The Enmity Paradox
Abstract
The “friendship paradox” of social networks states that, on average, “your friends have more friends than you do.” Here, we theoretically and empirically explore a related and overlooked paradox we refer to as the “enmity paradox.” We use empirical data from 24,687 people living in 176 villages in rural Honduras. We show that, for a real negative undirected network (created by symmetrizing antagonistic interactions), the paradox exists as it does in the positive world. Specifically, a person’s enemies have more enemies, on average, than a person does. Furthermore, in a mixed world of positive and negative ties, we study the conditions for the existence of the paradox, both theoretically and empirically, finding that, for instance, a person’s friends typically have more enemies than a person does. We also confirm the “generalized” enmity paradox for non-topological attributes in real data, analogous to the generalized friendship paradox (e.g., the claim that a person’s enemies are richer, on average, than a person is). As a consequence, the naturally occurring variance in the degree distribution of both friendship and antagonism in social networks can skew people’s perceptions of the social world.
The empirical observation that a person’s friends have, on average, more friends than they do is called the “friendship paradox” [1]. The friendship paradox can be explained by the fact that, in computing the average degree of individuals’ friends, high-degree individuals are counted more than individuals with low degree. It is a kind of sampling bias. Computing the average degree based on a person’s network neighbors’ perspective is biased towards a higher mean value than computing it from a person’s own perspective.
The friendship paradox has been generalized to non-topological characteristics in social networks, such as happiness and wealth (people’s friends are happier and richer than they are, on average) [2]. The positive correlation between network degree and various characteristics is the origin of this generalization. The friendship paradox has also been used in social network polling and estimating power-law degree distributions [3], and it has been studied in relation to some other topological properties of networks, such as betweenness, closeness, eigenvector, and Katz centrality [4, 5], as well as extensions to directed networks [5, 6]. Moreover, the friendship paradox can be considered a special case of human social sensing [7]. Furthermore, individuals with more social connections are more indicative of early trends than the average member of the population for many societal phenomena, from the spread of disease [8] to the spread of information [9]. It is even possible to exploit the friendship paradox to develop effective strategies to intervene in networks [10, 11, 12, 13].
Researchers have also recently examined what topological features influence the strength of friendship paradox. For the local formulation of the friendship paradox, for three classes of network models (the Poisson random graph, the configuration model, and a model of a random degree-assortative network), it has been shown that networks with more heterogeneous degree distributions and with negative assortativity tend to have the strongest friendship paradox [14]. Two formulations of friendship paradox have been examined based on the global and local structure of a network [1]. By exploiting a topological property called “inversity,” i.e., the Pearson correlation between a node’s degree and the inverse degree of its neighbors, it is possible to evaluate the relationship between these two formulations and the strength of the friendship paradox [12, 15]. Similar discussions for the generalized friendship paradox in directed networks are possible [6].
To date, the friendship paradox has been investigated primarily from the perspective of positive networks, and little attention has been paid to questions regarding a world in which solely negative ties exist or a world in which both positive and negative ties exist. As a result, it is unclear whether we can still observe these paradoxes in the face of antagonistic ties. Does a negative world manifest the same paradoxes? If so, what mechanisms would cause such paradoxes to occur in a negative world?
Thus, here, we explore the “enmity paradox,” by which we mean, most generally, that the mean number of enemies a person has is lower than the mean number of enemies their enemies have. Furthermore, we examine whether this paradox is observed in a mixed world of both positive and negative ties by comparing a person’s average number of friends with their enemies’ average number of friends, and by comparing a person’s average number of enemies with their friends’ average number of enemies.
The enmity paradox
It is a fact of mathematics that, in a population with variance in the degree distribution (and subject to certain provisos), the friendship paradox exists. But its extent is very much a result of underlying social factors (such as variation across people in the number of friends they want, or whether popular people are preferred as friends). Some aspects of this phenomenon can also be self-reinforcing as a consequence of positive feedback that results from the biased perception [16].
However, even though there is an intrinsic mathematical symmetry between positive and negative network objects (as instantiated by adjacency matrices), the empirical existence of an enmity paradox is not assured. We mathematically clarify and then empirically investigate the existence, origins, and manifestations of the enmity paradox.
First, we derive the equations for the enmity paradox, which are similar to the equations derived for the friendship paradox [1]. Based on our comparison of the mean number of enemies of individuals with the mean number of enemies’ enemies in the negative world, we theoretically assert that the enmity paradox should indeed arise in a similar manner to the friendship paradox.
Consider a simple signed network , where is the vertex set with nodes, and and are the set of positive and negative edges revealing two not-necessarily-dependent worlds. The adjacency matrices corresponding to the positive and negative interactions are denoted as and , respectively. In order to create undirected networks, we either (1) remove unreciprocated edges from the network, or (2) symmetrize the network by removing the edges’ direction. For example, the node is considered a neighbor of the node if, in the former, both edges and are included in the set , while, in the latter, if at least one of these edges exist in the edge set. An edge is referred to as a “friend” if it belongs to , and as an “enemy” if it belongs to . In addition, we also refer to a node as an -hop neighbor of node if there is a walk with length between and ; a walk can include repeated nodes. Here, we focus solely on the enmity and friendship paradoxes for undirected networks. The enmity paradox for directed networks are provided in the Appendix D.
There are two types of degrees for each node in these two parallel worlds, corresponding to positive network, and corresponding to negative network. The probability of a node with degree () is denoted as () or, more simply, (); and the probability of a node’s friend with positive degree and negative degree is denoted as and , respectively. Similarly, the probability of a node’s enemy with positive degree and negative degree is denoted as and , respectively. For simplicity, whenever it is clear from context, we denote the degree, the degree distribution, and the degree distributions of neighboring nodes corresponding to the friendship and enmity networks using , , and and .
To establish the enmity paradox, we need to compare the average negative degree of a random node with the average negative degree of a random enemy of a random node. The average negative degree of a random node can be written as . Going along a random negative edge to one of its enemies leads to a node with negative degree with probability proportional to , i.e., . Therefore, the average degree of a random enemy can be written as for enmity networks. Using Jenson’s inequality, it can be shown that . This inequality can be called the “enmity paradox” for the negative world, and it follows from the same mathematical facts as the friendship paradox in the positive world.
Social networks that simultaneously involve both positive and negative ties are theoretically more complicated. That is, analytically, we have shown that people have fewer enemies on average than their enemies; however, the result of mixing positive and negative worlds is not obvious. Do people have more or fewer enemies than their friends, or do they have more or fewer friends than their enemies?
Considering a dependency between positive and negative degrees with the correlation denoted by , we have the joint probability of degrees and as . For this scenario, the average degree of a person’s enemies would be denoted by ; the average degree of a person’s friends would be denoted by ; the average degree of a person’s friends’ enemies would be denoted by ; and the average degree of a person’s enemies’ friends would be denoted by , where the first two are driven before and the last two are as follows.
| (1a) | ||||
| (1b) | ||||
Therefore, we have three different regimes as follows: (1) If we have independent positive and negative worlds, i.e., , then and there is no difference between the average number of a person’s enemies and average number of enemies of a person’s friends, and similarly , which means no difference between the average number of a person’s friends and the average number of a person’s enemies’ friends. (2) If there is a positive correlation between the two worlds, i.e., (or when ), then we have paradoxes in the mixed world in the same direction as the enmity and friendship paradoxes, as a person’s friends have more enemies and a person’s enemies have more friends compared to a person. (3) Finally, if there is a negative correlation between the two worlds, i.e., (or when ), then we have paradoxes in the mixed world in the opposite direction with the enmity and friendship paradoxes, as a person’s friends have a smaller number of enemies and a person’s enemies have a smaller number of friends compared to the person.
Computation and representation of enmity paradox for empirical data
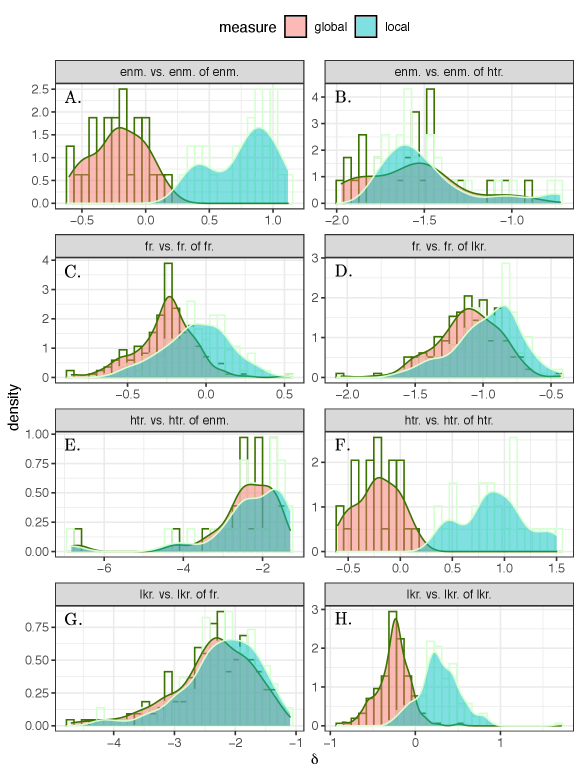
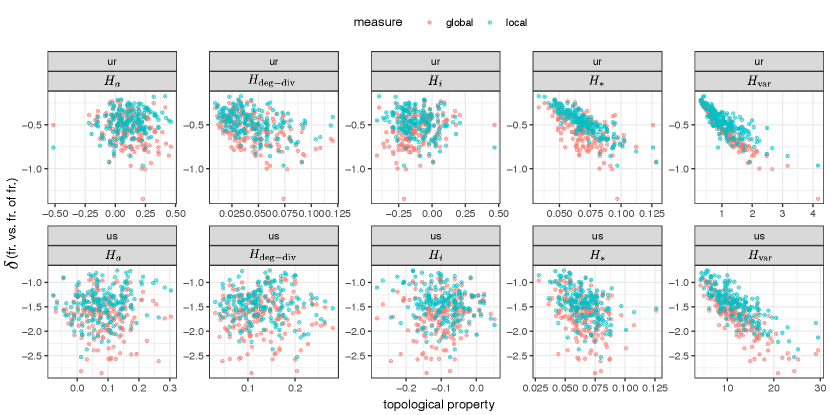
Investigating the enmity and friendship paradoxes in practice requires writing the equations using the data as we are given neither the generative probability of the ties nor the joint probability of negative and positive ties. The friendship paradox has previously been formulated in two different variations which relate to global bias and local bias [1, 6]. In the global formulation, we compare the average degree of a random node with the average degree of a random neighbor of a random node —or a random end of a random edge. In the local formulation, we compare the difference between the average of a random node’s degree and the average of that node’s neighbors’ degrees locally (Fig. 1). From now on, by “paradox strength,” we mean the magnitude of the global difference or of local difference .
