The Average Rate of Convergence of the Exact Line Search Gradient Descent Method
Revised March 5, 2024)
Abstract:
It is very well known that when the exact line search gradient descent method is applied to a convex quadratic objective, the worst-case rate of convergence (ROC), among all seed vectors, deteriorates as the condition number of the Hessian of the objective grows. By an elegant analysis due to H. Akaike, it is generally believed – but not proved – that in the ill-conditioned regime the ROC for almost all initial vectors, and hence also the average ROC, is close to the worst case ROC. We complete Akaike’s analysis using the theorem of center and stable manifolds. Our analysis also makes apparent the effect of an intermediate eigenvalue in the Hessian by establishing the following somewhat amusing result: In the absence of an intermediate eigenvalue, the average ROC gets arbitrarily fast – not slow – as the Hessian gets increasingly ill-conditioned.
We discuss in passing some contemporary applications of exact line search GD to polynomial optimization problems arising from imaging and data sciences.
Keywords: Gradient descent, exact line search, worst case versus average case rate of convergence, center and stable manifolds theorem, polynomial optimization problem
1 Introduction
Exact line search is usually deemed impractical in the optimization literature, but when the objective function has a specific global structure then its use can be beneficial. A notable case is when the objective is a polynomial. Polynomial optimization problems (POPs) abound in diverse applications; see, for example, [15, 13, 6, 4, 8, 14] and Section 1.2.
For the gradient descent (GD) method, a popular choice for the step size is , where is a Lipschitz constant satisfied by the gradient, i.e. . The rate of convergence of GD would then partly depend on how well one can estimate . Exact line search refers to the ‘optimum’ choice of step size, namely , where is the search direction, hence the nomenclature optimum gradient descent in the case of .111We use the terms ‘optimum GD’ and ‘GD with exact line search’ interchangeably in this article. When is, say, a degree 4 polynomial, it amounts to determining the univariate quartic polynomial followed by finding its minimizer, which is a very manageable computational task.
Let us recall the key benefit of exact line search. We focus on the case when the objective is a strictly convex quadratic, which locally approximates any smooth objective function in the vicinity of a local minimizer with a positive definite Hessian. By the invariance of GD (constant step size or exact line search) under rigid transformations, there is no loss of generality, as far as the study of ROC is concerned, to consider only quadratics of the form
| (1.1) |
Its gradient is Lipschitz continuous with Lipschitz constant . Also, it is strongly convex with the strong convexity parameter . In the case of constant step size GD, we have , so the rate of convergence is given the spectral radius of , which equals . From this, it is easy to check that the step size
| (1.2) |
minimizes the spectral radius of , and hence offers the optimal ROC
| (1.3) |
Gradient descent with exact line search involves non-constant step sizes: , with . For convenience, denote the iteration operator by OGD, i.e.
| (1.4) |
We set so that OGD is a well-defined self-map on . By norm equivalence, one is free to choose any norm in the study of ROC; and the first trick is to notice that by choosing the -norm, defined by , we have the following convenient relation:
| (1.5) |
Write (). By the Kantorovich inequality,222For a proof of the Kantorovich inequality , see, for example, [12, 7]. A good way to appreciate this result is to compare it with the following bound obtained from Rayleigh quotient: . Unless , Kantorovich’s bound is always sharper, and is the sharpest possible in the sense that there exists a vector so that equality holds.
| (1.6) |
which yields the well-known error bound for the optimum GD method:
| (1.7) |
So optimum GD satisfies the same upper-bound for its ROC as in (1.3). The constant step size GD method with the optimal choice of step size (1.2), however, should not be confused with the optimum GD method, they have the following fundamental differences:
-
•
The optimal step size (1.2) requires the knowledge of the two extremal eigenvalues, of which the determination is no easier than the original minimization problem. In contrast, the optimum GD method is blind to the values of and .
