The Block-Correlated Pseudo Marginal Sampler for State Space Models
Abstract
Particle Marginal Metropolis-Hastings (PMMH) is a general approach to Bayesian inference when the likelihood is intractable, but can be estimated unbiasedly. Our article develops an efficient PMMH method that scales up better to higher dimensional state vectors than previous approaches. The improvement is achieved by the following innovations. First, the trimmed mean of the unbiased likelihood estimates of the multiple particle filters is used. Second, a novel block version of PMMH that works with multiple particle filters is proposed. Third, the article develops an efficient auxiliary disturbance particle filter, which is necessary when the bootstrap disturbance filter is inefficient, but the state transition density cannot be expressed in closed form. Fourth, a novel sorting algorithm, which is as effective as previous approaches but significantly faster than them, is developed to preserve the correlation between the logs of the likelihood estimates at the current and proposed parameter values. The performance of the sampler is investigated empirically by applying it to non-linear Dynamic Stochastic General Equilibrium models with relatively high state dimensions and with intractable state transition densities and to multivariate stochastic volatility in the mean models. Although our focus is on applying the method to state space models, the approach will be useful in a wide range of applications such as large panel data models and stochastic differential equation models with mixed effects.
Keywords: Block PMMH; correlated PMMH; dynamic stochastic general equilibrium (DSGE) model; trimmed mean likelihood estimate
39C. 164, School of Mathematics and Applied Statistics (SMAS), University of Wollongong, Wollongong, 2522; Australian Center of Excellence for Mathematical and Statistical Frontiers (ACEMS); National Institute for Applied Statistics Research Australia (NIASRA); Email: [email protected]. Phone Number: (+61) 424379015.
Level 4, West Lobby, School of Economics, University of New South Wales Business School – Building E-12, Kensington Campus, UNSW Sydney – 2052, and ACEMS Email: [email protected], Phone Number: (+61) 424802159.
1 Introduction
Particle marginal Metropolis-Hastings (PMMH) (Andrieu and Roberts, , 2009) is a Bayesian inference method for statistical models having an intractable likelihood, when the likelihood can be estimated unbiasedly. Our article develops a PMMH sampling method for efficiently estimating the parameters of complex state space models. The method scales better than current approaches in the number of observations and latent states and can handle state transition densities that cannot be expressed in closed form; e.g., many dynamic stochastic general equilibrium (DSGE) models, which are a popular class of macroeconomic time series state space models, do not have closed form transition densities.
A key issue in efficiently estimating statistical models using a PMMH approach is that the variance of the log of the estimated likelihood grows with the number of observations and the dimension of the latent states (Deligiannidis et al., , 2018). Pitt et al., (2012) show that to obtain a balance between computational time and the mixing of the Markov chain Monte Carlo (MCMC) chain, the number of particles used in the particle filter should be such that the variance of the log of the estimated likelihood is in the range 1 to 3, depending on the efficiency of the proposal for . Pitt et al., (2012) also show that the efficiency of PMMH schemes deteriorates exponentially as that variance increases; we further note that in many complex statistical applications, it is computationally very expensive ensuring that the variance of the log of the estimated likelihood is within the required range.
Deligiannidis et al., (2018) propose a more efficient PMMH scheme, called the correlated pseudo-marginal (CPM) method, which correlates the random numbers in the (single) particle filters used to construct the estimated likelihoods at the current and proposed values of the parameters. This dependence induces a positive correlation between the estimated likelihoods and reduces the variance of the difference in the logs of the estimated likelihoods which appear in the Metropolis-Hastings (MH) acceptance ratio. They show that the CPM scales up with the number of observations compared to the standard pseudo marginal method of Andrieu et al., (2010) when the state dimension is small.
Tran et al., (2016) propose an alternative correlated pseudo marginal approach to that of Deligiannidis et al., , calling it the block pseudo marginal (BPM) method; the BPM divides the random numbers used in constructing likelihood estimators into blocks and then updates the parameters jointly with one randomly chosen block of the random numbers in each MCMC iteration; this induces a positive correlation between the numerator and denominator of the MH acceptance ratio, similarly to the CPM. They show that for large samples the correlation of the logs of the estimated likelihoods at the current and proposed values is close to , where is the number of blocks. However, they do not apply the BPM method for estimating time series state space models using the particle filter.
Our article introduces a new PMMH sampler, referred to as the multiple PMMH algorithm (MPM), which extends the CPM method of Deligiannidis (2018) and the BPM method of Tran (2016). The MPM sampler is innovative and addresses various issues in the following ways: (a) The likelihood estimator is a trimmed mean of unbiased likelihood estimators from multiple independent particle filters (PFs); these PFs can be run in parallel. This approach reduces the variance of the likelihood estimator compared to using a single particle filter. The algorithm is exact when there is no trimming and approximate otherwise, but our empirical results suggest that the approximation is very close to being exact. (b) The unknown parameters, and only the random numbers used in one of the PFs, are updated jointly. This is a novel block version of PMMH that works with multiple particle filters. See section 2.3 for details. (c) An auxiliary disturbance PF (ADPF) algorithm is proposed to estimate the likelihood efficiently for state space models such as DSGE models, where the bootstrap filter is very inefficient and the state transition density does not have a closed form so that an auxiliary PF cannot be constructed; see section 2.5 for details. (d) A novel sorting algorithm, which is as effective as previous approaches but is significantly faster than them, is proposed to maintain the correlation between the logs of the likelihood estimates at the current and proposed values. The standard resampling step in the particle filter introduces discontinuities that break down the correlation between the logs of the likelihood estimates at the current and proposed values, even when the current and proposed parameters are close. Section 3.2 shows that the MPM sampler with the proposed sorting algorithm can maintain the correlation between the logs of the estimated likelihoods for relatively high dimensional state space models. Note that the proposed PMMH sampler works with any particle filter algorithm, including the tempered particle filter of Herbst and Schorfheide, (2019), the standard bootstrap filter of Gordon et al., (1993), the disturbance particle filter of Murray et al., (2013), and the proposed auxiliary disturbance filter. When the number of state dimensions is greater than the number of disturbance dimensions, a disturbance particle filter is more efficient than a state-based particle filter. Additionally, the disturbance particle filter is useful for state space models with intractable state transition density.
We illustrate the MPM sampler empirically, and compare its performance to the CPM method, using a standard linear Gaussian state space model, a multivariate stochastic volatility in the mean model and two non-linear Dynamic Stochastic General Equilibrium (DSGE) models, using simulated and real data. Our work in estimating non-linear DSGE models is also related to Fernández-Villaverde and Rubio-Ramírez, (2007) and Hall et al., (2014) who use standard PMMH methods. We note that the MPM sampler will also be useful for other complex statistical models, such as panel data models and stochastic differential equation mixed effects models.
The rest of the article is organised as follows. Section 2 introduces the state space model and gives some examples. Section 2.3 discusses the MPM sampler. Section 3 presents results from both simulated and real data. Section 4 concludes with a discussion of our major results and findings. The paper has an online supplement containing some further technical and empirical results.
2 Bayesian Inference for State Space Models
Notation
We use the colon notation for collections of variables, i.e., and for , . Suppose is a stochastic process, with parameter , where the are the observations and the are the latent state vectors; random variables are denoted by capital letters and their realizations by lower case letters. We consider the state space model with the density of the density of given for , and is the density of given , .
2.1 Bayesian Inference
The objective of Bayesian inference is to obtain the posterior distribution of the model parameters and the latent states , given the observations and a prior distribution ; i.e.,
| (1) |
where
is the marginal likelihood. The likelihood
can be calculated exactly using the Kalman filter for linear Gaussian state space models (LGSS) and for linear DSGE models so that posterior samples can be obtained using an MCMC sampling scheme. However, the likelihood can be estimated unbiasedly, but not computed exactly, for non-linear and non-Gaussian state space models and the non-linear DSGE models described in section 3.4.
The bootstrap particle filter (Gordon et al., , 1993) provides an unbiased estimator of the likelihood for a general state space model. Andrieu and Roberts, (2009) and Andrieu et al., (2010) show that it is possible to use this unbiased estimator of the likelihood to carry out exact Bayesian inference for the parameters of the general state space model. They call this MCMC approach pseudo marginal Metropolis-Hastings (PMMH).
The non-linear (second-order) DSGE models considered in section 3.4 lie within the class of general non-linear state space models whose state transition density is difficult to work with or cannot be expressed in closed form. In such cases, it is useful to express the model in terms of the density of its latent disturbance variables as it can be expressed in closed form. The posterior in Eq. (1) becomes
| (2) |
which Murray et al., (2013) call the disturbance state-space model. The standard state space model can be recovered from the disturbance state space model by using the deterministic function . This gives us a state trajectory from any sample . In the disturbance state-space model the target becomes the posterior distribution over the parameters , the latent noise variables and the initial state , rather than .
2.2 Standard Pseudo Marginal Metropolis-Hastings
This section outlines the standard PMMH scheme which carries out MCMC on an expanded space using an unbiased estimate of the likelihood. Our paper focuses on MCMC based on the parameters, but it is straightforward to also use it to obtain posterior inference for the unobserved states; see, e.g., Andrieu et al., (2010). Let consist of all the random variables required to compute the unbiased likelihood estimate , with the density of ; let be the prior of . The joint posterior density and is
so that
is the posterior of and because the likelihood estimate is unbiased. We can therefore sample from the posterior density by sampling and from . The subscript indicates the number of particles used to estimate the likelihood.
Let be the proposal density for with the current value and the proposal density for given . We always assume that satisfies the reversibility condition
it is clearly satisfied by the standard PMMH where . We generate a proposal from and from , and accept both proposals with probability
| (3) | |||||
The expression in Eq. (3) is identical to a standard Metropolis-Hastings algorithm, except that estimates of the likelihood at the current and proposed parameters are used. Andrieu and Roberts, (2009) show that the resulting PMMH algorithm has the correct invariant distribution regardless of the variance of the estimated likelihoods. However, the performance of the PMMH approach crucially depends on the number of particles used to estimate the likelihood. The variance of the log of the estimated likelihood should be between 1 and 3 depending on the quality of the proposal for ; see Pitt et al., (2012) and Sherlock et al., (2015). In many applications of the non-linear state space models considered in this paper, it is computationally very expensive to ensure that the variance of the log of the estimated likelihood is within the required range. Section 2.3 discusses the new PMMH sampler, which we call the multiple PMMH algorithm (MPM), that builds on and extends, the CPM of Deligiannidis et al., (2018) and BPM of Tran et al., (2016).
2.3 Multiple PMMH (MPM)
This section discusses Algorithm 1, which is the proposed multiple PMMH (MPM) method that uses multiple particle filters to obtain the estimate of the likelihood. The novel version of block-correlated PMMH that works with multiple particle filters to induce a high correlation between successive logs of the estimated likelihoods is also discussed. We now define the joint target density of and as
| (4) |
where is the likelihood estimates obtained from particle filters discussed below. We update the parameters jointly with a randomly selected block in each MCMC iteration, with for any . The selected block is updated using , where is the non-negative correlation between the random numbers and and is a standard normal vector of the same length as . This is similar to component-wise MCMC whose convergence is well established in the literature; see, e.g. Johnson et al., (2013). Using this scheme, the acceptance probability is
| (5) |
-
•
Set the initial values of arbitrarily.
-
•
Sample for , and run particle filters to estimate the likelihood as the trimmed mean of ; a 0% is the mean and a 50% trimmed mean is the median.
-
•
For each MCMC iteration , ,
-
–
Sample from the proposal density .
-
–
Choose index with probability , sample , and set .
-
–
Run particle filters to compute the estimate of likelihood .
-
–
With the probability in Eq. (5), set , , and ; otherwise, set , , and .
-
–
We now discuss approaches to obtain a likelihood estimate from multiple particle filters which we then use in the MPM algorithm. Suppose that particle filters are run in parallel. Let be the unbiased estimate of the likelihood obtained from the th particle filter, for . The first approach takes the average of the unbiased likelihood estimates from the particle filter. The resulting likelihood estimate
| (6) |
is also unbiased (Sherlock et al., 2017b, ). The second approach is to take the trimmed mean as the likelihood estimate in MPM. For example, the trimmed mean averages the middle of the likelihood values. Although the trimmed mean does not give an unbiased estimate of the likelihood, we show in section 3 that the posterior based on the trimmed means approximates the exact posterior well.
2.4 Multidimensional Euclidean Sorting Algorithm
It is important that the logs of the likelihood estimates evaluated at the current and proposed values of and are highly correlated to reduce the variance of because this helps the Markov chain to mix well. However, the standard resampling step in the particle filter introduces discontinuities which breaks down the correlation between the logs of the likelihood estimates at the current and proposed values even when the current parameters and the proposed parameters are close. Sorting the particles from smallest to largest before resampling helps to preserve the correlation between the logs of the likelihood estimates at the current and proposed values (Deligiannidis et al., , 2018). However, such simple sorting is unavailable for multidimensional state particles.
This section discusses Algorithm 2, which is the fast multidimensional Euclidean sorting algorithm used to sort the multidimensional state or disturbance particles in the particle filter algorithm described in Algorithm S1 in section S1 of the online supplement. The algorithm is written in terms of state particles, but similar steps can be implemented for the disturbance particles. The algorithm takes the particles and the normalised weights as the inputs; it outputs the sorted particles , sorted weights , and sorted indices . Let be -dimensional particles at a time for the th particle, . Let be the Euclidean distance between two multidimensional particles. The first step is to calculate the means of the multidimensional particles at time for . The first sorting index, , is the index of the multidimensional particle having the smallest value of for . Therefore, the first sorted particle is with its associated weight . We then calculate the Euclidean distance between the selected multidimensional particle and the set of all remaining multidimensional particles, , for all . The next step is to sort the particles and weights according to the Euclidean distance from smallest to largest to obtain the sorted particles , sorted weights , and sorted indices .
Algorithm 2 simplifies the sorting algorithm proposed by Choppala et al., (2016). In Choppala et al., (2016), the first sorting index is the index of the multidimensional particle having the smallest value along its first dimension. To select the second sorted index, , we need to calculate the Euclidean distance between the first selected particle and the remaining multidimensional particles. Similarly, to select the third sorted index, , we need to calculate the Euclidean distance between the second selected particle and the remaining multidimensional particles. This process is repeated times, which is expensive for a large number of particles and long time series. In contrast, Algorithm 2 only needs to calculate the Euclidean distance of the first selected particle and the remaining particles once. Deligiannidis et al., (2018) use the Hilbert sorting method of Skilling, (2004) to order the multidimensional state particles, which requires calculating the Hilbert index for each multidimensional particle and is much more expensive than Algorithm 2. Table 1 shows the CPU time (in seconds) of the three sorting methods for different numbers of particles and state dimensions . The table shows that the proposed sorting algorithm is much faster than that in Choppala et al., (2016) and the Hilbert sorting method. For example, for state dimensions and particles, Algorithm 2 is and times faster than the Choppala et al., (2016) and the Hilbert sorting methods, respectively
Input: ,
Output: sorted particles , sorted weights , sorted indices
-
•
Calculate the means of the multidimensional particles at time for . The first sorting index, , is the index of the multidimensional particle having the smallest value of for . The first selected particle is with its associated weight .
-
•
Calculate the Euclidean distance between the selected multidimensional particle and the set of all remaining multidimensional particles, , for .
-
•
Sort the particles and weights according to the Euclidean distance from smallest to largest to obtain for . The sorted particles and for .
| actual | |||||
|---|---|---|---|---|---|
| 10 | 500 | 1.00 | 30.50 | 87.50 | 0.0002 |
| 1000 | 1.00 | 66.67 | 115.00 | 0.0003 | |
| 2000 | 1.00 | 172.40 | 141.00 | 0.0005 | |
| 30 | 500 | 1.00 | 39.67 | 141.00 | 0.0003 |
| 1000 | 1.00 | 113.00 | 214.00 | 0.0004 | |
| 2000 | 1.00 | 289.80 | 335.00 | 0.0005 |
2.5 The Auxiliary Disturbance Particle Filter
This section discusses the auxiliary disturbance particle filter we use to obtain the estimates of the likelihood in the MPM sampler described in section 2.3. It is particularly useful for state space models when the state dimension is substantially bigger than the disturbance dimension and the state transition density is intractable. Suppose that , where is the initial state vector with density , and , where is a vector of normally distributed latent noise with density Murray et al., (2013) express the standard state-space model in terms of the latent noise variables , and call
the disturbance state-space model. We note that the conditional distribution of depends on all the latent error variables,
We now discuss the proposal for used in the disturbance filter. The defensive mixture proposal density (Hesterberg, , 1995) is
| (7) |
where is the vector random variable used to generate the particles given . If the observation density is bounded, then Eq. (7) guarantees that the weights are bounded in the disturbance particle filter algorithm defined in Eq. (S2) of section S1 of the online supplement. In practice, we take and set in all the examples in section 3; see algorithm 4. If in Eq. (7), then is the bootstrap disturbance particle filter. However, the empirical performance of this filter is usually poor because the resulting likelihood estimate is too variable.
Algorithm 4 discusses how we obtain and the covariance matrix , for , at each iteration of the MPM algorithm. It is computationally cheap to obtain and for because they are obtained from the output of the disturbance particle filters run at each MCMC iteration and the ancestral tracing method is fast. The proposal mean and the covariance matrix , for , obtained at iteration are used to estimate the likelihood at the next iteration. At the first iteration, we use the bootstrap filter to initialise the mean and the covariance matrix , for . Algorithm 3 gives the MPM algorithm with ADPF.
-
•
Set the initial values of arbitrarily.
-
•
Sample for , run (disturbance) particle filters to estimate the likelihood as the trimmed mean of ; a 0% trimmed mean is the mean and a 50% trimmed mean is the median, and run the algorithm 4 to construct the (initial) proposal for the auxiliary disturbance particle filter.
-
•
For each MCMC iteration , ,
-
–
Sample from the proposal density .
-
–
Choose index with probability , sample , and set .
-
–
Run (disturbance) particle filters to compute the estimate of likelihood
-
–
Run algorithm 4 to construct the proposal for the auxiliary disturbance particle filter at iteration .
-
–
With the probability in Eq. (5), set , , and ; otherwise, set , , and .
