Members
Consider a set of nodes and let be their unique node ids, which for simplicity are assumed to be taken between and . Since all nodes are regular, also denotes the set of regular nodes. Suppose that out of the nodes at most are faulty such that ; actually, we will assume the worst case .
Let denote the set of nodes in the impetus committee, such that , where is a predetermined number that specifies the size of the impetus committee (from now on and impetus committee will be used interchangeably in the paper). The impetus committee is formed by randomly and uniformly picking a set of nodes out of . In addition to the impetus committee members, there is a primary node picked randomly and uniformly out of the remaining nodes.
Since , therefore on expectation, the impetus committee will have less than faulty nodes. Hence, will likely have less than faulty nodes as well. Nevertheless, as the members of are randomly picked, having or more faulty nodes in are at long odds.
Moreover, the primary might be faulty as well. However, a view change can address primary as well as impetus committee failure. We carry on with analysis to precisely determine the likelihood of different scenarios for picking the members in . In the formation of the number of possible ways to pick any specific set of nodes out of is . The probability to pick exactly correct nodes and faulty nodes in , such that , is Therefore, the probability of having at least faulty nodes () in will be:
| (1) |
If is unable to generate a block by the end of timeout period, then is replaced by another randomly chosen committee and a new primary through view change.
View Change Probability.
View change can be triggered either by the failure of impetus committee or failure of a primary. More specifically the two cases that can ultimately result in a view change are: (i) , where is the number of faulty nodes in (this comes with probability ), or (ii) when and the primary node is faulty. For the latter case ii, since we choose the primary randomly from nodes if the total number of faulty nodes is , then the probability of primary being faulty is at most ; hence, the probability that case ii occurs is less than . Therefore, the probability of having view change due to case i or ii is bounded by Since is approaching and , the upper bound of probability can be approximated by asymptotically to the limit of .
Probability of At Least One Correct Node in . For a view change to be initiated, it requires at least one correct node in . In the worse case, all the nodes in are faulty, namely, ; this is the total failure scenario that does not allow view changes.
We observe that the probability of not having any correct node in for different values of and in our experiments is at most . Consequently, the probability of avoiding total failure is extremely high.
4 The Protocol
The basic operation of our protocol, Hermes, is presented in Algorithms 1, 2, and 4, which describe the normal execution between the impetus committee and regular nodes. Algorithm 3 is executed by synchronization sub-protocol. If normal execution fails, then our protocol switches to view change mode executing Algorithms 5, 6 and 7 to recover from failure. Note that the members of and the primary also run themselves the protocols for regular nodes in normal mode.
4.1 Happy Case Execution
The currently designated primary node proposes a block by broadcasting a message to (Algorithm 1, lines 1-9). A message from primary sends a newly created block which contains the view number , block sequence number , transaction list , its hash , the previous blockhash and optional field which can be used by the primary to send the proof of negative responses () during first epoch of its view (new primary in its first epoch might request the latest from the previous view. If replicas do not have the they will send negative response ). More details about this can be found in the subsection 4.3. Let .
A node in begins phase of the algorithm after receipt of a message. Then, node broadcasts a message if it finds the message to be valid. The validity check of the message includes checking the validity of , , , and transactions inside (Algorithm 2, lines 1-3). If node receives messages from other members of for block then the node will successfully create a proposal block . This proposal block can be compressed into and then node will broadcast it to the regular committee members; aggregates the signatures of the members of that contributed to the . Let since the primary already has the payload (from block it already proposed), the impetus committee member will only forward to the primary instead of sending the whole (Algorithm 2 lines ).



Upon receipt of a message from , the regular nodes check if it is signed by at least members of . Regular nodes also verify the block by performing format checks and verification of each transaction against their history. If verification is successful, a regular node sends back a signed message to (4, lines 1-4). The confirmation of a block at height by a node is denoted by .
Each member of aggregates signatures for messages and then commits the block locally ( is used to show commit of a block by a node at the height ). The node then broadcasts message to regular nodes. Each member of will also send the message () to each client confirming the execution of the respective transaction (with the timestamp that the client submitted the transaction and its result ) that it contributed to the block (Algorithms 1, lines 21-25 and Algorithm 2 lines ). Upon receipt of a valid message from (for the current block in the sequence), the regular member also commits the block () as shown in Algorithm 4, lines 12-21. Each node (after committing the block) also sends a message as shown in Algorithm 4 line 22.
4.2 Synchronization Sub-Protocol
The impetus committee might be faulty, when it has or more faulty nodes (shown in red in Figures 4, 4, 4). In such a case, the faulty members of might attempt to not update regular nodes without triggering view change; namely, not sending and other messages to the nodes. (In the upper bound of , may include at most failed members of .) These nodes (shown in yellow in Figure 4) may not be participating in the consensus process as they have not received messages from members of (as majority of have failed). Therefore, they will need to sync their history (download messages) with other nodes.