The paradox in the global variation is the result of the oversampling of high-degree nodes. In the local variation, the paradox can be intensified locally if there is a positive correlation between a node’s degree and the inverse degree of its neighbors, or it can be attenuated if there is a negative correlation between these variables. This correlation measure is known as “inversity,” and although it is related to degree assortativity, it is not the same [12]; the relevance of such metrics has also been previously explored empirically [15].
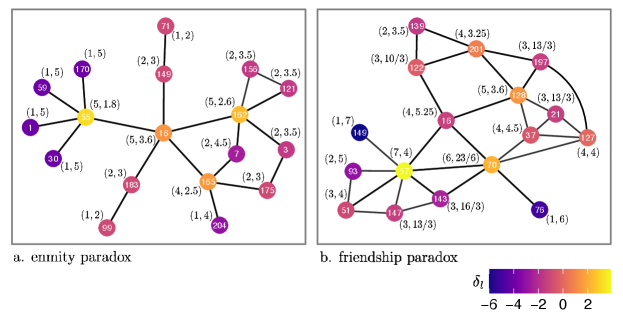
The enmity paradox can similarly be defined for local and global formulations. To illustrate the differences between these two mathematical formulations of the enmity and friendship paradoxes, we first redo the empirical computations for the enmity and friendship paradoxes using empirical data, followed by a matrix representation of the enmity and friendship paradoxes.
The global formulation of the enmity paradox is the comparison between the average degree of a random node , i.e., and the average degree of its neighbors’ degrees, i.e., , where the difference can be written using matrix formulation as Eq. 2,
| (2) |
where is a vector of ones with length (). In this notation, the and indicate the type of one’s neighbor, as one’s enemy and friend, respectively. The and denote the type of comparison as enemies or friends. This global quantity is a non-positive due to the Cauchy–Schwarz inequality () with and , where the equality happens when , i.e., when we have a -regular network. As a result, degree heterogeneity is directly related to the enmity “paradox strength,” since the numerator of the right-hand side in Eq. 2 is the negative variance of the negative degree distribution. These results are similar to the results for the friendship paradox.
For the local formulation, we have the difference between each individual’s degree and the average degree of its neighbors, which is reminiscent of a Laplacian matrix acting on the degree vector , where -th outcome of this operation can be written as ; and, by averaging out these outcomes, we have the local formulation of enmity paradox as Eq. Computation and representation of enmity paradox for empirical data,
| (3) |
where is the diagonal matrix of negative degrees. Eq. Computation and representation of enmity paradox for empirical data can also be written as , where, is the Laplacian matrix of the negative world acting on the negative degree vector, . Our derivation relies on the fact that is symmetric since we only consider undirected networks here (the formulations for directed networks are in the Appendix D). We can also demonstrate that this quantity is always non-positive. Since, for any two matrices and , we can write , thus Eq. Computation and representation of enmity paradox for empirical data can be written as follows,
| (4) |
where, is the matrix of all ones, and, due to the non-positive entries of the matrix for each pair (see Ref. [12]), the resultant trace should also be non-positive.
The difference between and can be written as Eq. Computation and representation of enmity paradox for empirical data, where is the variance of the negative degree of an endpoint of a random edge; is the variance of the inverse negative degree of an endpoint of a random edge; and is the average negative degree. This quantity is negative () if the correlation between the degree of one endpoint and the inverse degree of another endpoint on a random edge , i.e., is negative; it is positive () if the correlation is positive; and it is zero if the correlation is zero [12].
| (5) |
For a mixed world of positive and negative edges, the equations can be written as follows. The global formulation of the difference between number of friends of a random node with the number of friends of enemies of a random node can be formulated as Eq. 6a. And the global formulation of the difference between the number of enemies of a random node with the number of enemies of friends of a random node can be formulated as Eq. 6b.
| (6a) | ||||
| (6b) | ||||
The numerator of these equations can be reduced to which is negative when the correlation between the positive and negative degrees is positive.
For the local formulation, these equations reduce to Eq. 7.
| (7a) | ||||
| (7b) | ||||
Eq. 7a can be also written as the operation of the Laplacian matrix of the negative world on the positive degree vector , i.e., , where, . Similar statements can be shown regarding the relationships between and in a mixed world. The difference between (6a) / (6b) and (7a) / (7b) can be written by introducing the “generailized inversity” measure in the mixed world, i.e., the correlation between the positive degree / negative degree of one endpoint and the inverse negative/positive degree of another endpoint on a random negative/positive edge (see Eqs. [S32] and [S35] in Appendix G).
Generalized enmity paradox
In this section, we use a similar representation to the one used in the previous section to explore when the enmity paradox can be generalized for non-topological attributes such as happiness, wealth, and health (e.g., on average, a person’s friends are richer or happier than they are, as has previously been shown). Due to the similarity between the enmity and friendship paradox, we expect that the condition for generalization of the global definition is similar to the condition previously studied for the generalized friendship paradox [2]. Similarly, the condition for the relationship between the local and global formulation of the generalized enmity paradox should be similar to the condition of their relationships for the generalized friendship paradox [6]. Given the vector of non-topological characteristic denoted by , we define a diagonal matrix with diagonal entries . Thus, the generalized enmity paradox for the global definition of the difference can be written as Eq. 8.
| (8) |
The numerator can be reduced to , which is negative only if there is a negative correlation between and .
The local definition of enmity paradox can also be written as Eq. Generalized enmity paradox.
| (9) |
Using and , the numerator can be reduced to
Here, there are a variety of possibilities; for example, if , this quantity is always negative and all local differences are also negative, then this is merely an uninteresting sufficient condition. The relationship between and can be formalized using the edge-based correlation between on one endpoint of edge and the inverse degree of another endpoint of that edge, , i.e., , where [6]. If the aforementioned edge-based correlation is positive, we have ; if it is negative, we have ; and if there is no correlation, then two measures are equivalent. Using this relationship we have four possibilities of (positive, positive), (positive, negative), (negative, positive), and (negative, negative) for (, ) differences.
Higher order enmity paradox
We can also consider the paradoxes for higher-order neighbors. For example, in the global formulation, if the average degree of a random neighbor of a random node is greater than the average degree of a random node, is it also the case that the average degree of a random -hop neighbor of a random node is also larger—or for any random -hop neighbor of a random node (an -hop neighbor is a neighbor we arrive through a random walk with length ).
In this case, it is more specific to ask if there is a relationship between the paradox strength and the order of the neighbors. Here, the equation for global formulation of for an order of can be written as Eq. 10,
| (10) |
where, for can be written as follows.
| (11) |
Accordingly, we can see different scenarios under different conditions. If the degree of nodes that are connected have a positive correlation, i.e., , we still have similar paradoxes, i.e., the average degree of a neighbor of a neighbor of a random node is larger than the average degree of a random node. If we have the opposite inequality, we see a paradox in a counterintuitive sense in comparison with the friendship paradox. And if we have equality, we do not see any paradox. However, the paradox is always valid for odd since the numerator of Eq. 10 is always negative for odd due to Theorem 4.2 in Ref. [5] that was originally proposed in Ref. [17]. The theorem says that, given positive integers and such that is even, we have .
For a local definition, the equation can be reduced to Eq. 12,
| (12) |
where it can be both positive or negative under different circumstances. Statements similar to the relationship of and can be derived for this purpose.
Hence, theory suggests that the enmity and friendship paradoxes for higher orders may not always be true and might only hold under some circumstances (e.g., particular sorts of networks, or particular regimes such as related to whether geodesic backsteps are allowed); while we note these mathematical observations here, we leave empirical investigation of these details to future work.
Methods
Despite the mathematical similarity of the enmity paradox formulation and the friendship paradox, the empirical existence of the enmity paradox in real networks is not guaranteed given the differences between the negative and positive environments. Positivity, for example, is characterized by a large clustering coefficient, reciprocity, and homophily [18, 19], while negativity can even seem like mere noise [18, 20]. Here, we characterize some of these structural characteristics of social networks before investigating the enmity paradox in comparison between the positive and negative ties. These noteworthy differences can be partly explained via the inherent avoidance between the sender and receiver of negative ties, which leads to low information transfer [18]; in other words, people are more likely to know who likes them (because the other persons are more likely to so declare) than they are to know who dislikes them (which is information that is more often kept private) [21].
