33email: {luoqiu.li,bi_zhen,yehongbin,231sm}@zju.edu.cn
33email: {weidu.ch,huaixiao.thx}@alibaba-inc.com
Text-guided Legal Knowledge Graph Reasoning
Abstract
Recent years have witnessed the prosperity of legal artificial intelligence with the development of technologies. In this paper, we propose a novel legal application of legal provision prediction (LPP), which aims to predict the related legal provisions of affairs. We formulate this task as a challenging knowledge graph completion problem, which requires not only text understanding but also graph reasoning. To this end, we propose a novel text-guided graph reasoning approach. We collect amounts of real-world legal provision data from the Guangdong government service website and construct a legal dataset called LegalLPP. Extensive experimental results on the dataset show that our approach achieves better performance compared with baselines. The code and dataset are available in https://github.com/zxlzr/LegalPP for reproducibility.
1 Introduction
Legal Artificial Intelligence (LegalAI) mainly concentrates on applying artificial intelligence technologies to legal applications, which has become popular in recent years [16]. As most of the resources in this field are presented in text forms, such as legal provisions, judgment documents, and contracts, most LegalAI tasks are based on Natural Language Processing (NLP) technologies. In this paper, we introduce a novel application of Legal Provision Prediction (LPP) for LegalAI.
Legal Provision Prediction (LPP) aims to predict the related legal provisions of affairs. For example, given an affair “task_336: ……超出许可业务范围或无许可证的中介服务机构发布广告的处罚” (…Penalties for advertisements issued by intermediary service agencies that are beyond the scope of the licensed business or without a license), the task is to predict the most related legal provisions such as “ 人才市场管理规定_004/026/001 ” (Talent Market Management Regulations_004/026/001) as the Table 1 shows. LPP is a real-world application that plays a significant role in the legal domain, as it can reduce heavy and redundant work for legal specialists or government employees.
Intuitively, there are many domain knowledge and concepts with well-defined rules in LegalAI, which cannot be ignored; we formulate the legal provision prediction task as a knowledge graph completion problem. We regard affairs and legal provisions as entities and utilize their well-defined schema structure as relations (e.g., base_entry_is, base_law_is, etc.). In such a way, the LPP problem becomes a link prediction task in the knowledge graph (e.g., whether there exists the base_entry_is relation between the affair entity and the legal provision entity). Numerous link prediction approaches [1, 14, 5] have been proposed for knowledge graph completion; however, there are still several non-trivial challenges for LPP:
| Type | Affair | Legal_Provision |
|---|---|---|
| Graph Vertex (Entity) | task_336 | 人才市场管理规定_004/026/001 (Talent Market Management Regulations_004/026/001) |
| Vertex Description | 对人才中介服务机构超出许可业务范围发布广告、广告发布者为超出许可业务范围或无许可证的中介服务机构发布广告的处罚。 (The punishment for talent intermediary service agencies to publish advertisements beyond the scope of the licensed business, and the advertisement publishers to publish advertisements for intermediary service agencies that are beyond the scope of the licensed business or without a license.) | 人才中介服务机构通过各种形式、在各种媒体(含互联网)为用人单位发布人才招聘广告,不得超出许可业务范围… (Talent intermediary service agencies publish talent recruitment advertisements for employers in various forms and various media (including the Internet), and must not exceed the scope of the licensed business… |
-
•
Text Understanding. Many entities in the legal knowledge graph have well-formalized description information. For example, the legal provision ”task_336” has the description “ ……为超出许可业务范围或无许可证的中介服务机构发布广告的处罚。” (…Penalties for advertisements issued by intermediary service agencies that are beyond the scope of the licensed business or without a license). Those texts provide enriched information for understanding the affairs and legal provisions, which is quite important, and utilizing that description is of great significance.
-
•
Legal Reasoning. Some complex legal provisions may require sophisticated reasoning as legal data must strictly follow the rules well-defined in law. For example, given an affair “task_155: 市政府投资项目稽查” (Audit of municipal government investment projects), human beings can quickly obtain the related legal provisions through two-hop reasoning as “task_155: 市政府投资项目稽查” (Audit of municipal government investment projects) is following “深圳经济特区政府投资项目管理条例” (Shenzhen Special Economic Zone Government Investment Project Management Article) and “深圳经济特区政府投资项目管理条例” (Shenzhen Special Economic Zone Government Investment Project Management Article) has the provision of “深圳经济特区政府投资项目管理条例第3节第1款” (Section 1, Paragraph 3 of the Shenzhen Special Economic Zone Government Investment Project Management Regulations).