Suppose that node is a regular node that needs to be synchronized () (download missing blocks).
Let be a member of such that has received a timeout complaint mentioning that has not received blocks between the sequences and with respective hashes and . The fields and are optional and if node has not received any block after the block at sequence then . The message type shows which type of message is missing, e.g. a block, an aggregated view change message (will be discussed along with other message types in subsection 4.3). The view number identifies the primary. If node has not sent a block to the same node earlier such that its sequence or (validity condition for ), then the node will forward missing messages for missing blocks as shown in Figure 4.
If node times-out without receiving a valid expected message during the consensus process (as shown in the Figure 4) it will broadcast a complaint to regular nodes. Consequently, a node in can recover a block by receiving it from regular nodes (as shown in the Figure 4). Thus, members of and regular nodes synchronize their history (download missing blocks from each other) while keeping message complexity low (avoid quadratic message complexity).
When a new primary is elected it has to make sure that if a block is committed by at least a single correct node then it should be committed by at least nodes before proposing new blocks. is a specific type of timeout complaint by the new primary to request the latest uncommitted (actually the payload for ) from previous view. denotes the view of the current primary. A negative response from nodes for request will prove that this has not been committed by any node. If the primary receives a response for it will re-propose the block. Thus, this additional recovery step after view change makes sure that safety is held after the view change. More details about the will be discussed in the subsection 4.3.
Algorithm 3 is about synchronization sub-protocol. Lines 1-14 are executed if the node is a member of the impetus committee. In lines 1-10 node responds to the request from primary node. After sending the negative response to the primary, node forwards to regular nodes (Algorithm 3 line 8). In lines 11-13, the impetus committee member responds to the request of a regular node by sending the missing blocks to the node . Lines 15-27 are executed if node is not a member of the impetus committee. In lines 16-18, node responds to an impetus member request/complaint . In lines 19-26, node responds to request from the primary node.
The primary node might be malicious which can cause the impetus committee to fail by not proposing a block. Another possible cause of failure can be the presence of majority of malicious nodes in . As a result, impetus committee nodes cannot collect at least signatures for proposed block. In a rare case, it is also possible that both the primary and the impetus committee fail; in such a case the primary can collude with the to perform block equivocation. The failure can be detected if nodes send timeout complaint or a single node sends a complaint for equivocation by the primary and nodes receive it. Upon detecting failure, Hermes will switch to view change mode to select new primary and impetus committee.
4.3 View Change
The view change sub protocol in Hermes is different from conventional BFT-based protocols as it has additional recovery phase to make sure if a block is committed by a single node just before view change, then it will be committed eventually by all other correct nodes. A view change can be triggered if there is sufficient proof of maliciousness of the primary or the impetus committee. The two types of complaint by a node that can form a proof against the Byzantine primary are the complaints (as discussed in subsection 4.2) as well as complaint, where determines the reason for the complaint which can be either an invalid block or multiple s by the primary and/or with the same sequence number. A is simply formed by valid complaints or a single valid complaint. A single valid is required to trigger a view change.
During each epoch, a regular node waits to receive a proposed block from . If a regular node does not receive the block after a timeout then it considers that has failed and reports this to (Algorithm 4, lines 5-6). If nodes report a timeout, then there is at least one correct member that will broadcast the aggregated timeout complaints to all regular nodes (as in Algorithm 2, lines 27-29). Upon receipt of complaints the regular nodes send back confirm view change message to , where is the aggregated signature from at least complaints from messages (Algorithm 4, line 23-25). If complaint is of type then the confirm view will be of the form , where the node will be the node that has complained. If an impetus committee member receives a message and was not aware of the (therefore did not broadcast it to the regular nodes), it will also broadcast the to the regular nodes (Algorithm 2 line 24-25). This step is added to prevent a Byzantine member in from triggering the view change in a subset of regular nodes by sending the messages to few regular nodes.
Once a member in receives messages, then triggers view change by broadcasting message to all regular nodes (Algorithm 2, lines 30-34). Where is the aggregate signature for from messages sent by a regular node . Upon receipt of the message each regular node will begin the view change process (Algorithm 4, lines 26-33). In the view change, members of new impetus committee along with a new primary is selected by each node using a pre-specified common seed for pseudo-random number generation [24], which guarantees that every node selects the identical and primary. In pseudo-random generator algorithms, a random result can be reproduced using the same seed. For example the count for the epoch trial can be considered as input seed. Count for epoch trial is the total number of successful epochs that generated blocks plus total number of failed epochs that resulted in view change. In Hermes the main requirements for random generator include liveness, bias-resistance and public verifiability or determinism. By using the count for epoch trials as a seed for the the Pseudo-random generator we can satisfy the above mentioned requirements. There are other options like Verifiable Random Functions [25, 26] which can also be used in order to provide stronger guarantees like unpredictability.