-
•
Due to the linearity of the iteration process, GD with the optimal constant step size (1.2) achieves the ROC , with in (1.3), for any initial vector with a non-zero component in the dominant eigenvector of , and hence for almost all initial vectors . So for this method the worst case ROC is the same as the average ROC. (As the ROC is invariant under scaling of , the average and worst case ROC can be defined by taking the average and maximum, respectively, ROC over all seed vectors of unit length.) In contrast, OGD is nonlinear and the worst case ROC (1.3) is attained only for specific initial vectors ; see Proposition 3.1. It is much less obvious how the average ROC, defined by (1.10) below, compares to the worst case ROC.
Due to (1.5), we define the (one-step) shrinking factor by
| (1.8) |
Then, for any initial vector , the rate of convergence of the optimum gradient descent method applied to the minimization of (1.1) is given by
| (1.9) |
As depends only on the direction of , and is insensitive to sign changes in the components of (see (2.1)), the average ROC can be defined based on averaging over all on the unit sphere, or just over the positive octant of the unit sphere. Formally,
Definition 1.1
The average ROC of the optimum GD method applied to (1.1) is
| (1.10) |
where is the uniform probability measure on , and .
We have
| (1.11) |
Note that (1.7) only shows that the worst case ROC is upper bounded by ; for a proof of the equality () in (1.11), see Proposition 3.1.
1.1 Main results
In this paper, we establish the following result:
Theorem 1.2
(i) If has only two distinct eigenvalues, then the average ROC approaches 0 when . (ii) If has an intermediate eigenvalue uniformly bounded away from the two extremal eigenvalues, then the average ROC approaches the worst case ROC in (1.11), which approaches 1, when .
The second part of Theorem 1.2 is an immediate corollary of the following result:
Theorem 1.3
If has an intermediate eigenvalue, i.e. and there exists s.t. , then
| (1.12) |
where , , .
Remark 1.4
It is shown in [5, §2] that is lower-bounded by the right-hand side of (1.12) with the proviso of a difficult-to-verify condition on . The undesirable condition seems to be an artifact of the subtle argument in [5, §2], which also makes it hard to see whether the bound (1.12) is tight. Our proof of Theorem 1.3 uses Akaike’s results in [5, §1], but replace his arguments in [5, §2] by a more natural dynamical system approach. The proof shows that the bound is tight and holds for a set of of full measure, which also allows us to conclude the second part of Theorem 1.2. It uses the center and stable manifolds theorem, a result that was not available at the time [5] was written.
Remark 1.5
For constant step size GD, ill-conditioning alone is enough to cause slow convergence for almost all initial vectors. For exact line search, however, it is ill-conditioning in cahoot with an intermediate eigenvalue that causes the slowdown. This is already apparent from Akaike’s analysis; the first part of Theorem 1.2 intends to bring this point home, by showing that the exact opposite happens in the absence of an intermediate eigenvalue.
Organization of the proofs. In Section 2, we recall the results of Akaike, along with a few observations not directly found in [5]. These results and observations are necessary for the final proofs of Theorem 1.2(i) and Theorem 1.3, to be presented in Section 3 and Section 4, respectively. The key idea of Akaike is an interesting discrete dynamical system, with a probabilistic interpretation, underlying the optimum GD method. We give an exposition of this dynamical system in Section 2. A key property of this dynamical system is recorded in Theorem 2.2. In a nutshell, the theorem tells us that part of the properties of the dynamical system in the high-dimensional case is captured by the 2-dimensional case; so – while the final results say that there is a drastic difference between the and cases – the analysis of the latter case (in Section 4) uses some of the results in the former case (in Section 3). Appendix A records two auxiliary technical lemmas. Appendix B recalls a version of the theorem of center and stable manifolds stated in the monograph [17], and discusses a refinement of the result needed to prove the full version of Theorem 1.3.
Section 3 and Section 4 also present computations, in Figures 2 and 3, that serve to illustrate some key ideas behind the proofs.
Before proceeding to the proofs, we consider some contemporary applications of exact line search methods to POPs.
1.2 Applications of exact line search methods to POPs
In its abstract form, the phase retrieval problem seeks to recover a signal ( or ) from its noisy ‘phaseless measurements’ , with enough random ‘sensors’ . A plausible approach is to choose that solves
| (1.13) |
The two squares makes it a degree 4 POP.