-
–
Input: the number of particle filters , the number of particles for each particle filter , particles , weights , and ancestor indices .
Output: the mean and the covariance matrix , for .
-
1.
Given the particles with weights and ancestor indices from the output of the disturbance particle filters, the ancestral tracing algorithm of Kitagawa, (1996) is used to sample from particle approximations from the smoothing distribution . This consists of sampling one particle trajectory from each of the particle filters in parallel. For each particle filter, we first sample an index with the probability , tracing back its ancestral lineage and choosing the particle trajectory for .
-
2.
The mean and the covariance matrix are
3 Examples
Section 3.1 discusses the inefficiency measures used to compare the performance of different particle filters or PMMH samplers used in our article. Section 3.2 investigates empirically the performance of the proposed methods for estimating a high-dimensional linear Gaussian state space model. Section 3.3 discusses a multivariate stochastic volatility in mean model with GARCH diffusion processes. Sections 3.4.1 and 3.4.2 apply the proposed samplers to estimate non-linear small scale DSGE and medium scale DSGE models, respectively.
3.1 Definitions of Inefficiency
We use the inefficiency factor (IF) (also called the integrated autocorrelation time)
to measure the inefficiency of a PMMH sampler at estimating the posterior expectation of a univariate function of ; here, is the th autocorrelation of the iterates in the MCMC chain after it has converged to its stationary distribution. We estimate the using the CODA R package of Plummer et al., (2006). A low value of the estimate suggests that the Markov chain mixes well. Our measure of the inefficiency of a PMMH sampler that takes computing time (CT) into account for a given parameter based on is the time normalised inefficiency factor (TNIF) defined as For a given sampler, let and be the maximum and mean of the IF values over all the parameters in the model. The relative time normalized inefficiency factor (RTNIF) is a measure of the TNIF relative to the benchmark method, where the benchmark method depends on the example.
3.2 Linear Gaussian State Space Model
This section investigates (1) the efficiency of different approaches for obtaining likelihood estimates from particle filters, and (2) the performance of different PMMH samplers for estimating a single parameter , regardless of the dimension of the states. We consider the linear Gaussian state space model discussed in Guarniero et al., (2017) and Deligiannidis et al., (2018), where and are valued with
with , , , and for ; the true value of is . Although it is possible to use the more efficient fully adapted particle filter (Pitt et al., , 2012), we use the bootstrap filter for all methods to show that the proposed methods are useful for models where it is difficult to use better particle filter algorithms.
The first study compares the 0%, 5%, 10%, 25%, and 50% trimmed means of the likelihood estimates obtained from particle filters. The simulated data is generated from the model above with and time periods and and dimensions.
| actual | ||||||||
|---|---|---|---|---|---|---|---|---|
| 100 | 1 | |||||||
| 20 | ||||||||
| 1000 | ||||||||
| 250 | 1 | |||||||
| 20 | ||||||||
| 100 | ||||||||
| 1000 | ||||||||
| 1000 | 1 | |||||||
| 20 | ||||||||
| 100 | ||||||||
| 1000 |
Table 2 shows the variance of the log of the estimated likelihood obtained by using the five estimators of the likelihood for the dimensional linear Gaussian state space model with time periods. The table shows that: (a) there is no substantial reduction in the variance of the log of the estimated likelihood for the mean (0% trimmed mean). For example, the variance decreases by only a factor of times when increases from to when . (2) The 5%, 10%, 25%, and 50% trimmed means of the individual likelihood estimates decrease the variance substantially as and/or increase. The 25% and 50% trimmed mean estimates have the smallest variance for all cases. Similar results are obtained for with and and with ; see tables S3, S4, and S5 in section S4 of the online supplement.
We now examine empirically the ability of the proposed MPM samplers to maintain the correlation between successive values of the log of the estimated likelihood for the 10 dimensional linear Gaussian state space model with . We ran the different MPM approaches for iterations holding the current parameter at and the proposed parameter at . At each iteration we generated , where and and obtained and for the MPM approaches and computed their sample correlations.
Figure S2 in Section S4 of the online supplement reports the correlation estimates of the log of estimated likelihood obtained using different MPM approaches. The figure show that: (1) when the current and proposed values of the parameters are equal to , all MPM methods maintain a high correlation between the logs of the estimated likelihoods. The estimated correlations between logs of the estimated likelihoods when the number of particle filters is 100 are about 0.99; (2) when the current parameter and the proposed parameter are (slightly) different, the MPM methods can still maintain some of the correlations between the log of the estimated likelihoods. The MPM methods with 25% and 50% trimmed means of the likelihood perform the best to maintain the correlation between the logs of estimated likelihoods.
We now compare the efficiency of different sampling schemes for estimating the parameter of the linear Gaussian state space model. In all examples, we run the samplers for iterations, with the initial iterations discarded as warm up. The particle filter and the parameter samplers are implemented in Matlab running on CPU cores, a high performance computer cluster. The optimal number of CPU cores required for the MPM algorithm is equal to the number of particle filters , which means the properties of the sampler can be easily tuned to provide maximum parallel efficiency on a large range of hardware. The adaptive random walk proposal of Roberts and Rosenthal, (2009) is used for all samplers.
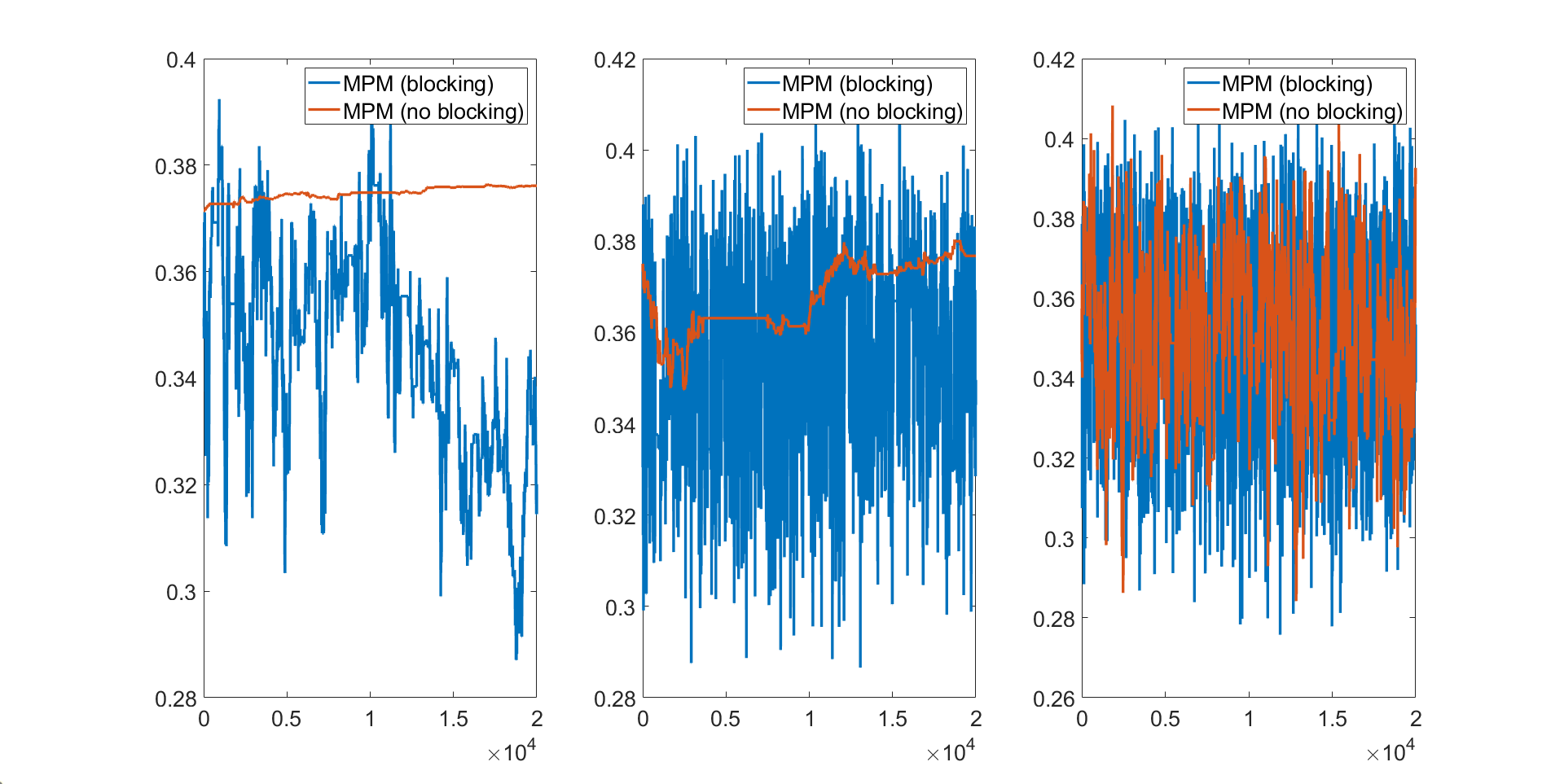
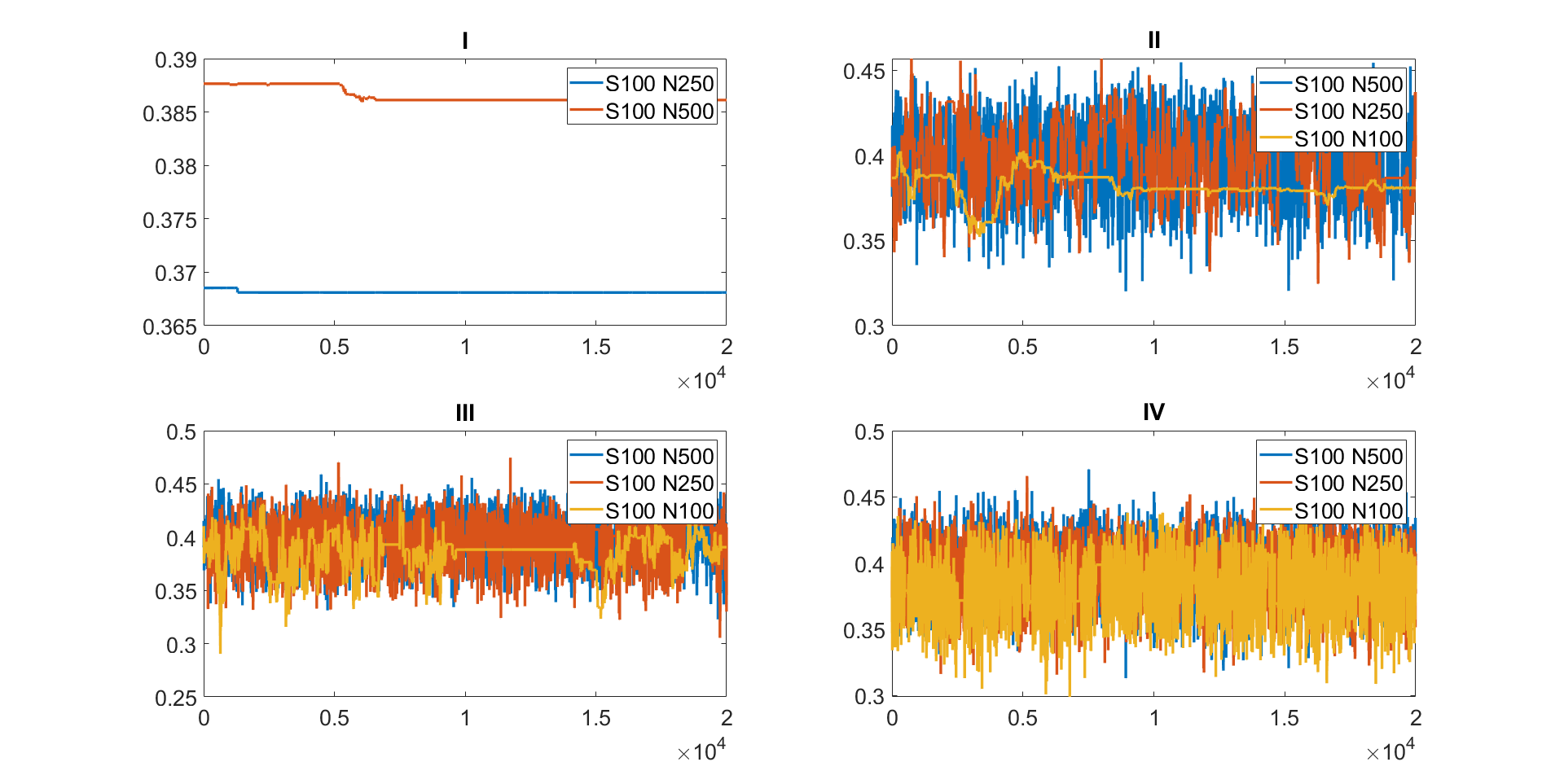
Figure 2 shows the trace plots of the parameter estimated using the MPM algorithm with the different trimmed means for estimating the 10 dimensional linear Gaussian state space model with . The figure shows that: (1) the MCMC chain gets stuck for the 5% trimmed mean approach with and and and for the 10% trimmed mean approach with and ; (2) the 10% trimmed mean approach requires at least and to make the MCMC chain mix well; (3) the 25% trimmed mean approach is the most efficient sampler as its MCMC chain does not get stuck even with and . Figure 1 compares the MPM algorithms with and without blocking with and for estimating the 10 dimensional linear Gaussian state space model with . The figure shows that the MPM (no blocking) with 5% and 10% trimmed means get stuck and the MPM (no blocking) with 25% trimmed means mixes poorly. The of the MPM (blocking) with 25% trimmed mean is times smaller than the MPM (no blocking) with 25% trimmed mean. All three panels show that the MPM (blocking) algorithms using trimmed means perform better than the MPM (no blocking). This suggests the usefulness of the MPM (blocking) sampling scheme.