After randomly choosing the new primary as well as the new impetus committee , each node sends a message to the new primary (Algorithm 5 line 1). The message has information about the latest block in the local history of the node ( message can be built from ). It includes the latest committed block sequence number , block hash , incremented view number , and signature evidence of at least () nodes that have confirmed the block (through message). The part of this message includes the latest and its respective message from the last primary (without its payload ) which was received by the node from (through block message). The inclusion of in the view change message is used to recover the block (transactions) if less than correct nodes have committed the block. We will discuss more about this at the end of the current section. The information in is used to determine whether nodes have different local histories, which in turn can allow them to synchronize their histories by getting the possible missing blocks from the new members of . Upon receipt of from node , the new primary extracts the parts (hash of the latest committed block), , and and also checks the validity of and . Out of the nodes that contribute to , it is guaranteed that at least are correct nodes and at least one out of these correct nodes has the latest block.
This guarantee is sufficient to generate next blocks in the new epoch on the top of the latest block.
The new primary, once it receives messages it aggregates them into which it broadcasts to members of (Algorithm 7, lines 1-6) and then will broadcast the message to all nodes (Algorithm 6). Upon receipt of , node makes sure that its history matches with the history in (agreed by at least nodes) and if it does, node sends back a message to the new primary (Algorithm 5, lines 2-8). The primary will aggregate responses into a single message and broadcast it to (Algorithm 7, lines 11-16) which will be forwarded to all the nodes (Algorithm 6). Upon receipt of , node is now ready to take part in new view (Algorithm 5, lines 9-12). If node ’s history does not match that of it will synchronize its history (Algorithm 5, lines 4-6).
Recovery During View Change.
Recall that we add a recovery phase to the view change in order to significantly reduce the latency. During this recovery phase, Hermes protocol makes sure that if there is any block that has been committed by at least one node, it will be committed by all correct nodes eventually. If there is in , then the new primary has to propose the respective block for the . If the new primary has already received the or the block for it will re-propose it in the first epoch of its view. On the other hand, if the new primary does not have the complete (including its payload ) for it will request it from using a complaint. If an impetus committee member has the (payload ) it will send it back to the primary. If not, it will forward the complaint to the regular nodes as well as sending a negative response to the primary (Algorithm 3, lines 1-10). Regular nodes will also send back the message for if they have it to the impetus committee (which will forward it to the primary) or a negative response to the primary. If the primary receives back the it will re-propose the block else it will have to propose another block with aggregated signatures for negative response being attached to it in order to prove that for was not committed by any correct node (Algorithm 1, lines 1-15). Therefore, if there is a in during recent view change, then in the first epoch after the view change the new primary either has to propose the relative block for or include negative responses in the first block that it proposes in the new view. If the primary fails to do so, a view change will occur (through complaint).
5 Analysis and Formal Proofs
In this section we provide proofs for R-safety, S-safety and liveness properties for Hermes.
5.1 Safety
Hermes has relaxed the agreement (safety) condition. In Hermes a block is committed if at least correct nodes commit the block. If nodes commit a block it is guaranteed that at least of these nodes are correct. Due to this relaxation in the agreement condition the client also needs to wait for at least messages for its transaction to consider it committed (to make sure at least correct nodes have committed the block). For further client and network interaction including addressing, client request de-duplication, censorship etc., we would defer to standard literature.
But it is also highly likely that Hermes holds stronger agreement condition where if a single correct node commits a block all other correct nodes will eventually commit the same block at the same height (due to low probability of the primary as well as the majority of nodes in are Byzantine). For simplicity we use as the set of all correct nodes such that and in the proof of correctness.
Lemma 1.
Hermes is R-safe during normal mode.
Proof.
Consider two different blocks and with respective heights and where each block has been committed by at least nodes. It suffices to show that . Suppose, for the sake of contradiction, that during happy case execution (normal mode) both and are committed at the same height (). Let be the set of nodes that commit such that and for each , (all members of have committed at height ). Similarly, let be the set of nodes that commit such that and for each , . Since and , we get for that . Hence, . Therefore, there is an such that and (that is, committed both blocks). However, since , can only commit one block at any specific sequence, and hence, it is impossible that executed both and with and . Therefore, , as needed. ∎
Lemma 2.
Hermes is R-safe during view change.
Proof.
Consider the latest block at height that was committed by at least nodes before the view change. We will show that will be included in the blockchain history after the view change. Let be the set of honest nodes that have committed (that is, for each ). Since the number of Byzantine nodes is , we get that . At least a node must have reported a view change message to the primary, such that is aware of and . Since the primary node collects view change messages into , we get that contains at least view change messages from the nodes in where at least one node is in too. Hence, when a node receives from the new primary, will know that has been committed, a guarantee that is valid. Thus, block will be inserted into the local history of every node that receives , and becomes part of the blockchain history.
