Textual Adversarial Attack using Metric-Guided Rewrite and Rollback
Abstract
Adversarial examples are helpful for analyzing and improving the robustness of text classifiers. Generating high-quality adversarial examples is a challenging task as it requires generating fluent adversarial sentences that are semantically similar to the original sentences and preserve the original labels, while causing the classifier to misclassify them. Existing methods prioritize misclassification by maximizing each perturbation’s effectiveness at misleading a text classifier; thus, the generated adversarial examples fall short in terms of fluency and similarity. In this paper, we propose a rewrite and rollback (R&R) framework for adversarial attack. It improves the quality of adversarial examples by optimizing a critique score which combines the fluency, similarity, and misclassification metrics. R&R generates high-quality adversarial examples by allowing exploration of perturbations that do not have immediate impact on the misclassification metric but can improve fluency and similarity metrics. We evaluate our method on 5 representative datasets and 3 classifier architectures. Our method outperforms current state-of-the-art in attack success rate by +16.2%, +12.8%, and +14.0% on the classifiers respectively. Code is available at https://github.com/DAI-Lab/fibber
1 Introduction
Recently, adversarial attacks in text classification have received a great deal of attention. Adversarial attacks are defined as subtle perturbations in the input text such that a classifier misclassifies it. They can serve as a tool to analyze and improve the robustness of text classifiers, thus being more and more important because security-critical classifiers are being widely deployed wu2019misinformation; torabi2019big; zhou2019fake.

Existing attack methods either adopt a synonym substitution approach (Jin2019IsBR; zang2019word) or use a pre-trained language model to propose substitutions for better fluency and naturalness (li2020bert; garg2020bae; li2021CLARE). They follow a similar framework: first, construct some candidate perturbations, and then, use the perturbations that most effectively mislead the classifier to modify the sentence. This process is repeated multiple times until an adversarial example is found. This framework prioritizes misclassification by picking perturbations that most effectively mislead the classifier. Despite the success in changing the classifier prediction, it has two main disadvantages. First, it is prone to modify words that are critical to the sentence’s meaning which decreases the similarity and is more likely to change the true label of the sentence, or introduce low-frequency words causing the fluency to decrease. Second, some perturbations do not have immediate impacts on misclassification, but can trigger it when combined with other perturbations, and these frameworks cannot find adversarial examples with these perturbations.
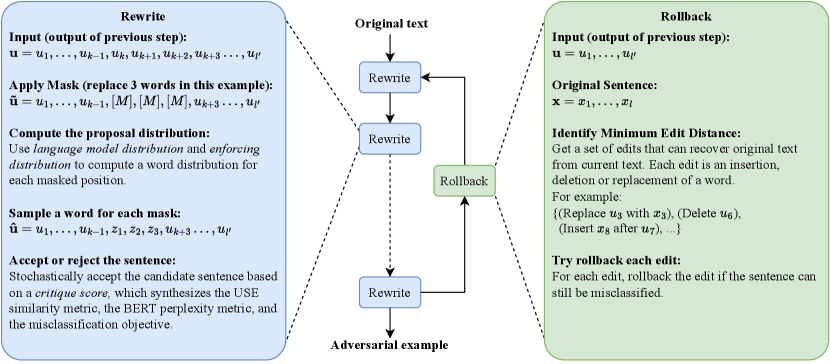
To overcome these problems, the attack method needs to consider fluency, similarity, and misclassification jointly, while also efficiently exploring various perturbations that do not show direct impacts on the latter. We define a critique score that combines fluency, similarity and misclassification metrics. Then, we present our design for a Rewrite and Rollback framework (R&R) which optimizes this score to generate better adversarial examples. In the rewrite stage, we explore multi-word substitutions proposed by a pre-trained language model. We accept or reject a substitution according to the critique score. We can generate a high-quality adversarial example after multiple iterations of rewrite. Rewrite may introduce changes that do not contribute to misclassification and may also reduce similarity and fluency. Therefore, we periodically apply the rollback operation to reduce the number of modifications without changing the misclassification result. Figure 1 illustrates the process using an example.