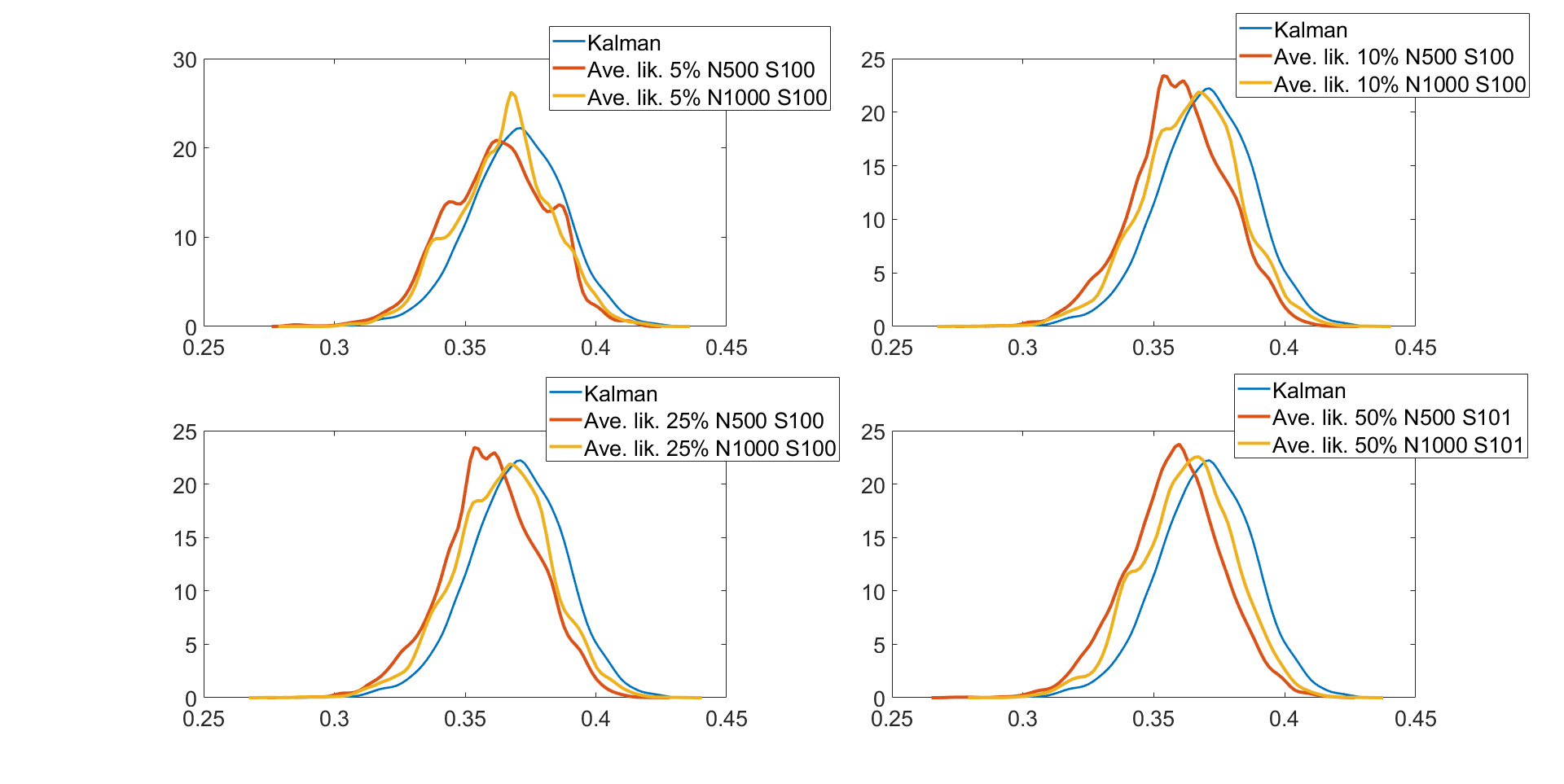
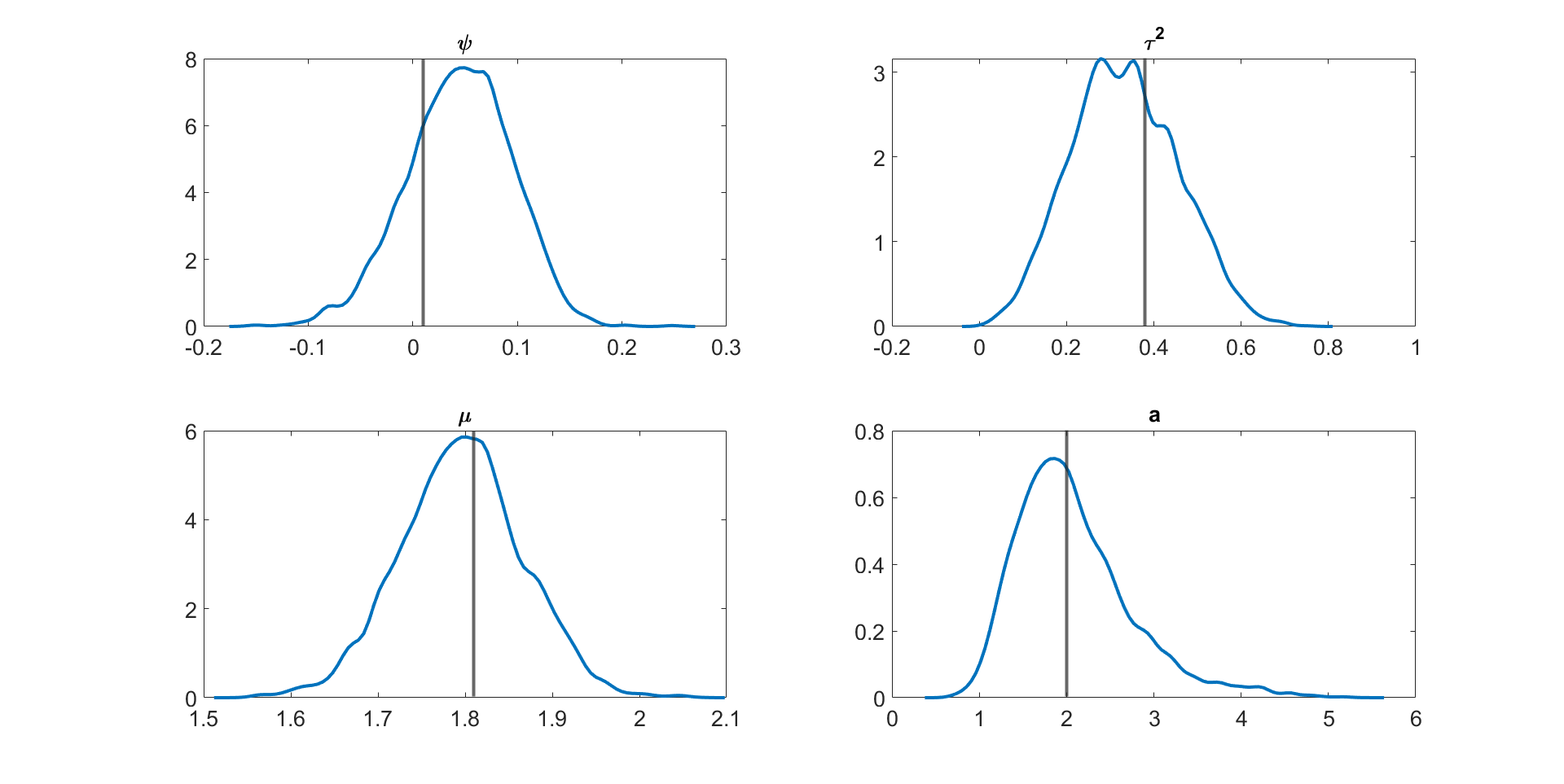
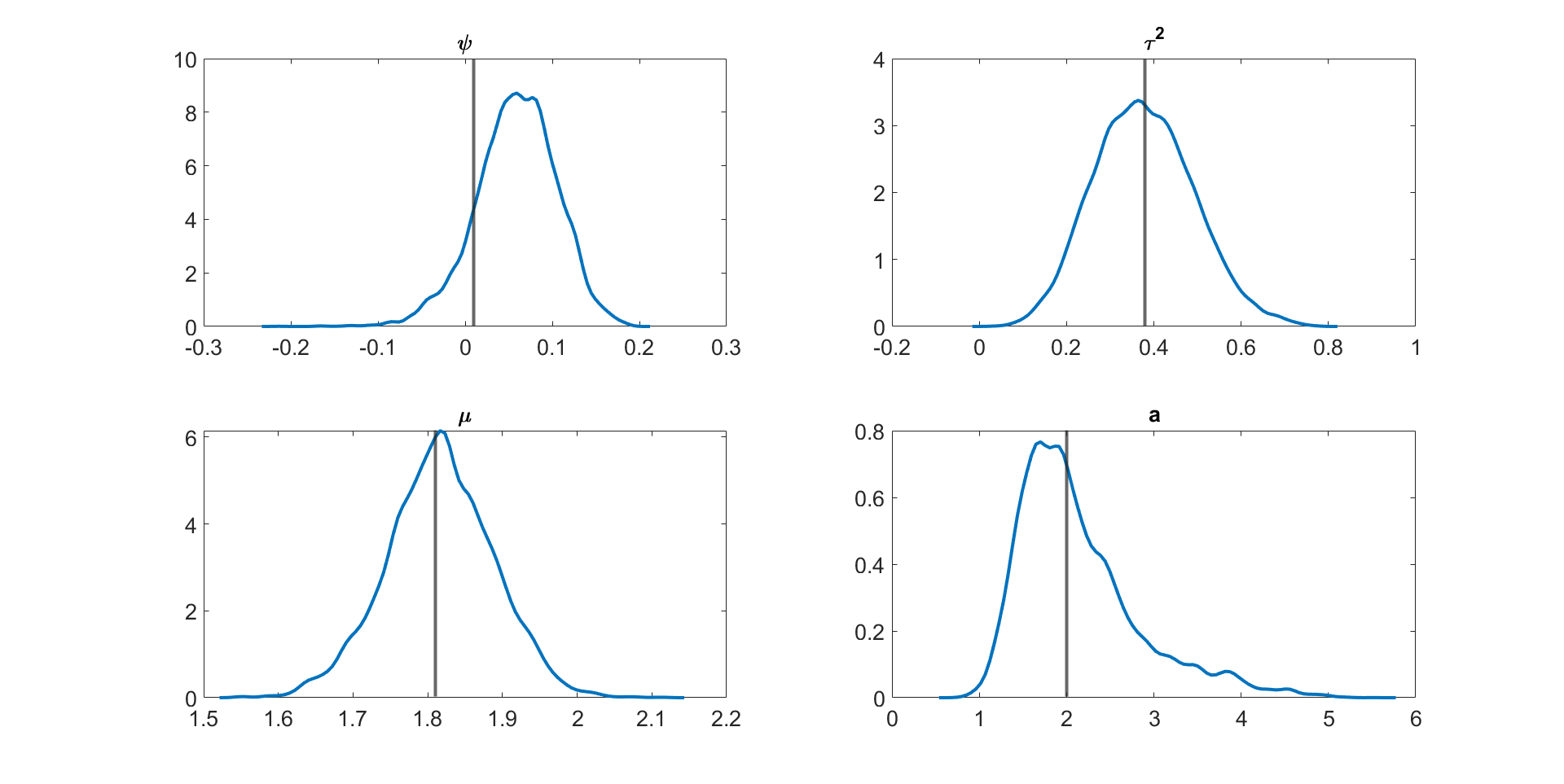
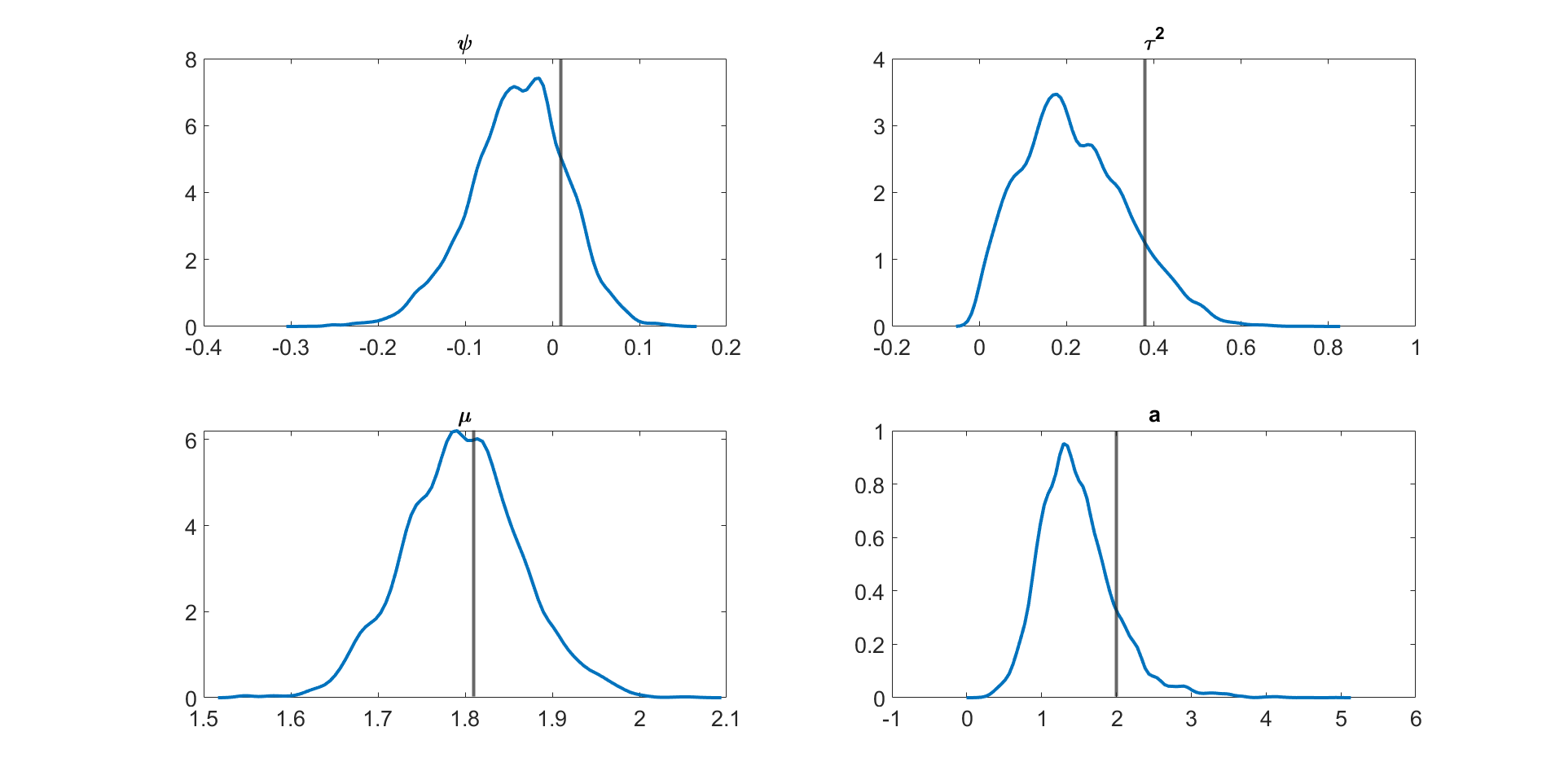
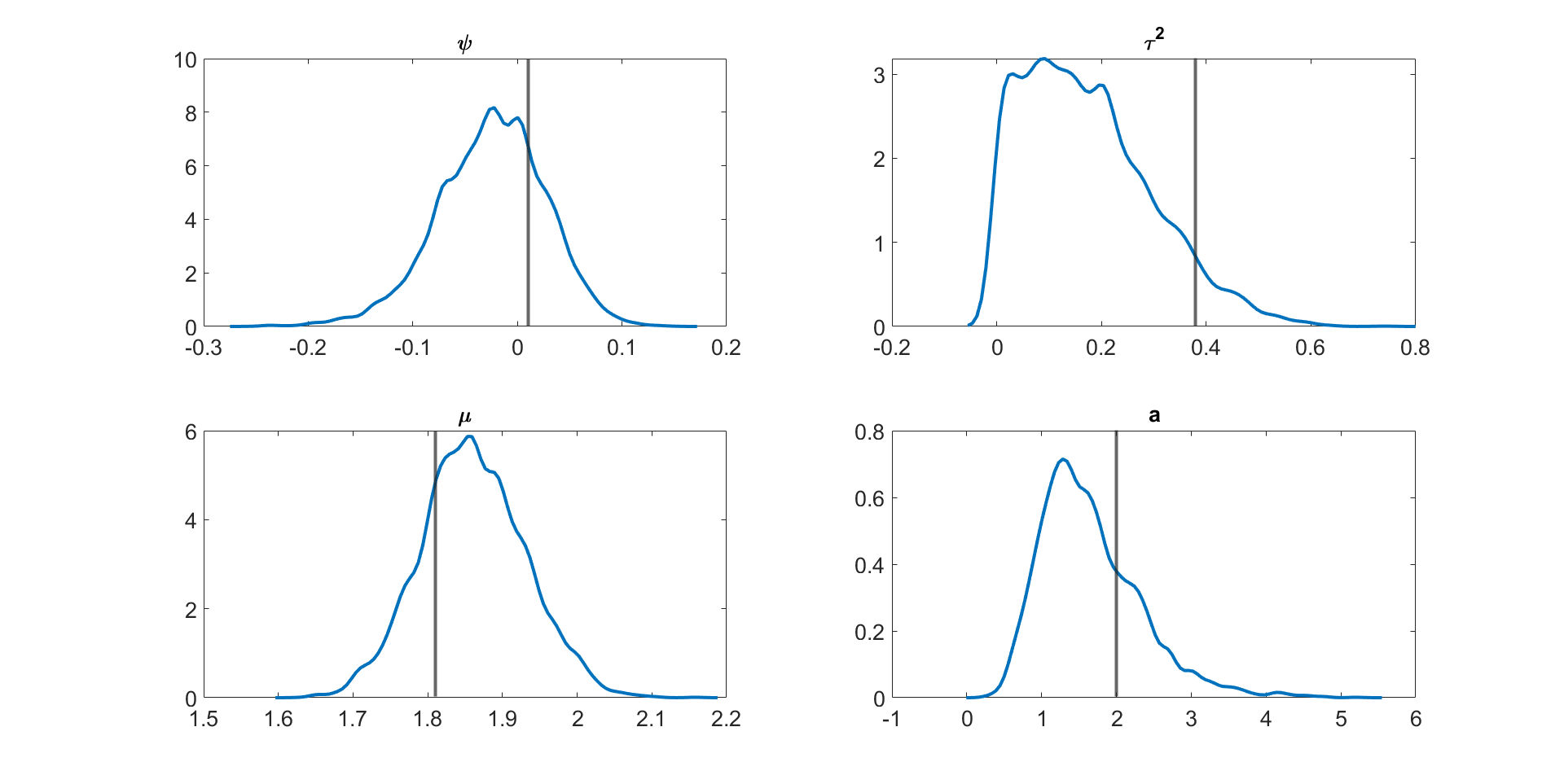
Table 3 shows the , , and values for the parameter in the linear Gaussian state space model with dimensions and time periods estimated using the following five different MCMC samplers: (1) the correlated PMMH of Deligiannidis et al., (2018), (2) the MPM with 5% trimmed mean, (3) the MPM with 10% trimmed mean, (4) the MPM with 25% trimmed mean, and (5) the MPM with 50% trimmed mean. In this paper, instead of using the Hilbert sorting method, we implement the correlated PMMH using the fast multidimensional Euclidean sorting method in section 2.4. The computing time reported in the table is the time to run a single particle filter for the CPM and particle filters for the MPM approach. The table shows the following points. (1) The correlated PMMH requires more than particles to improve the mixing of the MCMC chain for the parameter . (2) The CPU time for running a single particle filter with particles is times higher than running multiple particle filters with and . The MPM method can be much faster than the CPM method if it is run using high-performance computing with a large number of cores. (3) The MPM allows us to use much smaller number of particles for each independent PF and these multiple PFs can be run independently. (4) The values for the parameter estimated using the correlated PMMH with particles is , , , and times larger than the 5%, 10%, 25%, and 50% trimmed means approaches with and particles, respectively. (5) In terms of , the 5%, 10%, 25%, and 50% trimmed means with and are , , , and times smaller than the correlated PMMH with particles. (6) The best sampler for this example is the 50% trimmed mean approach with and particles. Table LABEL:tabledim10T200 in section S4 of the online supplement gives similar results for the 10 dimensional linear Gaussian state space model with . Figure 3 shows the kernel density estimates of the parameter estimated using Metropolis-Hastings algorithm with the (exact) Kalman filter method and the MPM algorithm with 5%, 10%, 25%, and 50% trimmed means of the likelihood. The figure shows the approximate posteriors obtained by various approaches using trimmed means are very close to the true posterior. Similar results are obtained for the case dimensions and time periods given in Figure S1 in Section S4 of the online supplement. Figure S1 also shows that the approximate posterior obtained using the MPM with trimmed mean of the likelihood is very close to the exact posterior obtained using the correlated PMMH.
In summary, the example suggests that: (1) for a high dimensional state space model, there is no substantial reduction in the variance of the log of the estimated likelihood for the method which uses the average of the likelihood from particle filters when and/or increases. Methods that use trimmed means of the likelihood reduce the variance substantially when and/or increases; (2) the 25% and 50% trimmed means approaches give the smallest variance of the log of the estimated likelihood for all cases; (3) the MPM method with 50% trimmed mean is best at maintaining the correlation between the logs of the estimated likelihoods in successive iterates; (4) the MPM (blocking) method is more efficient than the MPM (no blocking) for the same values of and ; (5) the approximate approaches that use the trimmed means of the likelihood gives accurate approximations to the true posterior; (6) the best sampler for estimating the 10 dimensional linear Gaussian state space model with is the 50% trimmed mean approach with and particles; (7) the MPM allows us to use much smaller number of particles for each independent PF and these multiple PFs can be run independently. These approaches can be made much faster if they are run using a high-performance computer cluster with a large number of cores.