∎
Therefore, we get the following theorem:
Theorem 3.
Under normal operation and a view change, Hermes provides relaxed safety guarantees (Hermes is R-safe).
Proof.
Lemma 4.
Hermes is S-safe during normal mode.
Proof.
We will prove this lemma by contradiction. Let us assume that during normal mode at least one correct node (say, node ) commits a block at height then we have . This means there exists a set such that and for each , () (all members of have confirmed at height ). We also assume that there is another node that has committed a block at height such that (). Therefore, there is another set such that and for each , (). Based on and , we get such that . Hence, . Therefore, there is an such that and (that is, confirmed both blocks). However, since , can only confirm one block at any specific level (height) during normal mode, and hence, it is impossible that confirmed both and with and . Therefore, . ∎
Lemma 5.
Hermes is S-safe during view change if there is no equivocation fault.
Proof.
Let us assume that a single node has committed a block at the height () just before the view change occurs. That means there is a set such that and for each , (). Therefore during view change there is another set such that and for each , . As , therefore we have such that . Thus, . Therefore, there is an such that and . Since contains for block , therefore the new primary has to re-propose block in the first epoch of the new view in the height as show in Algorithm 1 lines 1-20. ∎
5.2 The equivocation Case
If the previous primary is malicious it can propose multiple blocks at the same height/sequence (just before the view change). Suppose the malicious primary proposes two blocks and before the view change such that one of these blocks (say, block ) is committed by at most number of nodes where . In such a case it is not guaranteed that a block committed by nodes can remain in the chain after the view change.
If view change messages received by the new primary (correct) include a view change message by the node that contain the commit certificate ( message with signatures) for the block then it is guaranteed that the block will be re-proposed in the next epoch for the same height (not be revoked). But if the new primary collects the view change messages from another nodes (not the nodes that committed the block) then the new primary might either propose or in the next epoch. Therefore it is not guaranteed that the block that has been committed by at most nodes (at the height ) will be re-proposed at the same height. This can happen because of the fact that out of these nodes included in the prepared by the new primary at most nodes can be Byzantine whereas at most another might have received the block . At least one node can have the block . Therefore the new primary may receive two messages, (for block ) and (for block ) from the nodes in the view change message. The primary can re-propose any one of these blocks ( or for example) in the first epoch of the new view (if found to be valid). If block is proposed then it is fine as this block is committed by at most nodes. But if is proposed then the nodes that have committed the block will have to revoke the block and perform agreement on the block at the same height/sequence. Block can be proposed in the next epoch if there is no common transaction between block and . If there is at least one common transaction among the blocks and or some transactions in the block are invalid the primary can extract valid transactions from the block and propose them in another block. It should be noted that in such case the malicious primary and its culprits in the can be punished and their stake in the network can be slashed.
Lemma 6.
It is highly unlikely that a Byzantine primary as well as impetus committee perform equivocation.
Proof.
We prove this lemma three points. First the probability of performing equivocation by a Byzantine primary is low. Secondly, it is expensive for a Byzantine primary to perform equivocation and third there is not enough incentive for a Byzantine primary to perform equivocation as it will only cause processing delay in the network to recover from faults without affecting the client.
In order for an equivocation to take place the primary as well as the majority of nodes in the impetus committee have to be Byzantine. The probability of such an event with different values of and used in Section 7 is between and . For example if on average the network has a view change once per week it will take to years for a primary as well as the to be Byzantine and be able to propose multiple blocks at the same height to the network. Additionally, the primary as well as the members of impetus committee that are involved in equivocation will lose their stake in the network or can be blacklisted as described in subsection 3.1.
As mentioned in the subsection 5.2, in case of equivocation if less than nodes have commit a block then this block might get revoked. But it should also be noted that unlike other forking protocols (bitcoin, Ethereum etc) where a client has to wait for the confirmation time to make sure the block it has accepted will not be revoked, this (revoking of block ) has no affect on the client because a client will only consider a transaction in a specific block to be committed if and only if at least nodes in the network commit that block. Thus, if a client considers a transaction to be committed then it has been committed by nodes or correct nodes and it will not be revoked (as shown in the Lemma 2). Therefore a Byzantine primary has no strong incentive to perform equivocation as revoked transaction is not considered committed by the client (double spending attack is impossible). As a result, it is unlikely that equivocation will take place in Hermes.
∎
Theorem 7.
It is highly likely that Hermes will hold S-safety.
5.3 Liveness
Hermes uses different means to provide liveness while keeping message complexity low (at messages). As the main communication among the nodes occur through the , it is important that there must be at least one correct node in the to guarantee liveness. As shown in Section 3.2, the largest probability of total failure (for liveness) is considering different practical sizes of and that we have used in Section 7.