Several distinct measures might play an important role in explaining the friendship paradox. (1) We denote the clustering coefficient using , which is the local adaptation of the transitivity measure (Appendix B), and transitivity as . (2) The inversity measure () (which is not the same as degree assortativity, with which is negatively correlated) has a direct effect on the local friendship paradox strength [12]. (3) The degree assortativity () is also important [14]. (4) A heterogeneity index that captures starlike graphs—similar to the inversity measure—also seems to play an important role for the severity of friendship paradox. For degree assortativity, we can use extant measures [22]; and for starlike strength, we use a measure that represents topological heterogeneity in complex networks and is maximal for star graphs () [23]. We also consider (5) the variance of the degree (), and (6) a novel heterogeneity measure () that reflects degree diversity and has a close relationship with entropy [24]. To characterize other differences between positive and negative ties, we can also compare four more topological properties, including the reciprocity, the clustering coefficient, the homophily between the positive and negative ties, and the normalized betweenness-centrality (the mathematical definitions for all these measures are provided in Appendix B).
Maximum paradox strength
The severity of the paradoxes depends on network structure. The global paradox strength is proportionate to the variance of its degree sequence divided by its average degree. To maximize the global paradox strength given a constant average degree, we would need to maximize the degree variance by rewiring the edges so that the degree values oscillate between extreme values and . Similarly, a greedy rewiring algorithm can increase the local paradox strength [12]. A cross-rewiring of paired edges that connect the nodes with extreme degrees—substituting connections of smallest degree nodes with the largest degree nodes instead of connection of mediocre degree nodes—can increase the strength of the paradox, with star networks having the maximum value. Therefore, the enmity and friendship paradoxes would appear to have the greatest strength in both global and local formulations when connections have a star shape.
Results
We use data from a sociocentric network study of 24,687 people aged 11 to 93 years (with a mean age of 32) in 176 geographically isolated villages in western Honduras [11]. We first construct 176 binary directed signed networks. We use three name generators to determine (potentially overlapping) positive ties (“Who do you spend your free time with?” “Who is your closest friend?” and “Who do you discuss personal matters with?”). And we use one name generator for negative ties (“Who are the people with whom you do not get along well?”). Here, we focus on the enmity paradox for undirected (symmetrized) networks (an example village is illustrated in Fig. 2). Results for undirected (reciprocated) and directed networks are in the Appendices C and D, respectively.

Across the whole dataset, nodes have an average of () friends, and friends have an average of () friends. In order to find the difference at the individual level, we must remove isolated nodes; and the average consequent difference is (). For the enmity networks, a node has an average of () enemies, while an enemy has an average of () enemies. After removing the isolated nodes, the average difference between the number of enemies and the number of enemies of enemies is (). For the remaining analyses, we remove the isolated nodes from the constructed networks.
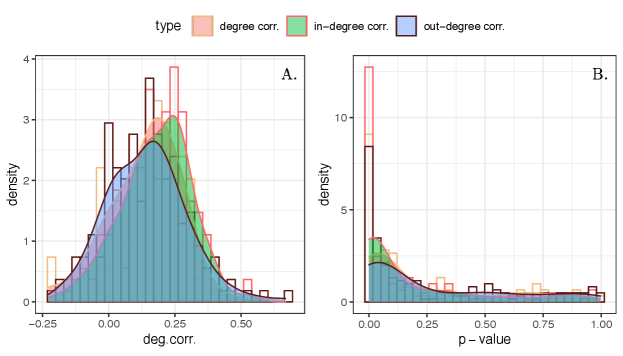
Core topological properties of friendship and enmity networks are presented in Fig. 3. The reciprocity of positive edges is much larger than the reciprocity of negative edges, in part due to the relative scarcity of negative ties. Therefore, we expect the undirected enmity networks constructed from reciprocated edges to be much sparser compared to the friendship networks (Appendix C). The clustering coefficient of positive edges is much larger than the clustering coefficient of negative edges; that is, friendship networks have more triangles than enmity networks (Fig. 2). The presence of starlike motifs is therefore expected to be more prevalent in negative environments (Fig. 2). This is in turn aligned with the results for both , and . The variance of degree for positive networks is much larger than the negative networks. Thus, it appears that, among the different factors contributing to the strength of the enmity paradox, the starlike indices ( and ) align with greater strength, and the lower opposes it. Finally, we also plotted the difference between the normalized betweenness centrality () of the positive and negative worlds to emphasize how the negative world has a more starlike shape as the maximum value of unnormalized is achieved by the central point in a star network [25].
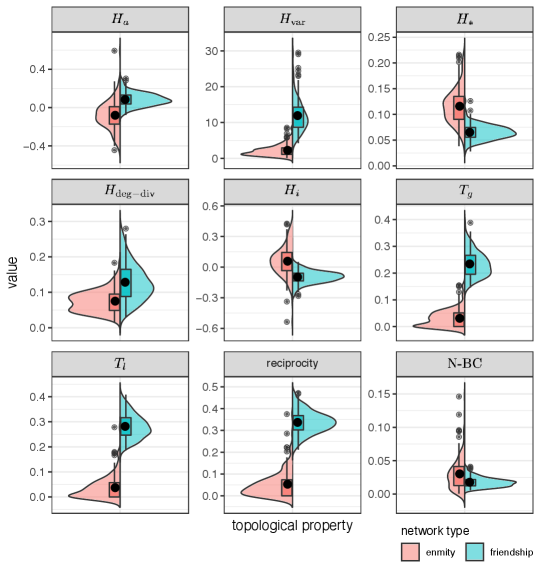
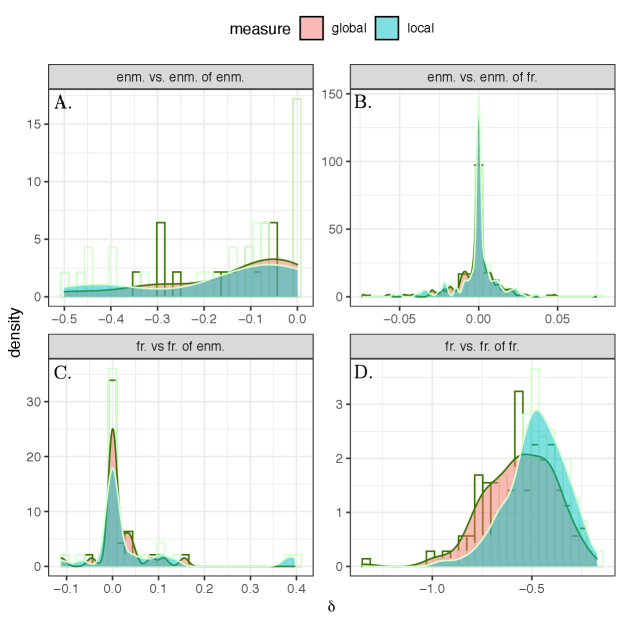
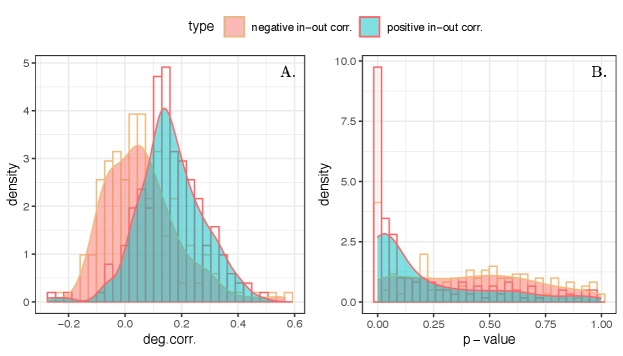
First, we study the global and local enmity paradox among the 176 villages and we present the histogram of these values in Fig. 4. We observe very similar strengths in the enmity and friendship paradoxes in negative and positive worlds, respectively. Additionally, given slightly negative values for friendship networks, we expect the strength of local paradox to be greater than the global paradox for friendship networks as compared to enmity networks (Eq. Computation and representation of enmity paradox for empirical data, Fig. 4, A and D, and Appendix, Fig. S12). The global and local paradoxes for enmity networks and also for the mixed worlds, however, are nearly equivalent, as expected due to their balanced values (Appendix, Fig. S12).
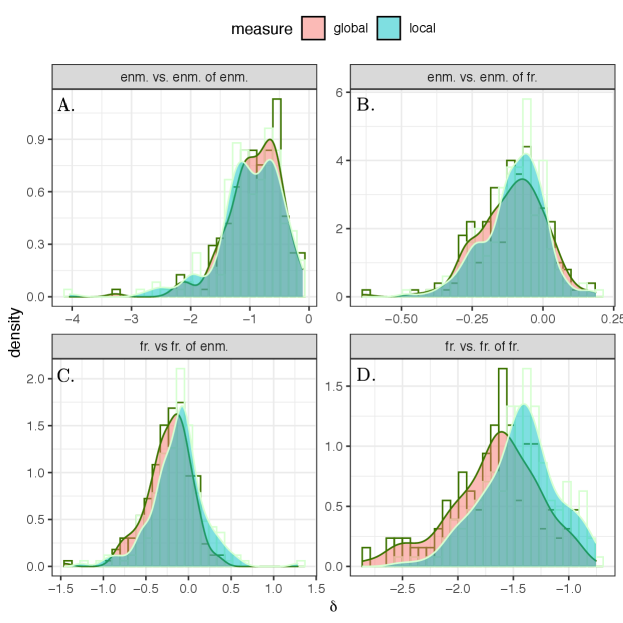
The results for the mixed worlds are also presented in Fig. 4. Although the paradoxes almost disappear in undirected (reciprocated) networks due to the sparsity of remaining negative edges (Appendix, Fig. S1), for undirected (symmetrized) networks, there is comparable strength in the paradoxes. In other words, in undirected networks using symmetrized edges, our friends are more likely to have enemies than we are (Fig. 4B) and our enemies are more likely to have friends than we are (Fig. 4C).