.
| I | II | III | IV | V | V actual | ||||||
| N | 50000 | 250 | 500 | 250 | 500 | 250 | 500 | 250 | 500 | 250 | 500 |
| S | 1 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| 50.73 | 88.09 | 4.59 | 3.03 | 1.21 | 1.40 | 1.10 | 1.00 | 0.90 | 9.98 | 9.00 | |
| CT | 8.18 | 1.00 | 2.00 | 1.00 | 2.00 | 1.00 | 2.00 | 1.00 | 2.00 | 0.99 | 1.98 |
| 415.08 | 88.10 | 9.17 | 3.03 | 2.42 | 1.40 | 2.20 | 1.00 | 1.80 | 9.88 | 17.82 | |
3.3 Multivariate Stochastic Volatility in Mean Model
This section investigates the performance of the proposed MPM samplers for estimating large multivariate stochastic volatility in mean models (see, e.g., Carriero et al., , 2018; Cross et al., , 2021), where each of the log volatility processes follows a GARCH (Generalized Autoregressive Conditional Heteroskedasticity) diffusion process (Shephard et al., , 2004). The GARCH diffusion model does not have a closed form state transition density, making it challenging to estimate using the Gibbs type MCMC sampler used in Cross et al., (2021). It is well-known that the Gibbs sampler is inefficient for generating parameters for a diffusion process, especially for the variance parameter (Stramer and Bognar, , 2011). Conversely, MPM samplers can efficiently estimate models with non-closed form state transition densities, making them well-suited for the GARCH diffusion model. This section demonstrates that MPM samplers can estimate this model efficiently and overcome the limitations of the Gibbs sampler.
Suppose that is a vector of daily stock prices and define as the log-return of the stocks. Let be the log-volatility process of the th stock at time . We also define, and . The model for is
| (8) |
where is a matrix that captures the effects of log-volatilities on the levels of the variables. The time-varying error covariance matrix depends on the unobserved latent variables such that
| (9) |
Each log-volatility is assumed to follow a continuous time GARCH diffusion process (Shephard et al., , 2004) satisfying
| (10) |
for , where the are independent Wiener processes. The following Euler scheme approximates the evolution of the log-volatilities in (10) by placing evenly spaced points between times and . We denote the intermediate volatility components by , and it is convenient to set and . The equation for the Euler evolution, starting at is (see, for example, Stramer and Bognar, (2011), pg. 234)
| (11) |
for , where . The initial state of is assumed normally distributed for . For this example, we assume for simplicity that the parameters , , and are the same across all stocks and for . This gives the same number of parameters regardless of the dimension of the stock returns so that we can focus on comparing different PMMH samplers.
We first report on a simulation study for the above model. We simulated ten independent datasets from the model described above with dimensions and observations. The true parameters are , , , and . The priors are , , , and . These prior densities are non-informative and cover almost all possible values in practice. We use latent points for the Euler approximations of the state transition densities. For each dataset, we run the MPM sampler with the 25% trimmed mean approach for iterations; the initial iterations are discarded as warm up. The particle filter and the parameter samplers are implemented in Matlab running on 20 CPU cores, a high performance computer cluster. The adaptive random walk proposal of Roberts and Rosenthal, (2009) is used for all samplers.
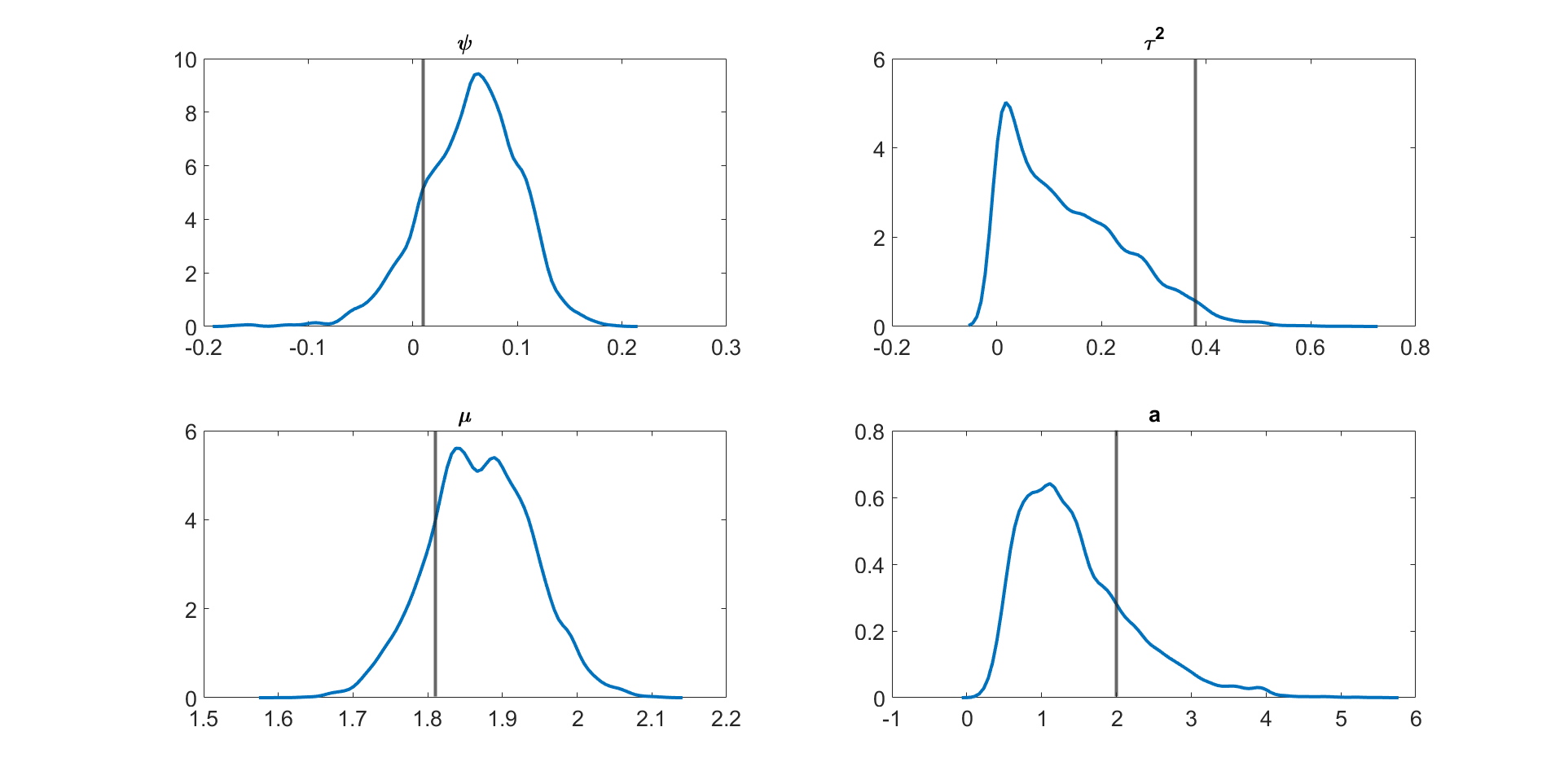
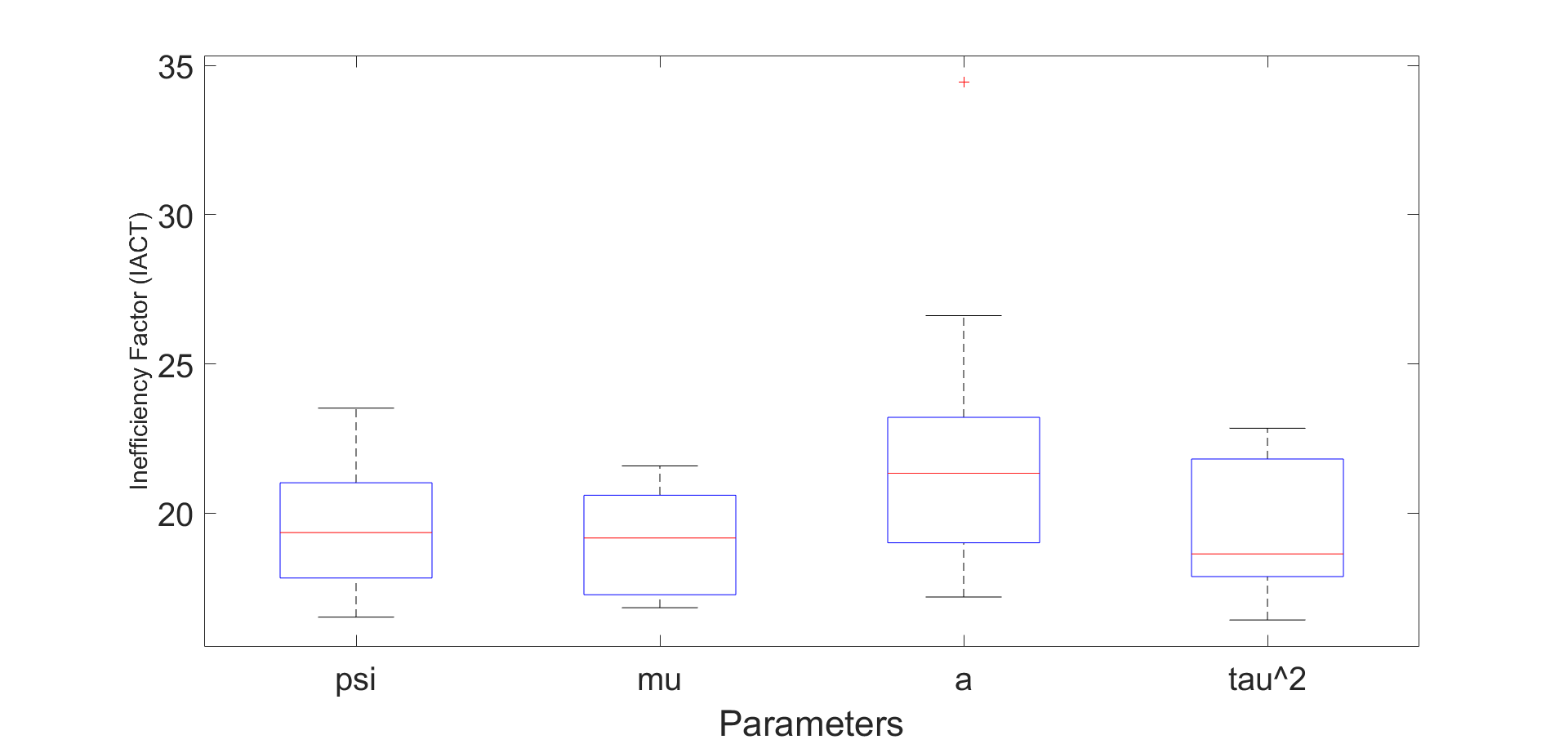
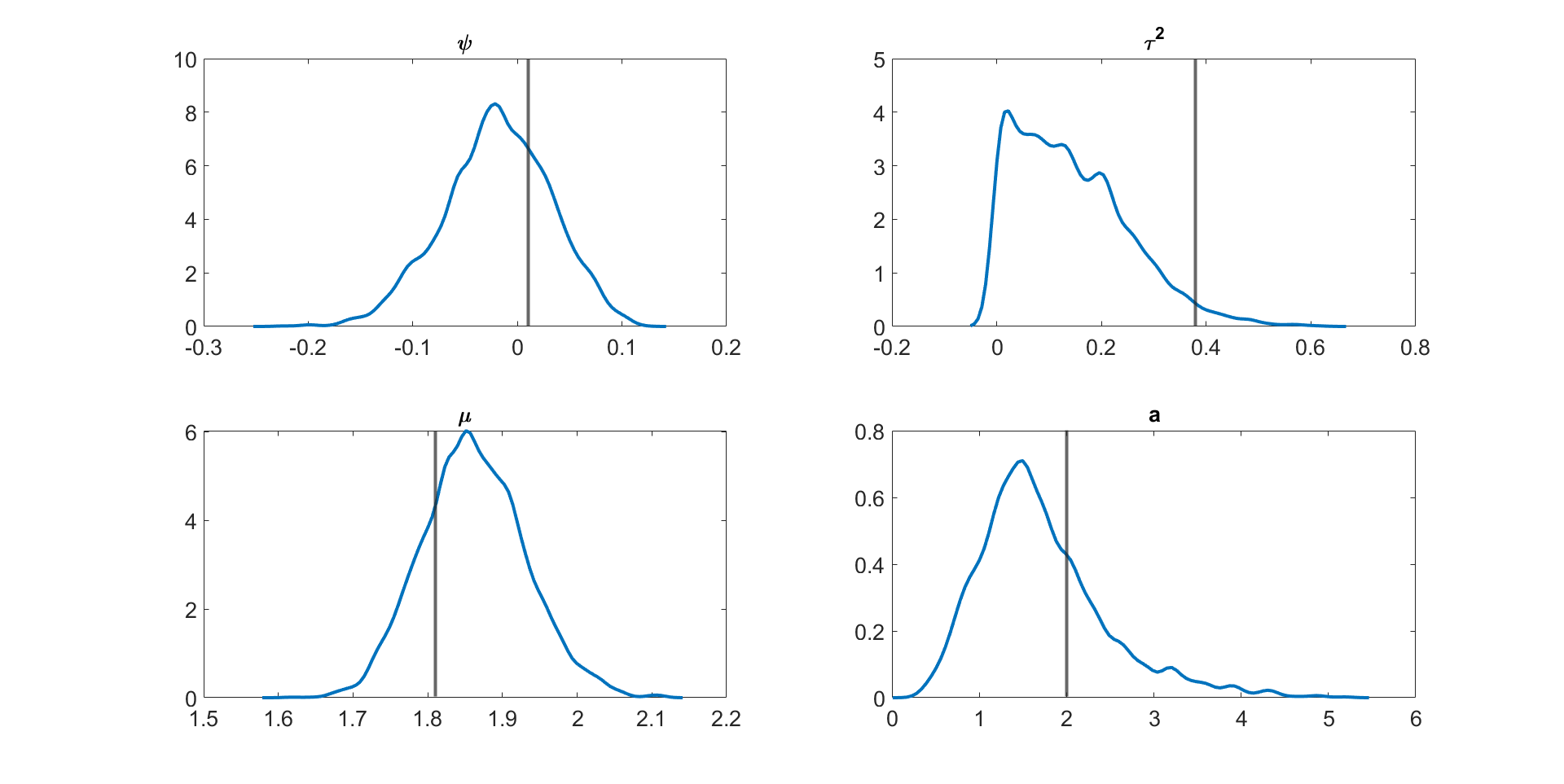
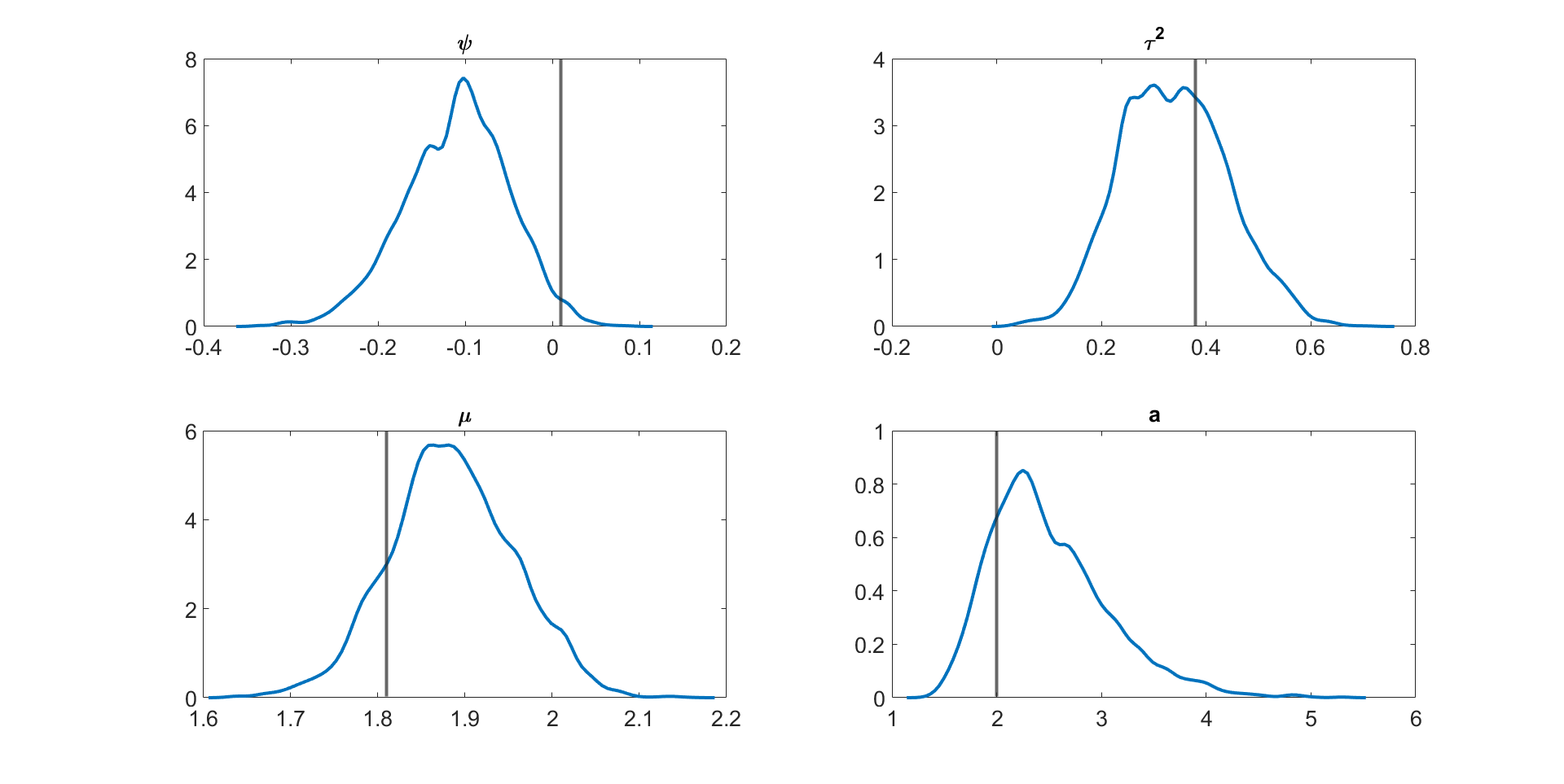
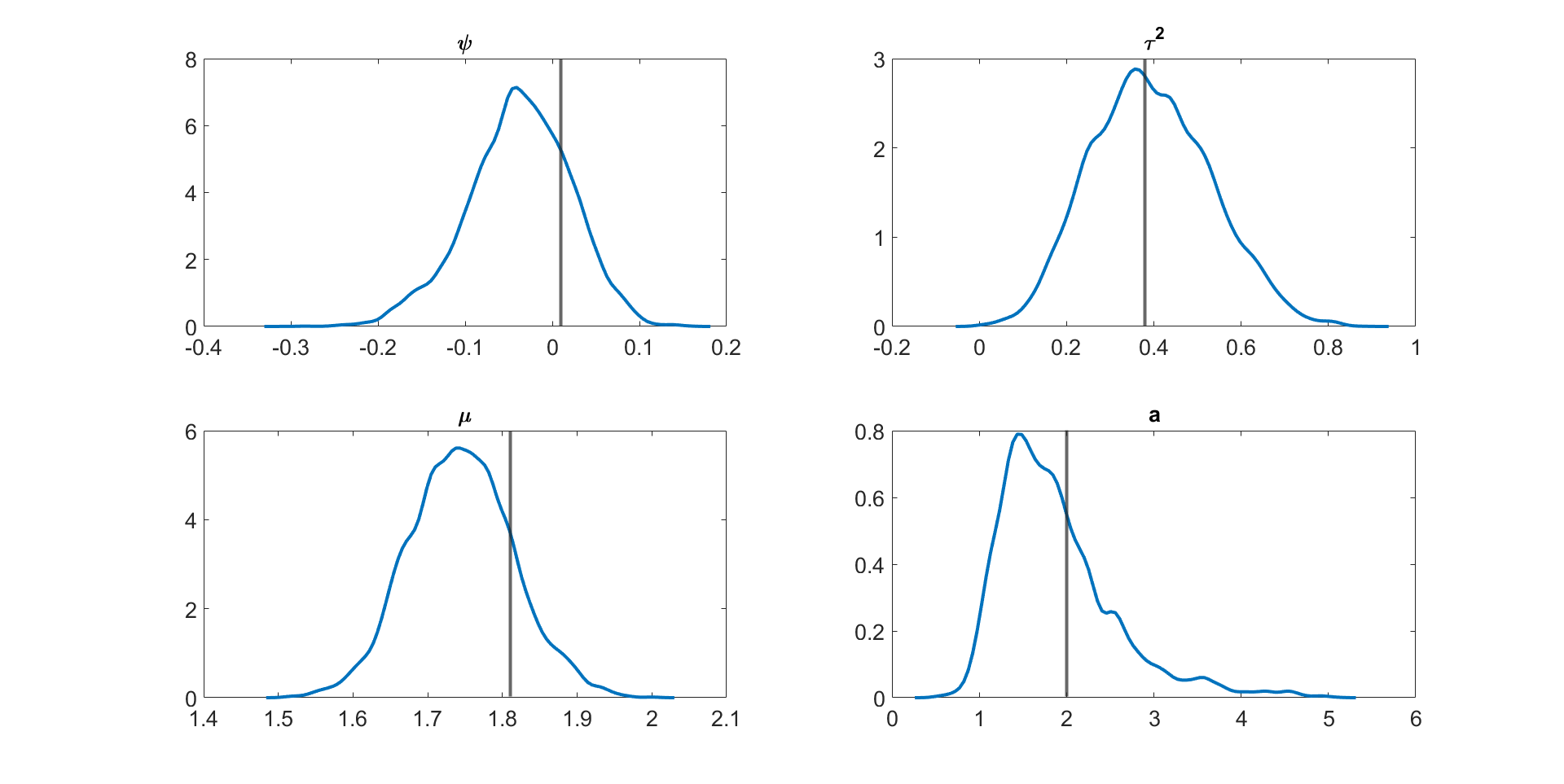
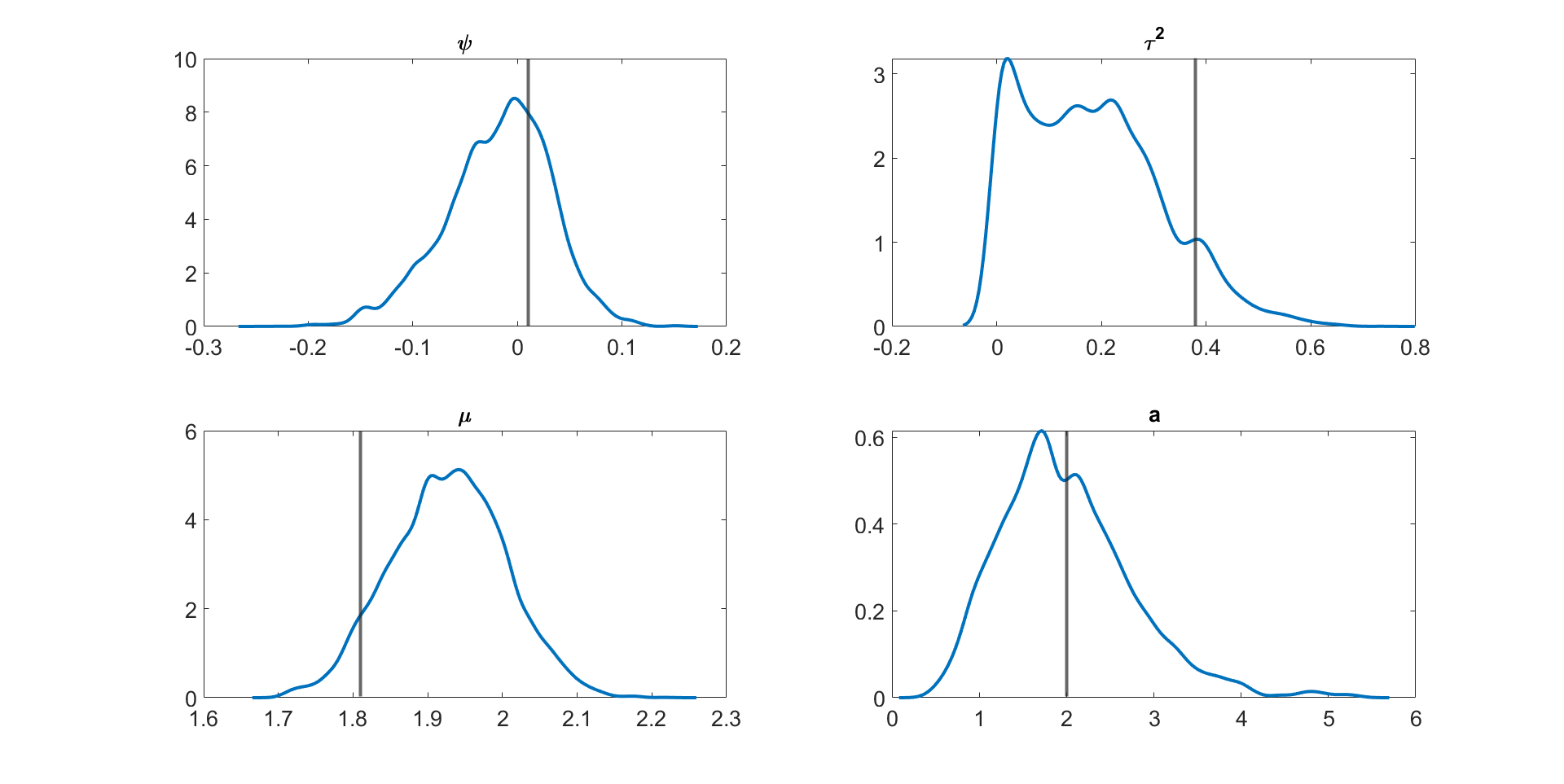
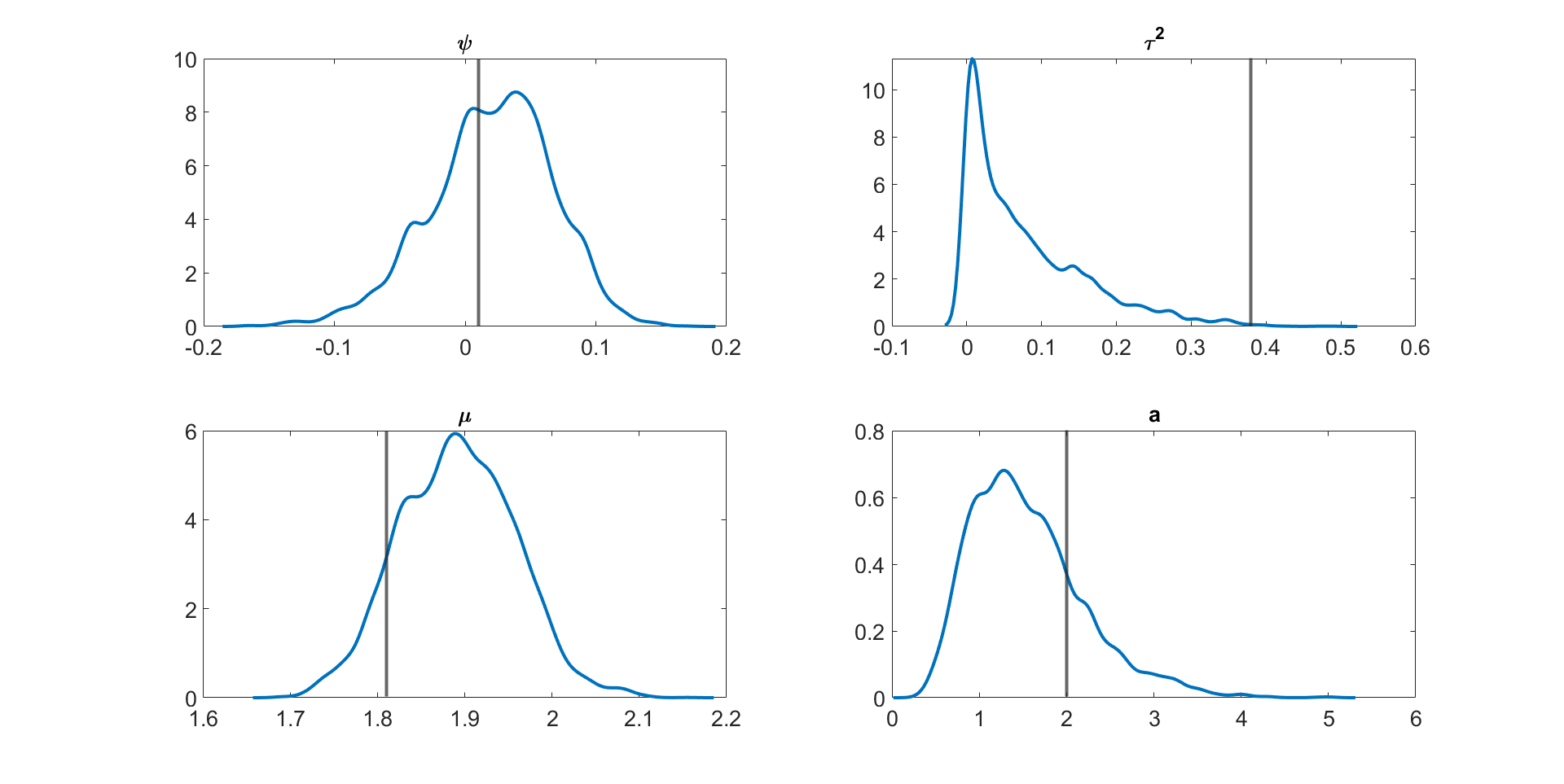
Figure 4 and Figures S3 to S11 in section S5 of the online supplement show the kernel density estimates of the parameters of the multivariate stochastic volatility in mean model described above estimated by the MPM sampler ( and ) using a 25% trimmed mean; the vertical lines show the true parameter values. The figures show that the model parameters are accurately estimated. Figure 5 shows the inefficiency factors () of the parameters over 10 simulated datasets with dimensions and time periods. The results suggest that the MPM sampler with only particles and particle filters is efficient because the values of the parameters are reasonably small.
We now apply the methods to a sample of daily US industry stock returns data obtained from the Kenneth French website111http://mba.tuck.dartmouth.edu/pages/faculty/ken.french/datalibrary.html, using a sample from January 4th, 2021 to the 26th of May, 2021, a total of 100 observations.
Table 4 shows the , , and for the parameters of the 20 dimensional multivariate stochastic volatility in mean model estimated using (1) the correlated PMMH, (2) the MPM sampler with the 25% trimmed mean of the likelihood estimate, and (3) the MPM sampler with the 50% trimmed mean of the likelihood estimate. The table shows that: (1) the MCMC chain obtained using the correlated PMMH with still gets stuck; (2) the CPU time for the correlated PMMH with particles is times slower than the MPM algorithm with and ; (3) the MPM sampler with and is less efficient than the MPM sampler with and . The MPM sampler with and can be made more efficient by running it on a high-performance computer cluster with many cores; (4) the best sampler in terms of and for estimating the 20 dimensional multivariate stochastic volatility in mean model is the MPM sampler with a 50% trimmed mean with and .