The key to solving the issues mentioned above is combining text representation and structured knowledge with legal reasoning. To this end, we propose a Text-guided Graph Reasoning (T-GraphR) approach for this task which bridges text representation with graph reasoning. Firstly, we utilize the pre-trained language model BERT [3] to represent entities with low dimension vectors. Then, we leverage graph neural networks (GNN) that assimilate generic message-passing inference algorithms to perform legal reasoning on the legal knowledge graph. We utilize two kinds of GNN, namely, R-GCN [11] and GAT [13]. Note that our approach is a model-agnostic method and is readily pluggable into other graph neural networks approaches. We collect legal provisions data from Guangdong government service website111https://www.gdzwfw.gov.cn/ and construct a dataset LegalLPP. Extensive experimental results show that our approach achieves significant improvements compared with baselines. We highlight our contributions as follows:
-
•
We propose a new legal task, namely, legal provision prediction, which requires both text representation and knowledge reasoning.
-
•
We formulate this task as a knowledge graph completion problem and introduce a novel text-guided graph reasoning approach that leveraging text and graph reasoning.
-
•
Extensive experimental results demonstrate that our approach achieves better performance compared with baselines.
-
•
We release the LegalLPP dataset, source code, and pre-trained models for future research purposes.
2 Data Collection
2.1 Data Acquisition
We collect all the data from the Guangdong government service website. We obtain about 140,482 raw affairs (including 1,552 unique affairs), and 4,042 laws with 269,053 legal provisions. We perform detailed analysis and conduct data preprocessing procedures to address those issues below:
Non-standard text. There exist a huge discrepancy for the legal provisions and affairs, including: Abbreviation, such as “劳动法” (Labor Law) is the abbreviation of “中华人民共和国劳动法” (People’s Republic of China Labor Law); Missing, such as missing of angle quotation mark (“《》” ) or the format of the version number (for example, the suffix of the “《广东省民用建筑节能条例》(2014年修正本)” (”Regulations on Energy Conservation of Civil Buildings in Guangdong Province” (Amended in 2014)). Those challenges make it difficult to establish the association between affairs and legal provisions. To handle those non-standard texts, we manually build a legal provision dictionary to normalize those non-standard texts.
Similar affairs. From the raw data, we observe that a huge portion of affairs is very similar (with the same affair vertexes). Statistically, we find that the ratio of unique items to the total number of items is roughly 1:100. We analyze those similar affairs and find that most parts of them have the same content, while only the time in the affair is different. We merge those similar affairs in the prepossessing procedure.
No legal provisions. We observe that several affairs do not have any linking legal provisions, which implies no legal provisions. This problem is mainly due to outdated laws. As the legal provision will change over time, several old provisions may be deleted, making several affairs impossible to link. Also, there exists a little legal provision that does not have standard formats (in general, the standard format of the legal provision is XX law, chapter X, article X, paragraph X); thus, affairs cannot be linked to those legal provisions either. We filter out those no legal provision affairs in the prepossessing procedure.

| Relation | Number | Description |
|---|---|---|
| base_entry_is | 4,526 | The legal provision is related to the affair |
| right_is | 1,090 | The affair has the right |
| base_law_is | 2,152 | The law is related to the affair |
| belongs_to | 182,624 | The legal provision belongs to the law |
2.2 Legal Knowledge Graph
Our proposed legal task is a real-world application. As the fast updating of affairs and legal provisions, newly added affairs cannot be linked with existing legal provisions. We notice that there exist relations between affairs and laws following a well-defined schema. From two-hop reasoning on the legal knowledge graph, it is possible to judge whether there exists a relation between an affair and legal provisions. In this paper, we formulate the legal provision prediction task as the link prediction problem in the legal knowledge graph. We model the legal provision, affair, law, right as entities, as shown in Figure 1. We detail the statistic of the legal knowledge graph in Table 2.
2.3 Dataset Construction
We randomly divide the triples with four type relations into the train, valid and test set with a ratio of 8:1:1, and we filter the triples with base_entry_is relation from the test set as the target test set. The detailed number of entities, relations, and triples of the LegalLPP dataset are shown in Table 3.
| Dataset | #Rel | #Ent | #Triple |
|---|---|---|---|
| Train(all) | 4 | 151,746 | 152,307 |
| Dev(all) | 4 | 22,086 | 19,037 |
| Test(all) | 4 | 22,070 | 19,042 |
| Test(target) | 1 | 768 | 454 |
3 Methodology
3.1 Problem Definition
A knowledge graph is a set of triplets in the form , and where is the entity vocabulary and is a collection of pre-defined relations as shown in Table 2. We are aimed at predicting whether there exists the relation base_entry_is between affair entities and legal provision entities. We construct positive triples with ground truth instances and negative triples with corrupted instances following [1].