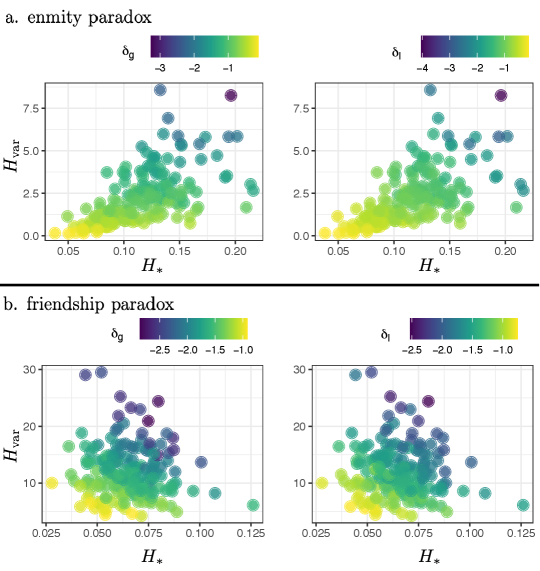
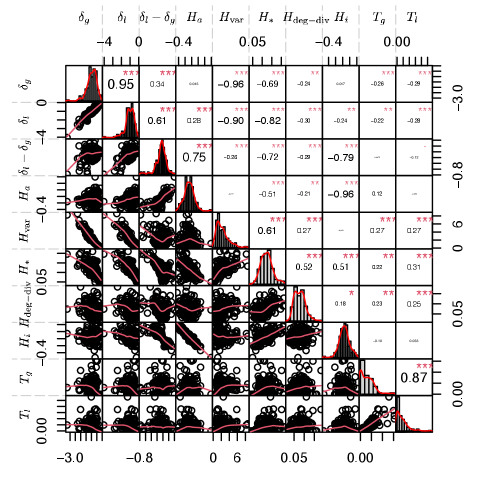
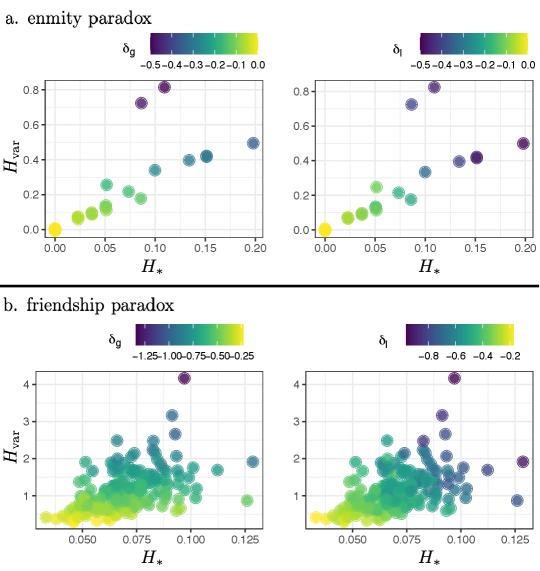
To understand the effect of different topological properties noted in Fig. 3 on the enmity paradox strength, we analyze the relationship between the local and global paradox measures and the topological properties. Using regression models, we can characterize the effect of various topological features on friendship and enmity paradox strengths (Appendix E). Among the measures, the degree variance and the starlike embedding , besides the degree diversity and inversity , can explain a significant portion of the intervillage variance in paradox strengths (). Furthermore, and also have large effects. This relationship is illustrated in Fig. 5 (the relationships between the strength and other heterogeneity measures are highlighted in Appendix, Figs. S5 and S6). As expected, the larger the variance and the more the starlike embedding, the stronger the paradox.
The higher-order enmity and friendship paradoxes are presented in Fig. 6 (for the first to the sixth order). Because high-degree individuals are counted exponentially more than individuals with low degrees when increasing the order of walks, the higher-order enmity and friendship paradoxes are more severe than the typical enmity and friendship paradoxes. This phenomenon is much more severe in local paradoxes when we compare the degree of a random node with its higher-order neighbors (Fig. 6, bottom row).
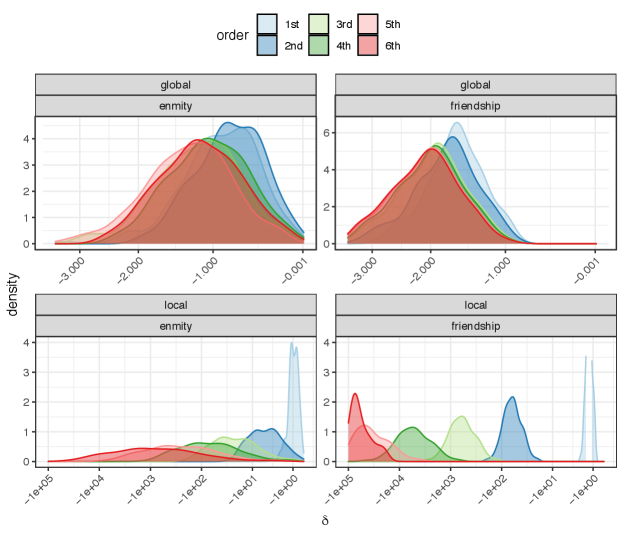
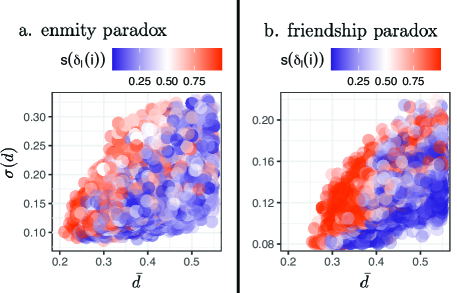
To investigate the relationship between a node’s contribution in the local enmity and friendship paradoxes and its topological features, we plot the nodal contribution versus the location of the nodes in a network. The location of the nodes is defined by using a simple fact in networks, namely that the nodes in the center of a network have a smaller distance from other nodes while the nodes in the periphery have a larger distance from other nodes. Therefore, if we embed every node using its average and standard deviation of distances from other nodes in a network—normalized by the network diameter within each network component separately—we find that, in a network, peripheral nodes have a greater paradox strength than central nodes (Fig. 7).
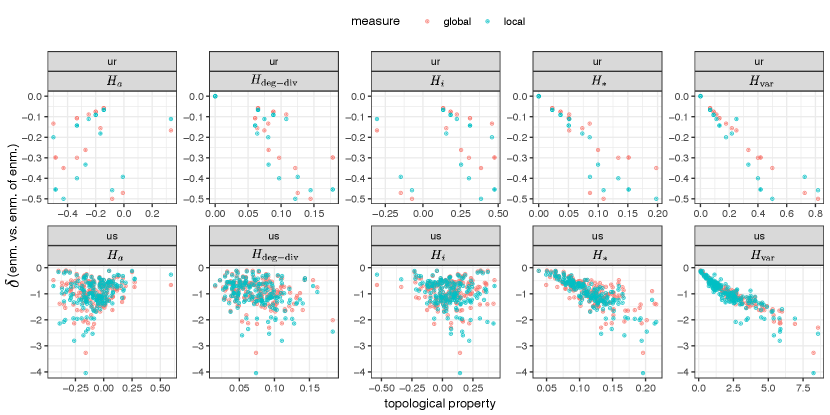
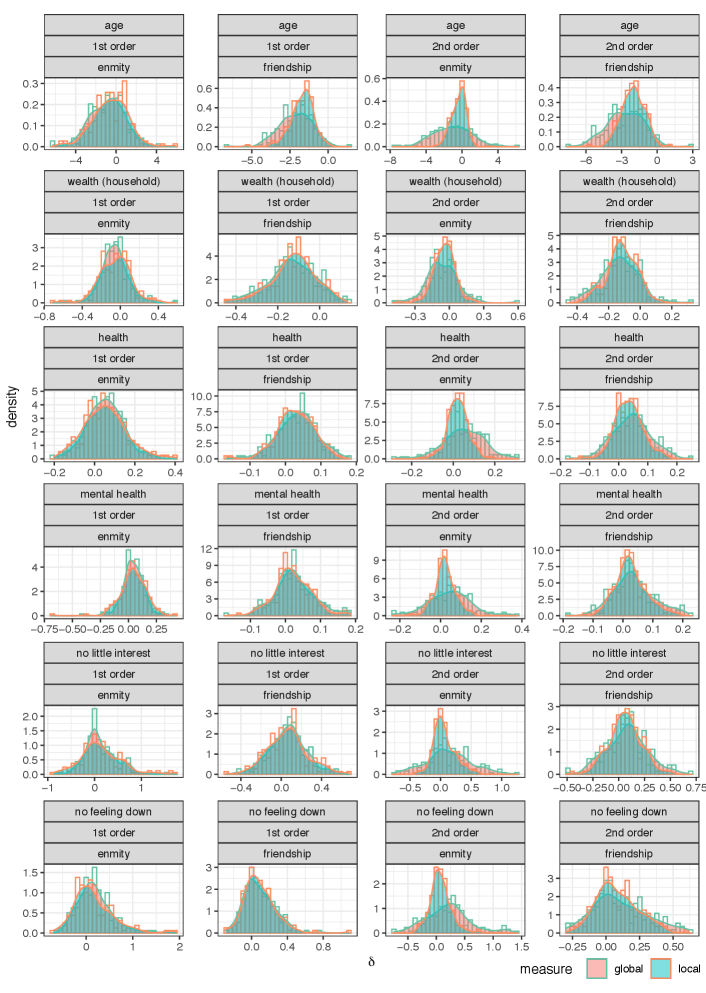
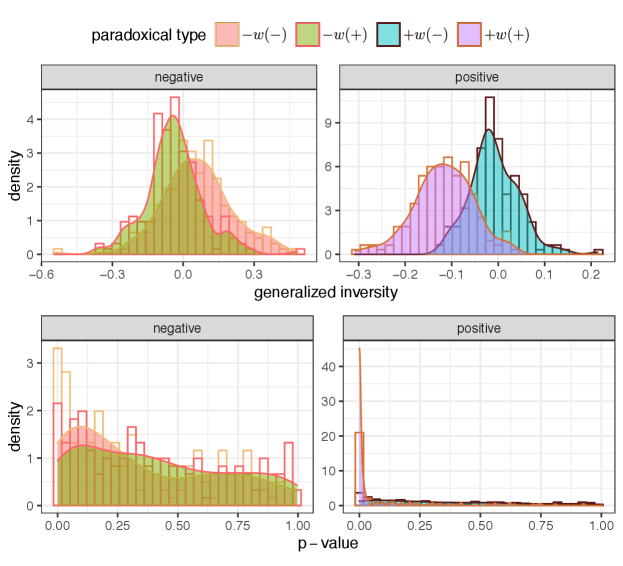
Finally, the results for the generalized enmity paradox are provided in Appendix F, Tables S3, and S4, and Figs. S8 and S9. The results document the existence, for instance, of the generalized paradoxes in both enmity and friendship with respect to wealth. Due to the higher correlation between non-topological features and positive degree, the generalized friendship paradox is stronger than the generalized enmity paradox.