Table 5 shows the , , and for the parameters of the dimensional multivariate stochastic volatility in the mean model estimated using: (1) the MPM sampler with the 25% trimmed mean of the likelihood, and (2) the MPM sampler with 50% trimmed mean of the likelihood. We do not consider the correlated PMMH as it is very expensive to run for this high dimensional model. The table shows that (1) increasing the number of particle filters from to reduces the , but increases the computational time substantially. However, the computational time can be reduced by using a high performance computer cluster with a larger number of cores; (2) the MPM sampler with and is less efficient than the MPM sampler with and . We recommend that if there is access to large computing resources, then the number of particle filters should be increased while keeping the number of particles in each particle filter reasonably small.
| Param. | I | II | III | ||
|---|---|---|---|---|---|
| N | 100000 | 250 | 100 | 250 | 100 |
| S | 1 | 100 | 250 | 100 | 250 |
| NA | |||||
| NA | |||||
| NA | |||||
| NA | |||||
| NA | |||||
| NA | |||||
| NA | |||||
| NA | |||||
| NA | |||||
| NA | |||||
| Time | 47.65 | 1.78 | 1.85 | 1.78 | 1.85 |
| Param. | I | II | |||
|---|---|---|---|---|---|
| N | 250 | 250 | 500 | 250 | 250 |
| S | 100 | 200 | 100 | 100 | 200 |
| Time | 2.85 | 7.06 | 8.71 | 2.85 | 7.06 |
3.4 DSGE models
In this section, we evaluate the effectiveness of the MPM samplers for estimating two non-linear DSGE models: the small scale and medium scale DSGE models as detailed in sections S8 and S9 of the online supplement. Due to the large dimension of the states compared to the dimension of the disturbances in these state space models, we employ the disturbance filter method introduced in section 2.5.
The state transition densities of the two non-linear DSGE models are intractable. Section S3 of the online supplement describes the state space representation of these models, which are solved using Dynare.
3.4.1 Nonlinear Small Scale DSGE Model
This section reports on how well a number of PMMH samplers of interest estimate the parameters of the nonlinear (second order) small scale DSGE model. The small scale DSGE model follows the setting in Herbst and Schorfheide, (2019) with nominal rigidities through price adjustment costs following Rotemberg, (1982), and three structural shocks. There are state variables, control variables ( variables combining the state and control variables) and exogenous shocks in the model. We estimate this model using observables, which means that the dimensions of , the state vector and the disturbance vector are , , and , respectively. Section S8 of the online supplement describes the model.
In this section, we use the delayed acceptance version of the MPM algorithm, calling it “delayed acceptance multiple PMMH” (DA-MPM), to speed up the computation. The delayed acceptance sampler (Christen and Fox, , 2005) avoids computing the expensive likelihood estimate if it is likely that the proposed draw will ultimately be rejected. The first accept-reject stage uses a cheap (or deterministic) approximation to the likelihood instead of the expensive likelihood estimate in the MH acceptance ratio. The particle filter is then used to estimate the likelihood only for a proposal that is accepted in the first stage; a second accept-reject stage ensures that detailed balance is satisfied with respect to the true posterior. We use the likelihood obtained from the central difference Kalman filter (CDKF) proposed by Norgaard et al., (2000) in the first accept-reject stage of the delayed acceptance scheme. Section S2 of the online supplement gives further details. The dimension of states is usually much larger than the dimension of the disturbances for the DSGE models. Two different sorting methods are also considered. The first sorts the state particles and the second sorts the disturbance particles using the sorting algorithm in section 2.4.
The PMMH samplers considered are: (1) The MPM (0% trimmed mean) with the auxiliary disturbance particle filter (ADPF), disturbance sorting, and the correlation between random numbers used in estimating the log of estimated likelihoods set to ; (2) the MPM (10% trimmed mean) with the ADPF, disturbance sorting, and the ; (3) the MPM (25% trimmed mean) with the ADPF, disturbance sorting, and the ; (4) the MPM (25% trimmed mean) with the ADPF, disturbance sorting, and , (5) the MPM (25% trimmed mean) with the ADPF, state sorting, and ; (6) the delayed acceptance MPM (DA-MPM) (25% trimmed mean) with ADPF, disturbance sorting, and the ; (7) the MPM (50% trimmed mean) with the ADPF, disturbance sorting, and the ; (8) the MPM (0% trimmed mean) with the bootstrap particle filter, disturbance sorting, and the ; (9) the correlated PMMH with , the bootstrap particle filter, and disturbance sorting. Each sampler ran for iterations, with the initial iterations discarded as burn-in. We use the adaptive random walk proposal of Roberts and Rosenthal, (2009) for and the adaptive scaling approach of Garthwaite et al., (2015) to tune the Metropolis-Hastings acceptance probability to . Section S8 of the online supplement gives details on model specifications and model parameters. We include measurement error in the observation equation. The measurement error variances are estimated together with other parameters. All the samplers ran on a high performance computer cluster with 20 CPU cores. The real dataset is obtained from Herbst and Schorfheide, (2019), using data from 1983Q1 to 2013Q4, which includes the Great Recession with a total of observations for each series.