Another case that could potentially prevent liveness is when repeatedly selecting a bad or malicious primary after a view change, which in turn triggers another view change, and this perpetuates without termination. However, as we show next, this extreme scenario may only occur with extremely low probability that fast approaches to . If the primary is malicious or the number of malicious nodes in the impetus committee is at least , then based on Algorithm 2 (lines 36-40), and Algorithm 4 (lines 28-38), a view change may occur. The probability of such a bad event causing a view change is approximately a constant (Section 3).
Treating each such bad event as a Bernoulli trial, we have that the bad events trigger consecutively view changes with probability at most , which fast approaches to with exponential rate as increases linearly. Therefore, the probability of this scenario is negligible and does not affect liveness.
Additionally, view change in Hermes also employ three techniques applied by the PBFT [5]. These techniques include: exponential backoff timer for view change; at least complaints will cause a view change. This technique has been customized in Hermes with additional phases as described in 4.3. The first phase that has been added to Hermes include broadcasting messages to regular nodes by impetus committee. The second phase include aggregation of at least messages by the members of into message and broadcasting it to regular nodes. These additional steps are added to make sure that at least replicas are aware of view change. And faulty nodes () cannot trigger a view change.
It should be noted that even during a view change the performance of Hermes will not be affected by the slack primary. This is because the primary will send its message to the impetus committee and the impetus committee will forward primary’s message to regular nodes. Therefore view change messages from primary will propagate proportional to the wire speed of prompt nodes.
6 Efficient Optimistic Responsiveness
Pipelining is an optimization technique that involves sending requests/messages back to back without waiting for their confirmation. This technique has been previously used in networking [27] as well as in consensus [28, 17] to improve performance. Therefore, as optimization the primary can propose a new block with sequence after phase for block with sequence without waiting for the block to get committed. The primary can wait only for majority of votes from the impetus committee to propose a new block. This technique decreases the wait time for the primary to propose next block while making sure that with high probability the protocol will make progress.
For safety condition to hold we need to replace with , where is an array of in message . As in basic Hermes the primary proposes the next block after it commits its parent block. There will be only one valid pending block in the network with . But in case of pipelined Hermes, Since the primary proposes a block after phase of its parent, by the end of timeout a node might receive multiple uncommitted blocks. Therefore, the information about latest uncommitted blocks has to be included in during the view change.
For state machine replication (SMR) in blockchains sending message, message and committing a block during phase has to be done in order (serially) for each block. This means a node will not confirm block at the sequence () before block with the sequence such that . Out of order messages can be cached. But other operations including signature verification and format checking can be done concurrently.
We leave more details on this to programmers who will be going to implement this protocol.

| Throughput with different network sizes when |
| all nodes have higher bandwidth |
| Latency with different network sizes when |
| all nodes have higher bandwidth |


7 Evaluations
We have implemented prototype of optimized Hermes as well as chained Hotstuff [17] (pipelined) using Golang programming language. We chose pipelined Hotstuff as it is a state-of-the-art consensus protocol. A variant of Hotstuff called Libra-BFT [29] is also used by Facebook. We implemented Hotstuff to keep similar code architecture with Hermes so that we can fairly compare both algorithms.
Experiments were conducted in the Amazon Web Services (AWS) cloud. Each node in the network was represented by an instance of type t2.large in AWS. Each t2.large instance has 2 virtual CPU (cores) and 8GB of memory. We recorded performance of Hermes as well as Hotsuff with network sizes of , , , , and nodes. The impetus committee size for each network size are , , , , and respectively. We adjusted values of and so that we can obtain the maximum failure probability of using Equation 1.
Randomly generated transactions were used during experiments to transfer funds among different accounts. Transactions were included in a block (batch). We used different block sizes of 1MB, 2MB and 3MB.