We consider also another data science problem: matrix completion. In this problem, we want to exploit the a priori low rank property of a data matrix in order to estimate it from just a small fraction of its entries , . If we know a priori that has rank , then similar to (1.13) we may hope to recover by solving
| (1.14) |
It is again a degree 4 POP.
Extensive theories have been developed for addressing the following questions: (i) Under what conditions – in particular how big the sample size for phase retrieval and for matrix completion – would the global minimizer of (1.13) or (1.14) recovers the underlying object of interest? (ii) What optimization algorithms would be able to compute the global minimizer?
It is shown in [13] that constant step size GD with an appropriate choice of initial vector and step size applied to the optimization problems above probably guarantees success in recovering the object of interest under suitable statistical models. For the phase retrieval problem, assume for simplicity , , write
| (1.15) |
Then
| (1.16) |
Under the Gaussian design of sensors , , considered in, e.g., [10, 9, 13], we have
At the global minimizer , , so
This suggests that when the sample size is large enough, we may expect that the Hessian of the objective is well-conditioned for . Indeed, when , the discussion in [13, Section 2.3] implies that grows slowly with :
with a high probability. However, unlike (1.1), the objective (1.15) is a quartic instead of a quadratic polynomial, so the Hessian is not constant in . We have the following phenomena:
-
(i)
On the one hand, in the directions given by , the Hessian has a condition number that grows (up to logarithmic factors) as , meaning that the objective can get increasingly ill-conditioned as the dimension grows, even within a small ball around with a fixed radius .
-
(ii)
On the other hand, most directions would not be too close to be parallel to , and with a high probability.
-
(iii)
Constant step-size GD, with a step size that can be chosen nearly constant in , has the property of staying away from the ill-conditioned directions, hence no pessimistically small step sizes or explicit regularization steps avoiding the bad directions are needed. Such an ‘implicit regularization’ property of constant step size GD is the main theme of the article [13].
To illustrate (i) and (ii) numerically, we compute the condition numbers of the Hessians at , and for , with , , , and :
| 14.1043 | 147.6565 | 17.2912, 16.0391, 16.7982 | |
| 12.1743 | 193.6791 | 15.3551, 14.9715, 14.5999 | |
| 11.4561 | 251.2571 | 14.3947, 13.8015, 14.0738 | |
| 11.5022 | 310.8092 | 13.9249, 13.6388, 13.5541 | |
| 10.8728 | 338.3008 | 13.2793, 12.9796, 13.3100 |
(The last column is based on three independent samples of .) Evidently, the condition numbers do not increase with the dimension in the first and third columns, while a near linear growth is observed in the second column.
We now illustrate (iii); moreover, we present experimental results suggesting that exact line search GD performs favorably compared to constant step size GD. For the latter, we first show how to efficiently compute the line search function by combining (1.15) and (1.16). Write . We can compute the gradient descent direction together with the line search polynomial by computing the following sequence of vectors and scalars, with the computational complexity of each listed in parenthesis:
In above, , for two vectors , of the same length, stands for componentwise multiplication, and . As we can see, the dominant steps are steps (1), (3) and (4). As only steps (1)-(3) are necessary for constant step size GD, we conclude that, for the phase retrieval problem, exact line search GD is about 50% more expensive per iteration than constant step size GD.
Figure 1 shows the rates of convergence for gradient descent with constant step size (suggested in [13, Section 1.4]) and exact line search for , , with the initial guess chosen by a so-called spectral initialization.333Under the Gaussian design , it is interesting to see that . As the Rayleigh quotient is maximized when is parallel to , an educated initial guess for would be a suitably scaled dominant eigenvector of , which can be computed from the data and sensors using the power method. See, for example, [13, 9] for more details and references therein. As the plots show, for each signal size the ROC for exact line search GD is more than twice as fast as that of constant step size GD.