Table 6 reports the relative time normalised inefficiency factor () of a PMMH sampler relative to the DA-MPM (25% trimmed mean) with the ADPF, disturbance sorting, and for the non-linear small scale models with observations. The computing time reported in the table is the time to run a single particle filter for the CPM and particle filters for the MPM approach. The table shows that: (1) The MPM sampler (0% trimmed mean) with the ADPF, disturbance sorting, , and particles is more efficient than the MPM sampler (0% trimmed mean) with the bootstrap particle filter, disturbance sorting, , and particles with the MCMC chain obtained by the latter getting stuck. (2) The running time taken the MPM method with particles filters, each with particles and disturbance sorting is times faster than the CPM with particles. (3) In terms of , the performance of MPM samplers with 0%, 10%, 25%, and 50% trimmed means, ADPF, disturbance sorting, and are , , , and times more efficient respectively, than the correlated PMMH with particles. (4) In terms of , the MPM (25% trimmed mean) with disturbance sorting, and is times more efficient than the MPM (25% trimmed mean) method with state sorting method and performs similarly to the MPM (25% trimmed mean) approach with ADPF, disturbance sorting, and . (5) The delayed acceptance MPM (25% trimmed mean) is slightly more efficient than the MPM (25% trimmed mean) approach. The delayed acceptance algorithm is times faster on average because the target Metropolis-Hastings acceptance probability is set to using the Garthwaite et al., (2015) approach, but it has higher maximum value. Table S8 in section S6 of the online supplement gives the details. (6) It is possible to use the tempered particle filter of Herbst and Schorfheide, (2019) within the MPM algorithm. However, the TPF is computationally expensive because of the tempering iterations and the random walk Metropolis-Hastings mutation steps. In summary, the best sampler with the smallest and is the delayed acceptance MPM (DA-MPM) (25% trimmed mean) with ADPF, disturbance sorting, and .
| I | II | III | IV | V | VI | VII | VIII | IX | VI actual | |
| S | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 1 | 100 |
| N | 250 | 100 | 100 | 100 | 100 | 100 | 100 | 250 | 20000 | 100 |
| NA | ||||||||||
| 1.26 | 1.11 | 1.25 | 1.00 | NA | ||||||
| NA | ||||||||||
| 2.47 | 2.49 | 2.44 | 1.00 | NA | ||||||
| Time | 9.73 | 5.00 | 5.00 | 5.00 | 5.55 | 1.00 | 6.82 | 47.27 | 0.11 |
3.4.2 Nonlinear Medium Scale DSGE Model
This section applies the MPM samplers with 50% trimmed mean for estimating the parameters of the second-order medium-scale DSGE model of Gust et al., (2017) discussed in Section S9 of the online supplement. The medium scale DSGE model is similar to the models in Christiano et al., (2005) and Smets and Wouters, (2007) with nominal rigidities in both wages and prices, habit formation in consumption, investment adjustment costs, along with five structural shocks. We do not consider the zero lower bound (ZLB) on the nominal interest rate because estimating such a model requires solving the fully nonlinear model using global methods instead of local perturbation techniques. The time taken to solve the fully nonlinear model depends on the choice of solution technique and can vary across methods such as value function iteration and time-iteration methods. Since the paper focuses on demonstrating the strength of the estimation algorithm, we restrict our sample to the period before the zero lower bound constraint on the nominal interest rate binds and the model can be solved (at a second order approximation) using perturbation methods. The estimation algorithm, however, can be applied to fully nonlinear models as well since the estimation step requires decision rules produced by the model solution (global or local methods).
The baseline model in Gust et al., (2017) consists of 12 state variables, 18 control variables (30 variables combining the state and control variables) and 5 exogenous shocks. We estimate this model using 5 observables; that means that the dimensions of , the state vector and the disturbance vector are , , and , respectively. We include measurement error in the observation equation and consider two cases. The measurement error variances are: (1) estimated and (2) fixed at the 25% of the sample variance of the observables over the estimation period. We use quarterly US data from 1983Q1 to 2007Q4, with a total of observations for each of the five series.
The PMMH samplers considered are: (1) the MPM (50% trimmed mean) with the auxiliary disturbance particle filter (ADPF), disturbance sorting, and the correlation between random numbers used in estimating the log of estimated likelihoods set to ; (2) the correlated PMMH of Deligiannidis et al., (2018). Each sampler ran for iterations, with the initial iterations discarded as burn-in. We use the adaptive random walk proposal of Roberts and Rosenthal, (2009) for . All the samplers ran on a high performance computer cluster with CPU cores.
Table 7 shows the of the correlated PMMH relative to the MPM sampler with 50% trimmed mean (ADPF, disturbance sorting, and ) for the non-linear medium scale DSGE model for the cases where the measurement error variances are estimated and fixed at 25% sample variance of the observables. The computing time reported in the table is the time to run a single particle filter for the CPM and particle filters for the MPM approach. The table shows that in terms of , the MPM sampler is and times more efficient than the correlated PMMH for the cases where the measurement error variances are estimated and fixed at 25% sample variance of the observables, respectively. The full details on the inefficiency factors for each parameter are given in table S11 in section S7 of the online supplement.
Table 8 gives the posterior means, , and quantile estimates of some of the parameters with standard errors in brackets for the medium scale DSGE model estimated using the MPM sampler with trimmed mean (, disturbance sorting, ADPF). The measurement error variances are fixed to of the sample variance of the observables. The table shows that the standard errors are relatively small for all parameters indicating that the parameters are estimated accurately. Table S10 in Section S7 of the online supplement gives the posterior means, , and quantile estimates of all parameters in the medium scale DSGE model.
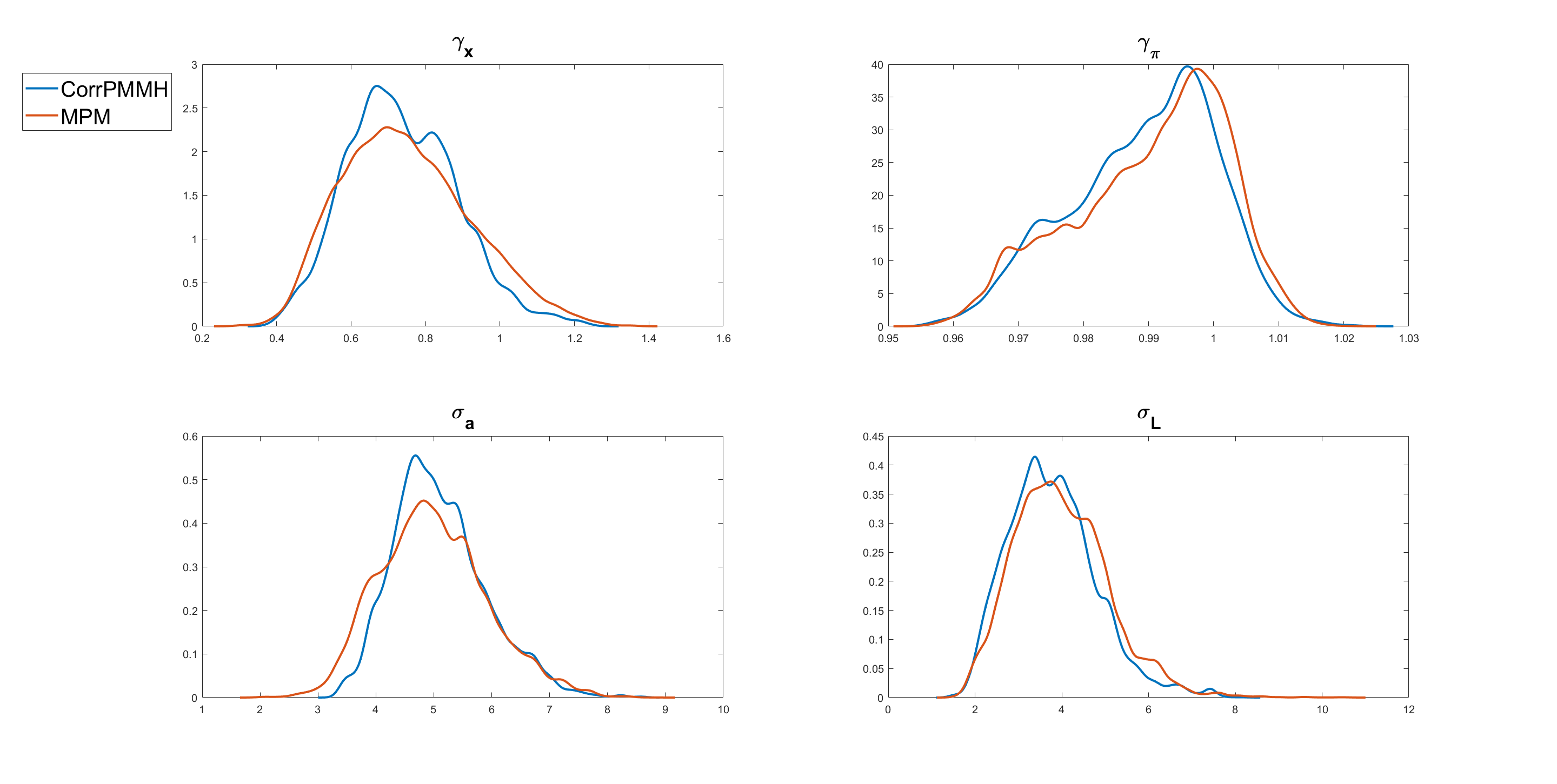
Figure 6 shows the kernel density estimates of some of the parameters of the medium scale DSGE model estimated using the MPM with 50% trimmed mean (ADPF, disturbance sorting, and ) and the correlated PMMH. The figure shows that the approximate posterior obtained using the MPM with 50% trimmed mean is very close to the exact posterior obtained using the correlated PMMH.
We also consider a variation of the medium scale DSGE model of Gust et al., (2017) described in section S9 of the online supplement. To study how well our approach performs with increasing state dimension, we estimate the model with the canonical definition of the output gap defined as the difference between output in the model with nominal rigidities and output in the model with flexible prices and wages. This variation is identical to the baseline model in Gust et al., (2017) except for the Taylor rule specification, which now uses the canonical definition of the output gap. This extension of the medium scale DSGE model consists of 21 state variables, 30 control variables (51 variables combining the state and control variables) and 5 exogenous shocks. We estimate this model using 5 observables; that means that the dimensions of , the state vector and the disturbance vector are , , and , respectively. The measurement error variances are fixed at 25% of the variance of the observables over the estimation period.
Table S12 of the online supplement shows the posterior means, 2.5% and 97.5% quantiles of the parameters of the extended medium scale DSGE model estimated using the MPM algorithm with a 50% trimmed mean (ADPF, disturbance sorting, and ) with and . The table shows that the s of the parameters are similar to the simpler medium scale DSGE model, indicating the performance of the MPM algorithm does not deteriorate with the extended model with the higher state dimensions.
| I | II | I actual | I | II | I actual | |
| Time |
| Param. | Estimates | ||
|---|---|---|---|
4 Summary and conclusions
The article proposes a general particle marginal approach (MPM) for estimating the posterior density of the parameters of complex and high-dimensional state-space models. It is especially useful when the single bootstrap filter is inefficient, while the more efficient auxiliary particle filter cannot be used because the state transition density is computationally intractable. The MPM method is a general extension of the PMMH method and makes four innovations: (a) it is based on the mean or trimmed mean of unbiased likelihood estimators; (b) it uses a novel block version of PMMH that works with multiple particle filters; (c) an auxiliary disturbance particle filter sampler is proposed to estimate the likelihood which is especially useful when the dimension of the states is much larger than the dimension of the disturbances; (d) a fast Euclidean sorting algorithm is proposed to preserve the correlation between the logs of the estimated likelihoods at the current and proposed parameter values. The MPM samplers are applied to complex multivariate stochastic volatility and DSGE models and shown to work well. Future research will consider developing better proposals for the parameter .
Online supplement for “The Block-Correlated Pseudo Marginal Sampler for State Space Models”
†† Level 4, West Lobby, School of Economics, University of New South Wales Business School – Building E-12, Kensington Campus, UNSW Sydney – 2052, Email: [email protected], Phone Number: (+61) 293852150. Website: http://www.pratitichatterjee.com39C. 164, School of Mathematics and Applied Statistics (SMAS), University of Wollongong, Wollongong, 2522; Australian Center of Excellence for Mathematical and Statistical Frontiers (ACEMS); National Institute for Applied Statistics Research Australia (NIASRA); Email: [email protected]. Phone Number: (+61) 424379015.
Level 4, West Lobby, School of Economics, University of New South Wales Business School – Building E-12, Kensington Campus, UNSW Sydney – 2052, and ACEMS Email: [email protected], Phone Number: (+61) 424802159.
S1 The Disturbance Particle Filter Algorithm
This section discusses the disturbance particle filter algorithm. Let be the random vector used to obtain the unbiased estimate of the likelihood. It has the two components and ; is the vector random variable used to generate the particles given . We can write
| (S1) |
where is the proposal density to generate , and is the initial state vector with density . Denote the distribution of as . For , let be the vector of random variables used to generate the ancestor indices using the resampling scheme and define as the distribution of . Common choices for and are iid and i.i.d. random variables, respectively.
Algorithm S1 takes the number of particles , the parameters , the random variables used to generate the disturbance particles , and the random variables used in the resampling steps as the inputs; it outputs the set of state particles , disturbance particles , ancestor indices , and the weights . At , the disturbance particles are obtained as a function of the random numbers using Eq. (S1) in step (1a) and the state particles are obtained from , for ; the weights for all particles are then computed in steps (1b) and (1c).
Step (2a) sorts the state or disturbance particles from smallest to largest using the Euclidean sorting procedure described in section 2.4 to obtain the sorted disturbance particles, sorted state particles and weights. Algorithm S2 resamples the particles using the correlated multinomial resampling to obtain the sorted ancestor indices . Step (2d) generates the disturbance particles as a function of the random numbers using Eq. (S1) and the state particles are obtained from , for ; we then compute the weights for all particles in step (2e) and (2f).
The disturbance particle filter provides the unbiased estimate of the likelihood
where
| (S2) |
Input: , , and
Output: , , , and
For
-
•
(1a) Generate from and set for
-
•
(1b) Compute the unnormalised weights , for
-
•
(1c) Compute the normalised weights for .
For
-
•
(2a) Sort the state particles or disturbance particles using the Euclidean sorting method of Choppala et al., (2016) and obtain the sorted index for , and the sorted state particles, disturbance particles, and weights , and , for .
-
•
(2b) Obtain the ancestor indices based on the sorted state particles using the correlated multinomial resampling in Algorithm S2.
-
•
(2c) Obtain the ancestor indices based on original order of the particles for .
-
•
(2d) Generate from and set , for
-
•
(2e) Compute the unnormalised weights , for
-
•
(2f) Compute the normalised weights for .
Input: , sorted states , sorted disturbances , and sorted weights
Output:
-
1.
Compute the cumulative weights
based on the sorted state particles or the sorted disturbance particles
-
2.
set for . Note that for is the ancestor index based on the sorted states or the sorted disturbances.
S2 Delayed Acceptance Multiple PMMH (DA-MPM)
Delayed acceptance MCMC can used to speed up the computation for models with expensive likelihoods (Christen and Fox, , 2005). The motivation in delayed acceptance is to avoid computing of the expensive likelihood if it is likely that the proposed draw will ultimately be rejected. A first accept-reject stage is applied with the cheap (or deterministic) approximation substituted for the expensive likelihood in the Metropolis-Hastings acceptance ratio. Then, only for a proposal that is accepted in the first stage, the computationally expensive likelihood is calculated with a second accept-reject stage to ensure detailed balance is satisfied with respect to the true posterior. This section discusses the delayed-acceptance mixed PMMH (DA-MPM) algorithm.
Given the current parameter value , the delayed acceptance Metropolis-Hastings (MH) algorithm proposes a new value from the proposal density and uses a cheap approximation to the likelihood in the MH acceptance probability
| (S3) |
As an alternative to particle filtering, Norgaard et al., (2000) develop the central difference Kalman filter (CDKF) for estimating the state in general non-linear and non-Gaussian state-space models. Andreasen, (2013) shows that the CDKF frequently outperforms the extended Kalman Filter (EKF) for general non-linear and non-Gaussian state-space models. We use the likelihood approximation, , obtained from the CDKF in the first stage accept-reject in Eq. (S3).
A second accept-reject stage is applied to a proposal that is accepted in the first stage, with the second acceptance probability
| (S4) |
The overall acceptance probability ensures that detailed balance is satisfied with respect to the true posterior. If a rejection occurs at the first stage, then the expensive evaluation of the likelihood at the second stage is avoided (Sherlock et al., 2017a, ). Algorithm S3 describes the Delayed Acceptance MPM algorithm.
-
•
Set the initial values of arbitrarily
- •
-
•
For each MCMC iteration , ,
-
–
(1) Sample from the proposal density .
-
–
(2) Compute the likelihood approximation using the central difference Kalman filter (CDKF).
-
–
(3) Accept the first stage proposal with the acceptance probability in Equation (S3). If the proposal is accepted, then go to step (4), otherwise go to step (8)
-
–
(4) Choose index with probability , sample , and set .
-
–
(5) Run particle filters to compute an estimate of likelihood .
- –
-
–
(7) Accept the second stage Metropolis-Hastings with acceptance probability in Equation (S4). If the proposal is accepted, then set , , , and . Otherwise, go to step (8).
-
–
(8) Otherwise, , , , and
-
–
S3 Overview of DSGE models
This section briefly overviews DSGE models. The equilibrium conditions for a wide variety of DSGE models can be summarized by
| (S5) |
is the expectation conditional on date information and ; is an vector containing all variables known at time ; is an vector of serially independent innovations. The solution to Eq. (S5) for can be written as
| (S6) |
such that
For our applications, we assume that , where is a scalar perturbation parameter. Under suitable differentiablity assumptions, and using the notation in Kollmann, (2015), we now describe the first and second order accurate solutions of DSGE models.
For most applications, the function in Eq. (S6) is analytically intractable and is approximated using local solution techniques. We use first and second order Taylor series approximations around the deterministic steady state with to approximate . The deterministic steady state satisfies .
A first order-accurate approximation, around the deterministic steady state is
| (S7) |
For Eq. (S7) to be stable, it is necessary for all the eigenvalues of to be less than 1 in absolute value. The initial value because we work with approximations around the deterministic steady state. For a given set of parameters , the matrices and can be solved using existing software; our applications use Dynare.