2 Problem Formulation
Let be a sentence of length , be its classification label, and be a text classifier that predicts a probability distribution over classes. The objective of an attack method is to \linenomathAMS
where is the length of the adversarial sentence. However, this formulation requiring human evaluation is intractable for large-scale data. Therefore, we approximate the sentence fluency with the perplexity of the sentence. It is defined as
where is measured by a language model. Low perplexity means the sentence is predictable by the language model, which usually indicates the sentence is fluent. Sentence similarity can be quantified as , where is a pre-trained sentence encoder that encodes the meaning of a sentence into a vector. We assume that high sentence similarity implies preservation of the sentence label. Thus, finding the adversarial sentence is formulated as a multi-objective optimization problem as follows: \linenomathAMS
| Construct | |||
We use a fine-tuned BERT-base model (Devlin2019BERTPO) to measure perplexity and use Unversal Sentence Encoder (USE) (cer2018universal) to measure sentence similarity. Ultimately, fluency, similarity, and the preservation of original label need to be verified by humans. We discuss human verification in Section 4.
Threat Model.
We assume the attacker can query the classifier for the prediction (i.e., the probability distribution over all classes). But they do not have knowledge on architecture of the classifier nor query for the gradient. They can also access some unlabeled text in the domain of the classifier.
3 Metric-Guided Rewrite and Rollback
In this section, we first give an overview, then introduce the rewrite and rollback components respectively. Finally, we give a summary of pre-trained models used in the framework.
3.1 Overview
R&R contains the rewrite and rollback steps. In the rewrite step, we randomly mask several consecutive words, and compute a proposal distribution, which is a distribution over the vocabulary on each masked position defined as Eq. (1). We construct a multi-word substitution111The number of words in each substitution, the number of rewrite steps between two rollback steps, the maximum number of rewrite steps, and the batch size are hyperparamters. for the masked positions according to the distribution, then compute the critique score defined as Eq. (3)-(5). If the score increases, we accept the substitution. If the score decreases, we accept it with a probability depending on the degree of decrease. The rewrite step contains randomness to encourage exploration of different modifications, while the critique score will guide the rewritten sentence to a high-quality adversarial example. After several steps of rewriting1, we apply a rollback operation on the sentences that have already been misclassified to reduce the number of changes introduced in the rewriting. In the rollback step, we identify a minimum set of edits required to change the current sentence back to the original sentence. We rollback an edit if it does not affect the misclassification.
We implement the framework to simultaneously rewrite a batch of sentences. We make multiple copies of an input text and create a batch1. The proposal distributions and critique scores for these copies can be computed in parallel on a GPU, while the randomness in the rewrite step leads to different rewritten sentences. The loop terminates when either the maximum number of rewrite steps is reached1 or half of the sentences in the batch are misclassified. Figure 2 shows the R&R framework.
3.2 Rewrite
In each rewrite, we mask then substitute a span of words. It is composed of the following steps.
Apply mask in the sentence.
First, we randomly pick consecutive words in the sentence, and replace them with mask, where can be , , or meaning replace, shrink, and expand operation respectively. Compared with CLARE li2021CLARE which masks one word at a time (i.e., ), masking multiple words can make it easier to modify common phrases. We use to denote the masked sentence.
Compute proposal distribution.
Then, we compute proposal distribution for masks in the sentence. This distribution assigns a high probability to words that can construct a fluent and legitimate paraphrase. Let be the words to be placed at the masked positions. The distribution is
| (1) |
where is a language model distribution that give high probability to words that can make a fluent sentence, and is the enforcing distribution, which give high probability to words that can lead to semantically similar sentences. and should be considered as two different weights of words and are multiplied together to get so that if either or is low, the word will have low probability in . This is a desired property because we want the adversarial sentence to have good fluency (i.e., high ) and high similarity (i.e., high ). is computed by sending into BERT and taking the predicted word distribution on masked positions. Depending on the position, the word distributions for masks are different. The enforcing distribution is measured by word embeddings. We use the sum of word embeddings as a sentence embedding, where is the counter-fitted word embedding (mrkvsic2016counter). Then we define the enforcing distribution as \linenomathAMS
| (2) |
is a hyper-parameter with a positive value. Larger penalizes more on dissimilar words. The ensures the value to be positive thus the values can be converted to a probability distribution over words. We use the conventional cosine similarity to compute the distance of two vectors. If the embedding of a word perfectly aligns with the sentence representation difference , it gets the largest probability. The enforcing distribution aims at making the candidate modification more similar to the original sentence. Note that enforcing distribution is identical on all masks.