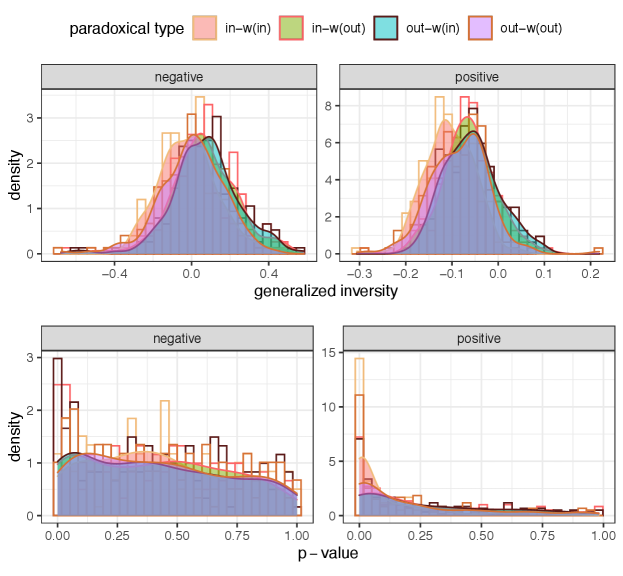
The results for undirected (reciprocated) and directed networks are provided in Appendix, Figs. S1 and S3, respectively. For undirected (reciprocated) networks, the enmity and mixed-world paradox strengths are much smaller compared to undirected (symmetrized) networks—due to the small reciprocity in enmity networks. For directed networks we almost have larger global enmity paradox strength. The local enmity and mixed-world paradox strengths can be explained using an inversity measure [6] (Appendices D and G, and Fig. S13).
Discussion
Our perception of the world can be distorted by the sampling bias towards high-degree nodes that arise as a result of the friendship paradox [1]. In our minds, if not in reality, our friends have more friends, our collaborators have more collaborators, and our colleagues are wealthier or happier than we ourselves. Here, we showed that the same observations hold with respect to antagonistic ties. Yet, with a lower clustering coefficient and lower degree assortativity and with greater inversity, we expect even more starlike shapes in enmity networks. These factors all make the enmity paradox even more probable than the friendship paradox. Moreover, the enmity paradox obtains in a negative world when comparing the number of an ego’s enemies with their enemies’ enemies as well as in mixed worlds when we compare an ego’s friends with the ego’s enemies’ friends and an ego’s enemies with an ego’s friends’ enemies.
Some topological differences between enmity and friendship networks (e.g., the smaller variance and smaller reciprocity in enmity networks) suggests possibly divergent perceptional biases. For example, since the paradox strength is proportional to the degree variance, it could be lower for enmity networks; however, we observe similar paradox patterns in both enmity networks and in a mixed world of friendship and antagonistic ties.
There is also a fundamental connection between the generalized friendship paradox (involving non-topological features) and the enmity paradox. If we treat the number of enemies a person has as a non-topological attribute for the positive network, then the enmity paradox follows from the generalized friendship paradox. Looking at the correlation between positive and negative degrees reveals these observations (Appendix, Fig. S10). As a result of the positive correlation between positive and negative degrees in most of the village networks (, ; in other words, the empirical reality that people who have many friends also tend to have more enemies), we are able to actually answer the question of why the enmity paradox exists in the first place through the lens of the generalized friendship paradox.
These paradoxes have further implications. Our understanding of social norms and of our social standing is influenced by our perceptions regarding those around us. For instance, the friendship paradox can help explain systematic biases in social perceptions such as regarding the prevalence of binge drinking and risky behaviors [16, 26]. Furthermore, the friendship paradoxes can explain why a given behavior in a society can be amplified. This can occur in two interwoven phases, where popular individuals act more intensely for activities associated with strategic complementarities, and those who are prone to certain behaviors interact more with other people who are also involved in that behavior, amplifying the effects of this behavior [16]. As a result, perceptions of behavior increase and this could contribute to an increase in the behavior along the lines of the perception. Misperceptions about the habits of one’s enemies could act similarly.
Such inter-personal influence, even if biased, can in turn be exploited to foster cascades, as field experiments have shown [10, 11, 13]. Indeed, as a result of phenomena like the friendship and enmity paradoxes, we could further perfect network targeting algorithms that exploit the friendship paradox; and taking into account a person’s enemies could make network targeting even more effective.
Biases associated with our antagonistic ties could be consequential in still another way. For instance, the friendship paradox may intensify homophilous patterns in network formation due to the misperception [16, 27]. Because of these paradoxes and the misperceptions they can give rise to, people might form a miscalbirated perception of their own attributes and thus seek out connections with people different than they might otherwise truly wish or “deserve.” The enmity paradox might similarly change our perceptions of reality and may function as a deterrent force in the formation of network ties between a person and the social connections around a person’s antagonists. When people judge whom to either befriend or avoid, they may be biased in their perceptions.
Acknowledgements.
This work was supported in part by the National Science Foundation under Grant No. 2030859 to the Computing Research Association for the CIFellows Project (A.G.), and also by the NOMIS Foundation. Also, we thank the Yale Center for Research Computing for guidance and use of the research computing infrastructure. Replication code is provided at https://github.com/Aghasemian/EnmityParadox.Appendix A Data
Our data come from wave 1 of a sociocentric network study of 24,687 people aged 11 to 93 years, with a mean of around 32 and a median of around 28 years old in 176 geographically isolated villages in western Honduras [11]. Using this empirical data, we first construct 176 binary directed signed networks (with no multi-edges or self-loops). We use three name generators to determine (overlapping) positive ties (“Who do you spend your free time with?” “Who is your closest friend?” and “Who do you discuss personal matters with?”) to construct the positive world, and one name generator for negative ties (“Who are the people with whom you do not get along well?”) to construct the negative world. Due to the village-based nature of our analysis, we also exclude the rare connections reported outside of the villages.
The reciprocity of negative ties in the analyzed dataset is much smaller than that of positive ties, which may influence the findings. There are several factors contributing to this, including self-censorship by individuals who do not share sensitive information in order to avoid embarrassment, reduce the risk of social norm violation, and protect their privacy [28, 29]. In addition, there can be a lack of information flow due to the avoidance of any interaction with the receiver of the antagonistic tie by the sender, which may result in the receiver being unaware of the tie and thus unable to “reciprocate” it [18]. Nevertheless, the amount of reciprocity depends on the question, and studying undirected networks in Honduras dataset can be justified based on the fact that negative ties are created from the question “Who are the people with whom you do not get along well?” that is a symmetric relationship in practice. If an individual does not get along with another individual , it may be reasonable, as a first approximation, to assume that the individual also does not get along with . Furthermore, we turned the directed networks into undirected ones by either removing unreciprocated edges or by symmetrizing them. However, alternative approaches are described below.
Appendix B Measures
-
1.
Inversity measure (): this measure is proposed in [12] where it has been shown it determines the relative effectiveness of the local and global strategies. Actually, the authors have shown that , where, and are the global and local mean number of neighbor’s enemies/friends, respectively, is the -th moment degree, and , i.e., the edge-based correlation of the degree of an endpoint of an edge with the inverse degree of another endpoint of that edge is the inversity measure.
-
2.
Degree assortativity (): this measure of homophily measures the tendency for vertices with similar degrees to connect with each other. In [14], the authors have shown that this measure has a key role in the strength of the local definition of the friendship paradox. For degree assortativity, we use the definition in [22], i.e., , where is the probability of a random endpoint of a random edge has degree , and is the probability of a random edge has endpoints of degree and . This definition is provided for undirected networks and it can be easily generalized for directed networks.