The second order accurate approximation (around the deterministic steady state) is
| (S8) |
where and for any vector , we define where is the strict upper triangle and diagonal of , such that . The term captures the level correction due to uncertainty from taking a second-order approximation. For our analysis we normalize the perturbation parameter to 1. As before, for a given set of parameters , the matrices can be solved using Dynare.
The measurement (observation) equation for the DSGE model and its approximations is
where is a known matrix; is an independent and sequence and it is also independent of the sequence. The matrix is usually unknown and is estimated from the data.
S3.1 Pruned State Space Representation of DSGE Models
To obtain a stable solution we use the pruning approach recommended in Kim et al., (2008); for details of how pruning is implemented in DSGE models, see Kollmann, (2015) and Andreasen et al., (2018). The pruned second order solution preserves only second order accurate terms by using the first order accurate solution to calculate and ; where is defined below. That is, we obtain the solution preserving only the second order effects by using instead of and instead of in Eq. (S8). We note that the variables are still expressed as deviations from steady state; however, for notational simplicity, we drop the superscript .
The evolution of is
with being functions of and , respectively. A consequence of using pruning in preserving only second order effects is that it increases the dimension of the state space. The pruning-augmented solution of the DSGE model is given by
The augmented state representation of the pruned second order accurate system becomes
where . We now summarize the state transition and the measurement equations for the pruned second order accurate system as
| (S9) |
The matrix selects the observables from the pruning augmented state space representation of the system. If and then and . If denotes the number of observables then the selection matrix , where and . The selection matrix consists only of zeros and ones.
S4 Additional tables and figures for the linear Gaussian state space model example
This section gives additional tables and figures for the linear Gaussian state space model in Section 3.2.
Tables S1 and S2 show the variance of the log of the estimated likelihood obtained by using five different approaches for the dimensional linear Gaussian state space model with and time periods, respectively. The table shows that for all approaches there is a substantial reduction in the variance of the log of the estimated likelihood when the number of particle filters increases and the number of particles within each particle filter increases.
Tables S3 – S5 show the variance of the log of the estimated likelihood obtained by using the five estimators of the likelihood for the dimensional linear Gaussian state space model with and time periods and with time period. The table shows that: (1) there is no substantial reduction in variance of the log of the estimated likelihood for the 0% trimmed mean. (2) The 5%, 10%, 25%, and 50% trimmed means decrease the variance substantially as and/or increase. The 25% and 50% trimmed means have the smallest variance for all cases.
| Single | |||||||
|---|---|---|---|---|---|---|---|
| 100 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 250 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 500 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 1000 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 |
| Single | |||||||
|---|---|---|---|---|---|---|---|
| 100 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 250 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 500 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 1000 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 |
| Single | |||||||
|---|---|---|---|---|---|---|---|
| 100 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 250 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 500 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 1000 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 |
| Single | |||||||
|---|---|---|---|---|---|---|---|
| 100 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 250 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 500 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 1000 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 |
| Single | |||||||
|---|---|---|---|---|---|---|---|
| 100 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 250 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 500 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 | |||||||
| 1000 | 1 | ||||||
| 20 | |||||||
| 50 | |||||||
| 100 | |||||||
| 500 | |||||||
| 1000 |
| I | II | III | IV | |||||||
| N | 20000 | 100 | 250 | 500 | 100 | 250 | 500 | 100 | 250 | 500 |
| S | 1 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| 42.076 | NA | 137.725 | 22.507 | 253.251 | 17.065 | 10.658 | 18.901 | 9.748 | 7.899 | |
| CT | 2.44 | 0.32 | 0.71 | 1.21 | 0.32 | 0.71 | 1.21 | 0.32 | 0.71 | 1.21 |
| 102.665 | NA | 97.785 | 27.234 | 81.040 | 12.116 | 12.896 | 6.048 | 6.921 | 9.558 | |
| 1 | NA | 0.952 | 0.265 | 0.789 | 0.119 | 0.126 | 0.059 | 0.067 | 0.093 | |
Table S6 reports the , , and values for the parameter in the linear Gaussian state space model with dimensions and time periods estimated using the four different MCMC samplers: (1) the correlated PMMH of Deligiannidis et al., (2018), (2) the MPM with 5% trimmed mean, (3) the MPM with 10% trimmed mean, and (4) the MPM with 25% trimmed mean. The computing time reported in the table is the time to run a single particle filter for the CPM and particle filters for the MPM approach. The table shows that: (1) The correlated PMMH requires more than particles to improve the mixing of the MCMC chain for the parameter ; (2) the CPU time for running a single particle filter with particles is times higher than running multiple particle filters with and . The MPM method can be much faster than the CPM method if it is run using high-performance computing with a large number of cores; (3) the MPM allows us to use a much smaller number of particles for each independent PF and these multiple PFs can be run independently; (4) in terms of , the 5%, 10%, and 25% trimmed means with and are , , and times smaller than the correlated PMMH with particles; (6) the best sampler for this example is the 25% trimmed mean approach with and particles. Figure S1 shows the kernel density estimates of the parameter estimated using Metropolis-Hastings algorithm with the (exact) Kalman filter method and the MPM algorithm with 5%, 10%, and 25% trimmed means. The figure shows that the approximate posteriors obtained by various approaches using the trimmed means are very close to the true posterior. Figure S1 also shows that the approximate posterior obtained using the MPM with the trimmed mean of the likelihood is very close to the exact posterior obtained using the correlated PMMH.
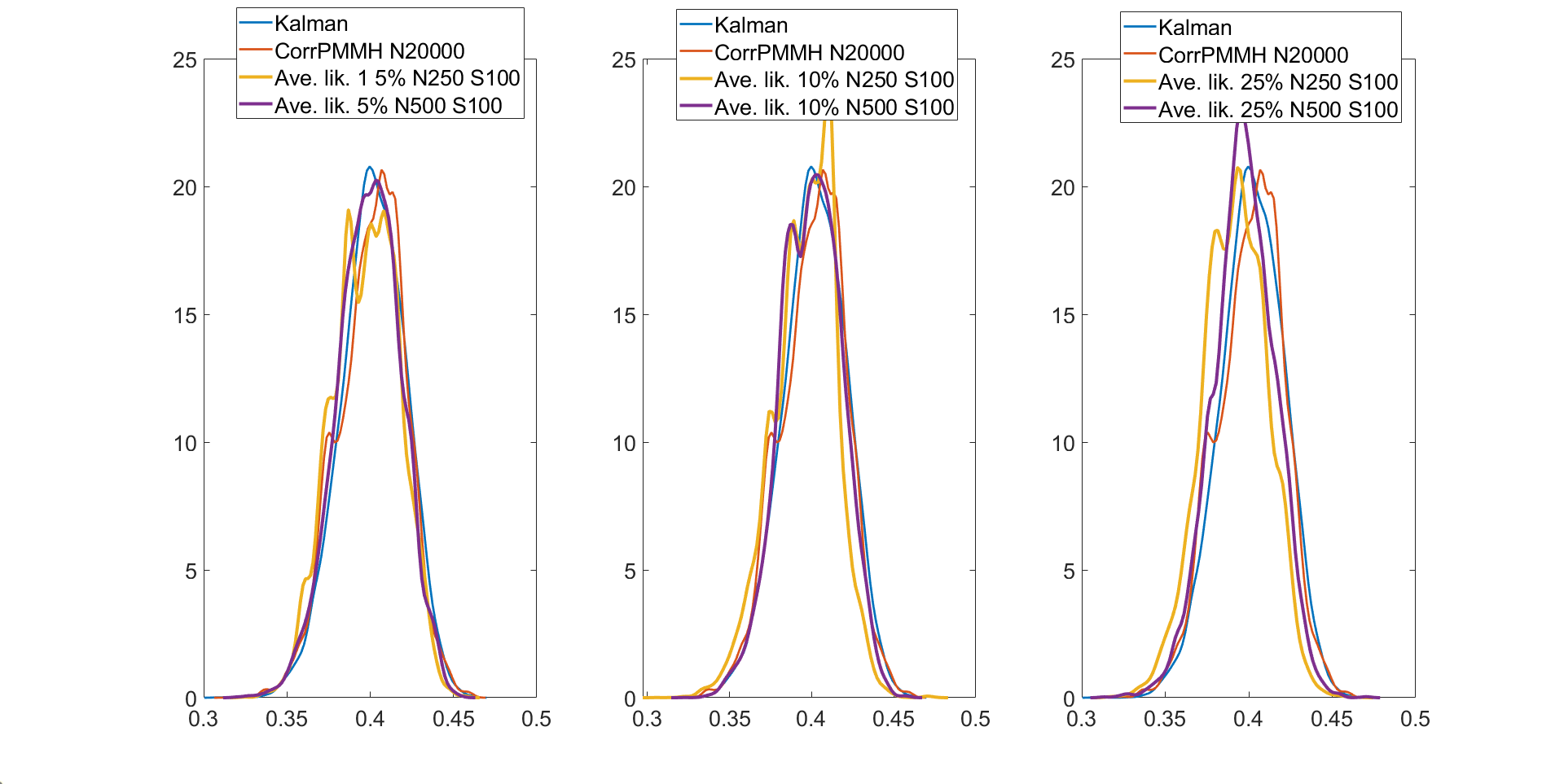
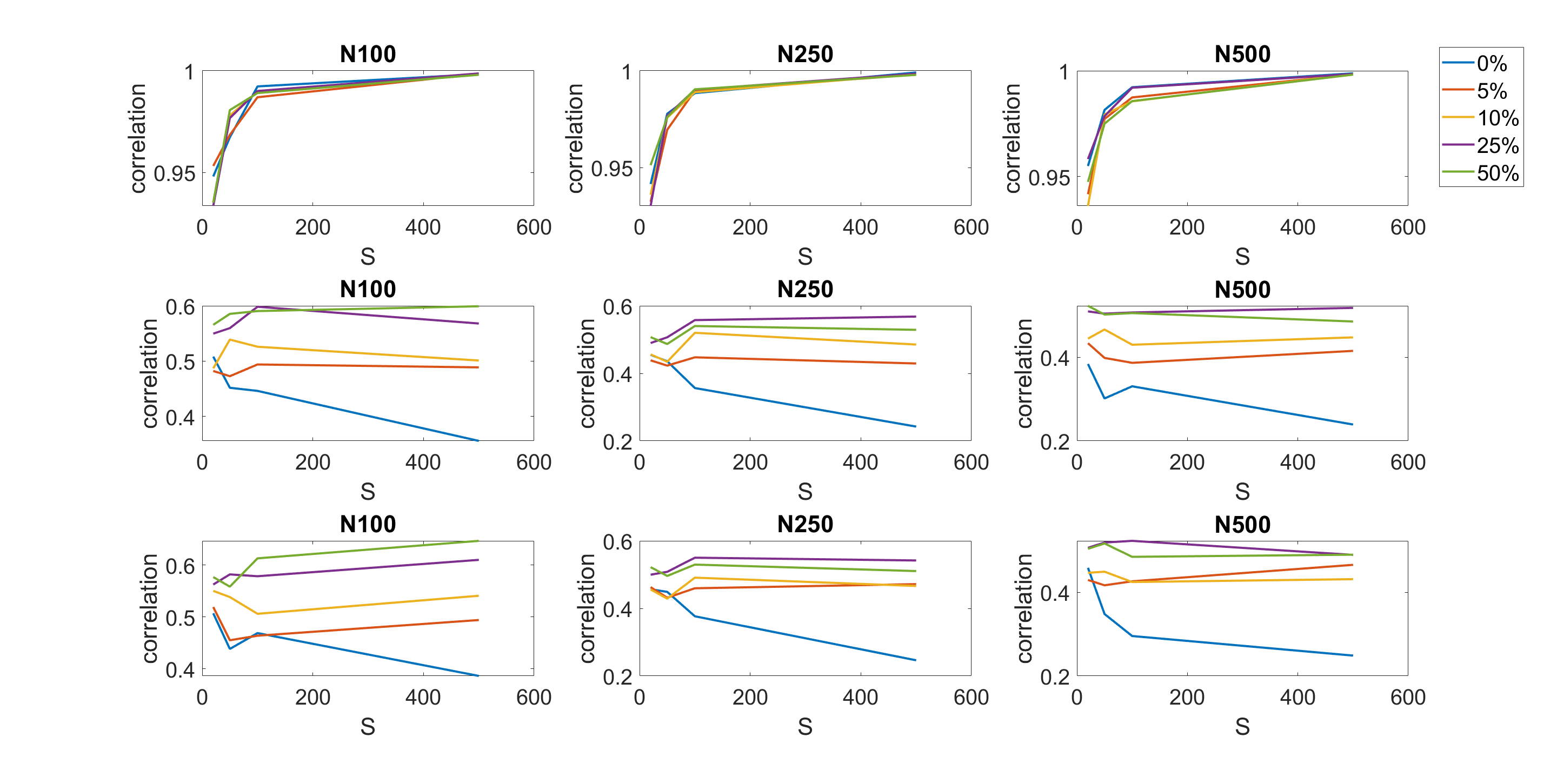
Figure S2 reports the correlation estimates at the current and proposed values of of the log of the estimated likelihood obtained using different MPM approaches. The figure show that: (1) When the current and proposed values of the parameters are equal to , all MPM methods maintain a high correlation between the logs of the estimated likelihoods. The estimated correlations between logs of the estimated likelihoods when the number of particle filters is 100 are about 0.99. (2) When the current parameter and the proposed parameter are (slightly) different, the MPM methods can still maintain some of the correlation between the log of the estimated likelihoods. The MPM methods with 25% and 50% trimmed means of the likelihood perform the best to maintain the correlation between the logs of the estimated likelihoods.
S5 Additional tables and figures for the multivariate stochastic volatility in mean model example
This section gives additional tables and figures for the multivariate stochastic volatility in mean example in Section 3.2.
Figures S3 to S11 show the kernel density estimates of the parameters of the multivariate stochastic volatility in mean model described above estimated using the MPM sampler ( and ) using a 25% trimmed mean with the vertical lines showing the true parameter values. The figures show that the model parameters are estimated well.
S6 Additional tables and figures for the small scale DSGE model example
This section gives additional tables and figures for the small scale DSGE model example in Section 3.4.1.
Table S7 gives the prior distributions for each model parameter for the non-linear small scale DSGE model in section 3.4.1. Table S8 reports the inefficiency factors for each parameter and the relative time normalised inefficiency factor (RTNIF) of a PMMH sampler relative to the MPM (0% trimmed mean) with the ADPF, disturbance sorting, and for the non-linear small scale models with time periods. Section 3.4.1 discusses the results.
| Param. | Domain | Density | Param (1) | Param (2) |
|---|---|---|---|---|
| 0.7 | 0.5 | |||
| 3.12 | 0.5 | |||
| N | 0.60 | 0.5 | ||
| 1.50 | 0.5 | |||
| 2.41 | 0.5 | |||
| 0.39 | 0.5 | |||
| 0.5 | 0.2 | |||
| 0.5 | 0.2 | |||
| 0.5 | 0.2 | |||
| IG | 5 | 0.5 | ||
| IG | 5 | 0.5 | ||
| IG | 5 | 0.5 | ||
| G | 1 | 1 | ||
| G | 1 | 1 | ||
| G | 1 | 1 |
| Param | I | II | III | IV | V | VI | VII | VIII | IX |
| S | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 1 |
| N | 250 | 100 | 100 | 100 | 100 | 100 | 100 | 250 | 20000 |
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| NA | |||||||||
| Time | 1.07 | 0.55 | 0.55 | 0.55 | 0.61 | 0.11 | 0.75 | 5.20 |
S7 Additional tables and figures for the medium scale DSGE model example
This section gives additional tables and figures for the medium scale DSGE model example in Section 3.4.2. Table S9 gives the prior distributions for each model parameter for the non-linear medium scale DSGE model in Section 3.4.2. Table S10 gives the mean, , and quantiles estimates of each parameter in the medium scale DSGE model estimated using the MPM sampler with a trimmed mean (, disturbance sorting, ADPF)) for the US quarterly dataset from 1983Q1 to 2007Q4. The measurement error variances are fixed to of the variance of the observables. The standard errors are relatively small for all parameters indicating that the parameters are estimated accurately.
Table S11 gives the inefficiency factor for each parameter in the medium scale DSGE model estimated using the MPM with 50% trimmed mean (ADPF, disturbance sorting, ) and the correlated PMMH samplers. Table S12 gives the mean, , and quantiles estimates of each parameter in the extended version of the medium scale DSGE model estimated using the MPM sampler with a trimmed mean (, disturbance sorting, ADPF)) for the US quarterly dataset from 1983Q1 to 2007Q4. The measurement error variances are fixed to of the variance of the observables.
| Param. | Domain | Density | Param. (1) | Param. (2) |
|---|---|---|---|---|
| G | ||||
| G | ||||
| G | ||||
| G | ||||
| G | ||||
| G | ||||
| G | ||||
| G | ||||
| G | ||||
| G | ||||
| N | ||||
| N | ||||
| N | ||||
| G | ||||
| N | ||||
| N | ||||
| G | ||||
| G | ||||
| G | ||||
| N | ||||
| N | ||||
| N |
| Param. | Estimates | ||
|---|---|---|---|
| Param. | I | II | I | II |
|---|---|---|---|---|
| NA | NA | |||
| NA | NA | |||
| NA | NA | |||
| NA | NA | |||
| NA | NA | |||
| Param. | Estimates | |||
|---|---|---|---|---|
S8 Description: Small scale DSGE model
The small scale DSGE model specification follows Herbst and Schorfheide, (2016), and is also used by Herbst and Schorfheide, (2019). The small scale DSGE model follows the environment in Herbst and Schorfheide, (2019) with nominal rigidities through price adjustment costs following Rotemberg, (1982), and three structural shocks. There are altogether state variables, control variables ( variables combining the state and control variables) and exogenous shocks in the model. We estimate this model using observables; that means that the dimensions of , the state vector and the disturbance vector are , , and , respectively.