Sample a candidate sentence.
We sample a candidate word for each masked position by . We do not consider the effect of sampling one word on other masked positions (i.e., we do not recompute proposal distribution for the remaining masks after sampling a word) because language model distribution already considers the position of the mask and assigns a different distribution for each mask, meanwhile recomputing is inefficient. We use to denote the candidate sentence.
Critique score and decision function.
We decide whether to accept the candidate sentence using a decision function. The decision function computes a heuristic critique score \linenomathAMS
| (3) | ||||
| (4) | ||||
| (5) |
Eq. (3) penalizes sentences with high perplexity, where is perplexity measured by a BERT model. Eq. (4) penalizes sentences with sentences with cosine similarity lower than , where is the sentence representation by USE. Eq. (5) penalizes sentences that cannot be misclassified where means the log probability of class predicted by the classifier. , and are hyperparameters.
The decision is made based on
| (6) |
If , the decision function accepts ; otherwise it accepts with probability . The computation of is motivated by the Metropolis–Hastings algorithm (hastings1970monte) (See Appendix 7). The critique score is a straightforward way to convert the multi-objective optimization problem into a single objective. Although it introduces several hyper-parameters, R&R is no more complicated than conventional methods, which also require hyper-parameter setting.
3.3 Rollback
In the rollback step, we eliminate modifications that do not correct the misclassification. It contains the following steps.
Find a minimum set of simple edits.
We first find a set of simple edits that change the current rewritten sentence back to the original sentence. Simple edits mean the insertion, deletion or replacement of a single word, which is different from the modification in the rewrite step.
Rollback edits.
For each edit, if reverting it does not correct the misclassification, then we revert the edit. For convenience, we scan each word in the sentence from right to left, and try to rollback each edit. Note that rollback may introduce grammar errors, but they can be fixed in future rewrite steps.
3.4 Vocabulary Adaptation
Computing is challenging because of the inconsistent vocabulary. The counter fitted word embeddings in works on a 65k-word vocabulary, while the BERT language model used in uses a 30k-word-piece vocabulary which contains common words and affixes. Rare words are handled as multiple affixes. For example “hyperparameter” does not appear in the BERT vocabulary, so it is handled as “hyper”, “##para”, and “##meter”. Since the BERT model is more complicated, we keep it as is and transfer word embeddings to BERT vocabulary. We train the word-piece embeddings as follows. Let be a plain text corpus tokenized by words. Let be word-piece tokenization of a word. Let be the original word embeddings and be the transferred embeddings on word-piece. We train the word-piece embeddings by minimizing the absolute error . We initialize by copying the embedding on words shared by two vocabularies and set other embeddings to . We optimize the absolute error using stochastic gradient descent. In each step, we sample 5000 words from , then update accordingly. Figure 9 in Appendix illustrates the algorithm.
3.5 Summary of pre-trained models in R&R
In R&R, we employ several pre-trained models. Choices are made according to the different characteristics of these pre-trained models.
BERT for masked word prediction and perplexity. Because BERT is originally trained for masked word prediction, it can predict the word distribution given context from both sides. Thus, BERT is preferable for generating . Estimating the perplexity for a sentence requires BERT to run in decoder mode and be fine-tuned. Perplexity can also be measured by other language models such as GPT2 radford2019language. We use BERT mainly for the consistent vocabulary with .
Word embedding and USE for similarity. Word embedding is more efficient as it only computes the sum of vectors and cosine similarity. In enforcing distribution, we need to replace the selected position with all possible ’s and measure the similarity, so we use word embeddings for efficiency. In the critique score, only the proposal sentence needs to be measured, so we can afford more computation time of USE.