-
3.
Starlike strength (): this measure is introduced by Estrada in Ref. [23] and it represents topological heterogeneity in complex networks; it is maximal for star graphs. The normalized heterogeneity index can be written as , where is the number of nodes in a network.
-
4.
Variance of the degree (): this typical degree heterogeneity measure is the variance of the degree distribution in a network.
-
5.
Degree-diversity (): this is a novel degree heterogeneity measure proposed in [24] that reflects the degree diversity and has a close relationship with the entropy of the degree distribution. Given a network , the authors define a heterogeneity index for a network of nodes as , where is the probability of a random node with degree , and are the minimum and maximum degrees, respectively, and the summation is only for , which . Then, for a completely homogeneous network of -regular network, it is the case that , and for the most heterogenous case, where the is uniform, . Therefore, the degree diversity is the normalized version of as .
-
6.
Transitivity and clustering coefficient : transitivity is one of the two most common topological features that is designed to measure the commonness of triangles in social networks. This global measure computes the fraction of transitive triads that are subgraphs of triangles [30]. Another topological feature, the clustering coefficient, which is very similar to transitivity, computes the fraction of triads that are subgraphs of triangles for each node , and then averages these values. As a result, we can consider the clustering coefficient as the local adaptation of the transitivity measure, and we refer to the clustering coefficient as , and transitivity as . In most graphs, these two measures take similar values; however, they are rare occasions that they disagree.
-
7.
Normalized betweenness-centrality (): the number of shortest paths traversing a node represents its importance in information flow in a network and is called betweenness centrality (). Freeman [25] proved that the maximum value of this measure is achieved by the central point in a star, and it is . Therefore, the is a normalization of by this maximum value.
Appendix C Enmity paradox in undirected networks
The generalized inversity in mixed worlds
Based on the inversity measure for undirected networks, it is possible to formalize the differences between global and local paradoxes in four different scenarios introduced in the main text: 1. the enmity paradox; 2. the friendship paradox; and the two mixed worlds of 3. when we compare the number of our friends with the number of our enemies’ friends; and 4. when we compare the number of our enemies with the number of our friends’ enemies.
Enmity paradox in undirected (reciprocated) networks
The results for undirected (symmetrized) networks have been provided in the main text. Here, the results for undirected networks constructed by only keeping the reciprocated edges are presented (see Fig. S1). Once the isolated nodes are removed, many undirected (reciprocated) networks disappear or become very small, and the results are limited to networks with at least nodes ( out of networks). Additionally, due to the small reciprocity in the negative world, the enmity paradox for undirected enmity networks constructed with reciprocated edges is much smaller than the friendship paradox for friendship networks constructed similarly (see Fig. S1, A versus D). Essentially, this observation reflects the sparsity of the networks created as a result of antagonistic ties being infrequently reciprocal compared to positive ones. The amount of reciprocity varies from question to question, and we believe that questions such as “Who are the people with whom you do not get along well” should be accompanied by greater reciprocity. Therefore, it is possible that measurement errors and self-censorship lead to smaller reciprocity, further justifying symmetrized undirected networks in our study.
The results for the mixed worlds in undirected (reciprocated) networks are also presented in Fig. S1. As with the enmity paradox of undirected networks constructed with reciprocated edges, we do not observe the paradoxes in the mixed worlds with reciprocated edges due to the sparsity of remaining negative edges; however, for undirected (symmetrized) networks (main text, Fig. 4) we see comparable strengths of the paradoxes.
Appendix D Enmity paradox in directed networks
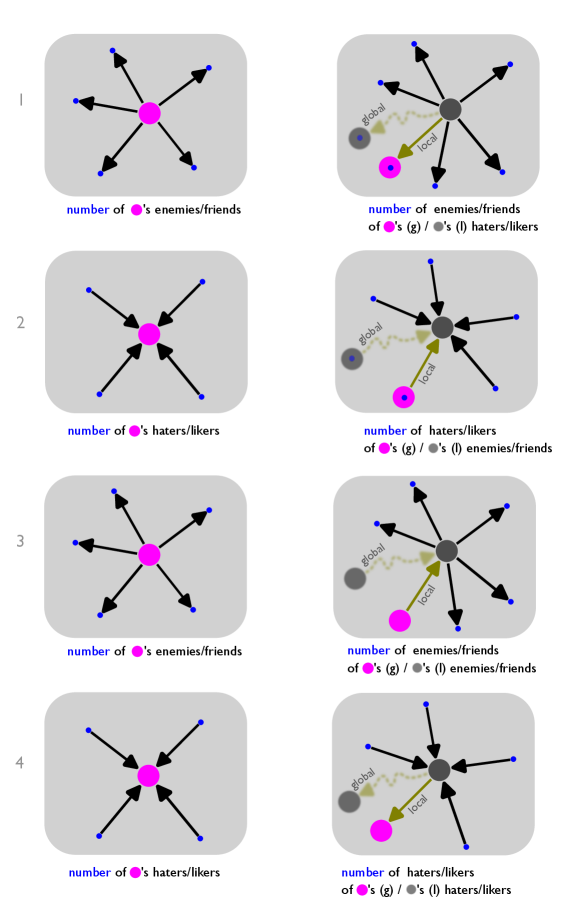
Here, we derive the equations of the enmity paradox for directed networks. We follow a similar convention as in Ref. [6] and use distinguishing names for those who introduce us as antagonistic/friendship connections and those we introduce as antagonistic/friendship connections. We name whom we report as antagonistic/friendship connection as “enemy”/“friend” and a person who introduce us as antagonistic/friendship connections as “hater”/“liker.”
Then, we have four possibilities that we should consider (Fig. S2): 1. our enemies/friends have more haters/likers than we do; 2. our haters/likers have more enemies/friends than we do; 3. our enemies/friends have more enemies/friends than we do; and 4. our haters/likers have more haters/likers than we do. Similar to what the authors in Ref. [6] have shown for the positive world of followers/followees, the first two statements are correct mathematically, but for the last two, a positive correlation between the in-degree and out-degree is required.
The global formulation of the enmity paradox for directed networks is a comparison between the average in-degree/out-degree of a random node and the average in-degree/out-degree of its neighbors’ in-degrees/out-degrees when the neighbor is chosen between the enemies and haters as described below. Here, means node is an enemy of node and node is a hater of node . In other words node reports node as its antagonistic connection. As a result of the symmetry, the equations for the directed friendship paradoxes are similar. To simplify the notation, we use instead of . As we did for the undirected networks in the main text, these equations can be generalized to the mixed world when positive and negative ties coexist.
-
1.
the average number of enemies of a random node versus the average number of enemies of a random hater 111In this notation, the and indicate the direction of one’s neighbor, as one’s in-neighbor and out-neighbor, respectively. The and denote the type of comparison as in-degree or out-degree..
(S5) -
2.
the average number of haters of a random node versus the average number of haters of a random enemy.
(S6) -
3.
the average number of enemies of a random node versus the average number of enemies of a random enemy.
(S7) -
4.
the average number of haters of a random node versus the average number of haters of a random hater.
(S8)
The global formulation of the last two scenarios is the same due to symmetry. It is not different when we compute the average number of haters of our haters or the average number of enemies of our enemies globally.
However, it matters when we have the local formulation. For the local formulation, we have again four possibilities (Fig. S2). The in-degree and out-degree vectors are denoted as and , while the diagonal in-degree and out-degree matrices are denoted as and , respectively. Therefore, is the -th entry of the out-degree vector , and, similarly, it can be defined for the in-degree vector .
-
1.
the average difference of the number of enemies of a random node with the average number of enemies of its haters.
(S9) -
2.
the average difference of the number of haters of a random node with the average number of haters of its enemies.
(S10) -
3.
the average difference of the number of enemies of a random node with the average number of enemies of its enemies.
(S11) -
4.
the average difference of the number of haters of a random node with the average number of haters of its haters.
(S12)
In the local formulation, . However, to compute the individual values of the vector of average difference we need to write it this way.
-
1.
the difference between the number of enemies of a random node with the average number of enemies of its haters.
(S13) -
2.
the difference between the number of haters of a random node with the average number of haters of its enemies.
(S14) -
3.
the difference between the number of enemies of a random node with the average number of enemies of its enemies.
(S15) -
4.
the difference between the number of haters of a random node with the average number of haters of its haters.
(S16)
The generalized inversity in directed networks
Based on the inversity measure expanded for directed networks, it is possible to formalize the differences between the four pairs of global and local paradoxes in directed networks [6]. Here, we summarize these equations in the following manner. (Detailed proof of the generalization of the inversity measure for directed networks is provided in Section G.)
-
1.
(S17) -
2.
(S18) -
3.
(S19) -
4.
(S20)
Similarly, we can easily generalize the equations corresponding to the local and global formulations of enmity and friendship paradoxes in directed networks to the mixed world of directed networks, when both antagonistic and friendship interactions coexist. For example, we can compare the number of enemies of a random node with the number of enemies of a random liker in the global and local formulations as and , respectively. However, a careful study of these mixed worlds for directed networks is out of scope of this study, though it could be examined in future work.
Also for the generalized enmity paradox, we can expand the equations for directed networks. The global formulation of the generalized paradox for directed networks can be written for enemies in Eq. S21, and for haters in Eq. S22.
| (S21) |
| (S22) |
Similarly, for the local formulation of the generalized paradox, we can write the equations for enemies and haters in Eqs. S23 and S24, respectively.
| (S23) |
| (S24) |
As part of an analysis of both directed and undirected village networks in western Honduras, we compared the average degrees of all nodes with the average degrees of their neighbors in Table S1. We define neighbors in directed networks in two ways: in-neighbors and out-neighbors. A comparison of the average degrees of the nodes is made with their neighbors’ average degrees. We consider four cases for directed networks corresponding to the scenarios presented in Fig. S2.