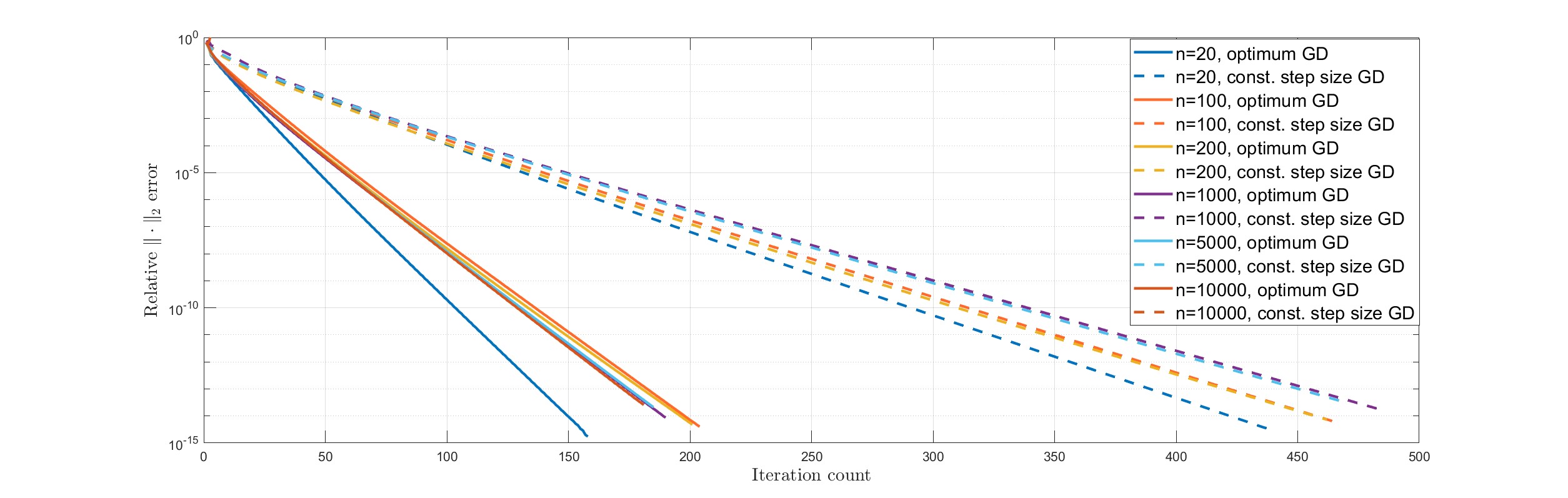 |
Not only is the speedup in ROC by exact line search outweighs the 50% increase in per-iteration cost, the determination of step size is automatic and requires no tuning. For each , the ROC for exact line search GD in Figure 1 is slightly faster than for – the ROC attained by optimum GD as if the degree 4 objective has a constant Hessian (Theorem 1.3)– suggesting also that the GD method implicitly avoids the ill-conditioned directions (recall the table above), akin to what is established in [13]. Unsurprisingly, our experiments also suggest that exact line search GD is more robust than its constant step size counterpart for different choices of initial vectors. Similar advantages for exact line search GD was observed for the matrix completion problem.
2 Properties of OGD and Akaike’s
Let be with the origin removed. For , define by . Notice from (1.8) that, for a fixed , is invariant under both scaling and sign-changes of the components, i.e.
| (2.1) | ||||
In other words, depends only on the equivalence class , where if .
By inspecting (1.4) one sees that
| (2.2) | ||||
This means , when well-defined, depends only on . In other words, OGD descends to a map
| (2.3) |
It can be shown that is well-defined on
| (2.4) |
also . (We exclude the proof here because it also follows from one of Akaike’s results; see (2.10) below.) Except when with , does not extend continuously to the whole ; see below.
Akaike’s map . While Akaike, a statistician, did not use jargons such as ‘invariance’ or ‘parametrization’ in his paper, the map introduced in [5] is the representation of under the identification of with
| (2.5) |
In above, , or simply , is usually called the standard simplex, or the probability simplex as Akaike would prefer. One can verify that is a well-defined bijection and hence
| (2.6) |
may be viewed as a parametrization of the quotient space . (Strictly speaking, the map is not a parametrization. As a manifold, is -dimensional, which means it deserves a parametrization with parameters. But, of course, we can identify any with by .)