4 Experiments
We conducted experiments on a wide range of datasets and multiple victim classifiers to show the efficacy of R&R. We first evaluate the quality of adversarial examples using automatic metrics. Then, we conducted human evaluation to show the necessity to generate highly similar and fluent adversarial examples. Finally, we conduct an ablation study to analyze each component of our method, and discuss defense against the attack.
Datasets. We use 3 conventional text classification datasets: topic classification, sentiment classification, and question type classification. We also use 2 security-critical datasets: hate speech detection and fake news detection. Dataset details are given in Table 1.
| Name | #C | Len | Description |
|---|---|---|---|
| AG | 4 | 43 | News topic classification by zhang2015character. |
| MR | 2 | 32 | Moview review dataset by pang2005seeing. |
| TREC | 6 | 8 | Question type classification by li2002learning. |
| HATE | 2 | 23 | Hate speech detection dataset by kurita20acl. |
| FAKE | 2 | 30 | Fake news detection dataset by yang2017satirical. We use the first sentence of the news for classification. |
| AG | MR | TREC | HATE | FAKE | |
|---|---|---|---|---|---|
| BERT-base | 92.8 | 88.2 | 97.8 | 94.0 | 81.2 |
| RoBERTa-large | 92.7 | 91.6 | 97.3 | 95.0 | 75.5 |
| FastText | 89.2 | 79.5 | 85.8 | 91.5 | 72.4 |
| Log Perplexity | 3.38 | 5.27 | 3.91 | 3.56 | 4.92 |
| AG | MR | TREC | HATE | FAKE | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Attack | ASR | Sim | PPL | ASR | Sim | PPL | ASR | Sim | PPL | ASR | Sim | PPL | ASR | Sim | PPL | |
|
\multirow3*
BERT |
TextFooler | 16.8 | 0.98 | 4.00 | 26.0 | 0.97 | 5.92 | 1.8 | 0.97 | 5.30 | 30.6 | 0.97 | 3.53 | 29.9 | 0.98 | 5.44 |
| CLARE | 28.8 | 0.97 | 3.60 | 48.4 | 0.97 | 5.70 | 2.5 | 0.96 | 5.58 | 31.0 | 0.97 | 3.99 | 48.9 | 0.98 | 5.02 | |
| R&R (Ours) | 54.1 | 0.98 | 3.64 | 63.4 | 0.98 | 5.36 | 10.8 | 0.97 | 5.29 | 55.3 | 0.98 | 4.06 | 57.0 | 0.98 | 5.05 | |
|
\multirow3*
RoBERTa |
TextFooler | 15.6 | 0.98 | 5.21 | 18.0 | 0.97 | 6.06 | 0.4 | 0.96 | 7.09 | 24.0 | 0.98 | 4.20 | 26.6 | 0.98 | 5.45 |
| CLARE | 23.3 | 0.97 | 5.24 | 45.9 | 0.97 | 5.67 | 2.5 | 0.97 | 6.53 | 35.7 | 0.97 | 4.37 | 46.0 | 0.98 | 5.20 | |
| R&R (Ours) | 41.2 | 0.98 | 3.73 | 48.5 | 0.97 | 5.53 | 12.5 | 0.97 | 5.17 | 55.7 | 0.97 | 4.07 | 59.6 | 0.98 | 5.25 | |
|
\multirow3*
FastText |
TextFooler | 25.8 | 0.98 | 4.16 | 33.1 | 0.98 | 5.85 | 6.5 | 0.98 | 5.04 | 21.7 | 0.98 | 3.44 | 35.3 | 0.98 | 5.46 |
| CLARE | 28.9 | 0.97 | 3.91 | 41.5 | 0.97 | 5.79 | 8.5 | 0.97 | 6.06 | 35.6 | 0.97 | 4.24 | 76.0 | 0.98 | 5.15 | |
| R&R (Ours) | 37.8 | 0.98 | 3.84 | 48.9 | 0.98 | 5.48 | 44.1 | 0.98 | 4.68 | 53.3 | 0.98 | 4.03 | 76.4 | 0.98 | 5.10 | |
Victim Classifiers. For each dataset, we use the full training set to train three victim classifiers: (1) BERT-base classifier Devlin2019BERTPO; (2) RoBERTa-large classifier liu2019roberta, and (3) FastText classifier joulin2017fasttext.