The empirical results for the aforementioned enmity paradox in directed networks, introduced by four different formulations in Eqs. S5-S12, and their corresponding friendship paradoxes have been provided in Fig. S3. The results indicate that we see global paradoxes for both enmity and friendship directed networks. Also, the strength of these paradoxes is maximum when comparing our number of haters with the number of haters of our enemies and our number of likers with the number of likers of our friends, as these two are mathematically supported. Thus, our enemies have more haters than we do, and our friends have more likers. As with the previous two mathematical facts, our likers have more friends than we do, and our haters have more enemies than we do, but the strength of these two mathematical paradoxes is smaller than those from the previous two facts. In order for the other four global paradoxes to be valid, the in- and out-degrees must be positively correlated [6]. In view of the positive correlation between in- and out-degrees (Fig. S11), we expect the other four global paradoxes to be satisfied as shown in Fig. S3. Alternatively, while there are local paradoxes when comparing our number of haters/likers with the number of haters/likers of our enemies/friends and also comparing our number of enemies/friends with the number of enemies/friends of our haters/likers, they do not exist or exist in a counterintuitive sense when we compare our number of enemies/friends with the number of enemies/friends of our enemies/friends, or when we compare our number of haters/likers with the number of haters/likers of our haters/likers. Generally, the difference between global and local paradoxes can be explained using the generalized inversity measures for directed networks. The correlations and p-values for the whole dataset are summarized for both enmity and friendship networks in the caption of Fig. S3. Also, a detailed analysis of these correlations has been provided in Fig. S13. Several applications can benefit from exploring the enmity paradox in directed mixed networks including both positive and negative ties. Future research can examine the details of the enmity paradox in such an environment, as well as the relationship between the paradox strength and the topological features of directed networks.
| enmity | friendship | |||
|---|---|---|---|---|
| value | node | neighbor | node | neighbor |
| (undirected) | ||||
| degree | 1.26 | 3.55 | 6.89 | 8.97 |
| (directed) | ||||
| 1. out-degree (in-neighbor) | 0.65 | 2.48 | 4.13 | 5.47 |
| 2. in-degree (out-neighbor) | 0.65 | 3.06 | 4.13 | 6.83 |
| 3. out-degree (out-neighbor) | 0.65 | 0.93 | 4.13 | 4.61 |
| 4. in-degree (in-neighbor) | 0.65 | 0.93 | 4.13 | 4.61 |
Appendix E Relationship of topological features with paradox strength
Our study examines the relationship of various topological features with friendship and enmity paradox strength using regression modeling. The correlation matrix for both enmity and friendship paradox data frames is shown in Fig. S4. Our regression analysis considers only a subset of these topological features due to their significant correlation, including , , , , and . The effect of is almost the same as the effect of with a negative sign since they are highly negatively correlated, whereas the effect of is almost the same as that of since they are highly positively correlated. The effect of regression of and on different topological features is in Table S2.
| Model (enmity paradox) | Model (enmity paradox) | Model (friendship paradox) | Model (friendship paradox) | |
| R2 | ||||
| Adj. R2 | ||||
| Num. obs. | ||||
| ; ; | ||||
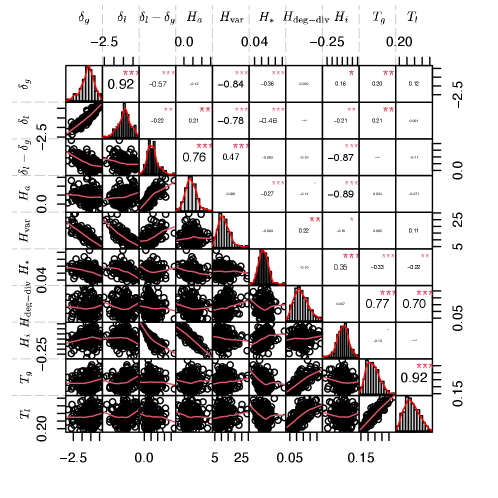
Figs. S5-S6 illustrate how the global and local enmity and friendship paradox strengths for undirected networks created by reciprocated () and symmetrized edges () changes with different topological measures. Among the different topological features, and have a negative correlation with the strength of the paradoxes. In these figures, shows a positive correlation with strength, and also and show a negative correlation with strength. Among the various measures, and are the most significant, with large effects for both undirected (symmetrized) and undirected (reciprocated) networks (see Figs. 5 [main text] and S7). It is expected that the paradoxes become stronger as the variance and starlike embedding increase.
Appendix F Generalized enmity and friendship paradoxes
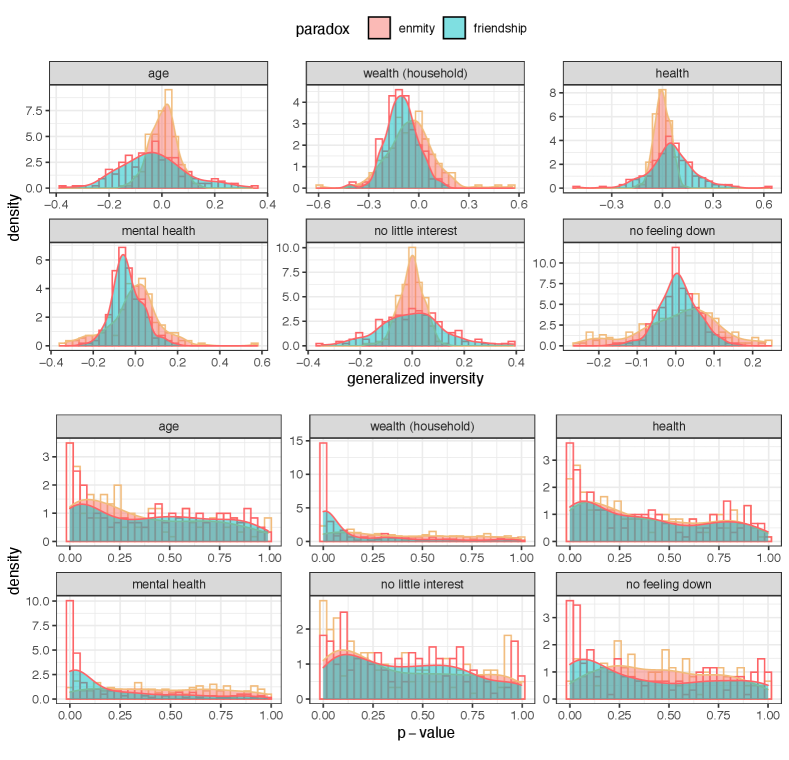
The results for global and local measures of the generalized enmity and friendship paradoxes for undirected (symmetrized) networks are provided in Tables S3 and S4. The distribution of these measures over village networks in the Honduras dataset is represented in Fig. S8. The difference between the global and local measures can be explained through the inversity measure defined as the following correlation: , i.e., . The distribution of these inversity measures and the p-values for village networks in the Honduras dataset is provided in Fig. S9. The results show the generalized paradoxes in both enmity and friendship paradoxes (e.g., wealth). Due to the higher correlation between topological features and positive degrees, generalized friendship paradoxes are stronger than generalized enmity paradoxes. We see an agreement in the existence of the generalized paradoxes for different attributes between the enmity and friendship networks. A further investigation of the generalized enmity paradox is left for future study.
| random ppl. | enmity | hypothesis: | |||
| in enmity | enemy of | enemy of enemy | estimate (significant) | ||
| attribute | network (n = 2857) | of random ppl. (n = 2816) | of random ppl. (n = 2816) | (1st order) | (2nd order) |
| (global) | |||||
| age | 33.33 2.81 | 34.19 3.34 | 34.41 3.62 | -0.86 (****) | -1.08 (****) |
| wealth (household) | 2.88 0.86 | 2.94 0.88 | 2.95 0.88 | -0.06 (****) | -0.06 (****) |
| health | 2.68 0.23 | 2.62 0.26 | 2.62 0.27 | 0.05 | 0.05 |
| mental health | 2.76 0.25 | 2.72 0.29 | 2.72 0.29 | 0.04 | 0.04 |
| no little interest | 11.35 0.80 | 11.21 0.94 | 11.22 0.95 | 0.14 | 0.13 |
| no feeling down | 11.58 0.71 | 11.40 0.85 | 11.38 0.86 | 0.19 | 0.21 |
| (local) | |||||
| age | 33.33 2.81 | 33.85 3.32 | 33.71 2.95 | -0.52 (****) | -0.38 (****) |
| wealth (household) | 2.88 0.86 | 2.94 0.87 | 2.92 0.87 | -0.06 (****) | -0.04 (****) |
| health | 2.68 0.23 | 2.62 0.26 | 2.65 0.24 | 0.05 | 0.02 |
| mental health | 2.76 0.25 | 2.72 0.30 | 2.74 0.26 | 0.04 | 0.02 |
| no little interest | 11.34 0.80 | 11.21 1.00 | 11.29 0.85 | 0.14 | 0.06 |
| no feeling down | 11.58 0.71 | 11.43 0.86 | 11.51 0.74 | 0.16 | 0.07 |
| ; ; ; | |||||
| random ppl. | friendship | hypothesis: | |||
| in friendship | friend of | friend of friend | estimate (significant) | ||
| attribute | network (n = 2821) | of random ppl. (n = 2816) | of random ppl. (n = 2816) | (1st order) | (2nd order) |
| global | |||||
| age | 32.60 2.25 | 34.70 2.67 | 35.30 2.95 | -2.1 (****) | -2.7 (****) |
| wealth (household) | 2.85 0.85 | 2.98 0.89 | 2.98 0.89 | -0.13 (****) | -0.13 (****) |
| health | 2.73 0.19 | 2.69 0.21 | 2.68 0.21 | 0.03 | 0.04 |
| mental health | 2.84 0.21 | 2.81 0.23 | 2.81 0.24 | 0.03 | 0.03 |
| no little interest | 11.56 0.72 | 11.49 0.74 | 11.48 0.76 | 0.06 | 0.07 |
| no feeling down | 11.82 0.59 | 11.73 0.67 | 11.72 0.68 | 0.09 | 0.1 |
| (local) | |||||
| age | 32.60 2.25 | 34.29 2.42 | 34.64 2.58 | -1.7 (****) | -2.04 (****) |
| wealth (household) | 2.85 0.85 | 2.97 0.88 | 2.96 0.88 | -0.12 (****) | -0.11 (****) |
| health | 2.73 0.19 | 2.70 0.21 | 2.69 0.21 | 0.03 | 0.03 |
| mental health | 2.84 0.21 | 2.82 0.23 | 2.81 0.23 | 0.02 | 0.03 |
| no little interest | 11.56 0.72 | 11.50 0.74 | 11.50 0.74 | 0.06 | 0.06 |
| no feeling down | 11.82 0.59 | 11.73 0.66 | 11.74 0.65 | 0.09 | 0.08 |
| ; ; ; | |||||
Appendix G The generalized inversity
To find the relationships between the global and local paradox strengths in the mixed worlds, i.e., and , we generalize the inversity measure originally proposed for a friendship network in Ref. [12]. The difference between and can be written as Eq. S25.