3.2 Framework Overview
Our text-guided graph reasoning approach consists of two main components, as shown in Figure 2. Our approach is not end-to-end as we firstly fine-tune the text representation and then leverage this feature to perform legal graph reasoning.
Text Representation Learning (§3.3). Given an affair and legal provision, we employ neural networks to encode the instance semantics into a vector. In this study, we implement the instance encoder with BERT [3]. We then apply an MLP layer to reduce the dimension of features (the dimension of BERT-base is 768, which is not convenient for training GNN) to obtain the text representations, which is more efficient for training and inference. We learn the text representation via fine-tuning with triple scores following TransE [1].
Legal Graph Reasoning (§3.4). After obtaining the learned text representations, we employ GNN to learn explicit relational knowledge. By assimilating generic message-passing inference algorithms with the neural-network counterpart, we can learn vertex embeddings with legal reasoning. Then we utilize a residual connection from the text representation to obtain the final representation. Finally, we utilize TransE [1], DistMult [14] and SimplE [5] as triple score functions.

3.3 Text Representation Learning
Given an input affair text and legal provision text , we utilize BERT [3] to obtain the text representations as follows:
| (1) |
where , are raw input text and , are the output [CLS] embeddings of BERT. We then leverage an MLP layer to reduce dimension as follows:
| (2) |
where , are the final text representations which will then be fed into the GNN. To obtain more representative features, we finetune the text representation with TransE triple score function as:
| (3) |
where is the score of triple , , , are entity representations from Eq. 2, is random initialized vectors. We further analyze the empirical performance of other triple score function of DistMult and SimplE. The DistMult and SimplE score function are calculated as:
| (4) |
| (5) |
DistMult is a simplified version of RESCAL [9] by using a diagonal matrix to encode relation. Different from DistMult, SimplE can handle asymmetric relations.
3.4 Legal Graph Reasoning
We feed the vertex representation into a graph encoder to obtain the hidden vectors, which explicitly models the graph structure of the legal knowledge graph. We use an implementation of the GNN model following GAT [13] and R-GCN [11].
GAT. The GAT model uses multiple graph attention layer connections for encoding vertexs. Specifically, GAT calculates the attention weights of neighboring nodes for aggregation. The attention weights of node and node are calculated as follows:
| (6) |
where represents transposition and is the concatenation operation. Once obtained, the normalized attention coefficients are used to compute a linear combination of the features corresponding to them, to serve as the final output features for every node (after potentially applying a nonlinearity, ):
| (7) |
where is the final graph node representation.
R-GCN. R-GCN utilizes multi-layer relational graph convolutional layer to represent node. The forward-pass update of an node denoted by in a relational multi-graph is shown as follows:
| (8) |
where is the final graph node representation, denotes the set of neighbor indices of node under relation . is a problem-specific normalization constant that can either be learned or chosen in advance (such as ). Note that, R-GCN considers the relation of triples in the convolution process and is able to learn different aggregation weights according to different relations.
Afterwards, we add a residual connection from the output of MLP layer to the graph node representation, denoted by:
| (9) |
where is the final entity representation of entities leveraging both text and graph reasoning.
Finally, we utilize the same score function of TransE, DistMult and SimpLE in the §3.3 to calculate triple scores. Note that, in the graph reasoning stage, and are combined with both text and graph features while is initialized from the tuned embedding in text representation learning (Eq. 3 and Eq. 5). Though our approach is not end-to-end, the entity embeddings (e.g., legal provisions, affairs) can be pre-computed, which is quite efficient in for inference.
4 Experiments
4.1 Settings
We conduct experiments on the LegalLPP dataset. We use Pytorch [10] to implement baselines and our approach on single Nvidia 1080Ti GPU. We leverage Graph Deep Library222https://www.dgl.ai/ to implement all the GNN components. We utilize bert-base-Chinese333https://github.com/google-research/bert to represent text. We employ Adam [6] as the optimizer. In the text representation learning stage, the learning rate is 5e-5 with the warm-up proportion being 0.1; the batch size is 64, the maximum sequence length of each entity’s text is 128. After 6 epochs of training, we generate 400-dimension text representations. In the legal graph reasoning stage, we set the learning rate of GNN to be 0.01. We train 4,000 epochs for GAT and R-GCN. We use TransE as the default triple score function. We evaluate the performance with Mean Rank (MR), Mean Reciprocal Rank (MRR), and HIT@N (N=1,3,10).