Baselines. We compare our method against two strong baseline attack methods: TextFooler (Jin2019IsBR) and CLARE (li2021CLARE).
Hyperparameters. In R&R, we use the BERT-base language model for . For each dataset, we fine-tune the BERT language model using 5k batches on the training set222We use the plain text to fine-tune the language model, and do not use the label. In the threat model, we assume the attacker can access plain text data from a similar domain. with batch size 32 and learning rate 0.0001, so it is adapted to the dataset. We set the enforcing distribution hyper-parameters . The decision function hyper-parameters , , , . To generate each paraphrase, we set maximum rewrite iterations to be , and replace a 3-word span in each iteration. We implement R&R in a 50-sentence batch and apply early-stop when half of the batch are misclassified. We apply rollback operation every 10 steps of rewrite. Then, we return the adversarial example with the best critique score.
Hardware and Efficiency. We conduct experiments on Nvidia RTX Titan GPUs. We measure the efficiency using average wall clock time. On the MR dataset, one attack on a BERT-base classifier using R&R takes 15.8 seconds on average. CLARE takes 14.4 seconds on average. TextFooler is the most efficient algorithm which takes 0.45 seconds.
Automatic Metrics. We evaluate the efficacy of the attack method using 3 automatic metrics:
Similarity (): We use Universal Sentence Encoder to encode the original and adversarial sentence, then use the cosine distance of two vectors to measure the similarity. We set a similarity threshold at 0.95, so the similarity of a legitimate adversarial example should be greater than 0.95.
Log Perplexity () shows the fluency of adversarial sentences.
Attack success rate (ASR) () shows the ratio of correctly classified text that can be successfully attacked.
Human Metrics: Automatic metrics are not always reliable. We use Mechanical Turk to verify the similarity, fluency, and whether the label of the text is preserved with respect to human evaluation.
Sentence similarity (): Turkers are shown pairs of original and adversarial sentences, and are asked whether the two sentences have the same semantic meaning. They annotate the sentence in a 5-likert, where 1 means strongly disagree, 2 means disagree, 3 means not sure, 4 means agree, and 5 means strongly agree.
Sentence fluency (): Turkers are shown a random shuffle of adversarial sentences, and are asked to rate the fluency in a 5-likert, where 1 describes a bad sentence, 3 describes a meaningful sentence with a few grammar errors, and 5 describes a perfect sentence.
Label match (): Turkers are shown a random shuffle of adversarial sentences and are asked whether it belongs to the class of the original sentence. They are asked to rate 0 as disagree, 0.5 as not sure, and 1 as agree.
We sample 100 adversarial sentences from each method, and each task is annotated by 2 Turkers. We do not annotate label matches on the FAKE dataset because identifying fake news is too challenging for Turkers. We require the location of the Turkers to be in the United States, and their Hit Approval Rate to be greater than 95%. The screenshots of the annotation tasks are shown on Figure 7 in Appendix.
Examples. Table 4 shows some examples. We find R&R makes natural modifications to the sentence and preserves the semantic meanings.