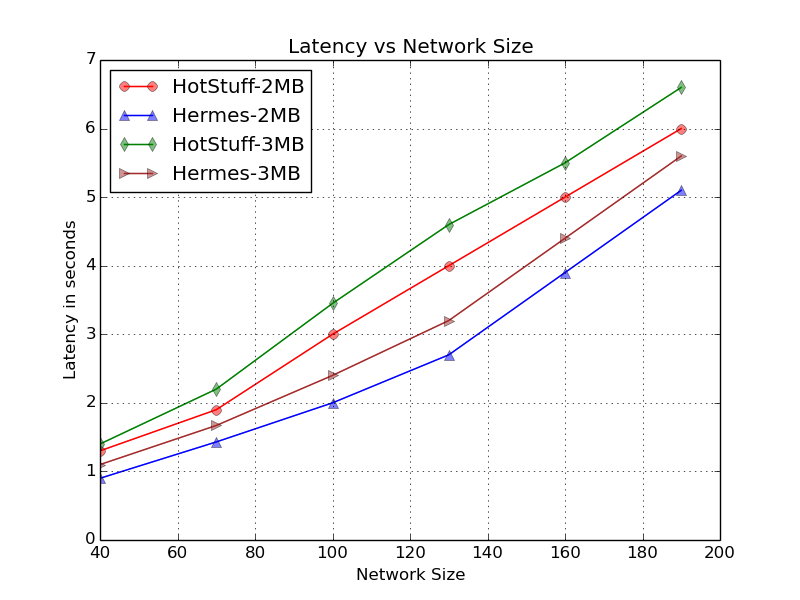
During our first evaluation all nodes had similar upload and download bandwidth of Gbps MBps. During our tests as shown in Figure 6 Hotstuff performs better with small network size ( and ). This is due to the reason that when is small, () has to be larger to maintain a safe failure probability. Therefore, as the network size grows larger the growth of remains sub linear to the growth while keeping safe failure probability. As a result, with larger Hermes performs better and its performance is comparable to the performance of HotStuff. Whereas, in terms of latency as shown in Figure 6, Hermes outperforms the Hotstuff. As it can be seen, Hermes has lower latency than the Hotstuff and variation in the latency of Hermes and Hotstuff with different block sizes of and grow larger when .
Next we introduced slack primaries and then compared the performance of Hermes and Hotstuff as shown in Figure 8 and Figure 8. We configured the upload speed of slack primary to Mbps (roughly equivalent to MBps). We reduced block size to MB and MB as with block size of MB we were experiencing very high latency and packet drops. As it can be seen in Figure 8 the throughput lead of Hermes grows from more than two times (when ) to four times when block size is MB and to times when block size is MB (with ). Similarly, Figure 8 shows that the latency of Hotstuff grows very fast with increase in network size when primary is slack.
8 Related Work
The most relevant work to our protocol is Proteus [13] in which the primary proposes block to a subset of nodes called root committee. But after confirmation from the root committee the primary proposes the block to all nodes which we have avoided in Hermes. Proteus has only focused on improving the message complexity. Moreover, the probability of view change in Proteus is higher () compared to Hermes () as the primary is chosen from the impetus committee. Proteus is only R-Safe whereas Hermes is R-safe and highly likely S-safe. To be S-safe Hermes has additional recovery phase during its view change sub protocol. Proteus holds responsiveness but is not efficiently optimistic responsive whereas Hermes is efficiently optimistic responsive.
Random selection of subset of nodes in a BFT committee has also been used inAlgorand [14], Consensus Through Herding [30], [15] and [16]. Algorand is a highly scalable BFT based protocol, but can tolerate percent of Byzantine nodes in the network while providing probabilistic safety (depending on the size of committee and number of Byzantine nodes in the network). Consensus Through Herding [30] achieve consensus in poly-logarithmic number of rounds. In [15, 16] protocols achieves Byzantine Agreement (BA) with sublinear round complexity under corrupt majority. All of these protocols operate in Synchronous environment under adaptive adversarial model. On the contrary, Hermes can operate in asynchronous environment and does not consider adaptive adversarial model.
Hot-stuff [17] is another BFT-based protocol linear message complexity . Hot-stuff has abolished the view change mode with the cost of an additional round of message complexity in normal mode. In Hot-stuff there can be multiple forks before the block gets committed. When a block gets committed, the blocks in its competitive forks will be revoked. This effectively causes wastage of resources (bandwidth, processing power etc.) that were consumed in proposing the revoked blocks. As the primary is changed with each block proposal, at most there can be failed epochs (where no blocks are generated) out of epochs. The rotating primary mechanism of Hotstuff cannot resolve the problem of slack primary. Because if there are slack nodes. Then at least times there will be sudden degradation in protocol performance due to slack primary. This results in inconsistent performance. Libra-BFT is [29] based on Hotstuff, but its synchronization module that is used to recover missing blocks has message complexity.
There has been another line of work presented in PRIME [31], Aavardak[32] and RBFT [33]. In these papers the authors have tried to address the performance attack (delaying proposal) by Byzantine primary by monitoring primary performance. In case of failing the expectation, primary is replaced by the network. But in their model, they have not considered the slack but honest nodes. That means slack primaries will also be treated as a Byzantine primary and will be replaced. Moreover, even a prompt primary might get replaced due to network glitch. This will result in higher number of expensive but unnecessary view changes. Moreover, if Proof-of-Stake (PoS) is used over BFT, then an honest but slack primary will seldom get chance to propose a block, hence will not be able to increase its stake regularly causing centralization of stake to prompt nodes. Furthermore, unlike Hermes these solutions do not address combination of problems which include message complexity, latency, and slack primary problem. Hermes does not consider addressing the Byzantine primary performance attack but performance monitoring module from these proposal can be added to Hermes to address this issue.