4.2 Baselines
We compare our approach with different kinds of baselines, as shown below:
No reasoning. We conduct TransE [1] as an baseline. We also utilize two separate BERT encoders to represent the text with the TransE triple score function as a baseline.
Graph only. We build the legal knowledge graph and leverage GNN approaches R-GCN and GAT without text features. The graph node representation is initialized randomly.
4.3 Evaluation Results
| Model | MR | MRR | HIT@1 | HIT@3 | HIT@10 | |
|---|---|---|---|---|---|---|
| No reasoning | TransE | 21615.832 | 0.179 | 0.121 | 0.196 | 0.258 |
| BERT | 404.308 | 0.103 | 0.051 | 0.095 | 0.207 | |
| Graph only | GAT | 14790.835 | 0.187 | 0.137 | 0.209 | 0.262 |
| R-GCN | 35767.694 | 0.175 | 0.119 | 0.187 | 0.267 | |
| T-GraphR | GAT (TransE) | 21339.555 | 0.197 | 0.133 | 0.214 | 0.291 |
| GAT (DistMult) | 19546.152 | 0.047 | 0.011 | 0.041 | 0.119 | |
| GAT (SimplE) | 18164.057 | 0.094 | 0.062 | 0.099 | 0.145 | |
| R-GCN (TransE) | 1414.584 | 0.179 | 0.126 | 0.192 | 0.242 | |
From Table 4, we observe:
1) Our approach T-GraphR with GAT achieves the best performance. We argue that our target task is to predict the base_entry_is relation between affairs and legal provisions, and there are only four relations in the graph; thus, GAT, which implicitly specifying different weights to different nodes in a neighborhood can obtain better performance.
2) Graph only approach achieves better performance than no reasoning methods BERT and TransE, which indicates that graph reasoning plays a vital role in legal provision prediction.
3) Our T-GraphR approach achieves the best performance and even obtain 12.8% hit@10 improvements compared with the text-only no reasoning model TransE.
4) The overall performance is still far from satisfactory (less than 0.3 with hit@10), and there is more room for future works.
We conduct experiments with different triple score function and report results in Table 4. We observe that TransE obtains better performance than DistMult and SimplE. We argue that the TransE model represents relations as translations, which aims to model the inversion and composition patterns; the DistMult utilizes the three-way interactions between head entities, relations, and tail entities which aims to model the symmetry pattern, the SimplE model the asymmetric relations by considering two (head and tail) vectors only. In our LPP task, those inversion and composition patterns are common in the legal knowledge graph; thus, such translation assumption is advantageous.
| Model | Affair | T-GraphR | BERT |
|---|---|---|---|
| Instance1 | 对占用道路、广场从事经营性车辆清洗活动的处罚 (Penalties for occupation of roads and plazas for cleaning vehicles) | 肇庆市城区市容和环境卫生管理条例_005/053/001 (Regulations of Zhaoqing City on City Appearance and Environmental Sanitation_005/053/001) | 中华人民共和国河道管理条例_003/035/001 (River Regulations of the People’s Republic of China_003/035/001) |
| Instance2 | 对未按规定缴纳城市生活垃圾处理费的行政处罚 (Administrative penalties for failure to pay municipal solid waste disposal fees) | 广东省城乡生活垃圾处理条例_004/037/001 (Guangdong Province Urban and Rural Domestic Waste Treatment Regulations_004/037/001) | 广东省环境保护条例_004/056/001 (Guangdong Environmental Protection Regulations_004/056/001) |
4.4 Case Studies
We present some predicted instances obtained by our model to demonstrate the generalization ability in Table 5. Our method can predict correct legal provisions with complex surface contexts. Moreover, by reasoning on the legal knowledge graph, we can leverage the well-defined structure, which boosts performance. However, vanilla BERT only considers text, neglecting the structured knowledge in the legal knowledge graph, which results in unsatisfactory performance.
4.5 Entity Visualization
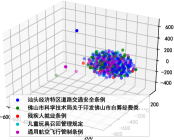



To further analyze the behavior of entity representations, we utilize T-SNE [8] to visualize five randomly selected entity embeddings. From Figure 3, we find that entity embeddings of the graph only approaches have a compact data distribution, while with pre-trained LMs, entities of different types are scattered. To conclude, text features can enhance the vertex’s discriminative ability to enhance node representations.