| Original (prediction: Technology): GERMANTOWN , Md . A Maryland - based \hltprivate lab that analyzes criminal - case DNA evidence has fired an analyst for allegedly falsifying test data . |
| Adversarial (prediction: Business): GERMANTOWN , Md . A Maryland - based \hltbio testing company that analyzes criminal - case DNA evidence has fired an analyst for allegedly falsifying test data . |
| Original (prediction: Sport): LeBron James scored 25 points , Jeff McInnis added a season - high 24 and the Cleveland Cavaliers won their sixth straight , 100 - 84 over the Charlotte Bobcats on Saturday night \hlt. |
| Adversarial (prediction: World): LeBron James scored 25 points , Jeff McInnis added a season - high 24 and the Cleveland Cavaliers won their sixth straight , 100 - 84 \hltSaturday over the \hltvisiting Charlotte Bobcats on Saturday night \hlt.. |
| Original (prediction: Negative): don ’ t be fooled by \hltthe impressive cast list - eye see you is pure junk . |
| Adversarial (prediction: Positive): don ’ t be fooled by \hltthis impressive cast list - eye see you is pure junk . |
| Original (prediction: Ask for description): What is die - casting ? |
| Adversarial (prediction: Ask for entity): What is \hltthe technique of die - casting ? |
| Original (prediction: Toxic) go back under \hltyour rock u irrelevant party puppet |
| Adversarial (prediction: Harmless) go back under \hltthe rock u irrelevant party puppet |
| AG | MR | TREC | HATE | FAKE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S. | F. | M. | S. | F. | M. | S. | F. | M. | S. | F. | M. | S. | F. | |
| TextFooler | 3.93 | 3.58 | 0.90 | 3.3 | 3.49 | 0.92 | 3.25 | 2.88 | 0.88 | 3.76 | 3.61 | 0.46 | 3.58 | 3.58 |
| CLARE | 3.75 | 3.65 | 0.93 | 2.44 | 3.33 | 0.74 | 3.00 | 3.00 | 0.75 | 3.89 | 4.41 | 0.81 | 3.67 | 3.65 |
| R&R (Ours) | 4.12 | 3.87 | 0.99 | 3.48 | 3.61 | 0.85 | 3.59 | 3.14 | 0.89 | 3.59 | 3.94 | 0.76 | 3.81 | 3.87 |
4.1 Is R&R effective in attacking classifiers?
Table 3 shows the ASR of R&R and baseline methods (with a rigorous 0.95 threshold on similarity). R&R achieves the best ASR on all datasets and across all classifiers. The average improvement compared with the CLARE baseline is +16.2%, +12.8%, +14.0% on BERT-base, RoBERTa-large and FastText classifiers respectively. This means that with the same rigorous similarity threshold, R&R is capable of finding more adversarial examples, i.e. for some text, R&R can find adversarial examples with a similarity higher than 0.95 while baseline methods cannot. We further measure whether R&R can outperform baselines with less rigorous similarity thresholds. On Figure 3, we set different thresholds and show the corresponding ASR. We observe that the curves of R&R are above the baseline curves in most cases, showing that R&R outperforms baselines on most threshold settings. It means R&R can achieve a higher ASR with various different similarity thresholds.

4.2 Does R&R generate semantically similar and fluent adversarial sentences?
Table 3 shows the USE similarity metric and log perplexity fluency metric (with a rigorous 0.95 threshold on similarity). Since we already apply a high threshold to ensure the adversarial examples are similar to the original sentences, the similarity metrics do not show significant differences. On AG, MR, TREC and FAKE datasets and 3 classifiers (a total of 12 settings), R&R outperforms baseline methods in 9 cases. This shows R&R keeps sentence fluency as high as baseline methods do, and does not sacrifice sentence fluency for higher ASR. The only failure case is on the HATE dataset, where TextFooler outperforms R&R in perplexity. Further investigation shows that it is because of the perplexity of the original sentence. If the original sentence has high perplexity, the corresponding adversarial sentence is likely to have high perplexity. It is possible that the original sentences that R&R succeeds on have higher perplexity than those successfully attacked by TextFooler. Therefore, we compute the average log perplexity for original sentences that are successfully attacked, and find that it is 3.24 for TextFooler and 3.94 for R&R. So TextFooler achieves low perplexity because it succeeds on original sentences with low perplexity while failing on those with higher perplexity.
USE similarity and log perplexity are proxy measures. To verify them, human annotations are needed. Table 5 shows the human evaluation results. R&R outperforms baselines on similarity and fluency on 4 datasets. This shows that by optimizing the critique score, R&R improves the similarity and fluency of adversarial sentences. Our method fails on the HATE dataset despite good automatic metrics. We hypothesize that this dataset collected from Twitter is more noisy than the others, causing the malfunction of automatic similarity and fluency metrics.