We now derive a formula for : By (1.4) and (2.6), has a representor with
where . Consequently,
| (2.7) |
The last expression is Akaike’s map defined in [5, §1]. Under the distinct eigenvalues assumption (see below), is well-defined for any in
| (2.8) |
i.e. the standard simplex with the standard basis of removed. Also, is continuous on its domain. By (2.11) below, when , extends continuously to . But for it does not extend continuously to any ; for example, if and , then (assuming ),
| (2.9) |
This follows from the case of Proposition 2.1 and the following diagonal property of .
Diagonal property. Thanks to the matrix being diagonal, is invariant under for any . Notice the correspondence between and via the projection . If we write to signify the dependence of on , then under this correspondence is simply acting on .
This obvious property will be useful for our proof later; for now, see (2.9) above for an example of the property in action.
Distinct eigenvalues assumption. It causes no loss of generality to assume that the eigenvalues are distinct: if consists of the distinct eigenvalues of , then , where each stands for an identity matrix of the appropriate size. Accordingly, each initial vector can be written in block form . It is easy to check that if we apply the optimum GD method to with and initial vector , then the ROC of the reduced system is identical to that of the original. Moreover, the map
is a submersion and hence has the property that is a null set in for any null set in ; see Lemma A.1. Therefore, it suffices to prove Theorem 1.2 and Theorem 1.3 under the distinct eigenvalues assumption.
So from now on we make the blanket assumption that .
Connection to variance. Akaike’s -dependent parametrization (2.5)-(2.6) does not only give the simple representation (2.7), the map also has an interesting probabilistic interpretation: if we think of as a probability distribution associated to the values in , then is the mean of the resulted random variable, the expression in the dominator of the definition of , i.e. , is the variance of the random variable. What, then, does the map do to ? It produces a new probability distribution, namely , to . The definition of in (2.7) suggests that will be bigger if is far from the mean , so the map polarizes the probabilities to the extremal values and . This also suggests that the map tends to increase variance. Akaike proved that it is indeed the case in [5, Lemma 2]: Using the notation for , the result can be expressed as
| (2.10) |
This monotonicity result is a key to Akaike’s proof of (2.12) below. As an immediate application, notice that by (2.8) is equivalent to saying that the random variable with probability attached to the value has a positive variance. Therefore (2.10) implies that if , then also, and so is well-defined for all .
The following fact is instrumental for our proof of the main result; it not explicitly stated in [5].
Proposition 2.1 (Independence of and )
The map depends only on , , defined by
In particular, when , is independent of ; in fact,
| (2.11) |
While elementary to check, it is not clear if Akaike was aware of the first part of the above proposition. It tells us that the condition number of does not play a role in the dynamics of . However, he must be aware of the second part of the proposition, as he proved the following nontrivial generalization of (2.11) in higher dimensions. When the dimension is higher than 2, is no longer an involution, but yet resembles (2.11) in the following way:
Theorem 2.2
[5, Theorem 2] For any , there exists such that
| (2.12) |
Our proof of Theorem 1.3 shall rely on this result, which says that the dynamical system defined by polarizes the probabilities to the two extremal eigenvalues. This makes part of the problem essentially two-dimensional. So we begin by analyzing the ROC in the 2-D case.
3 Analysis in 2-D and Proof of Theorem 1.2(i)
When , we may represent a vector in by with . Recall (2.11) and note that depends on only through . So, we may represent and in the parameter and the quantity as:
| (3.1) |
So , and the otherwise difficult-to-analyze ROC ((1.9)) is determined simply by
| (3.2) |
By (3.1), the value that maximizes is given by , with maximum value (). It may be instructive to see that the same can be concluded from Henrici’s proof of Kantorovich’s inequality in [12]: The one-step shrinking factor (in any dimension) attains it maximum value when and only when (i) for every such that , is either or , and (ii) . When , condition (i) is automatically satisfied, while condition (ii) means
| (3.3) |
This is equivalent to setting to .
These observations show that the worst case bound (1.7) is tight in any dimension :
Proposition 3.1
There exists initial vector such that equality holds in (1.7) for any iteration .