9 Conclusion
In this paper we proposed a highly efficient BFT-based consensus protocol for blockchains which addresses the problem of slack primary. Furthermore, this protocol has lower latency and message complexity. We also show that breaking strong safety in Hermes is unlikely and expensive for Byzantine primary. Breaking strong safety will only cause additional processing delay and will not result in double spending attack. Therefore, a Byzantine primary has no incentive to perform such attack. As a result the safety of Hermes is comparable to the safety of general BFT-based protocols.
References
- [1] Y. Kwon, J. Liu, M. Kim, D. Song, and Y. Kim, “Impossibility of full decentralization in permissionless blockchains,” in Proceedings of the 1st ACM Conference on Advances in Financial Technologies, ser. AFT ’19. New York, NY, USA: ACM, 2019, pp. 110–123. [Online]. Available: http://doi.acm.org/10.1145/3318041.3355463
- [2] F. C. Gärtner, “Byzantine failures and security: Arbitrary is not (always) random,” in INFORMATIK 2003 - Mit Sicherheit Informatik, Schwerpunkt ”Sicherheit - Schutz und Zuverlässigkeit”, 29. September - 2. Oktober 2003 in Frankfurt am Main, 2003, pp. 127–138. [Online]. Available: http://subs.emis.de/LNI/Proceedings/Proceedings36/article1040.html
- [3] M. M. Jalalzai, G. Richard, and C. Busch, “An experimental evaluation of bft protocols for blockchains,” in Blockchain – ICBC 2019, J. Joshi, S. Nepal, Q. Zhang, and L.-J. Zhang, Eds. Cham: Springer International Publishing, 2019, pp. 34–48.
- [4] M. J. Fischer, N. A. Lynch, and M. S. Paterson, “Impossibility of distributed consensus with one faulty process,” J. ACM, vol. 32, no. 2, pp. 374–382, Apr. 1985. [Online]. Available: http://doi.acm.org/10.1145/3149.214121
- [5] M. Castro and B. Liskov, “Practical Byzantine fault tolerance,” in Proceedings of the Third Symposium on Operating Systems Design and Implementation, ser. OSDI ’99. Berkeley, CA, USA: USENIX Association, 1999, pp. 173–186. [Online]. Available: http://dl.acm.org/citation.cfm?id=296806.296824
- [6] M. Vukolic, “The quest for scalable blockchain fabric: Proof-of-work vs. BFT replication,” in Open Problems in Network Security - IFIP WG 11.4 International Workshop, iNetSec 2015, Zurich, Switzerland, October 29, 2015, Revised Selected Papers, 2015, pp. 112–125.
- [7] L. Luu, V. Narayanan, C. Zheng, K. Baweja, S. Gilbert, and P. Saxena, “A secure sharding protocol for open blockchains,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’16. New York, NY, USA: ACM, 2016, pp. 17–30. [Online]. Available: http://doi.acm.org/10.1145/2976749.2978389
- [8] M. M. Jalalzai and C. Busch, “Window based BFT blockchain consensus,” in iThings, IEEE GreenCom, IEEE (CPSCom) and IEEE SSmartData 2018, July 2018, pp. 971–979.
- [9] J. Liu, W. Li, G. O. Karame, and N. Asokan, “Scalable Byzantine consensus via hardware-assisted secret sharing,” CoRR, vol. abs/1612.04997, 2016. [Online]. Available: http://arxiv.org/abs/1612.04997
- [10] R. Guerraoui, N. Knežević, V. Quéma, and M. Vukolić, “The next 700 bft protocols,” in Proceedings of the 5th European Conference on Computer Systems, ser. EuroSys ’10. New York, NY, USA: ACM, 2010, pp. 363–376. [Online]. Available: http://doi.acm.org/10.1145/1755913.1755950
- [11] G. Golan Gueta, I. Abraham, S. Grossman, D. Malkhi, B. Pinkas, M. Reiter, D. Seredinschi, O. Tamir, and A. Tomescu, “Sbft: A scalable and decentralized trust infrastructure,” in 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), 2019, pp. 568–580.
- [12] I. Eyal, A. E. Gencer, E. G. Sirer, and R. V. Renesse, “Bitcoin-ng: A scalable blockchain protocol,” in 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16). Santa Clara, CA: USENIX Association, 2016, pp. 45–59.
- [13] M. M. Jalalzai, C. Busch, and G. G. Richard, “Proteus: A scalable BFT consensus protocol for blockchains,” in 2019 IEEE International Conference on Blockchain (Blockchain 2019), Atlanta, USA, Jul. 2019.
- [14] Y. Gilad, R. Hemo, S. Micali, G. Vlachos, and N. Zeldovich, “Algorand: Scaling Byzantine agreements for cryptocurrencies,” in Proceedings of the 26th Symposium on Operating Systems Principles, ser. SOSP ’17. New York, NY, USA: ACM, 2017, pp. 51–68.