| (S25) | ||||
| (S26) |
The generalized inversity for the mixed world of is defined as the correlation between the positive degree of node and the inverse negative degree of node on the two endpoints of a random negative edge , which is derivable as follows: Using a similar convention as in Ref. [12], we denote the positive degree variable corresponding to one endpoint as and the inverse negative degree of the other endpoint as . The generalized inversity in this mixed world can be written as the following equation,
| (S27) |
where the first two moments of and in Eq. G are computed as follows 222In Eq. S29 and other equations regarding the generalized inversity for the mixed world of , denotes the size of nodes with non-zero negative degrees. For the mixed world of , denotes the size of nodes with non-zero positive degrees.:
| (S28) | ||||
| (S29) | ||||
| (S30) | ||||
| (S31) |
Therefore, Eq. G can be written as Eq. S32,
| (S32) |
where, and . Similarly, the difference and can be written as Eq. S33.
| (S33) | ||||
| (S34) |
And, through similar derivation, it can be shown that
| (S35) |
where, and .
For directed networks, we can similarly derive the equations corresponding to the inversity measure as follows. We only present the proof for the difference between and .
| (S36) | ||||
| (S37) |
The inversity in this scenario is defined as the correlation between the out-degree of node and the inverse in-degree of node on the two endpoints of a random edge , which can be derived as follows. We denote the out-degree variable corresponding to one endpoint as and the inverse in-degree of the other endpoint as . The inversity measure can be expanded for this directed network via the following equation,
| (S43) |
where, and .
References
- Feld [1991] S. L. Feld, Why your friends have more friends than you do, American journal of sociology 96, 1464 (1991).
- Eom and Jo [2014] Y.-H. Eom and H.-H. Jo, Generalized friendship paradox in complex networks: The case of scientific collaboration, Scientific reports 4, 1 (2014).
- Nettasinghe and Krishnamurthy [2019] B. Nettasinghe and V. Krishnamurthy, The friendship paradox: Implications in statistical inference of social networks, in 2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP) (IEEE, 2019) pp. 1–6.
- Grund [2014] T. Grund, Why your friends are more important and special than you think, Sociological Science 1, 128 (2014).
- Higham [2019] D. J. Higham, Centrality-friendship paradoxes: when our friends are more important than us, Journal of Complex Networks (2019).
- Alipourfard et al. [2020] N. Alipourfard, B. Nettasinghe, A. Abeliuk, V. Krishnamurthy, and K. Lerman, Friendship paradox biases perceptions in directed networks, Nature communications 11, 1 (2020).
- Galesic et al. [2021] M. Galesic, W. Bruine de Bruin, J. Dalege, S. L. Feld, F. Kreuter, H. Olsson, D. Prelec, D. L. Stein, and T. van Der Does, Human social sensing is an untapped resource for computational social science, Nature 595, 214 (2021).
- Christakis and Fowler [2010] N. A. Christakis and J. H. Fowler, Social network sensors for early detection of contagious outbreaks, PloS one 5, e12948 (2010).
- Garcia-Herranz et al. [2014] M. Garcia-Herranz, E. Moro, M. Cebrian, N. A. Christakis, and J. H. Fowler, Using friends as sensors to detect global-scale contagious outbreaks, PloS one 9, e92413 (2014).
- Kim et al. [2015] D. A. Kim, A. R. Hwong, D. Stafford, D. A. Hughes, A. J. O’Malley, J. H. Fowler, and N. A. Christakis, Social network targeting to maximise population behaviour change: a cluster randomised controlled trial, The Lancet 386, 145 (2015).
- Shakya et al. [2017] H. B. Shakya, D. Stafford, D. A. Hughes, T. Keegan, R. Negron, J. Broome, M. McKnight, L. Nicoll, J. Nelson, E. Iriarte, et al., Exploiting social influence to magnify population-level behaviour change in maternal and child health: study protocol for a randomised controlled trial of network targeting algorithms in rural honduras, BMJ open 7, e012996 (2017).
- Kumar et al. [2021] V. Kumar, D. Krackhardt, and S. Feld, Interventions with inversity in unknown networks can help regulate contagion, preprint arXiv:2105.08758 (2021).
- Alexander et al. [2022] M. Alexander, L. Forastiere, S. Gupta, and N. A. Christakis, Algorithms for seeding social networks can enhance the adoption of a public health intervention in urban india, Proceedings of the National Academy of Sciences 119, e2120742119 (2022).
- Cantwell et al. [2021] G. T. Cantwell, A. Kirkley, and M. E. J. Newman, The friendship paradox in real and model networks, Journal of Complex Networks 9, cnab011 (2021).
- Shirado et al. [2019] H. Shirado, G. Iosifidis, L. Tassiulas, and N. A. Christakis, Resource sharing in technologically defined social networks, Nature Communications 10, 1079 (2019).
- Jackson [2019] M. O. Jackson, The friendship paradox and systematic biases in perceptions and social norms, Journal of Political Economy 127, 777 (2019).
- Lagarias et al. [1984] J. C. Lagarias, J. E. Mazo, L. A. Shepp, and B. McKay, An inequality for walks in a graph, SIAM Review 26, 580 (1984).
- Harrigan and Yap [2017] N. Harrigan and J. Yap, Avoidance in negative ties: Inhibiting closure, reciprocity, and homophily, Social Networks 48, 126 (2017).
- Jackson [2010] M. O. Jackson, Social and economic networks (Princeton university press, 2010).
- Feng et al. [2022] D. Feng, R. Altmeyer, D. Stafford, N. A. Christakis, and H. H. Zhou, Testing for balance in social networks, Journal of the American Statistical Association 117, 156 (2022).
- Isakov et al. [2019] A. Isakov, J. H. Fowler, E. M. Airoldi, and N. A. Christakis, The structure of negative social ties in rural village networks, Sociological science 6, 197 (2019).
- Newman [2003] M. E. J. Newman, Mixing patterns in networks, Physical review E 67, 026126 (2003).
- Estrada [2010] E. Estrada, Quantifying network heterogeneity, Physical Review E 82, 066102 (2010).
- Jacob et al. [2017] R. Jacob, K. Harikrishnan, R. Misra, and G. Ambika, Measure for degree heterogeneity in complex networks and its application to recurrence network analysis, Royal Society open science 4, 160757 (2017).
- Freeman [2002] L. C. Freeman, Centrality in social networks: Conceptual clarification, Social network: critical concepts in sociology. Londres: Routledge 1, 238 (2002).
- Lerman et al. [2016] K. Lerman, X. Yan, and X.-Z. Wu, The” majority illusion” in social networks, PloS one 11, e0147617 (2016).
- Evtushenko and Kleinberg [2021] A. Evtushenko and J. Kleinberg, The paradox of second-order homophily in networks, Scientific Reports 11, 1 (2021).
- Tourangeau et al. [2000] R. Tourangeau, L. J. Rips, and K. Rasinski, The psychology of survey response (Cambridge University Press, 2000).
- Shoemaker et al. [2002] P. J. Shoemaker, M. Eichholz, and E. A. Skewes, Item nonresponse: Distinguishing between don’t know and refuse, International Journal of Public Opinion Research 14, 193 (2002).
- Latora et al. [2017] V. Latora, V. Nicosia, and G. Russo, Complex networks: principles, methods and applications (Cambridge University Press, 2017).
- Note [1] In this notation, the and indicate the direction of one’s neighbor, as one’s in-neighbor and out-neighbor, respectively. The and denote the type of comparison as in-degree or out-degree.
- Note [2] In Eq. S29 and other equations regarding the generalized inversity for the mixed world of , denotes the size of nodes with non-zero negative degrees. For the mixed world of , denotes the size of nodes with non-zero positive degrees.