Proof: We have proved the claim for . For a general dimension , observe that if the initial vector lies on the - plane, then – thanks to diagonalization – GD behaves exactly the same as in 2-D, with replaced by . That is, if we choose so that and for , then equality holds in (1.7) for any .
For any non-zero vector in , can be identified by with , which, by (2.5), is identified with where
| (3.4) |
Proof of the first part of Theorem 1.2. As the ROC depends only on the direction of , in 2-D the average ROC is given by
| (3.5) |
Note that
| (3.6) |
On the one hand, we have
| (3.7) |
so . On the other hand, by (3.6) and (3.1) one can verify that
| (3.8) |
See Figure 2 (left panel) illustrating the non-uniform convergence. Since , by the dominated convergence theorem,
This proves the first part of Theorem 1.2.
An alternate proof. While the average rate of convergence does not seem to have a closed-form expression, the average square rate of convergence can be expressed in closed-form:
| (3.9) |
By Jensen’s inequality,
| (3.10) |
Since the right-hand side of (3.9) ( the r.h.s. of (3.10)) goes to zero as approaches 0, so does the left-hand side of (3.10) and hence also the average ROC.
See Figure 2 (right panel, yellow curve) for a plot of how the average ROC varies with : as increases from 1, the average ROC does deteriorate – as most textbooks would suggest – but only up to a certain point, after that the average ROC does not only improve, but gets arbitrarily fast, as gets more and more ill-conditioned – quite the opposite of what most textbooks may suggest. See also Appendix C.
 |
 |
4 Proof of Theorem 1.3 and Theorem 1.2(ii)
Let . Denote by the map
Its domain, denoted by , is the simplex with its vertices removed. Notwithstanding, can be be smoothly extended to some open set of containing .
The 2-periodic points of according to correspond to the fixed points , which we denote more compactly by , of .
The map defined by (2.5)-(2.6) induces smooth one-to-one correspondences between , and . For any , let be the corresponding probability vector and denote by the corresponding limit probability according to . Theorem 2.2, together with (3.1), imply that
| (4.1) |
A computation shows that for any , the Jacobian matrix of at is:
| (4.2) |
where is defined as in Proposition 2.1. Since , the Jacobian matrix of at its fixed point is given by
its eigenvalues are 1 and
| (4.3) |
Each of the last eigenvalues, namely , is less than or equal to 1 if and only if . Consequently, we have the following:
Lemma 4.1
The spectrum of has at least one eigenvalue larger than one iff , where
| (4.4) |
Claim I: For almost all , there exists an open set around such that .
Claim II: For almost all , with .
Our proofs of these claims are based on (essentially part 2 of) the Theorem B.1.
By (4.3), is a local diffeomorphism at for every . The interval defined by (4.4) covers at least 70% of : ; it is easy to check that , while for , , may or may not fall into . If we make the assumption that
| (4.5) |
then Theorem B.1 can be applied verbatim to at for every and the argument below will prove the claim under the assumption (4.5), and hence a weaker version of Theorem 1.3.
Note that Claim I is local in nature, and follows immediately from Theorem B.1 – also a local result – for any in the interior of excluding . (If we invoke the refined version of Theorem B.1, there is no need to exclude the singularities. Either way suffices for proving Claim I.) Claim II, however, is global in nature. Its proof combines the refined version of Theorem B.1 with arguments exploiting the diagonal and polynomial properties of .
Proof of the claim II. By (2.12), it suffices to show that the set
has measure zero in . By (the refined version of) Theorem B.1 and Lemma 4.1, every fixed point , , of has a center-stable manifold, denoted by , with co-dimension at least 1. The diagonal property of , and hence of , ensures that can be chosen to lie on the plane , which is contained in the hyperplane . Therefore,
Of course, we also have , . So to complete the proof, it suffices to show that the set of points attracted to the hyperplane by has measure 0, i.e. it suffices to show that
| (4.6) |
is a null set.