- [15] R. P. T-H. Hubert Chan and E. Shi, “Sublinear round Byzantine agreement under corrupt majority.” [Online]. Available: http://elaineshi.com/docs/ba-cormaj.pdf
- [16] I. Abraham, T.-H. H. Chan, D. Dolev, K. Nayak, R. Pass, L. Ren, and E. Shi, “Communication complexity of Byzantine agreement, revisited,” 2018.
- [17] D. Malkhi, “Blockchain in the lens of BFT.” Boston, MA: USENIX Association, 2018.
- [18] L. Lamport, R. Shostak, and M. Pease, “The Byzantine generals problem,” ACM Trans. Program. Lang. Syst., vol. 4, no. 3, pp. 382–401, Jul. 1982. [Online]. Available: http://doi.acm.org/10.1145/357172.357176
- [19] E. Buchman, “Tendermint: Byzantine fault tolerance in the age of blockchains,” Jun 2016. [Online]. Available: http://atrium.lib.uoguelph.ca/xmlui/bitstream/handle/10214/9769/Buchman_Ethan_201606_MAsc.pdf
- [20] H. Attiya, C. Dwork, N. Lynch, and L. Stockmeyer, “Bounds on the time to reach agreement in the presence of timing uncertainty,” J. ACM, vol. 41, no. 1, p. 122–152, Jan. 1994. [Online]. Available: https://doi.org/10.1145/174644.174649
- [21] R. Pass and E. Shi, “Thunderella: Blockchains with optimistic instant confirmation,” in EUROCRYPT (2). Springer, 2018, pp. 3–33.
- [22] A. Bessani, J. Sousa, and E. E. P. Alchieri, “State Machine Replication for the Masses with BFT-SMART,” in 2014 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, 2014, pp. 355–362.
- [23] L. M. Bach, B. Mihaljevic, and M. Zagar, “Comparative analysis of blockchain consensus algorithms,” in 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), May 2018, pp. 1545–1550.
- [24] M. G. Luby and L. Michael, Pseudorandomness and Cryptographic Applications. Princeton, NJ, USA: Princeton University Press, 1994.
- [25] S. Micali, M. O. Rabin, and S. P. Vadhan, “Verifiable random functions,” 40th Annual Symposium on Foundations of Computer Science (Cat. No.99CB37039), pp. 120–130, 1999.
- [26] Y. Dodis and A. Yampolskiy, “A verifiable random function with short proofs and keys,” in Public Key Cryptography - PKC 2005, S. Vaudenay, Ed. Berlin, Heidelberg: Springer Berlin Heidelberg, 2005, pp. 416–431.
- [27] V. N. Padmanabhan and J. C. Mogul, “Improving http latency,” Comput. Netw. ISDN Syst., vol. 28, no. 1–2, p. 25–35, Dec. 1995. [Online]. Available: https://doi.org/10.1016/0169-7552(95)00106-1
- [28] N. Santos and A. Schiper, “Tuning paxos for high-throughput with batching and pipelining,” in Distributed Computing and Networking, L. Bononi, A. K. Datta, S. Devismes, and A. Misra, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2012, pp. 153–167.
- [29] M. Baudet, A. Ching, A. Chursin, G. Danezis, F. Garillot, Z. Li, D. Malkhi, O. Naor, D. Perelman, and A. Sonnino, “State machine replication in the libra blockchain,” 2019. [Online]. Available: https://developers.libra.org/docs/assets/papers/libra-consensus-state-machine-replication-in-the-libra-blockchain.pdf
- [30] T.-H. Hubert Chan, R. Pass, and E. Shi, “Consensus through herding,” in Advances in Cryptology – EUROCRYPT 2019, Y. Ishai and V. Rijmen, Eds. Springer International Publishing, 2019, pp. 720–749.
- [31] Y. Amir, B. Coan, J. Kirsch, and J. Lane, “Prime: Byzantine replication under attack,” IEEE Transactions on Dependable and Secure Computing, vol. 8, no. 4, pp. 564–577, 2011.
- [32] A. Clement, E. Wong, L. Alvisi, M. Dahlin, and M. Marchetti, “Making Byzantine Fault tolerant systems tolerate Byzantine Faults,” in Proceedings of the 6th USENIX Symposium on Networked Systems Design and Implementation, ser. NSDI’09. Berkeley, CA, USA: USENIX Association, 2009, pp. 153–168. [Online]. Available: http://dl.acm.org/citation.cfm?id=1558977.1558988
- [33] P.-L. Aublin, S. B. Mokhtar, and V. Quéma, “Rbft: Redundant Byzantine Fault Tolerance,” in Proceedings of the 2013 IEEE 33rd International Conference on Distributed Computing Systems, ser. ICDCS ’13. Washington, DC, USA: IEEE Computer Society, 2013, pp. 297–306.