5 Related Work
Knowledge Graph Completion. In this paper, we formulate the LPP problem as a knowledge graph completion task by link prediction. A variety of approaches such as TransE [1], ConvE [2], Analogy [7], RotatE [12] have been proposed to encode entities and relations into a continuous low-dimensional space [15]. TransE [1] regards the relation in the given fact as a translation from to within the low-dimensional space. RESCAL [9] studies on matrix factorization based knowledge graph embedding models using a bilinear form as score function. DistMult [14] simplifies RESCAL by using a diagonal matrix to encode relation. [5] propose a simple tensor factorization model called SimplE through a slight modification of the Polyadic Decomposition model [4]. Since the relation of the legal knowledge graph is quite small, we utilize TransE [1], DistMult [14] and SimplE [5] as score functions of knowledge graph completion for computation efficiency.
Graph Neural Networks. Recently, graph neural network (GNN) models have increasingly attracted attention, which is beneficial for graph data modeling and reasoning. Some existing literature such as R-GCN [11], GAT [13] use GNN for structure learning. [11] introduces a relational graph convolutional networks (R-GCN) for knowledge base completion tasks that can deal with the highly multi-relational data. [13] propose a graph attention networks (GAT) that leveraging masked self-attentional layers based on neural graph networks. However, as legal provision also has lots of text information which cannot be ignored; thus, we leverage pre-trained text representation as guidance for graph reasoning.
6 Conclusion
In this paper, we introduce an application of legal provision prediction, which requires text understanding and knowledge reasoning. This task can reduce heavy and redundant work for legal specialists or government employees. We formulate this task as a knowledge graph completion task and propose a text-guided graph reasoning approach. Experimental results demonstrate the efficacy of our approach, however, the task is still far from satisfactory.
References
- [1] Bordes, A., Usunier, N., García-Durán, A., Weston, J., Yakhnenko, O.: Translating embeddings for modeling multi-relational data. In: NIPS. pp. 2787–2795 (2013)
- [2] Dettmers, T., Minervini, P., Stenetorp, P., Riedel, S.: Convolutional 2d knowledge graph embeddings. In: AAAI. pp. 1811–1818. AAAI Press (2018)
- [3] Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). pp. 4171–4186. Association for Computational Linguistics, Minneapolis, Minnesota (Jun 2019). https://doi.org/10.18653/v1/N19-1423
- [4] Hitchcock, F.L.: The expression of a tensor or a polyadic as a sum of products. Journal of Mathematics and Physics 6(1-4), 164–189 (1927)
- [5] Kazemi, S.M., Poole, D.: Simple embedding for link prediction in knowledge graphs. In: Advances in neural information processing systems. pp. 4284–4295 (2018)
- [6] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. CoRR abs/1412.6980 (2015)
- [7] Liu, H., Wu, Y., Yang, Y.: Analogical inference for multi-relational embeddings. In: Proceedings ICML. pp. 2168–2178 (2017)
- [8] Maaten, L.v.d., Hinton, G.: Visualizing data using t-sne. Journal of machine learning research 9(Nov), 2579–2605 (2008)
- [9] Nickel, M., Tresp, V., Kriegel, H.: A three-way model for collective learning on multi-relational data. Proceedings of ICML pp. 809–816 (2011)
- [10] Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high-performance deep learning library. In: Advances in Neural Information Processing Systems. pp. 8024–8035 (2019)
- [11] Schlichtkrull, M., Kipf, T.N., Bloem, P., Van Den Berg, R., Titov, I., Welling, M.: Modeling relational data with graph convolutional networks. In: European Semantic Web Conference. pp. 593–607. Springer (2018)
- [12] Sun, Z., Deng, Z.H., Nie, J.Y., Tang, J.: Rotate: Knowledge graph embedding by relational rotation in complex space. Proceedings of ICLR (2019)
- [13] Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., Bengio, Y.: Graph Attention Networks. International Conference on Learning Representations (2018)
- [14] Yang, B., tau Yih, W., He, X., Gao, J., Deng, L.: Embedding entities and relations for learning and inference in knowledge bases. Proceedings of ICLR (2015)
- [15] Zhang, N., Deng, S., Sun, Z., Chen, J., Zhang, W., Chen, H.: Relation adversarial network for low resource knowledge graph completion. In: Proceedings of The Web Conference 2020. pp. 1–12 (2020)
- [16] Zhong, H., Xiao, C., Tu, C., Zhang, T., Liu, Z., Sun, M.: How does NLP benefit legal system: A summary of legal artificial intelligence. In: Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R. (eds.) Proceedings of ACL. pp. 5218–5230. Association for Computational Linguistics (2020)