We now argue that is non-singular for almost all . By the chain rule, it suffices to show that is non-singular for almost all . Note that the entries of are rational functions; in fact is of the form , where and are degree 2 polynomials in and for . So is of the form where is some polynomial in . It is clear that is not identically zero, as that would violate the invertibility of at many , as shown by (4.2). It then follows from Lemma A.2 that is non-zero almost everywhere, hence the almost everywhere invertibility of .
As is null, we can then use Lemma A.1 inductively to conclude that is null for any . So the set (4.6) is a countable union of null sets, hence is also null.
Computational examples in 3-D. Corresponding to the limit probability for , defined by (2.12), is the limit angle defined by , where . The limit probability and the limit angle are related by
| (4.7) |
This is just the inverse of the bijection between and (3.4) already seen in the 2-D case. Unlike the 2-D case, initial vectors uniformly sampled on the unit sphere will not resulted in a limit angle uniformly sampled on the interval .
We consider various choices of with , and for each we estimate the probability distribution of the limit angles with uniformly distributed on the unit sphere of . As we see from Figure 3, the computations suggest that when the intermediate eigenvalue equals , the distribution of the limit angles peaks at , the angle that corresponds to the slowest ROC . The mere presence of an intermediate eigenvalue, as long as it is not too close to or , concentrates the limit angle near . Moreover, the effect gets more prominent when is large. The horizontal lines in Figure 3 correspond to Akaike’s lower bound of ROC in (1.12); the computations illustrates that the bound is tight.
 |
 |
5 Open Question
The computational results in Appendix C suggest that our main results Theorem 1.2 and 1.3 should extend to objectives beyond strongly convex quadratics. The article [11] shows how to extend the worst case ROC (1.7) for strongly convex quadratics to general strongly convex functions:
Theorem 5.1
[11, Theorem 1.2] If satisfies for all , a global minimizer of on , and . Each iteration of the GD method with exact line search satisfies
The result is proved for the slightly bigger family of strongly convex functions that requires only regularity; see [11, Definition 1.1] or [7, Chapter 7] for the definition of .
The above result was anticipated by most optimization experts; compare it with, for example, [16, Theorem 3.4]. But the rigirous proof in [11] requires a tricky semi-definite programming formulation, which is tailored for the analysis of the worst case ROC. At this point, it is not clear how to generalize the average case ROC result in this article to objectives in .
Appendix A Two Auxiliary Measure Theoretic Lemmas.
The proof of Theorem 1.3 uses the following two lemmas.
Lemma A.1
Let and be open sets, , be with for almost all . Then whenever is of measure zero, so is .
Lemma A.2
The zero set of any non-zero polynomial has measure zero.
Appendix B The Theorem of Center and Stable Manifolds
Theorem B.1 (Center and Stable Manifolds)
Let 0 be a fixed point for the local diffeomorphism where is a neighborhood of zero in and . Let be the invariant splitting of into the generalized eigenspaces of corresponding to eigenvalues of absolute value less than one, equal to one, and greater than one. To each of the five invariant subspaces , , , , and there is associated a local f invariant embedded disc , , , , tangent to the linear subspace at and a ball around zero in a (suitably defined) norm such that:
-
1.
. is a contraction mapping.
-
2.
. If for all , then .
-
3.
. If for all , then .
-
4.
. If for all , then .
-
5.
. is a contraction mapping.
The assumption that is invertible in Theorem B.1 happens to be unnecessary. The proof of existence of and , based on [17, Theorem III.2], clearly does not rely on the invertibility of . That for and , however, is based on the applying [17, Theorem III.2] to ; and it is the existence of that is needed in our proof of Theorem 1.3. Fortunately, by a finer argument outlined in [17, Exercise III.2, Page 68] and [3], the existence of can be established without assuming the invertibility of . Thanks to the refinement, we can proceed with the proof without the extra assumption (4.5).
Appendix C The 2-D Rosenbrock function
While Akaike did not bother to explore what happened to the optimum GD method in 2-D, the 2-D Rosenbrock function , again a degree 4 polynomial, is often used in optimization textbooks to exemplify different optimization methods. In particular, due to the ill-conditioning near its global minimizer (), it is often used to illustrate the slow convergence of GD methods.