4.3 Do adversarial sentences preserve the original labels?
Preserving the original label is critical for an adversarial sentence to be legitimate. Table 5 also shows the human evaluation on label match. At least 76% of adversarial examples generated by R&R preserves the original label thus being legitimate. We also find that the label match is task dependent. Preserving original labels on AG dataset is easier than others, while the HATE dataset is the most challenging one.
4.4 How does each component in R&R contribute to the good performance?
We conduct ablation study on AG and FAKE datasets to understand the contribution of stochastic decision function, and periodic rollback.
Decision Function
In the Rewrite stage, we use a stochastic decision function based on the critique score. One alternative can be a deterministic greedy decision function, which accepts a rewrite only if the rewrite increases the critique score. Figure 4 shows the ASR with respect to different similarity thresholds. We find that the stochastic decision function outperforms the greedy one. We interpret the phenomenon as the greedy decision function gets stuck in local maxima, whereas the stochastic one can overcome this issue by accepting a slightly worse rewrite.

Rollback
We apply rollback periodically during the attack. We compare it with two alternatives: (1) no rollback (NRB) which only uses rewrite to construct the adversarial sentences, and (2) single rollback (SRB) which applies rollback once on the NRB results. Figure 5 shows the result. We find that rollback has a significant impact. NRB performs the worst. Without rollback, it is difficult to get high cosine similarity when many words in the sentence have been changed. Single rollback increases the number of overlapped words, which usually increases the similarity measurement. By periodically applying the rollback, the rollbacked sentence can be further rewritten to improve the similarity and fluency metrics, thus yielding to the best performance.

Multiple-Word Masking
In the Rewrite stage, we mask a span of multiple words in each iteration. Intuitively, when using a smaller span size, the masked words are easier to predict. The proposal distribution will assign high probability to the original words at masked positions. Therefore, the candidate sentences are likely to be identical to the original sentence, thus limiting the number of perturbations explored. When the span is large, predicting words becomes more difficult. Thus, we can sample different candidate sentences. But it is more likely to construct dissimilar or influential sentences. We vary the span size from 1, 2, 3, to 4 and show the results on Figure 6. We find that using span size 3 yields the best performance over most similarity thresholds.

4.4.1 How do existing defense methods work against R&R?
We further explore the defense against this attack:
-
[topsep=1pt, partopsep=1pt, leftmargin=12pt, itemsep=-2pt]
-
•
Adversarial attack methods sometimes introduce outlier words to trigger misclassification. Therefore we follow qi2020onion and apply a perplexity-based filtering to eliminate outlier words in sentences. We generate adversarial sentences on vanilla classifiers, then apply the filtering.
-
•
SHIELD (le2022shield) is a recently proposed algorithm that modifies the last layer of a neural network to defend against adversarial attack. We apply this method to classifiers and attack the robust classifier.
| AG | FAKE | |||
|---|---|---|---|---|
| +Filter | +SHIELD | +Filter | +SHIELD | |
| TextFooler | 6.2 | 8.2 | 13.8 | 16.7 |
| CLARE | 5.6 | 18.2 | 19.0 | 51.1 |
| R&R (ours) | 22.3 | 30.6 | 23.1 | 59.4 |
Table 6 shows the ASR of attack methods with a defense applied. We show that existing defense methods cannot effectively defend against R&R. It still outperforms baselines in ASR by large margin.
5 Related Work
Several recent works proposed word-level adversarial attacks on text classifiers. This type of attack misleads the classifier’s predictions by perturbing the words in the input sentence. TextFooler Jin2019IsBR shows the adversarial vulnerability of the state-of-the-art text classifiers. It uses heuristics to replace words with synonyms to mislead the classifier effectively. It relies on several pre-trained models, such as word embeddings mrkvsic2016counter, part-of-speech tagger, and Universal Sentence Encoder (cer2018universal) to perturb the sentence without changing its meaning. However, simple synonym substitution without considering the context results in unnatural sentences. Several works garg2020bae; li2020bert; li2021CLARE address this issue by using masked language models such as BERT Devlin2019BERTPO to propose more natural word substitutions. Our method also belongs to this category. But R&R does not maximize the efficacy of each perturbation, instead it allows exploring combinations of perturbations to generate adversarial examples with high similarity with the original sentence. Besides word-level attacks (zang2019word; ren-etal-2019-generating), there are also character-level attacks which introduce typos to trigger misclassification (papernot2016crafting; liang2017deep; samanta2018generating), and sentence-level attacks which attack a classifier by altering the sentence structure (iyyer2018adversarial). zhang2020adversarial gives a comprehensive survey on such attack methods. Other work on robustness to adversarial attacks in NLP includes robustness of the machine translation models (cheng2019robust), robustness in domain adaptation (oren2019distributionally), adversarial examples generated by reinforcement learning (wong2017dancin; vijayaraghavan2019generating), and certified robustness (jia2019certified). Adversarial attack libraries (morris2020textattack; zeng2021openattack) are also developed to help future research.