Households
Time is discrete, households live forever, the representative household derives utility from consumption relative to a habit stock (which is approximated by the level of technology )222This assumption ensures that the economy evolves along a balanced growth path even if the utility function is additively separable in consumption, real money balances and hours. and real money balances and disutility from hours worked . The household maximizes
subject to the budget constraint
and denote lump-sum taxes, aggregate residual profits and net cash inflow from trading a full set of state contingent securities; is the aggregate price index, and is the real wage; is the discount factor, is the coefficient of relative risk aversion, and are scale factors determining the steady state money balance holdings and hours. We set . is the level of aggregate productivity.
Firms
Final output is produced by a perfectly competitive representative firm which uses a continuum of intermediate goods and the production function
with . The demand for intermediate good is
and the aggregate price index is
Intermediate good is produced using the linear production technology
is an exogenous productivity process common to all firms, and is the labor input of firm i. Intermediate firms set prices and labor input () by maximizing the net present value of future profit. Nominal rigidities are introduced through price adjustment costs following Rotemberg, (1982).
with
The parameter governs the extent of price rigidity in the economy and is the steady state inflation rate associated with the final good. In equilibrium, households and firms use the same stochastic discount factor where
In a symmetric equilibrium all firms choose the same price.
Monetary and Fiscal Policy
The central bank conducts monetary policy following an interest rate feedback rule given by
where is an iid shock to the nominal interest rate, is the nominal target and captures interest rate smoothing in the conduct of policy,
is the gross inflation rate and is the target inflation rate. is the output in the absence of nominal rigidities. The parameters and capture the intensity with which the central bank responds to inflation and output gap in the model. Government expenditure accounts for a fraction of final output such that . The government budget constraint is
Aggregation
Combining the household budget constraint with the government budget constraint gives
where in equilibrium, .
Exogenous Processes
Aggregate technology grows at the rate and is the shock to aggregate demand such that
with . We define and evolves as
with . We summarize the nonlinear equilibrium conditions after detrending by deterministic technology, i.e define :
| (S10) |
| (S11) |
| (S12) |
After detrending, the steady state solution of the model is .
We solve the model in log deviations from steady state, i.e. using Dynare. The small scale DSGE model therefore consists of a consumption Euler equation, a new Keynesian Philip curve, a monetary policy rule, fiscal policy rule, three exogenous shock processes, and eight endogenous latent variables. We estimate the model using both first and second order approximations to assess the performance of our proposed method relative to existing methods. As explained, the source of nonlinearity in our case stems from taking a second order approximation of the equilibrium conditions.
The observables used in estimating the model consist of per capita GDP growth rate (), annualized quarter on quarter inflation rate () and annualized nominal rates (). The observed data is measured in percentages, and, after applying a log transformation to the endogenous variables, the measurement equations for our system using the transformed endogenous variables given by (a hatted variable denotes the log transformation).
Here, , , and since in steady state as evident from Equation (S11).
The model has the 15 parameters
We calibrate the parameters characterizing the share of fiscal expenditure in GDP , the elasticity of substitution across varieties and the parameter guiding the extent of nominal rigidities, . The remaining parameters along with the measurement errors in the observation equation are estimated. The steady-state inflation rate, , in the model relates to the estimated parameter for annualized inflation such that and the discount factor to the estimated parameter for annualized interest rate such that . The sample used for estimation is 1983Q1-2002Q4. The data set and the variables are identical to those used in Herbst and Schorfheide, (2019).333Data on all three observables are sourced from FRED. Per capita GDP growth rate is calculated using data on real gross domestic product (FRED mnemonic ‘GDPC1’) and Civilian Non-institutional Population (FRED mnemonic ‘CNP16OV’ / BLS series ‘LNS10000000’), Annualized Inflation is calculated using CPI price level (FRED mnemonic ‘CPIAUCSL’), the Federal Funds Rate (FRED mnemonic ‘FEDFUNDS’).
S9 Description: Medium scale DSGE model
The specification of the medium-scale model is similar to Smets and Wouters, (2007) and follows the specification in Gust et al., (2017). The model allows for habit formation in consumption, nominal rigidities in wages and prices, indexation in wages and prices, and investment adjustment costs. The model environment consists of monopolistically competitive intermediate goods-producing firms, a perfectly competitive final good-producing firm, households, and the government conducting fiscal and monetary policy. We describe the behavior of each agent in detail below. The baseline model in Gust et al., (2017) consists of 12 state variables, 18 control variables (30 variables combining the state and control variables) and 5 exogenous shocks. We estimate this model using 5 observables; that means that the dimensions of , the state vector and the disturbance vector are , , and , respectively. We also consider a variation of the medium scale DSGE model of Gust et al., (2017). To study how well our approach performs with increasing state dimension, we estimate the model with the canonical definition of the output gap defined as the difference between output in the model with nominal rigidities and output in the model with flexible prices and wages. This variation is identical to the baseline model in Gust et al., (2017) except for the Taylor rule specification, which now uses the canonical definition of the output gap. This extension of the medium scale DSGE model consists of 21 state variables, 30 control variables (51 variables combining the state and control variables) and 5 exogenous shocks. We estimate this model using 5 observables; that means that the dimensions of , the state vector and the disturbance vector are , , and , respectively.
S9.1 Firms
There is a continuum of monopolistically competitive firms producing differentiated intermediate goods. The final good () is produced by a perfectly competitive representative firm that uses a continuum of differentiated intermediate goods () such that
Under the constant elasticity of substitution aggregator, the demand for good produced by the firm is
The production function for the intermediate good producer is
and denote labor and capital inputs for the intermediate good producer and denotes labor augmenting technological progress. evolves as
is the deterministic growth rate of technology and introduces deviations about this deterministic trend. Following Rotemberg, (1982), intermediate good producing firm face quadratic costs in adjusting nominal prices and is given by
with describes the size of adjustment cost. The change in price is indexed to with
Here is the inflation target set by the central bank and is the lagged gross inflation in period . The parameter quantifies the extent of indexation to the central bank inflation target or lagged gross inflation with . The optimal price is set by each intermediate good producing firm by maximizing the expected present discounted value of profits
is the real marginal cost with . and denote the nominal wage and nominal rental rate of capital services respectively. is the stochastic discount factor from the optimization exercise of households.
S9.2 Households
There exists a continuum of infinitely lived monopolistically competitive households indexed by supplying differentiated labor service, . Household sells labor service to a representative employment agency which combines the differentiated labor services across the spectrum of households into a composite , which in turn is supplied to the intermediate goods producers for production in a perfectly competitive market. Differentiated labor services is aggregated via a Dixit-Stiglitz aggregator given by
The parameter is the constant elasticity of substitution across different varieties of labor services. Households maximize lifetime utility,
with consumption, being labor services, and denotes the loss in utility due to adjusting nominal wages . The utility cost of adjusting nominal wages is quadratic. The cost of adjusting nominal wages is
The parameter governs the size of wage adjustment costs. Wage contracts are indexed to productivity and inflation with
The parameter governs the degree of habit formation in household utility.444Habits are internal to households. Households also engage in savings. Households can save by investing in risk-free nominal bonds () and owning physical capital stock . Additionally, households can choose the extent of capital utilization . Utilization is combined with physical capital stock to transform physical capital to capital services . In the process of transforming physical capital to capital services via utilization , households incur costs of utilization
Households choose , , , investment , and subject to the budget constraint
The law of motion of capital
Accumulation of capital is subject to the investment adjustment costs
Consistent with Smets and Wouters, (2007), in the budget constraint and in the law of motion of capital represent shocks to demand for risk-free assets and an exogenous disturbance to the marginal efficiency of transforming final goods in to physical capital in with
and
S9.3 Monetary and fiscal policy
The central bank sets the nominal interest rate according to a Taylor rule with
The parameter governs the extent of interest rate smoothing; denotes the interest rate in the non-stochastic steady state with ; is the inflation target set by the central bank; in the Taylor rule is a proxy to quantify the output-gap in the economy with nominal rigidities relative to the flexible price benchmark. Consistent with Gust et al., (2017) we deviate from Smets and Wouters, (2007) and specify the the output-gap with
where is the aggregate level of capital utilization (with non-stochastic steady state of 1) and is the non-stochastic steady state level of aggregate labor. We estimate both versions of the model where the output gap is proxied by as well as using the canonical definition of the output gap – characterized as deviations of output in the model with nominal rigidities relative to the model without nominal rigidities and the Taylor rule being
with ; is the output in the flexible price model. The parameters , and quantify the extent of the central bank’s reaction to inflation, output-gap and output growth; is the exogenous disturbance to monetary policy with . Government spending evolves exogenously as a time-varying function of aggregate output with
such that
The government budget constraint satisfies , for each period.
S9.4 Market clearing
In a symmetric equilibrium, all intermediate goods firm choose the same price with , for all , and all households choose the same wage with . The aggregate production function is
Market clearing implies
S9.5 First-order conditions
The detailed first order conditions are summarized below:
| (S13) |
| (S14) |
| (S15) |
| (S16) |
| (S17) |
| (S18) |
| (S19) |
| (S20) |
| (S21) |
| (S22) |
| (S23) |
| (S24) |
| (S25) |
| (S26) |
| (S27) |
| (S28) |
When solving the model using the canonical definition of the output-gap, the Taylor rule is specified as follows where is the output in the model with flexible prices and wages.
| (S29) |
| (S30) |
| (S31) |
| (S32) |
| (S33) |
| (S34) |
| (S35) |
S9.6 De-trended equilibrium conditions
Labor augmenting technological progress evolves as
The deterministic component of labor augmenting technological process is the source of deterministic growth in the model. We summarize the de-trended stationary equilibrium conditions such that lower case letters denote stationary transformations.
| (S36) |
| (S37) |
| (S38) |
| (S39) |
| (S40) |
| (S41) |
| (S42) |
| (S43) |
| (S44) |
| (S45) |
| (S46) |
| (S47) |
| (S48) |
| (S49) |
| (S50) |
| (S51) |
| (S52) |
| (S53) |
| (S54) |
| (S55) |
| (S56) |
Equations S36-S56 summarize the detrended equilibrium conditions of the model. We solve the model by taking a second-order approximation of Equations S36-S56. To show that the solution algorithm can handle a higher dimensional state space, we solve a version of the model keeping all the conditions unchanged except for the Taylor Rule (Equation S51) which approximates the output gap using Equation S53 with
| (S57) |
The specification of the Taylor rule in Equation S57 follows the canonical definition of the output gap defined as the difference between output in the model with nominal rigidities () and output in the model with flexible prices and wages (). The number of state variables in the DSGE model increases from 12 to 21 when using the definition of the output gap consistent with the canonical definition and used in Smets and Wouters, (2007).
References
- Andreasen, (2013) Andreasen, M. M. (2013). Non-linear DSGE models and the central difference Kalman filter. Journal of Applied Econometrics, 28(6):929–955.
- Andreasen et al., (2018) Andreasen, M. M., Fernández-Villaverde, J., and Rubio-Ramírez, J. F. (2018). The pruned state-space system for non-linear DSGE models: Theory and empirical applications. Review of Economic Studies, 85(1):1–49.
- Andrieu et al., (2010) Andrieu, C., Doucet, A., and Holenstein, R. (2010). Particle Markov chain Monte Carlo methods. Journal of the Royal Statistical Society, Series B, 72(3):269–342.
- Andrieu and Roberts, (2009) Andrieu, C. and Roberts, G. (2009). The pseudo-marginal approach for efficient Monte Carlo computations. The Annals of Statistics, 37(2):697–725.
- Carriero et al., (2018) Carriero, A., Clark, T. E., and Marcellino, M. (2018). Measuring uncertainty and its impact on the economy. Review of Economics and Statistics, 100(5):799–815.
- Choppala et al., (2016) Choppala, P., Gunawan, D., Chen, J., Tran, M. N., and Kohn, R. (2016). Bayesian inference for state-space models using block and correlated pseudo marginal methods. arXiv:1612.07072v1.
- Christen and Fox, (2005) Christen, J. A. and Fox, C. (2005). Markov chain Monte Carlo using an approximation. Journal of Computational and Graphical Statistics, 14(4):795–810.
- Christiano et al., (2005) Christiano, L. J., Eichenbaum, M., and Evans, C. L. (2005). Nominal rigidities and the dynamic effects of a shock to monetary policy. Journal of political Economy, 113(1):1–45.
- Cross et al., (2021) Cross, J. L., Hou, C., Koop, G., and Poon, A. (2021). Macroeconomic forecasting with large stochastic volatility in mean VARs. BI Norwegian Business School, https://www.oru.se/contentassets/b70754c1297e4b65993aa6115c0f5d0c/cross—macroeconomic-forecasting-with-large-stochastic-volatility-in-mean-vars.pdf.
- Deligiannidis et al., (2018) Deligiannidis, G., Doucet, A., and Pitt, M. (2018). The correlated pseudo-marginal method. Journal of Royal Statistical Society Series B, 80(5):839–870.
- Fernández-Villaverde and Rubio-Ramírez, (2007) Fernández-Villaverde, J. and Rubio-Ramírez, J. F. (2007). Estimating macroeconomic models: A likelihood approach. Review of Economic Studies, 74(4):1059–1087.
- Garthwaite et al., (2015) Garthwaite, P. H., Fan, Y., and Sisson, S. A. (2015). Adaptive optimal scaling of Metropolis-Hastings algorithms using the Robbins-Monro process. Communications in Statistics - Theory and Methods, 45(17):5098–5111.
- Gordon et al., (1993) Gordon, N., Salmond, D., and Smith, A. (1993). A novel approach to nonlinear and non-Gaussian Bayesian state estimation. IEE-Proceedings F, 140(2):107–113.
- Guarniero et al., (2017) Guarniero, P., Johansen, A. M., and Lee, A. (2017). The iterated auxiliary particle filter. Journal of American Statistical Association, 112(520):1636–1647.
- Gust et al., (2017) Gust, C., Herbst, E., López-Salido, D., and Smith, M. E. (2017). The empirical implications of the interest-rate lower bound. American Economic Review, 107(7):1971–2006.
- Hall et al., (2014) Hall, J., Pitt, M. K., and Kohn, R. (2014). Bayesian inference for nonlinear structural time series models. Journal of Econometrics, 179(2):99–111.
- Herbst and Schorfheide, (2016) Herbst, E. and Schorfheide, F. (2016). Bayesian estimation of DSGE models (1st ed.). Princeton University Press.
- Herbst and Schorfheide, (2019) Herbst, E. and Schorfheide, F. (2019). Tempered particle filtering. Journal of Econometrics, 210(1):26–44.
- Hesterberg, (1995) Hesterberg, T. (1995). Weighted average importance sampling and defensive mixture distributions. Technometrics, 37(2):185–194.
- Johnson et al., (2013) Johnson, A. A., Jones, G. L., and Neath, R. C. (2013). Component-wise Markov chain Monte Carlo: Uniform and geometric ergodicity under mixing and composition. Statistical Science, 28(3):360–375.
- Kim et al., (2008) Kim, J., Kim, S., Schaumburg, E., and Sims, C. A. (2008). Calculating and using second-order accurate solutions of discrete time dynamic equilibrium models. Journal of Economic Dynamics and Control, 32(11):3397–3414.
- Kitagawa, (1996) Kitagawa, G. (1996). Monte Carlo filter and smoother for non-Gaussian nonlinear state space models. Journal of Computational and Graphical Statistics, 5(1):1–25.
- Kollmann, (2015) Kollmann, R. (2015). Tractable latent state filtering for non-linear DSGE models using a second-order approximation and pruning. Comnputational Economics, 45:239–260.
- Murray et al., (2013) Murray, L. M., Jones, E. M., and Parslow, J. (2013). On disturbance state-space models and the particle marginal Metropolis-Hastings sampler. SIAM/ASA Journal on Uncertainty Quantification, 1(1):494–521.
- Norgaard et al., (2000) Norgaard, M., Poulsen, N. K., and Ravn, O. (2000). New developments in state estimation for nonlinear systems. Automatica, 36(11):1627–1638.
- Pitt et al., (2012) Pitt, M. K., Silva, R. S., Giordani, P., and Kohn, R. (2012). On some properties of Markov chain Monte Carlo simulation methods based on the particle filter. Journal of Econometrics, 171(2):134–151.
- Plummer et al., (2006) Plummer, M., Best, N., Cowles, K., and Vines, K. (2006). CODA: Convergence Diagnosis and Output Analysis of MCMC. R News, 6(1):7–11.
- Roberts and Rosenthal, (2009) Roberts, G. O. and Rosenthal, J. S. (2009). Examples of adaptive MCMC. Journal of Computational and Graphical Statistics, 18(2):349–367.
- Rotemberg, (1982) Rotemberg, J. J. (1982). Sticky prices in the United States. Journal of Political Economy, 90(6):1187–1211.
- Shephard et al., (2004) Shephard, N., Chib, S., Pitt, M. K., et al. (2004). Likelihood-based inference for diffusion-driven models. technical report, https://www.nuff.ox.ac.uk/economics/papers/2004/w20/chibpittshephard.pdf.
- (31) Sherlock, C., Golightly, A., and Henderson, D. A. (2017a). Adaptive, delayed-acceptance MCMC for targets with expensive likelihoods. Journal of Computational and Graphical Statistics, 26(2):434–444.
- Sherlock et al., (2015) Sherlock, C., Thiery, A., Robert, G., and Rosenthal, J. (2015). On the efficiency of pseudo-marginal random walk Metropolis algorithms. The Annals of Statistics, 43(1):238–275.
- (33) Sherlock, C., Thiery, A. H., and Lee, A. (2017b). Pseudo-marginal Metropolis-Hastings sampling using averages of unbiased estimators. Biometrika, 104(3):727–734.
- Skilling, (2004) Skilling, J. (2004). Programming the Hilbert curve. AIP Conference Proceedings, 707(1):381–387.
- Smets and Wouters, (2007) Smets, F. and Wouters, R. (2007). Shocks and frictions in US business cycles: A Bayesian DSGE approach. The American Economic Review, 97(3):586–606.
- Stramer and Bognar, (2011) Stramer, O. and Bognar, M. (2011). Bayesian inference for irreducible diffusion processes using the pseudo-marginal approach. Bayesian Analysis, 6(2):231–258.
- Tran et al., (2016) Tran, M. N., Kohn, R., Quiroz, M., and Villani, M. (2016). Block-wise pseudo-marginal Metropolis-Hastings. arXiv:1603.02485v2.