A student will likely be confused if he applies the exact linesearch GD method to this objective function. Figure 4 (leftmost panel) shows the ROC of optimum GD applied to the 2-D Rosenbrock function. The black line illustrates the worst case ROC given by (1.11) under the pretense that the degree 4 Rosenbrock function is a quadratic with the constant Hessian ; the other lines show the ROC with 500 different initial guesses sampled from , . As predicted by the first part of Theorem 1.2, the average ROC is much faster than the worst case ROC shown by the black line not in spite of, but because of, the ill-conditioning of the Hessian.444To the best of the author’s knowledge, the only textbook that briefly mentions this difference between dimension 2 and above is [16, Page 62]. The same reference points to a specialized analysis for the 2-D case in an older optimization textbook, but the latter does not contain a result to the effect of the first part of Theorem 1.2.
 |
 |
 |
The student may be less confused if he tests the method on the higher dimensional Rosenbrock function:
See the next two panels of the same figure for and , which are consistent with what the second part of Theorem 1.2 predicts, namely, ill-conditioning leads to slow convergence for essentially all initial vectors.
References
- [1] Mathematics Stack Exchange: https://math.stackexchange.com/q/3215996 (version: 2019-05-06).
- [2] Mathematics Stack Exchange: https://math.stackexchange.com/q/1920302 (version: 2022-02-07).
- [3] MathOverflow: https://mathoverflow.net/q/443156 (version: 2023-03-21).
- [4] A. A. Ahmadi and A. Majumdar. Some applications of polynomial optimization in operations research and real-time decision making. Optimization Letters, 10(4):709–729, 2016.
- [5] H. Akaike. On a successive transformation of probability distribution and its application to the analysis of the optimum gradient method. Annals of the Institute of Statistical Mathematics, 11:1–16, 1959.
- [6] A. Aubry, A. De Maio, B. Jiang, and S. Zhang. Ambiguity function shaping for cognitive radar via complex quartic optimization. IEEE Transactions on Signal Processing, 61(22):5603–5619, 2013.
- [7] A. Beck. Introduction to Nonlinear Optimization: Theory, Algorithms, and Applications with MATLAB. Society for Industrial and Applied Mathematics, USA, 2014.
- [8] J. J. Benedetto and M. Fickus. Finite normalized tight frames. Adv. Comput. Math., 18(2):357–385, 2003.
- [9] E. J. Candès, X. Li, and M. Soltanolkotabi. Phase retrieval via Wirtinger flow: theory and algorithms. IEEE Trans. Inform. Theory, 61(4):1985–2007, 2015.
- [10] E. J. Candès, T. Strohmer, and V. Voroninski. PhaseLift: exact and stable signal recovery from magnitude measurements via convex programming. Comm. Pure Appl. Math., 66(8):1241–1274, 2013.
- [11] E. de Klerk, F. Glineur, and A. B. Taylor. On the worst-case complexity of the gradient method with exact line search for smooth strongly convex functions. Optimization Letters, 11(7):1185–1199, Oct 2017.
- [12] P. Henrici. Two remarks on the Kantorovich inequality. Amer. Math. Monthly, 68:904–906, 1961.
- [13] C. Ma, K. Wang, Y. Chi, and Y. Chen. Implicit regularization in nonconvex statistical estimation: gradient descent converges linearly for phase retrieval, matrix completion, and blind deconvolution. Found. Comput. Math., 20(3):451–632, 2020.
- [14] P. Mohan, N. K. Yip, and T. P.-Y. Yu. Minimal energy configurations of bilayer plates as a polynomial optimization problem. Nonlinear Analysis, June 2022.
- [15] J. Nie. Sum of squares method for sensor network localization. Computational Optimization and Applications, 43(2):151–179, 2009.
- [16] J. Nocedal and S. J. Wright. Numerical Optimization. Springer, New York, NY, USA, second edition, 2006.
- [17] M. Shub. Global stability of dynamical systems. Springer-Verlag, New York, 1987. With the collaboration of Albert Fathi and Rémi Langevin, Translated from the French by Joseph Christy.