6 Conclusion
In this paper, we formulate the textual adversarial attack as a multi-objective optimization problem. We use a critique score to synthesize the similarity, fluency, and misclassification objectives, and propose R&R that optimizes the critique score to generate high-quality adversarial examples. We conduct extensive experiments. Both automatic and human evaluation show that the proposed method succeeds in optimizing the automatic similarity and fluency metrics to generate adversarial examples of higher quality than previous methods.
Ethical Considerations
In this paper, we propose R&R to generate adversarial sentences. Like all other adversarial attack methods, this method could be abused by malicious users to attack NLP systems and obtain illegitimate benefits. However, it is still necessary for the research community to develop methods to exploit all vulnerabilities of a classifier based on which more robust classifiers can be developed.
Acknowledgments
Alfredo Cuesta-Infante has been funded by the Spanish Government research project MICINN PID2021-128362OB-I00.
History of this Paper
ArXiv:2010.11869v1 is an earlier version of this work. It introduces the proposal distribution and proposes to attack text classifiers by rewriting a sentence.
ArXiv:2104.08453v1 improves the framework by proposing the critique score and a stochastic decision function. It also conducts human evaluation to verify the quality of adversarial sentences.
ArXiv:2104.08453v2 fixes some typos.
ArXiv:2104.08453v3 is the current version and is accepted to Findings of AACL-IJCNLP2022. In this version, we introduce the rollback step because it can improve the quality of adversarial sentences. We also add a stronger baseline – CLARE.
7 Relation to Metropolis-Hastings Sampling
Metropolis-Hastings sampling (MHS) (hastings1970monte) is a Markov-chain Monte Carlo (MCMC) for generating independent unbiased samples from a distribution. Assume we have a target distribution of sentences such that legitimate adversarial sentences of have high probability, while other sentences (could be a meaningless sequence of words) have low probability, we may attempt to solve the adversarial attack problem by MHS. Because we are likely to get an adversarial sentence of by drawing samples from . To apply MHS, we need to choose a transition probability that defines the probability to transit from one sentence to the next sentence in the MCMC. Then the MHS has following steps:
-
1.
Start with .
-
2.
Get a candidate .
-
3.
Compute
(7) -
4.
With probability , use as new and go to step 2; otherwise use the previous and go to step 2.
-
5.
After sufficient iterations, is a sample drawn from . Note that MHS needs a lot of iterations considering the huge space of all sentences.
The rewrite step in R&R is similar to MHS, if we consider as the unnormalized target distribution333We apply the exponential function to make sure the probability mass is positive. and as the transition probability. The definition of in Eq. (6) and Eq. (7) is one significant difference, where R&R only uses target distribution and omits the transition probability. We find omitting it can make the sampling bias towards sentences with higher probability in target distribution (i.e., sentences with higher critique score), which benefits the adversarial attack efficacy.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1b37bf72-8f43-4bcc-9338-4001178477e5/mturk-similarity.png)
Fluency
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1b37bf72-8f43-4bcc-9338-4001178477e5/mturk-fluency.png)
Label Match
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1b37bf72-8f43-4bcc-9338-4001178477e5/mturk-label.png)
Classifier: BERT
 Classifier: RoBERTa
Classifier: RoBERTa
 Classifier: FastText
Classifier: FastText

